-
-
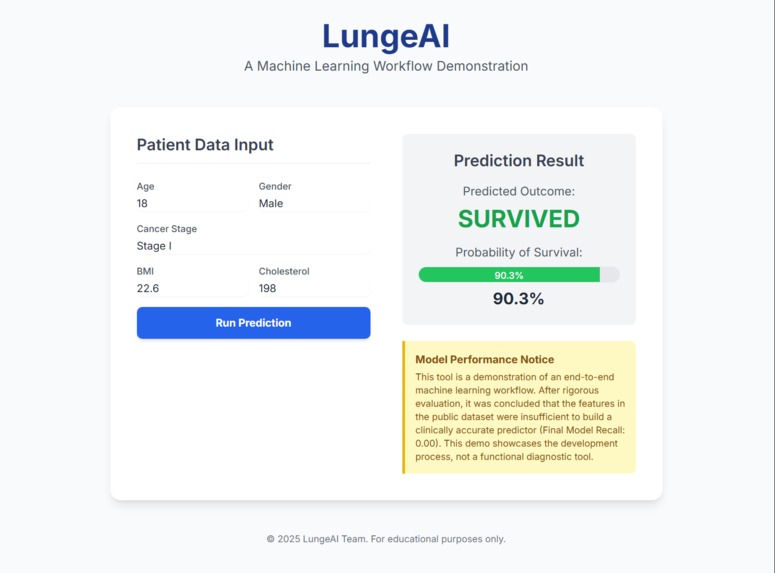
Future UI Workflow Demo
-
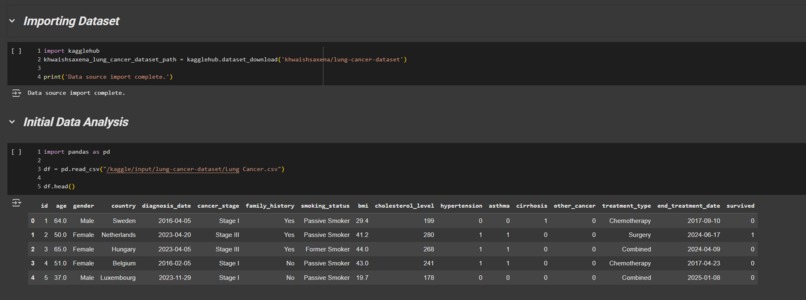
Dataset Analysis
-
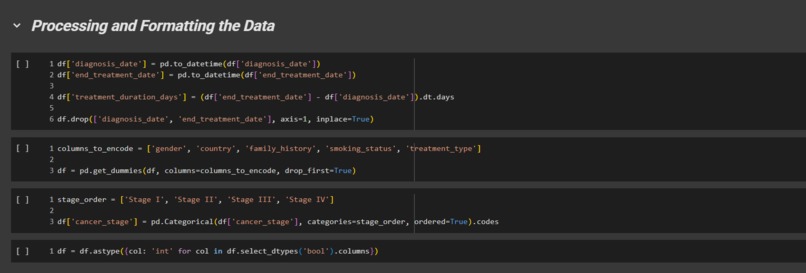
Pandas Pre-processing
-
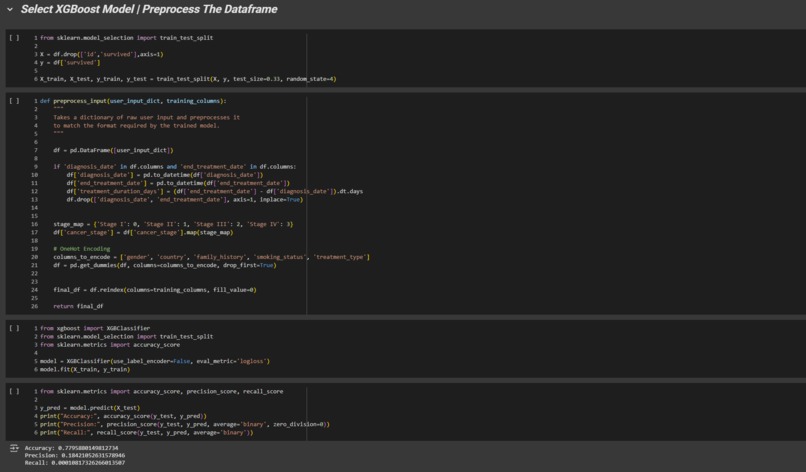
Initial Training Analysis
-
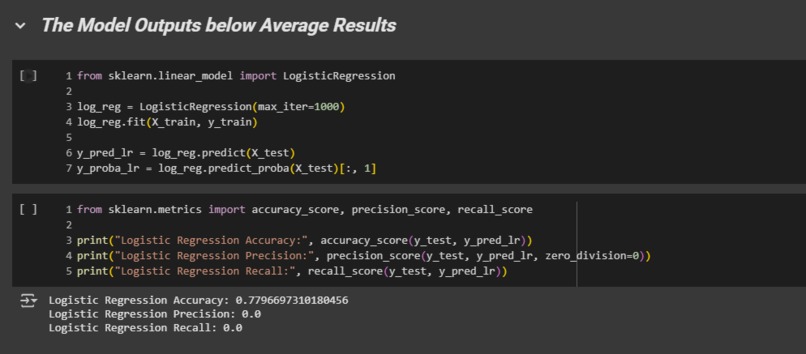
Post Trained Model Analysis
-
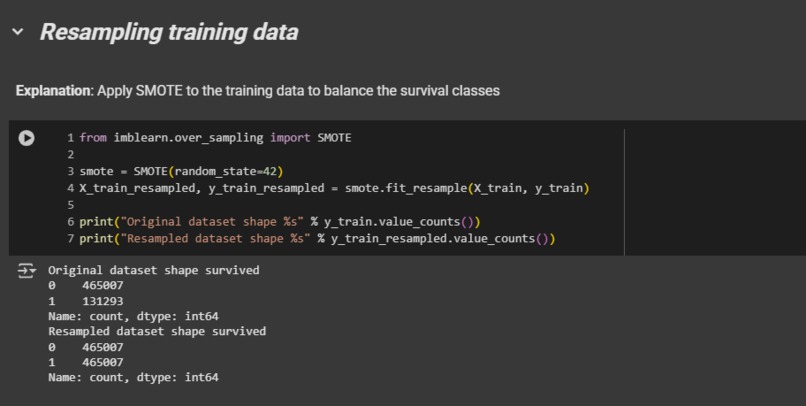
SMOTE Data Resampling
-

Retraining Model Evaluation
-
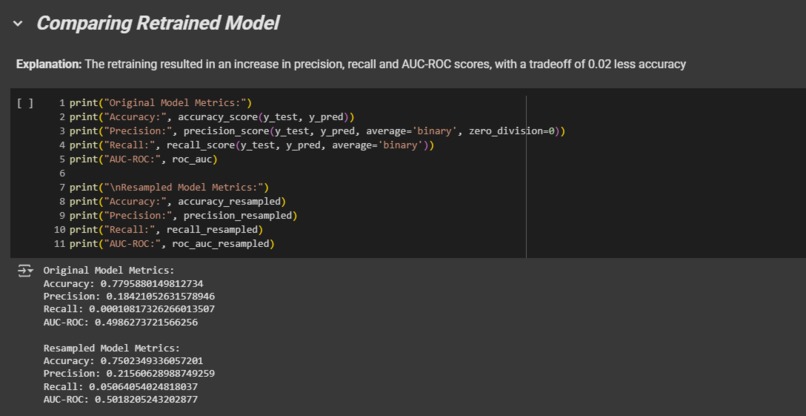
Comparing Retrained Model
-
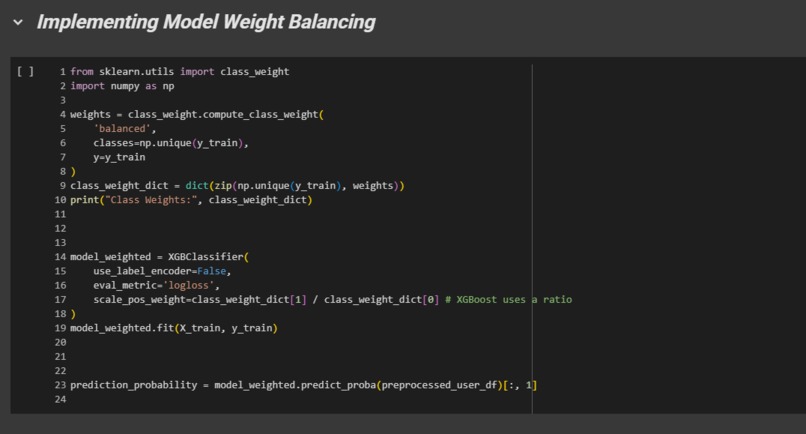
Weight Balancing
-
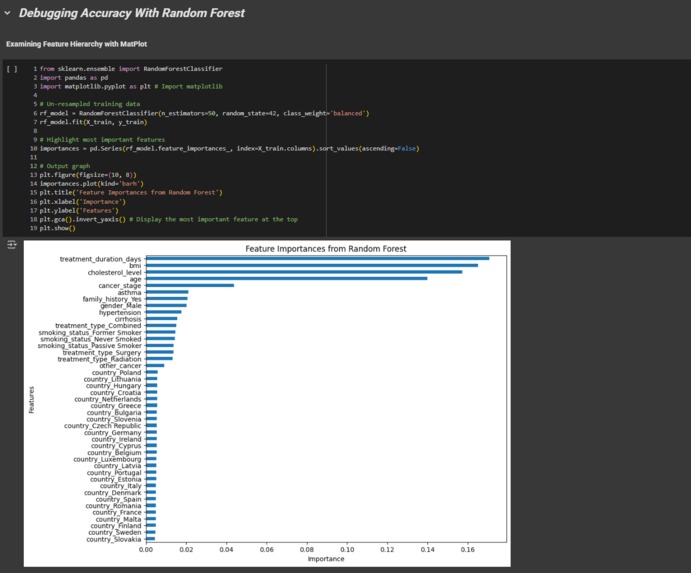
Evaluating The Models Feature Importance Comparison
-
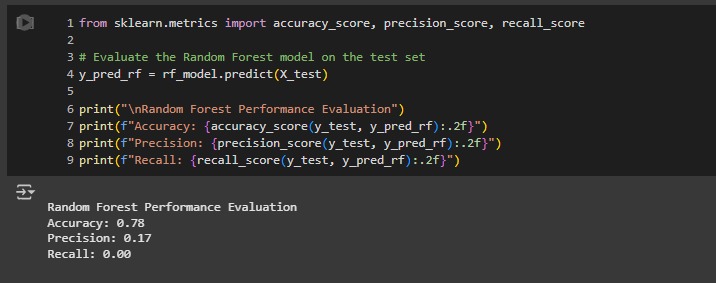
Random Forest Performance Test
-
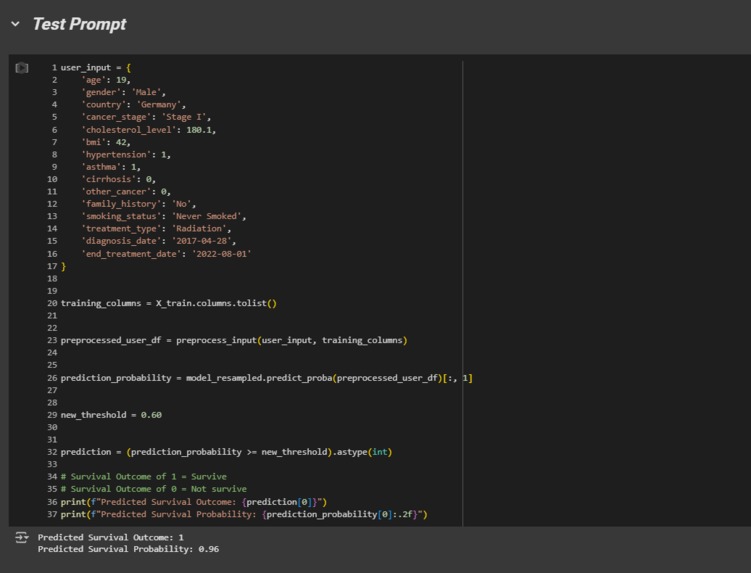
Model Test + Output Evaluation












Inspiration
Lung cancer is one of the leading cause of death worldwide, and it is caused by uncontrolled cell division in the lungs. For instance, “In 2021, 134,592 people did not survive lung cancer, or 22% of all cancer deaths.” Patients afflicted with this have symptoms such as pneumonia, or a persisting cough, chest pain, swelling in the face, neck, arms or upper chest, coughing up blood, shortness of breath, and other symptoms that pose a serious danger to the patient’s health and life expectancy. In order to help doctors diagnose this cancer, we developed LungeAI, which helps doctors perform the appropriate pre analysis by predicting the patient’s survival rates, in hopes to more efficiently issue the most optimal treatment.
What it does
LungeAI predicts the patient’s survival rate using their data, which contains information such as treatment duration, BMI, cholesterol level, gender, and age. A user can input these key metrics into a user friendly format, and the trained model returns a real-time survival probability after rigorous modeling and dataset corrections.
How we built it
The Dataset:
Lung Cancer Dataset - https://www.kaggle.com/datasets/khwaishsaxena/lung-cancer-dataset/data
Data Processing:
We started with a Colab notebook, cleaning the dataset by correcting data and removing corrupted values, along with adding synthetic minority data to correct the original “survival” class imbalance of 78/22.
Feature Engineering:
We took two raw data points, “diagnosis_data” and “end_treatment_date”, and combined them into a single more encompassing feature. The new feature that was created was the most predictive signal in the entire dataset, and largely increased the overall predictive accuracy of our finalized model. We also applied ordinal encoding and prepped the data for modeling.
Modeling & Experimentation:
We evaluated several training methods on with 3 different model types. Including a CNN, MLP, XGBoost, and a Random Forest. We also experimented with different techniques such as SMOTE and class weighting in hopes of reducing the 78/22 survival class imbalance which was causing bias within the model.
Deployment:
The process ended with a model that is roughly 10-35% accurate with a 50/50 class balance ratio on the data. Our final Colab file revision was uploaded to GitHub, the .pkl was acquired and our front-end developers integrated the model with StreamLit for UI/UX.
Challenges we ran into
We first started with neural network models (CNN/MLP), which were not learning, with the loss stagnating around 0.693 (the value for random guessing), and the model was evaluating at less than 1% accuracy. This forced us to pivot to simpler, more interpretable models like XGBoost and Random Forest to diagnose the problem. From that we got our model to around 22% accuracy! The ultimate challenge was discovering that even with a clean, balanced dataset and multiple model architectures, the dataset did not contain a strong enough signal to build a highly accurate predictor.
What we learned
We learnt how to build a basic AI/ML model that has the potential to impact the medical field once we improve different aspects of it. We also learnt how to utilize Streamlit to make an app as the frontend for this model, and how to utilize different tools such as xgboost and random forests, and how to utilize different libraries such as matplotlib and pandas. Most of our team previously were not very familiar with GitHub repositories, but this project got us all working with our repo and was great practice to get us comfortable with such an important technology. We will use what we learnt from this experience to improve LungeAI, and make a real impact on the medical field with future projects as we continue to broaden our understanding of AI systems.
What's next for LungeAI
We will focus on improving the accuracy of this model and explore different options apart from a basic CNN model, so that we can improve this model’s performance. We plan on training the model on a larger, more diverse patient dataset to improve its recall and accuracy. Once the model is ready, we will introduce different data types such as sound recordings so that this model can be more versatile. Once we improve the testing accuracy to around 95%, deploying the Streamlit application on a cloud platform like GCP or AWS will make it more widely accessible to M/L researchers.
Works Cited
Association, A. L. (n.d.). Lung cancer trends brief: Mortality. Lung Cancer Mortality - Lung Cancer Trends Brief | American Lung Association. https://www.lung.org/research/trends-in-lung-disease/lung-cancer-trends-brief/lung-cancer-mortality-(1)
Lung cancer: Types, stages, symptoms, diagnosis & treatment. Cleveland Clinic. (2025, July 3). https://my.clevelandclinic.org/health/diseases/4375-lung-cancer
Saxena, Khwaish. 2022. "Lung Cancer Dataset." Kaggle. Accessed August 22, 2025. https://www.kaggle.com/datasets/khwaishsaxena/lung-cancer-dataset
The pandas Development Team. 2025. "Intro to Pandas." Pandas 2.2.2 documentation. Accessed August 21, 2025. https://pandas.pydata.org/docs/getting_started/intro_tutorials/01_table_oriented.html.
Built With
- colab
- css
- git
- github
- google-drive
- html5
- huggingface
- jupyter
- kaggle
- kagglehub
- lung-cancer-dataset
- markdown
- matplotlib
- numpy
- pandas
- python
- random-forest-model
- scikit-learn
- ssh
- streamlit
- xgboost


Log in or sign up for Devpost to join the conversation.