-
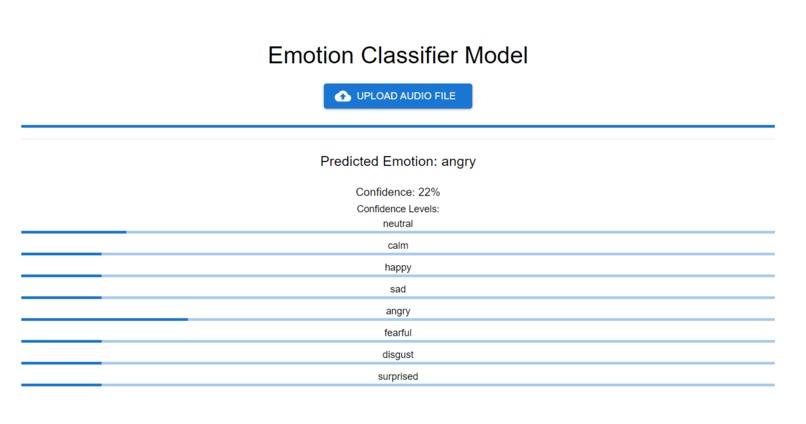
Webapp interface
-
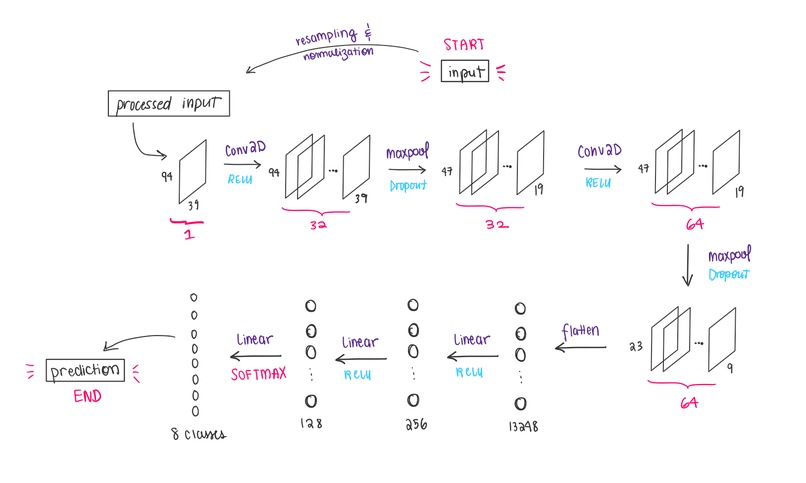
CNN model architecture
-
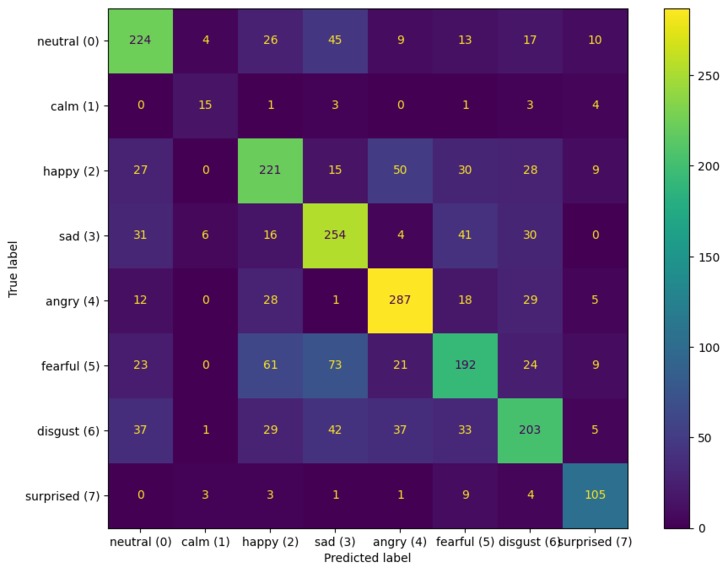
Confusion matrix over 8 emotions (test accuracy: 61.69%)



Inspiration
We were looking into different projects that involved audio/text/video processing, as that was a field of interest to us. One of us had previously worked on a text-based emotion classification task, in which context and semantics were important features. However, an audio-based emotion classification task might not depend as heavily on the semantics of what is being said, so this was an interesting avenue for us to explore!
What it does
Record audio, and we will try to predict what emotion is captured in the audio clip! Emotions that we predict will be one of either neutral, calm, happy, sad, angry, fearful, disgust, surprise.
How we built it
We used PyTorch to build a CNN model for image classification. Audio inputs (.wav files) were preprocessed using Pydub, Librosa, and Soundfile libraries, and then converted into MFCC (concatenated with delta and delta-delta features) to be passed as features to the CNN.
Our webapp uses a React frontend and a Flask backend.
Challenges we ran into
We ran into some issues during data preprocessing, notably when it came to how we wanted to have our data represented, and ensuring that this representation is consistent across all datasets, despite different recording conditions (decibels, silence, background noise, length of audio, etc.). We ended up experimenting with different preprocessing methods (padding, truncating, looping, stretching/contracting audio, etc.).
Furthermore, while trying to improve our model, we found out that our modified model never predicts a specific emotion 'surprise'. We had trouble figure out why that was, and have been unable to fix this.
That said, implementing the webapp was the hardest part of this project. None of us has experience working with React, and most of us have never made a webapp before. Implementing an audio recorder on React was challenging, so we decided to use a file upload system in the end.
Accomplishments that we're proud of
We are proud that we were able to make from scratch a model that predicts among 8 classes with a pretty good (61%) accuracy. Also, as this is our first time using React, we were happy to have created a functional webapp.
What we learned
We have learned how to build a machine learning model from scratch; from preprocessing data across multiple datasets, to building the model and choosing/testing hyperparameters, and more. We have also learnt how to use k-fold cross validation to evaluate our model's results.
Despite all the challenges, we were able to learn how to make a basic React and Flask webapp to showcase the results of our model.
What's next for Emotion Classifier
We are interested in further improving our model, as we have seen that our model is overfitting during evaluation. We might have to revisit our model's architecture to see how to increase our validation accuracies. We had tried modifying our preprocessing methods to remove silent segments from audio; this seemed to be working well, but we ran into the issue where our model never predicted 'surprise'. With more time, we would be looking into a solution to fix this.
It would also be interesting to have our webapp track correct vs bad predictions and somehow implement this as feedback for our model.
Built With
- flask
- javascript
- librosa
- pydub
- python
- react
- soundfile

Log in or sign up for Devpost to join the conversation.