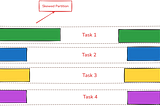
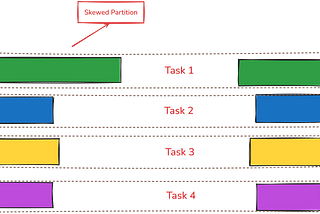
PinnedPublished inData Engineer ThingsFrom Bottlenecks to Balance: Dynamic Skew Join Fixes in SparkWhen working with large datasets in Spark, joins are a common operation. But what happens when data distribution isn’t uniform? Let’s dive…Apr 13, 2025A response icon1Apr 13, 2025A response icon1
PinnedPublished inData Engineer ThingsFine-Tuning Shuffle Partitions in Apache Spark for Maximum EfficiencyApache Spark’s shuffle partitions are critical in data processing, especially during operations like joins and aggregations. Properly…Feb 12, 2025Feb 12, 2025
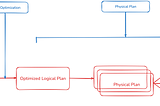
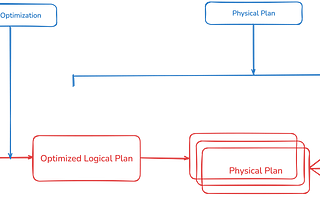
Published inData Engineer ThingsApache Spark SQL Engine and Query PlanningApache Spark is a powerful distributed computing framework that provides two interfaces for working with data:Apr 6, 2025Apr 6, 2025
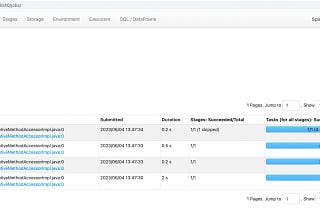
Published inData Engineer ThingsDeep Dive into Apache Spark Jobs and StagesUnderstanding how jobs and stages work is crucial to optimizing performance with large-scale data processing using Apache Spark. This blog…Mar 24, 2025A response icon1Mar 24, 2025A response icon1
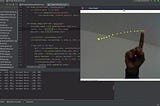
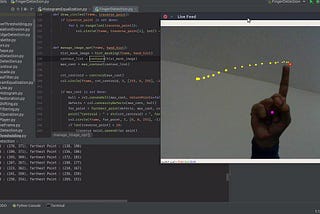
Amar Prakash PandeyFinger Detection and Tracking using OpenCV and PythonTL;DR. Code is here.Jul 28, 2018A response icon1Jul 28, 2018A response icon1
Amar Prakash PandeyWhat is Google Summer of Code? How to prepare for it?We will talk about Google Summer of Code but before that let’s talk about what Open Source Development is. Yes, it’s very important.Jul 2, 2017Jul 2, 2017