-
-
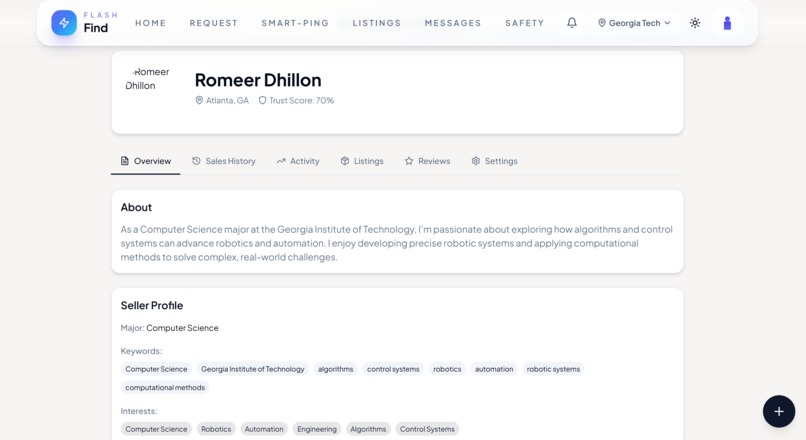
Profile picture of the user, contains information that would be beneficial for other users on the app.
-
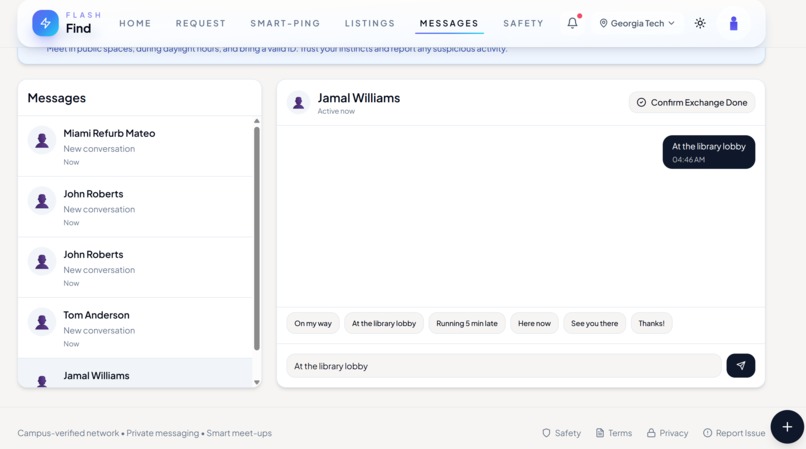
Message tab that allows the user to connect with buyers and sellers in the area.
-
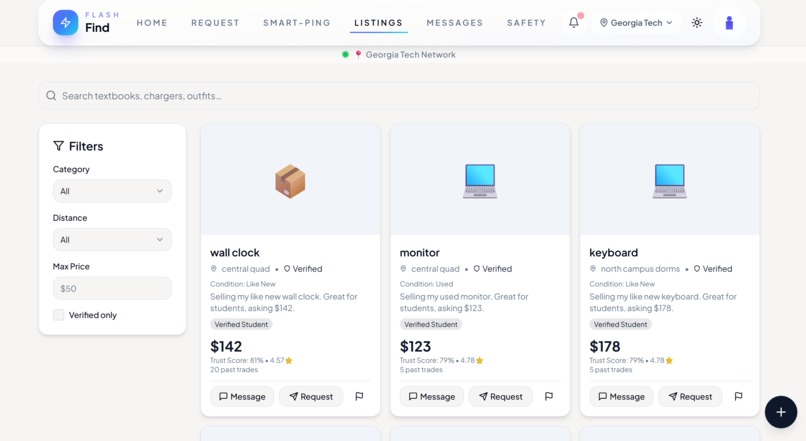
All Listings available for products that buyers might want.
-
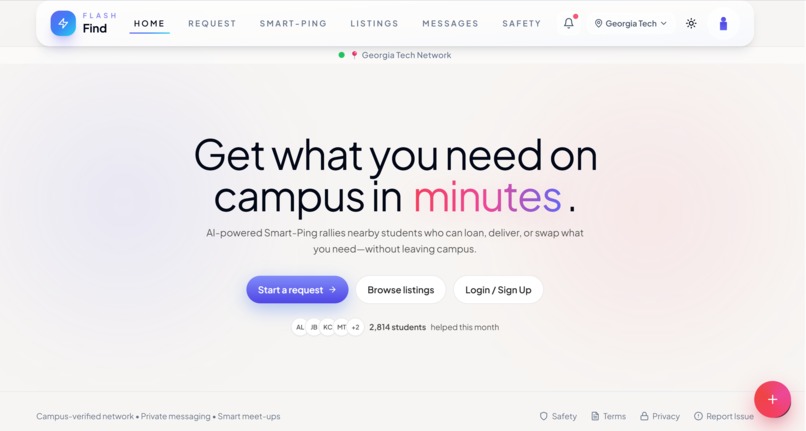
Home page: users are able to login and enter a prompt.
-
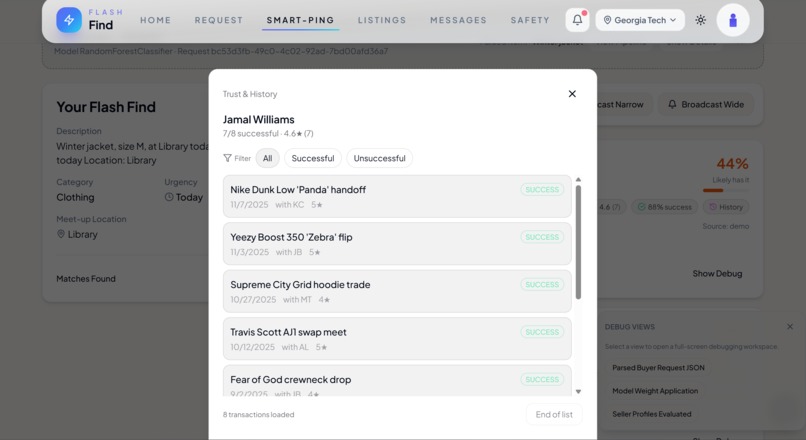
A Seller's profile with details about their order history and the outcome of those orders.
-
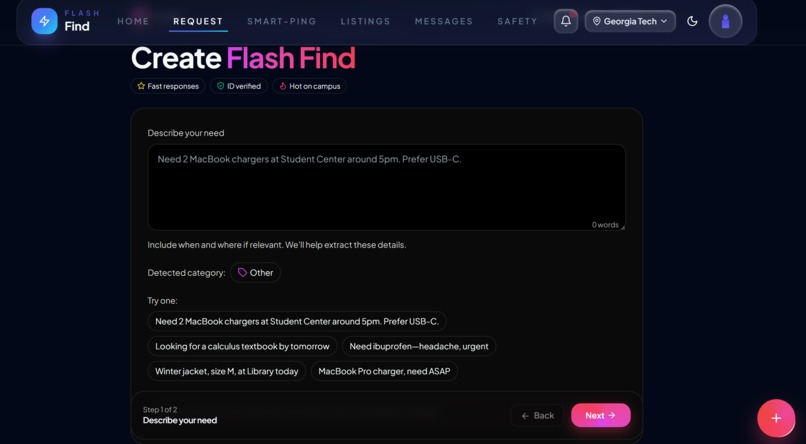
Flash Request page: Enables the user to ask the AI in full English Sentences what it wants
-
Home page: Dark mode







Inspiration
Our idea came from the everyday frustrations students face when they urgently need something but don't have time or access to get it - whether that's a forgotten charger before class or a missing calculator before an exam. Current campus marketplaces are too slow, fragmented, or inactive. We wanted to create a smart, predictive system that turns these moments of stress into instant solutions - saving time, strengthening campus community, and promoting sustainable reuse at the same time.
What it does
Our project is an AI-powered, hyperlocal campus marketplace designed to get students what they need when they need it. Whether it's a textbook, phone charger, or last-minute interview outfit, the platform uses an intelligent "Flash Request" system that lets students describe what they need in natural language ("I need a medium black blazer for an interview" or "Need a calculus textbook tomorrow afternoon").
Our AI instantly parses the intent, item, and urgency, then uses a predictive matching model to "Smart-Ping" nearby students most likely to have that item - even if it's not in active listings. By turning the campus into a living, on-demand inventory, the system connects a need to a person in real time, solving students' problems in minutes, not days. Beyond convenience, it also builds community, reduces waste, and strengthens social support networks, encouraging peer-to-peer sharing and sustainability.
How we built it
Our system is a full-stack application built around a "Two-Step AI" pipeline, with a Python/Flask backend and a React/TypeScript frontend. This design lets us use the perfect tool for each part of the job: a large AI for language and a small, fast AI for logic.
Google Gemini API (LLM): This is our "language expert." Its only job is to parse messy, unstructured human text. It takes a buyer's "Flash Request" or a seller's profile bio and translates them into clean, structured JSON objects. This is the perfect tool for the job because it removes all the "grey area" of human language (like "need a book for cheap") and turns it into hard, logical data. This process is governed by our Data Contract, a strict schema we designed to ensure the AI's output is always perfectly formatted for our next model.
Scikit-learn (custom ML model): This is our logic engine. We used Python and Pandas to train a Random Forest Classifier on our custom dataset, which is saved as a single .joblib file. This is a classic, lightweight ML model (not an LLM) that is fast and runs locally. It's the perfect tool for the second step because it applies its learned weights to do high-speed, mathematical comparisons on the JSON, checking data like price, category, and sales history.
FastAPI (backend service): This Python framework is the backbone of the backend. It handles authentication and MongoDB access, orchestrates calls to the Gemini proxy service, and loads the on-disk scikit-learn model to score match predictions before returning results to the React frontend.
React & TypeScript (the frontend): Our entire user interface is a modern single-page application built in React with TypeScript. This provides a responsive, interactive UI for the user to type in their "Flash Request." It then makes the API call to our Flask backend and displays the final list of "positive" seller matches returned by our ML model.
MongoDB (the database): We used this NoSQL, document-based database to store all persistent data, including our SellerProfile JSONs. It was the perfect choice because it allowed us to directly store the complex, nested JSON objects generated by our AI pipeline. This flexible, schema-less structure was ideal for handling the rich, evolving data our ML model depends on.
Challenges we ran into
Choosing the Right AI: Our biggest challenge was deciding between two models. We debated using a Sentence Transformer from Hugging Face (like all-MiniLM-L6-v2) to find "similar text," or training our own Random Forest Classifier. We chose the Random Forest because it was the only one that was based on logic rather than text understanding, which was critical for our "Smart-Ping" feature. All of the understanding and inference was already taken care of with the Gemini LLM, which means a lightweight tool was the perfect option.
Data Alignment: We ran into a "no matches" bug. This forced us to refactor our code to ensure the "live" data from the app was preprocessed in the exact same way as our "training" data. This was a critical challenge, as it involved aligning our Python scikit-learn model with our MongoDB database schema and the JSON output from the Gemini API.
The "Cold Start" Problem: We had no data to train our model. We solved this by building a synthetic data factory - a Python script that ran continuously, calling the Gemini API to generate our 400+ unique, labeled training files from scratch.
Accomplishments that we're proud of
Training Our Own Custom Logic Engine: We're incredibly proud of building and training our own Random Forest Classifier from scratch. Instead of just using a generic, pre-trained text model, we built a highly specialized "brain" that is lightweight, fast, and understands our specific logic - like price limits, item conditions, and seller sales history - which a simple text-matcher could never do.
Integrating a Two-Step AI Pipeline: We successfully designed and integrated two very different AI concepts in tandem. We use the Google Gemini API as our "translator to handle the complex "grey area" of human language, and our custom Scikit-learn model as our logic engine to handle high-speed, mathematical decision-making. This pipeline is efficient, scalable, and uses the best tool for each job.
Solving the "Cold Start" Problem with Synthetic Data: Our biggest accomplishment was building our model with zero initial data. We built a synthetic data factory - a Python script that ran continuously, calling the Gemini API to generate our entire 400-point labeled dataset of "perfect," "sparse," "positive," and "negative" training examples. Through careful prompt engineering, we were able to generate data points that mimicked real-world transaction logic. Seeing our model achieve high accuracy purely from this synthetic data was incredibly rewarding.
What we learned
How to Build a Complete ML Pipeline: We learned how to train a Random Forest model from scratch in Python. This involved defining a rigid Data Contract (our JSON schema), generating training data, and then using scikit-learn to train the model and generate its predictive weights.
Real-Time, High-Paced Collaboration: We learned to use a careful version control system in Git. Working under a tight deadline, we used a feature-branch workflow. This allowed our team's different skills to combine effectively, letting us work on the TypeScript frontend and the Python model training in parallel and then integrate them smoothly.
The Underlying Motivation: The fact that we were building an app that we would genuinely use as college students definitely motivated us as we were developing. We learned that solving a real-world challenge you care about is the best fuel for a hackathon. Working to make an impact in our own community kept us focused and driven.
What's next for FlashFind
We want to scale FlashFind to different communities, countries, and emergency zones, where rapid resource distribution is critical. In disaster or crisis scenarios, we want FlashFind to be used to broadcast urgent needs to nearby users or responders, ensuring that aid, supplies, and medical help reaches the right people faster. In the long-term, we want to create a world where anyone, anywhere, can instantly connect to the resources they need.
Built With
- flask
- gemini
- github
- joblib
- mangodb
- pandas
- python
- react
- scikit-learn
- shadcn
- tailwindcss
- typescript
- vite






Log in or sign up for Devpost to join the conversation.