בעיה י"ח

הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
כתבו את הפונקציה produceCSVDict –
def produceCSVDict(filename):
לפונקציה פרמטר אחד: filename, שם (מחרוזת) של קובץ csv הנמצא בתיקיית העבודה. הפונקציה קוראת את הקובץ ושומרת את תכנו בתור מילון. בכל זוג במילון המפתח הוא שם של משתנה (עמודה) בקובץ והערך הוא רשימה המכילה את ערכי משתנה זה בכל התצפיות בקובץ, מהראשונה ועד האחרונה, בסדר זה. הפונקציה מחזירה את המילון שיצרה.
נניח למשל שהפונקציה מקבלת את שמו של הקובץ freq.csv. הנה תוכן הקובץ כאשר הוא נפתח ב-Excel –
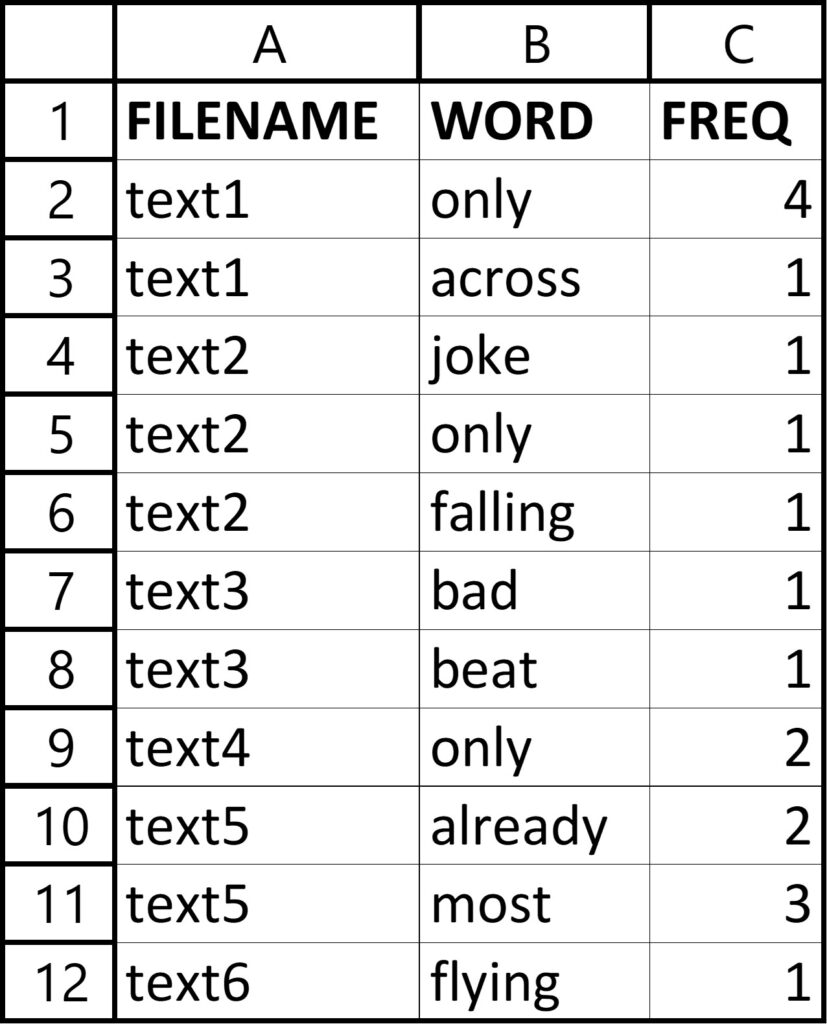
הקובץ שומר מידע על שלושה משתנים: FILENAME, WORD ו-FREQ, ויש בו מספר כלשהו של תצפיות (כאן מוצגות אחת עשרה לצורך הדגמה בלבד). בכל תצפית שמור מידע על אודות השכיחות של מילה אחת בקובץ טקסט מסוים. בתצורתו הגולמית של הקובץ מילים הסמוכות זו לזו בכל שורה מופרדות באמצעות פסיק. הנה כך מוצג הקובץ בפתיחתו בעורך פשוט –
FILENAME,WORD,FREQ
text1,only,4
text1,across,1
text2,joke,1
text2,only,1
text2,falling,1
text3,bad,1
text3,beat,1
text4,only,2
text5,already,2
text5,most,3
text6,flying,1
הפונקציה תיצור את המילון הזה ותחזיר אותו –
{‘FILENAME’: [‘text1′,’text1′,’text2′,’text2′,’text2’,
‘text3′,’text3′,’text4′,’text5′,’text5′,’text6’],
‘WORD’: [‘only’,’across’,’joke’,’only’,’falling’,’bad’,
‘beat’,’only’,’already’, ‘most’,’flying’],
‘FREQ’: [‘4’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘3’, ‘1’]}
כל המפתחות וכל הערכים ברשימות שבמילון יהיו מחרוזות.
לפתרון בקוד ראו כאן.
פתרון מפורט
בעיה זו כמו קודמתה עוסקת בקבצי טקסט – ספציפית בקבצי csv – והפעם נטפל בהם בגישה שונה מזו שנקטנו בה בפתרון לבעיה הקודמת. במקום לקרוא מקטעים-מקטעים מהקובץ באמצעות הזזת המצביע בתוך הקובץ וזימונים חוזרים ונשנים של הפונקציה read, נזמן את הפונקציה הזאת פעם אחת בלבד ונקרא את כל תוכן הקובץ בתור מחרוזת אחת. אחר כך נטפל במחרוזת זו באמצעות כלי הטיפול במחרוזות שיש בשפה. הפונקציה תתחיל אפוא בקטע קוד זה –
f = open(filename)
s = f.read()
f.close()
לאחר שיש בידינו מחרוזת המכילה את תוכן הקובץ כולו נמשיך ליצירת המילון. המהלך העקרוני של יצירתו הוא זה: נגדיר מילון ריק csvDict –
csvDict = {}
אחר כך נסרוק שורה-שורה במחרוזת הקובץ ונפצל כל שורה למילים. נוסיף זוגות למילון אגב סריקת שורות התצפיות (כלומר השורות שאינן השורה הראשונה, שורת שמות המשתנים). כך נתחיל בסריקת התצפית הראשונה –
text1,only,4
נפצל אותה לשלוש המחרוזות ‘text1’, ‘only’ ו-‘4’. אז נוסיף למילון, שהוא ריק בשלב זה, שלושה זוגות: בכל זוג המפתח הוא שם המשתנה שהמילה שייכת אליו והערך הוא רשימה המכילה את המילה –
{‘FILENAME’:[‘text1’], ‘WORD’:[‘only’], ‘FREQ’:[‘4’]}
בסריקת כל אחת ואחת משאר התצפיות שוב נפצל למילים ולאחר הפיצול נוסיף כל מחרוזת שהתקבלה מהפיצול לזוג המתאים במילון. למשל בתום סריקת התצפית השניה –
text1,across,1
יעודכן המילון ותוכנו יהיה זה –
{‘FILENAME’:[‘text1’, ‘text1’], ‘WORD’:[‘only’, ‘across’], ‘FREQ’:[‘4’, ‘1’]}
וכן הלאה.
מן האמור עולה כי הקוד כולו מטפל בשורות בקובץ, או ליתר דיוק, בתת מחרוזות של מחרוזת כל הקובץ המכילות את השורות בקובץ. אם כן לאחר קריאת כל מחרוזת הקובץ למשתנה s ניצור רשימה של כל תת המחרוזות – כלומר: השורות – הללו. נשתמש בפונקציה split –
lines = s.split(‘\n’)
הפיצול כאן הוא לפי תו מעבר שורה. עבור קובץ הדוגמה תיווצר רשימת המחרוזות lines הזאת –
[‘FILENAME,WORD,FREQ’,
‘text1,only,4’,
‘text1,across,1’,
‘text2,joke,1’,
‘text2,only,1’,
‘text2,falling,1’,
‘text3,bad,1’,
‘text3,beat,1’,
‘text4,only,2’,
‘text5,already,2’,
‘text5,most,3’,
‘text6,flying,1’]
כאמור לאחר מכן נסרוק מחרוזות-שורה אחת אחר השניה מתוך הרשימה lines, חוץ מהשורה המכילה את שמות המשתנים, ונפצל כל שורה לשלוש המילים שהיא מכילה. תחילת הסריקה תראה כך –
for line in lines[1:]:
words = line.split(“,”)
עבור כל שורה חוץ מהשורה הראשונה, לולאה זו יוצרת רשימה, words, שהיא תוצאה של פיצול מחרוזת השורה לשלושת רכיביה, כל רכיב בתור מחרוזת: מחרוזת שם הקובץ, מחרוזת המילה, ומחרוזת השכיחות – לדוגמה: ‘text1,across,1‘. הפיצול של כל שורה לשלוש המחרוזות המרכיבות אותה נעשה כאן לפי התו המפצל פסיק. לפי תיאור הבעיה זה התו המפריד בין מילים סמוכות בכל שורה בקובץ (אפשר שהתו המשמש בקובץ csv בתור תו מפצל יהיה שונה מפסיק).
בהינתן קובץ הדוגמה, רשימת המילים words המתקבלת בסריקת התצפית הראשונה היא זו –
[‘text1’, ‘only’, ‘4’]
בשלב זה, בסריקת שורת התצפית הראשונה ולאחר פיצול מחרוזת שורה זו לשלוש המחרוזות המרכיבות אותה והכנסתן לרשימה words, המילון csvDict עדיין ריק. עלינו ליצור בו שלושה זוגות. המפתחות בזוגות הם ‘FILENAME’, ‘WORD’, ו-‘FREQ’, והערך בכל זוג הוא המחרוזת המתאימה מתוך הרשימה words. כיצד נעשה זאת? בתוך words, רשימת המילים בשורה הנוכחית, יש לנו ביד את הערכים בזוגות של המילון. אבל איך נדע להתאים כל מילה למפתח שהיא שייכת אליו? איך נדע למשל שהמחרוזת ‘text1’ צריכה להיות ערך בזוג שהמפתח בו הוא ‘FREQ’?
התשובה טמונה באבחנה זו: לפנינו הֶקשר שכיח שבו רצוי להשתמש בסריקת אינדקסים: אנו מעוניינים להגיע מְערך הנמצא באינדקס מסוים ברצף אחד, הרשימה words, לערך הנמצא באינדקס שווה ברצף אחר שהוא שווה אורך לרצף הראשון (ראו בעיה ג’ ובעיה ט’), כלומר רשימה שניצור מהשורה הראשונה בקובץ’, שורת שמות המשתנים: [‘FILENAME’, ‘WORD’, ‘FREQ’]. מספר המילים שיש בשורת שמות המשתנים, כלומר 3, – שווה בדיוק למספר המילים שיש בכל אחת ואחת משאר השורות (כלומר שורות התצפיות) בקובץ. לכן, אם נסרוק את האינדקסים ברשימה words נוכל לגשת בקלות מכל מילה ברשימה words לשם המשתנה שהיא שייכת אליו ברשימת שמות המשתנים, וכך לדעת מה המפתח בזוג שהמילה נמצאת בו במילון. הקוד העושה זאת מופיע כאן בגרסה הסופית של הפונקציה כולה –
def produceCSVDict(filename):
f = open(filename)
s = f.read()
f.close()
csvDict = {}
lines = s.split(“\n”)
colnames = lines[0].split(“,”)
for line in lines[1:]:
words = line.split(“,”)
for i in range(len(words)):
if colnames[i] not in csvDict:
csvDict[colnames[i]] = [words[i]]
else:
csvDict[colnames[i]].append(words[i])
return csvDict
בשורה הששית בגוף הפונקציה, מיד לאחר שפיצלנו את מחרוזת הקובץ לרשימת מחרוזות-שורה lines, יצרנו רשימה בשם colnames המכילה את שמות המשתנים: היא התקבלה מפיצול של המחרוזת הראשונה ברשימה lines, כלומר המחרוזת המכילה את שורת שמות המשתנים; הפיצול – לפי תו מפצל פסיק. לאחר מכן מתחילה הלולאה החיצונית: עבור כל אחת ואחת משאר השורות בקובץ, כלומר משורות התצפיות, לולאה זו מפצלת את מחרוזת השורה הנסרקת הנוכחית לרשימת המילים המרכיבות אותה, זו הרשימה words. עבור כל רשימה כזו, לולאת ה-for הפנימית סורקת את מערכת האינדקסים המוגדרת ברשימה; בדוגמה שלנו, כיוון שבכל שורה יש 3 מילים, לולאת ה-for הפנימית סורקת את האינדקסים 0, 1 ו-2, בסדר זה. בתוך לולאת ה-for הפנימית השתמשנו באינדקסים הנסרקים כדי להכניס את הזוגות למילון: המילה words[i] שייכת לרשימה שאליה ממופה במילון שם המשתנה colnames[i]. למשל עבור words זו –
[‘text1’, ‘only’, ‘4’]
ועבור i == 0, הביטוי –
words[i]
הוא המילה ‘text1’, ושם המשתנה המתאים למילה זו ברשימה colnames, כלומר ‘FILENAME’, מתקבל מהביטוי –
colnames[i]
אם כן בכל סיבוב וסיבוב של לולאת ה-for הפנימית יש בידינו מפתח (שם משתנה קובץ) וגם מילה שיש להכניס לרשימה שהמפתח ממופה אליה. גוף הלולאה בנוי באופן שכבר פגשנוהו בפתרונות לבעיות קודמות: הוא מבחין בין שני מצבים. במצב האחד המפתח אינו קיים במילון. קיומו של מצב זה נבדק בחלק ה-if –
if colnames[i] not in csvDict:
שימו לב: למעשה חלק ה-If מטפל אך ורק בהכנסת המילים בתצפית הראשונה הנסרקת בלולאת ה-for החיצונית. התנאי כאן יחזיר True עבור כל אחת ואחת מהמילים בתצפית הזאת, ורק עבורן: לפני הכנסת הזוגות שהן משתייכות אליהם המילון הוא ריק, ולאחר הכנסתן כל שמות המשתנים בקובץ הם כבר מפתחות במילון. בדוגמה שלפנינו התנאי יתקיים שלוש פעמים – פעם אחת לכל מילה (מחרוזת) בתצפית הראשונה: ‘text1’, ‘only’ ו-‘4’. וכשהתנאי מתקיים מתבצעת הוראה זו –
csvDict[colnames[i]] = [words[i]]
הוראה זו מכניסה למילון זוג שהערך בו הוא רשימה המכילה את המילה באינדקס הנסרק הנוכחי ברשימת המילים בתצפית הראשונה, והמפתח הוא שם המשתנה המופיע באינדקס הזה ברשימת שמות המשתנים colnames. למשל עבור i == 0 ההוראה המתבצעת היא זו –
csvDict[colnames[0]] = [words[0]]
כלומר –
csvDict[‘FILENAME’] = [‘text1’]
והמילון המתקבל הוא זה –
{‘FILENAME’:[‘text1’] }
עבור i == 1 ההוראה המתבצעת היא זו –
csvDict[colnames[1]] = [words[1]]
כלומר –
csvDict[‘WORD’] = [‘only’]
והמילון המתקבל הוא זה –
{‘FILENAME’:[‘text1’], ‘WORD’:[‘only’]}
ולבסוף עבור i == 2 ההוראה המתבצעת היא זו –
csvDict[colnames[2]] = [words[2]]
כלומר –
csvDict[‘FREQ’] = [‘4’]
והמילון המתקבל הוא זה –
{‘FILENAME’:[‘text1’], ‘WORD’:[‘only’], ‘FREQ’:[‘4’]}
חלק ה-else מתייחס למצב אחר: המצב שבו הוכנסו כבר כל שלוש המילים בתצפית הראשונה, וממילא גם הוכנסו למילון כל המפתחות שצריכים להיות בו (שמות המשתנים בקובץ). מצב זה מתקיים עבור כל אחת ואחת מהשורות הבאות הנסרקות, החל מהתצפית השניה ואילך, ובהתקיימו מתבצעת הוראה זו –
csvDict[colnames[i]].append([words[i]])
בביטוי csvDict[colnames[i]] מופעל האופרטור [ ] כדי לקבל את הרשימה שאליה ממופה מפתח מסוים במילון: המפתח הזה הוא שם המשתנה הנמצא ברשימה colnames באינדקס שבה נמצאת המילה הנסרקת הנוכחית ברשימה words. למשל בסריקה של התצפית השניה בקובץ, ועבור i == 0, המילה הנמצאת באינדקס זה ברשימה words היא ‘text1’, ושם המשתנה שהיא משתייכת אליו הוא ‘FILENAME’. שם זה הוא כבר מפתח במילון, ספציפית בזוג הזה –
‘FILENAME’:[‘text1’]
ראינו כי זוג זה נוצר בסריקת המילים בתצפית הראשונה. אם כן הביטוי csvDict[colnames[i]] מחזיר את הרשימה הזאת –
[‘text1’]
לסוף הרשימה הזאת עלינו להוסיף את המילה ‘text1’ המופיעה באינדקס 0 ברשימת המילים של התצפית השניה. זה בדיוק מה שעושה זימון הפונקציה append בקוד. לאחריו המפתח ‘FILENAME’ ממופה לרשימה הזאת –
[‘text1’, ‘text1’]
ולאחר הכנסת שתי המילים האחרות בתצפית השניה למילון מתקבל המילון הזה –
{‘FILENAME’:[‘text1’, ‘text1’], ‘WORD’:[‘only’, ‘across’], ‘FREQ’:[‘4’, ‘1’]}
כך ממשיכה בניית המילון, שורה אחר שורה, עד שבסופו של דבר מתקבל המילון בגרסתו המלאה –
{‘FILENAME’: [‘text1′,’text1′,’text2′,’text2′,’text2’,
‘text3′,’text3′,’text4′,’text5′,’text5′,’text6’],
‘WORD’: [‘only’,’across’,’joke’,’only’,’falling’,’bad’,
‘beat’,’only’,’already’, ‘most’,’flying’],
‘FREQ’: [‘4’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘3’, ‘1’]}