-
-
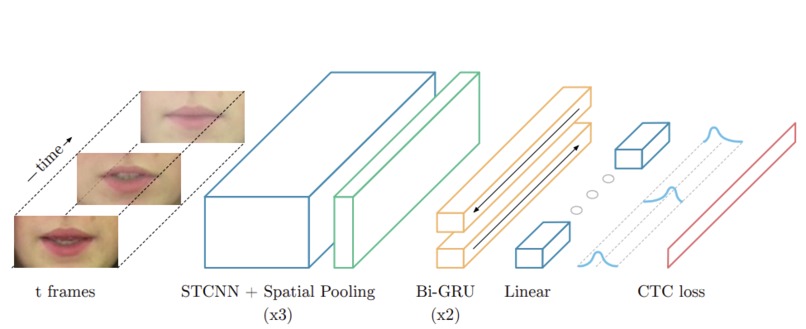
CTC (Connectionist Temporal Classification)
-
Data Pipeline & Raw String Processing
-

-

-
-

-
-









Inspiration
Communication for deaf individuals occurs through lipreading. However, lipreading is not a foolproof method of communication, as not all sounds can be easily distinguished from one another through lipreading alone. Much of it depends on audio quality, speaking speed, and clarity of speech.
Enter LipReading.ai with Automatic Speech Recognition through CTC (Connectionist Temporal Classification) Keras.
Bad audio? No problem. LipReading.ai is designed to generate captions just by reading lips.
Currently, more than 1.5 billion people live with hearing loss. 67% of them express frustration with not feeling like there are enough programs that aid communication. We aim to make a genuine human impact by closing the gap for disabled people and addressing sustainability for future generations through innovative use of technology.
What it does
LipRead.ai allows users to upload a video of the desired speaker and generates captions based on what they are saying. It allows disabled people to read audio with the power of AI and ML.
How we built it
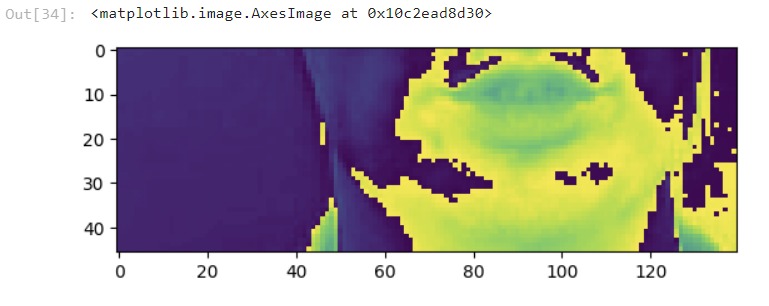
Using JupyterLab we created a deep neural network with 90 epochs yielding an 84% accuracy rate. We then employed the Tensorflow Sequential model for the input and output tensor. This loads the LipNet database videos, converts each frame to grayscale, crops the specific region of interest, normalizes the pixel values, and returns a list of frames as a tensor. OpenCV captures the frames of a person speaking, and an automatic speech text model is used to transcribe what they are saying. That dataset is subbed into the deep learning model training pipeline which loads the aligned transcriptions. Here, the annotations are preprocessed and we were able to decode this from purely the video, no audio.
For the front end, we set up the streamlit framework, loaded in the videos and displayed output tokens and the raw tokens being converted into a set of words.
We use 3D convolutions to pass the videos and condense them down to a classification-dense layer which predicts characters - single letters at a time. For this, a loss function called CTC (Connectionist Temporal Classification) handles this output. This function works great for word transcriptions that aren’t specifically aligned to frames. Given the structure of our model, it is likely to repeat the same letter or word multiple times if we use the standard cross entropy loss function. (CTC reduces duplicates by using a special token.) Then we used the greedy algorithm to take the most probable prediction when it comes to generating the output.
Keras implementation of the method described is in the paper 'LipNet: End-to-End Sentence-level Lipreading' by Yannis M. Assael, Brendan Shillingford, Shimon Whiteson, and Nando de Freitas (https://arxiv.org/abs/1611.01599).
Challenges we ran into
- Configuring GStreamer plugins to compile and parse OpenCV arrays
- Transcoding String Tensor of type objects from a source encoding to a destination encoding
Accomplishments that we're proud of
Successfully implementing Automatic Speech recognition using CTC loss that builds an ASR with Keras, which keeps everything nice and clean.
What's next for LipRead.ai
- Making it into a Chrome extension for video calling caption generating feature
- Using a DLib face detector to isolate the mouth instead of doing it statically
Built With
- anaconda
- asr
- jupyternotebook
- keras
- matplotlib
- python
- streamlit
- tensorflow



Log in or sign up for Devpost to join the conversation.