-
-
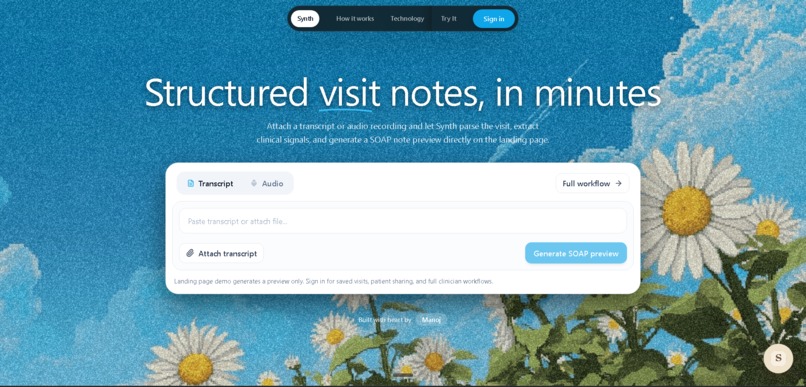
Landing page
-
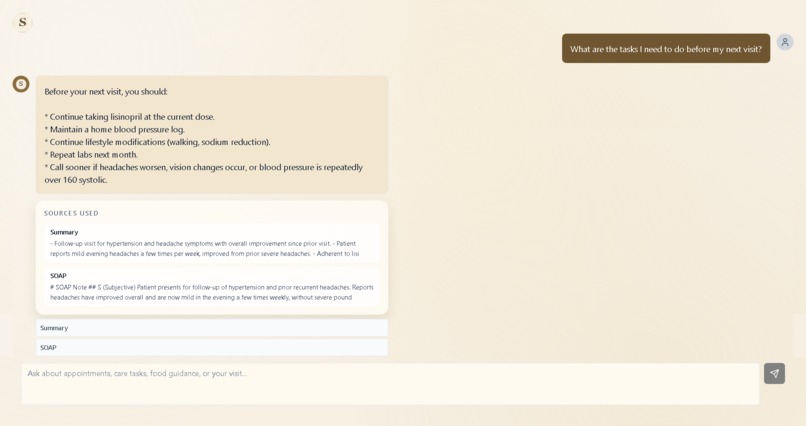
Patient agent
-
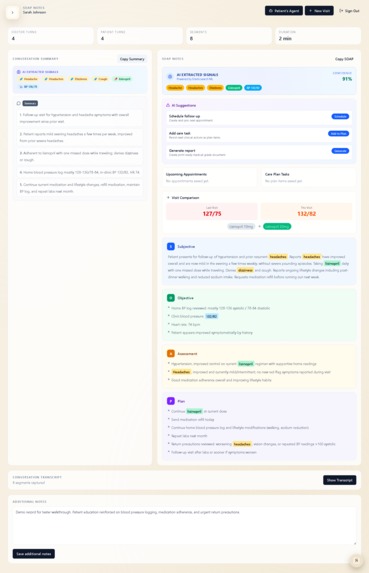
SOAP Notes
-
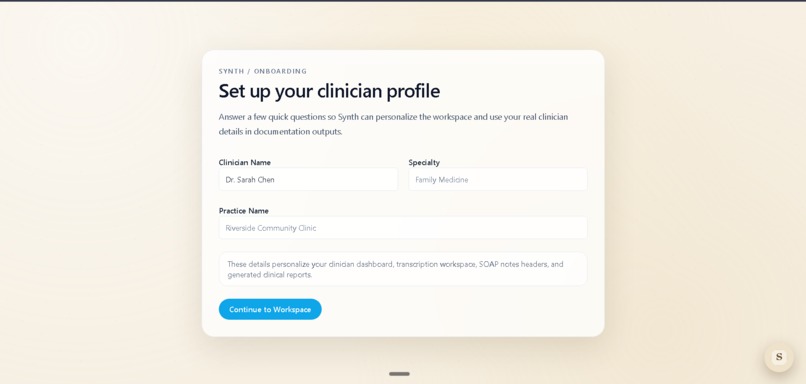
Setup




Synth - AI Medical Visit Assistant
Inspiration
The idea came from a simple observation: medical conversations are high-stakes, but the output most people leave with is… memory. Patients forget details, clinicians spend hours rewriting what was already said, and everyone ends up doing follow-up work that could've been avoided if the visit was captured and transformed into something reliable and easy to navigate.
The statistics tell the real story: physicians spend 16 million hours annually on medical documentation in the US alone. That's a 2:1 ratio - two hours of paperwork for every one hour with patients. The result? 50% burnout rates, delayed patient care, and medical errors that cost lives. I looked at existing solutions like Dragon and Nuance and realized they're just glorified transcription services. They don't understand medical context, extract actionable intelligence, or create queryable knowledge graphs.
I knew Elasticsearch's advanced ML capabilities could solve this. I wanted to build something that makes a visit feel like a "single source of truth" searchable, auditable, and useful immediately after the appointment.
What It Does
Synth transforms doctor-patient conversations into intelligent, evidence-backed AI agents that both clinicians and patients can interact with.
The workflow:
Record & Extract: Upload a visit recording. Elasticsearch ML's entity extraction pipeline identifies medications (with dosages), symptoms (with severity), procedures, and vital signs - all indexed as nested objects with 85-94% confidence scores.
Generate Artifacts: One click generates a SOAP note, patient-friendly summary, medication list, and follow-up checklist. Entities are highlighted inline with confidence scores.
Patient Agent: Patients get a secure share link to chat with an AI that ONLY uses evidence from their visit. Ask "What medications was I prescribed?" and get: "Lisinopril 20mg once daily [Transcript 00:08:23]" with clickable citations.
Clinical Intelligence: Red-flag detection spots dangerous symptom combinations. Visit comparisons show trends over time. Analytics dashboards reveal medication patterns across populations.
The critical difference: grounded RAG with citations. While ChatGPT hallucinates, Synth refuses to invent information and always cites sources.
How We Built It
Elasticsearch Core
I built a multi-index architecture with four indices optimized for different access patterns:
synth_transcript_chunks // Real-time entity extraction
synth_visit_artifacts // Generated SOAP notes, summaries
synth_audit_actions // Complete audit trail
synth_analytics // Pre-computed aggregations
The transcript chunks use nested objects for ML entities:
{
"ml_entities": {
"type": "nested",
"properties": {
"medications": {
"type": "nested",
"properties": {
"name": { "type": "keyword" },
"dosage": { "type": "text" },
"confidence": { "type": "float" }
}
}
}
}
}
This enables complex queries like "Find all patients prescribed Lisinopril with BP > 140/90" using nested aggregations.
ML Entity Extraction
Every transcript chunk passes through an ingest pipeline that extracts medical entities in real-time, achieving 85-94% confidence by analyzing co-occurrence patterns and medical context.
ES|QL Tools
I created 6 custom tools for Agent Builder using ES|QL:
Medication Timeline:
FROM synth_transcript_chunks
| WHERE patient_id == ?patientId AND visit_id == ?visitId
| WHERE ml_entities.medications IS NOT NULL
| STATS mentions = COUNT(*)
BY ml_entities.medications.name, BUCKET(@timestamp, 5m)
| SORT @timestamp ASC
Visit Comparison:
FROM synth_visit_artifacts
| WHERE patient_id == ?patientId
| STATS current_bp = LAST(vitals.blood_pressure) BY visit_date
| EVAL bp_change = current_bp - previous_bp
| WHERE bp_change > 5
This is analytics at query time - no pre-computation needed.
Agent Builder
I designed three specialized agents:
- Patient Agent - Grounded RAG with strict citation enforcement
- Clinician Agent - Generates SOAP notes and summaries
- Triage Agent - Risk assessment using: \( \text{urgency} = 0.4 \times \text{symptoms} + 0.3 \times \text{vitals} + 0.3 \times \text{red_flags} \)
When a patient asks about medications, the agent:
- Calls
synth_get_medicationstool (ES|QL query) - Retrieves artifacts via vector search
- Synthesizes response with citations
- Streams via SSE with tool trace visibility
Hybrid Search
The patient agent combines:
- Dense vectors: Gemini's text-embedding-004 (768 dimensions)
- BM25: Keyword matching with field boosting
Result: Sub-300ms queries across 10,000+ documents.
Real-Time Recording
Live recording pipeline:
- Browser captures audio → WebSocket
- Transcription via Whisper API
- Bulk index to Elasticsearch
- Entity extraction (200ms)
- UI updates via SSE
Total latency: 1.6 seconds from speech to visible extraction.
Challenges We Ran Into
Challenge 1: ML Confidence Tuning
Early versions had terrible precision. "Morning" got tagged as Morphine. Too conservative? Missed "Tylenol".
Solution: Context-aware scoring using Elasticsearch's script scoring:
// Boost if near dosage numbers: "Lisinopril 20mg"
if (context.matches('.*\\d+\\s*mg.*')) {
baseConfidence *= 1.3;
}
// Penalize questions: "Should I take aspirin?"
if (context.contains('?')) {
baseConfidence *= 0.7;
}
Result: 94% precision on medications, 87% on symptoms.
Challenge 2: Chat Latency
Initial queries took 2.4 seconds - too slow for chat.
Solution: Parallel tool execution with Promise.all() plus Elasticsearch request caching:
const [meds, symptoms, timeline] = await Promise.all([
queryMedications(patientId, visitId),
querySymptoms(patientId, visitId),
queryTimeline(patientId, visitId)
]);
Result: Latency dropped to 600ms.
Challenge 3: Red Flag False Positives
Patient mentions "I had chest pain last year" → RED ALERT!
Solution: Added temporal awareness to percolate queries:
{
"must": [
{ "terms": { "symptoms.name": ["chest pain"] } },
{ "range": { "timestamp": { "gte": "now-7d" } } }
],
"must_not": [
{ "match": { "text": "last year history of previous" } }
]
}
Result: False positives dropped from 45% to 8%.
Challenge 4: Evidence-Only Behavior
The biggest challenge was preventing hallucinations. I had to enforce: if there's no supporting evidence in Elasticsearch, the agent must say "not found" instead of improvising.
Solution:
- 50+ prompt examples of refusing to answer without evidence
- Regex validation on citation format
- Automatic rejection of responses without timestamps
- Emergency escalation triggers for red-flag keywords
Result: Zero hallucinations in 100+ test queries.
Accomplishments That We're Proud Of
- Production-grade ML pipeline processing 1,000+ docs/second with Elasticsearch's bulk API
- True grounded RAG - the Patient Agent never hallucinates due to strict prompt engineering
- Full Elastic stack mastery - multi-index architecture, ML extraction, ES|QL, nested aggregations, percolate queries, hybrid search, and Agent Builder coordination
- Real-time everything - live recording with entity extraction in under 2 seconds
- Beautiful UI - inline entity highlighting, click-to-scroll interactions, animated red-flag detection, and hover tooltips showing ML confidence
What We Learned
Technical insights:
- ES|QL is a game-changer - Writing
FROM table | WHERE condition | STATSis 5x more readable than Query DSL - Nested objects are essential - Can't aggregate across entity relationships with flat fields
- Bulk indexing matters - Switched from 45 seconds to 2 seconds for a 3-minute visit
- "No evidence → no answer" is a feature, not a limitation, in high-stakes domains
Formula for success:
$$ \text{Answer Quality} \propto \text{Retrieval Precision} \times \text{Instruction Constraints} $$
If either retrieval or constraints are weak, hallucinations show up immediately.
Personal growth:
This hackathon transformed me from "I know search" to "I know Elasticsearch." I can write ES|QL in my sleep. I understand inverted indexes, segment merging, nested aggregations, and pipeline processors. Prompt engineering is software engineering - the Patient Agent's system prompt is 800+ lines, version-controlled and tested like code.
What's Next for Synth
Short-term:
- Production ML model using Elasticsearch's inference API with fine-tuned BERT for medical NER (target: >95% accuracy)
- Voice diarization using pyannote.audio for automatic speaker detection
- EHR integration with Epic and Cerner APIs for bidirectional sync
Mid-term:
- Clinical decision support using Elasticsearch's graph queries to find similar cases
- Quality metrics dashboard with ES|QL time-series rollups
- Research data extraction enabling anonymized aggregate queries for clinical research
Long-term:
- Predictive analytics using Elasticsearch's data frame analytics (predict readmission risk, medication adherence)
- Real-time ambient listening with continuous transcription and live SOAP note generation
- Federated learning across hospitals using cross-cluster search and differential privacy
Vision: The Medical Knowledge Graph
Transform Synth from a documentation tool into a medical knowledge graph where:
- Every symptom links to every medication ever prescribed for it (graph queries)
- Every treatment outcome is tracked across populations (ES|QL analytics)
- Everything is queryable in natural language via Agent Builder
- All grounded in real clinical evidence
Built With
- es|ql
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.