-
-
Home Page
-
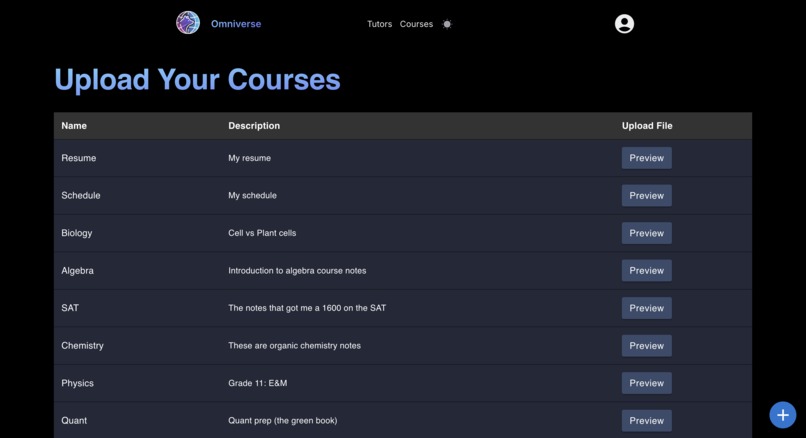
Courses Page
-
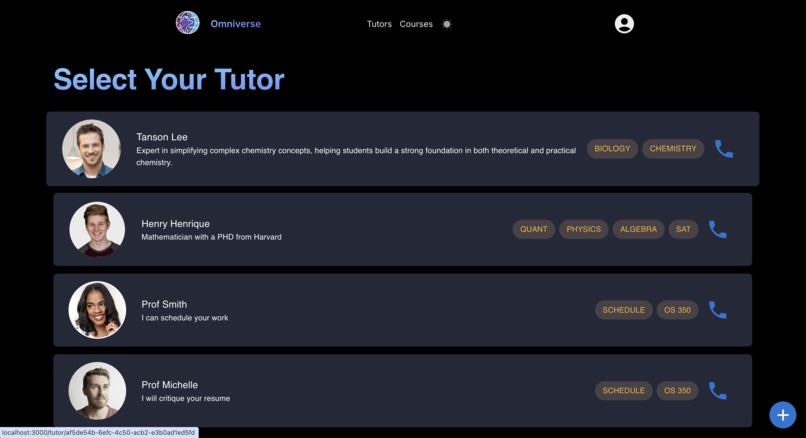
Tutor Page
-
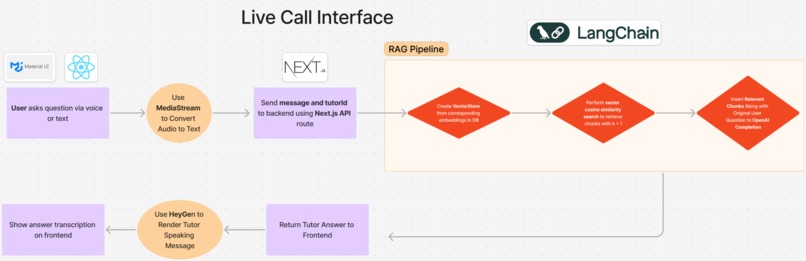
Live Call Pipeline with RAG
-
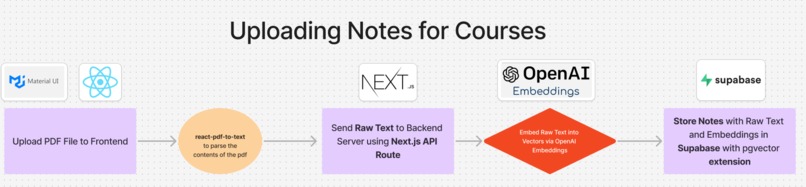
Embedding and Storing Course Notes
-
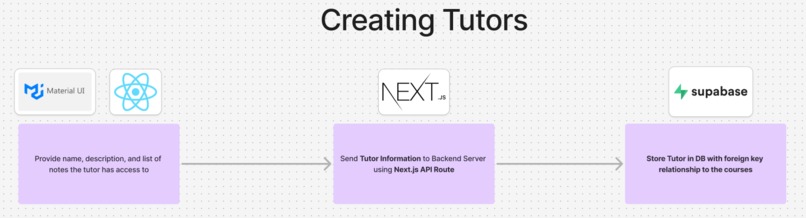
Tutor Creation






Inspiration
In our first year of university during COVID-19, we had these online office hour sessions through MS Teams for our math courses. These sessions ran for 12 hours a day, and were accessible from anywhere. Although we're fortunate that the pandemic is over and the school doesn't have to run these extensive online office hours anymore, I loved the idea of accessible high-quality tutoring at any time. Being able to talk to another person whenever you were stuck on a problem or didn't understand a certain concept is a gamechanger. However, nowadays when we want face-to-face help, we need to take into account the schedule of our professors, TAs, or tutors, and see when you can drop by their office for a quick 30 minute session. If a new question pops up, you need to head back to their office whenever their free.
We thought, what if we can build a platform that can allow anyone to have access to one-on-one tutoring, whenever they want, teaching them about whatever they want. That way, people who might not have access to high-quality in-person tutoring can also learn efficiently. And, for people who want to learn topics that don't typically provide professors or tutors (like my recent exploration into the fascinating world of installing drywall, for instance) can still get some face-to-face help whenever they need it.
That's why we called it the Omniverse. Help for anything, at any time.
What it does
Omniverse is your live personal assistant 24/7. A user can create a variety of tutors targeted towards any topic they want. You can upload any some of documents for this 'tutor' to read up on and understand the context of. Then, you can interact with them through a live video-call, receiving guidance and help about any subject within that topic.
How we built it
- Next.js
- React
- TypeScript
- HeyGen live-video generator API
- OpenAI's GPT API
- Supabase
Challenges we ran into
It was hard to extract meaningful data from the different types of files a user could possibly input (like pdfs, .txt files, etc.) so that our LLM can process and our HeyGen live model can provide appropriate responses. It took us ~8 hours of experimenting to get relevant, clean data from all possible types of file inputs. It was also hard to determine what constituted a "good" output, as many users could have different use cases for the Omniverse, and no one type of output is the "better" one.
Accomplishments that we're proud of
As this was just a 24 hour hackathon, we're very proud of the fact that we were able to get a full-stack application done in such a short period of time. We're also proud of the fact that our MVP, the live video-calls with our AI models, work well with any possible type of data input. For most users we've had try out our app, they all said the responses they received we're good and genuinely helpful.
What we learned
We learnt the importance of thinking about the user first. Ensuring that the responses our model gave actually made sense and provided good help for all use cases was very important to us. This all allowed us to create a more interactive application, something we aimed for from the very beginning.
What's next for Omniverse
There's a whole range of things that could be done with the Omniverse, from having an "interview mode" where our AI models could test our users about the content they inputted into the application. Being able to add custom models (celebrities, friends/family faces) will also be really cool.
Built With
- api
- generator
- gpt
- heygen
- live-video
- node.js
- openai's
- react
- typescript




Log in or sign up for Devpost to join the conversation.