-
-
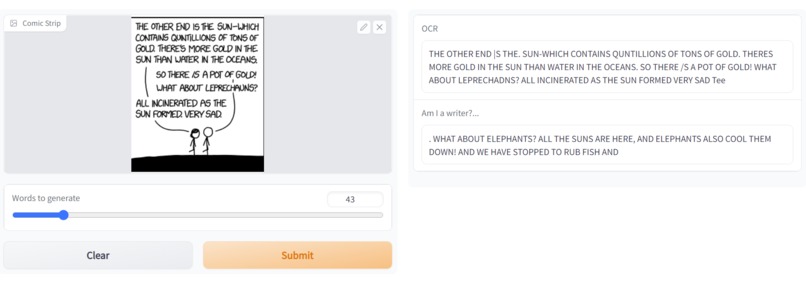
An example of our Gradio app in action.

Inspiration
As a team, we all shared a common love for comic books but thought there weren't enough in the world. Then we thought: why don't we just make more? That's where this project comes in: by doing OCR, we receive a prompt that can be fed into a text generation model, therefore creating endless amounts of comic book script potential!
What it does
It does optical character recognition on comic book strips and generates a continuation of the text as if there were more strips available.
How we built it
We used Tesseract-OCR for OCR, Cohere for generating text, and Gradio for the front end.
Challenges we ran into
At first, we were having trouble getting any open-source OCR model to work well with the given dataset right off the bat. However, we were able to overcome this hurdle with some creative data pre-processing.
Accomplishments that we're proud of
We're proud of both our OCR model's performance and the front end we were able to build in the short time we had.
What we learned
We learned that even though we were limited to using API calls of open-source models, our accuracy wasn't as long as we thought about how to pre-process the data creatively.
What's next for scribble
Creating a serverless backend with AWS Lambda and serving it on AWS EC2!


Log in or sign up for Devpost to join the conversation.