-
-

Super Awesome Project Logo
-
Our greatest inspiration.
-
GH Pr Comment
-

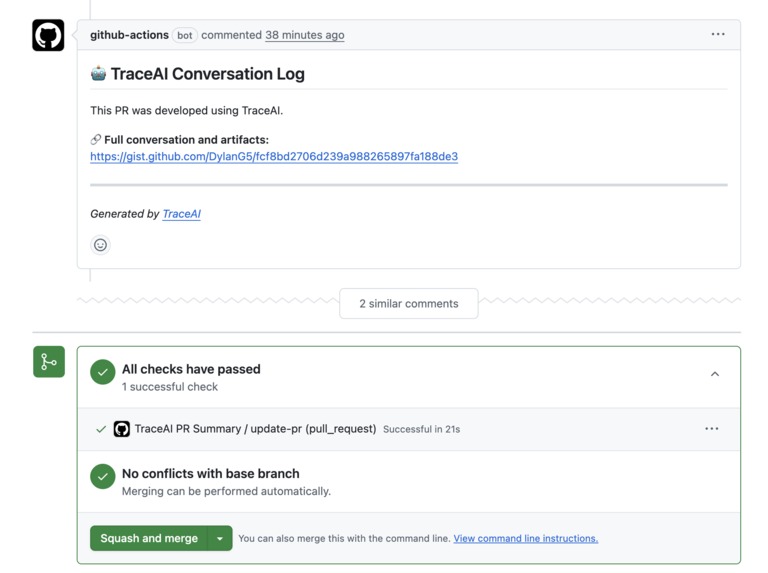
Conversation Recreated
-
VSCode inline preview
-
dropdown full prompt vscode






Inspiration
AI is shaping the future of software development. Teams around the world are integrating AI into their workflows to improve productivity and efficiency. However, as AI usage rapidly becomes standardized, development tools must evolve to ensure traceability—not only for the code bases being produced, but also for the prompts used to create them.
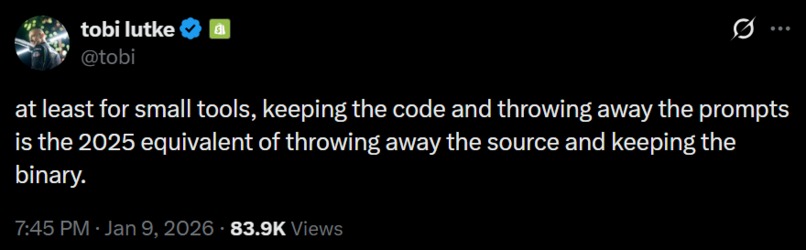
A wise man (that man being tobi from Shopify) once said:
Keeping the code and throwing away the prompts is the 2025 equivalent of throwing away the source and keeping the binary.
This idea inspired us to create TraceAI.
What it does
TraceAI is a VS Code extension that enhances your team's AI-assisted development workflow by bringing transparency, accountability, and context to AI-generated code.
It does this by:
Automatically processing AI agent conversations and linking them to pull requests, ensuring that prompts, discussions, and decisions are preserved as part of the project's history rather than being lost in chat logs.
Providing line-by-line annotations and PR-level summaries for AI-assisted changes, allowing developers to inspect the intent, assumptions, and rationale behind generated code directly within the editor.
By treating AI prompts as first-class development artifacts, TraceAI makes it easier for teams to review changes, onboard new contributors, debug unexpected behavior, and maintain long-term trust in AI-assisted codebases.
How we built it
TraceAI consists of two main implementations that work together: a Python pipeline for processing and storing conversations, and a TypeScript VS Code extension for displaying provenance in the editor.
The Python pipeline leverages Pydantic for type-safe data models, GitPython for git operations, PyGithub for GitHub API integration, and Click with Rich for a polished CLI experience. The pipeline's parser module reads Claude Code's JSONL conversation files from ~/.claude/projects/, extracting messages, timestamps, and tool calls. The mapper module then correlates user prompts with code changes by parsing Edit and Write tool operations and using git blame data to identify exact line ranges. Once processed, the GitHub client uploads structured conversation artifacts to GitHub Gists, creating both machine-readable JSON and human-readable Markdown summaries. The markdown generator produces comprehensive PR summaries with statistics, file lists, and conversation highlights, while an optional AI summarizer can generate intelligent summaries using the Anthropic API. The entire pipeline is accessible through a feature-rich CLI that supports git hooks for automatic processing on push, making it seamless to integrate into existing workflows.
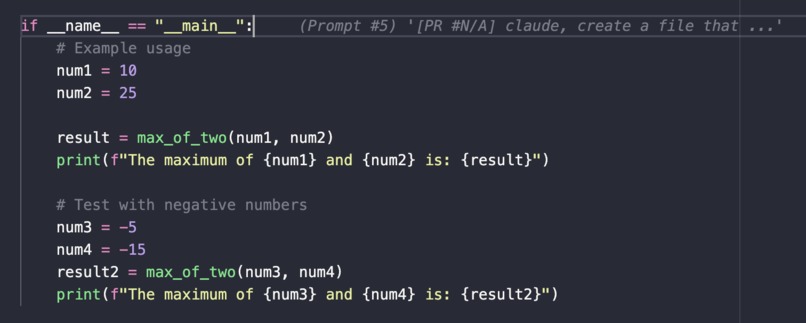
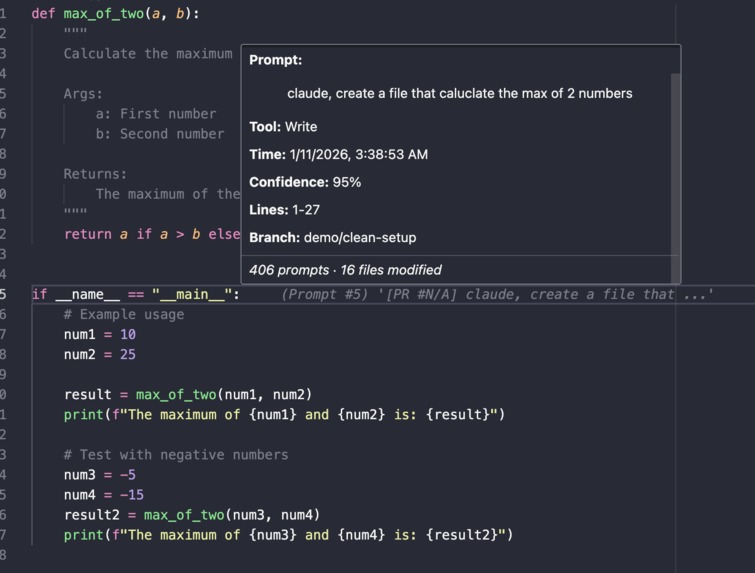
The VS Code extension is built with TypeScript and the VS Code Extension API, providing an intuitive interface for developers to explore AI-generated code provenance. The decoration provider displays GitLens-style inline annotations at the end of AI-generated lines, showing a preview of the prompt that created each section. When developers hover over these annotations, the hover provider reveals detailed tooltips with the full prompt, tool used, timestamp, confidence score, and links to the complete conversation. The unified loader intelligently fetches artifacts from GitHub Gists using Octokit, with a sophisticated caching system to minimize API calls, and falls back to local artifact files for development and backward compatibility. The extension automatically watches for config file changes, ensuring that updated artifacts are immediately reflected in the editor without manual refresh.
Challenges we ran into
One of our biggest challenges was reverse-engineering Claude Code's conversation format, which isn't publicly documented. We spent considerable time examining actual JSONL files in ~/.claude/projects/ to understand the complex nested structures for messages, tool calls, and metadata. Similarly, achieving accurate line-level mapping proved more difficult than anticipated—initially we planned to use git blame with timestamps, but this approach was imprecise for rapid edits and batch commits. We ultimately solved this by parsing Claude's tool calls directly, extracting exact line ranges from the old_string/new_string diffs in Edit and Write operations.
We also encountered challenges with handling multiple PRs modifying the same file and designing our storage architecture. Supporting multiple conversations per file would require complex merging logic that was beyond our MVP scope, so we focused on one conversation per PR. For storage, we chose GitHub Gists as a pragmatic solution for the hackathon, but this presented trade-offs around scalability and privacy—while Gists work well for individual PRs and default to secret (private) access, they aren't designed for large-scale organizational use and require careful consideration of what sensitive data might be included in conversations.
Accomplishments that we're proud of
We're most proud of achieving a complete end-to-end MVP that actually works—from parsing Claude conversations to displaying provenance directly in the editor. Having had mixed experiences with hackathons in the past, this represents a significant personal victory, especially given that none of us had prior experience building VS Code extensions. What made this particularly rewarding was our ability to problem-solve through the many challenges we encountered, from reverse-engineering undocumented formats to designing an intelligent mapping algorithm that combines tool call parsing with git blame correlation. The fact that we successfully navigated the entire VS Code extension ecosystem for the first time, while simultaneously building a robust Python pipeline with git integration, gave us confidence in our technical capabilities and approach to tackling complex, multi-faceted problems. Most importantly, we created something that we genuinely believe could help development teams, and seeing it all come together in a working prototype was incredibly satisfying.
What we learned
This project taught us a tremendous amount across multiple domains. We gained deep experience with VS Code extension development, learning provider patterns, workspace APIs, file watchers, and extension lifecycle management. We reverse-engineered Claude Code's conversation format, giving us insights into how AI tools structure their data internally. Our work with GitPython for programmatic git operations, git blame for timestamp correlation, and git hooks for automation expanded our understanding of git internals and automation patterns. Working with both PyGithub and Octokit gave us comprehensive experience with the GitHub API, from authentication and rate limits to error handling strategies. We also learned valuable lessons in system design and architecture—balancing simplicity versus scalability, making pragmatic choices for a hackathon timeline while keeping future extensibility in mind, and using tools like Pydantic for type-safe data modeling and Click/Rich for polished CLI design. Most importantly, we learned that with persistence and good problem-solving, we could successfully tackle complex, multi-component systems even when starting from scratch in unfamiliar domains.
What's next for TraceAI
Right now TraceAI is only implemented to work with Claude Code, but we envision a more general-purpose solution that supports multiple AI agents including Cursor, GitHub Copilot, and other coding assistants. This would require building adapter layers to parse different conversation formats and tool call structures. We're also exploring better storage architectures beyond GitHub Gists—considering options like PostgreSQL databases or cloud storage solutions that can scale to handle thousands of PRs and support advanced querying capabilities. Such improvements would enable organization-wide conversation search, analytics dashboards showing team-wide AI usage metrics, and a searchable library of successful prompts and conversations that teams can reuse. We're also interested in direct API integration with agent platforms where available, which would capture conversations in real-time rather than parsing local files, and further refinement of our mapping algorithm using AST analysis for even more accurate code attribution.
Built With
- claude
- githubapi
- json
- python
- typescript
- vscode




Log in or sign up for Devpost to join the conversation.