-
-
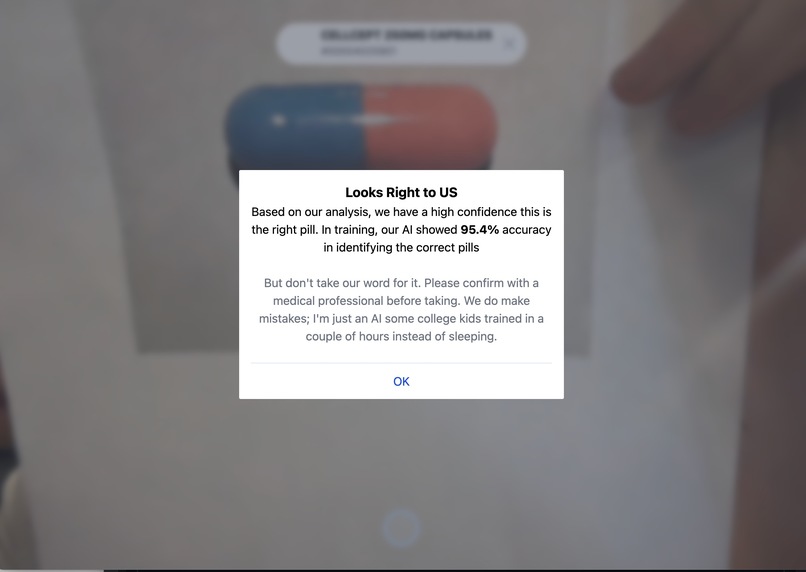
The model successfully identifying Cellcept pill
-
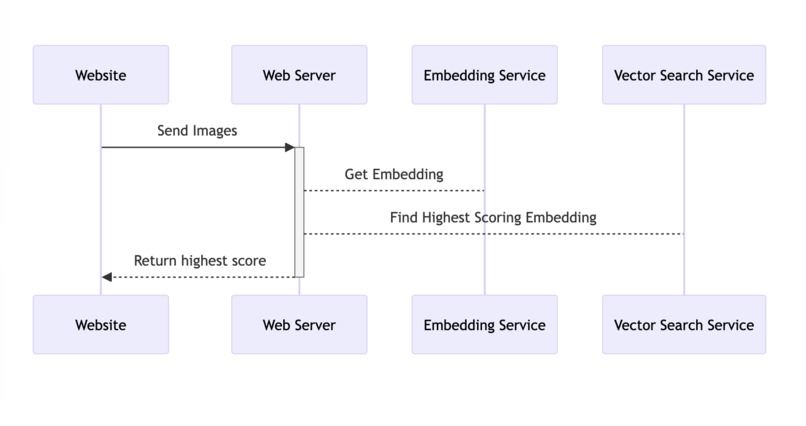
Our Service Architecture
-
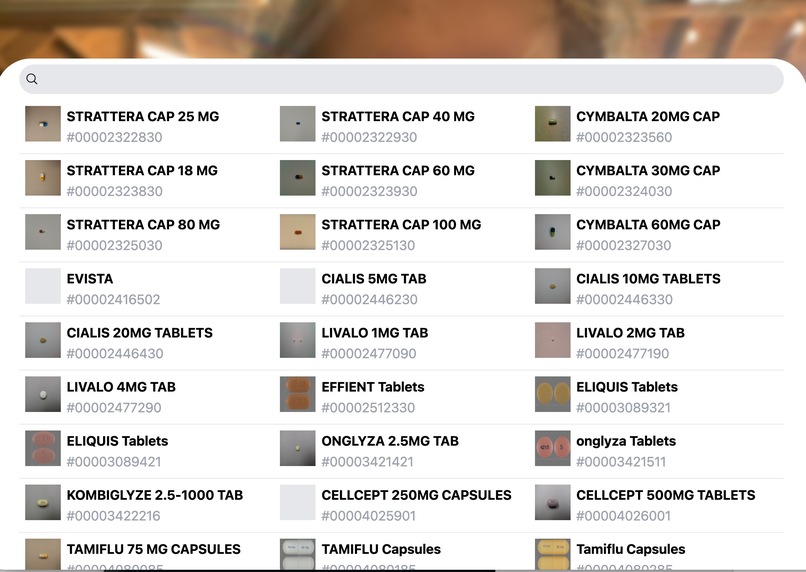
Options for users to choose their medication
-
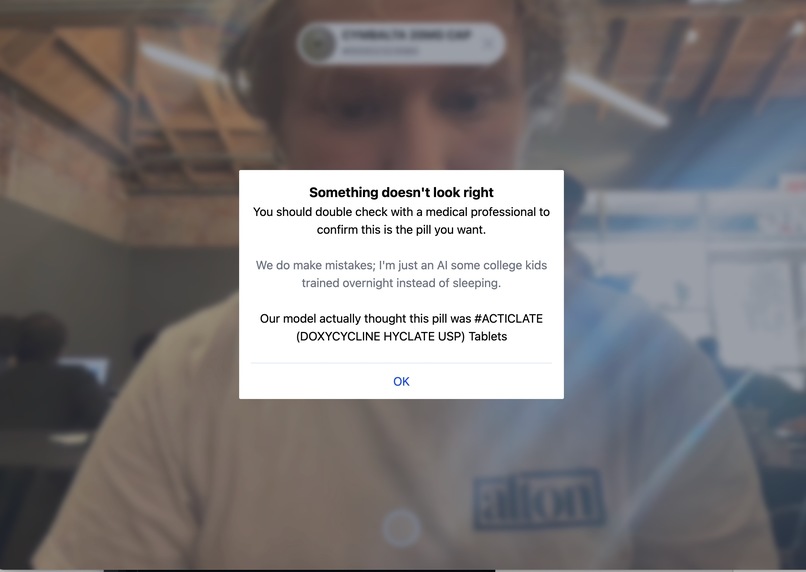
The model identifying object as not the correct pill
-
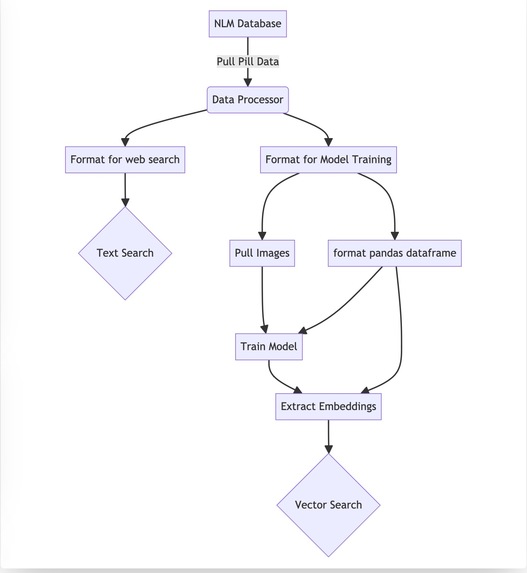
Data Pipeline Diagram





Check out our interactive charts on Github
Inspiration
When we learned that medical errors are the third leading cause of death in the United States, but are completely preventable, we were compelled to address the issue. Specifically, we want to reduce the amount of medication errors as a result of misprescribing or mislabeling.
What it does
Users tell us what pill they should have; we tell them if it looks right.
How we built it
We found an open database of 5000 high quality labeled images of pills from the National Library of Medicine. We pulled 3690 of them (it took us 3 hours, and we had to move on to other things.)
We fine tuned a Prototypical Network based on ResNet 12 for few shot learning based on detecting the correct pill. First, I trained it locally for ~30 minutes on my Mac, once it was clear there was learning, I switched to training on an NVIDIA T4 GPU on Google Cloud. We fine tuned for 5 hours, and at the end our accuracy got up to 95.4%.
We then generated embeddings for every pill and put them into a single JSON file.
We created a rust server to find the best match for any given embedding. This is so we can parallelize our euclidian distance for blazingly fast performance
We hosted the model at runtime through a simple FastAPI gateway, and connected it to our main node service.
When a request with an image of a pill comes in from a user. We embed that image in our py server, then send that embedding to our high performance vector search server to find the best match.
Our UI is written in SolidJS with custom styling using TailwindCSS.
Challenges we ran into
- We realistically only had 2 shots at fine tuning before we ran out of time, so that was EXTREMELY stressful
- As a Mac guy, I'm used to having issues with not being able to use Cuda — I never expected to have so many issues getting CUDA installed (mismatch between pytorch version and gpu version)
- The dataset we generated was GIANT (13.2 GB). To get it, we had to parallelize our data requests to an extreme degree, — however then we got blocked because of DDOS protection, so we had to batch our parallelization.
- Transferring that from my local computer to a google cloud instance also took some finagling
- Once the model was working, we had issues with getting it to work at runtime, so we ended up re-implementing the scoring independently (in rust) for performance
Accomplishments that we're proud of
- We successfully used few shot learning
- We got to much higher accuracy than we thought possible
- We formatted a custom dataset larger than anything else I've ever seen
- Our website looks amazing
- We are so humble
What we learned
- We learned how to fine tune few shot learning models
- We learned about different similarity scoring mechanisms
What's next for VeriPill
VeriPill is a proof of concept. We are not AI experts, but we were able to get a relatively accurate tool built overnight (literally.) Our methodology is well documented and open source, and the next generation of this tool could save thousands of lives.

Log in or sign up for Devpost to join the conversation.