-
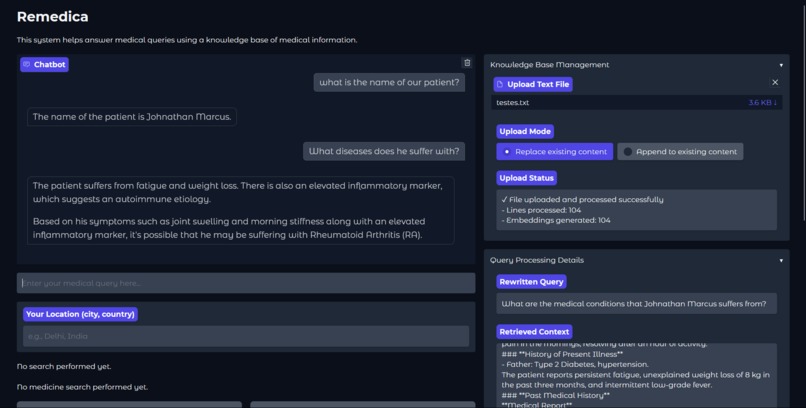
Live demo

Remedica
Inspiration
Remedica was inspired by the challenges faced by our grandparents in understanding their medical reports. Observing the difficulty many people experience in deciphering complex medical jargon, we set out to create a solution that simplifies health data and empowers individuals to take informed actions.
What it does
Remedica:
- Analyzes and simplifies uploaded medical reports.
- Offers clear, easy-to-understand summaries.
- Recommends suitable medications based on the reports.
- Suggests relevant doctors for further consultation and care.
How we built it
- Dataset: We utilized a publicly available medical dataset from Kaggle.
- Data Processing: The dataset was converted using a JavaScript script into the compatible format.
- Model Fine-Tuning: Using Unsloth, we Fine-Tuned a robust large language model hosted on Hugging Face.
- Ollama Conversion: After uploading the model to Hugging Face, we needed to convert it into an executable that could be run by the Ollama client. To do this, we had to create a modelfile to convert the .gguf file into a model that Ollama could understand locally.
- Personalized Suggestions: We integrated a Retrieval-Augmented Generation (RAG) with the fine-tuned large language model for personalized suggestions and data retrieval using Ollama.
- Deployment: we used Ollama for the large language model and Gradio for the user interface.
Challenges we ran into
- Accuracy: Training a precise model with limited GPUs was quite challenging. We had to explore multiple Jupyter notebooks and models. At times, the Colab instances kept disconnecting, or we ran out of our daily time limit.
- Picking the wrong LLM: In one of our first semi-successful iterations, we used LLaMA 3.1 8B instead of LLaMA 3.1 8B Instruct. This caused several issues, such as the LLM claiming to be a Chinese man from Shanghai instead of answering our questions.
- Tech Stack: Initially, we planned to have a full-stack application with Django as our backend and React as our frontend, but we faced multiple issues. It was too complex to interact with the RAG application, and around 2 a.m., we had to make the decision to switch to Gradio.
Accomplishments that we're proud of
- Developed an AI-powered RAG capable of simplifying complex medical reports for non-expert users.
- Successfully integrated recommendations for both medicines and doctors into a unified platform.
- Created a user-centric interface that makes navigating health information intuitive and straightforward.
What we learned
- How to fine-tune an LLM using just our local GPUs and free Colab notebooks.
- How to push models to Hugging Face after fine-tuning and compile them with a modelfile to work with Ollama.
- How to work with Gradio and its usefulness as a front-end framework.
- The importance of precision in fields like healthcare.
What's Next for Remedica
Enhanced Model Fine-Tuning: Fine-tune with domain-specific datasets (e.g., rare diseases, clinical trials) for improved accuracy, and train the model for at least one complete epoch.
Enhancing Model Accuracy: Although it is still an MVP, our model currently achieves a 83% accuracy rate. Our goal is to reduce hallucinations further and ensure the model reaches at least 95% accuracy, as this is a critical task.
Compliance with Authorities: Adopt federated learning and advanced encryption to ensure HIPAA/GDPR compliance, keeping patient data private and secure.
Cloud-Based Database Integration: Move embeddings and data to cloud platforms (AWS, GCP, Azure) for scalability and faster access.
Collaboration with Doctors: Partner with doctors to validate our responses and suggestions, ensuring accuracy and building user trust.
Built With
- colab
- gradio
- hugging-face
- javascript
- jupyter-notebook
- llama
- ollama
- python
- serpapi
- transformers
- unsloth




Log in or sign up for Devpost to join the conversation.