-
-

base screen
-
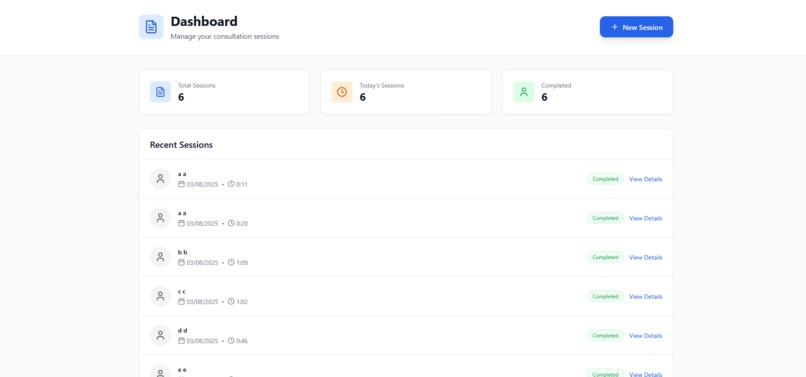
session view
-
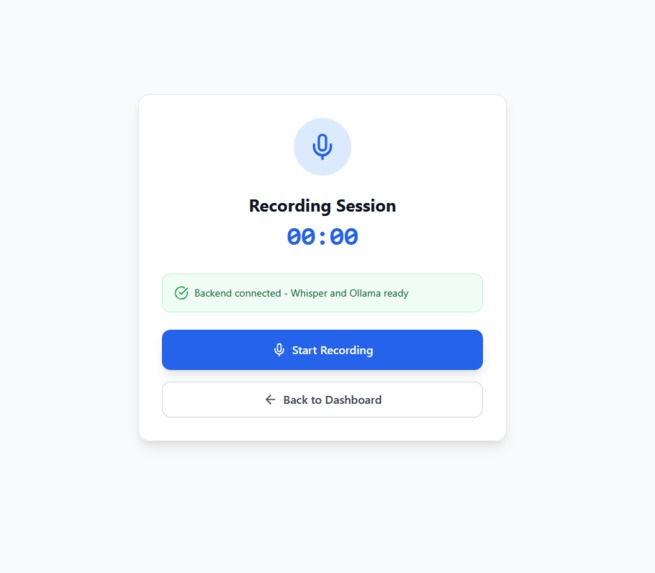
recording screen
-
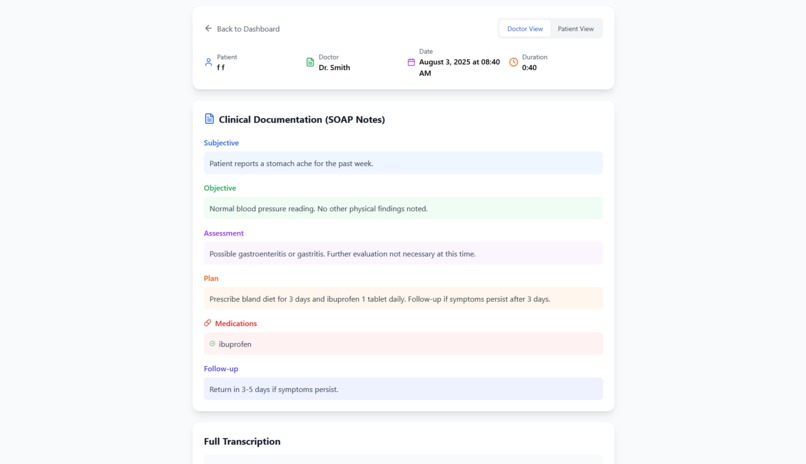
doctor's soap view




Inspiration
Most of us have experienced that awkward pause during a doctor’s appointment—when the physician stops to type. Despite their best efforts, the clicking of a keyboard can interrupt the rhythm of a conversation and create a barrier between doctor and patient. This moment of disconnect inspired Echo: a doctor’s favourite assistant (sorry, nurses).
What it does
Echo is a local-first AI-powered medical note-taking assistant. It listens to doctor–patient interactions (with patient consent), transcribes the conversation using Whisper, and summarizes it into structured SOAP notes using a local LLM (LLaMA 3.1 8B via Ollama). These notes are stored locally in a lightweight CSV-based system with client-side backups via localStorage.
Echo helps reduce documentation overhead while ensuring full privacy - no data leaves the device unless explicitly authorized. It's designed to be particularly useful in fast-paced medical environments like emergency care, where maintaining a conversation log can be vital. It also holds promise for mental health professionals, where seamless and respectful documentation is key.
How we built it
Frontend:
- React 18 built with Vite. TypeScript for structured, type-safe development
- Framer Motion for animations and transitions. Lucide React for icons
- Axios for HTTP requests
- React Router for navigation
Backend:
- Flask (Python) as the API layer
- OpenAI Whisper (base model) for transcription
- librosa and soundfile for audio handling
- FFmpeg for format conversion and optimization
AI & ML:
- Ollama with LLaMA 3.1 8B for SOAP (Subjective, Objective, Assessment, and Plan) note generation, which is a structured method healthcare professionals use to document patient encounters
- Custom prompting to maintain structured and consistent output
Data & Storage:
- CSV files for persistent, lightweight data storage
- localStorage for client-side backups and offline support
- Custom Python scripts to manage records
Audio:
- MediaRecorder API for browser-based audio capture
- WebM/WAV support and conversion tools to ensure quality
Challenges we ran into
Audio processing was a big hurdle, especially figuring out the correct pipeline with FFmpeg and ensuring format compatibility between the browser, Whisper, and the backend.
Prompting the local LLM to consistently return structured JSON (especially in SOAP format) was tricky—it required iteration and testing to get right.
Time constraints were tight, and juggling development with other commitments meant making careful trade-offs.
Accomplishments that we're proud of
- Built a working, well-scoped MVP that respects patient privacy and puts UX first
- Created a smooth and clean frontend experience, even without much prior frontend experience
- Successfully integrated local LLMs and AI transcription pipelines
- Prioritized ethical considerations like consent and data control throughout the user journey
- Managed to do all this within a short hackathon window (while attending other events!)
What we (I) learned
- How to use
ngrokto serve local apps to the web - How to persist data with localStorage and CSVs
- Better prompting strategies for JSON output with local models
- Audio format quirks and conversion workflows
- The importance of sleep - and how few bugs you fix without it 😅
What's next for Echo
Echo could be transformative across multiple medical and therapeutic contexts. Next steps include:
- Improving diarization to distinguish between speakers
- Adding audit trails and full export support for EHR systems
- Expanding use cases to mental health and therapy
- Supporting multi-session patient records and analytics
- Fine-tuning models on real doctor–patient conversations (with consent)
Ultimately, we hope Echo can help practitioners be more present—and help patients feel more heard.

Log in or sign up for Devpost to join the conversation.