-
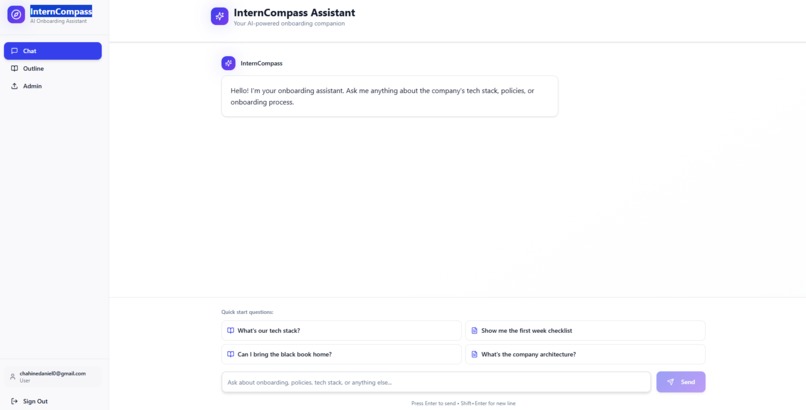
Main View
-
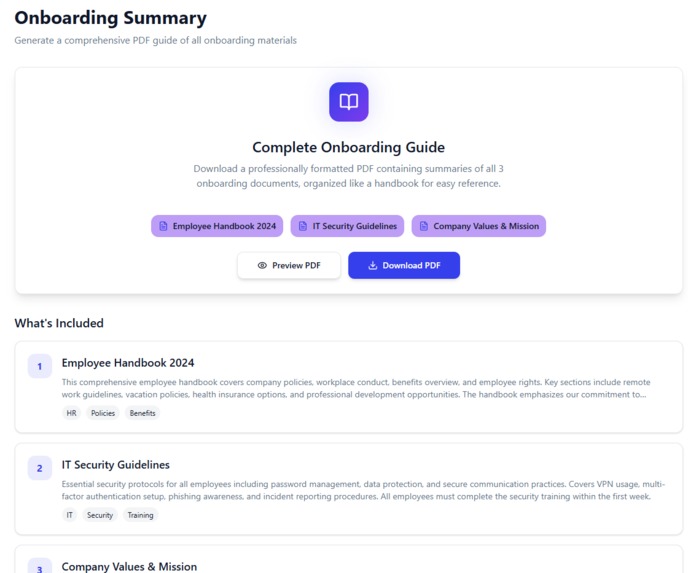
Onboarding Summary
-
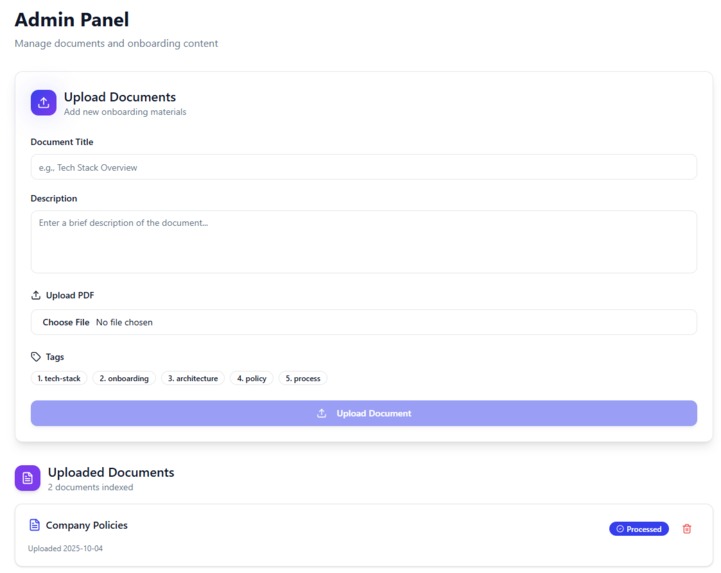
Admin Panel
-
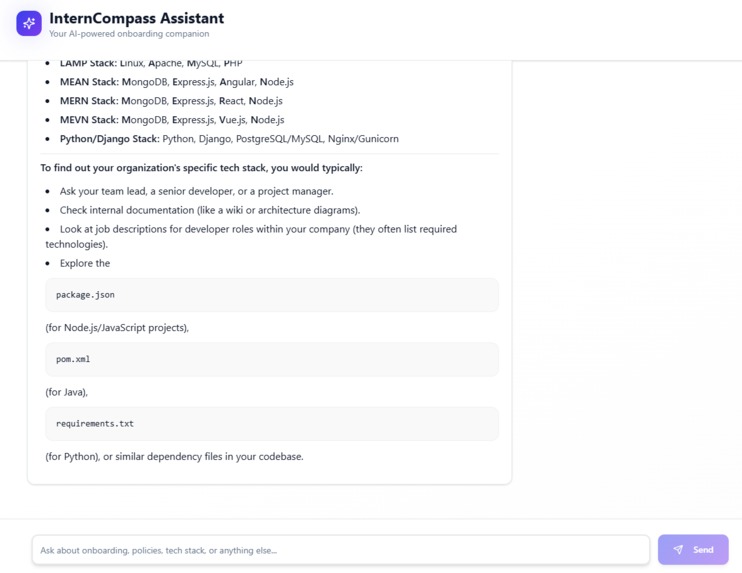
Chat Page
-
Login Page





🚀 Intern Compass – Project Story
💡 Inspiration
Corporate onboarding is often overwhelming—new hires face hundreds of pages of PDF handbooks, policies, and training materials. Many struggle to find what they need quickly, leading to repetitive questions and delayed productivity. Intern Compass was created to solve that: an intelligent assistant that understands natural language, provides accurate, cited answers from company documents, and makes onboarding efficient and stress-free.
⚙️ What It Does
Intern Compass transforms static PDFs into an interactive AI-powered knowledge base.
- Intelligent Document Processing – Upload and index company documents automatically
- RAG-Powered Q&A – Ask questions in plain English and get cited, accurate answers
- 5 AI Personas – Default, Mentor, Tech, Creative, and Academic for personalized interactions
- Real-Time Chat Interface – Conversational, markdown-enabled, and code-friendly
- Admin Dashboard – Manage documents, view analytics, and monitor performance
- Source Attribution – Every response includes verified citations
Intern Compass uses Retrieval-Augmented Generation (RAG) to ensure grounded, trustworthy responses—no hallucinations, just reliable information.
🧩 How We Built It
🛠 Tech Stack
- Frontend: React + TypeScript + Vite (styled with Tailwind + shadcn/ui)
- Backend: Express + TypeScript (robust error handling & rate limiting)
- Database: PostgreSQL (Neon) for document and embedding storage
- AI: Google Gemini (
gemini-1.5-pro+text-embedding-004) - Auth: Auth0 for secure user management
🧠 RAG Pipeline Overview
- Extract text with
pdf-parse - Chunk into ~512-token segments (50-token overlap)
- Generate 768-dim embeddings via Gemini
- Retrieve top-K similar chunks using cosine similarity
- Generate grounded, contextual answers
- Return sources with document names and page numbers
💎 Key Features
- Custom persona system
- API rate limiting (50 req/min)
- Structured emoji logging for clarity
- Batch embedding and failure recovery
- Smart document categorization
- Automated schema migrations
⚔️ Challenges
- Vector Storage: Switched from pgvector to JSONB for easier deployment on Neon
- Chunk Tuning: Found the balance between context and token limits (~512 tokens)
- Rate Limits: Built custom token bucket middleware for concurrency control
- Citation Accuracy: Preserved metadata through every pipeline stage
- Env Config: Managed dual frontend/backend setups with robust CORS
- File Uploads: Configured
multerfor safe 50MB uploads with full validation
🏆 Accomplishments
- End-to-end RAG pipeline built from scratch (no LangChain)
- Enterprise-level error handling & logging
- Clean, modular architecture with clear separation of concerns
- Comprehensive developer documentation and startup scripts
- Dynamic persona system adapting tone and style
- Verified, cited responses for full transparency
- Optimized embeddings and similarity calculations for performance
📚 What We Learned
Technical
- Deep RAG architecture tuning and semantic retrieval
- Practical use of embeddings and cosine similarity
- Advanced TypeScript typing and error handling
- Efficient database schema design for AI workloads
- Gemini API integration with retry and streaming mechanisms
Soft Skills
- Detailed documentation accelerates debugging
- Structured logging (with emojis!) simplifies tracing
- Balancing functionality and UX clarity is crucial
Insights
- Good observability = faster debugging
- Citation transparency builds user trust
- Proper environment setup matters as much as code
🌟 What’s Next
Short-Term
- Persistent conversation history
- Multi-document search
- Search filters (type, date, department)
- Feedback system for answer quality
- Markdown chat export
Mid-Term
- Hybrid search (semantic + keyword)
- Analytics dashboard
- Multi-language support
- Version tracking & update notifications
- Integration APIs (Slack, Teams, etc.)
Long-Term Vision
- Fine-tuned organizational models
- Support for video & audio training data
- Proactive AI suggestions
- Collaborative annotations
- Enterprise compliance & SSO
- Native mobile app
Technical Roadmap
- Migrate to
pgvectorfor better scale - Add Redis caching and response streaming
- Build full testing suite with CI/CD
- Implement monitoring and performance tracking
InternCompass aims to redefine corporate onboarding—making it faster, smarter, and more human. Our goal: AI that informs, not imagines.
Built With
- auth0
- axios
- cicd
- cors
- docker
- eslint
- express.js
- gemini
- jsonbcolumns
- node.js
- nodemon
- npm
- oauth
- pdf-parser
- postgresql
- prettier
- primsa
- rag
- ratelimiting
- rbac
- react
- redis
- render
- shadcn
- tailwind
- typescript
- vite







Log in or sign up for Devpost to join the conversation.