-
-
Design Pattern
-
Home Page
-

Dark Mode
-
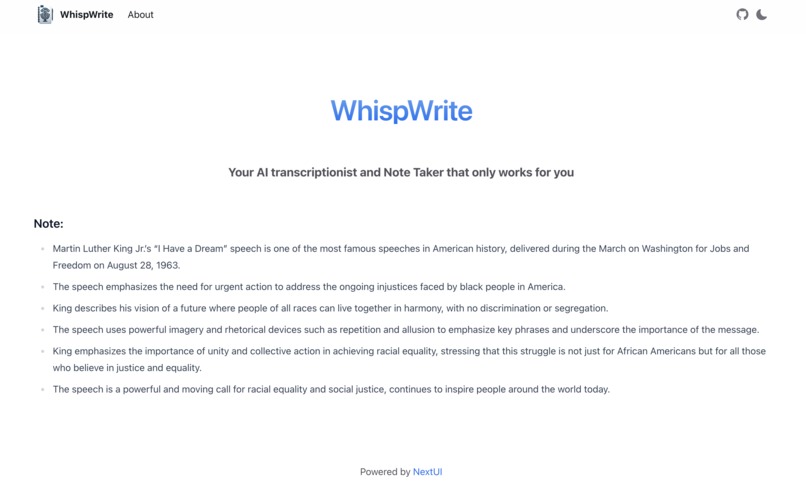
notes




Inspiration
This project emerged from the daily challenges we face as students. Balancing attention between listening to lectures and taking notes is a common struggle. Recognizing this, we envisioned a tool that could autonomously attend lectures and compile notes, offering a solution where existing alternatives fall short, mainly due to their cost. Our objective is to deliver a free, locally, operated LLM that prioritizes data security and privacy with no cost. We believe in the importance of consent when it comes to using recorded educational content, and we should not be uploading other's voices and videos to AI-hosing services without others knowing it. Yeah, OpenAI's APIs and ChatGPT keep your data for 30 days.
What it does
Our tool is designed to process audio recordings of any length, surpassing the typical limitations of online APIs. We have tested lectures with 2 hours long, and it work pretty well. It also takes notes of the audio giving you the main points as the summary.
How we built it
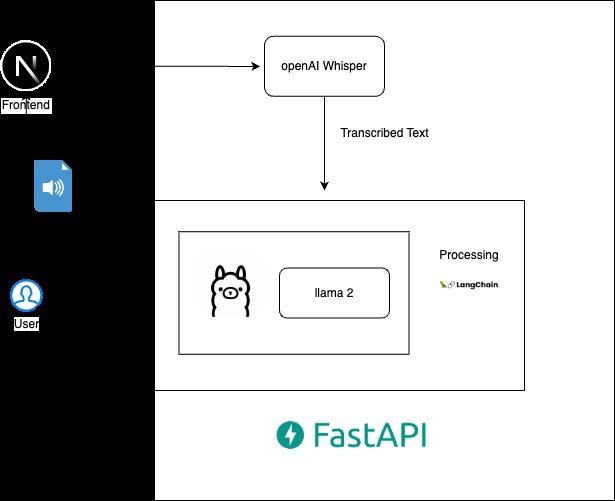
The development of our project started from the ground up, with a custom-built frontend using Next.js in Typescript, enhanced with Next UI components for a responsive user interface. On the backend, we crafted APIs to integrate with cutting-edge ML models using Python's FastAPI and Pydantic for robust data handling. The backbone of our application consists of OpenAI's Whisper for accurate transcription and Meta's Llama 2: 13B for advanced data processing. Given the resource-intensive nature of these models, we opted for the English-only variant of Whisper to optimize performance. To further refine our tool, we incorporated Ollama for local model management and LangChain for sophisticated prompt engineering, enabling detailed summaries of extensive lectures with enhanced control over the output. With Langchain's map reduce, we can process tens of thousands of words from the transcription.
Challenges we ran into
Performance is probably the most challenging part, because of the lack of Cuda GPU on our MacBook, we were having difficulty running the bigger model, but we found a sweet spot of base.en for whisper and 13B for llama 2. Also, we tried a lot of effort in prompt engineering to give the best notes given the limited model size. Langchain has some learning curve to use its modelO and chains, but we figured it out at the end.
Accomplishments that we're proud of
It is very useful and will be part of my future note-taking tool just for the capability to summarize super-long lectures. We hope others can take the benefit of using our app as it will be fully open-source.
What we learned
First, we learned how to properly do software development using Agile and Scrum. We have a really strict version-controlled practice to keep our collaboration as safe and as efficient as possible. Allen was first time introduced to front-end development and he has learned so much from building the app with Typescript. We have never learned about Langchain, llama, and fastAPI before but we hack our way through. Leveraging langChain and other techniques in interacting with LLM prepares us to build more sophisticated n-to-n agents in the future.
What's next for WhispWrite
The top of the list is to have integration with Notion API to directly export the notes to the best note-taking app: Notion. Then, we are thinking of having multi-lingual supports, and model selection from the web UI to allow users to select different LLMs.
Built With
- fastapi
- langchain
- llama2
- next.js
- nextui
- ollama
- python
- typescript
- whisper

Log in or sign up for Devpost to join the conversation.