-
-
results for "serverless" keyword
-
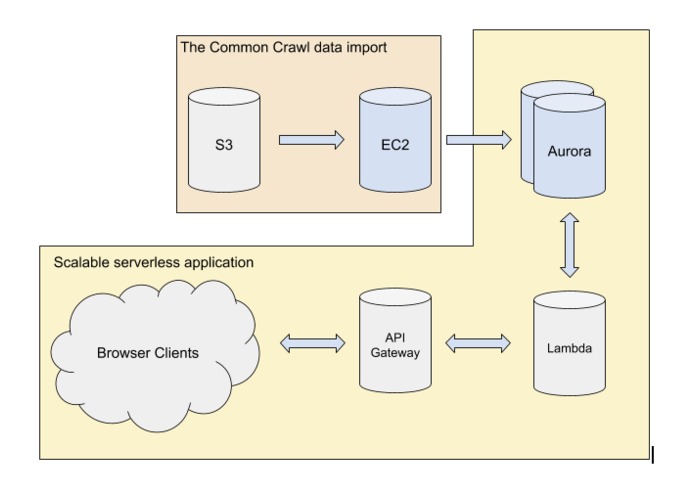
application architecture


Inspiration
I wanted to practically test Aurora MySQL features, explore it's deployment by trying to use it in serverless application. I also wanted to explore options for doing a full-text search using a SQL database on a large dataset.
What it does
The project imports the Common Crawl public dataset available on AWS and makes it searchable. The Common Crawl is a very large dataset containing data about most websites on the internet.
How I built it
I've spent several weeks building the application. I tried using AWS best practices I've learned to build as quickly as possible. First I've created a CI/CD pipeline for serverless application. Then I've implemented basic schema for the database and the data processing and import. This step included writing a custom tool in C++ for translation of WAR format to CSV and later direct SQL statements - the "warsql". After I got sample data in the database, I've built a simple front end for the application using serverless application framework.
Challenges I ran into
Data import was the most significant challenge on this project. The dataset is very large and my goal from the beginning was to stream it into the database. This turned out to be a very complicated task and I hit several issues.
1) MySQL tools and driver only allow streaming via file or pipe. This is not ideal. File access requires you to write ready-to-import data to the filesystem. The pipe approach seemed very heavy on the system.
2) "LOAD DATA IN FILE" is not supported on the Aurora cluster endpoint. This command must be issued directly to the writer instance.
3) Combination of 1) and 2) will run the writer instance out of memory and crash the MySQL database engine.
I've spent about two weeks fighting this engineering problem. Since I was running out of time, I ended up making changes to my C++ tool "warsql" and return back to using just simple INSERT statements. This unfortunately introduced significant performance issues, but was stable enough.
Another and much smaller issue I ran into is data encoding. My "warsql" tool seems to break the data on import, the UTF8 encoding seems to be ignored.
Accomplishments that I'm proud of
Despite problems I was able to complete the application and I learned a lot about importing a large dataset to Aurora. I've used latest AWS CI/CD tools and serverless application model to build a prototype in a very short time period.
What I learned
I've learned that having very good CI/CD pipeline early in the project helps to make quick iterations. I've learned that writing a C++ application to handle complex logic is much better time investment than trying to improve bash scripts.
What's next for Naive search
- Secure DB access
- Fix encoding issues
- Improve import speed
- Add ability restart import
- Optimize full-text search
- Multi-region deployment
Built With
- amazon-web-services
- api-gateway
- aurora
- codebuild
- codecommit
- codepipeline
- lambda
- node.js

Log in or sign up for Devpost to join the conversation.