-
-
Feedback Overflow
-
Interface
-
Overview Overflow
-




1. Inspiration
1.1 Problem Statement
As corporations or organizations expand their business to global scope, services they offer must comply with a complex and constantly evolving set of geo-specific regulations. Manually identifying and managing these regulatory requirements is time-consuming, error-prone, and costly. Failure to meet these compliance obligations can result in significant legal and financial consequences, exposing organizations to substantial risks.
1.2 Motivations and Aim
With the rise of generative AI and retrieval-based systems, we saw an opportunity to build a trusted AI assistant for legal insights. Our goal aligns with TechJam Track #3—this is not to replace lawyers, but to augment them, reduce research friction, and empower individuals to make more informed decisions from a higher level of surveillance.
We aim to build a working system that:
- Flags features requiring geo-specific compliance logic and provides clear reasoning for each assessment.
- Keeps evidence trails to streamline regulatory inquiries and audits.
- Provides actionable recommendations on how a feature can improve compliance or address potential violations.
- Learns from human feedback to continuously enhance accuracy and precision.
2. Features
2.1 Overview
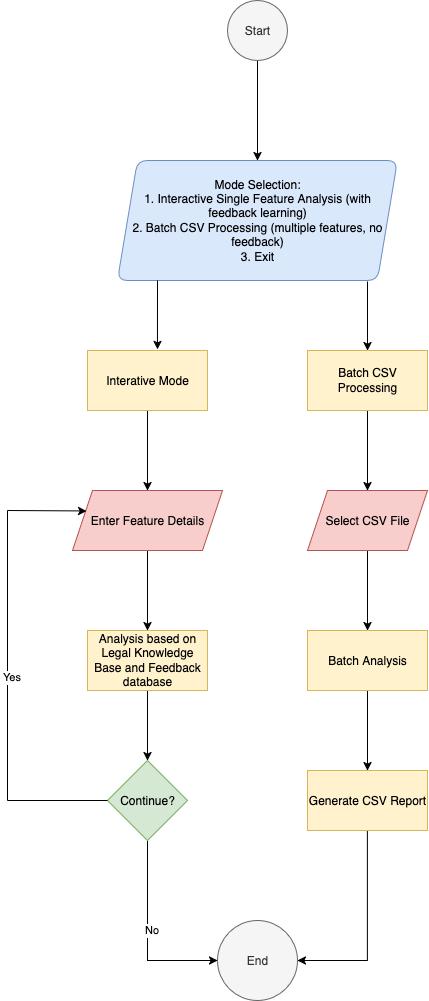
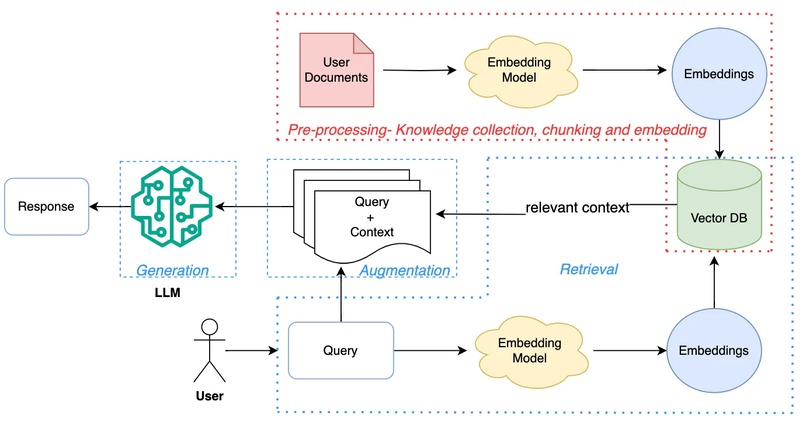
Our system is built around a Retrieval-Augmented Generation (RAG) model designed to assist with geo-specific compliance analysis. The main goal is to automatically determine whether a feature requires location-specific compliance logic, provide clear reasoning, and generate actionable recommendations—all while maintaining audit-ready evidence.
The RAG architecture combines knowledge retrieval with generative reasoning:
Data Preparation:
Relevant regulatory data and guidelines are curated into a structured knowledge base.
All relevant regulatory information, compliance guidelines, and feature-related terminologies are collected and structured into a knowledge base
Documents are pre-processed, cleaned, and converted into vector embeddings that capture semantic meaning, enabling efficient similarity-based retrieval
Query & Context: When a user submits a query about a feature, the system retrieves the most relevant documents or information from the knowledge base
The system converts the query into an embedding and performs a vector search against the knowledge base
The top-k relevant documents are retrieved to provide context for the model, ensuring that the reasoning is grounded in real regulatory knowledge, reducing hallucination or irrelevant answers
Generative Model: The retrieved context is fed into a large language model (LLM) alongside the user query
Based on both the query and the supporting documents, the LLM generates explanations, compliance assessments, and actionable recommendations, with a given format
Outputs are structured and organized, including clear reasoning, suggested next steps for the feature together with auditable resources
How We Built It
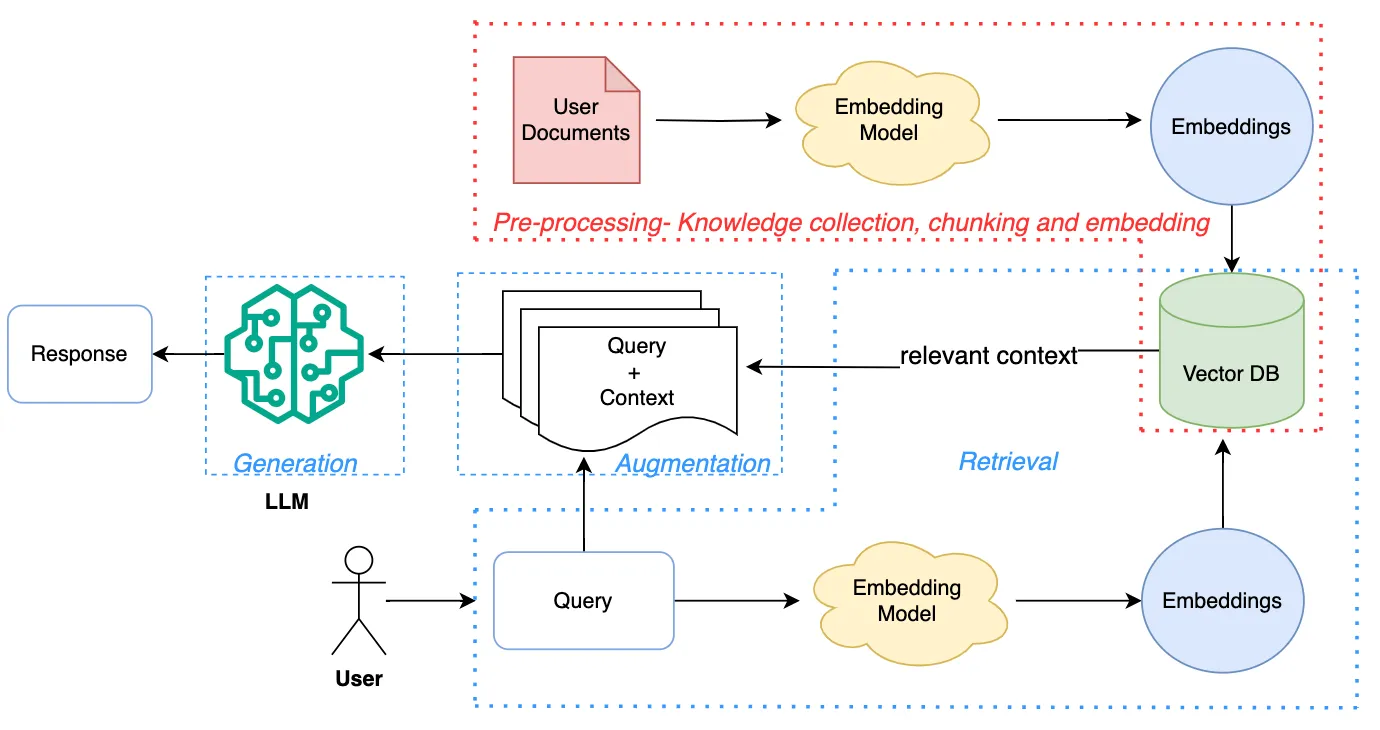
(Source: WTF in Tech by B. Pandit, 2025)
Data Collection:
- Gather regulatory and terminology sources provided, including links to laws and policies such as the EU Digital Services Act (DSA) and the Utah Social Media Regulation Act, as well as other relevant guidelines
Text Processing & Embedding:
- Pre-process the collected documents and break them into manageable chunks, and convert each chunk into a vector embedding using OpenAI’s text-embedding model
Vector Database Storage:
- Store all embeddings in a vector database, enabling efficient semantic search to retrieve the most relevant information quickly
Query Handling & Retrieval:
- When a user submits a query about a feature, the query is embedded with the same embedding model and vector search is performed to retrieve the top relevant document chunks from the knowledge base
Prompt Template & Structured Generation:
- We prepare a prompt template to structure the LLM’s output consistently, which treats the query and retrieved context as arguments to this template, guiding the model to generate outputs in a structured format containing:
- Compliance Flag: Whether the feature requires geo-specific compliance logic
- Reasoning: Clear explanations for the compliance assessment
- Regulations: Relevant laws and guidelines supporting the assessment
- Recommended Actions: Suggestions for improving the feature or addressing violations
- Audit-Ready Evidence Trails: Traceable records of decisions and outputs
Generative Reasoning: Feed the structured prompt with query and context into GPT-4-mini, to generate comprehensive outputs following the template, ensuring precision, explanability, and traceability
2.2 Cached Legal Data Retrieval
One of the core design challenges in building a compliance assistant is handling large volumes of regulatory text. These legal texts are:
Take long time to fetch and expensive to reprocess those data
Updated from time to time
To ensure speed, cost-efficiency and the context is up to date, we implemented a caching mechanism in the knowledge base loader.
How We Built It
Fetch once, reuse later: When a law document is first fetched from an online source, it is split into semantic chunks and stored as JSON in a local cache directory (legal_docs_cache/). We choose to store the file in JSON format because it is easy to debug, inspect, and extend with new metadata. Also, it is lightweight and human-readable for auditing
Fail-safe loading: If the cache fails or expires, the system re-fetches the law text, re-chunks it, and re-caches the result, preventing system break up occurs
Update Cache: Cached files will be updated when the cache history is more than 30 days. This strikes a balance between legal updates with runtime performance
Metadata tracking: Each chunk stores metadata (law type, source URL, last updated timestamp) for transparency and audit purposes
Optimized retrieval: Instead of scraping long legal documents at runtime, the retriever pulls from cached, structured, vectorized chunks which should significantly speed up compliance analysis queries
2.3 Context-Aware Smart Chunking
To ensure the retrieval of highly relevant legal context, we implemented a “smart chunking” strategy to tackle the challenges of processing large, complex legal documents.
The usual way of simple and generic splitting methods can be brittle, often breaking sentences or legal clauses, which leads to chunks that lose meaning and reduces precision. In contrast, our approach preserves the semantic and logical integrity of the text.
By aligning the chunking process with the inherent hierarchical structure of legal documents, each chunk becomes a meaningful, self-contained unit of information. Treating legal text as structured data rather than plain text not only mitigates the risk of fragmented or incoherent chunks but also improves the quality of the retrieved context and enhances the overall performance of the RAG system.
How We Built It
Our system uses the RecursiveCharacterTextSplitter from the LangChain library, but we have customized its behaviour to be law-specific and suits the logical structure of legal documents.
Logical Separators: The core of our strategy is using specific, logical separators tailored for each legal source. Instead of standard splitting on newlines or periods, this method breaks the documents based on its internal structure, such as articles, sections and parts. This is defined in the law_specific_data dictionary within the code
Examples: Separators like == Article and ==Recitals are used for EU Digital Services Act while separator SEC. is used for California SB976 to keep the entire legislative sections together.
Chunk Size and Overlap: We set a chunk_size of 1500 characters and a chunk_overlap of 200 characters. This combination is a carefully chosen balance so that the large chunk size can ensure each chunk contains sufficient context for the LLM to understand the full scope of a legal provision. The overlap is to prevent the loss of context at the boundaries of chunks
Metadata Enrichment: After splitting, we enrich each chunk with key metadata. The setup_knowledge_base method attaches law_type, source_url and last_updated information to each chunk. This metadata is critical for downstream processes
2.4 Query Translation & RAG Fusion
This optimization improves the system’s ability to understand and respond to user queries by translating a single query into multiple perspectives. By exploring the query in broader and deeper ways, the system retrieves more relevant context, enhancing the precision and performance of the analysis. Users experience more precise compliance assessments, richer reasoning, and actionable recommendations, even for complex or nuanced features.
How We Built It
Law Type Inference (LLM-Powered Filtering)
Before any document retrieval, the system uses an LLM to infer the most relevant legal frameworks from the user’s query description.
This inferred metadata is then used as a filter, narrowing the search space within our vector database to only the most relevant documents.
- Example:
For the query "Does the ‘automatic friend suggestion’ feature comply with child protection regulations in Utah?",
the system will analyze and determine that the Utah Social Media Regulation Act is the most relevant law.
Query Decomposition Break the original query into smaller, detailed sub-queries to capture specific aspects of compliance.
- Example:
For the same query, the system might generate sub-queries like:- “What child protection requirements in Utah apply to automatic friend suggestions for users under 18?”
- “What reporting or evidence obligations exist if a platform exposes minors to unsafe interactions?”
- “What child protection requirements in Utah apply to automatic friend suggestions for users under 18?”
Query Rephrasing (Generalization) Generate a broader, generalized version of the query to retrieve additional relevant context beyond the original phrasing.
- Example:
For the same query, the system might generate:
“How should social media platforms manage algorithmic user connections to comply with child protection laws?”
Query Enhancement Enrich each query variant with compliance-specific keywords, including relevant countries/regions, legal terms, and domain-specific phrases.
- Example:
For the same query, the system would generate enhanced terms such as:
“US”, “Regulations”, “Data protection”, etc.
These are appended to queries before embedding them for context retrieval.
Maximal Marginal Relevance (MMR) Retrieval For each of the generated query variants, we perform a vector search on the filtered document set. To ensure that the retrieved results are both relevant and non-redundant, we use MMR which selects the top documents that are highly relevant to the query while also being diverse from each other. This prevents the system from retrieving multiple, near identical chunks, providing a broader and comprehensive context.
RAG Fusion (Reciprocal Rank Fusion) After retrieving chunks for each query variant (original, decomposed, generalized, enhanced), we merge them using Reciprocal Rank Fusion (RRF).
- Each document contributes a score based on its rank:
$$ \text{score} = \frac{1}{k + \text{rank}} $$
Higher-ranked documents contribute more, and documents appearing in multiple query results accumulate higher fused scores
Finally, the fused results are sorted by score, repeated chunks are removed for cleaner context, and the top 8 chunks are selected to feed into the LLM
2.5 Prompt Engineering
To transform a general-purpose LLM into a specialized and reliable compliance analyst, we developed a multi-layered prompt template. This template serves as both a formatting guide and a reasoning scaffold. This optimization makes the system’s outputs clear, consistent, and trustworthy. Instead of receiving overly academic or inconsistent responses, users now get compliance analyses that are:
Easy to read: Legal reasoning is explained in plain, user-friendly language.
Structured and predictable: Every output follows the same format, so users know exactly where to find the compliance flag, reasoning, regulations, and recommended actions.
Trustworthy and auditable: Each conclusion is tied to cited sources, giving users confidence that the analysis is grounded in real laws.
How We Built It
Our prompt architecture is built on several key techniques.
Role and Rule Definition: The prompt begins by establishing the critical distinction. By clearly defining what constitutes "Geo-Specific Compliance Logic" versus "Business Logic" upfront, we set the foundational context and prevent the model from misinterpreting the core task. This acts as a system-wide directive that governs all subsequent reasoning.
Multi-Context Injection with Prioritization: We provide the LLM with multiple sources of truth, but we also tell it how to weigh them.
Knowledge Base Context: This is the primary source of regulatory information retrieved via RAG.
Internal Glossary: This provides definitions for domain-specific terms, reducing ambiguity.
Prioritized User Feedback: The instruction (prioritize this if relevant) is crucial. It directs the model to treat validated human feedback as the highest-priority context, allowing the system to self-correct and adapt based on expert input.
Chain-of-Thought (CoT) Reasoning: The analysis guideline forces the model to follow a specific, logical workflow. Instead of jumping to a conclusion, it must proceed step-by-step:
Identify geographical terms.
Discern the intent behind the logic (legal vs. business).
Acknowledge uncertainty if needed.
Cite specific evidence.
Assess risk.
Few-Shot Prompting and Strictly Structured Output: We provide three examples provided in the problem statement for reference. These examples act as a standard demonstrating the expected reasoning, tone and output structure. We also require the LLM to return its analysis in a clean, machine-readable JSON format.
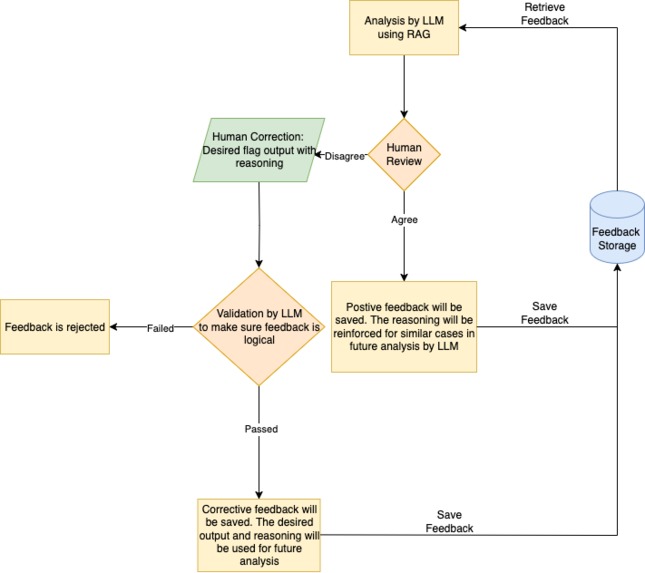
2.6 Automated Feedback Integration
The feedback integration feature allows the compliance analysis system to continuously improve itself through human-in-the-loop feedback. Its key objectives are:
Automation-first: Automatically iterate through human feedback knowledge base and synthesis analysis
Self-evolving system: Uses feedback to refine future compliance analyses
Safeguards: Logical validation prevents bad or irrelevant feedback from corrupting the knowledge base
Auditability: All feedback is timestamped, categorized, and stored for traceability
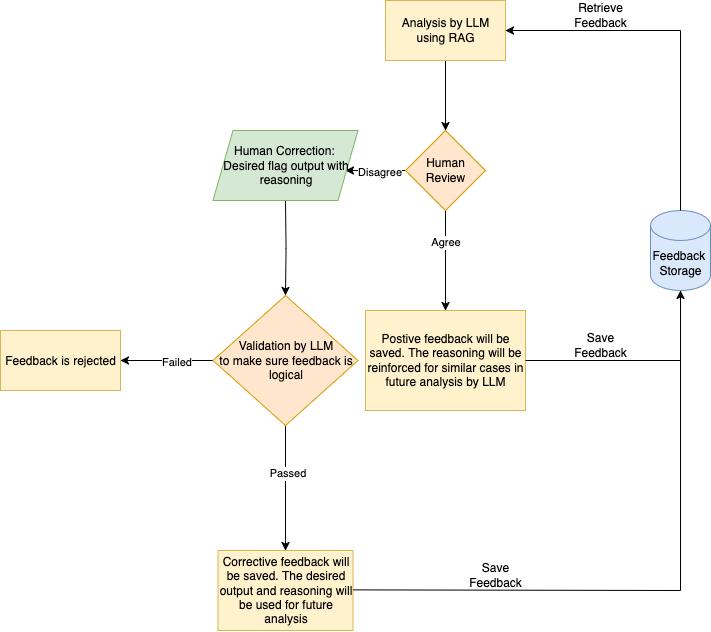
The feedback integration subsystem implements closed-loop self-improvement, treating each compliance analysis as part of an iterative pipeline. Human feedback is embedded by text-embedding LLM and ingested as structured, validated data and stored in a dedicated Chroma vector store. On future analyses, this store is queried alongside the legal knowledge base, and retrieved feedback is injected into the LLM prompt with priority weighting, ensuring prior corrections directly influence subsequent outputs.
To maintain robustness, the design enforces strict filtering at ingestion: corrective feedback must pass a logical validation step powered by an LLM-based meta-analysis before being admitted. This prevents irrelevant, emotional and nonsensical feedback from contaminating the knowledge base. Positive feedback, on the other hand, is stored directly to reinforce reasoning paths that should be replicated.
At a systems level, this creates a self-evolving multi-agent workflow:
The Analyst agent performs compliance reasoning.
The Human Feedback agent provides corrective signals.
The Judge agent reviews feedback against a rubric for quality control.
The Feedback Retriever injects accumulated human knowledge into future analyses.
The philosophy emphasizes guardrails-first automation—all feedback processing (validation, embedding, retrieval, fusion) is automated, but every stage preserves auditability via metadata (timestamp, source, original_query). This layered architecture ensures that automation is not only scalable but also directionally correct, continuously adapting toward compliance accuracy while retaining human oversight as the final arbiter of truth.
3. Challenges
Balancing Context Coverage and Performance
Problem: Simply feeding the user query into the system often produced outputs that lacked legal coverage and robust reasoning.
Solution: To address this, we implemented query translation, including decomposition and step-back techniques. This allows the system to explore the query from multiple perspectives, which dramatically improves context coverage and reasoning.
Another problem: However, this multi-perspective approach retrieved an overwhelming number of chunks, increasing processing time and computational cost.
Corresponding solution: We applied RAG Fusion (Reciprocal Rank Fusion) to intelligently merge and prioritize retrieved chunks. By selecting the top most relevant results, the system achieves a balance between coverage, reasoning depth, and response efficiency, demonstrating careful consideration of both analysis precision and time costing performance trade-offs.
Making Outputs Human-Readable
Problem: Early outputs from the system were too academic, heavily laden with legal jargon and dense terminology, sometimes output irrelevant outcomes, which increases hallucination and noises to the outputs. This made the results difficult to interpret for non-experts, reducing the system’s usability and real-world impact.
Solution: We leveraged prompt engineering and conducted extensive testing to guide the LLM to produce outputs that are human-friendly yet logically rigorous. The prompts structured the output to include clear compliance flags, reasoning, actionable recommendations, and audit trails in plain language. This improved accessibility without sacrificing technical accuracy, ensuring the system could empower decision-makers easily and efficiently.
Validating Human Feedback
Problem: Integrating corrective human feedback introduced the risk of context pollution, where inconsistent or illogical entries could degrade the knowledge base of our system. Early attempts using rule-based heuristics (e.g., keyword checks or law reference matching) proved too brittle to handle the diversity and nuance of real-world feedback at scale.
Solution: We introduced an LLM-based Judge module that automatically evaluates each feedback entry for logical consistency and relevance. This approach ensures that only high-quality, meaningful corrections enter the system. By offloading validation to the LLM, we maintain scalability and robustness, allowing the system to continuously improve while protecting its integrity.
4. Accomplishments
Building this system was a journey of solving complex, real-world challenges. We went beyond a standard proof-of concept to create a robust, intelligent and practical tool for legal compliance. Here are the accomplishments that stand out.
Self-Evolving System with an Automated Feedback Loop
Many systems can log feedback but ours learns from it automatically. We are especially proud of implementing a human-in-the-loop system that continuously improves. The crowning achievement here is our LLM-powered “Judge” agent, which acts as a logical gatekeeper to validate human feedback. This prevents irrelevant or incoherent suggestions from corrupting the knowledge base, ensuring the system evolves with high-quality, relevant data. This transforms our system from a static tool into a dynamic partner that grows smarter with every interaction.
Beyond Standard RAG: Precision-Driven Context Retrieval
We did not just implement a generic RAG pipeline, but we engineered a highly sophisticated retrieval process tailored for complex legal text.
Context-Aware Smart Chunking: By splitting documents along their logical semantic boundaries instead of arbitrary character counts, we ensure the context fed to our LLM is always coherent and complete.
Query Fusion for Deeper Understanding: Our system does not just take a query at face value. It automatically decomposes, rephrases and enhances the user’s question. Using Reciprocal Rank Fusion (RRF), we synthesize these multi-faceted search results into a more comprehensive context leading to more accurate answers.
Engineered for Real-World Efficiency and Scale
We built this system with the realities of enterprise use in mind.
Intelligent Caching: Our smart caching of legal documents significantly speeds up retrieval and reduces processing costs, while the 30-day refresh policy ensures the data remains current without constant, expensive re-fetching.
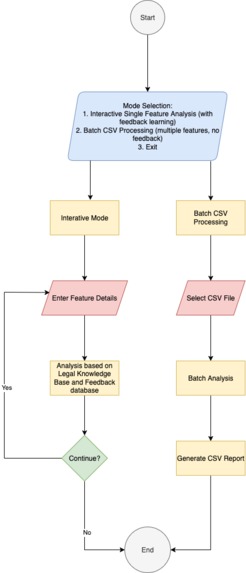
Scalable Dual-Mode Workflow: Recognizing that users can’t manually review every single feature, we designed a dual-mode workflow. Analyst can process hundreds of features in Batch Mode for a high-level overview and then switch to the interactive Feedback Mode for a deeper dive on specific, problematic cases. This design respects the user’s time and makes the system practical at scale.
Building Trust with End-to-End Auditability
In the legal and compliance space, trust is non negotiable. We embedded auditability into the core of our architecture. From the metadata attached to every chunk of text to the timestamped and categorized feedback logs, every decision the AI makes is traceable back to its source. This commitment to transparency ensures that our system is not a “black box” but a trustworthy assistant ready for regulatory security.
5. Key Insights
Building HypeDance taught us a lot about the challenges of applying AI to legal compliance:
Compliance is context-heavy: Laws are region-specific, cross-referenced, and often ambiguous. A simple keyword search is not enough, we learned the importance of structured chunking, law-specific metadata, and RAG pipelines to preserve context.
Human-in-the-loop feedback is essential: Compliance isn’t binary. We learned that adding a feedback mechanism and validating feedback with the model for logical consistency, helps the system improve without blindly accepting corrections. This balance between automation and expert oversight is critical for trust.
Auditability is as important as accuracy: Regulators and compliance teams need traceability. We realized it’s not enough to say “YES” or “NO”, the system must show why it reached that conclusion, which laws were considered, and provide an audit trail for human review.
Ambiguity must be surfaced, not hidden: Instead of forcing a YES/NO answer, having an “UNCLEAR” category turned out to be powerful. It signals where human judgment is required, reducing the risk of overconfidence from the AI.
Retrieval quality matters more than model size: The same LLM prompt produces drastically different results depending on how well the retrieval pipeline is designed. Techniques like multi-query generation, RRF fusion ranking, and enhanced queries with legal keywords made the system far more reliable than using a single naive search.
LLMs need scaffolding: Without structured prompts, responses varied wildly. By forcing the model to output structured JSON with fields (flag, reasoning, regulations, risk, etc.), we gained consistency and made results easier to analyze in batch reports.
6. What’s Next
Moving forward, we plan to expand HypeDance beyond a baseline RAG system into a next-generation compliance intelligence platform. Our near-term and long-term priorities are:
GraphRAG & Structured Legal Reasoning
We plan to implement GraphRAG to evolve from flat document retrieval into a graph-based representation of laws, obligations, and precedents, enabling the system to connect related clauses across jurisdictions, visualize dependencies (e.g., GDPR ↔ DSA overlaps), and uncover hidden relationships between legal provisions. By structuring regulations as interconnected nodes and edges rather than isolated text chunks, the system can provide analysts with explainable reasoning paths and richer context, allowing compliance implications to be traced not only at the document level but also across a broader network of interconnected legal concepts.
Multilingual & Cross-Jurisdiction Support
We aim to extend the system to handle non-English regulations by integrating translation pipelines and developing law-specific chunking strategies that preserve the semantic and structural integrity of diverse legal texts. This multilingual capability will not only broaden the system’s global coverage but also support comparative compliance checks across jurisdictions (e.g., “How does California SB 976 differ from Utah’s SB 152?”), enabling organizations to identify similarities, differences, and potential conflicts in legal obligations with greater clarity and efficiency.
Productization & User Experience
We will build a dashboard that lets compliance teams run batch analyses at scale, review tamper-evident audit trails, and export stakeholder-ready reports in one place. To increase trust and transparency, we’ll add explainability visualizations that pinpoint the exact law sections and clauses that supported each decision, with clickable traces back to sources. Finally, we’ll expose well-documented API endpoints so engineering teams can plug compliance checks directly into their development pipelines—enabling CI/CD for compliance with automated gates, regression comparisons, and structured JSON outputs for downstream tools.
Real-Time Legal Updates
We will automate legal corpus ingestion by continuously pulling updated statutes, amendments, and case law into the knowledge base, wired through webhooks/RSS feeds from official sources (e.g., EUR-Lex, US GovTrack). A change-detection pipeline will diff versions, re-chunk only affected sections with law-specific strategies, and refresh embeddings incrementally—so retrieval stays fast and precise. This end-to-end update loop ensures our compliance checks always reference the most up-to-date regulations, shrinking the lag between legal changes and system adaptation while preserving full audit trails of what changed, when, and why.
Development Tools
Programming Language: Python 3.11+
RAG Framework: LangChain
IDE: Google Colab, VSCode
Logging & Debugging tool: LangSmith
API
OpenAI API - GPT-4o-mini model
LangSmith API - Logging and Debugging
Libraries
Pandas - Data Processing
BeautifulSoup - Web Scraping / Parsing
LangChain Community (WebBaseLoader) - loading and structuring documents from the web.
LangChain (RecursiveCharacterTextSplitter) - splitting long regulations into semantically meaningful chunks.
LangChain OpenAI (OpenAIEmbeddings) - vector embeddings for semantic search.
LangChain OpenAI (ChatOpenAI) - GPT model interface for analysis, query expansion, and structured compliance outputs.
LangChain Community (Chroma) - vector store for legal corpora and feedback memory.
LangChain (ChatPromptTemplate) - structured prompts for compliance analysis.
LangChain (StructuredOutputParser, ResponseSchema) - enforce JSON-structured responses from the LLM.
LangChain Core (RunnablePassthrough) - chaining data transformations and components.
LangChain Schema (Document) - standardized document object with metadata (used in retrieval).
Assets
- Legal Text Sources (Additional)
General Data Protection Regulation (GDPR) (https://gdpr-info.eu/)
California Consumer Privacy Act (CCPA) (https://oag.ca.gov/privacy/ccpa)
EU Digital Services Act (DSA) (https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/digital-services-act_en)
EU Digital Markets Act (DMA) (https://en.wikipedia.org/wiki/Digital_Markets_Act)
Singapore Personal Data Protection Act (PDPA) (https://www.aseanbriefing.com/news/understanding-personal-data-protection-in-singapore/)
Japanese Act on the Protection of Personal Information (APPI) (https://www.ppc.go.jp/en/)











Log in or sign up for Devpost to join the conversation.