-
-
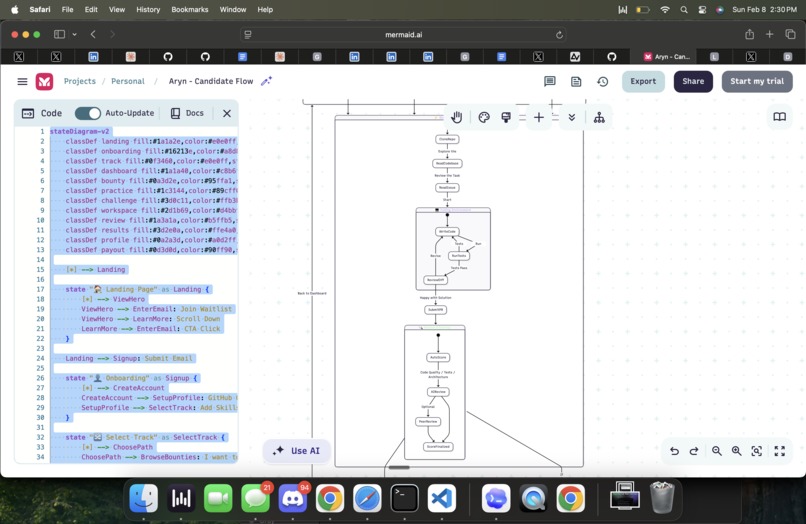
user flow p2
-
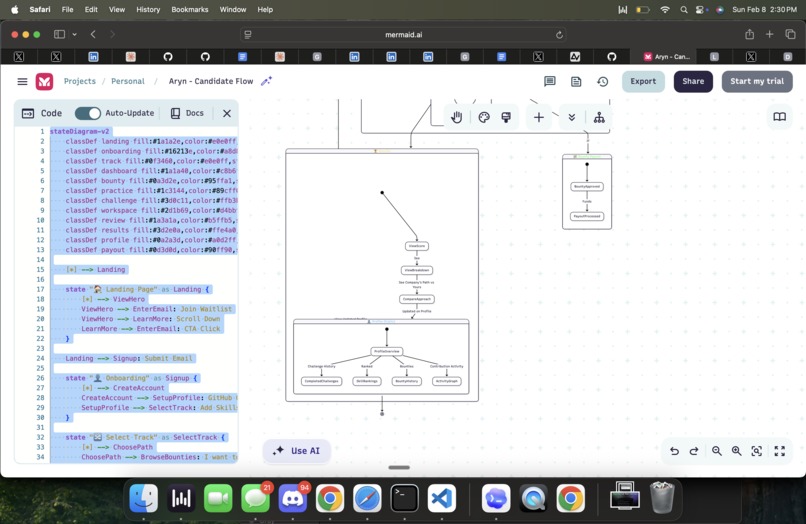
user flow p3
-
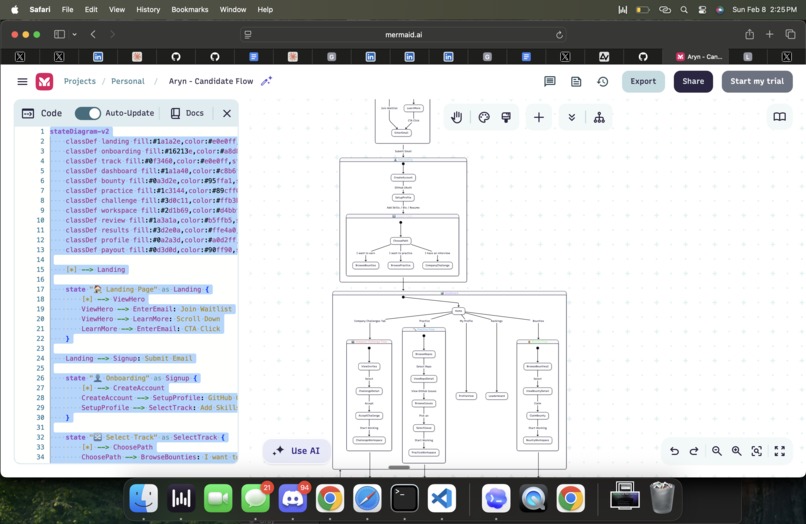
user flow p1



Merit — Hackathon Submission
Inspiration
AI broke technical interviews. ChatGPT can solve any LeetCode problem in seconds, and every hiring manager knows it. Startups have already moved on, they're using take-home projects and live codebase challenges instead. Big tech is next.
But there's no platform training engineers for this shift. You can grind LeetCode all day, but it won't teach you to navigate a real codebase, understand existing architecture, or ship production-ready code. We built Merit to fill that gap: a platform where engineers prove their skills by solving real issues in real codebases, not toy problems in isolation.
What it does
Merit drops participants into sandboxed coding environments with real open source codebases. Each challenge is a real GitHub issue tied to a specific commit hash. You browse issues, pick one, and get dropped into the code cold, just like your first day on the job.
The platform scores your work with an AI-powered code review that evaluates quality, architecture, correctness, and security. Pass the review, submit your PR, and earn points. A live leaderboard ranks participants by total points, challenges completed, and average score.
For engineers, it's interview prep that actually prepares you for interviews. For hackathons, it's a competition format that rewards real engineering skill, not pattern memorization.
How we built it
Merit runs on Next.js 14 with the App Router, TypeScript, and Tailwind CSS. Supabase handles auth (GitHub OAuth), database (Postgres with RLS policies), and storage (for processed codebase snapshots).
The workspace uses Monaco Editor for code editing and Shiki for syntax highlighting in the file viewer. When a challenge is created, we clone the repo at a specific commit, flatten the git history so candidates can't peek at future implementations, and upload the snapshot to Supabase Storage.
The AI code review layer is model-agnostic. We built an abstraction that supports OpenAI, Anthropic, and Gemini, swap providers with a single environment variable. The review acts as a quality gate: submissions are rejected unless the AI review passes with a score of 70 or higher.
Challenges we ran into
Git history was tricky. We needed to serve codebases at a specific point in time without exposing future commits. A naive clone still lets candidates run git log and see the solution. We solved this by flattening history entirely for the MVP, stripping the .git directory so the snapshot is just files, no version control.
Serverless file storage was another pain point. Early versions stored processed repos in /tmp, which breaks when the container cold starts. We moved everything to Supabase Storage with a file tree manifest so the workspace can reconstruct the directory structure on load.
Getting the AI review prompt right took iteration. Too strict and nothing passes. Too lenient and it's meaningless. We landed on a rubric that evaluates five categories (correctness, quality, architecture, security, performance) with severity levels, then computes a weighted score.
Accomplishments that we're proud of
The workspace feels real. You browse files, read code, write your solution, and submit, all in the browser. The AI review gives actionable feedback, not just pass/fail. The leaderboard updates live.
The model-agnostic AI layer means we're not locked into any provider. We can switch from OpenAI to Claude to Gemini without touching application code.
The whole thing is built to scale. RLS policies enforce access control at the database level. Snapshots live in object storage, not local disk. The architecture is ready for real load.
What we learned
Real codebase challenges are harder to set up than LeetCode-style problems, but they produce way better signal. Watching someone navigate unfamiliar code tells you more about their engineering ability than watching them recite a sorting algorithm.
AI code review is good enough to be a quality gate, not good enough to be the final judge. It catches obvious issues and enforces minimum standards, but nuanced evaluation still needs human eyes.
Building for hackathons is a great forcing function. The time constraint forced us to prioritize ruthlessly: what's the smallest thing that delivers the core value? Everything else is polish.
What's next for Merit
Short term: seed the platform with curated challenges from popular open source repos. Stripe, Vercel, Next.js, repos that engineers actually want to work in. Add bounties so participants can earn money while they prep.
Medium term: open it up to companies. Let them submit their own (private) codebases and use Merit as their actual interview platform. Candidates get real practice, companies get real signal, everyone wins.
Long term: build the largest database of ranked engineering talent based on actual work output. Your Merit profile becomes your portable reputation, proof that you can ship, not just that you can talk about shipping.
The interview is no longer a whiteboard. It's a real codebase. Merit is the platform built for that.

Log in or sign up for Devpost to join the conversation.