-
-
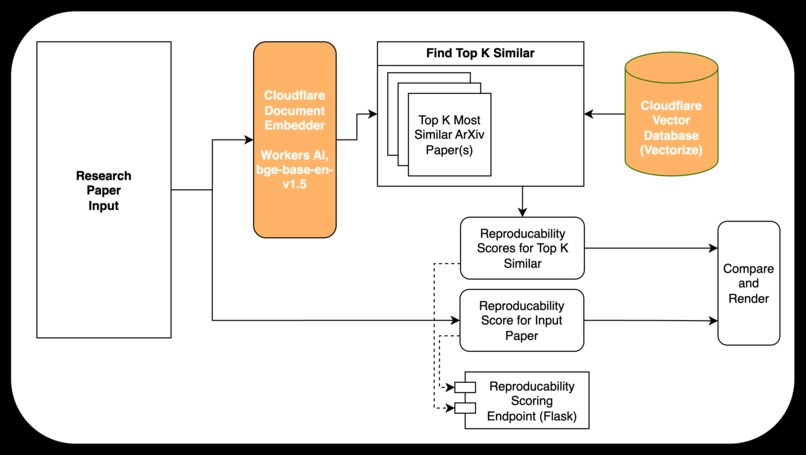
Pipeline
-
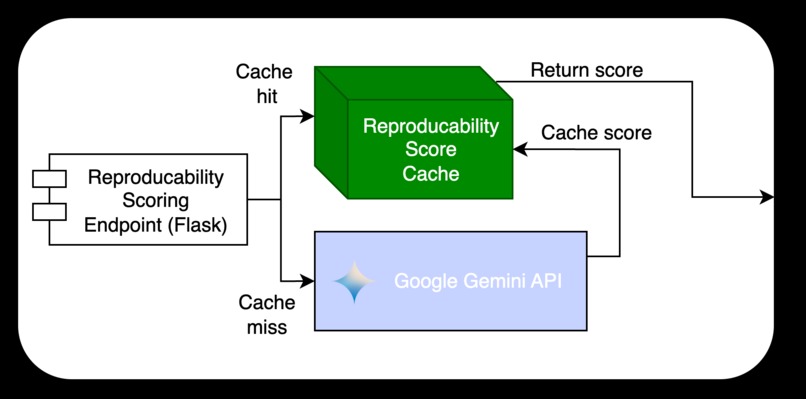
Scoring Endpoint


Inspiration
My friend and I both read machine learning papers for research + keeping up with the updates in the field. One of the main problems we both encountered was that many papers did not open source their code or provide enough details to reproduce their results.
We also found a research paper which showed that number of yes'es reproduciblity rubrics / benchmarks are positively correlated with acceptance into reputable ML conferences such as EMNLP.
Hence, we created this project to increase + improve the quality of reproducibility in modern ML research.
What it does
Our project, veriXiv (Verify x arXiv), takes in a link to an arXiv paper OR a PDF of some text, and computes a document embedding for this input.
Then, it uses Cloudflare to find the top-k most semantically similar papers (this is done by vector databases + embedding models).
Lastly, these texts get passed into the Gemini API, from which each paper / text is graded against a reproducibility rubric and converted to both a raw score and the graded reproducibility rubric. We also implemented a cool algorithm that finds where in the paper the model found evidence for each positive instance of the rubric.
Cool problems we solved
We multithreaded our reproducibility scoring function since each call was disjoint from each other.
One of the features we wanted to add was for users of the software to be able to see where in the paper they could find "evidence" of each positively labeled rubric field. To do this, we used an approach where instead of asking the model to return the page number (the model only sees a raw text file and not the pdf, so this would be hard + prone to hallucination), we split the pdf into pages and had the model grade each page separately. These individual grades would be collected and we searched for "spikes" or instances of positive assignments.
We provide a minimalist modern UI that is sort of a "workspace" for storing and organizing the previous queries that you've ran.


Log in or sign up for Devpost to join the conversation.