-
 GIF
GIF
-

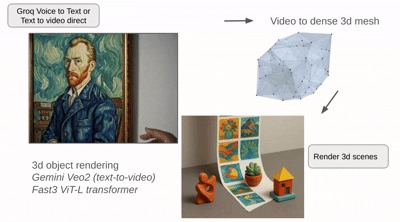
End to end pipeline to convert text or voice prompt to dense 3d mesh.
-
 GIF
GIF
Veo2 Prompt: Camera circles around slowly in a dark modern living room late at night, nobody
-
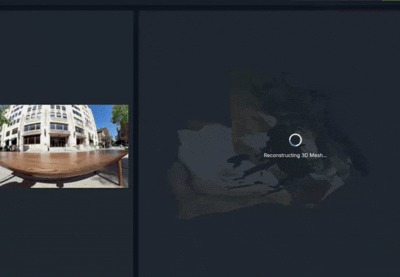 GIF
GIF
Text or voice prompt to to 3d dense mesh that can be imported into game engine or any design software.
-
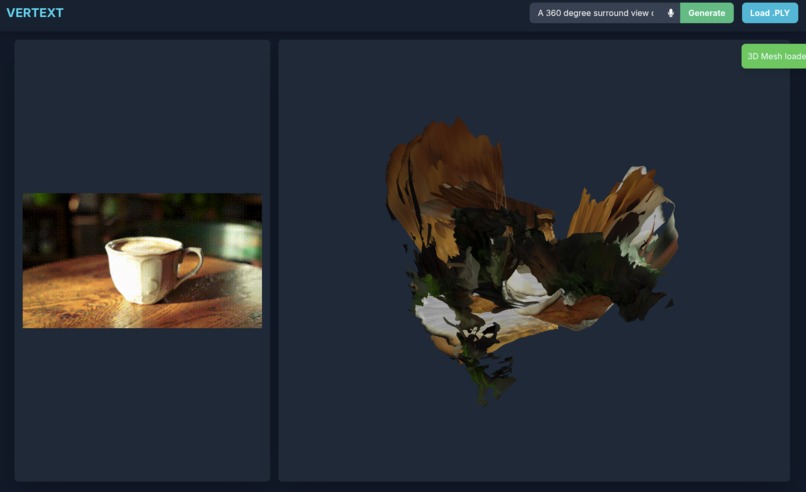
Web display with GIF and text or verbal prompt and 3d mesh, prompt "a 360 degree view of a coffe cup on a table"
-
Use Google Veo2 tfor text-to-video conversion.
-
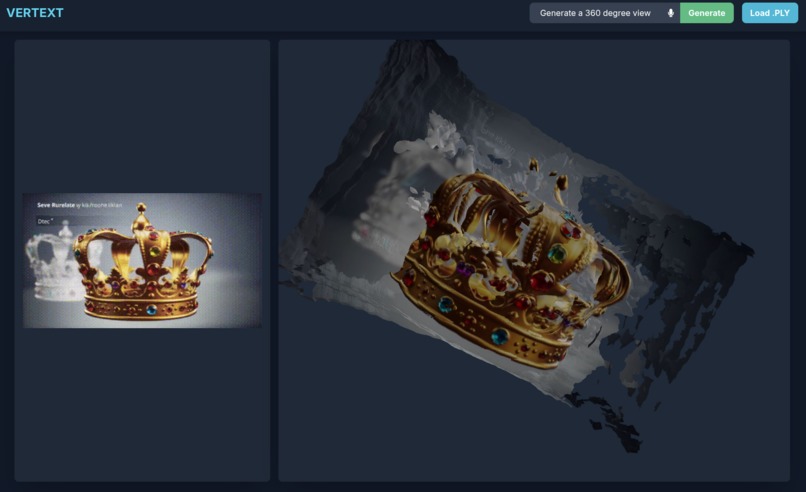
Prompt: A 360 degree view of a rotating king's crown.







Inspiration
We were fascinated by the idea of turning imagination into reality—how a simple line of text could evolve into a full 3D environment. Inspired by generative media tools and cinematic AI, we set out to explore how language could become a spatial canvas, combining storytelling with immersive design.
What it does
Our project transforms natural language prompts into immersive 3D scenes by combining generative video and geometry reconstruction. First, it creates short cinematic videos from text or verbal descriptions using a state-of-the-art video generation model. Then, it converts those videos into detailed 3D meshes using a high-speed transformer-based reconstruction system. The result is a fast, intuitive way to turn ideas into spatial experiences—bridging language, vision, and 3D design
Use Cases: Game Development: Import the mesh into Unity, Unreal, or Godot as environmental assets or characters. Artists can sketch in text, then refine the 3D form interactively, Education: Generate 3D visuals of historical or scientific concepts from text prompts (e.g., "a medieval village"). Use in VR/AR learning modules, Architecture Design: Quickly generate visual prototypes of landscapes, interiors, or thematic spaces from descriptive specs, Embodied AI: Train agents in custom environments derived from descriptive tasks. Generate synthetic 3D training data.
How we built it
Stage 1: We used Veo 2, Google’s latest text-to-video diffusion model, to generate cinematic 8-second clips from natural language prompts in text or verbal form (Groq Whisper API). Veo 2 accepts rich descriptions and camera terms (e.g. “tracking shot at dawn”) and outputs high-fidelity 720p video. It leverages a diffusion model guided by a multimodal transformer, trained on large-scale video-text data. While Google hasn’t disclosed the full parameter count, Veo 2 is part of its Gemini-scale ecosystem, likely operating in the billions of parameters.
Stage 2: We passed the generated videos through Fast3R, a high-speed transformer-based model for multi-view 3D reconstruction. Fast3R uses a ViT-L fusion transformer with 24 layers and 1 billion parameters, capable of processing 1,000+ views in a single forward pass. Unlike pairwise methods, Fast3R reconstructs geometry and camera poses jointly in one shot, making it ideal for dense video frame input. We extracted evenly spaced frames from the videos and used Fast3R to generate clean, textured 3D meshes—turning cinematic outputs into immersive environments.
Result: A lightweight app that transforms text prompts into realistic 3D mesh geometry and GIF in minutes that can be exported and applied for downstream uses in game design, embodied AI, .
Challenges we ran into
Syncing video frame output with 3D frame ingestion without quality loss or temporal misalignment. Managing GPU memory and batch size when scaling to hundreds of frames per video. Compressing and serving the final 3D outputs in a way that preserved fidelity while remaining lightweight and fast inference.
What we learned
We learned how to integrate multi-modal transformer models in a single pipeline—generating video from text, and then reconstructing that video into 3D scenes. We gained experience with high-throughput transformer architectures, 3D mesh processing, and video-to-geometry challenges.
What's next for Vertext
This project shows how storytelling, design, and AI can come together to lower the barrier to creating immersive worlds. It’s a step toward democratizing 3D content creation for artists, educators, and developers everywhere. Our next steps are to refine text to video prompt.
Inspiration
We were fascinated by the idea of turning imagination into reality—how a simple line of text could evolve into a full 3D environment. Inspired by generative media tools and cinematic AI, we set out to explore how language could become a spatial canvas, combining storytelling with immersive design.
What it does
Our project transforms natural language prompts into immersive 3D scenes by combining generative video and geometry reconstruction. First, it creates short cinematic videos from text or verbal descriptions using a state-of-the-art video generation model. Then, it converts those videos into detailed 3D meshes using a high-speed transformer-based reconstruction system. The result is a fast, intuitive way to turn ideas into spatial experiences—bridging language, vision, and 3D design
Use Cases: Game Development - Import the mesh into Unity, Unreal, or Godot as environmental assets or characters. Artists can sketch in text, then refine the 3D form interactively Education - Generate 3D visuals of historical or scientific concepts from text prompts (e.g., "a medieval village"). Use in VR/AR learning modules. Architecture Design - Quickly generate visual prototypes of landscapes, interiors, or thematic spaces from descriptive specs Embodied AI - Train agents in custom environments derived from descriptive tasks. Generate synthetic 3D training data.
How we built it
Stage 1: We used Veo 2, Google’s latest text-to-video diffusion model, to generate cinematic 8-second clips from natural language prompts in text or verbal form (Groq Whisper API). Veo 2 accepts rich descriptions and camera terms (e.g. “tracking shot at dawn”) and outputs high-fidelity 720p video. It leverages a diffusion model guided by a multimodal transformer, trained on large-scale video-text data. While Google hasn’t disclosed the full parameter count, Veo 2 is part of its Gemini-scale ecosystem, likely operating in the billions of parameters.
Stage 2: We passed the generated videos through Fast3R, a high-speed transformer-based model for multi-view 3D reconstruction. Fast3R uses a ViT-L fusion transformer with 24 layers and 1 billion parameters, capable of processing 1,000+ views in a single forward pass. Unlike pairwise methods, Fast3R reconstructs geometry and camera poses jointly in one shot, making it ideal for dense video frame input. We extracted evenly spaced frames from the videos and used Fast3R to generate clean, textured 3D meshes—turning cinematic outputs into immersive environments.
Result: A lightweight app that transforms text prompts into realistic 3D mesh geometry and GIF in minutes that can be exported and applied for downstream uses in game design, embodied AI, .
Challenges we ran into
Syncing video frame output with 3D frame ingestion without quality loss or temporal misalignment. Managing GPU memory and batch size when scaling to hundreds of frames per video. Compressing and serving the final 3D outputs in a way that preserved fidelity while remaining lightweight and fast inference.
What we learned
We learned how to integrate multi-modal transformer models in a single pipeline—generating video from text, and then reconstructing that video into 3D scenes. We gained experience with high-throughput transformer architectures, 3D mesh processing, and video-to-geometry challenges.
What's next for Vertext
This project shows how storytelling, design, and AI can come together to lower the barrier to creating immersive worlds. It’s a step toward democratizing 3D content creation for artists, educators, and developers everywhere. Our next steps are to refine text to video prompt engineering and continue building out the use cases with end-to-end integration. ngineering and continue building out the use cases with end-to-end integration.


Log in or sign up for Devpost to join the conversation.