-
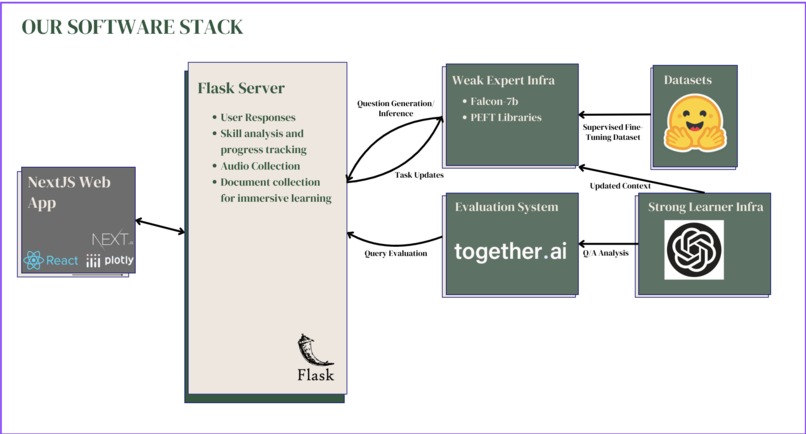
Full Stack Architecture
-
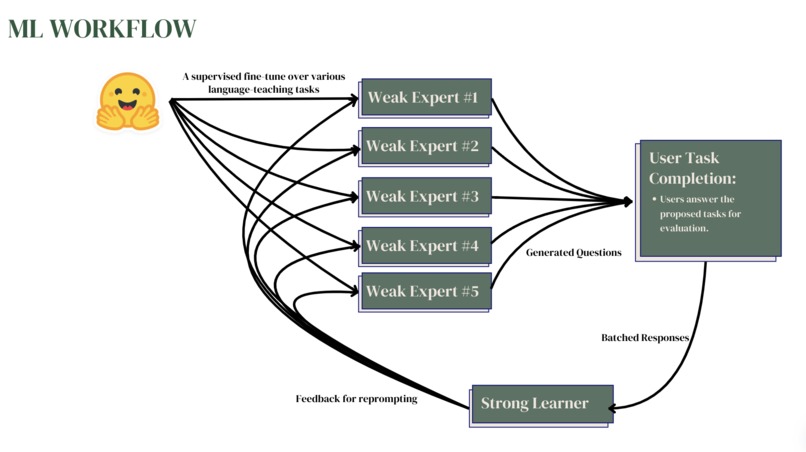
ML Workflow Architecture
-

Main page
-

Improvement page
-
Question page





Inspiration
I think we’ve all had a language we wish we knew better; from being able to better communicate to colleagues and classmates to friends and family at gatherings. Our team felt this strongly, and In response to the growing demand for personalized language education propelled by global connectivity, we found that despite a surge that valued the Language Learning Market at $62 billion in 2023—with projections of a 20% growth by 2024—current platforms fell far short or fluency. There’s a lack of genuine immersion and a tendency to make over-inflated claims of "personalization" and "adaptive learning" that are rarely substantiated, as users were often left navigating through static questions under the guise of a tailored experience.
Moreover, these platforms were ensnared by prohibitive paywalls and depended on manually crafted curricula, limiting accessibility and flexibility. Learners frequently voiced their frustrations, feeling that their journey halted at basic vocabulary acquisition and that the questions provided lacked the depth necessary for true educational advancement. After all, how many of us can claim we've truly mastered a language using Duolingo?
This is where Treelingo sets a new precedent. We're elevating the learning experience by focusing on deeper comprehension of the intricate structures and syntax that form the backbone of any language. Our vision for Treelingo is to deliver an educational platform that's not only accessible and customizable but one that fully immerses users in their language learning journey. With Treelingo, we're committed to filling the void left by other applications, advancing beyond mere vocabulary to foster genuine linguistic proficiency.
What it does
Treelingo is a promising solution to provide an accessible learning resource for ESL students. Think of Treelingo as a personal language tutor who can iteratively provide questions, assess the strength of student answers, and provide creative and detailed feedback on the gaps in reasoning the student is making. It then uses this feedback internally as well to creatively propose new questions that throw care to emphasize these key points.
While this idea is simple, building an environment that is truly adaptable on a per-user basis was a fairly challenging technical problem. When designing our adaptive pipeline, our group drew inspiration from existing research in utilizing language models to solve hard-to-specify objectives by using simpler proxy tasks (https://arxiv.org/abs/1810.08575). Essentially, the idea is to solve a complex task by decomposing it into simpler parts and utilizing several weak models which are domain experts in these subtasks along with a strong aggregate learner to guide these weaker models.
For Treelingo, we decided to decompose the complex task of teaching the nuances of language structure into the following subtasks: 1) Grammar and Syntax Analysis 2) Contextual understanding 3) Cultural Understanding. Taken together, we believe that these three subtasks constitute the majority of skills necessary to understand the intricacies of the English language and its structure. If given more time, our group would be eager to explore the addition of other subtasks to our pipeline.
How we built it
We first needed to design the weak learners so that they would be able to produce high-quality questions in their respective domains. We utilized several Huggingface datasets as our ground truth for the Grammar & Syntax, Contextual Understanding, and Cultural Understanding tasks. We used the Huggingface PEFT library and a custom implementation of QLoRA to fine-tune our weak expert models, which were all instances of Falcon-7b. Additionally, we built an evaluator system using Together.ai’s API to interact with Mixtral 8x7B and to generate analysis on why users made mistakes. Afterward, we designed our strong aggregate learner by utilizing prompt engineering techniques like chain-of-thought prompting. We made requests to GPT-4 using OpenAI’s API to identify generalized failures across each of the three domains; specific care was taken to ensure that all of these failures were no longer specific to the domain in which they were generated. After a list of distilled generalized failures was identified, these were used to update the context windows for each of the weak expert models so that subsequent iterations of the pipeline would have more targeted questions for the user. Frontend: We used a React-based frontend, along with other libraries like GraphJS and MaterialUI. This frontend then communicated to a REST-like backend server using the Axios library to handle requests. We use common Web APIs to handle the playing and capturing of audio. Backend: Our backend consists of a Flask app and a service that prompts the LLM models. We support multi-user with flask-session, and once we determine the session id, we persist our data (history of question/answers both for text and audio) in a database that is indexed by said session id. Our Flask-App then communicates with exposed functions from the LLM service to get the questions and to submit the answers. Our AI pipeline is very thorough and thus initially high latency but we optimized it through large use of threads for concurrency and latency. We employed text-to-speech and speech-to-text technologies to enable both the user and model to present content in text and speech. We used gTTS from Google for text-to-speech, and Google Speech Recognition for speech-to-text.
Challenges we ran into
Building the ML pipeline was surprisingly difficult. It sounds elegant at first, but the actual implementation caused us several headaches. 1) Fine-tuning each of the weak experts to produce high-quality questions for their respective tasks was our first major challenge. Because we ran into memory-constraint issues when loading large language models locally, we decided to explore quantized models and Huggingface libraries for parameter-efficient fine-tuning techniques. Our group initially explored using layer-freezing to tune model weights, but we eventually decided on pivoting to QLoRA as we observed it provided more hyperparameter tuning functionality and led to overall decreased cross-entropy loss for our tokenizer.
2) Prompt engineering the strong learner was another major hurdle our group ran into because we had to seamlessly adapt the input domain of our weak expert models. We decided on using context windows to store these adaptations rather than finetuning, due to the difficulty of modifying parameter weights of several models on the fly and applying chain-of-thought prompt engineering to distill important information. This data was passed onto our evaluation system to score user responses using Together.ai’s API to interact with Mixtral 8x7B and to generate analysis on why users made mistakes. Finally, our group explored various prompts for the strong aggregate model to provide recommendations on more targeted questions in the next question/answering cycle.
3) Integrating the results from our language models with our front end proved to be more complex than we anticipated. We ran into several challenges when sending GET and POST requests for .mp3 files and supporting both text and speech proved to be challenging. We used Flask-session to keep track of sessions and ran into several issues with it related to cross-origin requests. CORS will not attach cookies or similar by default so even if HTTP requests came from the same session, our backend service did not recognize those HTTP requests coming from the same session. This makes persisting data and retrieving the correct data especially challenging, because without the correct session_id, we will not be able to query our local DB. Writing an efficient query pipeline is also challenging as LLM’s API endpoint latency is high and often time unpredictable. Combined with the non-determinism of our task, all of these make debugging the backend especially challenging.
Accomplishments that we're proud of
Getting our pipeline to work and integrating it into our React and Flask apps.
What we learned
While our team had some experience with prompting language models, none of us had much experience with fine-tuning an LLM or designing a pipeline of this complexity. We also worked on several latency optimizations, such as building a thread pool to deal with blocking I/O operations and designing buffered/batched infrastructure. Finally, we learned a ton about web development technologies like Flask, GTTS (text-to-speech), (speech recognition), React, Next.js, and Chart.js.
What's next for Treeolingo
We’re interested in exploring the usages of this pipeline for educational opportunities beyond language. As mentioned earlier, the decomposition of tasks we defined is agnostic to language problems and could be reasonably adapted to help users learn other complex tasks. Imagine. Other important milestones include experimenting with more weak experts/subtasks, implementing a more robust fine-tuning pipeline by utilizing more feedback from the strong learner to guide weak experts, and adding additional modalities beyond text and speech.





Log in or sign up for Devpost to join the conversation.