-
-

TuneAI logo, designed by Lena :)
-
Landing page: Your Content, Your Soundtrack!
-
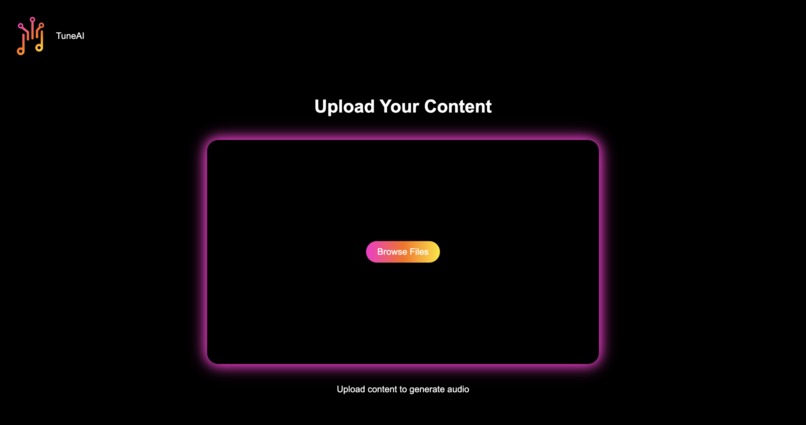
Easily upload your image or video to this page with intuitive UI.
-
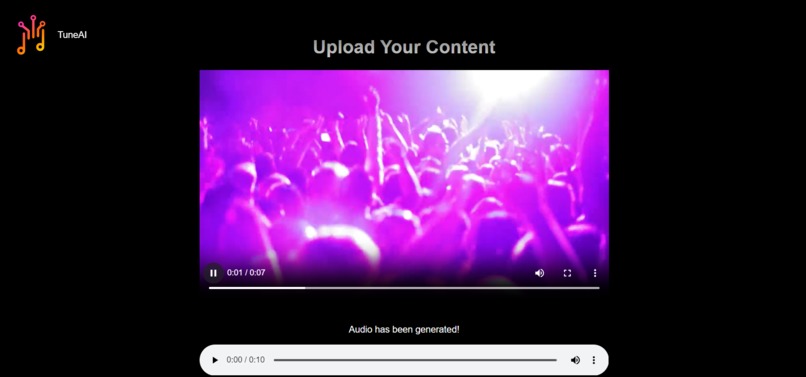
Your generated music is ready to play!




Inspiration
TuneAI was born out of a deep appreciation for the art of visual storytelling and the recognition that audio plays in enhancing the impact of videos. Our motivation to create TuneAI lies in the desire to provide content creators, filmmakers, and videographers with a powerful tool that simplifies the process of generating background audio and sound effects, making it more accessible and efficient than ever before.
What it does
TuneAI is an intelligent visual content to audio generator tool. We provide users with access to generative AI technology to create unique musical samples based on the context of their images or videos. Our model analyzes the video for its mood, tone, objects, scenery, and a variety of other contextual elements, and generates music based on a suitable genre, instrumentation, style, etc. Our music is sure to inspire you!
How we built it
After the video file is uploaded, we splice the video into multiple frames which are then analyzed by Salesforce BLIP image-to-text model, which gives us a list of image descriptors. These are then passed on to OpenAI GPT, which takes the image descriptors and comes up with the musical prompt, which is fed into Meta's MusicGen. The audio generated by MusicGen can be edited to fit the video. This whole pipeline is squashed into a function which is served on the backend (Flask). We used React to build our frontend and deployed on Vercel. Intel Cloud Max Series GPU allows us to perform inferencing at speed, allowing us to generate the audio in reasonable time.
Challenges we ran into
- Complex tasks: how do we ... do video understanding? ... translate that understanding into a type of music? ... how do we define or generate music? We answered all of these questions after a thorough investigation of current methods, models, and applications.
- Model selection: Making decisions to select the best models for our choice of architecture and design constraints (compute speed and memory and accuracy tradeoffs).
- Attempts to fine tune our models: We are venturing into rather new territory in the generative AI space for videos and audio. There are limited datasets that would allow us to tune (Example: In targeting our model for short form content, we wanted to use Tiktok videos to fine-tune the BLIP model. However, we cannot easily analyze sentiment or understand moods with a "describe what you see" type of model, especially since Tiktok present a lot of social trends. Video descriptors and metadata also do not provide much context. This proved to be unreliable upon testing and set us back initially.)
A second challenge was to figure out a way to increase the speed of inference, by setting up our environment in Intel Cloud as none of us had deep infrastructure experience . A huge shout-out to Rahul from Intel who helped us through some parts of the cloud setup, allowing us to use Max Series GPUs and 4th gen Xeon Processors for model training and inference.
Accomplishments that we're proud of
- Producing the first video-to-audio GenAI model pipeline in under 3 days.
- Overcoming various technical and non-technical obstacles along the way (overloaded network, laptop memory limit, little sleep) to produce a fully functioning web application which content creators, videographers and filmmakers can now use for audio inspiration.
What we learned
- State of the art generative AI
- Picked up new tech stack and skills: first time using Flask and websockets, experimented OpenAI prompt generation, learned about Transformer models.
- Quick problem solving, iterating, and pivoting if blocked.
What's next for TuneAI
- Accept longer form content, which would require access to more powerful compute (i.e. Intel Developer Cloud).
- Allow users to control the music generation process, providing additional context or specifications to their use cases.
- Fine tune the captioning model to understand context and moods for more agreeable generations.
- Speed up inference process by optimizing prompt generation.











Log in or sign up for Devpost to join the conversation.