-
-

The logo for SpokenVision!
-
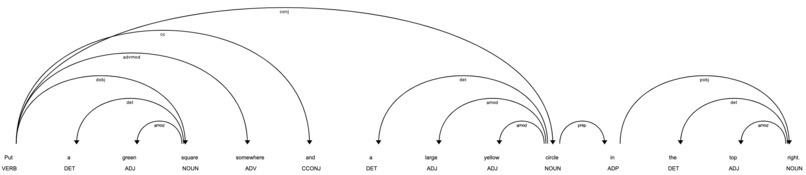
spaCy resolving dependencies in a natural language input to generate a layout.
-

Screenshot of app after several requests.



Inspiration
You never know where you’ll be when creativity strikes. Musicians can pull out their phones and record ideas for songs and writers can jot down promising premises on any old note app, but what can architects, UI designers, artists, and other general visual creators do? Mocking up an idea isn’t easily done on a mobile device, given the small screen and general lack of precision. We aim to bridge this gap, enabling visual artists to flex their creative muscles wherever they may be!
What it does
SpokenVision is a mobile app that automatically generates mockups for visual designs using only a user’s natural, spoken ideas. In this way, visual designers can generate ideas with the same level of ease as musicians or writers, without having to battle with their smartphone or disrupting their day-to-day activities. If a user doesn't like the design, discarding it isn’t a painful process since the mockup was efficiently generated in real-time!
How we built it
SpokenVision combines a variety of technologies to provide an intuitive, end-to-end user experience. Speech is collected and transcribed in real time using the powerful speech-to-text models hosted by Google Cloud through our Flutter-built app. The app then pings a serverless Google Cloud function endpoint, which holds a Python script that parses the transcribed user speech and generates an appropriate layout. To do this, we rely on the robust dependency parsing tools from the spaCy library to resolve syntactic relationships in the sentence. For example, if the user requests a “blue circle and a red square,” dependency parsing ensures the displayed circle and square each are of the requested color, i.e, any descriptors for the square are applied only to the displayed square. SpokenVision can correctly process more than one component at a time, performing better than simple keyword extraction by preserving syntactic dependencies. From there, we resolve location requests and map component locations to a valid region in available pixel space on the app’s canvas. Finally, all layout specifications are passed back to the Flutter frontend, which displays the mockup. From here, the user has the ability to either discard the generated mockup or continue to add to it with additional voice commands!
All in all, while the user data has passed through a lengthy processing pipeline, the user waits less than a second for their requested mockup in practice, keeping the entire process minimally disruptive!
Challenges we ran into
Cloud Functions can be tough to debug. This was definitely one of the more frustrating elements of the hack. Also, spaCy (which is generally wonderful) refused to cooperate at times, making the Cloud Function debugging all that more difficult! Finally having the backend interface effectively with the frontend was one of the more satisfying moments, though, so the frustration was definitely worth it!
On the frontend, it was difficult to dynamically update the canvas as new components were returned. At first, the canvas wouldn't respond to changes until we determined that returned elements needed to be stored in a mutable list whose state change triggered a canvas re-draw.
What's next for SpokenVision
The best part about this hack is that this is only the beginning! We were able to produce a prototype of the concept with a scalable backend and a robust framework for further design elements, so with additional time we could add features like:
- Design optimization algorithms, to use ambiguous layout elements as an opportunity to stimulate the creative process by making recommendations
- Integration of state-of-the-art deep learning natural language processing models to improve robustness to a wider variety of natural language inputs
- Features tailored to different types of visual art like UI design, architecture, and so on!
With more time and effort, SpokenVision could become a seamless, minimally disruptive tool for all kinds of visual designers!
Built With
- cloud-functions
- deep-learning
- flutter
- google-cloud
- natural-language-processing
- python
- spacy
- speech-to-text

Log in or sign up for Devpost to join the conversation.