-
-
PolEn Infographic/Layer Diagram

Inspiration
Whilst researching about significant economic events, we came across an article that highlighted how a single monetary policy decision made by the U.S. federal reserve contributed to over $10 trillion in global bond market losses. A change of this magnitude that corresponds to a mistake involving a singular decision within the context of economic health inspired us to conduct further research and understand the various parameters involved within the implementation of monetary policies and their consequences, and ultimately build an alternative solution based on this research.
What it does
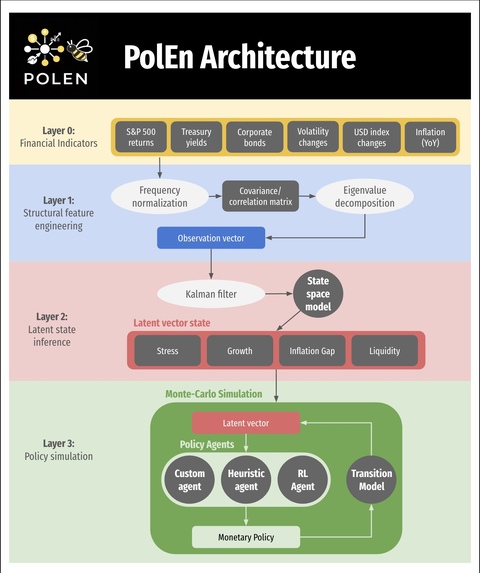
PolEn is a real-time macroeconomic policy engine, and it works by extracting historical data from FRED (Federal Reserve Database) and then it fits a 3-dimensional latent state model representing Stress, Liquidity, Growth and Inflation, and it then classifies the current economy into one of three regimes: Normal, Fragile, or Crisis. Given the current macro state, it simulates a certain amount of forward paths over a certain period under three policy actions: Ease, Hold, or Tighten, which are indicative of how the policy rates should be changed to shift the economic health indicator variables, and it then recommends the optimal action by minimizing a risk-adjusted loss function that penalizes stress, the Expected Shortfall, and crisis probability simultaneously. Additionally, we also trained a PPO reinforcement learning agent as a comparison point to our mathematical model. The final dashboard displays several economic health indicator variables (Stress, Growth, Inflation etc.) propagate over time and how they compare to historical data through calculated loss.
How we built it
Data layer: Raw FRED series (S&P 500, 2Y/10Y Treasuries, VIX, credit spreads, CPI, Fed Funds Rate) are transformed into rolling z-scored structural features, which include the yield curve slope, eigenvalue concentration from eigendecomposition of the cross-asset correlation matrix, credit spread levels, and VIX volatility. State estimation: A Kalman filter is fit into a linear state-space model to those features, recovering a 3D or 4D latent state via the Expectation-Maximization algorithm. Simulation: A Numba-JIT-compiled Monte Carlo engine propagates a certain number of paths forward using regime-switching Markov dynamic and stress-growth coupling. The paths and horizon (range of time) are inputs set by the users through the sliders. RL: A PPO agent trained in a custom Gymnasium environment learns a continuous rate-change policy using an Actor-Critic network with GAE advantage estimation narrative.
Challenges we ran into
One of the biggest challenges was making the Kalman model stable and reliable, since EM can converge to bad local solutions and a weak PCA initialization sometimes produced invalid covariance matrices, so we had to enforce positive-definite matrices and cap the transition dynamics with a spectral radius constraint to stop the latent states from exploding into larger values. Another major issue was the mismatch between timescales, since the model is learned on daily data but the simulator runs monthly, so converting the daily transition and noise terms into a stable monthly version required matrix initialization. We also had performance bottlenecks in Monte Carlo simulation, where thousands of paths in pure Python were too slow for interactive use, so we used Numba JIT to get it down to a usable speed, which added its own implementation constraints. On top of that, the latent stress factor from the Kalman filter can emerge with its sign flipped, so we added an automatic sign-correction step using VIX correlation.
Accomplishments that we're proud of
One of the strongest outcomes of the project was that the Kalman-EM model converged cleanly on real FRED data in 21 iterations to a log-likelihood of 1726.73, with a spectral radius of 0.9944, which is right near the stability boundary and fits the idea that real macro-financial systems are persistent. The system also revealed that in a Fragile regime, the gap between Ease and Tighten outcomes becomes about 1.8 times wider than in a Normal regime, which puts a number on something policymakers often intuitively feel but rarely quantify into a variable.
What we learned
This project made it clear that latent-variable modeling is powerful but harder to implement, because EM needs careful initialization and constant convergence checks to stay stable. It also showed that regime context is crucial: the same rate cut can reduce tail risk far more in a Crisis regime than in a Normal one, so policy can’t be treated as one-size-fits-all. More broadly, the project reinforced that monetary policy is better framed as a stochastic control problem when choosing the action that minimizes expected future regret across many possible paths, not just predicting a single outcome.
What's next for PolEn
Our future goals include expanding from a single rate policy to a multi-instrument setup where the RL agent can jointly control rates, and add fiscal policy so the state reflects deficits alongside monetary conditions, and extend the framework across major central banks for model spillover effects. We also want to construct a backtesting engine to replay crises like 2008, 2020, and 2022 with counterfactual policy paths by distributing EM fitting and Monte Carlo across a cluster with low-latency inference.
Built With
- fastapi
- fred
- gymnasium
- numba
- numpy
- pandas
- pyarrow
- pytest
- python
- pytorch
- scikit-learn
- scipy
- stable-baselines3
- streamlit
- tensorboard
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.