-
-
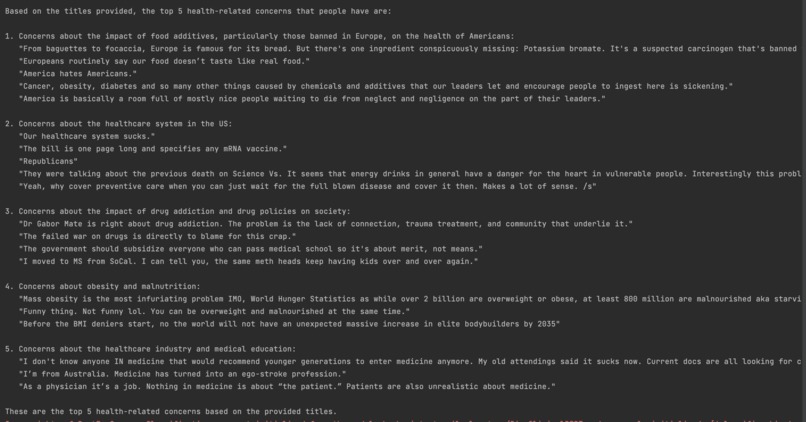
Results of reddit scraped and NLTK processed most relevant topics of discussion with examples
-

TaiPy solution
-
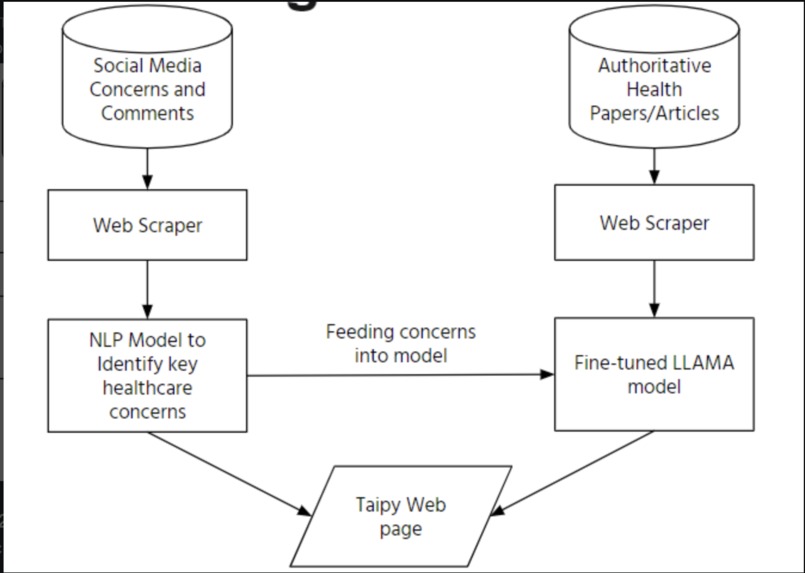
Infogenesis's revolutionary workflow



Inspiration
Scrolling through Reddit for discourse on important health topics, it's clear how much misinformation is out there, often contradicting modern research. The average person, caught in a whirlwind of daily tasks, rarely seeks out academic literature for the truth and believes incorrect information that can harm their health. Recognizing this gap, we were inspired to create a bridge between the public and the rich insights of contemporary studies. Our goal is simple yet profound: to make it effortless for everyone to access accurate, research-backed information on the topics they care about most to enhance their quality of life by improving their health, transforming casual scrolling into an opportunity for genuine learning to have a healthier, happier life.
What it does
Our project dynamically mines online forums to capture the pulse of current discussions. Leveraging advanced NLP, it discerns and segregates health-centric dialogues, employing a hyper-tuned LLAMA model enriched with the latest academic insights to delve into prevalent health narratives. This cutting-edge approach not only identifies but also elaborates on key health subjects, culminating in the generation of insightful, research-backed blogs in a convenient manner. These resources are then made accessible on a sleek Taipy page, offering a beacon of verified information in the murky waters of online discourse.
How we built it
Our project harnesses the power of cutting-edge technology to combat misinformation in health discussions online. At its core, it employs Natural Language Processing (NLP) techniques, leveraging libraries like NLTK for text analysis and sentiment assessment. Data scraping from public forums provides the raw material, which is then refined using NLP to distinguish health-related conversations. A specialized LLAMA model, fine-tuned with the latest academic health literature, interprets these discussions, generating factual, easy-to-understand content. This information is presented on a Taipy page, making credible health knowledge accessible and engaging. Our tech stack integrates Python for backend processes, employing libraries such as pandas for data manipulation, funneling the products into the Taipy GUI for visualization, and transformers for accessing advanced AI models, including the integration with OpenAI's API, ensuring our responses are grounded in the most current research and trends.
Our fine-tuned model is here: https://huggingface.co/AndyYu25/hacklytics24-medsummarizer
Challenges we ran into
One significant challenge we faced was refining our methodology to accurately identify and classify the most crucial health topics from broader health-related discussions. Distilling specific topics of paramount interest from extensive sentences laden with complex medical terminology and diverse subjects required advanced NLP techniques and significant fine-tuning of our model. This task was compounded by the vast and varied nature of health discourse online, where the relevance of topics can fluctuate widely based on current events, seasonal health issues, and emerging research findings. Furthermore, finding and utilizing a service to deploy the LLAMA to the web and integrate it into a site was its own obstacle as many frameworks do not interface easily with models constructed through python.
We were also unable to reserve any high-performance instance on Intel Cloud, forcing us to deploy a smaller model than we have fine-tuned.
Accomplishments that we're proud of
We're incredibly proud of developing a tool that has the potential to significantly impact public health understanding on a national scale. Our project stands out as a testament to the power of teamwork and the positive effects of leveraging technology for social good. By combining our diverse skills and shared commitment, we've created a platform that not only addresses the rampant issue of health misinformation but also empowers individuals with accurate, research-based information. This achievement reflects our dedication to improving lives through innovation and collaboration.
What we learned
We've gained valuable insights into the nuance of using social media as a platform for sharing healthcare information and understanding public opinion. Our exploration of leveraging NLP technologies and generative AI models to sift through this vast amount of data has been a driving force in our solution's development. We've experimented with various technology frameworks and diverse data analysis techniques to find the most effective solutions for our project. We've learned that data analysis is an iterative process, with each trial and error contributing to the evolution of our project.
What's next for InfoGenesis
Given more development time and resources we'd like to further optimize our models and automate our workflow to streamline the process of information translation from scraper/API to model. We'd also like to continue with the development of our website and push to a more dedicated server that can handle the model.
Built With
- beautiful-soup
- matplotlib
- natural-language-processing
- nltk
- openai
- python
- scikit-learn
- selenium
- taipy
- tensorflow


Log in or sign up for Devpost to join the conversation.