-
-
Links to the original Datasource
-
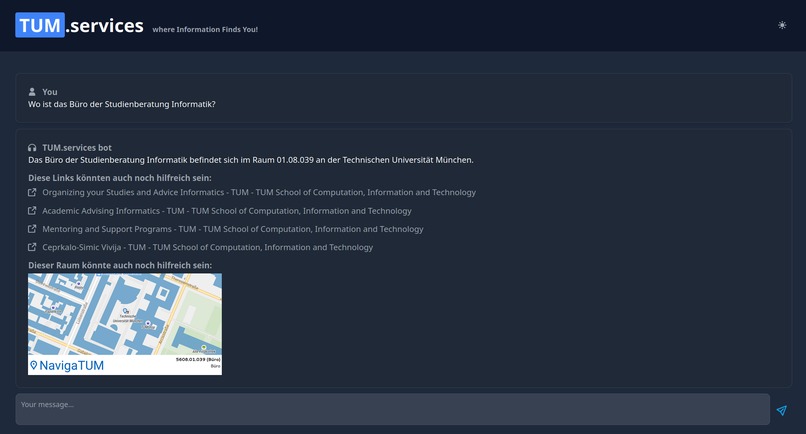
Integration of NavigaTUM
-
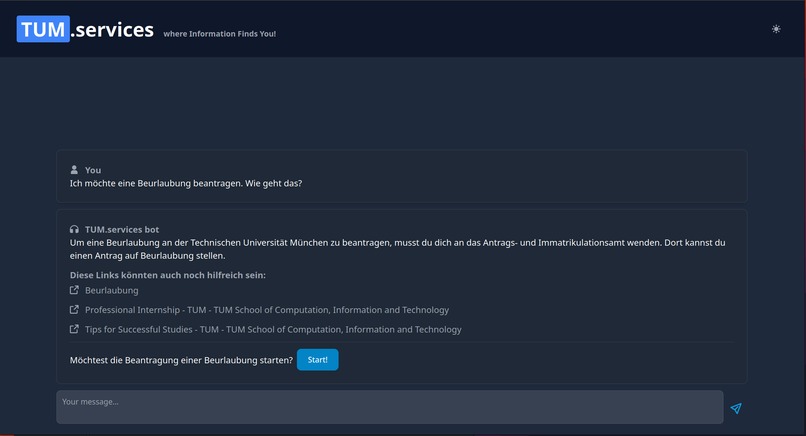
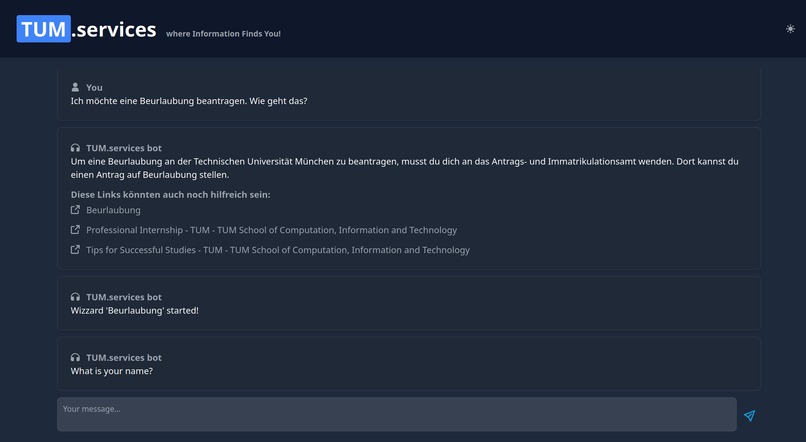
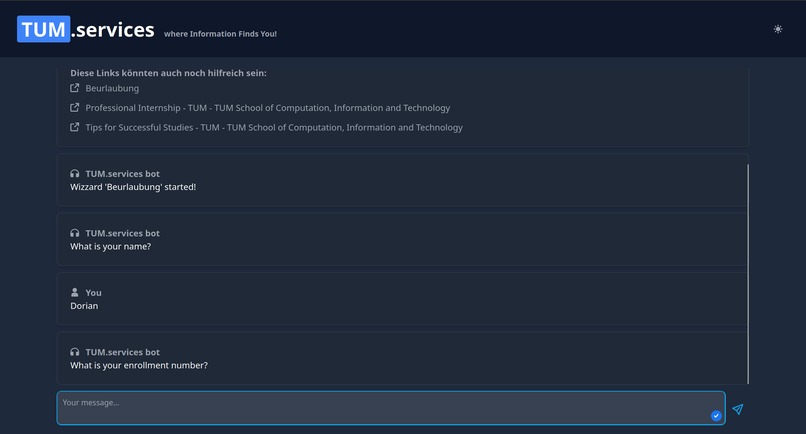
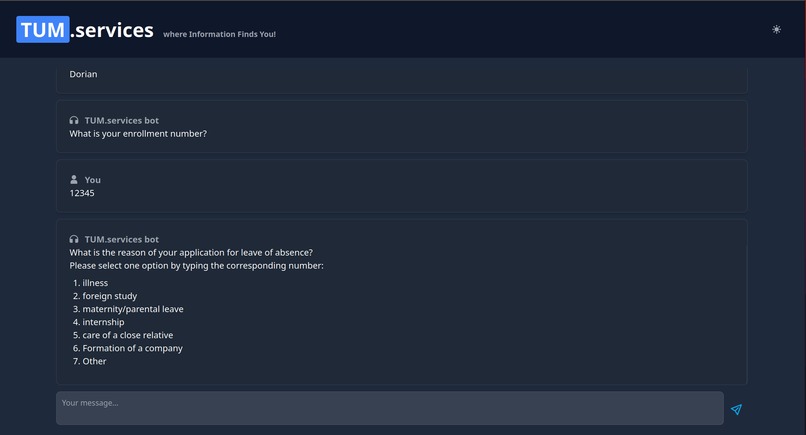
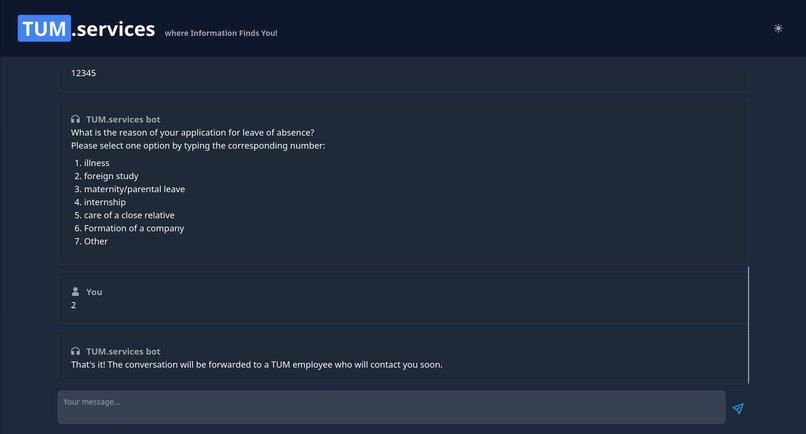
Wizard for filling out forms
-
-
-
-
-
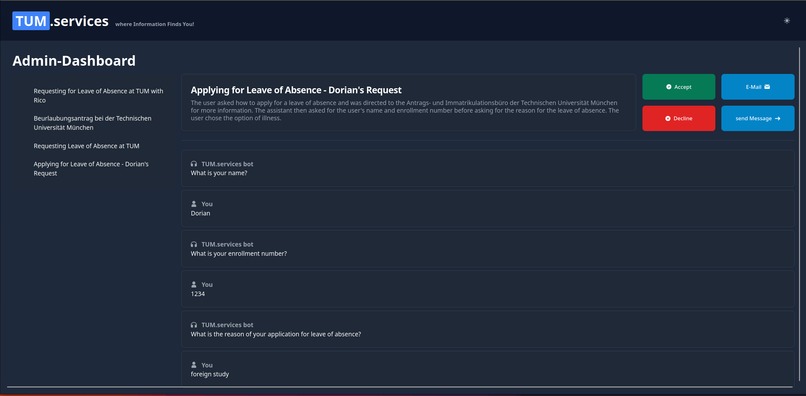
Interface for Employees with submitted forms









Inspiration
About two weeks ago, the Academic Programs Office Informatics announced, that they are heavily overloaded. They are just a few people who have to answer the Questions of almost 10000 students! However, since it can be hard to find certain information on one of the many websites of tum organizations, it's really important to have a helping hand from time to time. We want to provide that helping hand for all students while decreasing the workload on TUM employees at the same time! We also want to make information about studying at TUM more accessible by breaking down language barriers.
What it does
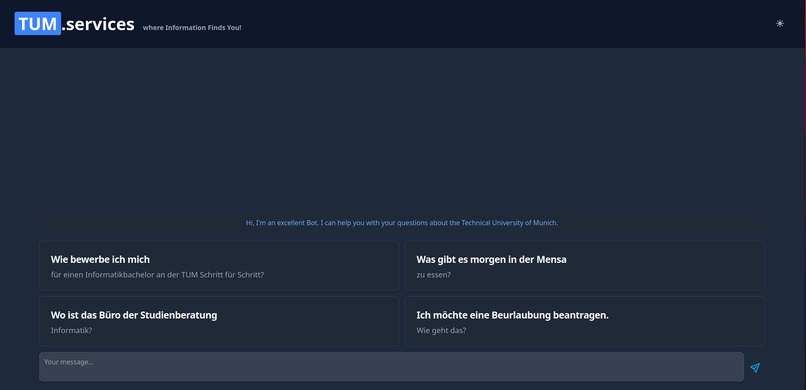
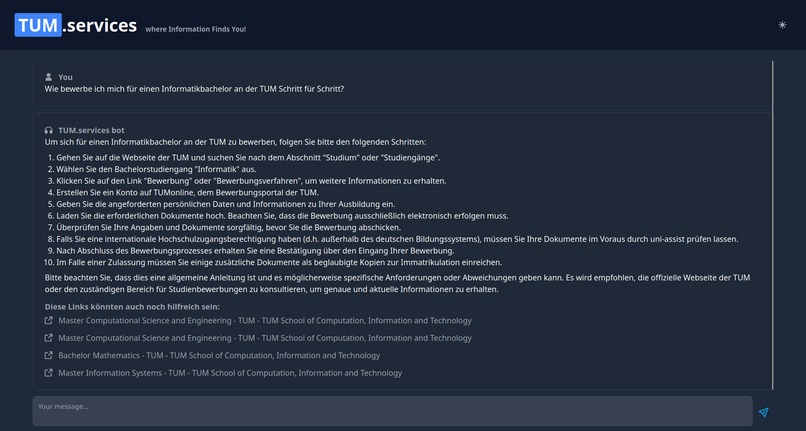
The first approach to solve this, that came to our mind, was to build a simple chatbot to help with everyday questions about studying at TUM. Using a custom process, we crawled nearly a thousand pages of the CIT Website and fed the data into a vector database, after preprocessing it into carefully crafted chunks. This made it possible to link every chunk to its origin and transparently show to the user where the information from an answer came from! This could already help to decrease the workload of the Academic Programs Office, since it can answer lots of questions all around studying at TUM. However, we wanted to go further than that! By providing an assistant for filling out documents, we want to decrease Bureaucracy and free up even more time. Additionally, by integrating a lot of already existing services (e.g. Roomfinder, NavigaTUM, Mensa Meal Plan) for TUM, we created the most EXCELLENT all-in-one solution you have ever seen ;)
How we built it
We started by crawling the CIT Website and feeding it into a vector-db. This DB is then combined with a LLM to precisely answer questions and provide the user with additional information, like links to relevant pages. To make our tool as user-friendly as possible, we decided to build a simple web interface which can be used in a chat-like fashion. We have also used other TUM-APIs to improve our service.
Challenges we ran into
Working with Large language models can be really frustrating since they are, unlike almost everything else in IT, very nondeterministic and seem to have their own will. Also, Google cloud stopped working on Sunday night and took down our infrastructure for a while.
Accomplishments that we're proud of
Initially, it looked like our plan would not work out, because the raw HTML text, we crawled from the website, did not play well with the LLM post-processing. However, we managed to optimize our crawling process and build specially crafted chunks which are easier to parse for the AI.
What we learned
Working with LLMs is surprisingly easy and difficult at the same time. It seems easy at first and is quick to set up but comes with lots of hurdles down the way.
What's next for tum.services
We'd like to make the form-assistant service usable in production and maybe combine it with a digital signage service. We also thought about an integration to TUMOnline which could open up even more opportunities for personal consultation.
Built With
- chatgpt
- fastapi
- langchain
- python
- svelte-kit
- tailwind
- typescript







Log in or sign up for Devpost to join the conversation.