-

Example 1/4
-

Example 2/4
-
Diagram
-
Theory
-

Example 3/4
-

Example 4/4






RL-Guided Diffusion: A Mixture-of-Experts Approach A novel method for generating images by using a Reinforcement Learning agent to dynamically select the best diffusion model at each step of the creation process.
Inspiration In deep learning, autoregressive models like diffusion models are incredibly powerful but often specialized. A model trained for photorealism might struggle with artistic styles, and vice-versa. This led to a key question: what if we could combine the "strengths" of multiple specialized models for a single task?
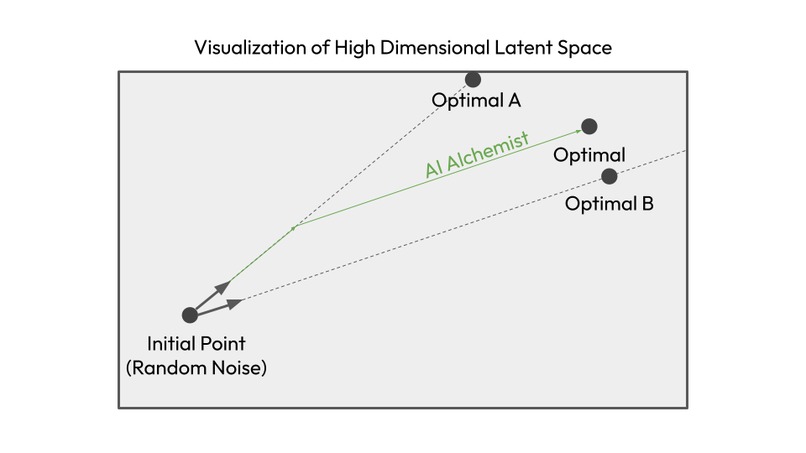
The inspiration came from a linear algebra analogy. Imagine the vast, high-dimensional latent space of all possible images. Any single diffusion model, trained on specific data, can effectively navigate a particular subspace of this total space. For example, a photorealistic model can find any point within the "photorealism" subspace, but it struggles to leave it.
We theorized that these specialized models act like basis vectors. While one vector can only point in one direction, a combination of vectors can span a much larger space. By applying different models sequentially, we aren't just blending images; we are performing a guided search through a combined subspace that is richer and more expressive than any single model's subspace. The reinforcement learning agent's job is to learn the optimal "linear combination" of these model steps, navigating this spanned subspace to find a final point (image) that better satisfies the prompt than any single model could alone.
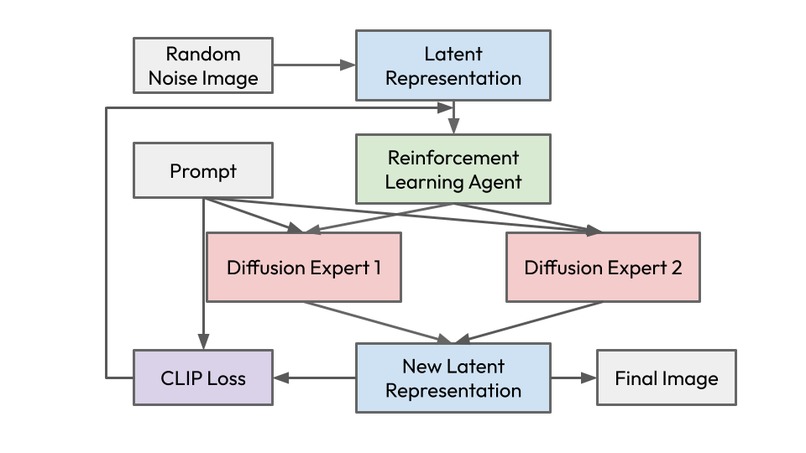
What it does This project introduces a framework where a text prompt is used to generate an image by drawing from a "palette" of different Stable Diffusion models. For our proof-of-concept, we use two models: a general-purpose model (runwayml/stable-diffusion-v1-5) and a stylized fantasy model (dreamlike-art/dreamlike-diffusion-1.0).
Here's how it works:
The generation process starts from a standard random noise tensor.
At each of the 50 diffusion steps, a simple Reinforcement Learning agent—a Multi-Armed Bandit—decides which model to use for that step.
After the step is performed, the in-progress image is decoded from its latent representation and scored against the original prompt using a CLIP model.
This CLIP score serves as a reward to update the RL agent, teaching it which model contributes more effectively to the desired outcome at different stages of generation.
This loop continues, dynamically blending the capabilities of both models, until the final image is produced.
The result is a unique composite image that intelligently combines the realistic structure from the generalist model and the artistic flair of the stylized one.
How We Built It The entire project is built in Python using the following key technologies:
PyTorch: The foundational library for all tensor operations and model handling.
Hugging Face diffusers: This was crucial for loading the pre-trained Stable Diffusion pipelines. Our core logic involves swapping out the UNet and VAE components of the pipelines on-the-fly based on the RL agent's decision.
Hugging Face transformers: We used this to load a pre-trained openai/clip-vit-large-patch14 model, which acts as our universal reward function by calculating the image-text similarity.
Reinforcement Learning Agent: We implemented a classic Upper-Confidence-Bound (UCB1) Multi-Armed Bandit from scratch using numpy. This agent is simple, efficient, and perfectly suited for balancing the exploration (trying out different models) and exploitation (using the model that gives the best rewards) trade-off.
Baseline Generation: To prove the effectiveness of our method, the script also generates two baseline images using only Model A and only Model B, starting from the exact same initial noise for a fair comparison.
Challenges We Ran Into Scheduler State Management: Our biggest technical hurdle was a recurring IndexError from the DPMSolverMultistepScheduler. We discovered that the scheduler's internal state was not being reset between the different generation loops (Model A, Model B, and the RL-guided process). This was a subtle but critical bug that we solved by instantiating a completely new, clean scheduler for each of the three generation processes, ensuring no state leakage.
Computational Performance: Decoding the latent tensor to a full PIL image at every single step to calculate the reward is computationally expensive and slow. While this provides the most accurate feedback to the RL agent, it's a significant bottleneck. For future versions, a less frequent reward calculation (e.g., every 5 steps) would be a necessary optimization.
API Inconsistencies: We ran into minor AttributeError issues where a function (numpy_to_pil) was a method of a pipeline instance rather than the class itself. This highlighted the importance of carefully reading library documentation and understanding object-oriented structures.
Accomplishments that we're proud of We are incredibly proud of successfully creating a working proof-of-concept for this complex idea. Seeing the RL agent learn and choose different models at different steps—and then seeing a final image that clearly blends the two—was a huge moment. We built a system that is not just a theoretical concept but a functional script that produces unique and compelling images. The final implementation is clean, well-commented, and includes the baseline comparisons needed to validate the results.
What we learned This project was a fantastic learning experience. We learned:
The power of modularity: Modern deep learning models can be treated as interchangeable components, opening up new avenues for creative composition.
The intricacies of the diffusers library: We gained a much deeper understanding of how schedulers, UNets, and VAEs interact within a diffusion pipeline.
The flexibility of CLIP: Using CLIP as a live reward signal is an extremely powerful technique for guiding generative processes toward a specific semantic goal, without needing a custom-trained reward model.
What's next for RL-Guided Diffusion This project has opened up a world of possibilities. Here are our next steps:
Expand the Palette: Integrate a wider variety of models. Imagine an agent choosing between models for photorealism, anime, oil painting, and pixel art—all for a single generation!
More Advanced RL: Graduate from a stateless Multi-Armed Bandit to a stateful RL agent like a Deep Q-Network (DQN). This would allow the agent to make decisions based on the current state of the image itself, potentially leading to even more nuanced results.
Dynamic Parameter Control: Allow the RL agent to control more than just which model to use. It could also learn to adjust other parameters like the guidance_scale at each step for finer control over the output.
Built With
- huggingface
- python

Log in or sign up for Devpost to join the conversation.