
The Open Superintelligence Stack
The compute and infrastructure platform for you to train, evaluate, and deploy your own agentic models
.png)

Find reliable compute across dozens
of providers from single-node to
large-scale clusters.

Instant access to 1-256 GPUs
Use your GPUs across clouds in a single platform. Deploy any Docker image—or start from pre-built environments.
On Demand
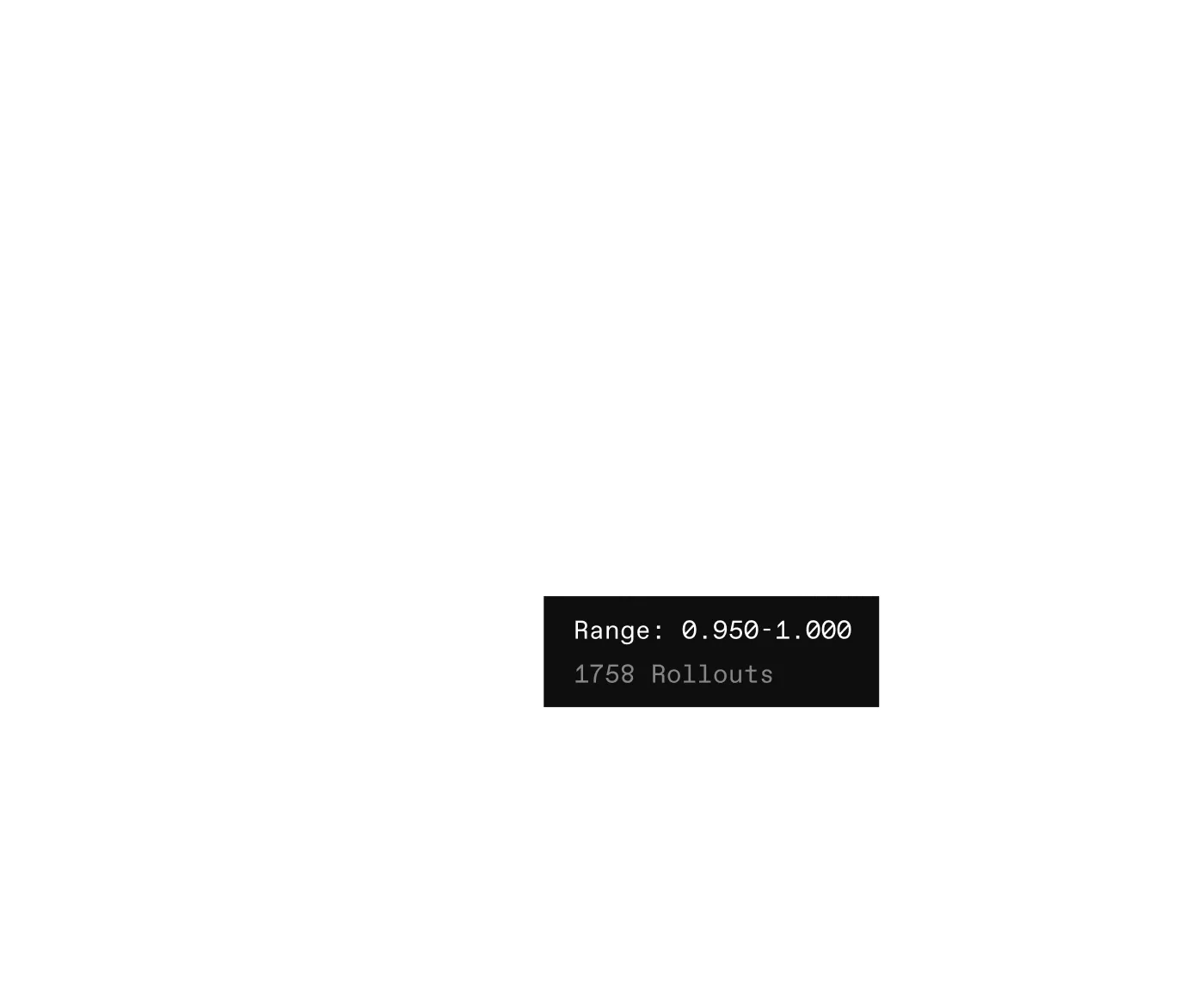
Request up to 256 GPUs instantly for training and reinforcement learning.


SLURM, K8s Orchestration
Orchestrate dynamic workloads with enterprise-grade scheduling and container automation.

Infiniband Networking
Scale distributed training with high-bandwidth interconnects across nodes.

Grafana Monitoring Dashboards
Visualize metrics in real time with customizable dashboards for full system observability.
Large-scale clusters of 8-5000+ GPUs
Request large-scale clusters from 50+ providers. Sell-back idle GPUs to our spot market.

Get quotes from 50+ datacenters within 24 hours.
Re-sell idle GPUs back to our spot market
Direct assistance from our research and infra engineering team.
Train, Evaluate, and Deploy Agentic Models

Train your own models
Train agentic models end-to-end with reinforcement learning inside of your own application. Build on hundreds of RL environments on our Hub.

Support for LoRA adapters and deploy your train models to a dedicated or
serverless API
Fully open-source stack, giving you full control and ownership
Leverage hundreds of open-source RL environments on our Hub
Spin up thousands of sandboxes for secure code execution with our natively integrated sandbox offering
Leverage our RL environments for your agentic model training
Access and contribute to our Environments Hub - with hundreds of open-source RL environments and a community of researchers and developers.



Our Contributions to the Frontier of Open-Source AI
Our end to end agent infrastructure allows you to build, share and train on RL environments with a full suite of tools to support.

.png)


Join Prime Intellect
We are seeking the most ambitious developers to join our team. Please send us examples of your exceptional work.
