

Странное упорядочение по-умолчанию в диапазонах символьных классов grep'а.
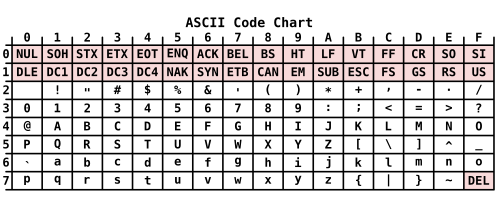
(Натолкнула на размышления вот эта строка из chrome/content/filterClasses.js проекта Adblock Plus. В POSIX API regcomp()/regexec() всё также работает, как и в JavaScript.)
Почему срабатывает следующее выражение?
> echo "a.b" | grep -E '[ -#]' a.bВедь в ASCII и UTF-8 точка находится после диеза.
Поправить легко:
> echo "a.b" | LANG= grep -E '[ -#]'
Оказывается, это устойчивое поведение.
> touch 'a ' ; touch 'a!' ; touch 'a"' ; touch 'a#' ; touch 'a.' ; touch 'a,' > ls a a, a! a. a" a# > LANG= ls a a! a" a# a, a.
Братцы, как называется эта Collating sequence для этих знаков, отличная от ASCII/Unicode?
Update: http://www.collation-charts.org/ (Спасибо Яше!)