-
-

Scrolling through discover page
-
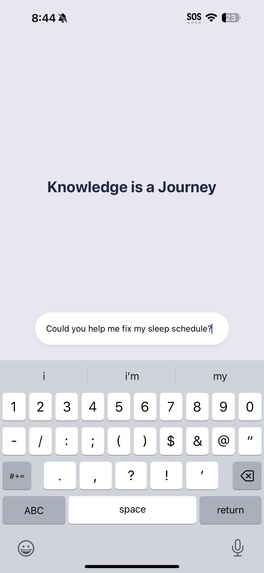
Create Journey Page
-

Results after creating journey to show you what it is about to create
-
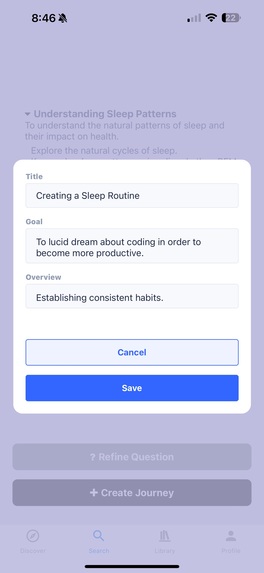
Edit screen for a journey module
-

Generated educational cards from creating a journey
-
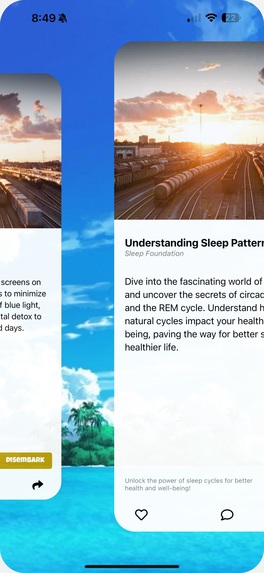
Swiping through different generated cards
-
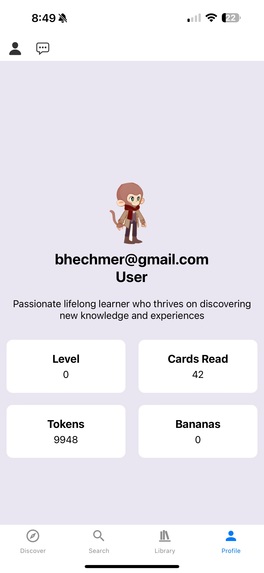
Profile page showcasing level, how many cards you've swiped through, how many tokens you have left, and if you've collected any bananas.
-

Scrolling through discover page








💡 Inspiration 💡
“There is no lack of educative content, but the correct delivery”
In an age where educational content is abundant, the challenge lies not in its availability but in its effective delivery and the unique perspective of the presenter. While technology like Google Search, ChatGPT, and advanced AI search bots like Perplexity.ai have made accessing content effortless, education efficiency isn’t limited by the speed of information queries. It is, rather, bounded by the speed of your brain’s information intake, which can only be boosted via proactively engaging, personalized, and even addictive learning experiences.
We planned to achieve this via 5 tools:
- 🖼Multimedia: LLM, text-to-image, AI Agent, and web-scraping enable a textual, visual, and interactive experience
- 🔎Diverse Content Perspectives: By tweaking prompts with different keywords, we can simulate a variety of content creators, offering a rich spectrum of views and styles.
- 📈Recommendation Algorithms: With LLMs, tagging and describing content becomes scalable and cost-effective, enhancing the efficiency of recommendation systems.
- 🎮Gamification: Use gamification to improve engagement.
- 💰Financial incentive: LLM automatically turns learners (question-askers and answer-seekers) into teachers (answer-generators) by reusing answers. In short, people get compensated for asking valuable frequently asked questions.
These elements have proved to be crucial for any content platform seeking viral success. Fortunately, the advent of Large Language Models (LLMs) has revolutionized the potential of content platforms, making it easier than ever to satisfy these critical aspects.
💻 What it does 💻
1️⃣Recommendation Driven Generation
We track and collect the user’s behavior data and interaction with the feed, and gradually learn the user's interest profile. Then, the learned profile, represented by a set of weighted tags, is used to accurately and automatically generate the user’s favoured content.
2️⃣Learning Journey Decomposer
Unlike ChatGPT or Perplexity, which spit out ineffective, lengthy responses when given users’ complex learning goals, we decompose them into a sequence of general and reusable learnable modules. This sequence, what we call a “learning journey”, gives just the needed amount of knowledge of every necessary aspect for you to reach your learning goal. Furthermore, since each module is reusable, it not only makes your learning transferable and generalizable but also boosts other user’s usage of your generated content, thereby boosting your reward.
3️⃣Subjectiveness, but safely and beneficially
Every content we generate is a RAG (Retrieval Augmented Generation) from trustworthy human-generated content on the Internet (with sources attached). This introduces subjectiveness, human nature, and opinions into the content, which is not achievable solely via the usage of any generative LLMs. While enforcing safety via negative prompts, the introduced subjectiveness brings humanized flavour to learners, hence making the content less rigid and more entertaining.
4️⃣ Gamified Mini Course Maker
Given a topic card, a gamified mini-course, with beautiful visuals and short multiple-choice questions, can be automatically created. Your performance will impact how much XP you will receive, which will impact your levelling progress.
👨💻How we built it 👨💻
How do we create contextual content for complex learning goals while reusing content?
Content Generation 1️⃣- User Generated Content
Users can ask questions and are assisted by LLMs to tailor the learning goal into desirable modules for the user to interact with via natural language. The user can iterate on the division of content in modules and when satisfied, a similarity search using InterSystems is used to find existing content modules that can be reused. Existing modules are combined with newly generated modules to create a full “Learning Journey” that meets the user’s learning goals.

Content Generation 2️⃣ - Automatically Generated Content
As the user scrolls their feed, we collect various data points like their CTR and interactions, which is used to assign weighted tags to the user interest profile. Users are recommended content modules based on their past activity using a custom recommendation algorithm on Pinecone. This is existing content that has been generated by other users that we think this user will find helpful using a combination of the user’s tags, and content tags, as well as tracking the user’s time spent and click-through rate on content.
However, because the content is customized specifically to the user’s interests and past questions, there could be a lack of “relevant" content for the user. Rather than showing the user something irrelevant, we utilized RSS feeds from forums like Reddit, Medium, and Quora to generate new “hot” questions that are specific to the user’s needs and interests. These questions follow the same flow described above to generate new cards, modules, and tags.

Rest of the App
The application was built using React-Native and Expo for the front end and Flask and Supabase for the back end.
😬 Challenges we ran into 😬
HCI (Human Computer Interaction) - ✅solved
In the course-making page, it is hard to build an AI Agent that uses natural language to communicate and manipulate a designed Learning Journey JSON object. Solely using chat completion doesn’t work since actions, like add/delete/modify, are not guaranteed to be precise (can cause unexpected errors). We used the OpenAI assistant API with function calling to ensure stability, but the high usage cost held us back.
Scalable RecSys - ✅solved
While we have 2000+ generated learning cards, how do we build RecSys with a deep learning effect but no deep learning infra? Also, we don’t have enough data for the training.
User Behaviour Tracking and RecSys data collection - ✅solved
Content displayed in full screen doesn’t have CTR data. But unlike TikTok, where video playback completion rate can be easily collected, reading content’s completion rate requires tracking and making inferences on the user's reading speed. We utilized a Bayesian Inference as a fast and robust model to make inferences.
Not enough Pinecone indices - ❌unsolved
To determine reusable content, we need to compare the cosine similarity of card contents. But as a free tier, we only have 1 available index to use. Thus, reusability is unsolved due to a lack of resources. We pivoted to Intersystem for a local DB solution.
😤 Accomplishments that we're proud of 😤
- A complete Recommendation System: we built the entire user behaviour tracking, data collection, model, efficient candidate picking and ranking pipeline that achieves similar performance as DNN, but didn’t use any neural network
- Bring humanity and subjectiveness into AIGC (AI-generated content) - Through tags from learned user interest profiles, prompt engineering, web scraping, and querying popular websites’ RSS top feeding pages, we’re able to systematically determine what topic is viral, trending, and worthwhile generating, and generate human-like content through RAGs, with backed sources.
- Coercing GPT into returning JSON data in the new JSON mode was difficult and required a lot of prompt engineering to ensure that the output was stable and consistent
🧠 What we learned 🧠
- It is possible to systematically generate viral and enticing textual content. Recommendation systems for full-screen content and non-full-screen content can be very different. Negative samples are hard to collect.
- There is a spectrum between casual reading casual learning and actual learning. LLM can create a smooth transition from the most casual to the most serious by developing knowledge details via creating stratified content and by adjusting styles from entertaining to profound. Assistant AI is in beta because it doesn’t support JSON mode. This made the API much less useful and the AI agent swarm is yet to come.
- In the age of LLM, a single man can build a recommendation system, with no shortage of computing power and data.
- We had a lot of ambitious goals for Iearn as a product and it was important to focus on delivering an MVP before focusing on additional “nice-to-haves”.
🔭 What's next for Iearn? 🔭
- Polishing Assistant API AI Agent for the learning journey decomposer
- Build a functional API to keep track of nitty-gritty features for gamification
- Multiple card types and more multimedia: introduce music, video, cooking recipes, mini javascript games, etc… We have one type of content module but the possibilities are endless in the different formats of AI-generated media.
- Socialization, build social media features for more user interaction
Built With
- expo.io
- flask
- google-custom-search
- gpt
- intersystems
- javascript
- lorem-picsum
- novita
- openai
- pinecone
- rag
- react-native
- supabase
- unsplash




Log in or sign up for Devpost to join the conversation.