-
-
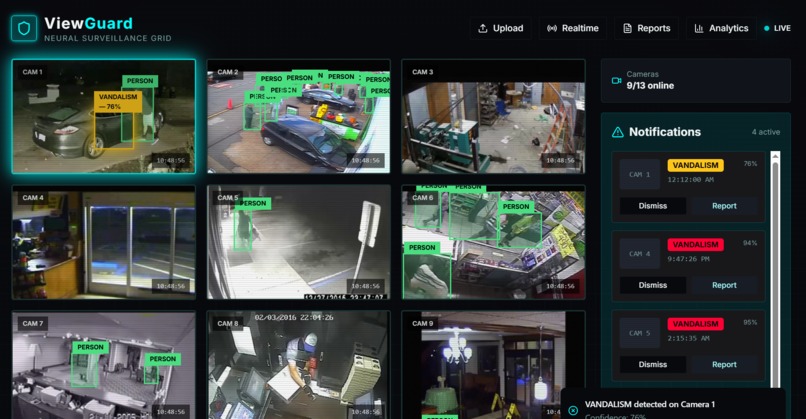
Dashboard
-

Landing Page
-
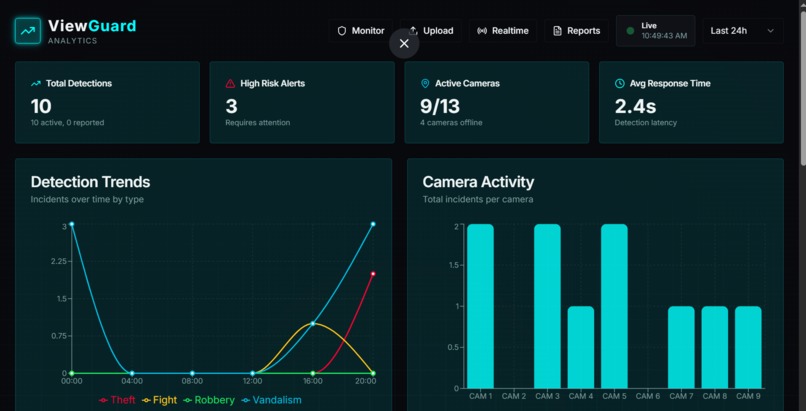
Analytics
-
Upload footage feature
-
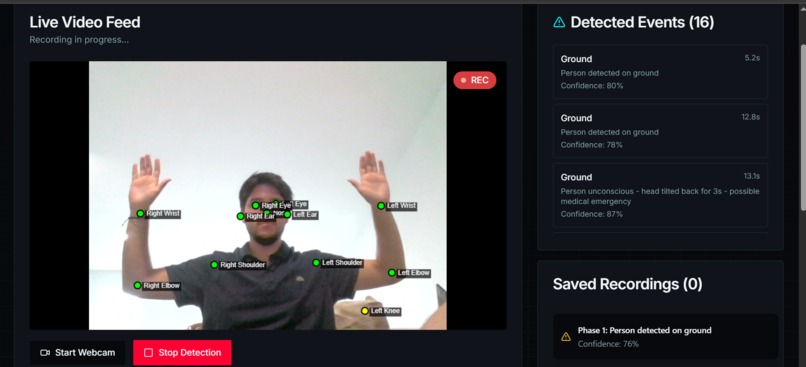
Live Demo





Inspiration
In an era with more cameras than ever, meaningful surveillance is still scarce. Most security systems are passive, they just record terabytes of footage that someone might review after an incident has already occurred. We were inspired by the gap between "recording" and "understanding." We wanted to build a solution that doesn't just record, but understands, analyzes, and acts in real-time.
What it does
ViewGuard is an end-to-end, intelligent surveillance platform. It's a "command center" for security that integrates multiple AI systems into one seamless UI.
Our platform has four primary features:
The Central AI Dashboard: A 3x3 grid displaying nine live camera feeds. The dashboard is powered by its own YOLOv8s Python server that performs real-time object detection, overlaying color-coded bounding boxes (for THEFT, FIGHT, FALL) directly onto the video feeds.
Conversational Voice AI (powered by ElevenLabs): Users can talk to the dashboard. You can ask, "What’s happening on Camera 4?" or "Review all incidents from the last hour," and our ElevenLabs-powered voice agent will respond with a human-sounding, conversational summary of the events.
Deep-Dive Live Analysis (Hybrid AI): You can expand any camera feed to "go live." This mode activates our Hybrid AI model, which fuses client-side TensorFlow.js pose detection with Google's Gemini VLM to perform deep, contextual analysis (like detecting a specific fall) and trigger instant alerts.
Instant Alerts & Persistent Library: The moment a threat is confirmed, our backend dispatches an alert via the Resend API. The incident is then saved to a fast, client-side persistent library for instant review, complete with video and the AI-generated timeline.
How we built it
ViewGuard is a full-stack monorepo, integrating a Python backend, a Next.js frontend, and multiple cloud AI services.
Frontend: Built with Next.js 14, React, and TypeScript. We used Tailwind CSS and shadcn/ui for a clean, professional, and responsive UI.
AI Dashboard Backend: A standalone Python server (detection_server.py) using YOLOv8s and OpenCV. It processes video feeds and streams the detection data to the frontend dashboard.
Live Analysis AI (Hybrid Model): We solved API latency by creating a hybrid prompt. We use TensorFlow.js (MoveNet) in the browser to extract pose data, then send that data along with the video frame and audio transcript to Google's Gemini VLM. This gives us a rapid, <3-second response.
Conversational AI: We integrated ElevenLabs to build our human-like, conversational voice assistant.
Infrastructure & Services: We use Supabase Auth for secure user authentication and the Resend API for all instant notifications.
Challenges we ran into
Our biggest challenge was systems integration. We weren't just building a simple app; we were orchestrating a Python YOLO server, a Next.js web app, a TensorFlow.js client, and two different cloud AI APIs (Gemini and ElevenLabs). Getting them all to communicate with low latency was a massive undertaking.
We also faced the "real-time" latency problem with our deep-analysis AI. We solved this by developing our "hybrid multi-modal prompt", where client-side TensorFlow.js pre-processes the data, dramatically reducing the inference load on Gemini and cutting our response time by over 70%.
Accomplishments that we're proud of
We're incredibly proud of building a truly multi-layered AI system. This isn't just one AI model; it's a team of specialized AIs (YOLOv8 for general detection, Gemini for deep analysis, ElevenLabs for voice) working together.
We're also proud of the conversational voice assistant. Being able to just talk to your security system and get a human-like response feels like something from the future.
Finally, we're proud of the seamless, end-to-end loop: See (YOLO) -> Understand (Gemini) -> Speak (ElevenLabs) -> Act (Resend) -> Remember (Library).
What we learned
We learned that the future of AI applications isn't one "mega-model" but a smart orchestration of specialized models. We learned how to build a robust, multi-part system and have it communicate effectively.
We also learned that the smartest solution is often a hybrid one. By combining client-side (TF.js) and server-side (Gemini) AI, we solved a latency problem that would have made our live demo impossible.
What's next for ViewGuard
We've built a powerful, feature-complete platform. The next steps are focused on scaling and refinement:
Unified AI Context: Feed the real-time YOLO detections into the ElevenLabs context so the voice assistant can report on events as they happen.
Scale the Backend: Containerize the Python YOLO server and deploy it for high-availability.
Mobile App: A native mobile app for security guards to receive and respond to alerts on the go.
Built With
- elevenlabs
- google-gemini
- next.js
- react
- resend
- supabase
- tailwind-css
- tensorflow
- typescript
- vlm



Log in or sign up for Devpost to join the conversation.