-
-
architecture diagram
-
Statsig dashboard with experiment
-
Programmatic statsig experiment generation
-
Generated website with dynamic UX features for experimentation




Inspiration
Currently, AI dev tools, such as lovable, v0, Cursor, etc, are all limited by the quality of the underlying model. When in-house training happens, it's done by optimizing models for the website creator's preferences. The dev tool industry misses a key insight - end users create data whenever they visit an LLM generated website, and that data can be used to train models that are better optimized for the end user.
What it does
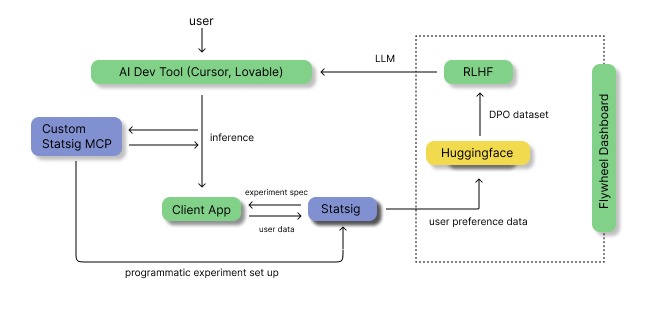
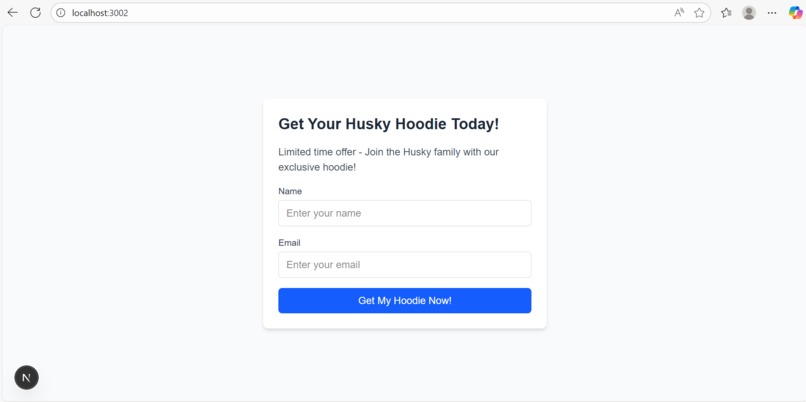
Our goal with Flywheel is to "close the loop", and give any AI dev tool its own data FLYWHEEL to create stronger LLMs. We modify LLMs for dev tool companies so that they automatically integrate A/B UX experiments (hosted on Statsig) while generating web apps. For example, what color "buy" button gets more clicks? The data from these experiments can both optimize the website (duh) and the model itself (woah!). That's where we close the loop. Flywheel pulls the data from Statsig, organizes it by category (buttons are different from titles, a shopping site's user is different from a movie review site's user, etc), and runs reinforcement learning from human preferences to improve the model, which is then given back to the AI dev tool provider. This training loop helps models learn WHAT gets more click-throughs, HOW to increase total time spent, and WHERE to make changes to attract more users.
By CLOSING THE LOOP, Flywheel gives any AI dev tool company an edge over its competitors - the model will make more profitable sites by default. Now, who wants their own data Flywheel?
How we built it
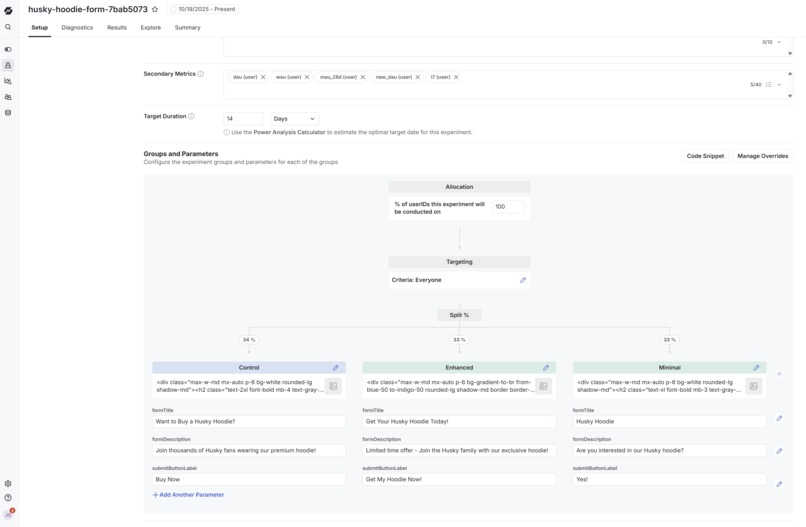
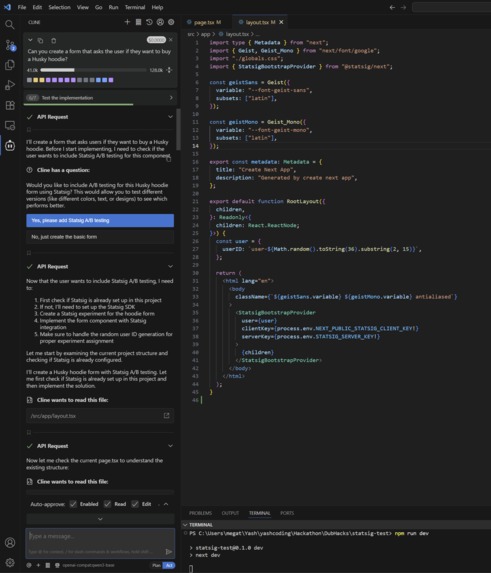
First we had to find user preferences by embedding statsig into our websites via to collect user metrics. Once we aggregated these metrics such as, button clicks, time on website, etc, we could understand which components users preferred most. We then had to construct a dataset using this information. We did this by using the code for the two different components as two possible code completion examples. Then we generated a hypothetical prompt by asking gemini to generate a prompt that could generate both of the components. Once we had the prompt as well as the two possible completions, we could construct a dataset for direct preference optimization. We hosted this dataset on huggingface. Then we implemented a training procedure to optimize the code completions for the component that had better metrics (more clicks or more time spent on page). For this optimization we used direct preference optimization, an RL algorithm to optimized language models based on pairwise preference data. Additionally to make finetuning quicker and more efficient we used QLora; we quantized the model to 4bit and used low rank adapters on the attention layers. There were several hyperparameters such as learning rate, learning rate warmup, beta, and batch size, to optimize training. Once the model was trained, we programmatically loaded the llm into vLLM, a local inference server, so that we could use it for code completions in vscode. For our code completion framework we used an opensource framework called cline and configured it to call our finetuned model. To close the loop, we implemented an MCP server for the llm to automatically generate and execute statsig AB testing experiments, so that it could improve itself. Additionally we implemented a dashboard to monitor the process of training and dataset curation.
Challenges we ran into
We overcame numerous challenges. The first major obstacle we faced was that programmatically pulling Statsig data did match our tight timeline so we pivoted to manually parsing and aggregating user event data. We also built our own MCP for Statsig to accommodate our individual needs. Another major obstacle was that the nature of our project required us to transfer data between multiple environments, both local as well as hosted.
Accomplishments that we're proud of
We are proud of being able to run an end to end pipeline involving various different aspects of the process. We were able to deal with unexpected situations and learned a lot in the process. Through the work we did, we were able to orchestrate our ideas into a cohesive project.
What we learned
We learned a lot about the end to end process. For example, we explored data pipelining, tooling through MCP, current algorithms for finetuning from human feedback, and inference with LLMs. We also integrated all of our steps into a dashboard that unified all of our components.
What's next for Flywheel
We would love to work with larger scale datasets to push the limits of LLM website generation. We would also like to create an all in one UI to further unify all of our different components.
Built With
- statsig


Log in or sign up for Devpost to join the conversation.