-
-
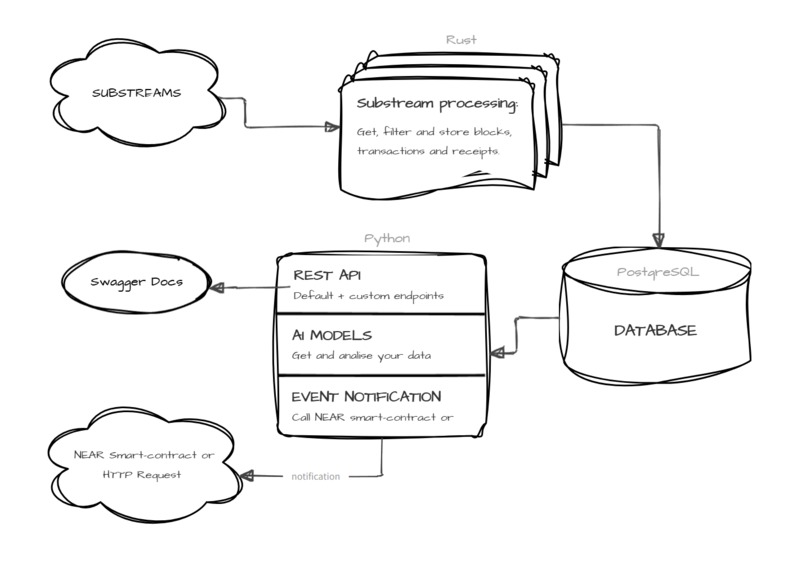
General Architecture
-
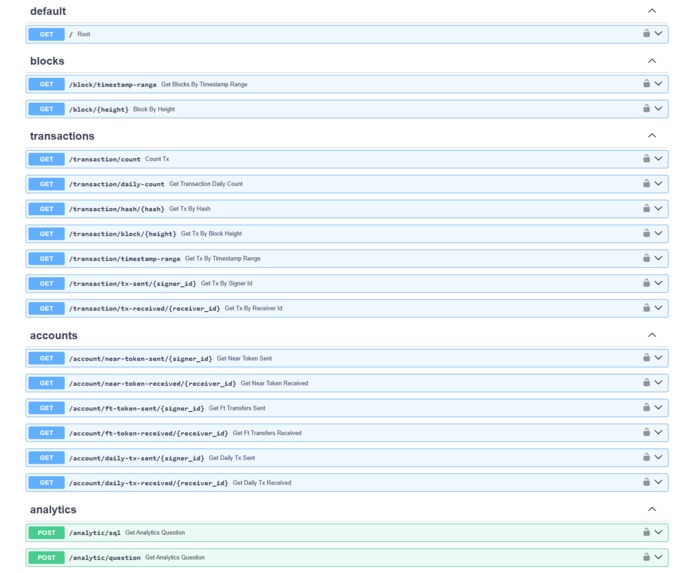
Pre-build API Endpoints
-

Comparison and Self-Sufficiency



Inspiration
In today’s data-driven world, the ability to collect, store, and analyze vast information is essential. The NEAR blockchain, for instance, holds data that can fuel new type of projects - user rating systems, interconnection of wallets, measure projects KPI and metrics, track blockchain trends, reveal behavior patterns, and even forecast developments across the ecosystem.
However, existing blockchain indexing and data solutions are often either limited or overly complex, making it challenging to access and process this data efficiently. From start NEAR has generated at 60 TB of data, emphasizing the need for more accessible tools.
Current solutions in the space:
- BigQuery: Expensive for reading large data volumes and lacks options to export extensive datasets.
- QueryAPI: Still in beta and marked asx unstable, with limited control over indexing, such as no options to stop or restart the indexer.
- Lake Framework: Requires a complex setup, depends on AWS, and needs an archival node to access historical data.
- Pikespeak API: A robust solution, though it's not open-source or adaptable to specific needs, and it require subscription even for simple API requests.
To address these challenges, we're excited to introduce NEAR River — a platform that enables anyone to effortlessly set up custom data flows and work seamlessly with any blockchain data.
What it does
NEAR River offers an new approach to collecting, storing, and analyzing blockchain data through several core components:
- Substreams – offers fast and efficient access to blockchain data, retrieving both historical and real-time blocks. Developed using Rust, our component is designed for optimal performance, enabling streamlined data collection, filtering, transformation, and storage in a local database.
- API – To make data accessible, we built a basic API with endpoints for retrieving general information on blocks, transactions, and user accounts. The API can be easily extended to add more specific endpoints tailored to your project’s needs.
- AI Integration – Our API, developed in python, is compatible with any AI model for data analysis. In our demo, we're use "Llama-3-sqlcoder-8b" for SQL generation and "meta-llama/Llama-3.2-1B-Instruct" for data analyse tasks from Hugging Face, but you can replace it with a model best suited to your requirements and hardware.
- Event Notifications – Set up automatic event triggers based on filters you define, enabling data transfers to smart-contracts or via standard HTTP calls.
Our goal is to make data access seamless, reliable, flexible, and fast, while offering new tools for data analytics and decision-making. Setting up the system is straightforward - just configure two ".env" files and launch Docker. Within minutes, your indexer will be fully operational and ready to collect the data you need! NEAR River offers a robust foundation for integrating AI with blockchain data, empowering a wide range of projects and services.
Configuration and Key Features: NEAR River offers a streamlined approach to configuring and utilizing blockchain data with a range of powerful features:
- Custom NEAR indexer setup: Simply adjust the .env files and start Docker to begin indexing.
- Time-based block selection: Retrieve information from specific time periods, targeting only the data you need.
- Transactions filter: Apply filters to store only relevant transaction data in PostgreSQL for efficient access and analysis.
- Pre-built, expandable API: Access transactions, receipts, blocks, and general blockchain data via default endpoints, with easy customization options for project-specific needs.
- Scalable and open-source architecture: Customize and extend both the indexer and API with your own logic and enhancements. Integrate advanced AI models to process data, unlocking fresh possibilities and insights for your applications and life.
- Comprehensive blockchain data access: Access historical and real-time data using substreams without the need to manage your own node.
- Optimized storage: Store essential NEAR blockchain data in less than 1TB.
- NEAR social integration: Parsed social.near calls for advanced search and filtering.
- Real-time event notifications: Set up user-defined conditions to listen for events and push updates via HTTP or smart-contracts, delivering real-time data streams.
- AI-Driven data Insights – Leverage powerful AI models to extract deep analytics and actionable insights directly from your setup. With built-in GPU support, the system ensures high-speed, efficient processing, making it easy to handle large data volumes in real-time.
- Unlimited local AI queries: Use AI on your own machine with no external API limits or additional costs.
AI Model Integration
For AI functionality, an Nvidia GPU with drivers is recommended, ideally with 24GB of VRAM. We set up two API endpoints to facilitate communication with the AI models, though this can be easily customized to fit other models as needed.
SQL Generation and Data Retrieval Endpoint:
/api/analytics/sqlFunction: Generates an SQL query based on a user question and the database schema. Example Workflow: Ask a question like, "What are the 10 most popular smart-contracts from last week?" The endpoint use AI model to generate SQL query, retrieves results directly from the database, and returns the data to the user.Question-Based Data Analysis Endpoint:
/api/analytics/questionFunction: Combines SQL generation with a question about the result data in a single request. Parameters:sql_question: Defines the SQL query based on what data to retrieve from the database.data_question: Asks specific questions about the returned data. Request will generate an SQL query, retrieve data from the database, and provide an AI-driven analysis of patterns and insights.
How we built it
- Research and Analysis: Reviewed NEAR solutions for data indexing, APIs, and analysis, identifying key challenges in data processing and the lack of Substreams documentation for NEAR.
- Substream Service Development: Created a Substreams service to retrieve and store blockchain data, adding configuration options for filtering and transformation to store only valuable information efficiently.
- API Creation: Built an API with predefined endpoints for easy data access and added optional API protection for secure usage (option in .env file).
- Streamlined Setup with Docker: Integrated Docker and simplified configuration with ".env" files to enable quick startup and effortless use of NEAR River.
- AI Model Integration: Researched and tested various AI models for SQL generation and data analysis. Set up GPU support and wrote prompts tailored to different use cases.
- Event Notifications: Added event notification capabilities, allowing data to be sent to NEAR smart-contracts or via HTTP based on user-defined filters.
- Smart-Contract Example: Developed a simple smart-contract to demonstrate notification functionality.
- Demo Deployment: Deployed NEAR River on a rented server to provide a live demo.
About the Demo
To showcase NEAR River's capabilities, we deployed it on a dedicated server with GPU support. The demo is configured to collect all data from the NEAR Mainnet starting from 1 Oct 2024 (block 129274113) to 7 Oct 2024, results in the database containing a comprehensive set of blocks, transactions, and receipts.
Our server setup includes an 8GB GPU, which is below the recommended 24GB for optimal AI performance. This hardware works for demo mode but has limited VRAM, leading to longer AI query execution times of around 40–50 seconds. Occasionally, we may also encounter errors due to insufficient GPU memory because we combined 2 models in small space. We launched the database, API with AI models, and substreams on a single server, which works for demonstration purposes. For a production environment, we need to split all containers across separate servers and setting up a master/slave database for more efficient read/write operations. The demo server isn’t powerful enough to handle large amounts of data quickly, so please include a time range or limits for faster responses.
For event listener functionality, we deployed a test smart-contract on the NEAR testnet, configuring NEAR River to trigger this contract with relevant transaction data. This demonstration smart-contract logs the received transaction details and increments an internal counter, exemplifying real-time event handling in action. You can explore an example of this event call and the smart-contract.
Example Use Cases
To make the most of NEAR's blockchain data with integrated AI, consider these use cases, each requiring updates to both the API and AI modules:
Project and Ecosystem Dashboards: Build dashboards that track custom transaction metrics, aggregate data, and extend the API to deliver key performance indicators (KPIs), statistics, and visualizations. AI integration enables data analysis over time, producing summaries and insights into ecosystem trends.
User Rating Systems: Create a dynamic rating system based on blockchain activity. Collect stats such as token transfers, social interactions, and other metrics to develop a user scoring system. AI can analyze patterns and adapt scores based on observed user behaviors.
Real-Time Game Services: Connect games to blockchain events, enabling live updates on player activities. AI can track patterns, helping adjust game mechanics, offer insights into player trends, or suggest in-game actions based on player activities.
Airdrop Services: Collect wallet addresses filtered through substream rules, generate a Merkle tree of qualifying addresses, and store the root in a smart-contract for distribution. AI can assist in analyzing participation data, adjusting criteria, and optimizing airdrop strategies.
These are just a few examples illustrating how AI models, combined with NEAR’s blockchain data, can power a variety of applications by leveraging historical and real-time data for advanced analysis, predictive insights, connections review, and decision-making.
Challenges we ran into
- How to set up and use Substreams on NEAR with limited documentation and resources.
- How to retrieve, filter, transform, and store data efficiently from Substreams.
- How to build an API that supports AI model integration and optimizes GPU processing.
- How to simplify the setup, configuration and usage.
- How to select the best open-source AI models for SQL generation and data analysis.
- How to write effective prompts and adjust model settings for accurate AI outputs.
- How to configure event listeners to trigger external calls or smart-contracts reliably.
Accomplishments that we're proud of
- Fast indexing and efficient data processing, achieved by using Rust and Substreams.
- Flexible integration with various AI models for powerful data analysis.
- Simple startup and configuration, making it a user-friendly, open-source solution.
- Pre-built API endpoints that are easily extensible and configurable.
- Real-time event listeners that can trigger external calls and interact with smart-contracts.
- Optimized GPU usage to support high-performance AI processing for faster insights.
- Effective filtering and transformation tools, allowing us to store only relevant data.
- Clear, concise documentation to make setup and customization easy for new users.
What's next: Future updates and self-sufficiency
NEAR River is designed to be a self-sufficient, open-source platform, offering both flexibility and scalability. Following a subscription model similar to Pikespeak, users gain access to an extended suite of pre-built API endpoints, ensuring that essential tools for blockchain data management are readily available.
Additionally, users/companies can request custom API endpoints, data aggregation, or AI-driven analytics tailored to their unique needs. This approach allows NEAR River to serve as a robust and adaptive solution, enabling projects across the ecosystem to derive powerful insights and meet diverse data demands with ease.
To-Do List:
- Add filter masks to enhance filtering options for Substreams and events.
- Update the
receipt_actions.argsfield to JSON format to improve data filtering and querying. - Data aggregation: create additional tables to collect aggregated data, improving performance when handling large data volumes.
- Deploy production infrastructure: a server for Substreams processing, a GPU server for the API, and master/slave database setup.
- Utilize the integrated AI not only to analyze query data but also to provide predictive insights and alert users of unusual patterns.




Log in or sign up for Devpost to join the conversation.