-
-
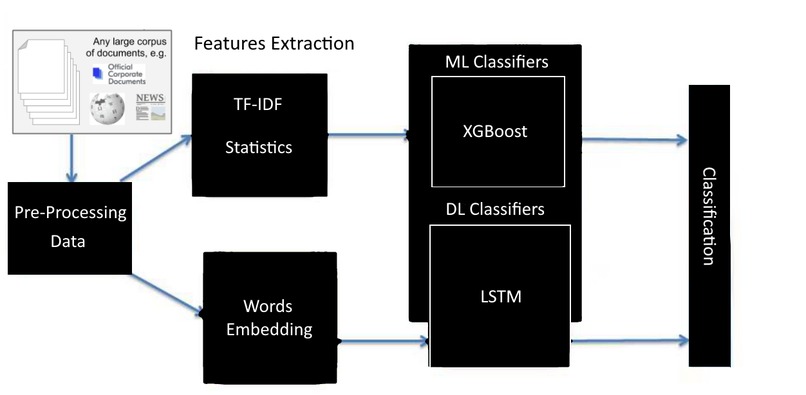
Architecture

Inspiration
As a data scientist, I am constantly seeking new ways to refine my knowledge and stay informed about current trends. Machine learning and deep learning are extremely capable tools that have revolutionized how we perceive data science, so it inspired me to use them as an approach to refresh my skills.
To do this, I chose to build a model based on machine studying and deep learning techniques. My aim was to see if I could create something that can recognize trends in information and make estimations regarding future outcomes. To do this, incorporating different varieties of layers into the convolutional alongside activators like ReLU, and sigmoid helped boost the accuracy level too!
After properly training the prototype using the provided datasets, testing its performance against various other relevant sets became necessary' This required multiple rounds wherein hyperparameters & regularization factors were adjusted until satisfactory results were achieved from the said examination. Seeing all those components come together perfectly gave me immense pleasure!
What it does
I have developed an API that distinquich authentic news from fabricated ones, utilizing a model I engineered. This model employs a multitude of algorithms to analyze textual content and verify its integrity or falsehood. The API leverages this innovative framework to evaluate the legitimacy of any given text.
How we built it
As previously stated, we built the text authenticity detection system by employing a combination of machine learning and deep learning methodologies. We utilized XGBoost for the classification of text and an LSTM model to determine long-term reliances between words that aid in verifying the legitimacy or falsity of textual content.
In order to optimize our system's efficacy, we selected Fastapi as our API framework. This choice enabled us to swiftly create a secure and high-performance API with minimal overheads.
The result looks promising!
Challenges we ran into
During the process of analyzing our data, we encountered a lot of obstacles. Among these challenges was the task of removing any duplicates and cleaning our dataset to ensure precision in analysis. Furthermore, one major hurdle that arose involved identifying outliers within our set which could potentially disrupt accurate results if not properly addressed. Thus, it became imperative for us to meticulously examine each value in order to identify those deviating from typical trends so as to eliminate them from further examination with utmost care and attention paid towards accuracy throughout this entire procedure.
Accomplishments that we're proud of
We're proud of our accomplishments in building an API based on the trained model. We worked hard to create a product that is both powerful and easy to use. We're proud of the work we've done.
What we learned
We learned about supervised learning algorithms, which are used for tasks like classification. We also learned various outliers removal techniques, and how to perform EDA analysis, etc.
What's next for Truth Guard
- Reassess the correctness of the model.
- Build a frontend for the API. . . .
Built With
- classification
- deep-learning
- fastapi
- machine-learning
- ml
- python


Log in or sign up for Devpost to join the conversation.