-
-
Website
-
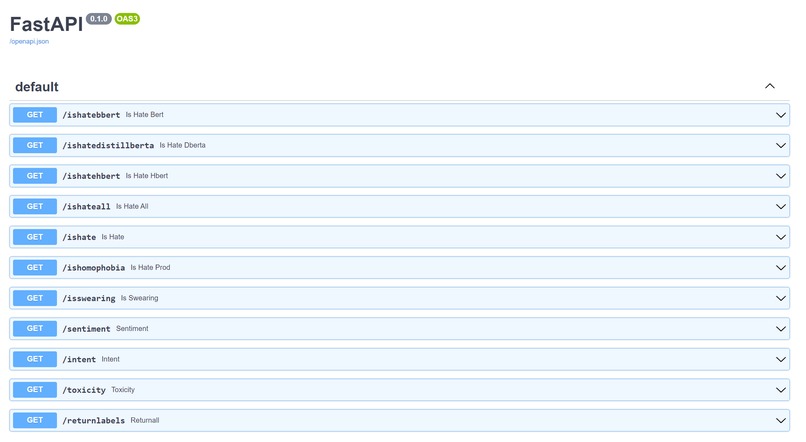
API
-

Streamlit Demo
-

Chrome Extension
-
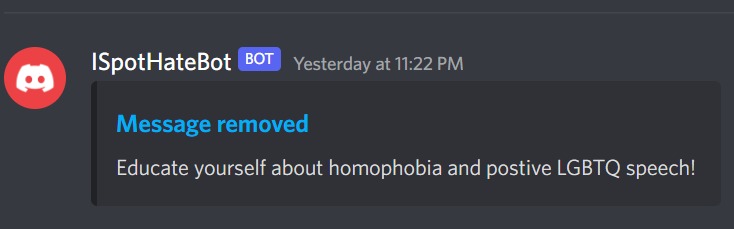
Discord Bot





Inspiration
Imagine this scenario: You run a consumer software startup; your audience ranges from 5 year olds to 105 year olds. You're scaling fast, but then disaster strikes: hateful content. It's a difficult line to walk between censorship, and offending new users. For small teams, machine learning is already a pain point; difficult to deploy at scale and expensive to develop pipelines. Designing a proper solution may save the hassle for many solutions related to hate speech detectino. Detecting hate speech is also important to protect users and promote a healthy community and social equity. The CDC has found a positive correlation between hate speech and self harm behaviour, showing just how important it is for us to mitigate and eradicate hate speech. The problem with detecting hate speech is that millions and billions of texts are being sent over the Internet at any moment, and it is very difficult to pinpoint quickly if something is hate speech or not.
What it does
Introducing ISpotHate, hate speech detection as a service. It allows companies to focus on their core product, rather than worrying about using complex methods to keep content safe and promote social equity. Our FREE API is one HTTP request away from eradicating hate speech, one word at a time. By simply using one line of code (http://ispothate.eastus.cloudapp.azure.com:8000/ishate?text={text}), replacing {text} with the actual text you want to query, we can get whether the text is hate speech or not. The API endpoint also supports a lot of other functions, as seen through the docs: http://ispothate.eastus.cloudapp.azure.com:8000/docs. Finally, we hosted many examples of apps that can use our API, including a Discord bot, a chrome extension, and a Streamlit interface for a machine learning workflow.
How we built it
We used fastAPI to generate a REST API endpoint, hosted on an Azure VM. We used state of the art machine learning models, from hate speech and homophobia detection papers, using Huggingface and Wandb to help streamline the training process. We first used exploratory data analysis and artifact analysis (Wandb) to determine the best datasets, and also consulting papers such as "Dataset for Identification of Homophobia and Transophobia in Multilingual YouTube Comments", and looked at discussion of approaches on Kaggle competitions such as "Toxic Comment Classification Challenge". We decided on using the FRENK-hate-en dataset for our base model training, as it had a comprehensive database of real world scraped hate speech, as well as having targeted types of hate speech labels and features. We also decided to use RedditBias and tweets_hate_speech_detection for our validation models. In order to use state of the art models and apply transfer learning, we trained a baseline of BERT, distillBERTa (ensembled), and hateBERT (as outlined by papers and validated to have the best base model accuracies) to determine the best model to run our final training on. After logging on WanDB, we decided to fine tune hateBERT on the training dataset with a hyperparameter optimization sweep, and logging/deploying the model on Huggingface. We then used Pytorch to load the model, and upload it to fastAPI, running on a gunicorn and uvicorn backend. We also configured the VM to run on HTTP with a custom domain, and added a Dockerfile for easy containization from an image for future runs. For the examples, we used the chrome extensions toolkit and chrome.storage to run the chrome extension, and used Flask and Uptimerobot to create the discord bot demo, by keeping the server alive while the bot was querying the API. Finally, we integrated the API into a machine learning workflow using Streamlit and Pytorch. We also set up Netlify pages for the website, hosting it using a custom domain and configuring DNS servers.
Challenges we ran into
The first challenge we ran into was the abundance of information. We looked at several papers and Kaggle challenge discussions, each with their own approaches and model pipelines, and we also had our own approaches. We had to weigh the pros and cons and do a lot of testing and research, in order to find the best model in terms of accuracy/F1, and efficiency in runtime. Since natural language processing and hate speech detection were relatively new for us, and targeted hate speech detection (e.g. homophobia detection) had surprisingly little useful information, it was quite difficult to determine a high accuracy model in a short period of time, but we were able to narrow things down by looking at baseline models first, and applying transfer learning and hyperparameter tuning to speed up model selection. The second challenge we ran into was hosting the model on fastAPI with an Azure VM. We had to set up uvicorn web workers, configure Ubuntu permissions, set up an SSL certificate, and run the API as a background script. This took some time to getting used to, but fastAPI had a standard documentation, so it ended up not taking that long. Finally, the chrome extenion took a lot of debugging, as chrome extension js does not support many features, and we had to find many workarounds. For example, the chrome extension could not fetch API requests from http (not https), so we had to host the model locally and configure CORS modifiers. Also, we had to find ways around accessing popup.js without also accessing the webpage body document. We ended up fixing most of the issues, and having a functional and efficient chrome extension that could query from a web API endpoint.
Accomplishments that we're proud of
We are proud of completing a production level machine learning pipeline and fastAPI endpoint in a short period of time. We are proud of having solved the challenges that we faced throughout the hackathon. We are also proud of having made many integrations of our API, and learning about different services and their pipelines (e.g. chrome extension, ML pipelines). We are proud of learning more about natural language processing and hate speech detection. We are most proud of having made a project that promotes social equity by eradicating hate speech, one word at a time!
What we learned
We learned how to deploy a machine learning model on fastAPI and Huggingface, as well as use MLOps tools such as Wandb, Raytune, and Huggingface. We learned how to use chrome extensions, and configure web scraping and CORS. We also learned how to host models on different services, such as Deta, Heroku, and Docker. Finally, we learned how to create a machine learning pipeline and train a high accuracy model using natural language processing papers in a short amount of time.
What's next for ISpotHate
In the future, we hope to provide long term support, as well as add more features/methods and models to the API to improve its functionality. We hope to do even more research into models, and provide more accurate machine learning models We also hope to find out support for integration with Chromium (e.g. using Apache with an HTTPS certification). The biggest bottleneck we faced was lack of CPU/GPU compute power: since most compute free tiers did not give enough memory for training, we either had to find workarounds or deploy locally. If we could find ways around this, we could train even more robust models.
References:
https://arxiv.org/abs/2109.00227
https://arxiv.org/abs/2207.10032
https://arxiv.org/abs/1906.02045
https://arxiv.org/abs/2203.14267
https://arxiv.org/abs/2103.14972
https://aclanthology.org/2022.ltedi-1.55/
https://adm.viu.ca/positive-space/how-homophobia-hurts-us-all
Built With
- discord
- docker
- fastapi
- huggingface
- javascript
- pytorch
- streamlit
- wandb






")



Log in or sign up for Devpost to join the conversation.