-
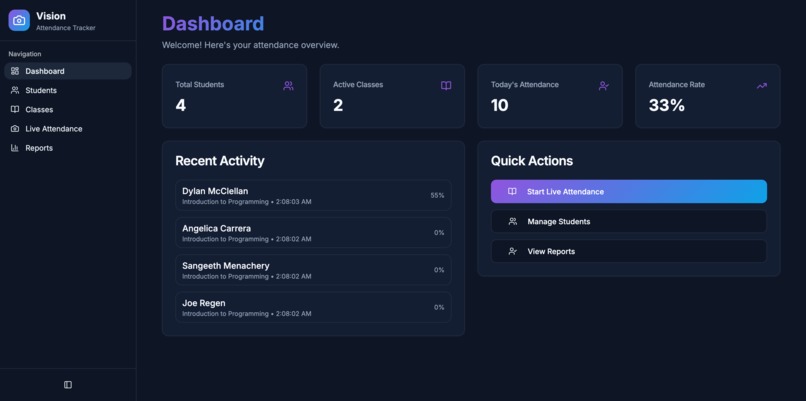
Dashboard
-
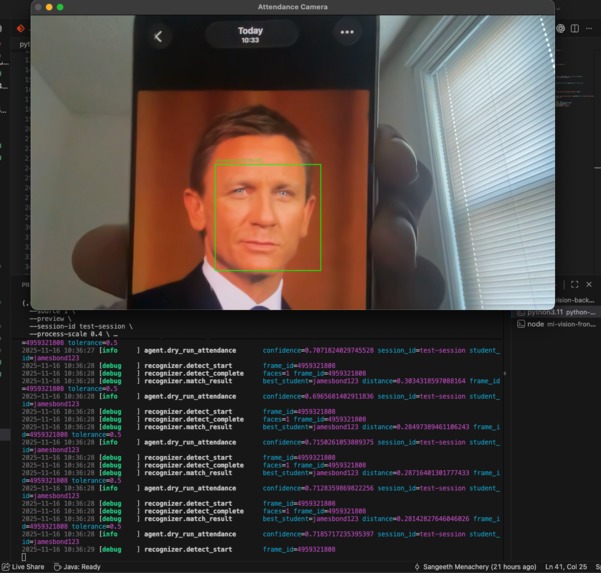
-
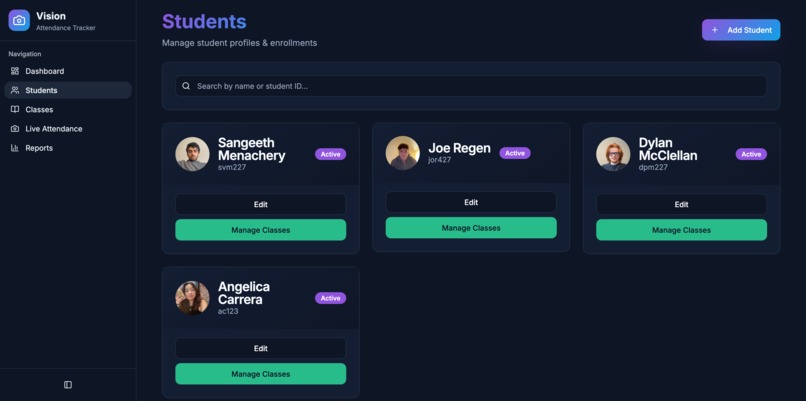
Students
-
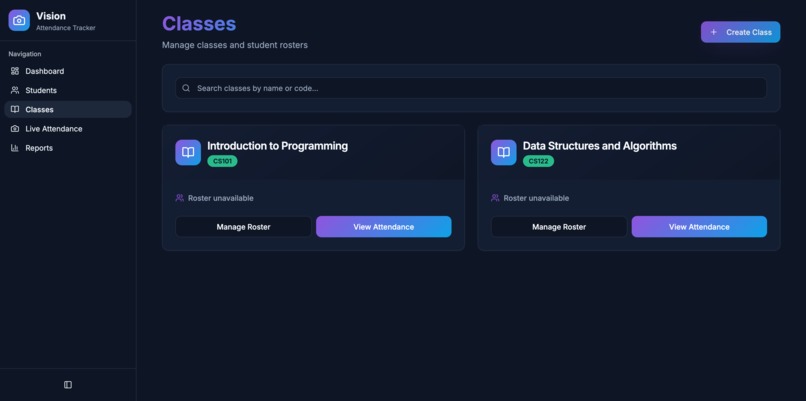
Classes
-
Live Attendance
-
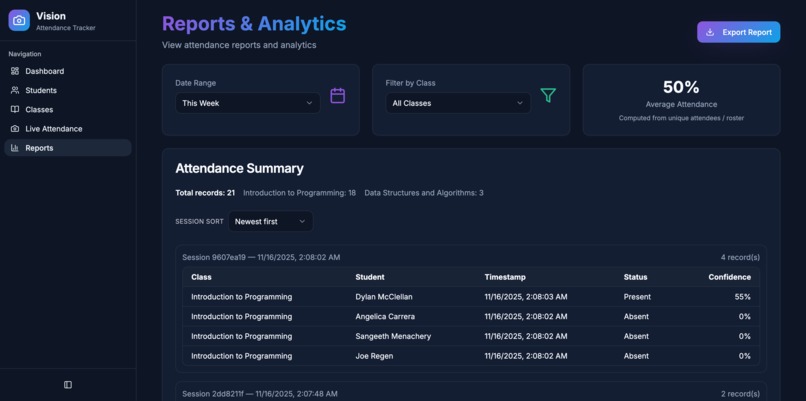
Reports






Summary
Creative ML-vision stack that ingests raw hyperspectral frames, applies GPU-accelerated face-recognition pipelines, and orchestrates real-time inferences across cloud-native microservices with automated deployment topology—accuracy reimagined.
Inspiration
We set out to reclaim classroom time by replacing manual roll call with a deterministic, AI-driven attendance pipeline hardened for enterprise schedules.
What it does
ML Vision streams live video, performs low-latency facial embeddings, reconciles detections against roster services, and emits signed attendance events plus analytics-ready reports.
How we built it
A Spring Boot microservice mesh, React SPA, and Python OpenCV/face-recognition pipeline communicate over REST and WebSocket channels, sharing session metadata to process camera frames in near real time.
Challenges
Synchronizing Python-side recognition events with Java persistence, tuning end-to-end latency on high-frame-rate feeds, and stabilizing cosine thresholds under adversarial lighting conditions required multiple profiling passes.
Accomplishments
Shipped an end-to-end system featuring continuous detection, roster CRUD workflows, encrypted object storage, and exportable attendance reports with audit metadata.
What we learned
Mastered cross-language contract design, face-recognition optimization (batching, quantized models), and jitter-free streaming in constrained classroom networks.
What’s next
Next iterations target adaptive accuracy tuning, native mobile capture surfaces, multi-camera federation, and richer reporting/alerting pipelines.

Log in or sign up for Devpost to join the conversation.