Если вы считаете Colorama полезной, не забудьте поблагодарить ее авторов и сделать пожертвование. Спасибо!
Установка
pip install colorama
# или
conda install -c anaconda colorama
Описание
Управляющие символы ANSI давно используются для создания цветного текста и позиционирования курсора в терминале на Unix и Mac. Colorama делает возможным их использование на платформе Windows, оборачивая stdout, удаляя найденные ANSI-последовательности (которые будут выглядеть как тарабарщина при выводе) и преобразуя их в соответствующие вызовы win32 для изменения состояния командной строки. На других платформах Colorama ничего не меняет.
В результате мы получаем простой кроссплатформенный API для отображения цветного терминального текста из Python, а также следующий приятный побочный эффект: существующие приложения или библиотеки, использующие ANSI-последовательности для создания цветного вывода на Linux или Mac, теперь могут работать и на Windows, просто вызвав colorama.init().
Альтернативный подход заключается в установке ansi.sys на машины с Windows, что обеспечивает одинаковое поведение для всех приложений, работающих с командной строкой. Colorama предназначена для ситуаций, когда это не так просто (например, может быть, у вашего приложения нет программы установки).
Демо-скрипты в репозитории исходного кода библиотеки выводят небольшой цветной текст, используя последовательности ANSI. Сравните их работу в Gnome-terminal и в Windows Command-Prompt, где отображение осуществляется с помощью Colorama:
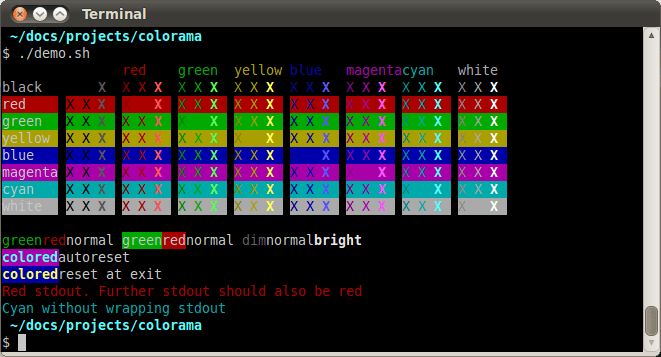
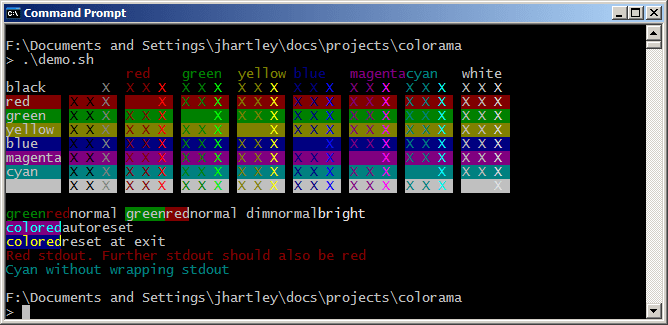
Эти скриншоты показывают, что в Windows Colorama не поддерживает ANSI ‘dim text’ (тусклый текст); он выглядит так же, как и ‘normal text’.
Использование
Инициализация
Приложения должны инициализировать Colorama с помощью:
from colorama import init
init()
В Windows вызов init() отфильтрует управляющие ANSI-последовательности из любого текста, отправленного в stdout или stderr, и заменит их на эквивалентные вызовы Win32.
На других платформах вызов init() не имеет никакого эффекта (если только вы не укажете другие дополнительные возможности; см. раздел «Аргументы Init», ниже). По задумке разработчиков такое поведение позволяет приложениям вызывать init() безоговорочно на всех платформах, после чего вывод ANSI должен просто работать.
Чтобы прекратить использование Colorama до выхода из программы, просто вызовите deinit(). Данный метод вернет stdout и stderr к их исходным значениям, так что Colorama будет отключена. Чтобы возобновить ее работу, используйте reinit(); это выгоднее, чем повторный вызов init() (но делает то же самое).
Цветной вывод
Кроссплатформенное отображение цветного текста может быть упрощено за счет использования константных обозначений для управляющих последовательностей ANSI, предоставляемых библиотекой Colorama:
from colorama import init
init()
from colorama import Fore, Back, Style
print(Fore.GREEN + 'зеленый текст')
print(Back.YELLOW + 'на желтом фоне')
print(Style.BRIGHT + 'стал ярче' + Style.RESET_ALL)
print('обычный текст')
При этом вы также можете использовать ANSI-последовательности напрямую в своем коде:
print('\033[31m' + 'красный текст')
print('\033[39m') # сброс к цвету по умолчанию
Еще одним вариантом является применение Colorama в сочетании с существующими ANSI библиотеками, такими как Termcolor или Blessings. Такой подход настоятельно рекомендуется для чего-то большего, чем тривиальное выделение текста:
from colorama import init
from termcolor import colored
# используйте Colorama, чтобы Termcolor работал и в Windows
init()
# теперь вы можете применять Termcolor для вывода
# вашего цветного текста
print(colored('Termcolor and Colorama!', 'red', 'on_yellow'))
Доступны следующие константы форматирования:
// цвет текста
Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
// цвет фона
Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
// яркость текста и общий сброс
Style: DIM, NORMAL, BRIGHT, RESET_ALL
Style.RESET_ALL сбрасывает настройки цвета текста, фона и яркости. Colorama выполнит этот сброс автоматически при выходе из программы.
Позиционирование курсора
Библиотекой поддерживаются ANSI-коды для изменения положения курсора. Пример их генерации смотрите в demos/demo06.py.
Аргументы Init
init() принимает некоторые **kwargs для переопределения поведения по умолчанию.
init(autoreset=False):
Если вы постоянно осуществляете сброс указанных вами цветовых настроек после каждого вывода, init(autoreset=True) будет выполнять это по умолчанию:
from colorama import init, Fore
init(autoreset=True)
print(Fore.GREEN + 'зеленый текст')
print('автоматический возврат к обычному')
init(strip=None):
Передайте True или False, чтобы определить, должны ли коды ANSI удаляться при выводе. Поведение по умолчанию — удаление, если программа запущена на Windows или если вывод перенаправляется (не на tty).
init(convert=None):
Передайте True или False, чтобы определить, следует ли преобразовывать ANSI-коды в выводе в вызовы win32. По умолчанию Colorama будет их конвертировать, если вы работаете под Windows и вывод осуществляется на tty (терминал).
init(wrap=True):
В Windows Colorama заменяет sys.stdout и sys.stderr прокси-объектами, которые переопределяют метод .write() для выполнения своей работы. Если эта обертка вызывает у вас проблемы, то ее можно отключить, передав init(wrap=False). Поведение по умолчанию — обертывание, если autoreset, strip или convert равны True.
Когда обертка отключена, цветной вывод на платформах, отличных от Windows, будет продолжать работать как обычно. Для кроссплатформенного цветного отображения текста можно использовать AnsiToWin32 прокси, предоставляемый Colorama, напрямую:
import sys
from colorama import init, Fore, AnsiToWin32
init(wrap=False)
stream = AnsiToWin32(sys.stderr).stream
# Python 2
print >>stream, Fore.RED + 'красный текст отправлен в stderr'
# Python 3
print(Fore.RED + 'красный текст отправлен в stderr', file=stream)
Распознаваемые ANSI-последовательности
Последовательности ANSI обычно имеют вид:
ESC [ <параметр> ; <параметр> ... <команда>
Где <параметр> — целое число, а <команда> — один символ. В <команда> передается ноль или более параметров. Если параметры не представлены, это, как правило, синоним передачи одного нуля. В последовательности нет пробелов; они были добавлены здесь исключительно для удобства чтения.
Единственные ANSI-последовательности, которые Colorama преобразует в вызовы win32, это:
ESC [ 0 m # сбросить все (цвета и яркость)
ESC [ 1 m # яркий
ESC [ 2 m # тусклый (выглядит так же, как обычная яркость)
ESC [ 22 м # нормальная яркость
# FOREGROUND (цвет текста)
ESC [ 30 м # черный
ESC [ 31 м # красный
ESC [ 32 м # зеленый
ESC [ 33 м # желтый
ESC [ 34 m # синий
ESC [ 35 m # пурпурный
ESC [ 36 m # голубой
ESC [ 37 m # белый
ESC [ 39 m # сброс
# ФОН
ESC [ 40 m # черный
ESC [ 41 m # красный
ESC [ 42 м # зеленый
ESC [ 43 m # желтый
ESC [ 44 m # синий
ESC [ 45 m # пурпурный
ESC [ 46 m # голубой
ESC [ 47 m # белый
ESC [ 49 m # сброс
# позиционирование курсора
ESC [ y;x H # позиционирование курсора в позиции x, y (у направлена вниз)
ESC [ y;x f # позиционирование курсора в точке x, y
ESC [ n A # перемещение курсора на n строк вверх
ESC [ n B # перемещение курсора на n строк вниз
ESC [ n C # перемещение курсора на n символов вперед
ESC [ n D # перемещение курсора на n символов назад
# очистить экран
ESC [ режим J # очистить экран
# очистить строку
ESC [ режим K # очистить строку
Несколько числовых параметров команды ‘m’ могут быть объединены в одну последовательность:
ESC [ 36 ; 45 ; 1 m # яркий голубой текст на пурпурном фоне
Все другие ANSI-последовательности вида ESC [ <параметр> ; <параметр> … <команда> молча удаляются из вывода в Windows.
Любые другие формы ANSI-последовательностей, такие как односимвольные коды или альтернативные начальные символы, не распознаются и не удаляются. Однако было бы здорово добавить их. Вы можете сообщить разработчикам, если это будет полезно для вас, через Issues на GitHub.
Текущий статус и известные проблемы
Лично я тестировал библиотеку только на Windows XP (CMD, Console2), Ubuntu (gnome-terminal, xterm) и OS X.
Некоторые предположительно правильные ANSI-последовательности не распознаются (см. подробности ниже), но, насколько мне известно, никто еще не жаловался на это. Загадка.
См. нерешенные проблемы и список пожеланий: https://github.com/tartley/colorama/issues
Если у вас что-то не работает или делает не то, что вы ожидали, авторы библиотеки будут рады услышать об этом в списке проблем, указанном выше, также они с удовольствием ждут и предоставляют доступ к коммиту любому, кто напишет один или, может, пару рабочих патчей.
]]>Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
Преимущества использования Apache Spark:
- Он запускает программы в памяти до 100 раз быстрее, чем Hadoop MapReduce, и в 10 раз быстрее на диске, потому что Spark выполняет обработку в основной памяти рабочих узлов и предотвращает ненужные операции ввода-вывода.
- Spark крайне удобен для пользователя, поскольку имеет API-интерфейсы, написанные на популярных языках, что упрощает задачу для разработчиков: такой подход скрывает сложность распределенной обработки за простыми высокоуровневыми операторами, что значительно снижает объем необходимого кода.
- Систему можно развернуть, используя Mesos, Hadoop через Yarn или собственный диспетчер кластеров Spark.
- Spark производит вычисления в реальном времени и обеспечивает низкую задержку благодаря их резидентному выполнению (в памяти).
Давайте приступим.
Настройка среды в Google Colab
Чтобы запустить pyspark на локальной машине, нам понадобится Java и еще некоторое программное обеспечение. Поэтому вместо сложной процедуры установки мы используем Google Colaboratory, который идеально удовлетворяет наши требования к оборудованию, и также поставляется с широким набором библиотек для анализа данных и машинного обучения. Таким образом, нам остается только установить пакеты pyspark и Py4J. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически обращаться к объектам Java из виртуальной машины Java.
Итоговый ноутбук можно скачать в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/pyspark_beginner.ipynb
Команда для установки вышеуказанных пакетов:
!pip install pyspark==3.0.1 py4j==0.10.9Spark Session
SparkSession стал точкой входа в PySpark, начиная с версии 2.0: ранее для этого использовался SparkContext. SparkSession — это способ инициализации базовой функциональности PySpark для программного создания PySpark RDD, DataFrame и Dataset. Его можно использовать вместо SQLContext, HiveContext и других контекстов, определенных до 2.0.
Вы также должны знать, что SparkSession внутренне создает SparkConfig и SparkContext с конфигурацией, предоставленной с SparkSession. SparkSession можно создать с помощью SparkSession.builder, который представляет собой реализацию шаблона проектирования Builder (Строитель).
Создание SparkSession
Чтобы создать SparkSession, вам необходимо использовать метод builder().
getOrCreate()возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.master(): если вы работаете с кластером, вам нужно передать имя своего кластерного менеджера в качестве аргумента. Обычно это будет либоyarn, либоmesosв зависимости от настройки вашего кластера, а при работе в автономном режиме используетсяlocal[x]. Здесь X должно быть целым числом, большим 0. Данное значение указывает, сколько разделов будет создано при использовании RDD, DataFrame и Dataset. В идеалеXдолжно соответствовать количеству ядер ЦП.appName()используется для установки имени вашего приложения.
Пример создания SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark_Tutorial')\
.getOrCreate()
# где "*" обозначает все ядра процессора.
Чтение данных
Используя spark.read мы может считывать данные из файлов различных форматов, таких как CSV, JSON, Parquet и других. Вот несколько примеров получения данных из файлов:
# Чтение CSV файла
csv_file = 'data/stocks_price_final.csv'
df = spark.read.csv(csv_file)
# Чтение JSON файла
json_file = 'data/stocks_price_final.json'
data = spark.read.json(json_file)
# Чтение parquet файла
parquet_file = 'data/stocks_price_final.parquet'
data1 = spark.read.parquet(parquet_file)
Структурирование данных с помощью схемы Spark
Давайте прочитаем данные о ценах на акции в США с января 2019 года по июль 2020 года, которые доступны в датасетах Kaggle.
Код для чтения данных в формате файла CSV:
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
)
data.printSchema()
Теперь посмотрим на схему данных с помощью метода PrintSchema.
Схема Spark отображает структуру фрейма данных или датасета. Мы можем определить ее с помощью класса StructType, который представляет собой коллекцию объектов StructField. Они в свою очередь устанавливают имя столбца (String), его тип (DataType), допускает ли он значение NULL (Boolean), и метаданные (MetaData).
Это бывает довольно полезно, даже учитывая, что Spark автоматически выводит схему из данных, так как иногда предполагаемый им тип может быть неверным, или нам необходимо определить собственные имена столбцов и типы данных. Такое часто случается при работе с полностью или частично неструктурированными данными.
Давайте посмотрим, как мы можем структурировать наши данные:
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('data', DateType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields = data_schema)
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
schema=final_struc
)
data.printSchema()
В приведенном выше коде создается структура данных с помощью StructType и StructField. Затем она передается в качестве параметра schema методу spark.read.csv(). Давайте взглянем на полученную в результате схему структурированных данных:
root
|-- _c0: integer (nullable = true)
|-- symbol: string (nullable = true)
|-- data: date (nullable = true)
|-- open: double (nullable = true)
|-- high: double (nullable = true)
|-- low: double (nullable = true)
|-- close: double (nullable = true)
|-- volume: integer (nullable = true)
|-- adjusted: double (nullable = true)
|-- market.cap: string (nullable = true)
|-- sector: string (nullable = true)
|-- industry: string (nullable = true)
|-- exchange: string (nullable = true)Различные методы инспекции данных
Существуют следующие методы инспекции данных: schema, dtypes, show, head, first, take, describe, columns, count, distinct, printSchema. Давайте разберемся в них на примере.
schema(): этот метод возвращает схему данных (фрейма данных). Ниже показан пример с ценами на акции.
data.schema
# -------------- Вывод ------------------
# StructType(
# List(
# StructField(_c0,IntegerType,true),
# StructField(symbol,StringType,true),
# StructField(data,DateType,true),
# StructField(open,DoubleType,true),
# StructField(high,DoubleType,true),
# StructField(low,DoubleType,true),
# StructField(close,DoubleType,true),
# StructField(volume,IntegerType,true),
# StructField(adjusted,DoubleType,true),
# StructField(market_cap,StringType,true),
# StructField(sector,StringType,true),
# StructField(industry,StringType,true),
# StructField(exchange,StringType,true)
# )
# )
dtypesвозвращает список кортежей с именами столбцов и типами данных.
data.dtypes
#------------- Вывод ------------
# [('_c0', 'int'),
# ('symbol', 'string'),
# ('data', 'date'),
# ('open', 'double'),
# ('high', 'double'),
# ('low', 'double'),
# ('close', 'double'),
# ('volume', 'int'),
# ('adjusted', 'double'),
# ('market_cap', 'string'),
# ('sector', 'string'),
# ('industry', 'string'),
# ('exchange', 'string')]
head(n)возвращает n строк в виде списка. Вот пример:
data.head(3)
# ---------- Вывод ---------
# [
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0, close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=2, symbol='TXG', data=datetime.date(2019, 9, 13), open=52.75, high=54.355, low=49.150002, close=52.27, volume=1025200, adjusted=52.27, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=3, symbol='TXG', data=datetime.date(2019, 9, 16), open=52.450001, high=56.0, low=52.009998, close=55.200001, volume=269900, adjusted=55.200001, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
# ]
show()по умолчанию отображает первые 20 строк, а также принимает число в качестве параметра для выбора их количества.first()возвращает первую строку данных.
data.first()
# ----------- Вывод -------------
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0,
# close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods',
# industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
take(n)возвращает первые n строк.describe()вычисляет некоторые статистические значения для столбцов с числовым типом данных.columnsвозвращает список, содержащий названия столбцов.
data.columns
# --------------- Вывод --------------
# ['_c0',
# 'symbol',
# 'data',
# 'open',
# 'high',
# 'low',
# 'close',
# 'volume',
# 'adjusted',
# 'market_cap',
# 'sector',
# 'industry',
# 'exchange']count()возвращает общее число строк в датасете.
data.count()
# возвращает количество строк данных
# -------- Вывод ---------
# 1292361distinct()— количество различных строк в используемом наборе данных.printSchema()отображает схему данных.
df.printSchema()
# ------------ Вывод ------------
# root
# |-- _c0: integer (nullable = true)
# |-- symbol: string (nullable = true)
# |-- data: date (nullable = true)
# |-- open: double (nullable = true)
# |-- high: double (nullable = true)
# |-- low: double (nullable = true)
# |-- close: double (nullable = true)
# |-- volume: integer (nullable = true)
# |-- adjusted: double (nullable = true)
# |-- market_cap: string (nullable = true)
# |-- sector: string (nullable = true)
# |-- industry: string (nullable = true)
# |-- exchange: string (nullable = true)Манипуляции со столбцами
Давайте посмотрим, какие методы используются для добавления, обновления и удаления столбцов данных.
1. Добавление столбца: используйте withColumn, чтобы добавить новый столбец к существующим. Метод принимает два параметра: имя столбца и данные. Пример:
data = data.withColumn('date', data.data)
data.show(5)
2. Обновление столбца: используйте withColumnRenamed, чтобы переименовать существующий столбец. Метод принимает два параметра: название существующего столбца и его новое имя. Пример:
data = data.withColumnRenamed('date', 'data_changed')
data.show(5)
3. Удаление столбца: используйте метод drop, который принимает имя столбца и возвращает данные.
data = data.drop('data_changed')
data.show(5)
Работа с недостающими значениями
Мы часто сталкиваемся с отсутствующими значениями при работе с данными реального времени. Эти пропущенные значения обозначаются как NaN, пробелы или другие заполнители. Существуют различные методы работы с пропущенными значениями, некоторые из самых популярных:
- Удаление: удалить строки с пропущенными значениями в любом из столбцов.
- Замена средним/медианным значением: замените отсутствующие значения, используя среднее или медиану соответствующего столбца. Это просто, быстро и хорошо работает с небольшими наборами числовых данных.
- Замена на наиболее частые значения: как следует из названия, используйте наиболее часто встречающееся значение в столбце, чтобы заменить отсутствующие. Это хорошо работает с категориальными признаками, но также может вносить смещение (bias) в данные.
- Замена с использованием KNN: метод K-ближайших соседей — это алгоритм классификации, который рассчитывает сходство признаков новых точек данных с уже существующими, используя различные метрики расстояния, такие как Евклидова, Махаланобиса, Манхэттена, Минковского, Хэмминга и другие. Такой подход более точен по сравнению с вышеупомянутыми методами, но он требует больших вычислительных ресурсов и довольно чувствителен к выбросам.
Давайте посмотрим, как мы можем использовать PySpark для решения проблемы отсутствующих значений:
# Удаление строк с пропущенными значениями
data.na.drop()
# Замена отсутствующих значений средним
data.na.fill(data.select(f.mean(data['open'])).collect()[0][0])
# Замена отсутствующих значений новыми
data.na.replace(old_value, new_vallue)
Получение данных
PySpark и PySpark SQL предоставляют широкий спектр методов и функций для удобного запроса данных. Вот список наиболее часто используемых методов:
- Select
- Filter
- Between
- When
- Like
- GroupBy
- Агрегирование
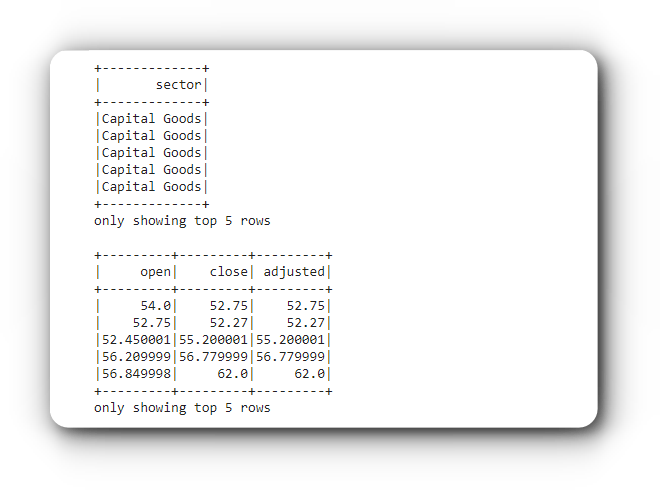
Select
Он используется для выбора одного или нескольких столбцов, используя их имена. Вот простой пример:
# Выбор одного столбца
data.select('sector').show(5)
# Выбор нескольких столбцов
data.select(['open', 'close', 'adjusted']).show(5)
Filter
Данный метод фильтрует данные на основе заданного условия. Вы также можете указать несколько условий, используя операторы AND (&), OR (|) и NOT (~). Вот пример получения данных о ценах на акции за январь 2020 года.
from pyspark.sql.functions import col, lit
data.filter( (col('data') >= lit('2020-01-01')) & (col('data') <= lit('2020-01-31')) ).show(5)
Between
Этот метод возвращает True, если проверяемое значение принадлежит указанному отрезку, иначе — False. Давайте посмотрим на пример отбора данных, в которых значения adjusted находятся в диапазоне от 100 до 500.
data.filter(data.adjusted.between(100.0, 500.0)).show()
When
Он возвращает 0 или 1 в зависимости от заданного условия. В приведенном ниже примере показано, как выбрать такие цены на момент открытия и закрытия торгов, при которых скорректированная цена была больше или равна 200.
data.select('open', 'close',
f.when(data.adjusted >= 200.0, 1).otherwise(0)
).show(5)
Like
Этот метод похож на оператор Like в SQL. Приведенный ниже код демонстрирует использование rlike() для извлечения имен секторов, которые начинаются с букв M или C.
data.select(
'sector',
data.sector.rlike('^[B,C]').alias('Колонка sector начинается с B или C')
).distinct().show()
GourpBy
Само название подсказывает, что данная функция группирует данные по выбранному столбцу и выполняет различные операции, такие как вычисление суммы, среднего, минимального, максимального значения и т. д. В приведенном ниже примере объясняется, как получить среднюю цену открытия, закрытия и скорректированную цену акций по отраслям.
data.select(['industry', 'open', 'close', 'adjusted'])\
.groupBy('industry')\
.mean()\
.show()
Агрегирование
PySpark предоставляет встроенные стандартные функции агрегации, определенные в API DataFrame, они могут пригодится, когда нам нужно выполнить агрегирование значений ваших столбцов. Другими словами, такие функции работают с группами строк и вычисляют единственное возвращаемое значение для каждой группы.
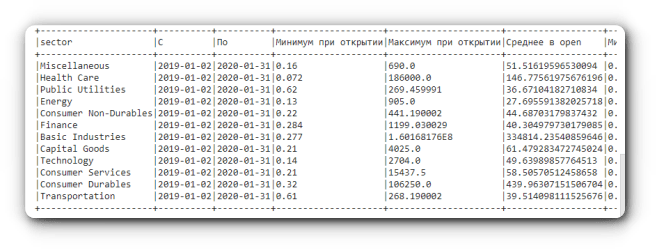
В приведенном ниже примере показано, как отобразить минимальные, максимальные и средние значения цен открытия, закрытия и скорректированных цен акций в промежутке с января 2019 года по январь 2020 года для каждого сектора.
from pyspark.sql import functions as f
data.filter((col('data') >= lit('2019-01-02')) & (col('data') <= lit('2020-01-31')))\
.groupBy("sector") \
.agg(f.min("data").alias("С"),
f.max("data").alias("По"),
f.min("open").alias("Минимум при открытии"),
f.max("open").alias("Максимум при открытии"),
f.avg("open").alias("Среднее в open"),
f.min("close").alias("Минимум при закрытии"),
f.max("close").alias("Максимум при закрытии"),
f.avg("close").alias("Среднее в close"),
f.min("adjusted").alias("Скорректированный минимум"),
f.max("adjusted").alias("Скорректированный максимум"),
f.avg("adjusted").alias("Среднее в adjusted"),
).show(truncate=False)
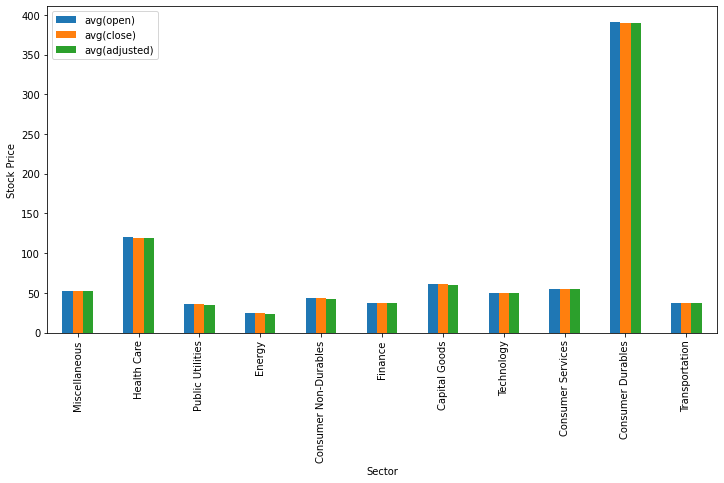
Визуализация данных
Для визуализации данных мы воспользуемся библиотеками matplotlib и pandas. Метод toPandas() позволяет нам осуществить преобразование данных в dataframe pandas, который мы используем при вызове метода визуализации plot(). В приведенном ниже коде показано, как отобразить гистограмму, отображающую средние значения цен открытия, закрытия и скорректированных цен акций для каждого сектора.
from matplotlib import pyplot as plt
sec_df = data.select(['sector',
'open',
'close',
'adjusted']
)\
.groupBy('sector')\
.mean()\
.toPandas()
ind = list(range(12))
ind.pop(6)
sec_df.iloc[ind ,:].plot(kind='bar', x='sector', y=sec_df.columns.tolist()[1:],
figsize=(12, 6), ylabel='Stock Price', xlabel='Sector')
plt.show()
Теперь давайте визуализируем те же средние показатели, но уже по отраслям.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
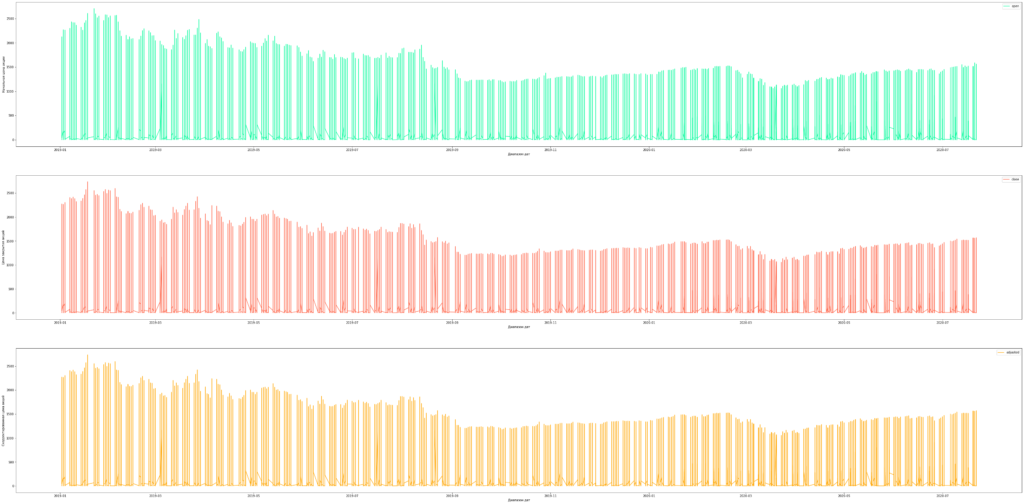
Также построим временные ряды для средних цен открытия, закрытия и скорректированных цен акций технологического сектора.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Запись/сохранение данных в файл
Метод write.save() используется для сохранения данных в различных форматах, таких как CSV, JSVON, Parquet и других. Давайте рассмотрим, как записать данные в файлы разных форматов. Мы можем сохранить как все строки, так и только выбранные с помощью метода select().
# CSV
data.write.csv('dataset.csv')
# JSON
data.write.save('dataset.json', format='json')
# Parquet
data.write.save('dataset.parquet', format='parquet')
# Запись выбранных данных в различные форматы файлов
# CSV
data.select(['data', 'open', 'close', 'adjusted'])\
.write.csv('dataset.csv')
# JSON
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.json', format='json')
# Parquet
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.parquet', format='parquet')
Заключение
PySpark — отличный инструмент для специалистов по данным, поскольку он обеспечивает масштабируемые анализ и ML-пайплайны. Если вы уже знакомы с Python, SQL и Pandas, тогда PySpark — хороший вариант для быстрого старта.
В этой статье было показано, как следует выполнять широкий спектр операций, начиная с чтения файлов и заканчивая записью результатов с помощью PySpark. Также мы охватили основные методы визуализации с использованием библиотеки matplotlib.
Мы узнали, что Google Colaboratory Notebooks — это удобное место для начала изучения PySpark без долгой установки необходимого программного обеспечения. Не забудьте ознакомиться с представленными ниже ссылками на ресурсы, которые могут помочь вам быстрее и проще изучить PySpark.
Также не стесняйтесь использовать предоставленный в статье код, доступ к которому можно получить, перейдя на Gitlab. Удачного обучения.
]]>Gensim может работать с большими текстовыми коллекциями. Этим она отличается от других программных библиотек машинного обучения, ориентированных на обработку в памяти. GenSim также предоставляет эффективные многоядерные реализации различных алгоритмов для увеличения скорости обработки. В нее добавлены более удобные средства для обработки текста, чем у конкурентов, таких как Scikit-learn, R и т. д.
В этом руководстве будут рассмотрены следующие концепции:
- Создание корпуса из заданного датасета.
- Матрицы TFIDF в Gensim.
- Создание биграммы и триграммы с помощью Gensim.
- Модели Word2Vec, с использованием Gensim.
- Модели Doc2Vec, с использованием Gensim.
- Создание тематической модели с LDA.
- Создание тематической модели с LSI.
Прежде чем двигаться дальше, давайте разберемся, что означают следующие термины:
- Корпус: коллекция текстовых документов.
- Вектор: форма представления текста.
- Модель: алгоритм, используемый для генерации представления данных.
- Тематическое моделирование: инструмент интеллектуального анализа информации, который используется для извлечения семантических тем из документов.
- Тема: повторяющаяся группа слов, часто встречающихся вместе.
Например:
У вас есть документ, состоящий из таких слов, как:
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid.
Их можно сгруппировать по разным темам:
| Тема 1 | Тема 2 | Тема 3 |
|---|---|---|
| glass | bat | car |
| cup | racquet | drive |
| water | score | keys |
| liquid | game | sterring |
Некоторые из методов тематического моделирования:
- Латентно-семантический анализ (LSI)
- Латентное размещение Дирихле (LDA)
Теперь, когда у нас есть базовое понимание терминологии, давайте перейдем к использованию пакета Gensim. Сначала установите библиотеку с помощью следующих команд:
pip install gensim
# или
conda install gensimШаг 1. Создайте корпус из заданного датасета
Вам необходимо выполнить следующие шаги, чтобы создать свою коллекцию документов:
- Загрузите выбранный датасет.
- Проведите предварительную обработку вашего набора данных.
- Создайте словарь.
- Создайте Bag of Words.
1.1 Загрузите выбранный датасет:
У вас может быть файл .txt в качестве набора данных или вы также можете загрузить необходимые датасеты с помощью API Gensim Downloader.
import os
# прочитать текстовый файл как объект
doc = open('sample_data.txt', encoding ='utf-8')
Gensim Downloader API – это модуль, доступный в библиотеке Gensim, который представляет собой API для скачивания, получения информации и загрузки датасетов/моделей.
import gensim.downloader as api
# проверка имеющихся моделей и датасетов
info_datasets = api.info()
print(info_datasets)
# информация ы конкретном наборе данных
dataset_info = api.info("text8")
# загрузка набора данных "text8"
dataset = api.load("text8")
# загрузка предварительно обученной модели
word2vec_model = api.load('word2vec-google-news-300')
Здесь мы будем использовать текстовый файл как необработанный набор данных, которые представляют собой текст со страницы Википедии.
1.2 Предварительная обработка набора данных
В NLP под предварительной обработкой текста понимают процесс очистки и подготовки текстовых данных. Для этого мы воспользуемся функцией simple_preprocess(), которая возвращает список токенов после их токенизации и нормализации.
import gensim
import os
from gensim.utils import simple_preprocess
# прочитать текстовый файл как объект
doc = open('nlp-wiki.txt', encoding ='utf-8')
# предварительная обработка файла для получения списка токенов
tokenized = []
for sentence in doc.read().split('.'):
# функция simple_preprocess возвращает список слов каждого предложения
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
doc.close()
Токенизированный вывод:
[['the', 'history', 'of', 'natural', 'language', 'processing', 'generally', 'started', 'in', 'the', 'although', 'work', 'can', 'be', 'found', 'from', 'earlier', 'periods'], ['in', 'alan', 'turing', 'published', 'an', 'article', 'titled', 'intelligence', 'which', 'proposed', 'what', 'is', 'now', 'called', 'the', 'turing', 'test', 'as', 'criterion', 'of', 'intelligence'], ['the', 'georgetown', 'experiment', 'in', 'involved', 'fully', 'automatic', 'translation', 'of', 'more', 'than', 'sixty', 'russian', 'sentences', 'into', 'english'], ['the', 'authors', 'claimed', 'that', 'within', 'three', 'or', 'five', 'years', 'machine', 'translation', 'would', 'be', 'solved', 'problem'],
...1.3 Создание словаря
Теперь у нас есть предварительно обработанные данные, которые можно преобразовать в словарь с помощью функции corpora.Dictionary(). Этот словарь представляет собой коллекцию уникальных токенов.
from gensim import corpora
# сохранение извлеченных токенов в словарь
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)
Dictionary(410 unique tokens: ['although', 'be', 'can', 'earlier', 'found']...)
1.3.1 Сохранение словаря
Вы можете сохранить (или загрузить) свой словарь на диске напрямую, а также в виде текстового файла, как показано ниже:
# сохраните словарь на диске
my_dictionary.save('my_dictionary.dict')
# загрузите обратно
load_dict = corpora.Dictionary.load('my_dictionary.dict')
# сохраните словарь в текстовом файле
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# загрузите текстовый файл с вашим словарем
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
1.4 Создание Bag of Words
Когда у нас есть словарь, мы можем создать корпус Bag of Words с помощью функции doc2bow(). Эта функция подсчитывает число вхождений и генерирует целочисленный идентификатор для каждого слова. Результат возвращается в виде разреженного вектора.
# преобразование в слов Bag of Word
bow_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(bow_corpus)
[[(0, 1), (1, 1), (2, 1),
...
(407, 1), (408, 1), (409, 1)], []]
1.4.1 Сохранение корпуса на диск
Код для сохранения/загрузки вашего корпуса:
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# сохранение корпуса на диск
MmCorpus.serialize(output_fname, bow_corpus)
# загрузка корпуса
load_corpus = MmCorpus(output_fname)
Шаг 2: Создание матрицы TF-IDF в Gensim
TF-IDF (Term Frequency – Inverse Document Frequency) – это часто используемая модель обработки естественного языка, которая помогает вам определять самые важные слова для каждого документа в корпусе. Она была разработана для коллекций небольшого размера.
Некоторые слова могут не являться стоп-словами, но при этом довольно часто встречаться в документах, имея малую значимость. Следовательно, эти слова необходимо удалить или снизить их важность. Модель TFIDF берет текст, написанный на одном языке, и гарантирует, что наиболее распространенные слова во всем корпусе не будут отображаться в качестве ключевых слов.
Вы можете построить модель TFIDF, используя Gensim и корпус, который вы разработали ранее, следующий образом:
from gensim import models
import numpy as np
# Вес слова в корпусе Bag of Word
word_weight =[]
for doc in bow_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)
Вес слов перед применением TF-IDF:
[['although', 1], ['be', 1], ['can', 1], ['earlier', 1],
...
['steps', 1], ['term', 1], ['transformations', 1]]Код (применение модели TF-IDF):
# создать модель TF-IDF
tfIdf = models.TfidfModel(bow_corpus, smartirs ='ntc')
# TF-IDF вес слова
weight_tfidf =[]
for doc in tfIdf[bow_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals=3)])
print(weight_tfidf)
Вес слов после применением TF-IDF:
[['although', 0.339], ['be', 0.19], ['can', 0.237], ['earlier', 0.339],
...
['steps', 0.191], ['term', 0.191], ['transformations', 0.191]]
Вы можете видеть, что словам, часто встречающимся в документах, теперь присвоены более низкие веса.
Шаг 3. Создание биграмм и триграмм с помощью Gensim
Многие слова употребляются в тексте вместе. Такие сочетания имеют другое значение, чем составляющие их слова по отдельности.
Например:
Beatboxing -> слова beat и boxing имеют собственные смысловые вариации, но вместе они представляют совсем иное значение.
Биграмма — группа из двух слов.
Триграмма — группа из трех слов.
Здесь мы будем использовать датасет text8, который можно загрузить с помощью API downloader Gensim. Код построения биграмм и триграмм:
import gensim.downloader as api
from gensim.models.phrases import Phrases
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Биграм с использованием модели фразера
bigram_model = Phrases(data, min_count=3, threshold=10)
print(bigram_model[data[0]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working_class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans_culottes', 'of', 'the', 'french_revolution', 'whilst', 'the', 'term', 'is', 'still' ...Для создания триграмм мы просто передаем полученную выше биграммную модель той же функции.
# Триграмма с использованием модели фразы
trigram_model = Phrases(bigram_model[data], threshold=10)
# Триграмма
print(trigram_model[bigram_model[data[0]]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early' ...Шаг 4: Создайте модель Word2Vec с помощью Gensim
Алгоритмы ML/DL не могут использовать текст напрямую, поэтому нам нужно некоторое числовое представление, чтобы эти алгоритмы могли обрабатывать данные. В простых приложениях машинного обучения используются CountVectorizer и TFIDF, которые не сохраняют связь между словами.
Word2Vec — метод преобразования текста для создания векторных представлений (Word Embeddings), которые отображают все слова, присутствующие в языке, в векторное пространство заданной размерности. Мы можем выполнять математические операции с этими векторами, которые помогают сохранить связь между словами.
Пример: queen — women + man = king.
Готовые векторно-семантические модели, такие как word2vec, GloVe, fasttext и другие можно загрузить с помощью API загрузчика Gensim. Иногда векторные представления определенных слов из вашего документа могут отсутствовать в упомянутых пакетах. Но вы можете решить данную проблему, обучив свою модель.
4.1) Обучение модели
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Разделим данные на две части
data_1 = data[:1200] # используется для обучения модели
data_2 = data[1200:] # используется для обновления модели
# Обучение модели Word2Vec
w2v_model = Word2Vec(data_1, min_count=0, workers=cpu_count())
# вектор слов для слова "время"
print(w2v_model.wv['time'])
Вектор для слова «time»:
[-0.04681756 -0.08213229 1.0628034 -1.0186515 1.0779341 -0.89710116
0.6538859 -0.81849015 -0.29984367 0.55887854 2.138567 -0.93843514
...
-1.4128548 -1.3084044 0.94601256 0.27390406 0.6346426 -0.46116787
0.91097695 -3.597664 0.6901859 1.0902803 ]Вы также можете использовать функцию most_similar(), чтобы найти слова, похожие на переданное.
# слова, похожие на "time"
print(w2v_model.wv.most_similar('time'))
# сохранение и загрузка модели
w2v_model.save('Word2VecModel')
model = Word2Vec.load('Word2VecModel')
Cлова, наиболее похожие на «time»:
[('moment', 0.6137239933013916), ('period', 0.5904807448387146), ('stage', 0.5393826961517334), ('decade', 0.51670902967453), ('lifetime', 0.4878680109977722), ('once', 0.4843854010105133), ('distance', 0.4821343719959259), ('breteuil', 0.4815649390220642), ('preestablished', 0.47662678360939026), ('point', 0.4757876396179199)]4.2) Обновление модели
# построим словарный запас по образцу из последовательности предложений
w2v_model.build_vocab(data_2, update=True)
# обучение вектора слов
w2v_model.train(data_2, total_examples=w2v_model.corpus_count, epochs=w2v_model.epochs)
print(w2v_model.wv['time'])
На выходе вы получите новые веса для слов.
Шаг 5: Создание модели Doc2Vec с помощью Gensim
В отличие от модели Word2Vec, модель Doc2Vec генерирует векторное представление для всего документа или группы слов. С помощью этой модели мы можем найти взаимосвязь между различными документами, как показано ниже:
Если натренировать модель на литературе типа «Алиса в Зазеркалье». Мы можем сказать, что
Алиса в Зазеркалье == Алиса в Стране чудес.
5.1) Обучите модель
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# получить датасета
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# Для обучения модели нам нужен список целевых документов
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# тренировочные данные
data_train = list(tagged_document(data))
# вывести обученный набор данных
print(data_train[:1])
Вывод – обученный датасет.
5.2) Обновите модель
# Инициализация модели
d2v_model = doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
# расширить словарный запас
d2v_model.build_vocab(data_train)
# Обучение модели Doc2Vec
d2v_model.train(data_train, total_examples=d2v_model.corpus_count, epochs=d2v_model.epochs)
# Анализ выходных данных
analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(analyze)
Вывод обновленной модели:
[-3.79053354e-02 -1.03341974e-01 -2.85615563e-01 1.37473553e-01
1.79868549e-01 3.42468806e-02 -1.68495290e-02 -1.86038092e-01
...
-1.20517321e-01 -1.48323074e-01 -5.70210926e-02 -2.15077385e-01]Шаг 6. Создание тематической модели с помощью LDA
LDA – популярный метод тематического моделирования, при котором каждый документ рассматривается как совокупность тем в определенной пропорции. Нам нужно вывести полезные качества тем, например, насколько они разделены и значимы. Темы хорошего качества зависят от:
- качества обработки текста,
- нахождения оптимального количества тем,
- настройки параметров алгоритма.
Выполните следующие шаги, чтобы создать модель.
6.1 Подготовка данных
Это делается путем удаления стоп-слов и последующей лемматизации ваших данных. Чтобы выполнить лемматизацию с помощью Gensim, нам нужно сначала загрузить пакет шаблонов и стоп-слова.
pip install pattern
# в python консоле
>>> import nltk
>>> nltk.download('stopwords')
import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level=logging.INFO)
# загрузка stopwords
stop_words = stopwords.words('english')
# добавление stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
lemmatizer = WordNetLemmatizer()
# загрузка датасета
dataset = api.load("text8")
data = [w for w in dataset]
# подготовка данных
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # для удаления стоп-слов
lemmatized_word = lemmatizer.lemmatize(word) # лемматизация
if lemmatized_word:
print
doc_out.append(lemmatized_word)
else:
continue
processed_data.append(doc_out) # processed_data это список слов
# вывод образца
print(processed_data[0][:10])
['anarchism', 'originated', 'term', 'abuse', 'first', 'used', 'early', 'working', 'class', 'radical']6.2 Создание словаря и корпуса
Обработанные данные теперь будут использоваться для создания словаря и корпуса.
dictionary = corpora.Dictionary(processed_data)
corpus = [dictionary.doc2bow(l) for l in processed_data]
6.3 Обучение LDA-модели
Мы будем обучать модель LDA с 5 темами, используя словарь и корпус, созданные ранее. Здесь используется функция LdaModel(), но вы также можете использовать функцию LdaMulticore(), поскольку она позволяет выполнять параллельную обработку.
# Обучение
LDA_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=5)
# сохранение модели
LDA_model.save('LDA_model.model')
# показать темы
print(LDA_model.print_topics(-1))
Слова, которые встречаются в более чем одной теме и имеют малое значение, могут быть добавлены в список запрещенных слов.
6.4 Интерпретация вывода
Модель LDA в основном дает нам информацию по трем направлениям:
- Темы в документе
- К какой теме принадлежит каждое слово
- Значение фи
Значением фи является вероятность того, что слово относится к определенной теме. Для выбранного слова сумма значений фи дает количество раз, оно встречается в документе.
# вероятность принадлежности слова к теме
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# сначала преобразуйте в bag of words
bow = LDA_model.id2word.doc2bow(bow_list)
# интерпретация данных
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics=True)
Шаг 7. Создание тематической модели с помощью LSI
Чтобы создать модель с LSI, просто выполните те же шаги, что и с LDA.
Только для обучения используйте функцию LsiModel() вместо LdaMulticore() или LdaModel().
from gensim.models import LsiModel
# Обучение модели с помощью LSI
LSI_model = LsiModel(corpus=corpus, id2word=dictionary, num_topics=7, decay=0.5)
# темы
print(LSI_model.print_topics(-1))
Заключение
Это только некоторые из возможностей библиотеки Gensim. Пользоваться ими очень удобно, особенно когда вы занимаетесь NLP. Вы, конечно, можете применять их по своему усмотрению.
]]>При использовании SQLAlchemy ORM взаимодействие с базой данных происходит через объект Session. Он также захватывает соединение с базой данных и транзакции. Транзакция неявно стартует как только Session начинает общаться с базой данных и остается открытой до тех пор, пока Session не коммитится, откатывается или закрывается.
Для создания объекта session можно использовать класс Session из sqlalchemy.orm.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
Создавать объект Session нужно будет каждый раз при взаимодействии с базой.
Конструктор Session принимает определенное количество аргументов, которые определяют режим его работы. Если создать сессию таким способом, то в дальнейшем конструктор Session нужно будет вызывать с одним и тем же набором параметров.
Чтобы упростить этот процесс, SQLAlchemy предоставляет класс sessionmaker, который создает класс Session с аргументами для конструктора по умолчанию.
from sqlalchemy.orm import Session, sessionmaker
session = sessionmaker(bind=engine)
Нужно просто вызвать sessionmaker один раз в глобальной области видимости.
Получив доступ к этому классу Session раз, можно создавать его экземпляры любое количество раз, не передавая параметры.
session = Session()Обратите внимание на то, что объект Session не сразу устанавливает соединение с базой данных. Это происходит лишь при первом запросе.
Вставка(добавление) данных
Для создания новой записи с помощью SQLAlchemy ORM нужно выполнить следующие шаги:
- Создать объект
- Добавить его в сессию
- Сохранить сессию
Создадим два новых объекта Customer:
c1 = Customer(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com'
)
c2 = Customer(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com'
)
print(c1.first_name, c2.last_name)
session.add(c1)
session.add(c2)
print(session.new)
session.commit()
Первый вывод: Dmitriy Golyshkin.
Два объекта созданы. Получить доступ к их атрибутам можно с помощью оператора точки (.).
Дальше в сессию добавляются объекты.
session.add(c1)
session.add(c2)Но добавление объектов не влияет на запись в базу, а лишь готовит объекты к сохранению в следующем коммите. Проверить это можно, получив первичные ключи объектов.
Значение атрибута id обоих объектов — None. Это значит, что они еще не сохранены в базе данных.
Вместо добавления одного объекта за раз можно использовать метод add_all(). Он принимает список объектов, которые будут добавлены в сессию.
session.add_all([c1, c2])Добавление объекта в сессию несколько раз не приводит к ошибкам. В любой момент на имеющиеся объекты можно посмотреть с помощью session.new.
IdentitySet([<__main__.Customer object at 0x000001BD25928C40>, <__main__.Customer object at 0x000001BD25928C70>])Наконец, для сохранения данных используется метод commit():
session.commit()После сохранения транзакции ресурсы соединения, на которые ссылается объект Session, возвращаются в пул соединений. Последующие операции будут выполняться в новой транзакции.
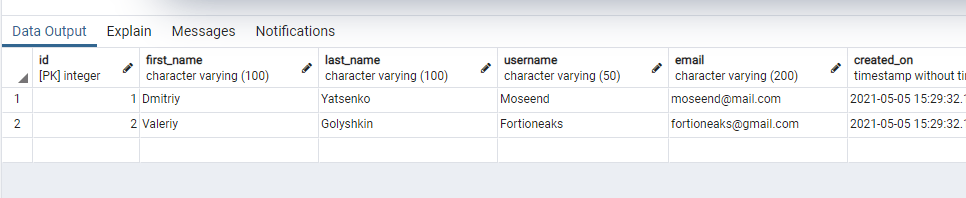
Сейчас таблица Customer выглядит вот так:
Пока что покупатели ничего не приобрели. Поэтому c1.orders и c2.orders вернут пустой список.
[] []Добавим еще потребителей в таблицу customers:
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
c3 = Customer(
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
)
c4 = Customer(
first_name = "Vladimir",
last_name = "Belousov",
username = "Andescols",
email = "andescols@mail.com",
)
c5 = Customer(
first_name = "Tatyana",
last_name = "Khakimova",
username = "Caltin1962",
email = "caltin1962@mail.com",
)
c6 = Customer(
first_name = "Pavel",
last_name = "Arnautov",
username = "Lablen",
email = "lablen@mail.com",
)
session.add_all([c3, c4, c5, c6])
session.commit()
Также добавим продукты в таблицу items:
i1 = Item(name = 'Chair', cost_price = 9.21, selling_price = 10.81, quantity = 5)
i2 = Item(name = 'Pen', cost_price = 3.45, selling_price = 4.51, quantity = 3)
i3 = Item(name = 'Headphone', cost_price = 15.52, selling_price = 16.81, quantity = 50)
i4 = Item(name = 'Travel Bag', cost_price = 20.1, selling_price = 24.21, quantity = 50)
i5 = Item(name = 'Keyboard', cost_price = 20.1, selling_price = 22.11, quantity = 50)
i6 = Item(name = 'Monitor', cost_price = 200.14, selling_price = 212.89, quantity = 50)
i7 = Item(name = 'Watch', cost_price = 100.58, selling_price = 104.41, quantity = 50)
i8 = Item(name = 'Water Bottle', cost_price = 20.89, selling_price = 25, quantity = 50)
session.add_all([i1, i2, i3, i4, i5, i6, i7, i8])
session.commit()
Создадим заказы:
o1 = Order(customer = c1)
o2 = Order(customer = c1)
line_item1 = OrderLine(order = o1, item = i1, quantity = 3)
line_item2 = OrderLine(order = o1, item = i2, quantity = 2)
line_item3 = OrderLine(order = o2, item = i1, quantity = 1)
line_item3 = OrderLine(order = o2, item = i2, quantity = 4)
session.add_all([o1, o2])
session.new
session.commit()
В данном случае в сессию добавляются только объекты Order (o1 и o2). Order и OrderLine связаны отношением один-ко-многим. Добавление объекта Order в сессию неявно добавляет также и объекты OrderLine. Но даже если добавить последние вручную, ошибки не будет.
Вместо передачи объекта Order при создании экземпляра OrderLine можно сделать следующее:
o3 = Order(customer = c1)
orderline1 = OrderLine(item = i1, quantity = 5)
orderline2 = OrderLine(item = i2, quantity = 10)
o3.line_items.append(orderline1)
o3.line_items.append(orderline2)
session.add_all([o3,])
session.new
session.commit()
После коммита таблицы orders и order_lines будут выглядеть вот так:
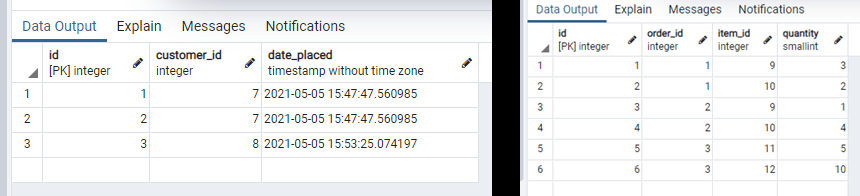
Если сейчас получить доступ к атрибуту orders объекта Customer, то вернется не-пустой список.
[<Order:1>, <Order:2>]С другой стороны отношения можно получить доступ к объекту Customer, которому заказ принадлежит через атрибут customer объекта Order — o1.customer.
Сейчас у покупателя c1 три заказа. Чтобы посмотреть все пункты в заказе нужно использовать атрибут line_items объекта Order.
c1.orders[0].line_items, c1.orders[1].line_items
([<OrderLine:1>, <OrderLine:2>], [<OrderLine:3>, <OrderLine:4>])Для получения элемента заказа используйте item.
for ol in c1.orders[0].line_items:
ol.id, ol.item, ol.quantity
print('-------')
for ol in c1.orders[1].line_items:
ol.id, ol.item, ol.quantity
Вывод:
(1, <Item:1-Chair>, 3)
(2, <Item:2-Pen>, 2)
-------
(3, <Item:1-Chair>, 1)
(4, <Item:2-Pen>, 4)
Все это возможно благодаря отношениям relationship() моделей.
Получение данных
Чтобы сделать запрос в базу данных используется метод query() объекта session. Он возвращает объект типа sqlalchemy.orm.query.Query, который называется просто Query. Он представляет собой инструкцию SELECT, которая будет использована для запроса в базу данных. В следующей таблице перечислены распространенные методы класса Query.
| Метод | Описание |
|---|---|
| all() | Возвращает результат запроса (объект Query) в виде списка |
| count() | Возвращает общее количество записей в запросе |
| first() | Возвращает первый результат из запроса или None, если записей нет |
| scalar() | Возвращает первую колонку первой записи или None, если результат пустой. Если записей несколько, то бросает исключение MultipleResultsFound |
| one | Возвращает одну запись. Если их несколько, бросает исключение MutlipleResultsFound. Если данных нет, бросает NoResultFound |
| get(pk) | Возвращает объект по первичному ключу (pk) или None, если объект не был найден |
| filter(*criterion) | Возвращает экземпляр Query после применения оператора WHERE |
| limit(limit) | Возвращает экземпляр Query после применения оператора LIMIT |
| offset(offset) | Возвращает экземпляр Query после применения оператора OFFSET |
| order_by(*criterion) | Возвращает экземпляр Query после применения оператора ORDER BY |
| join(*props, **kwargs) | Возвращает экземпляр Query после создания SQL INNER JOIN |
| outerjoin(*props, **kwargs) | Возвращает экземпляр Query после создания SQL LEFT OUTER JOIN |
| group_by(*criterion) | Возвращает экземпляр Query после добавления оператора GROUP BY к запросу |
| having(criterion) | Возвращает экземпляр Query после добавления оператора HAVING |
Метод all()
В базовой форме метод query() принимает в качестве аргументов один или несколько классов модели или колонок. Следующий код вернет все записи из таблицы customers.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
print(session.query(Customer).all())
[<Customer:1-Moseend>,
<Customer:2-Fortioneaks>,
<Customer:3-Antence73>,
<Customer:4-Andescols>,
<Customer:5-Caltin1962>,
<Customer:6-Lablen>]Так же можно получить записи из таблиц items и orders.
Чтобы получить сырой SQL, который используется для выполнения запроса в базу данных, примените sqlalchemy.orm.query.Query следующим образом: print(session.query(Customer)).
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customersВызов метода all() на большом объекте результата не очень эффективен. Вместо этого стоит использовать цикл for для перебора по объекту Query:
q = session.query(Customer)
for c in q:
print(c.id, c.first_name)
Предыдущие запросы вернули данные из всех колонок таблицы. Предотвратить это можно, передав названия колонок явно в метод query():
print(session.query(Customer.id, Customer.first_name).all())
Вывод:
[(1, 'Dmitriy'),
(2, 'Valeriy'),
(3, 'Vadim'),
(4, 'Vladimir'),
(5, 'Tatyana'),
(6, 'Pavel')]Обратите внимание на то, что каждый элемент списка — это кортеж, а не экземпляр модели.
Метод count()
count() возвращает количество элементов в результате.
session.query(Item).count()
# Вывод - 8
Метод first()
first() возвращает первый результат запроса или None, если последний не вернул данных.
session.query(Order).first()
# Вывод - Order:1
Метод get()
get() возвращает экземпляр с соответствующим первичным ключом или None, если такой объект не был найден.
session.query(Customer).get(1)
# Вывод - Customer:1-Moseend
Метод filter()
Этот метод позволяет отфильтровать результаты, добавив оператор WHERE. Он принимает колонку, оператор и значение. Например:
session.query(Customer).filter(Customer.first_name == 'Vadim').all()Этот запрос вернет всех покупателей, чье имя — Vadim. А вот SQL-эквивалент этого запроса:
print(session.query(Customer).filter(Customer.first_name == 'Vadim'))
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
WHERE
customers.first_name = %(first_name_1)sСтрока %(first_name_1)s в операторе WHERE — это заполнитель, который будет заменен на реальное значение (Vadim) при выполнении запроса.
Можно передать несколько фильтров в метод filter() и они будут объединены с помощью оператора AND. Например:
session.query(Customer).filter(Customer.id <= 5, Customer.last_name == "Arnautov").all()
Этот запрос вернет всех покупателей, чей первичный ключ меньше или равен 5, а фамилия начинается с "Ar".
session.query(Customer).filter(Customer.id <= 5, Customer.last_name.like("Ar%")).all()
Еще один способ комбинировать условия — союзы (and_(), or_() и not_()). Некоторые примеры:
# все клиенты с именем Vadim и Tatyana
session.query(Customer).filter(or_(
Customer.first_name == 'Vadim',
Customer.first_name == 'Tatyana'
)).all()
# найти всех с именем и Pavel фамилией НЕ Yatsenko
session.query(Customer).filter(and_(
Customer.first_name == 'Pavel',
not_(
Customer.last_name == 'Yatsenko',
)
)).all()
Следующий перечень демонстрирует, как использовать распространенные операторы сравнения с методом filter().
IS NULL
session.query(Order).filter(Order.date_placed == None).all()IS NOT NULL
session.query(Order).filter(Order.date_placed != None).all()
IN
session.query(Customer).filter(Customer.first_name.in_(['Pavel', 'Vadim'])).all()NOT INT
session.query(Customer).filter(Customer.first_name.notin_(['Pavel', 'Vadim'])).all()BETWEEN
session.query(Item).filter(Item.cost_price.between(10, 50)).all()NOT BETWEEN
session.query(Item).filter(not_(Item.cost_price.between(10, 50))).all()
LIKE
session.query(Item).filter(Item.name.like("%r")).all()
Метод like() выполняет поиск с учетом регистра. Для поиска совпадений без учета регистра используйте ilike().
session.query(Item).filter(Item.name.ilike("w%")).all()
NOT LIKE
session.query(Item).filter(not_(Item.name.like("W%"))).all()
Метод limit()
Метод limit() добавляет оператор LIMIT к запросу. Он принимает количество записей, которые нужно вернуть.
session.query(Customer).limit(2).all()
session.query(Customer).filter(Customer.username.ilike("%Andes")).limit(2).all()
SQL-эквивалент:
SELECT
customers. id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s Метод offset()
Метод offset() добавляет оператор OFFSET к запросу. Он принимает в качестве аргумента значение смещения. Часто используется с оператором limit().
session.query(Customer).limit(2).offset(2).all()
SQL-эквивалент:
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_addrees,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s OFFSET %(param_2)sМетод order_by()
Метод order_by() используется для сортировки результата с помощью оператора ORDER BY. Он принимает названия колонок, по которым необходимо сортировать результат. По умолчанию сортирует по возрастанию.
session.query(Item).filter(Item.name.ilike("wa%")).all()
session.query(Item).filter(Item.name.ilike("wa%")).order_by(Item.cost_price).all()
Чтобы сортировать по убыванию используйте функцию desc():
from sqlalchemy import desc
session.query(Item).filter(Item.name.ilike("wa%")).order_by(desc(Item.cost_price)).all()
Метод join()
Метод join() используется для создания SQL INNER JOIN. Он принимает название таблицы, с которой нужно выполнить SQL JOIN.
Используем join(), чтобы найти всех покупателей, у которых как минимум один заказ.
session.query(Customer).join(Order).all()
SQL-эквивалент:
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
JOIN orders ON customers.id = orders.customer_id
Этот оператор часто используется для получения данных из одной или нескольких таблиц в одном запросе. Например:
session.query(Customer.id, Customer.username, Order.id).join(Order).all()
Можно создать SQL JOIN для более чем двух таблиц, объединив несколько методов join() следующим образом:
session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Вот еще один пример, который использует 3 объединения для нахождения всех пунктов в первом заказе Dmitriy Yatsenko.
session.query(
Customer.first_name,
Item.name,
Item.selling_price,
OrderLine.quantity
).join(Order).join(OrderLine).join(Item).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
Order.id == 1,
).all()
Метод outerjoin()
Метод outerjoin() работает как join(), но создает LEFT OUTER JOIN.
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order).all()
В этом запросе левой таблицей является customers. Это значит, что он вернет все записи из customers и только те, которые соответствуют условию, из orders.
Создать FULL OUTER JOIN можно, передав в метод full=True. Например:
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order, full=True).all()
Метод group_by()
Результаты группируются с помощью group_by(). Этот метод принимает одну или несколько колонок и группирует записи в соответствии со значениями в колонке.
Следующий запрос использует join() и group_by() для подсчета количества заказов, сделанных Dmitriy Yatsenko.
from sqlalchemy import func
session.query(func.count(Customer.id)).join(Order).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
).group_by(Customer.id).scalar()
Метод having()
Чтобы отфильтровать результаты на основе значений, которые возвращают агрегирующие функции, используется метод having(), добавляющий оператор HAVING к инструкции SELECT. По аналогии с where() он принимает условие.
session.query(
func.count("*").label('username_count'),
Customer.town
).group_by(Customer.username).having(func.count("*") > 2).all()
Работа с дубликатами
Для работы с повторяющимися записями используется параметр DISTINCT. Его можно добавить к SELECT с помощью метода distinct(). Например:
from sqlalchemy import distinct
session.query(Customer.first_name).filter(Customer.id < 10).all()
session.query(Customer.first_name).filter(Customer.id < 10).distinct().all()
session.query(
func.count(distinct(Customer.first_name)),
func.count(Customer.first_name)
).all()
Приведение
Приведение (конвертация) данных от одного типа к другому — распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import cast, Date, distinct, union
session.query(
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
).all()
Объединения
Для объединения запросов используется метод union() объекта Query. Он принимает один или несколько запросов. Например:
s1 = session.query(Item.id, Item.name).filter(Item.name.like("Wa%"))
s2 = session.query(Item.id, Item.name).filter(Item.name.like("%e%"))
s1.union(s2).all()
[(2, 'Pen'),
(4, 'Travel Bag'),
(3, 'Headphone'),
(5, 'Keyboard'),
(7, 'Watch'),
(8, 'Water Bottle')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения используйте union_all().
s1.union_all(s2).all()Обновление данных
Для обновления объекта просто установите новое значение атрибуту, добавьте объект в сессию и сохраните ее.
i = session.query(Item).get(8)
i.selling_price = 25.91
session.add(i)
session.commit()
Таким образом можно обновлять только один объект за раз. Для обновления нескольких записей за раз используйте метод update() объекта Query. Он возвращает общее количество обновленных записей. Например:
session.query(Item).filter(
Item.name.ilike("W%")
).update({"quantity": 60}, synchronize_session='fetch')
session.commit()
Удаление данных
Для удаления объекта используйте метод delete() объекта сессии. Он принимает объект и отмечает его как удаленный для следующего коммита.
i = session.query(Item).filter(Item.name == 'Monitor').one()
session.delete(i)
session.commit()
<Item:6-Monitor>Этот коммит удаляет Monitor из таблицы items.
Для удаления нескольких записей за раз используйте метод delete() объекта Query.
session.query(Item).filter(
Item.name.ilike("W%")
).delete(synchronize_session='fetch')
session.commit()
Этот коммит удаляет все элементы, название которых начинается с W.
Сырые(raw) запросы
ORM предоставляет возможность использовать сырые SQL-запросы с помощью функции text(). Например:
from sqlalchemy import text
session.query(Customer).filter(text("first_name = 'Vladimir'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).order_by(text("first_name, id desc")).all()
Транзакции
Транзакция — это способ выполнения набора SQL-инструкций так, что выполняются или все вместе, или ни одна из них. Если хотя бы одна инструкция из транзакции была провалена, база данных возвращается к предыдущему состоянию.
В базе данных есть два заказа, в процессе отгрузки заказа есть такие этапы:
- В колонке
date_placedтаблицыordersустанавливается дата отгрузки. - Количество заказанных товаров вычитается из
items.
Оба действия должны быть выполнены как одно, чтобы убедиться, что данные в таблицах корректны.
В следующем коде определяем метод dispatch_order(), который принимает order_id в качестве аргумента и выполняет описанные выше задачи в одной транзакции.
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
order = session.query(Order).get(order_id)
if not order:
raise ValueError("Недействительный order_id: {}.".format(order_id))
try:
for i in order.line_items:
i.item.quantity = i.item.quantity - i.quantity
order.date_placed = datetime.now()
session.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
print("Возврат назад...")
session.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
В первом заказе 3 стула и 2 ручки. dispatch_order() с идентификатором заказа 1 даст следующий вывод:
Транзакция завершена.ORM построен на базе SQLAlchemy Core, поэтому имеющиеся знания должны пригодиться.
ORM позволяет быть более продуктивным, но также добавляет дополнительную сложность в запросы. Однако для большинства приложений преимущества перевешивают проигрыш в производительности.
Прежде чем двигаться дальше удалите все таблицы из sqlalchemy-tuts с помощью следующей команды: metadata.drop_all(engine).
Создание моделей
Модель — это класс Python, соответствующий таблице в базе данных, а его свойства — это колонки.
Чтобы класс был валидной моделью, нужно соответствовать следующим требованиям:
- Наследоваться от декларативного базового класса с помощью вызова функции
declarative_base(). - Объявить имя таблицы с помощью атрибута
__tablename__. - Объявить как минимум одну колонку, которая должна быть частью первичного ключа.
Последние два пункта говорят сами за себя, а вот для первого нужны детали.
Базовый класс управляет каталогом классов и таблиц. Другими словами, декларативный базовый класс — это оболочка над маппером и MetaData. Маппер соотносит подкласс с таблицей, а MetaData сохраняет всю информацию о базе данных и ее таблицах. По аналогии с Core в ORM методы create_all() и drop_all() объекта MetaData используются для создания и удаления таблиц.
Следующий код показывает, как создать модель Post, которая используется для сохранения постов в блоге.
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, unique=True)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
Разберем построчно:
- На 1-4 строках импортируются нужные классы и функции.
- В 6 строке создается базовый класс с помощью вызова функции
declarative_base(). - На 10-16 строках колонки объявляются как атрибуты класса.
Стоит обратить внимание на то, что для создания колонок используется тот же класс Column, что и для SQLAlchemy Core. Единственное отличие в том, что первым аргументом является тип, а не название колонки. Аргументы-ключевые слова, в свою очередь, переданные в Column(), работают одинаково в ORM и Core.
Поскольку ORM построен на базе Core, SQLAlchemy использует определение модели для создания объекта Table и связи его с моделью с помощью функции mapper(). Это завершает процесс маппинга модели Post с соответствующим экземпляром Table. Теперь модель Post можно использовать для управления базой данных и для осуществления запросов к ней.
Классический маппинг
После прошлого раздела может создаться впечатление, что для использования SQLAlchemy ORM нужно переписать все экземпляры Table в виде моделей. Но это не так.
Можно запросто мапить любые Python классы на экземпляры Table с помощью функции mapper(). Например:
from sqlalchemy import MetaData, Table, Integer, String, Column, Text, DateTime, Boolean
from sqlalchemy.orm import mapper
from datetime import datetime
metadata = MetaData()
post = Table('post', metadata,
Column('id', Integer(), primary_key=True),
Column('title', String(200), nullable=False),
Column('slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
class Post(object):
pass
mapper(Post, post)
Этот класс принимает два аргумента: класс для маппинга и объект Table.
После этого у класса Post будут атрибуты, соответствующие колонкам таблицы. Таким образом у Post сейчас следующие атрибуты:
post.idpost.titlepost.slugpost.contentpost.publishedpost.created_onpost.updated_on
Код в списке выше эквивалентен модели Post, которая была объявлена выше.
Теперь вы должны лучше понимать, что делает declarative_base().
Добавление ключей и ограничений
При использовании ORM ключи и ограничения добавляются с помощью атрибута __table_args__.
from sqlalchemy import Table, Index, Integer, String, Column, Text, \
DateTime, Boolean, PrimaryKeyConstraint, \
UniqueConstraint, ForeignKeyConstraint
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer)
username = Column(String(100), nullable=False)
email = Column(String(100), nullable=False)
password = Column(String(200), nullable=False)
__table_args__ = (
PrimaryKeyConstraint('id', name='user_pk'),
UniqueConstraint('username'),
UniqueConstraint('email'),
)
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, default=False)
user_id = Column(Integer(), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
__table_args__ = (
ForeignKeyConstraint(['user_id'], ['users.id']),
Index('title_content_index' 'title', 'content'), # composite index on title and content
)
Отношения
Один-ко-многим
Отношение один-ко-многим создается за счет передачи внешнего ключа в дочерний класс. Например:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
Строчка author_id = Column(Integer, ForeignKey('authors.id')) устанавливает отношение один-ко-многим между моделями Author и Book.
Функция relationship() добавляет атрибуты в модели для доступа к связанным данным. Как минимум — название класса, отвечающего за одну сторону отношения.
Строчка books = relationship("Book") добавляет атрибут books классу Author.
Имея объект a класса Author, получить доступ к его книгам можно через a.books. А если нужно получить автора книги через объект Book?
Для этого можно определить отдельное отношение relationship() в модели Author:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author")
Теперь через объект b класса Book можно получить автора b.author.
Как вариант можно использовать параметры backref для определения названия атрибута, который должен быть задан на другой стороне отношения.
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book", backref="book")
Relationship можно задавать на любой стороне отношений. Поэтому предыдущий код можно записать и так:
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", backref="books")
Один-к-одному
Установка отношения один-к-одному в SQLAlchemy почти не отличается от одного-ко-многим. Единственное отличие в том, что нужно передать дополнительный аргумент uselist=False в функцию relationship(). Например:
class Person(Base):
__tablename__ = 'persons'
id = Column(Integer(), primary_key=True)
name = Column(String(255), nullable=False)
designation = Column(String(255), nullable=False)
doj = Column(Date(), nullable=False)
dl = relationship('DriverLicense', backref='person', uselist=False)
class DriverLicense(Base):
__tablename__ = 'driverlicense'
id = Column(Integer(), primary_key=True)
license_number = Column(String(255), nullable=False)
renewed_on = Column(Date(), nullable=False)
expiry_date = Column(Date(), nullable=False)
person_id = Column(Integer(), ForeignKey('persons.id'))
Имея объект p класса Person, p.dl вернет объект DriverLicense. Если не передать uselist=False в функцию, то установится отношение один-ко-многим между Person и DriverLicense, а p.dl вернет список объектов DriverLicense вместо одного. При этом uselist=False никак не влияет на атрибут persons объекта DriverLicense. Он вернет объект Person как и обычно.
Многие-ко-многим
Для отношения многие-ко-многим нужна отдельная таблица. Она создается как экземпляр класса Table и затем соединяется с моделью с помощью аргумента secondary функции relationship().
author_book = Table('author_book', Base.metadata,
Column('author_id', Integer(), ForeignKey("authors.id")),
Column('book_id', Integer(), ForeignKey("books.id"))
)
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", secondary=author_book, backref="books")
Один автор может написать одну или несколько книг. Так и книга может быть написана одним или несколькими авторами. Поэтому здесь требуется отношение многие-ко-многим.
Для представления этого отношения была создана таблица author_book.
Через объект a класса Author можно получить все книги автора с помощью a.books. По аналогии через b класса Book можно вернуть список авторов b.authors.
В этом случае relationship() была объявлена в модели Book, но это можно было сделать и с другой стороны.
Может потребоваться хранить дополнительную информацию в промежуточной таблице. Для этого нужно определить эту таблицу как класс модели.
class Author_Book(Base):
__tablename__ = 'author_book'
id = Column(Integer, primary_key=True)
author_id = Column(Integer(), ForeignKey("authors.id"))
book_id = Column(Integer(), ForeignKey("books.id"))
extra_data = Column(String(100))
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Author_Book", backref='author')
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
authors = relationship("Author_Book", backref="book")
Создание таблиц
По аналогии с SQLAlchemy Core в ORM есть метод create_all() экземпляра MetaData, который отвечает за создание таблицы.
Base.metadata.create_all(engine)Для удаления всех таблиц есть drop_all.
Base.metadata.drop_all(engine)Пересоздадим таблицы с помощью моделей и сохраним их в базе данных, вызвав create_all(). Вот весь код для этой операции:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, SmallInteger
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from datetime import datetime
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer(), primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
username = Column(String(50), nullable=False)
email = Column(String(200), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
orders = relationship("Order", backref='customer')
class Item(Base):
__tablename__ = 'items'
id = Column(Integer(), primary_key=True)
name = Column(String(200), nullable=False)
cost_price = Column(Numeric(10, 2), nullable=False)
selling_price = Column(Numeric(10, 2), nullable=False)
quantity = Column(Integer())
class Order(Base):
__tablename__ = 'orders'
id = Column(Integer(), primary_key=True)
customer_id = Column(Integer(), ForeignKey('customers.id'))
date_placed = Column(DateTime(), default=datetime.now)
line_items = relationship("OrderLine", backref='order')
class OrderLine(Base):
__tablename__ = 'order_lines'
id = Column(Integer(), primary_key=True)
order_id = Column(Integer(), ForeignKey('orders.id'))
item_id = Column(Integer(), ForeignKey('items.id'))
quantity = Column(SmallInteger())
item = relationship("Item")
Base.metadata.create_all(engine)
Будем использовать таблицу созданную в предыдущей статье.
Вставка (добавление) записей
Есть несколько способов вставить записи в базу данных. Основной — метод insert() экземпляра Table. Его нужно вызвать, после чего использовать метод values() и передать значения для колонок в качестве аргументов-ключевых слов:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
print(ins)
Чтобы увидеть, какой SQL код будет сгенерирован в результате, достаточно вывести ins:
INSERT INTO customers (first_name, last_name, username, email, address, town, created_on, updated_on) VALUES (:first_name, :last_name, :username, :email, :address, :town, :created_on, :updated_on)Стоит обратить внимание на то, что внутри оператора VALUES находятся связанные параметры (параметры в формате :name), а не сами значения, переданные в метод values().
И только при выполнении запроса в базе данных диалект заменит их на реальные значения. Они также будут экранированы, что исключает вероятность SQL-инъекций.
Посмотреть на то, какие значения будут на месте связанных параметров, можно с помощью такой инструкции: ins.compile().params.
Вывод:
{'first_name': 'Dmitriy',
'last_name': 'Yatsenko',
'username': 'Moseend',
'email': 'moseend@mail.com',
'address': 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
'town': ' Vladivostok',
'created_on': None,
'updated_on': None}Инструкция создана, но не отправлена в базу данных. Для ее вызова нужно вызвать метод execute() на объекте Connection:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
conn = engine.connect()
r = conn.execute(ins)
Этот код вставляет следующую запись в таблицу customers:

Метод execute() возвращает объект типа ResultProxy. Последний предоставляет несколько атрибутов, один из которых называется inserted_primary_key. Он возвращает первичный ключ вставленной записи.
Еще один способ создания инструкции для вставки — использование функции insert() из библиотеки sqlalchemy.
from sqlalchemy import insert
ins = insert(customers).values(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com',
address = 'Narovchatova, bld. 8, appt. 37',
town = 'Magadan'
)
conn = engine.connect()
r = conn.execute(ins)
print(r.inserted_primary_key)
Вывод: (2,).
Вставка (добавление) нескольких записей
Вместо того чтобы передавать значения в метод values() в качестве аргументов-ключевых слов, их можно передать в метод execute().
from sqlalchemy import insert
conn = engine.connect()
ins = insert(customers)
r = conn.execute(ins,
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
address = 'Partizanskiy Prospekt, bld. 28/А, appt. 51',
town = ' Vladivostok'
)
Метод execute() достаточно гибкий, потому что он позволяет вставить несколько записей, передав значения в качестве списка словарей, где каждый — значения для одной строки:
r = conn.execute(ins, [
{
"first_name": "Vladimir",
"last_name": "Belousov",
"username": "Andescols",
"email":"andescols@mail.com",
"address": "Ul. Usmanova, bld. 70, appt. 223",
"town": " Naberezhnye Chelny"
},
{
"first_name": "Tatyana",
"last_name": "Khakimova",
"username": "Caltin1962",
"email":"caltin1962@mail.com",
"address": "Rossiyskaya, bld. 153, appt. 509",
"town": "Ufa"
},
{
"first_name": "Pavel",
"last_name": "Arnautov",
"username": "Lablen",
"email":"lablen@mail.com",
"address": "Krasnoyarskaya Ul., bld. 35, appt. 57",
"town": "Irkutsk"
},
])
print(r.rowcount)
Вывод: 3.
Прежде чем переходить к следующему разделу, добавим также записи в таблицы items, orders и order_lines:
items_list = [
{
"name":"Chair",
"cost_price": 9.21,
"selling_price": 10.81,
"quantity": 6
},
{
"name":"Pen",
"cost_price": 3.45,
"selling_price": 4.51,
"quantity": 3
},
{
"name":"Headphone",
"cost_price": 15.52,
"selling_price": 16.81,
"quantity": 50
},
{
"name":"Travel Bag",
"cost_price": 20.1,
"selling_price": 24.21,
"quantity": 50
},
{
"name":"Keyboard",
"cost_price": 20.12,
"selling_price": 22.11,
"quantity": 50
},
{
"name":"Monitor",
"cost_price": 200.14,
"selling_price": 212.89,
"quantity": 50
},
{
"name":"Watch",
"cost_price": 100.58,
"selling_price": 104.41,
"quantity": 50
},
{
"name":"Water Bottle",
"cost_price": 20.89,
"selling_price": 25.00,
"quantity": 50
},
]
order_list = [
{
"customer_id": 1
},
{
"customer_id": 1
}
]
order_line_list = [
{
"order_id": 1,
"item_id": 1,
"quantity": 5
},
{
"order_id": 1,
"item_id": 2,
"quantity": 2
},
{
"order_id": 1,
"item_id": 3,
"quantity": 1
},
{
"order_id": 2,
"item_id": 1,
"quantity": 5
},
{
"order_id": 2,
"item_id": 2,
"quantity": 5
},
]
r = conn.execute(insert(items), items_list)
print(r.rowcount)
r = conn.execute(insert(orders), order_list)
print(r.rowcount)
r = conn.execute(insert(order_lines), order_line_list)
print(r.rowcount)
Вывод:
8
2
5Получение записей
Для получения записей используется метод select() на экземпляре объекта Table:
s = customers.select()
print(s)
Вывод:
SELECT customers.id, customers.first_name, customers.last_name, customers.username, customers.email, customers.address, customers.town, customers.created_on, customers.updated_on
FROM customersТакой запрос вернет все записи из таблицы customers. Вместо этого можно также использовать функцию select(). Она принимает список или колонок, из которых требуется получить данные.
from sqlalchemy import select
s = select([customers])
print(s)
Вывод буде тот же.
Для отправки запроса нужно выполнить метод execute():
from sqlalchemy import select
conn = engine.connect()
s = select([customers])
r = conn.execute(s)
print(r.fetchall())
Вывод:
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109)),...)]Метод fetchall() на объекте ResultProxy возвращает все записи, соответствующие запросу. Как только результаты будут исчерпаны, последующие запросы к fetchall() вернут пустой список.
Метод fetchall() загружает все результаты в память сразу. В случае большого количества данных это не очень эффективно. Как вариант, можно использовать цикл для перебора по результатам:
s = select([customers])
rs = conn.execute(s)
for row in rs:
print(row)
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
...
(7, 'Pavel', 'Arnautov', 'Lablen', 'lablen@mail.com', 'Krasnoyarskaya Ul., bld. 35, appt. 57', 'Irkutsk', datetime.datetime(2021, 4, 22, 10, 32, 45, 364619), datetime.datetime(2021, 4, 22, 10, 32, 45, 364619))Дальше список часто используемых методов и атрибутов объекта ResultProxy:
| Метод/Атрибут | Описание |
| fetchone() | Извлекает следующую запись из результата. Если других записей нет, то последующие вызовы вернут None |
| fetchmany(size=None) | Извлекает набор записей из результата. Если их нет, то последующие вызовы вернут None |
| fetchall() | Извлекает все записи из результата. Если записей нет, то вернется None |
| first() | Извлекает первую запись из результата и закрывает соединение. Это значит, что после вызова метода first() остальные записи в результате получить не выйдет, пока не будет отправлен новый запрос с помощью метода execute() |
| rowcount | Возвращает количество строк в результате |
| keys() | Возвращает список колонок из источника данных |
| scalar() | Возвращает первую колонку первой записи и закрывает соединение. Если результата нет, то возвращает None |
Следующие сессии терминала демонстрируют рассмотренные выше методы и атрибуты в действии, где s = select([customers]).
fetchone()
r = conn.execute(s)
print(r.fetchone())
print(r.fetchone())
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
(2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))fetchmany()
r = conn.execute(s)
print(r.fetchmany(2))
print(len(r.fetchmany(5))) # вернется 4, потому что у нас всего 6 записей
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))]
4first()
r = conn.execute(s)
print(r.first())
print(r.first()) # вернется ошибка
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
Traceback (most recent call last):
...
sqlalchemy.exc.ResourceClosedError: This result object is closed.rowcount
r = conn.execute(s)
print(r.rowcount)
# вернется 6
keys()
r = conn.execute(s)
print(r.keys())
RMKeyView(['id', 'first_name', 'last_name', 'username', 'email', 'address', 'town', 'created_on', 'updated_on'])scalar()
r = conn.execute(s)
print(r.scalar())
# вернется 1
Важно отметить, что fetchxxx() и first() возвращают не кортежи или словари, а объекты типа LegacyRow, что позволяет получать доступ к данным в записи с помощью названия колонки, индекса или экземпляра Column. Например:
r = conn.execute(s)
row = r.fetchone()
print(row)
print(type(row))
print(row['id'], row['first_name']) # доступ к данным по названию колонки
print(row[0], row[1]) # доступ к данным по индексу
print(row[customers.c.id], row[customers.c.first_name]) # доступ к данным через объект класса
print(row.id, row.first_name) # доступ к данным, как к атрибуту
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
<class 'sqlalchemy.engine.row.LegacyRow'>
1 Dmitriy
1 Dmitriy
1 Dmitriy
1 DmitriyДля получения данных из нескольких таблиц нужно передать список экземпляров Table, разделенных запятыми в функцию select():
Этот код вернет Декартово произведение записей из обоих таблиц. О SQL JOIN поговорим позже отдельно.
Фильтр записей
Для фильтрования записей используется метод where(). Он принимает условие и добавляет оператор WHERE к SELECT:
s = select([items]).where(
items.c.cost_price > 20
)
print(s)
r = conn.execute(s)
print(r.fetchall())
Запрос вернет все элементы, цена которых выше 20.
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1
[(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50)]Дополнительные условия можно задать, просто добавив несколько вызовов метода where().
s = select([items]).\
where(items.c.cost_price + items.c.selling_price > 50).\
where(items.c.quantity > 10)
При использовании такого способа операторы просто объединяются при помощи AND. А как использовать OR или NOT?
Для этого есть:
- Побитовые операторы
- Союзы
Побитовые операторы
Побитовые операторы &, | и ~ позволяют объединять условия с операторами AND, OR или NOT из SQL.
Предыдущий запрос можно записать вот так с помощью побитовых операторов:
s = select([items]).\
where(
(items.c.cost_price + items.c.selling_price > 50) &
(items.c.quantity > 10)
)
Условия заключены в скобки. Это нужно из-за того, что побитовые операторы имеют более высокий приоритет по сравнению с операторами + и >.
s = select([items]).\
where(
(items.c.cost_price > 200 ) |
(items.c.quantity < 5)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50) &
(items.c.cost_price < 20)
)
print(s)
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1 OR items.quantity < :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1 AND items.cost_price < :cost_price_1Союзы
Условия можно объединять и с помощью функций-союзов and_(), or_() и not_(). Это предпочтительный способ добавления условий в SQLAlchemy.
from sqlalchemy import select, and_, or_, not_
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
or_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
not_(
items.c.name == 'Headphone'
),
)
)
Другие распространенные операторы сравнения
Следующий список демонстрирует как использовать остальные операторы сравнения при определении условий в SQLAlchemy
IS NULL
select([orders]).where(
orders.c.date_shipped == None
)
IS NOT NULL
select([orders]).where(
orders.c.date_shipped != None
)
IN
select([customers]).where(
customers.c.first_name.in_(["Valeriy", "Vadim"])
)
NOT IN
select([customers]).where(
customers.c.first_name.notin_(["Valeriy", "Vadim"])
)
BETWEEN
select([items]).where(
items.c.cost_price.between(10, 20)
)
NOT BETWEEN
from sqlalchemy import not_
select([items]).where(
not_(items.c.cost_price.between(10, 20))
)
LIKE
select([items]).where(
items.c.name.like("Wa%")
)
Метод like() выполняет сравнение с учетом регистра. Для сравнения без учета регистра используйте ilike().
NOT LIKE
select([items]).where(
not_(items.c.name.like("wa%"))
)
Сортировка результата c order_by
Метод order_by() добавляет оператор ORDER BY к инструкции SELECT. Он принимает одну или несколько колонок для сортировки. Для каждой колонки можно указать, выполнять ли сортировку по возрастанию (asc()) или убыванию (desc()). Если не указать ничего, то сортировка будет выполнена в порядке по возрастанию. Например:
s = select([items]).where(
items.c.quantity > 10
).order_by(items.c.cost_price)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity > :quantity_1 ORDER BY items.cost_price
[(3, 'Headphone', Decimal('15.52'), Decimal('16.81'), 50),
(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50)]Запрос возвращает записи, отсортированные по cost_price по возрастанию. Это эквивалентно следующему:
from sqlalchemy import asc
s = select([items]).where(
items.c.quantity > 10
).order_by(asc(items.c.cost_price))
rs = conn.execute(s)
rs.fetchall()
Для сортировки результатов по убыванию используйте функцию desc(). Пример:
from sqlalchemy import desc
s = select([items]).where(
items.c.quantity > 10
).order_by(desc(items.c.cost_price))
conn.execute(s).fetchall()
Вот еще один пример сортировки по двух колонкам: quantity по возрастанию и cost_price по убыванию.
s = select([items]).order_by(
items.c.quantity,
desc(items.c.cost_price)
)
conn.execute(s).fetchall()
Ограничение результатов c limit
Метод limit() добавляет оператор LIMIT в инструкцию SELECT. Он принимает целое число, определяющее число записей, которые должны вернуться. Например:
s = select([items]).order_by(
items.c.quantity
).limit(2)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items ORDER BY items.quantity
LIMIT :param_1
[(2, 'Pen', Decimal('3.45'), Decimal('4.51'), 3),
(1, 'Chair', Decimal('9.21'), Decimal('10.81'), 5)]Чтобы задавать «сдвиг» (начальное положение) в LIMIT, нужно использовать метод offset():
s = select([items]).order_by(
items.c.quantity
).limit(2).offset(2)
Ограничение колонок
Инструкции SELECT, созданные ранее, возвращают данные из всех колонок. Ограничить количество полей, возвращаемых запросом можно, передав название полей в виде списка в функцию select(). Например:
s = select([items.c.name, items.c.quantity]).where(
items.c.quantity == 50
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT items.name, items.quantity
FROM items
WHERE items.quantity = :quantity_1
RMKeyView(['name', 'quantity'])
[('Headphone', 50), ('Travel Bag', 50), ('Keyboard', 50), ('Monitor', 50), ('Watch', 50), ('Water Bottle', 50)]Запрос возвращает данные только из колонок name и quantity таблицы items.
По аналогии с SQL можно выполнять вычисления на вернувшихся строках до того, как они попадут в вывод. Например:
select([
items.c.name,
items.c.quantity,
items.c.selling_price * 5
]).where(
items.c.quantity == 50
)
Обратите внимание на то, что items.c.selling_price * 5 — это не реальная колонка, поэтому создается анонимное имя anon_1.
Колонке или выражению можно присвоить метку с помощью метода label(), который работает, добавляя оператор AS к SELECT.
select([
items.c.name,
items.c.quantity,
(items.c.selling_price * 5).label('price')
]).where(
items.c.quantity == 50
)
Доступ к встроенным функциям
Для доступа к встроенным функциям базы данных используется объект func. Следующий список показывает, как использовать функции для работы с датой/временем, математическими операциями и строками в базе данных PostgreSQL.
from sqlalchemy.sql import func
c = [
## функции даты/времени ##
func.timeofday(),
func.localtime(),
func.current_timestamp(),
func.date_part("month", func.now()),
func.now(),
## математические функции ##
func.pow(4,2),
func.sqrt(441),
func.pi(),
func.floor(func.pi()),
func.ceil(func.pi()),
## строковые функции ##
func.lower("ABC"),
func.upper("abc"),
func.length("abc"),
func.trim(" ab c "),
func.chr(65),
]
s = select(c)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
RMKeyView(['timeofday_1', 'localtime_1', 'current_timestamp_1', 'date_part_1', 'now_1', 'pow_1', 'sqrt_1', 'pi_1', 'floor_1', 'ceil_1', 'lower_1', 'upper_1', 'length_1', 'trim_1', 'chr_1'])
[('Thu Apr 22 12:33:07.655488 2021 EEST', datetime.time(12, 33, 7, 643174), datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 4.0, datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 16.0, 21.0, 3.14159265358979, 3.0, 4.0, 'abc', 'ABC', 3, 'ab c', 'A')]Также можно получить доступ к агрегирующим функциям из объекта object.
c = [
func.sum(items.c.quantity),
func.avg(items.c.quantity),
func.max(items.c.quantity),
func.min(items.c.quantity),
func.count(customers.c.id),
]
s = select(c)
rs = conn.execute(s)
print(rs.fetchall())
# вывод: [(1848, Decimal('38.5000000000000000'), 50, 3, 48)]
Группировка результатов с group_by
Группировка результатов выполняется с помощью оператора GROUP BY. Он часто используется в союзе с агрегирующими функциями. GROUP BY добавляется к SELECT с помощью метода group_by(). Последний принимает одну или несколько колонок и группирует строки по значениям в этих колонках. Например:
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town)
print(conn.execute(s).fetchall())
Вывод:
[(1, 'Ufa'), (1, 'Irkutsk'), (2, ' Vladivostok'), (1, 'Magadan'), (1, ' Naberezhnye Chelny')]Этот запрос возвращает количество потребителей в каждом городе.
Чтобы отфильтровать результат на основе значений агрегирующих функций, используется метод having(), добавляющий оператор HAVING к SELECT. По аналогии с where() он принимает условие.
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town).having(func.count("*") > 2)
Объединения (joins)
Экземпляр Table предоставляет два метода для создания объединений (joins):
join()— создает внутренний joinouterjoin()— создает внешний join (LEFT OUTER JOIN, если точнее)
Внутренний join возвращает только те колонки, которые соответствуют условию объединения, а внешний — также некоторые дополнительные.
Оба метода принимают экземпляр Table, определяют условие объединения на основе отношений во внешних ключах и возвращают конструкцию JOIN.
>>> print(customers.join(orders))
customers JOIN orders ON customers.id = orders.customer_idЕсли методы не могут определить условия объединения, или нужно предоставить другое условие, то это делается через передачу условия объединения в качестве второго аргумента.
customers.join(items,
customers.c.address.like(customers.c.first_name + '%')
)Когда в функции select() указываются таблицы или список колонок, SQLAlchemy автоматически размещает эти таблицы в операторе FROM. Но при использовании объединения таблицы, которые нужны во FROM, точно известны, поэтому используется select_from(). Этот же метод можно применять и для запросов, не использующих объединения. Например:
s = select([
customers.c.id,
customers.c.first_name
]).select_from(customers)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT customers.id, customers.first_name
FROM customers
RMKeyView(['id', 'first_name'])
[(1, 'Dmitriy'), (2, 'Valeriy'), (4, 'Vadim'), (5, 'Vladimir'), (6, 'Tatyana'), (7, 'Pavel')]Используем эти знания, чтобы найти все заказы, размещенные пользователем Dmitriy Yatsenko.
select([
orders.c.id,
orders.c.date_placed
]).select_from(
orders.join(customers)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
Последний запрос возвращает id и date_placed заказа. Было бы неплохо также знать товары и их общее количество.
Для этого нужно сделать 3 объединения вплоть до таблицы items.
s = select([
orders.c.id.label('order_id'),
orders.c.date_placed,
order_lines.c.quantity,
items.c.name,
]).select_from(
orders.join(customers).join(order_lines).join(items)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT orders.id AS order_id, orders.date_placed, order_lines.quantity, items.name
FROM orders JOIN customers ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id JOIN items ON items.id = order_lines.item_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1
RMKeyView(['order_id', 'date_placed', 'quantity', 'name'])
[(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 2, 'Pen'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 1, 'Headphone'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Pen')]
А вот как создавать внешнее объединение.
select([
customers.c.first_name,
orders.c.id,
]).select_from(
customers.outerjoin(orders)
)
Экземпляр Table, передаваемый в метод outerjoin(), располагается с правой стороны внешнего объединения. В результате последний запрос вернет все записи из таблицы customers (левой таблицы) и только те, которые соответствуют условию объединения из таблицы orders (правой).
Если нужны все записи из таблицы order, но лишь те, которые соответствуют условию, из orders, стоит использовать outerjoin():
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers)
)
Также можно создать FULL OUTER JOIN, передав full=True в метод outerjoin(). Например:
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers, full=True)
)
Обновление записей
Обновление данных выполняется с помощью функции update(). Например, следующий запрос обновляет selling_price и quantity для Water Bottle и устанавливает значения 30 и 60 соответственно.
from sqlalchemy import update
s = update(items).where(
items.c.name == 'Water Bottle'
).values(
selling_price = 30,
quantity = 60,
)
print(s)
rs = conn.execute(s)
Вывод:
UPDATE items SET selling_price=:selling_price, quantity=:quantity WHERE items.name = :name_1Удаление записей
Для удаления данных используется функция delete().
from sqlalchemy import delete
s = delete(customers).where(
customers.c.username.like('Vladim%')
)
print(s)
rs = conn.execute(s)
Вывод:
DELETE FROM customers WHERE customers.username LIKE :username_1Этот запрос удалит всех покупателей, чье имя пользователя начинается с Vladim.
Работа с дубликатами
Для обработки повторяющихся записей в результатах используется параметр DISTINCT. Его можно добавить в SELECT с помощью метода distinct(). Например:
# без DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
# с DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10).distinct()
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Magadan',), (' Vladivostok',), (' Naberezhnye Chelny',), ('Ufa',), ('Irkutsk',)]
SELECT DISTINCT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Ufa',), ('Irkutsk',), ('Magadan',), (' Naberezhnye Chelny',)]
Вот еще один пример использования distinct() с агрегирующей функцией count().Здесь считается количество уникальных городов в таблице customers.
select([
func.count(distinct(customers.c.town)),
func.count(customers.c.town)
])
Конвертация данных с cast
Приведение (конвертация) данных из одного типа в другой — это распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import func, cast, Date
s = select([
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
])
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT CAST(pi() AS INTEGER) AS pi, CAST(pi() AS NUMERIC(10, 2)) AS anon__1, CAST(:param_1 AS DATETIME) AS anon_1, CAST(:param_2 AS DATE) AS anon_2
[(3, Decimal('3.14'), datetime.datetime(2010, 12, 1, 0, 0), datetime.date(2010, 12, 1))]Union
Оператор UNION позволяет объединять результаты нескольких SELECT. Для добавления его к функции select() используется вызов union().
from sqlalchemy import union, desc
u = union(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
print(u)
rs = conn.execute(u)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_1 UNION SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_2 ORDER BY id DESC
[(8, 'Water Bottle'), (7, 'Watch'), (5, 'Keyboard'), (4, 'Travel Bag'), (3, 'Headphone'), (2, 'Pen')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения стоит использовать union_all().
from sqlalchemy import union_all, desc
union_all(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
Создание подзапросов
Данные можно получать и из нескольких таблиц с помощью подзапросов.
Следующий запрос возвращает идентификатор и название элементов, отсортированных по Dmitriy Yatsenko в его первом заказе:
s = select([items.c.id, items.c.name]).where(
items.c.id.in_(
select([order_lines.c.item_id]).select_from(customers.join(orders).join(order_lines)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
)
)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.id IN (SELECT order_lines.item_id
FROM customers JOIN orders ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1 AND orders.id = :id_1)
[(1, 'Chair'), (2, 'Pen'), (3, 'Headphone')]Тот же запрос можно написать и с использованием объединений:
select([items.c.id, items.c.name]).select_from(customers.join(orders).join(order_lines).join(items)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
«Сырые» запросы
SQLAlchemy предоставляет возможность выполнять сырые SQL-запросы с помощью функции text(). Например, следующая инструкция SELECT возвращает все заказы с товарами для Dmitriy Yatsenko.
from sqlalchemy.sql import text
s = text(
"""
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
"""
)
print(s)
rs = conn.execute(s, first_name='Dmitriy', last_name='Yatsenko')
print(rs.fetchall())
Вывод:
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
[(1, 1, 'Chair'), (1, 2, 'Pen'), (1, 3, 'Headphone'), (2, 1, 'Chair'), (2, 2, 'Pen')]Обратите внимание на то, что инструкция включает пару связанных параметров: first_name и last_name. Сами значения для них передаются уже в метод execute().
Эту же функцию можно встроить в select(). Например:
select([items]).where(
text("items.name like 'Wa%'")
).order_by(text("items.id desc"))
Выполнить сырой SQL можно и просто передав его прямо в execute(). Например:
rs = conn.execute("select * from orders;")
rs.fetchall()
Транзакции
Транзакция — это способ выполнять наборы SQL-инструкций так, чтобы выполнились или все, или ни одна из них. Если хотя бы одна из инструкций, участвующих в транзакции, проходит с ошибкой, база данных возвращается к состоянию, которое было до ее начала.
Сейчас в базе данных два заказа. Для совершения заказа нужно выполнить следующие два действия:
- Удалить заказанные товары из
items - Обновить колонку
date_shippedс датой
Оба действия должны быть выполнены как одно целое, чтобы быть уверенными в том, что данные корректные.
Объект Connection предоставляет метод begin(), который инициирует транзакцию и возвращает соответствующий объект Transaction. Последний в свою очередь предоставляет методы rollback() и commit() для отката до прежнего состояния или сохранения текущего состояния.
В следующем списке метод dispatch_order() принимает order_id в качестве аргумента и выполняет упомянутые выше действия с помощью транзакции.
from sqlalchemy import func, update
from sqlalchemy.exc import IntegrityError
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
r = conn.execute(select([func.count("*")]).where(orders.c.id == order_id))
if not r.scalar():
raise ValueError("Недействительный order_id: {}".format(order_id))
# брать товары в порядке очереди
s = select([order_lines.c.item_id, order_lines.c.quantity]).where(
order_lines.c.order_id == order_id
)
rs = conn.execute(s)
ordered_items_list = rs.fetchall()
# начало транзакции
t = conn.begin()
try:
for i in ordered_items_list:
u = update(items).where(
items.c.id == i.item_id
).values(quantity = items.c.quantity - i.quantity)
rs = conn.execute(u)
u = update(orders).where(orders.c.id == order_id).values(date_shipped=datetime.now())
rs = conn.execute(u)
t.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
t.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
Первый заказ включает 5 стульев и 2 ручки. Вызов функции dispatch_order() с идентификатором заказа 1 вернет такой результат.
Транзакция завершена.
Теперь items и order_lines должны выглядеть следующим образом:
В следующем заказе 5 стульев и 4 ручки, но в запасе остались лишь 1 стул и 1 ручка.
Запустим dispatch_order(2) для второго заказа.
(psycopg2.errors.CheckViolation) ОШИБКА: новая строка в отношении "items" нарушает ограничение-проверку "quantity_check"
DETAIL: Ошибочная строка содержит (1, Chair, 9.21, 10.81, -4).
[SQL: UPDATE items SET quantity=(items.quantity - %(quantity_1)s) WHERE items.id = %(id_1)s]
[parameters: {'quantity_1': 5, 'id_1': 1}]
(Background on this error at: http://sqlalche.me/e/14/gkpj)
Транзакция не удалась.
Выполнение закончилось с ошибкой, потому что в запасе недостаточно ручек. В итоге база данных вернулась к состоянию до начала транзакции.
]]>Таблицы в SQLAlchemy представлены в виде экземпляров класса Table. Его конструктор принимает название таблицы, метаданные и одну или несколько колонок. Например:
from sqlalchemy import MetaData, Table, String, Integer, Column, Text, DateTime, Boolean
from datetime import datetime
metadata = MetaData()
blog = Table('blog', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
Разберем код построчно:
- Импортируем несколько классов из sqlalchemy, которые используются для создания таблицы.
- Импортируем класс datetime из модуля datetime.
- Создаем объекта
MetaData. Он содержит всю информацию о базе данных и таблицах. ЭкземплярMetaDataиспользуется для создания или удаления таблиц в базе данных. - Наконец, создается схема таблицы. Колонки создаются с помощью экземпляра
Column. Конструктор этого класса принимает название колонки и тип данных. Также можно передать дополнительные аргументы для обозначения ограничений (constraints) и конструкций SQL. Вот самые популярные ограничения:
| Ограничение | Описание |
primary_key | Булево. Если значение равно True, отмечает колонку как первичный ключ таблицы. Для создания составного ключа, нужно просто установить значение True для каждой колонки. |
nullable | Булево. Если False, то добавляет ограничение NOT NULL. Значение по умолчанию равно True. |
default | Определяет значение по умолчанию, если при вставке данных оно не было передано. Может быть как скалярное значение, так и вызываемое значение Python. |
onupdate | Значение по умолчанию для колонки, которое устанавливается, если ничего не было передано при обновлении записи. Может принимать то же значение, что и default. |
unique | Булево. Если True, следит за тем, чтобы значение было уникальным. |
index | Булево. Если True, создает индексируемую колонку. По умолчанию False. |
auto_increment | Добавляет параметр auto_increment для колонки. Значение по умолчанию равно auto. Это значит, что значение основного ключа будет увеличиваться каждый раз при добавлении новой записи. Если нужно увеличить значение для каждого элемента составного ключа, то этот параметр нужно задать как True для всех колонок ключа. Для отключения поведения нужно установить значение False |
Типы колонок
Тип определяет то, какие данные колонка сможет хранить. SQLAlchemy предоставляет абстракцию для большого количества типов. Однако всего есть три категории:
- Общие типы
- Стандартные SQL-типы
- Типы отдельных разработчиков
Общие типы
Тип Generic указывает на те типы, которые поддерживаются большинством баз данных. При использовании такого типа SQLAlchemy подбирает наиболее подходящий при создании таблицы. Например, в прошлом примере была определена колонка published. Ее тип — Boolean. Это общий тип. Для базы данных PostgreSQL тип будет boolean. А для MySQL — SMALLINT, потому что там нет Boolean. В Python же этот тип данных представлен типом bool (True или False).
Следующая таблица описывает основные типы в SQLAlchemy и ассоциации в Python и SQL.
| SQLAlchemy | Python | SQL |
|---|---|---|
BigInteger | int | BIGINT |
Boolean | bool | BOOLEAN или SMALLINT |
Date | datetime.date | DATE |
DateTime | datetime.datetime | DATETIME |
Integer | int | INTEGER |
Float | float | FLOAT или REAL |
Numeric | decimal.Decimal | NUMERIC |
Text | str | TEXT |
Получить эти типы можно из sqlalchemy.types или sqlalchemy.
Стандартные типы SQL
Типы в этой категории происходят из самого SQL. Их поддерживает небольшое количество баз данных.
from sqlalchemy import MetaData, Table, Column, Integer, ARRAY
metadata = MetaData()
employee = Table('employees', metadata,
Column('id', Integer(), primary_key=True),
Column('workday', ARRAY(Integer)),
)
Доступ к ним можно также получить из sqlalchemy.types или sqlalchemy. Однако для разделения стандартные типы записаны в верхнем регистре. Например, есть тип ARRAY, который пока поддерживается только PostgreSQL.
Типы производителей
В пакете sqlalchemy можно найти типы, которые используются в конкретных базах данных. Например, в PostgreSQL есть тип INET для хранения сетевых данных. Для его использования нужно импортировать sqlalchemy.dialects.
from sqlalchemy import MetaData, Table, Column, Integer
from sqlalchemy.dialects import postgresql
metadata = MetaData()
comments = Table('comments', metadata,
Column('id', Integer(), primary_key=True),
Column('ipaddress', postgresql.INET),
)
Реляционные отношения (связи)
Таблицы в базе данных редко существуют сами по себе. Чаще всего они связаны с другими через специальные отношения. Существует три типа отношений:
- Один-к-одному
- Один-ко-многим
- Многие-ко-многим
Разберемся, как определять эти отношения в SQLAlchemy.
Отношение один-ко-многим
Две таблицы связаны отношением один-ко-многим, если запись в первой таблице связана с одной или несколькими записями второй. На изображении ниже такая связь существует между таблицей users и posts.
Для создания отношения нужно передать объект ForeignKey, в котором содержится название колонки в функцию-конструктор Column.
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', ForeignKey("users.id")),
)
В этом коде определяется внешний ключ для колонки user_id таблицы posts. Это значит, что эта колонка может содержать только значения из колонки id таблицы users.
Вместо того чтобы передавать название колонки в качестве строки, можно передать объект Column прямо в конструктор ForeignKey. Например:
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey(user.c.id)),
)
user.c.id ссылается на колонку id таблицы users. Важно лишь запомнить, что определение колонки (user.c.id) должно идти до ссылки на нее (posts.c.user_id).
Отношение один-к-одному
Две таблицы имеют связь один-к-одному, если запись в одной таблице связана только с одной записью в другой. На изображении ниже таблица employees связана с employee_details. Первая включает публичные записи о сотрудниках, а вторая — частные.
from sqlalchemy import MetaData, Table, Column, Integer, String, DateTime, ForeignKey
metadata = MetaData()
employees = Table('employees', metadata,
Column('employee_id', Integer(), primary_key=True),
Column('first_name', String(200), nullable=False),
Column('last_name', String(200), nullable=False),
Column('dob', DateTime(), nullable=False),
Column('designation', String(200), nullable=False),
)
employee_details = Table('employee_details', metadata,
Column('employee_id', ForeignKey('employees.employee_id'), primary_key=True),
Column('ssn', String(200), nullable=False),
Column('salary', String(200), nullable=False),
Column('blood_group', String(200), nullable=False),
Column('residential_address', String(200), nullable=False),
)
Для создания такой связи одна и та же колонка должна выступать одновременно основным и внешним ключом в employee_details.
Отношение многие-ко-многим
Две таблицы имеют связь многие-ко-многим, если запись в первой таблице связана с одной или несколькими таблицами во второй. Вместе с тем, запись во второй таблице связана с одной или несколькими в первой. Для таких отношений создается таблица ассоциаций. На изображении ниже отношение многие-ко-многим существует между таблицами posts и tags.
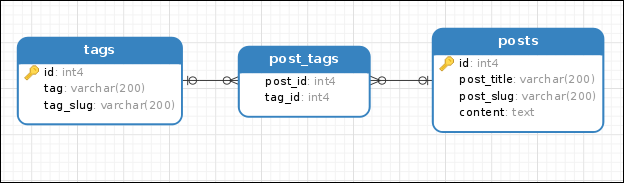
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
)
tags = Table('tags', metadata,
Column('id', Integer(), primary_key=True),
Column('tag', String(200), nullable=False),
Column('tag_slug', String(200), nullable=False),
)
post_tags = Table('post_tags', metadata,
Column('post_id', ForeignKey('posts.id')),
Column('tag_id', ForeignKey('tags.id'))
)
Процесс установки отношений почти не отличается от такового в SQL. Все потому что используется SQLAlchemy Core, который позволяет делать почти то же, что доступно в SQL.
Ограничения (constraint) на уровне таблицы
В прошлых разделах мы рассмотрели, как добавлять ограничения и индексы для колонки, передавая дополнительные аргументы в функцию-конструктор Column. По аналогии с SQL можно также определять ограничения с индексами и на уровне таблицы. В следующей таблице перечислены основные constraint и классы для их создания:
| Ограничения/индексы | Название класса |
| Основной ключ | PrimaryKeyConstraint |
| Внешний ключ | ForeignKeyConstraint |
| Уникальный ключ | UniqueConstraint |
| Проверочный ключ | CheckConstraint |
| Индекс | Index |
Получить доступ к этим классам можно через sqlalchemy.schema или sqlalchemy. Вот некоторые примеры использования:
Добавления Primary Key с помощью PrimaryKeyConstraint
parent = Table('parent', metadata,
Column('acc_no', Integer()),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', name='acc_no_pk')
)Здесь создается первичный ключ для колонки acc_no. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer(), primary=True),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
)Преимущественно PrimaryKeyConstraint используется для создания составного основного ключа (такого ключа, который использует несколько колонок). Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', 'acc_type', name='uniq_1')
)Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False, primary_key=True),
Column('acc_type', Integer, nullable=False, primary_key=True),
Column('name', String(16), nullable=False),
)Создание Foreign Key с помощью ForeignKeyConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', Integer, nullable=False),
Column('name', String(40), nullable=False),
ForeignKeyConstraint(['parent_id'],['parent.id'])
)Создаем внешний ключ в колонке parent_it, которая ссылается на колонку id таблицы parent. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', ForeignKey('parent.id'), nullable=False),
Column('name', String(40), nullable=False),
)Но реальную пользу ForeignKeyConstraint приносит при определении составного внешнего ключа (который также задействует несколько колонок). Например:
parent = Table('parent', metadata,
Column('id', Integer, nullable=False),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('id', 'ssn', name='uniq_1')
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(40), nullable=False),
Column('parent_id', Integer, nullable=False),
Column('parent_ssn', Integer, nullable=False),
ForeignKeyConstraint(['parent_id','parent_ssn'],['parent.id', 'parent.ssn'])
)Обратите внимание на то, что просто передать объект ForeignKey в отдельные колонки не получится — это приведет к созданию нескольких внешних ключей.
Создание Unique Constraint с помощью UniqueConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('ssn', name='unique_ssn')
)Определим ограничение уникальности для колонки ssn. Необязательное ключевое слово name позволяет задать имя для этого constraint. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, unique=True, nullable=False),
Column('name', String(16), nullable=False),
)UniqueConstraint часто используется для создания ограничения уникальности на нескольких колонках. Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, primary_key=True),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('acc_no', 'acc_type', name='uniq_1')
)В этом примере ограничения уникальности устанавливаются на acc_no и acc_type, в результате чего комбинация значений этих двух колонок всегда должна быть уникальной.
Создание ограничения проверки с помощью CheckConstraint
Ограничение CHECK позволяет создать условие, которое будет срабатывать при вставке или обновлении данных. Если проверка пройдет успешно, данные успешно сохранятся в базе данных. В противном случае возникнет ошибка.
Добавить это ограничение можно с помощью CheckConstraint.
employee = Table('employee', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(100), nullable=False),
Column('salary', Integer(), nullable=False),
CheckConstraint('salary < 100000', name='salary_check')
)Создание индексов с помощью Index
Аргумент-ключевое слово index также позволяет добавлять индекс для отдельных колонок. Для работы с ним есть класс Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name')
)В этом примере индекс создается для колонки first_name. Такой код эквивалентен следующему:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False, index=True),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
)Если запросы включают поиск по определенному набору полей, то увеличить производительность можно с помощью составного индекса (то есть, индекса для нескольких колонок). В этом основное назначение Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name', 'last_name')
)Связь с таблицами и колонками с помощью MetaData
Объект MetaData содержит всю информацию о базе данных и таблицах внутри нее. С его помощью можно получать доступ к объектам таблицы, используя такие два атрибута:
| Атрибут | Описание |
| tables | Возвращает объект-словарь типа immutabledict, где ключом выступает название таблицы, а значением — объект с ее данными |
| sorted_tables | Возвращает список объектов Table, отсортированных по порядку зависимости внешних ключей. Другими словами, таблицы с зависимостями располагаются перед самими зависимостями. Например, если у таблицы posts есть внешний ключ, указывающий на колонку id таблицы users, то таблица users будет расположена перед posts |
Вот два описанных атрибута в действии:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, Column, Text, DateTime, Boolean, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey("users.id")),
)
for t in metadata.tables:
print(metadata.tables[t])
print('-------------')
for t in metadata.sorted_tables:
print(t.name)
Ожидаемый вывод:
users
posts
-------------
users
postsПосле получения доступа к экземпляру Table можно получать доступ к любым деталям о колонках:
print(posts.columns) # вернуть список колонок
print(posts.c) # как и post.columns
print(posts.foreign_keys) # возвращает множество, содержащий внешние ключи таблицы
print(posts.primary_key) # возвращает первичный ключ таблицы
print(posts.metadata) # получим объект MetaData из таблицы
print(posts.columns.post_title.name) # возвращает название колонки
print(posts.columns.post_title.type) # возвращает тип колонки
Ожидаемый вывод:
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
{ForeignKey('users.id')}
PrimaryKeyConstraint(Column('id', Integer(), table=<posts>, primary_key=True, nullable=False))
MetaData()
post_title
VARCHAR(200)Создание таблиц
Для создания таблиц, хранящихся в экземпляре MetaData, вызовите метод MetaData.create_all() с объектом Engine.
metadata.create_all(engine)Этот метод создает таблицы только в том случае, если они не существуют в базе данных. Это значит, что его можно вызвать безопасно несколько раз. Также стоит отметить, что вызов метода после определения схемы не изменит ее. Для этого нужно использовать инструмент миграции под названием Alembic.
Удалить все таблицы можно с помощью MetaData.drop_all().
В дальнейшем будем работать с базой данных для приложения в сфере электронной коммерции. Она включает 4 таблицы:
- customers — хранит всю информацию о потребителях. Имеет следующие колонки:
- id — первичный ключ
- first_name — имя покупателя
- last_name — фамилия покупателя
- username — уникальное имя покупателя
- email — уникальный адрес электронной почты
- address — адрес
- town — город
- created_on — дата и время создания аккаунта
- updated_on — дата и время обновления аккаунта
- items — хранит информацию о товарах. Колонки:
- id — первичный ключ
- name — название
- cost_price — себестоимость товара
- selling_price — цена продажи
- quantity — количество товаров в наличии
- orders — информация о покупках потребителей. Колонки:
- id — первичный ключ
- customer_id — внешний ключ, указывающий на колонку
idтаблицы customers - date_placed — дата и время размещения заказа
- date_shipped — дата и время отгрузки заказа
- order_lines — подробности каждого товара в заказе. Колонки:
- id — первичный ключ
- order_id — внешний ключ, указывающий на
idтаблицы orders - item_id — внешний ключ, указывающий на
idтаблицы items - quantity — количество товаров в заказе
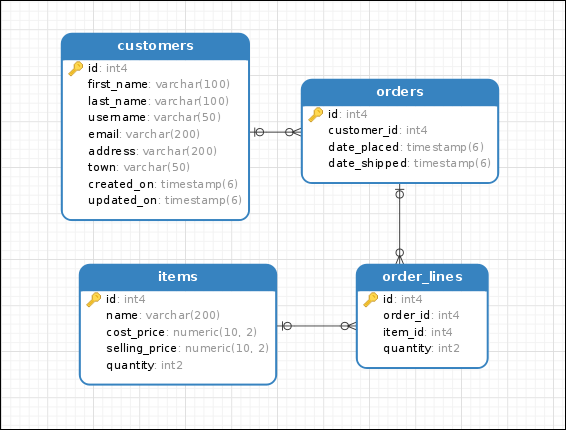
А вот и весь код для создания этих таблиц:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, CheckConstraint
from datetime import datetime
metadata = MetaData()
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
customers = Table('customers', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('last_name', String(100), nullable=False),
Column('username', String(50), nullable=False),
Column('email', String(200), nullable=False),
Column('address', String(200), nullable=False),
Column('town', String(50), nullable=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
items = Table('items', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(200), nullable=False),
Column('cost_price', Numeric(10, 2), nullable=False),
Column('selling_price', Numeric(10, 2), nullable=False),
Column('quantity', Integer(), nullable=False),
CheckConstraint('quantity > 0', name='quantity_check')
)
orders = Table('orders', metadata,
Column('id', Integer(), primary_key=True),
Column('customer_id', ForeignKey('customers.id')),
Column('date_placed', DateTime(), default=datetime.now),
Column('date_shipped', DateTime())
)
order_lines = Table('order_lines', metadata,
Column('id', Integer(), primary_key=True),
Column('order_id', ForeignKey('orders.id')),
Column('item_id', ForeignKey('items.id')),
Column('quantity', Integer())
)
metadata.create_all(engine)
Базу данных
sqlalchemy_tutsмы создали в предыдущем уроке: https://pythonru.com/biblioteki/ustanovka-i-podklyuchenie-sqlalchemy-k-baze-dannyh
В следующем материале рассмотрим, как выполнять CRUD-операции в базе данных с помощью SQL.
]]>Для работы с LightGBM доступны API на C, Python или R. Фреймворк также предоставляет CLI, который позволяет нам использовать библиотеку из командной строки. Оценщики (estimators) LightGBM оснащены множеством гиперпараметров для настройки модели. Кроме этого, в нем уже реализован большой набор функций оптимизации/потерь и оценочных метрики.
В рамках данного руководства мы рассмотрим Python API данного фреймворка. Мы постараемся объяснить и охватить большую часть этого API. Основная цель работы — ознакомить читателей с основными функциональными возможностями lightgbm, необходимыми для начала работы с ним.
Существуют и другие библиотеки (xgboost, catboost, scikit-learn), которые также обеспечивают реализацию деревьев решений с градиентным бустингом.
Давайте начнем.
Ноутбук с кодом в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/LightGBM_python.ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
import sklearn
import warnings
warnings.filterwarnings("ignore")
print("Версия LightGBM : ", lgb.__version__)
print("Версия Scikit-Learn : ", sklearn.__version__)
Версия LightGBM : 3.2.1
Версия Scikit-Learn : 0.23.2Загрузка датасетов
Мы будем использовать доступные в sklearn три набора данных (показаны ниже) для этого руководства.
- Boston Housing Dataset — это выборка для задач регрессии, которая содержит информацию о различных характеристиках домов в Бостоне и их цене в долларах. Она будет использоваться нами при решении регрессионных проблем.
- Breast Cancer Dataset — это датасет для задач классификации, содержащий информацию о двух типах опухолей. Он будет применяться для объяснения методов бинарной классификации.
- Wine Dataset — это набор данных классификации, содержащий информацию об ингредиентах, используемых в создании вин трех типов. Используется нами для объяснения задач мультиклассификации.
Ниже мы загрузили все три упомянутых датасета, вывели их описания для ознакомления с признаками(features) и размерами соответствующих выборок. Каждый датасет как pandas DataFrame. Посмотрим на них:
Boston Housing Dataset
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:29]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price"] = boston.target
boston_df.head()
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | Price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Breast Cancer Dataset
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:31]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = breast_cancer.target
breast_cancer_df.head()
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 0 is Mean Radius, field
10 is Radius SE, field 20 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | TumorType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Wine Dataset
from sklearn.datasets import load_wine
wine = load_wine()
for line in wine.DESCR.split("\n")[5:29]:
print(line)
wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names)
wine_df["WineType"] = wine.target
wine_df.head()
**Data Set Characteristics:**
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | WineType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
Обучение модели на train()
Самый простой способ создать оценщик (estimator) в lightgbm — использовать метод train(). Он принимает на вход оценочный параметр в виде словаря и обучающий датасет. Затем train тренирует оценщик и возвращает объект типа Booster, который является обученным оценщиком: его можно использовать для будущих предсказаний.
Ниже приведены некоторые из важных параметров метода train().
params— это словарь, определяющий параметры алгоритма деревьев решений с градиентным бустингом. Нам просто нужно предоставить целевую функцию для начала работы в зависимости от типа задачи (классификация/регрессия). Позже мы ознакомимся с часто используемым списком параметров, которые можно передать в этот словарь.train_set— этот параметр принимает объект типаDatasetфреймворка lightgbm, который содержит информацию о показателях и целевых значениях. Это внутренняя структура данных, разработанная lightgbm для обертывания данных.num_boost_round— указывает количество деревьев бустинга, которые будут использоваться в ансамбле. Ансамбль — это группа деревьев с градиентным бустингом, которую мы обычно называем оценщиком. Значение по умолчанию равно 100.valid_sets— принимает списокDatasetобъектов, которые являются выборками для валидации. Эти проверочные датасеты оцениваются после каждого цикла обучения.valid_names— принимает список строк той же длины, что и уvalid_sets, определяющих имена для каждой проверочной выборки. Эти имена будут использоваться при выводе оценочных метрик для валидационных наборов данных, а также при их построении.categorical_feature— принимает список строк/целых чисел или строку auto. Если мы передадим список строк/целых чисел, тогда указанные столбцы из набора данных будут рассматриваться как категориальные.verbose_eval— принимает значения типаboolилиint. Если мы установим значениеFalseили 0, тоtrainне будет выводить результаты расчета метрик на проверочных выборках, которые мы передали. Если нами было указано True, он будет печатать их для каждого раунда. При передаче целого числа, большего 1,trainотобразит результаты повторно после указанного количества раундов.
Dataset
Dataset представляет собой внутреннюю структуру данных lightgbm для хранения данных и меток. Ниже приведены важные параметры класса.
data— принимает массив библиотеки numpy, dataframe pandas, разреженные матрицы (sparse matrix) scipy, список массивов numpy, фрейм таблицы данных h2o в качестве входного значения, хранящего значения признаков (features).label— принимает массив numpy, pandas series или dataframe с одним столбцом. Данный параметр определяет целевые значения. Мы также можем установить дляlabelзначениеNone, если у нас нет таких значений. По умолчанию —None.feature_name— принимает список строк, определяющих имена показателей.categorical_feature— имеет то же значение, что и указанное выше в параметре методаtrain(). Мы можем определить категориальный показатель здесь или вtrain.
Регрессия
Первая проблема, которую мы решим с помощью lightgbm, — это простая задача регрессии с использованием датасета Boston housing, который был загружен нами ранее. Мы разделили этот набор данных на обучающую/тестовую выборки и создали из них экземпляр Dataset. Затем мы вызвали метод lightgbm.train(), предоставив ему датасеты для обучения и проверки. Мы установили количество итераций бустинга равным 10, поэтому для решения задачи будет создано 10 деревьев.
После завершения обучения train вернет экземпляр типа Booster, который мы позже сможем использовать для будущих предсказаний. Поскольку мы передали проверочный датасет в качестве входных данных, метод выведет значение l2 для валидации после каждой итерации обучения. Обратите внимание, что по умолчанию lightgbm минимизирует потерю l2 для задачи регрессии.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Размеры Train/Test: (379, 13) (127, 13) (379,) (127,)
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000840 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 961
[LightGBM] [Info] Number of data points in the train set: 379, number of used features: 13
[LightGBM] [Info] Start training from score 22.134565
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's l2: 92.7815
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[2] valid_0's l2: 80.7846
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[3] valid_0's l2: 70.6207
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[4] valid_0's l2: 61.6287
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[5] valid_0's l2: 55.0184
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[6] valid_0's l2: 49.3809
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[7] valid_0's l2: 44.3784
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[8] valid_0's l2: 40.2941
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[9] valid_0's l2: 36.8559
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] valid_0's l2: 33.9026Ниже мы сделали прогнозы по тренировочным и тестовым данным с использованием обученной модели. Затем рассчитали R2 метрики для них, используя соответствующий метод sklearn. Обратите внимание, метод predict() принимает массив numpy, dataframe pandas, scipy sparse matrix или фрейм таблицы данных h2o в качестве входных данных для предсказаний.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Test R2 Score : 0.68
Train R2 Score : 0.74raw_score— это логический параметр, при котором, если он установлен вTrue, результатом выполнения будут необработанные прогнозы. Для задач регрессии это не имеет никакого значения, но при классификации predict вернет значения функции, а не вероятности.pred_leaf— этот параметр принимает логические значения. Если заданоTrue, то будет возвращаться индекс листа каждого дерева, который был спрогнозирован для конкретного семпла. Размер вывода будетn_samples x n_trees.pred_contrib— возвращает массив показателей для каждого наблюдения. Результатом будет являться массив размера(n_features + 1)для каждого семпла, где последнее значение является ожидаемым значением, а первые n_features являются вкладом показателей в этот прогноз. Мы можем добавить вклад каждого показателя к последнему ожидаемому значению и получить фактический прогноз. Обычно такие значения называют SHAP.
idxs = booster.predict(X_test, pred_leaf=True)
print("Размерность: ", idxs.shape)
idxs
Размерность: (127, 10)
array([[10, 11, 12, ..., 5, 13, 6],
[ 3, 3, 3, ..., 3, 4, 2],
[ 2, 8, 2, ..., 2, 2, 3],
...,
[ 3, 3, 3, ..., 3, 4, 2],
[ 5, 0, 0, ..., 13, 0, 13],
[ 0, 5, 14, ..., 0, 3, 1]])
shap_vals = booster.predict(X_test, pred_contrib=True)
print("Размерность: ", shap_vals.shape)
print("\nЗначения Shap для нулевого семпла: ", shap_vals[0])
print("\nПредсказания с использованием значений SHAP: ", shap_vals[0].sum())
print("Предсказания без SHAP: ", test_preds[0])
Размерность: (127, 14)
Значения Shap для нулевого семпла: [-1.04268359e+00 0.00000000e+00 5.78385997e-02 0.00000000e+00
-5.09776692e-01 -1.81771187e+00 -5.44789659e-02 -2.41017058e-02
9.10266200e-03 -6.42845196e-03 5.32678196e-03 0.00000000e+00
-4.62999363e+00 2.21345647e+01]
Предсказания с использованием значений SHAP: 14.121657826104853
Предсказания без SHAP: 14.121657826104858Мы можем вызвать метод num_trees() в экземпляре бустера, чтобы получить количество деревьев в ансамбле. Обратите внимание: если мы не прекратим обучение раньше, число деревьев будет таким же, как num_boost_round. Но если мы прервем тренировку, тогда их количество будет отличаться от num_boost_round.
Позже в этом руководстве мы объясним, как можно остановить обучение, если производительность ансамбля не улучшается при оценке на проверочном наборе.
Экземпляр бустера имеет еще один важный метод feature_importance(), который может возвращать нам важность признаков на основе значений выигрыша (booster.feature_importance(importance_type="gain")) и разделения (booster.feature_importance(importance_type="split")) деревьев.
(array([4.56516126e+03, 0.00000000e+00, 1.49124010e+03, 0.00000000e+00,
1.20125020e+03, 6.15448327e+04, 4.08311499e+02, 8.27205796e+02,
2.62632999e+01, 4.70000000e+01, 2.03512299e+02, 0.00000000e+00,
4.28531050e+04])
array([21, 0, 7, 0, 9, 29, 7, 15, 1, 1, 4, 0, 44]))Бинарная классификация
В этом разделе объясняется, как мы можем, используя метод train(), создать бустер для задачи бинарной классификации. Обучаем модель на наборе данных о раке груди, а затем оцениваем ее точность, используя метрику из sklearn. Мы установили objective значение binary для информирования метода train() о том, что предоставленные нами данные предназначены для решения задачи бинарной классификации. Также установили параметр verbosity равным -1, чтобы предотвратить вывод сообщений во время обучения. Он по-прежнему будет печатать результаты оценки проверочного датасета, которые тоже можно отключить, передав для параметра verbose_eval значение False.
Обратите внимание, что для задач классификации метод бустера predict() возвращает вероятности. Мы добавили логику для преобразования вероятностей в целевой класс.
По умолчанию при решении задач бинарной классификации LightGBM использует для оценки бинарную логистическую функцию потери на проверочной выборке. Мы можем добавить параметр metric в словарь, который передается методу train(), с названиями любых метрик, доступных в lightgbm, и он будет использовать эти метрики. Позже мы более подробно обсудим перечень предоставляемых lightgbm метрик.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
booster = lgb.train({"objective": "binary", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.600128
[2] valid_0's binary_logloss: 0.537151
[3] valid_0's binary_logloss: 0.48676
[4] valid_0's binary_logloss: 0.443296
[5] valid_0's binary_logloss: 0.402604
[6] valid_0's binary_logloss: 0.37053
[7] valid_0's binary_logloss: 0.339712
[8] valid_0's binary_logloss: 0.316836
[9] valid_0's binary_logloss: 0.297812
[10] valid_0's binary_logloss: 0.278683
Test Accuracy: 0.95
Train Accuracy: 0.97Мультиклассовая классификация
В рамках этого раздела объясняется, как использовать метод train() для задач мультиклассовой классификации. Мы применяем его на выборке данных о вине, которая имеет три разных типа вина в качестве целевой переменной. Мы установили objective в значение multiclass. Всякий раз, когда нами используется метод train() для решения такой задачи, нам необходимо предоставить целочисленный параметр num_class, определяющим количество классов.
Метод predict() возвращает вероятности для каждого класса в случае мультиклассовых задач. Мы добавили логику для выбора класса с наибольшим значением вероятности в качестве фактического предсказания.
LightGBM по умолчанию использует для оценки мультиклассовую логистическую функцию потери на проверочном датасете при решении проблем бинарной классификации.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=wine.feature_names)
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=wine.feature_names)
booster = lgb.train({"objective": "multiclass", "num_class":3, "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = np.argmax(test_preds, axis=1)
train_preds = np.argmax(train_preds, axis=1)
print("\nTest Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (133, 13) (45, 13) (133,) (45,)
[1] valid_0's multi_logloss: 0.951806
[2] valid_0's multi_logloss: 0.837812
[3] valid_0's multi_logloss: 0.746033
[4] valid_0's multi_logloss: 0.671446
[5] valid_0's multi_logloss: 0.60648
[6] valid_0's multi_logloss: 0.54967
[7] valid_0's multi_logloss: 0.499026
[8] valid_0's multi_logloss: 0.458936
[9] valid_0's multi_logloss: 0.419804
[10] valid_0's multi_logloss: 0.385265
Test Accuracy: 0.98
Train Accuracy: 1.00Список важных параметров LightGBM
Теперь мы перечислим важные параметры lightgbm, которые могут быть предоставлены в виде словаря при вызове метода train(). Мы можем использовать те же параметры для оценщиков (LGBMModel, LGBMRegressor и LGBMClassifier), которые доступны в lightgbm, с той лишь разницей, что нам не нужно формировать словарь — мы можем передать их напрямую при создании экземпляра. Мы рассмотрим работу с оценщиками в следующем разделе.
objective— этот параметр позволяет нам определить целевую функцию, используемую для текущей задачи. Его значением по умолчанию является regression. Ниже приведен список часто используемых значений этого параметра.regressionregression_l1tweediebinarymulticlassmulticlassovacross_entropy- Другие доступные целевые функции
metric— данный параметр принимает метрики для расчета на оценочных наборах данных (в случае если эти выборки предоставлены как значение параметраeval_set/validation_sets). Мы можем предоставить более одной метрики, и все они будут посчитаны на проверочных датасетах. Ниже приведен список наиболее часто используемых значений этого параметра.rmsel2l1tweediebinary_loglossmulti_loglossauccross_entropy- Другие доступные метрики
boosting— этот параметр принимает одну из нижеперечисленных строк, определяющих, какой алгоритм использовать.gbdt— значение по умолчанию. Дерево решений с градиентным бустингомrf— Случайный лесdart— Dropout на множественных аддитивных регрессионных деревьяхgoss— Односторонняя выборка на основе градиента
num_iterations— данный параметр является псевдонимом дляnum_boost_round, который позволяет нам указать число деревьев в ансамбле для создания оценщика. По умолчанию 100.learning_rate— этот параметр используется для определения скорости обучения. По умолчанию 0.1.num_class— если мы работаем с задачей мультиклассовой классификации, то этот параметр должен содержать количество классов.num_leaves— данный параметр принимает целое число, определяющее максимальное количество листьев, разрешенное для каждого дерева. По умолчанию 31.num_threads— принимает целое число, указывающее количество потоков, используемых для обучения. Мы можем установить его равным числу ядер системы.seed— позволяет нам указать инициализирующее значение для процесса обучения, что предоставляет нам возможность повторно генерировать те же результаты.max_depth— этот параметр позволяет нам указать максимальную глубину, разрешенную для деревьев в ансамбле. По умолчанию -1, что позволяет деревьям расти как можно глубже. Мы можем ограничить это поведение, установив этот параметр.min_data_in_leaf— данный параметр принимает целочисленное значение, определяющее минимальное количество точек данных (семплов), которые могут храниться в одном листе дерева. Этот параметр можно использовать для контроля переобучения. Значение по умолчанию 20.bagging_fraction— этот параметр принимает значение с плавающей запятой от 0 до 1, которое позволяет указать, насколько большая часть данных будет случайно отбираться при обучении. Этот параметр может помочь предотвратить переобучение. По умолчанию 1.0.feature_fraction— данный параметр принимает значение с плавающей запятой от 0 до 1, которое информирует алгоритм о выборе этой доли показателей из общего числа для обучения на каждой итерации. По умолчанию 1.0, поэтому используются все показатели.extra_trees— этот параметр принимает логические значения, определяющие, следует ли использовать чрезвычайно рандомизированное дерево или нет.early_stopping_round— принимает целое число, указывающее, что мы должны остановить обучение, если оценочная метрика, рассчитанная на последнем проверочном датасете, не улучшается на протяжении определенного параметром числа итераций.monotone_constraints— этот параметр позволяет нам указать, должна ли наша модель обеспечивать увеличение, уменьшение или отсутствие связи отдельного показателя с целевым значением. Использование данного параметра объясняется в разделе «Монотонные ограничения».monotone_constraints_method— этот параметр принимает одну из нижеперечисленных строк, определяющих тип накладываемых монотонных ограничений.basic— базовый метод монотонных ограничений, который может чрезмерно ограничивать модель.intermediate— это более сложный метод ограничений, который немного менее ограничивает, чем базовый метод, но может занять больше времени.advanced— это расширенный метод ограничений, который менее ограничивает, чем базовый и промежуточный методы, но может занять больше времени.
interaction_constraints— этот параметр принимает список списков, в которых отдельные списки определяют индексы показателей, которым разрешено взаимодействовать друг с другом. Такое взаимодействие подробно объясняется в разделе «Ограничения взаимодействия показателей».verbosity— этот параметр принимает целочисленное значение для управления логированием сообщений при обучении.- < 0 — отображаются только фатальные ошибки.
- 0 — отображаются сообщения об ошибках/предупреждениях и перечисленные выше.
- 1 — отображаются информационные сообщения и перечисленные выше.
- > 1 — отображается отладочная информация и перечисленные выше.
is_unbalance— это логический параметр, который должен иметь значениеTrue, если данные не сбалансированы. Его следует использовать с задачами бинарной и мультиклассовой классификации.device_type— принимает одну из следующих строк, определяющих тип используемого для обучения оборудования.cpugpucuda
force_col_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по столбцам при обучении. Если в данных слишком много столбцов, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.force_row_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по строкам при обучении. Если в данных слишком много строк, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.
Стоит учитывать, что это не полный список параметров, доступных при работе с lightgbm, а только перечисление некоторых наиболее важных. Если вы хотите узнать обо всех параметрах, перейдите по ссылке ниже.
Полный список параметров LightGBM.
LGBMModel
Класс LGBMModel — это обертка для класса Booster, которая предоставляет подобный scikit-learn API для обучения и прогнозирования в lightgbm. Он позволяет нам создать объект оценщика со списком параметров в качестве входных данных. Затем мы можем вызвать метод fit() для обучения, передав ему тренировочные данные, и метод predict() для предсказания.
Параметры, которые мы передали в виде словаря аргументу params функции train(), теперь можно напрямую передать конструктору LGBMModel для создания модели. LGBMModel позволяет нам выполнять задачи как классификации, так и регрессии, указав цель (objective) задачи.
Регрессия
Ниже на простом примере объясняется, как мы можем использовать LGBMModel для выполнения задач регрессии с данными о жилье в Бостоне. Сначала нами был создан экземпляр LGBMModel с целью (objective) регрессии и числом деревьев, равным 10. Параметр n_estimators является псевдонимом параметра num_boost_round метода train().
Затем мы вызвали метод fit() для обучения модели, передав ему тренировочные данные. Обратите внимание, что он принимает в качестве входных данных массивы numpy, а не объект Dataset фреймворка lightgbm. Мы также предоставили набор данных, который будет использоваться в качестве оценочного датасета, и метрики, которые будут рассчитываться на нем. Параметры метода fit() почти такие же, как и у train().
Наконец, мы вызвали метод predict(), чтобы сделать прогнозы.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 9.70598 valid_0's l2: 94.206
[2] valid_0's rmse: 9.04855 valid_0's l2: 81.8763
[3] valid_0's rmse: 8.51309 valid_0's l2: 72.4727
[4] valid_0's rmse: 8.04785 valid_0's l2: 64.7678
[5] valid_0's rmse: 7.6032 valid_0's l2: 57.8086
[6] valid_0's rmse: 7.21651 valid_0's l2: 52.078
[7] valid_0's rmse: 6.88971 valid_0's l2: 47.4681
[8] valid_0's rmse: 6.63273 valid_0's l2: 43.9931
[9] valid_0's rmse: 6.40727 valid_0's l2: 41.0532
[10] valid_0's rmse: 6.21095 valid_0's l2: 38.5759
Test R2 Score: 0.65
Train R2 Score: 0.74Бинарная классификация
Ниже мы объясняем на простом примере, как мы можем использовать LGBMModel для задач классификации. У нас есть обученная модель с набором данных по раку груди. Обратите внимание, что метод predict() возвращает вероятности. Мы включили логику для вычисления класса по вероятностям.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.578847
[2] valid_0's binary_logloss: 0.524271
[3] valid_0's binary_logloss: 0.480868
[4] valid_0's binary_logloss: 0.441691
[5] valid_0's binary_logloss: 0.410361
[6] valid_0's binary_logloss: 0.381543
[7] valid_0's binary_logloss: 0.353827
[8] valid_0's binary_logloss: 0.33609
[9] valid_0's binary_logloss: 0.319685
[10] valid_0's binary_logloss: 0.30735
Test Accuracy: 0.90
Train Accuracy: 0.98LGBMRegressor
LGBMRegressor — еще одна обертка-оценщик вокруг класса Booster, предоставляемая lightgbm и имеющая тот же API, что и у оценщиков sklearn. Как следует из названия, он предназначен для задач регрессии.
LGBMRegressor почти такой же, как LGBMModel, с той лишь разницей, что он предназначен только для задач регрессии. Ниже мы объяснили использование LGBMRegressor на простом примере с использованием набора данных о жилье в Бостоне. Обратите внимание, что LGBMRegressor предоставляет метод score(), который рассчитывает для нас оценку R2, которую мы до сих пор получали с использованием метрик sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMRegressor(objective="regression_l2", n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric=["rmse", "l2", "l1"])
print("Test R2 Score: %.2f"%booster.score(X_train, Y_train))
print("Train R2 Score: %.2f"%booster.score(X_test, Y_test))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 8.31421 valid_0's l2: 69.1262 valid_0's l1: 6.0334
[2] valid_0's rmse: 7.61825 valid_0's l2: 58.0377 valid_0's l1: 5.54499
[3] valid_0's rmse: 7.00797 valid_0's l2: 49.1116 valid_0's l1: 5.14472
[4] valid_0's rmse: 6.45103 valid_0's l2: 41.6158 valid_0's l1: 4.7527
[5] valid_0's rmse: 5.97644 valid_0's l2: 35.7178 valid_0's l1: 4.41064
[6] valid_0's rmse: 5.55884 valid_0's l2: 30.9007 valid_0's l1: 4.11807
[7] valid_0's rmse: 5.20092 valid_0's l2: 27.0495 valid_0's l1: 3.85392
[8] valid_0's rmse: 4.88393 valid_0's l2: 23.8528 valid_0's l1: 3.63833
[9] valid_0's rmse: 4.63603 valid_0's l2: 21.4928 valid_0's l1: 3.45951
[10] valid_0's rmse: 4.40797 valid_0's l2: 19.4302 valid_0's l1: 3.27911
Test R2 Score: 0.75
Train R2 Score: 0.76LGBMClassifier
LGBMClassifier — еще одна обертка-оценщик вокруг класса Booster, которая предоставляет API, подобный sklearn, для задач классификации. Он работает точно так же, как LGBMModel, но только для задач классификации. Он также предоставляет метод score(), который оценивает точность переданных ему данных.
Обратите внимание, что LGBMClassifier предсказывает фактические метки классов для задач классификации с помощью метода predict(). Он предоставляет метод pred_proba(), если нам нужны вероятности целевых классов.
Бинарная классификация
Ниже мы приводим простой пример того, как мы можем использовать LGBMClassifier для задач бинарной классификации. Наше объяснение основано на его применении к датасету по раку груди.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
booster = lgb.LGBMClassifier(objective="binary", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.97
Train Accuracy: 0.97Мультиклассовая классификация
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
booster = lgb.LGBMClassifier(objective="multiclassova", n_estimators=10, num_class=3)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.96
Train Accuracy: 1.00Далее мы объясняем использование LGBMClassifier для задач мультиклассовой классификации с использованием набора данных Wine.
Обратите внимание, что LGBMModel, LGBMRegressor и LGBMClassifier предоставляют атрибут с названием booster_, возвращающий экземпляр класса Booster, который мы можем сохранить на диск после обучения и позже загрузить для прогнозирования.
Сохранение и загрузка модели
Теперь мы покажем, как сохранить обученную модель на диск, чтобы использовать ее позже для прогнозов. Lightgbm предоставляет нижеперечисленные методы для сохранения и загрузки моделей.
save_model()— этот метод принимает имя файла, в котором сохраняется модель.model_to_string()— данный метод возвращает строковое представление модели, которое мы затем можем сохранить в текстовый файл.lightgbm.Booster()— этот конструктор позволяет нам создать экземпляр классаBooster. У него есть два важных параметра, которые могут помочь нам загрузить модель из файла или из строки.model_file— этот параметр принимает имя файла, из которого загружается обученная модель.model_str— данный параметр принимает строку, содержащую информацию об обученной модели. Нам нужно передать этому параметру строку, которая была сгенерирована с помощьюmodel_to_string()после загрузки из файла.
Ниже мы объясняем на простых примерах, как использовать вышеупомянутые методы для сохранения моделей на диск, а затем загрузки с него.
Обратите внимание, что для сохранения модели, обученной с использованием LGBMModel, LGBMRegressor и LGBMClassifier, нам сначала нужно получить их экземпляр Booster с помощью атрибута booster_ оценщика, а затем сохранить его. LGBMModel, LGBMRegressor и LGBMClassifier не предоставляют функций сохранения и загрузки. Они доступны только с экземпляром Booster.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
verbose_eval=False,
feature_name=boston.feature_names.tolist(),
num_boost_round=10)
booster.save_model("lgb.model")
loaded_booster = lgb.Booster(model_file="lgb.model")
test_preds = loaded_booster.predict(X_test)
train_preds = loaded_booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.62
Train R2 Score: 0.76Кросс-валидация
Lightgbm позволяет нам выполнять кросс-валидацию с помощью метода cv(). Он принимает параметры модели в виде словаря, как метод train(). Затем мы можем предоставить набор данных для выполнения перекрестной проверки. По умолчанию данный метод производит 5-кратную кросс-валидацию. Мы можем изменить кратность, установив параметр nfold. Он также принимает разделитель данных sklearn, такой как KFold, StratifiedKFold, ShuffleSplit и StratifiedShuffleSplit. Мы можем предоставить эти разделители данных параметру folds метода cv().
Метод cv() возвращает словарь, содержащий информацию о среднем значении и стандартном отклонении потерь для каждого цикла обучения. Мы даже можем попросить метод вернуть экземпляр CVBooster, установив для параметра return_cvbooster значение True. Объект CVBooster содержит информацию о кросс-валидации.
from sklearn.model_selection import StratifiedShuffleSplit
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
nfold=5, stratified=True, shuffle=True,
verbose_eval=True)
cv_output = lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
metrics=["auc", "average_precision"],
folds=StratifiedShuffleSplit(n_splits=3),
verbose_eval=True,
return_cvbooster=True)
for key, val in cv_output.items():
print("\n" + key, " : ", val)
auc-mean : [0.9766666666666666, 0.9833333333333334, 0.9833333333333334, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
auc-stdv : [0.020548046676563275, 0.023570226039551608, 0.023570226039551608, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
average_precision-mean : [0.9833333333333334, 0.9888888888888889, 0.9888888888888889, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
average_precision-stdv : [0.013608276348795476, 0.015713484026367772, 0.015713484026367772, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
cvbooster : <lightgbm.engine.CVBooster object at 0x000001CDFDA4FA00>Построение графиков
Lightgbm предоставляет нижеперечисленные функции для построения графиков — plot_importance().
Этот метод принимает экземпляр класса Booster и с его помощью отображает важность показателей. Ниже мы создали график важности показателей, используя бустер, ранее обученный для задачи регрессии. У данного метода есть параметр important_type. Если он установлен в значение split, то график будет отображать количество раз каждый показатель использовался для разбиения. Также если установлено значение gain, то будет показан выигрыш от соответствующих разделений. Значение параметра important_type по умолчанию split.
Метод plot_importance() имеет еще один важный параметр max_num_features, который принимает целое число, определяющее, сколько признаков включить в график. Мы можем ограничить их количество с помощью этого параметра. Таким образом, на графике будет показано только указанное количество основных показателей.
lgb.plot_importance(booster, figsize=(8,6));
plot_metric()
Этот метод отображает результаты расчета метрики. Нам нужно предоставить экземпляр бустера методу, чтобы построить оценочною метрику, рассчитанную на наборе данных для оценки.
plot_split_value_histogram()
Этот метод принимает на вход экземпляр класса Booster и имя/индекс показателя. Затем он строит гистограмму значений разделения (split value) для выбранного признака.
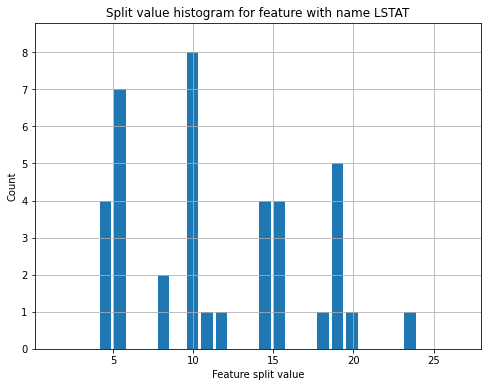
plot_tree()
Этот метод позволяет построить отдельное дерево ансамбля. Нам нужно указать экземпляр бустера и индекс дерева, которое мы хотим построить.
Ранняя остановка обучения
Ранняя остановка обучения — это процесс, при котором мы прекращаем обучение, если оценочная метрика, рассчитанная на оценочном датасете, не улучшается в течение указанного числа раундов. Lightgbm предоставляет параметр early_stopping_rounds как часть методов train() и fit(). Этот параметр принимает целочисленное значение, указывающее, что процесс обучения должен остановится, если результаты вычисления метрики не улучшились за указанное число итераций.
Обратите внимание, что для того, чтобы данный процесс работал, нам нужен набор данных для оценки, поскольку принятие решения об остановке обучения основано на результатах расчета метрики на оценочном датасете.
Ниже мы показываем использование параметра early_stopping_rounds для задач регрессии и классификации на простых примерах.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="binary", n_estimators=100, metric="auc")
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),],
early_stopping_rounds=3)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's auc: 0.979158
Training until validation scores don't improve for 3 rounds
[2] valid_0's auc: 0.979592
[3] valid_0's auc: 0.979592
[4] valid_0's auc: 0.988168
[5] valid_0's auc: 0.988602
[6] valid_0's auc: 0.98947
[7] valid_0's auc: 0.992727
[8] valid_0's auc: 0.995766
[9] valid_0's auc: 0.994572
[10] valid_0's auc: 0.995115
[11] valid_0's auc: 0.995332
Early stopping, best iteration is:
[8] valid_0's auc: 0.995766
Test Accuracy: 0.92
Train Accuracy: 0.96Lightgbm также предоставляет возможность ранней остановки обучения с помощью функции early_stopping(). Мы можем передать число раундов в функцию early_stopping() и использовать возвращаемую ее функцию обратного вызова в качестве входного параметра callbacks методов train() или fit(). Обратные вызовы рассматриваются более подробно в одном из следующих разделов.
Ограничения взаимодействия показателей
Когда lightgbm завершил обучение на датасете, отдельный узел в этих деревьях представляет некоторое условие, основанное на некотором значении показателя. Когда во время предсказания мы используем отдельное дерево, мы начинаем с его корневого узла, проверяя условие конкретного показателя, указанное в данном узле, с соответствующим значением показателя из нашего семпла. Решения принимаются нами на основе значений признаков из наблюдения и условий, представленных в дереве. Таким образом, мы идем по определенному пути, пока не достигнем листа дерева, где сможем сделать окончательный прогноз.
По умолчанию любой узел может быть связан с любым показателем в качестве условия. Этот процесс принятия окончательного решения путем прохождения узлов дерева, проверяя условие на соответствующих признаках, называется взаимодействием показателей, так как предиктор пришел к конкретному узлу после оценки условия предыдущего узла. Lightgbm позволяет нам определять ограничения на то, какой признак взаимодействует с каким. Мы можем предоставить список индексов, и указанные показатели будут взаимодействовать только друг с другом. Этим признакам не будет разрешено взаимодействовать с другими, и это ограничение будет применяться при создании деревьев в процессе обучения.
Ниже мы объясняем на простом примере, как наложить ограничение взаимодействия показателей на оценщик в lightgbm. Оценщики Lightgbm предоставляют параметр с названием interaction_constraints, который принимает список списков, где отдельные списки являются индексами признаков, которым разрешено взаимодействовать друг с другом.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'interaction_constraints':[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]]},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Монотонные ограничения
Lightgbm позволяет нам указывать монотонные ограничения для модели, которые определяют, связан ли отдельный показатель с увеличением/уменьшением целевого значения, или не связан вовсе. Таким образом, у нас есть возможность использовать монотонные значения -1, 0 и 1, тем самым заставляя модель устанавливать уменьшающуюся, нулевую и увеличивающуюся взаимосвязь показателя с целью. Мы можем предоставить список той же длины, что и количество признаков, указав 1, 0 или -1 для монотонной связи, используя параметр monotone_constraints. Ниже объясняется, как обеспечить монотонные ограничения в lightgbm.
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'monotone_constraints':(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1)},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Пользовательская функция цели/потерь
Lightgbm также позволяет определить целевую функцию, подходящую именно нам. Для этого нужно создать функцию, которая принимает список прогнозируемых и фактических меток в качестве входных данных и возвращает первую и вторую производные функции потерь, вычисленные с использованием предсказанных и фактических значений. Далее мы можем передать параметру objective оценщика определенную нами функцию цели/потерь. В случае использования метода train() мы должны предоставить ее через параметр fobj.
Ниже нами была разработана целевая функция средней квадратической ошибки (MSE). Затем мы передали ее параметру objective LGBMModel.
def first_grad(predt, dmat):
'''Вычисли первую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return 2*(y-predt)
def second_grad(predt, dmat):
'''Вычисли вторую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return [1] * len(predt)
def mean_sqaured_error(predt, dmat):
''''Функция MSE.'''
predt[predt < -1] = -1 + 1e-6
grad = first_grad(predt, dmat)
hess = second_grad(predt, dmat)
return grad, hess
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.78
Train R2 Score: 0.82Пользовательская функция оценки
Lightgbm позволяет нам определять нашу собственную оценочную метрику, если мы не хотим использовать метрики, предоставленные фреймворком. Для этого мы должны написать функцию, которая принимает на вход список предсказаний и фактических целевых значений. Она будет возвращать строку, определяющую название метрики, результат ее расчета и логическое значение, выражающее, стоит ли стремится к максимизации данной метрики или к ее минимизации. В случае, когда чем выше значение метрики, тем лучше, должно быть возвращено True, иначе — False.
Нам нужно указать ссылку на эту функцию в параметре feval, если мы используем метод train() для разработки нашего оценщика. При передаче в fit() нам нужно присвоить данную ссылку параметру eval_metric.
Далее объясняется на простых примерах, как можно использовать пользовательские оценочные метрики с lightgbm.
def mean_absolute_error(preds, dmat):
actuals = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
err = (actuals - preds).sum()
is_higher_better = False
return "MAE", err, is_higher_better
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse"},
feval=mean_absolute_error,
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.71
Train R2 Score: 0.76Функции обратного вызова
Lightgbm предоставляет пользователям список функций обратного вызова для разных целей, которые выполняются после каждой итерации обучения. Ниже приведен список доступных колбэков:
early_stopping(stopping_rounds)— эта функция обратного вызова принимает целое число, указывающее, следует ли останавливать обучение, если результаты расчета метрики на последнем оценочном датасете не улучшаются на протяжении указанного числа итераций.print_evaluation(period, show_stdv)— данный колбэк принимает целочисленные значения, определяющие, как часто должны выводиться результаты оценки. Полученные значения оценочной метрики печатаются через указанное число итераций.record_evaluation(eval_result)— эта функция получает на вход словарь, в котором будут записаны результаты оценки.reset_parameter()— данная функция обратного вызова позволяет нам сбрасывать скорость обучения после каждой итерации. Она принимает массив, размер которого совпадает с их количеством, или функцию, возвращающую новую скорость обучения для каждой итерации.
Параметр callbacks методов train() и fit() принимает список функций обратного вызова.
Ниже на простых примерах показано, как мы можем использовать различные колбэки. Функция обратного вызова early_stopping() также была рассмотрена в разделе «Ранняя остановка обучения» этого руководства.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),], eval_metric="rmse",
callbacks=[lgb.reset_parameter(learning_rate=np.linspace(0.1,1,10).tolist())])
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score : %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score : %.2f"%r2_score(Y_train, train_preds))
[1] valid_0's rmse: 20.8416
[2] valid_0's rmse: 12.9706
[3] valid_0's rmse: 6.60998
[4] valid_0's rmse: 4.28918
[5] valid_0's rmse: 3.96958
[6] valid_0's rmse: 3.89009
[7] valid_0's rmse: 3.80177
[8] valid_0's rmse: 3.88698
[9] valid_0's rmse: 4.2917
[10] valid_0's rmse: 4.39651
Test R2 Score : 0.82
Train R2 Score : 0.94На этом заканчивается наше небольшое руководство, объясняющее API LightGBM. Не стесняйтесь поделиться с нами своим мнением в разделе комментариев.
]]>Установка SQLAlchemy
Для установки SQLAlchemy введите следующее:
pip install sqlalchemyЧтобы проверить успешность установки введите следующее в командной строке:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.8'
Установка DBAPI
По умолчанию SQLAlchemy работает только с базой данных SQLite без дополнительных драйверов. Для работы с другими базами данных необходимо установить DBAPI-совместимый драйвер в соответствии с базой данных.
Что такое DBAPI?
DBAPI — это стандарт, который поощряет один и тот же API для работы с большим количеством баз данных. В следующей таблице перечислены все DBAPI-совместимые драйверы:
| База данных | DBAPI драйвер |
|---|---|
| MySQL | PyMySQL, MySQL-Connector, CyMySQL, MySQL-Python (по умолчанию) |
| PostgreSQL | psycopg2 (по умолчанию), pg8000, |
| Microsoft SQL Server | PyODBC (по умолчанию), pymssql |
| Oracle | cx-Oracle (по умолчанию) |
| Firebird | fdb (по умолчанию), kinterbasdb |
Все примеры в этом руководстве протестированы в PostgreSQL, но вы можете выбрать базу данных по вкусу. Для установки DBAPI psycopg2 для PostgreSQL введите следующую команду:
pip install psycopg2Подготовка к подключению
Первый шаг для подключения к базе данных — создания объекта Engine. Именно он отвечает за взаимодействие с базой данных. Состоит из двух элементов: диалекта и пула соединений.
Диалект SQLAlchemy
SQL — это стандартный язык для работы с базами данных. Однако и он отличается от базы к базе. Производители баз данных редко придерживаются одной и той же версии и предпочитают добавлять свои особенности. Например, если вы используете Firebird, то для получения id и name для первых 5 строк из таблицы employees нужна следующая команда:
select first 10 id, name from employeesА вот как получить тот же результат для MySQL:
select id, name from employees limit 10
Чтобы обрабатывать эти различия нужен диалект. Диалект определяет поведение базы данных. Другими словами он отвечает за обработку SQL-инструкций, выполнение, обработку результатов и так далее. После установки соответствующего драйвера диалект обрабатывает все отличия, что позволяет сосредоточиться на создании самого приложения.
Пул соединений SQLAlchemy
Пул соединений — это стандартный способ кэширования соединений в памяти, что позволяет использовать их повторно. Создавать соединение каждый раз при необходимости связаться с базой данных — затратно. А пул соединений обеспечивает неплохой прирост производительности.
При таком подходе приложение при необходимости обратиться к базе данных вытягивает соединение из пула. После выполнения запросов подключение освобождается и возвращается в пул. Новое создается только в том случае, если все остальные связаны.
Для создания движка (объекта Engine) используется функция create_engine() из пакета sqlalchemy. В базовом виде она принимает только строку подключения. Последняя включает информацию об источнике данных. Обычно это приблизительно следующий формат:
dialect+driver://username:password@host:port/databasedialect— это имя базы данных (mysql, postgresql, mssql, oracle и так далее).driver— используемый DBAPI. Этот параметр является необязательным. Если его не указать будет использоваться драйвер по умолчанию (если он установлен).usernameиpassword— данные для получения доступа к базе данных.host— расположение сервера базы данных.port— порт для подключения.database— название базы данных.
Вот код для создания движка некоторых популярных баз данных:
from sqlalchemy import create_engine
# Подключение к серверу MySQL на localhost с помощью PyMySQL DBAPI.
engine = create_engine("mysql+pymysql://root:pass@localhost/mydb")
# Подключение к серверу MySQL по ip 23.92.23.113 с использованием mysql-python DBAPI.
engine = create_engine("mysql+mysqldb://root:pass@23.92.23.113/mydb")
# Подключение к серверу PostgreSQL на localhost с помощью psycopg2 DBAPI
engine = create_engine("postgresql+psycopg2://root:pass@localhost/mydb")
# Подключение к серверу Oracle на локальном хосте с помощью cx-Oracle DBAPI.
engine = create_engine("oracle+cx_oracle://root:pass@localhost/mydb"))
# Подключение к MSSQL серверу на localhost с помощью PyODBC DBAPI.
engine = create_engine("oracle+pyodbc://root:pass@localhost/mydb")
Формат строки подключения для базы данных SQLite немного отличается. Поскольку это файловая база данных, для нее не нужны имя пользователя, пароль, порт и хост. Вот как создать движок для базы данных SQLite:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sqlite3.db') # используя относительный путь
engine = create_engine('sqlite:////path/to/sqlite3.db') # абсолютный путь
Подключение к базе данных
Но создание движка — это еще не подключение к базе данных. Для получения соединения нужно использовать метод connect() объекта Engine, который возвращает объект типа Connection.
from sqlalchemy import create_engine
# 1111 это мой пароль для пользователя postgres
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
engine.connect()
print(engine)
Но если запустить его, то будет следующая ошибка:
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError)
(Background on this error at: http://sqlalche.me/e/14/e3q8)Проблема в том, что предпринимается попытка подключиться к несуществующей базе данных. Для создания базы данных PostgreSQL нужно выполнить следующий код:
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
# Устанавливаем соединение с postgres
connection = psycopg2.connect(user="postgres", password="1111")
connection.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
# Создаем курсор для выполнения операций с базой данных
cursor = connection.cursor()
sql_create_database =
# Создаем базу данных
cursor.execute('create database sqlalchemy_tuts')
# Закрываем соединение
cursor.close()
connection.close()
Запустите скрипт еще раз, чтобы получить нужный вывод:
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Дополнительные аргументы
В следующей таблице перечислены дополнительные аргументы-ключевые слова, которые можно передать в функцию create_engine().
| Аргумент | Описание |
echo | Булево значение. Если задать True, то движок будет сохранять логи SQL в стандартный вывод. По умолчанию значение равно False |
pool_size | Определяет количество соединений для пула. По умолчанию — 5 |
max_overflow | Определяет количество соединений вне значения pool_size. По умолчанию — 10 |
encoding | Определяет кодировку SQLAlchemy. По умолчанию — UTF-8. Однако этот параметр не влияет на кодировку всей базы данных |
isolation_level | Уровень изоляции. Эта настройка контролирует степень изоляции одной транзакции. Разные базы данных поддерживают разные уровни. Для этого лучше ознакомиться с документацией конкретной базы данных |
Вот скрипт, в котором использованы дополнительные аргументы-ключевые слова при создании движка:
from sqlalchemy import create_engine
engine = create_engine(
"postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts",
echo=True, pool_size=6, max_overflow=10, encoding='latin1'
)
engine.connect()
print(engine)
Запустите его, чтобы получить следующий вывод:
2021-04-16 15:12:59,983 INFO sqlalchemy.engine.Engine select version()
2021-04-16 15:13:00,023 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,028 INFO sqlalchemy.engine.Engine select current_schema()
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine show standard_conforming_strings
2021-04-16 15:13:00,048 INFO sqlalchemy.engine.Engine [raw sql] {}
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Зачем использовать SQLAlchemy
Самая важная особенность SQLAlchemy — это ее ORM. ORM или Object Relational Mapper (объектно-реляционное отображение) позволяет работать с базой данных с помощью объектно-ориентированного кода, не используя SQL-запросы. Еще одна особенность SQLAlchemy — код приложения будет оставаться тем же вне зависимости от используемой базы данных. Это позволяет с легкостью мигрировать с одной базы данных на другую, не переписывая код.
У SQLAlchemy есть компонент, который называется SQLAlchemy Core. Это абстракция над традиционным SQL. Он предоставляет SQL Expression Language, позволяющий генерировать SQL-инструкции с помощью конструкций Python.
В отличие от ORM, который сосредоточен на моделях и объектах, Core фокусируется на таблицах, колонках, индексах и так далее (по аналогии с обычным SQL). SQL Expression Language очень похож на SQL, однако он стандартизирован, поэтому его можно использовать в разных базах данных. SQLAlchemy ORM и Core можно использовать независимо друг от друга. Под капотом SQLAlchemy ORM использует Core.
Так что использовать: Core или ORM?
Смысл ORM — упрощение процесса работы с базой данных. В процессе добавляется некая сложность, однако она незаметна, если работать с не очень большими объемами данных. Для большинства проектов ORM будет достаточно, однако там, где имеется много данных, стоит работать с чистым SQL.
Кто использует SQLAlchemy
- Hulu
- Fedora Project
- Dropbox
- OpenStack
- и многие другие.
Уроки по SQLAlchemy
Чтобы разобраться с руководством, нужно иметь базовые знания в Python и SQL.
]]>Установка PyInstaller не отличается от установки любой другой библиотеки Python.
pip install PyInstaller
Вот так можно проверить версию PyInstaller.
pyinstaller --versionЯ использую PyInstaller версии 4.2.
Создание exe файла с помощью PyInstaller
PyInstaller собирает в один пакет Python-приложение и все необходимые ему библиотеки следующим образом:
- Считывает файл скрипта.
- Анализирует код для выявления всех зависимостей, необходимых для работы.
- Создает файл spec, который содержит название скрипта, библиотеки-зависимости, любые файлы, включая те параметры, которые были переданы в команду PyInstaller.
- Собирает копии всех библиотек и файлов вместе с активным интерпретатором Python.
- Создает папку BUILD в папке со скриптом и записывает логи вместе с рабочими файлами в BUILD.
- Создает папку DIST в папке со скриптом, если она еще не существует.
- Записывает все необходимые файлы вместе со скриптом или в одну папку, или в один исполняемый файл.
Если использовать параметр команды onedir или -D при генерации исполняемого файла, тогда все будет помещено в одну папку. Это поведение по умолчанию. Если же использовать параметр onefile или -F, то все окажется в одном исполняемом файле.
Возьмем в качестве примера простейший скрипт на Python c названием simple.py, который содержит такой код.
import time
name = input("Введите ваше имя ")
print("Ваше имя ", name)
time.sleep(5)
Создадим один исполняемый файл. В командной строке введите:
pyinstaller --onefile simple.py
После завершения установки будет две папки, BUILD и DIST, а также новый файл с расширением .spec. Spec-файл будет называться так же, как и файл скрипта.
Python создает каталог распространения, который содержит основной исполняемый файл, а также все динамические библиотеки.
Вот что произойдет после запуска файла.
Добавление файлов с данными, которые будут использоваться exe-файлом
Есть CSV-файл netflix_titles.csv, и Python-script, который считывает количество записей в нем. Теперь нужно добавить этот файл в бандл с исполняемым файлом. Файл Python-скрипта назовем просто simple1.py.
import time
# pip install pandas
import pandas as pd
def count_records():
data = pd.read_csv('netflix_titles.csv')
print("Всего фильмов:", data.shape[0])
if __name__ == "__main__":
count_records()
time.sleep(5)
Создадим исполняемый файл с данными в папке.
pyinstaller --add-data "netflix_titles.csv;." simple1.py
Параметр --add-data позволяет добавить файлы с данными, которые нужно сохранить в одном бандле с исполняемым файлом. Этот параметр можно применить много раз.
Синтаксис add-data:
- add-data <source;destination> — Windows.
- add-data <source:destination> — Linux.
Можно увидеть, что файл теперь добавляется в папку DIST вместе с исполняемым файлом.
Также, открыв spec-файл, можно увидеть раздел datas, в котором указывается, что файл netflix_titles.csv копируется в текущую директорию.
...
a = Analysis(['simple1.py'],
pathex=['E:\\myProject\\pyinstaller-tutorial'],
binaries=[],
datas=[('netflix_titles.csv', '.')],
...Запустим файл simple1.exe, появится консоль с выводом: Всего фильмов: 7787.
Добавление файлов с данными и параметр onefile
Если задать параметр --onefile, то PyInstaller распаковывает все файлы в папку TEMP, выполняет скрипт и удаляет TEMP. Если вместе с add-data указать onefile, то нужно считать данные из папки. Путь папки меняется и похож на «_MEIxxxxxx-folder».
import time
import sys
import os
# pip install pandas
import pandas as pd
def count_records():
os.chdir(sys._MEIPASS)
data = pd.read_csv('netflix_titles.csv')
print("Всего фильмов:", data.shape[0])
if __name__ == "__main__":
count_records()
time.sleep(5)
Скрипт обновлен для чтения папки TEMP и файлов с данными. Создадим exe-файл с помощью onefile и add-data.
pyinstaller --onefile --add-data "netflix_titles.csv;." simple1.pyПосле успешного создания файл simple1.exe появится в папке DIST.
Можно скопировать исполняемый файл на рабочий стол и запустить, чтобы убедиться, что нет никакой ошибки, связанной с отсутствием файла.
Дополнительные импорты с помощью Hidden Imports
Исполняемому файлу требуются все импорты, которые нужны Python-скрипту. Иногда PyInstaller может пропустить динамические импорты или импорты второго уровня, возвращая ошибку ImportError: No module named…
Для решения этой ошибки нужно передать название недостающей библиотеки в hidden-import.
Например, чтобы добавить библиотеку os, нужно написать вот так:
pyinstaller --onefile --add-data "netflix_titles.csv;." — hidden-import "os" simple1.pyФайл spec
Файл spec — это первый файл, который PyInstaller создает, чтобы закодировать содержимое скрипта Python вместе с параметрами, переданными при запуске.
PyInstaller считывает содержимое файла для создания исполняемого файла, определяя все, что может понадобиться для него.
Файл с расширением .spec сохраняется по умолчанию в текущей директории.
Если у вас есть какое-либо из нижеперечисленных требований, то вы можете изменить файл спецификации:
- Собрать в один бандл с исполняемым файлы данных.
- Включить другие исполняемые файлы: .dll или .so.
- С помощью библиотек собрать в один бандл несколько программы.
Например, есть скрипт simpleModel.py, который использует TensorFlow и выводит номер версии этой библиотеки.
import time
import tensorflow as tf
def view_model():
print(tf.__version__)
if __name__ == "__main__" :
model = view_model()
time.sleep(5)
Компилируем модель с помощью PyInstaller:
pyinstaller -F simpleModel.pyПосле успешной компиляции запускаем исполняемый файл, который возвращает следующую ошибку.
...
File "site-packages\tensorflow_core\python_init_.py", line 49, in ImportError: cannot import name 'pywrap_tensorflow' from 'tensorflow_core.python' Исправим ее, обновив файл spec. Одно из решений — создать файл spec.
$ pyi-makespec simpleModel.py -F
wrote E:\pyinstaller-tutorial\simpleModel.spec
now run pyinstaller.py to build the executable
Команда pyi-makespec создает spec-файл по умолчанию, содержащий все параметры, которые можно указать в командной строке. Файл simpleModel.spec создается в текущей директории.
Поскольку был использован параметр --onefile, то внутри файла будет только раздел exe.
...
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='simpleModel',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True )Если использовать параметр по умолчанию или onedir, то вместе с exe-разделом будет также и раздел collect.
Можно открыть simpleModel.spec и добавить следующий текст для создания хуков.
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
import os
spec_root = os.path.realpath(SPECPATH)
options = []
from PyInstaller.utils.hooks import collect_submodules, collect_data_files
tf_hidden_imports = collect_submodules('tensorflow_core')
tf_datas = collect_data_files('tensorflow_core', subdir=None, include_py_files=True)
a = Analysis(['simpleModel.py'],
pathex=['E:\\myProject\\pyinstaller-tutorial'],
binaries=[],
datas=tf_datas + [],
hiddenimports=tf_hidden_imports + [],
hookspath=[],
...Создаем хуки и добавляем их в hidden imports и раздел данных.
Хуки
Файлы хуков расширяют возможность PyInstaller обрабатывать такие требования, как необходимость включать дополнительные данные или импортировать динамические библиотеки.
Обычно пакеты Python используют нормальные методы для импорта своих зависимостей, но в отдельных случаях, как например TensorFlow, существует необходимость импорта динамических библиотек. PyInstaller не может найти все библиотеки, или же их может быть слишком много. В таком случае рекомендуется использовать вспомогательный инструмент для импорта из PyInstaller.utils.hooks и собрать все подмодули для библиотеки.
Скомпилируем модель после обновления файла simpleModel.spec.
pyinstaller simpleModel.spec
Скопируем исполняемый файл на рабочий стол и увидим, что теперь он корректно отображает версию TensorFlow.
Вывод:
PyInstaller предлагает несколько вариантов создания простых и сложных исполняемых файлов из Python-скриптов:
- Исполняемый файл может собрать в один бандл все требуемые данные с помощью параметра
--add-data. - Исполняемый файл и зависимые данные с библиотеками можно собрать в один файл или папку с помощью
--onefileили--onedirсоответственно. - Динамические импорты и библиотеки второго уровня можно включить с помощью
hidden-imports. - Файл spec позволяет создать исполняемый файл для обработки скрытых импортов и других файлов данных с помощью хуков.
Что такое librosa?
Librosa — это пакет Python для анализа музыки и аудио. Он предоставляет строительные блоки для создания структур, которые помогают получать информацию о музыке.
Установка librosa в Python
Установим библиотеку с помощью команды pip:
pip install librosa
Для примера я скачал файл mp3-файл из https://www.bensound.com/ и конвертировал его в ogg для комфортной работы. Загрузим короткий ogg-файл (это может быть любой музыкальный файл в формате ogg):
import librosa
y, sr = librosa.load('bensound-happyrock.ogg')
Обработка аудио в виде временных рядов
В последней строке функция load считывает ogg-файл в виде временного рядя. Где, sr обозначает sample_rate.
- Time series (временной ряд) представлен массивом.
sample_rate— это количество сэмплов на секунду аудио.
По умолчанию звук микшируется в моно. Но его можно передискретизировать во время загрузки до 22050 Гц. Это делается с помощью дополнительных параметров в функции librosa.load.
Извлечение признаков из аудиофайла
У сэмпла есть несколько важных признаков. Есть фундаментальное понятие ритма в некоторых формах, а остальные либо имеют свою нюансы, либо связаны:
- Темп: скорость, с которой паттерны повторяются. Темп измеряется в битах в минуту (BPM). Если у музыки 120 BPM, это значит, что каждую минуту в ней 120 битов (ударов).
- Бит: отрезок времени. Это ритм, выстукиваемый в песне. Так, в одном такте 4 бита, например.
- Такт: логичное деление битов. Обычно в такте 3 или 4 бита, хотя возможны и другие варианты.
- Интервал: в программах для редактирования чаще всего встречаются интервалы. Обычно есть последовательность нот, например, 8 шестнадцатых одинаковой длины. Обычно интервал — 8 нот, триплеты или четверные.
- Ритм: список музыкальных звуков. Все ноты и являются ритмом.
Из аудио можно получить темп и биты:
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print(tempo)
print(beat_frames)
89.10290948275862
[ 3 40 75 97 132 153 183 211 246 275 303 332 361 389
...
4438 4466]Мел-кепстральные коэффициенты (MFCC)
Мел-кепстральные коэффициенты — один из важнейших признаков в обработке аудио.
MFCC — это матрица значений, которая захватывает тембральные аспекты музыкального инструменты: например, отличия в звучании металлической и деревянной гитары. Другими метриками эта разница не захватывается, но это ближайшее к тому, что может различать человек.
mfcc = librosa.feature.mfcc(y=y, sr=sr, hop_length=8192, n_mfcc=12)
# pip install seaborn matplotlib
import seaborn as sns
from matplotlib import pyplot as plt
mfcc_delta = librosa.feature.delta(mfcc)
sns.heatmap(mfcc_delta)
plt.show()
Здесь мы создаем тепловую карту данных MFCC, которая обеспечивает такой результат:
Нормализация ее в хроматограмму даст такой результат:
chromagram = librosa.feature.chroma_cqt(y=y, sr=sr)
sns.heatmap(chromagram)
plt.show()
Это лишь основы о том, что можно получить из аудиоданных для обучаемых алгоритмов. Много продвинутых примеров есть в документации librosa.
]]>Что такое отладка
Независимо от профессионализма, каждый разработчик имеет дело с ошибками — это является частью работы. Отладка ошибок — непростая задача; изначально много времени занимает процесс обнаружения ошибки и ее устранения. Следовательно, каждый разработчик должен знать как устранять ошибки.
В Django, процесс отладки можно сильно упростить. Вам только необходимо установить и подключить Django Debug Toolbar в приложение.
Теперь, когда мы знаем, почему отладка так важна, давайте настроим ее в проекте.
Подготовка приложения для демонстрации
Код примера есть в репозитории на GitLab.
Чтобы использовать панель инструментов отладки, нам нужен сайт. Если у вас есть свой проект, вы можете использовать его. В противном случае создайте новый и добавьте следующее представление и соответствующий путь.
Команды для создания нового приложения:
$ pip install django
$ django-admin startproject debug-tool
$ cd debug_tool
$ python manage.py startapp app
# app/views.py
from django.http import HttpResponse
def sample_view(request):
html = '<body><h1>Django sample_view</h1><br><p>Отладка sample_view</p></body>'
return HttpResponse(html)
Убедитесь в присутствии тега <body>. В противном случае инструмент отладчика не будет отображаться на страницах, шаблоны которых не имеют этого тега.
URL путь для кода будет:
# debug_tool/urls.py
from app import views as app_views
urlpatterns = [
path('admin/', admin.site.urls),
path('sample/', app_views.sample_view),
]
Теперь вы сможете повторять за мной.
Django Debug Toolbar
Рассмотрим инструменты, которые представлены в панели:
- Version: Предоставляет версию Django, которую мы используем.
- Time: Сообщает время, затраченное на загрузку веб-страницы.
- Setting: Показывает настройки страницы.
- Request: Показывает все запросы — views, файлы, куки и т.д.
- SQL: Список запросов к базе данных.
- Static Files: Предоставляет информацию о статических файлах.
- Templates: Предоставляет информацию о шаблонах.
- Cache: Сообщает информацию о существующем кэш.
- Loggin: Показывает количество зарегистрированных логов.
Установка Debug Toolbar в Django
Теперь установим библиотеку и настроим все необходимое для нее. Следуйте пошаговой инструкции:
1) Установка библиотеки
Для установки django-debug-toolbar, используем команду pip install. Запустите следующий код в терминале/оболочке ОС:
pip install django-debug-toolbar2) Добавление в INSTALLED_APPS
В settings.py добавьте следующую строку в раздел INSTALLED_APPS.
Проверьте, что бы debug_toolbar был добавлен после django.contrib.staticfiles.
# debug_tool/settings.py
INSTALLED_APPS = [
...
'debug_toolbar',
]
Также убедитесь, что в файле settings.py присутствует следующая строка STATIC_URL = '/static/'. Обычно она находится в конце модуля и не требует добавления.
Если ее нет, просто добавьте в конец файла.
3) Импорт в urls.py
Чтобы использовать Debug Toolbar, мы должны импортировать его пути. Следовательно, в urls.py добавьте код:
# debug_tool/urls.py
...
from django.conf import settings
from django.urls import path, include
# urlpatterns = [....
if settings.DEBUG:
import debug_toolbar
urlpatterns = [
path('__debug__/', include(debug_toolbar.urls)),
] + urlpatterns
Убедитесь, что DEBUG имеет значение TRUE в settings.py, чтобы все работало.
Вoт так выглядит мой файл urls.py:
4) Подключение MiddleWare
Добавьте middleware панели инструментов debug_toolbar.middleware.DebugToolbarMiddleware, в список MIDDLEWARE в settings.py.
# debug_tool/settings.py
...
MIDDLEWARE = [
...
'debug_toolbar.middleware.DebugToolbarMiddleware',
]
...
5) Упоминание INTERNAL_IPS
Django Debug Toolbar отображается только в том случае, если в списке INTERNAL_IPS есть IP приложения. Для разработки на локальном компьютере добавьте в список IP 127.0.0.1.
# debug_tool/settings.py
...
INTERNAL_IPS = [
'127.0.0.1',
]
Если списка INTERNAL_IPS еще нет, добавьте его в конец settings.py.
На этом мы закончили подключение панель отладки, теперь проверим как она работает.
Отображение Django Debug Toolbar
После добавления всего кода перейдите по на страницу 127.0.0.1:8000/sample/ в браузере.

Если вы видите боковую панель, как на изображении, все получилось! Если нет, проверьте, отсутствует ли в ваших файлах какой-либо из приведенных выше фрагментов кода.
Вот и все, панель инструментов будет появляться в правой части страницы при каждой загрузке.
Официальная документация на английском здесь.
]]>Синтаксис, ориентированный на набор данных, позволяет сосредоточиться на графиках, а не деталях их построения.
Официальная документация на английском: https://seaborn.pydata.org/index.html.
Установка seaborn
Официальные релизы seaborn можно установить из PyPI:
pip install seabornБиблиотека также входит в состав дистрибутива Anaconda:
conda install seaborn
Библиотека работает с Python версии 3.6+. Если их еще нет, эти библиотеки будут загружены при установке seaborn: numpy, scipy, pandas, matplotlib.
Как только вы установите Seaborn, можете скачать и построить тестовый график для одного из встроенных датасетов:
import seaborn as sns
df = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")
Выполнив этот код в Jupyter Notebook, увидите такой график.
Если вы не работаете с Jupyter, может потребоваться явный вызов matplotlib.pyplot.show():
import matplotlib.pyplot as plt
plt.show()
Давайте более детально рассмотрим построение популярных типов графиков.
Весь дальнейший код будет выполняться в Jupyter Notebook
Построение Bar Plot в Seaborn
Гистограммы отображают числовые величины на одной оси и переменные категории на другой. Они позволяют вам увидеть, значения параметров для каждой категории.
Гистограммы можно использовать для визуализации временных рядов, а также только категориальных данных.
Построение гистограммы
Чтобы нарисовать гистограмму в Seaborn нужно вызвать функцию barplot(), и передать ей категориальные и числовые переменные, которые нужно визуализировать, как это сделано в примере:
import matplotlib.pyplot as plt
import seaborn as sns
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=x, y=y);
В данном случае, у нас есть несколько категориальных переменных в списке — А, Б и В. А также непрерывные переменные (числа) в другом списке — 10, 50 и 30. Зависимость между этими двумя элементами визуализируется на гистограмме, для чего эти два списка передаются в функцию sns.barplot().
В результате получается четкая и простая гистограмма:
Чаще всего вы будете работать с датасетами, которые содержат гораздо больше данных, чем тот что приведен в примере. Иногда к этим наборам данным требуется сортировка, или подсчитать, сколько раз повторяются то или другое значение.
Когда вы работаете с данными можете столкнуться с ошибками и пропусками, которые в них имеются. К счастью, Seaborn защищает нас и автоматически применяет фильтр, который основан на вычислении среднего значения предоставленных данных.
Давайте импортируем классический датасет Titanic и визуализируем Bar Plot с этими данными:
# Импорт данных
titanic_dataset = sns.load_dataset("titanic")
# Постройка графика
sns.barplot(x="sex", y="survived", data=titanic_dataset);
В данном случае мы назначили осям Х и Y колонки "sex" и "survived", вместо жестко заданных.
Если мы выведем первые строки датасета (titanic_dataset.head()), увидим такую таблицу:
survived pclass sex age sibsp parch fare ...
0 0 3 male 22.0 1 0 7.2500 ...
1 1 1 female 38.0 1 0 71.2833 ...
2 1 3 female 26.0 0 0 7.9250 ...
3 1 1 female 35.0 1 0 53.1000 ...
4 0 3 male 35.0 0 0 8.0500 ...Убедитесь, что имена колонок совпадают с теми, которые вы назначили переменным x и y.
Наконец, мы используем эти данные и передаем их в качестве аргумента функции, с которой работаем. И получаем такой результат:
Построение горизонтальной гистограммы
Чтобы нарисовать горизонтальную, а не вертикальную гистограмму нужно просто поменять местами переменные передаваемые в x и y.
В этом случае категориальная переменная будет отображаться по оси Y, что приведет к постройке горизонтального графика:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=y, y=x);
График будет выглядеть так:
Как изменить цвет в barplot()
Изменить цвет столбцов довольно просто. Для этого нужно задать параметр color функции barplot и тогда цвет всех столбцов изменится на заданный.
Изменим на голубой:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=x, y=y, color='blue');
Тогда график будет выглядеть так:
Или, что еще лучше, установить аргумент pallete, который может принимать большое количество цветов. Довольно распространенное значение этого параметра hls:
sns.barplot(
x="embark_town",
y="survived",
palette='hls',
data=titanic_dataset
);
Что приведет к такому результату:
Группировка Bar Plot в Seaborn
Часто требуется сгруппировать столбцы на графиках по одному признаку. Допустим, вы хотите сравнить некоторые общие данные, выживаемость пассажиров, и сгруппировать их по заданным критериям.
Нам может потребоваться визуализировать количество выживших пассажиров, в зависимости от класса (первый, второй и третий), но также учесть, города из которого они прибыли.
Всю эту информацию можно легко отобразить на гистограмме.
Чтобы сгруппировать столбцы вместе, мы используем аргумент hue. Этот аргумент группирует соответствующие данные и сообщает библиотеке Seaborn, как раскрашивать столбцы.
Давайте посмотрим на только что обсужденный пример:
sns.barplot(x="class", y="survived", hue="embark_town", data=titanic_dataset);
Получим такой график:
Настройка порядка отображения групп столбцов на гистограмме
Вы можете изменить порядок следования столбцов по умолчанию. Это делается с помощью аргумента order, который принимает список значений и порядок их размещения.
Например, до сих пор он упорядочивал классы с первого по третий. Что, если мы захотим сделать наоборот?
sns.barplot(
x="class",
y="survived",
hue="embark_town",
order=["Third", "Second", "First"],
data=titanic_dataset
);
Получится такой график:
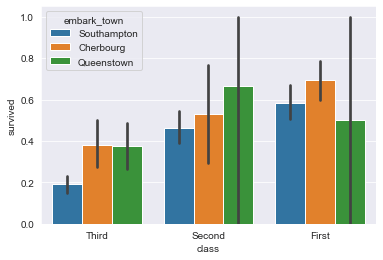
Изменяем доверительный интервал в barplot()
Вы также можете поэкспериментировать с доверительным интервалом, задав аргумент ci.
Например, вы можете отключить его, установив для него значение None, или использовать стандартное отклонение вместо среднего, установив sd, или даже установить верхний предел на шкале ошибок, установив capsize.
Давайте немного поэкспериментируем с атрибутом доверительного интервала:
sns.barplot(
x="class",
y="survived",
hue="embark_town",
ci=None,
data=titanic_dataset
);
Получим такой результат:
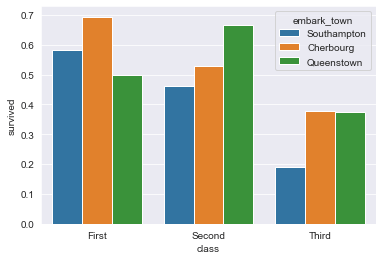
Или мы можем использовать стандартное отклонение:
sns.barplot(
x="class",
y="survived",
hue="who",
ci="sd",
capsize=0.1,
data=titanic_dataset
);
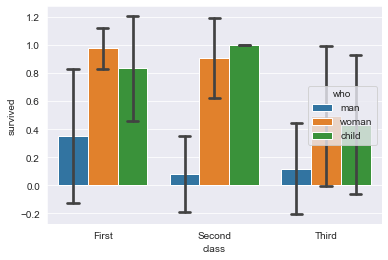
Мы рассмотрели несколько способов построения гистограммы в Seaborn на примерах. Теперь перейдем к тепловым картам.
Построение Heatmap в Seaborn
Давайте посмотрим, как мы можем работать с библиотекой Seaborn на Python, чтобы создать базовую тепловую карту корреляции.
Для наших целей мы будем использовать набор данных о жилье Ames, доступный на Kaggle.com. Он содержит более 30 показателей, которые потенциально могут повлиять на стоимость недвижимости.
Поскольку Seaborn была написана на основе библиотеки визуализации данных Matplotlib, их довольно просто использовать вместе. Поэтому помимо стандартных модулей мы также собираемся импортировать Matplotlib.pyplot.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Следующий код создает матрицу корреляции между всеми исследуемыми показателями и нашей переменной y (стоимость недвижимости).
dataframe.corr()
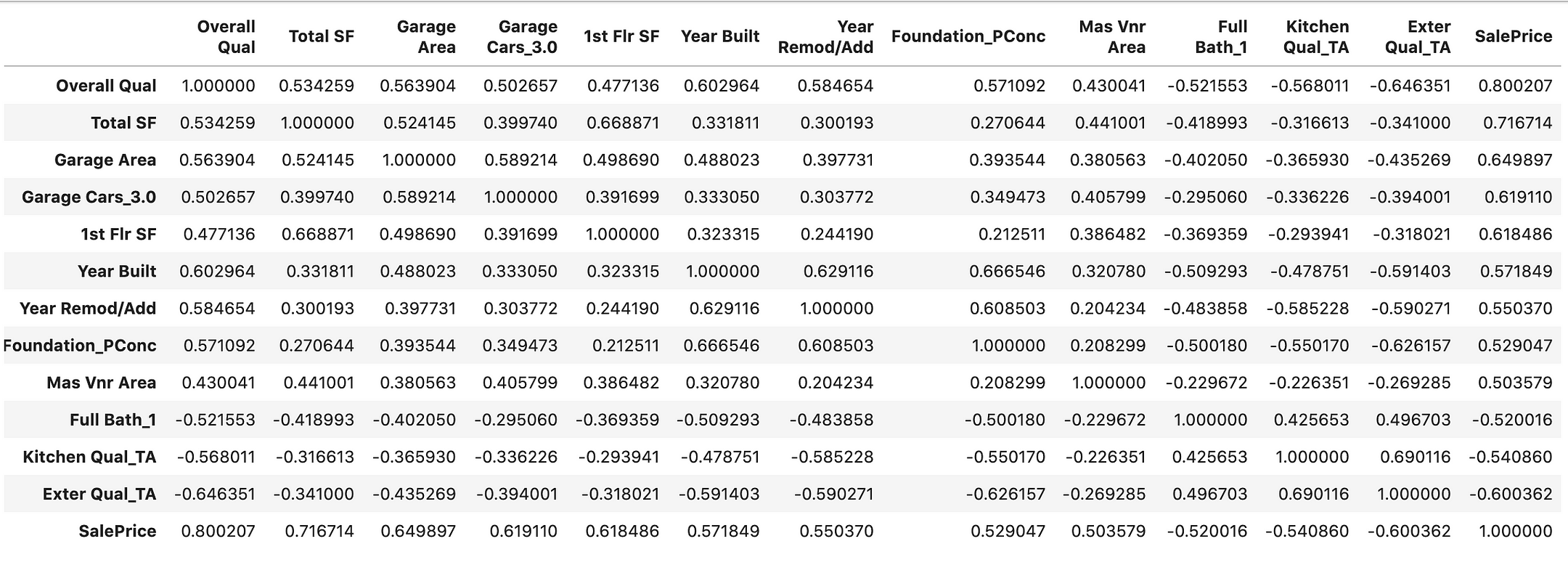
Корреляционная матрица всего с 13 переменными. Нельзя сказать, что она совсем не читабельна. Однако почему бы не облегчить себе жизнь визуализацией?
Простая тепловая карта в Seaborn
sns.heatmap(dataframe.corr());
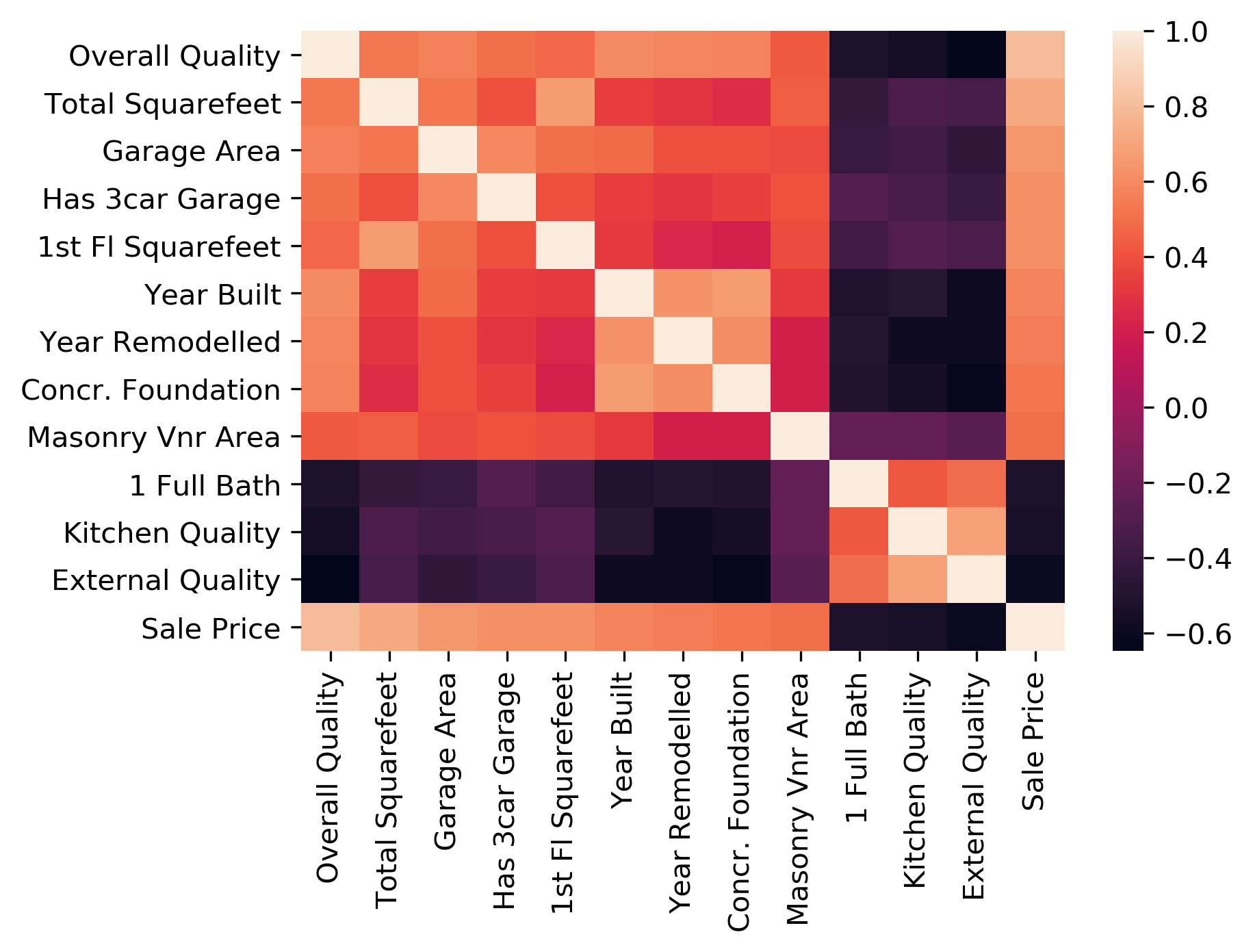
Seaborn прост в использовании, но в нем довольно сложно ориентироваться. Библиотека поставляется с множеством встроенных функций и обширной документацией. Может быть трудно понять, какие именно аргументы использовать, если вам не нужны все возможные навороты.
Давайте сделаем базовую тепловую карту более полезной с минимальными усилиями.
Взгляните на список аргументов heatmap:
seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)vmin,vmax— устанавливают диапазон значений, которые служат основой для цветовой карты (colormap).cmap— определяет конкретную colormap, которую мы хотим использовать (ознакомьтесь с полным диапазоном цветовых палитр здесь).center— принимает вещественное число для центрирования цветовой карты; еслиcmapне указан, используется colormap по умолчанию; если установлено значениеTrue— все цвета заменяются на синий.annot— при значенииTrueчисловые значения корреляции отображаются внутри ячеек.cbar— если установлено значениеFalse, цветовая шкала (служит легендой) исчезает.
# Увеличьте размер
heatmap plt.figure(figsize=(16, 6))
# Сохраните объект тепловой карты в переменной, чтобы легко получить к нему доступ,
# когда вы захотите включить дополнительные функции (например, отображение заголовка).
# Задайте диапазон значений для отображения на цветовой карте от -1 до 1 и установите для аннотации (annot) значение True,
# чтобы отобразить числовые значения корреляции на тепловой карте.
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True)
# Дайте тепловой карте название. Параметр pad (padding) определяет расстояние заголовка от верхней части тепловой карты.
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=12);
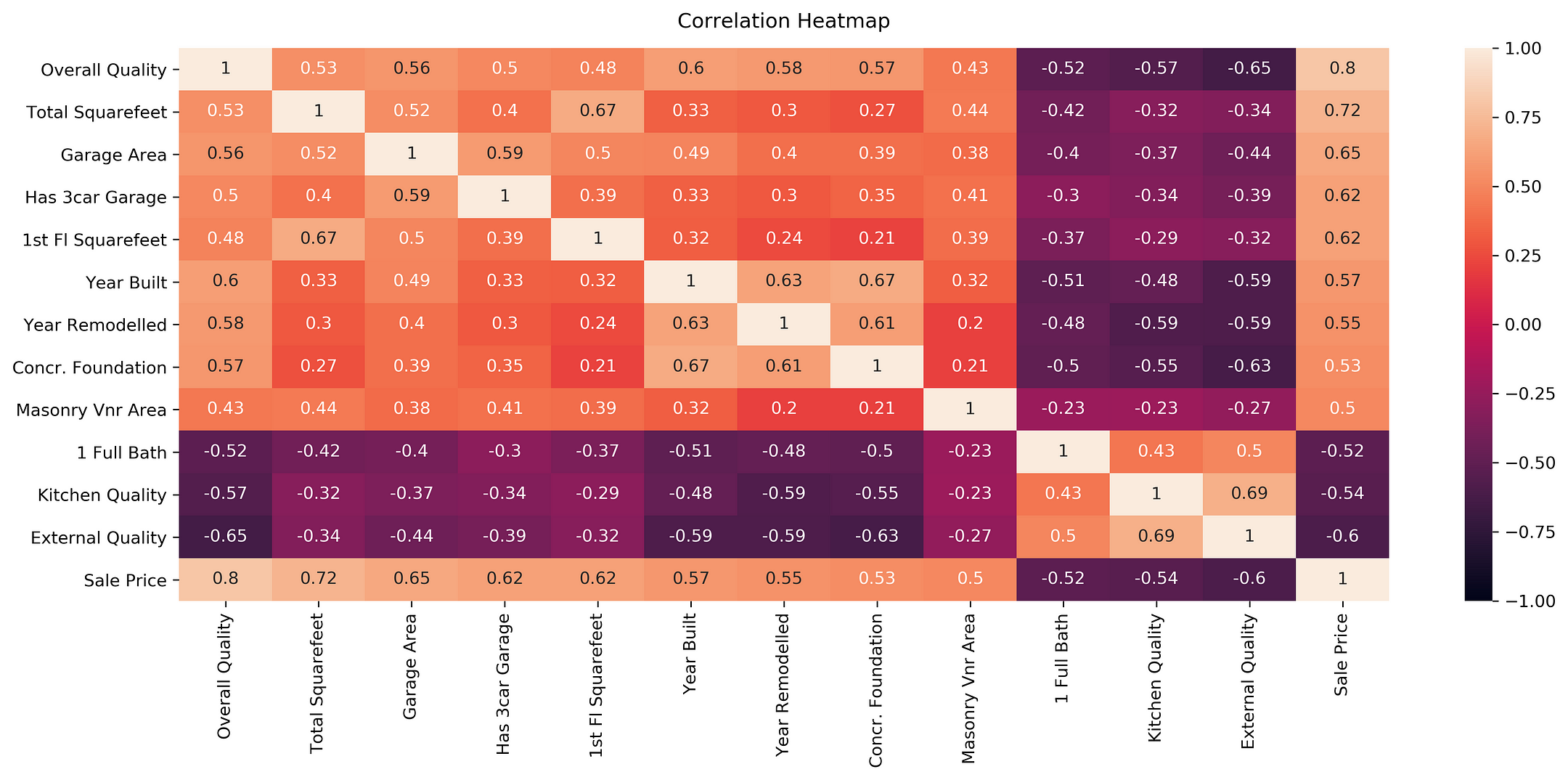
Для работы с heatmap лучше всего подходит расходящаяся цветовая палитра. Она имеет два очень разных темных (насыщенных) цвета на соответствующих концах диапазона интерполированных значений с бледной, почти бесцветной средней точкой. Проиллюстрируем это утверждение и разберемся с еще одной небольшой деталью: как сохранить созданную тепловую карту в файл png со всеми необходимыми x и y метками (xticklabels и yticklabels).
plt.figure(figsize=(16, 6))
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':18}, pad=12);
# Сохраните карту как png файл
# Параметр dpi устанавливает разрешение сохраняемого изображения в точках на дюйм
# bbox_inches, когда установлен в значение 'tight', не позволяет обрезать лейблы
plt.savefig('heatmap.png', dpi=300, bbox_inches='tight')
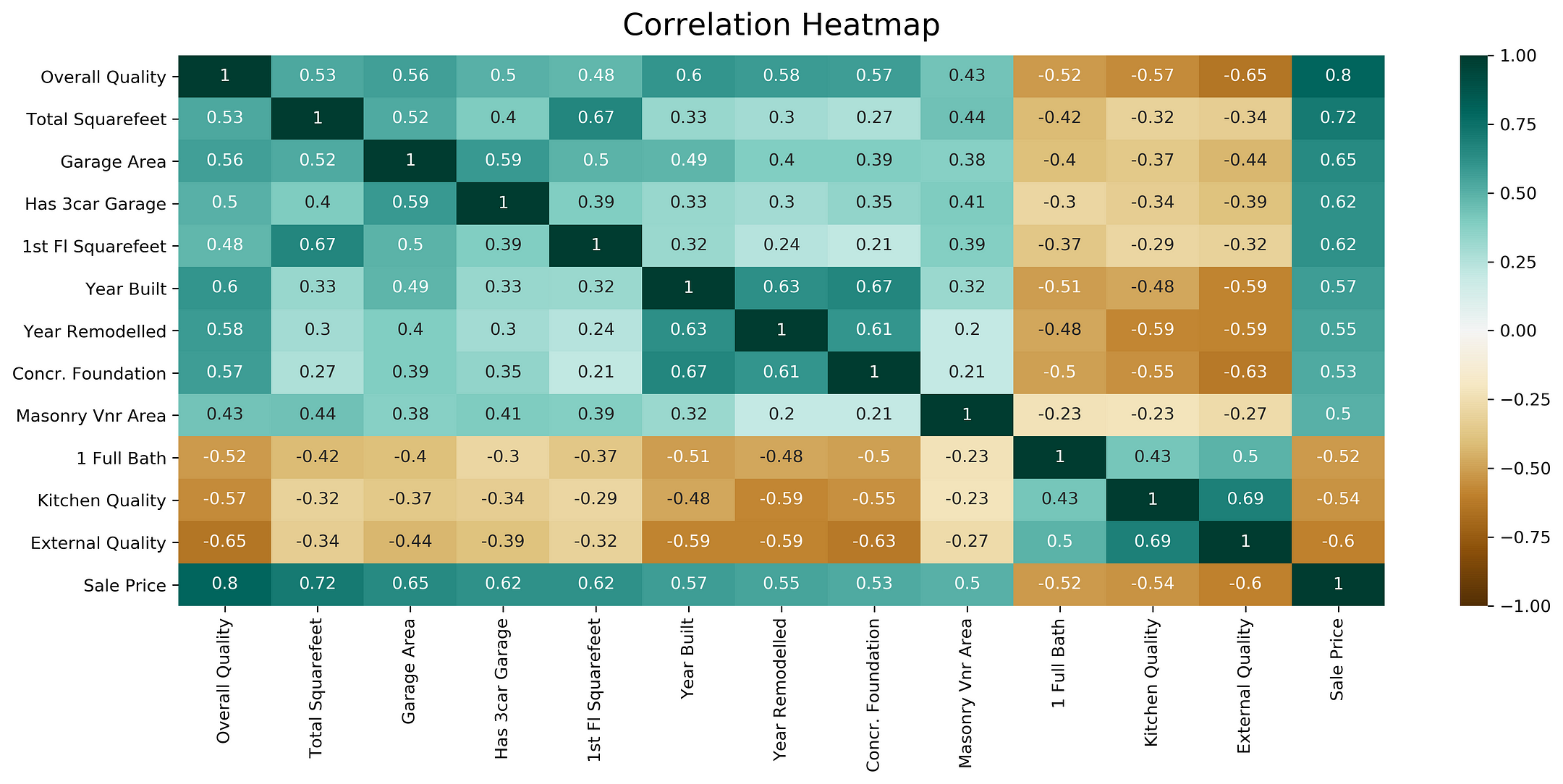
Треугольная тепловая карта корреляции
Взгляните на любую из приведенных выше тепловых карт. Если вы отбросите одну из ее половин по диагонали, обозначенной единицами, вы не потеряете никакой информации. Итак, давайте сократим тепловую карту, оставив только нижний треугольник.
Аргумент mask (маска) heatmap пригодится, чтобы скрыть часть тепловой карты. Маска — принимает в качестве аргумента массив логических значений или структуру табличных данных (dataframe). Если она предоставлена, ячейки тепловой карты, для которых значения маски является True, не отображаются.
Давайте воспользуемся функцией np.triu() библиотеки numpy, чтобы изолировать верхний треугольник матрицы, превращая все значения в нижнем треугольнике в 0. np.tril() будет делать то же самое, только для нижнего треугольника. В свою очередь функция np.ones_like() изменит все изолированные значения на 1.
np.triu(np.ones_like(dataframe.corr()))

plt.figure(figsize=(16, 6))
# Определите маску, чтобы установить значения в верхнем треугольнике на True
mask = np.triu(np.ones_like(dataframe.corr(), dtype=np.bool))
heatmap = sns.heatmap(dataframe.corr(), mask=mask, vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Triangle Correlation Heatmap', fontdict={'fontsize':18}, pad=16);
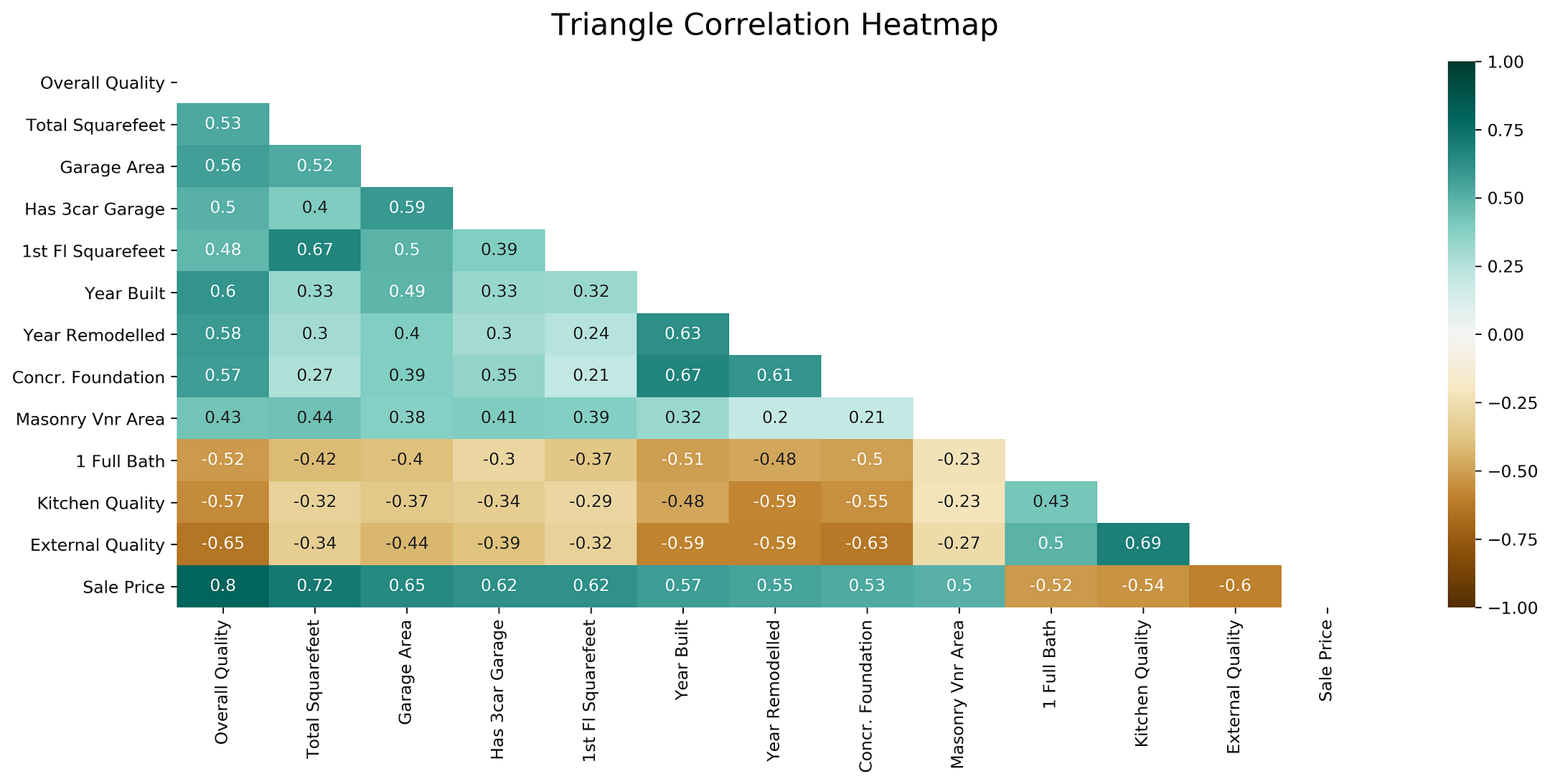
Корреляция независимых переменных с зависимой
Довольно часто мы хотим создать цветную карту, которая показывает выраженность связи между каждой независимой переменной, включенной в нашу модель, и зависимой переменной.
Следующий код возвращает корреляцию каждого параметра с «ценой продажи», единственной зависимой переменной в порядке убывания.
dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False)
Давайте используем полученный список в качестве данных для отображения на тепловой карте.
plt.figure(figsize=(8, 12))
heatmap = sns.heatmap(dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Features Correlating with Sales Price', fontdict={'fontsize':18}, pad=16);
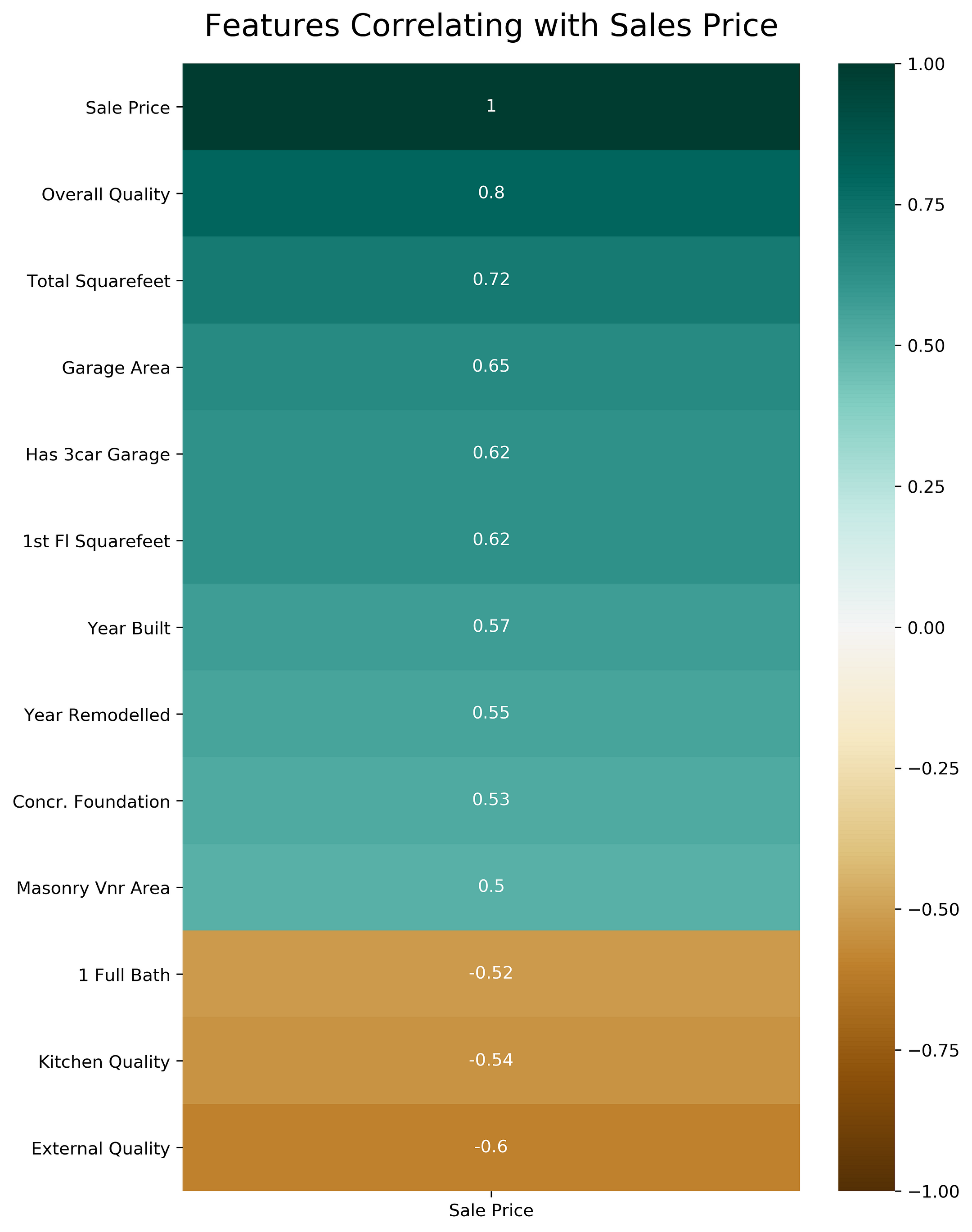
Эти примеры демонстрируют основную функциональность heatmap в Seaborn. Теперь перейдем к точечным диаграммам.
Построение Scatter Plot в Seaborn
Давайте рассмотрим процесс создания точечной диаграммы в Seaborn. Построим простые и трехмерные диаграммы рассеивания, а также групповые графики на базе FacetGrid.
Импорт данных
Мы будем использовать набор данных, основанный на мировом счастье. Сравнение его индекса с другими показателям отразит факторы, влияющие на уровень счастья в мире.
Построение точечной диаграммы
На графике отразим соотношение индекса счастья к экономике страны (ВВП на душу населения):
dataframe = pd.read_csv('2016.csv')
sns.scatterplot(data=dataframe, x="Economy (GDP per Capita)", y="Happiness Score");
При помощи Seaborn очень легко составлять простые графики наподобие диаграмм рассеивания. Нам не обязательно использовать объект Figure и экземпляры Axes или что-нибудь настраивать. Здесь мы передали dataframe в качестве аргумента с данными, а признаки с информацией, которую нужно визуализировать, в x и y.
Оси диаграммы по умолчанию подписываются именами столбцов, которые соответствуют заголовкам из загружаемого файла. Ниже мы рассмотрим, как это изменить.
После выполнения кода мы получим следующее:
Результат показал прямую зависимость между ВВП на душу населения и предполагаемого уровня счастья жителей конкретной страны или региона.
Построение группы графиков scatterplot при помощи FacetGrid
Если требуется сравнить много переменных друг с другом, например, среднюю продолжительность жизни наряду с оценкой счастья и уровнем экономики, нет необходимости строить 3D-график.
Несмотря на существование двумерных диаграмм, позволяющих визуализировать соотношение между множествами переменных, не все из них просты в применении.
При помощи объекта FacetGrid, библиотека Seaborn позволяет обрабатывать данные и строить на их основе групповые взаимосвязанные графики.
Взглянем на следующий пример:
grid = sns.FacetGrid(dataframe, col="Region", hue="Region", col_wrap=5)
grid.map(sns.scatterplot, "Economy (GDP per Capita)", "Health (Life Expectancy)")
grid.add_legend();
В этом примере мы создали экземпляр объекта FacetGrid с параметром dataframe в качестве данных. При передаче значения "Region" аргументу col библиотека сгруппирует датасет по регионам и построит диаграмму рассеивания для каждого из них.
Параметр hue задает каждому региону собственный оттенок. Наконец, при помощи аргумента col_wrap ширина области Figure ограничивается до 5-ти диаграмм. По достижении этого предела следующие графики будут построены на новой строке.
Для подготовки сетки перед выводом на экран мы используем метод map(). Тип диаграммы передается в первом аргументе со значением sns.scatterplot, а в качестве осей служат переменные x и y.
В результате будет сформировано 10 графиков по каждому региону с соответствующими им осями. Непосредственно перед печатью мы вызываем метод, добавляющий легенду с обозначением цветовой маркировки.
Построение 3D-диаграммы рассеивания
К сожалению, в Seaborn отсутствует собственный 3D-движок. Являясь лишь дополнением к Matplotlib, он опирается на графические возможности основной библиотеки. Тем не менее, мы все еще можем применить стиль Seaborn к трехмерной диаграмме.
Посмотрим, как она будет выглядеть с выборкой по уровням счастья, экономики и здоровья:
%matplotlib notebook
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv('Downloads/2016.csv')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
x = df['Happiness Score']
y = df['Economy (GDP per Capita)']
z = df['Health (Life Expectancy)']
ax.set_xlabel("Счастье")
ax.set_ylabel("Экономика")
ax.set_zlabel("Здоровье")
ax.scatter(x, y, z)
plt.show()
В результате выполнения кода появится интерактивная 3D-визуализация, которую можно вращать и масштабировать в трехмерном пространстве:
Настройка Scatter Plot
При помощи Seaborn можно легко настраивать различные элементы создаваемых диаграмм. Например, присутствует возможность изменения цвета и размера каждой точки на графике.
Попробуем задать некоторые параметры и посмотреть, как изменится его внешний вид:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
hue="Region",
size="Freedom"
);
Здесь мы применили оттенок к регионам — это означает, что данные по каждому из них будут раскрашены по-разному. Кроме того, при помощи аргумента size были заданы пропорции точек в зависимости от уровня свободы. Чем больше его значение, тем крупнее точка на диаграмме:
Или можно просто задать одинаковый цвет и размер для всех точек:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
color="red",
sizes=5
);
Отлично, вы узнали несколько способов построения scatter plot в Seaborn. Перейдем к еще одному популярному графику.
Построение Box Plot в Seaborn
Box Plot, называемые также:
- графиками прямоугольников,
- коробчатыми графиками,
- графиками размаха
- или ящиками с усами за свой вид.
Они используются для визуализации сводной статистики датасета. Box Plot отображают атрибуты распределения, такие как диапазон и распределение данных в диапазоне (прямоугольника, «усы», медиана).
Импорт данных
Для создания box plot нужны непрерывные числовые данные, поскольку такая диаграмма отображает сводную статистику — медиану, диапазон и выбросы. Для примера воспользуемся набором данных forestfires.csv (сведения об индексе влажности лесной подстилки, осадках, температуре, ветре и т.д.).
Импортируем pandas для загрузки и анализа датасета, seaborn и модуль pyplot из matplotlib для визуализации:
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
Воспользуемся pandas для чтения CSV-файла в dataframe и выведем первые 5 строк. Кроме того, проверим, содержит ли набор данных пропущенные значения (Null, NaN):
# укажите свой путь к файлу forestfires
dataframe = pd.read_csv("Downloads/forestfires.csv")
print(dataframe.isnull().values.any())
dataframe.head()
Код вернет False и верхнюю часть таблицы.
| X | Y | month | day | FFMC | DMC | DC | ISI | temp | RH | wind | rain | area | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7 | 5 | mar | fri | 86.2 | 26.2 | 94.3 | 5.1 | 8.2 | 51 | 6.7 | 0.0 | 0.0 |
| 1 | 7 | 4 | oct | tue | 90.6 | 35.4 | 669.1 | 6.7 | 18.0 | 33 | 0.9 | 0.0 | 0.0 |
| 2 | 7 | 4 | oct | sat | 90.6 | 43.7 | 686.9 | 6.7 | 14.6 | 33 | 1.3 | 0.0 | 0.0 |
| 3 | 8 | 6 | mar | fri | 91.7 | 33.3 | 77.5 | 9.0 | 8.3 | 97 | 4.0 | 0.2 | 0.0 |
| 4 | 8 | 6 | mar | sun | 89.3 | 51.3 | 102.2 | 9.6 | 11.4 | 99 | 1.8 | 0.0 | 0.0 |
Print вывел False, значит – никаких пропущенных значений нет. Если бы они были, то пришлось бы дополнительно обрабатывать отсутствующие значения.
После проверки данных нужно выбрать признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
FFMC = dataframe["FFMC"]
DMC = dataframe["DMC"]
DC = dataframe["DC"]
RH = dataframe["RH"]
ISI = dataframe["ISI"]
temp = dataframe["temp"]
Это те колонки, которые содержат непрерывные числовые данные.
Построение box plot
Для создания диаграммы воспользуемся функцией boxplot в Seaborn, которой в качестве аргументов передадим переменные для визуализации:
sns.boxplot(x=DMC);
Для визуализации распределения только одного признака мы передаем его в переменную x. В этом случае, Seaborn автоматически вычислит значения по оси y, что видно на следующем изображении.
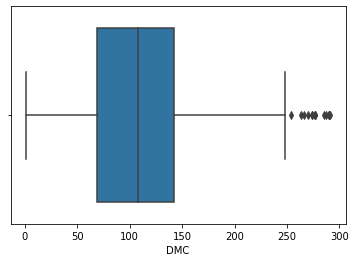
Если требуется определенное распределение, сегментированное по типу, то можно для функции boxplot в качестве аргументов передать категориальную переменную в x и непрерывную переменную в y.
sns.boxplot(x=dataframe["day"], y=DMC);
Теперь получилась блочная диаграмма, созданная для каждого дня недели.
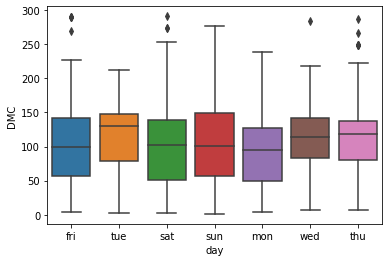
Если требуется визуализировать несколько столбцов одновременно, то аргументов x и y будет недостаточно. Для этих целей используется аргумент data, которому передается набор данных, содержащий требуемые переменные и их значения.
Создадим новый датасет, содержащий только те данные, которые мы хотим визуализировать. Затем к нему применим функцию melt(). Полученный в результате набор данных передается аргументу data. В аргументы x и y в этом случае передаются значения по умолчанию из melt (value и variable):
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
sns.boxplot(x="variable", y="value", data=pd.melt(df));
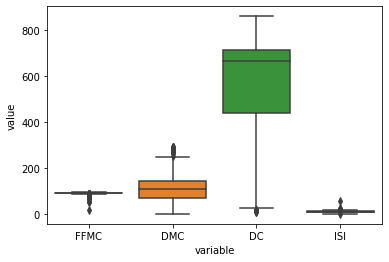
Изменение цвета boxplot
Seaborn автоматически назначает различные цвета различным переменным, чтобы можно было их легко визуально различить. Цвет диаграмм можно изменить, предоставив свой список цветов.
После определения списка цветов в виде HEX-значений или названий доcтупного цвета Matplotlib, можно передать их функции boxplot() в качестве аргумента palette:
colors = ['#78C850', '#F08030', '#6890F0','#F8D030', '#F85888', '#705898', '#98D8D8']
sns.boxplot(x=DMC, y=dataframe["day"], palette=colors);
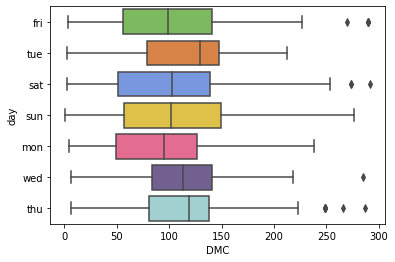
Настройка подписи осей
С помощью Seaborn можно легко настроить подписи по осям X и Y. Например, изменить размер шрифта, подписи или повернуть их, чтобы сделать более удобными для чтения.
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df))
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
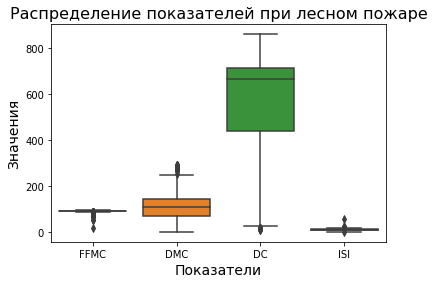
Изменение порядка отображения блоков
Для отображения блочных диаграмм в определенном порядке используется аргумент order, которому передается список имен столбцов в том порядке, в котором их нужно расположить:
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC", "FFMC", "ISI"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
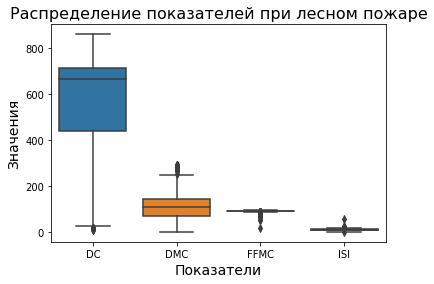
Создание subplots с помощью Matplotlib
Если необходимо разделить общий box plot на несколько для отдельных признаков, то это можно сделать. Определите область отрисовки (fig) и нужное количество координатных осей (axes) с помощью функции subplots из Matplotlib. Доступ к нужной области объекта axes можно получить через его индекс. Функция boxplot() принимает ax аргумент, который по индексу объекта axes получает область для построения диаграммы:
fig, axes = plt.subplots(1, 2)
sns.boxplot(x=day, y=DMC, orient='v', ax=axes[0])
sns.boxplot(x=day, y=DC, orient='v', ax=axes[1]);
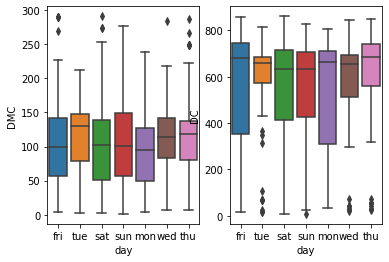
Box Plot с диаграммой рассеивания
Для более наглядного восприятия распределения можно наложить точечную диаграмму рассеивания на блочную.
С этой целью последовательно создаем две диаграммы. Диаграмма, созданная функцией stripplot(), будет наложена поверх box plot, так как они выводятся в одной и той же области:
df = pd.DataFrame(data=dataframe, columns=["DC", "DMC"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC"])
boxplot = sns.stripplot(x="variable", y="value", data=pd.melt(df), marker="o", alpha=0.3, color="black", order=["DC", "DMC"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);

Мы рассмотрели несколько способов построения Box Plot с помощью Seaborn и Python. Также узнали, как настроить цвета, подписи осей, порядок следования диаграмм, наложение точечных диаграмм и разделение диаграмм для отдельных величин.
Последний тип графика, о котором стоит упомянуть — Violin Plot.
Построение Violin Plot в Seaborn
Violin Plot или скрипичные диаграммы используются для визуализации распределения данных, отображая диапазон данных, медиану и область распределения данных.
Такие диаграммы, как и ящики с усами, показывают сводную статистику. Дополнительно они включают в себя графики плотности распределения, которые и определяют форму/распределение данных при визуализации.
Импорт данных
Для примера воспользуемся набором данных Gapminder, содержащем информацию о численности населения, продолжительности жизни и другие данные по странам и годам, начиная с 1952 года.
Импортируем pandas, seaborn и модуль pyplot из matplotlib:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Далее загрузим датасет и посмотрим из чего он состоит.
dataframe = pd.read_csv(
"Downloads/gapminder_full.csv",
error_bad_lines=False,
encoding="ISO-8859-1"
)
dataframe.head()
В результате получим:
| country | year | population | continent | life_exp | gdp_cap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 | Asia | 28.801 | 779.445314 |
| 1 | Afghanistan | 1957 | 9240934 | Asia | 30.332 | 820.853030 |
| 2 | Afghanistan | 1962 | 10267083 | Asia | 31.997 | 853.100710 |
| 3 | Afghanistan | 1967 | 11537966 | Asia | 34.020 | 836.197138 |
| 4 | Afghanistan | 1972 | 13079460 | Asia | 36.088 | 739.981106 |
Определим признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
country = dataframe.country
continent = dataframe.continent
population = dataframe.population
life_exp = dataframe.life_exp
gdp_cap = dataframe.gdp_cap
Построение простой скрипичной диаграммы
Теперь, после того как мы загрузили данные и выбрали величины, которые хотим визуализировать, можно создать скрипичную диаграмму. Используем функцию violinplot(), которой в качестве аргумента x передадим переменную для визуализации.
Значения по оси Y будут высчитаны автоматически.
sns.violinplot(x=life_exp);
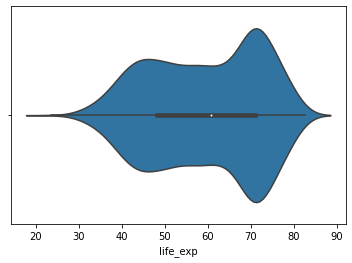
Отмечу, что можно было не выбирать предварительно данные по имени столбца и не сохранять в переменной life_exp. Используя аргумент data, которому передан наш набор данных, и аргумент x, которому присвоено имя переменной «life_exp», получим точно такой же результат.
sns.violinplot(x="life_exp", data=dataframe);
Обратите внимание на то, что на этом изображении Seaborn строит график распределения ожидаемой продолжительности жизни сразу по всем странам, так как использовалась только одна переменная life_exp. В большинстве случаев такого типа переменная рассматривается на основе других переменных, таких как country или continent в нашем случае.
Построение Violin Plot с осями X и Y
Для того чтобы получить визуализацию распределения данных, сегментированное по типу, необходимо в качестве аргументов функции использовать категориальную переменную для x и непрерывную для y.
В этом наборе данных много стран. Если построить диаграммы для всех стран, то их будет слишком много, чтобы их можно было рассмотреть. Можно, конечно, выделить подмножество из набора данных и просто построить диаграммы, скажем, для 10 стран.
Вместо этого, построим violinplot для континентов.
sns.violinplot(x=continent, y=life_exp, data=dataframe);
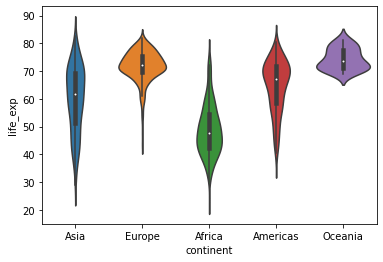
Изменение подписи осей заголовка диаграммы
Предположим, что необходимо изменить некоторые заголовки и подписи нашего графика, чтобы было проще его анализировать.
Несмотря на то, что Seaborn автоматически подписывает оси X и Y, можно изменить подписи с помощью функций set_title() и set_label() после создания объекта axes. Надо просто передать название, которое хотим дать нашему графику, функции set_title().
Для того чтобы подписать оси, используется функция set() с аргументами xlabel и ylabel или функции-обертки set_xlabel()/set_ylabel():
ax = sns.violinplot(x=continent, y=life_exp)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");

Изменение цвета violinplot
Для изменения цвета диаграмм можно создать список заранее выбранных цветов и передать этот список параметром pallete функции violinplot():
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
ax = sns.violinplot(x=continent, y=life_exp, palette=colors_list)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");
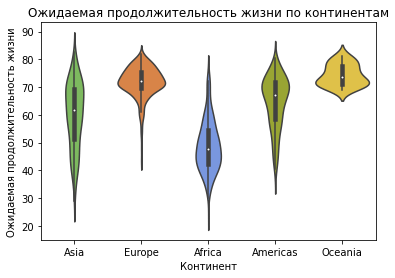
Violin Plot с диаграммой рассеивания
Точечную диаграмму распределения можно наложить на скрипичную диаграмму, чтобы увидеть размещение точек, составляющих это распределение. Для этого просто создается одна область рисования, а затем последовательно в ней создаются две диаграммы.
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
plt.figure(figsize=(16,8))
sns.violinplot(x=continent, y=life_exp,palette=colors_list)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
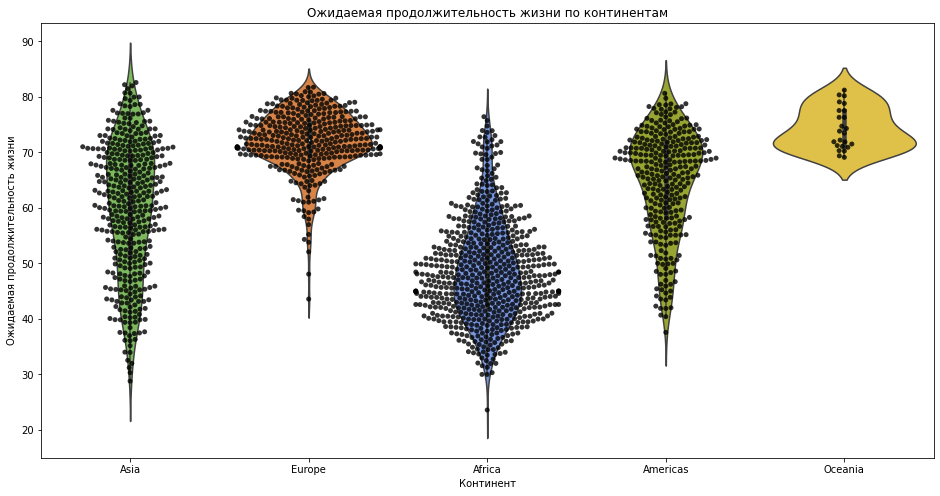
Изменение стиля скрипичной диаграммы
Можно легко изменить стиль и цвет нашей диаграммы, используя функции set_style() и set_palette() соответственно.
Seaborn поддерживает несколько различных вариантов изменения стиля и цветовой палитры графиков:
plt.figure(figsize=(16,8))
sns.set_palette("RdBu")
sns.set_style("darkgrid")
sns.violinplot(x=continent, y=life_exp)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
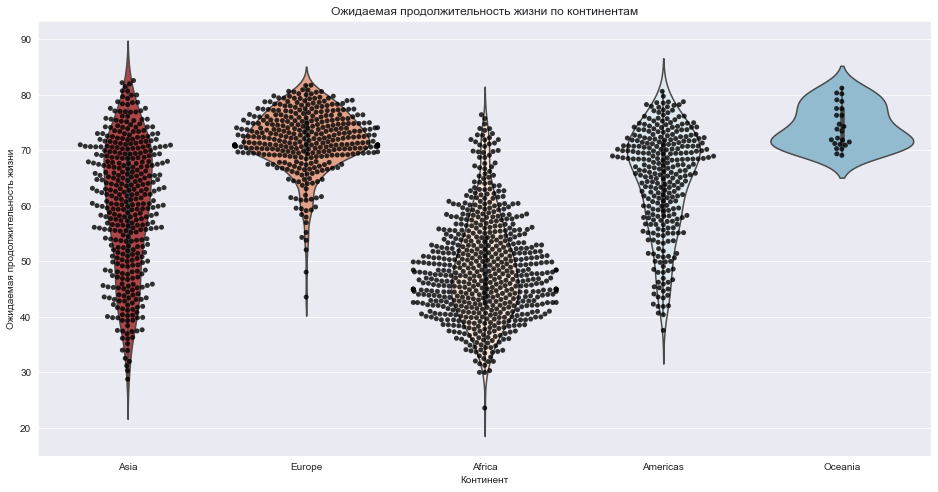
Построение Violin Plot для разных признаков
Если нужно разделить визуализацию столбцов из набора данных на их собственные диаграммы, то это можно сделать. Создайте область рисования и сетку, в ячейках которой будут графики.
Для отображения диаграммы в соответствующей ячейке применяется функция add_subplot(), которой передается адрес этой ячейки. Создание диаграммы делаем, как обычно, используя объект axes.
Можно использовать y=variable, либо data=variable.
fig = plt.figure(figsize=(6, 4))
gs = fig.add_gridspec(1, 3)
ax = fig.add_subplot(gs[0, 0])
sns.violinplot(data=population)
ax.set_xlabel("Население")
ax = fig.add_subplot(gs[0, 1])
sns.violinplot(data=life_exp)
ax.set_xlabel("Прод. жизни")
ax = fig.add_subplot(gs[0, 2])
sns.violinplot(data=gdp_cap)
ax.set_xlabel("Объем ВВП")
fig.tight_layout()
Группировка скрипичных диаграмм по категориальному признаку
По настоящему полезная вещь для violinplot — это группировка по значениям категориальной переменной. Например, если есть категориальная величина, имеющая два значения (обычно, True/False), то в этом случае можно группировать графики по этим значениям.
Допустим, есть набор данных по трудоустройству населения со столбцом employment и его значениями employed и unemployed. Тогда можно сгруппировать диаграммы по видам занятости.
Поскольку в наборе данных Gapminder нет столбца, подходящего для такой группировки, его можно сделать, рассчитав среднюю продолжительность жизни для определенного подмножества стран, например, европейских стран.
Назначим Yes/No значение новому столбцу above_average_life_exp для каждой страны. Если средняя продолжительность жизни выше, чем в среднем по датасету, то это значение равно Yes, и наоборот:
# Отделяем европейские страны от исходного датасет
europe = dataframe.loc[dataframe["continent"] == "Europe"]
# Вычисляем среднее значение переменной "life_exp"
avg_life_exp = dataframe["life_exp"].mean()
# Добавим новую колонку
europe.loc[:, "above_average_life_exp"] = europe["life_exp"] > avg_life_exp
europe["above_average_life_exp"].replace(
{True: "Yes", False: "No"},
inplace=True
)
Теперь, если вывести наш набор данных, то получим следующее:
| country | year | population | continent | life_exp | gdp_cap | above_average_life_exp | |
|---|---|---|---|---|---|---|---|
| 12 | Albania | 1952 | 1282697 | Europe | 55.23 | 1601.056136 | No |
| 13 | Albania | 1957 | 1476505 | Europe | 59.28 | 1942.284244 | No |
| 14 | Albania | 1962 | 1728137 | Europe | 64.82 | 2312.888958 | Yes |
| 15 | Albania | 1967 | 1984060 | Europe | 66.22 | 2760.196931 | Yes |
| 16 | Albania | 1972 | 2263554 | Europe | 67.69 | 3313.422188 | Yes |
Теперь можно построить скрипичные диаграммы, сгруппированные по новому столбцу, который мы вставили. Учитывая, что европейских стран много, для удобства визуализации выберем последние 50 строк, используя europe.tail():
europe = europe.tail(50)
ax = sns.violinplot(x=europe.country, y=europe.life_exp, hue=europe.above_average_life_exp)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
В результате получим:
Теперь страны с продолжительностью жизни меньше средней, ожидаемой отличаются по цвету.
Разделение скрипичных диаграмм по категориальному признаку
Если используется аргумент hue для категориальной переменной, имеющей два значения, то применив в функции violinplot() аргумент split и установив его в True, можно разделить скрипичные диаграммы пополам с учетом значения hue.
В нашем случае одна сторона скрипки (левая) будет представлять записи с ожидаемой продолжительностью жизни выше среднего, в то время как правая сторона будет использоваться для построения ожидаемой продолжительности жизни ниже среднего:
europe = europe.tail(50)
ax = sns.violinplot(
x=europe.country,
y=europe.life_exp,
hue=europe.above_average_life_exp,
split=True
)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
Мы рассмотрели несколько способов построения Violin Plot в Seaborn. Это последний тип графиков, на которые стоит обратить внимание.
В этой статье мы рассмотрели примеры построения графиков:
- Bar Plot
- Scatter Plot
- Box Plot
- Heatmap
- Violin Plot
Тест на знание основ Seaborn
Speedtest-cli — это интерфейс командной строки для проверки скорости с помощью сервиса speedtest.net.
Установка
Модуль не является предустановленным в Python. Для его установки нужно ввести следующую команду в терминале:
pip install speedtest-cliПосле установки библиотеки можно проверить корректность и версию пакета. Для этого используется такая команда:
& speedtest-cli --version
speedtest-cli 2.1.2
Python 3.8.5 (tags/v3.8.5:580fbb0, Jul 20 2020, 15:57:54) [MSC v.1924 64 bit (AMD64)]Возможности speedtest-cli
Что делает Speedtest-CLI?
Speedtest-cli — это модуль, используемый в интерфейсе командной строки для проверки пропускной способности с помощью speedtest.net. Для получения скорости в мегабитах введите команду: speedtest-cli.
Это команда даст результат скорости в мегабитах. Для получения результата в байтах нужно добавить один аргумент к команде.
$ speedtest-cli --bytes
Retrieving speedtest.net configuration...
Testing from ******** (******)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by ******** (***) [1.85 km]: 3.433 ms
Testing download speed.........................................................
Download: 22.98 Mbyte/s
Testing upload speed...............................................................
Upload: 18.57 Mbyte/sТакже с помощью модуля можно получить графическую версию результата тестирования. Для этого есть такой параметр:
$ speedtest-cli --share
Retrieving speedtest.net configuration...
Testing from ***** (****)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by ***** (***) [1.85 km]: 3.155 ms
Testing download speed.......................................
Download: 164.22 Mbit/s
Testing upload speed............................................................
Upload: 167.82 Mbit/s
Share results: http://www.speedtest.net/result/11111111111.pngКоманда вернет ссылку, по которой можно перейти в браузере:
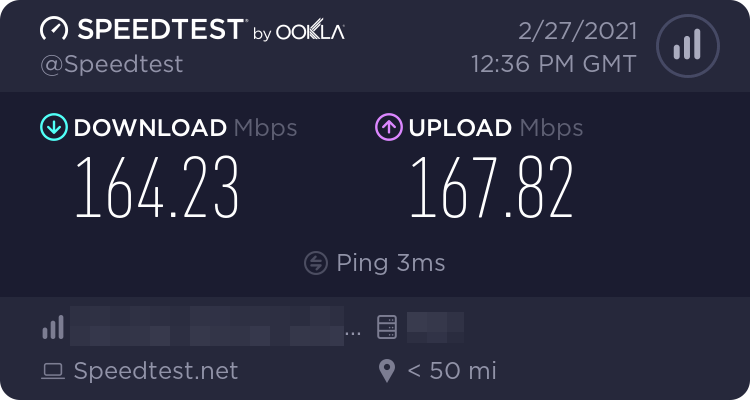
Для вывода более простой версии результатов теста, в которой будут только сведения о пинге, скорости скачивания и загрузки используйте параметр --simple.
$ speedtest-cli --simple
Ping: 3.259 ms
Download: 182.49 Mbit/s
Upload: 172.16 Mbit/sИспользование speedtest в Python
Рассмотрим пример программы Python для тестирования скорости интернета:
import speedtest
st = speedtest.Speedtest()
option = int(input('''
Выбери тип проверки:
1 - Скорость скачивания
2 - Скорость загрузки
3 - Пинг
Твой выбор: '''))
if option == 1:
print(st.download())
elif option == 2:
print(st.upload())
elif option == 3:
servernames =[]
st.get_servers(servernames)
print(st.results.ping)
else:
print("Пожалуйста, введите цифру от 1 до 3!")
Результат выполнения этой простой программы будет такой:
Выбери тип проверки:
1 - Скорость скачивания
2 - Скорость загрузки
3 - Пинг
Твой выбор: 2
136433948.59785312Дополнение
Что бы погрузится в библиотеку speedtest-cli используйте команду --help, что бы получить список всех доступных параметров:
speedtest-cli --help # или speedtest-cli -hВ SymPy есть разные функции, которые применяются в сфере символьных вычислений, математического анализа, алгебры, дискретной математики, квантовой физики и так далее. SymPy может представлять результат в разных форматах: LaTeX, MathML и так далее. Распространяется библиотека по лицензии New BSD. Первыми эту библиотеку выпустили разработчики Ondřej Čertík и Aaron Meurer в 2007 году. Текущая актуальная версия библиотеки — 1.6.2.
Вот где применяется SymPy:
- Многочлены
- Математический анализ
- Дискретная математика
- Матрицы
- Геометрия
- Построение графиков
- Физика
- Статистика
- Комбинаторика
Установка SymPy
Для работы SymPy требуется одна важная библиотека под названием mpmath. Она используется для вещественной и комплексной арифметики с числами с плавающей точкой произвольной точности. Однако pip установит ее автоматически при загрузке самой SymPy:
pip install sympyТакие дистрибутивы, как Anaconda, Enthough, Canopy и другие, заранее включают SymPy. Чтобы убедиться в этом, достаточно ввести в интерактивном режиме команду:
>>> import sympy
>>> sympy.__version__
'1.6.2'
Исходный код можно найти на GitHub.
Символьные вычисления в SymPy
Символьные вычисления — это разработка алгоритмов для управления математическими выражениями и другими объектами. Такие вычисления объединяют математику и компьютерные науки для решения математических выражений с помощью математических символов.
Система компьютерной алгебры же, такая как SymPy, оценивает алгебраические выражения с помощью тех же символов, которые используются в традиционных ручных методах. Например, квадратный корень числа с помощью модуля math в Python вычисляется вот так:
import math
print(math.sqrt(25), math.sqrt(7))
Вывод следующий:
5.0 2.6457513110645907Как можно увидеть, квадратный корень числа 7 вычисляется приблизительно. Но в SymPy квадратные корни чисел, которые не являются идеальными квадратами, просто не вычисляются:
import sympy
print(sympy.sqrt(7))
Вот каким будет вывод этого кода: sqrt(7).
Это можно упростить и показать результат выражения символически таким вот образом:
>>> import math
>>> print(math.sqrt(12))
3.4641016151377544
>>> import sympy
>>> print(sympy.sqrt(12))
2*sqrt(3)
В случае с модулем math вернется число, а вот в SymPy — формула.
Для рендеринга математических символов в формате LaTeX код SymPy, используйте Jupyter notebook:
from sympy import *
x = Symbol('x')
expr = integrate(x**x, x)
expr
Если выполнить эту команду в IDLE, то получится следующий результат:
Integral(x**x,x)А в Jupyter:

Квадратный корень неидеального корня также может быть представлен в формате LaTeX с помощью привычных символов:
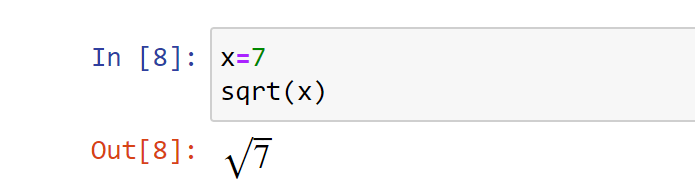
Символьные вычисления с помощью таких систем, как SymPy, помогают выполнять вычисления самого разного рода (производные, интегралы, пределы, решение уравнений, работа с матрицами) в символьном виде.
В пакете SymPy есть разные модули, которые помогают строить графики, выводить результат (LaTeX), заниматься физикой, статистикой, комбинаторикой, числовой теорией, геометрией, логикой и так далее.
Числа
Основной модуль в SymPy включает класс Number, представляющий атомарные числа. У него есть пара подклассов: Float и Rational. В Rational также входит Integer.
Класс Float
Float представляет числа с плавающей точкой произвольной точности:
>>> from sympy import Float
>>> Float(6.32)
6.32
SymPy может конвертировать целое число или строку в число с плавающей точкой:
>>> Float(10)
10.0
При конвертации к числу с плавающей точкой, также можно указать количество цифр для точности:
>>> Float('1.33E5')
133000.0
Представить число дробью можно с помощью объекта класса Rational, где знаменатель — не 0:
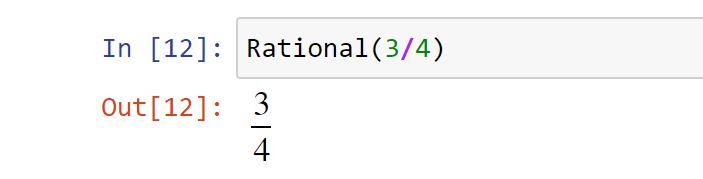
Если число с плавающей точкой передать в конструктор Rational(), то он вернет дробь:

Для упрощения можно указать ограничение знаменателя:
Rational(0.2).limit_denominator(100)
Выведется дробь 1/5 вместо 3602879701896397/18014398509481984.
Если же в конструктор передать строку, то вернется рациональное число произвольной точности:
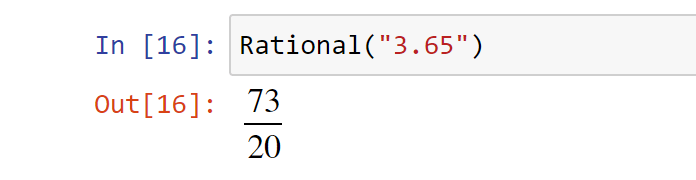
Также рациональное число можно получить, если в качестве аргументов передать два числа. Числитель и знаменатель доступны в виде свойств:
>>> a=Rational(3, 5)
>>> print(a)
3/5
>>> print("числитель:{}, знаменатель:{}".format(a.p, a.q))
числитель:3, знаменатель:5
Класс Integer
Класс Integer в SymPy представляет целое число любого размера. Конструктор принимает рациональные и числа с плавающей точкой. В результате он откидывает дробную часть:
>>> Integer(10)
10
>>> Integer(3.4)
3
>>> Integer(2/7)
0
Также есть класс RealNumber, который является алиасом для Float. В SymPy есть классы-одиночки Zero и One, доступные через S.Zero и S.One соответственно.
>>> S.Zero
0
>>> S.One
1
Другие числовые объекты-одиночки — Half, NaN, Infinity и ImaginaryUnit.
>>> from sympy import S
>>> print(S.Half)
1/2
>>> print(S.NaN)
nan
Бесконечность представлена в виде объекта-символа oo или как S.Infinity:

ImaginaryUnit можно импортировать как символ I, а получить к нему доступ — через S.ImaginaryUnit.
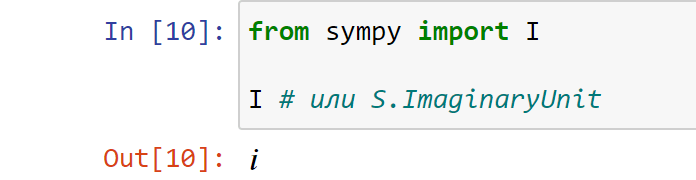
Символы
Symbol — самый важный класс в библиотеке SymPy. Как уже упоминалось ранее, символьные вычисления выполняются с помощью символов. И переменные SymPy являются объектами класса Symbol.
Аргумент функции Symbol() — это строка, содержащая символ, который можно присвоить переменной.
>>> from sympy import Symbol
>>> x = Symbol('x')
>>> y = Symbol('y')
>>> expr = x**2 + y**2
>>> expr
Код выше является эквивалентом этого выражения:
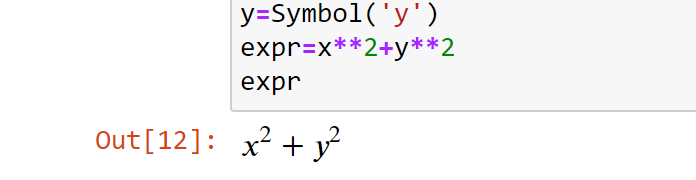
Символ может включать больше одной буквы:
from sympy import Symbol
s = Symbol('side')
s**3
Также в SymPy есть функция Symbols(), с помощью которой можно определить несколько символов за раз. Строка содержит названия переменных, разделенные запятыми или пробелами.
from sympy import symbols
x, y, z = symbols("x, y, z")
В модуле abc можно найти элементы латинского и греческого алфавитов в виде символов. Таким образом вместо создания экземпляра Symbol можно использовать метод:
from sympy.abc import x, z
Однако C, O, S, I, N, E и Q являются заранее определенными символами. Также символы с более чем одной буквы не определены в abc. Для них нужно использовать объект Symbol. Модуль abs определяет специальные имена, которые могут обнаружить определения в пространстве имен SymPy по умолчанию. сlash1 содержит однобуквенные символы, а clash2 — целые слова.
>>> from sympy.abc import _clash1, _clash2
>>> _clash1
{'C': C,'O': O,'Q': Q,'N': N,'I': I,'E': E,'S': S}
>>> _clash2
{'beta': beta,'zeta': zeta,'gamma': gamma,'pi': pi}
Индексированные символы (последовательность слов с цифрами) можно определить с помощью синтаксиса, напоминающего функцию range(). Диапазоны обозначаются двоеточием. Тип диапазона определяется символом справа от двоеточия. Если это цифра, то все смежные цифры слева воспринимаются как неотрицательное начальное значение.
Смежные цифры справа берутся на 1 больше конечного значения.
>>> from sympy import symbols
>>> symbols('a:5')
(a0,a1,a2,a3,a4)
>>> symbols('mark(1:4)')
(mark1,mark2,mark3)
Подстановка параметров
Одна из базовых операций в математических выражениях — подстановка. Функция subs() заменяет все случаи первого параметра на второй.
>>> from sympy.abc import x, a
>>> expr = sin(x) * sin(x) + cos(x) * cos(x)
>>> expr
Этот код даст вывод, эквивалентный такому выражению.
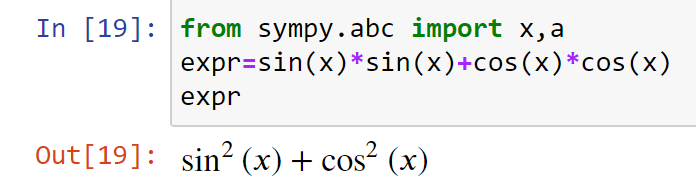
А кодом expr.subs(x,a) мы получим туже формулу, но с a вместо x.
Эта функция полезна, когда требуется вычислить определенное выражение. Например, нужно посчитать значения выражения, заменив a на 5:

>>> from sympy.abc import x
>>> from sympy import sin, pi
>>> expr = sin(x)
>>> expr1 = expr.subs(x, pi)
>>> expr1
0
Также функция используется для замены подвыражения другим подвыражением. В следующем примере b заменяется на a+b.
>>> from sympy.abc import a, b
>>> expr = (a + b)**2
>>> expr1 = expr.subs(b, a + b)
>>> expr1
Это дает такой вывод:
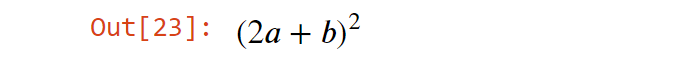
Функция simplify()
Функция simplify() используется для преобразования любого произвольного выражения, чтобы его можно было использовать как выражение SymPy. Обычные объекты Python, такие как целые числа, конвертируются в SymPy.Integer и так далее. Строки также конвертируются в выражения SymPy:
>>> expr = "x**2 + 3*x + 2"
>>> expr1 = sympify(expr)
>>> expr1.subs(x, 2)
12
Любой объект Python можно конвертировать в объект SymPy. Однако учитывая то, что при преобразовании используется функция eval(), не стоит использовать некорректные выражения, иначе возникнет ошибка SimplifyError.
>>> sympify("x***2")
...
SympifyError: Sympify of expression 'could not parse 'x***2'' failed, because of exception being raised:
SyntaxError: invalid syntax (<string>, line 1)
Функция simplify() принимает следующий аргумент: strict=False. Если установить True, то преобразованы будут только те типы, для которых определено явное преобразование. В противном случае также возникнет ошибка SimplifyError. Если же поставить False, то арифметические выражения и операторы будут конвертированы в их эквиваленты SumPy без вычисления выражения.

Функция evalf()
Функция вычисляет данное числовое выражение с точностью до 100 цифр после плавающей точки. Она также принимает параметр subs, как объект словаря с числовыми значениями для символов. Например такое выражение:
from sympy.abc import r
expr = pi * r**2
expr
Даст такой результат: ??2
Вычислим выражение с помощью evalf() и заменим r на 5:
>>> expr.evalf(subs={r: 5})
78.5398163397448
По умолчанию точность после плавающей точки — 15, но это значение можно перезаписать до 100. Следующее выражение вычисляет, используя вплоть до 20 цифр точности:
>>> expr = a / b
>>> expr.evalf(20, subs={a: 100, b: 3})
33.333333333333333333
Функция lambdify()
Функция lambdify() переводит выражения SymPy в функции Python. Если выражение, которое нужно вычислить, затрагивает диапазон значений, то функция evalf() становится неэффективной. Функция lambdify действует как лямбда-функция с тем исключением, что она конвертирует SymPy в имена данной числовой библиотеки, обычно NumPy. По умолчанию же она реализована на основе стандартной библиотеки math.
>>> expr =1 / sin(x)
>>> f = lambdify(x, expr)
>>> f(3.14)
627.8831939138764
У выражения может быть больше одной переменной. В таком случае первым аргументом функции является список переменных, а после него — само выражение:
>>> expr = a**2 + b**2
>>> f = lambdify([a, b], expr)
>>> f(2, 3)
13
Но чтобы использовать numpy в качестве основной библиотеки, ее нужно передать в качестве аргумента функции lambdify().
f = lambdify([a, b], expr, "numpy")
В этой функции использовались два массива numpy: a и b. В случае с ними выполнение гораздо быстрее:
>>> import numpy
>>> l1 = numpy.arange(1, 6)
>>> l2 = numpy.arange(6, 11)
>>> f(l1, l2)
array([ 37, 53, 73, 97, 125], dtype=int32)
Логические выражения
Булевы функции расположены в модуле sympy.basic.booleanarg. Их можно создать и с помощью стандартных операторов Python: & (And), | (Or), ~ (Not), а также >> и <<. Булевы выражения наследуются от класса Basic.
BooleanTrue.
Эта функция является эквивалентом True из Python. Она возвращает объект-одиночку, доступ к которому можно получить и с помощью S.true.
>>> from sympy import *
>>> x = sympify(true)
>>> x, S.true
(True, True)
BooleanFalse.
А эта функция является эквивалентом False. Ее можно достать с помощью S.False.
>>> from sympy import *
>>> x = sympify(false)
>>> x, S.false
(False,False)
And.
Функция логического AND оценивает два аргумента и возвращает False, если хотя бы один из них является False. Эта функция заменяет оператор &.
>>> from sympy import *
>>> from sympy.logic.boolalg import And
>>> x, y = symbols('x y')
>>> x = True
>>> y = True
>>> And(x, y), x & y
Or.
Оценивает два выражения и возвращает True, если хотя бы одно из них является True. Это же поведение можно получить с помощью оператора |.
>>> from sympy import *
>>> from sympy.logic.boolalg import Or
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Or(x, x|y)
Not.
Результат этой функции — отрицание булево аргумента. True, если аргумент является False, и False в противном случае. В Python за это отвечает оператор ~. Пример:
>>> from sympy import *
>>> from sympy.logic.boolalg import Or,And,Not
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Not(x), Not(y)
(False, True)
Xor.
Логический XOR (исключающий OR) возвращает True, если нечетное количество аргументов равняется True, а остальные — False. False же вернется в том случае, если четное количество аргументов True, а остальные — False. То же поведение работает в случае оператора ^.
>>> from sympy import *
>>> from sympy.logic.boolalg import Xor
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Xor(x, y)
True
В предыдущем примере один(нечетное число) аргумент является True, поэтому Xor вернет True. Если же количество истинных аргументов будет четным, результатом будет False, как показано дальше.
>>> Xor(x, x^y)
False
Nand.
Выполняет логическую операцию NAND. Оценивает аргументы и возвращает True, если хотя бы один из них равен False, и False — если они истинные.
>>> from sympy.logic.boolalg import Nand
>>> a, b, c = (True, False, True)
>>> Nand(a, c), Nand(a, b)
(False, True)
Nor.
Выполняет логическую операцию NOR. Оценивает аргументы и возвращает False, если один из них True, или же True, если все — False.
>>> from sympy.logic.boolalg import Nor
>>> a, b = False, True
>>> Nor(a), Nor(a, b)
(True, False)
Хотя SymPy и предлагает операторы ^ для Xor, ~ для Not, | для Or и & для And ради удобства, в Python они используются в качестве побитовых. Поэтому если операнды будут целыми числами, результаты будут отличаться.
Equivalent.
Эта функция возвращает отношение эквивалентности. Equivalent(A, B) будет равно True тогда и только тогда, когда A и B оба будут True или False. Функция вернет True, если все аргументы являются логически эквивалентными. В противном случае — False.
>>> from sympy.logic.boolalg import Equivalent
>>> a, b = True, False
>>> Equivalent(a, b), Equivalent(a, True)
( False, True)
Запросы
Модуль assumptions в SymPy включает инструменты для получения информации о выражениях. Для этого используется функция ask().
Следующие свойства предоставляют полезную информацию о выражении:
sympy.assumptions.ask(выражение)
algebraic(x)
Чтобы быть алгебраическим, число должно быть корнем ненулевого полиномиального уравнения с рациональными коэффициентами. √2, потому что √2 — это решение x2 − 2 = 0. Следовательно, это выражения является алгебраическим.
complex(x)
Предикат комплексного числа. Является истиной тогда и только тогда, когда x принадлежит множеству комплексных чисел.
composite(x)
Предикат составного числа, возвращаемый ask(Q.composite(x)) является истиной тогда и только тогда, когда x — это положительное число, имеющее как минимум один положительный делитель, кроме 1 и самого числа.
even, oddask() возвращает True, если x находится в множестве четных и нечетных чисел соответственно.
imaginary
Свойство представляет предикат мнимого числа. Является истиной, если x можно записать как действительное число, умноженное на мнимую единицу.
integer
Это свойство, возвращаемое Q.integer(x), будет истинным только в том случае, если x принадлежит множеству четных чисел.
rational, irrationalQ.irrational(x) истинно тогда и только тогда, когда x — это любое реальное число, которое нельзя представить как отношение целых чисел. Например, pi — это иррациональное число.
positive, negative
Предикаты для проверки того, является ли число положительным или отрицательным.
zero, nonzero
Предикат для проверки того, является ли число нулем или нет.
>>> from sympy import *
>>> x = Symbol('x')
>>> x = 10
>>> ask(Q.algebraic(pi))
False
>>> ask(Q.complex(5-4*I)), ask(Q.complex(100))
(True, True)
>>> x, y = symbols("x y")
>>> x, y = 5, 10
>>> ask(Q.composite(x)), ask(Q.composite(y))
(False, True)
>>> ask(Q.even(x)), ask(Q.even(y))
(True, None)
>>> ask(Q.imaginary(x)), ask(Q.imaginary(y))
(True, False)
>>> ask(Q.even(x)), ask(Q.even(y)), ask(Q.odd(x)), ask(Q.odd(y))
(True, True, False, False)
>>> ask(Q.positive(x)), ask(Q.negative(y)), ask(Q.positive(x)), ask(Q.negative(y))
(True, True)
>>> ask(Q.rational(pi)), ask(Q.irrational(S(2)/3))
(False, False)
>>> ask(Q.zero(oo)), ask(Q.nonzero(I))
(False, False)
Функции упрощения
SymPy умеет упрощать математические выражения. Для этого есть множество функций. Основная называется simplify(), и ее основная задача — представить выражение в максимально простом виде.
simplify
Это функция объявлена в модуле sympy.simplify. Она пытается применить методы интеллектуальной эвристики, чтобы сделать входящее выражение «проще». Следующий код упрощает такое выражение: sin^2(x)+cos^2(x)
>>> x = Symbol('x')
>>> expr = sin(x)**2 + cos(x)**2
>>> simplify(expr)
1
expand
Одна из самых распространенных функций упрощения в SymPy. Она используется для разложения полиномиальных выражений. Например:
>>> a, b = symbols('a b')
>>> expand((a+b)**2)
А тут вывод следующий: ?2+2??+?2.
>>> expand((a+b)*(a-b))
Вывод: ?2−?2.
Функция expand() делает выражение больше, а не меньше. Обычно это так и работает, но часто получается так, что выражение становится меньше после использования функции:
>>> expand((x + 1)*(x - 2) - (x - 1)*x)
-2
factor
Эта функция берет многочлен и раскладывает его на неприводимые множители по рациональным числам.
>>> x, y, z = symbols('x y z')
>>> expr = (x**2*z + 4*x*y*z + 4*y**2*z)
>>> factor(expr)
Вывод: ?(?+2?)2.
Функция factor() — это противоположность expand(). Каждый делитель, возвращаемый factor(), будет несокращаемым. Функция factor_list() предоставляет более структурированный вывод:
>>> expr=(x**2*z + 4*x*y*z + 4*y**2*z)
>>> factor_list(expr)
(1, [(z, 1), (x + 2*y, 2)])
collect
Эта функция собирает дополнительные члены выражения относительно списка выражений с точностью до степеней с рациональными показателями.
>>> expr = x*y + x - 3 + 2*x**2 - z*x**2 + x**3
>>> expr
Вывод: ?3−?2?+2?2+??+?−3.
Результат работы collect():
>>> expr = y**2*x + 4*x*y*z + 4*y**2*z + y**3 + 2*x*y
>>> collect(expr, y)
Вывод: ?3+?2(?+4?)+?(4??+2?).
cancel
Эта функция берет любую рациональную функцию и приводит ее в каноническую форму p/q, где p и q — это разложенные полиномы без общих множителей. Старшие коэффициенты p и q не имеют знаменателей, то есть, являются целыми числами.
>>> expr1=x**2+2*x+1
>>> expr2=x+1
>>> cancel(expr1/expr2)
x + 1
Еще несколько примеров:
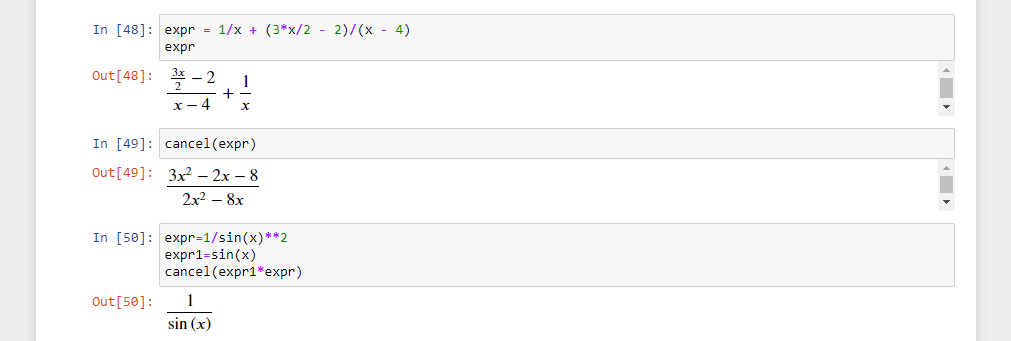
trigsimp
Эта функция используется для упрощения тригонометрических тождеств. Стоит отметить, что традиционные названия обратных тригонометрических функций добавляются в название функции в начале. Например, обратный косинус или арккосинус называется acos():
>>> from sympy import trigsimp, sin, cos
>>> from sympy.abc import x, y
>>> expr = 2*sin(x)**2 + 2*cos(x)**2
>>> trigsimp(expr)
2
Функция trigsimp использует эвристику для применения наиболее подходящего тригонометрического тождества.
powersimp
Эта функция сокращает выражения, объединяя степени с аналогичными основаниями и значениями степеней.
>>> expr = x**y*x**z*y**z
>>> expr
Вывод: ??????.
Можно сделать так, чтоб powsimp() объединяла только основания или степени, указав combine='base' или combine='exp'. По умолчанию это значение равно combine='all'. Также можно задать параметр force. Если он будет равен True, то основания объединятся без проверок.
>>> powsimp(expr, combine='base', force=True)
Вывод: ??(??)?.
combsimp
Комбинаторные выражения, включающие факториал и биномы, можно упростить с помощью функции combsimp(). В SymPy есть функция factorial().
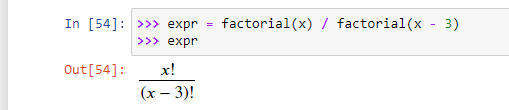
Для упрощения предыдущего комбинаторного выражения эта функция используется следующим образом.
>>> combsimp(expr)
?(?−2)(?−1)
binomial(x, y) — это количество способов, какими можно выбрать элементы y из множества элементов x. Его же можно записать и как xCy.
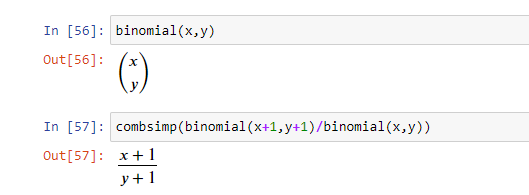
logcombine
Эта функция принимает логарифмы и объединяет их с помощью следующих правил:
log(x) + log(y) == log(x*y)— оба положительные.a*log(x) == log(x**a)если x является положительным и вещественным.
>>> logcombine(a*log(x) + log(y) - log(z))
?log(?)+log(?)−log(?)
Если здесь задать значение параметра force равным True, то указанные выше предположения будут считаться выполненными, если нет предположений о величине.
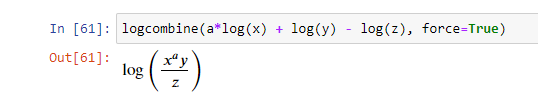
Производные
Производная функции — это ее скорость изменения относительно одной из переменных. Это эквивалентно нахождению наклона касательной к функции в точке. Найти дифференцирование математических выражений в форме переменных можно с помощью функции diff() из SymPy.
>>> from sympy import diff, sin, exp
>>> from sympy.abc import x, y
>>> expr = x*sin(x*x) + 1
>>> expr
Вывод: ?sin(?2)+1.
Чтобы получить несколько производных, нужно передать переменную столько раз, сколько нужно выполнить дифференцирование. Или же можно просто указать это количество с помощью числа.
>>> diff(x**4, x, 3)
24?
Также можно вызвать метод diff() выражения. Он работает по аналогии с функцией.
>>> expr = x*sin(x*x) + 1
>>> expr.diff(x)
Вывод: 2?2cos(?2)+sin(?2).
Неоцененная производная создается с помощью класса Derivative. У него такой же синтаксис, как и функции diff(). Для оценки же достаточно использовать метод doit.

Интеграция
SymPy включает и модуль интегралов. В нем есть методы для вычисления определенных и неопределенных интегралов выражений. Метод integrate() используется для вычисления обоих интегралов. Для вычисления неопределенного или примитивного интеграла просто передайте переменную после выражения.
Для вычисления определенного интеграла, передайте аргументы следующим образом:
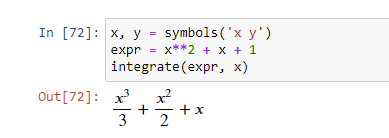
Пример определенного интеграла:
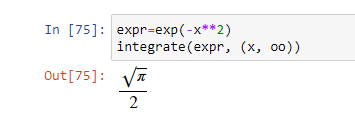
С помощью объекта Integral можно создать неоцененный интеграл. Он оценивается с помощью метода doit().
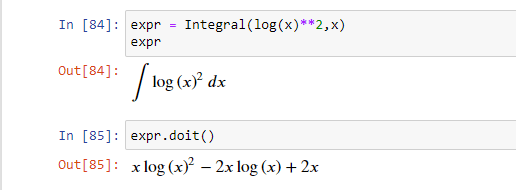
Трансформации интегралов
SymPy поддерживает разные виды трансформаций интегралов:
- laplace_tranfsorm.
- fourier_transform.
- sine_tranfsorm.
- cosine_transform.
- hankel_transform.
Эти функции определены в модуле sympy.integrals.transforms. Следующие примеры вычисляют преобразования Фурье и Лапласа соответственно:

>>> from sympy.integrals import laplace_transform
>>> from sympy.abc import t, s, a
>>> laplace_transform(t**a, t, s)
(s**(-a)*gamma(a + 1)/s, 0, re(a) > -1)
Матрицы
В математике матрица — это двумерный массив чисел, символов или выражений. Теория манипуляций матрицами связана с выполнением арифметических операций над матричными объектами при соблюдении определенных правил.
Линейная трансформация — одно из важнейших применений матрицы. Она часто используется в разных научных областях, особенно связанных с физикой. В SymPy есть модуль matrices, который работает с матрицами. В нем есть класс Matrix для представления матрицы.
Примечание: для выполнения кода в этом разделе нужно сперва импортировать модуль matrices следующим образом.
>>> from sympy.matrices import Matrix
>>> m=Matrix([[1, 2, 3], [2, 3, 1]])
>>> m
⎡1 2 3⎤
⎣2 3 1⎦
Матрица — это изменяемый объект. Также в модуле есть класс ImmutableMatrix для получения неизменяемой матрицы.
Базовое взаимодействие
Свойство shape возвращает размер матрицы.
>>> m.shape
(2, 2)
Методы row() и col() возвращают колонку или строку соответствующего числа.
>>> m.row(0)
[1 2 3]
>>> m.col(1)
⎡2⎤
⎣3⎦
Оператор slice из Python можно использовать для получения одного или большего количества элементов строки или колонки.
У класса Matrix также есть методы row_del() и col_del(), которые удаляют указанные строку/колонку из выбранной матрицы.
>>> m.row(1)[1:3]
[3, 1]
>>> m.col_del(1)
>>> m
⎡1 3⎤
⎣2 1⎦
По аналогии row_insert() и col_insert() добавляют строки и колонки в обозначенные индексы:
>>> m1 = Matrix([[10, 30]])
>>> m = m.row_insert(0, m1)
>>> m
⎡10 30⎤
⎢ 1 3 ⎥
⎣ 2 1 ⎦
Арифметические операции
Привычные операторы +, — и * используются для сложения, умножения и деления.
>>> M1 = Matrix([[3, 0], [1, 6]])
>>> M2 = Matrix([[4, 5], [6, 4]])
>>> M1 + M2
⎡7 5 ⎤
⎣7 10 ⎦
Умножение матрицы возможно лишь в том случае, если количество колонок первой матрицы соответствует количеству колонок второй. Результат будет иметь такое же количество строк, как у первой матрицы и столько же колонок, сколько есть во второй.
Для вычисления определителя матрицы используется метод det(). Определитель — это скалярное значение, которое может быть вычислено из элементов квадратной матрицы.
>>> M = Matrix([[4, 5], [6, 4]])
>>> M.det()
-14
Конструкторы матрицы
SymPy предоставляет множество специальных типов классов матриц. Например, Identity, матрица из единиц, нолей и так далее. Эти классы называются eye, zeroes и ones соответственно. Identity — это квадратная матрица, элементы которой по диагонали равны 1, а остальные — 0.
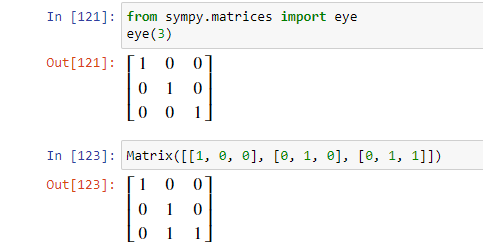
В матрице diag элементы по диагонали инициализируются в соответствии с предоставленными аргументами.
>>> from sympy.matrices import diag
>>> diag(1, 3)
⎡1 0 ⎤
⎣0 3 ⎦
Все элементы в матрице zero инициализируются как нули.
>>> from sympy.matrices import zeros
>>> zeros(2, 3)
⎡0 0 0⎤
⎣0 0 0⎦
По аналогии в матрице ones элементы равны 1:
>>> from sympy.matrices import zeros
>>> ones(2, 3)
⎡1 1 1⎤
⎣1 1 1⎦
Класс Function
В пакете SymPy есть класс Function, определенный в модуле sympy.core.function. Это базовый класс для всех математических функций, а также конструктор для неопределенных классов.
Следующие категории функций наследуются от класса Function:
- Функции для комплексных чисел
- Тригонометрические функции
- Функции целого числа
- Комбинаторные функции
- Другие функции
Функции комплексных чисел
Набор этих функций определен в модуле sympy.functions.elementary.complexes.
re — Эта функция возвращает реальную часть выражения:
>>> from sympy import *
>>> re(5+3*I)
5
>>> re(I)
0
im — Возвращает мнимую часть выражения:
>>> im(5+3*I)
3
>>> im(I)
1
sign — Эта функция возвращает сложный знак выражения..
Для реального выражения знак будет:
- 1, если выражение положительное,
- 0, если выражение равно нулю,
- -1, если выражение отрицательное.
Если выражение мнимое, то знаки следующие:
- l, если выражение положительное,
- -l, если выражение отрицательное.
>>> sign(1.55), sign(-1), sign(S.Zero)
(1,-1,0)
>>> sign (-3*I), sign(I*2)
(-I, I)
Функция abs возвращает абсолютное значение комплексного числа. Оно определяется как расстояние между основанием (0, 0) и точкой на комплексной плоскости. Эта функция является расширением встроенной функции abs() и принимает символьные значения.
Например, Abs(2+3*I), вернет √13.
conjugate — Функция возвращает сопряжение комплексного числа. Для поиска меняется знак мнимой части.
>>> conjugate(4+7*I)
4−7?
Тригонометрические функции
В SymPy есть определения всех тригонометрических соотношений: синуса, косинуса, тангенса и так далее. Также есть обратные аналоги: asin, acos, atan и так далее. Функции вычисляют соответствующее значение данного угла в радианах.
>>> sin(pi/2), cos(pi/4), tan(pi/6)
(1, sqrt(2)/2, sqrt(3)/3)
>>> asin(1), acos(sqrt(2)/2), atan(sqrt(3)/3)
(pi/2, pi/4, pi/6)
Функции целого числа
Набор функций для работы с целым числом.
Одномерная функция ceiling, возвращающая самое маленькое целое число, которое не меньше аргумента. В случае с комплексными числами округление до большего целого для целой и мнимой части происходит отдельно.
>>> ceiling(pi), ceiling(Rational(20, 3)), ceiling(2.6+3.3*I)
(4, 7, 3 + 4*I)
floor — Возвращает самое большое число, которое не больше аргумента. В случае с комплексными числами округление до меньшего целого для целой и мнимой части происходит отдельно.
>>> floor(pi), floor(Rational(100, 6)), floor(6.3-5.9*I)
(3, 16, 6 - 6*I)
frac — Функция представляет долю x.
>>> frac(3.99), frac(10)
(0.990000000000000, 0)
Комбинаторные функции
Комбинаторика — это раздел математики, в котором рассматриваются выбор, расположение и работа в конечной и дискретной системах.
factorial — Факториал очень важен в комбинаторике. Он обозначает число способов, которыми могут быть представлены объекты.
Кватернион
В математика числовая система кватернион расширяет комплексные числа. Каждый объект включает 4 скалярные переменные и 4 измерения: одно реальное и три мнимых.
Кватернион можно представить в виде следующего уравнения: q = a + bi + cj + dk, где a, b, c и d — это реальные числа, а i, j и k — квартенионные единицы, так что i2 == j2 == k2 = ijk.
Класс Quaternion расположен в модуле sympy.algebras.quaternion.
>>> from sympy.algebras.quaternion import Quaternion
>>> q = Quaternion(2, 3, 1, 4)
>>> q
2+3?+1?+4?
Кватернионы используются как в чистой, так и в прикладной математике, а также в компьютерной графике, компьютерном зрении и так далее.

add()
Этот метод класса Quaternion позволяет сложить два объекта класса:
>>> q1=Quaternion(1,2,4)
>>> q2=Quaternion(4,1)
>>> q1.add(q2)
5+3?+4?+0?
Также возможно добавить число или символ к объекту Quaternion.
>>> q1+2
3+2?+4?+0?
>>> q1+x
(?+1)+2?+4?+0?
mul()
Этот метод выполняет умножение двух кватернионов.
>>> q1 = Quaternion(1, 2)
>>> q2 = Quaternion(2, 4, 1)
>>> q1.mul(q2)
(−6)+8?+1?+2?
inverse()
Возвращает обратный кватернион.
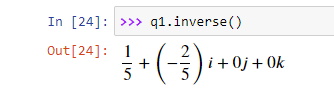
pow()
Возвращает степень кватерниона.
>>> q1.pow(2)
(−3)+4?+0?+0?
exp()
Вычисляет экспоненту кватерниона.
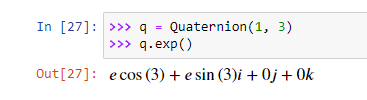
Уравнения
Поскольку символы = и == определены как символ присваивания и равенства в Python, их нельзя использовать для создания символьных уравнений. Для этого в SymPy есть функция Eq().
>>> x, y = symbols('x y')
>>> Eq(x, y)
?=?
Поскольку x=y возможно только в случае x-y=0, уравнение выше можно записать как:
>>> Eq(x-y, 0)
x−y=0
Модуль solver из SymPy предлагает функцию solveset():
solveset(equation,variable,domain)Параметр domain по умолчанию равен S.Complexes. С помощью функции solveset() можно решить алгебраическое уравнение.
>>> solveset(Eq(x**2-9, 0), x)
{−3,3}
>>> solveset(Eq(x**2-3*x, -2), x)
{1,2}
Линейное уравнение
Для решения линейных уравнений нужно использовать функцию linsolve().
Например, уравнения могут быть такими:
- x-y=4
- x+1=1
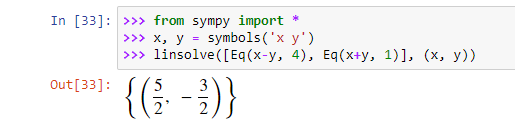
Функция linsolve() также может решать линейные уравнения в матричной форме:
>>> a, b = symbols('a b')
>>> a = Matrix([[1, -1], [1, 1]])
>>> b = Matrix([4, 1])
>>> linsolve([a, b], y)
Вывод будет тот же.
Нелинейное уравнение
Для таких уравнений используется функция nonlinsolve(). Пример такого уравнения:
>>> a, b = symbols('a b')
>>> nonlinsolve([a**2 + a, a - b], [a, b])
{(−1, −1),(0, 0)}
Дифференциальное уравнение
Для начала создайте функцию, передав cls=Function в функцию symbols. Для решения дифференциальных уравнений используйте dsolve.
>>> x = ymbol('x')
>>> f = symbols('f', cls=Function)
>>> f(x)
?(?)
Здесь f(x) — это невычисленная функция. Ее производная:
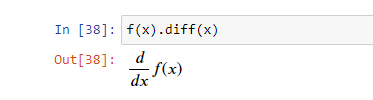
Сначала создается объект Eq, соответствующий следующему дифференциальному уравнению.
Графики
SymPy использует библиотеку matplotlib в качестве бэкенда для рендеринга двухмерных и трехмерных графиков математических функций. Убедитесь, что на вашем устройстве установлена matplotlib. Если нет, установите с помощью следующей команды.
pip install matplotlib
Функции для работы с графиками можно найти в модуле sympy.plotting:
plot— двухмерные линейные графики.plot3d— трехмерные линейные графики.plot_parametric— двухмерные параметрические графики.plot3d_parametric— трехмерные параметрические графики.
Функция plot() возвращает экземпляр класса Plot. Сам график может включать одно или несколько выражений SymPy. По умолчанию в качестве бэкенда используется matplotlib, но вместе нее можно взять texplot, pyglet или API Google Charts.
plot(expr,range,kwargs)
где expr — это любое валидное выражение SymPy. Если не сказано другое, то по умолчанию значение range равно (-10, 10).
Следующий график показывает квадрат для каждого значения в диапазоне от -10 до 10.
>>> from sympy.plotting import plot
>>> from sympy import *
>>> x = Symbol('x')
>>> plot(x**2, line_color='red')
Чтобы нарисовать несколько графиков для одного диапазона, перед кортежем нужно указать несколько выражений.
>>> plot(sin(x), cos(x), (x, -pi, pi))
Также для каждого выражения можно задать отдельный диапазон.
plot((expr1,range1),(expr2,range2))
Также в функции plot() можно использовать следующие необязательные аргументы-ключевые слова.
line_color— определяет цвет линии графика.title— название графика.xlabel— метка для оси X.ylabel— метка для оси Y.
>>> plot((sin(x), (x,-pi,pi)), line_color='red', title='Пример графика SymPy')
Функция plot3d() рендерит трехмерный график.
>>> from sympy.plotting import plot3d
>>> x, y = symbols('x y')
>>> plot3d(x*y, (x, -10, 10), (y, -10, 10))
По аналогии с двухмерным трехмерный график может включать несколько графиков для отдельных диапазонов:
>>> plot3d(x*y, x/y, (x, -5, 5), (y, -5, 5))
Функция plot3d_parametric_line() рендерит трехмерный линейный параметрический график:
>>> from sympy.plotting import plot3d_parametric_line
>>> plot3d_parametric_line(cos(x), sin(x), x, (x, -5, 5))
Чтобы нарисовать параметрический объемный график, используйте plot3d_parametric_surface().
Сущности
Модуль geometry в SymPy позволяет создавать двухмерные сущности, такие как линия, круг и так далее. Информацию о них можно получить через проверку коллинеарности или поиск пересечения.
Point
Класс point представляет точку Евклидового пространства. Следующие примеры проверяют коллинеарность точек:
>>> from sympy.geometry import Point
>>> from sympy import *
>>> x = Point(0, 0)
>>> y = Point(2, 2)
>>> z = Point(4, 4)
>>> Point.is_collinear(x, y, z)
True
>>> a = Point(2, 3)
>>> Point.is_collinear(x, a)
False
>>> x.distance(y)
2√2
Метод distance() класса Point вычисляет расстояние между двумя точками.
Line
Сущность Line можно получить из двух объектов Point. Метод intersection() возвращает точку пересечения двух линий.
>>> from sympy.geometry import Point, Line
>>> p1, p2 = Point(0, 5), Point(5, 0)
>>> l1 = Line(p1,p2)
>>> l2 = Line(Point(0, 0), Point(5, 5))
>>> l1.intersection(l2)
[Point2D(5/2, 5/2)]
>>> l1.intersection(Line(Point(0,0), Point(2,2)))
[Point2D(5/2, 5/2)]
>>> x, y = symbols('x y')
>>> p = Point(x, y)
>>> p.distance(Point(0, 0))
Вывод: √?2+?2
Triangle
Эта функция создает сущность Triangle из трех точек.
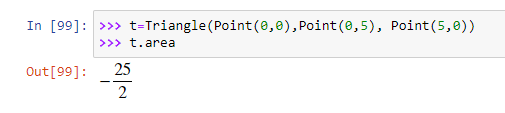
Ellipse
Эллиптическая геометрическая сущность создается с помощью объекта Point, который указывает на центр, а также горизонтальный и вертикальный радиусы.
ellipse(center,hradius,vradius)
>>> from sympy.geometry import Ellipse, Line
>>> e = Ellipse(Point(0, 0), 8, 3)
>>> e.area
24?
- vradius может быть получен косвенно с помощью параметра eccentricity.
apoapsis— это наибольшее расстояние между фокусом и контуром.- метод
equationэллипса возвращает уравнение эллипса.
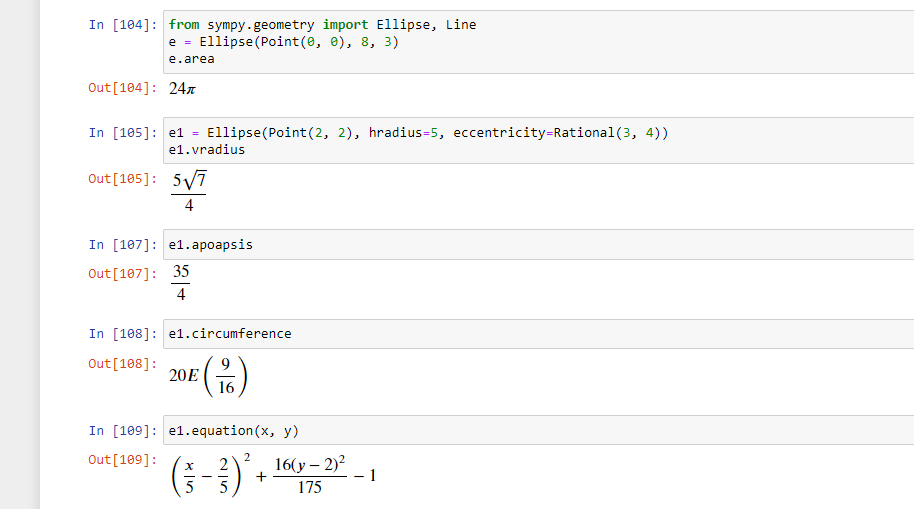
Множества
В математике множество — это четко определенный набор объектов, которые могут быть числами, буквами алфавита или даже другими множествами. Set — это также один из встроенных типов в Python. В SymPy же есть модуль sets. В нем можно найти разные типы множеств и операции поиска пересекающихся элементов, объединения и так далее.
Set — это базовый класс для любого типа множества в Python. Но стоит отметить, что в SymPy он отличается от того, что есть в Python. Класс interval представляет реальные интервалы, а граничное свойство возвращает объект FiniteSet.
>>> from sympy import Interval
>>> s = Interval(1, 10).boundary
>>> type(s)
sympy.sets.sets.FiniteSet
FiniteSet — это коллекция дискретных чисел. Ее можно получить из любой последовательности, будь то список или строка.
>>> from sympy import FiniteSet
>>> FiniteSet(range(5))
{{0,1,…,4}}
>>> numbers = [1, 3, 5, 2, 8]
>>> FiniteSet(*numbers)
{1,2,3,5,8}
>>> s = "HelloWorld"
>>> FiniteSet(*s)
{?,?,?,?,?,?,?}
По аналогии со встроенным множеством, Set из SymPy также является коллекцией уникальных объектов.
ConditionSet — это множество элементов, удовлетворяющих заданному условию.
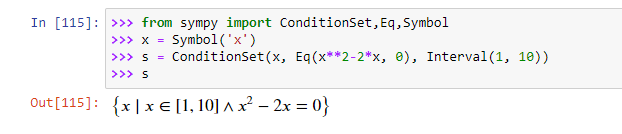
Union — составное множество. Оно включает все элементы из двух множеств. Если же какие-то повторяются, то в результирующем множестве будет только одна копия.
>>> from sympy import Union
>>> l1 = [3, 7]
>>> l2 = [9, 7, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> Union(a, b)
{1,3,7,9}
Intersection же включает только те элементы, которые есть в обоих множествах.
>>> from sympy import Intersection
>>> Intersection(a, b)
{7}
ProductSet представляет декартово произведение элементов из обоих множеств.
>>> from sympy import ProductSet
>>> l1 = [1, 2]
>>> l2 = [2, 3]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> set(ProductSet(a, b))
{(1, 2), (1, 3), (2, 2), (2, 3)}
Complement(a, b) исключает те элементы, которых нет в b.
>>> from sympy import Complement
>>> l1 = [3, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> Complement(a, b), Complement(b, a)
(FiniteSet(1), FiniteSet(2))
SymmetricDifference хранит только необщие элементы обоих множеств.
>>> from sympy import SymmetricDifference
>>> l1 = [3, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> SymmetricDifference(a, b)
{1,2}
Вывод в консоль
В SymPy есть несколько инструментов для вывода. Вот некоторые из них:
- str,
- srepr,
- ASCII pretty printer,
- Unicode pretty printer,
- LaTeX,
- MathML,
- Dot.
Объекты SymPy также можно отправить как ввод в другие языки программирования, такие как C, Fortran, JavaScript, Theano.
SymPy использует символы Юникод для рендеринга вывода. Если вы используете консоль Python для работы с SymPy, то лучше всего применять функцию init_session().
>>> from sympy import init_session
>>> init_session()
Python console for SymPy 1.6.2 (Python 3.8.5-64-bit) (ground types: python)
...
Выполним эти команды:
>>> from __future__ import division
>>> from sympy import *
>>> x, y, z, t = symbols('x y z t')
>>> k, m, n = symbols('k m n', integer=True)
>>> f, g, h = symbols('f g h', cls=Function)
>>> init_printing()
>>> Integral(sqrt(1/x), x)
⌠
⎮ ___
⎮ ╱ 1
⎮ ╱ ─ dx
⎮ ╲╱ x
⌡
Если нет LaTeX, но есть matplotlib, то последняя будет использоваться в качестве движка рендеринга. Если и matplotlib нет, то применяется Unicode pretty printer. Однако Jupyter notebook использует MathJax для рендеринга LaTeX.
В терминале, который не поддерживает Unicode, используется ASCII pretty printer (как в выводе из примера).
Для ASCII printer есть функция pprinter() с параметром use_unicode=False.
>>> pprint(Integral(sqrt(1/x), x), use_unicode=False)
/
|
| ___
| / 1
| / - dx
| \/ x
|
/Также доступ к Unicode printer можно получить из pprint() и pretty(). Если терминал поддерживает Unicode, то он используется автоматически. Если поддержку определить не удалось, то можно передать use_unicode=True, чтобы принудительно использовать Unicode.
Для получения LaTeX-формата используйте функцию latex().
>>> print(latex(Integral(sqrt(1/x), x)))
\int \sqrt{\frac{1}{x}}\, dx
Также доступен printer mathml. Для него есть функция pint_mathml().
>>> from sympy.printing.mathml import print_mathml
>>> print_mathml(Integral(sqrt(1/x),x))
<apply>
<int/>
<bvar>
<ci>x</ci>
</bvar>
<apply>
<root/>
<apply>
<power/>
<ci>x</ci>
<cn>-1</cn>
</apply>
</apply>
</apply>
>>> mathml(Integral(sqrt(1/x),x))
<apply><int/><bvar><ci>x</ci></bvar><apply><root/><apply><power/><ci>x</ci><cn
>-1</cn></apply></apply></apply>Пул соединений — это кэшированные соединения с базой данных, которые создаются и поддерживаются таким образом, чтобы не было необходимости пересоздавать их для новых запросов.
Реализация и использование пула соединений в приложении Python, работающим с базой данных PostgreSQL, дает несколько преимуществ.
Основное — улучшение времени и производительности. Как известно, создание соединения с базой данных PostgreSQL — операция, потребляющая ресурсы и время. А с помощью пула можно уменьшить время запроса и ответа для приложений, работающих с базой данных в Python. Рассмотрим, как его реализовать.
В модуле psycopg2 есть 4 класса для управления пулом соединений. С их помощью можно легко создавать пул и управлять им. Как вариант, того же результата можно добиться с помощью реализации абстрактного класса.
Классы psycopg2 для управления пулом соединений
В модуле psycopg2 есть четыре класса для управления пулом соединений:
- AbstractConnectionPool.
- SimpleConnectionPool.
- ThreadedConnectionPool.
- PersistentConnectionPool.
Примечание:
SimpleConnectionPool,ThreadedConnectionPoolиPersistentConnectionPoolявляются подклассамиAbstractConnectionPoolи реализуют методы из него.
Рассмотрим каждый из них по отдельности.
AbstractConnectionPool
Это базовый класс, реализующий обобщенный код пула, основанный на ключе.
psycopg2.pool.AbstractConnectionPool(minconn, maxconn, *args, **kwargs)AbstractConnectionPool — это абстрактный класс. Наследуемые должны реализовывать объявленные в нем методы. Если хотите создать собственную реализацию пула соединений, то нужно наследоваться от него и реализовать эти методы.
minconn — это минимальное требуемое количество объектов соединения. *args, *kwargs — аргументы, которые нужны для метода connect(), отвечающего за подключение к базе данных PostgreSQL.
SimpleConnectionPool
Это подкласс AbstractConnectionPool, реализующий его методы. Его уже можно использовать для пула соединений.
Этот класс подходит только для однопоточных приложений. Это значит, что если вы хотите создать пул соединений с помощью этого класса, то его нельзя будет передавать между потоками.
Синтаксис:
psycopg2.pool.SimpleConnectionPool(minconn, maxconn, *args, **kwargs)ThreadedConnectionPool
Он также является подклассом класса AbstractConnectionPool и реализует его методы.
Этот класс используется в многопоточной среде, т.е. пул, созданный с помощью этого класса, можно разделить между несколькими потоками.
psycopg2.pool.ThreadedConnectionPool(minconn, maxconn, *args, **kwargs)PersistentConnectionPool
Еще один подкласс AbstractConnectionPool, реализующий его методы.
Этот класс используется в многопоточных приложениях с пулом, распределяющим постоянные соединения разным потокам.
Как и предполагает название, каждый поток получает одно соединение из пула. Таким образом, у одного потока может быть не больше одного соединения из пула.
Пул соединений генерирует ключ с помощью идентификатора потока. Это значит, что для каждого потока при вызовах соединение не меняется.
Примечание: этот класс преимущественно предназначен для взаимодействия с Zope и, вероятно, не подходит для обычных приложений.
Синтаксис:
psycopg2.pool.PersistentConnectionPool(minconn, maxconn, *args, **kwargs)Посмотрим, как создать пул соединений.
Методы psycopg2 для управления пулом соединений
Следующие методы представлены в модуле Psycopg2 и используются для управления.
getconn(key=None)— для получения доступного соединения из пула. Параметрkeyнеобязательный. При использовании этого параметраgetconn()возвращает соединение, связанное с этим ключом. Key используется в классеPersistentConnectionPool.putconn(connection, key=None, close=False)— для возвращения соединения обратно в пул. Если параметрcloseравенTrue, то соединение удаляется и из пула. Если при получении соединения был использован ключ, то его же нужно передать при возвращении соединения.closeall()— закрывает все используемые соединения пула.
Создание пула соединений с помощью psycopg2
В этом примере используем SimpleConnectionPool для создания пула. Перед этим стоит рассмотреть аргументы, которые требуются для работы.
Нужно указать минимальное и максимальное количество соединений, имя пользователя, пароль, хост и базу данных.
minconn— это нижний лимит количества подключений.maxconn— максимальное количество возможных подключений.*args,**kwargs— аргументы для методаconnect(), необходимые для создания объекта соединений. Тут требуется указать имя хоста, пользователя, пароль, базу данных и порт.
Пример создания и управления пулом соединений PostgreSQL
Рассмотрим, как использовать класс SimpleConnectionPool для создания и управления пулом соединений из Python.
import psycopg2
from psycopg2 import pool
try:
# Подключиться к существующей базе данных
postgresql_pool = psycopg2.pool.SimpleConnectionPool(1, 20,
user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
if postgresql_pool:
print("Пул соединений создан успешно")
# Используйте getconn() для получения соединения из пула соединений.
connection = postgresql_pool.getconn()
if connection:
print("Соединение установлено")
cursor = connection.cursor()
cursor.execute("select * from mobile")
mobile_records = cursor.fetchall()
print ("Отображение строк с таблицы mobile")
for row in mobile_records:
print(row)
cursor.close()
# Используйте этот метод, чтобы отпустить объект соединения
# и отправить обратно в пул соединений
postgresql_pool.putconn(connection)
print("PostgreSQL соединение вернулось в пул")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка при подключении к PostgreSQL", error)
finally:
if postgresql_pool:
postgresql_pool.closeall
print("Пул соединений PostgreSQL закрыт")
Вывод:
Пул соединений создан успешно
Соединение установлено
Отображение строк с таблицы mobile
(1, 'IPhone 12', 800.0)
(2, 'Google Pixel 2', 900.0)
PostgreSQL соединение вернулось в пул
Пул соединений PostgreSQL закрытРазберем пример. В метод были переданы следующие значения:
- Minimum connection = 1. Это значит, что в момент создания пула создается как минимум одно соединение.
- Maximum connection = 20. Всего можно использовать 20 соединений с PostgreSQL.
- Другие параметры для подключения.
- Конструктор класса
SimpleConnectionPoolвозвращает экземпляр пула. - С помощью
getconn()делается запрос на подключение из пула - После этого выполняются операции в базе данных.
- И в конце закрываются все активные и пассивные объекты соединения для закрытия приложения.
Создание многопоточного пула соединений
Создадим пул соединений, который будет работать в многопоточной среде. Это можно сделать с помощью класса ThreadedConnectionPool.
import psycopg2
from psycopg2 import pool
try:
# Подключиться к существующей базе данных
postgresql_pool = psycopg2.pool.ThreadedConnectionPool(5, 20,
user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
if postgresql_pool:
print("Пул соединений создан успешно")
# Используйте getconn() для получения соединения из пула соединений.
connection = postgresql_pool.getconn()
if connection:
print("Соединение установлено")
cursor = connection.cursor()
cursor.execute("select * from mobile")
mobile_records = cursor.fetchall()
print ("Отображение строк с таблицы mobile")
for row in mobile_records:
print(row)
cursor.close()
# Используйте этот метод, чтобы отпустить объект соединения
# и отправить обратно в пул соединений
postgresql_pool.putconn(connection)
print("PostgreSQL соединение вернулось в пул")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка при подключении к PostgreSQL", error)
finally:
if postgresql_pool:
postgresql_pool.closeall
print("Пул соединений PostgreSQL закрыт")
Вывод будет таким же:
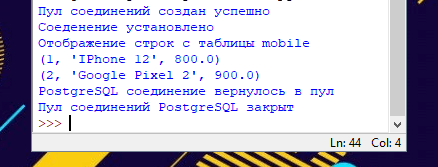
Подготовка
В большинстве случаев выполнять операцию в базе данных нужно лишь после завершения некой другой операции. Например, в банковской системе перевести сумму со счета А на счет Б можно только после снятия средств со счета А.
В транзакции или все операции выполняются, или не выполняется ни одна из них. Таким образом требуется выполнить все операции в одной транзакции, чтобы она была успешной.
Вот о чем дальше пойдет речь:
- Включение и выключение режима автокомита (автосохранения).
- Транзакции для сохранения изменений в базе данных.
- Поддержка свойства ACID транзакции.
- Откат всех операций в случае неудачи.
- Изменение уровня изоляции транзакции PostgreSQL из Python.
Управление транзакциями psycopg2
Транзакции PostgreSQL обрабатываются объектом соединения. Он отвечает за сохранение изменений или откат в случае неудачи.
С помощью объекта cursor выполняются операции в базе данных. Можно создать неограниченное количество объектов cursor из объекта connection. Если любая из команд объекта cursor завершается неудачно, или же транзакция отменяется, то следующие команды не выполняются вплоть до вызова метода connection.rollback().
- Объект соединения отвечает за остановку транзакции. Это можно сделать с помощью методов
commit()лиrollback(). - После использования метода
commit()изменения сохраняются в базе данных. - С помощью метода
rollback()можно откатить изменения.
Примечание: вызов метода
closе()или любого другого, отвечающего за уничтожение объекта соединения, приводит к неявному вызовуrollback(), вследствие чего все изменения откатываются.
Connection.autocommit
По умолчанию соединение работает в режиме автоматического сохранения, то есть свойство auto-commit равно True. Это значит, что при успешном выполнении запроса изменения немедленно сохраняются в базу данных, а откат становится невозможным.
Для выполнения запросов в транзакции это свойство нужно отключить. Для этого нужно сделать connection.autocommit=False. В этом случае будет возможность откатить выполненный запрос к оригинальному состоянию в случае неудачи.
Синтаксис autocommit:
connection.autocommit=True or FalseсConnection.commit
Если все операции в транзакции завершены, используйте connection.commit() для сохранения изменений в базе данных. Если метод не использовать, то все эффекты взаимодействия с данными не будут применены.
Синтаксис commit:
connection.commit()Connection.rollback
Если в транзакции хотя бы одна операция завершается неудачно, то отменить изменения можно с помощью connection.rollback().
Синтаксис rollback:
connection.rollback()Пример управления транзакциями PostgreSQL из Python
- Отключите режим автосохранения (auto-commit).
- Если все операции были выполнены успешно, используйте
connection.commit()для их сохранения в базе данных. - Если какая-то из операций была завершена неудачно, то откатиться к последнему состоянию можно с помощью
connection.rollback().
Примечание: транзакция остается открытой до явного вызова
commit()илиrollback().
Давайте понизим цену на один телефон и повысим на второй.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
connection.autocommit=False
cursor = connection.cursor()
amount = 200
query = """select price from mobile where id = 1"""
cursor.execute(query)
record = cursor.fetchone() [0]
price_a = int(record)
price_a -= amount
# Понизить цену у первого
sql_update_query = """update mobile set price = %s where id = 1"""
cursor.execute(sql_update_query,(price_a,))
query = """select price from mobile where id = 2"""
cursor.execute(query)
record = cursor.fetchone() [0]
price_b = int(record)
price_b += amount
# Повысить цену у второго
sql_update_query = """Update mobile set price = %s where id = 2"""
cursor.execute(sql_update_query, (price_b,))
# совершение транзакции
connection.commit()
print("Транзакция успешно завершена")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка в транзакции. Отмена всех остальных операций транзакции", error)
connection.rollback()
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вы получите следующий вывод после успешного завершения всех операций в транзакции.
Транзакция успешно завершена
Соединение с PostgreSQL закрытоЕсли хотя бы одна из операций будет завершена с ошибкой, то вывод будет таким.
Ошибка в транзакции. Отмена всех остальных операций транзакции
Соединение с PostgreSQL закрытоИнструкция With для управления транзакциями
Для создания транзакции внутри определенного блока в коде используйте инструкцию with.
Что делает инструкция with?Соединения и объекта cursor в psycopg2 — это всего лишь контекстные менеджеры, которые можно использовать с with. Основное преимущество в том, что это позволяет не писать явно commit или rollback.
Синтаксис:
with psycopg2.connect(connection_arguments) as conn:
with conn.cursor() as cursor:
cursor.execute(Query)
Когда соединение выходит из блока with, а запрос выполняется без ошибок или исключений, транзакция сохраняется. Если же в процессе возникла проблема, то транзакция откатывается.
При выходе за пределы блока соединение не закрывается, но объекты cursor и любые другие связанные объекты — да. Соединение можно использовать в более чем одном with, и каждый блок with — это всего лишь транзакция.
В этом примере выполним транзакцию в платформе для онлайн-торговки. Приобретем один товар, уменьшим баланс покупателя и переведем соответствующую сумму на счет компании.
import psycopg2
from psycopg2 import Error
connection = psycopg2.connect(**params)
with connection:
with connection.cursor() as cursor:
# Поиск цены товара
query = """select price from itemstable where itemid = 876"""
cursor.execute(query)
record = cursor.fetchone() [0]
item_price = int(record)
# Получение остатка на счету
query = """select balance from ewallet where userId = 23"""
cursor.execute(query)
record = cursor.fetchone() [0]
ewallet_balance = int(record)
new_ewallet_balance -= item_price
# Обновление баланса с учетом расхода
sql_update_query = """Update ewallet set balance = %s where id = 23"""
cursor.execute(sql_update_query,(new_ewallet_balance,))
# Зачисление на баланс компании
query = """select balance from account where accountId = 2236781258763"""
cursor.execute(query)
record = cursor.fetchone()
account_balance = int(record)
new_account_balance += item_price
# Обновление счета компании
sql_update_query = """Update account set balance = %s where id = 132456"""
cursor.execute(sql_update_query, (new_account_balance,))
print("Транзакция успешно завершена")
Уровни изоляции psycopg2
В системах баз данных с помощью уровней изоляции можно определить какой уровень целостности транзакции будет виден остальным пользователям и системам.
Например, когда пользователь выполняет действие или операцию, которые еще не завершены, подробности о них доступны другим пользователям, которые могут выполнить последовательные действия. Например, потребитель приобретает товар. Информация об этом становится известна другим системам, что нужно для подготовки счета, квитанции и подсчетов скидки, что ускоряет весь процесс.
Если уровень изоляции низкий, множество пользователей может получить доступ к одним и тем же данным одновременно. Однако это же может привести и к некоторым проблемам вплоть до утраченных обновлений. Поэтому нужно учитывать все. Более высокий уровень изоляции может заблокировать других пользователей или транзакции до завершения.
psycopg2.extensions предоставляет следующие уровня изоляции:
- psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT,
- psycopg2.extensions.ISOLATION_LEVEL_READ_UNCOMMITTED,
- psycopg2.extensions.ISOLATION_LEVEL_READ_COMMITTED,
- psycopg2.extensions.ISOLATION_LEVEL_REPEATABLE_READ,
- psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE,
- psycopg2.extensions.ISOLATION_LEVEL_DEFAULT.
Как задать уровни изоляции
Это можно сделать с помощью класса connection:
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)Также можно использовать метод connection.set_session.
connectio.set_session(isolation_level=None, readonly=None, deferrable=None, autocommit=None)
В этом случае isolation_level могут быть READ UNCOMMITED, REPEATABLE READ, SERIALIZE или другие из списка констант.
Подготовка базы данных
Перед выполнением следующей программы убедитесь, что у вас есть следующее:
- Имя пользователя и пароль для подключения к базе данных.
- Название хранимой процедуры или функции, которые нужно выполнить.
Для этого примера была создана функция get_production_deployment, которая возвращает список записей о сотрудниках, участвовавших в написании кода.
CREATE OR REPLACE FUNCTION filter_by_price(max_price integer)
RETURNS TABLE(id INT, model TEXT, price REAL) AS $$
BEGIN
RETURN QUERY
SELECT * FROM mobile where mobile.price <= max_price;
END;
$$ LANGUAGE plpgsql;Теперь посмотрим, как это выполнить.
import psycopg2
from psycopg2 import Error
def create_func(query):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
cursor.execute(query)
connection.commit()
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
postgresql_func = """
CREATE OR REPLACE FUNCTION filter_by_price(max_price integer)
RETURNS TABLE(id INT, model TEXT, price REAL) AS $$
BEGIN
RETURN QUERY
SELECT * FROM mobile where mobile.price <= max_price;
END;
$$ LANGUAGE plpgsql;
"""
create_func(postgresql_func)
Этот код добавит функцию в базу данных.
Детали вызова функции и хранимой процедуры PostgreSQL
Используем модуль psycopg2 для вызова функции PostgreSQL в Python. Дальше требуется выполнить следующие шаги:
- Метод
connect()вернет новый объект соединения. С его помощью и можно общаться с базой. - Создать объект
Cursorс помощью соединения. Именно он позволит выполнять запросы к базе данных. - Выполнить функцию или хранимую процедуру с помощью метода
cursor.callproc(). На этом этапе нужно знать ее название, а также параметры IN и OUT. Синтаксис метода следующий.cursor.callproc('filter_by_price',[IN and OUT parameters,])
Параметры следует разделить запятыми. - Этот метод возвращает либо строки базы данных, либо количество измененных строк. Все зависит от назначения самой функции.
Пример выполнения функции и хранимой процедуры
Посмотрим на демо. Процедура filter_by_price уже создана. В качестве параметра IN она принимает идентификатор приложения, а возвращает ID, модель и цену телефона.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# хранимая процедура
cursor.callproc('filter_by_price',[999,])
print("Записи с ценой меньше или равной 999")
result = cursor.fetchall()
for row in result:
print("Id = ", row[0], )
print("Model = ", row[1])
print("Price = ", row[2])
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
После предыдущего урока у меня осталось всего 2 записи, вывод вернул одну. Вторая с ценой 1000:
Записи с ценой меньше или равной 999
Id = 2
Model = Google Pixel 2
Price = 700.0
Соединение с PostgreSQL закрытоПосле этого обрабатываем результаты с помощью fetchone. Также можно использовать методы fetchall, fetchmany() в зависимости от того, что должна вернуть функция.
Также cursor.callproc() внутри вызывает метод execute() для вызова процедуры. Так что ничего не мешает использовать его явно:
cursor.execute("SELECT * FROM filter_by_price({price}); ".format(price=1000))Работать с датой и временем с помощью встроенного модуля datetime в большом проекте — непростая задача. Учитывая количество изменений, которые требуется применить, при получении «сырых» данных.
Для этих целей был создан модуль dateutil. Он предоставляет расширения для методов, уже имеющихся в datetime.
Установка модуля dateutil в Python
Прежде чем начинать работать с модулем dateutil нужно его установить с помощью следующей строки:
pip install python-dateutilВ этом примере используется пакетный менеджер pip, но ничего не мешает использовать Anaconda.
Работа с модулем
После установки можно начинать работать с самим модулем.
Dateutil разбит на несколько подклассов:
- easter,
- parser,
- relativedelta,
- rrule,
- tz
- и некоторые другие.
Их не так много, но в этом материале разберем лишь некоторые из них.
Импорт нужных методов
После установки модуля нужно выбрать требуемые методы. В верхней части кода нужные элементы сперва необходимо импортировать.
# нужно импортировать модуль datetime
from datetime import datetime, date
from dateutil.relativedelta import relativedelta, FR, TU
from dateutil.easter import easter
from dateutil.parser import parse
from dateutil import rrule
Это позволит использовать их для запуска примеров.
Datetime и relativedata
Итак, dateutil зависит от модуля datetime. Он использует его объекты.
Подкласс relativedelta расширяет возможности модуля datetime, предоставляя функции для работы с датами и временем относительно полученных данных.
Это значит, что вы можете добавлять дни, месяца и года к текущему объекту datetime. Также есть возможность работать с интервалами.
# Создание нескольких объектов datetime для работы
dt_now = datetime.now()
print("Дата и время прямо сейчас:", dt_now)
dt_today = date.today()
print("Дата сегодня:", dt_today)
Дата и время прямо сейчас: 2021-02-06 12:06:58.192574
Дата сегодня: 2021-02-06Попробуем поработать с полученной информацией с помощью относительных дат.
# Следующий месяц
print(dt_now + relativedelta(months=+1))
# Следующий месяц, плюс одна неделя
print(dt_now + relativedelta(months=+1, weeks=+1))
# Следующий месяц, плюс одна неделя, в 17:00.
print(dt_now + relativedelta(months=+1, weeks=+1, hour=17))
# Следующая пятница
print(dt_today + relativedelta(weekday=4))
2021-03-06 12:11:53.648565
2021-03-13 12:11:53.648565
2021-03-13 17:11:53.648565
2021-02-12С помощью базовых операций можно получить самую разную информацию.
# Узнаем последний вторник месяца
print(dt_today + relativedelta(day=31, weekday=TU(-1)))
# Мы также можем напрямую работать с объектами datetime
# Пример: Определение возраста.
birthday = datetime(1965, 12, 2, 12, 46)
print("Возраст:", relativedelta(dt_now, birthday).years)
Например, в примере выше удалось получить years объекта relativedelta.
2021-02-23
Возраст: 55К тому же с полученным объектом можно проводить самые разные манипуляции.
Datetime и easter
Подкласс easter используется для вычисления даты и времени с учетом разных календарей.
Этот подкласс довольно компактный и включает всего один аргумент с тремя вариантами:
- Юлианский календарь
EASTER_JULIAN=1. - Григорианский календарь
EASTER_ORTHODOX=2. - Западный календарь
EASTER_WESTERN=3.
Вот как это будет выглядеть в коде:
print("Юлианский календарь:", easter(2021, 1))
print("Григорианский календарь:", easter(2021, 2))
print("Западный календарь:", easter(2021, 3))
Юлианский календарь: 2021-04-19
Григорианский календарь: 2021-05-02
Западный календарь: 2021-04-04Datetime и parser
Подкласс parser добавляет продвинутый парсер даты и времени, с помощью которого можно парсить разные форматы даты и времени.
print(parse("Thu Sep 25 10:36:28 BRST 2003"))
# Мы также можем игнорировать часовой пояс
print(parse("Thu Sep 25 10:36:28 BRST 2003", ignoretz=True))
# Мы можем не указывать часовой пояс или год.
print(parse("Thu Sep 25 10:36:28"))
# Мы можем подставить переменные
default = datetime(2020, 12, 25)
print(parse("10:36", default=default))
Его можно использовать с разными явными аргументами, например, часовыми поясами. А с помощью переменных разные элементы можно удалить из финального результата.
2003-09-25 10:36:28
2003-09-25 10:36:28
2021-09-25 10:36:28
2020-12-25 10:36:00Datetime и rrule
Подкласс rrule использует пользовательский ввод для предоставлении информации о повторяемости объекта datetime.
# Вывод 5 дней от даты старта
print(list(rrule.rrule(rrule.DAILY, count=5, dtstart=parse("20201202T090000"))))
# Вывод 3 дней от даты старта с интервалом 10
print(list(rrule.rrule(rrule.DAILY, interval=10, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом неделя
print(list(rrule.rrule(rrule.WEEKLY, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом месяц
print(list(rrule.rrule(rrule.MONTHLY, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом год
print(list(rrule.rrule(rrule.YEARLY, count=3, dtstart=parse("20201202T090000"))))
Важная особенность модуля dateuitl — возможность работать с запланированными задачами и функциями календаря с помощью этого подкласса.
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 3, 9, 0), datetime.datetime(2020, 12, 4, 9, 0), datetime.datetime(2020, 12, 5, 9, 0), datetime.datetime(2020, 12, 6, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 12, 9, 0), datetime.datetime(2020, 12, 22, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 9, 9, 0), datetime.datetime(2020, 12, 16, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2021, 1, 2, 9, 0), datetime.datetime(2021, 2, 2, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2021, 12, 2, 9, 0), datetime.datetime(2022, 12, 2, 9, 0)]Выводы
Теперь вы знаете, что модуль dateutil дает возможность расширить количество информации, получаемой от datetime, что позволяет удобнее с ней работать.
]]>В итоге разберем, как использовать cursor.executemany() для выполнения вставки, обновления или удаления нескольких строк в один запрос.
Операция Insert
В этом разделе рассмотрим, как выполнять команду Insert для вставки одной или нескольких записей в таблицу PostgreSQL из Python с помощью Psycopg2.
Для выполнения запроса нужно сделать следующее:
- Установить psycopg2 с помощью pip.
- Установить соединение с базой данных из Python.
- Создать запрос Insert. Для этого требуется знать название таблицы и ее колонок.
- Выполнить запрос с помощью
cursor.execute(). В ответ вы получите количество затронутых строк. - После выполнения запроса нужно закоммитить изменения в базу данных.
- Закрыть объект
cursorи соединение с базой данных. - Также важно перехватить любые исключения, которые могут возникнуть в процессе.
- Наконец, можно проверить результаты, запросив данные из таблицы.
Теперь посмотрим реальный пример.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgres_insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE)
VALUES (%s,%s,%s)"""
record_to_insert = (5, 'One Plus 6', 950)
cursor.execute(postgres_insert_query, record_to_insert)
connection.commit()
count = cursor.rowcount
print (count, "Запись успешно добавлена в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 Запись успешно добавлена в таблицу mobile
Соединение с PostgreSQL закрыто- В этом примере использовался запрос с параметрами для передачи значений во время работы программы. А в конце изменения сохранились с помощью
cursor.commit. - С помощью запроса с параметрами можно передавать переменные python в качестве параметров на месте
%s.
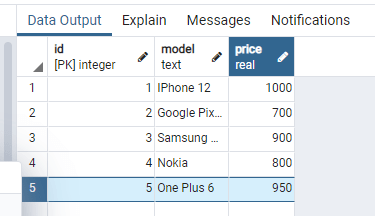
Операция Update
В этом разделе вы узнаете, как обновлять значение в одной или нескольких колонках для одной или нескольких строк таблицы. Для этого нужно изменить запрос к базе данных.
# Задать новое значение price в строке с id для таблицы mobile
Update mobile set price = %s where id = %sПосмотрим на примере обновления одной строки таблицы:
import psycopg2
from psycopg2 import Error
def update_table(mobile_id, price):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
print("Таблица до обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
# Обновление отдельной записи
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.execute(sql_update_query, (price, mobile_id))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_table(3, 970)
Убедимся, что обновление сработало. Вывод:
Таблица до обновления записи
(3, 'Samsung Galaxy S21', 900.0)
1 Запись успешно обновлена
Таблица после обновления записи
(3, 'Samsung Galaxy S21', 970.0)
Соединение с PostgreSQL закрытоУдаление строк и колонок
В этом разделе рассмотрим, как выполнять операцию удаления данных из таблицы с помощью программы на Python и Psycopg2.
# Удалить из таблицы ... в строке с id ...
Delete from mobile where id = %sМожно сразу перейти к примеру. Он выглядит следующим образом:
import psycopg2
from psycopg2 import Error
def delete_data(mobile_id):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Удаление записи
sql_delete_query = """Delete from mobile where id = %s"""
cursor.execute(sql_delete_query, (mobile_id,))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_data(4)
delete_data(5)
Убедимся, что запись исчезла из таблицы.
1 Запись успешно удалена
Соединение с PostgreSQL закрыто
1 Запись успешно удалена
Соединение с PostgreSQL закрытоCursor.executemany() запросов нескольких строк
Метод cursor.executemany() делает запрос в базу данных со всеми параметрами.
Очень часто нужно выполнить один и тот же запрос с разными данными. Например, обновить информацию о посещаемости студентов. Скорее всего, данные будут разные, но SQL останется неизменным.
Используйте cursor.executemany() для вставки, обновления и удаления нескольких строк в один запрос.
Синтаксис executemany():
executemany(query, vars_list)- В этом случае запросом может быть любая DML-операция (вставка, обновление, удаление).
vars_list— это всего лишь список кортежей, которые передаются в запрос.- Каждый кортеж содержит одну строку для вставки или удаления.
Теперь посмотрим, как использовать этот метод.
Вставка нескольких строк в таблицу PostgreSQL
Можно выполнить вставку нескольких строк с помощью SQL-запроса. Для этого используется запрос с параметрами и метод executemany().
import psycopg2
from psycopg2 import Error
def bulk_insert(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
sql_insert_query = """ INSERT INTO mobile (id, model, price)
VALUES (%s,%s,%s) """
# executemany() для вставки нескольких строк
result = cursor.executemany(sql_insert_query, records)
connection.commit()
print(cursor.rowcount, "Запись(и) успешно вставлена(ы) в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [ (4,'LG', 800) , (5,'One Plus 6', 950)]
bulk_insert(records_to_insert)
Проверим результат, вернув данные из таблицы.
2 Запись(и) успешно вставлена(ы) в таблицу mobile
Соединение с PostgreSQL закрытоПримечание: для этого запроса был создан список записей, включающий два кортежа. Также использовались заменители. Они позволяют передать значения в запрос уже во время работы программы.
Обновление нескольких строк в одном запросе
Чаще всего требуется выполнить один и тот же запрос, но с разными данными. Например, обновить зарплату сотрудников. Сумма будет отличаться, но не запрос.
Обновить несколько колонок таблицы можно с помощью cursor.executemany() и запроса с параметрами (%). Посмотрим на примере.
import psycopg2
from psycopg2 import Error
def update_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Обновить несколько записей
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.executemany(sql_update_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи обновлены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_in_bulk([(750, 4), (950, 5)])
Вывод:
2 Записи обновлены
Соединение с PostgreSQL закрытоПроверим результат.

Используйте cursor.rowcount, чтобы получить общее количество строк, измененных методом executemany().
Удаление нескольких строк из таблицы
В этом примере используем запрос Delete с заменителями, которые подставляют ID записей для удаления. Также есть список записей для удаления. В списке есть кортежи для каждой строки. В примере их два, что значит, что удалены будут две строки.
import psycopg2
from psycopg2 import Error
def delete_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
delete_query = """Delete from mobile where id = %s"""
cursor.executemany(delete_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи удалены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_in_bulk([(5,), (4,), (3,)])
Убедимся, что запрос был выполнен успешно.
3 Записи удалены
Соединение с PostgreSQL закрытоЦели:
- Получить все строки из базы данных PostgreSQL с помощью
fetchall()и ограниченное количество записей, используяfetchmany()иfetchone(). - Использовать переменные Python в операторе
whereдля передачи динамических значений.
Подготовка
Перед началом работы нужно убедиться, что у вас есть следующее:
- Имя пользователя и пароль для подключения к PostgreSQL
- Название базы данных, из которой требуется получить данные
В этом материале воспользуемся таблицей «mobile», которая была создана в первом руководстве по работе с PostgreSQL в Python. Если таблицы нет, то ее нужно создать.
Шаги для выполнения запроса SELECT из Python-программы
- Установить psycopg2 с помощью pip.
- Создать соединение с базой данных PostgreSQL.
- Создать инструкцию с запросом SELECT для получения данных из таблицы PostgreSQL.
- Выполнить запрос с помощью
cursor.execute()и получить результат. - Выполнить итерацию по объекту с помощью цикла и получить значения всех полей (колонок) базы данных для каждой строки.
- Закрыть объекты cursor и connection.
- Перехватить любые SQL-исключения, которые могут произойти в процессе.
Запить тестовых данных
Запишем несколько строк в базу данных, что бы потренироваться их получать.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки данных в таблицу
insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE) VALUES
(1, 'IPhone 12', 1000),
(2, 'Google Pixel 2', 700),
(3, 'Samsung Galaxy S21', 900),
(4, 'Nokia', 800)"""
cursor.execute(insert_query)
connection.commit()
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Пример получения данных с помощью fetchall()
В этом примере рассмотрим, как получить все строки из таблицы:
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgreSQL_select_Query = "select * from mobile"
cursor.execute(postgreSQL_select_Query)
print("Выбор строк из таблицы mobile с помощью cursor.fetchall")
mobile_records = cursor.fetchall()
print("Вывод каждой строки и ее столбцов")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Выбор строк из таблицы mobile с помощью cursor.fetchall
Вывод каждой строки и ее столбцов
Id = 1
Модель = IPhone 12
Цена = 1000.0
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Id = 4
Модель = Nokia
Цена = 800.0
Соединение с PostgreSQL закрытоПримечание: в этом примере использовалась команда
cursor.fetchall()для получения всех строк из базы данных.
Используйте cursor.execute() для выполнения запроса:
cursor.fetchall()— для всех строк.cursor.fetchone()— для одной.cursor.fetchmany(SIZE)— для определенного количества.
Передача переменных Python в качестве параметров запроса
В большинстве случаев требуется передавать переменные Python в запросы SQL для получения нужного результата. Например, приложение может передать ID пользователя для получения подробностей о нем из базы данных. Для этого требуется использовать запрос с параметрами.
Запрос с параметрами — это такой запрос, где применяются заполнители (%s) на месте параметров, а значения подставляются уже во время работы программы. Таким образом эти запросы компилируются всего один раз.
import psycopg2
from psycopg2 import Error
def get_mobile_details(mobile_id):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile where id = %s"
cursor.execute(postgresql_select_query, (mobile_id,))
mobile_records = cursor.fetchall()
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2])
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
get_mobile_details(2)
get_mobile_details(3)
Вывод:
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Соединение с PostgreSQL закрыто
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Соединение с PostgreSQL закрытоПолучение определенного количества строк
Если таблица содержит тысячи строк, то получение всех из них может занять много времени. Но существует альтернатива в виде cursor.fetchmany().
Вот ее синтаксис:
cursor.fetchmany([size=cursor.arraysize])size— это количество строк, которые требуется получить.- этот метод делает запрос на определенное количество строк из результата запроса.
fetchmany()возвращает список кортежей, содержащих строки. fetchmany()возвращает пустой список, если строки не были найдены. Количество строк зависит от аргумента SIZE. ОшибкаProgrammingErrorвозникает в том случае, если предыдущий вызов execute() не дал никаких результатов.
fetchmany() вернет меньше строк, если в таблице их меньше, чем было указано в аргументе SIZE.
Пример получения ограниченного количества строк из таблицы PostgreSQL с помощью cursor.fetchmany():
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile"
cursor.execute(postgresql_select_query)
mobile_records = cursor.fetchmany(2)
print("Вывод двух строк")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
mobile_records = cursor.fetchmany(2)
print("Вывод следующих двух строк")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Вывод двух строк
Id = 1
Модель = IPhone 12
Цена = 1000.0
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Вывод следующих двух строк
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Id = 4
Модель = Nokia
Цена = 800.0
Соединение с PostgreSQL закрытоИспользование cursor.fetchone
- Используйте
cursor.fetchone()для получения одной строки из таблицы PostgreSQL. - Также можно использовать этот же метод для получения следующей строки из результатов запроса.
- Он может вернуть и
none, если в результате не оказалось записей cursor.fetchall()иfetchmany()внутри также используют этот метод.
Пример получения одной строки из базы данных PostgreSQL:
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile"
cursor.execute(postgresql_select_query)
mobile_records_one = cursor.fetchone()
print ("Вывод первой записи", mobile_records_one)
mobile_records_two = cursor.fetchone()
print("Вывод второй записи", mobile_records_two)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод первой записи (1, 'IPhone 12', 1000.0)
Вывод второй записи (2, 'Google Pixel 2', 700.0)
Соединение с PostgreSQL закрытоЗдесь не инструкции по установки локального сервера, так как это не касается python. Скачайте и установите PostgreSQL с официального сайта https://www.postgresql.org/download/. Подойдут версии 10+, 11+, 12+.
Вот список разных модулей Python для работы с сервером базы данных PostgreSQL:
- Psycopg2,
- pg8000,
- py-postgreql,
- PyGreSQL,
- ocpgdb,
- bpsql,
- SQLAlchemy. Для работы SQLAlchemy нужно, чтобы хотя бы одно из перечисленных выше решений было установлено.
Примечание: все модули придерживаются спецификации Python Database API Specification v2.0 (PEP 249). Этот API разработан с целью обеспечить сходство разных модулей для доступа к базам данных из Python. Другими словами, синтаксис, методы и прочее очень похожи во всех этих модулях.
В этом руководстве будем использовать Psycopg2, потому что это один из самых популярных и стабильных модулей для работы с PostgreSQL:
- Он используется в большинстве фреймворков Python и Postgres;
- Он активно поддерживается и работает как с Python 3, так и с Python 2;
- Он потокобезопасен и спроектирован для работы в многопоточных приложениях. Несколько потоков могут работать с одним подключением.
В этом руководстве пройдемся по следующим пунктам:
- Установка Psycopg2 и использование его API для доступа к базе данных PostgreSQL;
- Вставка, получение, обновление и удаление данных в базе данных из приложения Python;
- Дальше рассмотрим управление транзакциями PostgreSQL, пул соединений и методы обработки исключений, что понадобится для разработки сложных программ на Python с помощью PostgreSQL.
Установка Psycopg2 с помощью pip
Для начала нужно установить текущую версию Psycopg2 для использования PostgreSQL в Python. С помощью команды pip можно установить модуль в любую операцию систему: Windows, macOS, Linux:
pip install psycopg2Также можно установить конкретную версию программы с помощью такой команды:
pip install psycopg2=2.8.6Если возникает ошибка установки, например «connection error: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:598)», то ее можно решить, сделав files.pythonhosted.org доверенным хостом:
python -m pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host pypi.python.org psycopg2
Модуль psycopg2 поддерживает:
- Python 2.7 и Python 3, начиная с версии 3.4.
- Сервер PostgreSQL от 7.4 до 12.
- Клиентскую библиотеку PostgreSQL от 9.1.
Проверка установки Psycopg2
После запуска команды должны появиться следующие сообщения:
- Collecting psycopg2
- Downloading psycopg2-2.8.6
- Installing collected packages: psycopg2
- Successfully installed psycopg2-2.8.6
При использовании anaconda подойдет следующая команда.
conda install -c anaconda psycopg2Подключение к базе данных PostgreSQL из Python
В этом разделе рассмотрим, как подключиться к PostgreSQL из Python с помощью модуля Psycopg2.
Вот какие аргументы потребуются для подключения:
- Имя пользователя: значение по умолчанию для базы данных PostgreSQL – postgres.
- Пароль: пользователь получает пароль при установке PostgreSQL.
- Имя хоста: имя сервера или IP-адрес, на котором работает база данных. Если она запущена локально, то нужно использовать localhost или 127.0.0.0.
- Имя базы данных: в этом руководстве будем использовать базу
postgres_db.
Шаги для подключения:
- Использовать метод
connect()с обязательными параметрами для подключения базы данных. - Создать объект cursor с помощью объекта соединения, который возвращает метод
connect. Он нужен для выполнения запросов. - Закрыть объект cursor и соединение с базой данных после завершения работы.
- Перехватить исключения, которые могут возникнуть в процессе.
Создание базы данных PostgreSQL с Psycopg2
Для начала создадим базу данных на сервере. Во время установки PostgreSQL вы указывали пароль, его нужно использовать при подключении.
import psycopg2
from psycopg2 import Error
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
try:
# Подключение к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432")
connection.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
# Курсор для выполнения операций с базой данных
cursor = connection.cursor()
sql_create_database = 'create database postgres_db'
cursor.execute(sql_create_database)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Пример кода для подключения к базе данных PostgreSQL из Python
Для подключения к базе данных PostgreSQL и выполнения SQL-запросов нужно знать название базы данных. Ее нужно создать прежде чем пытаться выполнить подключение.
import psycopg2
from psycopg2 import Error
try:
# Подключение к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Курсор для выполнения операций с базой данных
cursor = connection.cursor()
# Распечатать сведения о PostgreSQL
print("Информация о сервере PostgreSQL")
print(connection.get_dsn_parameters(), "\n")
# Выполнение SQL-запроса
cursor.execute("SELECT version();")
# Получить результат
record = cursor.fetchone()
print("Вы подключены к - ", record, "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
После подключения появится следующий вывод:
Информация о сервере PostgreSQL
{'user': 'postgres', 'dbname': 'postgres_db', 'host': '127.0.0.1', 'port': '5432', 'tty': '', 'options': '', 'sslmode': 'prefer', 'sslcompression': '0', 'krbsrvname': 'postgres', 'target_session_attrs': 'any'}
Вы подключены к - ('PostgreSQL 10.13, compiled by Visual C++ build 1800, 64-bit',)
Соединение с PostgreSQL закрытоРазбор процесса подключения в деталях
import psycopg2 — Эта строка импортирует модуль Psycopg2 в программу. С помощью классов и методов модуля можно взаимодействовать с базой.
from psycopg2 import Error — С помощью класса Error можно обрабатывать любые ошибки и исключения базы данных. Это сделает приложение более отказоустойчивым. Этот класс также поможет понять ошибку в подробностях. Он возвращает сообщение об ошибке и ее код.
psycopg2.connect() — С помощью метода connect() создается подключение к экземпляру базы данных PostgreSQL. Он возвращает объект подключения. Этот объект является потокобезопасным и может быть использован на разных потоках.
Метод connect() принимает разные аргументы, рассмотренные выше. В этом примере в метод были переданы следующие аргументы: user = "postgres", password = "1111", host = "127.0.0.1", port = "5432", database = "postgres_db".
cursor = connection.cursor() — С базой данных можно взаимодействовать с помощью класса cursor. Его можно получить из метода cursor(), который есть у объекта соединения. Он поможет выполнять SQL-команды из Python.
Из одного объекта соединения можно создавать неограниченное количество объектов cursor. Они не изолированы, поэтому любые изменения, сделанные в базе данных с помощью одного объекта, будут видны остальным. Объекты cursor не являются потокобезопасными.
После этого выведем свойства соединения с помощью connection.get_dsn_parameters().
cursor.execute() — С помощью метода execute объекта cursor можно выполнить любую операцию или запрос к базе данных. В качестве параметра этот метод принимает SQL-запрос. Результаты запроса можно получить с помощью fetchone(), fetchmany(), fetchall().
В этом примере выполняем SELECT version(); для получения сведений о версии PosgreSQL.
Блок try-except-finally — Разместим код в блоке try-except для перехвата исключений и ошибок базы данных.
cursor.close() и connection.close() — Правильно всегда закрывать объекты cursor и connection после завершения работы, чтобы избежать проблем с базой данных.
Создание таблицы PostgreSQL из Python
В этом разделе разберем, как создавать таблицу в PostgreSQL из Python. В качестве примера создадим таблицу Mobile.
Выполним следующие шаги:
- Подготовим запрос для базы данных
- Подключимся к PosgreSQL с помощью
psycopg2.connect(). - Выполним запрос с помощью
cursor.execute(). - Закроем соединение с базой данных и объект
cursor.
Теперь рассмотрим пример.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Создайте курсор для выполнения операций с базой данных
cursor = connection.cursor()
# SQL-запрос для создания новой таблицы
create_table_query = '''CREATE TABLE mobile
(ID INT PRIMARY KEY NOT NULL,
MODEL TEXT NOT NULL,
PRICE REAL); '''
# Выполнение команды: это создает новую таблицу
cursor.execute(create_table_query)
connection.commit()
print("Таблица успешно создана в PostgreSQL")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Таблица успешно создана в PostgreSQL
Соединение с PostgreSQL закрытоПримечание: наконец, коммитим изменения с помощью метода commit().
Соответствие типов данных Python и PostgreSQL
Есть стандартный маппер для конвертации типов Python в их эквиваленты в PosgreSQL и наоборот. Каждый раз при выполнении запроса PostgreSQL из Python с помощью psycopg2 результат возвращается в виде объектов Python.
| Python | PostgreSQL |
|---|---|
| None | NULL |
| bool | bool |
| float | real double |
| int long | smallint integer bigint |
| Decimal | numeric |
| str unicode | varchar text |
| date | date |
| time | time timetz |
| datetime | timestamp timestamptz |
| timedelta | interval |
| list | ARRAY |
| tuple namedtuple | Composite types IN syntax |
| dict | hstore |
Константы и числовые преобразования
При попытке вставить значения None и boolean (True, False) из Python в PostgreSQL, они конвертируются в соответствующие литералы SQL. То же происходит и с числовыми типами. Они конвертируются в соответствующие типы PostgreSQL.
Например, при выполнении запроса на вставку числовые объекты, такие как int, long, float и Decimal, конвертируются в числовые представления из PostgreSQL. При чтении из таблицы целые числа конвертируются в int, числа с плавающей точкой — во float, а десятичные — в Decimal.
Выполнение CRUD-операций из Python
Таблица mobile уже есть. Теперь рассмотрим, как выполнять запросы для вставки, обновления, удаления или получения данных из таблицы в Python.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки данных в таблицу
insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE) VALUES (1, 'Iphone12', 1100)"""
cursor.execute(insert_query)
connection.commit()
print("1 запись успешно вставлена")
# Получить результат
cursor.execute("SELECT * from mobile")
record = cursor.fetchall()
print("Результат", record)
# Выполнение SQL-запроса для обновления таблицы
update_query = """Update mobile set price = 1500 where id = 1"""
cursor.execute(update_query)
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
# Получить результат
cursor.execute("SELECT * from mobile")
print("Результат", cursor.fetchall())
# Выполнение SQL-запроса для удаления таблицы
delete_query = """Delete from mobile where id = 1"""
cursor.execute(delete_query)
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
# Получить результат
cursor.execute("SELECT * from mobile")
print("Результат", cursor.fetchall())
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 запись успешно вставлена
Результат [(1, 'Iphone12', 1100.0)]
1 Запись успешно удалена
Результат [(1, 'Iphone12', 1500.0)]
1 Запись успешно удалена
Результат []
Соединение с PostgreSQL закрытоПримечание: не забывайте сохранять изменения в базу данных с помощью
connection.commit()после успешного выполнения операции базы данных.
Работа с датой и временем из PostgreSQL
В этом разделе рассмотрим, как работать с типами date и timestamp из PostgreSQL в Python и наоборот.
Обычно при выполнении вставки объекта datetime модуль psycopg2 конвертирует его в формат timestamp PostgreSQL.
По аналогии при чтении значений timestamp из таблицы PostgreSQL модуль psycopg2 конвертирует их в объекты datetime Python.
Для этого примера используем таблицу Item. Выполните следующий код, чтобы подготовить таблицу.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Создайте курсор для выполнения операций с базой данных
cursor = connection.cursor()
# SQL-запрос для создания новой таблицы
create_table_query = '''CREATE TABLE item (
item_id serial NOT NULL PRIMARY KEY,
item_name VARCHAR (100) NOT NULL,
purchase_time timestamp NOT NULL,
price INTEGER NOT NULL
);'''
# Выполнение команды: это создает новую таблицу
cursor.execute(create_table_query)
connection.commit()
print("Таблица успешно создана в PostgreSQL")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Рассмотрим сценарий на простом примере. Здесь мы читаем колонку purchase_time из таблицы и конвертируем значение в объект datetime Python.
import psycopg2
import datetime
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки даты и времени в таблицу
insert_query = """ INSERT INTO item (item_Id, item_name, purchase_time, price)
VALUES (%s, %s, %s, %s)"""
item_purchase_time = datetime.datetime.now()
item_tuple = (12, "Keyboard", item_purchase_time, 150)
cursor.execute(insert_query, item_tuple)
connection.commit()
print("1 элемент успешно добавлен")
# Считать значение времени покупки PostgreSQL в Python datetime
cursor.execute("SELECT purchase_time from item where item_id = 12")
purchase_datetime = cursor.fetchone()
print("Дата покупки товара", purchase_datetime[0].date())
print("Время покупки товара", purchase_datetime[0].time())
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 элемент успешно добавлен
Дата покупки товара 2021-01-16
Время покупки товара 20:16:23.166867
Соединение с PostgreSQL закрытоПочему Redis?
Обычно при упоминании Redis у многих возникают ассоциации с базами данных NoSQL, но это в корне неверно. У Redis нет с ними ничего общего: ни в плане своего позиционирования, ни в плане исполнения. MongoDB, например, хранит данные на диске.
Выделение места для записей подразумевает, что эти данные должны быть сохранены: аккаунты пользователей, записи в блог, разрешения и так далее. Большая часть данных любых приложений относится к этой категории.
Тем не менее есть и исключения. Было бы крайне неэффективно хранить, например, содержимое корзины пользователя или информацию о последней посещенной странице. В краткосрочной перспективе такая информация была бы полезной, но нагружать ею базы данных, основанные на транзакционных системах — не очень разумно. Благо, существует такое понятие как RAM (ОЗУ или оперативное запоминающее устройство).
Redis — это резидентная база данных (такая, которая хранит записи прямо в оперативной памяти) в виде пар ключ-значение. Чтение и запись в память происходит намного быстрее, чем в случае с дисками, поэтому такой подход отлично подходит для хранения второстепенных данных.
Это улучшает пользовательский опыт, но одновременно делает базы данных чистыми. Если же в будущем решается, что такие данные тоже нужно хранить, то их всегда можно записать на диск (например, в базу данных SQL).
В этом руководстве познакомимся с библиотекой Python для Redis под названием redis-py. В среде Python его называют просто redis. Официальная документация этой библиотеки — просто одна страница с перечислением всех методов в алфавитном порядке.
Если вы планируете использовать Redis с каким-либо из фреймворков, то рекомендуется выбирать конкретную библиотеку: например, Flask-Redis, а не redis-py. Однако все они преимущественно повторяют синтаксис redis-py и имеют несколько минимальных отличий.
Установка Redis
Что бы протестировать работу Redis рекомендую использовать облачное решение. Зарегистрируйтесь на Redis Labs, они дают бесплатный сервер для обучения и тестирования.
- Пройдите регистрацию.
- Подтвердите почту.
- Создайте подписку (сервер).

4. Создайте базу данных:
После активации приложения вам понадобятся хост(Endpoint) и пароль (Default User Password).
Далее установим redis:
pip install redisСтрока подключения к Redis
Как и в случае с обычными базами данных подключить экземпляр Redis можно с помощью строки подключения. Вот как такая выглядит в Redis:
redis://:hostname.redislabs.com@mypassword:12345/0Разберем по пунктам:
[CONNECTION_METHOD]:[HOSTNAME]@[PASSWORD]:[PORT]/[DATABASE]
CONNECTION_METHOD— это суффикс, который нужен во всех URI Redis. Он определяет способ подключения к приложению.redis://— стандартное соединение,rediss://— подключается по SSL,redis-socket://— зарезервированный тип для сокетов Unix иredis-sentinel://— тип подключения для кластеров Redis с высоким уровнем доступности.HOSTNAME— URL или IP приложения Redis. Если вы используете облачное решение, то, скорее всего, вам нужен адрес AWS EC2. (Такова особенность современного капитализма, где все весь мелкий бизнес — это реселлеры с заранее настроенным ПО).PASSWORD— у приложения Redis есть пароль, но нет пользователей. Скорее всего, это связано с тем, что в случае с резидентной базой данных сложно было хранить их имена.PORT— выбранный порт.DATABASE— если не уверены, что здесь указать, просто напишите 0.
Создание клиента Redis
URI есть. Теперь нужно подключиться к Redis, создав объект клиента:
import redis
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com', # из Endpoint
port=17449, # из Endpoint
password='qwerty' # ваш пароль
)
Но почему StrictRedis, вы можете спросить? Есть два вида создания клиентов Redis: redis.Redis() и redis.StrictRedis(). StrictRedis пытается правильно применять типы данных. Старые экземпляры так не умеют. redis.Redis() — обратно совместимая с устаревшими экземплярами Redis версия с любыми наборами данных, а redis.StrictRedis() — нет. Если сомневаетесь — используйте StrictRedis.
Есть множество других аргументов, которые можно (и нужно) передать в redis.StrictRedis(), чтобы упростить себе жизнь. Обязательно передайте decode_responses=True, ведь это избавит необходимости явно расшифровывать каждое значение из базы. Также не лишним будет указать кодировку:
import redis
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com',
port=17449,
password='qwerty',
charset="utf-8",
decode_responses=True
)
Пример использования Redis
Хранилище ключ-значение Redis очень напоминает словари Python, отсюда и расшифровка — Remote Dictionary Service (удаленный сервис словарей). Ключи — это всегда строки, но значениями могут быть разные типы данных. Заполним приложение Redis несколькими записями, чтобы лучше понять, как они работают:
import redis
import time
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com',
port=17449,
password='qwerty',
charset="utf-8",
decode_responses=True
)
r.set('ip_address', '127.0.0.0')
r.set('timestamp', int(time.time()))
r.set('user_agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11)')
r.set('last_page_visited', 'home')
r.set([KEY], [VALUE]) — это основной синтаксис, чтобы задавать одиночные значения. Первый параметр — это ключ, а второй — присваиваемое ему значение.
По аналогии с обычными базами данных подключение к Redis осуществляется с помощью графического интерфейса, по типу TablePlus для проверки данных. Вот как выглядит тестовая база после выполнения кода выше:
| KEY | VALUE | TYPE | TTL |
|---|---|---|---|
| user_agent | Mozilla/5.0 (Macintosh; Intel Mac OS X 11) | STRING | -1 |
| last_page_visited | home | STRING | -1 |
| ip_address | 127.0.0.0 | STRING | -1 |
| timestamp | 1610803181 | STRING | -1 |
Кажется, операция прошла успешно. Узнать кое-что о Redis можно, просто взглянув на таблицу. Начнем с колонки type.
Типы данных в Redis
В Redis могут храниться данные 5 типов:
STRING(строка) — любое значение, сохраняемое с помощьюr.set(), хранится в виде строки. Вы также можете обратить внимание на то, что значениеtimestampбудет целым числом в Python, но здесь оно выступает строкой. Вы можете подумать, что это не очень удобно, но строки в Redis — это чуть больше, чем может показаться на первый взгляд. Во-первых, они являются бинарно-безопасными, что значит, что с их помощью можно хранить почти что угодно, вплоть до изображений и сериализованных объектов. У строк также есть несколько встроенных функций, которые позволяют управлять ими так, будто бы это целые числа (например INC для инкремента).LIST(список) — списки являются изменяемыми массивами строк в Redis, которые сортируются в порядке появления. После создания списка новые элементы могут добавляться в конец с помощью командыRPUSHили в начало с помощьюLPUSH. Можно также ограничить максимальное количество элементов в списке с помощью командыLTRIM. Если вы знакомы с методом вытеснения из кэша LRU, например, то должны быть знакомы с этой командой.SET(множество) — несортированный набор строк. По аналогии с множествами в Python в Redis элементы не могут повторяться. У множеств также есть уникальные функции по объединению и пересечению, что позволяет эффективно и быстро объединять данные из разных наборов.ZSET— те же множества, но уже сортированные. Однако в них по-прежнему могут храниться только уникальные значения. После создания порядок в них можно менять, что удобно для ранжирования уникальных элементов, например. СтруктураZSETпохожа на сортированные словари в Python за исключением того, что у них есть ключ для каждого значения (что было бы ненужным, ведь все множества уникальны).HASH(хэши) — хэши в Redis являются парами ключ-значение. Эта структура позволяют присваивать ключам значение из ключа и значения. Однако вложенными хэши быть не могут.
Срок хранения данных
В базе данных Redis есть четвертая колонка под названием ttl. В нашем примере для всех записей в ней было значение -1. Когда же там положительное значение, то оно указывает на количество секунд до истечения срока действия данных. Redis — отличное хранилище для временно полезных данных, однако не таких, которые нужны в долгосрочной перспективе. Вот когда полезно устанавливать срок действия — это позволяет не нагружать приложение информацией, которая быстро становится нерелевантной.
Вернемся к примеру, где хранится информация о сессии пользователя и зададим срок действия данных:
...
r.set('last_page_visited', 'home', 86400)
В этот раз передадим третье значение в r.set(). Оно указывает на количество секунд, которое должно пройти до истечения срока действия данных. Снова проверим базу данных:
| KEY | VALUE | TYPE | TTL |
|---|---|---|---|
| user_agent | Mozilla/5.0 (Macintosh; Intel Mac OS X 11) | STRING | -1 |
| last_page_visited | home | STRING | 86400 |
| ip_address | 127.0.0.0 | STRING | -1 |
| timestamp | 1610803181 | STRING | -1 |
Работа с каждым типом данных
Теория — это прекрасно, но мы знаем, зачем вы здесь: чтобы воспользоваться кодом, который можно будет применить в своем приложении. Рассмотрим несколько примеров распространенного использования 5 типов данных в Redis.
Строки
Если строки включают целые числа, то есть несколько методов, с помощью которых можно их изменять так, будто бы это целые числа. Это incr(), decr() и incrby():
# Создать строковое значение
r.set('index', '1')
print(f"index: {r.get('index')}")
# Увеличить строку на 1
r.incr('index')
print(f"index: {r.get('index')}")
# Уменьшить строку на 1
r.decr('index')
print(f"index: {r.get('index')}")
# Увеличить строку на 3
r.incrby('index', 3)
print(f"index: {r.get('index')}")
Это присвоит значение ‘1’ ключу index, увеличит его на 1, уменьшит на 1 и в итоге увеличит еще на 3:
index: 1
index: 2
index: 1
index: 4Списки
Добавим элементы в список Redis с помощью комбинации .lpush() и rpush(), а также удалим их оттуда с помощью .lpop(). Классика:
r.lpush('my_list', 'A')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Добавить вторую строку в список справа
r.rpush('my_list', 'B')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вставить третью строку в список справа
r.rpush('my_list', 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Удалить из списка 1 экземпляр, значение которого "C"
r.lrem('my_list', 1, 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вставить строку в наш список слева
r.lpush('my_list', 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вытащить первый элемент нашего списка и переместить его в конец
r.rpush('my_list', r.lpop('my_list'))
print(f"my_list: {r.lrange('my_list', 0, -1)}")
Вот как будет выглядеть список на разных этапах:
my_list: ['A']
my_list: ['A', 'B']
my_list: ['A', 'B', 'C']
my_list: ['A', 'B']
my_list: ['C', 'A', 'B']
my_list: ['A', 'B', 'C']Множества
Множества являются мощным инструментом отчасти благодаря их способности взаимодействовать между собой. Дальше создаются два отдельных множества и на них применяются операции .sunion() и .sinter():
# Добавить элемент в set 1
r.sadd('my_set_1', 'Y')
print(f"my_set_1: {r.smembers('my_set_1')}")
# Добавить элемент в set 1
r.sadd('my_set_1', 'X')
print(f"my_set_1: {r.smembers('my_set_1')}")
# Добавить элемент в set 2
r.sadd('my_set_2', 'X')
print(f"my_set_2: {r.smembers('my_set_2')}")
# Добавить элемент в set 2
r.sadd('my_set_2', 'Z')
print(f"my_set2: {r.smembers('my_set_2')}")
# Объединение set 1 и set 2
print(f"sunion: {r.sunion('my_set_1', 'my_set_2')}")
# Пересечение set 1 и set 2
print(f"sinter: {r.sinter('my_set_1', 'my_set_2')}")
Первая объединяет наборы без повторов, а вторая — выбирает общие элементы:
my_set_1: {'Y'}
my_set_1: {'X', 'Y'}
my_set_2: {'X'}
my_set2: {'X', 'Z'}
sunion: {'X', 'Y', 'Z'}
sinter: {'X'}Сортированные множества
Добавление элементов в сортированное множество с помощью .zadd() предполагает интересный синтаксис. Обратите внимание на то, что для добавления записей требуется словарь в формате {[VALUE]: [INDEX]}:
# Создали отсортированный set с 3 значениями
r.zadd('top_songs_set', {'Never Change - Jay Z': 1,
'Rich Girl - Hall & Oats': 2,
'The Prayer - Griz': 3})
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
# Добавили элемент в set с конфликтующим значением
r.zadd('top_songs_set', {"Can't Figure it Out - Bishop Lamont": 3})
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
# Индекс сдвига значения
r.zincrby('top_songs_set', 3, 'Never Change - Jay Z')
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
У элементов в сортированном множестве никогда не может быть одного и того же индекса, так что при попытке добавить элемент на место существующего индекса, текущий элемент (и все после него) сдвигаются, чтобы дать место новому. Также есть возможность менять индексы после их создания:
top_songs_set: ['Never Change - Jay Z', 'Rich Girl - Hall & Oats', 'The Prayer - Griz']
top_songs_set: ['Never Change - Jay Z', 'Rich Girl - Hall & Oats', "Can't Figure it Out - Bishop Lamont", 'The Prayer - Griz']'
top_songs_set: ['Rich Girl - Hall & Oats', "Can't Figure it Out - Bishop Lamont", 'The Prayer - Griz', 'Never Change - Jay Z']Хэши
Это просто добавление и получение данных из хэшей:
record = {
"name": "PythonRu",
"description": "Redis tutorials",
"website": "https://pythonru.com/"
}
r.hmset('business', record)
print(f"business: {r.hgetall('business')}")
Вывод такой же, как и ввод:
business: {'name': 'PythonRu', 'description': 'Redis tutorials', 'website': 'https://pythonru.com/'}Перед работой с программой нужно убедиться, что у вас есть база данных из прошлых уроков sqlite_python.db.
В этом примере будет использоваться таблица new_developers.
Пример вставки/получения объекта DateTime
Обычно при выполнении запроса на вставку объекта datetime модуль sqlite3 в Python конвертирует его в строковый формат. То же самое происходит при получении данных из таблицы — они возвращаются в строковом формате. Разберем на простом примере.
import sqlite3, datetime
def add_developer(dev_id, name, joining_date):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_create_table_query = '''CREATE TABLE new_developers (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
joiningDate timestamp);'''
cursor = sqlite_connection.cursor()
cursor.execute(sqlite_create_table_query)
# вставить данные разработчика
sqlite_insert_with_param = """INSERT INTO 'new_developers'
('id', 'name', 'joiningDate')
VALUES (?, ?, ?);"""
data_tuple = (dev_id, name, joining_date)
cursor.execute(sqlite_insert_with_param, data_tuple)
sqlite_connection.commit()
print("Разработчик успешно добавлен \n")
# получить данные разработчика
sqlite_select_query = """SELECT name, joiningDate from new_developers where id = ?"""
cursor.execute(sqlite_select_query, (1,))
records = cursor.fetchall()
for row in records:
developer= row[0]
joining_date = row[1]
print(developer, "присоединился", joining_date)
print("тип даты", type(joining_date))
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
add_developer(1, 'Mark', datetime.datetime.now())
Вывод:
Подключен к SQLite
Разработчик успешно добавлен
Mark присоединился 2020-12-28 10:58:48.828803
тип даты <class 'str'>
Соединение с SQLite закрытоКак можно видеть, в таблицу был вставлен объект даты, но после получения он стал строкой. Однако это не мешает конвертировать результат обратно в объект даты.
Для этого используется detect_types с PARSE_DECLTYPES и PARSE_COLNAMES в качестве аргументов в методе connect модуля sqlite3.
sqlite3.PARSE_DECLTYPES
Эта константа используется как значение параметра detect_types метода connect().
Если использовать этот параметр в методе connect(), то модуль sqlite3 будет парсить тип каждой получаемой колонки.
После парсинга используется словарь конвертации типов для поиска выполнения конкретной функции конвертации.
sqlite3.PARSE_COLNAMES
Эта константа нужна для того же параметра.
При ее использовании интерфейс SQLite сохранит значения имени каждой возвращаемой колонки. После этого можно аналогично использовать словарь для конвертации в нужный тип.
Посмотрим на следующий пример. В нем при считывании объекта datetime из таблицы SQLite нужно получить объединяющий тип — datetime.
import sqlite3, datetime
def add_developer(dev_id, name, joining_date):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db',
detect_types=sqlite3.PARSE_DECLTYPES |
sqlite3.PARSE_COLNAMES)
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_create_table_query = '''CREATE TABLE new_developers2 (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
joiningDate timestamp);'''
cursor = sqlite_connection.cursor()
cursor.execute(sqlite_create_table_query)
# вставить данные разработчика
sqlite_insert_with_param = """INSERT INTO 'new_developers2'
('id', 'name', 'joiningDate')
VALUES (?, ?, ?);"""
data_tuple = (dev_id, name, joining_date)
cursor.execute(sqlite_insert_with_param, data_tuple)
sqlite_connection.commit()
print("Разработчик успешно добавлен \n")
# получить данные разработчика
sqlite_select_query = """SELECT name, joiningDate from new_developers2 where id = ?"""
cursor.execute(sqlite_select_query, (1,))
records = cursor.fetchall()
for row in records:
developer= row[0]
joining_date = row[1]
print(developer, "присоединился", joining_date)
print("тип даты", type(joining_date))
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
add_developer(1, 'Mark', datetime.datetime.now())
Вывод:
Подключен к SQLite
Разработчик успешно добавлен
Mark присоединился 2020-12-28 11:11:01.304116
тип даты <class 'datetime.datetime'>
Соединение с SQLite закрытоВ результате вернувшиеся данные из таблицы представлены типом datetime.datetime.
- В качестве бинарных данных могут выступать файлы с любым расширением, изображения, видео или другие медиа;
- BLOB-данные можно считывать из таблицы SQLite.
Перед выполнением операций над BLOB-данными убедитесь, что вы знаете название таблицы SQLite. Для хранения этой информации нужно или создать новую, или изменить существующую, добавив колонку соответствующего типа.
В этом примере будет использоваться таблица new_employee. Ее можно создать с помощью следующего скрипта:
CREATE TABLE new_employee (id INTEGER PRIMARY KEY, name TEXT NOT NULL, photo BLOB NOT NULL, resume BLOB NOT NULL);Эта таблица содержит две BLOB-колонки:
- Колонка
photoдля хранения изображения сотрудника. - Колонка
resumeдля хранения файла резюме.
Но стоит также разобраться с тем, что же такое BLOB.
Что такое BLOB
BLOB (large binary object — «большой бинарный объект») — это тип данных, который используется для хранения «тяжелых» файлов, таких как изображения, видео, музыка, документы и так далее. Перед сохранением в базе данных эти файлы нужно конвертировать в бинарные данные — то есть, массив байтов.
Вставка изображений и файлов в таблицу
Вставим изображение и резюме сотрудника в таблицу new_employee. Для этого требуется выполнить следующие шаги:
- Установить SQLite-соединение с базой данных из Python;
- Создать объект cursor из объекта соединения;
- Создать INSERT-запрос. На этом этапе нужно знать названия таблицы и колонки, в которую будет выполняться вставка;
- Создать функцию для конвертации цифровых данных (например, изображений или файлов) в бинарные;
- Выполнить INSERT-запрос с помощью
cursor.execute(); - После успешного завершения операции закоммитить сохранения в базу данных;
- Закрыть объект
cursorи соединение; - Перехватить любые SQL-исключения.
Посмотрим на пример:
import sqlite3
def convert_to_binary_data(filename):
# Преобразование данных в двоичный формат
with open(filename, 'rb') as file:
blob_data = file.read()
return blob_data
def insert_blob(emp_id, name, photo, resume_file):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_blob_query = """INSERT INTO new_employee
(id, name, photo, resume) VALUES (?, ?, ?, ?)"""
emp_photo = convert_to_binary_data(photo)
resume = convert_to_binary_data(resume_file)
# Преобразование данных в формат кортежа
data_tuple = (emp_id, name, emp_photo, resume)
cursor.execute(sqlite_insert_blob_query, data_tuple)
sqlite_connection.commit()
print("Изображение и файл успешно вставлены как BLOB в таблиу")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
insert_blob(1, "Smith", "smith.jpg", "smith_resume.docx")
insert_blob(2, "David", "david.jpg", "david_resume.docx")
Вывод:
Подключен к SQLite
Изображение и файл успешно вставлены как BLOB в таблиу
Соединение с SQLite закрыто
Подключен к SQLite
Изображение и файл успешно вставлены как BLOB в таблиу
Соединение с SQLite закрытоВот как выглядит таблица после вставки данных:
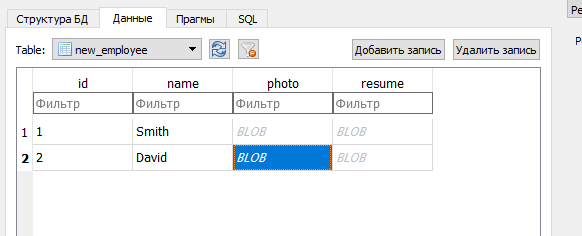
- В примере были вставлены id сотрудника, имя, фото и файл с резюме. Для последних двух были переданы местоположения файлов, так что программа смогла считать их и конвертировать в бинарные данные
- Как можно явно увидеть, изображение и файл конвертировались в бинарный формат в процессе чтения данных в режиме
rb. И только после этого данные были вставлены в колонку BLOB. Также был использован запрос с параметрами для вставки динамических данных в таблицу.
Получение изображения и файла, сохраненных в виде BLOB
Предположим, данные, которые хранятся в виде BLOB в базе данных, нужно получить, записать в файл на диске и открыть в привычном виде. Как это делается?
В этом примере считаем изображение сотрудника и файл с резюме из SQLite-таблицы.
Для этого нужно проделать следующие шаги:
- Установить SQLite-соединение с базой данных из Python;
- Создать объект
cursorиз объекта соединения; - Создать SELECT-запрос для получения BLOB-колонок из таблицы;
- Использовать
cursor.fetchall()для получения всех строк и перебора по ним; - Создать функцию для конвертации BLOB-данных в нужный формат и записать готовые файлы на диск;
- Закрыть объект
cursorи соединение.
import sqlite3, os
def write_to_file(data, filename):
# Преобразование двоичных данных в нужный формат
with open(filename, 'wb') as file:
file.write(data)
print("Данный из blob сохранены в: ", filename, "\n")
def read_blob_data(emp_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_fetch_blob_query = """SELECT * from new_employee where id = ?"""
cursor.execute(sql_fetch_blob_query, (emp_id,))
record = cursor.fetchall()
for row in record:
print("Id = ", row[0], "Name = ", row[1])
name = row[1]
photo = row[2]
resume_file = row[3]
print("Сохранение изображения сотрудника и резюме на диске \n")
photo_path = os.path.join("db_data", name + ".jpg")
resume_path = os.path.join("db_data", name + "_resume.txt")
write_to_file(photo, photo_path)
write_to_file(resume_file, resume_path)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_blob_data(1)
read_blob_data(2)
Вывод:
Подключен к SQLite
Id = 1 Name = Smith
Сохранение изображения сотрудника и резюме на диске
Данный из blob сохранены в: db_data\Smith.jpg
Данный из blob сохранены в: db_data\Smith_resume.txt
Соединение с SQLite закрыто
Подключен к SQLite
Id = 2 Name = David
Сохранение изображения сотрудника и резюме на диске
Данный из blob сохранены в: db_data\David.jpg
Данный из blob сохранены в: db_data\David_resume.txt
Соединение с SQLite закрытоИзображения и файлы действительно сохранились на диске.

Примечание: для копирования бинарных данных на диск они сперва должны быть конвертированы в нужный формат. В этом примере форматами были .jpg и .txt.
]]>CREATE FUNCTION и CREATE PROCEDURE с этой базой данных работать не будут. В этом материале рассмотрим, как создавать или переиспользовать SQL-функции из Python.
C API базы данных SQLite дает возможность создавать пользовательские функции или переопределять поведение существующих. Модуль sqlite3 — это всего лишь оболочка для этого C API, которая предоставляет возможность создавать или переопределять SQLite-функции из Python.
В этой статье мы рассмотрим:
- Использовать
connection.create_function()из sqlite3 в Python для создания и переопределения функций в SQLite; - Использовать
connection.create_aggregate()для создания агрегатных функций в SQLite.
Создание SQL-функций из Python для SQLite
В определенных случаях возникает необходимость совершать определенные вещи при выполнении SQL-запроса, особенно, если это обновление или получение данных. В таких случаях на помощь приходят пользовательские функции. Например, при получении имени пользователя нужно, чтобы оно вернулось в верхнем регистре.
В SQLite есть масса встроенных функций: LENGTH, LOWER, UPPER, SUBSTR, REPLACE и другие. Добавим к этому списку TOTITLE для конвертации любой строки и в строку с заглавными буквами.
Для начала нужно разобраться с connection.create_function().
Синтаксис:
create_function(name, num_params, func)Функция принимает три аргумента:
name— имя функцииnum_params— количество параметров, которые функция принимаетfunc— функция Python, которая вызывается внутри запроса
Эта функция создает пользовательскую функцию, которую можно использовать в инструкциях SQL, ссылаясь на ее name.
Примечание: если в качестве параметра num_params передать значение -1, то функция будет принимать любое количество аргументов. connection.create_function() может возвращать любые типы, поддерживаемые SQLite: bytes, str, int, float и None.
Создадим новую функцию в SQLite с помощью connection.create_function().
import sqlite3
def _to_title_case(string):
return str(string).title()
def get_developer_name(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_connection.create_function("TOTILECASE", 1, _to_title_case)
select_query = "SELECT TOTILECASE(name) FROM sqlitedb_developers where id = ?"
cursor.execute(select_query, (dev_id,))
name = cursor.fetchone()
print("Имя разработчика", name)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
get_developer_name(2)
Вывод:
Подключен к SQLite
Имя разработчика ('Viktoria',)
Соединение с SQLite закрытоРазбор примера в подробностях
В прошлом разделе была создана функция _to_title_case, которая принимает строку в качестве входящего значения и конвертирует ее в строку с заглавными буквами.
import sqlite3:
- Эта строка импортирует модуль sqlite3 в программу.
- С помощью классов и методов модуля sqlite3 можно взаимодействовать с базой данных SQLite.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных. - Дальше метод
connection.cursor()используется для получения объектаcursorиз объекта соединения.
сonnection.create_function():
- После этого вызывается
create_functionиз классаconnection. В нее передаются три аргумента: название функции, количество параметров, которые будет принимать_to_title_caseи функция Python, которая будет вызываться как SQL-функция. - После этого функция TOTITLECASE вызывается в запросе SELECT для получения имени разработчика в виде строки с заглавными буквами.
cursor.execute():
- Выполняем запрос с помощью метода
execute()объектаcursorи получаем имя с помощьюcursor.fetchone().
Наконец, объекты cursor и connection закрываются в блоке finally после завершения операции обновления.
Переопределение существующих функций SQLite
Иногда нужно переопределить уже существующие функции. Например, при возвращении имени пользователя необходимо, чтобы оно было в верхнем регистре.
В качестве демонстрации конвертируем встроенную в SQLite функцию LOWER в UPPER, чтобы при ее вызове она превращала входящие данные в верхний регистр.
Создадим новое определение для функции lower() с помощью метода connection.create_function(). Таким образом мы перезаписываем уже существующую реализацию функции lower().
import sqlite3
def lower(string):
return str(string).upper()
def get_developer_name(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_connection.create_function("lower", 1, lower)
select_query = "SELECT lower(name) FROM sqlitedb_developers where id = ?"
cursor.execute(select_query, (dev_id,))
name = cursor.fetchone()
print("Имя разработчика", name)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
get_developer_name(1)
Вывод:
Подключен к SQLite
Имя разработчика ('OLEG',)
Соединение с SQLite закрытоВ этой статье мы рассмотрим:
- Удаление одной, нескольких или всех строк или колонок из SQLite-таблицы с помощью Python;
- Использование запроса с параметрами для выполнения операции удаления из SQLite;
- Коммит и отмена последней операции;
- Массовое удаление в один запрос.
Подготовка
Перед выполнением следующих операций нужно знать название таблицы SQLite, а также ее колонок. В этом материале будет использоваться таблица sqlitedb_developers.
Пример удаления одной строки из SQLite-таблицы
Сейчас таблица sqlitedb_developers содержит шесть строк, а удалять будем разработчика, чей id равен 6. Вот что для этого нужно сделать:
- Присоединиться к SQLite из Python;
- Создать объект
Cursorс помощью полученного в прошлом шаге объекта соединения SQLite; - Создать DELETE-запрос для SQLite. Именно на этом этапе нужно знать названия таблицы и колонок;
- Выполнить DELETE-запрос с помощью
cursor.execute(); - После выполнения запроса необходимо закоммитить изменения в базу данных;
- Закрыть соединение с базой данных;
- Также важно не забыть перехватить исключения, которые могут возникнуть;
- Наконец, проверить результат операции.
Пример:
import sqlite3
def delete_record():
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_delete_query = """DELETE from sqlitedb_developers where id = 6"""
cursor.execute(sql_delete_query)
sqlite_connection.commit()
print("Запись успешно удалена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
delete_record()
Вывод: таблица sqlitedb_developers после удаления строки из Python.
Подключен к SQLite
Запись успешно удалена
Соединение с SQLite закрытоРазбор примера в подробностях
import sqlite3:
- На этой строке модуль sqlite3 импортируется в программу;
- С помощью классов и методов sqlite3 можно взаимодействовать с базой данных SQLite.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных SQLite из Python; - Дальше используется
sqliteConnection.cursor()для получения объектаCursor.
После этого создается DELETE-запрос для удаления шестой строки в таблице (для разработчика с id равным 6). В запросе этот разработчик упоминается.
cursor.execute():
- Выполняется операция из DELETE-запроса с помощью метода
execute()объектаCursor; - После успешного удаления записи изменения коммитятся в базу данных с помощью
connection.commit().
Наконец, закрываются Cursor и SQLite-соединение в блоке finally.
Примечание: если выполняется несколько операций удаления, и есть необходимость отменить все изменения в случае неудачи хотя бы с одной из них, нужно использовать функцию
rollback()класса соединения для отмены. Эту функцию стоит применять внутри блокаexcept.
Использование переменных в запросах для удаления строки
В большинстве случаев удалять строки из таблицы SQLite нужно с помощью ключа, который передается уже во время работы программы. Например, когда пользователь удаляет свою подписку, запись о нем нужно удалить из таблицы.
В таких случаях требуется использовать запрос с параметрами. В таких запросах на месте будущих значений ставятся заполнители (?). Это помогает удалять записи, получая значения во время работы программы, и избегать проблем SQL-инъекций. Вот пример с удалением разработчика с id=5.
import sqlite3
def delete_sqlite_record(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_update_query = """DELETE from sqlitedb_developers where id = ?"""
cursor.execute(sql_update_query, (dev_id, ))
sqlite_connection.commit()
print("Запись успешно удалена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
delete_sqlite_record(5)
Вывод: таблица sqlitedb_developers после удаления строки с помощью запроса с параметрами.
Подключен к SQLite
Запись успешно удалена
Соединение с SQLite закрытоРазберем последний пример:
- Запрос с параметрами использовался, чтобы получить id разработчика во время работы программы и подставить его на место
?. Он определяет id записи, которая будет удалена. - После этого создается кортеж данных с помощью переменных Python.
- Дальше DELETE-запрос вместе с данными передается в метод
cursor.execute(). - Наконец, изменения сохраняются в базе данных с помощью метода
commit()классаConnection.
Операция Delete для удаления нескольких строк
В примере выше был использован метод execute() объекта Cursor для удаления одной записи, но часто приходится удалять сразу несколько одновременно.
Вместо выполнения запроса DELETE каждый раз для каждой записи, можно выполнить операцию массового удаления в одном запросе. Удалить несколько записей из SQLite-таблицы в один запрос можно с помощью метода cursor.executemany().
Метод cursor.executemany(query, seq_param) принимает два аргумента: SQL-запрос и список записей для удаления.
Посмотрим на следующий пример. В нем удаляются сразу три разработчика.
import sqlite3
def delete_multiple_records(ids_list):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_update_query = """DELETE from sqlitedb_developers where id = ?"""
cursor.executemany(sqlite_update_query, ids_list)
sqlite_connection.commit()
print("Удалено записей:", cursor.rowcount)
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
ids_to_delete = [(4,),(3,)]
delete_multiple_records(ids_to_delete)
Подключен к SQLite
далено записей: 2
Соединение с SQLite закрытоРазберем последний пример:
- После соединения с базой данных SQLite готовится SQL-запрос с параметрами и одним заполнителем. Вместе с ним также передается список id в формате кортежа.
- Каждый элемент списка — это всего лишь кортеж каждой строки. Каждый кортеж содержит id разработчика. В этом примере три кортежа — то есть, три разработчика.
- Дальше вызывается
cursor.executemany(sqlite_delete_query, ids_list)для удаления нескольких записей из таблицы. И запрос, и список id передаютсяcursor.executemany()в качестве аргументов. - Чтобы увидеть количество затронутых записей, можно использовать метод
cursor.rowcount. Наконец, изменения сохраняются в базу данных с помощью методаcommitклассаConnection.
В этой статье мы рассмотрим:
- Обновление одной или нескольких колонок.
- Использование запроса с параметрами для передачи значения во время работы программы при запросе Update.
- Коммит и откат операции обновления.
- Обновление колонки с помощью значений date-time и timestamp.
- Выполнение массового обновления в одном запросе.
Подготовка
Перед выполнением следующих операций обновления таблицы SQLite нужно убедиться, что вам известно ее название, а также названия колонок.
В этом примере будет использоваться таблица sqlitedb_developers. Она была создана в первой части руководства по sqlite3 и заполнена во второй.
Обновления одной записи в таблице SQLite
Сейчас таблица sqlitedb_developers содержит шесть строк, поэтому обновим зарплату разработчика с id 4. Для выполнения запроса UPDATE из Python нужно выполнить следующие шаги:
- Сперва нужно установить SQLite-соединение из Python.
- Дальше необходимо создать объект
cursorс помощью объекта соединения. - После этого – создать запрос UPDATE. Для этого нужно знать названия таблицы и колонки, которую потребуется обновить.
- Дальше запрос выполняется с помощью
cursor.execute(). - После успешного завершения запроса нужно не забыть закоммитить изменения в базу данных.
- Соединение с базой данных закрывается.
- Также важно не забыть перехватывать все исключения SQLite.
- Наконец, нужно убедиться, что операция прошло успешно, получив данные из таблицы.
Посмотрим на программу.
import sqlite3
def update_sqlite_table():
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_update_query = """Update sqlitedb_developers set salary = 10000 where id = 4"""
cursor.execute(sql_update_query)
sqlite_connection.commit()
print("Запись успешно обновлена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
update_sqlite_table()
Вывод: таблица sqlitedb_developers после обновления строки из Python.
Подключен к SQLite
Запись успешно обновлена
Соединение с SQLite закрытоПроверить результат можно, посмотрев данные из таблицы.
Разбор примера в подробностях
import sqlite3:
- Эта строка импортирует модуль sqlite3 в программу.
- С помощью классов и методов из модуля можно взаимодействовать с базой данных.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных SQLite из Python. - Дальше метод
connection.cursor()используется для получения объектасursorиз объекта соединения.
После этого создается запрос UPDATE для обновления строки в таблицы. В нем указываются название колонки и новое значение. В таблице пять колонок, но код обновляет только одну из них – ту, что содержит данные о зарплате.
cursor.execute():
- Операция, сохраненная в запросе UPDATE, выполняется с помощью метода
execute()объектасursor. connection.commit()применяется для сохранения в базе данных.
Наконец, закрываются объекты сursor и соединение в блоке finally после завершения операции обновления.
Примечание: если выполняется операция массового обновления и есть необходимость откатить изменения в случае ошибки хотя бы при одном, нужно использовать функцию
rollback()классаconnection. Ее необходимо применить в блокеexcept.
Использование переменных Python в запросе UPDATE
Большую часть времени обновление таблицы нужно выполнять с помощью значений, получаемых при работе программы. Например, когда пользователи обновляют свой профиль через графический интерфейс, нужно обновить заданные ими значения в соответствующей таблице.
В таком случае рекомендуется использовать запрос с параметрами. Такие запросы используют заполнители (?) прямо внутри инструкций SQL. Это помогает обновлять значения с помощью переменных, а также предотвращать SQL-инъекции.
import sqlite3
def update_sqlite_table(dev_id, salary):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_update_query = """Update sqlitedb_developers set salary = ? where id = ?"""
data = (salary, dev_id)
cursor.execute(sql_update_query, data)
sqlite_connection.commit()
print("Запись успешно обновлена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
update_sqlite_table(3, 7500)
Вывод: таблица sqlitedb_deveopers после обновления с помощью переменной Python и запроса с параметрами.
Подключен к SQLite
Запись успешно обновлена
Соединение с SQLite закрытоПодтвердить операцию можно, получив данные из SQLite-таблицы из Python.
Разберем код:
- Запрос с параметрами был использован для того, чтобы получить значения при работе программы и установить их на места заполнителей. В этом случае один из них отвечает за колонку «salary», а второй – колонку
id. - После этого готовится кортеж с данными из двух переменных Python в определенном порядке. Этот кортеж вместе с запросом передается в метод
cursor.execute(). Важно помнить, что в данном случае порядок переменных в кортеже играет значение. - В конце изменения закрепляются с помощью метода
commitклассаconnection.
Обновление нескольких строк SQLite-таблицы
В последнем примере использовался метод execute() объекта cursor для обновления одного значения, но иногда в приложениях Python нужно обновить несколько строк. Например, нужно увеличить зарплату большинства разработчиков на 20%.
Вместе выполнения операции UPDATE каждый раз для каждой записи можно выполнить массовое обновление в один запрос. Изменить несколько записей в таблице SQLite в один запрос можно с помощью метода cursor.executemany().
Метод cursor.executemany(query, seq_param) принимает два аргумента: SQL-запрос и список записей для обновления.
Посмотрим на примере. Здесь обновляется зарплата 3 разработчиков.
import sqlite3
def update_multiple_records(record_list):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_update_query = """Update sqlitedb_developers set salary = ? where id = ?"""
cursor.executemany(sqlite_update_query, record_list)
sqlite_connection.commit()
print("Записей", cursor.rowcount, ". Успешно обновлены")
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
records_to_update = [(9700, 4), (7800, 5), (8400, 6)]
update_multiple_records(records_to_update)
Вывод: таблица sqlitedb_developers после обновления нескольких строк из Python.
Подключен к SQLite
Записей 3 . Успешно обновлены
Соединение с SQLite закрытоПроверить результат можно, получив данные из таблицы из Python.
Разберем код:
- После подключения к таблице SQLite готовится SQLite-запрос с двумя заполнителями (колонки salary и id), а также список записей для обновления в формате кортежа.
- Каждый элемент – это кортеж для каждой записи. Каждый кортеж содержит два значения: зарплату и id разработчика.
- Функция
cursor.executemany(sqlite_update_query, record_list)вызывается для обновления нескольких строк таблицы SQLite. - Чтобы узнать, какое количество записей было изменено, используется функция
cursor.rowcount. Наконец, данные сохраняются в базу данных с помощью методаcommitклассаconnection.
Обновление нескольких колонок таблицы SQLite
Можно обновить несколько колонок таблицы SQLite в один запрос. Для этого нужно лишь подготовить запрос с параметрами и заполнителями. Посмотрим на примере.
Вывод: таблица sqlitedb_developers после обновления нескольких колонок.
import sqlite3
def update_multiple_columns(dev_id, salary, email):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_update_query = """Update sqlitedb_developers set salary = ?, email = ? where id = ?"""
column_values = (salary, email, dev_id)
cursor.execute(sqlite_update_query, column_values)
sqlite_connection.commit()
print("Несколько столбцов успешно обновлены")
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
update_multiple_columns(3, 2500, 'bec9988@gmail.com')
Подключен к SQLite
Несколько столбцов успешно обновлены
Соединение с SQLite закрытоВ этой статье мы будем:
- Получать все строки с помощью с помощью
cursor.fetchall(). - Использовать
cursor.fetchmany(size)для получения ограниченного количества строк, а такжеcursor.fetchone()— для одной. - Использовать переменные Python в запросе SQLite для передачи динамических данных.
Подготовка
Перед работой с этой Python-программой нужно убедиться, что вы знаете название и подробности о колонках той SQLite-таблицы, с которой предстоит работать.
В этом примере будет использоваться таблица sqlitedb_developers. Она была создана в первой части руководства по sqlite3 и заполнена во второй.
Шаги для получения строк из таблицы SQLite
Для выполнения операции SELECT из Python нужно выполнить следующие шаги:
- Установить соединение с базой данных SQLite из Python;
- Создать запрос с инструкцией SELECT для SQLite. Именно на этом этапе понадобятся знания названия таблицы и подробностей о колонках;
- Выполнить SELECT-запрос с помощью метода
cursor.execute() - Получить строки с помощью объекта
Cursorи методаcursor.fetchall(); - Перебрать строки и получить для каждой ее соответствующее значение;
- Закрыть объект
Cursorи соединение с базой данных SQLite; - Перехватить любые исключения, которые могут возникнуть в процессе работы.
Пример программы на Python для получения всех строк из таблицы sqlitedb_developers.
import sqlite3
def read_sqlite_table(records):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_select_query = """SELECT * from sqlitedb_developers"""
cursor.execute(sqlite_select_query)
records = cursor.fetchall()
print("Всего строк: ", len(records))
print("Вывод каждой строки")
for row in records:
print("ID:", row[0])
print("Имя:", row[1])
print("Почта:", row[2])
print("Добавлен:", row[3])
print("Зарплата:", row[4], end="\n\n")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_sqlite_table()
Вывод:
Подключен к SQLite
Всего строк: 6
Вывод каждой строки
ID: 1
Имя: Oleg
Почта: oleg04@gmail.com
Добавлен: 2020-11-29
Зарплата: 8100.0
...
ID: 6
Имя: Nikita
Почта: aqillysso@gmail.com
Добавлен: 2020-11-27
Зарплата: 7400.0
Соединение с SQLite закрытоВ этом примере прямо отображаются строка и значение ее колонки. Если вам нужно использовать значения колонки в своей программе, то их можно сохранять в переменные Python. Для этого нужно написать, например, так: name = row[1].
Разбор примера
import sqlite3:
- Эта строка импортирует в программу модуль sqlite3.
- С помощью классов и методов из этого модуля можно прямо взаимодействовать с базой данных.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных SQLite из Python. - После этого готовится SELECT-запрос для получения всех строк из таблицы
sqlitedb_developers. Она содержит пять колонок. - Метод
connection.cursor()используется для получения объектаCursorиз объекта соединения.
cursor.execute() и cursor.fetchall():
- Выполняется SELECT-операция с помощью метода
execute()объектаCursor. - После успешного выполнения запроса используется метод
cursor.fetchall()для получения всех записей таблицыsqlitedb_developers. - В конце используется цикл для перебора всех записей и вывода их по одному.
После того как все записи были получены, объект Cursor закрывается с помощью cursor.close(), а соединение с базой данных — с помощью sqliteConnection.close().
Примечание:
- Используйте
cursor.execute()для выполнения запроса. cursor.fetchall()— получение всех строк.cursor.fetchone()— для одной строки.cursor.fetchmany(SIZE)— для ограниченного количества строк.
Использование переменных в качестве параметров Select-запроса
Часто есть необходимость передать переменную в SELECT-запрос для проверки определенного условия.
Предположим, приложение хочет сделать запрос для получения информации о разработчиках, используя их id. Для этого необходим запрос с параметрами. Это такой запрос, где внутри используются заполнители (?) на месте параметров, которые потом заменяются реальными значениями.
cursor.execute("SELECT salary FROM sqlitedb_developers WHERE id = "ID из программы")Рассмотрим пример.
import sqlite3
def get_developer_info(id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_select_query = """select * from sqlitedb_developers where id = ?"""
cursor.execute(sql_select_query, (id,))
records = cursor.fetchall()
print("Вывод ID ", id)
for row in records:
print("ID:", row[0])
print("Имя:", row[1])
print("Почта:", row[2])
print("Добавлен:", row[3])
print("Зарплата:", row[4], end="\n\n")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
get_developer_info(2)
Вывод:
Подключен к SQLite
Вывод ID 2
ID: 2
Имя: Viktoria
Почта: s_dom34@gmail.com
Добавлен: 2020-11-19
Зарплата: 6000.0
Соединение с SQLite закрытоПолучение нескольких строк из таблицы
В некоторых случаев попытка получить все строки из таблицы займет слишком много времени, особенно, если их там тысячи.
Для получения всех строк нужно больше ресурсов: памяти и времени обработки. А для улучшения производительности в таких случаях рекомендуется использовать метод fetchmany(size) класса сursor для получения фиксированного количество строк.
С помощью cursor.fetchmany(size) можно указать, сколько строк требуется прочесть. Рассмотрим на примере:
import sqlite3
def read_limited_rows(row_size):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_select_query = """SELECT * from sqlitedb_developers"""
cursor.execute(sqlite_select_query)
print("Чтение ", row_size, " строк")
records = cursor.fetchmany(row_size)
print("Вывод каждой строки \n")
for row in records:
print("ID:", row[0])
print("Имя:", row[1])
print("Почта:", row[2])
print("Добавлен:", row[3])
print("Зарплата:", row[4], end="\n\n")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_limited_rows(2)
Вывод:
Подключен к SQLite
Чтение 2 строк
Вывод каждой строки
ID: 1
Имя: Oleg
Почта: oleg04@gmail.com
Добавлен: 2020-11-29
Зарплата: 8100.0
ID: 2
Имя: Viktoria
Почта: s_dom34@gmail.com
Добавлен: 2020-11-19
Зарплата: 6000.0
Соединение с SQLite закрытоПримечание: в этой программе был сделан запрос на получение двух записей. Но если в таблице их меньше, то вернется именно такое количество.
Получение одной строки из таблицы
Когда нужно получить одну строку из таблицы SQLite, стоит использовать метод fetchone() класса cursor. Этот метод необходим в тех случаях, когда известно, что запрос вернет одну строку.
cursor.fetchone() получает только следующую строку из результата. Если же строк нет, то возвращается None. Пример:
import sqlite3
def read_single_row(developer_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_select_query = """SELECT * from sqlitedb_developers where id = ?"""
cursor.execute(sqlite_select_query, (developer_id, ))
print("Чтение одной строки \n")
record = cursor.fetchone()
print("ID:", record[0])
print("Имя:", record[1])
print("Почта:", record[2])
print("Добавлен:", record[3])
print("Зарплата:", record[4])
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_single_row(3)
Вывод:
Подключен к SQLite
Чтение одной строки
ID: 3
Имя: Valentin
Почта: exp3@gmail.com
Добавлен: 2020-11-23
Зарплата: 6500.0
Соединение с SQLite закрыто- Добавление одной или нескольких строк в таблицу SQLite.
- Добавление целых чисел, строк, чисел с плавающей точкой, с двойной точностью, а также значений
datetimeв таблицу SQLite. - Использование запросов с параметрами для добавления переменных Python в качестве динамических данных в таблицу.
Перед выполнением следующих программ нужно убедиться, что вам известны название таблицы, а также информация о ее колонках. В этом примере будет использоваться таблица sqlitedb_developers.
Эта таблица была создана в первой части руководства по sqlite3.
Пример вставки строки в таблицу SQLite
Сейчас таблица sqlitedb_developers пустая, и ее нужно заполнить. Для этого необходимо выполнить следующие шаги:
- Установить SQLite-соединение из Python.
- Создать объект
Cursorс помощью объекта соединения. - Создать INSERT-запрос. Для этого нужно знать таблицу и подробности о колонках.
- Выполнить запрос с помощью
cursor.execute(). - После успешного завершения нужно не забыть выполнить коммит изменений в базу данных.
- Также важно не забыть перехватить исключения SQLite.
- Наконец, следует проверить результат, вернув данные из таблицы.
Посмотрим на программу:
import sqlite3
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_query = """INSERT INTO sqlitedb_developers
(id, name, email, joining_date, salary)
VALUES
(1, 'Oleg', 'oleg04@gmail.com', '2020-11-29', 8100);"""
count = cursor.execute(sqlite_insert_query)
sqlite_connection.commit()
print("Запись успешно вставлена в таблицу sqlitedb_developers ", cursor.rowcount)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
Вывод:
Подключен к SQLite
Запись успешно вставлена в таблицу sqlitedb_developers 1
Соединение с SQLite закрытоТеперь можно проверить результат, посмотрев таблицу через программу DB Browser.

Разбор кода
import sqlite3:- На этой строке модуль sqlite3 импортируется в программу.
- С помощью классов и методов из модуля можно взаимодействовать с базой данных SQLite.
-
sqlite3.connect()иconnection.cursor():- С помощью метода
sqlite3.connect()устанавливается соединение с базой данных SQLite из Python. - Дальше используется
connection.cursor()для получения объектаcursorиз объекта соединения.
- С помощью метода
- После этого готовится INSERT-запрос для вставки данных в таблицу. В нем указываются названия колонок и их значения. Всего в таблице 5 колонок.
cursor.execute():- С помощью метода
execute()объектасursorвыполняется запрос INSERT. - Чтобы сохранить изменения в базе, нужно использовать
connection.commit(). - А с помощью
cursor.rowcountможно узнать количество отредактированных строк.
- С помощью метода
И в блоке finally после завершения операции закрываются объекты cursor и соединение.
Использование переменных в запросе INSERT
Иногда в колонку таблицы нужно вставить значение переменной Python. Этой переменной может быть что угодно: целое число, строка, число с плавающей точкой, datetime. Например, при регистрации пользователь вводит свои данные. Их и можно взять вставить в таблицу SQLite.
Для этого есть запрос с параметрами. Он позволяет использовать переменные Python на месте заполнителей (?) в запросе. Пример:
import sqlite3
def insert_varible_into_table(dev_id, name, email, join_date, salary):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_with_param = """INSERT INTO sqlitedb_developers
(id, name, email, joining_date, salary)
VALUES (?, ?, ?, ?, ?);"""
data_tuple = (dev_id, name, email, join_date, salary)
cursor.execute(sqlite_insert_with_param, data_tuple)
sqlite_connection.commit()
print("Переменные Python успешно вставлены в таблицу sqlitedb_developers")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
insert_varible_into_table(2, 'Viktoria', 's_dom34@gmail.com', '2020-11-19', 6000)
insert_varible_into_table(3, 'Valentin', 'exp3@gmail.com', '2020-11-23', 6500)
Вывод: таблица sqlitedb_developers после вставки переменной Python в качестве значения колонки.
Подключен к SQLite
Переменные Python успешно вставлены в таблицу sqlitedb_developers
Соединение с SQLite закрыто
Подключен к SQLite
Переменные Python успешно вставлены в таблицу sqlitedb_developers
Соединение с SQLite закрытоПроверить результат можно, получив данные из таблицы.
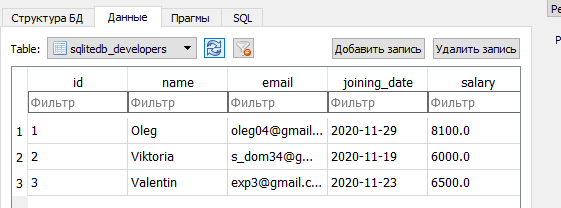
Вставка нескольких строк с помощью executemany()
В предыдущем примере для вставки одной записи в таблицу использовался метод execute() объекта cursor, но иногда требуется вставить несколько строчек.
Например, при чтении файла, например, CSV, может потребоваться добавить все записи из него в таблицу SQLite. Вместе выполнения запроса INSERT для каждой записи, можно выполнить все операции в один запрос. Добавить несколько записей в таблицу SQLite можно с помощью метода executemany() объекта cursor.
Этот метод принимает два аргумента: запрос SQL и список записей.
import sqlite3
def insert_multiple_records(records):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_query = """INSERT INTO sqlitedb_developers
(id, name, email, joining_date, salary)
VALUES (?, ?, ?, ?, ?);"""
cursor.executemany(sqlite_insert_query, records)
sqlite_connection.commit()
print("Записи успешно вставлены в таблицу sqlitedb_developers", cursor.rowcount)
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
records_to_insert = [(4, 'Jaroslav', 'idebylos@gmail.com', '2020-11-14', 8500),
(5, 'Timofei', 'ullegyddomm@gmail.com', '2020-11-15',6600),
(6, 'Nikita', 'aqillysso@gmail.com', '2020-11-27', 7400)]
insert_multiple_records(records_to_insert)
Снова проверка с помощью получения данных из таблицы.
Подключен к SQLite
Записи успешно вставлены в таблицу sqlitedb_developers 3
Соединение с SQLite закрыто
Разберем последний пример:
- После подключения к базе данных подготавливается список записей для вставки в таблицу. Каждая из них — это всего лишь строка.
- Инструкция SQLite INSERT содержит запрос с параметрами, где на месте каждого значения стоит вопросительный знак.
- Дальше с помощью cursor.executemany(sqlite_insert_query, recordList) в таблицу вставляются несколько записей.
- Чтобы узнать количество вставленных строк используется метод
cursor.rowcount. Наконец, нужно не забыть сохранить изменения в базе.
Подключение к SQLite в Python
В этом разделе разберем, как создавать базу данных SQLite и подключаться к ней в Python с помощью модуля sqlite3.
Для установки соединения нужно указать название базы данных, к которой требуется подключиться. Если указать название той, что уже есть на диске, то произойдет подключение. Если же указать другое, то SQLite создаст новую базу данных.
Для подключения к SQLite нужно выполнить следующие шаги
- Использовать метод
connect()из модуля sqlite3 и передать в качестве аргумента название базы данных. - Создать объект
cursorс помощью объекта соединения, который вернул прошлый метод для выполнения SQLite-запросов из Python. - Закрыть объект
cursorпосле завершения работы. - Перехватить исключение базы данных, если в процессе подключения произошла ошибка.
Следующая программа создает файл базы данных sqlite_python.db и выводит подробности о версии SQLite.
import sqlite3
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("База данных создана и успешно подключена к SQLite")
sqlite_select_query = "select sqlite_version();"
cursor.execute(sqlite_select_query)
record = cursor.fetchall()
print("Версия базы данных SQLite: ", record)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при подключении к sqlite", error)
finally:
if (sqlite_connection):
sqlite_connection.close()
print("Соединение с SQLite закрыто")
После подключения должно появиться следующее сообщение.
База данных создана и успешно подключена к SQLite
Версия базы данных SQLite: [('3.31.1',)]
Соединение с SQLite закрытоПонимание SQLite-подключения в подробностях
import sqlite3
- Эта строка импортирует в программу модуль sqlite3. С помощью классов и методов из этого модуля можно взаимодействовать с базой данных SQLite.
sqlite3.connect()
- С помощью метода
connect()выполняется подключение к базе данных. Этот метод возвращает объект подключения SQLite. - Объект
connectionне является потокобезопасным. Модуль sqlite3 не позволяет делиться подключением между потоками. Если попытаться сделать это, то можно получить исключение. - Метод
connect()принимает разные аргументы. В этом примере передается название базы данных.
cursor=sqliteConnection.cursor()
- С помощью объекта соединения создается объект
cursor, который позволяет выполнять SQLite-запросы из Python. - Для одного соединения можно создать неограниченное количество cursor. Он также не является потокобезопасным. Модуль не позволяет делиться объектами cursor между потоками. Если это сделать, то будет ошибка.
После этого создается запрос для получения версии базы данных.
cursor.execute()
- С помощью метода
executeобъектаcursorможно выполнить запрос в базу данных из Python. Он принимает SQLite-запрос в качестве параметра и возвращаетresultSet— то есть, строки базы данных - Получить результат запроса из
resultSetможно с помощью методов, например,fetchAll() - В этом примере
SELECT version();выполняется для получения версии базы данных SQLite.
Блок try-except-finally: весь код расположен в блоке try-except, что позволит перехватить исключения и ошибки базы данных, которые могут появиться в процессе.
- С помощью класса
sqlite3.Errorможно обработать любую ошибку и исключение, которые могут появиться при работе с SQLite из Python. - Это позволит сделать приложение более отказоустойчивым. Класс
sqlite3.Errorпозволит понять суть ошибки. Он возвращает сообщение и код ошибки.
cursor.close() и connection.close()
- Хорошей практикой считается закрывать объекты
connectionиcurosorпосле завершения работы, чтобы избежать проблем с базой данных.
Создание таблицы SQLite в Python
В этом разделе разберемся, как создавать таблицы в базе данных SQLite с помощью Python и модуля sqlite3. Создание таблицы — это DDL-запрос, выполняемый из Python.
В этом примере создадим базу sqlitedb_developers в базе данных sqlite_python.db.
Шаги для создания таблицы в SQLite с помощью Python:
- Соединиться с базой данных с помощью
sqlite3.connect(). Речь об этом шла в первом разделе. - Подготовить запрос создания таблицы.
- Выполнить запрос с помощью
cursor.execute(query). - Закрыть соединение с базой и объектом
cursor.
import sqlite3
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
sqlite_create_table_query = '''CREATE TABLE sqlitedb_developers (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email text NOT NULL UNIQUE,
joining_date datetime,
salary REAL NOT NULL);'''
cursor = sqlite_connection.cursor()
print("База данных подключена к SQLite")
cursor.execute(sqlite_create_table_query)
sqlite_connection.commit()
print("Таблица SQLite создана")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при подключении к sqlite", error)
finally:
if (sqlite_connection):
sqlite_connection.close()
print("Соединение с SQLite закрыто")
База данных подключена к SQLite
Таблица SQLite создана
Соединение с SQLite закрыто
Типы данных SQLite и соответствие типам Python
Перед переходом к выполнению CRUD-операций в SQLite из Python сначала нужно разобраться с типами данных SQLite и соответствующими им типами данных в Python, которые помогают хранить и считывать данные из таблицы.
У движка SQLite есть несколько классов для хранения значений. Каждое значение, хранящееся в базе данных, имеет один из следующих типов или классов.
Типы данных SQLite:
- NULL — значение NULL
- INTEGER — числовые значения. Целые числа хранятся в 1, 2, 3, 4, 6 и 8 байтах в зависимости от величины
- REAL — числа с плавающей точкой, например, 3.14, число Пи
- TEXT — текстовые значения. Могут храниться в кодировке UTF-8, UTF-16BE или UTF-16LE
- BLOB — бинарные данные. Для хранения изображений и файлов
Следующие типы данных из Python без проблем конвертируются в SQLite. Для конвертации достаточно лишь запомнить эту таблицу.
| Тип Python | Тип SQLite |
|---|---|
None | NULL |
int | INTEGER |
float | REAL |
str | TEXT |
bytes | BLOB |
Выполнение SQL запросов с помощью функции executescript
Скрипты SQLite отлично справляются со стандартными задачами. Это набор SQL-команд, сохраненных в файле (в формате .sql). Один файл содержит одну или больше SQL-операций, которые затем выполняются из командной строки.
Дальше несколько распространенных сценариев использования SQL-скриптов
- Создание резервных копий сразу нескольких баз данных за раз.
- Сравнение количества строк двух разных баз с одной схемой.
- Создание всех таблиц в одном скрипте, что позволит создать нужную схему на любом сервере
Выполнить скрипт из командной строки SQLite можно с помощью команды .read:
sqlite> .read sqlitescript.sqlНапример, этот простой скрипт создает две таблицы.
CREATE TABLE fruits (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
price REAL NOT NULL
);
CREATE TABLE drinks (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
price REAL NOT NULL
);Теперь посмотрим, как выполнить его из Python.
import sqlite3
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("База данных подключена к SQLite")
with open('sqlite_create_tables.sql', 'r') as sqlite_file:
sql_script = sqlite_file.read()
cursor.executescript(sql_script)
print("Скрипт SQLite успешно выполнен")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при подключении к sqlite", error)
finally:
if (sqlite_connection):
sqlite_connection.close()
print("Соединение с SQLite закрыто")
Таблицы SQLite создаются за счет выполнения скрипта из Python. Вывод:
База данных подключена к SQLite
Скрипт SQLite успешно выполнен
Соединение с SQLite закрытоПримечание: после соединения с SQLite все содержимое файла сохраняется в переменной. Затем используется команда
cursor.executescript(script)для выполнения всех инструкций за раз.
Исключения базы данных SQLite
sqlite3.Warning. ПодклассException. Его можно игнорировать, если нужно, чтобы оно не останавливало выполнение.sqlite3.Error. Базовый класс для остальных исключений модуля sqlite3. ПодклассException.sqlite3.DatabaseError. Исключение, которое возвращается при ошибках базы данных. Например, если попытаться открыть файл как базу sqite3, хотя он ею не является, то вернется ошибка «sqlite3.DatabaseError: file is encrypted or is not a database».sqlite3.IntegrityError. ПодклассDatabaseError. Эта ошибка возвращается, когда затрагиваются отношения в базе, например, например, не проходит проверка внешнего ключа.sqlite3.ProgrammingError. ПодклассDatabaseError. Эта ошибка возникает из-за ошибок программиста: создание таблицы с именем, которое уже занято, синтаксическая ошибка в SQL-запросах.sqlite3.OperationalError. ПодклассDatabaseError. Эту ошибку невозможно контролировать. Она появляется в ситуациях, которые касаются работы базы данных, например, обрыв соединения, неработающий сервер, проблемы с источником данных и так далее.sqlite3.NotSupportedError. Это исключение появляется при попытке использовать неподдерживаемое базой данных API. Пример: вызов методаrollback()для соединения, которое не поддерживает транзакции. Вызов коммита после команды создания таблицы.
Таким образом рекомендуется всегда писать код управления базой данных в блоке try, чтобы была возможность перехватывать исключения и предпринимать действия, которые помогут справиться с ними.
Например, попробуем добавить данные в таблицу, которой не существует и выведем весь стек исключений из Python.
import sqlite3
import traceback
import sys
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("База данных подключена к SQLite")
sqlite_insert_query = """INSERT INTO unknown_table_1
(id, text) VALUES (1, 'Демо текст')"""
count = cursor.execute(sqlite_insert_query)
sqlite_connection.commit()
print("Запись успешно вставлена в таблицу sqlitedb_developers ", cursor.rowcount)
cursor.close()
except sqlite3.Error as error:
print("Не удалось вставить данные в таблицу sqlite")
print("Класс исключения: ", error.__class__)
print("Исключение", error.args)
print("Печать подробноcтей исключения SQLite: ")
exc_type, exc_value, exc_tb = sys.exc_info()
print(traceback.format_exception(exc_type, exc_value, exc_tb))
finally:
if (sqlite_connection):
sqlite_connection.close()
print("Соединение с SQLite закрыто")
База данных подключена к SQLite
Не удалось вставить данные в таблицу sqlite
Класс исключения: <class 'sqlite3.OperationalError'>
Исключение ('no such table: unknown_table_1',)
Печать подробноcтей исключения SQLite:
['Traceback (most recent call last):\n', ' File "C:\\Users\\demo\\AppData\\Local\\Programs\\Python\\Python38\\sqlitet.py", line 13, in <module>\n count = cursor.execute(sqlite_insert_query)\n', 'sqlite3.OperationalError: no such table: unknown_table_1\n']
Соединение с SQLite закрытоИзменения timeout при подключении из Python
Бывает такое, что есть несколько подключений к базе данных SQLite, и одно из них выполняет определенное изменение. Для этого соединению требуется выполнить блокировку — база данных блокируется до тех пор, пока транзакция не будет завершена.
Параметр timeout, который задается при подключении, определяет, как долго соединение будет ожидать отключения блокировки перед возвращением исключения.
По умолчанию значение этого параметра равно 5.0 (5 секунд). Его не нужно задавать, потому что это значение по умолчанию. Таким образом при подключении к базе данных из Python, если ответ не будет получен в течение 5 секунд, вернется исключение. Однако параметр все-таки можно задать в функции sqlite3.connect.
Посмотрим, как это сделать из Python.
import sqlite3
def read_sqlite_table():
try:
sqlite_connection= sqlite3.connect('sqlite_python.db', timeout=20)
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_select_query = """SELECT count(*) from sqlitedb_developers"""
cursor.execute(sqlite_select_query)
total_rows = cursor.fetchone()
print("Всего строк: ", total_rows)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при подключении к sqlite", error)
finally:
if (sqlite_connection):
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_sqlite_table()
Вывод:
Подключен к SQLite
Всего строк: (0,)
Соединение с SQLite закрытоПолучение изменений с момента подключения к базе данных
Для статистики может потребоваться найти количество строк базы данных, которые были вставлены, удалены или изменены с момента открытия соединения. Для этого используется функция connection.total_changes модуля sqlite3.
Этот метод возвращается общее количество строк, которые были затронуты. Рассмотрим пример.
import sqlite3
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_query = """INSERT INTO sqlitedb_developers
(id, name, email, joining_date, salary)
VALUES (4, 'Alex', 'sale@gmail.com', '2020-11-20', 8600);"""
cursor.execute(sqlite_insert_query)
sql_update_query = """Update sqlitedb_developers set salary = 10000 where id = 4"""
cursor.execute(sql_update_query)
sql_delete_query = """DELETE from sqlitedb_developers where id = 4"""
cursor.execute(sql_delete_query)
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if (sqlite_connection):
print("Всего строк, измененных после подключения к базе данных: ", sqlite_connection.total_changes)
sqlite_connection.close()
print("Соединение с SQLite закрыто")
Подключен к SQLite
Всего строк, измененных после подключения к базе данных: 3
Соединение с SQLite закрытоСохранение резервной копии базы данных из Python
Модуль sqlite3 в Python предоставляет функцию для сохранения резервной копии базы данных SQLite. С помощью метода connection.backup() можно сделать резервную копию базы SQLite.
connection.backup(target, *, pages=0, progress=None, name="main", sleep=0.250)Эта функция делает полную резервную копию базы данных SQLite. Изменения записываются в аргумент target, который должен быть экземпляром другого соединения.
По умолчанию когда параметр pages равен 0 или отрицательному числу, вся база данных копируется в один шаг. В противном случае метод выполняет цикл, копируя заданное количество страниц за раз.
Аргумент name определяет базу данных, резервную копию которой нужно сделать. Аргумент sleep — количество секунд между последовательными попытками сохранить оставшиеся страницы. Аргумент sleep можно задать как в качестве целого числа, так и в виде числа с плавающей точкой.
Рассмотрим один пример копирования базы данных в другую.
import sqlite3
def progress(status, remaining, total):
print(f'Скопировано {total-remaining} из {total}...')
try:
sqlite_con = sqlite3.connect('sqlite_python.db')
backup_con = sqlite3.connect('sqlite_backup.db')
with backup_con:
sqlite_con.backup(backup_con, pages=3, progress=progress)
print("Резервное копирование выполнено успешно")
except sqlite3.Error as error:
print("Ошибка при резервном копировании: ", error)
finally:
if(backup_con):
backup_con.close()
sqlite_con.close()
Скопировано 3 из 5...
Скопировано 5 из 5...
Резервное копирование выполнено успешноПримечания:
- После подключения к SQLite обе базы данных были открыты с помощью двух разных подключений
- Дальше выполняется метод
connection.backup()с помощью экземпляра первого подключения. Также задано количество страниц, которые нужно скопировать за одну итерацию.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml
pip install requests
pip install beautifulsoup4Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
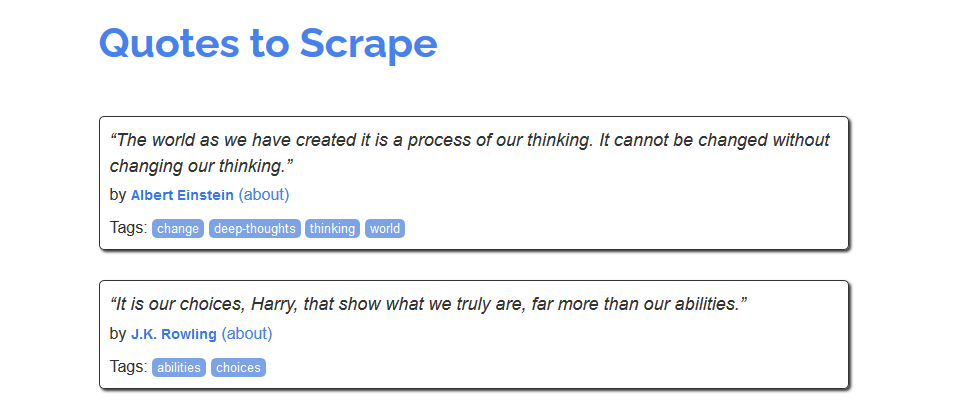
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
....
</div>
</footer>
</body>
</html>На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.
Создание скрипта скрапинга
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
print(soup)
Отрывок выше — это лишь начало кода. В первую очередь в верхней части файла выполняется импорт библиотек requests и Beautiful Soup. Затем в переменной url сохраняется адрес страницы, с которой будет поступать информация. Эта переменная затем передается функции requests.get(). Результат присваивается переменной response. Дальше используем конструктор BeautifulSoup(), чтобы поместить текст ответа в переменную soup. В качестве формата выберем lxml. Наконец, выведем переменную. Результат должен выглядеть приблизительно вот так.
Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
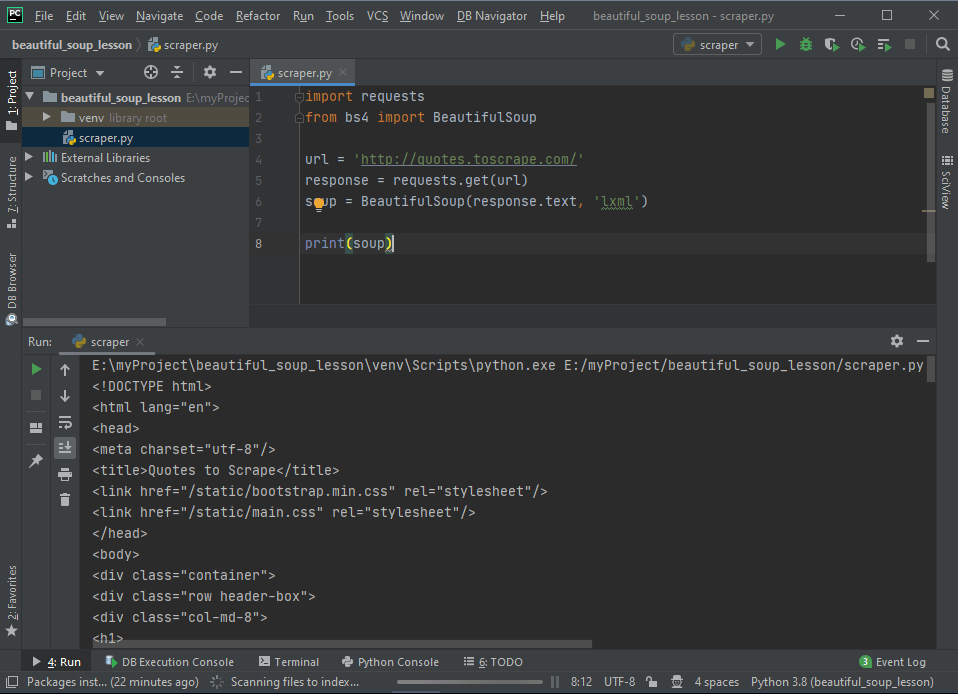
Прохождение по структуре HTML
HTML — это HyperText Markup Language («язык гипертекстовой разметки»), который работает за счет распространения элементов документа со специальными тегами. В HTML есть много разнообразных тегов, но стандартный шаблон включает три основных: html, head и body. Они организовывают весь документ. В случае со скрапингом интерес представляет только тег body.
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.
Если в браузере воспользоваться инструментом «Inspect» (CTRL+SHIFT+I), то можно достаточно просто увидеть, какая из частей разметки отвечает за тот или иной элемент страницы. Достаточно навести мышью на определенный тег span, как он подсветит соответствующую информацию на странице. Можно увидеть, что каждая цитата относится к тегу span с классом text.

Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.
Парсинг HTML-разметки
В HTML-документе хранится много информации, но благодаря Beautiful Soup проще находить нужные данные. Порой для этого требуется всего одна строка кода. Пойдем дальше и попробуем найти все теги span с классом text. Это, в свою очередь, вернет все теги. Когда нужно найти несколько одинаковых тегов, стоит использовать функцию find_all().
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
print(quotes)
Этот код сработает, а переменной quotes будет присвоен список элементов span с классом text из HTML-документа. Вывод этой переменной даст следующий результат.
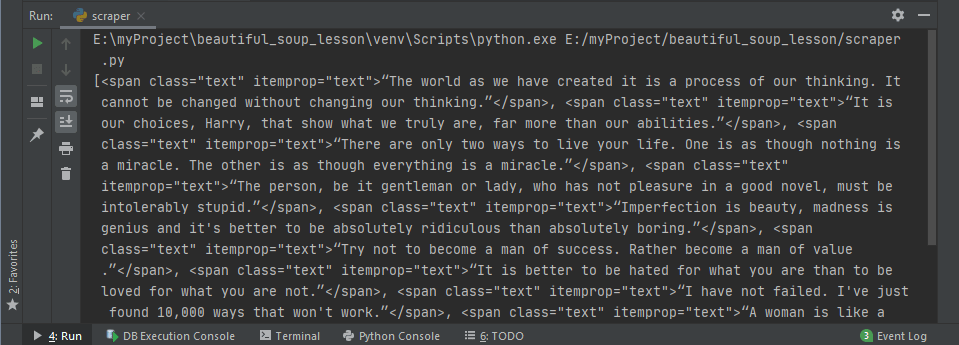
Свойство text библиотеки Beautiful Soup
Возвращаемая разметка — это не совсем то, что нужно. Для получения только данных — цитат в этом случае — можно использовать свойство .text из библиотеки Beautiful Soup. Обратите внимание на код, где происходит перебор всех полученных данных с выводом только нужного содержимого.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
for quote in quotes:
print(quote.text)
Это и дает вывод, который требовался с самого начала.
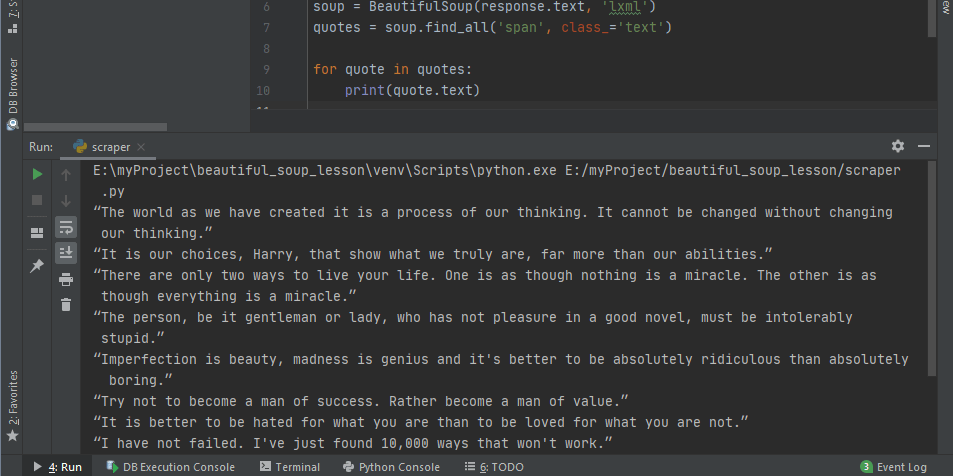
Для поиска и вывода всех авторов можно использовать следующий код. Работаем по тому же принципу — сперва нужно вручную изучить страницу. Можно обратить внимание на то, что каждый автор заключен в тег <small> с классом author. Дальше используем функцию find_all() и сохраняем результат в переменной authors. Также стоит поменять цикл, чтобы перебирать сразу и цитаты, и авторов.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
for quote in quotes:
print(quote.text)
Таким образом теперь есть и цитаты, и их авторы.
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
--Albert Einstein
“It is our choices, Harry, that show what we truly are, far more than our abilities.”
--J.K. Rowling
“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”
--Albert Einstein
....Наконец, добавим код получения всех тегов для каждой цитаты. Здесь уже немного сложнее, потому что сперва нужно получить каждый внешний блок каждой коллекции тегов. Если этот первый шаг не выполнить, то теги можно будет получить, но ассоциировать их с конкретной цитатой — нет.
Когда блок получен, можно опускаться ниже с помощью функции find_all для полученного подмножества. А уже дальше потребуется добавить внутренний цикл для завершения процесса.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
tags = soup.find_all('div', class_='tags')
for i in range(0, len(quotes)):
print(quotes[i].text)
print('--' + authors[i].text)
tagsforquote = tags[i].find_all('a', class_='tag')
for tagforquote in tagsforquote:
print(tagforquote.text)
print('\n')
Этот код даст такой результат. Круто, не так ли?
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
--Albert Einstein
change
deep-thoughts
thinking
world
“It is our choices, Harry, that show what we truly are, far more than our abilities.”
--J.K. Rowling
abilities
choices
....Практика парсинга с Beautiful Soup
Еще один хороший ресурс для изучения скрапинга — scrapingclub.com. Там есть множество руководств по использованию инструмента Scrapy. Также имеется несколько страниц, на которых можно попрактиковаться. Начнем с этой https://scrapingclub.com/exercise/list_basic/?page=1.
Нужно просто извлечь название элемента и его цену, отобразив данные в виде списка. Шаг первый — изучить исходный код для определения HTML. Судя по всему, здесь использовался Bootstrap.
После этого должен получиться следующий код.
# shop_scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/?page=1'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=1):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f'{n}: {itemPrice} за {itemName}')
1: $24.99 за Short Dress
2: $29.99 за Patterned Slacks
3: $49.99 за Short Chiffon Dress
4: $59.99 за Off-the-shoulder Dress
....Скрапинг с учетом пагинации
Ссылка выше ведет на одну страницу коллекции, включающей на самом деле несколько страниц. На это указывает page=1 в адресе. Скрипт Beautiful Soup можно настроить и так, чтобы скрапинг происходил на нескольких страницах. Вот код, который будет извлекать данные со всех связанных страниц. Когда все URL захвачены, скрипт может выполнять запросы к каждой из них и парсить результаты.
# shop_scraper.py
# версия для понимания процессов
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/?page=1'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=1):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f'{n}: {itemPrice} за {itemName}')
pages = soup.find('ul', class_='pagination')
urls = []
links = pages.find_all('a', class_='page-link')
for link in links:
pageNum = int(link.text) if link.text.isdigit() else None
if pageNum != None:
hrefval = link.get('href')
urls.append(hrefval)
for slug in urls:
newUrl = url.replace('?page=1', slug)
response = requests.get(newUrl)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=n):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f'{n}: {itemPrice} за {itemName}')
Результат будет выглядеть следующим образом.
1: $24.99 за Short Dress
2: $29.99 за Patterned Slacks
3: $49.99 за Short Chiffon Dress
...
52: $6.99 за T-shirt
53: $6.99 за T-shirt
54: $49.99 за BlazerЭтот код можно оптимизировать для более продвинутых читателей:
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/'
params = {'page': 1}
# задаем число больше номера первой страницы, для старта цикла
pages = 2
n = 1
while params['page'] <= pages:
response = requests.get(url, params=params)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=n):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f'{n}: {itemPrice} за {itemName}')
# [-2] предпоследнее значение, потому что последнее "Next"
last_page_num = int(soup.find_all('a', class_='page-link')[-2].text)
pages = last_page_num if pages < last_page_num else pages
params['page'] += 1
Выводы
Beautiful Soup — одна из немногих библиотек для скрапинга в Python. С ней очень просто начать работать. Скрипты можно использовать для сбора и компиляции данных из интернета, а результат — как для анализа данных, так и для других сценариев.
]]>Это неофициальный перевод документации FastAPI. Если у вас есть время и знания, можете помочь с официальным переводом здесь.
Введение
Весь использованный код можно копировать и использовать без изменений (этот код представляет собой проверенные python-файлы).
Для запуска любого из примеров нужно скопировать код в файл main.py и запустить uvicorn с помощью следующей команды:
uvicorn main:app --reloadINFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.Крайне рекомендуется писать или копировать код и запускать локально. Использование его в редакторе показывает основные преимущества FastAPI. Можно видеть, насколько мало кода нужно писать: все проверки типов, автозаполнения и так далее.
Установка FastAPI
Первый шаг — установка FastAPI.
При первом знакомстве лучше установить его вместе со всеми опциональными зависимостями и возможностями:
pip install fastapi[all]… что также включает uvicorn, который может быть использован как сервер для запуска кода.
Примечание
Можно также выполнить установку частями. Это может потребоваться при развертывании приложения:pip install fastapi
Также нужно установить uvicorn, чтобы он работал как сервер:pip install uvicorn
И так для каждой зависимости.
Первый запуск приложения
Простейший файл FastAPI может выглядеть вот так:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
Скопируйте содержимое в файл main.py и запустите сервер:
$ uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [60] using statreload
INFO: Started server process [62]
INFO: Waiting for application startup.
INFO: Application startup complete.
Примечание
Командаuvicorn main:appссылается на:
*main: файл main.py (модуль Python).
*app: объект, созданный внутри main.py на строкеapp = FastAPI().
*--reload: перезагружает сервер при изменениях кода. Используется только для разработки.
В выводе есть такая строка:
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)Она показывает URL работы сервера на локальной машине.
Проверка работы
Перейдите в браузере по ссылке http://127.0.0.1:8000. Там отобразится ответ в формате JSON:
{"message": "Hello World"}
Автоматическая документация API
Теперь стоит перейти на http://127.0.0.1:8000/docs.
На этой странице находится интерактивная документация по API (предоставляемая Swagger UI):
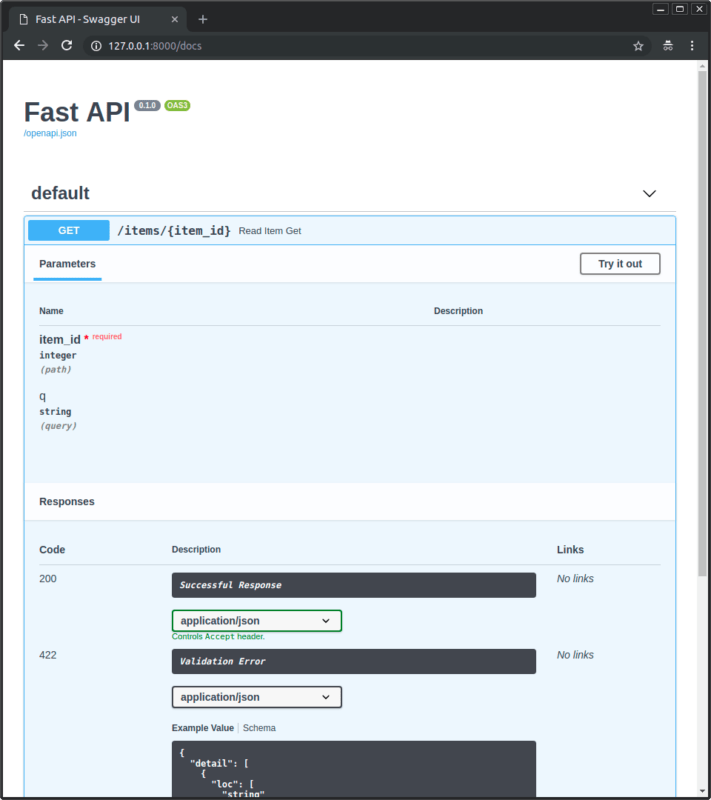
Альтернативная документация API
Также можно попробовать http://127.0.0.1:8000/redoc.
Это альтернативный вариант автоматической документации (от ReDoc):
OpenAPI
FastAPI генерирует «схему» из API с помощью стандарта OpenAPI.
Схема
Схема (schema) — это определение или описание чего-либо. Не код, отвечающий за реализацию, а просто абстрактное описание.
API-схема
В этом случае OpenAPI — это спецификация, которая предписывает, как именно определять схему API. Определение включает пути, возможные принимаемые параметры и так далее.
Схема данных
Понятие «схема» может также указывать на форму некоторых данных: например, JSON-содержимое. В этом случае тут будут указываться JSON-атрибуты, использованные типы данных и другое.
OpenAPI и JSON Schema
OpenAPI определяет схему API для созданного API. А она, в свою очередь, включает определения отправленных или полученных через API данных с помощью JSON — стандарта схем данных JSON.
Проверка openapi.json
Если интересно узнать, как работает чистая схема OpenAPI, то FastAPI автоматически генерирует JSON-схему с описаниями API.
Их можно увидеть прямо на сайте: http://127.0.0.1:8000/openapi.json. Там будет показан JSON в таком формате:
{
"openapi":"3.0.2",
"info":{
"title":"FastAPI",
"version":"0.1.0"
},
"paths":{
"/":{
"get":{
"summary":"Root",
"operationId":"root__get",
"responses":{
"200":{
"description":"Successful Response",
"content":{
"application/json":{
"schema":{
...
Для чего нужен OpenAPI
Схема OpenAPI — это то, что отвечает за работу двух включенных интерактивных систем документации.
И есть десятки альтернатив, все из которых основаны на OpenAPI. Их можно запросто добавлять в приложение, построенное с помощью FastAPI.
Его также можно использовать для автоматической генерации кода, чтобы у клиентов была возможность взаимодействовать через API. Например, для фронтенда, мобильных или IoT-приложений.
Из чего состоит наше приложение
Шаг №1: импорт FastAPI
FastAPI — это класс Python, который предоставляет всю функциональность для API.
from fastapi import FastAPI
...
Технические подробности
FastAPI— это класс, который наследуется прямо от Starlette.
Все возможности Starlette также можно использовать с FastAPI.
Шаг №2: создание «экземпляра» FastAPI
...
app = FastAPI()
...
Здесь переменная app будет экземпляром класса FastAPI. Она будет основной точкой взаимодействия для создания API. Это та же переменная, которая указывается в команде uvicorn: uvicorn main:app --reload
Если создать такое приложение:
from fastapi import FastAPI
my_awesome_api = FastAPI()
@my_awesome_api.get("/")
async def root():
return {"message": "Hello World"}
И сохранить его в файле main.py, то вызов uvicorn будет приблизительно следующим:
uvicorn main:my_awesome_api --reloadШаг №3: создание операции пути
Путь здесь указывает на последнюю часть URL, начиная с первой косой черты /.
Так, в URL https://example.com/items/foo значение пути будет — /items/foo.
Информация
«Путь» также часто называют конечной точкой (endpoint) или маршрутом (route).
При создании API «путь» — это основной способ разделения «concerns» и «resources».
Операция здесь — это один из HTTP-методов:
POSTGETPUTDELETEOPTIONSHEADPATCHTRACE
В протоколе HTTP с каждым путем можно взаимодействовать с помощью одного из таких методов.
При создании API обычно эти методы выполняют определенное действие:
POST— создает данныеGET— читает данныеPUT— обновляет данныеDELETE— удаляет данные
В OpenAPI каждый из таких методов называется operations.
Объявление декоратора операции пути:
...
@app.get("/")
...
@app.get("/") сообщает FastAPI, что следующая функция отвечает за обработку запросов к:
- пути
/, - с помощью операции
get.
О @декораторах
Синтаксис@somethingобозначает декораторы в Python. Они задаются в верхней части функции. Декоратор принимает функцию и что-то с ней делает.
В этом случае декоратор сообщает FastAPI, что функция ниже соответствует пути/и операцииget. Это и есть декоратор операции пути.
Также можно использовать другие операции:
@app.post()@app.put()@app.delete()
И более редкие:
@app.options()@app.head()@app.patch()@app.trace()
Рекомендация
Можно использовать любую операцию (любой HTTP-метод). FastAPI не требует какого-то специального значения. Представленная здесь информация — это рекомендация, а не требование.
Например, при использовании GraphQL обычно все действия выполняются с помощью операцийPOST.
Шаг №4: создание функции операции пути
Наша «функция операции пути»:
- Путь —
/; - Операция —
get; - Функция — функция под декоратором
@app.get("/").
...
async def root():
...
Это функция Python. Она будет вызвана FastAPI в момент получения запроса к URL / с помощью операции GET. В данном случае это асинхронная функция. Ее можно определить и как обычную (без async def):
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
return {"message": "Hello World"}
Если вы не знаете разницы, читайте: Async: «In a hurry? (ENG)
Шаг №5: возвращение ответа
...
return {"message": "Hello World"}
Можно вернуть dict, list или одиночные значения: str, int и так далее. Также можно возвращать модели Pydantic.
Есть масса других объектов и моделей, которые будут автоматически конвертированы в JSON (включая ORM и так далее).
Резюмируем
- Импортируем
FastAPI, - Создаем экземпляр
app, - Пишем декоратор операции пути (например,
@app.get("/")), - Пишем функцию операции пути (например,
def root(): ...), - Запускаем сервер разработки (например,
uvicorn main:app --reload).
Благодаря богатому пользовательскому опыту, возможности повторно использовать код и расширяемости Keras делает процесс написания кода простым и гибким. Помимо этого он также предлагает дополнительные возможности в составе приложений Keras.
Основные приложения — это модели глубокого обучения с натренированными весами.
Пользователь может использовать их для составления прогнозов или использования отдельных признаков в своей работе без необходимости создавать и тренировать собственные модели.
В этой статье речь пойдет о таких натренированных моделях, а также о том, как их использовать.
Натренированные модели Keras
В Keras доступны 10 натренированных моделей. Они используются для классификации изображений, а их веса натренированы с помощью набора данных ImageNet.
Эти модели доступны в модуле applications в Keras. Для работы с ними их нужно импортировать с помощью keras.applications._model_name_
Далее список доступных моделей:
| Xception | InceptionResNetV2 |
| VGG16 | MobileNet |
| VGG19 | MobileNetV2 |
| ResNet, ResNetV2 | DenseNet |
| InceptionV3 | NASNet |
Например: для загрузки и начала работы с моделью ResNet50
from keras.applications.resnet50 import ResNet50
model=ResNet50(weights='imagenet')
У всех моделей разные размеры весов и при создании экземпляра модели они загружаются автоматически. В зависимости от размеров процесс загрузки может занять некоторое время.

Что такое ImageNet?
ImageNet — это крупный набор данных с аннотированными объектами. Цель создания ImageNet — развития алгоритмов компьютерного зрения. Это коллекция объектов-изображений, включающая около 1000 категорий изображений с примечаниями.
С 2010 года проект ежегодно организовывает конкурс ImageNet Large Scale Visual Recognition Challenge, в рамках которого участники должны создавать модели на основе этой базы для классификации объектов или изображений.
Вот примеры популярных классов изображений в наборе:
- Животные:
- Рыбы,
- Птицы,
- Млекопитающие.
- Растения:
- Деревья,
- Цветы,
- Овощи.
- Материалы:
- Ткани.
- Инструменты:
- Посуда,
- Инструменты,
- Приборы.
- Место действия:
- Комнаты.
Эти категории в свою очередь делятся на подкатегории
Реализация натренированных моделей Keras
- Импорт модели и необходимых библиотек.
from keras.preprocessing import image from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions import numpy as np - Создание экземпляра модели.
model=ResNet50(weights='imagenet') - Анализ модели с помощью:
model.summary() - Изображение на ввод для прогноза.
path='./….../...png' # путь к изображению img=image.load_img(path,target_size=(224,224)) x=image.img_to_array(img) x=np.expand_dims(x,axis=0) x=preprocess_input(x) - Прогноз
res=model.predict(x) print(decode_predictions(res,top=5)[0])
Вот топ-5 прогнозов модели. Вывод модели:

Можно увидеть, что модель предсказывает изображения таких птиц, как щегол, якамар, дрозд, вьюрок или американская оляпка.
Имеющиеся модели можно использовать и для классификации изображений без натренированной модели.
Также существует способ использования моделей на собственных изображениях и составления прогнозов на основе своих классов. Это называется трансферным обучением, где используются отдельные признаки модели для конкретной проблемы.
Выводы
Статья иллюстрирует основную сферу применения Keras, то есть, натренированные модели. Рассматривает ImageNet и его классы. Также на примерах показывается, насколько легко классифицировать изображения с помощью имеющихся моделей, а также обозначается термин трансферного обучения. Имеющиеся модели — одни из лучших структур нейронных сетей для точной классификации изображений и объектов.
]]>Помимо классических графиков, таких как столбчатые и круговые, можно представлять данные и другими способами. В интернете и разных источниках можно найти самые разные примеры визуализации данных, некоторые из которых выглядят невероятно. В этом разделе речь пойдет только о графических представлениях, но не о подробных способах их реализации. Можете считать это введением в мир визуализации данных.
Для выполнения кода импортируйте pyplot и numpy
import matplotlib.pyplot as plt import numpy as np
Контурные графики
В научном мире часто встречается тип контурных графиков или контурных карт. Они подходят для представления трехмерных поверхностей с помощью контурных карт, составленных из кривых, которые, в свою очередь, являются точками на поверхности на одном уровне (с одним и тем же значением z).
Хотя визуально контурный график — довольно сложная структура, ее реализация не так сложна, и все благодаря matplotlib. Во-первых, нужна функция z = f(x, y) для генерации трехмерной поверхности. Затем, имея значения x и y, определяющие площадь карты для вывода, можно вычислять значения z для каждой пары x и y с помощью функции f(x, y), которая и используется для этих целей. Наконец, благодаря функции contour() можно сгенерировать контурную карту на поверхности. Также часто требуется добавить цветную карту. Это площади, ограниченные кривыми уровней, заполненные цветным градиентом. Например, следующее изображения показывает отрицательные значения с помощью темных оттенков синего, а приближение к желтому и красному указывает на более высокие значения.
dx = 0.01; dy = 0.01
x = np.arange(-2.0,2.0,dx)
y = np.arange(-2.0,2.0,dy)
X,Y = np.meshgrid(x,y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
C = plt.contour(X,Y,f(X,Y),8,colors='black')
plt.contourf(X,Y,f(X,Y),8)
plt.clabel(C, inline=1, fontsize=10)
plt.show()

Это стандартный цветовой градиент. Но с помощью именованного аргумента cmap можно выбрать из большого число цветных карт.
Более того при работе с таким визуальным представлением добавление градации цвета сторонам графа — это прямо необходимость. Для этого есть функция colorbar() в конце кода. В следующем изображении можно увидеть другой пример карты, которая начинается с черного, проходит через красный и затем превращается в желтый и белый на максимальных значениях. Это карта plt.cm.hot.
dx = 0.01; dy = 0.01
x = np.arange(-2.0,2.0,dx)
y = np.arange(-2.0,2.0,dy)
X,Y = np.meshgrid(x,y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
C = plt.contour(X,Y,f(X,Y),8,colors='black')
plt.contourf(X,Y,f(X,Y),8,cmap=plt.cm.hot)
plt.clabel(C, inline=1, fontsize=10)
plt.colorbar()
plt.show()

Лепестковые диаграммы
Еще один продвинутый тип диаграмм — лепестковые диаграммы. Он представляет собой набор круговых секторов, каждый из которых занимает определенный угол. Таким образом можно изобразить два значения, присвоив их величинам, обозначающим диаграмму: радиус r и угол θ. На самом деле, это полярные координаты — альтернативный способ представления функций на осях координат. С графической точки зрения такая диаграмма имеет свойства круговой и столбчатой. Как и в круговой диаграмме каждый сектор здесь указывает на значение в процентах по отношению к целому. Как и в столбчатой, расширение по радиусу — это числовое значение категории.
До сих пор в примерах использовался стандартный набор цветов, обозначаемых кодами (например, r — это красный). Однако есть возможность использовать любую последовательность цветов. Нужно лишь определить список строковых значений, содержащих RGB-коды в формате #rrggbb, которые будут соответствовать нужным цветам.
Странно, но для вывода лепестковой диаграммы нужно использовать функцию bar() и передать ей список углов θ и список радиальных расширений для каждого сектора.
N = 8
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array([4,7,5,3,1,5,6,7])
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = np.array(['#4bb2c5','#c5b47f','#EAA228','#579575','#839557','#958c12','#953579','#4b5de4'])
bars = plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.show()

В этом примере определена последовательность цветов в формате #rrggbb, но ничто не мешает использовать строки с реальными названиями цветов.
N = 8
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array([4,7,5,3,1,5,6,7])
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = np.array(['lightgreen','darkred','navy','brown','violet','plum','yellow','darkgreen'])
bars = plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.show()

Набор инструментов mplot3d
Набор mplot3d включен во все стандартные версии matplotlib и позволят расширить возможности создания трехмерных визуализаций данных. Если объект Figure выводится в отдельном окне, можно вращать оси трехмерного представления с помощью мыши.
Даже с этим пакетом продолжает использоваться объект Figure, но вместо объектов Axes определяется новый тип, Axes3D из этого набора. Поэтому нужно добавить один импорт в код.
from mpl_toolkits.mplot3d import Axes3D
Трехмерные поверхности
В прошлом разделе для представления трехмерных поверхностей использовался контурный график. Но с помощью mplot3D поверхности можно рисовать прямо в 3D. В этом примере используем ту же функцию z = f(x, y), что и в прошлом.
Когда meshgrid вычислена, можно вывести поверхность графика с помощью функции plot_surface().
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X = np.arange(-2,2,0.1)
Y = np.arange(-2,2,0.1)
X,Y = np.meshgrid(X,Y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
ax.plot_surface(X,Y,f(X,Y), rstride=1, cstride=1)
plt.show()

Трехмерная поверхность выделяется за счет изменения карты с помощью именованного аргумента cmap. Поверхность также можно вращать с помощью функции view_unit(). На самом деле, эта функция подстраивает точку обзора, откуда можно будет рассмотреть поверхность, изменяя аргументы elev и azim. С помощью их комбинирования можно получить поверхность, изображенную с любого угла. Первый аргумент настраивает высоту, а второй — угол поворота поверхности.
Например, можно поменять карту с помощью plt.cm.hot и повернуть угол на elev=30 и azim=125.
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X = np.arange(-2,2,0.1)
Y = np.arange(-2,2,0.1)
X,Y = np.meshgrid(X,Y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
ax.plot_surface(X,Y,f(X,Y), rstride=1, cstride=1, cmap=plt.cm.hot)
ax.view_init(elev=30,azim=125)
plt.show()

Диаграмма рассеяния
Самым используемым трехмерным графиком остается 3D график рассеяния. С его помощью можно определить, следуют ли точки определенным трендам и, что самое важное, скапливаются ли они.
В этом случае используется функция scatter() как и при построении обычного двумерного графика, но на объекте Axed3D. Таким образом можно визуализировать разные объекты Series, представленные через вызовы функции scatter() в единой трехмерной форме.
from mpl_toolkits.mplot3d import Axes3D
xs = np.random.randint(30,40,100)
ys = np.random.randint(20,30,100)
zs = np.random.randint(10,20,100)
xs2 = np.random.randint(50,60,100)
ys2 = np.random.randint(30,40,100)
zs2 = np.random.randint(50,70,100)
xs3 = np.random.randint(10,30,100)
ys3 = np.random.randint(40,50,100)
zs3 = np.random.randint(40,50,100)
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(xs,ys,zs)
ax.scatter(xs2,ys2,zs2,c='r',marker='^')
ax.scatter(xs3,ys3,zs3,c='g',marker='*')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_xlabel('X Label')
plt.show()

Столбчатые диаграммы в 3D
Также в анализе данных используются трехмерные столбчатые диаграммы. Здесь тоже нужно применять функцию bar() к объекту Axes3D. Если же определить несколько Series, то их можно накопить в нескольких вызовах функции bar() для одной 3D-визуализации.
from mpl_toolkits.mplot3d import Axes3D
x = np.arange(8)
y = np.random.randint(0,10,8)
y2 = y + np.random.randint(0,3,8)
y3 = y2 + np.random.randint(0,3,8)
y4 = y3 + np.random.randint(0,3,8)
y5 = y4 + np.random.randint(0,3,8)
clr = ['#4bb2c5','#c5b47f','#EAA228','#579575','#839557','#958c12','#953579','#4b5de4']
fig = plt.figure()
ax = Axes3D(fig)
ax.bar(x,y,0,zdir='y',color=clr)
ax.bar(x,y2,10,zdir='y',color=clr)
ax.bar(x,y3,20,zdir='y',color=clr)
ax.bar(x,y4,30,zdir='y',color=clr)
ax.bar(x,y5,40,zdir='y',color=clr)
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_zlabel('Z Axis')
ax.view_init(elev=40)
plt.show()

Многопанельные графики
Были рассмотрены самые разные способы представления данных на графике, в том числе и случаи, когда несколько наборов данных разделены в одном объекте Figure на нескольких подграфиках. В этом разделе речь пойдет о более сложных случаях.
Подграфики внутри графиков
Есть возможность рассматривать графики внутри других ограниченных рамками. Поскольку речь идет о границах — объектах Axes — то есть необходимость разделять основные (основного графика) от тех, которые принадлежат добавляемому графику. Для этого используется функция figures(). С ее помощью нужно получить объект Figure, где будут определены два разных объекта Axes с помощью add_axes().
fig = plt.figure()
ax = fig.add_axes([0.1,0.1,0.8,0.8])
inner_ax = fig.add_axes([0.6,0.6,0.25,0.25])
plt.show()

Чтобы лучше понять эффект этого режима, лучше заполнить предыдущий объект Axes с помощью реальных данных.
fig = plt.figure()
ax = fig.add_axes([0.1,0.1,0.8,0.8])
inner_ax = fig.add_axes([0.6,0.6,0.25,0.25])
x1 = np.arange(10)
y1 = np.array([1,2,7,1,5,2,4,2,3,1])
x2 = np.arange(10)
y2 = np.array([1,3,4,5,4,5,2,6,4,3])
ax.plot(x1,y1)
inner_ax.plot(x2,y2)
plt.show()

Сетка подграфиков
Есть другой способ создания подграфиков. С помощью функции subplots() их нужно добавить, разбив таким образом график на секторы. matplotlib позволяет работать даже с более сложными случаями с помощью функции GridSpec(). Это подразделение позволяет разбить область на сетку подграфиков, каждому из которых можно присвоить свой график, так что результатом будет сетка с подграфиками разных размеров с разными направлениями.
gs = plt.GridSpec(3,3)
fig = plt.figure(figsize=(6,6))
fig.add_subplot(gs[1,:2])
fig.add_subplot(gs[0,:2])
fig.add_subplot(gs[2,0])
fig.add_subplot(gs[:2,2])
fig.add_subplot(gs[2,1:])
plt.show()

Создать такую сетку несложно. Осталось разобраться, как заполнить ее данными. Для этого нужно использовать объект Axes, который возвращает каждая функция add_subplot(). В конце остается вызвать plot() для вывода конкретного графика.
gs = plt.GridSpec(3,3)
fig = plt.figure(figsize=(6,6))
x1 = np.array([1,3,2,5])
y1 = np.array([4,3,7,2])
x2 = np.arange(5)
y2 = np.array([3,2,4,6,4])
s1 = fig.add_subplot(gs[1,:2])
s1.plot(x,y,'r')
s2 = fig.add_subplot(gs[0,:2])
s2.bar(x2,y2)
s3 = fig.add_subplot(gs[2,0])
s3.barh(x2,y2,color='g')
s4 = fig.add_subplot(gs[:2,2])
s4.plot(x2,y2,'k')
s5 = fig.add_subplot(gs[2,1:])
s5.plot(x1,y1,'b^',x2,y2,'yo')
plt.show()

В прошлых материалах вы встречали примеры, демонстрирующие архитектуру библиотеки matplotlib. После знакомства с основными графическими элементами для графиков время рассмотреть примеры разных типов графиков, начиная с самых распространенных, таких как линейные графики, гистограммы и круговые диаграммы, и заканчивая более сложными, но все равно часто используемыми.
Поскольку визуализация — основная цель библиотеки, то этот раздел является очень важным. Умение выбрать правильный тип графика является фундаментальным навыком, ведь неправильная репрезентация может привести к тому, что данные, полученные в результате качественного анализа данных, будет интерпретированы неверно.
Для выполнения кода импортируйте pyplot и numpy
import matplotlib.pyplot as plt import numpy as np
Линейные графики
Линейные графики являются самыми простыми из всех. Такой график — это последовательность точек данных на линии. Каждая точка состоит из пары значений (x, y), которые перенесены на график в соответствии с масштабами осей (x и y).
В качестве примера можно вывести точки, сгенерированные математической функцией. Возьмем такую: y = sin (3 * x) / x
Таким образом для создания последовательности точек данных нужно создать два массива NumPy. Сначала создадим массив со значениями x для оси x. Для определения последовательности увеличивающихся значений используем функцию np.arrange(). Поскольку функция синусоидальная, то значениями должны быть числа кратные π (np.pi). Затем с помощью этой последовательности можно получить значения y, применив для них функцию np.sin() (и все благодаря NumPy).
После этого остается лишь вывести все точки на график с помощью функции plot(). Результатом будет линейный график.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
plt.plot(x,y)
plt.show()

Этот пример можно расширить для демонстрации семейства функций, например, такого (с разными значениями n):
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y)
plt.plot(x,y2)
plt.plot(x,y3)
plt.show()

Как можно увидеть на изображении, каждой линии автоматически присваивается свой цвет. При этом все графики представлены в одном масштабе. Это значит, что точки данных связаны с одними и теми же осями x и y. Вот почему каждый вызов функции plot() учитывает предыдущие вызовы, так что объект Figure применяет изменения с учетом прошлых команд еще до вывода (для вывода используется show()).
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,'k--',linewidth=3)
plt.plot(x,y2,'m-.')
plt.plot(x,y3,color='#87a3cc',linestyle='--')
plt.show()

Как уже говорилось в прошлых в разделах, вне зависимости от настроек по умолчанию можно выбрать тип начертания, цвет и так далее. Третьим аргументом функции plot() можно указать коды цветов, типы линий и все этой в одной строке. Также можно использовать два именованных аргумента отдельно: color — для цвета и linestyle — для типа линии.
| Код | Цвет |
|---|---|
| b | голубой |
| g | зеленый |
| r | красный |
| c | сине-зеленый |
| m | пурпурный |
| y | желтый |
| k | черный |
| w | белый |
На графике определен диапазон от — 2π до 2π на оси x, но по умолчанию деления обозначены в числовой форме. Поэтому их нужно заменить на множители числа π. Также можно поменять делители на оси y. Для этого используются функции xticks() и yticks(). Им нужно передать список значений. Первый список содержит значения, соответствующие позициям, где деления будут находиться, а второй — их метки. В этом случае будут использоваться LaTeX-выражения, что нужно для корректного отображения π. Важно не забыть добавить знаки $ в начале и конце, а также символ r в качестве префикса.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
plt.show()

Пока что на всех рассмотренных графиках оси x и y изображались на краях объекта Figure (по границе рамки). Но их же можно провести так, чтобы они пересекались — то есть, получит декартову система координат.
Для этого нужно сперва получить объект Axes с помощью функцию gca. Затем с его помощью можно выбрать любую из четырех сторон, создав область с границами и определив положение каждой: справа, слева, сверху и снизу. Ненужные части обрезаются (справа и снизу), а с помощью функции set_color() задается значение none. Затем стороны, которые соответствуют осям x и y, проходят через начало координат (0, 0) с помощью функции set_position().
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.show()
Теперь график будет состоять из двух пересекающихся в центре осей, который представляет собой начало декартовой системы координат.

Также есть возможность указать на определенную точку с помощью дополнительных обозначений и стрелки. Обозначением может выступать LaTeX-выражение, например, формула предела функции sinx/x, стремящейся к 0.
Для этого в matplotlib есть функция annotate(). Ее настройка кажется сложной, но большое количество kwargs обеспечивает требуемый результат. Первый аргумент — строка, представляющая собой LaTeX-выражение, а все остальные — опциональные. Точка, которую нужно отметить на графике представлена в виде списка, включающего ее координаты (x и y), переданные в аргумент xy. Расстояние заметки до точки определено в xytext, а стрелка — с помощью arrowprops.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
plt.annotate(r'$\lim_{x\to 0}\frac{\sin(x)}{x}= 1$', xy=[0,1],xycoords='data',
xytext=[30,30],fontsize=16, textcoords='offset points', arrowprops=dict(arrowstyle="->",
connectionstyle="arc3,rad=.2"))
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.show()
В итоге этот код сгенерирует график с математической формулой предела, представленной точкой, на которую указывает стрелка.

Линейные графики с pandas
Рассмотрим более практический и приближенный к анализу данных пример. С ним будет видно, насколько просто использовать библиотеку matplotlib для объектов Dataframe из библиотеки pandas. Визуализация данных в виде линейного графика — максимально простая задача. Достаточно передать объект в качестве аргумента функции plot() для получения графика с несколькими линиями.
import pandas as pd
data = {'series1':[1,3,4,3,5],
'series2':[2,4,5,2,4],
'series3':[3,2,3,1,3]}
df = pd.DataFrame(data)
x = np.arange(5)
plt.axis([0,5,0,7])
plt.plot(x,df)
plt.legend(data, loc=2)
plt.show()

Гистограммы
Гистограмма состоит из примыкающих прямоугольников, расположенных вдоль оси x, которые разбиты на дискретные интервалы, их называют bins. Их площадь пропорциональна частоте конкретного интервала. Такой способ визуализации часто используют в статистике для демонстрации распределения.
Для представления гистограммы в pyplot есть функция hist(). У нее также есть особенности, которых не найти у других функций, отвечающих за создание графиков. hist() не только рисует гистограмму, но также возвращает кортеж значений, представляющих собой результат вычислений гистограммы. Функция hist() может реализовывать вычисление гистограммы, чего достаточно для предоставления набора значений и количества интервалов, на которых их нужно разбить. Наконец hist() отвечает за разделение интервала на множество и вычисление частоты каждого. Результат этой операции не только выводится в графической форме, но и возвращается в виде кортежа.
Для понимания операции лучше всего воспользоваться практическим примером. Сгенерируем набор из 100 случайных чисел от 0 до 100 с помощью random.randint().
pop = np.random.randint(0,100,100)
pop
array([33, 90, 10, 68, 18, 67, 6, 54, 32, 25, 90, 6, 48, 34, 59, 70, 37,
50, 86, 7, 49, 40, 54, 94, 95, 20, 83, 59, 33, 0, 81, 18, 26, 69,
2, 42, 51, 7, 42, 90, 94, 63, 14, 14, 71, 25, 85, 99, 40, 62, 29,
42, 27, 98, 30, 89, 21, 78, 17, 33, 63, 80, 61, 50, 79, 38, 96, 8,
85, 19, 76, 32, 19, 14, 37, 62, 24, 30, 19, 80, 55, 5, 94, 74, 85,
59, 65, 17, 80, 11, 81, 84, 81, 46, 82, 66, 46, 78, 29, 40])
Дальше создаем гистограмму из этих данных, передавая аргумент функции hist(). Например, нужно разделить данные на 20 интервалов (значение по умолчанию — 10 интервалов). Для этого используется именованный аргумент bin.
n, bin, patches = plt.hist(pop, bins=20)
plt.show()

Столбчатые диаграммы
Еще один распространенный тип графиков — столбчатые диаграммы. Они похожа на гистограммы, но на оси x тут располагаются не числовые значения, а категории. В matplotlib для реализации столбчатых диаграмм используется функция bin().
index = [0,1,2,3,4]
values = [5,7,3,4,6]
plt.bar(index,values)
plt.show()
Всего нескольких строк кода достаточно для получения такой столбчатой диаграммы.

На последней диаграмме видно, что метки на оси x написаны под каждым столбцом. Поскольку каждый из них относится к отдельной категории, правильнее обозначать их строками. Для этого используется функция xticks(). А для правильного размещения нужно передать список со значениями позиций в качестве первого аргумента в той же функции. Результатом будет такая диаграмма.
index = np.arange(5)
values1 = [5,7,3,4,6]
plt.bar(index, values1)
plt.xticks(index+0.4,['A','B','C','D','E'])
plt.show()

Есть и множество других операций, которые можно выполнить для улучшения диаграммы. Каждая из них выполняется за счет добавления конкретного именованного аргумента в bar(). Например, можно добавить величины стандартного отклонения с помощью аргумента yerr вместе с соответствующими значениями. Часто этот аргумент используется вместе с error_kw, который принимает друге аргументы, отвечающие за представление погрешностей. Два из них — это eColor, который определяет цвета колонок погрешностей и capsize — ширину поперечных линий, обозначающих окончания этих колонок.
Еще один именованный аргумент — alpha. Он определяет степень прозрачности цветной колонки. Его значением может быть число от 0 до 1, где 0 — полностью прозрачный объект.
Также крайне рекомендуется использовать легенду, за которую отвечает аргумент label.
Результат — следующая столбчатая диаграмма с колонками погрешностей.
index = np.arange(5)
values1 = [5,7,3,4,6]
std1 = [0.8,1,0.4,0.9,1.3]
plt.title('A Bar Chart')
plt.bar(index, values1, yerr=std1, error_kw={'ecolor':'0.1','capsize':6},alpha=0.7,label='First')
plt.xticks(index+0.4,['A','B','C','D','E'])
plt.legend(loc=2)
plt.show()

Горизонтальные столбчатые диаграммы
В предыдущем разделе столбчатая диаграмма была вертикальной. Но блоки могут располагаться и горизонтально. Для этого режима есть специальная функция barh(). Аргументы и именованные аргументы, которые использовались для bar() будут работать и здесь. Единственное изменение в том, что поменялись роли осей. Категории теперь представлены на оси y, а числовые значения — на x.
index = np.arange(5)
values1 = [5,7,3,4,6]
std1 = [0.8,1,0.4,0.9,1.3]
plt.title('A Horizontal Bar Chart')
plt.barh(index, values1, xerr=std1, error_kw={'ecolor':'0.1','capsize':6},alpha=0.7,label='First')
plt.yticks(index+0.4,['A','B','C','D','E'])
plt.legend(loc=5)
plt.show()

Многорядные столбчатые диаграммы
Как и линейные графики, столбчатые диаграммы широко используются для одновременного отображения больших наборов данных. Но в случае с многорядными работает особая структура. До сих пор во всех примерах определялись последовательности индексов, каждый из которых соответствует столбцу, относящемуся к оси x. Индексы представляют собой и категории. В таком случае столбцов, которые относятся к одной и той же категории, даже больше.
Один из способов решения этой проблемы — разделение пространства индекса (для удобства его ширина равна 1) на то количество столбцов, которые к нему относятся. Также рекомендуется добавлять пустое пространство, которое будет выступать пропусками между категориями.
index = np.arange(5)
values1 = [5,7,3,4,6]
values2 = [6,6,4,5,7]
values3 = [5,6,5,4,6]
bw = 0.3
plt.axis([0,5,0,8])
plt.title('A Multiseries Bar Chart', fontsize=20)
plt.bar(index, values1, bw, color='b')
plt.bar(index+bw, values2, bw, color='g')
plt.bar(index+2*bw, values3, bw, color='r')
plt.xticks(index+1.5*bw,['A','B','C','D','E'])
plt.show()

В случае с горизонтальными многорядными столбчатыми диаграммами все работает по тому же принципу. Функцию bar() нужно заменить на соответствующую barh(), а также не забыть заменить xticks() на yticks(). И нужно развернуть диапазон значений на осях с помощью функции axis().
index = np.arange(5)
values1 = [5,7,3,4,6]
values2 = [6,6,4,5,7]
values3 = [5,6,5,4,6]
bw = 0.3
plt.axis([0,8,0,5])
plt.title('A Multiseries Bar Chart', fontsize=20)
plt.barh(index, values1, bw, color='b')
plt.barh(index+bw, values2, bw, color='g')
plt.barh(index+2*bw, values3, bw, color='r')
plt.yticks(index+0.4,['A','B','C','D','E'])
plt.show()

Многорядные столбчатые диаграммы с Dataframe из pandas
Как и в случае с линейными графиками matplotlib предоставляет возможность представлять объекты Dataframe с результатами анализа данных в форме столбчатых графиков. В этом случае все происходит даже быстрее и проще. Нужно лишь использовать функцию plot() по отношению к объекту Dataframe и указать внутри именованный аргумент kind, ему требуется присвоить тип графика, который будет выводиться. В данном случае это bar. Без дополнительных настроек результат должен выглядеть как на следующем изображении.
import pandas as pd
index = np.arange(5)
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df.plot(kind='bar')
plt.show()

Но для еще большего контроля (или просто при необходимости) можно брать части Dataframe в виде массивов NumPy и описывать их так, как в предыдущем примере. Для этого каждый нужно передать в качестве аргумента функциям matplotlib.
К горизонтальной диаграмме применимы те же правила, но нужно не забыть указать значение barh для аргумента kind. Результатом будет горизонтальная столбчатая диаграмма как на следующем изображении.

Многорядные сложенные столбчатые графики
Еще один способ представления многорядного столбчатого графика — сложенная форма, где каждый столбец установлен поверх другого. Это особенно полезно в том случае, когда нужно показать общее значение суммы всех столбцов.
Для превращения обычного многорядного столбчатого графика в сложенный нужно добавить именованный аргумент bottom в каждую функцию bar(). Каждый объект Series должен быть присвоен соответствующему аргументу bottom. Результатом будет сложенный столбчатый график.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([-0.5,3.5,0,15])
plt.title('A Multiseries Stacked Bar Chart')
plt.bar(index,series1,color='r')
plt.bar(index,series2,color='b',bottom=series1)
plt.bar(index,series3,color='g',bottom=(series2+series1))
plt.xticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

Здесь для создания аналогичного горизонтального графика нужно заменить bar() на barh(), не забыв про остальные параметры. Функцию xticks() необходимо поменять местами с yticks(), потому что метки категорий теперь будут расположены по оси y. После этого будет создан следующий горизонтальный график.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([0,15,-0.5,3.5])
plt.title('A Multiseries Horizontal Stacked Bar Chart')
plt.barh(index,series1,color='r')
plt.barh(index,series2,color='b',left=series1)
plt.barh(index,series3,color='g',left=(series2+series1))
plt.yticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

До сих пор объекты Series разделялись только по цветам. Но можно использовать, например, разную штриховку. Для этого сперва необходимо сделать цвет столбца белым и использовать именованный аргумент hatch для определения типа штриховки. Все они выполнены с помощью символов (|, /, -, \, *), соответствующих стилю столбца. Чем чаще он повторяется, тем теснее будут расположены линии. Так, /// — более плотный вариант чем //, а этот, в свою очередь, плотнее /.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([0,15,-0.5,3.5])
plt.title('A Multiseries Horizontal Stacked Bar Chart')
plt.barh(index,series1,color='w',hatch='xx')
plt.barh(index,series2,color='w',hatch='///',left=series1)
plt.barh(index,series3,color='w',hatch='\\\\\\',left=(series2+series1))
plt.yticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

Сложенные столбчатые графики с Dataframe из padans
В случае со сложенными столбчатыми графиками очень легко представлять значения объектов Dataframe с помощью функции plot(). Нужно лишь добавить в качестве аргумента stacked со значением True.
import pandas as pd
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df.plot(kind='bar',stacked=True)
plt.show()

Другие представления столбчатых графиков
Еще один удобный тип представления данных в столбчатом графике — с использованием двух Series из одних и тех же категорий, где они сравниваются путем размещения друг напротив друга вдоль оси y. Для этого нужно разместить значения y одного из графиков в отрицательной форме. Также в этом примере показано, как поменять внутренний цвет другим способом. Это делается с помощью задания значения для аргумента facecolor.
Также вы увидите, как добавить значение y с меткой в конце каждого столбца. Это поможет улучшить читаемость всего графика. Это делается с помощью цикла for, в котором функция text() показывает значение y. Настроить положение метки можно с помощью именованных аргументов ha и va, которые контролируют горизонтальное и вертикальное выравнивание соответственно. Результатом будет следующий график.
x0 = np.arange(8)
y1 = np.array([1,3,4,5,4,3,2,1])
y2 = np.array([1,2,5,4,3,3,2,1])
plt.ylim(-7,7)
plt.bar(x0,y1,0.9, facecolor='g')
plt.bar(x0,-y2,0.9,facecolor='b')
plt.xticks(())
plt.grid(True)
for x, y in zip(x0, y1):
plt.text(x, y + 0.05, '%d' % y, ha='center', va = 'bottom')
for x, y in zip(x0, y2):
plt.text(x, -y - 0.05, '%d' % y, ha='center', va = 'top')
plt.show()

Круговая диаграмма
Еще один способ представления данных — круговая диаграмма, которую можно получить с помощью функции pie().
Даже для нее нужно передать основной аргумент, представляющий собой список значений. Пусть это будут проценты (где максимально значение — 100), но это может быть любое значение. А уже сама функция определит, сколько будет занимать каждое значение.
Также в случае с этими графиками есть другие особенности, которые определяются именованными аргументами. Например, если нужно задать последовательность цветов, используется аргумент colors. В таком случае придется присвоить список строк, каждая из которых будет содержать название цвета. Еще одна возможность — добавление меток каждой доле. Для этого есть labels, которой присваивает список строк с метками в последовательности.
А чтобы диаграмма была идеально круглой, необходимо в конце добавить функцию axix() со строкой equal в качестве аргумента. Результатом будет такая диаграмма.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
plt.pie(values,labels=labels,colors=colors)
plt.axis('equal')
plt.show()

Чтобы сделать диаграмму более сложной, можно «вытащить» одну из частей. Обычно это делается с целью акцентировать на ней внимание. В этом графике, например, для выделения Nokia. Для этого используется аргумент explode. Он представляет собой всего лишь последовательность чисел с плавающей точкой от 0 до 1, где 1 — положение целиком вне диаграмма, а 0 — полностью внутри. Значение между соответствуют среднему градусу извлечения.
Заголовок добавляется с помощью функции title(). Также можно настроить угол поворота с помощью аргумента startangle, который принимает значение между 0 и 360, обозначающее угол поворота (0 – значение по умолчанию). Следующий график показывает все изменения.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
explode = [0.3,0,0,0]
plt.title('A Pie Chart')
plt.pie(values,labels=labels,colors=colors,explode=explode,startangle=180)
plt.axis('equal')
plt.show()

Но и это не все, что может быть на диаграмме. У нее нет осей, поэтому сложно передать точное разделение. Чтобы решить эту проблему, можно использовать autopct, который добавляет в центр каждой части текст с соответствующим значением.
Чтобы сделать диаграмму еще более привлекательной визуально, можно добавить тень с помощью shadow со значением True. Результат — следующее изображение.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
explode = [0.3,0,0,0]
plt.title('A Pie Chart')
plt.pie(values,labels=labels,colors=colors,explode=explode,shadow=True,autopct='%1.1f%%',startangle=180)
plt.axis('equal')
plt.show()

Круговые диаграммы с Dataframe из pandas
Даже в случае с круговыми диаграммами можно передавать значения из Dataframe. Однако каждая диаграмма будет представлять собой один Series, поэтому в примере изобразим только один объект, выделив его через df['series1'].
Указать тип графика можно с помощью аргумента kind в функции plot(), который в этом случае получит значение pie. Также поскольку он должен быть идеально круглым, обязательно задать figsize. Получится следующая диаграмма.
import pandas as pd
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df['series1'].plot(kind='pie', figsize=(6,6))
plt.show()

В этом материале обсудим некоторые особенности Keras. Также выполним классификацию рукописных цифр с помощью набора данных MNIST, используя Keras и его возможности.
Что такое Keras?
Keras — это библиотека нейронной сети в Python, использующая в качестве бэкенда TensorFlow, Microsoft CNTK или Theano. Ее можно установить вместе с движком с помощью PyPl.
pip install Keras
pip install tensorFlow
Зачем учить Keras?
Keras делает акцент на пользовательском опыте. С ее помощью пользователь может писать минимум кода для выполнения основных операций. Библиотека модульная и расширяемая. Модели и части кода можно использовать повторно и расширять в будущем.
Особенности Keras
Рассмотрим главные особенности Keras, из-за которых ее стоит учить:
1. Наборы помеченных данных
В Keras много помеченных наборов данных, которые можно импортировать и загрузить.
Пример: классификация небольших изображений CIFAR10, определение тональности рецензий IMDB, классификация новостных тем Reuters, рукописные цифры MNIST и некоторые другие (это лишь примеры самых известных наборов).
Для загрузки набора MNIST нужны следующие команды:
from Keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
2. Многочисленные реализованные слои и параметры
Keras содержит многочисленные слои и параметры, такие как функции потерь, оптимизаторы, метрики оценки. Они используются для создания, настройки, тренировки и оценки нейронных сетей.
Загрузим эти требуемые слои для построения классификатора цифр.
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.optimizers import Adam
from keras.utils import np_utils
Keras также поддерживает одно- и двухмерные сверточные и рекуррентные нейронные сети. Для классификатора используем сверточную нейронную сеть (слой Conv2D).
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
3. Методы для предварительной обработки данных
В Keras также масса методов для предварительной обработки. Будем использовать метод Keras.np_utils.to_categorical() для унитарной кодировки y_train и y_test.
Перед этим изменим форму и нормализуем данные в соответствии с требованиями.
# изменение размерности
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], X_train.shape[2], 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], X_test.shape[2], 1).astype('float32')
# нормализация, чтобы получить данные в диапазоне 0-1
X_train/=255
X_test/=255
number_of_classes = 10
y_train = np_utils.to_categorical(y_train, number_of_classes)
y_test = np_utils.to_categorical(y_test, number_of_classes)
4. Метод add() в Keras
Для добавления импортированных слоев используется метод add() с дополнительными параметрами.
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(X_train.shape[1], X_train.shape[2], 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(number_of_classes, activation='softmax')
5. Метод compile()
Перед тренировкой нужно настроить процесс обучения, что делается с помощью метода compile().
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
6. Метод fit()
Тренировка моделей Keras происходит с помощью массивов и метода fit().
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=200)
Тренировка занимает некоторое время. В данном случае прошло всего 5 epocs, но их число можно увеличить.
Тренировка выглядит вот так:

7. Оценка модели
После тренировки модели результаты проверяются на новых данных или с помощью predict_classes() или evaluate().
Проверим модель рукописных цифр. Можете взять в качестве примера это изображение.

Но сперва его нужно конвертировать в формат набора MNIST.
Этот формат представляет собой черно-белые изображения 28*28*1.
import cv2
img = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
resized = cv2.resize(img, (28,28), interpolation = cv2.INTER_AREA)
img = np.resize(resized, (28,28,1))
im2arr = np.array(img)
im2arr = im2arr.reshape(1,28,28,1)
y_pred = model.predict_classes(im2arr)
print(y_pred)
7
8. Модульность
Keras является модульным, поэтому можно сохранить модель и тренировать ее позже.
Это делается вот так:
model.save('model.h5')
Выводы
Это основные особенности Keras. Рассмотрели их на примере базовых операций: загрузки набора данных, построения модели, добавления параметров, компиляции, тренировки и оценки. С помощью этой статьи у вас была возможность создать собственный классификатор рукописных цифр на основе набора данных MNIST. Этот пример показывает, что проекты глубокого обучения могут состоять всего из 10 строк кода.
]]>Модуль pyplot — это коллекция функций в стиле команд, которая позволяет использовать matplotlib почти так же, как MATLAB. Каждая функция pyplot работает с объектами Figure и позволяет их изменять. Например, есть функции для создания объекта Figure, для создания области построения, представления линии, добавления метки и так далее.
pyplot является зависимым от состояния (stateful). Он отслеживает статус объекта Figure и его области построения. Функции выполняются на текущем объекте.
Простой интерактивный график
Для знакомства с библиотекой matplotlib и с самим pyplot начнем создавать простой интерактивный график. В matplotlib эта операция выполняется очень просто. Достаточно трех строчек кода.
Но сначала нужно импортировать пакет pyplot и обозначить его как plt.
import matplotlib.pyplot as plt
В Python конструкторы обычно не нужны. Все определяется неявно. Так, при импорте пакета уже создается экземпляр plt со всеми его графическими возможностями, который готов к работе. Нужно всего лишь использовать функцию plot() для передачи функций, по которым требуется построить график.
Поэтому достаточно передать значения, которые нужно представить в виде последовательности целых чисел.
plt.plot([1,2,3,4])
[<matplotlib.lines.Line2D at 0xa3eb438>]
В этом случае генерируется объект Line2D. Это линия, представляющая собой линейный тренд точек, нанесенных на график.
Теперь все настроено. Осталось лишь дать команду показать график с помощью функции show().
plt.show()
Результат должен соответствовать показанному на изображении. Он будет отображаться в окне, которое называется plotting window с панелью инструментов. Прямо как в MATLAB.

Окно графика
В этом окне есть панель управления, состоящая из нескольких кнопок.

Код в консоли IPython передается в консоль Python в виде набора команд:
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.show()
Если же вы используете IPython QtConsole, то могли заметить, что после вызова plot() график сразу отображается без необходимости вызывать show().
Если функции plt.plot() передать только список или массив чисел, matplotlib предположит, что это последовательность значений y на графике и свяжет ее с последовательностью натуральных чисел x: 0, 1, 2, 3, ….
Обычно график представляет собой пару значений (x, y), поэтому, если нужно определить его правильно, требуется два массива: в первом будут значения для оси x, а втором — для y. Функция plot() принимает и третий аргумент, описывающий то, как нужно представить точку на графике.
Свойства графика
На последнем изображении точки были представлены синей линией. Если не указывать явно, то график возьмет настройку функции plt.plot() по умолчанию:
- Размер осей соответствует диапазону введенных данных
- У осей нет ни меток, ни заголовков
- Легенды нет
- Соединяющая точки линия синяя
Для получения настоящего графика, где каждая пара значений (x, y) будет представлена в виде красной точки, нужно поменять это представление.
Если вы работаете в IPython, закройте окно, чтобы вернуться в консоль для введения новых команд. Затем нужно будет вызывать функцию show(), чтобы увидеть внесенные изменения.
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
Если же вы используете Jupyter QtConsole, то для каждой введенной команды будет появляться новый график.
в будущем в примерах средой разработки будет выступать IPython QtConsole.
Можно определить диапазон для осей x и y, задав значения в список [xmin, xmax, ymin, ymax] и передав его в качестве аргумента в функцию axis().
в IPython QtConsole для создания графика иногда нужно ввести несколько строк команд. Чтобы график при этом не генерировался с каждым нажатием Enter (перевод на новую строку), необходимо нажимать Ctrl + Enter. А когда график будет готов, остается лишь нажать Enter дважды.
Можно задать несколько свойств. Одно из них — заголовок, который задается через функцию title().
plt.axis([0,5,0,20])
plt.title('My first plot')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
На следующем изображении видно, как новые настройки делают график более читаемым. Так, конечные точки набора данных теперь распределены по графику, а не находятся на краях. А сверху есть заголовок.

matplotlib и NumPy
Даже matplot, которая является полностью графической библиотекой, основана на NumPy. Вы видели на примерах, как передавать списки в качестве аргументов. Это нужно как для представления данных, так и для того, чтобы задавать границы осей. Внутри эти списки конвертируются в массивы NumPy.
Таким образом можно прямо добавлять в качестве входящих данных массивы NumPy. Массив данных, обработанный pandas, может быть использован matplotlib без дальнейшей обработки.
В качестве примера рассмотрим, как перенести на один график три тренда. Возьмем функцию sin из модуля math. Последний сперва нужно импортировать. Для генерации точек по синусоиде нужно использовать библиотеку NumPy. Сгенерируем набор точек по оси x с помощью функции arrange(), а для оси y воспользуемся функцией map(). С ее помощью применим sin() ко всем элементам массива (без цикла for).
import math
import numpy as np
t = np.arange(0,2.5,0.1)
y1 = np.sin(math.pi*t)
y2 = np.sin(math.pi*t+math.pi/2)
y3 = np.sin(math.pi*t-math.pi/2)
plt.plot(t,y1,'b*',t,y2,'g^',t,y3,'ys')
plt.show()

Как видно на прошлом изображении, график представляет три разных тренда с помощью разных цветов и меток. В таких случаях когда тренд функции очевиден, график является не самой подходящим представлением — лучше использовать линии. Чтобы разделить их не только цветами, можно использовать паттерны, состоящие из комбинаций точек и дефисов.
plt.plot(t,y1,'b--',t,y2,'g',t,y3,'r-.')
plt.show()
если вы не пользуетесь IPython QtConsole со встроенной matplotlib или работаете с этим кодом в обычной сессии Python, используйте команду
plt.show()в конце кода для получения объекта графика со следующего изображения.

Использование kwargs
Объекты, которые создают график, имеют разные характеризующие их атрибуты. Все они являются значениями по умолчанию, но их можно настроить с помощью аргументов-ключевых слов — kwargs.
Эти ключевые слова передаются в качестве аргументов в функции. В документации по разным функциям библиотеки matplotlib они всегда упоминаются последними вместе с kwargs. Например, функция plot() описана следующим образом.
matplotlib.pyplot.plot(*args, **kwargs)
В качестве примера с помощью аргумента linewidth можно поменять толщину линии.
plt.plot([1,2,4,2,1,0,1,2,1,4], linewidth=2.0)
plt.show()

Работа с несколькими объектами Figure и осями
До сих пор во всех примерах команды pyplot были направлены на отображение в пределах одного объекта. Но matplotlib позволяет управлять несколькими Figure одновременно, а внутри одного объекта можно выводить подграфики.
Работая с pyplot, нужно помнить о концепции текущего объекта Figure и текущих осей (графика на объекте).
Дальше будет пример с двумя подграфиками на одном Figure. Функция subplot(), помимо разделения объекта на разные зоны для рисования, используется для фокусировки команды на конкретном подграфике.
Аргументы, переданные subplot(), задают режим разделения и определяют текущий подграфик. Этот график будет единственным, на который воздействуют команды. Аргумент функции subplot() состоит из трех целых чисел. Первое определяет количество частей, на которое нужно разбить объект по вертикали. Второе — горизонтальное разделение. А третье число указывает на текущий подграфик, для которого будут актуальны команды.
Дальше будут отображаться тренды синусоиды (синус и косинус), и лучше всего разделить полотно по вертикали на два горизонтальных подграфика. В график передают числа 211 и 212.
t = np.arange(0,5,0.1)
y1 = np.sin(2*np.pi*t)
y2 = np.sin(2*np.pi*t)
plt.subplot(211)
plt.plot(t,y1,'b-.')
plt.subplot(212)
plt.plot(t,y2,'r--')
plt.show()

Теперь — то же самое для двух вертикальных подграфиков. Передаем в качестве аргументов 121 и 122.
t = np.arange(0.,1.,0.05)
y1 = np.sin(2*np.pi*t)
y2 = np.cos(2*np.pi*t)
plt.subplot(121)
plt.plot(t,y1,'b-.')
plt.subplot(122)
plt.plot(t,y2,'r--')
plt.show()

Добавление элементов на график
Чтобы сделать график более информативным, недостаточно просто представлять данные с помощью линий и маркеров и присваивать диапазон значений с помощью двух осей. Есть и множество других элементов, которые можно добавить на график, чтобы наполнить его дополнительной информацией.
В этом разделе добавим на график текстовые блоки, легенду и так далее.
Добавление текста
Вы уже видели, как добавить заголовок с помощью функции title(). Два других текстовых индикатора можно добавить с помощью меток осей. Для этого используются функции xlabel() и ylabel(). В качестве аргумента они принимают строку, которая будет выведена.
количество команд для представления графика постоянно растет. Но их не нужно переписывать каждый раз. Достаточно использовать стрелки на клавиатуре, вызывая раннее введенные команды и редактируя их с помощью новых строк (в тексте они выделены жирным).
Теперь добавим две метки на график. Они будут описывать тип значений на каждой из осей.
plt.axis([0,5,0,20])
plt.title('My first plot')
plt.xlabel('Counting')
plt.ylabel('Square values')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Благодаря ключевым словам можно менять характеристики текста. Например, можно поменять заголовок, выбрав другой шрифт и увеличив его размер. Также можно менять цвета меток осей, чтобы акцентировать внимание на заголовке всего графика.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Но в matplotlib можно делать даже больше: pyplot позволяет добавлять текст в любом месте графика. Это делается с помощью специальной функции text().
text(x,y,s, fontdict=None, **kwargs)
Первые два аргумента — это координаты, в которых нужно разметить текст. s — это строка с текстом, а fontdict (опционально) — желаемый шрифт. Разрешается использовать и ключевые слова.
Добавим метку для каждой точки графика. Поскольку первые два аргумента в функции являются координатами, координаты всех точек по оси y немного сдвинутся.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
Теперь у каждой точки есть своя метка.

Поскольку matplotlib — это графическая библиотека, созданная для использования в научных кругах, она должна быть способна в полной мере использовать научный язык, включая математические выражения. matplotlib предоставляет возможность интегрировать выражения LaTeX, что позволяет добавлять выражения прямо на график.
Для этого их нужно заключить в два символа $. Интерпретатор распознает их как выражения LaTeX и конвертирует соответствующий график. Это могут быть математические выражения, формулы, математические символы или греческие буквы. Перед LaTeX нужно добавлять r, что означает сырой текст. Это позволит избежать появления исключающих последовательностей.
Также разрешается использовать ключевые слова, чтобы дополнить текст графика. Например, можно добавить формулу, описывающую тренд и цветную рамку.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Добавление сетки
Также на график можно добавить сетку. Часто это необходимо, чтобы лучше понимать положение каждой точки на графике.
Это простая операция. Достаточно воспользоваться функцией grid(), передав в качестве аргумента True.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Добавление легенды
Также на графике должна присутствовать легенда. pyplot предлагает функцию legend() для добавления этого элемента.
В функцию нужно передать строку, которая будет отображаться в легенде. В этом примере текст First series характеризует входящий массив данных.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.legend(['First series'])
plt.show()

По умолчанию легенда добавляется в правом верхнем углу. Чтобы поменять это поведение, нужно использовать несколько аргументов-ключевых слов. Так, для выбора положения достаточно передать аргумент loc со значением от 0 до 10. Каждая из цифр обозначает один из углов. Значение 1 — значение по умолчанию, то есть, верхний правый угол. В следующем примере переместим легенду в левый верхний угол, чтобы она не пересекалась с точками на графике.
| Код положения | Положение |
|---|---|
| 0 | лучшее |
| 1 | Верхний правый угол |
| 2 | Верхний левый угол |
| 3 | Нижний левый угол |
| 4 | Нижний правый угол |
| 5 | Справа |
| 6 | Слева по центру |
| 7 | Справа по центру |
| 8 | Снизу по центру |
| 9 | Сверху по центру |
| 10 | По центру |
Тут важно сделать одну ремарку. Легенды используются для указания определения набора данных с помощью меток, ассоциированных с определенным цветом и/или маркером. До сих пор в примерах использовался лишь один набор данных, переданный с помощью одной функции plot(). Но куда чаще один график может использоваться для нескольких наборов данных. С точки зрения кода каждый такой набор будет характеризоваться вызовом одной функции plot(), а порядок их определения будет соответствовать порядку текстовых меток, переданных в качестве аргумента функции legend().
import matplotlib.pyplot as plt
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.show()

Сохранение графиков
В этом разделе разберемся, как сохранять график разными способами. Если в будущем потребуется использовать график в разных Notebook или сессиях Python, то лучший способ — сохранять графики в виде кода Python. С другой стороны, если они нужны в отчетах или презентациях, то подойдет сохранение в виде изображения. Можно даже сохранить график в виде HTML-страницы, что пригодится при работе в интернете.
Сохранение кода
Как уже стало понятно, объем кода, отвечающего за представление одного графика, постоянно растет. Когда финальный результат удовлетворяет, его можно сохранить в файле .py, который затем вызывается в любой момент.
Также можно использовать команду %save [имя файла] [количество строк кода], чтобы явно указать, сколько строк нужно сохранить. Если весь код написан одним запросом, тогда нужно добавить лишь номер его строки. Если же использовалось несколько команд, например, от 10 до 20, то эти числа и нужно записать, разделив их дефисом (10-20).
В этом примере сохранить весь код, отвечающий за формирование графика, можно с помощью ввода со строки 171.
In [171]: import matplotlib.pyplot as plt
Такую команду потребуется ввести для сохранения в файл .py.
%save my_first_chart 171
После запуска команды файл my_first_chart.py окажется в рабочей директории.
# %load my_first_chart.py
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.show()
Позже, когда вы откроете сессию IPython, у вас уже будет готовый график и его можно редактировать с момента сохранения этой командой:
ipython qtconsole --matplotlib inline -m my_first_chart.py
Либо его можно загрузить заново в один запрос в QtConsole с помощью команды %load.
%load my_first_chart.py
Или запустить в уже активной сессии с помощью %run.
%run my_first_chart.py
в определенных случаях последняя команда будет работать только после ввода двух предыдущих.
Сохранение сессии в HTML-файл
С помощью IPython QtConsole вы можете конвертировать весь код и графику, представленные в текущей сессии, в одну HTML-страницу. Просто выберите File → Save to HTML/XHTML в верхнем меню.
Будет предложено сохранить сессию в одном из двух форматов: HTML и XHTML. Разница между ними заключается в типе сжатия изображения. Если выбрать HTML, то все картинки конвертируются в PNG. В случае с XHTML будет выбран формат SVG.
В этом примере сохраним сессию в формате HTML в файле my_session.html.
Дальше программа спросит, сохранить ли изображения во внешней директории или прямо в тексте. В первом случае все картинки будут храниться в папке my_session_files, а во втором — будут встроены в HTML-код.
Сохранение графика в виде изображения
График можно сохранить и виде файла-изображения, забыв обо всем написанном коде. Для этого используется функция savefig(). В аргументы нужно передать желаемое название будущего файла. Также важно, чтобы эта команда шла в конце, после всех остальных (иначе сохранится пустой PNG-файл).
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.savefig('my_chart.png')
Файл появится в рабочей директории. Он будет называться my_chart.png и включать изображение графика.
Обработка значений дат
Одна из основных проблем при анализе данных — обработка значений дат. Отображение даты по оси (обычно это ось x) часто становится проблемой.
Возьмем в качестве примера линейный график с набором данных, который включает 8 точек, где каждая представляет точку даты на оси x в следующем формате: день-месяц-год.
import datetime
import numpy as np
import matplotlib.pyplot as plt
events = [datetime.date(2015,1,23),
datetime.date(2015,1,28),
datetime.date(2015,2,3),
datetime.date(2015,2,21),
datetime.date(2015,3,15),
datetime.date(2015,3,24),
datetime.date(2015,4,8),
datetime.date(2015,4,24)]
readings = [12,22,25,20,18,15,17,14]
plt.plot(events,readings)
plt.show()

Автоматическая расстановка отметок в этом случае — настоящая катастрофа. Даты сложно читать, ведь между ними нет интервалов, и они наслаиваются друг на друга.
Для управления датами нужно определить временную шкалу. Сперва необходимо импортировать matplotlib.dates — модуль, предназначенный для работы с этим типом дат. Затем указываются шкалы для дней и месяцев с помощью MonthLocator() и DayLocator(). В этом случае форматирование играет важную роль, и чтобы не получить наслоение текста, нужно ограничить количество отметок, оставив только год-месяц. Такой формат передается в качестве аргумента функции DateFormatter().
Когда шкалы определены (один — для дней, второй — для месяцев) можно определить два вида пометок на оси x с помощью set_major_locator() и set_minor_locator() для объекта xaxis. Для определения формата текста отметок месяцев используется set_major_formatter.
Задав все эти изменения, можно получить график как на следующем изображении.
import matplotlib.dates as mdates
months = mdates.MonthLocator()
days = mdates.DayLocator()
timeFmt = mdates.DateFormatter('%Y-%m')
events = [datetime.date(2015,1,23),
datetime.date(2015,1,28),
datetime.date(2015,2,3),
datetime.date(2015,2,21),
datetime.date(2015,3,15),
datetime.date(2015,3,24),
datetime.date(2015,4,8),
datetime.date(2015,4,24)]
readings = [12,22,25,20,18,15,17,14]
fig, ax = plt.subplots()
plt.plot(events, readings)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(timeFmt)
ax.xaxis.set_minor_locator(days)
plt.show()

Математика — это масса понятий, которые являются одновременно важными и сложными. Для работы с ними в Python есть библиотека SciPy. В этом материале вы познакомитесь с ее функциями на примерах.
Что такое SciPy?
SciPy — это библиотека Python с открытым исходным кодом, предназначенная для решения научных и математических проблем. Она построена на базе NumPy и позволяет управлять данными, а также визуализировать их с помощью разных высокоуровневых команд. Если вы импортируете SciPy, то NumPy отдельно импортировать не нужно.
NumPy vs SciPy
И NumPy, и SciPy являются библиотеками Python, которые используются для математического и числового анализов. NumPy содержит данные массивов и операции, такие как сортировка, индексация, а SciPy состоит из числового кода. И хотя в NumPy есть функции для работы с линейной алгеброй, преобразованиями Фурье и т. д., в SciPy они представлены в полном виде вместе с массой других. А для полноценного научного анализа в Python нужно устанавливать и NumPy, и SciPy, поскольку последняя построена на базе NumPy.
Пакеты в SciPy
В SciPy есть набор пакетов для разных научных вычислений:
| Название | Описание |
|---|---|
cluster |
Алгоритмы кластерного анализа |
constants |
Физические и математические константы |
fftpack |
Быстрое преобразование Фурье |
integrate |
Решения интегральных и обычных дифференциальных уравнений |
interpolate |
Интерполяция и сглаживание сплайнов |
io |
Ввод и вывод |
linalg |
Линейная алгебра |
ndimage |
N-размерная обработка изображений |
odr |
Метод ортогональных расстояний |
optimize |
Оптимизация и численное решение уравнений |
signal |
Обработка сигналов |
sparse |
Разреженные матрицы |
spatial |
Разреженные структуры данных и алгоритмы |
special |
Специальные функции |
stats |
Статистические распределения и функции |
Подробное описание можно найти в официальной документации.
Эти пакеты нужно импортировать для использования библиотеки. Например:
from scipy import cluster
Прежде чем рассматривать каждую функцию в подробностях, разберемся с теми из них, которые являются одинаковыми в NumPy и SciPy.
Базовые функции
Взаимодействие с NumPy
SciPy построена на базе NumPy, поэтому можно использовать функции последней для работы с массивами. Чтобы узнать о них подробнее, используйте функции help(), info() или source().
help():
Функция help() подойдет для получения информации о любой функции. Ее можно использовать двумя способами:
- Без параметров
- С параметрами
Вот пример для обоих:
from scipy import cluster
help(cluster) # с параметром
help() # без параметра
При исполнении этого кода, первая help() вернет информацию о подмодуле cluster. А вторая — попросит пользователя ввести название модуля, ключевого слова и др., о чем требуется предоставить дополнительную информацию. Для выхода достаточно ввести quit и нажать Enter.
info():
Эта функция возвращает информацию о конкретных функциях, модулях и так далее.
scipy.info(cluster)
source():
Исходный код можно получить только для тех объектов, которые были написаны на Python. Функция не вернет ничего важного, если методы или объекты были написаны, например, на C. Синтаксис простой:
scipy.source(cluster)
Специальные функции
SciPy предоставляет набор специальных функций, используемых в математической физике: эллиптические настраиваемые функции, гамма, бета и так далее. Для их поиска нужно использовать функцию help().
Экспоненциальные и тригонометрические функции
Набор специальных функций SciPy включает такие, с помощью которых можно искать экспоненты и решать тригонометрические задачи.
Пример:
from scipy import special
a = special.exp10(3)
print(a)
b = special.exp2(3)
print(b)
c = special.sindg(90)
print(c)
d = special.cosdg(45)
print(d)
Вывод:
1000.0
8.0
1.0
0.7071067811865475
Есть и масса других функций из SciPy, с которым стоит познакомиться.
Интегральные функции
Есть и функции для решения интегралов. В их числе как обычные дифференциальные интеграторы, так и методы трапеций.
В SciPy представлена функция quad, которая занимается вычислением интеграла функции с одной переменной. Границы могут быть ±∞ (±inf) для обозначения бесконечных пределов. Синтаксис этой функции следующий:
quad(func, a, b, args=(), full_output=0, epsabs=1.49e-08,
epsrel=1.49e-08, limit=50, points=None, weight=None,
wvar=None, wopts=None, maxp1=50, limlst=50)
А здесь она внедрена в пределах a и b (могут быть бесконечностями).
from scipy import special
from scipy import integrate
a = lambda x:special.exp10(x)
b = scipy.integrate.quad(a, 0, 1)
print(b)
В этом примере функция a находится в пределах 0 и 1. После выполнения вывод будет такой:
(3.9086503371292665, 4.3394735994897923e-14)
Двойные интегральные функции
SciPy включает также и dblquad, которая используется для вычисления двойных интегралов. Двойной интеграл, как известно, состоит из двух реальных переменных. Функция dblquad() принимает функцию, которую нужно интегрировать, в качестве параметра, а также 4 переменных: две границы и функции dy и dx.
Пример:
from scipy import integrate
a = lambda y, x: x*y**2
b = lambda x: 1
c = lambda x: -1
integrate.dblquad(a, 0, 2, b, c)
Вывод:
(-1.3333333333333335, 1.4802973661668755e-14)
В SciPy есть другие функции для вычисления тройных интегралов, n интегралов, интегралов Ромберга и других. О них можно узнать подробнее с помощью help.
Функции оптимизации
В scipy.optimize есть часто используемые алгоритмы оптимизации:
- Неограниченная и ограниченная минимизация многомерных скалярных функций, то есть
minimize(например, Алгоритм Бройдена — Флетчера — Гольдфарба — Шанно, метод сопряженных градиентов, метод Нелдера — Мида и так далее) - Глобальная оптимизация (дифференциальная эволюция, двойной отжиг и т. д.)
- Минимизация наименьших квадратов и подбор кривой (метод наименьших квадратов, приближение с помощью кривых и т. д.)
- Минимизаторы скалярных одномерных функций и численное решение уравнений (минимизация скаляра и скаляр корня)
- Решатели систем многомерных уравнений с помощью таких алгоритмов, как Пауэлла, Левендберга — Марквардта.
Функция Розенброка
Функция Розенброка (rosen) — это тестовая проблема для оптимизационных алгоритмов, основанных на градиентах. В SciPy она определена следующим образом:
sum(100.0*(x[1:] - x[:-1]**2.0)**2.0 + (1 - x[+-1])**2.0)
Пример:
import numpy as np
from scipy.optimize import rosen
a = 1.2 * np.arange(5)
rosen(a)
Вывод:
7371.0399999999945
Nelder-Mead
Это числовой метод, который часто используется для поиска минимума/максимума функции в многомерном пространстве. В следующем примере метод использован вместе с алгоритмом Нелдера — Мида.
Пример:
from scipy import optimize
a = [2.4, 1.7, 3.1, 2.9, 0.2]
b = optimize.minimize(optimize.rosen, a, method='Nelder-Mead')
b.x
Вывод:
array([0.96570182, 0.93255069, 0.86939478, 0.75497872, 0.56793357])
Функции интерполяции
В сфере числового анализа интерполяция — это построение новых точек данных на основе известных. Библиотека SciPy включает подпакет scipy.interpolate, состоящий из сплайновых функций и классов, одно- и многомерных интерполяционных классов и так далее.
Одномерная интерполяция
Одномерная интерполяция — это область построения кривой, которая бы полностью соответствовала набору двумерных точек данных. В SciPy есть функция interp1d, которая используется для создания одномерной интерполяции.
Пример:
import matplotlib.pyplot as plt
from scipy import interpolate
x = np.arange(5, 20)
y = np.exp(x/3.0)
f = interpolate.interp1d(x, y)x1 = np.arange(6, 12)
y1 = f(x1) # использовать функцию интерполяции, возвращаемую `interp1d`
plt.plot(x, y, 'o', x1, y1, '--')
plt.show()
Вывод:

Многомерная интерполяция
Многомерная интерполяция (пространственная интерполяция) — это тип интерполяции функций, который состоит из более чем одной переменной. Следующий пример демонстрирует работу функции interp2a.
При интерполяции на двумерную сетку функция использует массивы x, y и z для приближения функции f: "z = f(x, y)" и возвращает функцию, у которой вызываемый метод использует сплайновую интерполяцию для поиска значения новых точек.
Пример:
from scipy import interpolate
import matplotlib.pyplot as plt
x = np.arange(0,10)
y = np.arange(10,25)
x1, y1 = np.meshgrid(x, y)
z = np.tan(xx+yy)
f = interpolate.interp2d(x, y, z, kind='cubic')
x2 = np.arange(2,8)
y2 = np.arange(15,20)
z2 = f(xnew, ynew)
plt.plot(x, z[0, :], 'ro-', x2, z2[0, :], '--')
plt.show()
Вывод:

Функции преобразования Фурье
Анализ Фурье — это метод, который помогает представлять функцию в виде суммы периодических компонентов и восстанавливать сигнал из них. Функции fft используются для получения дискретной трансформации Фурье реальной или комплексной последовательности.
Пример:
from scipy.fftpack import fft, ifft
x = np.array([0,1,2,3])
y = fft(x)
print(y)
Вывод:
[6.+0.j -2.+2.j -2.+0.j -2.-2.j]
Похожим образом можно найти обратное значение с помощью функции ifft.
Пример:
rom scipy.fftpack import fft, ifft
x = np.array([0,1,2,3])
y = ifft(x)
print(y)
Вывод:
[1.5+0.j -0.5-0.5j -0.5+0.j -0.5+0.5j]
Функции обработки сигналов
Обработка сигналов — это область анализа, модификации и синтеза сигналов: звуков, изображений и т. д. SciPy предоставляет некоторые функции, с помощью которых можно проектировать, фильтровать и интерполировать одномерные и двумерные данные.
Фильтрация:
Фильтруя сигнал, можно удалить нежелаемые составляющие. Для выполнения упорядоченной фильтрации используется функция order_filter. Она выполняет операцию на массиве. Синтаксис следующий:
order_filter(a, domain, rank)
a — N-мерный массив с входящими данными
domain — массив масок с тем же количеством размерностей, что и у массива a
rank — неотрицательное число, которое выбирает элементы из отсортированного списка (0, 1…)
Пример:
from scipy import signal
x = np.arange(35).reshape(7, 5)
domain = np.identity(3)
print(x,end='nn')
print(signal.order_filter(x, domain, 1))
Вывод:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]
[30 31 32 33 34]]
[[ 0. 1. 2. 3. 0.]
[ 5. 6. 7. 8. 3.]
[10. 11. 12. 13. 8.]
[15. 16. 17. 18. 13.]
[20. 21. 22. 23. 18.]
[25. 26. 27. 28. 23.]
[ 0. 25. 26. 27. 28.]]
Сигналы
Подпакет scipy.signal также состоит из функций, с помощью которых можно генерировать сигналы. Одна из таких — chirp. Она является генератором частотно-модулированного сигнала, а ее синтаксис следующий:
chirp(t, f0, t1, f1, method='linear', phi=0, vertex_zero=True)
Пример:
from scipy.signal import chirp, spectrogram
import matplotlib.pyplot as plt
t = np.linspace(6, 10, 500)
w = chirp(t, f0=4, f1=2, t1=5, method='linear')
plt.plot(t, w)
plt.title("Linear Chirp")
plt.xlabel('time in sec)')
plt.show()
Вывод:

Линейная алгебра
Линейная алгебра работает с линейными уравнениями и их представлениями с помощью векторных пространств и матриц. SciPy построена на базе библиотек ATLAS LAPACK и BLAS и является очень быстрой в сфере решения проблем, связанных с линейной алгеброй. В дополнение к функциям из numpy.linalg scipy.linalg также предоставляет набор продвинутых функций. Если numpy.linalg не используется вместе с ATLAS LAPACK и BLAS, то scipy.linalg работает намного быстрее.
Нахождение обратной матрицы
С математической точки зрения обратная матрица A — это матрица B, где AB = I, а I — это единичная матрица, состоящая из единиц по диагонали. Это можно обозначить как B=A-1. В SciPy такого можно добиться с помощью метода linalg.inv.
Пример:
import numpy as np
from scipy import linalg
A = np.array([[1,2], [4,3]])
B = linalg.inv(A)
print(B)
Вывод:
[[-0.6 0.4]
[ 0.8 -0.2]]
Нахождение определителей
Значение, полученное арифметическим путем из коэффициентов матрицы является определителем квадратной матрицы. В SciPy это делается с помощью функции det с таким синтаксисом:
det(a, overwrite_a=False, check_finite=True)
a — (M, M) — это квадратная матрица
overwrite_a(bool, optional) — разрешает перезаписывать данные
check_finite(bool, optional) — для проверки состоит ли матрица только из конечных чисел
Пример:
import numpy as np
from scipy import linalg
A = np.array([[1,2], [4,3]])
B = linalg.det(A)
print(B)
Вывод:
-5.0
Разреженные собственные значения
Разреженные собственные значения — это набор скаляров, связанных с линейными уравнениями. ARPACK предоставляет способ быстрого нахождения этих значений (собственных векторов). Вся функциональность скрыта в двух интерфейсах: scipy.sparse.linalg.eigs и scipy.sparse.linalg.eigsh.
Интерфейс eigs позволяет находить собственные значения реальных или комплексных несимметричных квадратных матриц, а eigsh содержит интерфейсы реальных симметричных или комплексных Эрмитовых матриц.
Функция eigh решает обобщенную проблему собственного значения для комплексной Эрмитовой или реально симметричной матрицы
Пример:
from scipy.linalg import eigh
import numpy as np
A = np.array([[1, 2, 3, 4], [4, 3, 2, 1], [1, 4, 6, 3], [2, 3, 2, 5]])
a, b = eigh(A)
print("Selected eigenvalues :", a)
print("Complex ndarray :", b)
Вывод:
Selected eigenvalues : [-2.53382695 1.66735639 3.69488657 12.17158399]
Complex ndarray : [[ 0.69205614 0.5829305 0.25682823 -0.33954321]
[-0.68277875 0.46838936 0.03700454 -0.5595134 ]
[ 0.23275694 -0.29164622 -0.72710245 -0.57627139]
[ 0.02637572 -0.59644441 0.63560361 -0.48945525]]
Разреженные структуры данных и алгоритмы
Разреженные данные состоят из объектов, которые в свою очередь состоят из линий, точек, поверхностей и так далее. Пакет scipy.spatial из SciPy может вычислять диаграммы Вороного, триангуляцию и другое с помощью библиотеки Qhull. Он также включает реализации KDTree для точечных запросов ближайших соседей.
Триангуляции Делоне
С математической точки зрения триангуляции Делоне для набора дискретных точек на плоской поверхности — это триангуляция, где ни одна точка из представленных не расположена внутри описанной окружности любого треугольника.
Пример:
import matplotlib.pyplot as plt
from scipy.spatial import Delaunay
points = np.array([[0, 1], [1, 1], [1, 0],[0, 0]])
a = Delaunay(points) # Объект Делоне
print(a)
print(a.simplices)
plt.triplot(points[:,0], points[:,1], a.simplices)
plt.plot(points[:,1], points[:,0], 'o')
plt.show()
Вывод:

Функции многомерной обработки изображений
Обработка изображений — это выполнение операций над изображением по получению информации или улучшенной копии этого изображения из оригинала. Пакет scipy.ndimage состоит из нескольких функций обработки и анализа изображений, которые нужны для работы с массивами с произвольной размерностью.
Свертка и корреляция
В SciPy есть несколько функций для свертки и корреляции изображений.
- Функция
correlate1dиспользуется для вычисления одномерной корреляции по заданной оси - Функция
correlateпредлагает многомерную корреляцию для любого массива с определенным ядром - Функция
convolve1dиспользуется для вычисления одномерной свертки вдоль заданной оси - Функция
convolveпредлагает многомерную свертку для любого массива с определенным ядром
Пример:
import numpy as np
from scipy.ndimage import correlate1d
correlate1d([3,5,1,7,2,6,9,4], weights=[1,2])
Вывод:
array([ 9, 13, 7, 15, 11, 14, 24, 17])
Файловый ввод/вывод
Пакет scipy.io предоставляет несколько функций, которые помогают управлять файлами в разных форматах, включая MATLAB, файлы IDL, Matrix Market и другие.
Для использования его нужно сначала импортировать:
import scipy.io as sio
Подробная информация есть в официальной документации.
]]>matplotlib — это библиотека, предназначенная для разработки двумерных графиков (включая 3D-представления). За последнее время она широко распространилась в научных и инженерных кругах (http://matplotlib.org):
Среди всех ее функций особо выделяются следующие:
- Простота в использовании
- Постепенное развитие и интерактивная визуализация данных
- Выражения и текст в LaTeX
- Широкие возможности по контролю графических элементов
- Экспорт в разные форматы, включая PNG, PDF, SVG и EPS
О Matplotlib
matplotlib спроектирована с целью максимально точно воссоздать среду MATLAB в плане графического интерфейса и синтаксической формы. Этот подход оказался успешным, ведь он позволил задействовать особенности уже проверенного ПО (MATLAB), распространив библиотеку в среду технологий и науки. Более того, она включает тот объем работы по оптимизации, который был проделан за много лет. Результат — простота в использовании, что особенно важно для тех, у кого нет опыта работы в этой сфере.
Помимо простоты библиотека matplotlib также унаследовала от MATLAB интерактивность. Это значит, что специалист можно вставлять команду за командой для постепенной разработки графического представления данных. Этот режим отлично подходит для более интерактивных режимов работы с Python, таких как IPython, QtConsole и Jupyter Notebook, предоставляя среду для анализа данных, где есть все, что можно найти, например в Mathematica, IDL или MATLAB.
Гений создателей этой библиотеки в использовании уже доступных, зарекомендовавших себя инструментов из области науки. И это не ограничивается лишь режимом исполнения MATLAB, но также моделями текстового представления научных выражений и символов LaTeX. Благодаря своим возможностям по представлению научных выражений LaTeX был незаменимым элементом научных публикаций и документаций, в которых требуются такие визуальные репрезентации, как интегралы, объединения и производные. А matplotlib интегрирует этот инструмент для улучшения качества отображения.
Не стоит забывать о том, что matplotlib — это не отдельное приложение, а библиотека такого языка программирования, как Python. Поэтому она на полную использует его возможности. Matplotlib воспринимается как графическая библиотека, позволяющая программными средствами настраивать визуальные элементы, из которых состоят графики, и управлять ими. Способность запрограммировать визуальное представление позволяет управлять воспроизводимостью данных в разных средах особенно при изменениях или обновлениях.
А поскольку matplotlib — это библиотека Python, она позволяет на полную использовать потенциал остальных библиотек языка. Чаще всего работе с анализом данных matplotlib взаимодействует с набором других библиотек, таких как NumPy и pandas, но можно добавлять и другие.
Наконец, графическое представление из этой библиотеки можно экспортировать в самые распространенные графические форматы (PNG и SVG) и затем использовать в других приложениях, документах, в сети и так далее.
Установка
Есть много вариантов установки matplotlib. Если это дистрибутив пакетов, такой как Anaconda или Enthought Canopy, то процесс очень простой. Например, используя пакетный менеджер conda, достаточно ввести следующее:
conda install matplotlib
Если его нужно установить прямо, то команды зависят от операционной системы
В системах Debian-Ubuntu:
sudo apt-get install python-matplotlib
В Fedora-Redhat:
sudo yum install python-matplotlib
В macOS или Windows нужно использовать pip
IPython и IPython QtConsole
Для знакомства со всеми инструментами мира Python часто используют IPython из терминала или QtConsole. Все благодаря тому, что IPython позволяет использовать интерактивность улучшенного терминала и интегрировать графику прямо в консоль.
Для запуска сессии IPython нужно использовать следующую команду:
ipython
Python 3.6.3 (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 3.6.3 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
Если же используется Jupyter QtConsole с возможностью отображения графики вместе с командами, то нужна эта:
jupyter qtconsole
На экране тут же отобразится новое окно с запущенной сессией IPython.
Однако ничто не мешает использовать стандартную сессию Python. Все примеры дальше будут работать и в таком случае.
Архитектура matplotlib
Одна из основных задач, которую выполняет matplotlib — предоставление набора функций и инструментов для представления и управления Figure (так называется основной объект) вместе со всеми внутренними объектами, из которого он состоит. Но в matplotlib есть также инструменты для обработки событий и, например, анимации. Благодаря им эта библиотека способна создавать интерактивные графики на основе событий по нажатию кнопки или движению мыши.
Архитектура matplotlib логически разделена на три слоя, расположенных на трех уровнях. Коммуникация непрямая — каждый слой может взаимодействовать только с тем, что расположен под ним, но не над.
Вот эти слои:
- Слой сценария
- Художественный слой
- Слой бэкенда
Слой бэкенда
Слой Backend является нижним на диаграмме с архитектурой всей библиотеки. Он содержит все API и набор классов, отвечающих за реализацию графических элементов на низком уровне.
FigureCanvas— это объект, олицетворяющий область рисования.Renderer— объект, который рисует поFigureCanvas.Event— объект, обрабатывающий ввод от пользователя (события с клавиатуры и мыши)
Художественный слой
Средним слоем выступает художественный (artist). Все элементы, составляющие график, такие как название, метки осей, маркеры и так далее, являются экземплярами этого объекта. Каждый из них играет свою роль в иерархической структуре.
Есть два художественных класса: примитивный и составной.
- Примитивный — это объекты, которые представляют собой базовые элементы для формирования графического представления графика, например, Line2D, или геометрические фигуры, такие как прямоугольник круг или даже текст.
- Составные — объекты, состоящие из нескольких базовых (примитивных). Это оси, шкалы и диаграммы.
На этом уровне часто приходится иметь дело с объектами, занимающими высокое положение в иерархии: график, система координат, оси. Поэтому важно полностью понимать, какую роль они играют. Следующее изображение показывает три основных художественных (составных объекта), которые часто используются на этом уровне.
Figure— объект, занимающий верхнюю позицию в иерархии. Он соответствует всему графическому представлению и может содержать много систем координат.Axes— это тот самый график. Каждая система координат принадлежит только одному объектуFigureи имеет два объектаAxis(или три, если речь идет о трехмерном графике). Другие объекты, такие как название, меткиxиy, принадлежат отдельно осям.Axisучитывает числовые значения в системе координат, определяет пределы и управляет обозначениями на осях, а также соответствующим каждому из них текстом. Положение шкал определяется объектомLocator, а внешний вид —Formatter.
Слой сценария (pyplot)
Художественные классы и связанные с ними функции (API matplotlib) подходят всем разработчикам, особенно тем, кто работает с серверами веб-приложений или разрабатывает графические интерфейсы. Но для вычислений, в частности для анализа и визуализации данных, лучше всего подходит слой сценария. Он включает интерфейс pyplot.
pylab и pyplot
Существуют две библиотеки: pylab и pyplot. Но в чем между ними разница? Pylab — это модуль, устанавливаемый вместе с matplotlib, а pyplot — внутренний модуль matplotlib. На оба часто ссылаются.
from pylab import *
# и
import matplotlib.pyplot as plt
import numpy as np
Pylab объединяет функциональность pyplot с возможностями NumPy в одном пространстве имен, поэтому отдельно импортировать NumPy не нужно. Более того, при импорте pylab функции из pyplot и NumPy можно вызывать без ссылки на модуль (пространство имен), что похоже на MATLAB.
plot(x,y)
array([1,2,3,4])
# вместо
plt.plot()
np.array([1,2,3,4]
Пакет pyplot предлагает классический интерфейс Python для программирования, имеет собственное пространство имеет и требует отдельного импорта NumPy. В последующих материалах используется этот подход. Его же применяет большая часть программистов на Python.
Модули Keras предоставляют различные классы и алгоритмы глубокого обучения. Дальше о них и пойдет речь.
Модули Keras
В Keras представлены следующие модули:
- Бэкенд
- Утилиты
- Обработка изображений
- Последовательная последовательности
- Обработка текста
- Обратный вызов
Модуль бэкенда в Keras
Keras — это высокоуровневый API, который не заостряет внимание на вычислениях на бэкенде. Однако он позволяет пользователям изучать свой бэкенд и делать изменения на этом уровне. Для этого есть специальный модуль.
Его конфигурация по умолчанию хранится в файле $Home/keras/keras.json.
Он выглядит вот так:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Можно дописать код, совместимый с этим бэкендом.
from Keras import backend as K
b=K.random_uniform_variable(shape=(3,4),low=0,high=1)
c=K.random_uniform_variable(shape=(3,4),mean=0,scale=1)
d=K.random_uniform_variable(shape=(3,4),mean=0,scale=1)
a=b + c * K.abs(d)
c=K.dot(a,K.transpose(b))
a=K.sum(b,axis=1)
a=K.softmax(b)
a=K.concatenate([b,c],axis=1)
Модуль утилит в Keras
Этот модуль предоставляет утилиты для операций глубокого обучения. Вот некоторые из них.
HDF5Matrix
Для преобразования входящих данных в формат HDF5.
from.utils import HDF5Matrix data=HDF5Matrix('data.hdf5','data')
to_categorical
Для унитарной кодировки (one hot encoding) векторов класса.
from keras.utils import to_categorical
labels = [0,1,2,3,4,5]
to_categorical(labels)
print_summary
Для вывода сводки по модели.
from keras.utils import print_summary
print_summary(model)
Модуль обработки изображений в Keras
Содержит методы для конвертации изображений в массивы NumPy. Также есть функции для представления данных.
Класс ImageDataGenerator
Используется для дополнения данных в реальном времени.
keras.preprocessing.image.ImageDataGenerator(featurewise_center, samplewise_center, featurewise_std_normalization, samplewise_std_normalization, zca_whitening, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip, vertical_flip)
Методы ImageDataGenerator
apply_transform:
Для применения изменений к изображению
apply_transform(x, transform_parameters)
flow
Для генерации серий дополнительных данных.
flow(x, y, batch_size=32, shuffle, sample_weight, seed, save_to_dir, save_prefix='', save_format='png', subset)
standardize
Для нормализации входящего пакета.
standardize(x)
Модуль обработки последовательности
Методы для генерации основанных на времени данных из ввода. Также есть функции для представления данных.
TimeseriesGenerator
Для генерации временных данных.
keras.preprocessing.sequence.TimeseriesGenerator(data, targets, length, sampling_rate, stride, start_index, end_index)
skipgrams
Конвертирует последовательность слов в кортежи слов.
keras.preprocessing.sequence.skipgrams(sequence, vocabulary_size, window_size=4, negative_samples=1.0, shuffle, categorical, sampling_table, seed)
Модуль предварительной обработки текста
Методы для конвертации текста в массивы NumPy. Есть также методы для подготовки данных.
Tokenizer
Используется для конвертации основного текста в векторы.
keras.preprocessing.text.Tokenizer(num_words, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ', char_level, oov_token=, document_count=0)
one_hot
Для кодировки текста в список слов.
keras.preprocessing.text.one_hot(text, n, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ')
text_to_word_sequence
Для конвертации текста в последовательность слов.
keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ')
Модуль обратного вызова
Предоставляет функции обратного вызова. Используется для изучения промежуточных результатов.
Callback
Для создания новых обратных вызовов.
keras.callbacks.callbacks.Callback()
BaseLogger
Для вычисления среднего значения метрик.
keras.callbacks.callbacks.BaseLogger(stateful_metrics)
History
Для записи событий.
keras.callbacks.callbacks.History()
ModelCheckpoint
Для сохранения модели после каждого временного промежутка.
keras.callbacks.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only, save_weights_only, mode='auto', period=1)
Выводы
Теперь вы знакомы с разными модулями Keras и знаете, для чего они нужны.
]]>Манипуляция строками
Python — это популярный язык, который благодаря своей простоте часто используется для обработки строк и текста. Большая часть операций может быть выполнена даже с помощью встроенных функций. А для более сложных используются регулярные выражения.
Встроенные методы для работы со строками
В большинстве случаев имеются сложные строки, которые желательно разделять на части и присваивать их правильным переменным. Функция split() позволяет разбить тексты на части, используя разделитель в качестве ориентира. Им может быть, например, запятая.
>>> text = '16 Bolton Avenue , Boston'
>>> text.split(',')
['16 Bolton Avenue ', 'Boston']
По первому элементу видно, что в конце у него остается пробел. Чтобы решить эту проблему, вместе со split() нужно также использовать функцию strip(), которая обрезает пустое пространство (включая символы новой строки)
>>> tokens = [s.strip() for s in text.split(',')]
>>> tokens
['16 Bolton Avenue', 'Boston']
Результат — массив строк. Если элементов не много, то можно выполнить присваивание вот так:
>>> address, city = [s.strip() for s in text.split(',')]
>>> address
'16 Bolton Avenue'
>>> city
'Boston'
Помимо разбития текста на части часто требуется сделать обратное — конкатенировать разные строки, получив в результате текст большого объема. Самый простой способ — использовать оператор +.
>>> address + ',' + city
'16 Bolton Avenue, Boston'
Но это сработает только в том случае, если строк не больше двух-трех. Если же их больше, то есть метод join(). Его нужно применять к желаемому разделителю, передав в качестве аргумента список строк.
>>> strings = ['A+','A','A-','B','BB','BBB','C+']
>>> ';'.join(strings)
'A+;A;A-;B;BB;BBB;C+'
Еще один тип операции, которую можно выполнять со строкой — поиск отдельных частей, подстрок. В Python для этого есть ключевое слово, используемое для обнаружения подстрок.
>>> 'Boston' in text
True
Но имеются и две функции, которые выполняют ту же задачу: index() и find().
>>> text.index('Boston')
19
>>> text.find('Boston')
19
В обоих случаях возвращаемое значение — наименьший индекс, где встречаются искомые символы. Разница лишь в поведении функций в случае, если подстрока не была найдена:
>>> text.index('New York')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>> text.find('New York')
-1
Если index() вернет сообщение с ошибкой, то find() – -1. Также можно посчитать, как часто символ или комбинация из нескольких (подстрока) встречаются в тексте. За это отвечает функция count().
>>> text.count('e')
2
>>> text.count('Avenue')
1
Еще одна доступная операция — замена или удаление подстроки (или отдельного символа). В обоих случаях применяется функция replace(), где удаление подстроки — это то же самое, что и замена ее на пустой символ.
Регулярные выражения
Регулярные выражения предоставляют гибкий способ поиска совпадающих паттернов в тексте. Выражение regex — это строка, написанная с помощью языка регулярных выражений. В Python есть встроенный модуль re, который отвечает за работу с регулярными выражениями.
В первую очередь его нужно импортировать:
>>> import re
Модуль re предоставляет набор функций, которые можно поделить на три категории:
- Поиск совпадающих паттернов
- Замена
- Разбиение
Теперь разберем на примерах. Регулярное выражение для поиска одного или последовательности пробельных символов — \s+. В прошлом разделе вы видели, как для разделения текста на части с помощью split() используется символ разделения. В модуле re есть такая же функция. Она выполняет аналогичную задачу, но в качестве аргумента условия разделения принимает паттерн с регулярным выражением, что делает ее более гибкой.
>>> text = "This is an\t odd \n text!"
>>> re.split('\s+', text)
['This', 'is', 'an', 'odd', 'text!']
Разберемся чуть подробнее с принципом работы модуля re. При вызове функции re.split() сперва компилируется регулярное выражение, а только потом вызывается split() с готовым текстовым аргументом. Можно скомпилировать функцию регулярного выражения с помощью re.compile() и получить объект, который будет использоваться повторно, сэкономив таким образом циклы CPU.
Это особенно важно для операций последовательного поиска подстроки во множестве или массиве строк.
>>> regex = re.compile('\s+')
Создав объект regex с помощью функции compile(), вы сможете прямо использовать split() следующим образом.
>>> regex.split(text)
['This', 'is', 'an', 'odd', 'text!']
Для поиска совпадений паттерна с другими подстроками в тексте используется функция findall(). Она возвращает список всех подстрок, которые соответствуют условиям.
Например, если нужно найти в строке все слова, начинающиеся с латинской «A» в верхнем регистре, или, например, с «a» в любом регистре, необходимо ввести следующее:
>>> text = 'This is my address: 16 Bolton Avenue, Boston'
>>> re.findall('A\w+',text)
['Avenue']
>>> re.findall('[A,a]\w+',text)
['address', 'Avenue']
Есть еще две функции, которые связаны с findall():match() и search(). И если findall() возвращает все совпадения в списке, то search() — только первое. Более того, он является конкретным объектом.
>>> re.search('[A,a]\w+',text)
<_sre.SRE_Match object; span=(11, 18), match='address'>
Этот объект не содержит значение подстроки, соответствующей паттерну, а всего лишь индексы начала и окончания.
>>> search = re.search('[A,a]\w+',text)
>>> search.start()
11
>>> search.end()
18
>>> text[search.start():search.end()]
'address'
Функция match() ищет совпадение в начале строке; если его нет для первого символа, то двигается дальше и ищет в самой строке. Если совпадений не найдено вовсе, то она ничего не вернет.
>>> re.match('[A,a]\w+',text)
В случае успеха же она возвращает то же, что и функция search().
>>> re.match('T\w+',text)
<_sre.SRE_Match object; span=(0, 4), match='This'>
>>> match = re.match('T\w+',text)
>>> text[match.start():match.end()]
'This'
Агрегация данных
Последний этап работы с данными — агрегация. Он включает в себя преобразование, в результате которого из массива получается целое число. На самом деле, ранее упоминаемые функции sum(), mean() и count() — это тоже агрегация. Они работают с наборами данных и выполняют вычисления, результатом которых всегда является одно значение. Однако более формальный способ, дающий больше контроля над агрегацией, включает категоризацию наборов данных.
Категоризация набора, необходимая для группировки, — это важный этап в процессе обработки данных. Это тоже процесс преобразования, ведь после разделения на группы, применяется функция, которая конвертирует или преобразовывает данные определенным образом в зависимости от того, к какой группе они принадлежат. Часто фазы группировки и применения функции происходит в один шаг.
Также для этого этапа анализа данных pandas предоставляет гибкий и производительный инструмент — GroupBy.
Как и в случае с join те, кто знаком с реляционными базами данных и языком SQL, увидят знакомые вещи. Однако языки, такие как SQL, довольно ограничены, когда их применяют к группам. А вот гибкость таких языков, как Python, со всеми доступными библиотеками, особенно pandas, дает возможность выполнять очень сложные операции.
GroupBy
Теперь разберем в подробностях механизм работы GroupBy. Он использует внутренний механизм, процесс под названием split-apply-combine. Это паттерн, который можно разбить на три фазы, выделив отдельные операции:
- Разделение — разделение на группы датасетов
- Применение — применение функции к каждой группе
- Комбинирование — комбинирование результатов разных групп
Рассмотрите процесс подробно на следующей схеме. На первом этапе, разделении, данные из структуры (Dataframe или Series) разделяются на несколько групп в соответствии с заданными критериями: индексами или значениями в колонках. На жаргоне SQL значения в этой колонке называются ключами. Если же вы работаете с двухмерными объектами, такими как Dataframe, критерий группировки может быть применен и к строке (axis = 0), и колонке (axis = 1).
Вторая фаза состоит из применения функции или, если быть точнее, — вычисления, основанного на функции, результатом которого является одно значение, характерное для этой группы.
Последний этап собирает результаты каждой группы и комбинирует их в один объект.
Практический пример
Теперь вы знаете, что процесс агрегации данных в pandas разделен на несколько этапов: разделение-применение-комбинирование. И пусть в библиотеке они не выражены явно конкретными функциями, функция groupby() генерирует объект GroupBy, который является ядром целого процесса.
Для лучшего понимания этого механизма стоит обратиться к реальному примеру. Сперва создадим Dataframe с разными числовыми и текстовыми значениями.
>>> frame = pd.DataFrame({ 'color': ['white','red','green','red','green'],
... 'object': ['pen','pencil','pencil','ashtray','pen'],
... 'price1' : [5.56,4.20,1.30,0.56,2.75],
... 'price2' : [4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | object | price1 | price2 |
|---|-------|---------|--------|--------|
| 0 | white | pen | 5.56 | 4.75 |
| 1 | red | pencil | 4.20 | 4.12 |
| 2 | green | pencil | 1.30 | 1.60 |
| 3 | red | ashtray | 0.56 | 0.75 |
| 4 | green | pen | 2.75 | 3.15 |
Предположим, нужно посчитать среднюю стоимость в колонке price1 с помощью меток из колонки color. Есть несколько способов, как этого можно добиться. Например, можно получить доступ к колонке price1 и затем вызвать groupby(), где колонка color будет выступать аргументом.
>>> group = frame['price1'].groupby(frame['color'])
>>> group
<pandas.core.groupby.SeriesGroupBy object at 0x00000000098A2A20>
Результат — объект GroupBy. Однако в этой операции не было никаких вычислений; пока что была лишь собрана информация, которая необходима для вычисления среднего значения. Теперь у нас есть group, где все строки с одинаковым значением цвета сгруппированы в один объект.
Чтобы понять, как произошло такое разделение на группы, вызовите атрибут groups для объекта GroupBy.
>>> group.groups
{'green': Int64Index([2, 4], dtype='int64'),
'red': Int64Index([1, 3], dtype='int64'),
'white': Int64Index([0], dtype='int64')}
Как видите, здесь перечислены все группы и явно обозначены строки Dataframe в них. Теперь нужно применить операцию для получения результатов каждой из групп.
>>> group.mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> group.sum()
color
green 4.05
red 4.76
white 5.56
Name: price1, dtype: float64
Группировка по иерархии
В прошлом разделе данные были сгруппированы по значениям колонки-ключа. Тот же подход можно использовать и для нескольких колонок, сделав группировку нескольких ключей иерархической.
>>> ggroup = frame['price1'].groupby([frame['color'],frame['object']])
>>> ggroup.groups
{('green', 'pen'): Int64Index([4], dtype='int64'),
('green', 'pencil'): Int64Index([2], dtype='int64'),
('red', 'ashtray'): Int64Index([3], dtype='int64'),
('red', 'pencil'): Int64Index([1], dtype='int64'),
('white', 'pen'): Int64Index([0], dtype='int64')}
>>> ggroup.sum()
color object
green pen 2.75
pencil 1.30
red ashtray 0.56
pencil 4.20
white pen 5.56
Name: price1, dtype: float64
Группировка может работать не только с одной колонкой, но и с несколькими или целым Dataframe. Также если объект GroupBy не потребуется использовать несколько раз, просто удобно выполнять группировки и расчеты за раз, без объявления дополнительных переменных.
>>> frame[['price1','price2']].groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
>>> frame.groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Итерация с группировкой
Объект GroupBy поддерживает операцию итерации для генерации последовательности из двух кортежей, содержащих названия групп и их данных.
>>> for name, group in frame.groupby('color'):
... print(name)
... print(group)
green
color object price1 price2
2 green pencil 1.30 1.60
4 green pen 2.75 3.15
red
color object price1 price2
1 red pencil 4.20 4.12
3 red ashtray 0.56 0.75
white
color object price1 price2
0 white pen 5.56 4.75
В последнем примере для иллюстрации был применен вывод переменных. Но операцию вывода на экран можно заменить на функцию, которую требуется применить.
Цепочка преобразований
Из этих примеров должно стать понятно, что при передаче функциям вычисления или другим операциям группировок (вне зависимости от способа их получения) результатом всегда является Series (если была выбрана одна колонка) или Dataframe, сохраняющий систему индексов и названия колонок.
>>> result1 = frame['price1'].groupby(frame['color']).mean()
>>> type(result1)
<class 'pandas.core.series.Series'>
>>> result2 = frame.groupby(frame['color']).mean()
>>> type(result2)
<class 'pandas.core.frame.DataFrame'>
Таким образом становится возможным выбрать одну колонку на разных этапах процесса. Дальше три примера выбора одной колонки на трех разных этапах. Они иллюстрируют гибкость такой системы группировки в pandas.
>>> frame['price1'].groupby(frame['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> frame.groupby(frame['color'])['price1'].mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> (frame.groupby(frame['color']).mean())['price1']
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
Но также после операции агрегации имена некоторых колонок могут не нести нужное значение. Поэтому часто оказывается полезным добавлять префикс, объясняющий бизнес-логику такого объединения. Добавление префикса (вместо использования полностью нового имени) помогает отслеживать источник данных. Это важно в случае применения процесса цепочки преобразований (когда Series или Dataframe генерируются друг из друга), где важно отслеживать исходные данные.
>>> means = frame.groupby('color').mean().add_prefix('mean_')
>>> means
| | mean_price1 | mean_price2 |
|-------|-------------|-------------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Функции для групп
Хотя многие методы не были реализованы специально для GroupBy, они корректно работают с Series. В прошлых примерах было видно, насколько просто получить Series на основе объекта GroupBy, указав имя колонки и применив метод для вычислений. Например, можно использование вычисление квантилей с помощью функции quantiles().
>>> group = frame.groupby('color')
>>> group['price1'].quantile(0.6)
color
green 2.170
red 2.744
white 5.560
Name: price1, dtype: float64
Также можно определять собственные функции агрегации. Для этого функцию нужно создать и передать в качестве аргумента функции mark(). Например, можно вычислить диапазон значений для каждой группы.
>>> def range(series):
... return series.max() - series.min()
...
>>> group['price1'].agg(range)
color
green 1.45
red 3.64
white 0.00
Name: price1, dtype: float64
Функция agg() позволяет использовать функции агрегации для всего объекта Dataframe.
>>> group.agg(range)
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 1.45 | 1.55 |
| red | 3.64 | 3.37 |
| white | 0.00 | 0.00 |
Также можно использовать больше функций агрегации одновременно с помощью mark(), передав массив со списком операций для выполнения. Они станут новыми колонками.
>>> group['price1'].agg(['mean','std',range])
| | mean | std | range |
|-------|-------|----------|-------|
| color | | | |
| green | 2.025 | 1.025305 | 1.45 |
| red | 2.380 | 2.573869 | 3.64 |
| white | 5.560 | NaN | 0.00 |
Продвинутая агрегация данных
В этом разделе речь пойдет о функциях transform() и apply(), которые позволяют выполнять разные виды операций, включая очень сложные.
Предположим, что в одном Dataframe нужно получить следующее: оригинальный объект (с данными) и полученный с помощью вычисления агрегации, например, сложения.
>>> frame = pd.DataFrame({ 'color':['white','red','green','red','green'],
... 'price1':[5.56,4.20,1.30,0.56,2.75],
... 'price2':[4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | price1 | price2 |
|---|-------|--------|--------|
| 0 | white | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 |
| 2 | green | 1.30 | 1.60 |
| 3 | red | 0.56 | 0.75 |
| 4 | green | 2.75 | 3.15 |
>>> sums = frame.groupby('color').sum().add_prefix('tot_')
>>> sums
| | tot_price1 | tot_price2 | price2 |
|-------|------------|------------|--------|
| color | | | 4.75 |
| green | 4.05 | 4.75 | 4.12 |
| red | 4.76 | 4.87 | 1.60 |
| white | 5.56 | 4.75 | 0.75 |
>>> merge(frame,sums,left_on='color',right_index=True)
| | color | price1 | price2 | tot_price1 | tot_price2 |
|---|-------|--------|--------|------------|------------|
| 0 | white | 5.56 | 4.75 | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 | 4.76 | 4.87 |
| 3 | red | 0.56 | 0.75 | 4.76 | 4.87 |
| 2 | green | 1.30 | 1.60 | 4.05 | 4.75 |
| 4 | green | 2.75 | 3.15 | 4.05 | 4.75 |
Благодаря merge() можно сложить результаты агрегации в каждой строке. Но есть и другой способ, работающий за счет transform(). Эта функция выполняет агрегацию, но в то же время показывает значения, сделанные с помощью вычислений на основе ключевого значения в каждой строке Dataframe.
>>> frame.groupby('color').transform(np.sum).add_prefix('tot_')
| | tot_price1 | tot_price2 |
|---|------------|------------|
| 0 | 5.56 | 4.75 |
| 1 | 4.76 | 4.87 |
| 2 | 4.05 | 4.75 |
| 3 | 4.76 | 4.87 |
| 4 | 4.05 | 4.75 |
Метод transform() — более специализированная функция с конкретными условиями: передаваемая в качестве аргумента функция должна возвращать одно скалярное значение (агрегацию).
Метод для более привычных GroupBy — это apply(). Он в полной мере реализует схему разделение-применение-комбинирование. Функция разделяет объект на части для преобразования, вызывает функцию для каждой из частей и затем пытается связать их между собой.
>>> frame = pd.DataFrame( { 'color':['white','black','white','white','black','black'],
... 'status':['up','up','down','down','down','up'],
... 'value1':[12.33,14.55,22.34,27.84,23.40,18.33],
... 'value2':[11.23,31.80,29.99,31.18,18.25,22.44]})
>>> frame
| | color | price1 | price2 | status |
|---|-------|--------|--------|--------|
| 0 | white | 12.33 | 11.23 | up |
| 1 | black | 14.55 | 31.80 | up |
| 2 | white | 22.34 | 29.99 | down |
| 3 | white | 27.84 | 31.18 | down |
| 4 | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> frame.groupby(['color','status']).apply( lambda x: x.max())
| | | color | price1 | price2 | status |
|-------|--------|-------|--------|--------|--------|
| color | status | | | | |
| black | down | black | 23.40 | 18.25 | down |
| | up | black | 18.33 | 31.80 | up |
| white | down | white | 27.84 | 31.18 | down |
| | up | white | 12.33 | 11.23 | up |
>>> frame.rename(index=reindex, columns=recolumn)
| | color | price1 | price2 | status |
|--------|-------|--------|--------|--------|
| first | white | 12.33 | 11.23 | up |
| second | black | 14.55 | 31.80 | up |
| third | white | 22.34 | 29.99 | down |
| fourth | white | 27.84 | 31.18 | down |
| fifth | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> temp = pd.date_range('1/1/2015', periods=10, freq= 'H')
>>> temp
DatetimeIndex(['2015-01-01 00:00:00', '2015-01-01 01:00:00',
'2015-01-01 02:00:00', '2015-01-01 03:00:00',
'2015-01-01 04:00:00', '2015-01-01 05:00:00',
'2015-01-01 06:00:00', '2015-01-01 07:00:00',
'2015-01-01 08:00:00', '2015-01-01 09:00:00'],
dtype='datetime64[ns]', freq='H')
>>> timeseries = pd.Series(np.random.rand(10), index=temp)
>>> timeseries
2015-01-01 00:00:00 0.317051
2015-01-01 01:00:00 0.628468
2015-01-01 02:00:00 0.829405
2015-01-01 03:00:00 0.792059
2015-01-01 04:00:00 0.486475
2015-01-01 05:00:00 0.707027
2015-01-01 06:00:00 0.293156
2015-01-01 07:00:00 0.091072
2015-01-01 08:00:00 0.146105
2015-01-01 09:00:00 0.500388
Freq: H, dtype: float64
>>> timetable = pd.DataFrame( {'date': temp, 'value1' : np.random.rand(10),
... 'value2' : np.random.rand(10)})
>>> timetable
| | date | value1 | value2 |
|---|---------------------|----------|----------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 |
Затем Dataframe добавляется колонка с набором текстовых значений, которые будут выступать ключевыми значениями.
>>> timetable['cat'] = ['up','down','left','left','up','up','down','right',
'right','up']
>>> timetable
| | date | value1 | value2 | cat |
|---|---------------------|----------|----------|-------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 | up |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 | down |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 | left |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 | left |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 | up |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 | up |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 | down |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 | right |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 | right |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 | up |
Но в этом примере все равно есть повторяющиеся ключи.
]]>Нейронная сеть — это стек из слоев. Каждый из них получает входящие данные, делает вычисления и передает результат следующему. В Keras есть много встроенных слоев. Например, Conv2D, MaxPooling2D, Dense и Flatten имеют по несколько сценариев использования, но их нужно применять в соответствии с определенными требованиями. Однако иногда может потребоваться делать вычисления, которые не связаны с тем, что умеет Keras.
В таком случае нужно будет создать собственный слой и определить алгоритм для вычислений на основе входящих данных. В Keras есть инструмент для создания кастомных слоев. В этом материале разберемся, что они собой представляют и рассмотрим примеры построения таких слоев.
Кастомные слои Keras можно добавить двумя путями:
- Лямбда-слой
- Кастомный слой класса
Лямбда-слой в Keras
Лямбда-слои используются в Keras в тех случаях, когда нет нужды добавлять веса предыдущему слою. Этот слой создается для простых операций. Он напоминает лямбда-функции.
Сперва определяется функция, принимающая предыдущий слой в качестве источника входящих данных, затем выполняются вычисления, и возвращаются обновленные тензоры. После этого функция передается кастомному лямбда-слою.
Самое распространенное применение лямбда-слоя — определение собственной функции активации.
Предположим, нужно определить собственную функцию активации ReLU с помощью лямбда-слоя.
from keras.layer import Lambda
from keras import backend as K
def custom_function(input):
return K.maximum(0.,input)
lambda_output = Lambda(custom_function)(input)
Этого достаточно для создания.
После этого слой добавляется в модель тем же способом, что и остальные.
model.add(lambda_output)
Кастомный слой класса в Keras
А теперь создадим собственный слой с весами. Для этого нужно реализовать четыре метода:
__init__— инициализируется переменная класса и переменная суперклассаbuild(input_shape)— определяются весаcall(x)— определяется алгоритм вычислений. В качестве аргумента принимается тензорcompute_output_shape(input_shape)— определяется форма вывода слоя
Рассмотрим получившуюся реализацию:
from keras import backend as K
from keras.layers import Layer
class custom_layer(Layer):
def __init__(self,output_dim,**kwargs):
self.output_dim=output_dim
super(custom_layer,self).__init__(**kwargs)
def build(self,input_shape):
self.W=self.add_weight(name=’kernel’,
shape=(input_shape[1],
self.output_dim),
initializer=’uniform’,
trainable=True)
self.built = True
def call(self,x):
return K.dot(x,self.W)
def compute_output_shape(self,input_shape):
return (input_shape[0], self.output_dim)
Здесь используется всего один тензор, но их можно передать несколько в одном списке.
Выводы
Эта статья посвящена принципам создания кастомных слоев Keras. Есть два способа: лямбда-слои и слои класса. Первые нужны для базовых операций, а вторые — для применения весов ко входящим данным.
]]>Процесс подготовки данных для анализа включает сборку данных в Dataframe с возможными добавлениями из других объектов и удалением ненужных частей. Следующий этап — трансформация. После того как данные внутри структуры организованы, нужно преобразовать ее значения. Этот раздел будет посвящен распространенным проблемам и процессам, которые требуются для их решения с помощью функций библиотеки pandas.
Среди них удаление элементов с повторяющимися значениями, изменение индексов, обработка числовых значений данных и строк.
Удаление повторов
Дубликаты строк могут присутствовать в Dataframe по разным причинам. И в объектах особо крупного размера их может быть сложно обнаружить. Для этого в pandas есть инструменты анализа повторяющихся данных для крупных структур.
Для начала создадим простой Dataframe с повторяющимися строками.
>>> dframe = pd.DataFrame({'color': ['white','white','red','red','white'],
... 'value': [2,1,3,3,2]})
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 1 | white | 1 |
| 2 | red | 3 |
| 3 | red | 3 |
| 4 | white | 2 |
Функция duplicated() способна обнаружить дубликаты. Она вернет объект Series, состоящий из булевых значений, где каждый элемент соответствует строке. Их значения равны True, если строка является дубликатом (все повторения за исключением первого) и False, если повторов этого элемента не было.
>>> dframe.duplicated()
0 False
1 False
2 False
3 True
4 True
dtype: bool
Объект с булевыми элементами может быть особенно полезен, например, для фильтрации. Так, чтобы увидеть строки-дубликаты, нужно просто написать следующее:
>>> dframe[dframe.duplicated()]
| | color | value |
|---|-------|-------|
| 3 | red | 3 |
| 4 | white | 2 |
Обычно повторяющиеся строки удаляются. Для этого в pandas есть функция drop_duplicates(), которая возвращает Dataframe без дубликатов.
>>> dframe = dframe.drop_duplicates()
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 2 | red | 3 |
Маппинг
Библиотека pandas предоставляет набор функций, использующих маппинг для выполнения определенных операций. Маппинг — это всего лишь создание списка совпадений двух разных значений, что позволяет привязывать значение определенной метке или строке.
Для определения маппинга лучше всего подходит объект dict:
map = {
'label1' : 'value1,
'label2' : 'value2,
...
}
Функции, которые будут дальше встречаться в этом разделе, выполняют конкретные операции, но всегда принимают объект dict.
• replace() — Заменяет значения
• map() — Создает новый столбец
• rename() — Заменяет значения индекса
Замена значений с помощью маппинга
Часто бывает так, что в готовой структуре данных присутствуют значения, не соответствующие конкретным требованиям. Например, текст может быть написан на другом языке, являться синонимом или, например, выраженным в другом виде. В таких случаях используется операция замены разных значений.
Для примера определим Dataframe с разными объектами и их цветами, включая два названия цветов не на английском.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','rosso','verde','black','yellow'],
... 'price':[5.56,4.20,1.30,0.56,2.75]})
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | rosso | mug | 4.20 |
| 2 | verde | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Для замены некорректных значений новыми нужно определить маппинг соответствий, где ключами будут выступать новые значения.
>>> newcolors = {
... 'rosso': 'red',
... 'verde': 'green'
... }
Теперь осталось использовать функцию replace(), задав маппинг в качестве аргумента.
>>> frame.replace(newcolors)
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Как видно выше, два цвета были заменены на корректные значения в Dataframe. Распространенный пример — замена значений NaN на другие, например, на 0. Функция replace() отлично справляется и с этим.
>>> ser = pd.Series([1,3,np.nan,4,6,np.nan,3])
>>> ser
0 1.0
1 3.0
2 NaN
3 4.0
4 6.0
5 NaN
6 3.0
dtype: float64
>>> ser.replace(np.nan,0)
0 1.0
1 3.0
2 0.0
3 4.0
4 6.0
5 0.0
6 3.0
dtype: float64
Добавление значений с помощью маппинга
В предыдущем примере вы узнали, как менять значения с помощью маппинга. Теперь попробуем использовать маппинг на другом примере — для добавления новых значений в колонку на основе значений в другой. Маппинг всегда определяется отдельно.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','red','green','black','yellow']})
>>> frame
| | color | item |
|---|--------|---------|
| 0 | white | ball |
| 1 | red | mug |
| 2 | green | pen |
| 3 | black | pencil |
| 4 | yellow | ashtray |
Предположим, что нужно добавить колонку с ценой вещи из объекта. Также предположим, что имеется список цен. Определим его в виде объекта dict с ценами для каждого типа объекта.
>>> prices = {
... 'ball' : 5.56,
... 'mug' : 4.20,
... 'bottle' : 1.30,
... 'scissors' : 3.41,
... 'pen' : 1.30,
... 'pencil' : 0.56,
... 'ashtray' : 2.75
... }
Функция map(), примененная к Series или колонке объекта Dataframe принимает функцию или объект с маппингом dict. В этому случае можно применить маппинг цен для элементов колонки, добавив еще одну колонку price в Dataframe.
>>> frame['price'] = frame['item'].map(prices)
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Переименование индексов осей
По примеру того, как работает изменение значений в Series и Dataframe, можно трансформировать метки оси с помощью маппинга. Для замены меток индексов в pandas есть функция rename(), которая принимает маппинг (объект dict) в качестве аргумента.
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
>>> reindex = {
... 0: 'first',
... 1: 'second',
... 2: 'third',
... 3: 'fourth',
... 4: 'fifth'}
>>> frame.rename(reindex)
| | color | item | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
По умолчанию переименовываются индексы. Если же нужно поменять названия колонок, то используется параметр columns. В следующем примере присвоим несколько маппингов двум индексам с параметром columns.
>>> recolumn = {
... 'item':'object',
... 'price': 'value'}
>>> frame.rename(index=reindex, columns=recolumn)
| | color | object | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
В тех случаях когда заменить нужно только одно значение, все можно и не писать.
>>> frame.rename(index={1:'first'}, columns={'item':'object'})
| | color | object | price |
|-------|--------|---------|-------|
| 0 | white | ball | 5.56 |
| first | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Пока что функция rename() возвращала объект Dataframe с изменениями, не трогая оригинальный объект. Но если нужно поменять его, то необходимо передать значение True параметру inplace.
>>> frame.rename(columns={'item':'object'}, inplace=True)
>>> frame
| | color | object | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Дискретизация и биннинг
Более сложный процесс преобразования называется дискретизацией. Он используется для обработки большим объемов данных. Для анализа их необходимо разделять на дискретные категории, например, распределив диапазон значений на меньшие интервалы и посчитав статистику для каждого. Еще один пример — большое количество образцов. Даже здесь необходимо разделять весь диапазон по категориям и внутри них считать вхождения и статистику.
В следующем случае, например, нужно работать с экспериментальными значениями, лежащими в диапазоне от 0 до 100. Эти данные собраны в список.
>>> results = [12,34,67,55,28,90,99,12,3,56,74,44,87,23,49,89,87]
Вы знаете, что все значения лежат в диапазоне от 0 до 100, а это значит, что их можно разделить на 4 одинаковых части, бины. В первом будут элементы от 0 до 25, во втором — от 26 до 50, в третьем — от 51 до 75, а в последнем — от 75 до 100.
Для этого в pandas сначала нужно определить массив со значениями разделения:
>>> bins = [0,25,50,75,100]
Затем используется специальная функция cut(), которая применяется к массиву. В нее нужно добавить и бины.
>>> cat = pd.cut(results, bins)
>>> cat
(0, 25]
(25, 50]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(75, 100]
(0, 25]
(0, 25]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(0, 25]
(25, 50]
(75, 100]
(75, 100]
Levels (4): Index(['(0, 25]', '(25, 50]', '(50, 75]', '(75, 100]'],
dtype=object)
Функция cut() возвращает специальный объект типа Categorical. Его можно считать массивом строк с названиями бинов. Внутри каждая содержит массив categories, включающий названия разных внутренних категорий и массив codes со списком чисел, равных элементам results. Число соответствует бину, которому был присвоен соответствующий элемент results.
>>> cat.categories
IntervalIndex([0, 25], (25, 50], (50, 75], (75, 100]]
closed='right'
dtype='interval[int64]')
>>> cat.codes
array([0, 1, 2, 2, 1, 3, 3, 0, 0, 2, 2, 1, 3, 0, 1, 3, 3], dtype=int8)
Чтобы узнать число вхождений каждого бина, то есть, результаты для всех категорий, нужно использовать функцию value_counts().
>>> pd.value_counts(cat)
(75, 100] 5
(50, 75] 4
(25, 50] 4
(0, 25] 4
dtype: int64
У каждого класса есть нижний предел с круглой скобкой и верхний — с квадратной. Такая запись соответствует математической, используемой для записи интервалов. Если скобка квадратная, то число лежит в диапазоне, а если круглая — то нет.
Бинам можно задавать имена, передав их в массив строк, а затем присвоив его параметру labels в функции cut(), которая используется для создания объекта Categorical.
>>> bin_names = ['unlikely','less likely','likely','highly likely']
>>> pd.cut(results, bins, labels=bin_names)
unlikely
less likely
likely
likely
less likely
highly likely
highly likely
unlikely
unlikely
likely
likely
less likely
highly likely
unlikely
less likely
highly likely
highly likely
Levels (4): Index(['unlikely', 'less likely', 'likely', 'highly likely'],
dtype=object)
Если функции cut() передать в качестве аргумента целое число, а не границы бина, то диапазон значений будет разделен на указанное количество интервалов.
Пределы будут основаны на минимуме и максимуме данных.
>>> pd.cut(results, 5)
(2.904, 22.2]
(22.2, 41.4]
(60.6, 79.8]
(41.4, 60.6]
(22.2, 41.4]
(79.8, 99]
(79.8, 99]
(2.904, 22.2]
(2.904, 22.2]
(41.4, 60.6]
(60.6, 79.8]
(41.4, 60.6]
(79.8, 99]
(22.2, 41.4]
(41.4, 60.6]
(79.8, 99]
(79.8, 99]
Levels (5): Index(['(2.904, 22.2]', '(22.2, 41.4]', '(41.4, 60.6]',
'(60.6, 79.8]', '(79.8, 99]'], dtype=object)
Также в pandas есть еще одна функция для биннинга, qcut(). Она делит весь набор на квантили. Так, в зависимости от имеющихся данных cut() обеспечит разное количество данных для каждого бина. А qcut() позаботится о том, чтобы количество вхождений было одинаковым. Могут отличаться только границы.
>>> quintiles = pd.qcut(results, 5)
>>> quintiles
[3, 24]
(24, 46]
(62.6, 87]
(46, 62.6]
(24, 46]
(87, 99]
(87, 99]
[3, 24]
[3, 24]
(46, 62.6]
(62.6, 87]
(24, 46]
(62.6, 87]
[3, 24]
(46, 62.6]
(87, 99]
(62.6, 87]
Levels (5): Index(['[3, 24]', '(24, 46]', '(46, 62.6]', '(62.6, 87]',
'(87, 99]'], dtype=object)
>>> pd.value_counts(quintiles)
[3, 24] 4
(62.6, 87] 4
(87, 99] 3
(46, 62.6] 3
(24, 46] 3
dtype: int64
В этом примере видно, что интервалы отличаются от тех, что получились в результате использования функции cut(). Также можно обратить внимание на то, что qcut() попыталась стандартизировать вхождения для каждого бина, поэтому в первых двух больше вхождений. Это связано с тем, что количество объектов не делится на 5.
Определение и фильтрация лишних данных
При анализе данных часто приходится находить аномальные значения в структуре данных. Для примера создайте Dataframe с тремя колонками целиком случайных чисел.
>>> randframe = pd.DataFrame(np.random.randn(1000,3))
С помощью функции describe() можно увидеть статистику для каждой колонки.
>>> randframe.describe()
| | 0 | 1 | 2 |
|-------|-------------|-------------|-------------|
| count | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | -0.036163 | 0.037203 | 0.018722 |
| std | 1.038703 | 0.986338 | 1.011587 |
| min | -3.591217 | -3.816239 | -3.586733 |
| 25% | -0.729458 | -0.581396 | -0.665261 |
| 50% | -0.025864 | 0.005155 | -0.002774 |
| 75% | 0.674396 | 0.706958 | 0.731404 |
| max | 3.115554 | 2.899073 | 3.425400 |
Лишними можно считать значения, которые более чем в три раза больше стандартного отклонения. Чтобы оставить только подходящие, нужно использовать функцию std().
>>> randframe.std()
0 1.038703
1 0.986338
2 1.011587
dtype: float64
Теперь используйте фильтр для всех значений Dataframe, применив соответствующее стандартное отклонение для каждой колонки. Функция any() позволит использовать фильтр для каждой колонки.
>>> randframe[(np.abs(randframe) > (3*randframe.std())).any(1)]
| | 0 | 1 | 2 |
|-----|-----------|-----------|-----------|
| 87 | -2.106846 | -3.408329 | -0.067435 |
| 129 | -3.591217 | 0.791474 | 0.243038 |
| 133 | 1.149396 | -3.816239 | 0.328653 |
| 717 | 0.434665 | -1.248411 | -3.586733 |
| 726 | 1.682330 | 1.252479 | -3.090042 |
| 955 | 0.272374 | 2.224856 | 3.425400 |
Перестановка
Операции перестановки (случайного изменения порядка) в объекте Series или строках Dataframe можно выполнить с помощью функции numpy.random.permutation().
Для этого примера создайте Dataframe с числами в порядке возрастания.
>>> nframe = pd.DataFrame(np.arange(25).reshape(5,5))
>>> nframe
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
Теперь создайте массив из пяти чисел от 0 до 4 в случайном порядке с функцией permutation(). Этот массив будет новым порядком, в котором потребуется разместить и значения строк из Dataframe.
>>> new_order = np.random.permutation(5)
>>> new_order
array([2, 3, 0, 1, 4])
Теперь примените его ко всем строкам Dataframe с помощью функции take().
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 0 | 0 | 1 | 2 | 3 | 4 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 1 | 5 | 6 | 7 | 8 | 9 |
Как видите, порядок строк поменялся, а индексы соответствуют порядку в массиве new_order.
Перестановку можно произвести и для отдельной части Dataframe. Это сгенерирует массив с последовательностью, ограниченной конкретным диапазоном, например, от 2 до 4.
>>> new_order = [3,4,2]
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 2 | 10 | 11 | 12 | 13 | 14 |
Случайная выборка
Вы уже знаете, как доставать отдельные части Dataframe для последующей перестановки. Но иногда ее потребуется отобрать случайным образом. Проще всего сделать это с помощью функции np.random.randint().
>>> sample = np.random.randint(0, len(nframe), size=3)
>>> sample
array([1, 4, 4])
>>> nframe.take(sample)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
В этом случае один и тот же участок попадается даже чаще.
]]>Слои являются основными элементами, необходимыми при создании нейронных сетей. Последовательные слои отвечают за архитектуру модели глубокого обучения. Каждый из них выполняет вычисления на основе данных, полученных из предыдущего. Затем информация передается дальше. В конце концов, последний слой выдает требуемый результат. В этом материале разберем типы слоев Keras, их свойства и параметры.
Слои Keras
Для определения или создания слоя Keras нужна следующая информация:
- Форма ввода: для понимания структуры входящей информации
- Количество: для определения количества узлов/нейронов в слое
- Инициализатор: для определения весов каждого входа, что важно для выполнения вычислений
- Активаторы: для преобразования входных данных в нелинейный формат, чтобы каждый нейрон мог обучаться эффективнее
- Ограничители: для наложения ограничений на веса при оптимизации
- Регуляторы: для применения штрафов к параметрам во время оптимизации
Различные слои в Keras
Основные слои Keras
Dense
Вычисляет вывод следующим образом:
output=activation(dot(input,kernel)+bias)
Здесь activation — это активатор, а kernel — взвешенная матрица, применяемая к входящим тензорам. bias — это константа, помогающая настроить модель наилучшим образом.
Dense-слой получает информацию со всех узлов предыдущего слоя. Вот его аргументы и значения по умолчанию:
Dense(units, activation=NULL, use_bias=TRUE,kernel_initializer='glorot_uniform',
bias_regularizer=NULL, activity_regularizer=NULL,
kernel_constraint=NULL, bias_constrain=NULL)
Activation
Используется для применения функции активации к выводу. То же самое, что передача активации в Dense-слой. Имеет следующие аргументы:
Activation(activation_function)
Если функцию активации не передать, то будет выполнена линейная активация.
Dropout
Dropout применяется в нейронных сетях для решения проблемы переобучения. Для этого он случайным образом выбирает доли единиц и при каждом обновлении назначает им значение 0.
Аргументы:
Dropout(rate, noise_shape=NULL, seed=NULL)
Flatten
Flatten используется для конвертации входящих данных в меньшую размерность.
Например, входящий слой размерности (batch_size, 3,2) «выравнивается» для вывода размерности (batch_size, 6). Он имеет следующие аргументы.
Flatten(data_format=None)
Input
Этот слой используется в Keras для создания модели на основе ввода и вывода модели. Он является точкой входа в модель графа.
Аргументы:
Input(shape, batch_shape, name, dtype,
sparse=FALSE,tensor=NULL)
Reshape
Изменить вывод под конкретную размерность
Аргумент:
Reshape(target_shape)
Выдаст следующий результат:
(batch_size,)+ target_shape
Permute
Поменять ввод для соответствия конкретному шаблону. Этот же слой используется для изменения формы ввода с помощью определенных шаблонов.
Аргументы:
Permute(dims)
Lambda
Слои Lambda используются для создания дополнительных признаков слоев, которых нет в Keras.
Аргументы:
Lambda(lambda_fun,output_shape=None, mask=None, arguments=None)
Masking
Пропустить временной промежуток, если все признаки равны mask_value.
Аргументы:
Masking(mask_value=0.0)
Сверточные сети Keras
Conv1D и Conv2D
Здесь определяется взвешенное ядро. Производится операция свертки, результатом которой становятся тензоры.
Аргументы:
Conv1D(filters,kernel_size,strides=1, padding='valid',
data_format='channels_last', dilation_rate=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None)
Conv2D(filters,kernel_size,strides=(1,1) , padding='valid',
data_format='channels_last', dilation_rate=(1,1) ,
activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None,
activity_regularizer=None, kernel_constraint=None,
bias_constraint=None)
Слои пулинга (подвыборки)
Они используются для уменьшения размера ввода и извлечения важной информации.
MaxPooling1D и MaxPooling2D
Извлекаем максимум
Аргументы:
MaxPooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last')
MaxPooling2D(pool_size=(2,2), strides=None, padding='valid',
data_format='channels_last')
AveragePooling1D и AveragePooling2D
Извлекаем среднее
Аргументы:
AveragePooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last')
AveragePooling1D(pool_size=(2,2), strides=None, padding='valid',
data_format=None)
Рекуррентный слой
Этот слой используется для вычисления последовательных данных — временного ряда или естественного языка.
SimpleRNN
Это полностью связанная RNN (рекуррентная нейронная сеть), где вывод подается обратно в качестве входящих данных
Аргументы:
SimpleRNN(units, activation, use_bias, kernel_initializer,
recurrent_initializer, bias_initializer, kernel_regularizer,
recurrent_regularizer, bias_regularizer, activity_regularizer,
kernel_constraint, recurrent_constraint, bias_constraint,
dropout, recurrent_dropout, return_sequences, return_state)
LSTM
Это увеличенная форма RNN с хранилищем для информации.
LSTM(units, activation , recurrent_activation, use_bias,
kernel_initializer, recurrent_initializer, bias_initializer,
unit_forget_bias, kernel_regularizer, recurrent_regularizer,
bias_regularizer, activity_regularizer, kernel_constraint,
recurrent_constraint, bias_constraint, dropout,
recurrent_dropout, implementation, return_sequences,
return_state)
В Keras есть и другие слои, но чаще всего используются описанные выше.
Выводы
Этот материал посвящен концепции слоев в моделях Keras. Вы узнали о требованиях для построения слоя, а также об их типах: основные слои, сверточные слои, подвыборки, рекуррентные слои, а также их свойства и параметры.
]]>Это руководство посвящено глубокому обучению и важным алгоритмам в Keras. Разберем сферы применение алгоритма и его реализацию в Keras.
Глубокое обучение — это подраздел машинного обучения, использующий алгоритмы, вдохновленные работой человеческого мозга. В последнем десятилетии было несколько важных разработок в этой области. Библиотека Keras – результат одной из них. Она позволяет создавать модели нейронных сетей в несколько строк кода.
В свое время был бум в исследовании алгоритмов глубокого обучения, а Keras обеспечивает простоту их создания для пользователей.
Но прежде чем переходить к глубокому обучению, осуществим установку Keras.
Популярные алгоритмы глубокого обучения с Keras
Вот самые популярные алгоритмы глубокого обучения:
- Автокодировщики
- Сверточные нейронные сети
- Рекурентные нейронные сети
- Долгая краткосрочная память
- Глубокая машина Больцмана
- Глубокие сети доверия
В этом материале рассмотрим автокодировщики глубокого обучения
Автокодировщики
Эти типы нейронных сетей способны сжимать входящие данные и воссоздавать их заново. Это очень старые алгоритмы глубокого обучения. Они кодируют ввод в до уровня узкого места («бутылочного горлышка»), а затем декодируют для получения исходных данных. Таким образом на уровне «бутылочного горлышка» образуется сжатая форма ввода.
Определение аномалий и устранение шумов на изображении — основные сферы применения автокодировщиков.
Типы автокодировщиков
Есть 7 типов автокодировщиков глубокого обучения:
- Шумоподавляющие автокодировщики
- Глубокие автокодировщики
- Разреженные автокодировщики
- Сжимающие автокодировщики
- Сверточные автокодировщики
- Вариационные автокодировщики
- Неполные автокодировщики
Для примера будет создан шумоподавляющий автокодировщик
Реализации шумоподавляющего автокодировщика в Keras
В целях реализации на Keras будем работать с базой данных цифр MNIST.
Для начала добавим на изображения шумы. Затем создадим автокодировщик для удаления шума и воссоздания оригинальных изображений.
- Импортируем требуемые модули
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.layers import Input,Dense,Conv2D,MaxPooling2D,UpSampling2D from keras.models import Model from keras import backend as K - Загружаем изображения MNIST из модуля datasetes
from keras.datasets import mnist (x_train,y_train),(x_test,y_test)=mnist.load_data() - Конвертируем набор в диапазон от 0 до 1
x_train=x_train.astype('float32')/255 x_test=x_test.astype('float32')/255 x_train=np.reshape(x_train,(len(x_train),28,28,1)) x_test=np.reshape(x_test,(len(x_test),28,28,1)) - Добавляем шум на изображения с помощью Гауссового распределения
noise_factor=0.5 x_train_noisy=x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0,size=x_train.shape) x_test_noisy=x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0,size=x_test.shape) x_train_noisy= np.clip(x_train_noisy,0.,1.) x_test_noisy= np.clip(x_test_noisy,0.,1.) - Визуализируем добавленный шум
n=5 plt.figure(figsize=(20,2)) for i in range(n): ax=plt.subplot(1,n,i+1) plt.imshow(x_test_noisy[i].reshape(28,28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show() - Определяем входящий слой и создаем модель
input_img=Input(shape=(28,28,1)) x=Conv2D(128,(7,7),activation='relu',padding='same')(input_img) x=MaxPooling2D((2,2),padding='same')(x) x = Conv2D(32, (2, 2), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) encoded = Conv2D(1, (7, 7), activation='relu', padding='same')(x) - «Бутылочное горлышко» закодировано и состоит из сжатых изображений
input_encoded = Input(shape=(7, 7, 1)) x = Conv2D(32, (7, 7), activation='relu', padding='same')(input_encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(128, (2, 2), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (7, 7), activation='sigmoid', padding='same')(x) - Тренируем автокодировщик
encoder = Model(input_img, encoded, name="encoder") decoder = Model(input_encoded, decoded, name="decoder") autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder") autoencoder.compile(optimizer='adam', loss='binary_crossentropy') autoencoder.summary() autoencoder.fit(x_train, x_train, epochs=20, batch_size=256, shuffle=True, validation_data=(x_test, x_test))В этом примере модель тренировалась в течение 20
epoch. Лучшего результата можно добиться, увеличив это значение до 100. - Получаем предсказания по шумным данным
x_test_result = autoencoder.predict(x_test_noisy, batch_size=128) - Заново визуализируем воссозданные изображения
n=5
plt.figure(figsize=(20,2))
for i in range(n):
ax=plt.subplot(1,n,i+1)
plt.imshow(x_test_result[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
Как видите, автокодировщик способен воссоздать изображения и избавиться от шумов. Можно добиться лучших результатов, увеличив количество epoch.
Вывод
Этот материал представляет собой пример реализации глубокого обучения на Keras. Теперь вы знаете, что такое автокодировщики, какими они бывают, зачем они нужны, и как именно работают. В примере мы разобрали построение нейронной сети для устранения шума из данных.
]]>Прежде чем приступать к работе с данными, их нужно подготовить и собрать в виде структуры, так чтобы они поддавались обработке с помощью инструментов из библиотеки pandas. Дальше перечислены некоторые из этапов подготовки.
- Загрузка
- Сборка
- Объединение (merge)
- Конкатенация (concatenating)
- Комбинирование (combining)
- Изменение
- Удаление
Прошлый материал был посвящен загрузке. На этом этапе происходит конвертация из разных форматов в одну структуру данных, такую как Dataframe. Но даже после этого требуются дополнительные этапы подготовки. Поэтому дальше речь пойдет о том, как выполнять операции получения данных в объединенной структуре данных.
Данные из объектов pandas можно собрать несколькими путями:
- Объединение — функция
pandas.merge()соединяет строки вDataframeна основе одного или нескольких ключей. Этот вариант будет знаком всем, кто работал с языком SQL, поскольку там есть аналогичная операция. - Конкатенация — функция
pandas.concat()конкатенирует объекты по оси. - Комбинирование — функция
pandas.DataFrame.combine_first()является методом, который позволяет соединять пересекающиеся данные для заполнения недостающих значений в структуре, используя данные другой структуры.
Более того, частью подготовки является поворот — процесс обмена строк и колонок.
Соединение
Операция соединения (merge), которая соответствует JOIN из SQL, состоит из объединения данных за счет соединения строк на основе одного или нескольких ключей.
На самом деле, любой, кто работал с реляционными базами данных, обычно использует запрос JOIN из SQL для получения данных из разных таблиц с помощью ссылочных значений (ключей) внутри них. На основе этих ключей можно получать новые данные в табличной форме как результат объединения других таблиц. Эта операция в библиотеке pandas называется соединением (merging), а merge() — функция для ее выполнения.
Сначала нужно импортировать библиотеку pandas и определить два объекта Dataframe, которые будут примерами в этом разделе.
>>> import numpy as np
>>> import pandas as pd
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'price': [12.33,11.44,33.21,13.23,33.62]})
>>> frame1
| | id | price |
|---|---------|-------|
| 0 | ball | 12.33 |
| 1 | pencil | 11.44 |
| 2 | pen | 33.21 |
| 3 | mug | 13.23 |
| 4 | ashtray | 33.62 |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'color': ['white','red','red','black']})
>>> frame2
| | color | id |
|---|-------|--------|
| 0 | white | pencil |
| 1 | red | pencil |
| 2 | red | ball |
| 3 | black | pen |
Выполним соединение, применив функцию merge() к двум объектам.
>>> pd.merge(frame1,frame2)
| | id | price | color |
|---|--------|-------|-------|
| 0 | ball | 12.33 | red |
| 1 | pencil | 11.44 | white |
| 2 | pencil | 11.44 | red |
| 3 | pen | 33.21 | black |
Получившийся объект Dataframe состоит из всех строк с общим ID. В дополнение к общей колонке добавлены и те, что присутствуют только в первом и втором объектах.
В этом случае функция merge() была использована без явного определения колонок. Но чаще всего необходимо указывать, на основе какой колонки выполнять соединение.
Для этого нужно добавить свойство с названием колонки, которое будет ключом соединения.
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'color': ['white','red','red','black','green'],
... 'brand': ['OMG','ABC','ABC','POD','POD']})
>>> frame1
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'brand': ['OMG','POD','ABC','POD']})
>>> frame2
| | brand | id |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
В этом случае два объекта Dataframe имеют колонки с одинаковыми названиями. Поэтому при запуске merge результата не будет.
>>> pd.merge(frame1,frame2)
Empty DataFrame
Columns: [brand, color, id]
Index: []
Необходимо явно задавать условия соединения, которым pandas будет следовать, определяя название ключа в параметре on.
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='brand')
| | brand | color | id_x | id_y |
|---|-------|-------|--------|--------|
| 0 | OMG | white | ball | pencil |
| 1 | ABC | red | pencil | ball |
| 2 | ABC | red | pen | ball |
| 3 | POD | black | mug | pencil |
| 4 | POD | black | mug | pen |
Как и ожидалось, результаты отличаются в зависимости от условий соединения.
Но часто появляется другая проблема, когда есть два Dataframe без колонок с одинаковыми названиями. Для исправления ситуации нужно использовать left_on и right_on, которые определяют ключевые колонки для первого и второго объектов Dataframe. Дальше следует пример.
>>> frame2.columns = ['brand','sid']
>>> frame2
| | brand | sid |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
>>> pd.merge(frame1, frame2, left_on='id', right_on='sid')
| | brand_x | color | id | brand_y | sid |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | ABC | ball |
| 1 | ABC | red | pencil | OMG | pencil |
| 2 | ABC | red | pencil | POD | pencil |
| 3 | ABC | red | pen | POD | pen |
По умолчанию функция merge() выполняет inner join (внутреннее соединение). Ключ в финальном объекте — результат пересечения.
Другие возможные варианты: left join, right join и outer join (левое, правое и внешнее соединение). Внешнее выполняет объединение всех ключей, комбинируя эффекты правого и левого соединений. Для выбора типа нужно использовать параметр how.
>>> frame2.columns = ['brand','id']
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='id',how='outer')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='left')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='right')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on=['id','brand'],how='outer')
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
| 5 | OMG | NaN | pencil |
| 6 | POD | NaN | pencil |
| 7 | ABC | NaN | ball |
| 8 | POD | NaN | pen |
Для соединения нескольких ключей, нужно просто в параметр on добавить список.
Соединение по индексу
В некоторых случаях вместо использования колонок объекта Dataframe в качестве ключей для этих целей можно задействовать индексы. Затем для выбора конкретных индексов нужно задать значения True для left_join или right_join. Они могут быть использованы и вместе.
>>> pd.merge(frame1,frame2,right_index=True, left_index=True)
| | brand_x | color | id_x | brand_y | id_y |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | OMG | pencil |
| 1 | ABC | red | pencil | POD | pencil |
| 2 | ABC | red | pen | ABC | ball |
| 3 | POD | black | mug | POD | pen |
Но у объектов Dataframe есть и функция join(), которая оказывается особенно полезной, когда необходимо выполнить соединение по индексам. Она же может быть использована для объединения множества объектов с одинаковыми индексами, но без совпадающих колонок.
При запуске такого кода
>>> frame1.join(frame2)
Будет ошибка, потому что некоторые колонки в объекте frame1 называются так же, как и во frame2. Нужно переименовать их во втором объекте перед использованием join().
>>> frame2.columns = ['brand2','id2']
>>> frame1.join(frame2)
В этом примере соединение было выполнено на основе значений индексов, а не колонок. Также индекс 4 представлен только в объекте frame1, но соответствующие значения колонок во frame2 равняются NaN.
Конкатенация
Еще один тип объединения данных — конкатенация. NumPy предоставляет функцию concatenate() для ее выполнения.
>>> array1 = np.arange(9).reshape((3,3))
>>> array1
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> array2 = np.arange(9).reshape((3,3))+6
>>> array2
array([[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
>>> np.concatenate([array1,array2],axis=1)
array([[0, 1, 2, 6, 7, 8],
[3, 4, 5, 9, 10, 11],
[6, 7, 8, 12, 13, 14]])
>>> np.concatenate([array1,array2],axis=0)
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
С библиотекой pandas и ее структурами данных, такими как Series и Dataframe, именованные оси позволяют и дальше обобщать конкатенацию массивов. Для этого в pandas есть функция concat().
>>> ser1 = pd.Series(np.random.rand(4), index=[1,2,3,4])
>>> ser1
1 0.636584
2 0.345030
3 0.157537
4 0.070351
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4), index=[5,6,7,8])
>>> ser2
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
>>> pd.concat([ser1,ser2])
1 0.636584
2 0.345030
3 0.157537
4 0.070351
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
По умолчанию функция concat() работает на axis=0 и возвращает объект Series. Если задать 1 значением axis, то результатом будет объект Dataframe.
>>> pd.concat([ser1,ser2],axis=1)
| | 0 | 1 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Проблема с этой операцией в том, что конкатенированные части не определяются в итоговом объекте. Например, нужно создать иерархический индекс на оси конкатенации. Для этого требуется использовать параметр keys.
>>> pd.concat([ser1,ser2], keys=[1,2])
1 1 0.953608
2 0.929539
3 0.036994
4 0.010650
2 5 0.200771
6 0.709060
7 0.813766
8 0.218998
dtype: float64
В случае объединения двух Series по axis=1 ключи становятся заголовками колонок объекта Dataframe.
>>> pd.concat([ser1,ser2], axis=1, keys=[1,2])
| | 1 | 2 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Пока что в примерах конкатенация применялась только к объектам Series, но та же логика работает и с Dataframe.
>>> frame1 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[1,2,3], columns=['A','B','C'])
>>> frame2 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[4,5,6], columns=['A','B','C'])
>>> pd.concat([frame1, frame2])
| | A | B | C |
|---|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 |
| 2 | 0.727480 | 0.296619 | 0.367309 |
| 3 | 0.282516 | 0.524227 | 0.462000 |
| 4 | 0.078044 | 0.751505 | 0.832853 |
| 5 | 0.843225 | 0.945914 | 0.141331 |
| 6 | 0.189217 | 0.799631 | 0.308749 |
>>> pd.concat([frame1, frame2], axis=1)
| | A | B | C | A | B | C |
|---|----------|----------|----------|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 | NaN | NaN | NaN |
| 2 | 0.727480 | 0.296619 | 0.367309 | NaN | NaN | NaN |
| 3 | 0.282516 | 0.524227 | 0.462000 | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | 0.078044 | 0.751505 | 0.832853 |
| 5 | NaN | NaN | NaN | 0.843225 | 0.945914 | 0.141331 |
| 6 | NaN | NaN | NaN | 0.189217 | 0.799631 | 0.308749 |
Комбинирование
Есть еще одна ситуация, при которой объединение не работает за счет соединения или конкатенации. Например, если есть два набора данных с полностью или частично пересекающимися индексами.
Одна из функций для Series называется combine_first(). Она выполняет объединение с выравниваем данных.
>>> ser1 = pd.Series(np.random.rand(5),index=[1,2,3,4,5])
>>> ser1
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4),index=[2,4,5,6])
>>> ser2
2 0.315847
4 0.275937
5 0.352538
6 0.865549
dtype: float64
>>> ser1.combine_first(ser2)
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
6 0.865549
dtype: float64
>>> ser2.combine_first(ser1)
1 0.075815
2 0.315847
3 0.884463
4 0.275937
5 0.352538
6 0.865549
dtype: float64
Если же требуется частичное пересечение, необходимо обозначить конкретные части Series.
>>> ser1[:3].combine_first(ser2[:3])
1 0.075815
2 0.332282
3 0.884463
4 0.275937
5 0.352538
dtype: float64
Pivoting — сводные таблицы
В дополнение к сборке данных для унификации собранных из разных источников значений часто применяется операция поворота. На самом деле, выравнивание данных по строке и колонке не всегда подходит под конкретную ситуацию. Иногда требуется перестроить данные по значениям колонок в строках или наоборот.
Поворот с иерархическим индексированием
Вы уже знаете, что Dataframe поддерживает иерархическое индексирование. Эта особенность может быть использована для перестраивания данных в объекте Dataframe. В контексте поворота есть две базовые операции:
- Укладка (stacking) — поворачивает структуру данных, превращая колонки в строки
- Обратный процесс укладки (unstacking) — конвертирует строки в колонки
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
С помощью функции stack() в Dataframe можно развернуть данные и превратить колонки в строки, получив Series:
>>> ser5 = frame1.stack()
white ball 0
pen 1
pencil 2
black ball 3
pen 4
pencil 5
red ball 6
pen 7
pencil 8
dtype: int32
Из объекта Series с иерархическим индексировании можно выполнить пересборку в развернутую таблицу с помощью unstack().
>>> ser5.unstack()
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Обратный процесс можно выполнить и на другом уровне, определив количество уровней или название в качестве аргумента функции.
>>> ser5.unstack(0)
| | white | black | red |
|--------|-------|-------|-----|
| ball | 0 | 3 | 6 |
| pen | 1 | 4 | 7 |
| pencil | 2 | 5 | 8 |
Поворот из «длинного» в «широкий» формат
Наиболее распространенный способ хранения наборов данных — точная регистрация данных, которые будут заполнять строки текстового файла: CSV или таблицы в базе данных. Это происходит особенно в таких случаях: чтение выполняется с помощью инструментов; результаты вычислений итерируются; или данные вводятся вручную. Похожий пример таких файлов — логи, заполняемые строка за строкой с помощью постоянно поступающих данных.
Необычная особенность этого типа набора данных — элементы разных колонок, часто повторяющиеся в последующих строках. Они всегда в табличной форме, поэтому их можно воспринимать как формат длинных или упакованных.
Чтобы лучше разобраться с этой концепцией, рассмотрим следующий Dataframe.
>>> longframe = pd.DataFrame({'color':['white','white','white',
... 'red','red','red',
... 'black','black','black'],
... 'item':['ball','pen','mug',
... 'ball','pen','mug',
... 'ball','pen','mug'],
... 'value': np.random.rand(9)})
>>> longframe
| | color | item | value |
|---|-------|------|----------|
| 0 | white | ball | 0.896313 |
| 1 | white | pen | 0.344864 |
| 2 | white | mug | 0.101891 |
| 3 | red | ball | 0.697267 |
| 4 | red | pen | 0.852835 |
| 5 | red | mug | 0.145385 |
| 6 | black | ball | 0.738799 |
| 7 | black | pen | 0.783870 |
| 8 | black | mug | 0.017153 |
Этот режим записи данных имеет свои недостатки. Первый — повторение некоторых полей. Если воспринимать колонки в качестве ключей, то данные в этом формате будет сложно читать, а особенно — понимать отношения между значениями ключей и остальными колонками.
Но существует замена для длинного формата — широкий способ организации данных в таблице. В таком режиме данные легче читать, а также налаживать связь между таблицами. Плюс, они занимают меньше места. Это более эффективный способ хранения данных, пусть и менее практичный, особенно на этапе заполнения объекта данными.
В качестве критерия нужно выбрать колонку или несколько из них как основной ключ. Значения в них должны быть уникальными.
pandas предоставляет функцию, которая позволяет выполнить трансформацию Dataframe из длинного типа в широкий. Она называется pivot(), а в качестве аргументов принимает одну или несколько колонок, которые будут выполнять роль ключа.
Еще с прошлого примера вы создавали Dataframe в широком формате. Колонка color выступала основным ключом, item – вторым, а их значения формировали новые колонки в объекте.
>>> wideframe = longframe.pivot('color','item')
>>> wideframe
| | value | | |
|-------|----------|----------|----------|
| item | ball | mug | pen |
| color | | | |
| black | 0.738799 | 0.017153 | 0.783870 |
| red | 0.697267 | 0.145385 | 0.852835 |
| white | 0.896313 | 0.101891 | 0.344864 |
В таком формате Dataframe более компактен, а данные в нем — куда более читаемые.
Удаление
Последний этап подготовки данных — удаление колонок и строк. Определим такой объект в качестве примера.
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Для удаления колонки используйте команду del к Dataframe с определенным названием колонки.
>>> del frame1['ball']
>>> frame1
| | pen | pencil |
|-------|-----|--------|
| white | 1 | 2 |
| black | 4 | 5 |
| red | 7 | 8 |
Для удаления нежеланной строки используйте функцию drop() с меткой соответствующего индекса в аргументе.
>>> frame1.drop('white')
| | pen | pencil |
|-------|-----|--------|
| black | 4 | 5 |
| red | 7 | 8 |
Модуль pickle предоставляет мощный алгоритм сериализации и десериализации структур данных Python. Pickling — это процесс, при котором иерархия объекта конвертируется в поток байтов.
Это позволяет переносить и хранить объект, так что получатель может восстановить его, сохранив все оригинальные черты.
В Python за этот процесс отвечает модуль pickle, но имеется и cPickle, который является результатом работы по оптимизации первого (написан на C). Он в некоторых случаях может быть быстрее оригинального pickle в тысячу раз. Однако интерфейс самих модулей почти не отличается.
Прежде чем переходить к функциям библиотеки, рассмотрим cPickle в подробностях .
Сериализация объекта с помощью cPickle
Формат данных, используемый pickle (или cPickle), универсален для Python. По умолчанию для превращения в человекочитаемый вид используется представление в виде ASCII. Затем, открыв файл в текстовом редакторе, можно понять его содержимое. Для использования модуля его сначала нужно импортировать:
>>> import pickle
Создадим объект с внутренней структурой, например, dict.
>>> data = { 'color': ['white','red'], 'value': [5, 7]}
Теперь выполним сериализацию с помощью функции dumps() модуля cPickle.
>>> pickled_data = pickle.dumps(data)
Чтобы увидеть, как прошла сериализация, необходимо изучить содержимое переменной pickled_data.
>>> print(pickled_data)
Когда данные сериализованы, их можно записать в файл, отправить через сокет, канал или другими способами.
А после передачи их можно пересобрать (выполнить десериализацию) с помощью функции loads() из модуля cPickle.
>>> nframe = pickle.loads(pickled_data)
>>> nframe
{'color': ['white', 'red'], 'value': [5, 7]}
Процесс “pickling” в pandas
Когда дело доходит до сериализации (или десериализации), то pandas с легкостью справляется с задачей. Не нужно даже импортировать модуль cPickle, а все операции выполняются неявно.
Также формат сериализации в pandas не целиком в ASCII.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
index=['up','down','left','right'])
>>> frame.to_pickle('frame.pkl')
Теперь у вас есть файл frame.pkl, содержащий всю информацию об объекте Dataframe.
Для его открытия используется следующая команда:
>>> pd.read_pickle('frame.pkl')
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| up | 0 | 1 | 2 | 3 |
| down | 4 | 5 | 6 | 7 |
| left | 8 | 9 | 10 | 11 |
| right | 12 | 13 | 14 | 15 |
На этом примере видно, что все нюансы скрыты от пользователя pandas, что делает работу простой и понятной, особенно для тех, кто занимается непосредственно анализом данных.
]]>Примечание. При использовании формата важно убедиться, что открываемый файл безопасен. Формат не очень защищен от вредоносных данных.
Keras поддерживает разный бэкенд и его производительность сильно зависит от сделанного выбора. В этом материале речь пойдет о двух самых распространенных вариантах: TensorFlow и Theano. Создадим модель нейронной сети и проверим ее производительность на примерах.
Бэкенд Keras
Keras — это высокоуровневый API для разработки нейронных сетей, поэтому низкоуровневыми вычислениями он не занимается. Для этих целей он опирается на «бэкенд-движки». Поддержка реализована в модульном виде, что значит, что к Keras можно присоединить несколько движков.
TensorFlow и Theano — самые распространенные варианты
TensorFlow
Это платформа для машинного обучения с открытым исходным кодом, разработанная в Google и выпущенная в ноябре 2015 году.
Theano
Это библиотека Python, созданная для управления и оценки математических выражений, созданная Университетом Монреаля и выпущенная в 2007 году.
Изменения движка Keras
По умолчанию движком бэкенда Keras является TensorFlow. Чтобы убедиться в этом, проверьте конфигурационный файл по этому пути:
$HOME/.keras/keras.json
Он выглядит следующим образом:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Или импортируйте Keras и введите:
keras.backend.backend()
Для изменения движка выполните следующие шаги:
- Откройте конфигурационный файл в любом текстовом редакторе.
subl $HOME/.keras/keras.json - Измените значение
backendнаtheano - Проверьте используемый движок
Движок в игре меняется в один шаг. Не нужно ничего менять в самом коде, а дальше мы увидим, как можно запускать модели Keras на разных движках.
Проверим модель на разных движках Keras
Создадим нейронную сеть типа многослойный перцептрон для бинарной классификации. Проверим производительность модели на основе времени тренировки и ее точности.
Сначала используем TensorFlow.
В этом примере использовалось железо со следующей конфигурацией:
- Процессор Intel Core i5 7-го поколения
- Keras 2.3.1
- Python 3.6.0
- TensorFlow 1.14.0
- Theano 1.0.4
Результаты относительны и могут отличаться в зависимости от конфигураций систем и разных версий библиотек.
Создадим нейронную сеть
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
Сгенерируем случайный ввод для тестирования
x_train=np.random.random((1000,20))
y_train=np.random.randint(2,size=(100,1))
x_test=np.random.random((100,20))
y_test=np.random.randint(2,size=(100,1))
Создадим модель
model=Sequential()
model.add(Dense(64, input_dim=20,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
Скомпилируем модель
model.compile(loss='binary_crossentropy', optimizer='rmsprop',metrics=['accuracy'])
Для вычисления времени тренировки используем модуль Time из Python.
Добавим переменные до и после тренировки.
import time
start=time.time()
model.fit(x_train,y_tarin,epochs=20,batch_size=128)
end=time.time()
print("running time: ",end-start)
Посчитаем величину потерь и точность модели
score=model.evaluate(x_test,y_test,batch_size=128)
print("score: ",score)
Можно увидеть, что тренировка этой модели заняла 0,5446 секунд, величина потерь — 0,6998, а точность — 0,4199
Теперь переключимся на Theano и выполним те же шаги.
Тренировка этой модели заняла 1,066 секунд, величина потерь — 0,6747, а точность — 0,6700. В системе с этим примером TensorFlow сработал быстрее, но у Theano выше точность.
Выводы
Этот материал объясняет поддержку разных движков в Keras и показывает, как между ними переключаться. В качестве примеров были использованы TensorFlow и Theano. Также было показано сравнение эффективности модели нейронной сети на обоих движках.
]]>Чтение и запись в файлы Microsoft Excel
Данные очень легко читать из файлов CSV, но они часто хранятся в табличной форме в формате Excel.
pandas предоставляет специальные функции для работы с ним:
to_excel()read_excel()
Функция read_excel() может читать из файлов Excel 2003 (.xls) и Excel 2007 (.xlsx). Это возможно благодаря модулю xlrd.
Для начала откроем файл Excel и введем данные со следующий таблиц. Разместим их в листах sheet1 и sheet2. Сохраним файл как ch05_data.xlsx.
| white | red | green | black | |
|---|---|---|---|---|
| a | 12 | 23 | 17 | 18 |
| b | 22 | 16 | 19 | 18 |
| c | 14 | 23 | 22 | 21 |
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Для чтения данных из файла XLS нужно всего лишь конвертировать его в Dataframe, используя для этого функцию read_excel().
>>> pd.read_excel('ch05_data.xlsx')
По умолчанию готовый объект pandas Dataframe будет состоять из данных первого листа файла. Но если нужно загрузить и второй, то достаточно просто указать его номер (индекс) или название в качестве второго аргумента.
>>> pd.read_excel('ch05_data.xlsx','Sheet2')
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
>>> pd.read_excel('ch05_data.xlsx',1)
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Запись работает по тому же принципу. Для конвертации объекта Dataframe в Excel нужно написать следующее.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['exp1','exp2','exp3','exp4'],
... columns = ['Jan2015','Fab2015','Mar2015','Apr2005'])
>>> frame.to_excel('data2.xlsx')
>>> frame
| Jan2015 | Feb2015 | Mar2015 | Apr2015 | |
|---|---|---|---|---|
| exp1 | 0.671044 | 0.437715 | 0.497103 | 0.070595 |
| exp2 | 0.864018 | 0.575196 | 0.240343 | 0.471081 |
| exp3 | 0.957986 | 0.311648 | 0.381975 | 0.622556 |
| exp4 | 0.407909 | 0.015926 | 0.180611 | 0.579783 |
В рабочей директории будет создан файл с соответствующими данными.
Данные JSON
JSON (JavaScript Object Notation) стал одним из самых распространенных стандартных форматов для передачи данных в сети.
Одна из главных его особенностей — гибкость, хотя структура и не похожа на привычные таблицы.
В этом разделе вы узнаете, как использовать функции read_json() и to_json() для использования API. А в следующем — познакомитесь с другим примером взаимодействия со структурированными данными формата, который чаще встречается в реальной жизни.
http://jsonviewer.stack.hu/ — полезный онлайн-инструмент для проверки формата JSON. Нужно вставить данные в этом формате, и сайт покажет, представлены ли они в корректной форме, а также покажет дерево структуры.
{
"up": {
"white": 0,
"black": 4,
"red": 8,
"blue": 12
},
"down": {
"white": 1,
"black": 5,
"red": 9,
"blue": 13
},
"right": {
"white": 2,
"black": 6,
"red": 10,
"blue": 14
},
"left": {
"white": 3,
"black": 7,
"red": 11,
"blue": 15
}
}
Начнем с самого полезного примера, когда есть объект Dataframe и его нужно конвертировать в файл JSON. Определим такой объект и используем его для вызова функции to_json(), указав название для итогового файла.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
>>> frame.to_json('frame.json')
Он будет находится в рабочей папке и включать все данные в формате JSON.
Обратную операцию можно выполнить с помощью функции read_json(). Параметром здесь должен выступать файл с данными.
>>> pd.read_json('frame.json')
| down | left | right | up | |
|---|---|---|---|---|
| black | 5 | 7 | 6 | 4 |
| blue | 13 | 15 | 14 | 12 |
| red | 9 | 11 | 10 | 8 |
| white | 1 | 3 | 2 | 0 |
Это был простейший пример, где данные JSON представлены в табличной форме (поскольку источником файла frame.json служил именно такой объект — Dataframe). Но в большинстве случаев у JSON-файлов нет такой четкой структуры. Поэтому нужно конвертировать файл в табличную форму. Этот процесс называется нормализацией.
Библиотека pandas предоставляет функцию json_normalize(), которая умеет конвертировать объект dict или список в таблицу. Для начала ее нужно импортировать:
>>> from pandas.io.json import json_normalize
Создадим JSON-файл как в следующем примере с помощью любого текстового редактора и сохраним его в рабочей директории как books.json.
[{"writer": "Mark Ross",
"nationality": "USA",
"books": [
{"title": "XML Cookbook", "price": 23.56},
{"title": "Python Fundamentals", "price": 50.70},
{"title": "The NumPy library", "price": 12.30}
]
},
{"writer": "Barbara Bracket",
"nationality": "UK",
"books": [
{"title": "Java Enterprise", "price": 28.60},
{"title": "HTML5", "price": 31.35},
{"title": "Python for Dummies", "price": 28.00}
]
}]
Как видите, структура файла более сложная и не похожа на таблицу. В таком случае функция read_json() уже не сработает. Однако данные в нужной форме все еще можно получить. Во-первых, нужно загрузить содержимое файла и конвертировать его в строку.
>>> import json
>>> file = open('books.json','r')
>>> text = file.read()
>>> text = json.loads(text)
После этого можно использовать функцию json_normalize(). Например, можно получить список книг. Для этого необходимо указать ключ books в качестве второго параметра.
>>> json_normalize(text,'books')
| price | title | |
|---|---|---|
| 0 | 23.56 | XML Cookbook |
| 1 | 50.70 | Python Fundamentals |
| 2 | 12.30 | The NumPy library |
| 3 | 28.60 | Java Enterprise |
| 4 | 31.35 | HTML5 |
| 5 | 28.30 | Python for Dummies |
Функция считает содержимое всех элементов, у которых ключом является books. Все свойства будут конвертированы в имена вложенных колонок, а соответствующие значения заполнят объект Dataframe. В качестве индексов будет использоваться возрастающая последовательность чисел.
Однако в этом случае Dataframe включает только внутреннюю информацию. Не лишним было бы добавить и значения остальных ключей на том же уровне. Для этого необходимо добавить другие колонки, вставив список ключей в качестве третьего элемента функции.
>>> json_normalize(text,'books',['nationality','writer'])
| price | title | writer | nationality | |
|---|---|---|---|---|
| 0 | 23.56 | XML Cookbook | Mark Ross | USA |
| 1 | 50.70 | Python Fundamentals | Mark Ross | USA |
| 2 | 12.30 | The NumPy library | Mark Ross | USA |
| 3 | 28.60 | Java Enterprise | Barbara Bracket | UK |
| 4 | 31.35 | HTML5 | Barbara Bracket | UK |
| 5 | 28.30 | Python for Dummies | Barbara Bracket | UK |
Результатом будет Dataframe с готовой структурой.
Формат HDF5
До сих пор в примерах использовалась запись данных лишь в текстовом формате. Но когда речь заходит о больших объемах, то предпочтительнее использовать бинарный. Для этого в Python есть несколько инструментов. Один из них — библиотека HDF5.
HDF расшифровывается как hierarchical data format (иерархический формат данных), а сама библиотека используется для чтения и записи файлов HDF5, содержащих структуру с узлами и возможностью хранить несколько наборов данных.
Библиотека разработана на C, но предусматривает интерфейсы для других языков: Python, MATLAB и Java. Она особенно эффективна при сохранении больших объемов данных. В сравнении с остальными форматами, работающими в бинарном виде, HDF5 поддерживает сжатие в реальном времени, используя преимущества повторяющихся паттернов в структуре для уменьшения размера файла.
Возможные варианты в Python — это PyTables и h5py. Они отличаются по нескольким аспектам, а выбирать их стоит, основываясь на том, что нужно программисту.
h5py предоставляет прямой интерфейс с высокоуровневыми API HDF5, а PyTables скрывает за абстракциями многие детали HDF5 с более гибкими контейнерами данных, индексированные таблицы, запросы и другие способы вычислений.
В pandas есть классовый dict под названием HDFStore, который использует PyTables для хранения объектов pandas. Поэтому перед началом работы с форматом необходимо импортировать класс HDFStore:
>>> from pandas.io.pytables import HDFStore
Теперь данные объекта Dataframe можно хранить в файле с расширением .h5. Для начала создадим Dataframe.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
Дальше нужен файл HDF5 под названием mydata.h5. Добавим в него содержимое объекта Dataframe.
>>> store = HDFStore('mydata.h5')
>>> store['obj1'] = frame
Можете догадаться, как хранить несколько структур данных в одном файле HDF5, указав для каждой из них метку. С помощью этого формата можно хранить несколько структур данных в одном файле, при том что он будет представлен переменной store.
>>> store
<class 'pandas.io.pytables.HDFStore'>
File path: ch05_data.h5
Обратный процесс также прост. Учитывая наличие файла HDF5 с разными структурами данных вызвать их можно следующим путем.
Взаимодействие с базами данных
В большинстве приложений текстовые файлы редко выступают источниками данных, просто потому что это не эффективно. Они хранятся в реляционных базах данных (SQL) или альтернативных (NoSQL), которые стали особо популярными в последнее время.
Загрузка из SQL в Dataframe — это простой процесс, а pandas предлагает дополнительные функции для еще большего упрощения.
Модуль pandas.io.sql предоставляет объединенный интерфейс, независимый от базы данных, под названием sqlalchemy. Он упрощает режим соединения, поскольку команды неизменны вне зависимости от типа базы. Для создания соединения используется функция create_engine(). Это же позволяет настроить все необходимые свойства: ввести имя пользователя, пароль и порт, а также создать экземпляр базы данных.
Вот список разных типов баз данных:
>>> from sqlalchemy import create_engine
# For PostgreSQL:
>>> engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')
# For MySQL
>>> engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# For Oracle
>>> engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
# For MSSQL
>>> engine = create_engine('mssql+pyodbc://mydsn')
# For SQLite
>>> engine = create_engine('sqlite:///foo.db')
Загрузка и запись данных с SQLite3
Для первого примера используем базу данных SQLite, применив встроенный Python sqlite3. SQLite3 — это инструмент, реализующий реляционную базу данных очень простым путем. Это самый легкий способ добавить ее в любое приложение на Python. С помощью SQLite фактически можно создать встроенную базу данных в одном файле.
Идеальный вариант для тех, кому нужна база, но нет желания устанавливать реальную. SQLite3 же можно использовать для тренировки или для использования функций базы при сборе данных, не выходя за рамки программы.
Создадим объект Dataframe, который будет использоваться для создания новой таблицы в базе данных SQLite3.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Теперь нужно реализовать соединение с базой.
>>> engine = create_engine('sqlite:///foo.db')
Конвертируем объект в таблицу внутри базы данных.
>>> frame.to_sql('colors',engine)
А вот для чтения базы нужно использовать функцию read_sql(), указав название таблицы и движок.
>>> pd.read_sql('colors',engine)
| index | white | red | blue | black | green | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 3 | 15 | 16 | 17 | 18 | 19 |
На примере видно, что даже в этом случае процесс записи очень прост благодаря API библиотеки pandas.
Однако того же можно добиться и без них. Это покажет, почему pandas считается эффективным инструментом для работы с базой данных.
Во-первых, нужно установить соединение и создать таблицу, определив правильные типы данных, которые впоследствии будут загружаться.
>>> import sqlite3
>>> query = """
... CREATE TABLE test
... (a VARCHAR(20), b VARCHAR(20),
... c REAL, d INTEGER
... );"""
>>> con = sqlite3.connect(':memory:')
>>> con.execute(query)
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> con.commit()
Теперь можно добавлять сами данные с помощью SQL INSERT.
>>> data = [('white','up',1,3),
... ('black','down',2,8),
... ('green','up',4,4),
... ('red','down',5,5)]
>>> stmt = "INSERT INTO test VALUES(?,?,?,?)"
>>> con.executemany(stmt, data)
<sqlite3.Cursor object at 0x0000000009E7D8F0>
>>> con.commit()
Наконец, можно перейти к запросам из базы данных. Это делается с помощью SQL SELECT.
>>> cursor = con.execute('select * from test')
>>> cursor
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> rows = cursor.fetchall()
>>> rows
[('white', 'up', 1.0, 3),
('black', 'down', 2.0, 8),
('green', 'up', 4.0, 4),
('red', 'down', 5.0, 5)]
Конструктору Dataframe можно передать список кортежей, а если нужны названия колонок, то их можно найти в атрибуте description своего cursor.
>>> cursor.description
(('a', None, None, None, None, None, None),
('b', None, None, None, None, None, None),
('c', None, None, None, None, None, None),
('d', None, None, None, None, None, None))
>>> pd.DataFrame(rows, columns=zip(*cursor.description)[0])
Этот подход куда сложнее.
Загрузка и запись с помощью PostgreSQL
Начиная с pandas 0.14, PostgreSQL также поддерживается. Для начала нужно проверить версию библиотеки.
>>> pd.__version__
>>> '0.22.0'
Для запуска примера база PostgreSQL должна быть установлена в системе. В этом примере была создана база postgres, где пользователя зовут postgres, а пароль — password. Замените значения на соответствующие в вашей системе.
Сначала нужно установить библиотеку psycopg2, которая предназначена для управления соединениями с базой данных.
В Anaconda:
conda install psycopg2
Или с помощью PyPl:
pip install psycopg2
Теперь можно установить соединение:
>>> import psycopg2
>>> engine = create_engine('postgresql://postgres:password@localhost:5432/
postgres')
Примечание. В этом примере вне зависимости от установленной версии в Windows может возникать ошибка:
from psycopg2._psycopg import BINARY, NUMBER, STRING,
DATETIME, ROWID
ImportError: DLL load failed: The specified module could not
be found.
Это почти наверняка значит, что DLL для PostgreSQL (в частности, libpq.dll) не установлены в PATH. Добавьте одну из папок
postgres\x.x\binв PATH и теперь соединение Python с базой данных PostgreSQL должно работать без проблем.
Создайте объект Dataframe:
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index=['exp1','exp2','exp3','exp4'],
... columns=['feb','mar','apr','may']);
Вот как просто переносить данные в таблицу. С помощью to_sql() вы без проблем запишите их в таблицу dataframe.
>>> frame.to_sql('dataframe',engine)
pgAdmin III — это графическое приложение для управления базами данных PostgreSQL. Крайне удобный инструмент для Windows и Linux. С его помощью можно легко изучить созданную базу данных.
Если вы хорошо знаете язык SQL, то есть и классический способ рассмотреть созданную таблицу с помощью сессии psql.
>>> psql -U postgres
В этом случае соединение произошло от имени пользователя postgres. Оно может отличаться. После соединения просто осуществите SQL-запрос к таблице.
postgres=# SELECT * FROM DATAFRAME;
index| feb | mar | apr | may
-----+-----------------+-----------------+-----------------+-----------------
exp1 |0.757871296789076|0.422582915331819|0.979085739226726|0.332288515791064
exp2 |0.124353978978927|0.273461421503087|0.049433776453223|0.0271413946693556
exp3 |0.538089036334938|0.097041417119426|0.905979807772598|0.123448718583967
exp4 |0.736585422687497|0.982331931474687|0.958014824504186|0.448063967996436
(4 righe)
Даже конвертация таблицы в объект Dataframe — тривиальная задача. Для этого есть функция read_sql_table(), которая считывает данные из таблицы и записывает их в новый объект.
>>> pd.read_sql_table('dataframe',engine)
Но когда нужно считать данные из базы, конвертация целой таблицы в Dataframe — не самая полезная операция. Те, кто работают с реляционными базами данных, предпочитают использовать для этих целей SQL. Он подходит для выбора того. какие данные и в каком виде требуется получить с помощью SQL-запроса.
Текст запроса может быть использован в функции read_sql_query().
>>> pd.read_sql_query('SELECT index,apr,may FROM DATAFRAME WHERE apr >
0.5',engine)
Чтение и запись данных в базу данных NoSQL: MongoDB
Среди всех баз данных NoSQL (BerkeleyDB, Tokyo Cabinet и MongoDB) MongoDB — одна из самых распространенных. Она доступна в разных системах и подходит для чтения и записи данных при анализе данных.
Работу нужно начать с того, что указать на конкретную директорию.
mongod --dbpath C:\MongoDB_data
Теперь, когда сервис случает порт 27017, к базе можно подключиться, используя официальный драйвер для MongoDB, pymongo.
>>> import pymongo
>>> client = MongoClient('localhost',27017)
Один экземпляр MongoDB способен поддерживать несколько баз данных одновременно. Поэтому нужно указать на конкретную.
>>> db = client.mydatabase
>>> db
Database(MongoClient('localhost', 27017), 'mycollection')
>>> # Чтобы ссылаться на этот объект, используйте
>>> client['mydatabase']
Database(MongoClient('localhost', 27017), 'mydatabase')
Когда база данных определена, нужно определить коллекцию. Она представляет собой группу документов, сохраненных в MongoDB. Ее можно воспринимать как эквивалент таблиц из SQL.
>>> collection = db.mycollection
>>> db['mycollection']
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
>>> collection
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
Теперь нужно добавить данные в коллекцию. Создайте Dataframe.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Перед добавлением его нужно конвертировать в формат JSON. Процесс конвертации не такой простой, потому что нужно задать данные, которые будут записаны в базу, чтобы потом с легкостью извлекать их снова в объекте.
>>> import json
>>> record = json.loads(frame.T.to_json()).values()
>>> record
[{'blue': 7, 'green': 9, 'white': 5, 'black': 8, 'red': 6},
{'blue': 2, 'green': 4, 'white': 0, 'black': 3, 'red': 1},
{'blue': 17, 'green': 19, 'white': 15, 'black': 18, 'red': 16},
{'blue': 12, 'green': 14, 'white': 10, 'black': 13, 'red': 11}]
Теперь все готово для добавления документа в коллекцию. Для этого используется функция insert().
>>> collection.mydocument.insert(record)
[ObjectId('54fc3afb9bfbee47f4260357'), ObjectId('54fc3afb9bfbee47f4260358'),
ObjectId('54fc3afb9bfbee47f4260359'), ObjectId('54fc3afb9bfbee47f426035a')]
В этом случае каждый объект представлен на отдельной строке. Когда данные загружены в документ базы данных, можно выполнить и обратный процесс, то есть, прочитать данные и конвертировать их в Dataframe.
>>> cursor = collection['mydocument'].find()
>>> dataframe = (list(cursor))
>>> del dataframe['_id']
>>> dataframe
Была удалена колонка с ID для внутренней навигации по MongoDB.
В этом материале вы узнаете, как установить Keras на ОС Linux и Windows, а также ознакомитесь с проблемами, которые могут возникнуть в процессе, и требованиями для установки.
Как установить Keras на Linux
Keras — это фреймворк Python для глубокого обучения, поэтому в первую очередь нужно, чтобы Python был установлен в системе.
В Ubuntu он есть по умолчанию. Рекомендуется использовать последнюю версию, то есть python3. Для проверки наличия его в системе выполните следующее:
- Откройте терминал (Ctrl+Alt+T)
- Введите
python3 -Vилиpython3 –version
Выводом будет версия Python 3.
Python 3.6.9
Если Python 3 не установлен, воспользуйтесь следующими инструкциями:
- Добавьте
PPA, запустив следующую командуsudo add-apt-repository ppa:jonathonf/python-3.6Введите пароль суперпользователя.
- Проверьте обновления и установите Python 3.6 или больше
sudo apt-get update sudo apt-get install python3.6 - Снова проверьте версию Python 3.
Теперь пришло время устанавливать Keras.
Но сначала нужно установить один из бэкенд-движков: Tensorflow, Theano или Microsoft CNTK. Лучше всего использовать первый.
Установите Tensorflow из PyPl:
pip3 install tensorflow
Теперь установка Keras:
- Установите Keras из PyPl:
pip3 install Keras
- Или установите его из Github:
- Клонируйте репозиторий
git clone https://github.com/keras-team/keras.git - Перейдите в папку keras
cd Keras - Запустите команду install
sudo python3 setup.py install
Keras установлен.
Как установить Keras на Windows?
Прежде чем переходить к установке Keras, нужно убедиться, что в системе есть Python. Нужна версия как минимум Python 3.5+.
Для проверки установленной версии:
- Откройте
cmd - Введите
python -Vилиpython –version
Отобразится текущая версия Python.
Python 3.7.3
Если Python не установлен или загружена более старая версия:
- Зайдите на сайт python.org
- Выберите последнюю версию Python для Windows
- В нижней части страницы выберите установочный файл
Windows x86-для 64-битной версии системы илиWindows x86— для 32-битной. - После загрузки программы установки дважды кликните по файлу.
- Снова проверьте версию Python в
cmd
Теперь нужно установить один из движков: Tensorflow, Theano или Microsoft CNTK. Рекомендуется использовать первый.
Установите Tensofrflow с помощью пакетного менеджера pip3:
pip3 install tensorflow
Теперь установите Keras
- Установите Keras из PyPl:
pip3 install Keras - Установите Keras из Github
Клонируйте git-репозиторийgit clone https://github.com/keras-team/keras.git - Перейдите в папку
kerascd keras - Запустите команду
installpython3 setup.py install
Создайте первую программу в Keras
Создадим регрессионную предсказательную модель на основе данных о ценах Boston Housing с помощью Keras. Данные включают 13 признаков домов и включают 506 объектов. Задача — предсказать цены.
Это классическая регрессионная проблема машинного обучения, а набор данных доступен в модуле Keras.dataset.
Реализация:
import numpy as np
import pandas as pd
# загрузить набор данных, это может занять некоторое время
from keras.datasets import boston_housing
(train_x,train_y),(test_x,test_y)=boston_housing.load_data()
Нормализация данных
mean=train_x.mean(axis=0)
train_x-=mean
std=train_x.std(axis=0)
train_x/=std
test_x-=mean
test_x/=std
Построение нейронной сети
from keras import models, layers
def build_model():
model=models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(train_x.shape[1],)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',loss='mse',metrics=['mae'])
return model
Тренировка модели
model=build_model()
model.fit(train_x,train_y,epochs=80,batch_size=16,verbose=0)
Оценка модели с помощью среднеквадратической ошибки модели и средней абсолютной ошибки
test_mse, test_mae=model.evaluate(test_x, test_y)
test_mae
2.6441757678985596
Модель получает довольно высокую среднюю ошибку с этими данными. Лучшие результаты можно получить за счет дальнейшей предварительной обработки данных.
Выводы
Статья посвящена пошаговой установке Keras в Linux (Ubuntu) и Windows. Она также включает базовую реализацию предсказательной модели ценообразования Boston Housing, которая является хорошо исследованной регрессионной проблемой моделирования в машинном обучении.
]]>Вы уже знакомы с библиотекой pandas и ее базовой функциональностью по анализу данных. Также знаете, что в ее основе лежат два типа данных: Dataframe и Series. На их основе выполняется большая часть взаимодействия с данными, вычислений и анализа.
В этом материале вы познакомитесь с инструментами, предназначенными для чтения данных, сохраненных в разных источниках (файлах и базах данных). Также научитесь записывать структуры в эти форматы, не задумываясь об используемых технологиях.
Этот раздел посвящен функциям API I/O (ввода/вывода), которые pandas предоставляет для чтения и записи данных прямо в виде объектов Dataframe. Начнем с текстовых файлов, а затем перейдем к более сложным бинарным форматам.
А в конце узнаем, как взаимодействовать с распространенными базами данных, такими как SQL и NoSQL, используя для этого реальные примеры. Разберем, как считывать данные из базы данных, сохраняя их в виде Dataframe.
Инструменты API I/O
pandas — библиотека, предназначенная для анализа данных, поэтому логично предположить, что она в первую очередь используется для вычислений и обработки данных. Процесс записи и чтения данных на/с внешние файлы — это часть обработки. Даже на этом этапе можно выполнять определенные операции, готовя данные к взаимодействию.
Первый шаг очень важен, поэтому для него представлен полноценный инструмент в библиотеке, называемый API I/O. Функции из него можно разделить на две категории: для чтения и для записи.
| Чтение | Запись |
|---|---|
| read_csv | to_csv |
| read_excel | to_excel |
| read_hdf | to_hdf |
| read_sql | to_sql |
| read_json | to_json |
| read_html | to_html |
| read_stata | to_stata |
| read_clipboard | to_clipboard |
| read_pickle | to_pickle |
| read_msgpack | to_msgpack (экспериментальный) |
| read_gbq | to_gbq (экспериментальный) |
CSV и текстовые файлы
Все привыкли к записи и чтению файлов в текстовой форме. Чаще всего они представлены в табличной форме. Если значения в колонке разделены запятыми, то это формат CSV (значения, разделенные запятыми), который является, наверное, самым известным форматом.
Другие формы табличных данных могут использовать в качестве разделителей пробелы или отступы. Они хранятся в текстовых файлах разных типов (обычно с расширением .txt).
Такой тип файлов — самый распространенный источник данных, который легко расшифровывать и интерпретировать. Для этого pandas предлагает набор функций:
read_csvread_tableto_csv
Чтение данных из CSV или текстовых файлов
Самая распространенная операция по взаимодействию с данными при анализе данных — чтение их из файла CSV или как минимум текстового файла.
Для этого сперва нужно импортировать отдельные библиотеки.
>>> import numpy as np
>>> import pandas as pd
Чтобы сначала увидеть, как pandas работает с этими данными, создадим маленький файл CSV в рабочем каталоге, как показано на следующем изображении и сохраним его как ch05_01.csv.
white,red,blue,green,animal
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
Поскольку разделителем в файле выступают запятые, можно использовать функцию read_csv() для чтения его содержимого и добавления в объект Dataframe.
>>> csvframe = pd.read_csv('ch05_01.csv')
>>> csvframe
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Это простая операция. Файлы CSV — это табличные данные, где значения одной колонки разделены запятыми. Поскольку это все еще текстовые файлы, то подойдет и функция read_table(), но в таком случае нужно явно указывать разделитель.
>>> pd.read_table('ch05_01.csv',sep=',')
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В этом примере все заголовки, обозначающие названия колонок, определены в первой строчке. Но это не всегда работает именно так. Иногда сами данные начинаются с первой строки.
Создадим файл ch05_02.csv
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_csv('ch05_02.csv')
| 1 | 5 | 2 | 3 | cat | |
|---|---|---|---|---|---|
| 0 | 2 | 7 | 8 | 5 | dog |
| 1 | 3 | 3 | 6 | 7 | horse |
| 2 | 2 | 2 | 8 | 3 | duck |
| 3 | 4 | 4 | 2 | 1 | mouse |
| 4 | 4 | 4 | 2 | 1 | mouse |
В таком случае нужно убедиться, что pandas не присвоит названиям колонок значения первой строки, передав None параметру header.
>>> pd.read_csv('ch05_02.csv', header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Также можно самостоятельно определить названия, присвоив список меток параметру names.
>>> pd.read_csv('ch05_02.csv', names=['white','red','blue','green','animal'])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В более сложных случаях когда нужно создать Dataframe с иерархической структурой на основе данных из файла CSV, можно расширить возможности функции read_csv() добавив параметр index_col, который конвертирует колонки в значения индексов.
Чтобы лучше разобраться с этой особенностью, создайте новый CSV-файл с двумя колонками, которые будут индексами в иерархии. Затем сохраните его в рабочую директорию под именем ch05_03.csv.
Создадим файл ch05_03.csv
color,status,item1,item2,item3
black,up,3,4,6
black,down,2,6,7
white,up,5,5,5
white,down,3,3,2
white,left,1,2,1
red,up,2,2,2
red,down,1,1,4
>>> pd.read_csv('ch05_03.csv', index_col=['color','status'])
| item1 | item2 | item3 | ||
|---|---|---|---|---|
| color | status | |||
| black | up | 3 | 4 | 6 |
| down | 2 | 6 | 7 | |
| white | up | 5 | 5 | 5 |
| down | 3 | 3 | 2 | |
| left | 1 | 2 | 1 | |
| red | up | 2 | 2 | 2 |
| down | 1 | 1 | 4 |
Использованием RegExp для парсинга файлов TXT
Иногда бывает так, что в файлах, из которых нужно получить данные, нет разделителей, таких как запятая или двоеточие. В таких случаях на помощь приходят регулярные выражения. Задать такое выражение можно в функции read_table() с помощью параметра sep.
Чтобы лучше понимать regexp и то, как их использовать для разделения данных, начнем с простого примера. Например, предположим, что файл TXT имеет значения, разделенные пробелами и отступами хаотично. В таком случае regexp подойдут идеально, ведь они позволяют учитывать оба вида разделителей. Подстановочный символ /s* отвечает за все символы пробелов и отступов (если нужны только отступы, то используется /t), а * указывает на то, что символов может быть несколько. Таким образом значения могут быть разделены большим количеством пробелов.
| . | Любой символ за исключением новой строки |
| \d | Цифра |
| \D | Не-цифровое значение |
| \s | Пробел |
| \S | Не-пробельное значение |
| \n | Новая строка |
| \t | Отступ |
| \uxxxx | Символ Unicode в шестнадцатеричном виде |
Возьмем в качестве примера случай, где значения разделены отступами или пробелами в хаотическом порядке.
Создадим файл ch05_04.txt
white red blue green
1 5 2 3
2 7 8 5
3 3 6 7
>>> pd.read_table('ch05_04.txt',sep='\s+', engine='python')
| white | red | blue | green | |
|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 |
| 1 | 2 | 7 | 8 | 5 |
| 2 | 3 | 3 | 6 | 7 |
Результатом будет идеальный Dataframe, в котором все значения корректно отсортированы.
Дальше будет пример, который может показаться странным, но на практике он встречается не так уж и редко. Он пригодится для понимания принципов работы regexp. На самом деле, о разделителях (запятых, пробелах, отступах и так далее) часто думают как о специальных символах, но иногда ими выступают и буквенно-цифровые символы, например, целые числа.
В следующем примере необходимо извлечь цифровую часть из файла TXT, в котором последовательность символов перемешана с буквами.
Не забудьте задать параметр None для параметра header, если в файле нет заголовков колонок.
Создадим файл ch05_05.txt
000END123AAA122
001END124BBB321
002END125CCC333
>>> pd.read_table('ch05_05.txt', sep='\D+', header=None, engine='python')
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 123 | 122 |
| 1 | 1 | 124 | 321 |
| 2 | 2 | 125 | 333 |
Еще один распространенный пример — удаление из данных отдельных строк при извлечении. Так, не всегда нужны заголовки или комментарии. Благодаря параметру skiprows можно исключить любые строки, просто присвоим ему массив с номерами строк, которые не нужно парсить.
Обратите внимание на способ использования параметра. Если нужно исключить первые пять строк, то необходимо писать skiprows = 5, но для удаления только пятой строки — [5].
Создадим файл ch05_06.txt
########### LOG FILE ############
This file has been generated by automatic system
white,red,blue,green,animal
12-Feb-2015: Counting of animals inside the house
1,5,2,3,cat
2,7,8,5,dog
13-Feb-2015: Counting of animals outside the house
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_table('ch05_06.txt',sep=',',skiprows=[0,1,3,6])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Чтение файлов TXT с разделением на части
При обработке крупных файлов или необходимости использовать только отдельные их части часто требуется считывать их кусками. Это может пригодится, если необходимо воспользоваться перебором или же целый файл не нужен.
Если требуется получить лишь часть файла, можно явно указать количество требуемых строк. Благодаря параметрам nrows и skiprows можно выбрать стартовую строку n (n = SkipRows) и количество строк, которые нужно считать после (nrows = 1).
>>> pd.read_csv('ch05_02.csv',skiprows=[2],nrows=3,header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 2 | 2 | 8 | 3 | duck |
Еще одна интересная и распространенная операция — разбитие на части того куска текста, который требуется парсить. Затем для каждой части может быть выполнена конкретная операция для получения перебора части за частью.
Например, нужно суммировать значения в колонке каждой третьей строки и затем вставить результат в объект Series. Это простой и непрактичный пример, но с его помощью легко разобраться, а поняв механизм работы, его проще будет применять в сложных ситуациях.
>>> out = pd.Series()
>>> i = 0
>>> pieces = pd.read_csv('ch05_01.csv',chunksize=3)
>>> for piece in pieces:
... out.set_value(i,piece['white'].sum())
... i = i + 1
...
>>> out
0 6
1 6
dtype: int64
Запись данных в CSV
В дополнение к чтению данных из файла, распространенной операцией является запись в файл данных, полученных, например, в результате вычислений или просто из структуры данных.
Например, нужно записать данные из объекта Dataframe в файл CSV. Для этого используется функция to_csv(), принимающая в качестве аргумента имя файла, который будет сгенерирован.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index = ['red', 'blue', 'yellow', 'white'],
columns = ['ball', 'pen', 'pencil', 'paper'])
>>> frame.to_csv('ch05_07.csv')
Если открыть новый файл ch05_07.csv, сгенерированный библиотекой pandas, то он будет напоминать следующее:
,ball,pen,pencil,paper
0,1,2,3
4,5,6,7
8,9,10,11
12,13,14,15
На предыдущем примере видно, что при записи Dataframe в файл индексы и колонки отмечаются в файле по умолчанию. Это поведение можно изменить с помощью параметров index и header. Им нужно передать значение False.
>>> frame.to_csv('ch05_07b.csv', index=False, header=False)
Файл ch05_07b.csv
1,2,3
5,6,7
9,10,11
13,14,15
Важно запомнить, что при записи файлов значения NaN из структуры данных представлены в виде пустых полей в файле.
>>> frame3 = pd.DataFrame([[6,np.nan,np.nan,6,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [20,np.nan,np.nan,20.0,np.nan],
... [19,np.nan,np.nan,19.0,np.nan]
... ],
... index=['blue','green','red','white','yellow'],
... columns=['ball','mug','paper','pen','pencil'])
>>> frame3
| Unnamed: 0 | ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|---|
| 0 | blue | 6.0 | NaN | NaN | 6.0 | NaN |
| 1 | green | NaN | NaN | NaN | NaN | NaN |
| 2 | red | NaN | NaN | NaN | NaN | NaN |
| 3 | white | 20.0 | NaN | NaN | 20.0 | NaN |
| 4 | yellow | 19.0 | NaN | NaN | 19.0 | NaN |
>>> frame3.to_csv('ch05_08.csv')
,ball,mug,paper,pen,pencil
blue,6.0,,,6.0,
green,,,,,
red,,,,,
white,20.0,,,20.0,
yellow,19.0,,,19.0,
Но их можно заменить на любое значение, воспользовавшись параметром na_rep из функции to_csv. Это может быть NULL, 0 или то же NaN.
>>> frame3.to_csv('ch05_09.csv', na_rep ='NaN')
,ball,mug,paper,pen,pencil
blue,6.0,NaN,NaN,6.0,NaN
green,NaN,NaN,NaN,NaN,NaN
red,NaN,NaN,NaN,NaN,NaN
white,20.0,NaN,NaN,20.0,NaN
yellow,19.0,NaN,NaN,19.0,NaN
Примечание: в предыдущих примерах использовались только объекты
Dataframe, но все функции применимы и по отношению кSeries.
Чтение и запись файлов HTML
pandas предоставляет соответствующую пару функций API I/O для формата HTML.
read_html()to_html()
Эти две функции очень полезны. С их помощью можно просто конвертировать сложные структуры данных, такие как Dataframe, прямо в таблицы HTML, не углубляясь в синтаксис.
Обратная операция тоже очень полезна, потому что сегодня веб является одним из основных источников информации. При этом большая часть информации не является «готовой к использованию», будучи упакованной в форматы TXT или CSV. Необходимые данные чаще всего представлены лишь на части страницы. Так что функция для чтения окажется полезной очень часто.
Такая деятельность называется парсингом (веб-скрапингом). Этот процесс становится фундаментальным элементом первого этапа анализа данных: поиска и подготовки.
Примечание: многие сайты используют
HTML5для предотвращения ошибок недостающих модулей или сообщений об ошибках. Настоятельно рекомендуется использовать модульhtml5libв Anaconda.
conda install html5lib
Запись данных в HTML
При записи Dataframe в HTML-таблицу внутренняя структура объекта автоматически конвертируется в сетку вложенных тегов <th>, <tr> и <td>, сохраняя иерархию. Для этой функции даже не нужно знать HTML.
Поскольку структуры данных, такие как Dataframe, могут быть большими и сложными, это очень удобно иметь функцию, которая сама создает таблицу на странице. Вот пример.
Сначала создадим простейший Dataframe. Дальше с помощью функции to_html() прямо конвертируем его в таблицу HTML.
>>> frame = pd.DataFrame(np.arange(4).reshape(2,2))
Поскольку функции API I/O определены в структуре данных pandas, вызывать to_html() можно прямо к экземпляру Dataframe.
>>> print(frame.to_html())
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>0</th>
<th>1</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>0</td>
<td>1</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>3</td>
</tr>
</tbody>
</table>
Результат — готовая таблица HTML, сохранившая всю внутреннюю структуру.
В следующем примере вы увидите, как таблицы автоматически появляются в файле HTML. В этот раз сделаем объект более сложным, добавив в него метки индексов и названия колонок.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['white','black','red','blue'],
... columns = ['up','down','right','left'])
>>> frame
| up | down | right | left | |
|---|---|---|---|---|
| white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Теперь попробуем написать страницу HTML с помощью генерации строк. Это простой пример, но он позволит разобраться с функциональностью pandas прямо в браузере.
Сначала создадим строку, которая содержит код HTML-страницы.
>>> s = ['<HTML>']
>>> s.append('<HEAD><TITLE>My DataFrame</TITLE></HEAD>')
>>> s.append('<BODY>')
>>> s.append(frame.to_html())
>>> s.append('</BODY></HTML>')
>>> html = ''.join(s)
Теперь когда метка html содержит всю необходимую разметку, можно писать прямо в файл myFrame.html:
>>> html_file = open('myFrame.html','w')
>>> html_file.write(html)
>>> html_file.close()
В рабочей директории появится новый файл, myFrame.html. Двойным кликом его можно открыть прямо в браузере. В левом верхнем углу будет следующая таблица:

Чтение данных из HTML-файла
pandas может с легкостью генерировать HTML-таблицы на основе данных Dataframe. Обратный процесс тоже возможен. Функция read_html() осуществляет парсинг HTML и ищет таблицу. В случае успеха она конвертирует ее в Dataframe, который можно использовать в процессе анализа данных.
Если точнее, то read_html() возвращает список объектов Dataframe, даже если таблица одна. Источник может быть разных типов. Например, может потребоваться прочитать HTML-файл в любой папке. Или попробовать парсить HTML из прошлого примера:
>>> web_frames = pd.read_html('myFrame.html')
>>> web_frames[0]
| Unnamed: 0 | up | down | right | left | |
|---|---|---|---|---|---|
| 0 | white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| 1 | black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| 2 | red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| 3 | blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Все теги, отвечающие за формирование таблицы в HTML в финальном объекте не представлены. web_frames — это список Dataframe, хотя в этом случае объект был всего один. К нему можно обратиться стандартным путем. Здесь достаточно лишь указать на него через индекс 0.
Но самый распространенный режим работы функции read_html() — прямой парсинг ссылки. Таким образом страницы парсятся прямо, а из них извлекаются таблицы.
Например, дальше будет вызвана страница, на которой есть HTML-таблица, показывающая рейтинг с именами и баллами.
>>> ranking = pd.read_html('https://www.meccanismocomplesso.org/en/
meccanismo-complesso-sito-2/classifica-punteggio/')
>>> ranking[0]
| # | Nome | Exp | Livelli | right |
|---|---|---|---|---|
| 0 | 1 | Fabio Nelli | 17521 | NaN |
| 1 | 2 | admin | 9029 | NaN |
| 2 | 3 | BrunoOrsini | 2124 | NaN |
| … | … | … | … | … |
| 247 | 248 | emilibassi | 1 | NaN |
| 248 | 249 | mehrbano | 1 | NaN |
| 249 | 250 | NIKITA PANCHAL | 1 | NaN |
Чтение данных из XML
В списке функции API I/O нет конкретного инструмента для работы с форматом XML (Extensible Markup Language). Тем не менее он очень важный, поскольку многие структурированные данные представлены именно в нем. Но это и не проблема, ведь в Python есть много других библиотек (помимо pandas), которые подходят для чтения и записи данных в формате XML.
Одна их них называется lxml и она обеспечивает идеальную производительность при парсинге даже самых крупных файлов. Этот раздел будет посвящен ее использованию, интеграции с pandas и способам получения Dataframe с нужными данными. Больше подробностей о lxml есть на официальном сайте http://lxml.de/index.html.
Возьмем в качестве примера следующий файл. Сохраните его в рабочей директории с названием books.xml.
<?xml version="1.0"?>
<Catalog>
<Book id="ISBN9872122367564">
<Author>Ross, Mark</Author>
<Title>XML Cookbook</Title>
<Genre>Computer</Genre>
<Price>23.56</Price>
<PublishDate>2014-22-01</PublishDate>
</Book>
<Book id="ISBN9872122367564">
<Author>Bracket, Barbara</Author>
<Title>XML for Dummies</Title>
<Genre>Computer</Genre>
<Price>35.95</Price>
<PublishDate>2014-12-16</PublishDate>
</Book>
</Catalog>
В этом примере структура файла будет конвертирована и преподнесена в виде Dataframe. В первую очередь нужно импортировать субмодуль objectify из библиотеки.
>>> from lxml import objectify
Теперь нужно всего лишь использовать его функцию parse().
>>> xml = objectify.parse('books.xml')
>>> xml
<lxml.etree._ElementTree object at 0x0000000009734E08>
Результатом будет объект tree, который является внутренней структурой данных модуля lxml.
Чтобы познакомиться с деталями этого типа, пройтись по его структуре или выбирать элемент за элементом, в первую очередь нужно определить корень. Для этого используется функция getroot().
>>> root = xml.getroot()
Теперь можно получать доступ к разным узлам, каждый из которых соответствует тегам в оригинальном XML-файле. Их имена также будут соответствовать. Для выбора узлов нужно просто писать отдельные теги через точки, используя иерархию дерева.
>>> root.Book.Author
'Ross, Mark'
>>> root.Book.PublishDate
'2014-22-01'
В такой способ доступ к узлам можно получить индивидуально. А getchildren() обеспечит доступ ко всем дочерним элементами.
>>> root.getchildren()
[<Element Book at 0x9c66688>, <Element Book at 0x9c66e08>]
При использовании атрибута tag вы получаете название соответствующего тега из родительского узла.
>>> [child.tag for child in root.Book.getchildren()]
['Author', 'Title', 'Genre', 'Price', 'PublishDate']
А text покажет значения в этих тегах.
>>> [child.text for child in root.Book.getchildren()]
['Ross, Mark', 'XML Cookbook', 'Computer', '23.56', '2014-22-01']
Но вне зависимости от возможности двигаться по структуре lxml.etree, ее нужно конвертировать в Dataframe. Воспользуйтесь следующей функцией, которая анализирует содержимое eTree и заполняет им Dataframe строчка за строчкой.
>>> def etree2df(root):
... column_names = []
... for i in range(0, len(root.getchildren()[0].getchildren())):
... column_names.append(root.getchildren()[0].getchildren()[i].tag)
... xmlframe = pd.DataFrame(columns=column_names)
... for j in range(0, len(root.getchildren())):
... obj = root.getchildren()[j].getchildren()
... texts = []
... for k in range(0, len(column_names)):
... texts.append(obj[k].text)
... row = dict(zip(column_names, texts))
... row_s = pd.Series(row)
... row_s.name = j
... xmlframe = xmlframe.append(row_s)
... return xmlframe
>>> etree2df(root)
| Author | Title | Genre | Price | PublishDate | |
|---|---|---|---|---|---|
| 0 | Ross, Mark | XML Cookbook | Computer | 23.56 | 2014-01-22 |
| 1 | Bracket, Barbara | XML for Dummies | Computer | 35.95 | 2014-12-16 |
Keras — очень полезная библиотека для тех, кто только начинает свое знакомство с нейронными сетями. Это высокоуровневый фреймворк со скрытой бэкенд-реализацией, необходимый для построения моделей нейронных сетей. Из этого материала вы узнаете о достоинствах и ограничениях Keras.
Преимущества Keras
1. Простой в использовании с высокой скоростью развертывания
Keras — это простой в использовании API, с помощью которого очень легко создавать модели нейронных сетей. Он подходит для реализации алгоритмов глубокого обучения и обработки естественного языка. Модель нейронной сети можно построить с помощью всего нескольких строчек кода.
Вот пример:
from keras.models import Sequential
from keras.layers import Dense, Activation
model= Sequential()
model.add(Dense(64, activation=’relu’,input_dim=50))
model.add(Dense(28, activation=’relu’))
model.add(Dense(10,activation=’softmax’))
Здесь видно, что разобраться как с кодом, так и с потоком не составит труда. Функции и параметры очень простые, поэтому и писать их не сложно. Есть внушительный набор функций для обработки данных. Keras предоставляет несколько слоев, включая поддержку свертываемых и рекуррентных слоев.
2. Качественная документация и поддержка от сообщества
У Keras один из лучших примеров документации. Она представляет каждую функцию последовательно и очень подробно. Примеры кода также полезны и просты для понимания.
У Keras есть отличная поддержка со стороны сообщества. Многие разработчики предпочитают Keras для участия в соревнованиях по Data Science. Также многие исследователи публикуют свой код и руководства для широкой аудитории.
3. Поддержка разных движков и модульность
Keras предлагает поддержку несколько бэкенд-движков, включая Tensorflow, Theano и CNTK. Любой из них может быть выбран на основе требований проекта.
Можно также тренировать модель Keras на основе одного движка, а проверять результаты — на другом. Поменять движок в Keras также очень легко. Для этого его имя нужно просто записать в конфигурационном файле.
4. Натренированные модели
Keras предоставляет несколько моделей глубокого обучения с натренированными весами. Их можно использовать для предсказания или извлечения признаков.
У этих моделей встроенные веса, которые являются результатами тренировки модели на данных ImageNet.
Вот некоторые из представленных моделей:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet
5. Поддержка нескольких GPU
Keras позволяет тренировать модель как на одном, так и на нескольких GPU. Это обеспечивает поддержку параллелизма данных и позволяет обрабатывать большие объемы.
Ограничения Keras
Вот некоторые из недостатков инструмента.
1. Проблемы в низкоуровневом API
Иногда возникают низкоуровневые ошибки бэкенда. Это происходит в тех случаях, когда предпринимаются попытки выполнить операции, для которых Keras не предназначен.
Однако он не позволяет изменять что-либо в бэкенде. Следовательно, сложно заниматься отладкой на основе логов с ошибками.
2. Требуются улучшения некоторых особенностей
Инструменты Keras для подготовки данных не так хороши, как в случае с другими пакетами, например scikit-learn. Они не подходят для построения базовых алгоритмов машинного обучения: кластерного анализа или метода главных компонент. Нет и возможности динамического создания графиков.
3. Медленнее бэкенда
Иногда Keras очень медленный при работе на GPU, а его операции занимают больше времени в сравнении с бэкендом. Поэтому скоростью приходится жертвовать в угоду удобству использования.
Выводы
Этот материал — лишь основные достоинства и недостатки работы с Keras. На их основе вы должны решать, когда использовать фреймворк, а когда лучше отдать предпочтение альтернативам.
]]>Иерархическое индексирование — это важная особенность pandas, поскольку она позволяет иметь несколько уровней индексов в одной оси. С ее помощью можно работать с данными в большом количестве измерений, по-прежнему используя для этого структуру данных из двух измерений.
Начнем с простого примера, создав Series с двумя массивами индексов — структуру с двумя уровнями.
>>> mser = pd.Series(np.random.rand(8),
... index=[['white','white','white','blue','blue','red','red',
'red'],
... ['up','down','right','up','down','up','down','left']])
>>> mser
white up 0.661039
down 0.512268
right 0.639885
blue up 0.081480
down 0.408367
red up 0.465264
down 0.374153
left 0.325975
dtype: float64
>>> mser.index
MultiIndex(levels=[['blue', 'red', 'white'], ['down', 'left', 'right', 'up']],
labels=[[2, 2, 2, 0, 0, 1, 1, 1], [3, 0, 2, 3, 0, 3, 0, 1]])
За счет спецификации иерархического индексирования, выбор подмножеств значений в таком случае заметно упрощен. Можно выбрать значения для определенного значения первого индекса стандартным способом:
>>> mser['white']
up 0.661039
down 0.512268
right 0.639885
dtype: float64
Или же значения для конкретного значения во втором индекса — таким:
>>> mser[:,'up']
white 0.661039
blue 0.081480
red 0.465264
dtype: float64
Если необходимо конкретное значение, просто указываются оба индекса.
>>> mser['white','up']
0.66103875558038194
Иерархическое индексирование играет важную роль в изменении формы данных и групповых операциях, таких как сводные таблицы. Например, данные могут быть перестроены и использованы в объекте Dataframe с помощью функции unstack(). Она конвертирует Series с иерархическими индексами в простой Dataframe, где второй набор индексов превращается в новые колонки.
>>> mser.unstack()
| down | left | right | up | |
|---|---|---|---|---|
| blue | 0.408367 | NaN | NaN | 0.081480 |
| red | 0.374153 | 0.325975 | NaN | 0.465264 |
| white | 0.512268 | NaN | 0.639885 | 0.661039 |
Если необходимо выполнить обратную операцию — превратить Dataframe в Series, — используется функция stack().
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.stack()
red ball 0
pen 1
pencil 2
paper 3
blue ball 4
pen 5
pencil 6
paper 7
yellow ball 8
pen 9
pencil 10
paper 11
white ball 12
pen 13
pencil 14
paper 15
dtype: int32
В Dataframe можно определить иерархическое индексирование для строк и колонок. Для этого необходимо определить массив массивов для параметров index и columns.
>>> mframe = pd.DataFrame(np.random.randn(16).reshape(4,4),
... index=[['white','white','red','red'], ['up','down','up','down']],
... columns=[['pen','pen','paper','paper'],[1,2,1,2]])
>>> mframe
| pen | paper | ||||
|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | ||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
Изменение порядка и сортировка уровней
Иногда потребуется поменять порядок уровней на оси или отсортировать значения на определенном уровне.
Функция swaplevel() принимает в качестве аргументов названия уровней, которые необходимо поменять относительно друг друга и возвращает новый объект с соответствующими изменениями, оставляя данные в том же состоянии.
>>> mframe.columns.names = ['objects','id']
>>> mframe.index.names = ['colors','status']
>>> mframe
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
>>> mframe.swaplevel('colors','status')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| status | colors | ||||
| up | white | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | white | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | red | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | red | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
А функция sort_index() сортирует данные для конкретного уровня, указанного в параметрах.
>>> mframe.sort_index(level='colors')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| red | down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
| up | -1.721348 | 0.989703 | -1.454304 | -0.249718 | |
| white | down | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
Общая статистика по уровню
У многих статистических методов для Dataframe есть параметр level, в котором нужно определить, для какого уровня нужно определить статистику.
Например, если нужна статистика для первого уровня, его нужно указать в параметрах.
>>> mframe.sum(level='colors')
| objects | pen | paper | ||
|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 |
| colors | ||||
| white | 2.143731 | 2.044471 | 0.343945 | -0.349614 |
| red | -1.834594 | 0.548174 | -1.559332 | 0.036068 |
Если же она необходима для конкретного уровня колонки, например, id, тогда требуется задать параметр axis и указать значение 1.
>>> mframe.sum(level='id', axis=1)
| id | 1 | 2 | paper |
|---|---|---|---|
| colors | status | ||
| white | up | 1.165374 | 0.605568 |
| down | 1.322302 | 1.089289 | |
| red | up | -3.175653 | 0.739985 |
| down | -0.218274 | -0.155743 |
В предыдущих разделах вы видели, как легко могут образовываться недостающие данные. В структурах они определяются как значения NaN (Not a Value). Такой тип довольно распространен в анализе данных.
Но pandas спроектирован так, чтобы лучше с ними работать. Дальше вы узнаете, как взаимодействовать с NaN, чтобы избегать возможных проблем. Например, в библиотеке pandas вычисление описательной статистики неявно исключает все значения NaN.
Присваивание значения NaN
Если нужно специально присвоить значение NaN элементу структуры данных, для этого используется np.NaN (или np.nan) из библиотеки NumPy.
>>> ser = pd.Series([0,1,2,np.NaN,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
>>> ser['white'] = None
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
Фильтрование значений NaN
Есть несколько способов, как можно избавиться от значений NaN во время анализа данных. Это можно делать вручную, удаляя каждый элемент, но такая операция сложная и опасная, к тому же не гарантирует, что вы действительно избавились от всех таких значений. Здесь на помощь приходит функция dropna().
>>> ser.dropna()
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
Функцию фильтрации можно выполнить и прямо с помощью notnull() при выборе элементов.
>>> ser[ser.notnull()]
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
В случае с Dataframe это чуть сложнее. Если использовать функцию pandas dropna() на таком типе объекта, который содержит всего одно значение NaN в колонке или строке, то оно будет удалено.
>>> frame3 = pd.DataFrame([[6,np.nan,6],[np.nan,np.nan,np.nan],[2,np.nan,5]],
... index = ['blue','green','red'],
... columns = ['ball','mug','pen'])
>>> frame3
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| green | NaN | NaN | NaN |
| red | 2.0 | NaN | 5.0 |
>>> frame3.dropna()
Empty DataFrame
Columns: [ball, mug, pen]
Index: []
Таким образом чтобы избежать удаления целых строк или колонок нужно использовать параметр how, присвоив ему значение all. Это сообщит функции, чтобы она удаляла только строки или колонки, где все элементы равны NaN.
>>> frame3.dropna(how='all')
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| red | 2.0 | NaN | 5.0 |
Заполнение NaN
Вместо того чтобы отфильтровывать значения NaN в структурах данных, рискуя удалить вместе с ними важные элементы, можно заменять их на другие числа. Для этих целей подойдет fillna(). Она принимает один аргумент — значение, которым нужно заменить NaN.
>>> frame3.fillna(0)
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 0.0 | 0.0 | 0.0 |
| red | 2.0 | 0.0 | 5.0 |
Или же NaN можно заменить на разные значения в зависимости от колонки, указывая их и соответствующие значения.
>>> frame3.fillna({'ball':1,'mug':0,'pen':99})
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 1.0 | 0.0 | 99.0 |
| red | 2.0 | 0.0 | 5.0 |
Функции для элементов
Библиотека Pandas построена на базе NumPy и расширяет возможности последней, используя их по отношению к новым структурам данных: Series и Dataframe. В их числе универсальные функции, называемые ufunc. Они применяются к элементам структуры данных.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Например, можно найти квадратный корень для каждого значения в Dataframe с помощью функции np.sqrt().
>>> np.sqrt(frame)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0.000000 | 1.000000 | 1.414214 | 1.732051 |
| blue | 2.000000 | 2.236068 | 2.449490 | 2.645751 |
| yellow | 2.828427 | 3.000000 | 3.162278 | 3.316625 |
| white | 3.464102 | 3.605551 | 3.741657 | 3.872983 |
Функции для строк и колонок
Применение функций не ограничивается универсальными, но включает и те, что были определены пользователем. Важно отметить, что они работают с одномерными массивами, выдавая в качестве результата единое число. Например, можно определить лямбда-функцию, которая вычисляет диапазон значений элементов в массиве.
>>> f = lambda x: x.max() - x.min()
Эту же функцию можно определить и следующим образом:
>>> def f(x):
... return x.max() - x.min()
С помощью apply() новая функция применяется к Dataframe.
>>> frame.apply(f)
ball 12
pen 12
pencil 12
paper 12
dtype: int64
В этот раз результатом является одно значение для каждой колонки, но если нужно применить функцию к строкам, а на колонкам, нужно лишь поменять значение параметра axis и указать 1.
>>> frame.apply(f, axis=1)
red 3
blue 3
yellow 3
white 3
dtype: int64
Метод apply() не обязательно вернет скалярную величину. Он может вернуть и объект Series. Можно также включить и применить несколько функций одновременно. Это делается следующим образом:
>>> def f(x):
... return pd.Series([x.min(), x.max()], index=['min','max'])
После этого функция используется как и в предыдущем примере. Но теперь результатом будет объект Dataframe, а не Series, в котором столько строк, сколько значений функция возвращает.
>>> frame.apply(f)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| min | 0 | 1 | 2 | 3 |
| max | 12 | 13 | 14 | 15 |
Статистические функции
Большая часть статистических функций массивов работает и с Dataframe, поэтому для них не нужно использовать apply(). Например, sum() и mean() могут посчитать сумму или среднее значение соответственно для элементов внутри объекта Dataframe.
>>> frame.sum()
ball 24
pen 28
pencil 32
paper 36
dtype: int64
>>> frame.mean()
ball 6.0
pen 7.0
pencil 8.0
paper 9.0
dtype: float64
Есть даже функция describe(), которая позволяет получить всю статистику за раз.
>>> frame.describe()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| count | 4.000000 | 4.000000 | 4.000000 | 4.000000 |
| mean | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| std | 5.163978 | 5.163978 | 5.163978 | 5.163978 |
| min | 0.000000 | 1.000000 | 2.000000 | 3.000000 |
| 25% | 3.000000 | 4.000000 | 5.000000 | 6.000000 |
| 50% | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| 75% | 9.000000 | 10.000000 | 11.000000 | 12.000000 |
| max | 12.000000 | 13.000000 | 14.000000 | 15.000000 |
Сортировка и ранжирование
Еще одна операция, использующая индексирование pandas, — сортировка. Сортировка данных нужна часто, поэтому важно иметь возможность выполнять ее легко. Библиотека pandas предоставляет функцию sort_index(), которая возвращает новый объект, идентичный стартовому, но с отсортированными элементами.
Сначала рассмотрим варианты, как можно сортировать элементы Series. Операция простая, ведь сортируется всего один список индексов.
>>> ser = pd.Series([5,0,3,8,4],
... index=['red','blue','yellow','white','green'])
>>> ser
red 5
blue 0
yellow 3
white 8
green 4
dtype: int64
>>> ser.sort_index()
blue 0
green 4
red 5
white 8
yellow 3
dtype: int64
В этом примере элементы были отсортированы по алфавиту на основе ярлыков (от A до Z). Это поведение по умолчанию, но достаточно сделать значением параметра ascending False и элементы объекта отсортируются иначе.
>>> ser.sort_index(ascending=False)
yellow 3
white 8
red 5
green 4
blue 0
dtype: int64
В случае с Dataframe можно выполнить сортировку независимо для каждой из осей. Если требуется отсортировать элементы по индексам, то нужно просто использовать sort_index() как обычно. Если же требуется сортировка по колонкам, то необходимо задать значение 1 для параметра axis.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.sort_index()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| blue | 4 | 5 | 6 | 7 |
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
| yellow | 8 | 9 | 10 | 11 |
>>> frame.sort_index(axis=1)
| ball | paper | pen | pencil | |
|---|---|---|---|---|
| red | 0 | 3 | 1 | 2 |
| blue | 4 | 7 | 5 | 6 |
| yellow | 8 | 11 | 9 | 10 |
| white | 12 | 15 | 13 | 14 |
Но это лишь то, что касается сортировки по индексам. Но часто приходится сортировать объект по значениям его элементов. В таком случае сперва нужно определить объект: Series или Dataframe.
Для первого подойдет функция sort_values().
>>> ser.sort_values()
blue 0
yellow 3
green 4
red 5
white 8
dtype: int64
А для второго — та же функция sort_values(), но с параметром by, значением которого должна быть колонка, по которой требуется отсортировать объект.
>>> frame.sort_values(by='pen')
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Если сортировка основана на двух или больше колонках, то by можно присвоить массив с именами колонок.
>>> frame.sort_values(by=['pen','pencil'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Ранжирование тесно связано с операцией сортировки. Оно состоит из присваивания ранга (то есть, значения, начинающегося с 0 и постепенно увеличивающегося) к каждому элементу Series. Он присваивается элементам, начиная с самого младшего значения.
>>> ser.rank()
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
Ранг может быть присвоен и согласно порядку, в котором элементы содержатся в структуре (без операции сортировки). В таком случае нужно добавить параметр method со значением first.
>>> ser.rank(method='first')
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
По умолчанию даже ранжирование происходит в возрастающем порядке. Для обратного нужно задать значение False для параметра ascending.
>>> ser.rank(ascending=False)
red 2.0
blue 5.0
yellow 4.0
white 1.0
green 3.0
dtype: float64
Корреляция и ковариантность
Два важных типа статистических вычислений — корреляция и вариантность. В pandas они представлены функциями corr() и cov(). Для их работы нужны два объекта Series.
>>> seq2 = pd.Series([3,4,3,4,5,4,3,2],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq = pd.Series([1,2,3,4,4,3,2,1],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq.corr(seq2)
0.7745966692414835
>>> seq.cov(seq2)
0.8571428571428571
Их же можно применить и по отношению к одному Dataframe. В таком случае функции вернут соответствующие матрицы в виде двух новых объектов Dataframe.
>>> frame2 = pd.DataFrame([[1,4,3,6],[4,5,6,1],[3,3,1,5],[4,1,6,4]],
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 1 | 4 | 3 | 6 |
| blue | 4 | 5 | 6 | 1 |
| yellow | 3 | 3 | 1 | 5 |
| white | 4 | 1 | 6 | 4 |
>>> frame2.corr()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 1.000000 | -0.276026 | 0.577350 | -0.763763 |
| pen | -0.276026 | 1.000000 | -0.079682 | -0.361403 |
| pencil | 0.577350 | -0.079682 | 1.000000 | -0.692935 |
| paper | -0.763763 | -0.361403 | -0.692935 | 1.000000 |
>>> frame2.cov()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 2.000000 | -0.666667 | 2.000000 | -2.333333 |
| pen | -0.666667 | 2.916667 | -0.333333 | -1.333333 |
| pencil | 2.000000 | -0.333333 | 6.000000 | -3.666667 |
| paper | -2.333333 | -1.333333 | -3.666667 | 4.666667 |
С помощью метода corwith() можно вычислить попарные корреляции между колонками и строками объекта Dataframe и Series или другим DataFrame().
>>> ser = pd.Series([0,1,2,3,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0
blue 1
yellow 2
white 3
green 9
dtype: int64
>>> frame2.corrwith(ser)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
>>> frame2.corrwith(frame)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
В отличие от других структур данных в Python pandas не только пользуется преимуществами высокой производительности массивов NumPy, но и добавляет в них индексы.
Этот выбор оказался крайне удачным. Несмотря на и без того отличную гибкость, которая обеспечивается существующими динамическими структурами, внутренние ссылки на их элементы (а именно ими и являются метки) позволяют разработчикам еще сильнее упрощать операции.
В этом разделе речь пойдет о некоторых базовых функциях, использующих этот механизм:
- Переиндексирование
- Удаление
- Выравнивание
Переиндексирование df.reindex()
Вы уже знаете, что после объявления в структуре данных объект Index нельзя менять. Но с помощью операции переиндексирования это можно решить.
Существует даже возможность получить новую структуру из уже существующей, где правила индексирования заданы заново.
>>> ser = pd.Series([2,5,7,4], index=['one','two','three','four']) >>> ser
one 2
two 5
three 7
four 4
dtype: int64
Для того чтобы провести переиндексирование объекта Series библиотека pandas предоставляет функцию reindex(). Она создает новый объект Series со значениями из другого Series, которые теперь переставлены в соответствии с новой последовательностью меток.
При операции переиндексирования можно поменять порядок индексов, удалить некоторые из них или добавить новые. Если метка новая, pandas добавит NaN на место соответствующего значения.
>>> ser.reindex(['three','four','five','one'])
three 7.0
four 4.0
five NaN
one 2.0
dtype: float64
Как видно по выводу, порядок меток можно поменять полностью. Значение, которое раньше соответствовало метке two, удалено, зато есть новое с меткой five.
Тем не менее в случае, например, с большим Dataframe, не совсем удобно будет указывать новый список меток. Вместо этого можно использовать метод, который заполняет или интерполирует значения автоматически.
Для лучшего понимания механизма работы этого режима автоматического индексирования создадим следующий объект Series.
>>> ser3 = pd.Series([1,5,6,3],index=[0,3,5,6])
>>> ser3
0 1
3 5
5 6
6 3
dtype: int64
В этом примере видно, что колонка с индексами — это не идеальная последовательность чисел. Здесь пропущены цифры 1, 2 и 4. В таком случае нужно выполнить операцию интерполяции и получить полную последовательность чисел. Для этого можно использовать reindex с параметром method равным ffill. Более того, необходимо задать диапазон значений для индексов. Тут можно использовать range(6) в качестве аргумента.
>>> ser3.reindex(range(6),method='ffill')
0 1
1 1
2 1
3 5
4 5
5 6
dtype: int64
Теперь в объекте есть элементы, которых не было в оригинальном объекте Series. Операция интерполяции сделала так, что наименьшие индексы стали значениями в объекте. Так, индексы 1 и 2 имеют значение 1, принадлежащее индексу 0.
Если нужно присваивать значения индексов при интерполяции, необходимо использовать метод bfill.
>>> ser3.reindex(range(6),method='bfill')
0 1
1 5
2 5
3 5
4 6
5 6
dtype: int64
В этом случае значения индексов 1 и 2 равны 5, которое принадлежит индексу 3.
Операция отлично работает не только с Series, но и с Dataframe. Переиндексирование можно проводить не только на индексах (строках), но также и на колонках или на обоих. Как уже отмечалось, добавлять новые индексы и колонки возможно, но поскольку в оригинальной структуре есть недостающие значения, на их месте будет NaN.
>>> frame.reindex(range(5), method='ffill',columns=['colors','price','new', 'object'])
| item | colors | price | new | object |
|---|---|---|---|---|
| id | ||||
| 0 | blue | 1.2 | blue | ball |
| 1 | green | 1.0 | green | pen |
| 2 | yellow | 3.3 | yellow | pencil |
| 3 | red | 0.9 | red | paper |
| 4 | white | 1.7 | white | mug |
Удаление
Еще одна операция, связанная с объектами Index — удаление. Удалить строку или колонку не составит труда, потому что метки используются для обозначения индексов и названий колонок.
В этом случае pandas предоставляет специальную функцию для этой операции, которая называется drop(). Метод возвращает новый объект без элементов, которые необходимо было удалить.
Например, возьмем в качестве примера случай, где из объекта нужно удалить один элемент. Для этого определим базовый объект Series из четырех элементов с 4 отдельными метками.
>>> ser = pd.Series(np.arange(4.), index=['red','blue','yellow','white'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white 3.0
dtype: float64
Теперь, предположим, необходимо удалить объект с меткой yellow. Для этого нужно всего лишь указать ее в качестве аргумента функции drop().
>>> ser.drop('yellow')
red 0.0
blue 1.0
white 3.0
dtype: float64
Для удаления большего количества элементов, передайте массив с соответствующими индексами.
>>> ser.drop(['blue','white'])
red 0.0
yellow 2.0
dtype: float64
Если речь идет об объекте Dataframe, значения могут быть удалены с помощью ссылок на метки обеих осей. Возьмем в качестве примера следующий объект.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Для удаления строк просто передайте индексы строк.
>>> frame.drop(['blue','yellow'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
Для удаления колонок необходимо указывать индексы колонок, а также ось, с которой требуется удалить элементы. Для этого используется параметр axis. Чтобы сослаться на название колонки, нужно написать axis=1.
>>> frame.drop(['pen','pencil'],axis=1)
| ball | paper | |
|---|---|---|
| red | 0 | 3 |
| blue | 4 | 7 |
| yellow | 8 | 11 |
| white | 12 | 15 |
Арифметика и выравнивание данных
Наверное, самая важная особенность индексов в этой структуре данных — тот факт, что pandas может выравнивать индексы двух разных структур. Это особенно важно при выполнении арифметических операций на их значениях. В этом случае индексы могут быть не только в разном порядке, но и присутствовать лишь в одной из двух структур.
В качестве примера можно взять два объекта Series с разными метками.
>>> s1 = pd.Series([3,2,5,1],['white','yellow','green','blue'])
>>> s2 = pd.Series([1,4,7,2,1],['white','yellow','black','blue','brown'])
Теперь воспользуемся базовой операцией сложения. Как видно по примеру, некоторые метки есть в обоих структурах, а остальные — только в одной. Если они есть в обоих случаях, их значения складываются, а если только в одном — то значением будет NaN.
>>> s1 + s2
black NaN
blue 3.0
brown NaN
green NaN
white 4.0
yellow 6.0
dtype: float64
При использовании Dataframe выравнивание работает по тому же принципу, но проводится и для рядов, и для колонок.
>>> frame1 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2 = pd.DataFrame(np.arange(12).reshape((4,3)),
... index=['blue','green','white','yellow'],
... columns=['mug','pen','ball'])
>>> frame1
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame2
| mug | pen | ball | |
|---|---|---|---|
| blue | 0 | 1 | 2 |
| green | 3 | 4 | 5 |
| white | 6 | 7 | 8 |
| yellow | 9 | 10 | 11 |
>>> frame1 + frame2
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Ядром pandas являются две структуры данных, в которых происходят все операции:
- Series
- Dataframes
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
Series — это объект библиотеки pandas, спроектированный для представления одномерных структур данных, похожих на массивы, но с дополнительными возможностями. Его структура проста, ведь он состоит из двух связанных между собой массивов. Основной содержит данные (данные любого типа NumPy), а в дополнительном, index, хранятся метки.

Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
>>> s = pd.Series([12,-4,7,9])
>>> s
0 12
1 -4
2 7
3 9
dtype: int64
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
Если не определить индекс при объявлении объекта, метки будут соответствовать индексам (положению в массиве) элементов объекта Series.
Однако лучше создавать Series, используя метки с неким смыслом, чтобы в будущем отделять и идентифицировать данные вне зависимости от того, в каком порядке они хранятся.
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
>>> s = pd.Series([12,-4,7,9], index=['a','b','c','d'])
>>> s
a 12
b -4
c 7
d 9
dtype: int64
Если необходимо увидеть оба массива, из которых состоит структура, можно вызвать два атрибута: index и values.
>>> s.values
array([12, -4, 7, 9], dtype=int64)
>>> s.index
Index(['a', 'b', 'c', 'd'], dtype='object')
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
>>> s[2]
7
Или же можно выбрать метку, соответствующую положению индекса.
>>> s['b']
-4
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
>>> s[0:2]
a 12
b -4
dtype: int64
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
>>> s[['b','c']]
b -4
c 7
dtype: int64
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
>>> s[1] = 0
>>> s
a 12
b 0
c 7
d 9
dtype: int64
>>> s['b'] = 1
>>> s
a 12
b 1
c 7
d 9
dtype: int64
Создание Series из массивов NumPy
Новый объект Series можно создать из массивов NumPy и уже существующих Series.
>>> arr = np.array([1,2,3,4])
>>> s3 = pd.Series(arr)
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> s4 = pd.Series(s)
>>> s4
a 12
b 1
c 7
d 9
dtype: int64
Важно запомнить, что значения в массиве NumPy или оригинальном объекте Series не копируются, а передаются по ссылке. Это значит, что элементы объекта вставляются динамически в новый Series. Если меняется оригинальный объект, то меняются и его значения в новом.
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> arr[2] = -2
>>> s3
0 1
1 2
2 -2
3 4
dtype: int32
На этом примере можно увидеть, что при изменении третьего элемента массива arr, меняется соответствующий элемент и в s3.
Фильтрация значений
Благодаря тому что основной библиотекой в pandas является NumPy, многие операции, применяемые к массивам NumPy, могут быть использованы и в случае с Series. Одна из таких — фильтрация значений в структуре данных с помощью условий.
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
>>> s[s > 8]
a 12
d 9
dtype: int64
Операции и математические функции
Другие операции, такие как операторы (+, -, * и /), а также математические функции, работающие с массивами NumPy, могут использоваться и для Series.
Для операторов можно написать простое арифметическое уравнение.
>>> s / 2
a 6.0
b 0.5
c 3.5
d 4.5
dtype: float64
Но в случае с математическими функциями NumPy необходимо указать функцию через np, а Series передать в качестве аргумента.
>>> np.log(s)
a 2.484907
b 0.000000
c 1.945910
d 2.197225
dtype: float64
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Так, можно объявить Series, в котором будут повторяющиеся значения.
>>> serd = pd.Series([1,0,2,1,2,3], index=['white','white','blue','green',' green','yellow'])
>>> serd
white 1
white 0
blue 2
green 1
green 2
yellow 3
dtype: int64
Чтобы узнать обо всех значениях в Series, не включая дубли, можно использовать функцию unique(). Возвращаемое значение — массив с уникальными значениями, необязательно в том же порядке.
>>> serd.unique()
array([1, 0, 2, 3], dtype=int64)
На unique() похожа функция value_counts(), которая возвращает не только уникальное значение, но и показывает, как часто элементы встречаются в Series.
>>> serd.value_counts()
2 2
1 2
3 1
0 1
dtype: int64
Наконец, isin() показывает, есть ли элементы на основе списка значений. Она возвращает булевые значения, которые очень полезны при фильтрации данных в Series или в колонке Dataframe.
>>> serd.isin([0,3])
white False
white True
blue False
green False
green False
yellow True
dtype: bool
>>> serd[serd.isin([0,3])]
white 0
yellow 3
dtype: int64
Значения NaN
В предыдущем примере мы попробовали получить логарифм отрицательного числа и результатом стало значение NaN. Это значение (Not a Number) используется в структурах данных pandas для обозначения наличия пустого поля или чего-то, что невозможно обозначить в числовой форме.
Как правило, NaN — это проблема, для которой нужно найти определенное решение, особенно при работе с анализом данных. Эти данные часто появляются при извлечении информации из непроверенных источников или когда в самом источнике недостает данных. Также значения NaN могут генерироваться в специальных случаях, например, при вычислении логарифмов для отрицательных значений, в случае исключений при вычислениях или при использовании функций. Есть разные стратегии работы со значениями NaN.
Несмотря на свою «проблемность» pandas позволяет явно определять NaN и добавлять это значение в структуры, например, в Series. Для этого внутри массива достаточно ввести np.NaN в том месте, где требуется определить недостающее значение.
>>> s2 = pd.Series([5,-3,np.NaN,14])
>>> s2
0 5.0
1 -3.0
2 NaN
3 14.0
dtype: float64
Функции isnull() и notnull() очень полезны для определения индексов без значения.
>>> s2.isnull()
0 False
1 False
2 True
3 False
dtype: bool
>>> s2.notnull()
0 True
1 True
2 False
3 True
dtype: bool
Они возвращают два объекта Series с булевыми значениями, где True указывает на наличие значение, а NaN — на его отсутствие. Функция isnull() возвращает True для значений NaN в Series, а notnull() — True в тех местах, где значение не равно NaN. Эти функции часто используются в фильтрах для создания условий.
>>> s2[s2.notnull()]
0 5.0
1 -3.0
3 14.0
dtype: float64
s2[s2.isnull()]
2 NaN
dtype: float64
Series из словарей
Series можно воспринимать как объект dict (словарь). Эта схожесть может быть использована на этапе объявления объекта. Даже создавать Series можно на основе существующего dict.
>>> mydict = {'red': 2000, 'blue': 1000, 'yellow': 500,
'orange': 1000}
>>> myseries = pd.Series(mydict)
>>> myseries
blue 1000
orange 1000
red 2000
yellow 500
dtype: int64
На этом примере можно увидеть, что массив индексов заполнен ключами, а данные — соответствующими значениями. В таком случае соотношение будет установлено между ключами dict и метками массива индексов. Если есть несоответствие, pandas заменит его на NaN.
>>> colors = ['red','yellow','orange','blue','green']
>>> myseries = pd.Series(mydict, index=colors)
>>> myseries
red 2000.0
yellow 500.0
orange 1000.0
blue 1000.0
green NaN
dtype: float64
Операции с сериями
Вы уже видели, как выполнить арифметические операции на объектах Series и скалярных величинах. То же возможно и для двух объектов Series, но в таком случае в дело вступают и метки.
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
В следующем примере добавляются два объекта Series, у которых только некоторые метки совпадают.
>>> mydict2 = {'red':400,'yellow':1000,'black':700}
>>> myseries2 = pd.Series(mydict2)
>>> myseries + myseries2
black NaN
blue NaN
green NaN
orange NaN
red 2400.0
yellow 1500.0
dtype: float64
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
Dataframe — это табличная структура данных, напоминающая таблицы из Microsoft Excel. Ее главная задача — позволить использовать многомерные Series. Dataframe состоит из упорядоченной коллекции колонок, каждая из которых содержит значение разных типов (числовое, строковое, булевое и так далее).

В отличие от Series у которого есть массив индексов с метками, ассоциированных с каждым из элементов, Dataframe имеет сразу два таких. Первый ассоциирован со строками (рядами) и напоминает таковой из Series. Каждая метка ассоциирована со всеми значениями в ряду. Второй содержит метки для каждой из колонок.
Dataframe можно воспринимать как dict, состоящий из Series, где ключи — названия колонок, а значения — объекты Series, которые формируют колонки самого объекта Dataframe. Наконец, все элементы в каждом объекте Series связаны в соответствии с массивом меток, называемым index.
Создание Dataframe
Простейший способ создания Dataframe — передать объект dict в конструктор DataFrame(). Объект dict содержит ключ для каждой колонки, которую требуется определить, а также массив значений для них.
Если объект dict содержит больше данных, чем требуется, можно сделать выборку. Для этого в конструкторе Dataframe нужно определить последовательность колонок с помощью параметра column. Колонки будут созданы в заданном порядке вне зависимости от того, как они расположены в объекте dict.
>> data = {'color' : ['blue', 'green', 'yellow', 'red', 'white'],
'object' : ['ball', 'pen', 'pencil', 'paper', 'mug'],
'price' : [1.2, 1.0, 0.6, 0.9, 1.7]}
>>> frame = pd.DataFrame(data)
>>> frame
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Даже для объектов Dataframe если метки явно не заданы в массиве index, pandas автоматически присваивает числовую последовательность, начиная с нуля. Если же индексам Dataframe нужно присвоить метки, необходимо использовать параметр index и присвоить ему массив с метками.
>>> frame2 = pd.DataFrame(data, columns=['object', 'price'])
>>> frame2
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Теперь, зная о параметрах index и columns, проще использовать другой способ определения Dataframe. Вместо использования объекта dict можно определить три аргумента в конструкторе в следующем порядке: матрицу данных, массив значений для параметра index и массив с названиями колонок для параметра columns.
В большинстве случаев простейший способ создать матрицу значений — использовать np.arrange(16).reshape((4,4)). Это формирует матрицу размером 4х4 из чисел от 0 до 15.
>>> frame3 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame3
Выбор элементов
Если нужно узнать названия всех колонок Dataframe, можно вызвать атрибут columns для экземпляра объекта.
>>> frame.columns
Index(['color', 'object', 'price'], dtype='object')
То же можно проделать и для получения списка индексов.
>>> frame.index
RangeIndex(start=0, stop=5, step=1)
Весь же набор данных можно получить с помощью атрибута values.
>>> frame.values
array([['blue', 'ball', 1.2],
['green', 'pen', 1.0],
['yellow', 'pencil', 0.6],
['red', 'paper', 0.9],
['white', 'mug', 1.7]], dtype=object)
Указав в квадратных скобках название колонки, можно получить значений в ней.
>>> frame['price']
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Возвращаемое значение — объект Series. Название колонки можно использовать и в качестве атрибута.
>>> frame.price
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
>>> frame.loc[2]
color yellow
object pencil
price 0.6
Name: 2, dtype: object
Возвращаемый объект — это снова Series, где названия колонок — это уже метки массива индексов, а значения — данные Series.
Для выбора нескольких строк можно указать массив с их последовательностью.
>>> frame.loc[[2,4]]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
>>> frame[0:1]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
>>> frame[1:3]
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
>>> frame['object'][3]
'paper'
Присваивание и замена значений
Разобравшись с логикой получения доступа к разным элементам Dataframe, можно следовать ей же для добавления новых или изменения уже существующих значений.
Например, в структуре Dataframe массив индексов определен атрибутом index, а строка с названиями колонок — columns. Можно присвоить метку с помощью атрибута name для этих двух подструктур, чтобы идентифицировать их.
>>> frame.index.name = 'id'
>>> frame.columns.name = 'item'
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
>>> frame['new'] = 12
>>> frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
frame['new'] = [3.0, 1.3, 2.2, 0.8, 1.1]
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
Колонки Dataframe также могут быть созданы с помощью присваивания объекта Series одной из них, например, определив объект Series, содержащий набор увеличивающихся значений с помощью np.arrange().
>>> ser = pd.Series(np.arange(5))
>>> ser
0 0
1 1
2 2
3 3
4 4
dtype: int32
frame['new'] = ser
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
>>> frame['price'][2] = 3.3
Вхождение значений
Функция isin() используется с объектами Series для определения вхождения значений в колонку. Она же подходит и для объектов Dataframe.
>>> frame.isin([1.0,'pen'])
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
Возвращается Dataframe с булевыми значениями, где True указывает на те значения, где членство подтверждено. Если передать это значение в виде условия, тогда вернется Dataframe, где будут только значения, удовлетворяющие условию.
>>> frame[frame.isin([1.0,'pen'])]
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
Для удаления целой колонки и всего ее содержимого используется команда del.
>>> del frame['new']
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
>>> frame[frame < 1.2]
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Результатом будет Dataframe со значениями меньше 1,2 на своих местах. На месте остальных будет NaN.
Dataframe из вложенного словаря
В Python часто используется вложенный dict:
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
Эта структура данных, будучи переданной в качестве аргумента в DataFrame(), интерпретируется pandas так, что внешние ключи становятся названиями колонок, а внутренние — метками индексов.
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
>>> frame2 = pd.DataFrame(nestdict)
>>> frame2
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
При работе с табличным структурами данных иногда появляется необходимость выполнить операцию перестановки (сделать так, чтобы колонки стали рядами и наоборот). pandas позволяет добиться этого очень просто. Достаточно добавить атрибут T.
>>> frame2.T
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
Зная, что такое Series и Dataframes, и понимая как они устроены, проще разобраться со всеми их достоинствами. Главная особенность этих структур — наличие объекта Index, который в них интегрирован.
Объекты Index являются метками осей и содержат другие метаданные. Вы уже знаете, как массив с метками превращается в объект Index, и что для него нужно определить параметр index в конструкторе.
>>> ser = pd.Series([5,0,3,8,4], index=['red','blue','yellow','white','green'])
>>> ser.index
Index(['red', 'blue', 'yellow', 'white', 'green'], dtype='object')
В отличие от других элементов в структурах данных pandas (Series и Dataframe) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
>>> ser.idxmin()
'blue'
>>> ser.idxmax()
'white'
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
>>> serd = pd.Series(range(6), index=['white','white','blue','green', 'green','yellow'])
>>> serd
white 0
white 1
blue 2
green 3
green 4
yellow 5
dtype: int64
Если метке соответствует несколько значений, то она вернет не один элемент, а объект Series.
>>> serd['white']
white 0
white 1
dtype: int64
То же применимо и к Dataframe. При повторяющихся индексах он возвращает Dataframe.
В случае с маленькими структурами легко определять любые повторяющиеся индексы, но если структура большая, то растет и сложность этой операции. Для этого в pandas у объектов Index есть атрибут is_unique. Он сообщает, есть ли индексы с повторяющимися метками в структуре (Series или Dataframe).
>>> serd.index.is_unique
False
>>> frame.index.is_unique
True
Операции между структурами данных
Теперь когда вы знакомы со структурами данных, Series и Dataframe, а также базовыми операциями для работы с ними, стоит рассмотреть операции, включающие две или более структур.
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
add()sub()div()mul()
Для их вызова нужно использовать другую спецификацию. Например, вместо того чтобы выполнять операцию для двух объектов Dataframe по примеру frame1 + frame2, потребуется следующий формат:
>>> frame1.add(frame2)
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Результат такой же, как при использовании оператора сложения +. Также стоит обратить внимание, что если названия индексов и колонок сильно отличаются, то результатом станет новый объект Dataframe, состоящий только из значений NaN.
Операции между Dataframe и Series
Pandas позволяет выполнять переносы между разными структурами, например, между Dataframe и Series. Определить две структуры можно следующим образом.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> ser = pd.Series(np.arange(4), index=['ball','pen','pencil','paper'])
>>> ser
ball 0
pen 1
pencil 2
paper 3
dtype: int32
Они были специально созданы так, чтобы индексы в Series совпадали с названиями колонок в Dataframe. В таком случае можно выполнить прямую операцию.
>>> frame - ser
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |
По результату видно, что элементы Series были вычтены из соответствующих тому же индексу в колонках значений Dataframe.
Если индекс не представлен ни в одной из структур, то появится новая колонка с этим индексом и значениями NaN.
>>> ser['mug'] = 9
>>> ser
ball 0
pen 1
pencil 2
paper 3
mug 9
dtype: int64
>>> frame - ser
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| red | 0 | NaN | 0 | 0 | 0 |
| blue | 4 | NaN | 4 | 4 | 4 |
| yellow | 8 | NaN | 8 | 8 | 8 |
| white | 12 | NaN | 12 | 12 | 12 |
Библиотека pandas в Python — это идеальный инструмент для тех, кто занимается анализом данных, используя для этого язык программирования Python.
В этом материале речь сначала пойдет об основных аспектах библиотеки и о том, как установить ее в систему. Потом вы познакомитесь с двумя структурам данных: series и dataframes. Сможете поработать с базовым набором функций, предоставленных библиотекой pandas, для выполнения основных операций по обработке. Знакомство с ними — ключевой навык для специалиста в этой сфере. Поэтому так важно перечитать материал до тех, пока он не станет понятен на 100%.
А на примерах сможете разобраться с новыми концепциями, появившимися в библиотеке — индексацией структур данных. Научитесь правильно ее использовать для управления данными. В конце концов, разберетесь с тем, как расширить возможности индексации для работы с несколькими уровнями одновременно, используя для этого иерархическую индексацию.
Библиотека Python для анализа данных
Pandas — это библиотека Python с открытым исходным кодом для специализированного анализа данных. Сегодня все, кто использует Python для изучения статистических целей анализа и принятия решений, должны быть с ней знакомы.
Библиотека была спроектирована и разработана преимущественно Уэсом Маккини в 2008 году. В 2012 к нему присоединился коллега Чан Шэ. Вместе они создали одну из самых используемых библиотек в сообществе Python.
Pandas появилась из необходимости в простом инструменте для обработки, извлечения и управления данными.
Этот пакет Python спроектирован на основе библиотеки NumPy. Такой выбор обуславливает успех и быстрое распространение pandas. Он также пользуется всеми преимуществами NumPy и делает pandas совместимой с большинством другим модулей.
Еще одно важное решение — разработка специальных структур для анализа данных. Вместо того, чтобы использовать встроенные в Python или предоставляемые другими библиотеками структуры, были разработаны две новых.
Они спроектированы для работы с реляционными и классифицированными данными, что позволяет управлять данными способом, похожим на тот, что используется в реляционных базах SQL и таблицах Excel.
Дальше вы встретите примеры базовых операций для анализа данных, которые обычно используются на реляционных или таблицах Excel. Pandas предоставляет даже более расширенный набор функций и методов, позволяющих выполнять эти операции эффективнее.
Основная задача pandas — предоставить все строительные блоки для всех, кто погружается в мир анализа данных.
Установка pandas
Простейший способ установки библиотеки pandas — использование собранного решения, то есть установка через Anaconda или Enthought.
Установка в Anaconda
В Anaconda установка занимает пару минут. В первую очередь нужно проверить, не установлен ли уже pandas, и если да, то какая это версия. Для этого введите следующую команду в терминале:
conda list pandas
Если модуль уже установлен (например в Windows), вы получите приблизительно следующий результат:
# packages in environment at C:\Users\Fabio\Anaconda:
#
pandas 0.20.3 py36hce827b7_2
Если pandas не установлена, ее необходимо установить. Введите следующую команду:
conda install pandas
Anaconda тут же проверит все зависимости и установит дополнительные модули.
Solving environment: done
## Package Plan ##
Environment location: C:\Users\Fabio\Anaconda3
added / updated specs:
- pandas
The following new packages will be installed:
Pandas: 0.22.0-py36h6538335_0
Proceed ([y]/n)?
Press the y key on your keyboard to continue the installation.
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Если требуется обновить пакет до более новой версии, используется эта интуитивная команда:
conda update pandas
Система проверит версию pandas и версию всех модулей, а затем предложит соответствующие обновления. Затем предложит перейти к обновлению.
Установка из PyPI
Pandas можно установить и с помощью PyPI, используя эту команду:
pip install pandas
Установка в Linux
Если вы работаете в дистрибутиве Linux и решили не использовать эти решения, то pandas можно установить как и любой другой пакет.
В Debian и Ubuntu используется команда:
sudo apt-get install python-pandas
А для OpenSuse и Fedora — эта:
zypper in python-pandas
Установка из источника
Если есть желание скомпилировать модуль pandas из исходного кода, тогда его можно найти на GitHub по ссылке https://github.com/pandas-dev/pandas:
git clone git://github.com/pydata/pandas.git
cd pandas
python setup.py install
Убедитесь, что Cython установлен. Больше об этом способе можно прочесть в документации: (http://pandas.pydata.org/pandas-docs/stable/install.html).
Репозиторий для Windows
Если вы работаете в Windows и предпочитаете управлять пакетами так, чтобы всегда была установлена последняя версия, то существует ресурс, где всегда можно загрузить модули для Windows: Christoph Gohlke’s Python Extension Packages for Windows (www.lfd.uci.edu/~gohlke/pythonlibs/). Каждый модуль поставляется в формате WHL для 32 и 64-битных систем. Для установки нужно использовать приложение pip:
pip install SomePackage-1.0.whl
Например, для установки pandas потребуется найти и загрузить следующий пакет:
pip install pandas-0.22.0-cp36-cp36m-win_amd64.whl
При выборе модуля важно выбрать нужную версию Python и архитектуру. Более того, если для NumPy пакеты не требуются, то у pandas есть зависимости. Их также необходимо установить. Порядок установки не имеет значения.
Недостаток такого подхода в том, что нужно устанавливать пакеты отдельно без менеджера, который бы помог подобрать нужные версии и зависимости между разными пакетами. Плюс же в том, что появляется возможность освоиться с модулями и получить последние версии вне зависимости от того, что выберет дистрибутив.
Проверка установки pandas
Библиотека pandas может запустить проверку после установки для верификации управляющих элементов (документация утверждает, что тест покрывает 97% всего кода).
Во-первых, нужно убедиться, что установлен модуль nose. Если он имеется, то тестирование проводится с помощью следующей команды:
nosetests pandas
Оно займет несколько минут и в конце покажет список проблем.
Модуль Nose
Этот модуль спроектирован для проверки кода Python во время этапов разработки проекта или модуля Python. Он расширяет возможности модуль
unittest. Nose используется для проверки кода и упрощает процесс.Здесь о нем можно почитать подробнее: _http://pythontesting.net/framework/nose/nose-introduction/.
Первые шаги с pandas
Лучший способ начать знакомство с pandas — открыть консоль Python и вводить команды одна за одной. Таким образом вы познакомитесь со всеми функциями и структурами данных.
Более того, данные и функции, определенные здесь, будут работать и в примерах будущих материалов. Однако в конце каждого примера вы вольны экспериментировать с ними.
Для начала откройте терминал Python и импортируйте библиотеку pandas. Стандартная практика для импорта модуля pandas следующая:
>>> import pandas as pd
>>> import numpy as np
Теперь, каждый раз встречая pd и np вы будете ссылаться на объект или метод, связанный с этими двумя библиотеками, хотя часто будет возникать желание импортировать модуль таким образом:
>>> from pandas import *
В таком случае ссылаться на функцию, объект или метод с помощью pd уже не нужно, а это считается не очень хорошей практикой в среде разработчиков Python.
Важный аспект NumPy, которому пока не уделялось внимание — процесс чтения данных из файла. Это очень важный момент, особенно когда нужно работать с большим количеством данных в массивах. Это базовая операция анализа данных, поскольку размер набора данных почти всегда огромен, и в большинстве случаев не рекомендуется работать с ним вручную.NumPy предлагает набор функций, позволяющих специалисту сохранять результаты вычислений в текстовый или бинарный файл. Таким же образом можно считывать и конвертировать текстовые данные из файла в массив.
Загрузка и сохранение данных в бинарных файлах
NumPy предлагает пару функций, save() и load(), которые позволяют сохранять, а позже и получать данные, сохраненные в бинарном формате.
При наличии массива, который нужно сохранить, содержащего, например, результаты анализа данных, остается лишь вызвать функцию call() и определить аргументы: название файла и аргументы. Файл автоматически получит расширение .npy.
>>> data=([[ 0.86466285, 0.76943895, 0.22678279],
[ 0.12452825, 0.54751384, 0.06499123],
[ 0.06216566, 0.85045125, 0.92093862],
[ 0.58401239, 0.93455057, 0.28972379]])
>>> np.save('saved_data',data)
Когда нужно восстановить данные из файла .npy, используется функция load(). Она требует определить имя файла в качестве аргумента с расширением .npy.
>>> loaded_data = np.load('saved_data.npy')
>>> loaded_data
array([[ 0.86466285, 0.76943895, 0.22678279],
[ 0.12452825, 0.54751384, 0.06499123],
[ 0.06216566, 0.85045125, 0.92093862],
[ 0.58401239, 0.93455057, 0.28972379]])
Чтение файлов с табличными данными
Часто данные для чтения или сохранения представлены в текстовом формате (TXT или CSV). Их можно сохранить в такой формат вместо двоичного, потому что таким образом к ним можно будет получать доступ даже вне NumPy, с помощью других приложений. Возьмем в качестве примера набор данных в формате CSV (Comma-Separated Values — значения, разделенные запятыми). Данные здесь хранятся в табличной форме, а значения разделены запятыми.
id,value1,value2,value3
1,123,1.4,23
2,110,0.5,18
3,164,2.1,19
Для чтения данных в текстовом файле и получения значений в массив NumPy предлагает функцию genfromtxt(). Обычно она принимает три аргумента: имя файла, символ-разделитель и указание, содержат ли данные заголовки колонок.
>>> data = np.genfromtxt('ch3_data.csv', delimiter=',', names=True)
>>> data
array([(1.0, 123.0, 1.4, 23.0), (2.0, 110.0, 0.5, 18.0),
(3.0, 164.0, 2.1, 19.0)],
dtype=[('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')])
Как видно по результату, можно запросто получить структурированный массив, где заголовки колонок станут именами полей.
Эта функция неявно выполняет два цикла: первый перебирает строки одна за одной, а вторая — разделяет и конвертирует значения в них, вставляя специально созданные последовательные элементы. Плюс в том, что даже при недостатке данных функция их дополнит.
Возьмем в качестве примера предыдущий файл с удаленными элементами. Сохраним его как data2.csv.
id,value1,value2,value3
1,123,1.4,23
2,110,,18
3,,2.1,19
Выполнение этих команд приведет к тому, что genfromtxt() заменит пустые области на значения nan.
>>> data2 = np.genfromtxt('ch3_data2.csv', delimiter=',', names=True)
>>> data2 array([(1.0, 123.0, 1.4, 23.0), (2.0, 110.0, nan, 18.0),
(3.0, nan, 2.1, 19.0)],
dtype=[('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'),
('value3', '<f8')])
В нижней части массива указаны заголовки колонок из файла. Их можно использовать как ярлыки-индексы, используемые для получения данных по колонкам.
>>> data2['id']
array([ 1., 2., 3.])
А с помощью числовых значений можно получать данные из конкретных строк.
>>> data2[0]
(1.0, 123.0, 1.4, 23.0)
В предыдущих примерах вы видели только одно- или двухмерные массивы. Но NumPy позволяет создавать массивы, которые будут более сложными не только в плане размера, но и по своей структуре. Они называются структурированными массивами. В них вместо отдельных элементов содержатся structs или записи.
Например, можно создать простой массив, состоящий из structs в качестве элементов. Благодаря параметру dtype можно определить условия, которые будут представлять элементы struct, а также тип данных и порядок.
| byte | b1 |
| int | i1, i2, i4, i8 |
| float | f2, f4, f8 |
| complex | c8, c16 |
| string | a<n> |
Например, если необходимо определить struct, содержащий целое число, строку длиной 6 символов и булево значение, потребуется обозначить три типа данных в dtype в нужном порядке.
Примечание: результат
dtypeи другие атрибуты формата могут отличаться на разных операционных системах и дистрибутивах Python.
>>> structured = np.array([(1, 'First', 0.5, 1+2j),(2, 'Second', 1.3, 2-2j), (3, 'Third', 0.8, 1+3j)], dtype=('i2, a6, f4, c8'))
>>> structured
array([(1, b'First', 0.5, 1+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('f0', '<i2'), ('f1', 'S6'), ('f2', '<f4'), ('f3', '<c8')])
Тип данных можно указать и явно с помощью int8, uint8, float16, complex16 и так далее.
>>> structured = np.array([(1, 'First', 0.5, 1+2j),(2, 'Second', 1.3,2-2j), (3, 'Third', 0.8, 1+3j)],dtype=('int16, a6, float32, complex64'))
>>> structured
array([(1, b'First', 0.5, 1.+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('f0', '<i2'), ('f1', 'S6'), ('f2', '<f4'), ('f3', '<c8')])
В обоих случаях будет одинаковый результат. В массиве имеется последовательность dtype, содержащая название каждого элемента struct с соответствующим типом данных.
Указывая соответствующий индекс, вы получаете нужную строку, включающую struct.
>>> structured[1]
(2, 'bSecond', 1.3, 2.-2.j)
Имена, присваиваемые каждому элементу struct автоматически, по сути, представляют собой имена колонок массива. Используя их как структурированный указатель, можно ссылаться на все элементы одного типа или одной и той же колонки.
>>> structured['f1']
array([b'First', b'Second', b'Third'],
dtype='|S6')
Имена присваиваются автоматически с символом f (он значит field (поле)) и увеличивающимся целым числом, обозначающим позицию в последовательности. Но было бы куда удобнее иметь более логичные имена. Это можно сделать в момент создания массива:
>>> structured = np.array([(1,'First',0.5,1+2j),
(2,'Second',1.3,2-2j), (3,'Third',0.8,1+3j)],
dtype=[('id','i2'),('position','a6'),('value','f4'),('complex','c8')])
>>> structured
array([(1, b'First', 0.5, 1.+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('id', '<i2'), ('position', 'S6'), ('value', '<f4'), ('complex', '<c8')])
Или позже, переопределив кортежи имен, присвоенных атрибуту dtype структурированного массива:
>>> structured.dtype.names = ('id','order','value','complex')
Теперь можно использовать понятные имена для разных типов полей:
>>> structured['order']
array([b'First', b'Second', b'Third'], dtype='|S6')
В этом разделе описываются общие понятия, лежащие в основе библиотеки NumPy. Разница между копиями и представлениями при возвращении значений. Также рассмотрим механизм “broadcasting”, который неявно происходит во многих функциях NumPy.
Копии или представления объектов
Как вы могли заметить, при управлении массивом в NumPy можно возвращать его копию или представление. Но ни один из видов присваивания в NumPy не приводит к появлению копий самого массива или его элементов.
>>> a = np.array([1, 2, 3, 4])
>>> b = a
>>> b
array([1, 2, 3, 4])
>>> a[2] = 0
>>> b
array([1, 2, 0, 4])
Если присвоить один массив a переменной b, то это будет не операция копирования; массив b — это всего лишь еще один способ вызова a. Изменяя значение третьего элемента в a, вы изменяете его же и в b.
>>> c = a[0:2]
>>> c
array([1, 2])
>>> a[0] = 0
>>> c
array([0, 2])
Даже получая срез, вы все равно указываете на один и тот же массив. Если же нужно сгенерировать отдельный массив, необходимо использовать функцию copy().
>>> a = np.array([1, 2, 3, 4])
>>> c = a.copy()
>>> c
array([1, 2, 3, 4])
>>> a[0] = 0
>>> c
array([1, 2, 3, 4])
В этом случае даже при изменении объектов в массиве a, массив c будет оставаться неизменным.
Векторизация
Векторизация, как и транслирование, — это основа внутренней реализации NumPy. Векторизация — это отсутствие явного цикла при разработке кода. Самих циклов избежать не выйдет, но их внутренняя реализация заменяется на другие конструкции в коде. Приложение векторизации делает код более емким и читаемым. Можно сказать, что он становится более «Pythonic» внешне. Благодаря векторизации многие операции принимают более математический вид. Например, NumPy позволяет выражать умножение двух массивов вот так:
a * b
Или даже умножение двух матриц:
A * B
В других языках подобные операции выражаются за счет нескольких вложенных циклов и конструкции for. Например, так бы выглядела первая операция:
for (i = 0; i < rows; i++){
c[i] = a[i]*b[i];
}
А произведение матриц может быть выражено следующим образом:
for( i=0; i < rows; i++){
for(j=0; j < columns; j++){
c[i][j] = a[i][j]*b[i][j];
}
}
Использование NumPy делает код более читаемым и математическим.
Транслирование (Broadcasting)
Транслирование позволяет оператору или функции применяться по отношению к двум или большему количеству массивов, даже если они не одной формы. Тем не менее не все размерности поддаются транслированию; они должны соответствовать определенным правилам.
С помощью NumPy многомерные массивы можно классифицировать через форму (shape) — кортеж, каждый элемент которого представляет длину каждой размерности.
Транслирование может работать для двух массивов в том случае, если их размерности совместимы: их длина равна, или длина одной из них — 1. Если эти условия не соблюдены, возникает исключение, сообщающее, что два массива не совместимы.
>>> A = np.arange(16).reshape(4, 4)
>>> b = np.arange(4)
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> b
array([0, 1, 2, 3])
В таком случае вы получаете два массива:
4 x 4
4
Есть два правила транслирования. В первую очередь нужно добавить 1 к каждой недостающей размерности. Если правила совместимости соблюдены, можно использовать транслирование и переходить ко второму правилу. Например:
4 x 4
4 x 1
Правило транслирования соблюдено. Можно переходить ко второму. Оно объясняет, как увеличить размер меньшего массива, чтобы он соответствовал большему, и можно было применить функцию или оператор поэлементно.
Второе правило предполагает, что недостающие элементы заполняются копиями заданных значений.

Когда у двух массивов одинаковые размерности, их значения можно суммировать.
>>> A + b
array([[ 0, 2, 4, 6],
[ 4, 6, 8, 10],
[ 8, 10, 12, 14],
[12, 14, 16, 18]])
Это простой случай, в котором один из массивов меньше второго. Могут быть и более сложные, когда у двух массивов разные размеры, и каждый меньше второго в конкретных размерностях.
>>> m = np.arange(6).reshape(3, 1, 2)
>>> n = np.arange(6).reshape(3, 2, 1)
>>> m
array([[[0, 1]],
[[2, 3]],
[[4, 5]]])
>>> n
array([[[0],
[1]],
[[2],
[3]],
[[4],
[5]]])
Даже в таком случае, анализируя форму двух массивов, можно увидеть, что они совместимы, а правила транслирования могут быть применены.
3 x 1 x 2
3 x 2 x 1
В этом случае размерности обоих массивов расширяются (транслирование).
m* = [[[0,1], n* = [[[0,0],
[0,1]], [1,1]],
[[2,3], [[2,2],
[2,3]], [3,3]],
[[4,5], [[4,4],
[4,5]]] [5,5]]]
Затем можно использовать, например, оператор сложения для двух массивов поэлементно.
>>> m + n
array([[[ 0, 1],
[ 1, 2]],
[[ 4, 5],
[ 5, 6]],
[[ 8, 9],
[ 9, 10]]])
Часто требуется создать новый массив на основе уже существующих. В этом разделе речь пойдет о процессе создания массивов за счет объединения или разделения ранее определенных.
Объединение массивов
Можно осуществить слияние массивов для создания нового, который будет содержать все элементы объединенных. NumPy использует концепцию стекинга и предлагает для этого кое-какие функции. Например, можно осуществить вертикальный стекинг с помощью функции vstack(), которая добавит второй массив в первый с помощью новых рядов. А функция hstack() осуществляет горизонтальная стекинг, добавляя второй массив в виде колонок.
>>> A = np.ones((3, 3))
>>> B = np.zeros((3, 3))
>>> np.vstack((A, B))
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> np.hstack((A,B))
array([[ 1., 1., 1., 0., 0., 0.],
[ 1., 1., 1., 0., 0., 0.],
[ 1., 1., 1., 0., 0., 0.]])
Еще две функции, которые выполняют стекинг для нескольких массивов — это column_stack() и row_stack(). Они работают независимо от первых двух. Их используют для одномерных массивов, для объединения значения в ряды или колонки и формирования двумерного массива.
>>> a = np.array([0, 1, 2])
>>> b = np.array([3, 4, 5])
>>> c = np.array([6, 7, 8])
>>> np.column_stack((a, b, c))
array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
>>> np.row_stack((a, b, c))
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
Разделение массивов
Из прошлого раздела вы узнали, как собирать массивы с помощью стекинга. Теперь разберемся с разделением их на части. В NumPy для этого используется разделение. Также имеется набор функций, который работают в горизонтальной (hsplit()) и вертикальной (vsplit()) ориентациях.
>>> A = np.arange(16).reshape((4, 4))
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
Так, если нужно разбить массив горизонтально, то есть, поделить ширину массива на две части, то матрица A размером 4×4 превратится в две матрицы 2×4.
>>> [B,C] = np.hsplit(A, 2)
>>> B
array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]])
>>> C
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])
Если же нужно разбить массив вертикально, то есть поделить высоту на две части, то матрица A размером 4×4 превратится в 2 размерами 4×2.
>>> [B,C] = np.vsplit(A, 2)
>>> B
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> C
array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])
Более сложная команда — функция split(). Она позволяет разбить массив на несимметричные части. Массив передается в качестве аргумента, но вместе с ним необходимо указать и индексы частей, на которые его требуется разбить. Если указать параметр axis = 1, то индексами будут колонки, а если axis = 0 — ряды.
Например, необходимо разбить матрицу на три части. Первая из которых будет включать первую колонку, вторая — вторую и третью колонки, а третья — последнюю. Здесь нужно указать следующие индексы.
>>> [A1,A2,A3] = np.split(A,[1,3],axis=1)
>>> A1
array([[ 0],
[ 4],
[ 8],
[12]])
>>> A2
array([[ 1, 2],
[ 5, 6],
[ 9, 10],
[13, 14]])
>>> A3
array([[ 3],
[ 7],
[11],
[15]])
То же самое можно проделать и для рядов.
>>> [A1,A2,A3] = np.split(A,[1,3],axis=0)
>>> A1
array([[0, 1, 2, 3]])
>>> A2
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> A3
array([[12, 13, 14, 15]])
Эта же особенность включает функции vsplit() и hsplit().
До этого момента индексы и срезы использовать для извлечения подмножеств. В этих методах используются числовые значения. Но есть альтернативный путь получения элементов — с помощью условий и булевых операторов.
Предположим, что нужно выбрать все значения меньше 0,5 в матрице размером 4х4, которая содержит случайные значения между 0 и 1.
>>> A = np.random.random((4, 4))
>>> A
array([[ 0.03536295, 0.0035115 , 0.54742404, 0.68960999],
[ 0.21264709, 0.17121982, 0.81090212, 0.43408927],
[ 0.77116263, 0.04523647, 0.84632378, 0.54450749],
[ 0.86964585, 0.6470581 , 0.42582897, 0.22286282]])
Когда матрица из случайных значений определена, можно применить оператор условия. Результатом будет матрица из булевых значений: True, если элемент соответствовал условию и False — если нет. В этом примере можно видеть все элементы со значениями меньше 0,5.
>>> A < 0.5
array([[ True, True, False, False],
[ True, True, False, True],
[False, True, False, False],
[False, False, True, True]], dtype=bool)
На самом деле, булевы массивы используются для неявного извлечения частей массивов. Добавив прошлое условие в квадратные скобки, можно получить новый массив, который будет включать все элементы меньше 0,5 из предыдущего.
>>> A[A < 0.5]
array([ 0.03536295, 0.0035115 , 0.21264709, 0.17121982, 0.43408927,
0.04523647, 0.42582897, 0.22286282])
Управление размерностью
Вы уже видели, как можно превращать одномерный массив в матрицу с помощью функции reshape().
>>> a = np.random.random(12)
>>> a
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
>>> A = a.reshape(3, 4)
>>> A
array([[ 0.77841574, 0.39654203, 0.38188665, 0.26704305],
[ 0.27519705, 0.78115866, 0.96019214, 0.59328414],
[ 0.52008642, 0.10862692, 0.41894881, 0.73581471]])
Функция reshape() возвращает новый массив и таким образом может создавать новые объекты. Но если необходимо изменить объект, поменяв его форму, нужно присвоить кортеж с новыми размерностями атрибуту shape массива.
>>> a.shape = (3, 4)
>>> a
array([[ 0.77841574, 0.39654203, 0.38188665, 0.26704305],
[ 0.27519705, 0.78115866, 0.96019214, 0.59328414],
[ 0.52008642, 0.10862692, 0.41894881, 0.73581471]])
Как видно на примере, в этот раз оригинальный массив изменил форму, и ничего не возвращается. Обратная операция также возможна. Можно конвертировать двухмерный массив в одномерный с помощью функции ravel().
>>> a = a.ravel()
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
Или прямо повлиять на атрибут shape самого массива.
>>> a.shape = (12)
>>> a
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
Еще одна важная операция — транспонирование матрицы. Это инверсия колонок и рядов. NumPy предоставляет такую функциональность в функции transpose().
>>> A.transpose()
array([[ 0.77841574, 0.27519705, 0.52008642],
[ 0.39654203, 0.78115866, 0.10862692],
[ 0.38188665, 0.96019214, 0.41894881],
[ 0.26704305, 0.59328414, 0.73581471]])
В прошлых разделах вы узнали, как создавать массив и выполнять операции с ним. В этом — речь пойдет о манипуляции массивами: о выборе элементов по индексам и срезам, а также о присваивании для изменения отдельных значений. Наконец, узнаете, как перебирать их.
Индексы
При работе с индексами массивов всегда используются квадратные скобки ([ ]). С помощью индексирования можно ссылаться на отдельные элементы, выделяя их или даже меняя значения.
При создании нового массива шкала с индексами создается автоматически.

Для получения доступа к одному элементу на него нужно сослаться через его индекс.
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[4]
14
NumPy также принимает отрицательные значения. Такие индексы представляют собой аналогичную последовательность, где первым элемент будет представлен самым большим отрицательным значением.
>>> a[–1]
15
>>> a[–6]
10
Для выбора нескольких элементов в квадратных скобках можно передать массив индексов.
>>> a[[1, 3, 4]]
array([11, 13, 14])
Двухмерные массивы, матрицы, представлены в виде прямоугольного массива, состоящего из строк и колонок, определенных двумя осями, где ось 0 представлена строками, а ось 1 — колонками. Таким образом индексация происходит через пару значений; первое — это значение ряда, а второе — колонки. И если нужно получить доступ к определенному элементу матрицы, необходимо все еще использовать квадратные скобки, но уже с двумя значениями.
>>> A = np.arange(10, 19).reshape((3, 3))
>>> A
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
Если нужно удалить элемент третьей колонки во второй строке, необходимо ввести пару [1, 2].
>>> A[1, 2]
15
Срезы
Срезы позволяют извлекать части массива для создания новых массивов. Когда вы используете срезы для списков Python, результирующие массивы — это копии, но в NumPy они являются представлениями одного и того же лежащего в основе буфера.
В зависимости от части массива, которую необходимо извлечь, нужно использовать синтаксис среза; это последовательность числовых значений, разделенная двоеточием (:) в квадратных скобках.
Чтобы получить, например, часть массива от второго до шестого элемента, необходимо ввести индекс первого элемента — 1 и индекса последнего — 5, разделив их :.
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[1:5]
array([11, 12, 13, 14])
Если нужно извлечь элемент из предыдущего отрезка и пропустить один или несколько элементов, можно использовать третье число, которое представляет собой интервал последовательности. Например, со значением 2 результат будет такой.
>>> a[1:5:2]
array([11, 13])
Чтобы лучше понять синтаксис среза, необходимо рассматривать и случаи, когда явные числовые значения не используются. Если не ввести первое число, NumPy неявно интерпретирует его как 0 (то есть, первый элемент массива). Если пропустить второй — он будет заменен на максимальный индекс, а если последний — представлен как 1. То есть, все элементы будут перебираться без интервалов.
>>> a[::2]
array([10, 12, 14])
>>> a[:5:2]
array([10, 12, 14])
>>> a[:5:]
array([10, 11, 12, 13, 14]
В случае с двухмерными массивами срезы тоже работают, но их нужно определять отдельно для рядов и колонок. Например, если нужно получить только первую строку:
>>> A = np.arange(10, 19).reshape((3, 3))
>>> A
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
>>> A[0,:]
array([10, 11, 12])
Как видно по второму индексу, если оставить только двоеточие без числа, будут выбраны все колонки. А если нужно выбрать все значения первой колонки, то необходимо писать обратное.
>>> A[:,0]
array([10, 13, 16])
Если же необходимо извлечь матрицу меньшего размера, то нужно явно указать все интервалы с соответствующими индексами.
>>> A[0:2, 0:2]
array([[10, 11],
[13, 14]])
Если индексы рядов или колонок не последовательны, нужно указывать массив индексов.
>>> A[[0,2], 0:2]
array([[10, 11],
[16, 17]])
Итерация по массиву
В Python для перебора по элементам массива достаточно использовать такую конструкцию.
>>> for i in a:
... print(i)
...
10
11
12
13
14
15
Но даже здесь в случае с двухмерным массивом можно использовать вложенные циклы внутри for. Первый цикл будет сканировать ряды массива, а второй — колонки. Если применить цикл for к матрице, она всегда будет перебирать в первую очередь по строкам.
>>> for row in A:
... print(row)
...
[10 11 12]
[13 14 15]
[16 17 18]
Если необходимо перебирать элемент за элементом можно использовать следующую конструкцию, применив цикл for для A.flat:
>>> for item in A.flat:
... print(item)
...
10
11
12
13
14
15
68
16
17
18
Но NumPy предлагает и альтернативный, более элегантный способ. Как правило, требуется использовать перебор для применения функции для конкретных рядов, колонок или отдельных элементов. Можно запустить функцию агрегации, которая вернет значение для каждой колонки или даже каждой строки, но есть оптимальный способ, когда NumPy перебирает процесс итерации на себя: функция apply_along_axis().
Она принимает три аргумента: функцию, ось, для которой нужно применить перебор и сам массив. Если ось равна 0, тогда функция будет применена к элементам по колонкам, а если 1 — то по рядам. Например, можно посчитать среднее значение сперва по колонкам, а потом и по рядам.
>>> np.apply_along_axis(np.mean, axis=0, arr=A)
array([ 13., 14., 15.])
>>> np.apply_along_axis(np.mean, axis=1, arr=A)
array([ 11., 14., 17.])
В прошлом примере использовались функции из библиотеки NumPy, но ничто не мешает определять собственные. Можно использовать и ufunc. В таком случае перебор по колонкам и по рядам выдает один и тот же результат. На самом деле, ufunc выполняет перебор элемент за элементом.
>>> def foo(x):
... return x/2
...
>>> np.apply_along_axis(foo, axis=1, arr=A)
array([[5., 5.5, 6. ],
[6.5, 7., 7.5],
[8., 8.5, 9. ]])
>>> np.apply_along_axis(foo, axis=0, arr=A)
array([[5., 5.5, 6.],
[6.5, 7., 7.5],
[8., 8.5, 9.]])
В этом случае функция ufunct делит значение каждого элемента надвое вне зависимости от того, был ли применен перебор к ряду или колонке.
Вы уже знаете, как создавать массив NumPy и как определять его элементы. Теперь пришло время разобраться с тем, как применять к ним различные операции.
Арифметические операторы
Арифметические операторы — первые, которые предстоит использовать. К числу наиболее очевидных относятся прибавление и умножение на скаляр.
>>> a = np.arange(4)
>>> a
array([0, 1, 2, 3])
>>> a+4
array([4, 5, 6, 7])
>>> a*2
array([0, 2, 4, 6])
Их можно использовать для двух массивов. В NumPy эти операции поэлементные, то есть, они применяются только к соответствующим друг другу элементам. Это должны быть объекты, которые занимают одно и то же положение, так что результатом станет новый массив, содержащий итоговые величины в тех же местах, что и операнды.
>>> b = np.arange(4,8)
>>> b
array([4, 5, 6, 7])
>>> a + b
array([ 4, 6, 8, 10])
>>> a – b
array([–4, –4, –4, –4])
>>> a * b
array([ 0, 5, 12, 21])
Более того, эти операторы доступны и для функций, если те возвращают массив NumPy. Например, можно перемножить массив на синус или квадратный корень элементов массива b.
>>> a * np.sin(b)
array([–0. , –0.95892427, –0.558831 , 1.9709598 ])
>>> a * np.sqrt(b)
array([ 0. , 2.23606798, 4.89897949, 7.93725393])
И даже в случае с многомерными массивами можно применять арифметические операторы поэлементно.
>>> A = np.arange(0, 9).reshape(3, 3)
>>> A
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> B = np.ones((3, 3))
>>> B
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> A * B
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.]])
Произведение матриц
Выбор оператора для поэлементного применения — это странный аспект работы с библиотекой NumPy. В большинстве инструментов для анализа данных оператор * обозначает произведение матриц. Он применяется к обоим массивам. В NumPy же подобное произведение обозначается функцией dot(). Эта операция не поэлементная.
>>> np.dot(A,B)
array([[ 3., 3., 3.],
[ 12., 12., 12.],
[ 21., 21., 21.]])
Каждый элемент результирующей матрицы — сумма произведений каждого элемента соответствующей строки в первой матрице с соответствующим элементом из колонки второй. Рисунок ниже показывает процесс произведения матриц (для двух элементов).

Еще один вариант записи произведения матриц — использование одной из двух матриц в качестве объекта функции dot().
>>> A.dot(B)
array([[ 3., 3., 3.],
[ 12., 12., 12.],
[ 21., 21., 21.]])
Но поскольку произведение матриц — это не коммутативная операция, порядок операндов имеет значение. В данном случае A*B не равняется B*A.
>>> np.dot(B,A)
array([[ 9., 12., 15.],
[ 9., 12., 15.],
[ 9., 12., 15.]])
Операторы инкремента и декремента
На самом деле, в Python таких операторов нет, поскольку нет операторов ++ или --. Для увеличения или уменьшения значения используются += и -=. Они не отличаются от предыдущих, но вместо создания нового массива с результатами присваивают новое значение тому же массиву.
>>> a = np.arange(4)
>>> a
array([0, 1, 2, 3])
>>> a += 1
>>> a
array([1, 2, 3, 4])
>>> a –= 1
>>> a
array([0, 1, 2, 3])
Таким образом использование этих операторов дает возможность получать более масштабные результаты, чем в случае с обычными операторами инкремента, увеличивающими значения на один. Их можно использовать в самых разных ситуациях. Например, они подходят для изменения значений без создания нового массива.
array([0, 1, 2, 3])
>>> a += 4
>>> a
array([4, 5, 6, 7])
>>> a *= 2
>>> a
array([ 8, 10, 12, 14])
Универсальные функции (ufunc)
Универсальная функция, известная также как ufunc, — это функция, которая применяется в массиве к каждому элементу. Это значит, что она воздействует на каждый элемент массива ввода, генерируя соответствующий результат в массив вывода. Финальный массив соответствует по размеру массиву ввода.
Под это определение подпадает множество математических и тригонометрических операций; например, вычисление квадратного корня с помощью sqrt(), логарифма с log() или синуса с sin().
>>> a = np.arange(1, 5)
>>> a
array([1, 2, 3, 4])
>>> np.sqrt(a)
array([ 1. , 1.41421356, 1.73205081, 2. ])
>>> np.log(a)
array([ 0. , 0.69314718, 1.09861229, 1.38629436])
>>> np.sin(a)
array([ 0.84147098, 0.90929743, 0.14112001, –0.7568025 ])
Многие функции уже реализованы в библиотеке NumPy.
Функции агрегации
Функции агрегации выполняют операцию на наборе значений, например, на массиве, и выдают один результат. Таким образом, сумма всех элементов массива — это результат работы функции агрегации. Многие из таких функций реализованы в классе ndarray.
>>> a = np.array([3.3, 4.5, 1.2, 5.7, 0.3])
>>> a.sum()
15.0
>>> a.min()
0.29999999999999999
>>> a.max()
5.7000000000000002
>>> a.mean()
3.0
>>> a.std()
2.0079840636817816
Сейчас уже, возможно, и наступила эра глубокого обучения и больших данных, где сложные алгоритмы анализируют изображения на основе демонстрации им миллионов примеров, но цветовые пространства все еще отлично подходят для анализа. Простые методы остаются крайне мощными.
Из этого материала вы узнаете, как просто сегментировать объект из изображения на основе цвета с помощью Python и OpenCV. Популярная библиотека компьютерного зрения, написанная на C/C++ и связанная с Python, OpenCV, предлагает простые способы манипулирования цветовыми пространствами.
Вы можете не знать OpenCV или другие библиотеки, но должны быть знакомы с основами Python, чтобы понять, о чем дальше пойдет речь.
Что такое цветовые пространства?
В наиболее распространенном цветовом пространстве, RGB (Красный Зеленый Синий) цвета представлены с точки зрения их составляющих красного, зеленого и синего. Если говорить в более техническом плане, RGB описывает цвет как кортеж трех компонентов. Каждый из них может быть значением от 0 до 255, где (0, 0, 0) представляет черный цвет, а (255, 255, 255) — белый.
RGB считается «аддитивным» цветовым пространством, где цвета являются произведением красного, синего и зеленого света на черный фон.
Вот еще несколько примеров цветов RGB:
| Цвет | Значение RGB |
|---|---|
| Красный | 255, 0, 0 |
| Оранжевый | 255, 128, 0 |
| Розовый | 255, 153, 255 |
RGB — одна из пяти основных моделей цветового пространства, у каждой из которых есть свои ответвления. Всего их так много, потому что каждое пространство используется для разных целей.
В издательском деле используется CMYK, потому что оно описывает комбинации, которые необходимы для получения цвета на белом фоне. Если в RGB кортеж 0 — это черный, то в CMYK — это белый. Таким образом принтеры содержат картриджи с голубым, пурпурным, желтым и черным цветами.
В определенных областях медицины сканируются стеклянные слайды с образцами окрашенной ткани. Они сохраняются в виде изображений. Такие анализируются в пространстве HED — представлении насыщенности типов краски — гематоксилина, эозина и 3,3’-Диаминобензидина.
HSV и HSL — это описания оттенка, насыщенности и яркости. Они подходят для определения контрастности на изображениях. Такие пространства часто используются для выбора цвета в ПО для веб-дизайна.
На самом деле, цвет — это непрерывное явление, а это значит, что их существует бесконечное количество. Цветовые пространства, тем не менее, изображают цвета в виде дискретных структур (фиксированное целое число), что вполне допустимо, ведь возможности восприятия человеческого глаза тоже ограничены. Цветовые пространства способны передавать все цвета, которые мы различаем.
Теперь, когда с цветовыми пространствами все понятно, можно переходить к описанию того, как их использовать в OpenCV.
Простая сегментация с помощью цветовых пространств
Для демонстрации техники сегментации на основе цветовых пространств будем использовать набор изображений рыбы-клоуна. Они легко распознаются благодаря своему ярко-оранжевому окрасу, поэтому на картинке будем искать именно Немо.
Ключевые требуемые библиотеки: передовой пакет для научных вычислений NumPy, инструмент построения графиков Matplotlib и, конечно, OpenCV. В этом примере используются версии OpenCV 3.2.0, NumPy 1.12.1 и Matplotlib 2.0.2. Но небольшие отличия в версиях не должны сильно повлиять на понимание самой концепции работы.
Цветовые пространства и чтение изображений в OpenCV
В первую очередь необходимо настроить пространство. Python 3.x уже должен быть установлен в вашей системе. Обратите внимание, что несмотря на использование OpenCV 3.x, импортировать все равно необходимо cv2:
import cv2
Если библиотека на компьютере еще не установлена, импорт не сработает. Здесь можно ознакомиться с руководством по установке для разных операционных систем. После импорта можно ознакомиться со всеми преобразованиями цветовых пространств, которые доступные в OpenCV, и сохранить их все в переменную:
flags = [i for i in dir(cv2) if i.startswith('COLOR_')]
Список и количество флагов может незначительно отличаться в зависимости от версии OpenCV, но их в любом случае будет много. Посмотрите только на общее количество:
>>> len(flags)
258
>>> flags[40]
'COLOR_BGR2RGB'
Первые символы после COLOR обозначают оригинальное цветовое пространство, а символы после 2 — целевое. Этот флаг представляет преобразование из BGR (Blue, Green, Red) в RGB. Эти пространства очень похожи. У них лишь отличаются значения первого и последнего каналов.
Для просмотра изображений потребуется matplotlib.pyplot, а также NumPy. Если они не установлены, то используйте команды pip3 install matplotlib и pip3 install numpy перед импортами:
import matplotlib.pyplot as plt
import numpy as np
Теперь можно загружать и изучать изображение. Обратите внимание, что если вы работаете из командной строки или терминала, изображения появятся во всплывающем окне. Если это Jupyter Notebook или что-то другое, то они будут отображаться ниже. Вне зависимости от настройки вы увидите изображение, сгенерированное командой show():
nemo = cv2.imread('./images/nemo0.jpg')
plt.imshow(nemo)
plt.show()
")
А это точно Немо… или Дори? Похоже, синий и красный каналы перемешались. Дело в том, что цветовым пространством по умолчанию в OpenCV является BGR. Чтобы исправить это, используйте cvtColor(image, flag) и рассмотренный выше флаг:
nemo = cv2.cvtColor(nemo, cv2.COLOR_BGR2RGB)
plt.imshow(nemo)
plt.show()
")
Теперь Немо похож на себя.
Визуализация Немо в цветовом пространстве RGB
HSV — отличный выбор для сегментации по цвету, но чтобы узнать, почему это так, необходимо сравнить RGB и HSV, чтобы увидеть распределение цветов их пикселей. Трехмерный график прекрасно это демонстрирует. Каждая ось здесь представляет один из каналов цветового пространства.
Вот график цветового рассеивания изображения Немо в RGB:

Здесь можно видеть, что оранжевые элементы изображения распределены по всем значениям красного, зеленого и синего. Таким образом сегментировать Немо в пространстве RGB на основе значений RGB — совсем не простая задача.
Визуализация Немо в цветовом пространстве HSV
Теперь посмотрим, как будет выглядеть Немо в пространстве HSV и сравним результаты.
Как уже упоминалось, HSV — это Hue, Saturation и Value (оттенок, насыщенность и яркость). Это цилиндрическое цветовое пространство. Цвета, или оттенки, меняются при движении по кругу цилиндра. Вертикальная ось отвечает за яркость: от темного (0 в нижней части) до светлого сверху. Третья ось, насыщенность, определяет тени оттенков при движении от центра к краю вдоль радиуса цилиндра (от менее к более насыщенному)
Для конвертации из RGB в HSV можно использовать cvtColor():
hsv_nemo = cv2.cvtColor(nemo, cv2.COLOR_RGB2HSV)
Сейчас hsv_nemo хранит представление Немо в HSV. С помощью уже знакомой техники можно посмотреть на график изображения в HSV:

В пространстве HSV оранжевый цвет Немо более локализован и визуально различим. Насыщенность и значения оранжевого различаются, но они расположены в небольшом диапазоне вдоль оси оттенка. Это ключевой момент, который можно использовать для сегментации.
Выбор диапазона
Попробуем разбить Немо на основе простого диапазона значений оранжевого цвета. Можно выбрать диапазон, внимательно рассмотрев график или воспользоваться онлайн-инструментом, например, RGB в HSV. Здесь выбраны образцы яркого и темного оранжевого цветов, близких к красному.
light_orange = (1, 190, 200)
dark_orange = (18, 255, 255)
Когда необходимый цветовой диапазон выбран, можно использовать cv2.inRange(), чтобы разбить Немо. inRange() принимает три параметра: изображение, нижнее и верхнее значения диапазона. Она возвращает бинарную маску (ndarray из единиц и нулей) размером с оригинальное изображение. Единицы обозначают значения в пределах диапазона, а нули — вне его:
mask = cv2.inRange(hsv_nemo, light_orange, dark_orange)
Чтобы наложить маску поверх оригинального изображения, используется cv2.bitwise_and(). Она сохраняет каждый пиксель изображения, если соответствующее значение маски равно 1:
result = cv2.bitwise_and(nemo, nemo, mask=mask)
Чтобы увидеть, что именно произошло, стоит рассмотреть саму маску и оригинальное изображение с ее наложением:
plt.subplot(1, 2, 1)
plt.imshow(mask, cmap="gray")
plt.subplot(1, 2, 2)
plt.imshow(result)
plt.show()

Уже на этом этапе проделана отличная работа по захвату оранжевых частей рыбы. Проблема лишь в том, что у Немо есть и белые полосы. К счастью, можно по тому же принципу добавить еще одну маску:
light_white = (0, 0, 200)
dark_white = (145, 60, 255)
После определения диапазона необходимо взглянуть на выбранные цвета:

Верхний предел — это светло-голубой, потому что в тенях белый приобретает оттенки синего. Создадим вторую маску и посмотрим, захватывает ли она белые полосы Немо. Ее можно создать по принципу первой:
mask_white = cv2.inRange(hsv_nemo, light_white, dark_white)
result_white = cv2.bitwise_and(nemo, nemo, mask=mask_white)
plt.subplot(1, 2, 1)
plt.imshow(mask_white, cmap="gray")
plt.subplot(1, 2, 2)
plt.imshow(result_white)
plt.show()

Неплохо. Теперь можно объединить маски. В таком случае единицы будут в тех местах, где значения — белый или оранжевый, что и требуется для получения результата. Соединим маски и посмотрим на результат:
final_mask = mask + mask_white
final_result = cv2.bitwise_and(nemo, nemo, mask=final_mask)
plt.subplot(1, 2, 1)
plt.imshow(final_mask, cmap="gray")
plt.subplot(1, 2, 2)
plt.imshow(final_result)
plt.show()

По сути, грубая сегментация Немо в пространстве HSV уже готова. Все еще есть «блуждающие» пиксели вдоль границы сегментации, но их можно исправить с помощью гауссовского размытия.
Гауссовское размытие — это фильтр, использующий гауссовскую функцию для преобразования каждого пикселя изображения. В результате уменьшаются количество шумов и детализация. Вот как применять фильтр к изображению:
blur = cv2.GaussianBlur(final_result, (7, 7), 0)
plt.imshow(blur)
plt.show()

Обобщает ли эта сегментация родственников Немо?
Ради интереса посмотрим, как эта сегментация обобщает все изображения рыб-клоунов. Имеется набор картинок из Google, лицензированных для общего использования.
В первую очередь загрузим их все в список:
path = "./images/nemo"
nemos_friends = []
for i in range(6):
friend = cv2.cvtColor(cv2.imread(path + str(i) + ".jpg"), cv2.COLOR_BGR2RGB)
nemos_friends.append(friend)
Код выше, использованный для сегментации одной рыбы, можно применить для получения функции, которая будет принимать исходное изображение и выдавать сегментированное.
def segment_fish(image):
''' Cегментация рыбы-клоуна из предоставленного изображения '''
# Конвертация изображения в HSV
hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
# Установка оранжевого диапазона
light_orange = (1, 190, 200)
dark_orange = (18, 255, 255)
# Применение оранжевой маски
mask = cv2.inRange(hsv_image, light_orange, dark_orange)
# Установка белого диапазона
light_white = (0, 0, 200)
dark_white = (145, 60, 255)
# Применение белой маски
mask_white = cv2.inRange(hsv_image, light_white, dark_white)
# Объединение двух масок
final_mask = mask + mask_white
result = cv2.bitwise_and(image, image, mask=final_mask)
# Сглаживание сегментации с помощью размытия
blur = cv2.GaussianBlur(result, (7, 7), 0)
return blur
Таким образом сегментация превращается в одну строку:
results = [segment_fish(friend) for friend in nemos_friends]
Посмотрим на результаты в цикле:
for i in range(1, 6):
plt.subplot(1, 2, 1)
plt.imshow(nemos_friends[i])
plt.subplot(1, 2, 2)
plt.imshow(results[i])
plt.show()

У рыбы на переднем плане оранжевые оттенки темнее выбранного диапазона.

Нижняя часть родственника Немо, которая находится в тени, полностью исключена, зато фиолетовые анемоны на фоне выглядят как голубоватые полосы…



В целом простая сегментация успешно определила большинство родственников Немо. Но очевидно, что сегментация таким способом не обязательно подойдет для всех изображений.
Выводы
Из этого руководства вы увидели, какие бывают цветовые пространства, как изображение распределяется с RGB и HSV, и как использовать OpenCV для конвертации между пространствами и сегментирования диапазонов.
В целом, вы узнали, как использовать цветовые пространства для сегментации объектов на изображениях, и должны были понять потенциал библиотеки для выполнения подобных задач. Когда освещение и фон под контролем или просто с более однородным набором данных техника сегментации работает просто, быстро и надежно.
]]>Основной элемент библиотеки NumPy — объект ndarray (что значит N-размерный массив). Этот объект является многомерным однородным массивом с заранее заданным количеством элементов. Однородный — потому что практически все объекты в нем одного размера или типа. На самом деле, тип данных определен другим объектом NumPy, который называется dtype (тип-данных). Каждый ndarray ассоциирован только с одним типом dtype.
Количество размерностей и объектов массива определяются его размерностью (shape), кортежем N-положительных целых чисел. Они указывают размер каждой размерности. Размерности определяются как оси, а количество осей — как ранг.
Еще одна странность массивов NumPy в том, что их размер фиксирован, а это значит, что после создания объекта его уже нельзя поменять. Это поведение отличается от такового у списков Python, которые могут увеличиваться и уменьшаться в размерах.
Простейший способ определить новый объект ndarray — использовать функцию array(), передав в качестве аргумента Python-список элементов.
>>> a = np.array([1, 2, 3])
>>> a
array([1, 2, 3])
Можно легко проверить, что новый объект — это ndarray, передав его функции type().
>>> type(a)
<type 'numpy.ndarray'>
Чтобы узнать ассоциированный тип dtype, необходимо использовать атрибут dtype.
Примечание: результат
dtype,shapeи других может быть разным для разных операционных систем и дистрибутивов Python.
>>> a.dtype
dtype('int64')
Только что созданный массив имеет одну ось, а его ранг равняется 1, то есть его форма — (3,1). Для получения этих значений из массива необходимо использовать следующие атрибуты: ndim — для осей, size — для длины массива, shape — для его формы.
>>> a.ndim
1
>>> a.size
3
>>> a.shape
(3,)
Это был пример простейшего одномерного массива. Но функциональность массивов может быть расширена и до нескольких размерностей. Например, при определении двумерного массива 2×2:
>>> b = np.array([[1.3, 2.4],[0.3, 4.1]])
>>> b.dtype
dtype('float64')
>>> b.ndim
2
>>> b.size
4
>>> b.shape
(2, 2)
Ранг этого массива — 2, поскольку у него 2 оси, длина каждой из которых также равняется 2.
Еще один важный атрибут — itemsize. Он может быть использован с объектами ndarray. Он определяет размер каждого элемента массива в байтах, а data — это буфер, содержащий все элементы массива. Второй атрибут пока не используется, потому что для получения данных из массива применяется механизм индексов, речь о котором подробно пойдет в следующих разделах.
>>> b.itemsize
8
>>> b.data
<read-write buffer for 0x0000000002D34DF0, size 32, offset 0 at
0x0000000002D5FEA0>
Создание массива
Есть несколько вариантов создания массива. Самый распространенный — список из списков, выступающий аргументом функции array().
>>> c = np.array([[1, 2, 3],[4, 5, 6]])
>>> c
array([[1, 2, 3],
[4, 5, 6]])
Функция array() также может принимать кортежи и последовательности кортежей.
>>> d = np.array(((1, 2, 3),(4, 5, 6)))
>>> d
array([[1, 2, 3],
[4, 5, 6]])
Она также может принимать последовательности кортежей и взаимосвязанных списков.
>>> e = np.array([(1, 2, 3), [4, 5, 6], (7, 8, 9)])
>>> e
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Типы данных
Пока что рассматривались только значения простого целого числа и числа с плавающей запятой, но массивы NumPy сделаны так, чтобы включать самые разные типы данных. Например, можно включать строки:
Типы данных, поддерживаемые NumPy
| Тип данных | Описание |
|---|---|
bool |
Булевы значения (True или False) хранятся в виде байтов |
int |
Тип по умолчанию — целое число (то же, что long в C; обычно int64 или int32) |
intc |
Идентичный int в C (обычно int32 или int64) |
intp |
Целое число для использования в качестве индексов (то же, что и size_t в C, обычно int32 или int64) |
int8 |
Байт (от — 128 до 127) |
int16 |
Целое число (от -32768 до 32767) |
int32 |
Целое число (от -2147483648 до 2147483647) |
int64 |
Целое число (от -9223372036854775808 до 9223372036854775807) |
uint8 |
Целое число без знака (от 0 до 255) |
uint16 |
Целое число без знака (от 0 до 65535) |
uint32 |
Целое число без знака (от 0 до 4294967295) |
uint64 |
Целое число без знака (от 0 до 18446744073709551615) |
float |
Обозначение float64 |
float16 |
Число с плавающей точкой половинной точности; бит на знак, 5-битная экспонента, 10-битная мантисса |
float32 |
Число с плавающей точкой единичной точности; бит на знак, 8-битная экспонента, 23-битная мантисса |
float64 |
Число с плавающей точкой двойной точности; бит на знак, 11-битная экспонента, 52-битная мантисса |
complex |
Обозначение complex128 |
complex64 |
Комплексное число, представленное двумя 32-битными float (с действительной и мнимой частями) |
complex128 |
Комплексное число, представленное двумя 64-битными float (с действительной и мнимой частями) |
Параметр dtype
Функция array() не принимает один аргумент. На примерах видно, что каждый объект ndarray ассоциирован с объектом dtype, определяющим тип данных, которые будут в массиве. По умолчанию функция array() можно ассоциировать самый подходящий тип в соответствии со значениями в последовательностях списков или кортежей. Их можно определить явно с помощью параметра dtype в качестве аргумента.
Например, если нужно определить массив с комплексными числами в качестве значений, необходимо использовать параметр dtype следующим образом:
>>> f = np.array([[1, 2, 3],[4, 5, 6]], dtype=complex)
>>> f
array([[ 1.+0.j, 2.+0.j, 3.+0.j],
[ 4.+0.j, 5.+0.j, 6.+0.j]])
Функции генерации массива
Библиотека NumPy предоставляет набор функций, которые генерируют ndarray с начальным содержимым. Они создаются с разным значениями в зависимости от функции. Это очень полезная особенность. С помощью всего одной строки кода можно сгенерировать большой объем данных.
Функция zeros(), например, создает полный массив нулей с размерностями, определенными аргументом shape. Например, для создания двумерного массива 3×3, можно использовать:
>>> np.zeros((3, 3))
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
А функция ones() создает массив, состоящий из единиц.
>>> np.ones((3, 3))
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
По умолчанию две функции создают массивы с типом данных float64. Полезная фишка — arrange(). Она генерирует массивы NumPy с числовыми последовательностями, которые соответствуют конкретным требованиям в зависимости от переданных аргументов. Например, для генерации последовательности значений между 0 и 10, нужно передать всего один аргумент — значение, которое закончит последовательность.
>>> np.arange(0, 10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Если в начале нужен не ноль, то необходимо обозначить уже два аргумента: первый и последний.
>>> np.arange(4, 10)
array([4, 5, 6, 7, 8, 9])
Также можно сгенерировать последовательность значений с точным интервалом между ними. Если определено и третье значение в arrange(), оно будет представлять собой промежуток между каждым элементом.
>>> np.arange(0, 12, 3)
array([0, 3, 6, 9])
Оно может быть и числом с плавающей точкой.
>>> np.arange(0, 6, 0.6)
array([ 0. , 0.6, 1.2, 1.8, 2.4, 3. , 3.6, 4.2, 4.8, 5.4])
Пока что в примерах были только одномерные массивы. Для генерации двумерных массивов все еще можно использовать функцию arrange(), но вместе с reshape(). Она делит линейный массив на части способом, который указан в аргументе shape.
>>> np.arange(0, 12).reshape(3, 4)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Похожая на arrange() функция — linspace(). Она также принимает в качестве первых двух аргументов первое и последнее значения последовательности, но третьим аргументом является не интервал, а количество элементов, на которое нужно разбить последовательность.
>>> np.linspace(0,10,5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
Еще один способ получения массива — заполнение его случайными значениями. Это можно сделать с помощью функции random() из модуля numpy.random. Эта функция генерирует массив с тем количеством элементов, которые указаны в качестве аргумента.
>>> np.random.random(3)
array([ 0.78610272, 0.90630642, 0.80007102])
Полученные числа будут отличаться с каждым запуском. Для создания многомерного массива, нужно передать его размер в виде аргумента.
>>> np.random.random((3,3))
array([[ 0.07878569, 0.7176506 , 0.05662501],
[ 0.82919021, 0.80349121, 0.30254079],
[ 0.93347404, 0.65868278, 0.37379618]])
Научимся писать парсеры с помощью Scrapy, мощного фреймворка для извлечения, обработки и хранения данных.
В этом руководстве вы узнаете, как использовать фреймворк Python, Scrapy, с помощью которого можно обрабатывать большие объемы данных. Обучение будет основано на процессе построения скрапера для интернет-магазина Aliexpress.com.
Базовые знания HTML и CSS помогут лучше и быстрее освоить материал.
Обзор Scrapy
")
Веб-скрапинг (парсинг) стал эффективным путем извлечения информации из сети для последующего принятия решений и анализа. Он является неотъемлемым инструментом в руках специалиста в области data science. Дата сайентисты должны знать, как собирать данные с веб-страниц и хранить их в разных форматах для дальнейшего анализа.
Любую страницу в интернете можно исследовать в поисках информации, а все, что есть на странице — можно извлечь. У каждой страницы есть собственная структура и веб-элементы, из-за чего необходимо писать собственных сканеров для каждой страницы.
Scrapy предоставляет мощный фреймворк для извлечения, обработки и хранения данных.
Scrapy использует Spiders — автономных сканеров с определенным набором инструкций. С помощью фреймворка легко разработать даже крупные проекты для скрапинга, так чтобы и другие разработчики могли использовать этот код.
Scrapy vs. Beautiful Soup
В этом разделе будет дан обзор одного из самых популярных инструментов для парсинга, BeautifulSoup, и проведено его сравнение со Scrapy.
Scrapy — это Python-фреймворк, предлагающий полноценный набор инструментов и позволяющий разработчикам не думать о настройке кода.
BeautifulSoup также широко используется для веб-скрапинга. Это пакет Python для парсинга документов в форматах HTML и XML и извлечения данных из них. Он доступен для Python 2.6+ и Python 3.
Вот основные отличия между ними:
| Scrapy | BeautifulSoup |
|---|---|
| Функциональность | |
| Scrapy — это самый полный набор инструментов для загрузки веб-страниц, их обработки и сохранения в файлы и базы данных | BeautifulSoup — это в принципе просто парсер HTML и XML, требующий дополнительных библиотек, таких как requests и urlib2 для открытия ссылок и сохранения результатов. |
| Кривая обучения | |
| Scrapy — это движущая сила веб-сканирования, предлагающая массу способов парсинга страниц. Обучение тому, как он работает, требует много времени, но после освоения процесс сканирования превращается в одну строку кода. Потребуется время, чтобы стать экспертом в Scrapy и изучить все его особенности | BeautifulSoup относительно прост для понимания новичкам в программировании и позволяет решать маленькие задачи за короткий срок. |
| Скорость и нагрузка | |
| Scrapy с легкостью выполняет крупную по объему работу. Он может сканировать несколько ссылок одновременно менее чем за минуту в зависимости от общего количества. Это происходит плавно благодаря Twister, который работает асинхронно (без блокировки) | BeautifulSoup используется для простого и эффективного парсинга. Он работает медленнее Scrapy, если не использовать multiprocessing. |
| Расширяемость | |
Scrapy предоставляет функциональность Item pipelines, с помощью которой можно писать функции для веб-сканера. Они будут включать инструкции о том, как робот должен проверять, удалять и сохранять данные в базу данных. Spider Contracts используются для проверки парсеров, благодаря чему можно создавать как базовые, так и глубокие парсеры. Он же позволяет настраивать множество переменных: повторные попытки, перенаправление и т. д. |
Если проект не предполагает большого количества логики, BeautifulSoup отлично для этого подходит, но если нужна настраиваемость, например прокси, управление куки и распределение данных, то Scrapy справляется лучше. |
Синхронность означает, что необходимо ждать, пока процесс завершит работу, прежде чем начинать новый, а асинхронный позволяет переходить к следующему процессу, пока предыдущий еще не завершен.
Установка Scrapy
С установленным Python 3.0 (и новее) при использовании Anaconda можно применить команду conda для установки scrapy. Напишите следующую команду в Anaconda:
conda install -c conda-forge scrapy
Чтобы установить Anaconda, посмотрите эти руководства PythonRu для Mac и Windows.
Также можно использовать установщик пакетов pyhton pip. Это работает в Linux, Mac и Windows:
pip install scrapy
Scrapy Shell
Scrapy предоставляет оболочку веб-сканера Scrapy Shell, которую разработчики могут использовать для проверки своих предположений относительно поведения сайта. Возьмем в качестве примера страницу с планшетами на сайте Aliexpress. С помощью Scrapy можно узнать, из каких элементов она состоит и понять, как это использовать в конкретных целях.
Откройте командную строку и напишите следующую команду:
scrapy shell
При использовании Anaconda можете написать эту же команду прямо в anaconda prompt. Вывод будет выглядеть приблизительно вот так:
2020-03-14 16:28:16 [scrapy.utils.log] INFO: Scrapy 2.0.0 started (bot: scrapybot)
2020-03-14 16:28:16 [scrapy.utils.log] INFO: Versions: lxml 4.3.2.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1c 28 May 2019), cryptography 2.6.1, Platform Windows-10-10.0.18362-SP0
....
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
Необходимо запустить парсер на странице с помощью команды fetch в оболочке. Он пройдет по странице, загружая текст и метаданные.
fetch(“https://www.aliexpress.com/category/200216607/tablets.html”)
Примечание: всегда заключайте ссылку в кавычки, одинарные или двойные
Вывод будет следующий:
2020-03-14 16:39:53 [scrapy.core.engine] INFO: Spider opened
2020-03-14 16:39:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.aliexpress.com/robots.txt> (referer: None)
2020-03-14 16:39:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.aliexpress.com/category/200216607/tablets.html> (referer: None)
Парсер возвращает response (ответ), который можно посмотреть с помощью команды view(response). А страница откроется в браузере по умолчанию.
С помощью команды print(response.text) можно посмотреть сырой HTML.
Отобразится скрипт, который генерирует страницу. Это то же самое, что вы видите по нажатию правой кнопкой мыши в пустом месте и выборе «Просмотр кода страница» или «Просмотреть код». Но поскольку нужна конкретная информация, а не целый скрипт, с помощью инструментов разработчика в браузере необходимо определить требуемый элемент. Возьмем следующие элементы:
- Название планшета
- Цена планшета
- Количество заказов
- Имя магазина
Нажмите правой кнопкой по элементу и кликните на «Просмотреть код».
Инструменты разработчика сильно помогут при работе с парсингом. Здесь видно, что есть тег <a> с классом item-title, а сам текст включает название продукта:
<a data-p4p="true" class="item-title" href="//aliexpress.ru
/item/32719104234.html?spm=a2g0o.productlist.0.0.248552054LjgSt&
amp;algo_pvid=ff95978b-3cdf-4d85-8ab6-da9c1cf5f78b&
algo_expid=ff95978b-3cdf-4d85-8ab6-da9c1cf5f78b-0&
btsid=0b0a3f8115842002308095415e318f&
ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_"
title="Планшет с 10,1-дюймовым дисплеем, восьмиядерным
процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ 128 ГБ, 10
дюймов" target="_blank" data-spm-anchor-
id="a2g0o.productlist.0.0">Планшет с 10,1-дюймовым дисплеем,
восьмиядерным процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ
128 ГБ, 10 дюймов</a>
Использование CSS-селекторов для извлечения
Извлечь эту информацию можно с помощью атрибутов элементов или CSS-селекторов в виде классов. Напишите следующее в оболочке Scrapy, чтобы получить имя продукта:
response.css(".item-title::text").extract_first()
Вывод:
'Планшет с 10,1-дюймовым дисплеем, восьмиядерным процессором 3g 4g LTE, Android 9,0, ОЗУ 8 Гб, ПЗУ 128 ГБ, 10 дюймов'
extract_first() извлекает первый элемент, соответствующий селектору css. Для извлечения всех названий нужно использовать extract():
response.css(".item-title::text").extract()
Следующий код извлечет ценовой диапазон этих продуктов:
response.css(".price-current::text").extract()
То же можно повторить для количества заказов и имени магазина.
Использование XPath для извлечения
XPath — это язык запросов для выбора узлов в документах типа XML. Ориентироваться по документу можно с помощью XPath. Scrapy использует этот же язык для работы с объектами документа HTML. Использованные выше CSS-селекторы также конвертируются в XPath, но в большинстве случаев CSS очень легко использовать. И тем не менее важно значить, как язык работает в Scrapy.
Откройте оболочку и введите fetch("https://www.aliexpress.com/category/200216607/tablets.html/") как и раньше. Попробуйте написать следующий код:
response.xpath('/html').extract()
Он покажет весь код в теге <html>. / указывает на прямого потомка узла. Если нужно получить теги <div> в html, то необходимо писать:
response.xpath('/html//div').extract()
Для XPath важно научиться понимать, как используются / и //, чтобы ориентироваться в дочерних узлах.
Если необходимо получить все теги <div>, то нужно написать то же самое, но без /html:
response.xpath("//div").extract()
Можно и дальше фильтровать начальные узлы, чтобы получить нужные узлы с помощью атрибутов и их значений. Это синтаксис использования классов и их значений.
response.xpath("//div[@class='quote'/span[@class='text']").extract()
response.xpath("//div[@class='quote']/span[@class='text']/text()").extract()
Используйте text() для извлечения всего текста в узлах
Создание проекта Scrapy и собственного робота (Spider)
Парсинг хорошо подходит для создания агрегатора, который будет использоваться для сравнения данных. Например, нужно купить планшет, предварительно сравнив несколько продуктов и их цены. Для этого можно исследовать все страницы и сохранить данные в файл Excel. В этом примере продолжим парсить aliexpress.com на предмет информации о планшетах.
Создадим робота (Spider) для страницы. В первую очередь необходимо создать проект Scrapy, где будут храниться код и результаты. Напишите следующее в терминале или anaconda.
scrapy startproject aliexpress
Это создаст скрытую папку в директории с Python или Anaconda по умолчанию. Она будет называться aliexpress, но можно выбрать любое название. Структура директории следующая:

| Файл/папка | Назначение |
|---|---|
scrapy.cfg |
Файл настройки развертывания |
aliexpress/ |
Модуль Python проекта, отсюда импортируется код |
__init.py__ |
Файл инициализации |
items.py |
Python файл с элементами проекта |
pipelines.py |
Файл, который содержит пайплайн проекта |
settings.py |
Файл настроек проекта |
spiders/ |
Папка, в которой будут храниться роботы |
__init.py__ |
Файл инициализации |
После создания проекта нужно перейти в новую папку и написать следующую команду:
scrapy genspider aliexpress_tabletshttps://www.aliexpress.com/category/200216607/tablets.html
Это создает файл шаблона с названием aliexpress_tables.py в папке spiders, как и было описано выше. Вот код из этого файла:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
def parse(self, response):
pass
В коде можно увидеть name, allowed_domains, start_urls и функцию parse.
- name — это имя робота. Удачные и правильно подобранные имена позволят проще отслеживать всех имеющихся роботов. Они должны быть уникальны, ведь именно они используются для запуска командой
scrapy crawl name_of_spider. - allowed_domains (опционально) — список разрешенных для парсинга доменов. Запрос к URL, не указанным в этом списке, не будет выполнен. Он должен включать только домен сайта (например, aliexpress.com), а не целый URL, указанный в
start_urls, иначе возникнут ошибки. - start_urls — запрос к упомянутым URL. С них робот начнет проводить поиск, если конкретный URL не указан. Первыми загруженными страницами будут те, что указаны здесь. Последующие запросы будут генерироваться последовательно из данных, сохраненных в начальных URL.
- parse — эта функция вызывается, когда парсинг URL успешно выполнен. Ее еще называют функцией обратного вызова.
Response(используемый в оболочке Scrapy) возвращается как результат парсинга, передается этой функции, а внутри нее находится код для извлечения.
можно использовать функцию
parse()из BeautifulSoup в Scrapy для парсинга HTML-документа.
Примечание: извлечь данные можно с помощью css-селекторов, используя как
response.css(), так и XPath (XML), что позволит получить доступ к дочерним элементам. Примерresponse.xpath()будет описан в коде функцииpass().
Добавим изменения в файл aliexpress_tablet.py. В start_urls теперь еще один URL. Логику извлечения можно указать в функции pass():
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html',
'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
def parse(self, response):
print("procesing:"+response.url)
# Извлечение данных с помощью селекторов CSS
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
# Извлечение данных с использованием xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
# извлечение данных строки
for item in row_data:
# создать словарь для хранения извлеченной информации
scraped_info = {
'page': response.url,
'product_name': item[0], # item[0] означает продукт в списке и т. д., индекс указывает, какое значение назначить
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
# генерируем очищенную информацию для скрапа
yield scraped_info
zip()берет n элементов итерации и возвращает список кортежей. Элемент с индексом i в кортеже создается с помощью элемента с индексом i каждого элемента итерации.
yield используется каждый раз при определении функции генератора. Функция генератора — это обычная функция, отличие которой в том, что она использует yield вместо return. yield используется каждый раз, когда вызывающая функция требует значения. Функция с yield сохраняет свое локальное состояние при выполнении и продолжает исполнение с того момента, где остановилась после того, как выдала одно значение. В данном случае yield возвращает Scrapy сгенерированный словарь, который будет обработан и сохранен.
Теперь можно запустить робота и посмотреть результат:
scrapy crawl aliexpress_tablets
Экспорт данных
Данные должны быть представлены в форматах CSV или JSON, чтобы их можно было анализировать. Этот раздел руководства посвящен тому, как получить такой файл из имеющихся данных.
Для сохранения файла CSV откройте settings.py в папке проекта и добавьте следующие строки:
FEED_FORMAT="csv"
FEED_URI="aliexpress.csv"
После сохранения settings.py снова запустите scrapy crawl aliexpress_tablets в папке проекта. Будет создан файл aliexpress.csv.
Примечание: при каждом запуске паука он будет добавлять файл.
- FEED_FORMAT — настройка необходимого формата сохранения данных. Поддерживаются следующие:
+ JSON + CSV + JSON Lines + XML - FEED_URI — местоположение файла. Его можно сохранить в локальном хранилище или по FTP.
Feed Export также может добавить временную метку в имя файла. Или его можно использовать для выбора папки, куда необходимо сохранить данные.
%(time)s— заменяется на временную метку при создании ленты%(name)s— заменяется на имя робота
Например:
- Сохранить по FTP используя по одной папке на робота:
Изменения для FEED, сделанные в settings.py, будут применены ко всем роботам в проекте. Можно указать и отдельные настройки для конкретного робота, которые перезапишут те, что есть в settings.py.
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html',
'https://www.aliexpress.com/category/200216607/tablets/2.html?site=glo&g=y&tag=']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.json",
'FEED_FORMAT': 'json'}
def parse(self, response):
print("procesing:"+response.url)
# Извлечение данных с помощью селекторов CSS
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
# Извлечение данных с использованием xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
# извлечение данных строки
for item in row_data:
# создать словарь для хранения извлеченной информации
scraped_info = {
'page': response.url,
'product_name': item[0], # item[0] означает продукт в списке и т. д., индекс указывает, какое значение назначить
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
# генерируем очищенную информацию для скрапа
yield scraped_info
response.url вернет URL страницы, с которой был сгенерирован ответ. После запуска парсера с помощью scrapy crawl aliexpress_tables можно просмотреть json-файл в каталоге проекта.
Следующие страницы, пагинация
Вы могли обратить внимание на две ссылки в start_urls. Вторая — это страница №2 результатов поиска планшетов. Добавлять все ссылки непрактично. Робот должен быть способен исследовать все страницы сам, а в start_urls указывается только одна стартовая точка.
Если у страницы есть последующие, в ее конце всегда будут навигационные элементы, которые позволяют перемещаться вперед и назад.
Вот такой код:
<div class="list-pagination"><div class="product-pagination-wrap"><div class="next-pagination next-medium next-normal"><div class="next-pagination-pages"><button disabled="" aria-label="Previous page, current page 1" type="button" class="next-btn next-medium next-btn-normal next-pagination-item next-prev" role="button"><i class="next-icon next-icon-arrow-left next-xs next-btn-icon next-icon-first"></i>Предыдущая</button><div class="next-pagination-list"><button aria-label="Page 1, 7 pages" type="button" class="next-btn next-medium next-btn-normal next-pagination-item next-current" role="button">1</button>
...
<button aria-label="Page 7, 7 pages" type="button" class="next-btn next-medium next-btn-normal next-pagination-item" role="button">7</button></div><button aria-label="Next page, current page 1" type="button" class="next-btn next-medium next-btn-normal next-pagination-item next-next" role="button">След. стр.<i class="next-icon next-icon-arrow-right next-xs next-btn-icon next-icon-last"></i></button></div></div><div class="jump-aera"><span class="total-page">Всего 24 стр</span><span>Перейти на страницу</span><span class="next-input next-large"><input aria-label="Large" height="100%" autocomplete="off" value=""></span><span class="jump-btn">ОК</span></div></div></div>
Здесь видно, что тег <span> с классом .ui-pagination-active — это текущая страница, а дальше идут теги <a> со ссылками на следующие страницы. Каждый раз нужно будет получать тег <a> после тега <span>. Здесь в дело вступает немного CSS. В этом случае нужно получить соседний, а на дочерний узел, так что потребуется сделать CSS-селектор, который будет искать теги <a> после тега <span> с классом .ui-pagination-active.
Запомните! У каждой веб-страницы собственная структура. Нужно будет изучить ее, чтобы получить желаемый элемент. Всегда экспериментируйте с response.css(SELECTOR) в Scrapy Shell, прежде чем переходить к коду.
Измените aliexpress_tabelts.py следующим образом:
import scrapy
class AliexpressTabletsSpider(scrapy.Spider):
name = 'aliexpress_tablets'
allowed_domains = ['aliexpress.com']
start_urls = ['https://www.aliexpress.com/category/200216607/tablets.html']
custom_settings={ 'FEED_URI': "aliexpress_%(time)s.json",
'FEED_FORMAT': 'json'}
def parse(self, response):
print("procesing:"+response.url)
# Извлечение данных с помощью селекторов CSS
product_name=response.css('.item-title::text').extract()
price_range=response.css('.price-current::text').extract()
# Извлечение данных с использованием xpath
orders=response.xpath("//em[@title='Total Orders']/text()").extract()
company_name=response.xpath("//a[@class='store $p4pLog']/text()").extract()
row_data=zip(product_name,price_range,orders,company_name)
# извлечение данных строки
for item in row_data:
# создать словарь для хранения извлеченной информации
scraped_info = {
'page': response.url,
'product_name': item[0], # item[0] означает продукт в списке и т. д., индекс указывает, какое значение назначить
'price_range': item[1],
'orders': item[2],
'company_name': item[3],
}
# генерируем очищенную информацию для скрапа
yield scraped_info
NEXT_PAGE_SELECTOR = '.ui-pagination-active + a::attr(href)'
next_page = response.css(NEXT_PAGE_SELECTOR).extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse)
В этом коде:
- Сначала извлекается ссылка следующей страницы с помощью
next_page = response.css(NET_PAGE_SELECTOR).extract_first(), а потом, если переменнаяnext_pageполучает ссылку и она не пустая, запускается телоif. response.urljoin(next_page)— методparse()будет использовать этот метод для построения нового URL и получения нового запроса, который будет позже направлен вызову.- После получения нового URL он парсит ссылку, исполняя тело
forи снова начинает искать новую страницу. Так будет продолжаться до тех пор, пока страницы не закончатся.
Теперь можно просто расслабиться и смотреть, как робот парсит страницы. Этот извлечет все из последующих страниц. Процесс займет много времени, а размер файла будет 1,1 МБ.
Scrapy сделает для вас все!
Из этого руководства вы узнали о Scrapy, о его отличиях от BeautifulSoup, о Scrapy Shell и о создании собственных проектов. Scrapy перебирает на себя весь процесс написания кода: от создания файлов проекта и папок до обработки дублирующихся URL. Весь процесс парсинга занимает минуты, а Scrapy предоставляет поддержку всех распространенных форматов данных, которые могут быть использованы в других программах.
Теперь вы должны лучше понимать, как работает Scrapy, и как использовать его в собственных целях. Чтобы овладеть Scrapy на высоком уровне, нужно разобраться со всеми его функциями, но вы уже как минимум знаете, как эффективно парсить группы веб-страниц.
]]>Немного истории
В ранние годы существования Python разработчикам необходимо было проводить сложные вычисления, особенно когда язык использовался в научном сообществе.
Первой попыткой упростить задачу был модуль Numeric. Его разработал программист по имени Джим Хагунин в 1995 году. Следом за ней появился пакет Numarray. Оба решения специализировались на вычислениях массивов. У каждого свои преимущества в зависимости от сценария. Поэтому и использовались они по обстоятельствам. Такая неопределенность привела к тому, что приняли решение объединить два пакета. Для этих целей Трэвис Олифант начал разработку библиотеки NumPy, первая версия которой вышла в 2006 году.
С тех пор NumPy стала библиотекой №1 в Python для научных вычислений и по сегодняшний день она является самым популярным пакетом для вычислений многомерных и просто крупных массивов. Он также включает множество функций, которые позволяют эффективно проводить операции и выполнять высокоуровневые математические расчеты.
Сейчас NumPy — это проект с открытым исходным кодом, который распространяется по лицензии BSD. В его развитии внесли свою лепту множество разработчиков.
Установка NumPy
Модуль представлен как пакет по умолчанию во множестве дистрибутивов Python, но если его нет, то для установки используйте одну из следующих команд.
В Linux (Ubuntu и Debian):
sudo apt-get install python-numpy
Для Linux (Fedora):
sudo yum install numpy scipy
В Windows с Anaconda или pip:
conda install numpy
pip install numpy
Когда NumPy установлен, импортируйте модуль с помощью этой команды.
import numpy as np
В этом материале описаны продвинутые функции библиотеки Requests.
Объекты Session
Объект Session позволяет сохранять определенные параметры между запросами. Он же сохраняет куки всех запросов, сделанных из экземпляра Session.
Объект Session включает все методы основного API Requests.
Попробуем передать куки между запросами:
s = requests.Session()
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("https://httpbin.org/cookies")
print(r.text)
# '{"cookies": {"sessioncookie": "123456789"}}'
Session могут также использоваться для предоставления данных по умолчанию для методов запроса. Для этого их нужно передать в параметры объекта:
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# отправка с 'x-test' и 'x-test2'
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
Любые словари, переданные методу запроса? будут объединены с заданными значениями уровня сессии. Параметры уровня методов перезаписывают параметры сессии.
Удалите значение из параметра словаря:
Иногда нужно будет не включать ключи уровня сессии в параметры словаря. Для этого необходимо установить значения ключаNoneв параметре уровня методов. Они будут пропускаться автоматически.
Все значения, содержащиеся в сессии, прямо доступны. Подробнее об этом в документации API Session.
Объекты запросов и ответов
Каждый раз при вызове запроса происходят две вещи. Во-первых, создается объект Request, который будет направлен на сервер, чтобы сделать запрос или вернуть определенный ресурс. Во-вторых, когда библиотека получает ответ от сервера, генерируется объект Response. Он содержит всю информацию, которую вернул сервер и оригинальный объект Request. Вот простой запрос для получения крайне важной информации с серверов Википедии:
>>> r = requests.get('https://ru.wikipedia.org/wiki/Монти_Пайтон')
Если нужно получить доступ к заголовкам, которые вернул сервер, делается следующее:
>>> r.headers
{'Date': 'Fri, 06 Mar 2020 10:40:21 GMT', 'Content-Type': 'text/html; charset=UTF-8',
'Server': 'mw1258.eqiad.wmnet', 'X-Powered-By': 'PHP/7.2.26-1+0~20191218.33+debian9~1.gbpb5a340+wmf1',
'X-Content-Type-Options': 'nosniff', 'P3P': 'CP="See [https://ru.wikipedia.org/wiki/Special:CentralAutoLogin/P3P](https://ru.wikipedia.org/wiki/Special:CentralAutoLogin/P3P) for more info."',
'Content-language': 'ru', 'Vary': 'Accept-Encoding,Cookie,Authorization',
'Last-Modified': 'Fri, 21 Feb 2020 10:40:21 GMT', 'Backend-Timing': 'D=181758 t=1583491220993575',
'X-ATS-Timestamp': '1583491221', 'Content-Encoding': 'gzip',
'X-Varnish': '1017342992 492505475', 'Age': '82909', 'X-Cache': 'cp3050 miss, cp3056 hit/43',
'X-Cache-Status': 'hit-front', 'Server-Timing': 'cache;desc="hit-front"',
'Strict-Transport-Security': 'max-age=106384710; includeSubDomains; preload',
'X-Client-IP': '111.111.111.1', 'Cache-Control': 'private, s-maxage=0, max-age=0, must-revalidate',
'Accept-Ranges': 'bytes', 'Content-Length': '41759', 'Connection': 'keep-alive'}
А если нужны те, что были направлены серверу, тогда сперва нужно получить доступ к запросу, а потом — к его заголовкам:
>>> r.request.headers
{'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
Подготовка запросов
При получении объекта Response от вызова API или Session, используется атрибут PreparedRequest функции request. В некоторых случаях над телом и заголовками (и чем угодно еще) можно будет провести дополнительную работу перед отправкой запроса. Простейший способ следующий:
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = req.prepare()
# делаем что-то с prepped.body
prepped.body = 'No, I want exactly this as the body.'
# делаем что-то с prepped.headers
del prepped.headers['Content-Type']
resp = s.send(prepped,
stream=stream,
verify=verify,
proxies=proxies,
cert=cert,
timeout=timeout
)
print(resp.status_code)
Поскольку с объектом Request не происходит ничего особенного, его можно сразу подготовить и изменить объект PreparedRequest. Затем он отправляется с остальными параметрами, которые вы бы отправили в requests.* или Session.*.
Однако этот код лишен кое-каких преимуществ использования объекта Session. Если точнее, состояние уровня Session, например куки, не будет применено к запросу. Чтобы получить PreparedRequest с примененным состоянием, замените вызов к Request.prepare() вызовом к Session.prepare_request():
from requests import Request, Session
s = Session()
req = Request('GET', url, data=data, headers=headers)
prepped = s.prepare_request(req)
# делаем что-то с prepped.body
prepped.body = 'Seriously, send exactly these bytes.'
# делаем что-то с prepped.headers
prepped.headers['Keep-Dead'] = 'parrot'
resp = s.send(prepped,
stream=stream,
verify=verify,
proxies=proxies,
cert=cert,
timeout=timeout
)
print(resp.status_code)
При использовании потока “prepared request” помните, что он не учитывает окружение. Это может привести к проблемам в том случае, если переменные окружения используются для изменения поведения запросов. Например: самозаверенные SSL-сертификаты, определенные в REQUESTS_CA_BUNDLE, учитываться не будут. Результат — SSL: CERTIFICATE_VERIFY_FAILED. Обойти это поведение можно, явно объединив настройки окружения с сессией:
from requests import Request, Session
s = Session()
req = Request('GET', url)
prepped = s.prepare_request(req)
# Объединяем настройки среды в сессию
settings = s.merge_environment_settings(prepped.url, {}, None, None, None)
resp = s.send(prepped, **settings)
print(resp.status_code)
Проверка сертификата SSL
Библиотека Requests может верифицировать SSL-сертификаты для HTTPS-запросов так же, как и браузер. Для проверки сертификата хоста, нужно просто добавить аргумент verify:
>>> requests.get('https://kennethreitz.com', verify=True)
requests.exceptions.SSLError: hostname 'kennethreitz.com'
doesn't match either of '*.herokuapp.com', 'herokuapp.com'
Если такового нет или он недействителен, вернется ошибка SSLError. Но у Github, например, есть:
>>> requests.get('https://github.com', verify=True)
<Response [200]>
verify можно передать и файлу CA_BUNDLE для частных сертификатов. Или же настроить переменную среды REQUESTS_CA_BUNDLE.
Библиотека может игнорировать проверку SSL-сертификатов, если значение verify — False.
>>> requests.get('https://kennethreitz.com', verify=False)
<Response [200]>
По умолчанию значение verify — True. Параметр подходит только для сертификатов хостов.
Можно также определить файл локального сертификата в виде пути или пары ключ-значение:
>>> requests.get('https://kennethreitz.com', cert=('/path/server.crt', '/path/key'))
<Response [200]>
Если указан неправильный путь или недействительный сертификат, произойдет следующее:
>>> requests.get('https://kennethreitz.com', cert='/wrong_path/server.pem')
SSLError: [Errno 336265225] _ssl.c:347: error:140B0009:SSL routines:SSL_CTX_use_PrivateKey_file:PEM lib
Работа с содержанием ответа
По умолчанию при запросе тело ответа загружается сразу же. Переписать это поведение и отсрочить загрузку тела ответа до того момента, пока не будет получен доступ к атрибуту Response.content, можно с помощью параметра stream:
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master'
r = requests.get(tarball_url, stream=True)
Сейчас загружаются только заголовки ответа, а соединение остается открытым. Это позволяет сделать получение контента по условию:
if int(r.headers['content-length']) < TOO_LONG:
content = r.content
# ...
Можно и дальше контролировать процесс работы с помощью методов Response.iter_content и Response.iter_lines или чтения их из лежащей в основе библиотеки urllib3 urllib3.HTTPResponse в Response.raw.
Постоянное соединение
Благодаря urllib3 постоянное соединение поддерживается на 100% автоматически прямо в сессии. Любые запросы в сессии будут автоматически использовать соответствующее соединение.
Стоит отметить, что соединения сбрасываются и возвращаются в пул для повторного использовать только после чтения данных тела. Важно задать значение stream равным False или читать свойство property объекта Response.
Потоковые загрузки
Requests поддерживает потоковые загрузки, которые позволяют отправлять крупные потоки или файлы без их чтения прямо в память. Для этого нужно предоставить файловый объект в data:
with open('massive-body') as f:
request.post('http://some.url/streamed', data=f)
Запросы для данных, разбитых на части (chunk-encoded)
Requests также поддерживает механизм передачи с разбиением на части для входящих и исходящих запросов. Для отправления такого нужно предоставить генератор (или любой итератор без определенной длины) в data:
def gen():
yield 'hi'
yield 'there'
request.post('http://some.url/chunked', data=gen())
POST для нескольких файлов типа multipart
Можно отправить несколько файлов одним запросом. Например, предположим, необходимо загрузить файлы изображений в HTML-форму images для нескольких файлов :
<input type="file" name="images" multiple="true" required="true"/>
Чтобы сделать это, просто представьте файлы в виде списка кортежей такого формата (form_field_name, file_info):
>>> url = 'https://httpbin.org/post'
>>> multiple_files = [
... ('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
... ('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
>>> r = requests.post(url, files=multiple_files)
>>> r.text
{
...
'files': {'images': 'data:image/png;base64,iVBORw ....'}
'Content-Type': 'multipart/form-data; boundary=3131623adb2043caaeb5538cc7aa0b3a',
...
}
Предупреждение:
Рекомендуется открывать файлы в бинарном режиме. Это важно, потому чтоRequestsможет попробовать предоставить заголовокContent-Length. В таком случае значением будет количеством байт в файле. А ошибки возникнут, если открыть файл в текстовом режиме.
Хуки (перехват управления)
В Requests есть система хуков, которую можно использовать для управления частями процесса запроса или обработки событий.
Доступные хуки:
response: ответ, сгенерированный из объектаRequest.
Можно назначать функцию перехвата для каждого запроса, передавая словарь {hook_name: callback_function} в параметр запроса hooks:
hooks=dict(response=print_url)
callback_function получит кусок данных в качестве первого аргумента.
def print_url(r):
print(r.url)
Если при выполнении обратного вызова произойдет ошибка, отобразится предупреждение.
Если функция вернет значение, предполагается, что оно должно заменить данные, которые были переданы. Когда функция не возвращает ничего, нет никакого эффекта.
Выведем некоторые аргументы метода запроса:
>>> requests.get('http://httpbin.org', hooks=dict(response=print_url))
http://httpbin.org
<Response [200]>
Собственная аутентификация
Requests позволяет указать собственный механизм аутентификации.
Любой вызываемый объект, передаваемый в качестве аргумента auth методу запроса, может изменить запрос до его отправки.
Реализации аутентификации — это подклассы requests.auth.AuthBase, и их легко определить. Requests предоставляет две общие схемы реализации аутентификации в requests.auth:HTTPBasicAuth и HTTPDigestAuth.
Представим, что есть веб-сервис, который отвечает только в том случае, если значение заголовка X-Pizza — значение пароля. Такое маловероятно, но мало ли.
from requests.auth import AuthBase
class PizzaAuth(AuthBase):
"""Прикрепляет аутентификацию HTTP Pizza к данному объекту запроса."""
def __init__(self, username):
# любые данные, связанные с аутентификацией
self.username = username
def __call__(self, r):
# изменить и вернуть запрос
r.headers['X-Pizza'] = self.username
return r
Теперь можно сделать запрос с помощью PizzaAuth:
>>> requests.get('http://pizzabin.org/admin', auth=PizzaAuth('kenneth'))
<Response [200]>
Потоковые запросы
С помощью requests.Response.iter_lines() можно запросто перебирать потоковые API, такие как Twitter Streaming API.
Используем его для отслеживания ключа словаря requests:
import requests
import json
r = requests.post('https://stream.twitter.com/1/statuses/filter.json',
data={'track': 'requests'}, auth=('username', 'password'), stream=True)
for line in r.iter_lines(decode_unicode=True):
if line:
print(json.loads(line))
Прокси
Если есть необходимость использовать прокси, можно настроить индивидуальные запросы с помощью аргумента proxies для любого метода запроса:
import requests
proxies = {
"http": "10.10.1.10:3128",
"https": "10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
Также их можно настроить с помощью переменных среды HTTP_PROXY и HTTPS_PROXY.
$ export HTTP_PROXY="10.10.1.10:3128"
$ export HTTPS_PROXY="10.10.1.10:1080"
$ python
>>> import requests
>>> requests.get("http://example.org")
Для использования HTTP Basic Auth (аутентификации) со своим прокси, используется синтаксис http://user:password@host/:
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
SOCKS
Новое в версии 2.10.0
В дополнение к базовым прокси HTTP Requests также поддерживает прокси с помощью протокола SOCKS. Это опциональная функция, требующая дополнительных библиотек. Их можно получить с помощью pip:
$ pip install requests[socks]
После установки использовать прокси SOCKS так же просто, как и HTTP:
proxies = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}
При использовании socks5 разрешение DNS работает на стороне клиента, а не на стороне прокси-сервера. Это работает в соответствии с curl, который использует схему, чтобы определять, на чьей стороне разрешать DNS. Если необходимо заниматься преобразованием на стороне прокси-сервера, тогда используется socks5h.
Соответствие стандартам
Requests соответствует всем актуальным спецификациям и RFC (технические стандарты, применяемые в сети) там, где подобное соответствие не создает трудностей для пользователей. Такое внимание к спецификациям может привести к необычному поведению, которое покажется необычным для тех, кто не знаком с ними.
Кодировки
Когда вы получаете ответ, Requests предполагает, какую кодировку использовать для декодирования во время вызова метода Response.text. Библиотека сначала проверит кодировку в заголовке HTTP, и если там ничего не указано, воспользуется charade, чтобы попробовать угадать.
Она не будет вести себя подобным образом только в одном случае — если кодировка не указано явно, а значение Content-Type — text. В таком случае, согласно RFC 2616, кодировка по умолчанию — ISO-8859-1. Библиотека следует этому правилу. Если вам требуется другая кодировка, вы можете вручную настроить свойство Response. encoding или использовать сырой Response.content.
Методы HTTP
Requests предоставляет доступ ко всем методам HTTP: GET, OPTIONS, HEAD, POST, PUT, PATCH, DELETE. Далее будут детальные примеры того, как их использовать с GitHub API.
Начнем с самого популярного метода — GET. GET — это идемпотентный метод, который возвращает ресурс по заданному URL. Он используется для получения данных из определенного места. Пример — попытка получить информацию об определенном коммите из GitHub. Пусть будет коммит a050faf. Это будет выглядеть вот так:
>>> import requests
>>> r = requests.get('https://api.github.com/repos/kennethreitz/requests/git/commits/a050faf084662f3a352dd1a941f2c7c9f886d4ad')
Нужно подтвердить, что GitHub ответил правильно. Если да — необходимо определить тип контента. Это делается следующим образом:
>>> if (r.status_code == requests.codes.ok):
... print(r.headers['content-type'])
...
application/json; charset=utf-8
Итак, GitHub возвращает JSON. Можно использовать метод r.json для парсинга его в объекты Python.
>>> commit_data = r.json()
>>> print(commit_data.keys())
['committer', 'author', 'url', 'tree', 'sha', 'parents', 'message']
>>> print(commit_data['committer'])
{'date': '2012-05-10T11:10:50-07:00', 'email': 'me@kennethreitz.com', 'name': 'Kenneth Reitz'}
>>> print(commit_data['message'])
makin' history
Пока что все просто. Но посмотрим, что еще есть в API GitHub. Можно просто почитать документацию, но еще интереснее, если просто поэкспериментировать с Requests. Используем метод OPTIONS, чтобы увидеть какие еще методы HTTP поддерживаются для этого ресурса.
>>> verbs = requests.options(r.url)
>>> verbs.status_code
500
Оказывается, что у GitHub, как и у многих API, не реализован метод OPTIONS. Так что придется все-таки использовать документацию. Но если бы метод OPTION был реализован, он вернул бы примерно следующее.
>>> verbs = requests.options('http://a-good-website.com/api/cats')
>>> print(verbs.headers['allow'])
GET,HEAD,POST,OPTIONS
В документации указано, что единственные разрешенные методы для коммитов — POST. Они создают новые коммиты. Но поскольку используется репозиторий Requests, лучше не делать туда бесполезные POST. Вместо этого можно поиграть с функцией Issues.
Эта документация была добавлена в ответ на “Issue #482”. Возьмем ее в качестве примера.
>>> r = requests.get('https://api.github.com/repos/kennethreitz/requests/issues/482')
>>> r.status_code
200
>>> issue = json.loads(r.text)
>>> print(issue['title'])
Feature any http verb in docs
>>> print(issue['comments'])
3
Есть три комментария. Рассмотрим последний из них.
>>> r = requests.get(r.url + '/comments')
>>> r.status_code
200
>>> comments = r.json()
>>> print(comments[0].keys())
['body', 'url', 'created_at', 'updated_at', 'user', 'id']
>>> print(comments[2]['body'])
Probably in the "advanced" section
Можем сообщить автору, что он не прав. Но сперва узнаем, кто это.
>>> print(comments[2]['user']['login'])
kennethreitz
Теперь скажем этому kennethreitz, что ему лучше отправляться в раздел для начинающих. Согласно документации API GitHub это делается с помощью метода POST.
>>> body = json.dumps({"body": "Sounds great! I'll get right on it!"})
>>> url = "https://api.github.com/repos/kennethreitz/requests/issues/482/comments"
>>> r = requests.post(url=url, data=body)
>>> r.status_code
404
Похоже, нужно авторизоваться. В Requests можно выполнить любой вид аутентификации, включая базовую.
>>> from requests.auth import HTTPBasicAuth
>>> auth = HTTPBasicAuth('fake@example.com', 'not_a_real_password')
>>> r = requests.post(url=url, data=body, auth=auth)
>>> r.status_code
201
>>> content = r.json()
>>> print(content['body'])
Sounds great! I'll get right on it.
Теперь попробуем отредактировать сообщение. Для этого нужен метод PATCH.
>>> print(content["id"])
5804413
>>> body = json.dumps({"body": "Sounds great! I'll get right on it once I feed my cat."})
>>> url = "https://api.github.com/repos/kennethreitz/requests/issues/comments/5804413"
>>> r = requests.patch(url=url, data=body, auth=auth)
>>> r.status_code
200
С баловством покончено. Используем DELETE для удаления сообщения.
>>> r = requests.delete(url=url, auth=auth)
>>> r.status_code
204
>>> r.headers['status']
'204 No Content'
Напоследок можно посмотреть, как много запросов было использовано. Для этого нужно сделать запрос HEAD к заголовкам и не скачивать целую страницу.
>>> r = requests.head(url=url, auth=auth)
>>> print(r.headers)
...
'x-ratelimit-remaining': '4995'
'x-ratelimit-limit': '5000'
...
Осталось написать программу на Python, которая бы использовала остальные 4995 запросов.
Заголовки Link
Многие API используют заголовки Link. Они делают API более описательными и простыми в использования. GitHub используют пагинацию в своем API, например:
>>> url = 'https://api.github.com/users/kennethreitz/repos?page=1&per_page=10'
>>> r = requests.head(url=url)
>>> r.headers['link']
<https://api.github.com/users/kennethreitz/repos?page=2&per_page=10>; rel="next", <https://api.github.com/users/kennethreitz/repos?page=6&per_page=10>; rel="last"
Requests автоматически парсит эти ссылки и позволяет с легкостью их использовать.
>>> r.links["next"]
{'url': 'https://api.github.com/users/kennethreitz/repos?page=2&per_page=10', 'rel': 'next'}
>>> r.links["last"]
{'url': 'https://api.github.com/users/kennethreitz/repos?page=7&per_page=10', 'rel': 'last'}
Пользовательские HTTP-методы
Иногда вы будете работать с сервером, который по какой-то причине требует использовать методы HTTP за исключение базовых. Например, метод MKCOL, который используют сервера WEBDAV. Однако с ними также можно работать в Requests. В данном случае используется встроенный метод .request. Например:
>>> r = requests.request('MKCOL', url, data=data)
>>> r.status_code
200 # если вызов был правильный
Таким образом можно использовать любой метод, разрешенный сервером.
Transport Adapters
Начиная с версии v1.0.0, Requests использует внутренний модульный дизайн. Одна из причин — внедрение Transport Adapters. Они предоставляют средство для определения методов взаимодействия с HTTP. В частности, позволяют применять настройку для каждого сервиса по отдельности.
Requests поставляются с одним таким Transport Adapter — HTTPAdapter. Он предоставляет возможность взаимодействия с HTTP и HTTPS посредством библиотеки urllib3 из Requests по умолчанию. При инициализации Session один из них «крепится» к объекту Session HTTP, а второй — к HTTPS.
Requests дают возможность пользователям создавать и использовать собственные Transport Adapters с конкретной функциональностью. После создания Transport Adapter может быть прикреплен к объему Session вместе с указанием сервисов, к которым он должен применяться.
>>> s = requests.Session()
>>> s.mount('https://github.com/', MyAdapter())
Вызов mount регистрирует экземпляр Transport Adapter в префиксе. После этого HTTP-запросы, сделанные с помощью этого Session и URL которых начинается с этого префикса, будут использовать указанный Transport Adapter.
Многие подробности использования Transport Adapter лежат за рамками этого материала, но вы сможете разобраться лучше на следующем примере.
Пример: конкретная версия SSL
Разработчики Requests заранее определили, какая версия SSL будет использоваться по умолчанию в urllib3. Обычно это работает так, как нужно, но иногда требуется подключиться к конечной точке, которая использует версию, не совместимую с той, что указана по умолчанию.
В этом случае можно задействовать Transport Adapter, используя большую часть существующей реализации HTTPAdapter и добавив параметр ssl_version, который передается через urllib3. Настроим Transport Adapter, чтобы библиотека использовала SSLv3:
from urllib3.poolmanager import PoolManager
from requests.adapters import HTTPAdapter
class Ssl3HttpAdapter(HTTPAdapter):
""""Transport adapter" который позволяет использовать SSLv3."""
def init_poolmanager(self, connections, maxsize, block=False):
self.poolmanager = PoolManager(
num_pools=connections, maxsize=maxsize,
block=block, ssl_version=ssl.PROTOCOL_SSLv3)
Блокирующий или не-блокирующий
С Transport Adapter по умолчанию Requests не предоставляет никакого не-блокирующего IO (ввода-вывода). Свойство Response.content будет блокировать до тех пор, пока весь ответ не загрузится. Если требуется большая детализация, потоковые возможности библиотеки позволяют получать маленькие порции ответа в определенное время. Но и эти вызовы будут блокироваться.
Если не хочется использовать блокировку IO, есть масса проектов, совмещающих Requests с одним из асинхронных фреймворков Python. Например, requests-threads, grequests, requests-futures и requests-async.
Порядок заголовков
В необычных обстоятельствах может понадобится предоставить заголовки в определенном порядке. Если передать OrderedDict в headers, это и будет обозначенный порядок. Но порядок заголовков по умолчанию в Requests будет иметь более высокий приоритет, поэтому если их перезаписать в headers, они могут отображаться беспорядочно в сравнении с теми, что указаны в аргументе.
Чтобы решить эту проблему, необходимо настроить заголовки по умолчанию для объекта Session, предоставив ему OrderedDict. Этот порядок и станет приоритетным.
Таймауты
У большинства запросов к внешнем серверам есть прикрепленный таймаут в том случае, если сервер не отвечает вовремя. По умолчанию запросы не прерываются, только если время не указано явно. Без таймаута код может висеть по несколько минут.
connect — это количество секунд, которые Requests будет выжидать для настройки соединения с вызовом удаленной машины (соответствующей connect()) в сокете. Хорошей практикой считается настраивать это время чуть больше значения кратного 3, что является стандартным окном ретрансляции пакета TCP.
Когда клиент подключился к серверу и отправил HTTP-запрос, таймаут read — это количество секунд, которые клиент будет ждать ответа от сервера. (Если точнее, это то количество секунд, которое клиент прождет между отправкой байтов с сервера. В 99,9% случаев оно меньше того времени с момента, когда сервер отправляет первый байт).
Если определить одно значение для таймаута, вот так:
r = requests.get('https://github.com', timeout=5)
Оно будет применено к таймауту connect и read. Если нужны отдельные значения, стоит определить их в кортеже:
r = requests.get('https://github.com', timeout=(3.05, 27))
Если сервер очень медленный, можно указать Requests, чтобы он ждал вечно, передав значение None.
r = requests.get('https://github.com', timeout=None)
Для работы понадобится python 3.6+, библиотеки SQLAlchemy и Flask. Код урока здесь.
Версии библиотек в файлеrequirements.txt
В этом материале речь пойдет об основах SQLAlchemy. Создадим веб-приложение на Flask, фреймворке языка Python. Это будет минималистичное приложение, которое ведет учет книг.
С его помощью можно будет добавлять новые книги, читать уже существующие, обновлять и удалять их. Эти операции — создание, чтение, обновление и удаление — также известны как «CRUD» и составляют основу почти всех веб-приложений. О них отдельно пойдет речь в статье.
Но прежде чем переходить к CRUD, разберемся с отдельными элементами приложения, начиная с SQLAlchemy.
Что такое SQLAlchemy?
Стоит отметить, что существует расширение для Flask под названием flask-sqlalchemy, которое упрощает процесс использования SQLAlchemy с помощью некоторых значений по умолчанию и других элементов. Они в первую очередь облегчают выполнение базовых задач. Но в этом материале будет использоваться только чистый SQLAlchemy, чтобы разобраться в его основах без разных расширений.
Как написано на сайте библиотеки «SQLAlchemy — это набор SQL-инструментов для Python и инструмент объектно-реляционного отображения (ORM), который предоставляет разработчикам всю мощь и гибкость SQL».
При чтении этого определения в первую очередь возникает вопрос: а что же такое объектно-реляционное отображение? ORM — это техника, используемая для написания запросов к базам данных с помощью парадигм объектно-ориентированного программирования выбранного языка (Python в этом случае).
Если еще проще, ORM — это своеобразный переводчик, который переводит код с одного набора абстракций в другой. В этом случае — из Python в SQL.
Есть масса причин, почему стоит использовать ORM, а не вручную сооружать строки SQL. Вот некоторые из них:
- Ускорение веб-разработки, ведь пропадает необходимость переключаться между написанием кода Python и SQL
- Устранение повторяющегося кода
- Оптимизация рабочего процесса и более эффективные запросы к базе данных
- Абстрагирование системы базы данных, так что переключение между несколькими базами становится более плавным
- Генерация шаблонного кода для основных операций CRUD
Углубимся еще сильнее.
Зачем использовать ORM, когда можно писать сырой SQL? При написании запросов на сыром SQL, мы передаем их базе данных в виде строк. Следующий запрос написан на сыром SQL:
#импорт sqlite
import sqlite3
# подключаемся к базе данных коллекции книг
conn = sqlite3.connect('books-collection.db')
# создаем объект cursor, для работы с базой данных
c = conn.cursor()
# делаем запрос, который создает таблицу books с идентификатором и именем
c.execute('''
CREATE TABLE books
(id INTEGER PRIMARY KEY ASC,
name varchar(250) NOT NULL)
''' )
# выполняет запрос, который вставляет значения в таблицу
c.execute("INSERT INTO books VALUES(1, 'Чистый Python')")
# сохраняем работу
conn.commit()
# закрываем соединение
conn.close()
Нет ничего плохого в использовании чистого SQL для обращения к базам данных, только если вы не сделаете ошибку в запросе. Это может быть, например, опечатка в названии базы, к которой происходит обращение или неправильное название таблицы. Компилятор Python здесь ничем не поможет.
SQLAlchemy — один из множества ORM-инструментов для Python. При работе с маленькими приложения чистый SQL может сработать. Но если это большой сайт с массой данных, такой подход сильнее подвержен ошибкам и просто более сложен.
Создание базы данных с помощью SQLAlchemy
Создадим файл для настройки базы данных. Можете назвать его как угодно, но пусть это будет database_setup.py.
import sys
# для настройки баз данных
from sqlalchemy import Column, ForeignKey, Integer, String
# для определения таблицы и модели
from sqlalchemy.ext.declarative import declarative_base
# для создания отношений между таблицами
from sqlalchemy.orm import relationship
# для настроек
from sqlalchemy import create_engine
# создание экземпляра declarative_base
Base = declarative_base()
# здесь добавим классы
# создает экземпляр create_engine в конце файла
engine = create_engine('sqlite:///books-collection.db')
Base.metadata.create_all(engine)
В верхней части файла импортируем все необходимые модули для настройки и создания баз данных. Для определения колонок в таблицах импортируем Column, ForeignKey, Integer и String.
Далее импортируем расширение declarative_base. Base = declarative_base() создает базовый класс для определения декларативного класса и присваивает его переменной Base.
Согласно документации declarative_base() возвращает новый базовый класс, который наследуют все связанные классы. Это таблица, mapper() и объекты класса в пределах его определения.
Далее создаем экземпляр класса create_engine, который указывает на базу данных с помощью engine = create_engine('sqlite:///books-collection.db'). Можно назвать базу данных как угодно, но здесь пусть будет books-collection.
Последний этап настройки — добавление Base.metadata.create_all(engine). Это добавит классы (напишем их чуть позже) в виде таблиц созданной базы данных.
После настройки базы данных создаем классы. В SQLAlchemy классы являются объектно-ориентированными или декларативными представлениями таблицы в базе данных.
# мы создаем класс Book наследуя его из класса Base.
class Book(Base):
__tablename__ = 'book'
id = Column(Integer, primary_key=True)
title = Column(String(250), nullable=False)
author = Column(String(250), nullable=False)
genre = Column(String(250))
Для этого руководства достаточно одной таблицы: Book. Она будет содержать 4 колонки: id, title, author и genre. Integer и String используются для определения типа значений, которые будут храниться в колонках. Колонка с названием, именем автора и жанром — это строки, а id — число.
Есть много атрибутов класса, которые используются для определения колонок, но рассмотрим уже использованные:
primary_key: при значенииTrueуказывает на значение, используемое для идентификации каждой уникальной строки таблицы.String(250): String — тип значения, а значение в скобках — максимальная длина строки.Integer: указывает тип значения (целое число).nullable: еслиFalse, это значит, что для создания строки обязательно должно быть значение .
На этом процесс настройки заканчивается. Если сейчас использовать команду python database_setup.py в командной строке, будет создана пустая база данных books-collection.db. Теперь можно наполнять ее данными и пробовать обращаться.
CRUD с SQLAlchemy на примерах
В начале кратко была затронута тема операций CRUD. Пришло время их использовать.
Создадим еще один файл и назовем его populate.py (или любым другим именем).
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# импортируем классы Book и Base из файла database_setup.py
from database_setup import Book, Base
engine = create_engine('sqlite:///books-collection.db')
# Свяжим engine с метаданными класса Base,
# чтобы декларативы могли получить доступ через экземпляр DBSession
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
# Экземпляр DBSession() отвечает за все обращения к базе данных
# и представляет «промежуточную зону» для всех объектов,
# загруженных в объект сессии базы данных.
session = DBSession()
В первую очередь импортируем все зависимости и некоторые классы из файла database_setup.py.
Затем сообщим программе, с какой базой данных хотим взаимодействовать. Это делается с помощью функции create_engine.
Что бы создать соединение между определениями класса и таблицами в базе данных, используем команду Base.metadata.bind.
Для создания, удаления, чтения или обновления записей в базе данных SQLAlchemy предоставляет интерфейс под названием Session. Для выполнения запросов необходимо добавлять и фиксировать (делать комит) запроса. Используем метод flush(). Он переносит изменения из памяти в буфер транзакции базы данных без фиксации изменения.
CREATE:
Стандартный процесс создания записи следующий:
entryName = ClassName(property="value", property="value" ... )
# Чтобы сохранить наш объект ClassName, мы добавляем его в наш сессию:
session.add(entryName)
'''
Чтобы сохранить изменения в нашу базу данных и зафиксировать
транзакцию, мы используем commit(). Любое изменение,
внесенное для объектов в сессии, не будет сохранено
в базу данных, пока вы не вызовете session.commit().
'''
session.commit()
Создать первую книгу можно с помощью следующей команды:
bookOne = Book(title="Чистый Python", author="Дэн Бейде", genre="компьютерная литература")
session.add(bookOne)
session.commit()
READ:
В зависимости от того, что нужно прочитать, используются разные функции. Рассмотрим два варианты их использования в приложении.
session.query(Book).all() — вернет список всех книг
session.query(Book).first() — вернет первый результат или None, если строки нет
UPDATE:
Для обновления записей в базе данных, нужно проделать следующее:
- Найти запись
- Сбросить значения
- Добавить новую запись
- Зафиксировать сессию в базе данных (сделать комит)
Если еще не заметили, в записи bookOne есть ошибка. Книгу «Чистый Python» написал Дэн Бейдер, а не «Дэн Бейде». Обновим имя автора с помощью 4 описанных шагов.
Для поиска записи используется filter(), который фильтрует запросы на основе атрибутов записей. Следующий запрос выдаст книгу с id=1 (то есть, «Чистый Python»)
editedBook = session.query(Book).filter_by(id=1).one()
Чтобы сбросить и зафиксировать имя автора, нужны следующие команды:
editedBook.author = "Дэн Бейдер"
session.add(editedBook)
session.commit()
Можно использовать all(), one() или first() для поиска записи в зависимости от ожидаемого результата. Но есть несколько нюансов, о которых важно помнить.
all()— возвращает результаты запроса в виде спискаone()— возвращает один результат или вызывает исключение. Вызовет исключениеsqlaclhemy.orm.exc.NoResultFoud, если результат не найден илиsqlaclhemy.orm.exc.NoResultFoud, если были возвращены несколько результатовfirst()— вернет первый результат запроса илиNone, если он не содержит строк, но без исключения
DELETE:
Удаление значений из базы данных — это почти то же самое, что и обновление:
- Находим запись
- Удаляем запись
- Фиксируем сессию
bookToDelete = session.query(Book).filter_by(title='Чистый Python').one()
session.delete(bookToDelete)
session.commit()
Теперь когда база данных настроена и есть базовое понимание CRUD-операций, пришло время написать небольшое приложение Flask. Но в сам фреймворк не будем углубляться. О нем можно подробнее почитать в других материалах.
Создадим новый файл app.py в той же папке, что и database_setup.py и populate.py. Затем импортируем необходимые зависимости.
from flask import Flask, render_template, request, redirect, url_for
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from database_setup import Base, Book
app = Flask(__name__)
# Подключаемся и создаем сессию базы данных
engine = create_engine('sqlite:///books-collection.db?check_same_thread=False')
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
session = DBSession()
# страница, которая будет отображать все книги в базе данных
# Эта функция работает в режиме чтения.
@app.route('/')
@app.route('/books')
def showBooks():
books = session.query(Book).all()
return render_template("books.html", books=books)
# Эта функция позволит создать новую книгу и сохранить ее в базе данных.
@app.route('/books/new/', methods=['GET', 'POST'])
def newBook():
if request.method == 'POST':
newBook = Book(title=request.form['name'], author=request.form['author'], genre=request.form['genre'])
session.add(newBook)
session.commit()
return redirect(url_for('showBooks'))
else:
return render_template('newBook.html')
# Эта функция позволит нам обновить книги и сохранить их в базе данных.
@app.route("/books/<int:book_id>/edit/", methods=['GET', 'POST'])
def editBook(book_id):
editedBook = session.query(Book).filter_by(id=book_id).one()
if request.method == 'POST':
if request.form['name']:
editedBook.title = request.form['name']
return redirect(url_for('showBooks'))
else:
return render_template('editBook.html', book=editedBook)
# Эта функция для удаления книг
@app.route('/books/<int:book_id>/delete/', methods=['GET', 'POST'])
def deleteBook(book_id):
bookToDelete = session.query(Book).filter_by(id=book_id).one()
if request.method == 'POST':
session.delete(bookToDelete)
session.commit()
return redirect(url_for('showBooks', book_id=book_id))
else:
return render_template('deleteBook.html', book=bookToDelete)
if __name__ == '__main__':
app.debug = True
app.run(port=4996)
Наконец, нужно создать шаблоны: books.html, newBook.html, editBook.html и deleteBook.html. Для этого создадим папку с шаблонами во Flask templates на том же уровне, где находится файл app.py. Внутри него создадим четыре файла.
books.html
<html>
<body>
<h1>Books</h1>
<a href="{{url_for('newBook')}}">
<button>Добавить книгу</button>
</a>
<ol>
{% for book in books %}
<li> {{book.title}} by {{book.author}} </li>
<a href="{{url_for('editBook', book_id = book.id )}}">
Изменить
</a>
<a href="{{url_for('deleteBook', book_id = book.id )}}" style="margin-left: 10px;">
Удалить
</a>
<br> <br>
{% endfor %}
</ol>
</body>
</html>
Теперь newBook.html.
<h1>Add a Book</h1>
<form action="#" method="post">
<div class="form-group">
<label for="name">Название:</label>
<input type="text" maxlength="100" name="name" placeholder="Название книги">
<label for="author">Автор:</label>
<input maxlength="100" name="author" placeholder="Автор книги">
<label for="genre">Жанр:</label>
<input maxlength="100" name="genre" placeholder="Жанр книги">
<button type="submit">Добавить</button>
</div>
</form>
Дальше editBook.html.
<form action="{{ url_for('editBook',book_id = book.id)}}" method="post">
<div class="form-group">
<label for="name">Название:</label>
<input type="text" class="form-control" name="name" value="{{book.title }}">
<button type="submit">Обновить</button>
</div>
</form>
<a href='{{ url_for('showBooks') }}'>
<button>Отменить</button>
</a>
И deleteBook.html.
<h2>Вы уверены, что хотите удалить {{book.title}}?</h2>
<form action="#" method='post'>
<button type="submit">Удалить</button>
</form>
<a href='{{url_for('showBooks')}}'>
<button>Отменить</button>
</a>
Если запустить приложение app.py и перейти в браузере на страницу https://localhost:4996/books, отобразится список книг. Добавьте несколько и если все работает, это выглядит вот так:

Расширение приложения и выводы
Если вы добрались до этого момента, то теперь знаете чуть больше о том, как работает SQLAlchemy. Это важная и объемная тема, а в этом материале речь шла только об основных вещах, поэтому поработайте с другими CRUD-операциями и добавьте в приложение новые функции.
Можете добавить таблицу Shelf в базу данных, чтобы отслеживать свой прогресс чтения, или даже реализовать аутентификацию с авторизацией. Это сделает приложение более масштабируемым, а также позволит другим пользователям добавлять собственные книги.
Предок NumPy, Numeric, был разработан Джимом Хугунином. Также был создан пакет Numarray с дополнительной функциональностью. В 2005 году Трэвис Олифант выпустил пакет NumPy, добавив особенности Numarray в Numeric. Это проект с исходным кодом, и в его развитии поучаствовало уже много человек.
NumPy или Numerical Python — это библиотека Python, которая предлагает следующее:
- Мощный N-мерный массив
- Высокоуровневые функции
- Инструменты для интеграции кода C/C++ и Fortran
- Использование линейной алгебры, Преобразований Фурье и возможностей случайных чисел
Она также предлагает эффективный многомерный контейнер общих данных. С ее помощью можно определять произвольные типы данных. Официальный сайт библиотеки — www.numpy.org
Установка NumPy в Python
-
Ubuntu Linux
sudo apt update -y sudo apt upgrade -y sudo apt install python3-tk python3-pip -y sudo pip install numpy -y -
Anaconda
conda install -c anaconda numpy
Массив NumPy
Это мощный многомерный массив в форме строк и колонок. С помощью библиотеки можно создавать массивы NumPy из вложенного списка Python и получать доступ к его элементам.
Массив NumPy — это не то же самое, что и класс array.array из Стандартной библиотеки Python, который работает только с одномерными массивами.
-
Одномерный массив NumPy.
import numpy as np a = np.array([1,2,3]) print(a)Результатом кода выше будет
[1 2 3]. -
Многомерные массивы.
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a)Результат —
[[1 2 3] [4 5 6]].
Атрибуты массива NumPy
-
ndarray.ndim
Возвращает количество измерений массива.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.ndim)Вывод кода сверху будет 2, поскольку «a» — это 2-мерный массив.
-
ndarray.shape
Возвращает кортеж размера массива, то есть (n,m), где n — это количество строк, а m — количество колонок.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.shape)Вывод кода — (2,3), то есть 2 строки и 3 колонки.
-
ndarray.size
Возвращает общее количество элементов в массиве.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.size)Вывод — 6, потому что 2 х 3.
-
ndarray.dtype
Возвращает объект, описывающий тип элементов в массиве.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.dtype)Вывод — «int32», поскольку это 32-битное целое число.
Можно явно определить тип данных массива NumPy.import numpy as np a = np.array([[1,2,3],[4,5,6]], dtype = float) print(a.dtype)Этот код вернет
float64, потому что это 64-битное число с плавающей точкой. -
ndarray.itemsize
Возвращает размер каждого элемента в массиве в байтах.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.itemsize)Вывод — 4, потому что 32/8.
-
ndarray.data
Возвращает буфер с актуальными элементами массива. Это альтернативный способ получения доступа к элементам через их индексы.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.data)Этот код вернет список элементов.
-
ndarray.sum()
Функция вернет сумму все элементов ndarray.import numpy as np a = np.random.random((2,3)) print(a) print(a.sum())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет3.422183052180838. Поскольку используется генератор случайных чисел, ваш результат будет отличаться. -
ndarray.min()
Функция вернет элемент с минимальным значением из ndarray.import numpy as np a = np.random.random((2,3)) print(a.min())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет0.36277909. Поскольку используется генератор случайных чисел, ваш результат будет отличаться. -
ndarray.max()
Функция вернет элемент с максимальным значением из ndarray.import numpy as np a = np.random.random((2,3)) print(a.min())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет0.7115755. Поскольку используется генератор случайных чисел, ваш результат будет отличаться
Функции NumPy
-
type(numpy.ndarray)
Это функция Python, используемая, чтобы вернуть тип переданного параметра. В случае с массивом numpy, она вернетnumpy.ndarray.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(type(a))Код выше вернет
numpy.ndarray. -
numpy.zeroes()numpy.zeros((rows, columns), dtype)
Эта функция создаст массив numpy с заданным количеством измерений, где каждый элемент будет равняться 0. Если dtype не указан, по умолчанию будет использоваться dtype.import numpy as np np.zeros((3,3)) print(a)Код вернет массив numpy 3×3, где каждый элемент равен 0.
-
numpy.ones()numpy.ones((rows,columns), dtype)
Эта функция создаст массив numpy с заданным количеством измерений, где каждый элемент будет равняться 1. Если dtype не указан, по умолчанию будет использоваться dtype.import numpy as np np.ones((3,3)) print(a)Код вернет массив numpy 3 x 3, где каждый элемент равен 1.
-
numpy.empty()numpy.empty((rows,columns))
Эта функция создаст массив, содержимое которого будет случайным — оно зависит от состояния памяти.import numpy as np np.empty((3,3)) print(a)Код вернет массив numpy 3×3, где каждый элемент будет случайным.
-
numpy.arrange()numpy.arrange(start, stop, step)
Эта функция используется для создания массива numpy, элементы которого лежат в диапазоне значений отstartдоstopс разницей равнойstep.import numpy as np a=np.arange(5,25,4) print(a)Вывод этого кода —
[5 9 13 17 21] -
numpy.linspace()numpy.linspace(start, stop, num_of_elements)
Эта функция создаст массив numpy, элементы которого лежат в диапазоне значений междуstartдоstop, аnum_of_elements— это размер массива. Тип по умолчанию —float64.import numpy as np a=np.linspace(5,25,5) print(a)Вывод —
[5 10 15 20 25]. -
numpy.logspace()numpy.logspace(start, stop, num_of_elements)
Эта функция используется для создания массива numpy, элементы которого лежат в диапазоне значений отstartдоstop, аnum_of_elements— это размер массива. Тип по умолчанию — float64. Все элементы находятся в пределах логарифмической шкалы, то есть представляют собой логарифмы соответствующих элементов.import numpy as np a = np.logspace(5,25,5) print(a)Вывод —
[1.e+05 1.e+10 1.e+15 1.e+20 1.e+25]. -
numpy.sin()numpy.sin(numpy.ndarray)
Этот код вернет синус параметра.import numpy as np a = np.logspace(5,25,2) print(np.sin(a))Вывод кода сверху равен
[0.0357488 -0.3052578]. Также естьcos(),tan()и так далее. -
numpy.reshape()numpy.reshape(dimensions)
Эта функция используется для изменения количества измерений массива numpy. От количества аргументов вreshapeзависит, сколько измерений будет в массиве numpy.import numpy as np a = np.arange(9).reshape(3,3) print(a)Вывод этого года — 2-мерный массив 3×3.
-
numpy.random.random()numpy.random.random((rows, column))
Эта функция возвращает массив с заданным количеством измерений, где каждый элемент генерируется случайным образом.a = np.random.random((2,2))Этот код вернет ndarray 2×2.
-
numpy.exp()numpy.exp(numpy.ndarray)
Функция вернет ndarray с экспоненциальной величиной каждого элемента.b = np.exp([10])Значением кода выше будет
22025.4657948. -
numpy.sqrt()numpy.sqrt(numpy.ndarray)
Эта функция вернет ndarray с квадратным корнем каждого элемента.b = np.sqrt([16])Этот код вернет значение 4.
Базовые операции NumPy
a = np.array([5, 10, 15, 20, 25])
b = np.array([0, 1, 2, 3])
-
Этот код вернет разницу двух массивов
c = a - b. -
Этот код вернет массив, где каждое значение возведено в квадрат
b**2. -
Этот код вернет значение в соответствии с заданным выражением
10 * np.sin(a). -
Этот код вернет
Trueдля каждого элемента, чье значение удовлетворяет условиеa < 15.
Базовые операции с массивом NumPy
a = np.array([[1,1], [0,1]])
b = np.array([[2,0],[3,4]])
-
Этот код вернет произведение элементов обоих массивов
a * b. -
Этот код вернет матричное произведение обоих массивов
a @ b
илиa.dot(b).
Выводы
Из этого материала вы узнали, что такое numpy и как его устанавливать, познакомились с массивов numpy, атрибутами и операциями массива numpy, а также базовыми операциями numpy.
]]>Прежде чем начать, убедитесь, что установлена последняя версия Requests.
Для начала, давайте рассмотрим простые примеры.
Создание GET и POST запроса
Импортируйте модуль Requests:
import requests
Попробуем получить веб-страницу с помощью get-запроса. В этом примере давайте рассмотрим общий тайм-лайн GitHub:
r = requests.get('https://api.github.com/events')
Мы получили объект Response с именем r. С помощью этого объекта можно получить всю необходимую информацию.
Простой API Requests означает, что все типы HTTP запросов очевидны. Ниже приведен пример того, как вы можете сделать POST запрос:
r = requests.post('https://httpbin.org/post', data = {'key':'value'})
Другие типы HTTP запросов, такие как : PUT, DELETE, HEAD и OPTIONS так же очень легко выполнить:
r = requests.put('https://httpbin.org/put', data = {'key':'value'})
r = requests.delete('https://httpbin.org/delete')
r = requests.head('https://httpbin.org/get')
r = requests.options('https://httpbin.org/get')
Передача параметров в URL
Часто вам может понадобится отправить какие-то данные в строке запроса URL. Если вы настраиваете URL вручную, эти данные будут представлены в нем в виде пар ключ/значение после знака вопроса. Например, httpbin.org/get?key=val. Requests позволяет передать эти аргументы в качестве словаря, используя аргумент params. Если вы хотите передать key1=value1 и key2=value2 ресурсу httpbin.org/get, вы должны использовать следующий код:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('https://httpbin.org/get', params=payload)
print(r.url)
Как видно, URL был сформирован правильно:
https://httpbin.org/get?key2=value2&key1=value1Ключ словаря, значение которого None, не будет добавлен в строке запроса URL.
Вы можете передать список параметров в качестве значения:
>>> payload = {'key1': 'value1', 'key2': ['value2', 'value3']}
>>> r = requests.get('https://httpbin.org/get', params=payload)
>>> print(r.url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Содержимое ответа (response)
Мы можем прочитать содержимое ответа сервера. Рассмотрим снова тайм-лайн GitHub:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.text
'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests будет автоматически декодировать содержимое ответа сервера. Большинство кодировок unicode декодируются без проблем.
Когда вы делаете запрос, Requests делает предположение о кодировке, основанное на заголовках HTTP. Эта же кодировка текста, используется при обращение к r.text. Можно узнать, какую кодировку использует Requests, и изменить её с помощью r.encoding:
>>> r.encoding
'utf-8'
>>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, Requests будет использовать новое значение r.encoding всякий раз, когда вы будете использовать r.text. Вы можете сделать это в любой ситуации, где нужна более специализированная логика работы с кодировкой содержимого ответа.
Например, в HTML и XML есть возможность задавать кодировку прямо в теле документа. В подобных ситуациях вы должны использовать r.content, чтобы найти кодировку, а затем установить r.encoding. Это позволит вам использовать r.text с правильной кодировкой.
Requests может также использовать пользовательские кодировки в случае, если в них есть потребность. Если вы создали свою собственную кодировку и зарегистрировали ее в модуле codecs, используйте имя кодека в качестве значения r.encoding.
Бинарное содержимое ответа
Вы можете также получить доступ к телу ответа в виде байтов для не текстовых ответов:
>>> r.content
b'[{"repository":{"open_issues":0,"url":"https://github.com/...
Передача со сжатием gzip и deflate автоматически декодируются для вас.
Например, чтобы создать изображение на основе бинарных данных, возвращаемых при ответе на запрос, используйте следующий код:
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
Содержимое ответа в JSON
Если вы работаете с данными в формате JSON, воспользуйтесь встроенным JSON декодером:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.json()
[{'repository': {'open_issues': 0, 'url': 'https://github.com/...
Если декодирование в JSON не удалось, r.json() вернет исключение. Например, если ответ с кодом 204 (No Content), или на случай если ответ содержит не валидный JSON, попытка обращения к r.json() будет возвращать ValueError: No JSON object could be decoded.
Следует отметить, что успешный вызов r.json() не указывает на успешный ответ сервера. Некоторые серверы могут возвращать объект JSON при неудачном ответе (например, сведения об ошибке HTTP 500). Такой JSON будет декодирован и возвращен. Для того, чтобы проверить успешен ли запрос, используйте r.raise_for_status() или проверьте какой r.status_code.
Необработанное содержимое ответа
В тех редких случаях, когда вы хотите получить доступ к “сырому” ответу сервера на уровне сокета, обратитесь к r.raw. Если вы хотите сделать это, убедитесь, что вы указали stream=True в вашем первом запросе. После этого вы уже можете проделать следующее:
>>> r = requests.get('https://api.github.com/events', stream=True)
>>> r.raw
<urllib3.response.HTTPResponse object at 0x101194810>
>>> r.raw.read(10)
'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03'
Однако, можно использовать подобный код как шаблон, чтобы сохранить результат в файл:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
Использование r.iter_content обработает многое из того, с чем бы вам пришлось иметь дело при использовании r.raw напрямую. Для извлечения содержимого при потоковой загрузке, используйте способ, описанный выше. Обратите внимание, что chunk_size можно свободно скорректировать до числа, которое лучше подходит в вашем случае.
Важное замечание об использовании
Response.iter_contentиResponse.raw.Response.iter_contentбудет автоматически декодироватьgzipиdeflate.Response.raw— необработанный поток байтов, он не меняет содержимое ответа. Если вам действительно нужен доступ к байтам по мере их возврата, используйтеResponse.raw.
Пользовательские заголовки
Если вы хотите добавить HTTP заголовки в запрос, просто передайте соответствующий dict в параметре headers.
Например, мы не указали наш user-agent в предыдущем примере:
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
Заголовкам дается меньший приоритет, чем более конкретным источникам информации. Например:
- Заголовки авторизации, установленные с помощью
headers=будут переопределены, если учетные данные указаны.netrc, которые, в свою очередь переопределены параметромauth=. - Они же будут удалены при редиректе.
- Заголовки авторизации с прокси будут переопределены учетными данными прокси-сервера, которые указаны в вашем URL.
- Content-Length будут переопределены, когда вы определите длину содержимого.
Кроме того, запросы не меняют свое поведение вообще, основываясь на указанных пользовательских заголовках.
Значения заголовка должны быть
string, bytestring или unicode. Хотя это разрешено, рекомендуется избегать передачи значений заголовковunicode.
Более сложные POST запросы
Часто вы хотите послать некоторые form-encoded данные таким же образом, как это делается в HTML форме. Для этого просто передайте соответствующий словарь в аргументе data. Ваш словарь данных в таком случае будет автоматически закодирован как HTML форма, когда будет сделан запрос:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
Аргумент data также может иметь несколько значений для каждого ключа. Это можно сделать, указав data в формате tuple, либо в виде словаря со списками в качестве значений. Особенно полезно, когда форма имеет несколько элементов, которые используют один и тот же ключ:
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
Бывают случаи, когда нужно отправить данные не закодированные методом form-encoded. Если вы передадите в запрос строку вместо словаря, эти данные отправятся в не измененном виде.
К примеру, GitHub API v3 принимает закодированные JSON POST/PATCH данные:
import json
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
r = requests.post(url, data=json.dumps(payload))
Вместо того, чтобы кодировать dict, вы можете передать его напрямую, используя параметр json (добавленный в версии 2.4.2), и он будет автоматически закодирован:
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
r = requests.post(url, json=payload)
Обратите внимание, параметр json игнорируется, если передаются data или files.
Использование параметра json в запросе изменит заголовок Content-Type на application/json.
POST отправка Multipart-Encoded файла
Запросы упрощают загрузку файлов с многостраничным кодированием (Multipart-Encoded) :
>>> url = 'https://httpbin.org/post'
>>> files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": "<censored...binary...data>"
},
...
}
Вы можете установить имя файла, content_type и заголовки в явном виде:
>>> url = 'https://httpbin.org/post'
>>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": "<censored...binary...data>"
},
...
}
Можете отправить строки, которые будут приняты в виде файлов:
>>> url = 'https://httpbin.org/post'
>>> files = {'file': ('report.csv', 'some,data,to,send\nanother,row,to,send\n')}
>>> r = requests.post(url, files=files)
>>> r.text
{
...
"files": {
"file": "some,data,to,send\\nanother,row,to,send\\n"
},
...
}
В случае, если вы отправляете очень большой файл как запрос multipart/form-data, возможно понадобиться отправить запрос потоком. По умолчанию, requests не поддерживает этого, но есть отдельный пакет, который это делает — requests-toolbelt. Ознакомьтесь с документацией toolbelt для получения более детальной информации о том, как им пользоваться.
Для отправки нескольких файлов в одном запросе, обратитесь к расширенной документации.
Предупреждение!
Настоятельно рекомендуется открывать файлы в бинарном режиме. Это связано с тем, что запросы могут пытаться предоставить для вас заголовок Content-Length, и если это значение будет установлено на количество байтов в файле будут возникать ошибки, при открытии файла в текстовом режиме.
Коды состояния ответа
Мы можем проверить код состояния ответа:
>>> r = requests.get('https://httpbin.org/get')
>>> r.status_code
200
У requests есть встроенный объект вывода кодов состояния:
>>> r.status_code == requests.codes.ok
True
Если мы сделали неудачный запрос (ошибка 4XX или 5XX), то можем вызвать исключение с помощью r.raise_for_status():
>>> bad_r = requests.get('https://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
Но если status_code для r оказался 200, то когда мы вызываем raise_for_status() мы получаем:
>>> r.raise_for_status()
None
Заголовки ответов
Мы можем просматривать заголовки ответа сервера, используя словарь Python:
>>> r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}
Это словарь особого рода, он создан специально для HTTP заголовков. Согласно с RFC 7230, имена заголовков HTTP нечувствительны к регистру.
Теперь мы можем получить доступ к заголовкам с большим буквами или без, если захотим:
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
Cookies
Если в запросе есть cookies, вы сможете быстро получить к ним доступ:
>>> url = 'https://example.com/some/cookie/setting/url'
>>> r = requests.get(url)
>>> r.cookies['example_cookie_name']
'example_cookie_value'
Чтобы отправить собственные cookies на сервер, используйте параметр cookies:
>>> url = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'
Cookies возвращаются в RequestsCookieJar, который работает как dict, но также предлагает более полный интерфейс, подходящий для использования в нескольких доменах или путях. Словарь с cookie может также передаваться в запросы:
>>> jar = requests.cookies.RequestsCookieJar()
>>> jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
>>> jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
>>> url = 'https://httpbin.org/cookies'
>>> r = requests.get(url, cookies=jar)
>>> r.text
'{"cookies": {"tasty_cookie": "yum"}}'
Редиректы и история
По умолчанию Requests будет выполнять редиректы для всех HTTP глаголов, кроме HEAD.
Мы можем использовать свойство history объекта Response, чтобы отслеживать редиректы .
Список Response.history содержит объекты Response, которые были созданы для того, чтобы выполнить запрос. Список сортируется от более ранних, до более поздних ответов.
Например, GitHub перенаправляет все запросы HTTP на HTTPS:
>>> r = requests.get('https://github.com/')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[<Response [301]>]
Если вы используете запросы GET, OPTIONS, POST, PUT, PATCH или DELETE, вы можете отключить обработку редиректа с помощью параметра allow_redirects:
>>> r = requests.get('https://github.com/', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
Если вы используете HEAD, вы также можете включить редирект:
>>> r = requests.head('https://github.com/', allow_redirects=True)
>>> r.url
'https://github.com/'
>>> r.history
[<Response [301]>]
Тайм-ауты
Вы можете сделать так, чтобы Requests прекратил ожидание ответа после определенного количества секунд с помощью параметра timeout.
Почти весь код должен использовать этот параметр в запросах. Несоблюдение этого требования может привести к зависанию вашей программы:
>>> requests.get('https://github.com/', timeout=0.001)
Traceback (most recent call last):
File "", line 1, in
requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001)
Timeout это не ограничение по времени полной загрузки ответа. Исключение возникает, если сервер не дал ответ за timeout секунд (точнее, если ни одного байта не было получено от основного сокета за timeout секунд).
Ошибки и исключения
В случае неполадок в сети (например, отказа DNS, отказа соединения и т.д.), Requests вызовет исключение ConnectionError.
Response.raise_for_status() вызовет HTTPError если в запросе HTTP возникнет статус код ошибки.
Если выйдет время запроса, вызывается исключение Timeout. Если запрос превышает заданное значение максимального количества редиректов, то вызывают исключение TooManyRedirects.
Все исключения, которые вызывает непосредственно Requests унаследованы от requests.exceptions.RequestException.
Тест на знание основ Requests
PIL, известная как библиотека Python Imaging Library, может быть использована для работы с изображениями достаточно легким способом. У PIL не было никаких изменений и развития с 2009. Поэтому, добрые пользователи этого сайта предложили взглянуть на Pillow еще раз. Эта статья поможет вам узнать как пользоваться Pillow.
Что такое Pillow?
Pillow это форк PIL (Python Image Library), которая появилась благодаря поддержке Алекса Кларка и других участников. Основана на коде PIL, а затем преобразилась в улучшенную, современную версию. Предоставляет поддержку при открытии, управлении и сохранении многих форматов изображения. Многое работает так же, как и в оригинальной PIL.
Загрузка и установка Pillow
Перед началом использования Pillow, нужно загрузить и установить ее. Pillow доступна для Windows, Mac OS X и Linux. Самая “свежая” версия — это версия “8.1.0”, она поддерживается на python 3.6 и выше. Для установки Pillow на компьютеры Windows используйте conda или pip:
conda install -c anaconda pillow
pip install PillowДля установки Pillow на компьютерах Linux просто используйте:
$ sudo pip install PillowА установки Pillow на MacOS X нужно для начала установить XCode, а затем Homebrew. После того как Homebrew установлен, используйте:
$ brew install libtiff libjpeg webp littlecms
$ sudo pip install PillowУбедитесь, что Pillow установлена
Убедитесь, что Pillow установлена, откройте терминал и наберите следующее в текущей строке:
$ python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:06:47) [MSC v.1914 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from PIL import ImageЕсли система показывает снова >>>, значит модули Pillow правильно установлены.
Форматы файлов
Перед началом использования модуля Pillow, давайте укажем некоторые поддерживаемые типы файлов: BMP, EPS, GIF, IM, JPEG, MSP, PCX PNG, PPM, TIFF, WebP, ICO, PSD, PDF. Некоторые типы файлов возможны только для чтения, в то время как другие доступны только для написания. Чтобы увидеть полный список поддерживаемых типов файла и больше информации о них, ознакомьтесь с руководством к Pillow.
Как использовать Pillow для работы с изображениями
Поскольку мы собираемся работать с изображениями, для начала, скачаем одно. Если у вас уже есть изображение, которое хотите использовать, пропустите этот шаг, описанный ниже.
В нашем примере будем использовать стандартное тестовое изображение под названием «Lenna» или «Lena». Это изображение используется во многих экспериментах по обработке изображений. Просто зайдите сюда и загрузите изображение. Если вы нажмете на изображение, оно сохранится как изображение с количеством пикселей 512×512.
Использование Pillow
Давайте посмотрим на возможные варианты использования этой библиотеки. Основные функции находятся в модуле Image. Вы можете создавать экземпляры этого класса несколькими способами. Путем загрузки изображений из файлов, обработки других изображений, либо создания изображений с нуля. Импортируйте модули Pillow, которые вы хотите использовать.
from PIL import Image
Затем вы получите доступ к функциям.
myimage = Image.open(filename)
myimage.load()
Загрузка изображения
Используйте метод open идентификации файла на компьютере, а затем загрузить идентифицированный файл с помощью myfile.load(). Как только изображение будет загружено, с ним можно работать. Часто используется блок try except при работе с файлами. Чтобы загрузить изображение с помощью try except используйте:
from PIL import Image, ImageFilter
try:
original = Image.open("Lenna.png")
except FileNotFoundError:
print("Файл не найден")
Когда мы считываем файлы с диска с помощью функции open(), нам не нужно знать формат файла. Библиотека автоматически определяет формат, основанный на содержании файла.
Теперь, когда у вас есть объект Image, вы можете использовать доступные атрибуты для проверки файла. Например, если вы хотите увидеть размер изображения, вы можете использовать атрибут format.
print("Размер изображения:")
print(original.format, original.size, original.mode)
Атрибут size — это tuple(кортеж), содержащий ширину и высоту (в пикселях). Обычные mode: L для изображений с оттенками серого, RGB для изображений с истинным цветным изображением и CMYK для печати изображений. В результате кода выше, вы должны получить следующее (если используете «Lenna.png»):
Размер изображения:
PNG, (512, 512), RGB
Размытие изображения
Этот пример загрузит и размоет изображение с жесткого диска.
# импортируем необходимые модули
from PIL import Image, ImageFilter
try:
# загружаем изображение с жесткого диска
original = Image.open("Lenna.png")
except FileNotFoundError:
print("Файл не найден")
# размываем изображение
blurred = original.filter(ImageFilter.BLUR)
# открываем оригинал и размытое изображение
original.show()
blurred.show()
# сохраняем изображение
blurred.save("blurred.png")
Размытое изображение должно выглядеть следующим образом:

Чтобы открыть изображение, мы использовали методы show(). Если вы ничего не видите, можете сначала установить ImageMagick и попробовать снова.
Создание миниатюр
Есть необходимость создавать миниатюры для изображений. Миниатюры представляют собой уменьшенные версии изображений, но все же содержат все наиболее важные аспекты изображения.
from PIL import Image
size = (128, 128)
saved = "lenna.jpeg"
img = Image.open("Lenna.png")
img.thumbnail(size)
img.save(saved)
img.show()
Результат выполнения скрипта, можно увидеть в миниатюре:

Фильтры в Pillow
В модуле Pillow предоставляет следующий набор предопределенных фильтров для улучшения изображения:
- BLUR
- CONTOUR
- DETAIL
- EDGE_ENHANCE
- EDGE_ENHANCE_MORE
- EMBOSS
- FIND_EDGES
- SMOOTH
- SMOOTH_MORE
- SHARPEN
В нашем последнем примере мы покажем, как вы можете применить фильтр CONTOUR к вашему изображению. Приведенный ниже код примет наше изображение и применит к нему фильтр.
from PIL import Image, ImageFilter
img = Image.open("Lenna.png")
img = img.filter(ImageFilter.CONTOUR)
img.save("LennaC" + ".jpg")
img.show()
Ниже вы можете увидеть изображение с примененным фильтром CONTOUR:
