-
-
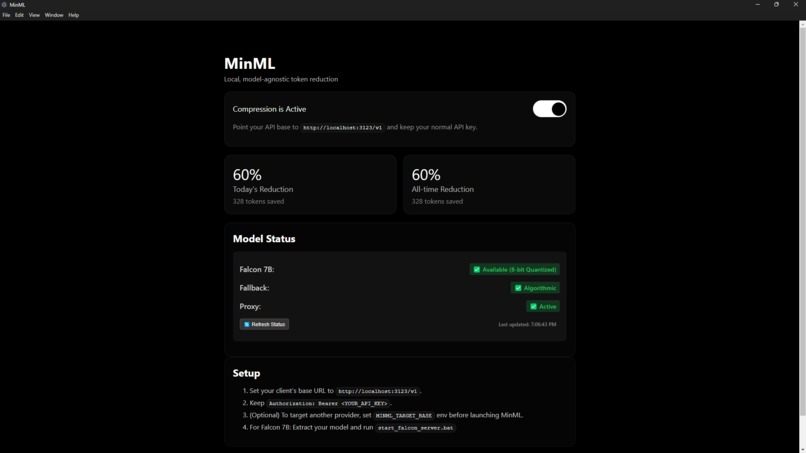
MinML interface via electron app
-
Website
-

Website continued
-
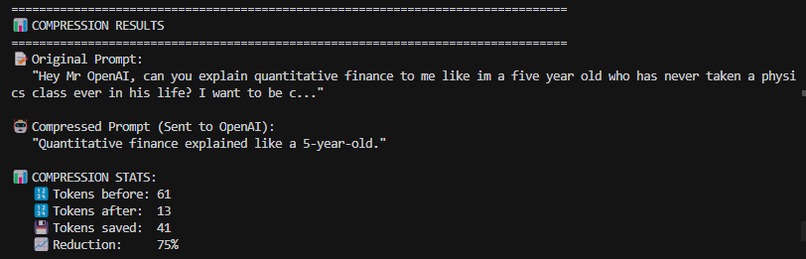
Compression Example




Inspiration
As a builder I use a lot of AI models on my day to day within Cursor including: Gpt5, Claude Sonnet and Opus, Cursors base model, and many more. The more models I try the more I notice a problem that is consistently occurring throughout the use of every model and that of course is cost. Whether you're making api calls or fine tuning a model on cloud cost is everything and it's the reason why so many people hesitate to use high end models or create api keys in the first place.
So I thought, what if there was a way to reduce the cost involved with making calls to models and maybe even increasing the performance at the same time? My first thought was a compression system.
The English language is actually compressed more now than ever before. Simple texts and phrases have been shortened down to 3 or 4 letters by the younger generation (including me). Like the word "really" becoming "rlly" or "for real" becoming "fr". With data like this all across the internet I then started brainstorming the idea of a "Semantic Compression System" for LLM's. A process that reduces the amount of tokens the users model would need to ingest a prompt by getting rid of pieces of the prompt that aren't valuable to the model.
For example, this could include: removing white space, removing filler words, removing names or heavy descriptions that can be distilled and keeping keywords.
The compression processes would need to be something thats completed automated and running in the background of a user's system locally monitoring for api calls to agents or models via the users system, intercepting, compressing, and finally sending it back to the user's desired model with minimal overhead and optimal reduction of the amount of tokens used by around 30 percent or greater.
Thats when I started building MinML.
What it does
MinML is a semantic compression system for LLM's. MinML does the compression work in the back while you relax and have conversations with your favourite model's on whether the sky is blue or the grass is green.
It sits transparently between your apps and any LLM (OpenAI, Anthropic, OSS, or local runtimes). A tiny proxy/agent intercepts requests on your machine, extracts protected spans (task, topic, audience/level, constraints, output format), and rewrites the prompt into a shorter, high-information version while preserving those spans. Each rewrite is scored for retention vs. reduction; if the score dips, we fall back to a deterministic compressor.
Compressed prompts are then forwarded to your chosen model with no workflow changes. A minimal black-and-white desktop UI offers a one-button “Activate Compression,” live token/$ meters, per-request receipts, and net savings that account for vendor prompt-caching when applicable.
Everything runs on-device with no prompt logging for full privacy. In early local tests, MinML delivered ~30% average token savings across 20 prompts (best case ~52% on single prompts) while keeping intent intact.
How I built it
Under the hood, a local daemon (FastAPI with a Rust core via PyO3) monitors LLM API calls, applies the compression pipeline, and forwards traffic. The Electron desktop app (macOS/Windows) exposes a one-click toggle, retention score, and savings calculator. The compression pipeline is: slot extraction → protected-span masking → rewrite → unmask, followed by guardrails (never-longer on both characters and tokens, duplicate-token collapse, monotonic compression across levels).
A lightweight student model (Falcon-7B-Instruct fine-tuned from GPT-OSS traces, then 4-bit quantized) performs slot extraction + rewrites on capable machines; when it’s unavailable or risky, a Rust-accelerated rules fallback guarantees deterministic output. Token counts/costs are computed locally via Hugging Face tokenizers, so you can evaluate savings without calling any external API.
I chose to use PyO3 as a bridge from Rust → Python for low-latency text ops, Electron for a single cross-platform desktop build, and Hugging Face tokenizers for fast, local token accounting. For optional server mode, MinML can sit behind an OpenAI-compatible gateway (e.g., vLLM), and for fully offline mode we can run a quantized student as a GGUF with llama.cpp or just run hardcoded algorithms. This gives us three deployment options, local-only, proxy, or hybrid without changing the products surface area.
Challenges I ran into
Running GPT-OSS locally was great for teaching but unrealistic for the target laptop footprint, so I moved to a teacher → student setup and backed it with a rules fallback. I learned (painfully) that strict JSON labeling is brittle under time pressure; slot-aware plain-text compression with a scorer shipped faster and was more robust. I hit infra quirks around provider-specific hosts/paths (e.g., Vertex), Windows PATH/accelerate setup, and even a pipeline composition bug where concatenating stage outputs sometimes made prompts longer - fixed by moving to a replace-then-transform design with hard guards.
Another issue I ran into was the struggle of finding a usable dataset. After a lot of research I was able to find a dataset that fit my needs and had outputs and inputs of GPT-OSS on hugging face.
Finding a platform to do the fine-tuning on was also an issue, as I couldn't run GPT-OSS locally I had to resort to using either GCP or AWS from which I decided to use AWS sage maker as my application to help me fine tune MinML's model.
Trying to create fast and efficient algorithms that wouldn't cause overhead was also in issue, after some research and lots of trial and error I decided on using a Rust power core with Python pass through for optimal speed (PyO3).
Accomplishments that I proud of
We shipped a working local compression layer with a clean, one-toggle UI; a quantized student model that runs on a standard laptop; and a Rust core that keeps latency low when we rely on rules. The system is slot-aware (protects task/audience/constraints), has deterministic decompression templates (e.g., “Explain {subject}.”), enforces a never-longer rule, and tracks real token/$ savings per request. On our initial test set we saw ~30% average token reduction (up to 52% on single prompts), with qualitative fidelity verified by round-trip tests.
The student can be bundled as a single GGUF file and executed via llama.cpp, which simplifies distribution and avoids driver/toolchain drift. For server experiments, we validated that vLLM’s OpenAI-compatible endpoint lets orgs drop MinML in front of any existing client SDK with a one-line base-URL change.
What I learned
Preserving structure (task, audience, constraints) matters more than stylistic brevity-protected spans + masking are the unlock. Quantization is a superpower for laptop inference. For trust, a deterministic fallback and visible guardrails beat clever heuristics every time. Finally, encoding ≠ encryption: privacy claims must be backed by local processing, optional encryption-at-rest, and clear policies.
When we tried strict JSON-only outputs for every step, we saw brittleness; using constrained decoding libraries selectively (only at schema boundaries) gave us reliability without sacrificing speed. And on the MLOps side, parameter-efficient finetuning (LoRA/QLoRA) was far more practical than full-model updates, especially for quick iteration during a hackathon.
What's next for MinML
We’re productizing a local OpenAI-compatible proxy that doubles as a universal token cache with per-request receipts and vendor-cache awareness (so users see net savings). On the UI side: a macOS menubar app and Chrome/IDE extensions that show before/after diffs and token meters inline. On the compression side: stronger intent extraction, dynamic slot weighting (entities/numbers > adjectives), multi-candidate A/B selection with retention/length scoring, and domain presets (docs, code, legal, medical). We’re also extending to code/files/PDFs with structure-aware operators, adding privacy modes (memory-only, encrypted store), and shipping org-level dashboards with shared-savings pricing tiers.
For distribution we’ll ship two paths: (1) a zero-config desktop app (Electron) with an embedded local model (GGUF via llama.cpp); and (2) an optional team gateway using an OpenAI-compatible server (e.g., vLLM) so companies can roll MinML out behind a single endpoint. On the research side we’ll keep improving the student with LoRA+ schedules and QLoRA ablations, and we’ll formalize retention scoring as a small benchmark suite released with the repo.
Other Notes
I wasn't able to capture this in my video, but I also created an electron application that constantly updates the user's prompt reductions with percentages and tokens saved this auto updates after every call which can be seen in the project media section.
Although I didnt use gpt-oss-20b directly/locally I used a fine tuned trained version of a base model/student (falcon) that was done using gpt-oss-20b direct inputs and outputs learning compression.

Log in or sign up for Devpost to join the conversation.