-
-

the what
-
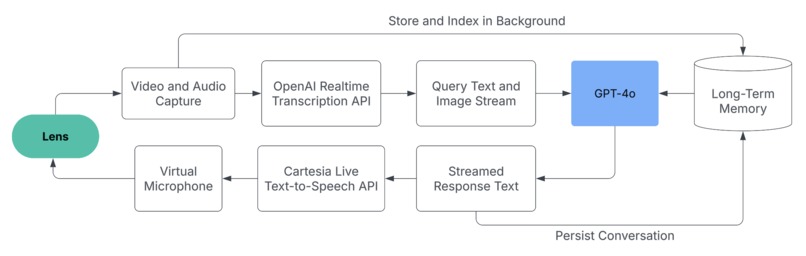
the how


bffr you have wanted secret glasses that give you mysterious AI powers too
What it does
Lens allows you to extend your cognition. It can passively monitor for opportunities to speak or actively respond to questions. Additionally, it can maintain a long context for memory retrieval.
How we built it
see this doc and this presentation
Lens was built through a series of hacky methods to circumvent Meta’s limitations on their glasses. Since they don’t provide an SDK for their glasses, we needed to implement our methods to capture live audio and camera from the glasses. To do this, we created a Messenger Bot which the glasses call when operating. The Messenger Bot uses a Chrome extension to stream the media and audio to our Websocket server which receives the audio chunks and forwards it to OpenAI’s transcription service. From here, the response is streamed to OpenAI’s completions API to generate a response to the user’s query, along with any context. From the response, we use Cartesia to generate speech from the text and play it through an Virtual-Cable input device on the machine to transmit the audio back to the glasses. We use a pub-sub architecture to manage asynchronous, live data flow throughout our application. This means our glasses don’t have any set “request” or “response” periods – it’s continuously monitoring what it sees, and what you say, to give a response.
For passive detection, a “thinking” chat request is created at a set interval in the backend. The agent can choose to speak up, or not say anything at all. If you instruct the agent to remind you of something in the future, it can store this information in the context.
Challenges we ran into
How do we access the live camera and audio capture from the Meta Raybans without an SDK? We set up a video call system to circumvent Meta’s restrictions on accessing camera and audio streams from the glasses. The Meta Raybans calls our Messenger Bot account which streams the audio and video to our API through a series of hacky methods. How do we create and manage context/memory? Store user queries and responses in memory and attach them to each request to the API. How do we communicate between the Meta Raybans and our API? Lots and lots of communication layers. Pub Sub :-) How do we use the captured audio to generate a response? Capture the MediaStream from the Chrome tab from which the Messenger call is running and stream it to the API through a WebSocket connection. The How do we handle terrible documentation from OpenAI? Thug it out and play around until it works. How do we interrupt responses if a user starts speaking? Responses are streamed back to the user via layers of queues: the first layer streams the output tokens from OpenAI to Cartesia, and the next layer streams the synthesized speech from Cartesia to the user. If the user starts speaking, we flush these queues. How do we reduce latency from user -> transcription -> output -> audio -> user? Experiment with other models and audio chunking methods. Wait for Cartesia or ElevanLabs to release a realtime text-to-audio model.
Accomplishments that we're proud of
Building a hacky solution that works Successful usage of our own models that have far superior capabilities than Meta’s trashy AI in their glasses
What we learned
In this project, we learned about the effectiveness of the publisher subscriber model for audio streaming and processing in real-time. Also that Meta does not like their data getting scraped.
What's next for Lens
Acquisition by Meta!!! The First Open-Source Smart Glasses™ (or a cease and desist) Easier way to get context -> move to using videos Find way around streaming through messenger calls ultimately


Log in or sign up for Devpost to join the conversation.