-
-
Landing Page
-

Features
-
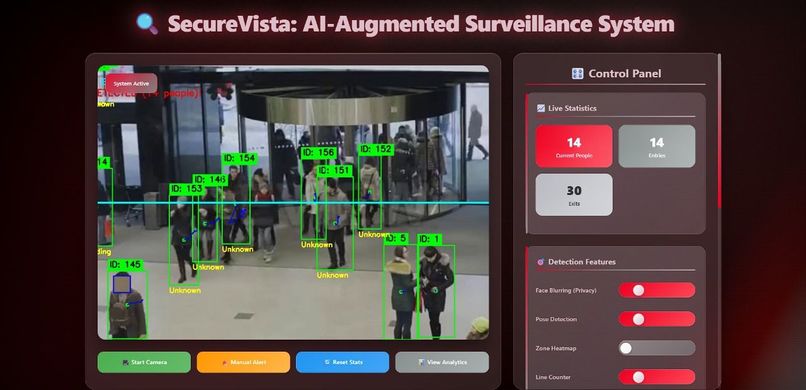
Entry Exit management System
-
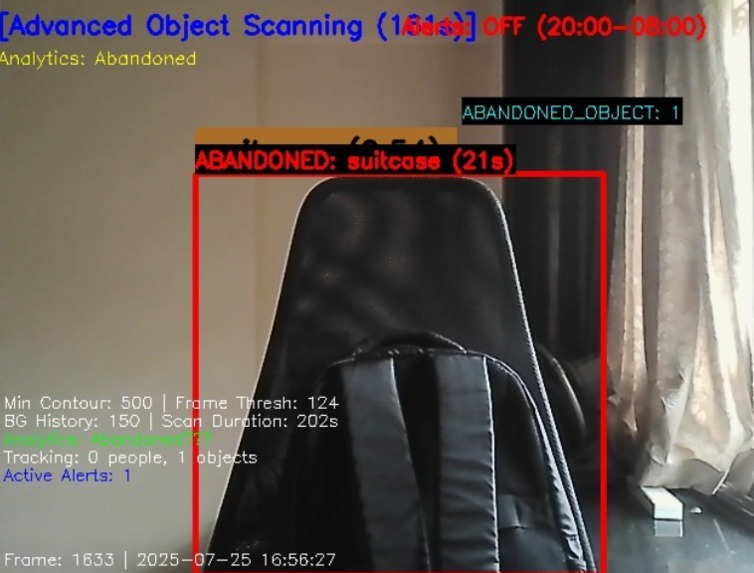
Abandoned Object Detection
-

Fall Detection
-

Night Vision like object detection
-
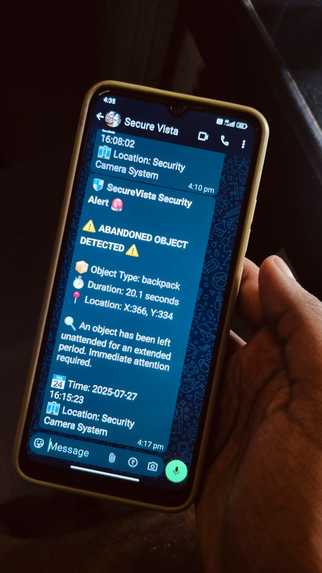
Threat Alert on Whatsapp
-
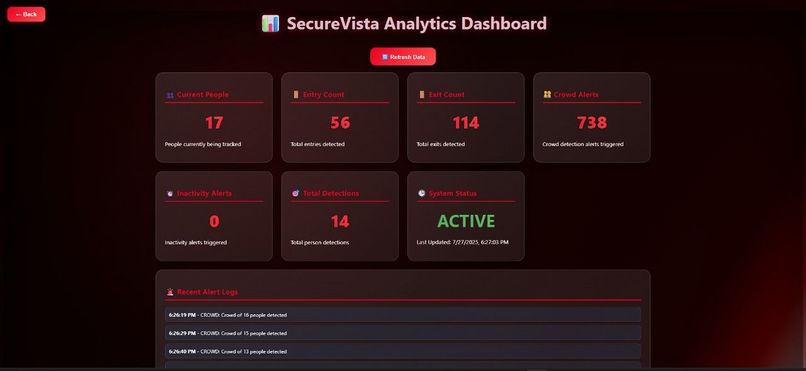
Dashboard
-
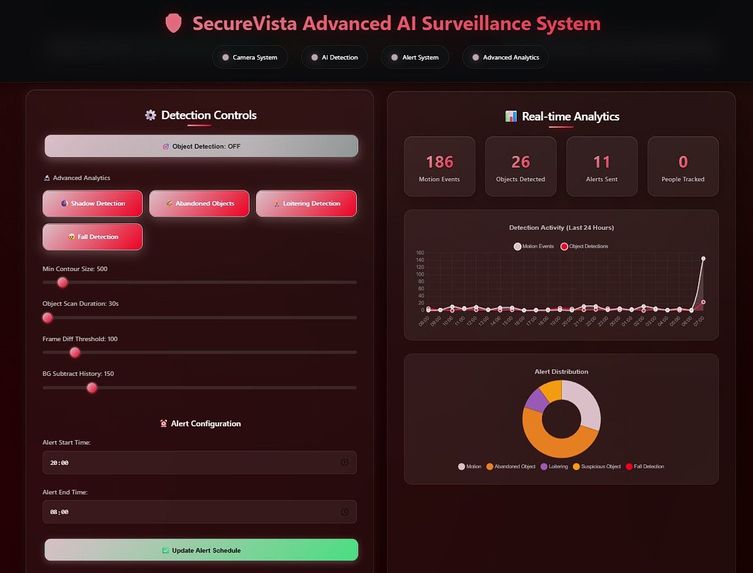
Dashboard
-

#3










💡Inspiration
We identified a critical flaw in campus security infrastructure: the Human Latency Gap. Traditional CCTV systems are largely passive, and studies show that operators can miss up to 95% of security events after just 20 minutes of continuous monitoring due to fatigue and cognitive overload.
We reframed this challenge not as a surveillance problem, but as a data throughput and response-latency problem. With SecureVista, our objective was to move security from reactive incident review to deterministic, real-time prevention, reducing the time gap between event and response (Δt) to near zero.
🛡️ What it does
SecureVista is an autonomous surveillance pipeline that upgrades standard IP cameras into intelligent, proactive safety agents.
Automated Threat Detection: Instantly identifies weapons, unauthorized access to facilities, and aggressive behavior in academic or residential zones.
Behavioral Analytics: Detects loitering in restricted areas (labs, hostels, exam halls) and analyzes motion and shadow patterns to minimize false alarms.
Health & Safety Monitoring: Uses pose estimation to detect falls or medical emergencies, especially valuable in hostels, libraries, and senior faculty areas, triggering immediate alerts.
Real-Time Command Dashboard: A low-latency React dashboard that streams alerts, live evidence snapshots, and incident metadata to security teams via Twilio SMS/WhatsApp for rapid response.
SecureVista enables cities to shift from passive monitoring to active, intelligent protection, ensuring safer learning and living environments.
⚙️ How we built it
We engineered a Distributed Edge-Inference Pipeline designed for high throughput.
1. The Vision Backbone (Detection)
We utilized a customized YOLOv8 architecture, fine-tuned on a custom dataset for security-specific classes. To improve localization accuracy in crowded city scenes, we optimized the loss function during training:
$$ \mathcal{L}_{CIoU} = 1 - IoU + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v $$
2. State Estimation (Tracking)
Detection alone is jittery. To maintain object identity across frames (handling occlusion), we implemented a robust state estimation model using a Kalman Filter. The tracker predicts the future position of a subject using the state update equation:
x̂(k|k) = x̂(k|k−1) + Kₖ · [ zₖ − Hₖ · x̂(k|k−1) ]
This allows SecureVista to "remember" a threat even if they briefly pass behind a pillar. Simultaneously, we run MediaPipe for pose estimation to detect specific actions like falling or crouching.
3. Asynchronous Orchestration
To prevent the inference engine from blocking the video stream, we used Python's threading module to decouple the frame capture from the processing logic.
- Frame Buffer: A LIFO (Last-In-First-Out) queue ensures the model always processes the latest frame, dropping older ones if the GPU is saturated.
- Communication: We used FastAPI with WebSockets to push alerts to the frontend in real-time (<100ms latency), rather than having the client poll the server.
🌍 Impact
SecureVista transforms urban surveillance from passive monitoring into an intelligent, real-time decision system, significantly reducing the delay between incident occurrence and response (Δt). In modern smart cities, where thousands of cameras generate continuous data streams, the real challenge is not visibility but timely action.
By converting raw video feeds into actionable insights in under milliseconds, SecureVista enables:
1.Faster Incident Response – Reduces response time from minutes to seconds through instant alerts
2.Proactive Crime Prevention – Identifies threats like weapons, intrusions, or suspicious behavior before escalation
3.Operational Efficiency – Eliminates reliance on continuous human monitoring and reduces fatigue-related misses
4.Scalable City-Wide Safety – Extends intelligent surveillance across large urban environments without increasing manpower
5.Privacy-Preserving Monitoring – Processes data at the edge, transmitting only alerts and metadata instead of raw footage
SecureVista bridges the critical gap between detection and action, enabling cities to become not just smart but responsive, resilient, and secure at scale.
👥 Who Benefits
SecureVista creates value across the entire smart city ecosystem:
City Administrations & Smart City Authorities Gain a scalable, AI-driven infrastructure to enhance urban safety and optimize resource allocation
Law Enforcement Agencies Receive real-time alerts with actionable intelligence, improving response speed and situational awareness
Emergency Response Teams Instantly detect incidents such as accidents, falls, or violence, enabling faster intervention
Public Infrastructure Operators (Transport hubs, government buildings, public spaces) Achieve continuous, automated monitoring without increasing workforce dependency
Citizens Experience safer environments with quicker emergency responses while maintaining privacy
Security Personnel Shift from passive monitoring to AI-assisted decision-making, increasing effectiveness and reducing cognitive load
🚧 Challenges we ran into
- The "Flicker" False Positive: Initial models would flag a threat for 1 frame due to lighting noise. We implemented a Temporal Consistency Algorithm that only triggers an alert if detection confidence exceeds a threshold τ for k consecutive frames.
- Shadow Noise: In outdoor settings, moving shadows were often misclassified as intruders. We implemented a Shadow Analysis module (using
cv2.createBackgroundSubtractorMOG2) to differentiate between solid objects and transient light artifacts. - Dependency Hell: Integrating MediaPipe (CPU-bound) with YOLOv8 (GPU-bound) caused resource contention. We solved this by containerizing the services and optimizing the thread allocation.
🏅 Accomplishments that we're proud of
- 🏆 Winner of CodeVeda: Secured top spot in the 48hr Hackathon organized by IIT Madras BS and Manipal University Jaipur.
- Real-Time Performance: Achieved <150ms end-to-end latency (Camera → Server → Dashboard).
- Scalability: The system successfully runs 4 concurrent 1080p streams on a single node without significant frame drops.
- Privacy-First: By processing at the edge, no raw video footage needs to be sent to the cloud—only the metadata and alert snapshots are transmitted.
🧠 What we learned
- Data Drift: Models trained on well-lit datasets fail in low-light corridors. We learned the importance of Gamma Correction preprocessing to normalize input feeds.
- Bottlenecks: We discovered that in high-FPS computer vision, the bottleneck is often not the GPU compute, but the CPU-bound video decoding and memory copying between RAM and VRAM.
🚀 What's next for SecureVista
- Action Recognition: Moving beyond bounding boxes to Video Vision Transformers (ViViT) to detect complex interactions like fights.
- Federated Learning: Implementing a decentralized training loop where edge nodes update the global model weights without sharing privacy-sensitive video data.
- Blockchain Identity: Integrating a blockchain-based identity management system for tamper-proof access logs.



Log in or sign up for Devpost to join the conversation.