-
-
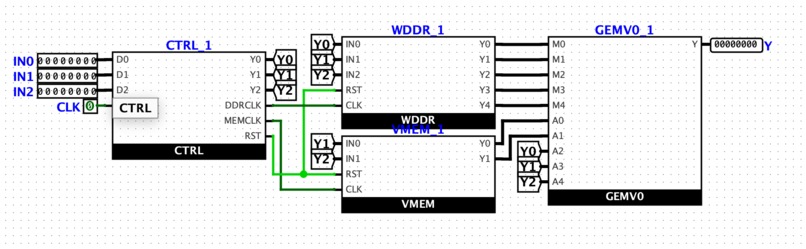
General Architecture
-
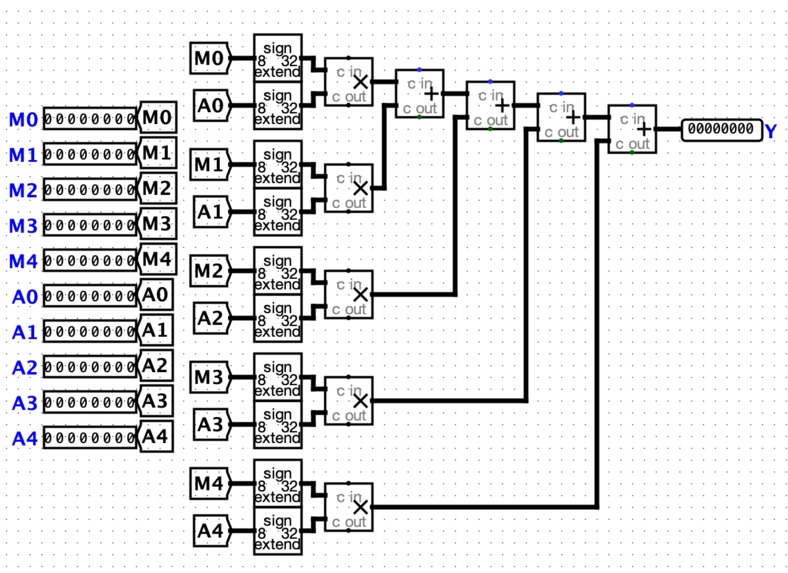
GEMV Product of Sums Unit


Inspiration
The inspiration for this project came from attempting to run a large language model on my laptop . I was surprised to learn that it worked, but it was outputting words at a rate of 1 token per second, which was underwhelmingly slow. At the time, I was also researching projects on emulating retro video game consoles using FPGAs, so the idea to create an AI accelerator chip came naturally.
What it does
The kernel was designed for the Intel Altera Max 10 FPGA device, which is a chip that can be programmed to emulate logic circuits based on VHDL (hardware description language) code. It receives instructions via an 8-bit register (8 electrical pins that are set to either 0 or 1), and reads data from an additional 2 8-bit registers.
The functional computation kernel does two things: it stores weights and inputs for neural network, and it matrix-multiplies these weights/inputs to produce an output. It is specifically designed to perform up to 5 simultaneous multiplications, with the intention of accelerating the time it takes to process inputs fed to a neural network (a process called inference).
Additionally, it implements DDR: double data rate. This means that users can write to its input pins on both low and high clock periods. This essentially means that data transfer rates to/from the chip are done twice as fast. All in all, the chip can compute 5 multiplications and sums in 2 clock cycles, which is significantly faster than most small, single-core processors.
In addition to the chip design, the project includes a compiler and emulator written in Python. A custom assembly language was developed to simplify programming the chip, which the compiler was programmed to transform into binary. The emulator is capable of running the compiled files, its purpose is to simulate/test programs that were written for the chip on the user's personal computer.
The intention is to use the chip alongside other microprocessors, like Raspberry Pi or Arduino. The target audiences are the UF GAITOR club and the UF Audio Engineering Society. The kernel can enable these groups to run simple neural networks on embedded devices, such as audio processors or internet-of-things products.
How we built it
An early proof-of-concept for the chip was first designed and simulated in a program called Logisim. This provided a high-level overview of its components and architecture, as well some VHDL designs that were used in the final product.
Then, work on a revised version began on the program Quartus - a tool by Intel made specifically for programming the Altera Max 10 device. We used VHDL (hardware description language) to model the circuit's components and use functional timing diagrams to verify results.
Once the circuit was finished, we began working on the compiler and emulator - both written in Python. The emulator was fairly easy, it consisted of rewriting the VHDL components into python functions. Meanwhile, the compiler was organized into three components: a lexer (for converting raw files into tokens), a parser (for deriving the assembly language's grammar from text), and an assembler (for converting the grammar into binary code).
Challenges we ran into
Timing and synchronization was by far the greatest challenge. The problem was trying to coordinate multiple units, some of which would finish executing faster than others. This was resolved by lowering the clock speed and adding synchronization circuits that wait for all signals to be received before moving on to the next stage of the chip's execution.
Additionally, a lot of time was wasted in trying to set up a demo that used quantized neural network. We could not figure out the correct parameters to use, which meant that the circuit kept returning wrong values. This was resolved by using normalization instead. The demo now achieves low error rates.
Accomplishments that we're proud of
- Designing and implementing a circuit, assembler, and emulator in 24 hours.
- Getting the circuit to work in the Quartus functional simulator.
- Implementing a demo of the project using a neural network.
What's next for Functional Computation Kernel
In the future, we hope to test the design by implementing neural networks on a physical circuit. We also look forward to optimizing the multiplier (for faster clock cycles) and expanding the chip's memory to allow for larger neural networks.
URLs
project repository: https://github.com/zeim839/osc-mini-hack demo: https://github.com/zeim839/osc-mini-hack/tree/main/demo
Built With
- python
- quartus
- vhdl


Log in or sign up for Devpost to join the conversation.