-
-

Logo
-

Home
-
Murmur Circles
-
Murmur 0%
-
Murmur 50%
-
Murmur 100%
-
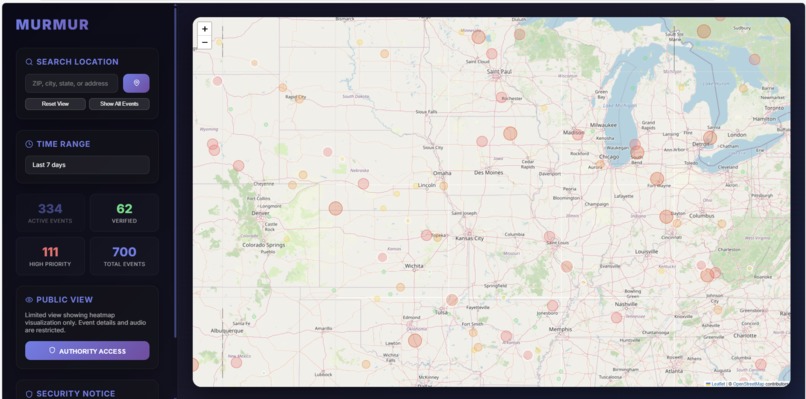
Heat Map
-
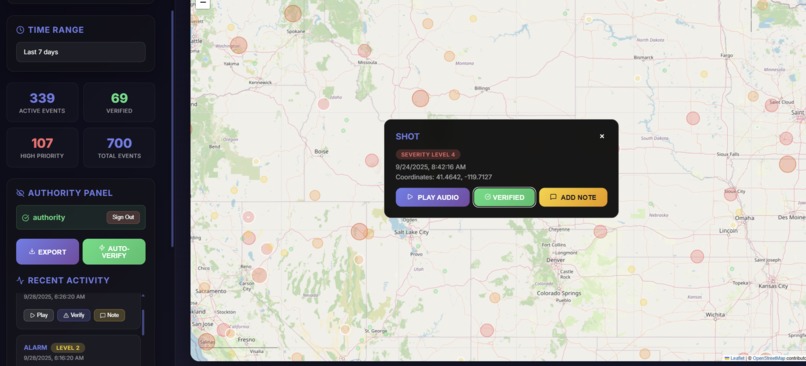
Authority Side Heat Map
-
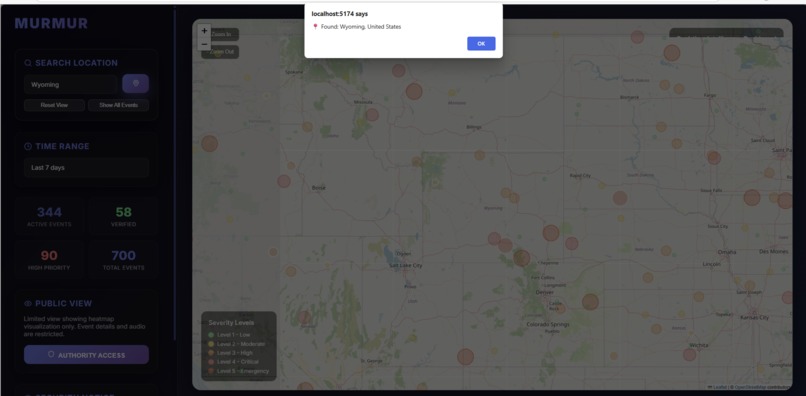
Heat Map Zoom









Inspiration
Murmur (n.): a low, continuous sound: subtle, early, and easy to miss. From Latin murmurare “to rumble.”
We built Murmur to stop people from dying at the hands of other people. Not just to “save lives” in the general sense, but to prevent those moments when anger, fear, or hate turns fatal. We’re living through heated times where people can be attacked for what they say or even what they believe. That reality is the spark behind Murmur.
Our initial insight was simply that many violent or dangerous situations, large-scale or small, often begin with a distinct acoustic event. A scream. A gasp. A yelp for help. A sharp bang. These sounds are early, universal signals that something is wrong.
All Murmur aims to do is catch them first, and stop them fast.
What it does
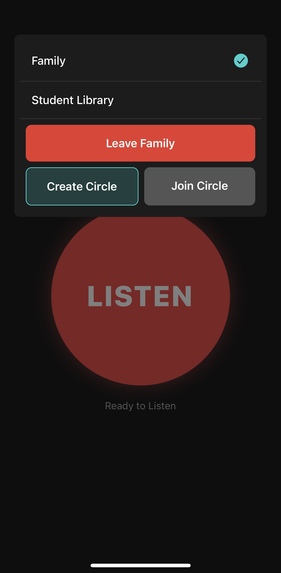
Mobile app that auto-detects dangerous situations and notifies authorities + your circle when risk crosses a threshold. Runs hands-free in the background to speed response; useful for schools and personal safety.
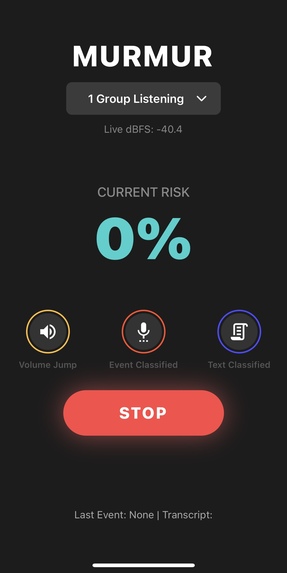
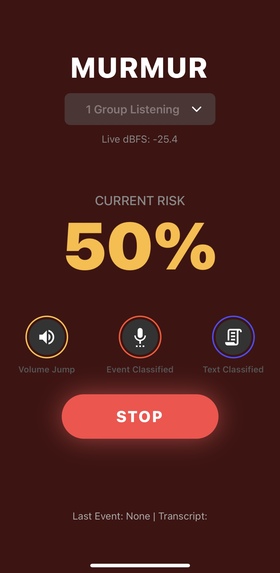
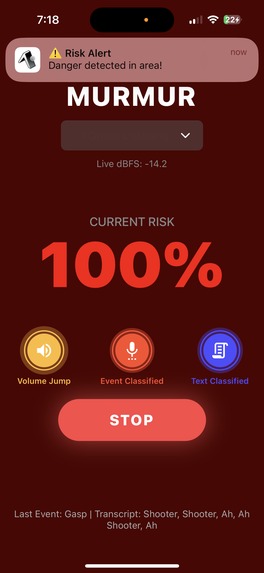
How it works (3-tier pipeline) Tier 1 – Decibel Jump: Monitors sudden spikes in loudness (no raw audio stored) to gate deeper checks. Tier 2 – Event Classifier: On spikes, listens briefly to classify screams/gasps/gunshot-like sounds. Tier 3 – NLP Context (parallel to Tier 2): Transcribes short snippets to distinguish “help/shooter” vs cheering/news/jokes. If combined risk exceeds threshold → auto-alerts (authorities + trusted contacts).
Web dashboard (Murmur Intelligence) Live map & timeline of acoustic risk events with severity. Public heatmap vs Authority mode (login) for event details: play snippet, verify, add notes, CSV export. Search & zoom to areas; live stats and recent-activity feed.
Murmur is unique because it requires minimal user effort and can run in the background if consented by the user to quicken authority response time to several dangers. Murmur is most applicable in schools and personally dangerous situations.
How we built it
Mobile app: React Native (Expo). We use Expo-AV to read the mic, Reanimated for the live visualizer, and Expo Notifications for push alerts.
Backend bridge: A tiny Flask server on the laptop streams JSON to the phone. Audio stays as short rolling buffers; we don’t keep long recordings unless an alert fires (configurable).
Web dashboard: React + JS with Leaflet (CDN) for the heatmap and tools like CSV export.
Tier 1 — Loudness jump (NumPy): Continuously measures volume and spectrum on 0.5s slices. It learns the room’s “normal” and only wakes deeper checks when it sees a sudden spike and spectral change (so a door slam or scream pops, but a fan doesn’t).
Tier 2 — Event classifier (Hugging Face model): A PANNs CNN14 audio tagger (Google AudioSet-trained) gives probabilities for sounds like “Scream,” “Gunshot,” “Applause.” We take the highest “danger” label as the event score, but preempt it when clearly safe sounds (applause/cheering/fireworks) dominate. If the model isn’t available, we fall back to simple spectrogram features to estimate “scream-like.”
Tier 3 — Text understanding (Whisper → Qwen): We only transcribe when Tier 1 or 2 thinks something’s up. Whisper turns the snippet into text; a tiny Qwen-Instruct prompt answers one word: SAFE or DANGER with confidence.
Fusion & alerting: We combine three signals: event score (most weight), text decision, and loudness jump. We smooth them over a couple of seconds, and apply a short cooldown. A very confident DANGER from text can override. On alert, we can save a short WAV clip and notify the phone instantly.
Challenges we ran into
False positives (technical). Real life is noisy. We cut misfires with an auto-calibrated 3-tier pipeline: T1 = loudness jump (no speech content) → T2 = event classifier with safe-sound preemption (applause/cheering) → T3 = ultra-short ASR + “here/now danger” text check. We weight + smooth signals and add cooldowns to avoid alert spam. This mirrors other safety tech (alarms, fall/crash detection): occasional false alarms are acceptable when the upside is catching real harm. Privacy.
Default mode only tracks decibel changes, not speech. Only on a spike that coincides with another danger trigger (Tier-2 audio event or Tier-3 text flagging) do we analyze a 3 - 5s rolling buffer, process it in-memory, then immediately discard it. Recording is user-initiated/consented, runs only while they choose, and we plan a TOS stating: no long-term audio storage, minimal data, easy stop.
Accomplishments that we're proud of
Three-tier audio safety ML pipeline (loudness → spectral events → transcript cues) Only one of us had audio ML experience prior.
Significantly fewer false positives via adaptive baselines + cross-signal agreement.
Privacy-by-design: no raw audio retention; short, in-memory buffers only.
Shipped end-to-end: Python ML + Flask API + React Native app + React web dashboard.
What we learned
Model orchestration: fusing signal, event, and text models into one decision.
Auto-calibration > fixed thresholds in noisy, real-world audio.
Latency tradeoffs (chunking, background ASR, cooldowns) for realtime UX.
Field testing is mandatory to harden against music/games/crowds.
What's next for Murmur
Classroom hardware route: Low-cost Raspberry Pi + mic bundles running Murmur at the edge; pursue educational licensing for schools.
Granular location: Multi-sensor fusion (phone + Wi-Fi/BLE + room mics) to pinpoint incidents to rooms/zones for faster response.
Area blast alerts: Opt-in regional notifications that raise community alertness when multiple nearby devices trigger.
911 escalation: Policy-gated workflow to auto-place a 911 call after multi-signal confirmation and human-on-the-loop checks.
Model tuning: Continue fine-tuning event and text models, improve dB baseline adaptation, and drive down false positives with hard-negative mining.
Reliability & edge: On-device fallbacks, offline buffering, and privacy-first processing to reduce cloud dependency.
Policy & trust: Write a more fleshed out ToS/Privacy Policy, consent flows, audit logs, and admin controls for schools and communities.
Built With
- cnn14
- expo-av
- expo-cli
- expo-notifications
- expo-router
- fireworks-chat-completions
- fireworks.ai-whisper-v3-turbo
- flask
- hook-mobile
- ionicons
- javascript
- json
- leaflet.js
- librosa
- lucide-react
- nominatim-geocoding-api
- numpy
- openai-whisper
- openstreetmap-tiles
- panns
- python
- pytorch
- react
- react-native
- reanimated
- rest
- safe-area-context
- scipy
- sounddevice
- soundfile
- typescript
- vite











Log in or sign up for Devpost to join the conversation.