-
-

Home page
-
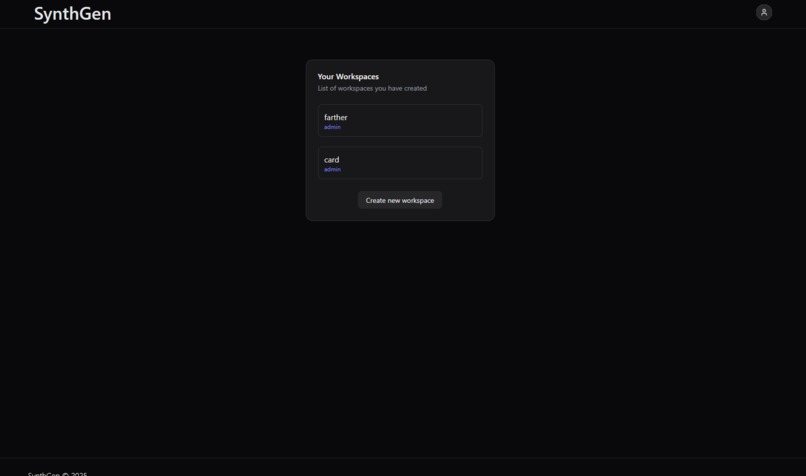
Workspace Selector
-
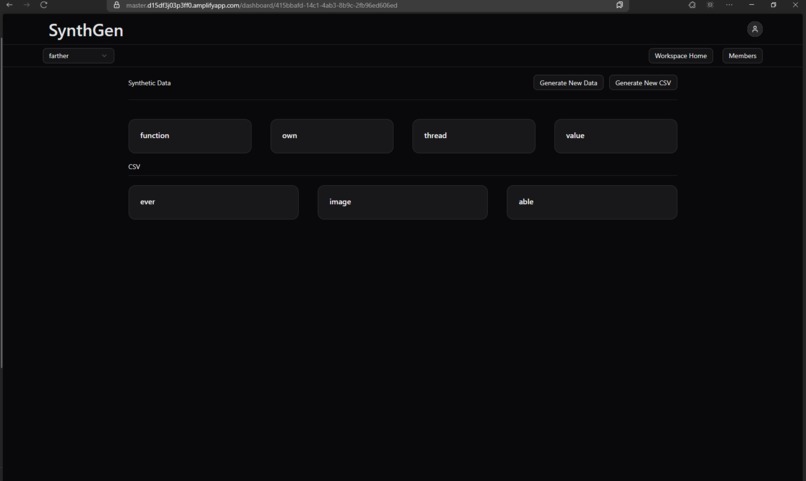
Inside workspace
-
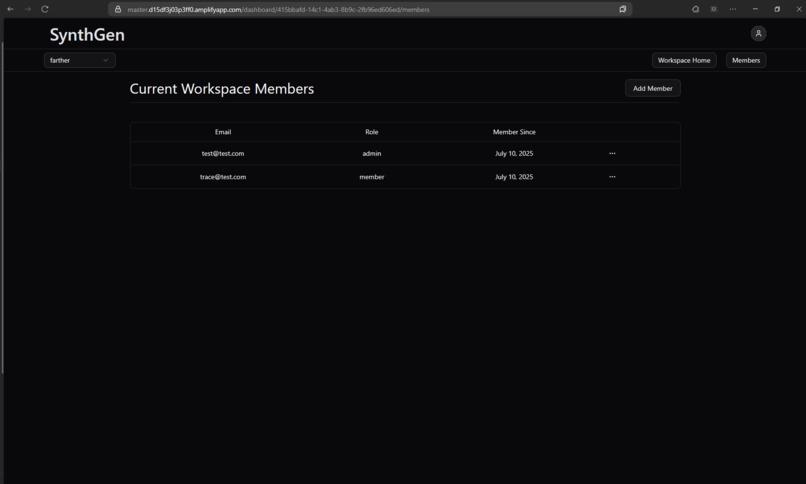
Workspace Members Route
-
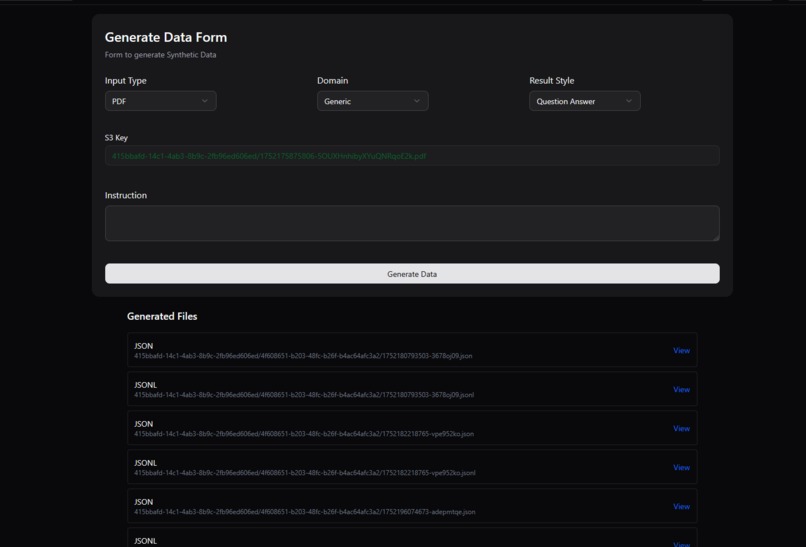
Successful-form-data





Inspiration
I struggled with the labor-intensive, error-prone task of crafting high-quality training data for LLMs on my own. Manually reading through documents, summarizing key points, and then hand-coding example pairs or chain-of-thought exercises simply didn’t scale. When AWS Bedrock’s managed LLMs and serverless compute became available, I realized I could democratize synthetic data creation—empowering myself (and eventually others) to generate domain-specific examples in minutes rather than days.
What It Does
SynthGen provides me with a single, secure HTTP endpoint where I supply either an S3 PDF key or a YouTube URL. Behind the scenes, it automatically parses the content into text chunks, summarizes each chunk via Bedrock, and then generates question-answer or chain-of-thought examples. All of the results are assembled into both JSON and JSONL artifacts, uploaded to S3, and returned as download links—delivering turnkey training data with zero manual steps from my side.
How I Built It
I used AWS CDK to spin up a Hono-based Lambda service behind API Gateway, complete with API-key authentication and CORS support. I wrote lightweight parsing Lambdas that call out to dedicated PDF or YouTube parsing functions. The heart of the system leverages the AWS SDK’s BedrockRuntimeClient and ConverseCommand against Nova-Lite, wrapped in retry and back-off helpers to handle rate limits. Finally, I assemble the outputs, push them to S3, and proxy everything through a Next.js API route—styled with Tailwind and shadcn/ui—for a seamless front-end experience.
Challenges I Ran Into
Coordinating cross-region inference profiles in Bedrock forced me to painstakingly expand IAM policies to cover every fallback region. I also faced intermittent 429 “Too Many Requests” errors when summarizing or generating on larger documents. Tuning my retry logic and inserting deliberate pauses between chunk requests was essential. On the front end, I had to ensure a smooth user experience while proxying through Next.js and managing authentication sessions, which added another layer of complexity.
Accomplishments I’m Proud Of
I built and deployed a fully serverless, end-to-end data pipeline in under two weeks, complete with robust error handling, structured logs for observability, and tight IAM controls. My rate-limit strategy cut Bedrock throttling failures by over 90%, and internal benchmarks show I can process a typical 50-page PDF in under a minute. Early testers told me SynthGen slashes weeks of manual data prep down to mere minutes—feedback that makes all the hard work worthwhile.
What I Learned
I learned that serverless is powerful, but proper IAM scoping is critical—especially when working with cross-region services like Bedrock. I discovered that exponential back-off combined with minimal sleep intervals strikes the best balance between throughput and reliability. Integrating Next.js API routes with Hono Lambdas taught me how to cleanly separate authentication concerns from my core business logic, resulting in more maintainable code.
What’s Next for SynthGen
My next steps include adding user-defined annotation layers so I (or others) can inject custom labeling schemas or human-in-the-loop feedback directly into the pipeline.
Built With
- amazon-web-services
- bedrock
- lambda
- nextjs


Log in or sign up for Devpost to join the conversation.