-
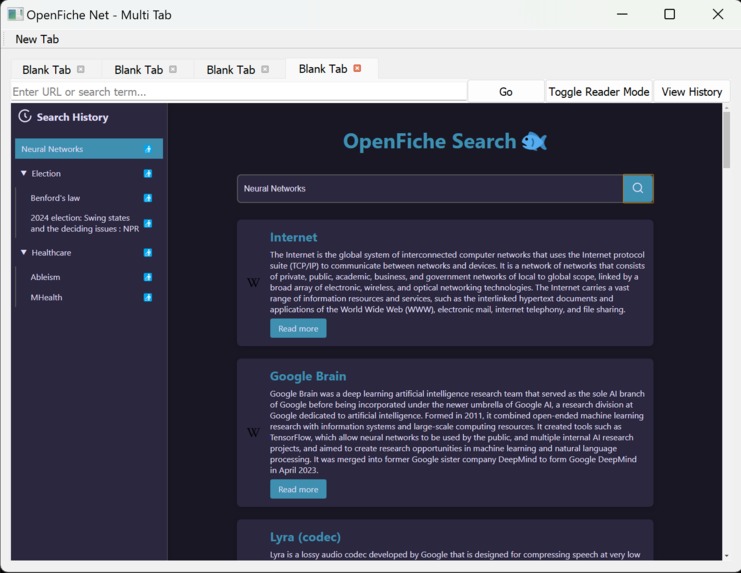
Search engine inside our browser
-
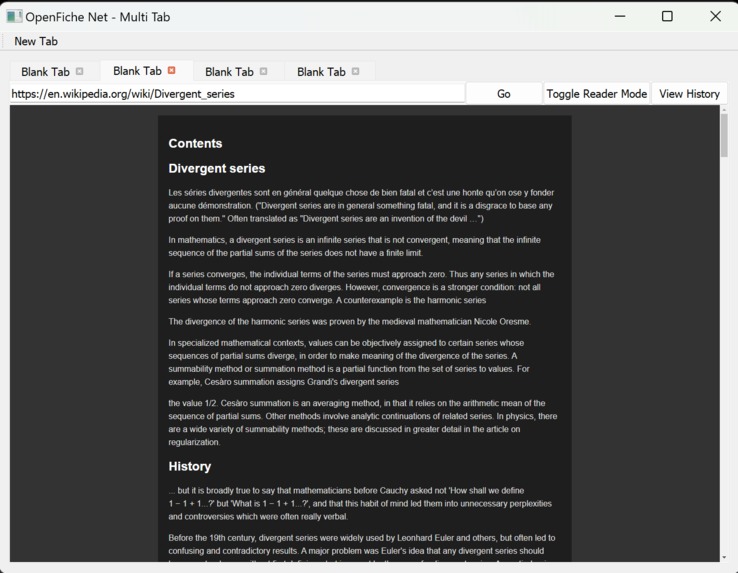
Reader mode
-
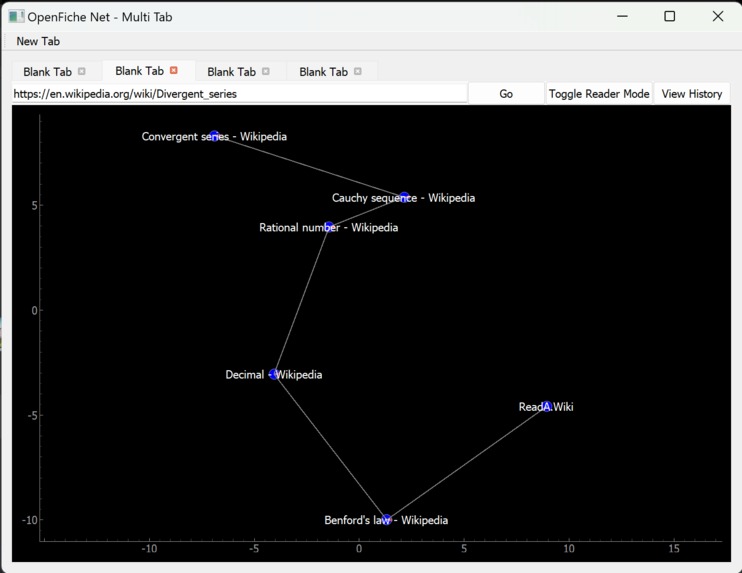
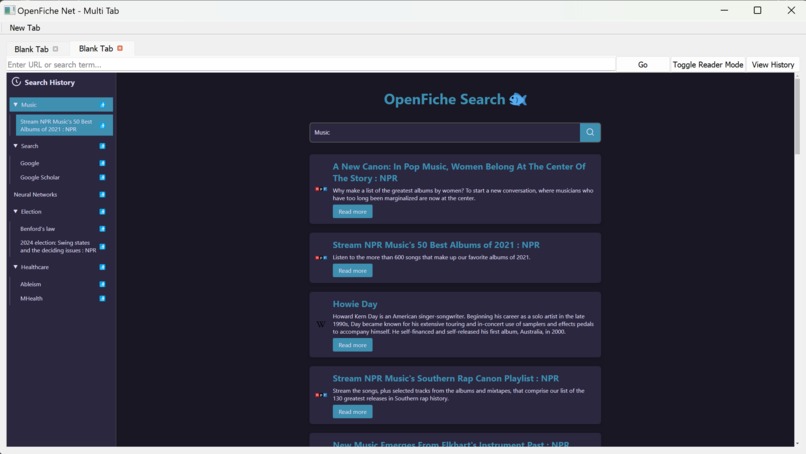
Git-style browser history
-
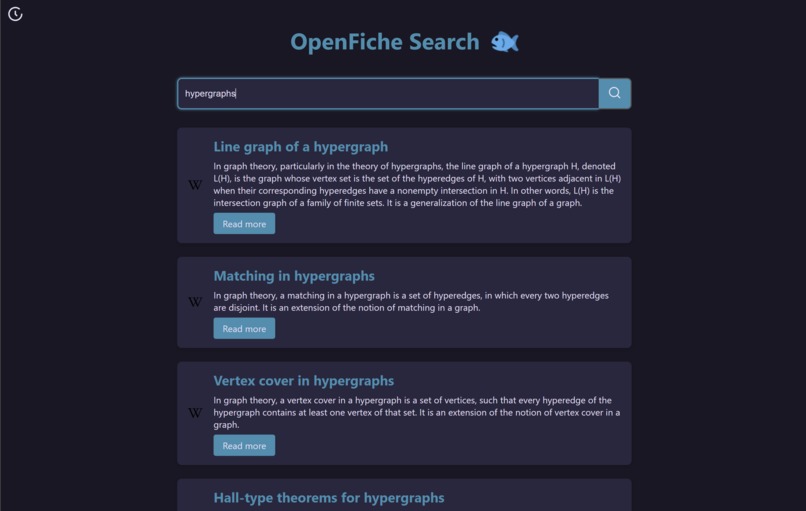
Search Engine
-
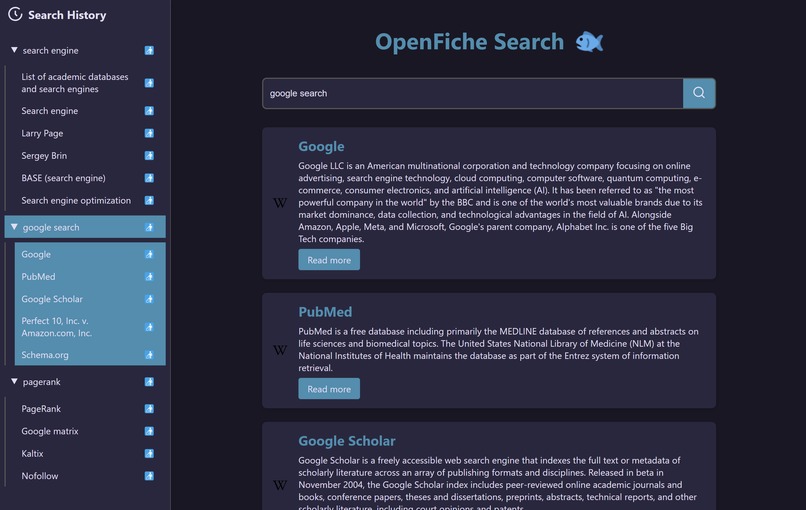
Search Engine with multiple results in history
-
Multiple Sources






Inspiration
The internet user experience, following the boom in AI technologies, has become a frustrating experience. Given almost any query and one must trudge through several results that point either to AI slop or advertised results, neither of which answer simple queries correctly. Perhaps the worst part is that we know the search used to be better when Google was governed by PageRank. Even when you do find a result that you think contains the information you desired, you will probably be faced with a paywall or an endless barrage of advertisements, rendering the whole search useless. To that end, we intend to streamline searching and reading, especially in an academic context, through Openfiche, inspired by Microfiche machines
What it does
OpenFiche is a post-AI search engine that preserves high-quality, human-generated content—akin to microfiche for the web. Our goal is to make the internet search simple and quick, filtering out the noise and surfacing content as it was meant to be read.
- The search engine searches through a vast catalogue of NPR, CNN, and Wikipedia pages: services that can generally be trusted to produce accurate information
- A browser with research centric capabilities like a git-style search history manager and an advanced reader mode that blocks out distractions
How we built it
Search engine: Used a web crawler to explore and build a website specific webgraph using the hyperlink networks. We did this for NPR, CNN, and Wikipedia. We tried Bloomberg and Reuters too but they had stronger bot protections. Once we had a graph, we used NLTK to compute the keywords for each index site and computed the PageRank score. Using a linear combination of the keyword relevance and PageRank score, we sorted the results in descending order and returned those links.
Browser interface: We built the browser interface using the React framework and used Flask to handle the backend. Our site is hosted through Vercel over at reada.wiki
The OpenFiche Net browser is built on an abstraction of the chromium web engine with QT, we developed from the ground up our own tools and subroutines for a unique git graph style history view, and a reader mode to improve the reading experience as well as tab tracking and management. The OpenFiche Net browser is light weight and performant to focus on what’s important.
Challenges we ran into
- Compute time and underestimating the size of webgraphs, especially that of Wikipedia which, in our dataset, had over 300k pages (of which we scraped about ~85-90%) even at a search depth of 2
- Web standards can different when trying to find and parse metadata when different websites sometimes use different formats and have meta data in different places.
Accomplishments that we're proud of
- We managed to scrape over 320,000 pages for this project using consumer level hardware. In that process, we got IP banned by NPR on our main scraping machine!
- Managed to implement PageRank and NLP keyword analysis to create an efficient search algorithm. Searching through the aforementioned 320,000 pages is no joke!
- Added innovative features to a browser created from a very minimal abstraction of a web browser that significantly improve user experience while remaining performant
What we learned
- Web scraping is hard and slow, especially if your goal is to create a webgraph.
What's next for OpenFiche
- We'd love to index way more pages so that we can have a better results
- Make it prettier

Log in or sign up for Devpost to join the conversation.