Синтаксис:
lambda [аргументы] : выражение
Лямбда-функция может иметь ноль или более аргументов перед символом ‘:’. При вызове такой функции выполняется выражение, указанное после ‘:’.
Пример определения лямбда-функции:
get_cube = lambda x : x ** 3
Приведенная выше лямбда-функция начинается с ключевого слова lambda, за которым следует параметр x. Выражение x ** 3 после ‘:’ возвращает вызывающему коду значение куба переданного числа. Сама лямбда-функция lambda x : x ** 3 присваивается переменной get_cube для ее последующего вызова как именованной функции. Имя переменной становится именем функции, чтобы мы могли работать с ней как с обычной функцией.
Пример вызова лямбда-функции:
>>> get_cube(4)
64
Приведенное выше определение лямбда-функции аналогично следующей стандартной функции:
def get_cube(x):
return x ** 3
Выражение не обязательно должно всегда возвращать значение. Следующая лямбда-функция не возвращает ничего.
Пример лямбда-функции, не возвращающей значение:
>>> welcome = lambda user: print('Welcome, ' + name + '!')
>>> welcome('Anon')
Welcome, Anon!
Примечание:
Лямбда-функция может иметь только одно выражение. Очевидно, что она не может заменить функцию, тело которой содержит условия, циклы и т.д.
Следующая лямбда-функция содержит несколько параметров.
Пример лямбда-функции с тремя параметрами:
>>> get_prod = lambda a, b, c : a * b * c
>>> get_prod(3, 5, 7)
105
Также лямбда-функция может принимать любое количество параметров.
Пример лямбда-функции с неопределенным числом аргументов (используются только первые 3):
Лямбда-функция без параметров
Ниже приведен пример лямбда-функции без параметров.
>>> welcome = lambda : print('Welcome!')
>>> welcome()
Welcome!
Анонимная функция
Мы можем объявить лямбда-функцию и вызвать ее как анонимную функцию, не присваивая ее переменной.
Пример анонимной лямбда-функции:
>>> (lambda x: x**3)(10)
1000
Здесь lambda x: x3 определяет анонимную функцию и вызывает ее один раз, передавая аргументы в скобках (lambda x: x3)(10).
В Python функции, как и литералы, можно передавать в качестве аргументов.
Лямбда-функции особенно полезны, когда мы хотим отправить функцию на вход другой функции. Мы можем передать анонимную лямбда-функцию, не присваивая ее переменной, в качестве аргумента другой функции.
Пример передачи лямбда-функции в качестве параметра:
def run_task(task):
print('Before running the task')
task()
print('After running the task')
run_task(lambda : print('Task is complete!')) # передача анонимной функции
important_task = lambda : print('Important task is complete!')
run_task(important_task) # передача лямбда-функции
Вывод:
Before running the task
Task is complete!
After running the task
Before running the task
Important task is complete!
After running the task
Представленная выше функция run_task() определена с параметром task, который вызывается как функция внутри run_task(). run_task(lambda : print(‘Task is complete!’)) вызывает функцию run_task() с анонимной лямбда-функцией в качестве аргумента.
В Python есть встроенные функции, которые принимают в качестве аргументов другие функции. Функции map(), filter() и reduce() являются важными инструментами функционального программирования. Все они принимают на вход функцию. Такая функция-аргумент может быть обычной функцией или лямбда-функцией.
Пример передачи лямбда-функции в map():
>>> prime_cube_list = map(lambda x: x**3, [2, 3, 5, 7, 11]) # передача анонимной функции
>>> next(prime_cube_list)
8
>>> next(prime_cube_list)
27
>>> next(prime_cube_list)
125
>>> next(prime_cube_list)
343
>>> next(prime_cube_list)
1331
Давайте посмотрим на следующий фрагмент:
# Простая программа на Python для демонстрации
# работы yield
# Функция-генератор, которая выдает 2 при
# первом обращении, 4 — при втором и
# 8 — при третьем
def simple_generator():
yield 2
yield 4
yield 8
# Код для проверки simple_generator()
for value in simple_generator():
print(value)
Вывод:
2
4
8
Функция с return отправляет указанное значение обратно вызвавшему его коду, в то время как yield может создавать последовательность возвращаемых значений. Мы должны использовать yield, когда хотим обработать множество объектов, но не хотим хранить их все в памяти.
Yield применяется в генераторах Python. Такой генератор определяется как обычная функция, но всякий раз, когда ей нужно выдать значение, она делает это с помощью ключевого слова yield, а не return. Если тело def содержит yield, то функция автоматически становится генератором.
# Программа на Python для генерации степеней 2
# от 2 до 256
def get_next_num():
n = 2
# Бесконечный цикл для генерации степеней 2
while True:
yield n
n *= 2 # При последующем обращении к
# get_next_num() выполнение
# продолжится отсюда
# Код для проверки get_next_num()
for num in get_next_num():
if num > 256:
break
print(num)
Вывод:
2
4
8
16
32
64
128
256
Кубический корень обозначается символом «3√». В случае с квадратным корнем мы использовали только символ ‘√’ без указания степени, который также называется радикалом.
Например, кубический корень из 125, обозначаемый как 3√125, равен 5, так как при умножении 5 на само себя три раза получается 5 x 5 x 5 = 125 = 5^3.
Кубический корень в Python
Чтобы вычислить кубический корень в Python, используйте простое математическое выражение x ** (1. / 3.), результатом которого является кубический корень из x в виде значения с плавающей точкой. Для проверки, корректно ли произведена операция извлечения корня, округлите полученный результат до ближайшего целого числа и возведите его в третью степень, после сравните, равен ли результат x.
x = 8
cube_root = x ** (1./3.)
print(cube_root)
Вывод
2.0
В Python для того, чтобы возвести число в степень, мы используем оператор **. Указание степени, равной 1/3, в выражении с ** позволяет получить кубический корень данного числа.
Извлечение кубического корня из отрицательного числа в Python
Мы не можем найти кубический корень из отрицательных чисел указанным выше способом. Например, кубический корень из целого числа -64 должен быть равен -4, но Python возвращает 2+3.464101615137754j.
Чтобы найти кубический корень из отрицательного числа в Python, сначала нужно применить функцию abs(), а затем можно воспользоваться представленным ранее простым выражением с ** для его вычисления.
Давайте напишем полноценную функцию, которая будет проверять, является ли входное число отрицательным, а затем вычислять его кубический корень соответствующим образом.
def get_cube_root(x):
if x < 0:
x = abs(x)
cube_root = x**(1/3)*(-1)
else:
cube_root = x**(1/3)
return cube_root
print(round(get_cube_root(64)))
print(get_cube_root(-64))
Вывод
4
-3.9999999999999996
Как видите, нам нужно округлить результат, чтобы получить целочисленное значение кубического корня.
Использование функции Numpy cbrt()
Библиотека numpy предлагает еще один вариант нахождения кубического корня в Python, который заключается в использовании метода cbrt(). Функция np.cbrt() вычисляет кубический корень для каждого элемента переданного ей массива.
import numpy as np
cubes = [125, -64, 27, -8, 1]
cube_roots = np.cbrt(cubes)
print(cube_roots)
Вывод
[ 5. -4. 3. -2. 1.]
Функция np.cbrt() — самый простой способ получения кубического корня числа. Она не испытывает проблем с отрицательными входными данными и возвращает целочисленное число, например, -4 для переданного в качестве аргумента числа -64, в отличие от вышеописанных подходов.
]]>В этой статье мы рассмотрим несколько примеров использования циклов for с функцией range() в Python.
Циклы for в Python
Циклы for повторяют определённый код для некоторого набора значений.
Из документации Python можно узнать, что в нем циклы for работают несколько иначе, чем в таких языках, как JavaScript или C.
Цикл for присваивает итерируемой переменной каждое значение из предоставленного списка, массива или строки и повторяет код в теле цикла for для каждого установленного таким образом значения переменной-итератора.
В приведенном ниже примере мы используем цикл for для вывода каждого числа в нашем массиве.
# Простой пример цикла for
for i in [0, 1, 2, 3, 4, 5]:
print(i, end="; ") # выведет: 0; 1; 2; 3; 4; 5;
В тело цикла for можно включить и более сложную логику. В следующем примере мы выводим результат небольшого вычисления, основанного на значении переменной i.
# Пример посложнее
for i in [0, 1, 2, 3, 4, 5]:
x = (i-2)*(i+2) - i**2 + 4
print(x, end="; ") # выведет: 0; 0; 0; 0; 0; 0;
Когда значения в массиве для нашего цикла for представляют собой некоторую закономерную последовательность, мы можем использовать функцию Python range() вместо того, чтобы вписывать содержимое нашего массива вручную.
Функция Range в Python
Функция range() возвращает последовательность целых чисел на основе переданных ей аргументов. Дополнительную информацию можно найти в документации Python по функции range().
range(stop)
range(start, stop[, step])
Аргумент start — это первое значение в диапазоне. Если функция range() вызывается только с одним аргументом, то Python считает, что start = 0.
Аргумент stop — это верхняя граница диапазона. Важно понимать, что само граничное значение не включается в последовательность.
В примере ниже у нас есть диапазон, начинающийся со значения по умолчанию, равному 0, и включающий целые числа меньше 6.
# Использование range() с единственным аргументом
for i in range(6):
print(i, end="; ") # выведет: 0; 1; 2; 3; 4; 5;
В следующем примере мы задаем start = -2 и включаем целые числа меньше 4.
# В этот раз передаются два аргумента
for i in range(-2, 4):
print(i, end="; ") # выведет: -2; -1; 0; 1; 2; 3;
Необязательное значение step (шаг) управляет приращением между значениями последовательности. По умолчанию step = 1.
В нашем последнем примере мы используем диапазон целых чисел от -2 до 6 и задаем step = 2.
# Здесь используются все аргументы range()
for i in range(-2, 6, 2):
print(i, end="; ") # выведет: -2; 0; 2; 4;
Заключение
В этой статье мы рассмотрели циклы for в Python и функцию range().
Циклы for обеспечивают повторное выполнение блока кода для всех значений в указанном списке, массиве, строке или последовательности, определенной с помощью функции range().
Как было показано, мы можем использовать range(), чтобы упростить написание цикла for. При вызове данной функции вы обязаны указать stop значение, также вами могут быть определены начальное значение и шаг между целыми числами в возвращаемом диапазоне.
]]>В повседневной практике необходимость изменить одно или несколько значений в списке возникает довольно часто. Предположим, вы создаете меню для ресторана и замечаете, что неправильно определили один из пунктов. Чтобы исправить подобную ошибку, вам нужно просто заменить существующий элемент в списке.
Замена элемента в списке на Python
Вы можете заменить элемент в списке на Python, используя цикл for, обращение по индексу или list comprehension. Первые два метода изменяют существующий список, а последний создает новый с заданными изменениями.
Давайте кратко опишем каждый метод:
- Обращение по индексу: мы используем порядковый номер элемента списка для изменения его значения. Знак равенства используется для присвоения нового значения выбранному элементу.
- List comprehension или генератор списка создает новый список из существующего. Синтаксис list comprehension позволяет добавлять различные условия для определения значений в новом списке.
- Цикл For выполняет итерацию по элементам списка. Для внесения изменений в данном случае используется обращение по индексу. Мы применяем метод enumerate() для создания двух списков: с индексами и с соответствующими значениями элементов — и итерируем по ним.
В этом руководстве мы рассмотрим каждый из этих методов. Для более полного понимания приведенных подходов мы также подготовили примеры использования каждого из них.
Замена элемента в списке на Python: обращение по индексу
Самый простой способ заменить элемент в списке — это использовать синтаксис обращения к элементам по индексу. Такой способ позволяет выбрать один элемент или диапазон последовательных элементов, а с помощью оператора присваивания вы можете изменить значение в заданной позиции списка.
Представим, что мы создаем программу, которая хранит информацию о ценах в магазине одежды. Цена первого товара в нашем списке должна быть увеличена на $2.
Начнем с создания списка, который содержит цены на наши товары:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Мы используем обращение по индексу для выбора и изменения первого элемента в нашем списке 29.30. Данное значение имеет нулевой индекс. Это связано с тем, что списки индексируются, начиная с нуля.
prices[0] = 31.30
print(prices)
Наш код выбирает элемент в нулевой позиции и устанавливает его значение равным 31.30, что на $2 больше прежней цены. Далее мы возвращаем список со скорректированной ценой первого товара:
[31.30, 10.20, 44.00, 5.99, 81.90]
Мы также можем изменить наш список, добавив два к текущему значению prices[0]:
prices[0] = prices[0] + 2
print(prices)
prices[0] соответствует первому элементу в нашем списке (тот, который находится в позиции с нулевым индексом).
Этот код выводит список с теми же значениями, что и в первом случае:
[31.30, 10.20, 44.00, 5.99, 81.90]
Замена элемента в списке на Python: list comprehension
Применение генератора списка в Python может быть наиболее изящным способом поиска и замены элемента в списке. Этот метод особенно полезен, если вы хотите создать новый список на основе значений существующего.
Использование list comprehension позволяет перебирать элементы существующего списка и образовывать из них новый список на основе определенного критерия. Например, из последовательности слов можно скомпоновать новую, выбрав только те, которые начинаются на «C».
Здесь мы написали программу, которая рассчитывает 30% скидку на все товары в магазине одежды, стоимость которых превышает $40. Мы используем представленный ранее список цен на товары:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Далее мы применяем list comprehension для замены элементов в нашем списке:
sale_prices = [round(price - (price * 30 / 100), 2) if price > 40 else price for price in prices]
print(sale_prices)
Таким образом, наш генератор проходит по списку «prices» и ищет значения стоимостью более 40 долларов. К найденным товарам применяется скидка в 30%. Мы округляем полученные значения цен со скидкой до двух десятичных знаков после точки с помощью метода round().
Наш код выводит следующий список с новыми ценами:
[29.3, 10.2, 30.8, 5.99, 57.33]
Замена элемента в списке на Python: цикл for
Вы можете изменить элементы списка с помощью цикла for. Для этого нам понадобится функция Python enumerate(). Эта функция возвращает два списка: список с номерами индексов и список со значениями соответствующих элементов. Мы можем выполнить необходимые итерации по этим двум последовательностям с помощью единственного цикла for.
В этом примере мы будем использовать тот же список цен:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Затем мы определим цикл for, который проходит по данному списку с помощью функции enumerate():
for index, item in enumerate(prices):
if item > 40:
prices[index] = round(prices[index] - (prices[index] * 30 / 100), 2)
print(prices)
В коде выше переменная «index» содержит позиционный номер элемента. В свою очередь «item» — это значение, хранящееся в элементе списка на данной позиции. Индекс и соответствующее значение, возвращаемые методом enumerate(), разделяются запятой.
Подобное получение двух или более значений из возвращаемого функцией кортежа называется распаковкой. Мы «распаковали» элементы двух списков из метода enumerate().
Здесь мы используем ту же формулу, что и ранее, для расчета 30% скидки на товары стоимостью более 40 долларов. Давайте запустим наш код и посмотрим, что получится:
[29.3, 10.2, 30.8, 5.99, 57.33]
Наш код успешно изменяет товары в списке «prices» в соответствии с нашей скидкой.
Заключение
Вы можете заменить элементы в списке на Python с помощью обращения по индексу, list comprehension или цикла for.
Если вы хотите изменить одно значение в списке, то наиболее подходящим будет обращение по индексу. Для замены нескольких элементов в списке, удовлетворяющих определенному условию, хорошим решением будет использование list comprehension. Хотя циклы for более функциональны, они менее элегантны, чем генераторы списков.
]]>Определение функции
Функция — это многократно используемый блок программных инструкции, предназначенный для выполнения определенной задачи. Для определения функции в Python используется ключевое слово def. Ниже приведен синтаксис определения функции.
Синтаксис:
def имя_функции(параметры):
"""docstring"""
инструкция1
инструкция2
...
...
return [выражение]
За ключевым словом def следует подходящий идентификатор (имя функции) и круглые скобки. В круглых скобках может быть дополнительно указан один или несколько параметров. Символ ‘:’ после круглых скобок начинает блок с отступом (тело функции).
Первой инструкцией в теле функции может быть строка, которая называется docstring. Она описывает функциональность функции/класса. Строка docstring не является обязательной.
В общем случае тело функции содержит одну или несколько инструкций, которые выполняют некоторые действия. В нем также может использоваться ключевое слово pass.
Последней командой в блоке функции зачастую является инструкция return. Она возвращает управление обратно вызвавшему функцию окружению. Если после оператора return стоит выражение, то его значение также передается в вызывающий код.
В следующем примере определена функция welcome().
Пример созданной пользователем функции:
def welcome():
"""This function prints 'Welcome!'"""
print('Welcome!')
Выше мы определили функцию welcome(). Первая инструкция — это docstring, в котором сообщается о том, что делает эта функция. Вторая — это метод print, который выводит указанную строку на консоль. Обратите внимание, что welcome() не содержит оператор return.
Чтобы вызвать определенную ранее функцию, просто используйте выражение, состоящее из ее имени и двух круглых скобок ‘()’, в любом месте кода. Например, приведенная выше функция может быть вызвана так: welcome().
Пример вызова определенной пользователем функции:
welcome()
Вывод:
Welcome!
По умолчанию все функции возвращают None, если отсутствует оператор return.
returned_value = welcome()
print(returned_value)
Вывод:
Welcome!
None
Функция help() выводит docstring, как показано ниже.
>>> help(welcome)
Help on function welcome in module __main__:
welcome()
This function prints 'Welcome!'
Параметры функции
Функции также могут принимать на вход один или несколько параметров (они же аргументы) и использовать их для вычислений, определенных внутри функционального блока. В таком случае параметрам/аргументам даются подходящие формальные имена. Для примера изменим функцию welcome(): теперь она принимает в качестве параметра строку user_name; также изменена инструкция с функцией print() для отображения более персонализированного приветствия.
Пример функции с аргументами:
def welcome(user_name):
print('Welcome, ' + user_name + '!')
welcome('Anon') # вызов функции с параметром
Вывод:
Welcome, Anon!
Именованные аргументы, используемые в определении функции, называются формальными параметрами. В свою очередь, объекты, передаваемые в функцию при ее вызове, называются фактическими аргументами/параметрами.
Параметры функции могут иметь аннотацию для указания типа аргумента с использованием синтаксиса parameter:type. Например, следующая аннотация указывает тип параметра string.
Пример использования аннотации типов:
def welcome(user_name:str):
print('Welcome, ' + user_name + '!')
welcome('Anon') # передача строки в функцию
# пройдет нормально
welcome(42) # а передача числа в функцию
# вызовет ошибку
Передача нескольких параметров
Функция может иметь множество параметров. Представленная ниже вариация welcome() принимает три аргумента.
Пример определения функции с несколькими параметрами:
def welcome(first_name:str, last_name:str):
print('Welcome, ' + first_name + ' ' + last_name + '!')
welcome('Anton', 'Chekhov') # передача аргументов в функцию
Вывод:
Welcome, Anton Chekhov!
Неизвестное количество аргументов
Функция в Python может иметь неизвестное заранее число параметров. Укажите * перед аргументом, если вы не знаете, какое количество параметров передаст пользователь.
Пример функции с неизвестным числом параметров (используются только первые 3):
def welcome(*name_parts):
message = 'Welcome, ' + name_parts[0] + " "
message += name_parts[1] + " " + name_parts[2]
print(message + "!")
welcome('Anton', 'Pavlovich', 'Chekhov')
Вывод:
Welcome, Anton Pavlovich Chekhov!
Следующая функция работает с любым количеством аргументов.
Пример функции, использующей все переданные ей параметры:
def welcome(*name_parts):
message = 'Welcome,'
for part in name_parts:
message += " " + part
print(message + "!")
welcome('Anton', 'Pavlovich', 'Chekhov',
'and', 'Fyodor', 'Mikhailovich', 'Dostoevsky')
Вывод:
Welcome, Anton Pavlovich Chekhov and Fyodor Mikhailovich Dostoevsky!
Аргументы-ключевые слова
Чтобы использовать функцию с параметрами, необходимо предоставить ей фактические аргументы в количестве, соответствующем числу формальных. С другой стороны, при вызове функции мы не обязаны соблюдать указанный в определении порядок параметров. Но в таком случае при передаче значений аргументов мы должны явно указать имена соответствующих формальных параметров. В следующем примере фактические значения передаются с использованием имен параметров.
def welcome(first_name:str, last_name:str):
print('Welcome, ' + first_name + ' ' + last_name + '!')
welcome(last_name='Chekhov', first_name='Anton') # передача
# аргументов в функцию в произвольном порядке
Вывод:
Welcome, Anton Chekhov!
Аргументы-ключевые слова **kwarg
Функция может иметь только один параметр с префиксом **. Он инициализирует новое упорядоченное отображение (словарь), содержащее все оставшееся без соответствующего формального параметра аргументы-ключевые слова.
Пример использования **kwarg:
def welcome(**name_parts):
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
welcome(last_name='Chekhov', first_name='Anton')
welcome(last_name='Chekhov', first_name='Anton', age='28')
welcome(last_name='Chekhov') # вызовет KeyError
Вывод:
Welcome, Anton Chekhov!
Welcome, Anton Chekhov!
При использовании параметра ** порядок аргументов не имеет значения. Однако их имена должны быть идентичными. Доступ к аргументам-ключевым словам для получения переданных значений осуществляется с помощью такого выражения: имя_параметра_kwarg[‘имя_переданного_аргумента’].
Если функция обращается к аргументу-ключевому слову, но вызывающий код не передает этот параметр, то она вызовет исключение KeyError, как показано ниже.
Пример функции, вызывающей KeyError:
def welcome(**name_parts):
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
welcome(last_name='Chekhov') # вызывет KeyError: необходимо предоставить аргумент 'first_name'
Вывод:
Traceback (most recent call last):
...
line 2, in welcome
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
KeyError: 'first_name'
Параметры со значением по умолчанию
При определении функции ее параметрам могут быть присвоены значения по умолчанию. Такое значение заменяется на соответствующий фактический аргумент, если он был передан при вызове функции. Однако если фактический параметр не был предоставлен, то внутри функции будет использоваться значение по умолчанию.
Представленная ниже функция welcome() определена с параметром name, имеющим значение по умолчанию ‘Anon’. Оно будет заменено только в том случае, если вызывающей стороной будет передан какой-либо фактический аргумент.
Пример функции со значением по умолчанию:
def welcome(user:str = 'Anon'):
print('Welcome, ' + user + '!')
welcome()
welcome('Chekhov')
Вывод:
Welcome, Anon!
Welcome, Chekhov!
Функция с возвращаемым значением
Чаще всего нам нужен результат работы функции для использования в дальнейших вычислениях. Следовательно, когда функция завершает выполнение, она также должна возвращать какое-то результирующее значение.
Для того, чтобы передать подобное значение внешнему коду, функция должна содержать инструкцию с оператором return. В этом случае возвращаемое значение должно быть указано после return.
Пример функции с возвращаемым значением:
def get_product(a, b):
return a * b
Ниже показано, как при вызове функции get_product() получить результат ее работы.
Пример использования функции с возвращаемым значением:
result = get_product(6, 7)
print(result)
result = get_product(3, get_product(4, 5))
print(result)
Вывод:
42
60
Enum в Python
Перечисления — это наборы символических имен, связанных с уникальными константными значениями. Они используются для создания простых пользовательских типов данных, таких как времена года, недели, виды оружия в игре, планеты, оценки или дни. По соглашению имена перечислений начинаются с заглавной буквы и употребляются в единственном числе.
Модуль enum используется для создания перечислений в Python. Вы можете определить их с помощью ключевого слова class или с помощью функционального API.
Существуют специальные производные перечисления enum.IntEnum, enum.IntFlag и enum.Flag.
Простой пример использования enum в Python
Ниже приведен простой пример кода на Python, использующего перечисления.
#!/usr/bin/python3
from enum import Enum
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
ranged_weapon = Weapon.BOW
print(ranged_weapon)
if ranged_weapon == Weapon.BOW:
print("It's a bow")
print(list(Weapon))
В примере у нас есть перечисление Weapon, которое имеет четыре различных значения: SWORD, BOW, DAGGER и CLUB. Чтобы получить доступ к одному из членов enum, мы должны указать название перечисления, за которым следует точка и имя интересующей нас символической константы.
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
Перечисление Weapon создается нами с помощью ключевого слова class, то есть происходит наследование от базового класса enum.Enum. После этого мы явно задаем числа, соответствующие значениям перечисления.
ranged_weapon = Weapon.BOW
print(ranged_weapon)
Здесь символическая константа присваивается переменной и выводится на консоль.
if ranged_weapon == Weapon.BOW:
print("It's a bow")
Данный фрагмент демонстрирует использование Weapon.BOW в выражении if.
print(list(Weapon))
С помощью встроенной функции list мы получаем список всех возможных значений для перечисления Weapon.
Вывод:
Weapon.BOW
It's a bow
[, , , ]
Еще один пример использования enum в Python
В следующем примере представлена другая часть базовой функциональности перечислений в Python.
#!/usr/bin/python3
from enum import Enum
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
weapon = Weapon.SWORD
print(weapon)
print(isinstance(weapon, Weapon))
print(type(weapon))
print(repr(weapon))
print(Weapon['SWORD'])
print(Weapon(1))
И снова мы имеем дело с enum Weapon, созданным с помощью класса.
print(weapon)
Здесь мы выводим человекочитаемое строковое представление одного из членов перечисления.
print(isinstance(weapon, Weapon))
С помощью метода isinstance мы проверяем, имеет ли переменная значение типа Weapon.
print(type(weapon))
Функция type выводит тип переменной.
print(repr(weapon))
Функция repr предоставляет дополнительную информацию о перечислении.
print(Weapon['SWORD'])
print(Weapon(1))
Доступ к символической константе можно получить как по ее имени, так и по значению (индексу).
Вывод:
Weapon.SWORD
True
Weapon.SWORD
Weapon.SWORD
Функциональное создание enum в Python
Перечисления Python также могут быть созданы с помощью функционального API.
from enum import Enum
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=1)
weapon = Weapon.DAGGER
print(weapon)
if weapon == Weapon.DAGGER:
print("Dagger")
Есть несколько способов, как мы можем указать значения, используя функциональный API. В последующих примерах мы будем применять различные варианты их задания.
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=1)
Здесь наименования символических констант задаются в строке, разделенные пробелами. Число, переданное в start, определяет начало нумерации значений для членов перечисления.
Вывод:
Weapon.DAGGER
Dagger
Итерирование enum в Python
Мы можем выполнять итерацию по перечислениям Python.
from enum import Enum
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=10)
for weapon in Weapon:
print(weapon)
for weapon in Weapon:
print(weapon.name, weapon.value)
В этом примере мы создаем перечисление Weapon, где символьные константы задаются в виде списка строк.
for weapon in Weapon:
print(weapon)
В коде выше мы выполняем итерации по членам перечисления в цикле for.
for weapon in Weapon:
print(weapon.name, weapon.value)
Здесь мы выводим их имена и значения.
Вывод:
Weapon.SWORD
Weapon.BOW
Weapon.DAGGER
Weapon.CLUB
SWORD 10
BOW 11
DAGGER 12
CLUB 13
Автоматическое назначение имен для enum в Python
Значения символьных констант могут быть автоматически установлены с помощью функции auto().
#!/usr/bin/python3
from enum import Enum, auto
class Weapon(Enum):
SWORD = auto()
BOW = auto()
DAGGER = auto()
CLUB = auto()
for weapon in Weapon:
print(weapon.value)
В этом фрагменте мы создали перечисление Weapon, члены которого получают значения с помощью функции auto.
Вывод:
1
2
3
4
Уникальные значения enum в Python
Значения символьных констант могут быть принудительно уникальными с помощью декоратора @unique.
#!/usr/bin/python3
from enum import Enum, unique
@unique
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 3
# CLUB = 4
for weapon in Weapon:
print(weapon)
Данный пример завершается с ошибкой ValueError: duplicate values found in : CLUB -> DAGGER, потому что члены CLUB и DAGGER имеют одинаковые значения. Если мы закомментируем декоратор @unique, пример выведет три члена; CLUB игнорируется.
Python enum __members__
Специальный атрибут members представляет собой упорядоченное отображение имен на символьные константы enum, доступное только для чтения.
#!/usr/bin/python3
from enum import Enum
Weapon = Enum('Weapon', [('SWORD', 1), ('BOW', 2),
('DAGGER', 3), ('CLUB', 4)])
for name, member in Weapon.__members__.items():
print(name, member)
В этом примере мы используем свойство members. Члены перечисления заданы списком кортежей с помощью функционального API.
Вывод:
SWORD Weapon.SWORD
BOW Weapon.BOW
DAGGER Weapon.DAGGER
CLUB Weapon.CLUB
enum.Flag
Enum.Flag — это базовый класс для создания пронумерованных констант, которые можно объединять с помощью побитовых операций без потери их принадлежности к Flag.
#!/usr/bin/python3
from enum import Flag, auto
class Permission(Flag):
READ = auto()
WRITE = auto()
EXECUTE = auto()
print(list(Permission))
print(Permission.READ | Permission.WRITE)
Пример выше показывает, как флаг может быть использован для проверки или установки разрешений.
Вывод:
[<Permission.READ: 1>, <Permission.WRITE: 2>, <Permission.EXECUTE: 4>]
Permission.WRITE|READКод #1: Демонстрация работы yield
# Код на Python3 для демонстрации
# использования ключевого слова yield
# генерация нового списка, состоящего
# только из четных чисел
def get_even(list_of_nums) :
for i in list_of_nums:
if i % 2 == 0:
yield i
# инициализация списка
list_of_nums = [1, 2, 3, 8, 15, 42]
# вывод начального списка
print ("До фильтрации в генераторе: " + str(list_of_nums))
# вывод только четных значений из списка
print ("Только четные числа: ", end = " ")
for i in get_even(list_of_nums):
print (i, end = " ")
Вывод
До фильтрации в генераторе: [1, 2, 3, 8, 15, 42]
Только четные числа: 2 8 42
Код #2
# Данная Python программа выводит
# числа от 1 до 15, возведенные в куб,
# используя yield и, следовательно, генератор
# Функция ниже будет бесконечно генерировать
# последовательность чисел в третьей степени,
# начиная с 1
def nextCube():
acc = 1
# Бесконечный цикл
while True:
yield acc**3
acc += 1 # После повторного обращения
# исполнение продолжится отсюда
# Ниже мы запрашиваем у генератора
# и выводим ровно 15 чисел
count = 1
for num in nextCube():
if count > 15:
break
print(num)
count += 1
Вывод:
1
8
27
64
125
216
343
512
729
1000
1331
1728
2197
2744
3375
Преимущества yield:
- Поскольку генераторы автоматически сохраняют и управляют состояниями своих локальных переменных, программист не должен заботиться о накладных расходах, связанных с выделением и освобождением памяти.
- Так как при очередном вызове генератор возобновляет свою работу, а не начинает с самого начала, общее время выполнения сокращается.
Недостатки yield:
- Иногда использование yield может вызвать ошибки, особенно если вызов функции не обрабатывается должным образом.
- За оптимизацию времени работы и используемой памяти приходится платить сложностью кода, поэтому иногда трудно сходу понять логику, лежащую в его основе.
Практическое применение
Один из вариантов практического применения генераторов заключается в том, что при обработке большого объема данных и поиске в нем, выгодно использовать yield, так как зачастую нам не нужно повторно осматривать уже проверенные объекты. Такой подход значительно сокращает затраченное программой время. В зависимости от конкретной ситуации существует множество различных вариантов использования yield.
# Код Python3 для демонстрации
# использования ключевого слова yield
# Поиск слова pythonru в тексте
# Импорт библиотеки для работы
# с регулярными выражениями
import re
# Этот генератор создает последовательность
# значений True: по одному на каждое
# найденное слово pythonru
# Также для наглядности он выводит
# обработанные слова
def get_pythonru (text) :
text = re.split('[., ]+', text)
for word in text:
print(word)
if word == "pythonru":
yield True
# Инициализация строки, содержащей текст для поиска
text = "В Интернете есть множество сайтов, \
но только один pythonru. \
Программа никогда не прочтет \
последнее предложение."
# Инициализация переменной с результатом
result = "не найден"
# Цикл произведет единственную итерацию
# в случае наличия в тексте pythonru и
# не сделает ни одной, если таких слов нет
for j in get_pythonru(text):
result = "найден"
break
print ('Результат поиска: %s' % result)
Вывод
В
Интернете
есть
множество
сайтов
но
только
один
pythonru
Результат поиска: найден
В этом материале разберемся с этой ошибкой, и по каким еще причинам она возникает. Разберем несколько примеров, чтобы понять, как с ней справляться.
Ошибка «SyntaxError: unexpected EOF while parsing» возникает в том случае, когда программа добирается до конца файла, но не весь код еще выполнен. Это может быть вызвано ошибкой в структуре или синтаксисе кода.
EOF значит End of File. Представляет собой последний символ в Python-программе.
Python достигает конца файла до выполнения всех блоков в таких случаях:
- Если забыть заключить код в специальную инструкцию, такую как, циклы for или while, или функцию.
- Не закрыть все скобки на строке.
Разберем эти ошибки на примерах построчно.
Пример №1: незавершенные блоки кода
Циклы for и while, инструкции if и функции требуют как минимум одной строки кода в теле. Если их не добавить, результатом будет ошибка EOF.
Рассмотрим такой пример цикла for, который выводит все элементы рецепта:
ingredients = ["325г муки", "200г охлажденного сливочного масла", "125г сахара", "2 ч. л. ванили", "2 яичных желтка"]
for i in ingredients:
Определяем переменную ingredients, которая хранит список ингредиентов для ванильного песочного печенья. Используем цикл for для перебора по каждому из элементов в списке. Запустим код и посмотрим, что произойдет:
File "main.py", line 4
^
SyntaxError: unexpected EOF while parsingВнутри цикла for нет кода, что приводит к ошибке. То же самое произойдет, если не заполнить цикл while, инструкцию if или функцию.
Для решения проблемы требуется добавить хотя бы какой-нибудь код. Это может быть, например, инструкция print() для вывода отдельных ингредиентов в консоль:
for i in ingredients:
print(i)
Запустим код:
325г муки
200г охлажденного сливочного масла
125г сахара
2 ч. л. ванили
2 яичных желткаКод выводит каждый ингредиент из списка, что говорит о том, что он выполнен успешно.
Если же кода для такого блока у вас нет, используйте оператор pass как заполнитель. Выглядит это вот так:
for i in ingredients:
pass
Такой код ничего не возвращает. Инструкция pass говорит о том, что ничего делать не нужно. Такое ключевое слово используется в процессе разработке, когда разработчики намечают будущую структуру программы. Позже pass заменяются на реальный код.
Пример №2: незакрытые скобки
Ошибка «SyntaxError: unexpected EOF while parsing» также возникает, если не закрыть скобки в конце строки с кодом.
Напишем программу, которая выводит информацию о рецепте в консоль. Для начала определим несколько переменных:
name = "Капитанская дочка"
author = "Александр Пушкин"
genre = "роман"
Отформатируем строку с помощью метода .format():
print('Книга "{}" - это {}, автор {}'.format(name, genre, author)
Значения {} заменяются на реальные из .format(). Это значит, что строка будет выглядеть вот так:
Книга "НАЗВАНИЕ" - это ЖАНР, автор АВТОРЗапустим код:
File "main.py", line 7
^
SyntaxError: unexpected EOF while parsingНа строке кода с функцией print() мы закрываем только один набор скобок, хотя открытыми были двое. В этом и причина ошибки.
Решаем проблему, добавляя вторую закрывающую скобку («)») в конце строки с print().
print('Книга "{}" - это {}, автор {}'.format(name, genre, author))
Теперь на этой строке закрываются две скобки. И все из них теперь закрыты. Попробуем запустить код снова:
Книга "Капитанская дочка" это роман. Александр ПушкинТеперь он работает. То же самое произойдет, если забыть закрыть скобки словаря {} или списка [].
Выводы
Ошибка «SyntaxError: unexpected EOF while parsing» возникает, если интерпретатор Python добирается до конца программы до выполнения всех строк.
Для решения этой проблемы сперва нужно убедиться, что все инструкции, включая while, for, if и функции содержат код. Также нужно проверить, закрыты ли все скобки.
]]>Представьте приложение для поиска по сети, которое открывает тысячу соединений. Можно открывать соединение, получать результат и переходить к следующему, двигаясь по очереди. Однако это значительно увеличивает задержку в работе программы. Ведь открытие соединение — операция, которая занимает время. И все это время последующие операции находятся в процессе ожидания.
А вот асинхронность предоставляет способ открытия тысячи соединений одновременно и переключения между ними. По сути, появляется возможность открыть соединение и переходить к следующему, ожидая ответа от первого. Так продолжается до тех пор, пока все не вернут результат.

На графике видно, что синхронный подход займет 45 секунд, в то время как при использовании асинхронности время выполнения можно сократить до 20 секунд.
Где асинхронность применяется в реальном мире?
Асинхронность больше всего подходит для таких сценариев:
- Программа выполняется слишком долго.
- Причина задержки — не вычисления, а ожидания ввода или вывода.
- Задачи, которые включают несколько одновременных операций ввода и вывода.
Это могут быть:
- Парсеры,
- Сетевые сервисы.
Разница в понятиях параллелизма, concurrency, поточности и асинхронности
Параллелизм — это выполнение нескольких операций за раз. Многопроцессорность — один из примеров. Отлично подходит для задач, нагружающих CPU.
Concurrency — более широкое понятие, которое описывает несколько задач, выполняющихся с перекрытием друг друга.
Поточность — поток — это отдельный поток выполнения. Один процесс может содержать несколько потоков, где каждый будет работать независимо. Отлично подходит для IO-операций.
Асинхронность — однопоточный, однопроцессорный дизайн, использующий многозадачность. Другими словами, асинхронность создает впечатление параллелизма, используя один поток в одном процессе.
Составляющие асинхронного программирования
Разберем различные составляющие асинхронного программирования подробно. Также используем код для наглядности.
Сопрограммы
Сопрограммы (coroutine) — это обобщенные формы подпрограмм. Они используются для кооперативных задач и ведут себя как генераторы Python.
Для определения сопрограммы асинхронная функция использует ключевое слово await. При его использовании сопрограмма передает поток управления обратно в цикл событий (также известный как event loop).
Для запуска сопрограммы нужно запланировать его в цикле событий. После этого такие сопрограммы оборачиваются в задачи (Tasks) как объекты Future.
Пример сопрограммы
В коде ниже функция async_func вызывается из основной функции. Нужно добавить ключевое слово await при вызове синхронной функции. Функция async_func не будет делать ничего без await.
import asyncio
async def async_func():
print('Запуск ...')
await asyncio.sleep(1)
print('... Готово!')
async def main():
async_func() # этот код ничего не вернет
await async_func()
asyncio.run(main())
Вывод:
Warning (from warnings module):
File "\AppData\Local\Programs\Python\Python38\main.py", line 8
async_func() # этот код ничего не вернет
RuntimeWarning: coroutine 'async_func' was never awaited
Запуск ...
... Готово!Задачи (tasks)
Задачи используются для планирования параллельного выполнения сопрограмм.
При передаче сопрограммы в цикл событий для обработки можно получить объект Task, который предоставляет способ управления поведением сопрограммы извне цикла событий.
Пример задачи
В коде ниже создается create_task (встроенная функция библиотеки asyncio), после чего она запускается.
import asyncio
async def async_func():
print('Запуск ...')
await asyncio.sleep(1)
print('... Готово!')
async def main():
task = asyncio.create_task (async_func())
await task
asyncio.run(main())
Вывод:
Запуск ...
... Готово!Циклы событий
Этот механизм выполняет сопрограммы до тех пор, пока те не завершатся. Это можно представить как цикл while True, который отслеживает сопрограммы, узнавая, когда те находятся в режиме ожидания, чтобы в этот момент выполнить что-нибудь другое.
Он может разбудить спящую сопрограмму в тот момент, когда она ожидает своего времени, чтобы выполниться. В одно время может выполняться лишь один цикл событий в Python.
Пример цикла событий
Дальше создаются три задачи, которые добавляются в список. Они выполняются асинхронно с помощью get_event_loop, create_task и await библиотеки asyncio.
import asyncio
async def async_func(task_no):
print(f'{task_no}: Запуск ...')
await asyncio.sleep(1)
print(f'{task_no}: ... Готово!')
async def main():
taskA = loop.create_task (async_func('taskA'))
taskB = loop.create_task(async_func('taskB'))
taskC = loop.create_task(async_func('taskC'))
await asyncio.wait([taskA,taskB,taskC])
if __name__ == "__main__":
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
except :
pass
Вывод:
taskA: Запуск ...
taskB: Запуск ...
taskC: Запуск ...
taskA: ... Готово!
taskB: ... Готово!
taskC: ... Готово!Future
Future — это специальный низкоуровневый объект, который представляет окончательный результат выполнения асинхронной операции.
Если этот объект подождать (await), то сопрограмма дождется, пока Future не будет выполнен в другом месте.
В следующих разделах посмотрим, на то, как Future используется.
Сравнение многопоточности и асинхронности
Прежде чем переходить к асинхронности попробуем проверить многопоточность на производительность и сравним результаты. Для этого теста будем получать данные по URL с разной частотой: 1, 10, 50, 100 и 500 раз соответственно. После этого сравним производительность обоих подходов.
Реализация
Многопоточность:
import requests
import time
from concurrent.futures import ProcessPoolExecutor
def fetch_url_data(pg_url):
try:
resp = requests.get(pg_url)
except Exception as e:
print(f"Возникла ошибка при получении данных из url: {pg_url}")
else:
return resp.content
def get_all_url_data(url_list):
with ProcessPoolExecutor() as executor:
resp = executor.map(fetch_url_data, url_list)
return resp
if __name__=='__main__':
url = "https://www.uefa.com/uefaeuro-2020/"
for ntimes in [1,10,50,100,500]:
start_time = time.time()
responses = get_all_url_data([url] * ntimes)
print(f'Получено {ntimes} результатов запроса за {time.time() - start_time} секунд')
Вывод:
Получено 1 результатов запроса за 0.9133939743041992 секунд
Получено 10 результатов запроса за 1.7160518169403076 секунд
Получено 50 результатов запроса за 3.842841625213623 секунд
Получено 100 результатов запроса за 7.662721633911133 секунд
Получено 500 результатов запроса за 32.575703620910645 секундProcessPoolExecutor — это пакет Python, который реализовывает интерфейс Executor. fetch_url_data — функция для получения данных по URL с помощью библиотеки request. После получения get_all_url_data используется, чтобы замапить function_url_data на список URL.
Асинхронность:
import asyncio
import time
from aiohttp import ClientSession, ClientResponseError
async def fetch_url_data(session, url):
try:
async with session.get(url, timeout=60) as response:
resp = await response.read()
except Exception as e:
print(e)
else:
return resp
return
async def fetch_async(loop, r):
url = "https://www.uefa.com/uefaeuro-2020/"
tasks = []
async with ClientSession() as session:
for i in range(r):
task = asyncio.ensure_future(fetch_url_data(session, url))
tasks.append(task)
responses = await asyncio.gather(*tasks)
return responses
if __name__ == '__main__':
for ntimes in [1, 10, 50, 100, 500]:
start_time = time.time()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_async(loop, ntimes))
# будет выполняться до тех пор, пока не завершится или не возникнет ошибка
loop.run_until_complete(future)
responses = future.result()
print(f'Получено {ntimes} результатов запроса за {time.time() - start_time} секунд')
Вывод:
Получено 1 результатов запроса за 0.41477298736572266 секунд
Получено 10 результатов запроса за 0.46897053718566895 секунд
Получено 50 результатов запроса за 2.3057644367218018 секунд
Получено 100 результатов запроса за 4.6860511302948 секунд
Получено 500 результатов запроса за 18.013994455337524 секундНужно использовать функцию get_event_loop для создания и добавления задач. Чтобы использовать более одного URL, нужно применить функцию ensure_future.
Функция fetch_async используется для добавления задачи в объект цикла событий, а fetch_url_data — для чтения данных URL с помощью пакета session. Метод future_result возвращает ответ всех задач.
Результаты
Как можно увидеть, асинхронное программирование на порядок эффективнее многопоточности для этой программы.
Выводы
Асинхронное программирование демонстрирует более высокие результаты в плане производительности, задействуя параллелизм, а не многопоточность. Его стоит использовать в тех программах, где этот параллелизм можно применить.
]]>Прочитав статью, вы узнаете как:
- Использовать функцию
runдля запуска внешнего процесса. - Получить стандартный вывод процесса и информацию об ошибках.
- Проверить код возврата процесса и вызвать исключение в случае сбоя.
- Запустить процесс, используя оболочку в качестве посредника.
- Установить время ожидания завершения процесса.
- Использовать класс
Popenнапрямую для создания конвейера (pipe) между двумя процессами.
Так как модуль subprocess почти всегда используют с Linux все примеры будут касаться Ubuntu. Для пользователей Windows советую скачать терминал Ubuntu 18.04 LTS.
Функция «run»
Функция run была добавлена в модуль subprocess только в относительно последних версиях Python (3.5). Теперь ее использование является рекомендуемым способом создания процессов и должно решать наиболее распространенные задачи. Прежде всего, давайте посмотрим на простейший случай применения функции run.
Предположим, мы хотим запустить команду ls -al; для этого в оболочке Python нам нужно ввести следующие инструкции:
>>> import subprocess
>>> process = subprocess.run(['ls', '-l', '-a'])
Вывод внешней команды ls отображается на экране:
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
-rw-r--r-- 1 cnc cnc 3771 Apr 27 15:40 .bashrcЗдесь мы просто использовали первый обязательный аргумент функции run, который может быть последовательностью, «описывающей» команду и ее аргументы (как в примере), или строкой, которая должна использоваться при запуске с аргументом shell=True (мы рассмотрим последний случай позже).
Захват вывода команды: stdout и stderr
Что, если мы не хотим, чтобы вывод процесса отображался на экране. Вместо этого, нужно чтобы он сохранялся: на него можно было ссылаться после выхода из процесса? В этом случае нам стоит установить для аргумента функции capture_output значение True:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
Как мы можем впоследствии получить вывод (stdout и stderr) процесса? Если вы посмотрите на приведенные выше примеры, то увидите, что мы использовали переменную process для ссылки на объект CompletedProcess, возвращаемый функцией run. Этот объект представляет процесс, запущенный функцией, и имеет много полезных свойств. Помимо прочих, stdout и stderr используются для «хранения» соответствующих дескрипторов команды, если, как уже было сказано, для аргумента capture_output установлено значение True. В этом случае, чтобы получить stdout, мы должны использовать:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
>>> process.stdout
b'total 12\ndrwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .\ndrwxr-xr-x 1 root root 4096 Apr 27 15:40 ..\n-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history\n-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout...По умолчанию stdout и stderr представляют собой последовательности байтов. Если мы хотим, чтобы они хранились в виде строк, мы должны установить для аргумента text функции run значение True.
Управление сбоями процесса
Команда, которую мы запускали в предыдущих примерах, была выполнена без ошибок. Однако при написании программы следует принимать во внимание все случаи. Так, что случится, если порожденный процесс даст сбой? По умолчанию ничего «особенного» не происходит. Давайте посмотрим на примере: мы снова запускаем команду ls, пытаясь вывести список содержимого каталога /root, который не доступен для чтения обычным пользователям:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
Мы можем узнать, не завершился ли запущенный процесс ошибкой, проверив его код возврата, который хранится в свойстве returncode объекта CompletedProcess:
>>> process.returncode
2
Видите? В этом случае returncode равен 2, подтверждая, что процесс столкнулся с ошибкой, связанной с недостаточными правами доступа, и не был успешно завершен. Мы могли бы проверять выходные данные процесса таким образом чтобы при возникновении сбоя возникало исключение. Используйте аргумент check функции run: если для него установлено значение True, то в случае, когда внешний процесс завершается ошибкой, возникает исключение CalledProcessError:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
ls: cannot open directory '/root': Permission deniedОбработка исключений в Python довольно проста. Поэтому для управления сбоями процесса мы могли бы написать что-то вроде:
>>> try:
... process = subprocess.run(['ls', '-l', '-a', '/root'], check=True)
... except subprocess.CalledProcessError as e:
... print(f"Ошибка команды {e.cmd}!")
...
ls: cannot open directory '/root': Permission denied
['ls', '-l', '-a', '/root'] failed!
>>>Исключение CalledProcessError, как мы уже сказали, возникает, когда код возврата процесса не является 0. У данного объекта есть такие свойства, как returncode, cmd, stdout, stderr; то, что они представляют, довольно очевидно. Например, в приведенном выше примере мы просто использовали свойство cmd, чтобы отобразить последовательность, которая использовалась для запуска команды при возникновении исключения.
Выполнение процесса в оболочке
Процессы, запущенные с помощью функции run, выполняются «напрямую», это означает, что для их запуска не используется оболочка: поэтому для процесса не доступны никакие переменные среды и не выполняются раскрытие и подстановка выражений. Давайте посмотрим на пример, который включает использование переменной $HOME:
>>> process = subprocess.run(['ls', '-al', '$HOME'])
ls: cannot access '$HOME': No such file or directoryКак видите, переменная $HOME не была заменена на соответствующее значение. Такой способ выполнения процессов является рекомендованным, так как позволяет избежать потенциальные угрозы безопасности. Однако, в некоторых случаях, когда нам нужно вызвать оболочку в качестве промежуточного процесса, достаточно установить для параметра shell функции run значение True. В таких случаях желательно указать команду и ее аргументы в виде строки:
>>> process = subprocess.run('ls -al $HOME', shell=True)
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
...Все переменные, существующие в пользовательской среде, могут использоваться при вызове оболочки в качестве промежуточного процесса. Хотя это может показаться удобным, такой подход является источником проблем. Особенно при работе с потенциально опасным вводом, который может привести к внедрению вредоносного shell-кода. Поэтому запуск процесса с shell=True не рекомендуется и должен использоваться только в безопасных случаях.
Ограничение времени работы процесса
Обычно мы не хотим, чтобы некорректно работающие процессы бесконечно исполнялись в нашей системе после их запуска. Если мы используем параметр timeout функции run, то можем указать количество времени в секундах, в течение которого процесс должен завершиться. Если он не будет завершен за это время, процесс будет остановлен сигналом SIGKILL. Который, как мы знаем, не может быть перехвачен. Давайте продемонстрируем это, запустив длительный процесс и предоставив timeout в секундах:
>>> process = subprocess.run(['ping', 'google.com'], timeout=5)
PING google.com (216.58.208.206) 56(84) bytes of data.
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=1 ttl=118 time=15.8 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=2 ttl=118 time=15.7 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=3 ttl=118 time=19.3 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=4 ttl=118 time=15.6 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=5 ttl=118 time=17.0 ms
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/subprocess.py", line 495, in run
stdout, stderr = process.communicate(input, timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1028, in communicate
stdout, stderr = self._communicate(input, endtime, timeout)
File "/usr/lib/python3.8/subprocess.py", line 1894, in _communicate
self.wait(timeout=self._remaining_time(endtime))
File "/usr/lib/python3.8/subprocess.py", line 1083, in wait
return self._wait(timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1798, in _wait
raise TimeoutExpired(self.args, timeout)
subprocess.TimeoutExpired: Command '['ping', 'google.com']' timed out after 4.999637200000052 seconds
В приведенном выше примере мы запустили команду ping без указания фиксированного числа пакетов ECHO REQUEST, поэтому она потенциально может работать вечно. Мы также установили время ожидания в 5 секунд с помощью параметра timeout. Как мы видим, ping была запущена, а по истечении 5 секунд возникло исключение TimeoutExpired и процесс был остановлен.
Функции call, check_output и check_call
Как мы уже говорили ранее, функция run является рекомендуемым способом запуска внешнего процесса. Она должна использоваться в большинстве случаев. До того, как она была представлена в Python 3.5, тремя основными функциями API высокого уровня, применяемыми для создания процессов, были call, check_output и check_call; давайте взглянем на них вкратце.
Прежде всего, функция call: она используется для выполнения команды, описанной параметром args; она ожидает завершения команды; ее результатом является соответствующий код возврата. Это примерно соответствует базовому использованию функции run.
Поведение функции check_call практически не отличается от run, когда для параметра check задано значение True: она запускает указанную команду и ожидает ее завершения. Если код возврата не равен 0, возникает исключение CalledProcessError.
Наконец, функция check_output. Она работает аналогично check_call, но возвращает вывод запущенной программы, то есть он не отображается при выполнении функции.
Работа на более низком уровне с классом Popen
До сих пор мы изучали функции API высокого уровня в модуле subprocess, особенно run. Все они под капотом используют класс Popen. Из-за этого в подавляющем большинстве случаев нам не нужно взаимодействовать с ним напрямую. Однако, когда требуется большая гибкость, без создания объектов Popen не обойтись.
Предположим, например, что мы хотим соединить два процесса, воссоздав поведение конвейера (pipe) оболочки. Как мы знаем, когда передаем две команды в оболочку, стандартный вывод той, что находится слева от пайпа «|», используется как стандартный ввод той, которая находится справа. В приведенном ниже примере результат выполнения двух связанных конвейером команд сохраняется в переменной:
$ output="$(dmesg | grep sda)"Чтобы воссоздать подобное поведение с помощью модуля subprocess без установки параметра shell в значение True, как мы видели ранее, мы должны напрямую использовать класс Popen:
dmesg = subprocess.Popen(['dmesg'], stdout=subprocess.PIPE)
grep = subprocess.Popen(['grep', 'sda'], stdin=dmesg.stdout)
dmesg.stdout.close()
output = grep.comunicate()[0]
Рассматривая данный пример, вы должны помнить, что процесс, запущенный с использованием класса Popen, не блокирует выполнение скрипта.
Первое, что мы сделали в приведенном выше фрагменте кода, — это создали объект Popen, представляющий процесс dmesg. Мы установили stdout этого процесса на subprocess.PIPE. Данное значение указывает, что пайп к указанному потоку должен быть открыт.
Затем мы создали еще один экземпляр класса Popen для процесса grep. В конструкторе Popen мы, конечно, указали команду и ее аргументы, но вот что важно, мы установили стандартный вывод процесса dmesg в качестве стандартного ввода для grep (stdin=dmesg.stdout), чтобы воссоздать поведение конвейера оболочки.
После создания объекта Popen для команды grep мы закрыли поток stdout процесса dmesg, используя метод close(). Это, как указано в документации, необходимо для того, чтобы первый процесс мог получить сигнал SIGPIPE. Дело в том, что обычно, когда два процесса соединены конвейером, если один справа от «|» (grep в нашем примере) завершается раньше, чем тот, что слева (dmesg), то последний получает сигнал SIGPIPE (пайп закрыт) и по умолчанию тоже заканчивает свою работу.
Однако при репликации пайплайна между двумя командами в Python возникает проблема. stdout первого процесса открывается как в родительском скрипте, так и в стандартном вводе другого процесса. Таким образом, даже если процесс grep завершится, пайп останется открытым в вызывающем процессе (нашем скрипте), поэтому dmesg никогда не получит сигнал SIGPIPE. Вот почему нам нужно закрыть поток stdout первого процесса в нашем основном скрипте после запуска второго.
Последнее, что мы сделали, — это вызвали метод communicate() объекта grep. Этот метод можно использовать для необязательной передачи данных в stdin процесса. Он ожидает завершения процесса и возвращает кортеж. Где первый элемент — это stdout (на который ссылается переменная output), а второй — stderr процесса.
Заключение
В этом руководстве мы увидели рекомендуемый способ создания внешних процессов в Python с помощью модуля subprocess и функции run. Использование этой функции должно быть достаточным для большинства случаев. Однако, когда требуется более высокий уровень гибкости, следует использовать класс Popen напрямую.
Как всегда, мы советуем вам взглянуть на документацию subprocess, чтобы получить полную информацию о функциях и классах, доступных в данном модуле.
В этом руководстве поговорим об ошибке «NameError name is not defined». Разберем несколько примеров и разберемся, как эту ошибку решать.
Что такое NameError?
NameError возникает в тех случаях, когда вы пытаетесь использовать несуществующие имя переменной или функции.
В Python код запускается сверху вниз. Это значит, что переменную нельзя объявить уже после того, как она была использована. Python просто не будет знать о ее существовании.
Самая распространенная NameError выглядит вот так:
NameError: name 'some_name' is not definedРазберем частые причина возникновения этой ошибки.
Причина №1: ошибка в написании имени переменной или функции
Для человека достаточно просто сделать опечатку. Также просто для него — найти ее. Но это не настолько просто для Python.
Язык способен интерпретировать только те имена, которые были введены корректно. Именно поэтому важно следить за правильностью ввода всех имен в коде.
Если ошибку не исправить, то возникнет исключение. Возьмем в качестве примера следующий код:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print(boooks)
Он вернет:
Traceback (most recent call last):
File "main.py", line 3, in <module>
print(boooks)
NameError: name 'boooks' is not definedДля решения проблемы опечатку нужно исправить. Если ввести print(books), то код вернет список книг.
Таким образом при возникновении ошибки с именем в первую очередь нужно проверить, что все имена переменных и функций введены верно.
Причина №2: вызов функции до объявления
Функции должны использоваться после объявления по аналогии с переменными. Это связано с тем, что Python читает код сверху вниз.
Напишем программу, которая вызывает функцию до объявления:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print_books(books)
def print_books(books):
for b in books:
print(b)
Код вернет:
Traceback (most recent call last):
File "main.py", line 3, in <module>
print_books(books)
NameError: name 'print_books' is not definedНа 3 строке мы пытаемся вызвать print_books(). Однако эта функция объявляется позже.
Чтобы исправить эту ошибку, нужно перенести функцию выше:
def print_books(books):
for b in books:
print(b)
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print_books(books)
Причина №3: переменная не объявлена
Программы становятся больше, и порой легко забыть определить переменную. В таком случае возникнет ошибка. Причина в том, что Python не способен работать с необъявленными переменными.
Посмотрим на программу, которая выводит список книг:
for b in books:
print(b)
Такой код вернет:
Traceback (most recent call last):
File "main.py", line 1, in <module>
for b in books:
NameError: name 'books' is not definedПеременная books объявлена не была.
Для решения проблемы переменную нужно объявить в коде:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
for b in books:
print(b)
Причина №4: попытка вывести одно слово
Чтобы вывести одно слово, нужно заключить его в двойные скобки. Таким образом мы сообщаем Python, что это строка. Если этого не сделать, язык будет считать, что это часть программы. Рассмотрим такую инструкцию print():
print(Books)
Этот код пытается вывести слово «Books» в консоль. Вместо этого он вернет ошибку:
Traceback (most recent call last):
File "main.py", line 1, in <module>
print(Books)
NameError: name 'Books' is not definedPython воспринимает «Books» как имя переменной. Для решения проблемы нужно заключить имя в скобки:
print("Books")
Теперь Python знает, что нужно вывести в консоли строку, и код возвращает Books.
Причина №5: объявление переменной вне области видимости
Есть две области видимости переменных: локальная и глобальная. Локальные переменные доступны внутри функций или классов, где они были объявлены. Глобальные переменные доступны во всей программе.
Если попытаться получить доступ к локальной переменной вне ее области видимости, то возникнет ошибка.
Следующий код пытается вывести список книг вместе с их общим количеством:
def print_books():
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
for b in books:
print(b)
print(len(books))
Код возвращает:
Traceback (most recent call last):
File "main.py", line 5, in <module>
print(len(books))
NameError: name 'books' is not definedПеременная books была объявлена, но она была объявлена внутри функции print_books(). Это значит, что получить к ней доступ нельзя в остальной части программы.
Для решения этой проблемы нужно объявить переменную в глобальной области видимости:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
def print_books():
for b in books:
print(b)
print(len(books))
Код выводит название каждой книги из списка books. После этого выводится общее количество книг в списке с помощью метода len().
List comprehension — это упрощенный подход к созданию списка, который задействует цикл for, а также инструкции if-else для определения того, что в итоге окажется в финальном списке.
Преимущества list comprehension
У list comprehension есть три основных преимущества.
- Простота. List comprehension позволяют избавиться от циклов for, а также делают код более понятным. В JavaScript, например, есть нечто похожее в виде
map()иfilter(), но новичками они воспринимаются сложнее. - Скорость. List comprehension быстрее for-циклов, которые он и заменяет. Это один из первых пунктов при рефакторинге Python-кода.
- Принципы функционального программирования. Это не так важно для начинающих, но функциональное программирование — это подход, при котором изменяемые данные не меняются. Поскольку list comprehensions создают новый список, не меняя существующий, их можно отнести к функциональному программированию.
Создание первого list comprehension
List comprehension записывается в квадратных скобках и задействует цикл for. В процессе создается новый список, куда добавляются все элементы оригинального. По мере добавления элементов их можно изменять.
Для начала возьмем простейший пример: создадим список из цифр от 1 до 5, используя функцию range().
>>> nums = [n for n in range(1,6)]
>>> print(nums)
[1, 2, 3, 4, 5]
В этом примере каждое значение диапазона присваивается переменной n. Каждое значение возвращается неизменным и добавляется в новый список. Это — та самая n перед циклом for.
В качестве итерируемого объекта не обязательно должна быть функция range(). Это может быть любое итерируемое значение.
List comprehension с изменением
Теперь пойдем чуть дальше и добавим изменение для каждого значения в цикле.
>>> nums = [1, 2, 3, 4, 5]
>>> squares = [n*n for n in nums]
>>> print(squares)
[1, 4, 9, 16, 25]
В этом примере два изменения по сравнению с прошлым кодом. Во-первых, в качестве источника используется уже существующий список. Во-вторых, list comprehension создает список, где каждое значение — это возведенное в квадрат значения оригинального списка.
List comprehension с if
Теперь добавим проверку с помощью if, чтобы не добавлять все значения.
>>> nums = [1, 2, 3, 4, 5]
>>> odd_squares = [n*n for n in nums if n%2 == 1]
>>> print(odd_squares)
[1, 9, 25]
Инструкция if идет после цикла — в данном случае порядок играет роль.
List comprehension с вложенным циклом for
В последнем примере рассмотрим пример со вложенным циклом for.
>>> matrix = [[x for x in range(1, 4)] for y in range(1, 4)]
>>> print(matrix)
[[1, 2, 3], [1, 2, 3], [1, 2, 3]]
Может показаться, что здесь все стало чуть сложнее. Но достаточно разбить код на несколько строк, чтобы увидеть, что нет ничего особенного.
matrix = [
[x for x in range(1, 4)]
for y in range(1, 4)
]
print(matrix)
Последний пример. Создадим список дней рождения из списка словарей. Для этого используем знакомые тактики.
people = [{
"first_name": "Василий",
"last_name": "Марков",
"birthday": "9/25/1984"
}, {
"first_name": "Регина",
"last_name": "Павленко",
"birthday": "8/21/1995"
}]
birthdays = [
person[term]
for person in people
for term in person
if term == "birthday"
]
print(birthdays)
В этом примере мы сперва перебираем people, присваивая каждый словарь person. После этого перебираем каждый идентификатор в словаре, присваивая ключи term. Если значение term равно birthday, то значение person[term] добавляет в list comprehension.
['9/25/1984', '8/21/1995']Теперь можете попробовать поработать с list comprehension на собственных примерах. Это сделает код более быстрым и компактным.
]]>Основные особенности функций в Python:
- Используются чтобы избегать повторений в коде,
- Используются для разделения кода на мелкие модули
- Позволяют скрывать код и создавать ясность для понимания модулей,
- Позволяют повторно использовать код и сохранять память,
- Код из функции можно выполнить только по ее имени,
- Простой синтаксис:
def имя_функции(параметры):.
Правила создания функций:
- Для объявления функции в Python используется ключевое слово
def. - Название функции должно начинаться с символа латинского алфавита в любом регистре или нижнего подчеркивания.
- В каждой функции есть двоеточие и отступ, после которого записывается сам код программы.
- Зарезервированные ключевые слова не могут использоваться в качестве названия функции.
- Функция может содержать несколько параметров или не иметь их совсем.
Создание функции в Python
Для создания нужно написать ключевое слово def. Синтаксис следующий:
def function_name():
# логика функции
return result # возврат значенияСоздадим и вызовем реальную функцию в Python:
def my_fun():
print("Как вызвать функцию в Python?")
my_fun() # вызов функции
Вывод: Как вызвать функцию в Python?.
Вызов функции в Python
После создания функции ее можно вызвать, написав имя или присвоив ее переменной:
def my_fun():
x = 22 ** 5
return x
# 1. Вызов функции
my_fun()
# 2. Вызов функции и присвоение результат переменной
a = my_fun()
# 3. Вызов функции и вывод результат в консоль
print(my_fun())
Создадим простую функцию, которая ничего не возвращает и вызовем ее.
def my_fun():
print("Hello World")
print("Функция вызвана")
my_fun()
Вывод:
Hello World
Функция вызванаВ этом примере вызов функции my_fun() привел к выводу двух строк.
Вызов вложенных функций в Python
Одна функция внутри другой — это вложенные функции. Создавать вложенные функции можно с помощью того же ключевого слова def. После создания функции нужно вызвать как внешнюю, так и внутреннюю. Создадим программу, чтобы разобраться с этим на примере.
def out_fun():
print("Привет, это внешняя функция")
def in_fun():
print("Привет, это внутренняя функция")
in_fun()
out_fun()
Вывод:
Привет, это внешняя функция
Привет, это внутренняя функцияЗдесь функция in_fun() определена внутри out_fun(). Для вызова in_fun() нужно сперва вызвать out_fun(). После этого out_fun() начнет выполняться, что приведет к вызову in_fun().
Внутренняя функция не будет выполняться, если не вызвать внешнюю.
Еще один пример. Программа для вывода результата сложения двух чисел с помощью вложенных функций в Python.
def fun1():
a = 6
def fun2(b):
a = 4
print ("Сумма внутренней функции", a + b)
print("Значение внешней переменной a", a)
fun2(4)
fun1()
Вывод:
Значение внешней переменной a 6
Сумма внутренней функции 8Функции как объекты первого класса
В Python функции — это объекты первого класса. У них есть те же свойства и методы, что и обычных объектов. Так, функцию можно присвоить переменной, передать ее в качестве аргумента, сохранить в структуре данных и вернуть в качестве результата работы другой функции. Все данные в Python представлены в качестве объектов или отношений.
Особенности функций как объектов первого класса:
- Функции можно присваивать переменным.
- Функция может быть примером объекта.
- Функцию можно вернуть из функции.
- У функций те же свойства и методы, что и у объектов.
- Функцию можно передать в качестве аргумента при вызове другой функции.
Разберем на примере:
def my_object(text):
return text.upper()
print(my_object("Вызов my_object"))
upper = my_object
print(upper("Вызов upper"))
Вывод:
ВЫЗОВ MY_OBJECT
ВЫЗОВ UPPERНапишем программу для вызова функции в классе (точнее, это будет метод класса).
class Student:
no = 101
name = "Владимир"
def show(self):
print("№ {}\nИмя {}".format(self.no, self.name))
stud = Student()
stud.show()
Вывод:
№ 101
Имя ВладимирВ Python есть несколько методов для удаления элементов из списка: remove(), pop() и clear(). Помимо них также существует ключевое слово del.
Рассмотрим их все.
Пример списка:
my_list = ['Python', 50, 11.50, 'Alex', 50, ['A', 'B', 'C']]
Индекс начинается с 0. В списке my_list на 0-ой позиции находится строка «Python». Далее:
- Целое число 50
- Число с плавающей точкой 11.50
- Снова строка — «Alex»
- Еще одно число 50
- Список из строк «A», «B» и «C»
Метод remove()
Метод remove() — это встроенный метод, который удаляет первый совпадающий элемент из списка.
Синтаксис: list.remove(element).
Передается элемент, который нужно удалить из списка.
Метод не возвращает значений.
Как использовать:
- Если в списке есть повторяющиеся элементы, первый совпадающий будет удален.
- Если элемента нет, будет брошена ошибка с сообщением о том, что элемент не найден.
- Метод не возвращает значений.
- В качестве аргумента нужно передать валидное значение.
Пример: использование метод remove() для удаления элемента из списка
В этом списке есть строки и целые числа. Есть повторяющиеся элементы: строка «Mars» и число 12.
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
my_list.remove(12) # удаляем элемент 12 в начале
print(my_list)
my_list.remove('Mars') # удаляем первый Mars из списка
print(my_list)
my_list.remove(100) # ошибка
print(my_list)
Вывод:
['USA', 'Sun', 14, 'Mars', 12, 'Mars']
['USA', 'Sun', 14, 12, 'Mars']
Traceback (most recent call last):
File "wb.py", line 6, in <module>
my_list.remove(100) # ошибка
ValueError: list.remove(x): x not in listМетод pop()
Этот метод удаляет элемент на основе переданного индекса.
Синтаксис: list.pop(index).
Принимает лишь один аргумент — индекс.
- Для удаления элемента списка нужно передать его индекс. Индексы в списках стартуют с 0. Для получения первого передайте 0. Для удаления последнего передайте -1.
- Этот аргумент не является обязательным. Значение по умолчанию равно -1, поэтому по умолчанию будет удален последний элемент.
- Если этот индекс не найден или он вне диапазона, то метод выбросит исключение
IndexError: pop index.
Возвращает элемент, удаленный из списка по индексу. Сам же список обновляется и больше не содержит этот элемент.
Пример: использования метода pop() для удаления элемента
Попробуем удалить элемент с помощью pop:
- По индексу
- Не передавая индекс
- Передав индекс вне диапазона
Удалим из списка «Sun». Индекс начинается с 0, поэтому индекс для «Sun» будет 2.
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
# Передавая индекс как 2, чтобы удалить Sun
name = my_list.pop(2)
print(name)
print(my_list)
# метод pop() без индекса - возвращает последний элемент
item = my_list.pop()
print(item)
print(my_list)
# передача индекса за пределами списка
item = my_list.pop(15)
print(item)
print(my_list)
Вывод:
Sun
[12, 'USA', 14, 'Mars', 12, 'Mars']
Mars
[12, 'USA', 14, 'Mars', 12]
Traceback (most recent call last):
File "wb.py", line 14, in <module>
item = my_list.pop(15)
IndexError: pop index out of rangeМетод clear()
Метод clear() удаляет все элементы из списка.
Синтаксис: list.clear().
Нет ни параметров, ни возвращаемого значения.
Пример
Метод clear() очистит данный список. Посмотрим:
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
element = my_list.clear()
print(element)
print(my_list)
Вывод:
None
[]Ключевое слово del
Для удаления элемента из списка можно использовать ключевое слово del с названием списка после него. Также потребуется передать индекс того элемента, который нужно удалить.
Синтаксис: del list[index].
Также можно выбрать элементы в определенном диапазоне и удалить их с помощью del. Для этого нужно передать начальное и конечное значение диапазона.
Синтаксис: del list[start:stop].
Вот пример того как с помощью del можно удалить первый, последний и сразу несколько элементов списка:
my_list = list(range(7))
print("Исходный список", my_list)
# Чтобы удалить первый элемент
del my_list[0]
print("После удаления первого элемента", my_list)
# Чтобы удалить элемент по индексу
del my_list[5]
print("После удаления элемента", my_list)
# Чтобы удалить несколько элементов
del my_list[1:5]
print("После удаления нескольких элементов", my_list)
Вывод:
Исходный список [0, 1, 2, 3, 4, 5, 6]
После удаления первого элемента [1, 2, 3, 4, 5, 6]
После удаления элемента [1, 2, 3, 4, 5]
После удаления нескольких элементов [1]Как удалить первый элемент списка
Для этого можно использовать методы remove(), pop(). В случае с remove потребуется передать индекс первого элемента, то есть 0. Также можно использовать ключевое слово del.
Пример показывает применение всех этих способов.
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list)
my_list.remove('A')
print("С использованием remove()", my_list)
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
my_list.pop(0)
print("С использованием pop()", my_list)
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
del my_list[0]
print("С использованием del", my_list)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
С использованием remove() ['B', 'C', 'D', 'E', 'F']
С использованием pop() ['B', 'C', 'D', 'E', 'F']
С использованием del ['B', 'C', 'D', 'E', 'F']Как удалить несколько элементов из списка
Методы remove() и pop() могут удалить только один элемент. Для удаления нескольких используется метод del.
Например, из списка ['A', 'B', 'C', 'D', 'E', 'F'] нужно удалить элементы B, C и D. Вот как это делается с помощью del.
my_list2 = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list2)
del my_list2[1:4]
print("С использованием del", my_list2)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
С использованием del ['A', 'E', 'F']Как удалить элемент из списка с помощью индекса в Python
Для удаления элемента по индексу используйте pop(). Для этого также подойдет ключевое слово del.
# Использование del для удаления нескольких элементов из списка
my_list1 = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list1)
element = my_list1.pop(2)
print("Используя pop", my_list1)
# Использование del для удаления нескольких элементов из списка
my_list2 = ['A', 'B', 'C', 'D', 'E', 'F']
del my_list2[2]
print("Используя del", my_list2)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
Используя pop ['A', 'B', 'D', 'E', 'F']
Используя del ['A', 'B', 'D', 'E', 'F']Выводы
В Python есть много способов удаления данных из списка. Это методы remove(), pop(), clear() и ключевое слово del.
remove()— удаляет первый встреченный элемент в списке, который соответствует условию.pop()— удаляет элемент по индексу.clear()— удаляет все элементы списка.
abs(x) в Python возвращает абсолютное значение аргумента x, который может быть целым или числом с плавающей точкой, или же объектом, реализующим функцию __abs__(). Для комплексных чисел функция возвращает их величину. Абсолютное значение любого числового значения -x или +x — это всегда соответствующее положительное +x.
| Аргумент | x | целое число, число с плавающей точкой, комплексное число, объект, реализующий __abs__() |
| Возвращаемое значение | |x| | возвращает абсолютное значение входящего аргумента |
Пример abs() с целым числом
Следующий код демонстрирует, как получить абсолютное значение 42 положительного числа 42.
x = 42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Вывод: Абсолютное значение 42 это 42
Вывод: «Абсолютное значение 42 это 42».
То же самое, но уже с отрицательным -42.
x = -42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Вывод: Абсолютное значение -42 это 42
Пример с числом float
Вот как получить абсолютное значение 42.42 и для -42.42:
x = 42.42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Абсолютное значение 42.42 это 42.42
x = -42.42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Абсолютное значение -42.42 это 42.42
Комплексное число
Абсолютное значение комплексного числа (3+10j).
complex_number = (3+10j)
abs_complex_number = abs(complex_number)
print(f"Абсолютное значение {complex_number} это {abs_complex_number}")
# Абсолютное значение (3+10j) это 10.44030650891055
abs() vs fabs()
abs(x) вычисляет абсолютное значение аргумента x. По аналогии функция fabs(x) модуля math вычисляет то же значение. Разница лишь в том, что math.fabs(x) возвращает число с плавающей точкой, а abs(x) вернет целое число, если в качестве аргумента было целое число. Fabs расшифровывается как float absolute value.
Пример c fabs():
x = 42
print(abs(x))
# 42
import math
print(math.fabs(x))
# 42.0
abs() vs. np.abs()
И abs() в Python, и np.abs() в NumPy вычисляют абсолютное значение числа, но есть два отличия. np.abs(x) всегда возвращает число с плавающей точкой. Также np.abs(x) принимает массив NumPy, вычисляя значение для каждого элемента коллекции.
Пример:
x = 42
print(abs(x))
# 42
import numpy as np
print(np.fabs(x))
# 42.0
a = np.array([-1, 2, -4])
print(np.abs(a))
# [1 2 4]
abs и np.abs абсолютно идентичны. Нет разницы какой использовать. У первой преимущество лишь в том, что ее вызов короче.
Вывод
Функция abs() — это встроенная функция, возвращающая абсолютное значение числа. Она принимает целые, с плавающей точкой и комплексные числа на вход.
Если передать в abs() целое число или число с плавающей точкой, то функция вернет не-отрицательное значение n и сохранит тип. Для целого числа — целое число. Для числа с плавающей точкой — число с плавающей точкой.
>>> abs(20)
20
>>> abs(20.0)
20.0
>>> abs(-20.0)
20.0
Комплексные числа состоят из двух частей и могут быть записаны в форме a + bj, где a и b — это или целые числа, или числа с плавающей точкой. Абсолютное значение a + bj вычисляется математически как math.sqrt(a**2 + b**2).
>>> abs(3 + 4j)
5.0
>>> math.sqrt(3**2 + 4**2)
5.0
Таким образом, результат всегда положительный и всегда является числом с плавающей точкой.
]]>√25 = ±5
Для отрицательного числа результат извлечения квадратного корня включает комплексные числа, обсуждение которых выходит за рамки данной статьи.
Математическое представление квадрата числа
Все мы в детстве узнали, что, когда число умножается само на себя, мы получаем его квадрат. Также квадрат числа можно представить как многократное умножение этого числа. Попробуем разобраться в этом на примере.
Предположим, мы хотим получить квадрат 5. Если мы умножим число (в данном случае 5) на 5, мы получим квадрат этого числа. Для обозначения квадрата числа используется следующая запись:
52 = 25
При программировании на Python довольно часто возникает необходимость использовать функцию извлечения квадратного корня. Есть несколько способов найти квадратный корень числа в Python.
1. Используя оператор возведения в степень
num = 25
sqrt = num ** (0.5)
print("Квадратный корень из числа "+str(num)+" это "+str(sqrt))
Вывод:
Квадратный корень из числа 25 это 5.0Объяснение: Мы можем использовать оператор «**» в Python, чтобы получить квадратный корень. Любое число, возведенное в степень 0.5, дает нам квадратный корень из этого числа.
2. Использование math.sqrt()
Квадратный корень из числа можно получить с помощью функции sqrt() из модуля math, как показано ниже. Далее мы увидим три сценария, в которых передадим положительный, нулевой и отрицательный числовые аргументы в sqrt().
a. Использование положительного числа в качестве аргумента.
import math
num = 25
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.0.
b. Использование ноля в качестве аргумента.
import math
num = 0
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 0 это 0.0.
c. Использование отрицательного числа в качестве аргумента.
import math
num = -25
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод:
Traceback (most recent call last):
File "C:\wb.py", line 3, in <module>
sqrt = math.sqrt(num)
ValueError: math domain errorОбъяснение: Когда мы передаем отрицательное число в качестве аргумента, мы получаем следующую ошибку «math domain error». Из чего следует, что аргумент должен быть больше 0. Итак, чтобы решить эту проблему, мы должны использовать функцию sqrt() из модуля cmath.
3. Использование cmath.sqrt()
Ниже приведены примеры применения cmath.sqrt().
а. Использование отрицательного числа в качестве аргумента.
import cmath
num = -25
sqrt = cmath.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа -25 это 5j.
Объяснение: Для отрицательных чисел мы должны использовать функцию sqrt() модуля cmath, которая занимается математическими вычислениями над комплексными числами.
b. Использование комплексного числа в качестве аргумента.
import cmath
num = 4 + 9j
sqrt = cmath.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа (4+9j) это (2.6314309606938298+1.7100961671491028j).
Объяснение: Для нахождения квадратного корня из комплексного числа мы также можем использовать функцию cmath.sqrt().
4. Использование np.sqrt()
import numpy as np
num = -25
sqrt = np.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод:
...
RuntimeWarning: invalid value encountered in sqrt
Квадратный корень из числа -25 это nan5. Использование scipy.sqrt()
import scipy as sc
num = 25
sqrt = sc.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.0.
Объяснение: Как и функция sqrt() модуля numpy, в scipy квадратный корень из положительных, нулевых и комплексных чисел может быть успешно вычислен, но для отрицательных возвращается nan с RunTimeWarning.
6. Использование sympy.sqrt()
import sympy as smp
num = 25
sqrt = smp.sqrt(num)
print("Квадратный корень из числа "+str(num)+" это "+str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.
Объяснение: sympy — это модуль Python для символьных вычислений. С помощью функции sympy.sqrt() мы можем получить квадратный корень из положительных, нулевых, отрицательных и комплексных чисел. Единственная разница между этим и другими методами заключается в том, что, если при использовании sympy.sqrt() аргумент является целым числом, то результат также является целым числом, в отличие от других способов, в которых возвращаемое значение всегда число с плавающей точкой, независимо от типа данных аргумента.
Заключение
Наконец, мы подошли к завершению этой статьи. В начале мы кратко затронули использование квадратного корня в математике. Затем мы обсудили принципы внутреннего устройства функции извлечения квадратного корня и ее возможную реализацию. В завершении мы рассмотрели различные методы применения этой функции в Python.
]]>join в Python отвечает за объединение списка строк с помощью определенного указателя. Часто это используется при конвертации списка в строку. Например, так можно конвертировать список букв алфавита в разделенную запятыми строку для сохранения.
Метод принимает итерируемый объект в качестве аргумента, а поскольку список отвечает этим условиям, то его вполне можно использовать. Также список должен состоять из строк. Если попробовать использовать функцию для списка с другим содержимым, то результатом будет такое сообщение: TypeError: sequence item 0: expected str instance, int found.
Посмотрим на короткий пример объединения списка для создания строки.
vowels = ["a", "e", "i", "o", "u"]
vowels_str = ",".join(vowels)
print("Строка гласных:", vowels_str)
Этот скрипт выдаст такой результат:
Строка гласных: a,e,i,o,uПочему join() — метод строки, а не списка?
Многие часто спрашивают, почему функция join() относится к строке, а не к списку. Разве такой синтаксис не было бы проще запомнить?
vowels_str = vowels.join(",")Это популярный вопрос на StackOverflow, и вот простой ответ на него:
Функция
join()может использоваться с любым итерируемым объектом, но результатом всегда будет строка, поэтому и есть смысл иметь ее в качестве API строки.
Объединение списка с несколькими типами данных
Посмотрим на программу, где предпринимается попытка объединить элементы списка разных типов:
names = ['Java', 'Python', 1]
delimiter = ','
single_str = delimiter.join(names)
Вывод:
Traceback (most recent call last):
File "test.py", line 3, in <module>
single_str = delimiter.join(names)
TypeError: sequence item 2: expected str instance, int foundЭто лишь демонстрация того, что join нельзя использовать для объединения элементов разного типа. Только строковые значения.
Что бы избежать этой ошибки, превратите все элементы списка в строки:
names = ['Java', 'Python', 1]
names = [str(i) for i in names]
Разбитие строки с помощью join
Также функцию join() можно использовать, чтобы разбить строку по определенному разделителю.
>>> print(",".join("Python"))
P,y,t,h,o,n
Если передать в качестве аргумента функции строку, то она будет разбита по символам с определенным разделителем.
Обратное преобразование строки в список
Помимо join() есть и функция split(), которая используется для разбития строки. Она работает похожим образом. Посмотрим на код:
names = ['Java', 'Python', 'Go']
delimiter = ','
single_str = delimiter.join(names)
print('Строка: {0}'.format(single_str))
split = single_str.split(delimiter)
print('Список: {0}'.format(split))
Вывод:
Строка: Java,Python,Go
Список: ['Java', 'Python', 'Go']Вот и все что нужно знать об объединении и разбитии строк.
]]>Если неправильно организовать отступы, пробелы или табуляции в программе, то вернется ошибка IndentationError: expected an intended block.
В этом руководстве рассмотрим, что это за ошибка и когда она появляется. Разберем пример и посмотрим, как решить эту проблему.
IndentationError: expected an indented block
Языки программирования, такие как C и JavaScript, не требуют отступов. В них для структуризации кода используются фигурные скобы. В Python этих скобок нет.
Структура программы создается с помощью отступов. Без них интерпретатор не сможет корректно распознавать разные блоки кода. Возьмем такой код в качестве примера:
def find_average(grades):
average = sum(grades) / len(grades)
print(average)
return average
Откуда Python знает, какой код является частью функции find_average(), а какой — основной программы? Вот почему так важны отступы.
Каждый раз, когда вы забываете поставить пробелы или символы табуляции, Python напоминает об этом с помощью ошибки отступа.
Пример возникновения ошибки отступа
Напишем программу, которая извлекает все бублики из списка с едой в меню. Они после этого будут добавлены в отдельный список.
Для начала создадим список всей еды:
lunch_menu = ["Бублик с сыром", "Сэндвич с сыром", "Cэндвич с огурцом", "Бублик с лососем"]
Меню содержит два сэндвича и два бублика. Теперь напишем функцию, которая создает новый список бубликов на основе содержимого списка lunch_menu:
def get_bagels(menu):
bagels = []
for m in menu:
if "Бублик" in m:
bagels.append(m)
return bagels
get_bagels() принимает один аргумент — список меню, по которому она пройдется в поиске нужных элементов. Она проверяет, содержит ли элемент слово «Бублик», и в случае положительного ответа добавит его в новый список.
Наконец, функцию нужно вызвать и вывести результат:
bagels = get_bagels(lunch_menu)
print(bagels)
Этот код вызывает функцию get_bagels() и выводит список бубликов в консоль. Запустим код и посмотрим на результат:
File "test.py", line 4
bagels = []
^
IndentationError: expected an indented block
Ошибка отступа.
Решение ошибки IndentationError
Ошибка отступа сообщает, что отступ был установлен неправильно. Его нужно добавить на 4 строке. Посмотрим на код:
def get_bagels(menu):
bagels = []
Значение переменной bagels должно присваиваться внутри функции, но этого не происходит, что и приводит к ошибке. Для решения проблемы нужно добавить отступ:
def get_bagels(menu):
bagels = []
Теперь запустим код:
['Бублик с сыром', 'Бублик с лососем']Код нашел все бублики и добавил их в новый список. После этого вывел его в консоль.
Вывод
Ошибка IndentationError: expected an indented block возникает, если забыть добавить отступ в коде. Для исправления нужно проверить все отступы, которые должны присутствовать.
]]>В математике возведение в степень — это операция, при которой число умножается само на себя несколько раз. Python предоставляет встроенные операторы и функции для выполнения возведения в степень.
Оператор ** для возведения в степень
Многие разработчики считают, что символ карет (^) — это оператор возведения числа в степень, ведь именно он обозначает эту операцию в математике. Однако в большинстве языков программирования этот знак выступает в качестве побитового xor.
В Python оператор возведения в степень обозначается двумя символами звездочки ** между основанием и числом степени.
Функциональность этого оператора дополняет возможности оператора умножения *: разница лишь в том, что второй оператор указывает на то, сколько раз первые операнд будет умножен сам на себя.
print(5**6)Чтобы умножить число 5 само на себя 6 раз, используется ** между основанием 5 и операндом степени 6. Вывод:
15625Проверим оператор с другими значениями.
Инициализируем целое число, отрицательное целое, ноль, два числа с плавающей точкой float, одно больше нуля, а второе — меньше. Степеням же присвоим случайные значения.
num1 = 2
num2 = -5
num3 = 0
num4 = 1.025
num5 = 0.5
print(num1, '^12 =', num1**12)
print(num2, '^4 =', num2**4)
print(num3, '^9999 =', num3**9999)
print(num4, '^-3 =', num4**-3)
print(num5, '^8 =', num5**8)
Вывод:
2 ^12 = 4096
-5 ^4 = 625
0 ^9999 = 0
1.025 ^-3 = 0.928599410919749
0.5 ^8 = 0.00390625pow() или math.power() для возведения в степень
Также возводить в степень в Python можно с помощью функции pow() или модуля math, в котором есть своя реализация этого же модуля.
В обе функции нужно передать два аргумента: основание и саму степень. Попробуем вызвать обе функции и посмотрим на результат.
import math
print(pow(-8, 7))
print(math.pow(-8, 7))
print(pow(2, 1.5))
print(math.pow(2, 1.5))
print(pow(4, 3))
print(math.pow(4,3))
print(pow(2.0, 5))
print(math.pow(2.0, 5))
Вывод:
-2097152
-2097152.0
2.8284271247461903
2.8284271247461903
64
64.0
32.0
32.0Отличие лишь в том, что math.pow() всегда возвращает значение числа с плавающей точкой, даже если передать целые числа. А вот pow() вернет число с плавающей точкой, если таким же был хотя бы один из аргументов.
numpy.np() для возведения в степень
В модуле numpy есть своя функция power() для возведения в степень. Она принимает те же аргументы, что и pow(), где первый — это основание, а второй — значение степени.
Выведем те же результаты.
print(np.power(-8, 7))
print(np.power(2, 1.5))
print(np.power(4, 3))
print(np.power(2.0, 5))
-2097152
2.8284271247461903
64
32.0Как получить квадрат числа в Python?
Для возведения числа в квадрат, нужно указать 2 в качестве степени. Встроенной функции для получения квадрата в Python нет.
Например, квадрат числа 6 — 6**2 —> 36.
Сравнение времени работы разных решений
Теперь сравним, сколько занимает выполнение каждой из трех функций и оператора **. Для этого используем модуль timeit.
Основанием будет 2, а значением степени — 9999999.
import numpy as np
import math
import time
start = time.process_time()
val = 2**9999999
print('** за', time.process_time() - start, 'ms')
start = time.process_time()
val = pow(2, 9999999)
print('pow() за', time.process_time() - start, 'ms')
start = time.process_time()
val = np.power(2, 9999999)
print('np.power() за', time.process_time() - start, 'ms')
start = time.process_time()
val = math.pow(2, 9999999)
print('math.pow() за', time.process_time() - start, 'ms')
** за 0.078125 ms
pow() за 0.0625 ms
np.power() за 0.0 ms
Traceback (most recent call last):
File "C:\Programs\Python\Python38\test.py", line 18, in <module>
val = math.pow(2, 9999999)
OverflowError: math range errorВ первую очередь можно обратить внимание на то, что math.pow() вернула ошибку OverflowError. Это значит, что функция не поддерживает крупные значения степени.
Различия между остальными достаточно простые, но можно увидеть, что np.power() — самая быстрая.
В этом руководстве мы научимся считывать файл построчно, используя функции readline(), readlines() и объект файла на примерах различных программ.
Пример 1: Чтение файла построчно функцией readline()
В этом примере мы будем использовать функцию readline() для файлового объекта, получая каждую строку в цикле.
Как использовать функцию file.readline()
Следуйте пунктам приведенным ниже для того, чтобы считать файл построчно, используя функцию readline().
- Открываем файл в режиме чтения. При этом возвращается дескриптор файла.
- Создаём бесконечный цикл while.
- В каждой итерации считываем строку файла при помощи
readline(). - Если строка не пустая, то выводим её и переходим к следующей. Вы можете проверить это, используя конструкцию
if not. В противном случае файл больше не имеет строк и мы останавливаем цикл с помощьюbreak.
- В каждой итерации считываем строку файла при помощи
- К моменту выхода из цикла мы считаем все строки файла в итерациях одну за другой.
- После этого мы закрываем файл, используя функцию
close.
# получим объект файла
file1 = open("sample.txt", "r")
while True:
# считываем строку
line = file1.readline()
# прерываем цикл, если строка пустая
if not line:
break
# выводим строку
print(line.strip())
# закрываем файл
file1.close
Вывод:
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 2: Чтение строк как список функцией readlines()
Функция readlines() возвращает все строки файла в виде списка. Мы можем пройтись по списку и получить доступ к каждой строке.
В следующей программе мы должны открыть текстовый файл и получить список всех его строк, используя функцию readlines(). После этого мы используем цикл for, чтобы обойти данный список.
# получим объект файла
file1 = open("sample.txt", "r")
# считываем все строки
lines = file1.readlines()
# итерация по строкам
for line in lines:
print(line.strip())
# закрываем файл
file1.close
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 3: Считываем файл построчно из объекта File
В нашем первом примере, мы считываем каждую строку файла при помощи бесконечного цикла while и функции readline(). Но Вы можете использовать цикл for для файлового объекта, чтобы в каждой итерации цикла получать строку, пока не будет достигнут конец файла.
Ниже приводится программа, демонстрирующая применение оператора for-in, для того, чтобы перебрать строки файла.
Для демонстрации откроем файл с помощью with open. Это применимо и к предыдущим двум примерам.
# получим объект файла
with open("sample.txt", "r") as file1:
# итерация по строкам
for line in file1:
print(line.strip())
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Выводы
В этом руководстве мы научились считывать текстовый файл построчно с помощью примеров программ на Python.
]]>С другой стороны, переменная, объявленная внутри определенного блока кода, будет видна только внутри этого же блока — она называется локальной.
Разберемся с этими понятиями на примере.
Пример локальных и глобальных переменных
def sum():
a = 10 # локальные переменные
b = 20
c = a + b
print("Сумма:", c)
sum()
Вывод: Сумма: 30.
Переменная объявлена внутри функции и может использоваться только в ней. Получить доступ к этой локальной функции в других нельзя.
Для решения этой проблемы используются глобальные переменные.
Теперь взгляните на этот пример с глобальными переменными:
a = 20 # определены вне функции
b = 10
def sum():
c = a + b # Использование глобальных переменных
print("Сумма:", c)
def sub():
d = a - b # Использование глобальных переменных
print("Разница:", d)
sum()
sub()
Вывод:
Сумма: 30
Разница: 10В этом коде были объявлены две глобальные переменные: a и b. Они используются внутри функций sum() и sub(). Обе возвращают результат при вызове.
Если определить локальную переменную с тем же именем, то приоритет будет у нее. Посмотрите, как в функции msg это реализовано.
def msg():
m = "Привет, как дела?"
print(m)
msg()
m = "Отлично!" # глобальная переменная
print(m)
Вывод:
Привет, как дела?
Отлично!Здесь была объявлена локальная переменная с таким же именем, как и у глобальной. Сперва выводится значение локальной, а после этого — глобальной.
Ключевое слово global
Python предлагает ключевое слово global, которое используется для изменения значения глобальной переменной в функции. Оно нужно для изменения значения. Вот некоторые правила по работе с глобальными переменными.
Правила использования global
- Если значение определено на выходе функции, то оно автоматически станет глобальной переменной.
- Ключевое слово
globalиспользуется для объявления глобальной переменной внутри функции. - Нет необходимости использовать
globalдля объявления глобальной переменной вне функции. - Переменные, на которые есть ссылка внутри функции, неявно являются глобальными.
Пример без использования глобального ключевого слова.
c = 10
def mul():
c = c * 10
print(c)
mul()
Вывод:
line 5, in mul
c = c * 10
UnboundLocalError: local variable 'c' referenced before assignmentЭтот код вернул ошибку, потому что была предпринята попытка присвоить значение глобальной переменной. Изменять значение можно только с помощью ключевого слова global.
c = 10
def mul():
global c
c = c * 10
print("Значение в функции:", c)
mul()
print("Значение вне функции:", c)
Вывод:
Значение в функции: 100
Значение вне функции: 100Здесь переменная c была объявлена в функции mul() с помощью ключевого слова global. Ее значение умножается на 10 и становится равным 100. В процессе работы программы можно увидеть, что изменение значения внутри функции отражается на глобальном значении переменной.
Глобальные переменные в модулях Python
Преимущество использования ключевого слова global — в возможности создавать глобальные переменные и передавать их между модулями. Например, можно создать name.py, который бы состоял из глобальных переменных. Если их изменить, то изменения повлияют на все места, где эти переменные встречаются.
1. Создаем файл name.py для хранения глобальных переменных:
a = 10
b = 20
msg = "Hello World"
2. Создаем файл change.py для изменения переменных:
import name
name.a = 15
name.b = 25
name.msg = "Dood bye"
Меняем значения a, b и msg. Эти переменные были объявлены внутри name, и для их изменения модуль нужно было импортировать.
3. В третий файл выводим значения измененных глобальных переменных.
import name
import change
print(name.a)
print(name.b)
print(name.msg)
Значение изменилось. Вывод:
15
25
Dood byeGlobal во вложенных функциях
Можно использовать ключевое слово global во вложенных функциях.
def add():
a = 15
def modify():
global a
a = 20
print("Перед изменением:", a)
print("Внесение изменений")
modify()
print("После изменения:", a)
add()
print("Значение a:", a)
Вывод:
Перед изменением: 15
Внесение изменений
После изменения: 15
Значение a: 20В этом коде значение внутри add() принимает значение локальной переменной x = 15. В modify() оно переназначается и принимает значение 20 благодаря global. Это и отображается в переменной функции add().
Функция input() возвращает все в виде строки, поэтому нужно выполнить явную конвертацию, чтобы получить целое число. Для этого пригодится функция int().
# вывод суммы двух чисел, введенных пользователем
num_1 = int(input("Введите первое число: "))
num_2 = int(input("Введите второе число: "))
print("Тип num_1:", type(num_1))
print("Тип num_2:", type(num_2))
result = num_1 + num_2
print("Сумма введенных чисел:", result)
int(string) конвертирует переданную строку в целое число.
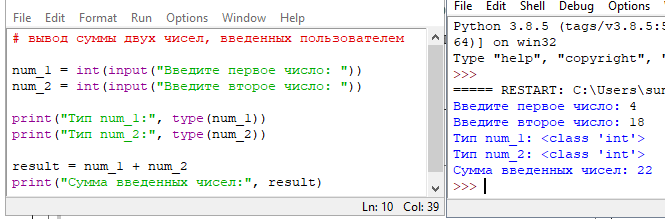
Ввода числа float
По аналогии можно использовать функцию float().
float_1 = float(input("Введите число: "))
print("Тип float_1:", type(float_1))
result = float_1 ** 2
print("Число в квадрате:", result)
Вывод примера:
Введите число: 1.8
Тип float_1: <class 'float'>
Число в квадрате: 3.24Ввод чисел в строку через пробел
Но что произойдет, если вы не знаете количество элементов ввода?
Предположим, что от пользователя нужно получить список чисел и вернуть их сумму. При этом вы не знаете количество элементов в этом списке. Как же запросить ввод для него?
Для этого можно использовать split и функции map. Метод split() делит введенную строку на список подстрок. После этого map() выполняет функцию int() для каждого элемента списка.
entered_list = input("Введите список чисел, разделенных пробелом: ").split()
print("Введенный список:", entered_list)
num_list = list(map(int, entered_list))
print("Список чисел: ", num_list)
print("Сумма списка:", sum(num_list))
Введите список чисел, разделенных пробелом: 1 34 4 6548
Введенный список: ['1', '34', '4', '6548']
Список чисел: [1, 34, 4, 6548]
Сумма списка: 6587В коде выше:
input()возвращает список, содержащий числа, разделенные запятыми.split()возвращает список строк, разделенных пробелами.map()выполняет операциюint()для всех элементов списка и возвращает объектmap.list()конвертирует объектmapснова в список.
Есть альтернативный способ получить список:
entered_list = input("Введите список чисел, разделенных пробелом: ").split()
num_list = [int(i) for i in entered_list]
print("Список чисел: ", num_list)
Обработка ошибок при пользовательском вводе
Часто при конвертации типов возникает исключение ValueError.
Это происходит в тех случаях, когда введенные пользователем данные не могут быть конвертированы в конкретный тип.
Например, пользователь вводит случайную строку в качестве возраста.
num = int(input("Введите возраст: "))
Функция int() ожидает целочисленное значение, обернутое в строку. Любое другое значение приводит к ошибке. Вот что будет, если, попробовать ввести «Двадцать»:
Введите возраст: Двадцать
---------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-10-1fa1cb611d10> in <module>
----> 1 num_1 = int(input('Введите возраст: '))
ValueError: invalid literal for int() with base 10: 'Двадцать'Чтобы убедиться, что пользователь вводит только подходящую информацию, нужно обработать массу подобных ошибок. Для этого будем использовать перехват исключений.
try:
num = int(input("Введите число: "))
print("Все верно. Число:", num)
except ValueError:
print("Это не число.")
Посмотрим, как ввод «Двадцать» сработает теперь:
Введите число: Двадцать
Это не число.В этом примере если пользователь вводит нечисловое значение, то возникает исключение. Однако оно перехватывается инструкцией except, которая в ответ выводит: «Это не число». Благодаря использованию конструкции try-except программа не прекратит работать при некорректном вводе.
- Рекурсивную функцию поиска факториала.
- Как рекурсивные функции работают в коде.
- Действительно ли рекурсивные функции выполняют свои задачи лучше итеративных?
Рекурсивные функции
Рекурсивная функция — это та, которая вызывает сама себя.
В качестве простейшего примера рассмотрите следующий код:
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)
Вызывая рекурсивную функцию здесь и передавая ей целое число, вы получаете факториал этого числа (n!).
Вкратце о факториалах
Факториал числа — это число, умноженное на каждое предыдущее число вплоть до 1.
Например, факториал числа 7:
7! = 7*6*5*4*3*2*1 = 5040
Вывести факториал числа можно с помощью функции:
num = 3
print(f"Факториал {num} это {factorial_recursive(num)}")
Эта функция выведет: «Факториал 3 это 6». Еще раз рассмотрим эту рекурсивную функцию:
def factorial_recursive(n):
...По аналогии с обычной функцией имя рекурсивной указывается после def, а в скобках обозначается параметр n:
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)Благодаря условной конструкции переменная n вернется только в том случае, если ее значение будет равно 1. Это еще называют условием завершения. Рекурсия останавливается в момент удовлетворения условиям.
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)В коде выше выделен фрагмент самой рекурсии. В блоке else условной конструкции возвращается произведение n и значения этой же функции с параметром n-1.
Это и есть рекурсия. В нашем примере это так сработало:
3 * (3-1) * ((3-1)-1) # так как 3-1-1 равно 1, рекурсия остановиласьДетали работы рекурсивной функции
Чтобы еще лучше понять, как это работает, разобьем на этапы процесс выполнения функции с параметром 3.
Для этого ниже представим каждый экземпляр с реальными числами. Это поможет «отследить», что происходит при вызове одной функции со значением 3 в качестве аргумента:
# Первый вызов
factorial_recursive(3):
if 3 == 1:
return 3
else:
return 3*factorial_recursive(3-1)
# Второй вызов
factorial_recursive(2):
if 2 == 1:
return 2
else:
return 2*factorial_recursive(2-1)
# Третий вызов
factorial_recursive(1):
if 1 == 1:
return 1
else:
return 1*factorial_recursive(1-1)
Рекурсивная функция не знает ответа для выражения 3*factorial_recursive(3–1), поэтому она добавляет в стек еще один вызов.
Как работает рекурсия
/\ factorial_recursive(1) - последний вызов || factorial_recursive(2) - второй вызов || factorial_recursive(3) - первый вызов
Выше показывается, как генерируется стек. Это происходит благодаря процессу LIFO (last in, first out, «последним пришел — первым ушел»). Как вы помните, первые вызовы функции не знают ответа, поэтому они добавляются в стек.
Но как только в стек добавляется вызов factorial_recursive(1), для которого ответ имеется, стек начинает «разворачиваться» в обратном порядке, выполняя все вычисления с реальными значениями. В процессе каждый из слоев выпадает в процессе.
- factorial_recursive(1) завершается, отправляет 1 в
- factorial_recursive(2) и выпадает из стека.
- factorial_recursive(2) завершается, отправляет 2*1 в
- factorial_recursive(3) и выпадает из стека. Наконец, инструкция else здесь завершается, возвращается 3 * 2 = 6, и из стека выпадает последний слой.
Рекурсия в Python имеет ограничение в 3000 слоев.
>>> import sys
>>> sys.getrecursionlimit()
3000
Рекурсивно или итеративно?
Каковы же преимущества рекурсивных функций? Можно ли с помощью итеративных получить тот же результат? Когда лучше использовать одни, а когда — другие?
Важно учитывать временную и пространственную сложности. Рекурсивные функции занимают больше места в памяти по сравнению с итеративными из-за постоянного добавления новых слоев в стек в памяти. Однако их производительность куда выше.
Рекурсия может быть медленной, если реализована неправильно
Тем не менее рекурсия может быть медленной, если ее неправильно реализовать. Из-за этого вычисления будут происходить чаще, чем требуется.
Написание итеративных функций зачастую требуется большего количества кода. Например, дальше пример функции для вычисления факториала, но с итеративным подходом. Выглядит не так изящно, не правда ли?
def factorial_iterative(num):
factorial = 1
if num < 0:
print("Факториал не вычисляется для отрицательных чисел")
else:
for i in range (1, num + 1):
factorial = factorial*i
print(f"Факториал {num} это {factorial}")
find(). Он помогает найти индекс первого совпадения подстроки в строке. Если символ или подстрока не найдены, find возвращает -1.
Синтаксис
string.find(substring,start,end)Метод find принимает три параметра:
substring(символ/подстрока) — подстрока, которую нужно найти в данной строке.start(необязательный) — первый индекс, с которого нужно начинать поиск. По умолчанию значение равно 0.end(необязательный) — индекс, на котором нужно закончить поиск. По умолчанию равно длине строки.
Поиск символов методом find() со значениями по умолчанию
Параметры, которые передаются в метод, — это подстрока, которую требуются найти, индекс начала и конца поиска. Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
В этом примере используем метод со значениями по умолчанию.
Метод find() будет искать символ и вернет положение первого совпадения. Даже если символ встречается несколько раз, то метод вернет только положение первого совпадения.
>>> string = "Добро пожаловать!"
>>> print("Индекс первой буквы 'о':", string.find("о"))
Индекс первой буквы 'о': 1
Поиск не с начала строки с аргументом start
Можно искать подстроку, указав также начальное положение поиска.
В этом примере обозначим стартовое положение значением 8 и метод начнет искать с символа с индексом 8. Последним положением будет длина строки — таким образом метод выполнит поиска с индекса 8 до окончания строки.
>>> string = "Специалисты назвали плюсы и минусы Python"
>>> print("Индекс подстроки 'али' без учета первых 8 символов:", string.find("али", 8))
Индекс подстроки 'али' без учета первых 8 символов: 16
Поиск символа в подстроке со start и end
С помощью обоих аргументов (start и end) можно ограничить поиск и не проводить его по всей строке. Найдем индексы слова «пожаловать» и повторим поиск по букве «о».
>>> string = "Добро пожаловать!"
>>> start = string.find("п")
>>> end = string.find("ь") + 1
>>> print("Индекс первой буквы 'о' в подстроке:", string.find("о", start, end))
Индекс первой буквы 'о' в подстроке: 7
Проверка есть ли символ в строке
Мы знаем, что метод find() позволяет найти индекс первого совпадения подстроки. Он возвращает -1 в том случае, если подстрока не была найдена.
>>> string = "Добро пожаловать!"
>>> print("Есть буква 'г'?", string.find("г") != -1)
Есть буква 'г'? False
>>> print("Есть буква 'т'?", string.find("т") != -1)
Есть буква 'т'? True
Поиск последнего вхождения символа в строку
Функция rfind() напоминает find(), а единое отличие в том, что она возвращает максимальный индекс. В обоих случаях же вернется -1, если подстрока не была найдена.
В следующем примере есть строка «Добро пожаловать!». Попробуем найти в ней символ «о» с помощью методов find() и rfind().
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом rfind:", string.rfind("о"))
Поиск 'о' методом rfind: 11
Вывод показывает, что find() возвращает индекс первого совпадения подстроки, а rfind() — последнего совпадения.
Второй способ поиска — index()
Метод index() помогает найти положение данной подстроки по аналогии с find(). Единственное отличие в том, что index() бросит исключение в том случае, если подстрока не будет найдена, а find() просто вернет -1.
Вот рабочий пример, показывающий разницу в поведении index() и find():
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом index:", string.index("о"))
Поиск 'о' методом index: 1
В обоих случаях возвращается одна и та же позиция. А теперь попробуем с подстрокой, которой нет в строке:
>>> string = "Добро пожаловать"
>>> print("Поиск 'г' методом find:", string.find("г"))
Поиск 'г' методом find: 1
>>> print("Поиск 'г' методом index:", string.index("г"))
Traceback (most recent call last):
File "pyshell#21", line 1, in module
print("Поиск 'г' методом index:", string.index("г"))
ValueError: substring not found
В этом примере мы пытались найти подстроку «г». Ее там нет, поэтому find() возвращает -1, а index() бросает исключение.
Поиск всех вхождений символа в строку
Чтобы найти общее количество совпадений подстроки в строке можно использовать ту же функцию find(). Пройдемся циклом while по строке и будем задействовать параметр start из метода find().
Изначально переменная start будет равна -1, что бы прибавлять 1 у каждому новому поиску и начать с 0. Внутри цикла проверяем, присутствует ли подстрока в строке с помощью метода find.
Если вернувшееся значение не равно -1, то обновляем значением count.
Вот рабочий пример:
my_string = "Добро пожаловать"
start = -1
count = 0
while True:
start = my_string.find("о", start+1)
if start == -1:
break
count += 1
print("Количество вхождений символа в строку: ", count )
Количество вхождений символа в строку: 4Выводы
- Метод
find()помогает найти индекс первого совпадения подстроки в данной строке. Возвращает -1, если подстрока не была найдена. - В метод передаются три параметра: подстрока, которую нужно найти,
startсо значением по умолчанию равным 0 иendсо значением по умолчанию равным длине строки. - Можно искать подстроку в данной строке, задав начальное положение, с которого следует начинать поиск.
- С помощью параметров
startиendможно ограничить зону поиска, чтобы не выполнять его по всей строке. - Функция
rfind()повторяет возможностиfind(), но возвращает максимальный индекс (то есть, место последнего совпадения). В обоих случаях возвращается -1, если подстрока не была найдена. index()— еще одна функция, которая возвращает положение подстроки. Отличие лишь в том, чтоindex()бросает исключение, если подстрока не была найдена, аfind()возвращает -1.find()можно использовать в том числе и для поиска общего числа совпадений подстроки.
В этой статье рассмотрим самые популярные встроенные функции Python. Для каждой из них будет представлено описание и один пример. Примеры выполняются в консоли Python Shell.
1. abs()
Функция abs() в Python возвращает абсолютное значение числа. Если это комплексное число, то абсолютным значением будет величина целой и мнимой частей.
>>> abs(-5.6)
5.6
2. chr()
Функция chr() возвращает строку, представляющую символ Unicode для переданного числа. Она является противоположностью ord(), которая принимает символ и возвращает его числовой код.
>>> chr(97)
'a'
3. callable()
Вызываемый объект — это объект, который можно вызвать. Функция callable() сообщает, является ли объект вызываемым. Если да, то возвращает True, а в противном случае — False.
>>> callable(5)
False
4. complex()
Комплексное число — это число, представленное в форме a + bi. Оно принимает целые числа или строки и возвращает соответствующее комплексное число. Если передать неподходящее значение, то вернется ошибка ValueError.
>>> complex(3)
(3+0j)
>>> complex(-3,-2)
(-3-2j)
5. dict()
Эта функция используется в Python для создания словарей. Это же можно делать и вручную, но функция предоставляет большую гибкость и дополнительные возможности. Например, ей в качестве параметра можно передать несколько словарей, объединив их в один большой.
>>> dict({"a":1, "b":2}, c = 3)
{'a': 1, 'b': 2, 'c': 3}
>>> list = [["a",1],["b",2]]
>>> dict(list)
{'a': 1, 'b': 2}
6. dir()
Функция dir() получает список вех атрибутов и методов объекта. Если объект не передать, то функция вернет все имена модулей в локальном пространстве имен.
>>> x = ["Яблоко", "Апельсин", "Гранат"]
>>> print(dir(x))
['__add__', '__class__', '__contains__',....]
7. enumerate()
В качестве параметра эта функция принимает последовательность. После этого она перебирает каждый элемент и возвращает его вместе со счетчиком в виде перечисляемого объекта. Основная особенность таких объектов — возможность размещать их в цикле для перебора.
>>> x = "Строка"
>>> list(enumerate(x))
[(0, 'С'), (1, 'т'), (2, 'р'), (3, 'о'), (4, 'к'), (5, 'а')]
8. eval()
eval() обрабатывает переданное в нее выражение и исполняет его как выражение Python. После этого возвращается значение. Чаще всего эта функция используется для выполнения математических функций.
>>> eval('2+2')
4
>>> eval('2*7')
14
>>> eval('5/2')
2.5
9. filter()
Как можно догадаться по названию, эта функция используется для перебора итерируемых объектов и последовательностей, таких как списки, кортежи и словари. Но перед ее использованием нужно также иметь подходящую функцию, которая бы проверяла каждый элемент на валидность. Если элемент подходит, он будет возвращаться в вывод.
list1 = [3, 5, 4, 8, 6, 33, 22, 18, 76, 1]
result = list(filter(lambda x: (x%2 != 0) , list1))
print(result)
10. float()
Эта встроенная функция конвертирует число или строку в число с плавающей точкой и возвращает результат. Если из-за некорректного ввода конвертация не проходит, возвращаются ValueError или TypeError.
>>> float('596')
596.0
>>> float(26)
26.0
11. hash()
У большинства объектов в Python есть хэш-номер. Функция hash() возвращает значение хэша переданного объекта. Объекты с __hash__() — это те, у которых есть соответствующее значение.
>>> hash('Hello World')
-2864993036154377761
>>> hash(True)
1
12. help()
Функция help() предоставляет простой способ получения доступа к документации Python без интернета для любой функции, ключевого слова или модуля.
>>> help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
13. input()
Функция input() — это быстрый и удобный способ получить данные от пользователя. Вызов этой функции предоставляет пользователю возможность ввести на экране текст. Затем он конвертируется в строку и возвращается в программу.
>>> value = input("Пожалуйста, введите значение: ")
Пожалуйста, введите значение: 123
>>> value
'123'
14. int()
Эта функция возвращает целое число из объекта, переданного в параметра. Она может конвертировать числа с разным основанием (шестнадцатеричные, двоичные и так далее) в целые.
>>> int(5.6)
5
>>> int('0101', 2)
5
15. iter()
Эта функция принимает объект и возвращает итерируемый объект. Сам по себе он бесполезен, но оказывается крайне эффективным при использовании в циклах for и while. Благодаря этому объект можно перебирать по одному свойству за раз.
>>> lis = ['a', 'b', 'c', 'd', 'e']
>>> x = iter(lis)
>>> next(x)
'a'
>>> next(x)
'b'
>>> next(x)
'c'
>>> next(x)
'd'
16. max()
Эта функция используется для нахождения «максимального» значения в последовательности, итерируемом объекте и так далее. В параметрах можно менять способ вычисления максимального значения.
>>> max('a', 'A')
'a'
>>> x = [5, 7, 8, 2, 5]
>>> max(x)
8
>>> x = ["Яблоко", "Апельсин", "Автомобиль"]
>>> max(x, key = len)
'Яблоко'
17. min()
Эта функция используется для нахождения «минимального» значения в последовательности, итерируемом объекте и так далее. В параметрах можно менять способ вычисления минимального значения.
>>> min('a','A')
'A'
>>> x = [5, 7, 8, 2, 5]
>>> min(x)
2
>>> x = ["Виноград", "Манго", "Фрукты", "Клубника"]
>>> min(x)
'Виноград'
18. len()
Эта функция используется для вычисления длины последовательности или итерируемого объекта.
>>> x = (2, 3, 1, 6, 7)
>>> len(x)
5
>>> len("Строка")
6
19. list()
В качестве параметра функция list() принимает итерируемый объект и возвращает список. Она обеспечивает большие гибкость и скорость при создании списков по сравнению с обычным способом.
>>> list("Привет")
['П', 'р', 'и', 'в', 'е', 'т']
>>> list({1:"a", 2:"b", 3:"c"})
[1, 2, 3]
20. map()
Используется для применения определенной функции к итерируемому объекту. Она возвращает результат в виде итерируемого объекта (списки, кортежи, множества). Можно передать и несколько объектов, но в таком случае нужно будет и соответствующее количество функций.
>>> def inc(x):
x = x + 1
return x
>>> lis = [1,2,3,4,5]
>>> result = map(inc,lis)
>>> for x in result:
print(x)
2
3
4
5
6
21. next()
Используется для итерируемых объектов. Умеет получать следующий (next) элемент в последовательности. Добравшись до конца, выводит значение по умолчанию.
>>> lis = ['a', 'b', 'c', 'd', 'e']
>>> x = iter(lis)
>>> next(x)
'a'
>>> next(x)
'b'
>>> next(x)
'c'
>>> next(x)
'd'
22. ord()
Функция ord() принимает один символ или строку длиной в один символ и возвращает соответствующее значение Unicode. Например, ord("a") вернет 97, а 97 — a.
>>> ord('a')
97
>>> ord('A')
65
23. reversed()
Эта функция предоставляет простой и быстрый способ развернуть порядок элементов в последовательности. В качестве параметра она принимает валидную последовательность, например список, а возвращает итерируемый объект.
>>> x = [3,4,5]
>>> b = reversed(x)
>>> list(b)
[5, 4, 3]
24. range()
Используется для создания последовательности чисел с заданными значениями от и до, а также интервалом. Такая последовательность часто используется в циклах, особенно в цикле for.
>>> list(range(10,20,2))
[10, 12, 14, 16, 18]
25. reduce()
Выполняет переданную в качестве аргумента функцию для каждого элемента последовательности. Она является частью functools, поэтому перед ее использованием соответствующий модуль нужно импортировать.
>>> list1 = [2, 5, 3, 1, 8]
>>> functools.reduce(operator.add,list1)
19
>>> list1 = [2, 5, 3, 1, 8]
>>> functools.reduce(operator.mul,list1)
240
>>> list1 = [2, 5, 3, 1, 8]
>>> functools.reduce(operator.truediv,list1)
0.016666666666666666
26. sorted()
Используется для сортировки последовательностей значений разных типов. Например, может отсортировать список строк в алфавитном порядке или список числовых значений по возрастанию или убыванию.
>>> X = [4, 5, 7, 3, 1]
>>> sorted(X)
[1, 3, 4, 5, 7]
27. str()
Используется для создания строковых представлений объектов, но не меняет сам объект, а возвращает новый. У нее есть встроенные механизмы кодировки и обработки ошибок, которые помогают при конвертации.
>>> str(5)
'5'
>>> X = [5,6,7]
>>> str(X)
'[5, 6, 7]'
28. set()
Функция set() используется для создания наборов данных, которые передаются в качестве параметра. Обычно это последовательность, например строка или список, которая затем преобразуется в множество уникальных значений.
>>> set()
set()
>>> set("Hello")
{'e', 'l', 'o', 'H'}
>>> set((1,2,3,4,5))
{1, 2, 3, 4, 5}
29. sum()
Вычисление суммы — стандартная задача во многих приложениях. И для этого в Python есть встроенная функция. Она автоматически суммирует все элементы и возвращает сумму.
>>> x = [1, 2, 5, 3, 6, 7]
>>> sum(x)
24
30. tuple()
Принимает один аргумент (итерируемый объект), которым может быть, например, список или словарь, последовательность или итератор и возвращает его в форме кортежа. Если не передать объект, то вернется пустой кортеж.
>>> tuple("Привет")
('П', 'р', 'и', 'в', 'е', 'т')
>>> tuple([1, 2, 3, 4, 5])
(1, 2, 3, 4, 5)
31. type()
Функция type применяется в двух сценариях. Если передать один параметр, то она вернет тип этого объекта. Если же передать три параметра, то можно создать объект type.
>>> type(5)
<class 'int'>
>>> type([5])
<class 'list'>
В Python достаточно просто работать с числами, ведь сам язык является простым и одновременно мощным. Он поддерживает всего три числовых типа:
int(целые числа)float(числа с плавающей точкой)complex(комплексные числа)
Хотя int и float присутствуют в большинстве других языков программирования, наличие типа комплексных чисел — уникальная особенность Python. Теперь рассмотрим в деталях каждый из типов.
Целые и числа с плавающей точкой в Python
В программирование целые числа — это те, что лишены плавающей точкой, например, 1, 10, -1, 0 и так далее. Числа с плавающей точкой — это, например, 1.0, 6.1 и так далее.
Создание int и float чисел
Для создания целого числа нужно присвоить соответствующее значение переменной. Возьмем в качестве примера следующий код:
var1 = 25Здесь мы присваиваем значение 25 переменной var1. Важно не использовать одинарные или двойные кавычки при создании чисел, поскольку они отвечают за представление строк. Рассмотрим следующий код.
var1 = "25"
# или
var1 = '25'
В этих случаях данные представлены как строки, поэтому не могут быть обработаны так, как требуется. Для создания числа с плавающей точкой, типа float, нужно аналогичным образом присвоить значение переменной.
var1 = 0.001Здесь также не стоит использовать кавычки.
Проверить тип данных переменной можно с помощью встроенной функции type(). Можете проверить результат выполнения, скопировав этот код в свою IDE.
var1 = 1 # создание int
var2 = 1.10 # создание float
var3 = "1.10" # создание строки
print(type(var1))
print(type(var2))
print(type(var3))
Вывод:
<class 'int'>
<class 'float'>
<class 'str'>В Python также можно создавать крупные числа, но в таком случае нельзя использовать запятые.
# создание 1,000,000
var1 = 1,000,000 # неправильно
Если попытаться запустить этот код, то интерпретатор Python вернет ошибку. Для разделения значений целого числа используется нижнее подчеркивание. Вот пример корректного объявления.
# создание 1,000,000
var1 = 1_000_000 # правильно
print(var1)
Значение выведем с помощью функции print:
1000000Арифметические операции над целыми и числами с плавающей точкой
Используем такие арифметические операции, как сложение и вычитание, на числах. Для запуска этого кода откройте оболочку Python, введите python или python3. Терминал должен выглядеть следующим образом:
Сложение
В Python сложение выполняется с помощью оператора +. В терминале Python выполните следующее.
>>> 1+3Результатом будет сумма двух чисел, которая выведется в терминале.
Теперь запустим такой код.
>>> 1.0 + 2
3.0В нем было выполнено сложение целого и числа с плавающей точкой. Можно обратить внимание на то, что результатом также является число с плавающей точкой. Таким образом сложение двух целых чисел дает целое число, но если хотя бы один из операндов является числом с плавающей точкой, то и результат станет такого же типа.
Вычитание
В Python для операции вычитания используется оператор -. Рассмотрим примеры.
>>> 3 - 1
2
>>> 1 - 5
-4
>>> 3.0 - 4.0
-1.0
>>> 3 - 1.0
2.0Положительные числа получаются в случае вычитания маленького числа из более крупного. Если же из маленького наоборот вычесть большое, то результатом будет отрицательно число. По аналогии с операцией сложения при вычитании если один из операндов является числом с плавающей точкой, то и весь результат будет такого типа.
Умножение
Для умножения в Python применяется оператор *.
>>> 8 * 2
16
>>> 8.0 * 2
16.0
>>> 8.0 * 2.0
16.0Если перемножить два целых числа, то результатом будет целое число. Если же использовать число с плавающей точкой, то результатом будет также число с плавающей точкой.
Деление
В Python деление выполняется с помощью оператора /.
>>> 3 / 1
3.0
>>> 4 / 2
2.0
>>> 3 / 2
1.5В отличие от трех предыдущих операций при делении результатом всегда будет число с плавающей точкой. Также нужно помнить о том, что на 0 делить нельзя, иначе Python вернет ошибку ZeroDivisionError. Вот пример такого поведения.
>>> 1 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zeroДеление без остатка
При обычном делении с использованием оператора / результатом будет точное число с плавающей точкой. Но иногда достаточно получить лишь целую часть операции. Для этого есть операции интегрального деления. Стоит рассмотреть ее на примере.
>>> 2 // 1
2
>>> 4 // 3
1
>>> 5 // 2
2Результатом такой операции становится частное. Остаток же можно получить с помощью модуля, о котором речь пойдет дальше.
Остаток от деления
Для получения остатка деления двух чисел используется оператор деления по модулю %.
>>> 5 % 2
1
>>> 4 % 2
0
>>> 3 % 2
1
>>> 5 % 3
2На этих примерах видно, как это работает.
Возведение в степень
Число можно возвести в степень с помощью оператора **.
>>> 3**2
9
>>> 2**4
16
>>> 3**3
27Комплексные числа
Комплексные числа — это числа, которые включают мнимую часть. Python поддерживает их «из коробки». Их можно запросто создавать и использовать. Пример:
# создание двух комплексных чисел
var1 = 2 + 2j
var2 = 3 + 4j
# сложение двух комплексных чисел
sum = var1 + var2
print("Сумма двух комплексных чисел равна: ", sum)
В этом примере были созданы два комплексных числа a+bj. После этого было выполнено их сложение с помощью оператора +. Результат вывели на экран с помощью функции print().
Сумма двух комплексных чисел равна: (5+6j)Конвертация типов чисел
Конвертация типа — это метод конвертации числа из одного типа в другой. Для этого можно использовать функции float(), int() и complex().
x = 1 # создание целого числа
y = 2.0 # создание числа с плавающей точкой
z = 2+3j # создание комплексного числа
a = float(x) # преобразование целого числа в число с плавающей точкой
b = int(x) # преобразование числа с плавающей точкой в целое число
c = complex(x) # преобразование целого числа в комплексное
d = complex(y) # преобразование числа с плавающей точкой в комплексное
print(a, type(a))
print(b, type(b))
print(c, type(c))
print(d, type(d))
Можно увидеть, как числа изменились за счет использования простых встроенных функций Python.
1.0 <class 'float'>
1 <class 'int'>
(1+0j) <class 'complex'>
(2+0j) <class 'complex'>Случайные числа
Случайные числа используются в играх, криптографии и так далее. В Python нативной поддержки случайных чисел нет, но есть встроенный модуль random, который используется для работы с целыми числами. Рассмотрим пример генерации случайных чисел с помощью такого модуля.
import random
print(random.randrange(1, 1000))
Результатом будет новое число от 1 до 1000, у каждого свое.
Встроенные математические функции
В Python есть множество встроенных функций для работы с числами. Вот самые важные из них.
round()
Функция round() используется для округления чисел с плавающей точкой до ближайшего целого. Пр этом тип данных не меняется. Целое число — это также число с плавающей точкой. Пример:
# создание чисел
a = 0.01
b = 1.45
c = 2.25
d = 3.7
e = 4.5
# округление чисел
print(round(a))
print(round(b))
print(round(c))
print(round(d))
print(round(e))
В выводе можно увидеть, что все числа с плавающей точкой были округлены до ближайшего целого.
0
1
2
4
4abs()
Эта функция используется для генерации абсолютного значения числа. Оно всегда положительное, хотя число можно быть как положительным, так и отрицательным. Пример:
# создание чисел
a = 1.1
b = -1.5
c = 2
d = -3
e = 0
# отображение абсолютного значения
print(round(a))
print(round(b))
print(round(c))
print(round(d))
print(round(e))
Вывод:
1.1
1.5
2
3
0pow()
Функция pow() используется для возведения числа в степень. Она повторяет то, что можно сделать и с помощью оператора **.
Функции pow() нужно передать два параметра. Первый — число, которое нужно возвести в степень, а второе — сама степень. Пример:
base = 8
power = 2
print(pow(base, power))
Возведем 8 в степень 2. Вывод:
64Библиотека math
В Python есть полноценная библиотека, с помощью которой можно выполнять почти любую математическую операцию — math. Все это есть в стандартной библиотеке, поэтому дополнительные действия выполнять не нужно. В модуле есть кое-какие константы, среди которых PI, e и так далее. Есть и кое-какие математические методы: log(), exp(), sqrt(), тригонометрические функции и так далее.
Выводы
В этом материале вы узнали об основах работы с числами в Python. Это поможет выполнять математические операции при работе с кодом.
]]>Важно и то, что в Python этот процесс очень простой.
Как создать файл в Python в три строки
С помощью следующего кода можно создать файл с названием BabyFile.txt и записать в него текст «Привет, файл!»:
my_file = open("BabyFile.txt", "w+")
my_file.write("Привет, файл!")
my_file.close()
В начале объявляется переменная my_file. После этого используются встроенные функции open и write для открытия и записи в файл. "w+" сообщает, что запись будет осуществляться в новый файл. Если он существует, то новое содержимое нужно записать поверх уже существующего. Если же вместо этого использовать параметр "w", тогда файл будет создан только в том случае, если он не существовал до этого.
Важно заметить, что в конце файл всегда нужно закрывать, чтобы изменения сохранились.
Как записывать, добавляя новое содержимое
С созданием файла разобрались. Теперь можно узнать, как редактировать, удалять и даже копировать файлы.
Если нужно добавить новые данные в файл, тогда вместо "w+" нужно просто использовать параметр "a+".
my_file = open("BabyFile.txt", "a+")
my_file.write("и еще кое-что!")
my_file.close()
Однако в таком случае не будет добавлена новая строка, поэтому важно не забыть использовать символ \n.
Для чтения же файла нужно выполнить такую команду:
my_file = open("BabyFile.txt", "a+")
file_contents == my_file.read()
print(file_contents)
Привет, файл!и еще кое-что!Удаление и перемещение файлов
Зная, как создавать файл, важно уметь определять, существует ли он в системе. Это важно, ведь в противном случае можно попробовать записать, отредактировать или удалить файл, которого не существует, что приведет к ошибке.
Для этого используется модуль os, который также по умолчанию доступен в Python. Достаточно лишь импортировать его и можно приступать к использованию — для этого используются path и методы isfile(), isdir() или exists().
os.path.isfile("/путь/к/файлу")
С помощью этого модуля можно даже переименовывать файлы. Это просто:
os.rename("/путь/к/файлу", "/новый_путь/к/переименованному_файлу")
Особенно круто то, что если отредактировать путь, то файл переместится в соответствующую локацию. Как вариант, можно также использовать модуль shutil:
shutil.move("/путь/к/файлу", "/новый_путь/к/переименованному_файлу")
Наконец, для удаления файлов используется os.remove().
Вот и все. Теперь вы знаете, как создавать файлы, изменять их или удалять.
Краткий итог
Как в Python создать файл
- Создать файл
my_file = open("file.txt", "w+") - Записать в файл
my_file.write("Привет, файл!") - Сохранить и закрыть файл
my_file.close()
sorted() возвращает новый отсортированный список итерируемого объекта (списка, словаря, кортежа). По умолчанию она сортирует его по возрастанию.
Сортировка строк осуществляется по ASCII-значениям.
- Возвращаемое значение —
List(список). - Синтаксис:
sorted(iterable,key=None,reverse=False). iterable: строка, список, кортеж, множество, словарьkey(необязательный параметр): если указать ключ, то сортировка будет выполнена по функции этого ключа.reverse(необязательный параметр): по умолчанию сортировка выполняется по возрастанию. Если указатьreverse=True, то можно отсортировать по убыванию.
# Сортировка строки
s2="hello"
print(sorted(s2)) # Вывод:['e', 'h', 'l', 'l', 'o']
print(sorted(s2, reverse=True)) # Вывод:['o', 'l', 'l', 'h', 'e']
# Сортировка списка
l1=[1, 4, 5, 2, 456, 12]
print(sorted(l1)) # Вывод:[1, 2, 4, 5, 12, 456]
print(sorted(l1, reverse=True)) # Вывод:[456, 12, 5, 4, 2, 1]
# Сортировка кортежа
t1=(15, 3, 5, 7, 9, 11, 42)
print(sorted(t1)) # Вывод:[3, 5, 7, 9, 11, 15, 42]
print(sorted(t1, reverse=True)) # Вывод:[42, 15, 11, 9, 7, 5, 3]
# Сортировка списка кортежей
t2=[(1, 2), (11, 12), (0, 2), (3, 2)]
print(sorted(t2)) # Вывод:[(0, 2), (1, 2), (3, 2), (11, 12)]
print(sorted(t2, reverse=True)) # Вывод:[(11, 12), (3, 2), (1, 2), (0, 2)]
# Сортировка множества
s1={1, 4, 3, 6, 2, 8, 11, 32}
print(sorted(s1)) # Вывод:[1, 2, 3, 4, 6, 8, 11, 32]
print(sorted(s1, reverse=True)) # Вывод:[32, 11, 8, 6, 4, 3, 2, 1]
# Сортировка словаря
d1={2: 'red', 1: 'green', 3: 'blue'}
# Вернется список отсортированных ключей
print(sorted(d1)) # Вывод:[1, 2, 3]
# Вернется список отсортированных значений
print(sorted(d1.values())) # Вывод:['blue', 'green', 'red']
# Вернется список кортежей (ключ, значение), отсортированный по ключам.
print(sorted(d1.items())) # Вывод:[(1, 'green'), (2, 'red'), (3, 'blue')]
# Сортировка словаря в обратном порядке
print(sorted(d1, reverse=True)) # Вывод:[3, 2, 1]
print(sorted(d1.values(), reverse=True)) # Вывод:['red', 'green', 'blue']
print(sorted(d1.items(), reverse=True)) # Вывод:[(3, 'blue'), (2, 'red'), (1, 'green')]
Параметр key
Итерируемый объект можно также отсортировать по функции, указанной в параметре key. Это может быть:
- Встроенная функция,
- Определенная пользователем функция,
- Лямбда-функция,
- itemgetter,
- attrgetter.
1. Встроенная функция
len()— посчитает длину объекта. Если указать len в виде параметра key, то сортировка будет выполнена по длине.
# Сортировка словаря на основе функции len
l1 = {'carrot': 'vegetable', 'red': 'color', 'apple': 'fruit'}
# Возвращает список ключей, отсортированных по функции len
print(sorted(l1, key=len))
# Вывод: ['red', 'apple', 'carrot']
# Возвращает список значений, отсортированных на основе функции len
print(sorted(l1.values(), key=len))
# Вывод: ['fruit', 'color', 'vegetable']
# Сортировка списка на основе функции len
l1 = ['blue', 'green', 'red', 'orange']
print(sorted(l1, key=len))
# Вывод: ['red', 'blue', 'green', 'orange']
abs() вернет абсолютно значение числа. Если задать abs для key, то сортировка будет основана на абсолютном значении.
# Сортировка списка по абсолютному значению
l1 = [1, -4, 5, -7, 9, 2]
print(sorted(l1, key=abs))
# Вывод: [1, 2, -4, 5, -7, 9]
str.lower() — конвертирует все символы в верхнем регистре в нижний регистр. В таком случае список будет отсортирован так, будто бы все символы в нижнем регистре.
s1 = "Hello How are you"
# Разбивает строку и сортирует по словам
print(sorted(s1.split()))
# Вывод: ['Hello', 'How', 'are', 'you']
# Разбивает строку и сортирует после применения str.lower ко всем элементам
print(sorted(s1.split(), key=str.lower))
# Вывод: ['are', 'Hello', 'How', 'you']
d1 = {'apple': 1, 'Banana': 2, 'Pears': 3}
# Возвращает список ключей, отсортированный по значениям
print(sorted(d1))
# Вывод: ['Banana', 'Pears', 'apple']
# Возвращает список ключей, отсортированный после применения str.lower ко всем элементам
print(sorted(d1, key=str.lower))
# Вывод: ['apple', 'Banana', 'Pears']
2. Пользовательские функции
Также можно указывать свои функции.
Пример №1: по умолчанию сортировка кортежа происходит по первому элементу в нем. Добавим функцию, которая будет возвращать второй элемент кортежа. Теперь и сортировка будет опираться на соответствующий элемент.
# напишем функцию для получения второго элемента
def sort_key(e):
return e[1]
l1 = [(1, 2, 3), (2, 1, 3), (11, 4, 2), (9, 1, 3)]
# По умолчанию сортировка выполняется по первому элементу
print(sorted(l1))
# Вывод: [(1, 2, 3), (2, 1, 3), (9, 1, 3), (11, 4, 2)]
# Сортировка по второму элементу с помощью функции sort_key
print(sorted(l1, key=sort_key))
# Вывод: [(2, 1, 3), (9, 1, 3), (1, 2, 3), (11, 4, 2)]
Пример №2: можно сортировать объекты класса с помощью функций. Вот как это происходит:
- У класса
Studenесть три атрибута:name,rollno,grade. - Создаются три объекта этого класса:
s1,s2,s3. - Создается список
s4, который содержит все три объекта. - Дальше происходит сортировка по этому списку.
- Определенная функция (
sort_key) возвращает атрибутrollno. - В функции sorted эта функция задана для параметра
key. - Теперь
sorted()возвращает список объектовStudent, которые отсортированы по значениюrollno.
class Student:
def __init__(self, name, rollno, grade):
self.name = name
self.rollno = rollno
self.grade = grade
def __repr__(self):
return f"{self.name}-{self.rollno}-{self.grade}"
# Создание объектов
s1 = Student("Paul", 15, "second")
s2 = Student("Alex", 12, "fifth")
s3 = Student("Eva", 21, "first")
s4 = [s1, s2, s3]
# Сортировка списка объектов
# Создание функции, которая вернет rollno объекта
def sort_key(s):
return s.rollno
# сортировка списка объектов без ключевого параметра, вызывает TypeError
print(sorted(s4))
# Вывод: TypeError: '>' not supported between instances of 'Student' and 'Student'
# Сортировка списка объектов по атрибуту: rollno
s5 = sorted(s4, key=sort_key)
print(s5)
# Вывод: [Alex-12-fifth, Paul-15-second, Eva-21-first]
3. Лямбда-функция
Также в качестве ключа можно задать лямбда-функцию. Сортировка будет выполняться по ней.
Пример №1: сортировка списка объектов класса на основе лямбда-функции, переданной для параметра key.
class Student:
def __init__(self, name, rollno, grade):
self.name = name
self.rollno = rollno
self.grade = grade
def __repr__(self):
return f"{self.name}-{self.rollno}-{self.grade}"
# Создание объектов
s1 = Student("Paul", 15, "second")
s2 = Student("Alex", 12, "fifth")
s3 = Student("Eva", 21, "first")
s4 = [s1, s2, s3]
# Сортировка списка объектов
# Создание lambda-функции, которая вернет rollno объекта
s5 = sorted(s4, key=lambda x: x.rollno)
print(s5)
# Вывод: [Alex-12-fifth, Paul-15-second, Eva-21-first]
Пример №2: сортировка кортежей по второму элементу. Лямбда-функция просто возвращает его для каждого переданного объекта.
l1 = [( 1, 2, 3), (3, 1, 1), (8, 5, 3), (3, 4, 2)]
# Сортировка по второму элементу в кортеже.
# Lambda-функция возвращает второй элемент в кортеже.
print(sorted(l1, key=lambda x: x[1]))
# Вывод: [(3, 1, 1), (1, 2, 3), (3, 4, 2), (8, 5, 3)]
4. itemgetter
operator — это встроенный модуль, включающий много операторов. itemgetter(n) создает функцию, которая принимает итерируемый объект (список, кортеж, множество) и возвращает n-элемент из него.
Пример №1: сортировка списка кортежей по третьему элементу в каждом из них. itemgetter() возвращает функцию, которая получает третий элемент в кортеже. По умолчанию если key не указать, то сортировка будет выполнена по первому элементу кортежа.
from operator import itemgetter
l1 = [(1, 2, 3), (3, 1, 1), (8, 5, 3), (3, 4, 2)]
# Сортировка по третьему элементу в кортеже
print(sorted(l1, key=itemgetter(2)))
# Вывод: [(3, 1, 1), (1, 2, 3), (3, 4, 2), (8, 5, 3)]
Пример №2: сортировка списка словарей по ключу age.
from operator import itemgetter
# Создание списка словарей
d1 = [{'name': 'Paul', 'age': 30},
{'name': 'Alex', 'age': 7},
{'name': 'Eva', 'age': 3}]
# Сортировка по key(age) в словаре
print(sorted(d1, key=itemgetter('age')))
# Вывод: [{'name': 'Eva', 'age': 3}, {'name': 'Alex', 'age': 7}, {'name': 'Paul', 'age': 30}]
Пример №3: сортировка значений словаря с помощью itemgetter.
from operator import itemgetter
d = {'a': [1, 2, 3], 'b': [3, 4, 5], 'c': [1, 1, 2]}
print(sorted(d.values(), key=itemgetter(1)))
# Вывод: [[1, 1, 2], [1, 2, 3], [3, 4, 5]]
5. attrgetter
operator.attrgetter(attr)
operator.attrgetter(*attrs)Возвращает вызываемый объект, который получает attr операнда. Если требуется больше одного аргумента, то возвращается кортеж атрибутов. Названия также могут включать троеточия.
Пример: сортировка списка объекта классов с помощью attrgetter. Функция attrgetter может получить атрибут объекта, а функция sorted будет выполнять сортировку на основе этого атрибута.
from operator import attrgetter
class Student:
def __init__(self, name, rollno, grade):
self.name = name
self.rollno = rollno
self.grade = grade
def __repr__(self):
return f"{self.name}-{self.rollno}-{self.grade}"
# Создание объектов
s1 = Student("Paul", 15, "second")
s2 = Student("Alex", 12, "fifth")
s3 = Student("Eva", 21, "first")
s4 = [s1, s2, s3]
# Сортировка списка объектов по атрибуту: rollno
s5 = sorted(s4, key=attrgetter('rollno'))
print(s5)
# Вывод: [Alex-12-fifth, Paul-15-second, Eva-21-first]
Многоуровневая сортировка
- С помощью
itemgetterможно также выполнять сортировку на нескольких уровнях.
В следующем примере сортировка значений словаря будет выполнена по второму элементу. Если же некоторые из них будут равны, то сортировка пройдет по третьему элементу.
from operator import itemgetter
d = {'a': [1, 2, 9], 'b': [3, 2, 5], 'c': [1, 1, 2]}
# Сортировка по второму, затем по третьему элементу
print(sorted(d.values(), key=itemgetter(1, 2)))
# Вывод: [[1, 1, 2], [3, 2, 5], [1, 2, 9]]
- Многоуровневая сортировка с помощью лямбда-функции в
key.
А в этом примере сортировка кортежа будет проходить по второму элементу. В случае равенства используется третий.
l1 = [(1, 2, 3), (4, 2, 0), (2, 1, 7)]
# Сортировка по второму элементу
# Если второй элемент равен, сортировка по третьему элементу.
print(sorted(l1, key=lambda x: x[1:3]))
Сортировка смешанных типов данных
Функция sorted не поддерживает смешанные типы данных. При попытке выполнить сортировку она вернет ошибку TypeError.
# список, содержащий смешанные типы данных
l1 = [1, 'a', 2]
print(sorted(l1))
# Вывод: TypeError: '>' not supported between instances of 'str' and 'int'
Выводы
- При сортировке списка объектов класса параметр
keyявляется обязательным. Если его не указать, то вернется ошибка TypeError. - Для сортировки списка объектов класса можно использовать в качестве параметра
keyопределенную пользователем функцию, лямбда-функцию илиattrgetter. - Функция
sorted()возвращает список. - Метода
sortотсортирует сам оригинальный список. Но функцияsortedвозвращает новый список, не изменяя оригинальный. - Метод
sortиспользуется только для сортировки списка. Его нельзя использовать для строки, кортежа или словаря.
- Введение
В Python все является объектом. И функции — не исключение. Поскольку они тоже являются объектами, их можно передавать в качестве аргументов другим функциям и возвращать в качестве результата. У них также есть атрибуты: __name__ и __doc__.
Функция — это группа инструкций, которые выполняют определенную задачу. Задача функции — организовать код, избежать повторений и заново использовать отдельные блоки.
def function_name(args):
'''docstring'''
statements(s)Синтаксис функций очень простой. Она начинается с ключевого слова def. Дальше идет уникальное имя, параметры и двоеточие. Также может быть документация (docstring), которая описывает назначение функции.
Все инструкции, которые идут дальше, составляют тело функции. Они должны иметь корректные отступы. В конце также может быть инструкция return.
def basic_function(a):
'''Базовая функция'''
print('Базовая функция:', a)
return a + 1
print('старт программы')
print('имя:', basic_function.__name__)
print('док:', basic_function.__doc__)
b = basic_function(1)
print('конец программы:', b)
Вывод:
старт программы
имя: basic_function
док: Базовая функция
Базовая функция: 1
конец программы: 2Функция — это вызываемый объект. Как можно догадаться, это подразумевает объект, который можно вызвать. Проверить эту особенность можно с помощью встроенной функции callable().
Декораторы
Итак, декоратор — это функция, которая принимает функцию, делает что-то и возвращает другую функцию.
def decorator(func):
def wrapper():
print('функция-оболочка')
func()
return wrapper
def basic():
print('основная функция')
wrapped = decorator(basic)
print('старт программы')
basic()
wrapped()
print('конец программы')
Если запустить эту программу:
старт программы
основная функция
функция-оболочка
основная функция
конец программыРазберемся с тем, что здесь произошло. Функция decorator — это, как можно понять по названию, декоратор. Она принимает в качестве параметра функцию func. Крайне оригинальные имена. Внутри функции объявляется другая под названием wrapper. Объявлять ее внутри необязательно, но так проще работать.
В этом примере функция wrapper просто вызывает оригинальную функцию, которая была передана в декоратор в качестве аргумента, но это может быть любая другая функциональность.
В конце возвращается функция wrapper. Напомним, что нам все еще нужен вызываемый объект. Теперь результат можно вызывать с оригинальным набором возможностей, а также новым включенным кодом.
Но в Python есть синтаксис для упрощения такого объявления. Чтобы декорировать функции, используется символ @ рядом с именем декоратора. Он размещается над функцией, которую требуется декорировать.
def decorator(func):
'''Основная функция'''
print('декоратор')
def wrapper():
print('-- до функции', func.__name__)
func()
print('-- после функции', func.__name__)
return wrapper
@decorator
def wrapped():
print('--- обернутая функция')
print('- старт программы...')
wrapped()
print('- конец программы')
Вывод:
декоратор
- старт программы...
-- до функции wrapped
--- обернутая функция
-- после функции wrapped
- конец программыМожно использовать тот же декоратор с любым количеством функций, а также — декорировать функцию любым декоратором.
def decorator_1(func):
print('декоратор 1')
def wrapper():
print('перед функцией')
func()
return wrapper
def decorator_2(func):
print('декоратор 2')
def wrapper():
print('перед функцией')
func()
return wrapper
@decorator_1
@decorator_2
def basic_1():
print('basic_1')
@decorator_1
def basic_2():
print('basic_2')
print('>> старт')
basic_1()
basic_2()
print('>> конец')
Вывод:
декоратор 2
декоратор 1
декоратор 1
>> старт
перед функцией
перед функцией
basic_1
перед функцией
basic_2
>> конецКогда у функции несколько декораторов, они вызываются в обратном порядке относительно того, как были вызваны. То есть, такой вызов:
@decorator_1
@decorator_2
def wrapped():Равен следующему:
a = decorator_1(decorator_2(wrapped))Если декорированная функция возвращает значение, и его нужно сохранить, то нужно сделать так, чтобы его возвращала и функция-обертка.
Декоратор-класс
Добавив метод __call__ в класс, его можно превратить в вызываемый объект. А поскольку декоратор — это всего лишь функция, то есть, вызываемый объект, класс можно превратить в декоратор с помощью функции __call__.
Лучше всего разобрать это на примере.
class Decorator:
def __init__(self, func):
print('> Класс Decorator метод __init__')
self.func = func
def __call__(self):
print('> перед вызовом класса...', self.func.__name__)
self.func()
print('> после вызова класса')
@Decorator
def wrapped():
print('функция wrapped')
print('>> старт')
wrapped()
print('>> конец')
Вывод:
> Класс Decorator метод __init__
>> старт
> перед вызовом класса... wrapped
функция wrapped
> после вызова класса
>> конецОтличие в том, что класс инициализируется при объявлении. Он должен получить функцию в качестве аргумента для метода __init__. Это и будет декорируемая функция.
При вызове декорируемой функции на самом деле вызывается экземпляр класса. А поскольку объект вызываемый, то вызывается функция __call__.
Функция с аргументами
А что если функция, которую требуется декорировать, должна получать аргументы? Для этого нужно вернуть функцию с той же сигнатурой, что и у декорируемой.
def decorator_with_args(func):
print('> декоратор с аргументами...')
def decorated(a, b):
print('до вызова функции', func.__name__)
ret = func(a, b)
print('после вызова функции', func.__name__)
return ret
return decorated
@decorator_with_args
def add(a, b):
print('функция 1')
return a + b
@decorator_with_args
def sub(a, b):
print('функция 2')
return a - b
print('>> старт')
r = add(10, 5)
print('r:', r)
g = sub(10, 5)
print('g:', g)
print('>> конец')
Вывод:
> декоратор с аргументами...
> декоратор с аргументами...
>> старт
до вызова функции add
функция 1
после вызова функции add
r: 15
до вызова функции sub
функция 2
после вызова функции sub
g: 5
>> конецА в случае с классом? Тот же принцип. Нужно лишь добавить желаемую сигнатуру в функцию __call__.
class Decorator:
def __init__(self, func):
print('> Класс Decorator метод __init__')
self.func = func
def __call__(self, a, b):
print('> до вызова из класса...', self.func.__name__)
self.func(a, b)
print('> после вызова из класса')
@Decorator
def wrapped(a, b):
print('функция wrapped:', a, b)
print('>> старт')
wrapped(10, 20)
print('>> конец')
Вывод:
> Класс Decorator метод __init__
>> старт
> до вызова из класса... wrapped
функция wrapped: 10 20
> после вызова из класса
>> конецМожно использовать *args и **kwargs и для функции wrapper, если сигнатура заранее неизвестна, или будут приниматься разные типы функций.
Декораторы с аргументами
В декоратор можно передать и сам параметр. В этом случае нужно добавить еще один слой абстракции, то есть — еще одну функцию-обертку.
Это обязательно, поскольку аргумент передается декоратору. Затем функция, которая вернулась, используется для декорации нужной. Проще разобраться на примере.
def decorator_with_args(name):
print('> decorator_with_args:', name)
def real_decorator(func):
print('>> сам декоратор', func.__name__)
def decorated(*args, **kwargs):
print('>>> перед функцие', func.__name__)
ret = func(*args, **kwargs)
print('>>> после функции', func.__name__)
return ret
return decorated
return real_decorator
@decorator_with_args('test')
def add(a, b):
print('>>>> функция add')
return a + b
print('старт программы')
r = add(10, 10)
print(r)
print('конец программы')
Вывод:
> decorator_with_args: test
>> сам декоратор add
старт программы
>>> перед функцие add
>>>> функция add
>>> после функции add
20
конец программыВ декораторах-классах выполняются такие же настройки. Теперь конструктор класса получает все аргументы декоратора. Метод __call__ должен возвращать функцию-обертку, которая, по сути, будет выполнять декорируемую функцию. Например:
class DecoratorArgs:
def __init__(self, name):
print('> Декоратор с аргументами __init__:', name)
self.name = name
def __call__(self, func):
def wrapper(a, b):
print('>>> до обернутой функции')
func(a, b)
print('>>> после обернутой функции')
return wrapper
@DecoratorArgs("teste")
def add(a, b):
print('функция add:', a, b)
print('>> старт')
add(10, 20)
print('>> конец')
Вывод:
> Декоратор с аргументами __init__: teste
>> старт
>>> до обернутой функции
функция add: 10 20
>>> после обернутой функции
>> конецДокументация
Один из атрибутов функции — строка документации (docstring), доступ к которой можно получить с помощью __doc__. Это строковая константа, определяемая как первая инструкция в объявлении функции.
При декорации возвращается новая функция с другими атрибутами. Но они не изменяются.
def decorator(func):
'''Декоратор'''
def decorated():
'''Функция Decorated'''
func()
return decorated
@decorator
def wrapped():
'''Оборачиваемая функция'''
print('функция wrapped')
print('старт программы...')
print(wrapped.__name__)
print(wrapped.__doc__)
print('конец программы')
В этом примере функция wrapped — это, по сути, функция decorated, которую она заменяет.
старт программы...
decorated
Функция Decorated
конец программыВот где на помощь приходит функция wraps из модуля functools. Она сохраняет атрибуты оригинальной функции. Нужно лишь декорировать функцию wrapper с ее помощью.
from functools import wraps
def decorator(func):
'''Декоратор'''
@wraps(func)
def decorated():
'''Функция Decorated'''
func()
return decorated
@decorator
def wrapped():
'''Оборачиваемая функция'''
print('функция wrapped')
print('старт программы...')
print(wrapped.__name__)
print(wrapped.__doc__)
print('конец программы')
Вывод:
старт программы...
wrapped
Оборачиваемая функция
конец программыПриложения
До этого момента мы не касались того, как декораторы используются в реальных приложения. Поэтому перейдем к примерам.
Таймеры
Базовая функциональность — время работы функции. Есть возможность получить время до и после вызова функции, использовав полученный результат (для записи в лог, базу данных, для отладки и так далее).
from datetime import datetime
import time
def elapsed(func):
def wrapper(a, b, delay=0):
start = datetime.now()
func(a, b, delay)
end = datetime.now()
elapsed = (end - start).total_seconds() * 1000
print(f'>> функция {func.__name__} время выполнения (ms): {elapsed}')
return wrapper
@elapsed
def add_with_delay(a, b, delay=0):
print('сложить', a, b, delay)
time.sleep(delay)
return a + b
print('старт программы')
add_with_delay(10, 20)
add_with_delay(10, 20, 1)
print('конец программы')
Вывод:
старт программы
сложить 10 20 0
>> функция add_with_delay время выполнения (ms): 36.006
сложить 10 20 1
>> функция add_with_delay время выполнения (ms): 1031.255
конец программыЛоги
Еще один распространенный сценарий применения для декоратора — логирование функций.
import logging
def logger(func):
log = logging.getLogger(__name__)
def wrapper(a, b):
log.info("Вызов функции ", func.__name__)
ret = func(a, b)
log.info("Вызвана функция ", func.__name__)
return ret
return wrapper
@logger
def add(a, b):
print('a + b:', a + b)
return a + b
print('>> старт')
add(10, 20)
add(20, 30)
print('>> конец')
Функция обратного вызова
Функция обратного вызова — это функция, которая вызывается при срабатывании определенного события (переходе на страницу, получении сообщения или окончании обработки процессором).
Можно передать функцию, чтобы она выполнилась после определенного события. Это используется, например, в HTTP-серверах в ответ на URL-запросы.
app = {}
def callback(route):
def wrapper(func):
app[route] = func
def wrapped():
ret = func()
return ret
return wrapped
return wrapper
@callback('/')
def index():
print('index')
return 'OK'
print('> старт')
route = app.get('/')
if route:
resp = route()
print('ответ:', resp)
print('> конец')
Проверка состояний
Декораторы можно использовать для проверки состояния перед выполнение функции: например, зарегистрирован ли пользователь, есть ли у него достаточное количество прав или валидны ли аргументы (типы, значения и так далее).
user_permissions = ["user"]
def check_permission(permission):
def wrapper_permission(func):
def wrapped_check():
if permission not in user_permissions:
raise ValueError("Недостаточно прав")
return func()
return wrapped_check
return wrapper_permission
@check_permission("user")
def check_value():
return "значение"
@check_permission("admin")
def do_something():
return "только админ"
print('старт программы')
check_value()
do_something()
print('конец программы')
Вывод:
Traceback (most recent call last):
File "C:\Programs\Python\Python38-32\test.py", line 22, in <module>
do_something()
File "C:\Programs\Python\Python38-32\test.py", line 7, in wrapped_check
raise ValueError("Недостаточно прав")
ValueError: Недостаточно правСоздание singleton
Декоратор можно использовать для декорирования класса. Отличие лишь в том, что декоратор получает класс, а не функцию.
Singleton — это класс с одним экземпляром. Его можно сохранить как атрибут функции-обертки и вернуть при запросе. Это полезно в тех случаях, когда, например, ведется работа с соединением с базой данных.
def singleton(cls):
'''Класс Singleton (один экземпляр)'''
def wrapper_singleton(*args, **kwargs):
if not wrapper_singleton.instance:
wrapper_singleton.instance = cls(*args, **kwargs)
return wrapper_singleton.instance
wrapper_singleton.instance = None
return wrapper_singleton
@singleton
class TheOne:
pass
print('старт')
first_one = TheOne()
second_one = TheOne()
print(id(first_one))
print(id(second_one))
print('конец')
Вывод:
старт
56909912
56909912
конецОбработка ошибок
Можно убедиться, что обрабатываются определенные типы ошибок без использования блока try для каждой функции. Результат после этого добавляется в лог или останавливает выполнение программы.
def error_handler(func):
def wrapper(*args, **kwargs):
ret = 0
try:
ret = func(*args, **kwargs)
except:
print('>> Ошибка в функции', func.__name__)
return ret
return wrapper
@error_handler
def div(a, b):
return a / b
print('старт')
print(div(10, 2))
print(div(10, 0))
print('конец')
Вывод:
старт
5.0
>> Ошибка в функции div
0
конецВыводы
В этом материале была разобрана тема декораторов в Python. Это удобный инструмент, который улучшает код тем, что делает его проще и гибче.
Вот некоторые из особенностей декораторов:
- Их можно использовать повторно.
- Они могут получать параметры и возвращать значения.
- Могут хранить значения/
- Могут декорировать классы.
- Они могут добавлять функциональность в другие функции или классы.
В Python есть встроенные декораторы: classmethod, property и staticmethod.
Декораторы можно использовать и с другими методами (например, «магическими»), чтобы расширить возможности классов и всего проекта.
]]>В этом материале рассмотрим 7 способов запуска кода, написанного на Python. Они будут работать вне зависимости от операционной системы, среды Python или местоположения кода.
Где запускать Python-скрипты и как?
Python-код можно запустить одним из следующих способов:
- С помощью командной строки операционной системы (shell или терминал);
- С помощью конкретной версии Python или Anaconda;
- Использовать Crontab;
- Запустить код с помощью другого Python-скрипта;
- С помощью файлового менеджера;
- Использовать интерактивный режим Python;
- Использовать IDE или редактор кода.
Запуск Python-кода интерактивно
Для запуска интерактивной сессии нужно просто открыть терминал или командную строку и ввести python (или python3 в зависимости от версии). После нажатия Enter запустится интерактивный режим.
Вот как запустить интерактивный режим в разных ОС.
Интерактивный режим в Linux
Откройте терминал. Он должен выглядеть приблизительно вот так :
После нажатия Enter будет запущен интерактивный режим Python.
Интерактивный режим в macOS
На устройствах с macOS все работает похожим образом. Изображение ниже демонстрирует интерактивный режим в этой ОС.
Интерактивный режим в Windows
В Windows нужно открыть командную строку и ввести python. После нажатия Enter появится приблизительно следующее:
Запуск Python-скриптов в интерактивном режиме
В таком режиме можно писать код и исполнять его, чтобы получить желаемый результат или отчет об ошибке. Возьмем в качестве примера следующий цикл.

Этот код должен выводить целые числа от 0 до 5. В данном случае вывод — все, что появилось после print(i).
Для выхода из интерактивного режима нужно написать следующее:
>>> exit()
И нажать Enter. Вы вернетесь в терминал, из которого и начинали.
Есть и другие способы остановки работы с интерактивным режимом Python. В Linux нужно нажать Ctrl + D, а в Windows — Ctrl + Z + Enter.
Стоит отметить, что при использовании этого режима Python-скрипты не сохраняются в локальный файл.
Как выполняются Python-скрипты?
Отличный способ представить, что происходит при выполнении Python-скрипта, — использовать диаграмму ниже. Этот блок представляет собой скрипт (или функцию) Python, а каждый внутренний блок — строка кода.
Первая строка (кода):
Вторая = строка кода
Третья строка > кода:
Четвертая (строка == кода)
Пятая строка кодаПри запуске скрипта интерпретатор Python проходит сверху вниз, выполняя каждую из них. Именно таким образом происходит выполнение кода.
Но и это еще не все.
Блок-схема выполнения кода интерпретатором
- Шаг 1: скрипт или .py-файл компилируется, и из него генерируются бинарные данные. Готовый файл имеет расширение .pyc или .pyo.
- Шаг 2: генерируется бинарный файл. Он читается интерпретатором для выполнения инструкций.
Это набор инструкций, которые приводят к финальному результату.
Иногда полезно изучать байткод. Если вы планируете стать опытным Python-программистом, то важно уметь понимать его для написания качественного кода.
Это также пригодится для принятия решений в процессе. Можно обратить внимание на отдельные факторы и понять, почему определенные функции/структуры данных работают быстрее остальных.
Как запускать Python-скрипты?
Для запуска Python-скрипта с помощью командной строки сначала нужно сохранить код в локальный файл.
Возьмем в качестве примера файл, который был сохранен как python_script.py. Сохранить его можно вот так:
- Создать Python-скрипт из командной строки и сохранить его,
- Создать Python-скрипт с помощью текстового редактора или IDE и сохранить его. Просто создайте файл, добавьте код и сохраните как «python_script.py»
Сохранить скрипт в текстовом редакторе достаточно легко. Процесс ничем не отличается от сохранения простого текстового файла.
Но если использовать командную строку, то здесь нужны дополнительные шаги. Во-первых, в самом терминале нужно перейти в директорию, где должен быть сохранен файл. Оказавшись в нужной папке, следует выполнить следующую команду (на linux):
sudo nano python_script.pyПосле нажатия Enter откроется интерфейс командной строки, который выглядит приблизительно следующим образом:
Теперь можно писать код и с легкостью сохранять его прямо в командной строке.
Как запускать скрипт в командной строке?
Скрипты можно запустить и с помощью команды Python прямо в интерфейсе терминала. Для этого нужно убедиться, что вы указали путь до него или находитесь в той же папке. Для выполнения скрипта (python_script.py) откройте командную строку и напишите python3 python_script.py.
Замените python3 на python, если хотите использовать версию Python2.x.
Вот что будет храниться в самом файле python_script.py:
for i in range(0,5):
print(i)
Вывод в командной строке будет следующим:
~$ python python_script.py
0
1
2
3
4Предположим, что нужно сохранить вывод этого года (0, 1, 2, 3, 4). Для этого можно использовать оператор pipe.
Это делается вот так:
python python_script.py > newfile.txtПосле этого будет создан файл «newfile.txt» с сохраненным выводом.
Как выполнять код интерактивно
Есть больше 4 способов запустить Python-скрипт интерактивно. Рассмотрим их все подробно.
Использование import для запуска скриптов
Импорт модулей для загрузки скриптов и библиотек используется постоянно. Можно даже написать собственный скрипт (например code1.py) и импортировать его в другой файл без необходимости повторять то же самое.
Вот как нужно импортировать code1.py в новом скрипте.
>>> import code1
Но таким образом импортируется все содержимое файла code1.py. Это не проблема до тех пор, пока не появляется необходимость, в том, чтобы код был оптимизирован и быстро работал.
Предположим, что внутри файла есть маленькая функция, например chart_code1(), которая рисует красивый график. И нужна только она. Вместо того чтобы взывать весь скрипт целиком, можно вызвать ее.
Вот как это обычно делается.
>>> from code1 import chart_code1
Теперь появляется возможность использовать chart_code1 в новом файле так, будто бы эта функция была написана здесь.
Использование importlib для запуска кода
import_module() из importlib позволяет импортировать и исполнять другие Python-скрипты.
Это работает очень просто. Для скрипта code1.py нужно сделать следующее:
import importlib
import.import_module('code1')
И нет необходимости добавлять .py в import_module().
Разберем случай, когда есть сложная структура папок, и нужно использовать importlib. Предположим, что структура следующая:
level1 | +– __init__.py – level2 | +– __init__.py – level3.py
В таком случае, написав, например, importlib.import_module("level3"), вы получите ошибку. Это называется относительным импортом и работает за счет явного использования относительного пути.
Так, для запуска скрипта level3.py можно написать так:
importlib.import_module('.level3', 'level1.level')
# или так
importlib.import_module('level1.level2.level3')
Запуск кода с помощью runpy
Модуль runpy ищет и исполняет Python-скрипт без импорта. Он также легко используется, ведь достаточно просто вызывать имя модуля в run_module().
Вот как, например, выполнить code1.py с помощью runpy.
>>> import runpy
>>> runpy.run_module(mod_name="code1")
Запуск кода динамически
Рассмотрим функцию exec(), которая также используется для динамического выполнения скриптов. В Python2 эта функция была инструкцией.
Вот как она помогает выполнять код динамически на примере строки.
>>> print_the_string = 'print("Выполнен динамический код")'
>>> exec(print_the_string)
Однако этот способ уже устарел. Он медленный и непредсказуемый, а Python предлагает массу других вариантов.
Запуск скриптов Python из текстового редактора
Для запуска кода с помощью текстового редактора можно использовать команду по умолчанию (run) или горячие клавиши (Function + F5 или просто F5 в зависимости от ОС).
Вот пример того, как код выполняется в IDLE.
Но стоит обратить внимание на то, что в данном случае нет контроля над виртуальной средой, как это бывает при исполнении с помощью интерфейса командной строки.
Поэтому IDE и продвинутые редакторы текста куда лучше базовых редакторов.
Запуск кода из IDE
IDE можно использовать не только для запуска Python-кода, но также для выбора среды и отладки.
Интерфейс этих программ может отличаться, но список возможностей должен совпадать: сохранение, запуск и редактирование кода.
Запуск кода из файлового менеджера
Что если бы был способ запустить Python-скрипт двойным кликом по файлу с ним. Это можно сделать, создав исполняемый файл. Например, в случае с Windows для этого достаточно создать файл с расширением .exe и запустить его двойным кликом.
Как запустить Python-скрипт из другого кода
Хотя об этом явно не говорилось, можно прийти к выводу, что в случае с Python есть возможность:
- Запустить скрипт в командной строке, и этот скрипт будет вызывать другой код;
- Использовать модуль для загрузки другого скрипта.
Основные моменты
- Python-код можно писать в интерактивном и не-интерактивном режимах. При выходе из интерактивного режима вы теряете данные. Поэтому лучше использовать
sudo nano your_python_filename.py. - Код можно запускать с помощью IDE, редактора кода или командной строки.
- Есть разные способы импорта кода и использования его из другого скрипта. Выбирайте вдумчиво, рассматривая все преимущества и недостатки.
- Python читает написанный код, транслирует его в байткод, который затем используется как инструкция — все это происходит при запуске скрипта. Поэтому важно учиться использовать байткод для оптимизации Python-кода.
SQL и Python — обязательные инструменты для любого специалиста в сфере анализа данных. Это руководство — все, что вам нужно для первоначальной настройки и освоения основ работы с SQLite в Python. Оно включает следующие пункты:
- Загрузка библиотеки
- Создание и соединение с базой данных
- Создание таблиц базы данных
- Добавление данных
- Запросы на получение данных
- Удаление данных
- И многое другое!
SQLite3 (часто говорят просто SQLite) — это часть стандартного пакета Python 3, поэтому ничего дополнительно устанавливать не придется.
Что будем создавать
В процессе этого руководства создадим базу данных в SQLite с помощью Python, несколько таблиц и настроим отношения:

Типы данных SQLite в Python
SQLite для Python предлагает меньше типов данных, чем есть в других реализациях SQL. С одной стороны, это накладывает ограничения, но, с другой стороны, в SQLite многое сделано проще. Вот основные типы:
NULL— значениеNULLINTEGER— целое числоREAL— число с плавающей точкойTEXT— текстBLOB— бинарное представление крупных объектов, хранящееся в точности с тем, как его ввели
К сожалению, других привычных для SQL типов данных в SQLite нет.
Первые шаги с SQLite в Python
Начнем руководство с загрузки библиотеки. Для этого нужно использовать следующую команду:
import sqlite3
Следующий шаг — создание базы данных.
Создание базы данных SQLite в Python
Есть несколько способов создания базы данных в Python с помощью SQLite. Для этого используется объект Connection, который и представляет собой базу. Он создается с помощью функции connect().
Создадим файл .db, поскольку это стандартный способ управления базой SQLite. Файл будет называться orders.db. За соединение будет отвечать переменная conn.
conn = sqlite3.connect('orders.db')
Эта строка создает объект connection, а также новый файл orders.db в рабочей директории. Если нужно использовать другую, ее нужно обозначить явно:
conn = sqlite3.connect(r'ПУТЬ-К-ПАПКИ/orders.db')
Если файл уже существует, то функция connect осуществит подключение к нему.
перед строкой с путем стоит символ «r». Это дает понять Python, что речь идет о «сырой» строке, где символы «/» не отвечают за экранирование.
Функция connect создает соединение с базой данных SQLite и возвращает объект, представляющий ее.
Резидентная база данных
Еще один способ создания баз данных с помощью SQLite в Python — создание их в памяти. Это отличный вариант для тестирования, ведь такие базы существуют только в оперативной памяти.
conn = sqlite3.connect(:memory:)
Однако в большинстве случаев (и в этом руководстве) будет использоваться описанный до этого способ.
Создание объекта cursor
После создания объекта соединения с базой данных нужно создать объект cursor. Он позволяет делать SQL-запросы к базе. Используем переменную cur для хранения объекта:
cur = conn.cursor()
Теперь выполнять запросы можно следующим образом:
cur.execute("ВАШ-SQL-ЗАПРОС-ЗДЕСЬ;")
Обратите внимание на то, что сами запросы должны быть помещены в кавычки — это важно. Это могут быть одинарные, двойные или тройные кавычки. Последние используются в случае особенно длинных запросов, которые часто пишутся на нескольких строках.
Создание таблиц в SQLite в Python
Пришло время создать первую таблицу в базе данных. С объектами соединения (conn) и cursor (cur) это можно сделать. Будем следовать этой схеме.
Начнем с таблицы users.
cur.execute("""CREATE TABLE IF NOT EXISTS users(
userid INT PRIMARY KEY,
fname TEXT,
lname TEXT,
gender TEXT);
""")
conn.commit()
В коде выше выполняются следующие операции:
- Функция
executeотвечает за SQL-запрос - SQL генерирует таблицу
users IF NOT EXISTSпоможет при попытке повторного подключения к базе данных. Запрос проверит, существует ли таблица. Если да — проверит, ничего ли не поменялось.- Создаем первые четыре колонки:
userid,fname,lnameиgender.Userid— это основной ключ. - Сохраняем изменения с помощью функции
commitдля объекта соединения.
Для создания второй таблицы просто повторим последовательность действий, используя следующие команды:
cur.execute("""CREATE TABLE IF NOT EXISTS orders(
orderid INT PRIMARY KEY,
date TEXT,
userid TEXT,
total TEXT);
""")
conn.commit()
После исполнения этих двух скриптов база данных будет включать две таблицы. Теперь можно добавлять данные.
Добавление данных с SQLite в Python
По аналогии с запросом для создания таблиц для добавления данных также нужно использовать объект cursor.
cur.execute("""INSERT INTO users(userid, fname, lname, gender)
VALUES('00001', 'Alex', 'Smith', 'male');""")
conn.commit()
В Python часто приходится иметь дело с переменными, в которых хранятся значения. Например, это может быть кортеж с информацией о пользователе.
user = ('00002', 'Lois', 'Lane', 'Female')
Если его нужно загрузить в базу данных, тогда подойдет следующий формат:
cur.execute("INSERT INTO users VALUES(?, ?, ?, ?);", user)
conn.commit()
В данном случае все значения заменены на знаки вопроса и добавлен параметр, содержащий значения, которые нужно добавить.
Важно заметить, что SQLite ожидает получить значения в формате кортежа. Однако в переменной может быть и список с набором кортежей. Таким образом можно добавить несколько пользователей:
more_users = [('00003', 'Peter', 'Parker', 'Male'), ('00004', 'Bruce', 'Wayne', 'male')]
Но нужно использовать функцию executemany вместо обычной execute:
cur.executemany("INSERT INTO users VALUES(?, ?, ?, ?);", more_users)
conn.commit()
Если применить execute, то функция подумает, то пользователь хочет передать в таблицу два объекта (два кортежа), а не два кортежа, каждый из которых содержит по 4 значения для каждого пользователя. Хотя в первую очередь вообще должна была возникнуть ошибка.
SQLite и предотвращение SQL-инъекций
Использование способа с вопросительными знаками (?, ?, …) также помогает противостоять SQL-инъекциям. Поэтому рекомендуется использовать его, а не упомянутый до этого.
Скрипты для загрузки данных
Следующие скрипты можно скопировать и вставить для добавления данных в обе таблицы:
customers = [
('00005', 'Stephanie', 'Stewart', 'female'), ('00006', 'Sincere', 'Sherman', 'female'), ('00007', 'Sidney', 'Horn', 'male'),
('00008', 'Litzy', 'Yates', 'female'), ('00009', 'Jaxon', 'Mills', 'male'), ('00010', 'Paul', 'Richard', 'male'),
('00011', 'Kamari', 'Holden', 'female'), ('00012', 'Gaige', 'Summers', 'female'), ('00013', 'Andrea', 'Snow', 'female'),
('00014', 'Angelica', 'Barnes', 'female'), ('00015', 'Leah', 'Pitts', 'female'), ('00016', 'Dillan', 'Olsen', 'male'),
('00017', 'Joe', 'Walsh', 'male'), ('00018', 'Reagan', 'Cooper', 'male'), ('00019', 'Aubree', 'Hogan', 'female'),
('00020', 'Avery', 'Floyd', 'male'), ('00021', 'Elianna', 'Simmons', 'female'), ('00022', 'Rodney', 'Stout', 'male'),
('00023', 'Elaine', 'Mcintosh', 'female'), ('00024', 'Myla', 'Mckenzie', 'female'), ('00025', 'Alijah', 'Horn', 'female'),
('00026', 'Rohan', 'Peterson', 'male'), ('00027', 'Irene', 'Walters', 'female'), ('00028', 'Lilia', 'Sellers', 'female'),
('00029', 'Perla', 'Jefferson', 'female'), ('00030', 'Ashley', 'Klein', 'female')
]
orders = [
('00001', '2020-01-01', '00025', '178'), ('00002', '2020-01-03', '00025', '39'), ('00003', '2020-01-07', '00016', '153'),
('00004', '2020-01-10', '00015', '110'), ('00005', '2020-01-11', '00024', '219'), ('00006', '2020-01-12', '00029', '37'),
('00007', '2020-01-14', '00028', '227'), ('00008', '2020-01-18', '00010', '232'), ('00009', '2020-01-22', '00016', '236'),
('00010', '2020-01-26', '00017', '116'), ('00011', '2020-01-28', '00028', '221'), ('00012', '2020-01-31', '00021', '238'),
('00013', '2020-02-02', '00015', '177'), ('00014', '2020-02-05', '00025', '76'), ('00015', '2020-02-08', '00022', '245'),
('00016', '2020-02-12', '00008', '180'), ('00017', '2020-02-14', '00020', '190'), ('00018', '2020-02-18', '00030', '166'),
('00019', '2020-02-22', '00002', '168'), ('00020', '2020-02-26', '00021', '174'), ('00021', '2020-02-29', '00017', '126'),
('00022', '2020-03-02', '00019', '211'), ('00023', '2020-03-05', '00030', '144'), ('00024', '2020-03-09', '00012', '112'),
('00025', '2020-03-10', '00006', '45'), ('00026', '2020-03-11', '00004', '200'), ('00027', '2020-03-14', '00015', '226'),
('00028', '2020-03-17', '00030', '189'), ('00029', '2020-03-20', '00004', '152'), ('00030', '2020-03-22', '00026', '239'),
('00031', '2020-03-23', '00012', '135'), ('00032', '2020-03-24', '00013', '211'), ('00033', '2020-03-27', '00030', '226'),
('00034', '2020-03-28', '00007', '173'), ('00035', '2020-03-30', '00010', '144'), ('00036', '2020-04-01', '00017', '185'),
('00037', '2020-04-03', '00009', '95'), ('00038', '2020-04-06', '00009', '138'), ('00039', '2020-04-10', '00025', '223'),
('00040', '2020-04-12', '00019', '118'), ('00041', '2020-04-15', '00024', '132'), ('00042', '2020-04-18', '00008', '238'),
('00043', '2020-04-21', '00003', '50'), ('00044', '2020-04-25', '00019', '98'), ('00045', '2020-04-26', '00017', '167'),
('00046', '2020-04-28', '00009', '215'), ('00047', '2020-05-01', '00014', '142'), ('00048', '2020-05-05', '00022', '173'),
('00049', '2020-05-06', '00015', '80'), ('00050', '2020-05-07', '00017', '37'), ('00051', '2020-05-08', '00002', '36'),
('00052', '2020-05-10', '00022', '65'), ('00053', '2020-05-14', '00019', '110'), ('00054', '2020-05-18', '00017', '36'),
('00055', '2020-05-21', '00008', '163'), ('00056', '2020-05-24', '00024', '91'), ('00057', '2020-05-26', '00028', '154'),
('00058', '2020-05-30', '00022', '130'), ('00059', '2020-05-31', '00017', '119'), ('00060', '2020-06-01', '00024', '137'),
('00061', '2020-06-03', '00017', '206'), ('00062', '2020-06-04', '00013', '100'), ('00063', '2020-06-05', '00021', '187'),
('00064', '2020-06-09', '00025', '170'), ('00065', '2020-06-11', '00011', '149'), ('00066', '2020-06-12', '00007', '195'),
('00067', '2020-06-14', '00015', '30'), ('00068', '2020-06-16', '00002', '246'), ('00069', '2020-06-20', '00028', '163'),
('00070', '2020-06-22', '00005', '184'), ('00071', '2020-06-23', '00022', '68'), ('00072', '2020-06-27', '00013', '92'),
('00073', '2020-06-30', '00022', '149'), ('00074', '2020-07-04', '00002', '65'), ('00075', '2020-07-05', '00017', '88'),
('00076', '2020-07-09', '00007', '156'), ('00077', '2020-07-13', '00010', '26'), ('00078', '2020-07-16', '00008', '55'),
('00079', '2020-07-20', '00019', '81'), ('00080', '2020-07-22', '00011', '78'), ('00081', '2020-07-23', '00026', '166'),
('00082', '2020-07-27', '00014', '65'), ('00083', '2020-07-30', '00021', '205'), ('00084', '2020-08-01', '00026', '140'),
('00085', '2020-08-05', '00006', '236'), ('00086', '2020-08-06', '00021', '208'), ('00087', '2020-08-07', '00021', '169'),
('00088', '2020-08-08', '00004', '157'), ('00089', '2020-08-11', '00017', '71'), ('00090', '2020-08-13', '00025', '89'),
('00091', '2020-08-16', '00014', '249'), ('00092', '2020-08-18', '00012', '59'), ('00093', '2020-08-19', '00013', '121'),
('00094', '2020-08-20', '00025', '179'), ('00095', '2020-08-22', '00017', '208'), ('00096', '2020-08-26', '00024', '217'),
('00097', '2020-08-28', '00004', '206'), ('00098', '2020-08-30', '00017', '114'), ('00099', '2020-08-31', '00017', '169'),
('00100', '2020-09-02', '00022', '226')
]
Используйте следующие запросы:
cur.executemany("INSERT INTO users VALUES(?, ?, ?, ?);", customers)
cur.executemany("INSERT INTO orders VALUES(?, ?, ?, ?);", orders)
conn.commit()
Получение данных с SQLite в Python
Следующий момент касательно SQLite в Python — выбор данных. Структура формирования запроса та же, но к ней будет добавлен еще один элемент.
Использование fetchone() в SQLite в Python
Начнем с использования функции fetchone(). Создадим переменную one_result для получения только одного результата:
cur.execute("SELECT * FROM users;")
one_result = cur.fetchone()
print(one_result)
Она вернет следующее:
[(1, 'Alex', 'Smith', 'male')]
Использование fetchmany() в SQLite в Python
Если же нужно получить много данных, то используется функция fetchmany(). Выполним другой скрипт для генерации 3 результатов:
cur.execute("SELECT * FROM users;")
three_results = cur.fetchmany(3)
print(three_results)
Он вернет следующее:
[(1, 'Alex', 'Smith', 'male'), (2, 'Lois', 'Lane', 'Female'), (3, 'Peter', 'Parker', 'Male')]
Использование fetchall() в SQLite в Python
Функцию fetchall() можно использовать для получения всех результатов. Вот что будет, если запустить скрипт:
cur.execute("SELECT * FROM users;")
all_results = cur.fetchall()
print(all_results)
Удаление данных в SQLite в Python
Теперь рассмотрим процесс удаления данных с SQLite в Python. Здесь та же структура. Предположим, нужно удалить любого пользователя с фамилией «Parker». Напишем следующее:
cur.execute("DELETE FROM users WHERE lname='Parker';")
conn.commit()
Если затем сделать следующей запрос:
cur.execute("select * from users where lname='Parker'")
print(cur.fetchall())
Будет выведен пустой список, подтверждающий, что запись удалена.
Объединение таблиц в SQLite в Python
Наконец, посмотрим, как использовать объединение данных для более сложных запросов. Предположим, нужно сгенерировать запрос, включающий имя и фамилию каждого покупателя заказа.
Для этого напишем следующее:
cur.execute("""SELECT *, users.fname, users.lname FROM orders
LEFT JOIN users ON users.userid=orders.userid;""")
print(cur.fetchall())
Тот же подход работает с другими SQL-операциями.
Выводы
В этом материале вы узнали все, что требуется для работы с SQLite в Python: загрузка библиотеки, создание баз и таблиц, добавление, запрос и удаление данных.
]]>В этой статье вы узнаете о том, что такое лямбда-функции в Python. На самом деле, если вы знаете, что такое функции и умеете с ними работать, то знаете и что такое лямбда.
Лямбда-функция в Python — это просто функция Python. Но это некий особенный тип с ограниченными возможностями. Если есть желание погрузиться глубже и узнать больше, то эта статья целиком посвящена lambda.
Что такое лямбда в Python?
Прежде чем переходить как разбору понятия лямбда в Python, попробуем понять, чем является обычная функция Python на более глубоком уровне.
Для этого потребуется немного поменять направление мышление. Как вы знаете, все в Python является объектом.
Например, когда мы запускаем эту простейшую строку кода
x = 5
Создается объект Python типа int, который сохраняет значение 5. x же является символом, который ссылается на объект.
Теперь проверим тип x и адрес, на которой он ссылается. Это можно сделать с помощью встроенных функций type и id.
>>> type(x)
<class 'int'>
>>> id(x)
4308964832
В итоге x ссылается на объект типа int, а расположен он по адресу, который вернула функция id.
Просто и понятно.
А что происходит при определении вот такой функции:
>>> def f(x):
... return x * x
...
Повторим упражнение и узнаем type и id объекта f.
>>> def f(x):
... return x * x
...
>>> type(f)
<class 'function'>
>>> id(f)
4316798080
Оказывается, в Python есть класс function, а только что определенная функция f — это его экземпляр. Так же как x был экземпляром класса integer. Другими словами, о функциях можно думать как о переменных. Разница лишь в том, что переменные хранят данные, а функции — код.
Это же значит, что функции можно передать в качестве аргументов другим функциям или даже использовать их как тип возвращаемого значения.
Рассмотрим простой пример, где функция f передается другой функции.
def f(x):
return x * x
def modify_list(L, fn):
for idx, v in enumerate(L):
L[idx] = fn(v)
L = [1, 3, 2]
modify_list(L, f)
print(L)
#вывод: [1, 9, 4]
Попробуйте разобраться самостоятельно с тем, что делает этот код, прежде чем читать дальше.
Итак, modify_list — это функция, которая принимает список L и функцию fn в качестве аргументов. Затем она перебирает список элемент за элементом и применяет функцию к каждому из них.
Это общий способ изменения объектов списка, ведь он позволяет передать функцию, которая займется преобразованием. Так, если передать modify_list функцию f, то результатом станет список, где все значения будут возведены в квадрат.
Но можно передать и любую другую, которая изменит оригинальный список другим способом. Это очень мощный инструмент.
Теперь, когда с основами разобрались, стоит перейти к лямбда. Лямбда в Python — это просто еще один способ определения функции. Вот базовый синтаксис лямбда-функции в Python:
lambda arguments: expression
Лямбда принимает любое количество аргументов (или ни одного), но состоит из одного выражения. Возвращаемое значение — значение, которому присвоена функция. Например, если нужно определить функцию f из примера выше, то это можно сделать вот так:
>>> f = lambda x: x * x
>>> type(f)
<class 'function'>
Но возникает вопрос: а зачем нужны лямбда-функции, если их можно объявлять традиционным образом? Но на самом деле, они полезны лишь в том случае, когда нужна одноразовая функция. Такие функции еще называют анонимными. И, как вы увидите дальше, есть масса ситуаций, где они оказываются нужны.
Лямбда с несколькими аргументами
Определить лямбда-функцию с одним аргументом не составляет труда.
>>> f = lambda x: x * x
>>> f(5)
25
А если их должно быть несколько, то достаточно лишь разделить значения запятыми. Предположим, что нужна функция, которая берет два числовых аргумента и возвращает их произведение.
>>> f = lambda x, y: x * y
>>> f(5, 2)
10
Отлично! А как насчет лямбда-функции без аргументов?
Лямбда-функция без аргументов
Допустим, нужно создать функцию без аргументов, которая бы возвращала True. Этого можно добиться с помощью следующего кода.
>>> f = lambda: True
>>> f()
True
Несколько лямбда-функций
В определенный момент возникнет вопрос: а можно ли иметь лямбда-функцию из нескольких строк.
Ответ однозначен: нет.
Лямбда-функции в Python всегда принимают только одно выражение. Если же их несколько, то лучше создать обычную функцию.
Примеры лямбда-функций
Теперь рассмотрим самые распространенные примеры использования лямбда-функций.
Лямбда-функция и map
Распространенная операция со списками в Python — применение операции к каждому элементу.
map() — это встроенная функция Python, принимающая в качестве аргумента функцию и последовательность. Она работает так, что применяет переданную функцию к каждому элементу.
Предположим, есть список целых чисел, которые нужно возвести в квадрат с помощью map.
>>> L = [1, 2, 3, 4]
>>> list(map(lambda x: x**2, L))
[1, 4, 9, 16]
Обратите внимание на то, что в Python3 функция map возвращает объект Map, а в Python2 — список.
Так, вместо определения функции и передачи ее в map в качестве аргумента, можно просто использовать лямбда для быстрого определения ее прямо внутри. В этом есть смысл, если упомянутая функция больше не будет использоваться в коде.
Вот еще один пример.
Лямбда-функция и filter
filter() — это еще одна встроенная функция, которая фильтрует последовательность итерируемого объекта.
Другими словами, функция filter отфильтровывает некоторые элементы итерируемого объекта (например, списка) на основе какого-то критерия. Критерий определяется за счет передачи функции в качестве аргумента. Она же применяется к каждому элементу объекта.
Если возвращаемое значение — True, элемент остается. В противном случае — отклоняется. Определим, например, простую функцию, которая возвращает True для четных чисел и False — для нечетных:
def even_fn(x):
if x % 2 == 0:
return True
return False
print(list(filter(even_fn, [1, 3, 2, 5, 20, 21])))
#вывод: [2, 20]
С лямбда-функциями это все можно сделать максимально сжато. Код выше можно преобразовать в такой, написанный в одну строку.
print(list(filter(lambda x: x % 2 == 0, [1, 3, 2, 5, 20, 21])))
И в этом сила лямбда-функций.
Лямбда-функция и сортировка списков
Сортировка списка — базовая операция в Python. Если речь идет о списке чисел или строк, то процесс максимально простой. Подойдут встроенные функции sort и sorted.
Но иногда имеется список кастомных объектов, сортировать которые нужно на основе значений одного из полей. В таком случае можно передать параметр key в sort или sorted. Он и будет являться функцией.
Функция применяется ко всем элементам объекта, а возвращаемое значение — то, на основе чего выполнится сортировка. Рассмотрим пример. Есть класс Employee.
class Employee:
def __init__(self, name, age):
self.name = name
self.age = age
Теперь создадим экземпляры этого класса и добавим их в список.
Alex = Employee('Alex', 20)
Amanda = Employee('Amanda', 30)
David = Employee('David', 15)
L = [Alex, Amanda, David]
Предположим, что мы хотим отсортировать его на основе поля age сотрудников. Вот что нужно сделать для этого:
L.sort(key=lambda x: x.age)
print([item.name for item in L])
# вывод: ['David', 'Alex', 'Amanda']
Лямбда-выражение было использовано в качестве параметра key вместо отдельного ее определения и затем передачи в функцию sort.
Пара слов о выражениях и инструкциях
Как уже упоминалось, лямбда могут иметь только одно выражение (expression) в теле.
Обратите внимание, что речь идет не об инструкции (statement).
Выражение и инструкции — две разные вещи, в которых часто путаются. В программировании инструкцией является строка кода, выполняющая что-то, но не генерирующая значение.
Например, инструкция if или циклы for и while являются примерами инструкций. Заменить инструкцию на значение попросту невозможно.
А вот выражения — это значения. Запросто можно заменить все выражения в программе на значения, и программа продолжит работать корректно.
Например:
3 + 5— выражение со значением 810 > 5— выражение со значением TrueTrue and (5 < 3)— выражение со значением False
Тело лямбда-функции должно являться выражением, поскольку его значение будет тем, что она вернет. Обязательно запомните это для работы с лямбда-функциями в будущем.
]]>Получение и обработка информации — один из важнейших элементов любого языка программирования, особенно если речь идет о получении информации от пользователей.
Python, будучи медленным относительно таких языков, как C или Java, предлагает продвинутые инструменты для получения, анализа и обработки данных от конечного пользователя.
В этом материале речь пойдет о том, какие функции Python можно использовать для этих целей.
Ввод в Python
Для получения информации с клавиатуры в Python есть функции input() или raw_input() (о разнице между ними чуть позже). У них есть опциональный параметр prompt, который является выводимой строкой при вызове функции.
Когда input() или raw_input() вызываются, поток программы останавливается до тех пор, пока пользователь не введет данные через командную строку. Для ввода нужно нажать Enter после завершения набора текста. Обычно Enter добавляет символ новой строки (\n), но не в этом случае. Введенная строка просто будет передана приложению.
Интересно, что кое-что поменялось в принципе работе функции между Python 2 и Python 3, что отразилось в разнице между input() и raw_input(). Об этом дальше.
Сравнение функций input и raw_input
Разница между этими функциями зависит от версии Python. Так, в Python 2 функция raw_input() используется для получения ввода от пользователя через командную строку, а input() оценивает ее и попробует запустить как код Python.
В Python 3 от raw_input() избавились, оставив только input(). Она используется для получения ввода пользователя с клавиатуры. Возможности input() из Python 2 в Python 3 работать не будут. Для той же операции нужно использовать инструкцию eval(input()).
Взгляните на пример функции raw_input в Python 2.
# Python 2
txt = raw_input("Введите что-нибудь, чтобы проверить это: ")
print "Это то, что вы только что ввели?", txt
Вывод
Введите что-нибудь, чтобы проверить это: Привет, мир!
Это то, что вы только что ввели? Привет, мир!
А вот как она работает в Python 3
# Python 3
txt = input("Введите что-нибудь, чтобы проверить это: ")
print("Это то, что вы только что ввели?", txt)
Вывод
Введите что-нибудь, чтобы проверить это: Привет, мир 3!
Это то, что вы только что ввели? Привет, мир 3!
Дальше в материале будет использоваться метод input из Python 3, если не указано другое.
Строковый и числовой ввод
По умолчанию функция input() конвертирует всю получаемую информацию в строку. Прошлый пример продемонстрировал это.
С числами нужно работать отдельно, поскольку они тоже изначально являются строками. Следующий пример показывает, как можно получить информацию числового типа:
# Ввод запрашивается и сохраняется в переменной
test_text = input ("Введите число: ")
# Преобразуем строку в целое число.
# функция float() используется вместо int(),
# для преобразования пользовательского ввода в десятичный формат,
test_number = int(test_text)
# Выводим в консоль переменную
print ("Введенное число: ", test_number)
Вывод
Введите число: 13
Введенное число: 13
Того же можно добиться и таким образом:
test_number = int(input("Введите число: "))
Здесь сразу после сохранения ввода происходит преобразование и присваивание значения переменной.
Нужно лишь отметить, что если пользователь ввел не целое число, то код вернет исключение (даже если это число с плавающей точкой).
Обработка исключений ввода
Есть несколько способов, как можно удостовериться в том, что пользователь ввел корректные данные. Один из них — перехватывать все возможные ошибки, которые могут возникнуть.
Вот такой код считается небезопасным:
test2word = input("Сколько вам лет? ")
test2num = int(test2word)
print("Ваш возраст ", test2num)
Запустим его и введем следующее:
Сколько вам лет? Пять
При вызове функции int() со строкой Пять появится исключение ValueError, и программа остановит работу.
Вот как можно сделать код безопаснее и обработать ввод:
test3word = input("Введите свое счастливое число: ")
try:
test3num = int(test3word)
print("Это правильный ввод! Ваше счастливое число: ", test3num)
except ValueError:
print("Это не правильный ввод. Это не число вообще! Это строка, попробуйте еще раз.")
Этот блок оценит ввод. Если он является целым числом, представленным в виде строки, то функция input() конвертирует его в целое число. Если нет, то программа выдаст исключение, но вместо ошибки оно будет перехвачено. В результате вызовется вторая инструкция print.
Вот так будет выглядеть вывод с исключением.
Введите свое счастливое число: Семь
Это не правильный ввод. Это не число вообще! Это строка, попробуйте еще раз.
Такой код можно объединить с другой конструкцией, например, циклом for, чтобы убедиться, что код будет выполняться постоянно, до тех пор, пока пользователь не введет те данные, которые требуются.
Полный пример
# Создадим функцию для демонстрации примера
def example():
# Бесконечный цикл, который продолжает выполняться
# до возникновения исключения
while True:
test4word = input("Как вас зовут? ")
try:
test4num = int(input("Сколько часов вы играете на своем мобильном телефоне?" ))
# Если полученный ввод не число, будет вызвано исключение
except ValueError:
# Цикл будет повторяться до правильного ввода
print("Error! Это не число, попробуйте снова.")
# При успешном преобразовании в целое число,
# цикл закончится.
else:
print("Впечатляет, ", test4word, "! Вы тратите", test4num*60, "минут или", test4num*60*60, "секунд на игры в своем телефоне!")
break
# Вызываем функцию
example()
Вывод:
Как вас зовут? Александр
Сколько часов вы играете на своем мобильном телефоне? 3
Впечетляет, Александр! Вы тратите 180 минут или 10800 секунд на игры в своем телефоне!
Выводы
В этой статье вы узнали, как встроенные инструменты Python используются для получения пользовательского ввода в разных форматах. Также научились обрабатывать исключения и ошибки, которые могут возникнуть в процессе.
]]>Конструкции dataclass доступны в Python 3.7 и старше. Их можно использовать как контейнеры данных и не только. Конструкции dataclass позволяют писать шаблонный код и упрощают процесс создания классов, ведь в них для этого есть специальные методы.
Первый Dataclass
Создадим DataClass, представляющий собой точку в трехмерной системе координат.
Декоратор @dataclass используется для создания Data Class. x, y и z являются его полями. Стоит отметить, что с ними необходимо использовать определения типов данных. При этом они не являются объявлениями статического типа, и кто угодно может передать данные любого типа кроме int полям x, y или z.
from dataclasses import dataclass
@dataclass
class Coordinate:
x: int
y: int
z: int
По умолчанию у Data Class есть методы __init__, __repr__ и __eq__, поэтому их не нужно реализовывать самостоятельно.
И пусть __init__, __repr__ и __eq__ не реализованы в классе Coordinate их по-прежнему можно использовать благодаря dataclass. Это здорово экономит время.
from dataclasses import dataclass
@dataclass
class Coordinate:
x: int
y: int
z: int
a = Coordinate(4, 5, 3)
print(a) # результат: Coordinate(x=4, y=5, z=3)
Значения по умолчанию для полей
Полям можно присваивать значения по умолчанию. Используем пример. Как видно по полю pi, можно запросто присвоить значение по умолчанию для полей в DataClass.
from dataclasses import dataclass
@dataclass
class CircleArea:
r: int
pi: float = 3.14
@property
def area(self):
return self.pi * (self.r ** 2)
a = CircleArea(2)
print(repr(a)) # вернется: CircleArea(r=2, pi=3.14)
print(a.area) # вернется: 12.56
Изменение полей и DataClass
Изменять поля и DataClass можно за счет параметров декоратора или функции поля. Все случаи будут рассмотрены в примерах.
Data Class: изменяемые или нет?
По умолчанию dataclass изменяемые, что значит, что полям можно присваивать значения. Но их же можно сделать и неизменяемыми, задав значение True для параметра frozen.
Изменяемый пример
from dataclasses import dataclass
@dataclass
class CircleArea:
r: int
pi: float = 3.14
@property
def area(self):
return self.pi * (self.r ** 2)
a = CircleArea(2)
a.r = 5
print(repr(a)) # вернется: CircleArea(r=5, pi=3.14)
print(a.area) # вернется: 78.5
Неизменяемый пример
Когда значение frozen равно True, присваивать значения полям больше нельзя. Дальше показано соответствующее исключение.
from dataclasses import dataclass
@dataclass(frozen=True)
class CircleArea:
r: int
pi: float = 3.14
@property
def area(self):
return self.pi * (self.r ** 2)
a = CircleArea(2)
a.r = 5
# Вернется исключение: dataclasses.FrozenInstanceError:
# cannot assign to field 'r'
Сравнение Data Classes
Представьте, что вы хотите создать DataClass, представляющий Vector и сравнить их. Как это сделать? Для сравнения нужны методы __lt__ или __gt__.
По умолчанию значение параметра order в Data Class равняется False. Если поменять его на True, то методы __lt__, __le__, __gt__ и __ge__ для Data Class будут сгенерированы автоматически. Таким образом можно сравнить объекты так, будто бы они являются кортежами полей.
Разберем на примере. Задав order значение True, можно сравнить v2 и v1. Но есть проблема логики сравнения. Если сравнить, например, v2 > v1, то векторы будут сравниваться вот так: (8, 15) > (7, 20). Таким образом значением операции будет True.
Стоит напомнить, что сравнение кортежей происходит по порядку. Сначала сравниваются 8 и 7, и если результат равен
True, то результатом всего сравнения будетTrue. Если бы они были равны, то произошло бы сравнение15 > 20и результат стал быFalse.
from dataclasses import dataclass, field
@dataclass(order=True)
class Vector:
x: int
y: int
v1 = Vector(8, 15)
v2 = Vector(7, 20)
print(v2 > v1)
Очевидно, что в таком сравнении нет никакого смысла. Правильнее было бы сравнивать величину векторов. Проблема в том, что не хотелось бы высчитывать эту величину самостоятельно при создании экземпляров.
В этом случае можно воспользоваться функцией field и методом __post_init__. Функция field позволит настроить поле magnitude, а __post_init__ — определить величину вектора после инициализации.
Поле magnitude было изменено с помощью функции field из Data Class. Задавая значение False для init, мы утверждаем, что не хотим иметь параметр magnitude в методе __init__. Потому что его значение можно задать с помощью метода __post_init__ после инициализации.
Конвертация в словарь или кортеж
Можно получить атрибуты Data Class в кортеже или словаре. Для этого нужно лишь импортировать функции asdict и astuple из Data Class.
from dataclasses import dataclass, asdict, astuple
@dataclass
class Vector:
x: int
y: int
z: int
v = Vector(4, 5, 7)
print(asdict(v)) # Вернется : {'x': 4, 'y': 5, 'z': 7}
print(astuple(v)) # Вернется : (4, 5, 7)
Наследование
Можно создавать подклассы для Data Class как для обычных классов в Python.
from dataclasses import dataclass
@dataclass
class Employee:
name: str
lang: str
@dataclass
class Developer(Employee):
salary: int
Alex = Developer('Alex', 'Python', 5000)
print(Alex) # Вернется: Developer(name='Alex', lang='Python', salary=5000)
Но есть распространенная ошибка при использовании наследования. Когда значением поля lang по умолчанию является Python, нужно задавать значения по умолчанию для полей следом за lang.
from dataclasses import dataclass
@dataclass
class Employee:
name: str
lang: str = 'Python'
@dataclass
class Developer(Employee):
salary: int
Alex = Developer('Alex', 'Python', 5000)
# Вернется: TypeError: non-default argument 'salary' follows default argument
Чтобы понять, зачем это нужно, рассмотрим, как выглядит метод __init__. Вспомним, что параметры со значением по молчанию всегда идут после параметров без них.
def __init__(name: str, lang: str = 'Python', salary: int):
...
Исправим, задав значение по умолчанию для поля salary.
from dataclasses import dataclass
@dataclass
class Employee:
name: str
lang: str = 'Python'
@dataclass
class Developer(Employee):
salary: int = 0
Alex = Developer('Alex', 'Python', 5000)
print(Alex) # Вернется: Developer(name='Alex', lang='Python', salary=5000)
Преимущества слотов
По умолчанию атрибуты хранятся в словаре. Можно получить преимущество от слотов для более быстрого доступа к атрибутам и использовать меньше памяти. Однако в подробностях эта тема здесь рассматриваться не будет.
from dataclasses import dataclass
@dataclass
class Employee:
name: str
lang: str
Alex = Employee('Alex', 'Python')
print(Alex.__dict__) # {name': 'Alex', 'lang': 'Python'}
Слоты нужны для использования меньшего количества памяти и более быстрого доступа к атрибутам.
from dataclasses import dataclass
@dataclass
class Employee:
__slots__ = ('name', 'lang')
name: str
lang: str
Alex = Employee('Alex', 'Python')
Параметры Dataclass
Некоторые параметры в декораторе Data Class были изменены для настройки Data Class. Вот они:
init: метод__init__будет сгенерирован в Data Class при значенииTrue. (True– значение по умолчанию)repr: метод__repr__будет сгенерирован в Data Class при значенииTrue. (True– значение по умолчанию)eq: метод__eq__будет сгенерирован в Data Class при значенииTrue. (True– значение по умолчанию)order: методы__lt__,__le__,__gt__и__ge__будут сгенерированы в Data Class при значенииTrue. (False– значение по умолчанию)unsafe_hash: метод__hash__будет сгенерирован в Data Class при значенииTrue. (False– значение по умолчанию)frozen: еслиTrue, то значения полям присваивать нельзя (False– значение по умолчанию).
Примечание:
eqдолжно быть равноTrue, если значениеorderравняетсяTrue, иначе будет исключениеValueError.
Параметры полей
init: это поле включено в сгенерированный метод__init__при значенииTrue(True– значение по умолчанию)repr: это поле включено в сгенерированный метод__init__при значенииTrue(True– значение по умолчанию)compare: это поле включено в методы общего сравнения и равенства при значенииTrue(True– значение по умолчанию)hash: это поле включено в сгенерированный метод__hash__при значенииTrue(None– значение по умолчанию)default: это будет значение по умолчанию для поля (если указано)default_factory: если указано, должно быть вызываемым объектом без аргументов, который вызывается, когда для поля требуется значение по умолчаниюmetadata: это может быть мапинг илиNone– пустой словарь.
Сортировка — это навык, которым должен обладать каждый программист. Не только для прохождения собеседований, но и для понимания дисциплины в целом. Разные алгоритмы сортировки — отличная демонстрация того, как внутренняя логика может влиять на сложность, скорость и эффективность программы.
Разберем 5 самых распространенных алгоритмов и реализуем их в Python.
Bubble Sort (пузырьковая сортировка)
Этот вид сортировки изучают в начале знакомства с дисциплиной Computer Science, поскольку он максимально просто демонстрирует саму концепцию сортировки.
При этом подходе осуществляется перебор по списку и сравнение соседних элементов. Они меняются местами в том случае, если порядок неправильный. Так продолжается до тех пор, пока все элементы не расположатся в нужном порядке. Из-за большого количества повторений у пузырьковой сортировки его сложность в худшем случае — O(n^2).

def bubble_sort(arr):
def swap(i, j):
arr[i], arr[j] = arr[j], arr[i]
n = len(arr)
swapped = True
x = -1
while swapped:
swapped = False
x = x + 1
for i in range(1, n-x):
if arr[i - 1] > arr[i]:
swap(i - 1, i)
swapped = True
Selection Sort (сортировка выбором)
Сортировка выбором — также простой алгоритм, но более эффективный по сравнению с пузырьковой сортировкой. В большинстве случаев сортировка выбором будет более удачным выбором из двух.
В этом алгоритме список (или массив) делится на две части: список с отсортированными элементами и список с элементами, которые только нужно сортировать. Сначала ищется самый маленький элемент во втором. Он добавляется в конце первого. Таким образом алгоритм постепенно формирует список от меньшего к большему. Так происходит до тех пор, пока не будет готовый отсортированный массив.

def selection_sort(arr):
for i in range(len(arr)):
minimum = i
for j in range(i + 1, len(arr)):
# Выбор наименьшего значения
if arr[j] < arr[minimum]:
minimum = j
# Помещаем это перед отсортированным концом массива
arr[minimum], arr[i] = arr[i], arr[minimum]
return arr
Insertion Sort (сортировка вставками)
Сортировка вставками быстрее и проще двух предыдущих. Именно так большинство людей тасует карты любой игре. На каждой итерации программа берет один из элементов и подыскивает для него место в уже отсортированном списке. Так происходит до тех пор, пока не останется ни одного неиспользованного элемента.

def insertion_sort(arr):
for i in range(len(arr)):
cursor = arr[i]
pos = i
while pos > 0 and arr[pos - 1] > cursor:
# Меняем местами число, продвигая по списку
arr[pos] = arr[pos - 1]
pos = pos - 1
# Остановимся и сделаем последний обмен
arr[pos] = cursor
return arr
Merge Sort (сортировка слиянием)
Сортировка слиянием — элегантный пример использования подхода «Разделяй и властвуй». Он состоит из двух этапов:
- Несортированный список последовательно делится на N списков, где каждый включает один «несортированный» элемент, а N — это число элементов в оригинальном массиве.
- Списки последовательно сливаются группами по два, создавая новые отсортированные списки до тех пор, пока не появится один финальный отсортированный список.

def merge_sort(arr):
# Последнее разделение массива
if len(arr) <= 1:
return arr
mid = len(arr) // 2
# Выполняем merge_sort рекурсивно с двух сторон
left, right = merge_sort(arr[:mid]), merge_sort(arr[mid:])
# Объединяем стороны вместе
return merge(left, right, arr.copy())
def merge(left, right, merged):
left_cursor, right_cursor = 0, 0
while left_cursor < len(left) and right_cursor < len(right):
# Сортируем каждый и помещаем в результат
if left[left_cursor] <= right[right_cursor]:
merged[left_cursor+right_cursor]=left[left_cursor]
left_cursor += 1
else:
merged[left_cursor + right_cursor] = right[right_cursor]
right_cursor += 1
for left_cursor in range(left_cursor, len(left)):
merged[left_cursor + right_cursor] = left[left_cursor]
for right_cursor in range(right_cursor, len(right)):
merged[left_cursor + right_cursor] = right[right_cursor]
return merged
Quick Sort (быстрая сортировка)
Как и сортировка слиянием, быстрая сортировка использует подход «Разделяй и властвуй». Алгоритм чуть сложнее, но в стандартных реализациях он работает быстрее сортировки слиянием, а его сложность в худшем случае редко достигает O(n^2). Он состоит из трех этапов:
- Выбирается один опорный элемент.
- Все элементы меньше опорного перемешаются слева от него, остальные — направо. Это называется операцией разбиения.
- Рекурсивно повторяются 2 предыдущих шага к каждому новому списку, где новые опорные элементы будут меньше и больше оригинального соответственно.

def partition(array, begin, end):
pivot_idx = begin
for i in xrange(begin+1, end+1):
if array[i] <= array[begin]:
pivot_idx += 1
array[i], array[pivot_idx] = array[pivot_idx], array[i]
array[pivot_idx], array[begin] = array[begin], array[pivot_idx]
return pivot_idx
def quick_sort_recursion(array, begin, end):
if begin >= end:
return
pivot_idx = partition(array, begin, end)
quick_sort_recursion(array, begin, pivot_idx-1)
quick_sort_recursion(array, pivot_idx+1, end)
def quick_sort(array, begin=0, end=None):
if end is None:
end = len(array) - 1
return quick_sort_recursion(array, begin, end)
По аналогии со списками кортежи в Python — это стандартный тип, позволяющий хранить значения в виде последовательности. Они полезны в тех случаях, когда необходимо передать данные, не позволяя изменять их. Эти данные могут быть использованы, но в оригинальной структуре изменения не отобразятся.
В этом руководстве вы познакомитесь с кортежами Python в подробностях:
- Узнаете, как их создавать. Увидите, что значит неизменяемый тип на примерах
- Разберетесь, чем кортежи в Python отличаются от списков
- Познакомитесь с операциями: срезами, конкатенацией, умножением и так далее
- Увидите встроенные функции
- Научитесь присваивать сразу несколько значений кортежами
Кортеж Python
Эта структура данных используется для хранения последовательности упорядоченных и неизменяемых элементов.
Кортежи создают с помощью круглых скобок (). Для создания нужно написать следующее:
cake = ('c','a','k','e')
print(type(cake))
<class 'tuple'>
Примечание: type() — это встроенная функция для проверки типа данных переданного параметра.
Кортежи могут включать однородные и разнородные значения. Но после объявления их уже нельзя будет поменять:
mixed_type = ('C',0,0,'K','I','E')
for i in mixed_type:
print(i,":",type(i))
C : <class 'str'>
0 : <class 'int'>
0 : <class 'int'>
K : <class 'str'>
I : <class 'str'>
E : <class 'str'>
# Попробуйте изменить 0 на «O»
mixed_type[1] = "O"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-16-dec28c299a95> in <module>()
----> 1 mixed_type[1] = 'O' # Попробуйте изменить 0 на «O»
TypeError: 'tuple' object does not support item assignment
Последняя ошибка появилась из-за попытки поменять значения внутри кортежа.
Кортежи можно создавать и вот так:
numbers_tuple = 1,2,3,4,5
print(type(numbers_tuple))
<class 'tuple'>
Кортежи против списков
Как вы могли заметить, кортежи очень похожи на списки. По сути, они являются неизменяемыми списками. Это значит, что после создания кортежа хранимые в нем значения нельзя удалять или менять. Добавлять новые также нельзя:
numbers_tuple = (1,2,3,4,5)
numbers_list = [1,2,3,4,5]
# Добавим число в кортеж
numbers_tuple.append(6)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-26-e48876d745ce> in <module>()
3
4 # Добавим число в кортеж
----> 5 numbers_tuple.append(6)
AttributeError: 'tuple' object has no attribute 'append'
Ошибка появляется, потому что нельзя добавлять новые элементы в кортеж, что работает в случае со списками.
# Добавим число в список
numbers_list.append(6)
numbers_list.append(7)
numbers_list.append(8)
# Удалить число из списка
numbers_list.remove(7)
print(numbers_list)
[1, 2, 3, 4, 5, 6, 8]
Но зачем использовать этот тип данных, если он неизменяемый?
Кортежи не только предоставляют доступ только для чтения к элементам, но и работают быстрее списков. Рассмотрим в качестве примера следующий код:
>>> import timeit
>>> timeit.timeit('x=(1,2,3,4,5,6,7,8,9)', number=100000)
0.0018976779974764213
>>> timeit.timeit('x=[1,2,3,4,5,6,7,8,9]', number=100000)
0.019868606992531568
Какую роль играет неизменяемость в случае с кортежами?
Согласно официальной документации Python неизменяемый — это «объект с фиксированным значением», но в отношении кортежей «значение» — это чересчур размытый термин. Лучше использовать id. id определяет расположения объекта в памяти.
Рассмотрим подробнее:
# Кортеж 'n_tuple' со списком в качестве одного из его элементов.
n_tuple = (1, 1, [3,4])
# Элементы с одинаковым значением имеют одинаковый идентификатор.
id(n_tuple[0]) == id(n_tuple[1])
True
# Элементы с разным значением имеют разные идентификаторы.
id(n_tuple[0]) == id(n_tuple[2])
False
print(id(n_tuple[0]), id(n_tuple[2]))
4297148528, 4359711048
n_tuple.append(5)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-40-3cd388e024ff> in <module>()
----> 1 n_tuple.append(5)
AttributeError: 'tuple' object has no attribute 'append'
Добавить элемент в кортеж нельзя, поэтому появляется последняя ошибка AttributeError. Вот почему эта структура данных неизменна. Но всегда можно сделать вот так:
n_tuple[2].append(5)
n_tuple
(1, 1, [3, 4, 5])
Это позволяет изменять оригинальный кортеж? Куда в таком случае делась их неизменяемость?
Суть в том, что id списка в кортеже не меняется несмотря на добавленный в него элемент 5.
id(n_tuple[2])
4359711048
Теперь вы знаете следующее:
Некоторые кортежи (которые содержат только неизменяемые объекты: строки и так далее) — неизменяемые, а другие (содержащие изменяемые типы, например, списки) изменяемые. Но это очень обсуждаемая тема среди программистов на Python и необходимы кое-какие познания, чтобы полностью понять ее. В целом же кортежи неизменяемые.
- Вы не можете добавлять в них новые элементы. У этого типа нет методов
append()илиextend() - Удалять элементы тоже нельзя, также из-за неизменяемости. Методов
remove()иpop()здесь нет - Искать элементы в кортеже можно, потому что этот процесс его не меняет
- Разрешено использовать оператор
inдля проверки наличия элемента в кортеже
Так что если вы планируете использовать постоянный набор значений для перебора, используйте кортеж вместо списка. Он будет работать быстрее. Плюс, это безопаснее, ведь такой тип данных защищен от записи.
Если вы хотите узнать больше о списках Python, обязательно ознакомьтесь с этим руководством!
Стандартные операции с кортежами
Python предоставляет несколько способов для управления кортежами. Рассмотрим их на примерах.
Срезы
Значение индекса первого элемента в кортеже — 0. По аналогии со списками эти значения можно использовать с квадратными скобками [] для получения доступа к кортежам:
numbers = (0,1,2,3,4,5)
numbers[0]
0
Можно использовать и отрицательные значения:
numbers[-1]
5
Индексы позволяют получать отдельные элементы, а с помощью срезов становятся доступны и подмножества. Для этого нужно использовать диапазоны индексов:
[Начальный индекст (включен):Конечный индекс (исключен):Частота]
Частота в данном случае является опциональным параметром, а его значение по умолчанию равно 1.
# Элемент с индексом 4 исключен
numbers[1:4]
(1, 2, 3)
# Это возвращает все элементы в кортеже
numbers[:]
(0, 1, 2, 3, 4, 5)
# Частота = 2
numbers[::2]
(0, 2, 4)
Совет: значение частоты может быть и негативным, чтобы развернуть кортеж.
numbers[::-1]
(5, 4, 3, 2, 1, 0)
Объединение кортежей
Можно объединять кортежи для создания нового объекта. Операция объединения выполняет конкатенацию двух кортежей.
x = (1,2,3,4)
y = (5,6,7,8)
# Объединение двух кортежей для формирования нового кортежа
z = x + y
print(z)
(1, 2, 3, 4, 5, 6, 7, 8)
y = [5,6,7,8]
z = x + y
print(z)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-55-d442c6414a4c> in <module>()
1 y = [5,6,7,8]
----> 2 z = x + y
3 print(z)
TypeError: can only concatenate tuple (not "list") to tuple
Разрешается объединять только определенные типы данных. Так, попытка соединить кортеж и список закончится ошибкой.
Умножение кортежей
Операция умножения приводит к тому, что кортеж повторяется несколько раз.
x = (1,2,3,4)
z = x*2
print(z)
(1, 2, 3, 4, 1, 2, 3, 4)
Функции кортежей
В отличие от списков у кортежей нет методов, таких как append(), remove(), extend(), insert() или pop() опять-таки из-за их неизменяемости. Но есть другие:
count() и len()
count() возвращает количество повторений элемента в кортеже.
a = [1,2,3,4,5,5]
a.count(5)
2
len() — длину кортежа:
a = (1,2,3,4,5)
print(len(a))
5
any()
Функцию any() можно использовать, чтобы определить являются ли элементы кортежа итерируемыми. Если да, то она вернет True.
a = (1,)
print(any(a))
True
Обратите внимание на запятую (,) в объявлении кортежа a. Если ее не указать при создании объекта с одним элементом? Python предположит, что вы по ошибке добавили лишнюю пару скобок (это ни на что не влияет), но тип данных в таком случае — это не кортеж. Поэтому важно не забывать использовать запятую при объявлении кортежа с одним элементом.
И снова к функции any. В булевом контексте значение элемента не имеет значения. Пустой кортеж вернет False, а кортеж с хотя бы одним элементом — True.
b = ()
print(any(b))
False
Функция может быть полезной, если кортеж вызывается? и нужно удостовериться, что он не пустой.
tuple()
Функция tuple() используется для конвертации данных в кортеж. Например, так можно превратить список в кортеж.
a_list = [1,2,3,4,5]
b_tuple = tuple(a_list)
print(type(b_tuple))
<class 'tuple'>
min() и max()
Функция max()q возвращает самый большой элемент последовательности, а min() — самый маленький. Возьмем следующий пример:
print(max(a))
print(min(a))
5
A
Эти функции можно использовать и для кортежей со строками.
# Строка «Apple» автоматически преобразуется в последовательность символов.
a = ('Apple')
print(max(a))
p
sum()
С помощью этой функции можно вернуть сумму элементов в кортеже. Работает только с числовыми значениями.
sum(a)
28
sorted()
Чтобы получить кортеж с отсортированными элементами, используйте sorted() как в следующем примере:
a = (6,7,4,2,1,5,3)
sorted(a)
[1, 2, 3, 4, 5, 6, 7]
Но важно отметить, что возвращаемый тип — список, а не кортеж. При этом последовательность в оригинальном объекте неизменна, а сам он остается кортежем.
Присваивание несколько кортежей
Кортежи можно использовать для присваивания нескольких значений одновременно. Вот так:
a = (1,2,3)
(one,two,three) = a
print(one)
1
a — это кортеж из трех элементов и (one, two, three) — кортеж трех переменных. Присваивание (one, two, three) кортежу a присваивает каждое значение a каждой переменной: one, two и three по очереди. Это удобно, если нужно присвоить определенному количеству переменных значений в кортеже.
Выводы
Теперь вы знаете, что такое кортежи, как их создавать, какие самые распространенные операции, и как ими можно управлять. Также — распространенные методы структур Python. А в качестве бонуса научились присваивать нескольким переменным разные значения.
]]>Модуль sys предлагает методы, которые позволяют работать с разными элементами среды выполнения Python. С его помощью можно взаимодействовать с интерпретатором, используя разные функции. Но для начала его нужно импортировать.
import sys
В этом материале речь пойдет о следующих возможностях модуля sys:
sys.argvsys.maxsizesys.pathsys.versionsys.exit
sys.argv
Метод argv возвращает аргументы командной строки, переданные скрипту Python, в виде списка. Важно отметить, что первый аргумент (с индексом 0) в списке — это название самого скрипта. Остальные представлены в виде последовательности.
В следующем примере файл с кодом называется test.py.
Время для примера:
import sys
print("Привет {}. Добро пожаловать в руководство по {} на {}".format(sys.argv[1], sys.argv[2], sys.argv[3]))
Сохраните этот код в файле test.py и запустите его в командной строке вместе со следующими аргументами:
python test.py Студенты sys PythonRu
Перед этим необходимо перейти в директорию с файлом или ввести полный абсолютный путь к нему.
В указанной выше команде первым аргументом функции argv является элемент Студенты. sys и PythonRu — второй и третий аргументы.
Нулевым параметром является название самого скрипта, которое командная строка определяет автоматически.
Вывод:
Привет Студенты. Добро пожаловать в руководство по sys на PythonRu
sys.maxsize
Эта функция возвращает целое число, которое обозначает, какое максимально значение может иметь переменная типа Py_ssize_t в программе Python. Это значение зависит от платформы, где программа была запущена. Если это 32-битная платформа, значение обычно 2*33 — 1 (2147483647), а в 64-битной — 2**63 — 1 (9223372036854775807).
Пример (обновите код в test.py):
import sys
print(sys.maxsize)
Вывод:
9223372036854775807
sys.path
Метод path из модуля sys возвращает все пути для поиска модулей Python. Формат вывода — список строк.
Ту же операцию можно выполнить обратившись к переменным среды в панели управления и найдя в ней PYTHONPATH. Первый элемент вывода — расположение исполняемого скрипта. Если же эта директория недоступна, то первый элемент будет пустой.
Такое может произойти в том случае, если скрипт был вызван интерактивно (с помощью IDLE, интегрированной среды разработки и обучения на языке Python) или же из стандартного ввода (с помощью инструкции exec). В дальнейшем список может быть изменен в соответствии с требованиями. В него можно добавлять только строки и байты (другие типы будут игнорироваться).
Пример:
import sys
print(sys.path)
Вывод:
['C:\\Users\\user_name, 'C:\\Users\\ user_name \\Anaconda3\\pkgs\\nb_anacondacloud-1.2.0-py35_0\\Lib\\site-packages\\nb_anacondacloud-1.2.0-py3.5.egg-info', 'C:\\Users\\ user_name \\AppData\\Local\\Programs\\Python\\Python36\\python.exe', 'C:\\ProgramData\\Anaconda3\\DLLs', 'C:\\ProgramData\\Anaconda3\\lib', 'C:\\ProgramData\\Anaconda3', '', 'C:\\ProgramData\\Anaconda3\\lib\\site-packages', 'C:\\ProgramData\\Anaconda3\\lib\\site-packages\\win32', 'C:\\ProgramData\\Anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\ProgramData\\Anaconda3\\lib\\site-packages\\Pythonwin', 'C:\\ProgramData\\Anaconda3\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\ user_name \\.ipython']
sys.version
Этот метод показывает версию интерпретатора Python. Он также предоставляет информацию о номере сборки и компиляторе. Информация отображается в виде строки. Рекомендуется использовать метод version_info для получения информации о версии, а не извлекать ее из вывода sys.version.
Пример:
import sys
print(sys.version)
Вывод:
3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)]
sys.exit
Метод exit выходит из программы Python или завершает конкретный процесс. Он используется для безопасного завершения программы в случае исключения. Под капотом sys.exit вызывает исключение SystemExit. Это то же самое, что exit или quit в Python.
При вызове SystemExit также исполняются функции блока finally из инструкции try.
Этот метод может включать опциональный аргумент. Его значение по умолчанию равно 0, что значит, что программа была завершена нормально. Если значение отличается, это говорит о не-нормальном завершении.
Пример:
import sys
sys.exit()
sys.exit(0)
Выводы:
В этом материале вы познакомились с базовыми методами из модуля sys, которые помогают взаимодействовать со средой исполнения Python.
Множества (set) в Python — это встроенный тип, предлагающий широкий набор возможностей, которые повторяют теорию множеств из математики. Тем не менее интерпретация может отличаться от той, что принята в математике. Set импортировать не нужно. А в этом материале вы узнаете о нем все, что потребуется для работы.
Что это
Множества — это неупорядоченная коллекция уникальных элементов, сгруппированных под одним именем. Множество может быть неоднородным — включать элементы разных типов. Множество всегда состоит только из уникальных элементов (дубли запрещены) в отличие от списков и кортежей в Python. Объект set — это также коллекция уникальных хэшируемых объектов. Объект называется хэшируемым в том случае, если его значение хэша не меняется. Это используется в ключах словарей и элементах множеств, ведь значения хэшей применяются в их внутренних структурах.
Чаще всего множества в Python используются для проверки на принадлежность, удаления повторов из последовательности и выполнения математических операций, таких как пересечение, объединение, поиск разностей и симметрических разностей. Изображение ниже показывает два примера множеств (алфавит и цифры), каждый из которых включает уникальные неизменяемые объекты.
Создание множеств Python
Создать объект set в Python можно двумя путями:
- Использовать фигурные скобки
{} - Использовать встроенную функцию
set()
Примечание: не используйте зарезервированные ключевые слова и названия встроенных классов в качестве имен для множеств. Это не поощряется в программировании на Python.
Множество создается при размещении всех элементов внутри фигурных скобок {}, как показано на примере ниже.
s1 = {} # Это создаст пустое множество
s2 = {1, 'pythonru', 20.67}
Еще один способ создать (или определить) множество Python — использовать функцию set(). Пример ниже.
s1 = set() # Это создаст пустое множество
s2 = set({1, 'pythonru', 20.67})
Первый способ (с использованием фигурных скобок {}) определенно проще.
Нет ограничений на количество элементов в объекте set, но запрещено добавлять элементы изменяемых типов, такие как список или словарь. Если попробовать добавить список (с набором элементов), интерпретатор выдаст ошибку.
s5 = { 1, 2, 3, [5, 6, 7, 8] }
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
Добавление элементов в множества Python
Объекты set в Python поддерживают добавление элементов двумя путями: по одному с помощью метода add() или группами с помощью update(). Оба описаны дальше.
Добавление одного элемента в множество Python
Один элемент можно добавить с помощью метода add(). Такой код выглядит следующим образом.
set1 = {1, 3, 4}
set1.add(2)
print(set1)
{1, 2, 3, 4}
Добавление нескольких элементов в множество Python
Больше одного элемента можно добавить с помощью update(). Код следующий.
set2 = {1, 2, 3}
set2.update([4, 5, 6])
print(set2) # {1, 2, 3, 4, 5, 6}
Удаление элементов из множеств Python
Один или несколько элементов можно удалить из объекта set с помощью следующих методов. Их отличие в виде возвращаемого значения.
remove()discard()pop()
remove()
Метод remove() полезен в тех случаях, когда нужно удалить из множества конкретный элемент и вернуть ошибку в том случае, если его нет в объекте.
Следующий код показывает метод remove() в действии.
set1 = {1, 2, 3, 4, 'a', 'p'}
set1.remove(2)
print(set1)
{1, 3, 4, 'a', 'p'}
set1.remove(5)
# Error element not found
discard()
Метод discard() полезен, потому что он удаляет конкретный элемент и не возвращает ошибку, если тот не был найден во множестве.
set1 = {1, 3, 4, 'a', 'p'}
set1.discard('a')
print(set1)
# {1, 3, 4 'p'}
set1.discard(6)
print(set1)
# {1, 3, 4, 'p'}
pop()
Метод pop() удаляет по одному элементу за раз в случайном порядке. Set — это неупорядоченная коллекция, поэтому pop() не требует аргументов (индексов в этом случае). Метод pop() можно воспринимать как неконтролируемый способ удаления элементов по одному из множеств в Python.
set1 = {1, 3, 4, “p”}
set1.pop()
3 # случайный элемент будет удален (ваш результат может отличаться)
Методы множеств Python
У объектов set есть несколько встроенных методов. Увидеть их все можно с помощью команды dir(). dir(object) в Python показывает самые важные атрибуты разных типов объектов.
Вот что выдаст функция для объекта set в Python.
set1 = { 1, 2, 3, 4}
dir(set1)
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__init_subclass__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
Часто используемые функции множеств Python
Из всех методов, перечисленных в dir(), только несколько из них используются постоянно. Вы уже знакомы с add, update, remove, pop и discard.
Вот на какие также стоит обратить внимание.
Функция принадлежности (членства)
Она проверяет на наличие конкретного элемента в множестве.
num_set = {1 ,3, 5, 7, 9, 10}
7 in num_set
# True
2 in num_set
# False
1 not in num_set
# False
Разные функции
len(num_set) — вернет количество элементов в объекте set.
6
copy() — создает копию существующего множества и сохраняет ее в новом объекте.
new_set = num_set.copy()
clear() —очищает множество (удаляет все элементы за раз)
num_set.clear()
del — удаляет множество целиком
del num_set
Дальше речь пойдет об операциях union, issubset, issuperset, difference_update и других.
Операции множеств в Python
В этом разделе вы узнаете о разных операциях над множествами, которые являются частью теории множеств.
Объединение множеств
При использовании на двух множествах вы получаете новый объект, содержащий элементы обоих (без повторов). Операция объединения в Python выполняется двумя способам: с помощью символа | или метода union().

A = {1, 2, 3}
B = {2, 3, 4, 5}
C = A | B # используя символьный метод
C = A.union(B) # используя метод union
print(C)
# {1, 2, 3, 4, 5}
Пересечение множеств
При использовании на двух множествах вы получаете новый объект, содержащий общие элементы обоих (без повторов). Операция пересечения выполняется двумя способами: с помощью символа & или метода intersection().

A = {1, 2, 3, 4}
B = {3,4,5,6}
C = A & B # используя символьный метод
C = A.intersection(B) # используя метод intersection
print(C)
# {3,4}
Разность множеств
При использовании на двух множествах вы получаете новый объект, содержащий элементы, которые есть в первом, но не втором (в данном случае — в множестве “A”). Операция разности выполняется двумя способами: с помощью символа - или метода difference().

A = {1, 2, 3, 4}
B = {3,4,5,6}
C = A - B # используя символьный метод
C = A.difference(B) # используя метод difference
print(C)
# {1,2}
Симметричная разность множеств
При использовании на двух множествах вы получаете новый объект, содержащий все элементы, кроме тех, что есть в обоих. Симметрическая разность выполняется двумя способами: с помощью символа ^ или метода symmetric_difference().

C = A ^ B # используя символьный метод
C = A.symmetric_difference(B) # используя метод symmetric_difference
print(C)
# {1, 2, 5, 6}
Подмножество и надмножество в Python
Множество B (SetB) называется подмножество A (SetA), если все элементы SetB есть в SetA. Проверить на подмножество в Python можно двумя способами: с помощью символа <= или метода issubset(). Он возвращает True или False в зависимости от результата.
A = {1, 2, 3, 4, 5}
B = {2,3,4}
B <= A # используя символьный метод
B.issubset(A) # используя метод issubset
# True

Множество A (SetA) называется надмножество B (SetB), если все элементы SetB есть в SetA. Проверить на надмножество в Python можно двумя способами: с помощью символа >= или метода issuperset(). Он возвращает True или False в зависимости от результата.
A = {1, 2, 3, 4, 5}
B = {2,3,4}
A >= B # используя символьный метод
A.issuperset(B) # используя метод issubset
# True
Бонус
А теперь бонус для тех, кто дочитал до этого места. Многие начинающие программисты задаются вопросом, как удалить повторяющиеся элементы из списка?
Ответ: просто передайте список функции set() и все дубли будут удалены автоматически. Результат потом можно снова передать в функцию list(), чтобы он снова стал списком.
List1 = [1, 2, 3, 5, 3, 2, 4, 7]
List_without_duplicate = set(List1)
print(List_without_duplicate)
# (1, 2, 3, 5, 4, 7) преобразован в множество
back_to_list = list(List_without_duplicate)
# [1, 2, 3, 5, 4, 7] снова преобразован в список
Выводы
Теперь вы знакомы с объектами set в Python и теорией множеств на практике. Знаете как создавать множества, менять их, добавляя или удаляя элементы. Вы также знаете, как использовать метод dir и другие методы для множеств в Python. Наконец, познакомились с операциями union, intersection, difference, symmetric difference, subset и superset.
Для грамотного использования любой функции или метода, рекомендуется сначала рассмотреть их внутреннюю реализацию: понять, какие аргументы они получают и какое значение возвращают. Функция map принимает два аргумента: iterable и function (итерируемый объект и функция) и применяет функцию к каждому элементу объекта. Возвращаемое значение — объект map. Он является итератором, который можно конвертировать в список или множество с помощью встроенных функций.
В этом материале разберем в подробностях аргументы и возвращаемое значение функции map.
Первый аргумент: функция
Первым аргументом функции map является функция. Думая о функциях в Python, в первую очередь в голову приходят те, что определяются с помощью ключевого слова def, но в map можно использовать в том числе встроенные и анонимные функции или даже методы.
Встроенные — это заранее созданные функции. Map — одна из них. Анонимные, называемые также лямбда-функциями, — это функции, которые определяются без имени с ключевым словом lambda. Разберем на примерах.
Обычные функции
Есть список чисел, которые нужно удвоить. Первый вариант — перебрать список с помощью цикла for. Второй — использовать генерацию списка. Но очевидно, что можно задействовать и функцию map.
elements = [1,2,3,4]
elements_by2 =[]
for element in elements:
elements_by2.append(element*2)
#elements_by2 = [2,4,6,8]
elements = [1,2,3,4]
element_by2 = [ element*2 for element in elements]
#elements_by2 = [2,4,6,8]
В первую очередь функция определяется с помощью def. Она принимает в качестве аргумента число и возвращает это число, умноженное на два. Затем эта функция применяется к каждому элементу списка с помощью map. Поскольку функция map возвращает объект map, его нужно конвертировать в список с помощью встроенной функции list.
def multiply(x):
return x*2
elements = [1,2,3,4]
elements_by2 = list(map(multiply,elements))
#elements_by2 = [2,4,6,8]
Можно сделать и что-нибудь посложнее, например, вернуть 0 на месте четных чисел, а нечетные вывести как есть.
def even_odd(x):
if x%2==0:
return 0
else:
return x
elements = [1,2,3,4]
elements_new = list(map(even_odd,elements))
#elements_new = [1,0,3,0]
Идея должна быть ясна — применение одной функции к каждому элементу итерируемого объекта.
Анонимные функции
Вместе с функцией map можно использовать и анонимные функции. Это довольно частый сценарий.
У анонимных функциях следующий синтаксис:
lambda аргументы: выражение
Эти функции нужны для краткосрочного использования. Они могут иметь любое количество аргументов, а возвращаемое значение определяется выражением. Их можно найти не только в Python, но и в других языках программирования.
Рассмотрим предыдущую проблему с помощью анонимной функции. Есть список элементов и необходимость их удвоить. В таком случае у лямбда-функции есть один аргумент (x), который возвращает значение, умноженное на 2 (x*2).
elements = [1,2,3,4]
elements_by2 = map(lambda x: x*2, elements)
#elements_by2 =[2,4,6,8]
Также функцию map можно использовать и с методами. Методы похожи на функции, но есть некоторые отличия. В частности, методы связаны с ассоциированными с ними объектами.
Есть список городов, в названиях которых нужно сделать первую букву заглавной. Этого можно добиться с помощью комбинации из функции map и метода title.
cities = ['madrid', 'munich', 'valencia']
cities_cap = list(map(lambda x:x.title(),cities))
#cities_cap = ['Madrid', 'Munich', 'Valencia']
Встроенные функции
В стандартной библиотеке Python много доступных функций, которые можно использовать в map. Все они перечислены в документации Python.
elements = [1,2,3,4]
elements_str = list(map(str,elements))
#elements_str = ['1','2','3','4']
Предположим, есть список чисел, каждый из элементов которого нужно превратить в строку. Это запросто можно сделать с помощью функции map и встроенной функции str.
Второй аргумент: итерируемый объект
Самый распространенный итерируемый объект — списки, но бывают и объекты других типов. Итерируемый объект — это объект с определенным количеством значений, которые можно перебрать, например, с помощью цикла for. Множества, кортежи, словари также являются итерируемыми объектами и их можно использовать в качестве аргументов для функции map. Вот некоторые примеры.
Есть кортеж из чисел, каждое их значение в котором нужно увеличить на единицу. Это запросто делается с помощью функции map. Также потребуется использовать встроенную функцию tuple(), чтобы превратить возвращаемый объект map в кортеж.
elements = (1,2,3,4)
elements_plus1 = tuple(map(lambda x:x+1,elements))
#elements_plus1 = (2,3,4,5)
Есть множество чисел, и для каждого нужно получить куб. Множество будет вторым аргументом функции map. Чтобы превратить результат в множество, потребуется использовать встроенную функцию set().
def cube(x):
return x**3
elements = {1,2,3,4}
elements_cube = set(map(cube,elements))
#elements_cube = {8,1,27,64}
elements2 = {1,2,3,4}
elements2_cube = set(map(lambda x:x**3,elements))
#elements2_cube = {8,1,27,64}
Итерируемый объект может быть и словарем.
elements = {'hidrogen':1, 'helium':2, 'carbon':6}
elements_upper = list(map(lambda x:x.title(),elements))
#elements_upper = ['Hidrogen','Helium','Carbon']
Или списком кортежей. Можно создать новый список, который будет содержать только каждый третий элемент каждого кортежа. Или даже изменить каждый третий элемент.
students = [('Amanda','161cm','51kg'), ('Patricia','165cm','61kg'), ('Marcos','191cm', '101kg')]
students_height = list(map(lambda x:x[1], students))
#список со строками
#students_height = ['161cm','165cm','191cm']
students_weight = list(map(lambda x:int(x[2][:-2]), students))
#список с цислами
#students_weight = [51, 61, 101]
В последнем примере итерируемым объектом будет функция range. Предположим, что нужно создать список строк от 0 до 20. Это можно добиться с помощью функции range в качестве итерируемого объекта для функции map.
list_num = list(range(0,21))
#list_num = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
list_str = list(map(str,range(0,21)))
#list_str = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20']
Теперь перейдем к третьему аспекту — возвращаемому значению.
Возвращаемое значение: итератор
Функция map возвращает объект map, который является итератором. Его можно превратить в список, множество или кортеж с помощью встроенной функции.
elements = [1,2,3,4]
elements_by2 = map(lambda x:x*2,elements)
print(type(elements_by2))
#<class 'map'>
elements_list = list(map(lambda x:x*2,elements))
print(type(elements_list))
#<class 'list'>
elements_set = set(map(lambda x:x*2,elements))
print(type(elements_set))
#<class 'set'>
elements_tuple = tuple(map(lambda x:x*2,elements))
print(type(elements_tuple))
#<class 'tuple'>
Резюме
- Функция map принимает два аргумента:
(1) функцию
(2) итерируемый объект. - Применяет функцию к каждому элементу итерируемого объекта и возвращает объект map.
- Функция может быть (1) обычной, (2) анонимной или (3) встроенной.
- Списки, множества, кортежи и другие итерируемые объекты могут выступать в качестве второго аргумента функции map.
- Объект map можно запросто конвертировать в другой итерируемый объект с помощью встроенных функций.
На примерах узнайте, какие возможности предлагает функция print в Python.
Многие из вас при чтении этого руководства наверняка подумают, что в этой простой функции нет ничего нераскрытого, потому что именно с print многие начинают свое знакомство с Python, выводя на экран заветную фразу Hello, World!. Это естественно не только для Python, но и для любого языка, что функция print является базовой и одним из первых шагов при изучении как программирования в целом, так и конкретного синтаксиса. Однако со временем многие переходят к более продвинутым темам, забывая о возможностях простых на первый взгляд функций.
Это руководство целиком посвящено функции print в Python — из него вы узнаете о том, насколько она недооценена.
Начнем с вывода фразы Hello, World!.
print("Hello, World!")
Hello, World!
Если в Python 2 скобки можно не использовать, то в Python3 они обязательны. Если их не указать, то будет вызвана синтаксическая ошибка.
print("Hello, World!")
File "<ipython-input-6-a1fcabcd869c>", line 1
print "Hello, World!"
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print("Hello, World!")?
Из текста выше можно сделать вывод, что в Python 3 print() — это не инструкция, а функция.
Чтобы убедиться, проверим type/class функции print().
type(print)
builtin_function_or_method
Возвращается builtin_function_or_method. Это значит, что это ранее определенная или встроенная функция Python.
Предположим, что нужно добавить перенос строки или вертикальный отступ между двумя выводами. Для этого достаточно вызвать print(), не передавая аргументов.
print("Hello, World!");print("Hello, World!")
Hello, World!
Hello, World!
print("Hello, World!")
print()
print("Hello, World!")
Hello, World!
Hello, World!
Рассмотрим синтаксис функции print().
print(value, ..., sep='', end='\n', file=sys.stdout, flush=False)
Как вы знаете, функция print выводит значения в поток данных или в sys.stdout по умолчанию. sys.stdout или стандартный вывод системы означают, что функция print выведет значение на экран. Его можно поменять на stdin или stderr.
Необязательные аргументы:
- sep — это может быть строка, которую необходимо вставлять между значениями, по умолчанию — пробел.
Вставим список слов в
printи разделим их с помощью символа новой строки. Еще раз: по умолчанию разделитель добавляет пробел между каждым словом.print('туториал', 'по', 'функции', 'print()')туториал по функции print()# \n перенесет каждое слово на новую строку print('туториал', 'по', 'функции', 'print()', sep='\n')туториал по функции print()Также можно разделить слова запятыми или добавить два символа новой строки (
\n), что приведет к появлению пустой строки между каждой строкой с текстом или, например, знак плюс (+).print('туториал', 'по', 'функции', 'print()', sep=',')туториал,по,функции,print()print('туториал', 'по', 'функции', 'print()', sep='\n\n')туториал по функции print()print('туториал', 'по', 'функции', 'print()', sep=',+')туториал,+по,+функции,+print()Прежде чем переходить к следующему аргументу,
end, стоит напомнить, что в функцию можно передать и переменную. Например, определим список целых чисел и вставим его в функциюpass. Это список и будет выведен.int_list = [1,2,3,4,5,6] print(int_list)[1, 2, 3, 4, 5, 6] - end — это строка, которая добавляется после последнего значения. По умолчанию — это перенос на новую строку (
\n). С помощью аргументаendпрограммист может самостоятельно определить окончание выраженияprint.Предположим, есть две строки, а задача состоит в том, чтобы объединить их, оставив пробел. Для этого нужно в первой функции
printуказать первую строку,str1и аргументendс кавычками. В таком случае на экран выведутся две строки с пробелом между ними.str1 = 'туториал по' str2 = 'функции print()' print(str1) print(str2)туториал по функции print()print(str1, end=' ') print(str2)туториал по функции print()Возьмем другой пример, где есть функция, которая должна выводить значения списка на одной строке. Этого можно добиться с помощью такого значения аргумента
end:def value(items): for item in items: print(item, end=' ') value([1,2,3,4])1 2 3 4 - file — файлоподобный объект (поток). По умолчанию — это
sys.stdout. Здесь можно указать файл, в который нужно записать или добавить данные из функцииprint.Таким образом вывод функции можно сохранять в файлы форматов
.csvили.txt. Рассмотрим это на примере с перебором всех элементов списка. Он сохраняется в текстовом файле. В первую очередь файл нужно открыть в режимеappend. Далее определяется функция, чей вывод будет добавляться внутрь текстового файла.file = open('print.txt','a+') def value(items): for item in items: print(item, file=file) file.close() # закройте файл после работы с ним. value([1,2,3,4,5,6,7,8,9,10])Когда исполнение будет завершено, появится файл
print.txtв текущей папке.Теперь очевидно, что вывод можно сохранять в файлы, а не только выводить на экран.
- flush — определяет, нужно ли принудительно очищать поток. По умолчанию значение равно
False.Как правило, вывод в файл или консоль буферизируется как минимум до тех пор, пока не будет напечатан символ новой строки. Буфер значит, что вывод хранится в определенном регистре до тех пор, пока файл не будет готов к сохранению значения или не окажется закрыт. Задача
flush— убедиться в том что, буферизированный вывод благополучно добрался до точки назначения.import time print('Пожалуйста, введите ваш электронный адрес : ', end=' ') # print('Пожалуйста, введите ваш электронный адрес : ', end=' ', flush=True) # запустите код выше, чтобы увидеть разницу. time.sleep(5)Пожалуйста, введите ваш электронный адрес :Если запустить написанный выше код, вы заметите, что строка с запросом на ввод не появится до тех пор, пока таймер не закончится, а программа не закроется. Но если добавить аргумент
flush=True, то строка отобразится сразу, но нужно будет подождать 5 секунд, чтобы программа закрылась.Каким-то образом Jupyter Notebook или Jupyter Lab иначе разбираются с этой особенностью и все равно показывают текст перед 5-секундным таймером, поэтому если хочется проверить эту особенность
print, то функцию необходимо запускать в командной строке, а не в Jupyter.
А теперь посмотрим, как можно использовать функцию print для получения ввода от пользователя в Jupyter Notebook. Для этого используется встроенная функция input().
tutorial_topic = input()
print("Тема сегодняшнего урока: ", end='')
print(tutorial_topic)
функция print()
Тема сегодняшнего урока: функция print()
Здесь указан опциональный аргумент end, который объединяет статическую инструкцию в print и ввод пользователя.
Рассмотрим другие интересные способы вывода значений переменных в функции print.
- Для отображения значения переменной вместе с определенной строкой, нужно лишь добавить запятые между ними. В этом случае положение строки и переменной не имеет значения.
a = 2 b = "PythonRU" print(a,"— целое число, а",b,"— строка.")2 — целое число, а PythonRU — строка. - Можно использовать метод
format, передавая ему любые значения переменных для вывода. При их передаче нужно указывать номера индексов (в том порядке, в котором они размещаются в аргументе) в строке. В таком случае функцияprintбудет выступать шаблоном.Также важно запомнить, что номера индексов указываются в фигурных скобках
{}, которые выступают заполнителями.Разберем это на примере:
a = 2 b = "PythonRU" print("{0} — целое число, а {1} — строка.".format(a,b))2 — целое число, а PythonRU — строка.Если поставить одинаковый номер индекса в обоих местах, то при выводе на этих позициях будут одни и те же значения.
a = 2 b = "PythonRU" print("{1} — целое число, а {1} — строка.".format(a,b))PythonRU — целое число, а PythonRU — строка. - Вместо аргумента
formatможно использовать знак процента (%) для вывода значений переменных.Этот способ тоже работает по принципу заполнителей. Но здесь не нужно указывать номера индексов, а только обозначить тип данных, которые получит функция.
%d— это заполнитель для числовых или десятичных значений.%s— заполнитель для строк.
a = 2 b = "PythonRU" print("%d — целое число, а %s — строка."%(a,b))2 — целое число, а PythonRU — строка.Посмотрим, что произойдет, если указать
%sдля переменнойa, которая является целым числом.print("%s — целое число, а %s — строка."%(a,b))2 — целое число, а PythonRU — строка.Как видно, все работает. Причина в том, что функция
printнеявно выполняетtypecastingи конвертирует целое число в строку. Но в обратном порядке это работать не будет. Функция не сможет конвертировать строку в целое число, а вместо этого выведетсяTypeError.print("%d — целое число, а %d — строка."%(a,b))--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-121-68c55041ecfe> in <module> ----> 1 print("%d — целое число, а %d — строка."%(a,b)) TypeError: %d format: a number is required, not str
Вывод
Это руководство — отличная отправная точка для новичков, желающих добиться высокого уровня мастерства в Python. Поиграйте с функций print еще и разберитесь с другими возможностями, которые не были рассмотрены здесь.
Обработка файлов в Python с помощью модуля os включает создание, переименование, перемещение, удаление файлов и папок, а также получение списка всех файлов и каталогов и многое другое.
В индустрии программного обеспечения большинство программ тем или иным образом обрабатывают файлы: создают их, переименовывают, перемещают и так далее. Любой программист должен обладать таким навыком. С этим руководством вы научитесь использовать модуль os в Python для проведения операций над файлами и каталогами вне зависимости от используемой операционной системы.
Важно знать, что модуль os используется не только для работы с файлами. Он включает массу методов и инструментов для других операций: обработки переменных среды, управления системными процессами, а также аргументы командной строки и даже расширенные атрибуты файлов, которые есть только в Linux.
Модуль встроенный, поэтому для работы с ним не нужно ничего устанавливать.
Вывод текущей директории
Для получения текущего рабочего каталога используется os.getcwd():
import os
# вывести текущую директорию
print("Текущая деректория:", os.getcwd())
os.getcwd() возвращает строку в Юникоде, представляющую текущий рабочий каталог. Вот пример вывода:
Текущая деректория: C:\python3\bin
Создание папки
Для создания папки/каталога в любой операционной системе нужна следующая команда:
# создать пустой каталог (папку)
os.mkdir("folder")
После ее выполнения в текущем рабочем каталоге тут же появится новая папка с названием «folder».
Если запустить ее еще раз, будет вызвана ошибка FileExistsError, потому что такая папка уже есть. Для решения проблемы нужно запускать команду только в том случае, если каталога с таким же именем нет. Этого можно добиться следующим образом:
# повторный запуск mkdir с тем же именем вызывает FileExistsError,
# вместо этого запустите:
if not os.path.isdir("folder"):
os.mkdir("folder")
Функция os.path.isdir() вернет True, если переданное имя ссылается на существующий каталог.
Изменение директории
Менять директории довольно просто. Проделаем это с только что созданным:
# изменение текущего каталога на 'folder'
os.chdir("folder")
Еще раз выведем рабочий каталог:
# вывод текущей папки
print("Текущая директория изменилась на folder:", os.getcwd())
Вывод:
Текущая директория изменилась на folder: C:\python3\bin\folder
Создание вложенных папок
Предположим, вы хотите создать не только одну папку, но и несколько вложенных:
# вернуться в предыдущую директорию
os.chdir("..")
# сделать несколько вложенных папок
os.makedirs("nested1/nested2/nested3")
Это создаст три папки рекурсивно, как показано на следующем изображении:

Создание файлов
Для создания файлов в Python модули не нужны. Можно использовать встроенную функцию open(). Она принимает название файла, который необходимо создать в качестве первого параметра и желаемый режим открытия — как второй:
# создать новый текстовый файл
text_file = open("text.txt", "w")
# запить текста в этот файл
text_file.write("Это текстовый файл")
w значит write (запись), a — это appending (добавление данных к уже существующему файлу), а r — reading (чтение). Больше о режимах открытия можно почитать здесь.
Переименование файлов
С помощью модуля os достаточно просто переименовать файл. Поменяем название созданного в прошлом шаге.
# переименовать text.txt на renamed-text.txt
os.rename("text.txt", "renamed-text.txt")
Функция os.rename() принимает 2 аргумента: имя файла или папки, которые нужно переименовать и новое имя.
Перемещение файлов
Функцию os.replace() можно использовать для перемещения файлов или каталогов:
# заменить (переместить) этот файл в другой каталог
os.replace("renamed-text.txt", "folder/renamed-text.txt")
Стоит обратить внимание, что это перезапишет путь, поэтому если в папке folder уже есть файл с таким же именем (renamed-text.txt), он будет перезаписан.
Список файлов и директорий
# распечатать все файлы и папки в текущем каталоге
print("Все папки и файлы:", os.listdir())
Функция os.listdir() возвращает список, который содержит имена файлов в папке. Если в качестве аргумента не указывать ничего, вернется список файлов и папок текущего рабочего каталога:
Все папки и файлы: ['folder', 'handling-files', 'nested1', 'text.txt']
А что если нужно узнать состав и этих папок тоже? Для этого нужно использовать функцию os.walk():
# распечатать все файлы и папки рекурсивно
for dirpath, dirnames, filenames in os.walk("."):
# перебрать каталоги
for dirname in dirnames:
print("Каталог:", os.path.join(dirpath, dirname))
# перебрать файлы
for filename in filenames:
print("Файл:", os.path.join(dirpath, filename))
os.walk() — это генератор дерева каталогов. Он будет перебирать все переданные составляющие. Здесь в качестве аргумента передано значение «.», которое обозначает верхушку дерева:
Каталог: .\folder
Каталог: .\handling-files
Каталог: .\nested1
Файл: .\text.txt
Файл: .\handling-files\listing_files.py
Файл: .\handling-files\README.md
Каталог: .\nested1\nested2
Каталог: .\nested1\nested2\nested3
Метод os.path.join() был использован для объединения текущего пути с именем файла/папки.
Удаление файлов
Удалим созданный файл:
# удалить этот файл
os.remove("folder/renamed-text.txt")
os.remove() удалит файл с указанным именем (не каталог).
Удаление директорий
С помощью функции os.rmdir() можно удалить указанную папку:
# удалить папку
os.rmdir("folder")
Для удаления каталогов рекурсивно необходимо использовать os.removedirs():
# удалить вложенные папки
os.removedirs("nested1/nested2/nested3")
Это удалит только пустые каталоги.
Получение информации о файлах
Для получения информации о файле в ОС используется функция os.stat(), которая выполняет системный вызов stat() по выбранному пути:
open("text.txt", "w").write("Это текстовый файл")
# вывести некоторые данные о файле
print(os.stat("text.txt"))
Вывод:
os.stat_result(st_mode=33206, st_ino=14355223812608232, st_dev=1558443184, st_nlink=1, st_uid=0, st_gid=0, st_size=19, st_atime=1575967618, st_mtime=1575967618, st_ctime=1575966941)
Это вернет кортеж с отдельными метриками. В их числе есть следующие:
-
st_size— размер файла в байтахst_atime— время последнего доступа в секундах (временная метка)st_mtime— время последнего измененияst_ctime— в Windows это время создания файла, а в Linux — последнего изменения метаданных
Для получения конкретного атрибута нужно писать следующим образом:
# например, получить размер файла
print("Размер файла:", os.stat("text.txt").st_size)
Вывод:
Размер файла: 19
На этой странице больше об атрибутах.
Выводы
Работать с файлами и каталогами в Python очень просто. Не имеет значения даже используемая операционная система, хотя отдельные уникальные для системы функции можно использовать: например, os.chown() или os.chmod() в Linux. Более подробно эта тема освещена в официальной документации Python.
В этом руководстве речь пойдет об операторах языка программирования Python. Вы узнаете об арифметических, логических и битовых операторах, а также операторах сравнения, присваивания, принадлежности, тождественности и их синтаксисе. Все это будет проиллюстрировано примерами.
Оператор в Python — это символ, который выполняет операцию над одним или несколькими операндами.
Операндом выступает переменная или значение, над которыми проводится операция.
Введение в операторы Python
Операторы Python бывают 7 типов:
- Арифметические операторы
- Операторы сравнения
- Операторы присваивания
- Логические операторы
- Операторы принадлежности
- Операторы тождественности
- Битовые операторы
Арифметические операторы Python
Этот тип включает операторы для проведения базовых арифметических операций.
Сложение (+)
Складывает значение по обе стороны оператора.
Пример:
>>> 3+4
7
Вычитание (-)
Вычитает значение правой стороны из значения в левой.
Пример:
>>> 3-4
-1
Умножение (*)
Перемножает значения с обеих сторон оператора.
Пример:
>>> 3*4
12
Деление (/)
Делит значение левой стороны на значение правой. Тип данных результата деления — число с плавающей точкой.
Пример:
>>> 3/4
0.75
Возведение в степень (**)
Возводит первое число в степень второго.
Пример:
>>> 3**4
81
Деление без остатка (//)
Выполняет деление и возвращает целочисленное значение частного, убирая цифры после десятичной точки.
Пример:
>>> 4//3
1
>>> 10//3
3
Деление по модулю (остаток от деления) (%)
Выполняет деление и возвращает значение остатка.
Пример:
>>> 3%4
3
>>> 4%3
1
>>> 10%3
1
>>> 10.5%3
1.5
Операторы сравнения
Операторы сравнения в Python проводят сравнение операндов. Они сообщают, является ли один из них больше второго, меньше, равным или и то и то.
Меньше (<)
Этот оператор проверяет, является ли значение слева меньше, чем правое.
Пример:
>>> 4<3
False
Больше (>)
Проверяет, является ли значение слева больше правого.
Пример:
>>> 4>3
True
Меньше или равно (<=)
Проверяет, является ли левая часть меньше или равной правой.
Пример:
>>> 7<=7
True
Больше или равно (>=)
Проверяет, является ли левая часть больше или равной правой.
Пример:
>>> 0>=0
True
Равно (==)
Этот оператор проверяет, равно ли значение слева правому. 1 равна булевому True, а 2 (двойка) — нет. 0 равен False.
Пример:
>>> 3==3.0
True
>>> 1==True
True
>>> 7==True
False
>>> 0==False
True
>>> 0.5==True
False
Не равно (!=)
Проверяет, не равно ли значение слева правому. Оператор <> выполняет ту же задачу, но его убрали в Python 3.
Когда условие выполнено, возвращается True. В противном случае — False. Это возвращаемое значение можно использовать в последующих инструкциях и выражениях.
Пример:
>>> 1!=1.0
False
>>> 1==True # Это вызывает SyntaxError
Операторы присваивания
Оператор присваивания присваивает значение переменной. Он может манипулировать значением до присваивания. Есть 8 операторов присваивания: 1 простой и 7 с использованием арифметических операторов.
Присваивание (=)
Присваивает значение справа левой части. Стоит обратить внимание, что == используется для сравнения, а = — для присваивания.
Пример:
>>> a = 7
>>> print(a)
7
Сложение и присваивание (+=)
Суммирует значение обеих сторон и присваивает его выражению слева. a += 10 — это то же самое, что и a = a + 10.
То же касается и все остальных операторов присваивания.
Пример:
>>> a += 2
>>> print(a)
9
Вычитание и присваивание (-=)
Вычитает значение справа из левого и присваивает его выражению слева.
Пример:
>>> a -= 2
>>> print(a)
7
Деление и присваивание (/=)
Делит значение слева на правое. Затем присваивает его выражению слева.
Пример:
>>> a /= 7
>>> print(a)
1.0
Умножение и присваивание (*=)
Перемножает значения обеих сторон. Затем присваивает правое левому.
Пример:
>>> a *= 8
>>> print(a)
8.0
Деление по модулю и присваивание (%=)
Выполняет деление по модулю для обеих частей. Результат присваивает левой части.
Пример:
>>> a %= 3
>>> print(a)
2.0
Возведение в степень и присваивание (**=)
Выполняет возведение левой части в степень значения правой части. Затем присваивает значение левой части.
Пример:
>>> a **= 5
>>> print(a)
32.0
Деление с остатком и присваивание (//=)
Выполняет деление с остатком и присваивает результат левой части.
Пример:
>>> a //= 3
>>> print(a)
10.0
Это один из важных операторов Python
Логические операторы Python
Это союзы, которые позволяют объединять по несколько условий. В Python есть всего три оператора: and (и), or (или) и not (не).
И (and)
Если условия с двух сторон оператора and истинны, тогда все выражение целиком считается истинным.
Пример:
>>> a = 7 > 7 and 2 > -1
>>> print(a)
False
Или (or)
Выражение ложно, если оба операнда с двух сторон ложные. Если хотя бы одно из них истинное, то и все выражение истинно.
Пример:
>>> a = 7 > 7 or 2 > -1
>>> print(a)
True
Не (not)
Этот оператор инвертирует булевые значения выражения. True превращается в False и наоборот. В примере внизу булево значение 0 — False. Поэтому оно превращается в True.
Пример:
>>> a = not(0)
>>> print(a)
True
Операторы принадлежности
Эти операторы проверяют, является ли значение частью последовательности. Последовательность может быть списком, строкой или кортежем. Есть всего два таких оператора: in и not in.
В (in)
Проверяет, является ли значение членом последовательности. В этом примере видно, что строки fox нет в списке питомцев. Но cat — есть, поэтому она возвращает True. Также строка me является подстрокой disappointment. Поэтому она вернет True.
Пример:
>>> pets=['dog','cat', 'ferret']
>>> 'fox' in pets
False
>>> 'cat' in pets
True
>>> 'me' in 'disappointment'
True
Нет в (not in)
Этот оператор проверяет, НЕ является ли значение членом последовательности.
Пример:
>>> 'pot' not in 'disappointment'
True
Операторы тождественности
Эти операторы проверяют, являются ли операнды одинаковыми (занимают ли они одну и ту же позицию в памяти).
Это (is)
Если операнды тождественны, то вернется True. В противном случае — False. Здесь 2 не является 20, поэтому вернется False. Но '2' — это то же самое, что и "2". Разные кавычки не меняют сами объекты, поэтому вернется True.
Пример:
>>> 2 is 20
False
>>> '2' is "2"
True
Это не (is not)
2 — это число, а '2' — строка. Поэтому вернется True.
Пример:
>>> 2 is not '2'
True
Битовые операторы Python
Эти операторы работают над операндами бит за битом.
Бинарное И (&)
Проводит побитовую операцию and над двумя значением. Здесь бинарная 2 — это 10, а 3 — 11. Результатом побитового and является 10 — бинарная 2. Побитовое and над 011(3) и 100(4) выдает результат 000(0).
Пример:
>>> 2&3
2
>>> 3&4
0
Бинарное ИЛИ (|)
Проводит побитовую операцию or на двух значениях. Здесь or для 10(2) и 11(3) возвращает 11(3).
Пример:
>>> 2|3
3
Бинарное ИЛИ НЕТ (^)
Проводит побитовую операцию xor (исключающее или) на двух значениях. Здесь результатом ИЛИ НЕ для 10(2) и 11(3) будет 01(1).
Пример:
>>> 2^3
1
Инвертирующий оператор (~)
Он возвращает инвертированные двоичные числа. Другими словами, переворачивает биты. Битовая 2 — это 00000010. Ее инвертированная версия — 11111101. Это бинарная -3. Поэтому результат -3. Похожим образом ~1 равняется -2.
Пример:
>>> ~-3
2
Еще раз, инвертированная -3 — это 2.
Бинарный сдвиг влево (<<)
Он сдвигает значение левого операнда на позицию, которая указана справа. Так, бинарная 2 — это 10. 2 << 2 сдвинет значение на две позиции влево и выйдет 1000 — это бинарная 8.
Пример:
>>> 2<<2
8
Бинарный сдвиг вправо (>>)
Сдвигает значение левого оператора на позицию, указанную справа. Так, бинарная 3 — это 11. 3 >> 2 сдвинет значение на два положение вправо. Результат — 00, то есть 0. 3 >> 1 сдвинет на одну позицию вправо, а результатом будет 01 — бинарная 1.
Пример:
>>> 3>>2
>>> 3>>1
1
Выводы
В этом уроке были рассмотрены все 7 типов операторов Python. Для каждого был предложен пример в IDE. Для понимания особенностей работы операторов нужно продолжать с ними работать, использовать в условных конструкциях и объединять.
]]>Эта статья посвящена математическим функциям в Python. Для выполнения математических операций необходим модуль math.
Что такое модуль?
В C и C++ есть заголовочные файлы, в которых хранятся функции, переменные классов и так далее. При включении заголовочных файлов в код появляется возможность не писать лишние строки и не использовать одинаковые функции по несколько раз. Аналогично в Python для этого есть модули, которые включают функции, классы, переменные и скомпилированный код. Модуль содержит группу связанных функций, классов и переменных.
Есть три типа модулей в Python:
- Модули, написанные на Python (
.py). - Модули, написанные на
Cи загружаемые динамически (.dll,.pyd,.so,.slи так далее). - Модули, написанные на
C, но связанные с интерпретатором.import sys print(sys.builtin_module_names)('_ast', '_bisect', '_codecs', '_codecs_cn', '_codecs_hk', '_codecs_iso2022', '_codecs_jp', '_codecs_kr', '_codecs_tw', '_collections', '_csv', '_datetime', '_functools', '_heapq', '_imp', '_io', '_json', '_locale', '_lsprof', '_md5', '_multibytecodec', '_opcode', '_operator', '_pickle', '_random', '_sha1', '_sha256', '_sha512', '_sre', '_stat', '_string', '_struct', '_symtable', '_thread', '_tracemalloc', '_warnings', '_weakref', '_winapi', 'array', 'atexit', 'audioop', 'binascii', 'builtins', 'cmath', 'errno', 'faulthandler', 'gc', 'itertools', 'marshal', 'math', 'mmap', 'msvcrt', 'nt', 'parser', 'signal', 'sys', 'time', 'winreg', 'xxsubtype', 'zipimport', 'zlib').
Для получения списка модулей, написанных на C, но связанных с Python, можно использовать следующий код.
Как видно из списка выше, модуль math написан на C, но связан с интерпретатором. Он содержит математические функции и переменные, о которых дальше и пойдет речь.
Функции представления чисел
ceil() и floor() — целая часть числа
Сeil() и floor() — функции общего назначения. Функция ceil округляет число до ближайшего целого в большую сторону. Функция floor убирает цифры десятичных знаков. Обе принимают десятичное число в качестве аргумента и возвращают целое число.
Пример:
# Импорт модуля math
import math
# Дробный номер
number=8.10
# выводим целую часть числа с округлением к большему
print("Верхний предел 8.10 это:",math.ceil(number))
# выводим целую часть числа с округлением к меньшему
print("Нижний предел 8.10 это:",math.floor(number))
Вывод:
Верхний предел 8.10 это: 9
Нижний предел 8.10 это: 8
Функция fabs() — абсолютное значение
Функция fabs используется для вычисления абсолютного значения числа. Если число содержит любой отрицательный знак (-), то функция убирает его и возвращает положительное дробное число.
Пример:
# Импорт модуля math
import math
number = -8.10
# вывод абсолютного значения числа
print(math.fabs(number))
Вывод:
8.1
factorial() — функция факториала
Эта функция принимает положительное целое число и выводит его факториал.
Пример:
# Импорт модуля math
import math
number = 5
# вывод факториала числа
print("факториала числа", math.factorial(number))
Вывод:
факториала числа 120
Примечание: при попытке использовать отрицательное число, возвращается ошибка значения (Value Error).
Пример:
# Импорт модуля math
import math
number = -5
# вывод факториала числа
print("факториала числа", math.factorial(number))
Вывод:
ValueError: factorial() not defined for negative values
Функция fmod() — остаток от деления
Функция fmod(x,y) возвращает x % y. Разница в том, что выражение x % y работает только с целыми числами, а эту функцию можно использовать и для чисел с плавающей точкой.
Пример:
# Импорт модуля math
import math
print(math.fmod(5,2))
print(math.fmod(-5,2))
print(math.fmod(-5.2,2))
print(math.fmod(5.2,2))
Вывод:
1.0
-1.0
-1.2000000000000002
1.2000000000000002
Функция frexp()
Эта функция возвращает мантиссу и показатель степени в виде пары (m,n) любого числа x, решая следующее уравнение.
")
Пример:
# Импорт модуля math
import math
print(math.frexp(24.8))
Вывод:
(0.775, 5)
Функция fsum() — точная сумма float
Вычисляет точную сумму значений с плавающей точкой в итерируемом объекте и сумму списка или диапазона данных.
Пример:
# Импорт модуля math
import math
# сумма списка
numbers=[.1,.2,.3,.4,.5,.6,.7,.8,8.9]
print("сумма ", numbers, ":", math.fsum(numbers))
# сумма диапазона
print("сумма чисел от 1 до 10:", math.fsum(range(1,11)))
Вывод:
сумма [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 8.9] : 12.5
сумма чисел от 1 до 10: 55.0
Функции возведения в степень и логарифма
Функция exp()
Эта функция принимает один параметр в виде дробного числа и возвращает e^x.
Пример:
# Импорт модуля math
import math
print("e в степени 5 ", math.exp(5))
print("e в степени 2.5", math.exp(2.5))
Вывод:
e в степени 5 148.4131591025766
e в степени 2.5 12.182493960703473
Функция expm1()
Эта функция работает так же, как и exp, но возвращает exp(x)-1. Здесь, expm1 значит exm-m-1, то есть, exp-minus-1.
Пример:
# Импорт модуля math
import math
print(math.exp(5)-1)
print(math.expm1(5))
Вывод:
147.4131591025766
147.4131591025766
Функция log() — логарифм числа
Функция log(x[,base]) находит логарифм числа x по основанию e (по умолчанию). base— параметр опциональный. Если нужно вычислить логарифм с определенным основанием, его нужно указать.
Пример:
# Импорт модуля math
import math
# логарифм с основанием e
print(math.log(2))
# логарифм с указанным основанием (2)
print(math.log(64,2))
Вывод:
0.6931471805599453
6.0
Функция log1p()
Эта функция похожа на функцию логарифма, но добавляет 1 к x. log1p значит log-1-p, то есть, log-1-plus.
Пример:
# Импорт модуля math
import math
print(math.log1p(2))
Вывод:
1.0986122886681098
Функция log10()
Вычисляет логарифм по основанию 10.
Пример:
# Импорт модуля math
import math
print(math.log10(1000))
Вывод:
3.0
Функция pow() — степень числа
Используется для нахождение степени числа. Синтаксис функции pow(Base, Power). Она принимает два аргумента: основание и степень.
Пример:
# Импорт модуля math
import math
print(math.pow(5,4))
Вывод:
625.0
Функция sqrt() — квадратный корень числа
Эта функция используется для нахождения квадратного корня числа. Она принимает число в качестве аргумента и находит его квадратный корень.
Пример:
# Импорт модуля math
import math
print(math.sqrt(256))
Вывод:
16.0
Тригонометрические функции
В Python есть следующие тригонометрические функции.
| Функция | Значение |
|---|---|
sin |
принимает радиан и возвращает его синус |
cos |
принимает радиан и возвращает его косинус |
tan |
принимает радиан и возвращает его тангенс |
asin |
принимает один параметр и возвращает арксинус (обратный синус) |
acos |
принимает один параметр и возвращает арккосинус (обратный косинус) |
atan |
принимает один параметр и возвращает арктангенс (обратный тангенс) |
sinh |
принимает один параметр и возвращает гиперболический синус |
cosh |
принимает один параметр и возвращает гиперболический косинус |
tanh |
принимает один параметр и возвращает гиперболический тангенс |
asinh |
принимает один параметр и возвращает обратный гиперболический синус |
acosh |
принимает один параметр и возвращает обратный гиперболический косинус |
atanh |
принимает один параметр и возвращает обратный гиперболический тангенс |
Пример:
# Импорт модуля math
import math
# функция синусы
print("синус PI/2 :", math.sin(math.pi/2))
# функция косинуса
print("косинус 0 :", math.cos(0))
# функция тангенса
print("тангенс PI/4 :", math.tan(math.pi/4))
print()
# функция арксинуса
print("арксинус 0 :", math.acos(0))
# функция арккосинуса
print("арккосинус 1 :", math.acos(1))
# функция арктангенса
print("арктангенс 0.5 :", math.atan(0.5))
print()
# функция гиперболического синуса
print("гиперболический синус 1 :", math.sinh(1))
# функция гиперболического косинуса
print("гиперболический косинус 0 :", math.cos(0))
# функция гиперболического тангенса
print("гиперболический тангенс 1 :", math.tan(1))
print()
# функция обратного гиперболического синуса
print("обратный гиперболический синус 1 :", math.acosh(1))
# функция обратного гиперболического косинуса
print("обратный гиперболический косинус 1 :", math.acosh(1))
# функция обратного гиперболического тангенса
print("обратный гиперболический тангенс 0.5 :", math.atanh(0.5))
Вывод:
синус PI/2 : 1.0
косинус 0 : 1.0
тангенс PI/4 : 0.9999999999999999
арксинус 0 : 1.5707963267948966
арккосинус 1 : 0.0
арктангенс 0.5 : 0.4636476090008061
гиперболический синус 1 : 1.1752011936438014
гиперболический косинус 0 : 1.0
гиперболический тангенс 1 : 1.5574077246549023
обратный гиперболический синус 1 : 0.0
обратный гиперболический косинус 1 : 0.0
обратный гиперболический тангенс 0.5 : 0.5493061443340549
Функция преобразования углов
Эти функции преобразуют угол. В математике углы можно записывать двумя способами: угол и радиан. Есть две функции в Python, которые конвертируют градусы в радиан и обратно.
degrees(): конвертирует радиан в градусы;radians(): конвертирует градус в радианы;
Пример:
# Импорт модуля math
import math
print(math.degrees(1.57))
print(math.radians(90))
Вывод:
89.95437383553924
1.5707963267948966
Математические константы
В Python есть две математические константы: pi и e.
pi: это математическая константа со значением3.1416..e: это математическая константа со значением2.7183..
Пример:
# Импорт модуля math
import math
# вывод значения PI
print("значение PI", math.pi)
# вывод значения e
print("значение e", math.e)
Вывод:
значение PI 3.141592653589793
значение e 2.718281828459045
Из этого руководства вы узнаете о базовых встроенных типах данных Python: числовых, строковых и логических (булевых).
Целые числа
В Python 3 фактически нет предела длины целочисленного значения. Конечно, оно ограничено объемом доступной в системе памяти (как и любые другие типы данных), но в остальном — может быть таким длинным, как нужно:
>>> print(123123123123123123123123123123123123123123123123 + 1)
123123123123123123123123123123123123123123123124
Python интерпретирует последовательность десятичных цифр без префикса как десятичное число:
>>> print(10)
10
Следующие строки могут быть добавлены к значению числа, чтобы обозначить основание отличное от 10:
| Префикс | Интерпретация | Основание |
|---|---|---|
| 0b (ноль + «b» в нижнем регистре) 0B (ноль + «b» в верхнем регистре) |
Двоичное | 2 |
| 0o (ноль + «o» в нижнем регистре) 0O (ноль + «O» в верхнем регистре) |
Восьмеричное | 8 |
| 0x (ноль + «x» в нижнем регистре) 0X (ноль + «X» в верхнем регистре) |
Шестнадцатеричное | 16 |
Например:
>>> print(0o10)
8
>>> print(0x10)
16
>>> print(0b10)
2
Чтобы больше узнать о значениях целых чисел с основанием не равным 10, обратитесь к следующим статьям в Википедии: двоичная, восьмеричная, шестнадцатеричная.
Базовый тип целого числа в Python, вне зависимости от используемого основания, называется int:
>>> type(10)
<class 'int'>
>>> type(0o10)
<class 'int'>
>>> type(0x10)
<class 'int'>
Примечание: отличный момент, чтобы напомнить, что функцию print() не нужно использовать при работе в командной строке. Просто вводите значения после
>>>и нажимайте Enter для отображения:>>> 10 10 >>> 0x10 16 >>> 0b10 2Многие примеры будут использовать эту особенность интерпретатора.
Но это не работает с файлами скриптов. Значение в строке файла со скриптом не делает ничего само по себе.
Числа с плавающей точкой
Тип float в Python означает число с плавающей точкой. Значения float определяются с десятичной точкой. По желанию можно добавить символ e или E после целого числа, чтобы обозначить, что это экспоненциальная запись.
>>> 4.2
4.2
>>> type(4.2)
<class 'float'>
>>> 4.
4.0
>>> .2
0.2
>>> .4e7
4000000.0
>>> type(.4e7)
<class 'float'>
>>> 4.2e-4
0.00042
Подробнее: представление float
Далее следует более подробная информация о том, как Python изнутри представляет числа с плавающей точкой. Вы без проблем можете пользоваться этим типом данных, не понимая этот уровень, так что не волнуйтесь, если описанное здесь покажется чересчур сложным. Информация представлена для особо любопытных.
Почти все платформы представляют числа с плавающей точкой Python как 64-битные значения двойной точности в соответствии со стандартом IEEE 754. В таком случае максимальное значение числа с плавающей точкой — это приблизительно 1.8 х 10308. Числа больше Python будет помечать в виде строки inf:
>>> 1.79e308
1.79e+308
>>> 1.8e308
inf
Ближайшее к нулю ненулевое значение — это приблизительно 5.0*10**-342. Все что ближе — это уже фактически ноль:
>>> 5e-324
5e-324
>>> 1e-325
0.0
Числа с плавающей точкой представлены в виде двоичных (с основанием 2) фракций. Большая часть десятичных фракций не может быть представлена в виде двоичных, поэтому в большинстве случаев внутреннее представление — это приближенное к реальному значение. На практике отличия представленного и реального значения настолько малы, что это не должно создавать проблем.
Дальнейшее чтение: для получения дополнительной информации о числах с плавающей точкой в Python и возможных проблемах, связанных с этим типом данных, читайте официальную документацию Python.
Комплексные числа
Сложные числа определяются следующим образом: <вещественное число>+<мнимая часть>j. Например:
>>> 2+3j
(2+3j)
>>> type(2+3j)
<class 'complex'>
Строки
Строки — это последовательности символов. Строковый тип данных в Python называется str.
Строковые литералы могут выделяться одинарными или двойными кавычками. Все символы между открывающей и закрывающей кавычкой являются частью строки:
>>> print("Я строка.")
Я строка.
>>> type("Я строка.")
<class 'str'>
>>> print('Я тоже.')
Я тоже.
>>> type('Я тоже.')
<class 'str'>
Строка может включать сколько угодно символов. Единственное ограничение — ресурсы памяти устройства. Строка может быть и пустой.
А что, если нужно использовать символ кавычки в строке? Первой идеей может быть нечто подобное:
>>> ''
''
Но, как видите, такой подход не работает. Строка в этом примере открывается одинарной кавычкой, поэтому Python предполагает, что следующая закрывает ее, хотя она задумывалась как часть строки. Закрывающая кавычка в конце вносит неразбериху и приводит к синтаксической ошибке.
Если нужно включить кавычки одного типа в строку, то стоит выделить ее целиком кавычками другого типа. Если строка содержит одинарную кавычку, просто используйте в начале и конце двойные или наоборот:
>>> print('Эта строка содержит одну кавычку (').')
SyntaxError: invalid syntax
Как видите, это не так хорошо работает. Строка в этом примере открывается одиночной кавычкой, поэтому Python предполагает, что следующая одинарная кавычка, та, которая в скобках является закрывающим разделителем. Окончательная одинарная кавычка тогда лишняя и вызывает показанную синтаксическую ошибку.
Если вы хотите включить любой тип символа кавычки в строку, самый простой способ — разделить строку с другим типом. Если строка должна содержать одну кавычку, разделите ее двойными кавычками и наоборот:
>>> print("Эта строка содержит одну кавычку (').")
Эта строка содержит одну кавычку (').
>>> print('Эта строка содержит одну кавычку (").')
Эта строка содержит одну кавычку (").
Управляющие последовательности (исключенные последовательности)
Иногда нужно, чтобы Python по-другому интерпретирован символ или последовательность нескольких символов в строке. Этого можно добиться двумя способами:
- Можно «подавить» специальное значение конкретных символов в этой строке;
- Можно создать специальную интерпретацию для символов в строке, которые обычно воспринимаются буквально;
Для этого используется обратный слэш (\). Обратный слэш в строке указывает, что один или несколько последующих символов нужно интерпретировать особым образом. (Это называется исключенной последовательностью, потому что обратный слэш заставляет последовательность символов «исключаться» из своего привычного значения).
Посмотрим, как это работает.
Подавление значения специальных символов
Вы видели, к каким проблемам приводит использовать кавычек в строке. Если она определена одиночными кавычками, просто так взять и использовать такую же кавычку как часть текста, нельзя, потому что она имеет особенное значение — завершает строку:
>>> print('Эта строка содержит одну кавычку (').')
SyntaxError: invalid syntax
Обратный слэш перед одинарной кавычкой «освобождает» ее от специального значения и заставляет Python воспринимать буквальное значение:
>>> print('Эта строка содержит символ одинарной кавычки (\').')
Эта строка содержит символ одинарной кавычки (').
То же работает и со строками, определенными двойными кавычками:
>>> print("Эта строка содержит символ одинарной кавычки (\").")
Эта строка содержит символ одинарной кавычки (").
Следующая таблица управляющих последовательностей описывает символы, которые заставляют Python воспринимать отдельные символы буквально:
| Управляющий символ | Стандартная интерпретация | Исключенная интерпретация |
|---|---|---|
| \’ | Завершает строку, открытую одинарной кавычкой | Символ одинарной кавычки |
| \» | Завершает строку, открытую двойными кавычками | Символ двойных кавычек |
| \newline | Завершает строку ввода | Новая строка игнорируется |
| \\ | Показывает исключенную последовательность | Символ обратного слэша |
Обычно символ новой строки (newline) заменяет enter. Поэтому он в середине строки заставит Python думать, что она неполная:
>>> print('a
SyntaxError: EOL while scanning string literal
Чтобы разбить строку на несколько строк кода, добавьте обратный слэш перед переходом на новую строку и newline будет игнорироваться:
>>> print('a\
... b\
... c')
abc
Для включения буквального значения обратного слэша, исключите его с помощью еще одного:
>>> print('foo\\bar')
foo\bar
Добавление специального значения символам
Предположим, что необходимо создать строку, которая будет содержать символ табуляции. Некоторые текстовые редакторы вставляют его прямо в код. Но многие программисты считают, что это не правильный подход по нескольким причинам:
- Компьютер видит разницу между символом табуляции и последовательностью пробелов, но программист — нет. Человек, читающий код, не способен отличить пробелы от символа табуляции.
- Некоторые текстовые редакторы настроены так, чтобы автоматически удалять символы табуляции и заменять их на соответствующее количество пробелов.
- Некоторые REPL-среды Python не будут вставлять символы табуляции в код.
В Python (и большинстве других распространенных языков) символ табуляции определяется управляющей последовательностью \t:
>>> print('foo\tbar')
foo bar
Она заставляет символ \t терять свое привычное значение и интерпретируется как символ табуляции.
Вот список экранированных последовательностей, которые заставляют Python использовать специальное значение вместе буквальной интерпретации:
| Управляющая последовательность | «Исключенная» интерпретация |
|---|---|
| \a | ASCII: символ Bell (BEL) |
| \b | ASCII: символ возврата на одну позицию (BS) |
| \f | ASCII: символ разрыва страница (FF) |
| \n | ASCII: символ перевода строки (LF) |
\N{<name>} |
Символ из базы Unicode с именем <name> |
| \r | ASCII: символ возврата каретки (CR) |
| \t | ASCII: символ горизонтальной табуляции (TAB) |
| \uxxxx | Символ Unicode с 16-битным шестнадцатеричным значением |
| \Uxxxxxxxx | Символ Unicode с 32-битным шестнадцатеричным значением |
| \v | ASCII: символ вертикальной табуляции (VT) |
| \ooo | Символ с восьмеричным значением ooo |
| \xhh | Символ с шестнадцатеричными значением hh |
Примеры:
>>> print("a\tb")
a b
>>> print("a\141\x61")
aaa
>>> print("a\nb")
a
b
>>> print('\u2192 \N{rightwards arrow}')
→ →
Такой тип исключенной последовательности обычно используется для вставки символов, которые не легко ввести с клавиатуры или вывести.
«Сырые» строки
Литералу «сырой» строки предшествует r или R, которая подавляет экранирование, так что обратный слэш выводится как есть:
>>> print('foo\nbar')
foo
bar
>>> print(r'foo\nbar')
foo\nbar
>>> print('foo\\bar')
foo\bar
>>> print(R'foo\\bar')
foo\\bar
Строки в тройных кавычка
Есть и другой способ объявления строк в Python. Строки в тройных кавычках определяют группами из трех одинарных или двойных кавычек. Исключенные последовательности в них все еще работают, но одинарные и двойные кавычки, а также новые строки могут использоваться без управляющих символов. Это удобный способ создавать строки, включающие символы одинарных и двойных кавычек:
>>> print('''Эта строка содержит одинарные (') и двойные (") кавычки.''')
Эта строка содержит одинарные (') и двойные (") кавычки.
Таким же образом удобно создавать строки, разбитые на несколько строк кода:
>>> print("""Это cтрока,
которая растянута
на несколько строк""")
Это cтрока,
которая растянута
на несколько строк
Наконец, этот способ используется для создания комментариев кода Python.
Булев тип, Булев контекст и «истинность»
В Python 3 три типа Булевых данных. Объекты булевого типа принимают одно из двух значений, True или False:
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
Многие выражения в Python оцениваются в булевом контексте. Это значит, что они интерпретируются как истинные или ложные.
«Истинность» объекта типа Boolean самоочевидна: объекты равные True являются истинными, а те, что равны False — ложными. Но не-Булевы объекты также могут быть оценены в Булевом контексте.
Обработка ошибок увеличивает отказоустойчивость кода, защищая его от потенциальных сбоев, которые могут привести к преждевременному завершению работы.

Прежде чем переходить к обсуждению того, почему обработка исключений так важна, и рассматривать встроенные в Python исключения, важно понять, что есть тонкая грань между понятиями ошибки и исключения.
Ошибку нельзя обработать, а исключения Python обрабатываются при выполнении программы. Ошибка может быть синтаксической, но существует и много видов исключений, которые возникают при выполнении и не останавливают программу сразу же. Ошибка может указывать на критические проблемы, которые приложение и не должно перехватывать, а исключения — состояния, которые стоит попробовать перехватить. Ошибки — вид непроверяемых и невозвратимых ошибок, таких как OutOfMemoryError, которые не стоит пытаться обработать.
Обработка исключений делает код более отказоустойчивым и помогает предотвращать потенциальные проблемы, которые могут привести к преждевременной остановке выполнения. Представьте код, который готов к развертыванию, но все равно прекращает работу из-за исключения. Клиент такой не примет, поэтому стоит заранее обработать конкретные исключения, чтобы избежать неразберихи.
Ошибки могут быть разных видов:
- Синтаксические
- Недостаточно памяти
- Ошибки рекурсии
- Исключения
Разберем их по очереди.
Синтаксические ошибки (SyntaxError)
Синтаксические ошибки часто называют ошибками разбора. Они возникают, когда интерпретатор обнаруживает синтаксическую проблему в коде.
Рассмотрим на примере.
a = 8
b = 10
c = a b
File "<ipython-input-8-3b3ffcedf995>", line 3
c = a b
^
SyntaxError: invalid syntax
Стрелка вверху указывает на место, где интерпретатор получил ошибку при попытке исполнения. Знак перед стрелкой указывает на причину проблемы. Для устранения таких фундаментальных ошибок Python будет делать большую часть работы за программиста, выводя название файла и номер строки, где была обнаружена ошибка.
Недостаточно памяти (OutofMemoryError)
Ошибки памяти чаще всего связаны с оперативной памятью компьютера и относятся к структуре данных под названием “Куча” (heap). Если есть крупные объекты (или) ссылки на подобные, то с большой долей вероятности возникнет ошибка OutofMemory. Она может появиться по нескольким причинам:
- Использование 32-битной архитектуры Python (максимальный объем выделенной памяти невысокий, между 2 и 4 ГБ);
- Загрузка файла большого размера;
- Запуск модели машинного обучения/глубокого обучения и много другое;
Обработать ошибку памяти можно с помощью обработки исключений — резервного исключения. Оно используется, когда у интерпретатора заканчивается память и он должен немедленно остановить текущее исполнение. В редких случаях Python вызывает OutofMemoryError, позволяя скрипту каким-то образом перехватить самого себя, остановить ошибку памяти и восстановиться.
Но поскольку Python использует архитектуру управления памятью из языка C (функция malloc()), не факт, что все процессы восстановятся — в некоторых случаях MemoryError приведет к остановке. Следовательно, обрабатывать такие ошибки не рекомендуется, и это не считается хорошей практикой.
Ошибка рекурсии (RecursionError)
Эта ошибка связана со стеком и происходит при вызове функций. Как и предполагает название, ошибка рекурсии возникает, когда внутри друг друга исполняется много методов (один из которых — с бесконечной рекурсией), но это ограничено размером стека.
Все локальные переменные и методы размещаются в стеке. Для каждого вызова метода создается стековый кадр (фрейм), внутрь которого помещаются данные переменной или результат вызова метода. Когда исполнение метода завершается, его элемент удаляется.
Чтобы воспроизвести эту ошибку, определим функцию recursion, которая будет рекурсивной — вызывать сама себя в бесконечном цикле. В результате появится ошибка StackOverflow или ошибка рекурсии, потому что стековый кадр будет заполняться данными метода из каждого вызова, но они не будут освобождаться.
def recursion():
return recursion()
recursion()
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
<ipython-input-3-c6e0f7eb0cde> in <module>
----> 1 recursion()
<ipython-input-2-5395140f7f05> in recursion()
1 def recursion():
----> 2 return recursion()
... last 1 frames repeated, from the frame below ...
<ipython-input-2-5395140f7f05> in recursion()
1 def recursion():
----> 2 return recursion()
RecursionError: maximum recursion depth exceeded
Ошибка отступа (IndentationError)
Эта ошибка похожа по духу на синтаксическую и является ее подвидом. Тем не менее она возникает только в случае проблем с отступами.
Пример:
for i in range(10):
print('Привет Мир!')
File "<ipython-input-6-628f419d2da8>", line 2
print('Привет Мир!')
^
IndentationError: expected an indented block
Исключения
Даже если синтаксис в инструкции или само выражение верны, они все равно могут вызывать ошибки при исполнении. Исключения Python — это ошибки, обнаруживаемые при исполнении, но не являющиеся критическими. Скоро вы узнаете, как справляться с ними в программах Python. Объект исключения создается при вызове исключения Python. Если скрипт не обрабатывает исключение явно, программа будет остановлена принудительно.
Программы обычно не обрабатывают исключения, что приводит к подобным сообщениям об ошибке:
Ошибка типа (TypeError)
a = 2
b = 'PythonRu'
a + b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-86a706a0ffdf> in <module>
1 a = 2
2 b = 'PythonRu'
----> 3 a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Ошибка деления на ноль (ZeroDivisionError)
10 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-43-e9e866a10e2a> in <module>
----> 1 10 / 0
ZeroDivisionError: division by zero
Есть разные типы исключений в Python и их тип выводится в сообщении: вверху примеры TypeError и ZeroDivisionError. Обе строки в сообщениях об ошибке представляют собой имена встроенных исключений Python.
Оставшаяся часть строки с ошибкой предлагает подробности о причине ошибки на основе ее типа.
Теперь рассмотрим встроенные исключения Python.
Встроенные исключения
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
Прежде чем переходить к разбору встроенных исключений быстро вспомним 4 основных компонента обработки исключения, как показано на этой схеме.
Try: он запускает блок кода, в котором ожидается ошибка.Except: здесь определяется тип исключения, который ожидается в блокеtry(встроенный или созданный).Else: если исключений нет, тогда исполняется этот блок (его можно воспринимать как средство для запуска кода в том случае, если ожидается, что часть кода приведет к исключению).Finally: вне зависимости от того, будет ли исключение или нет, этот блок кода исполняется всегда.
В следующем разделе руководства больше узнаете об общих типах исключений и научитесь обрабатывать их с помощью инструмента обработки исключения.
Ошибка прерывания с клавиатуры (KeyboardInterrupt)
Исключение KeyboardInterrupt вызывается при попытке остановить программу с помощью сочетания Ctrl + C или Ctrl + Z в командной строке или ядре в Jupyter Notebook. Иногда это происходит неумышленно и подобная обработка поможет избежать подобных ситуаций.
В примере ниже если запустить ячейку и прервать ядро, программа вызовет исключение KeyboardInterrupt. Теперь обработаем исключение KeyboardInterrupt.
try:
inp = input()
print('Нажмите Ctrl+C и прервите Kernel:')
except KeyboardInterrupt:
print('Исключение KeyboardInterrupt')
else:
print('Исключений не произошло')
Исключение KeyboardInterrupt
Стандартные ошибки (StandardError)
Рассмотрим некоторые базовые ошибки в программировании.
Арифметические ошибки (ArithmeticError)
- Ошибка деления на ноль (Zero Division);
- Ошибка переполнения (OverFlow);
- Ошибка плавающей точки (Floating Point);
Все перечисленные выше исключения относятся к классу Arithmetic и вызываются при ошибках в арифметических операциях.
Деление на ноль (ZeroDivisionError)
Когда делитель (второй аргумент операции деления) или знаменатель равны нулю, тогда результатом будет ошибка деления на ноль.
try:
a = 100 / 0
print(a)
except ZeroDivisionError:
print("Исключение ZeroDivisionError." )
else:
print("Успех, нет ошибок!")
Исключение ZeroDivisionError.
Переполнение (OverflowError)
Ошибка переполнение вызывается, когда результат операции выходил за пределы диапазона. Она характерна для целых чисел вне диапазона.
try:
import math
print(math.exp(1000))
except OverflowError:
print("Исключение OverFlow.")
else:
print("Успех, нет ошибок!")
Исключение OverFlow.
Ошибка утверждения (AssertionError)
Когда инструкция утверждения не верна, вызывается ошибка утверждения.
Рассмотрим пример. Предположим, есть две переменные: a и b. Их нужно сравнить. Чтобы проверить, равны ли они, необходимо использовать ключевое слово assert, что приведет к вызову исключения Assertion в том случае, если выражение будет ложным.
try:
a = 100
b = "PythonRu"
assert a == b
except AssertionError:
print("Исключение AssertionError.")
else:
print("Успех, нет ошибок!")
Исключение AssertionError.
Ошибка атрибута (AttributeError)
При попытке сослаться на несуществующий атрибут программа вернет ошибку атрибута. В следующем примере можно увидеть, что у объекта класса Attributes нет атрибута с именем attribute.
class Attributes(obj):
a = 2
print(a)
try:
obj = Attributes()
print(obj.attribute)
except AttributeError:
print("Исключение AttributeError.")
2
Исключение AttributeError.
Ошибка импорта (ModuleNotFoundError)
Ошибка импорта вызывается при попытке импортировать несуществующий (или неспособный загрузиться) модуль в стандартном пути или даже при допущенной ошибке в имени.
import nibabel
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-6-9e567e3ae964> in <module>
----> 1 import nibabel
ModuleNotFoundError: No module named 'nibabel'
Ошибка поиска (LookupError)
LockupError выступает базовым классом для исключений, которые происходят, когда key или index используются для связывания или последовательность списка/словаря неверна или не существует.
Здесь есть два вида исключений:
- Ошибка индекса (
IndexError); - Ошибка ключа (
KeyError);
Ошибка ключа
Если ключа, к которому нужно получить доступ, не оказывается в словаре, вызывается исключение KeyError.
try:
a = {1:'a', 2:'b', 3:'c'}
print(a[4])
except LookupError:
print("Исключение KeyError.")
else:
print("Успех, нет ошибок!")
Исключение KeyError.
Ошибка индекса
Если пытаться получить доступ к индексу (последовательности) списка, которого не существует в этом списке или находится вне его диапазона, будет вызвана ошибка индекса (IndexError: list index out of range python).
try:
a = ['a', 'b', 'c']
print(a[4])
except LookupError:
print("Исключение IndexError, индекс списка вне диапазона.")
else:
print("Успех, нет ошибок!")
Исключение IndexError, индекс списка вне диапазона.
Ошибка памяти (MemoryError)
Как уже упоминалось, ошибка памяти вызывается, когда операции не хватает памяти для выполнения.
Ошибка имени (NameError)
Ошибка имени возникает, когда локальное или глобальное имя не находится.
В следующем примере переменная ans не определена. Результатом будет ошибка NameError.
try:
print(ans)
except NameError:
print("NameError: переменная 'ans' не определена")
else:
print("Успех, нет ошибок!")
NameError: переменная 'ans' не определена
Ошибка выполнения (Runtime Error)
Ошибка «NotImplementedError»
Ошибка выполнения служит базовым классом для ошибки NotImplemented. Абстрактные методы определенного пользователем класса вызывают это исключение, когда производные методы перезаписывают оригинальный.
class BaseClass(object):
"""Опередляем класс"""
def __init__(self):
super(BaseClass, self).__init__()
def do_something(self):
# функция ничего не делает
raise NotImplementedError(self.__class__.__name__ + '.do_something')
class SubClass(BaseClass):
"""Реализует функцию"""
def do_something(self):
# действительно что-то делает
print(self.__class__.__name__ + ' что-то делает!')
SubClass().do_something()
BaseClass().do_something()
SubClass что-то делает!
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-1-57792b6bc7e4> in <module>
14
15 SubClass().do_something()
---> 16 BaseClass().do_something()
<ipython-input-1-57792b6bc7e4> in do_something(self)
5 def do_something(self):
6 # функция ничего не делает
----> 7 raise NotImplementedError(self.__class__.__name__ + '.do_something')
8
9 class SubClass(BaseClass):
NotImplementedError: BaseClass.do_something
Ошибка типа (TypeError)
Ошибка типа вызывается при попытке объединить два несовместимых операнда или объекта.
В примере ниже целое число пытаются добавить к строке, что приводит к ошибке типа.
try:
a = 5
b = "PythonRu"
c = a + b
except TypeError:
print('Исключение TypeError')
else:
print('Успех, нет ошибок!')
Исключение TypeError
Ошибка значения (ValueError)
Ошибка значения вызывается, когда встроенная операция или функция получают аргумент с корректным типом, но недопустимым значением.
В этом примере встроенная операция float получат аргумент, представляющий собой последовательность символов (значение), что является недопустимым значением для типа: число с плавающей точкой.
try:
print(float('PythonRu'))
except ValueError:
print('ValueError: не удалось преобразовать строку в float: \'PythonRu\'')
else:
print('Успех, нет ошибок!')
ValueError: не удалось преобразовать строку в float: 'PythonRu'
Пользовательские исключения в Python
В Python есть много встроенных исключений для использования в программе. Но иногда нужно создавать собственные со своими сообщениями для конкретных целей.
Это можно сделать, создав новый класс, который будет наследовать из класса Exception в Python.
class UnAcceptedValueError(Exception):
def __init__(self, data):
self.data = data
def __str__(self):
return repr(self.data)
Total_Marks = int(input("Введите общее количество баллов: "))
try:
Num_of_Sections = int(input("Введите количество разделов: "))
if(Num_of_Sections < 1):
raise UnAcceptedValueError("Количество секций не может быть меньше 1")
except UnAcceptedValueError as e:
print("Полученная ошибка:", e.data)
Введите общее количество баллов: 10
Введите количество разделов: 0
Полученная ошибка: Количество секций не может быть меньше 1
В предыдущем примере если ввести что-либо меньше 1, будет вызвано исключение. Многие стандартные исключения имеют собственные исключения, которые вызываются при возникновении проблем в работе их функций.
Недостатки обработки исключений в Python
У использования исключений есть свои побочные эффекты, как, например, то, что программы с блоками try-except работают медленнее, а количество кода возрастает.
Дальше пример, где модуль Python timeit используется для проверки времени исполнения 2 разных инструкций. В stmt1 для обработки ZeroDivisionError используется try-except, а в stmt2 — if. Затем они выполняются 10000 раз с переменной a=0. Суть в том, чтобы показать разницу во времени исполнения инструкций. Так, stmt1 с обработкой исключений занимает больше времени чем stmt2, который просто проверяет значение и не делает ничего, если условие не выполнено.
Поэтому стоит ограничить использование обработки исключений в Python и применять его в редких случаях. Например, когда вы не уверены, что будет вводом: целое или число с плавающей точкой, или не уверены, существует ли файл, который нужно открыть.
import timeit
setup="a=0"
stmt1 = '''\
try:
b=10/a
except ZeroDivisionError:
pass'''
stmt2 = '''\
if a!=0:
b=10/a'''
print("time=",timeit.timeit(stmt1,setup,number=10000))
print("time=",timeit.timeit(stmt2,setup,number=10000))
time= 0.003897680000136461
time= 0.0002797570000439009
Выводы!
Как вы могли увидеть, обработка исключений помогает прервать типичный поток программы с помощью специального механизма, который делает код более отказоустойчивым.
Обработка исключений — один из основных факторов, который делает код готовым к развертыванию. Это простая концепция, построенная всего на 4 блоках: try выискивает исключения, а except их обрабатывает.
Очень важно поупражняться в их использовании, чтобы сделать свой код более отказоустойчивым.
]]>1. Обработка исключений Python
В этом материале речь пойдет о блоках try/except, finally и raise. Вместе с тем будет рассмотрено, как создавать собственные исключения в Python.
2. Обработка исключений в Python
Рассмотрим разные типы исключений в Python, которые появляются при срабатывании исключения в коде Python.
3. Блоки try/except
Если код может привести к исключению, его лучше заключить в блок try. Рассмотрим на примере.
try:
for i in range(3):
print(3/i)
except:
print("Деление на 0")
print("Исключение было обработано")
Программа вывела сообщение, потому что было обработано исключение.
Следом идет блок except. Если не определить тип исключения, то он будет перехватывать любые. Другими словами, это общий обработчик исключений.
Если код в блоке try приводит к исключению, интерпретатор ищет блок except, который указан следом. Оставшаяся часть кода в try исполнена не будет.
Исключения Python особенно полезны, если программа работает с вводом пользователя, ведь никогда нельзя знать, что он может ввести.
a. Несколько except в Python
У одного блока try может быть несколько блоков except. Рассмотрим примеры с несколькими вариантами обработки.
a, b = 1, 0
try:
print(a/b)
print("Это не будет напечатано")
print('10'+10)
except TypeError:
print("Вы сложили значения несовместимых типов")
except ZeroDivisionError:
print("Деление на 0")
Когда интерпретатор обнаруживает исключение, он проверяет блоки except соответствующего блока try. В них может быть объявлено, какие типы исключений они обрабатывают. Если интерпретатор находит соответствующее исключение, он исполняет этот блок except.
В первом примере первая инструкция приводит к ZeroDivisionError. Эта ошибка обрабатывается в блоке except, но инструкции в try после первой не исполняются. Так происходит из-за того, что после первого исключения дальнейшие инструкции просто пропускаются. И если подходящий или общий блоки except не удается найти, исключение не обрабатывается. В таком случае оставшаяся часть программы не будет запущена. Но если обработать исключение, то код после блоков except и finally исполнится. Попробуем.
a, b = 1, 0
try:
print(a/b)
except:
print("Вы не можете разделить на 0")
print("Будет ли это напечатано?")
Рассмотрим вывод:
Вы не можете разделить на 0
Будет ли это напечатано?
b. Несколько исключений в одном except
Можно использовать один блок except для обработки нескольких исключений. Для этого используются скобки. Без них интерпретатор вернет синтаксическую ошибку.
try:
print('10'+10)
print(1/0)
except (TypeError,ZeroDivisionError):
print("Неверный ввод")
Неверный ввод
c. Общий except после всех блоков except
В конце концов, завершить все отдельные блоки except можно одним общим. Он используется для обработки всех исключений, которые не были перехвачены отдельными except.
try:
print('1'+1)
print(sum)
print(1/0)
except NameError:
print("sum не существует")
except ZeroDivisionError:
print("Вы не можете разделить на 0")
except:
print("Что-то пошло не так...")
Что-то пошло не так...
Здесь первая инструкция блока пытается осуществить операцию конкатенации строки python с числом. Это приводит к ошибке TypeError. Как только интерпретатор сталкивается с этой проблемой, он проверяет соответствующий блок except, который ее обработает.
Отдельную инструкцию нельзя разместить между блоками try и except.
try:
print("1")
print("2")
except:
print("3")
Это приведет к синтаксической ошибке.
Но может быть только один общий или блок по умолчанию типа except. Следующий код вызовет ошибку «default 'except:' must be last»:
try:
print(1/0)
except:
raise
except:
print("Исключение поймано")
finally:
print("Хорошо")
print("Пока")
4. Блок finally в Python
После последнего блока except можно добавить блок finally. Он исполняет инструкции при любых условиях.
try:
print(1/0)
except ValueError:
print("Это ошибка значения")
finally:
print("Это будет напечатано в любом случае.")
Это будет напечатано в любом случае.
Traceback (most recent call last):
File “<pyshell#113>”, line 2, in <module>
print(1/0)
ZeroDivisionError: division by zero
Стоит обратить внимание, что сообщение с ошибкой выводится после исполнения блока finally. Почему же тогда просто не использовать print? Но как видно по последнему примеру, блок finally запускается даже в том случае, если перехватить исключение не удается.
А что будет, если исключение перехватывается в except?
try:
print(1/0)
except ZeroDivisionError:
print(2/0)
finally:
print("Ничего не происходит")
Ничего не происходит
Traceback (most recent call last):
File "<pyshell#1>", line 2, in <module>
print(1/0)
ZeroDivisionError: division by zero
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<pyshell#1>", line 4, in <module>
print(2/0)
ZeroDivisionError: division by zero
Как видите, код в блоке finally исполняется в любом случае.
5. Ключевое слово raise в Python
Иногда нужно будет разбираться с проблемами с помощью вызова исключения. Обычная инструкция print тут не сработает.
raise ZeroDivisionError
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
raise ZeroDivisionError
ZeroDivisionError
Разберемся на примере операции деления:
a,b=int(input()),int(input()) # вводим 1 затем 0
if b==0:
raise ZeroDivisionError
Traceback (most recent call last):
File "<pyshell#2>", line 3, in <module>
raise ZeroDivisionError
ZeroDivisionError
Здесь ввод пользователя в переменные a и b конвертируется в целые числа. Затем проверяется, равна ли b нулю. Если да, то вызывается ZeroDivisionError.
Что будет, если то же самое добавить в блоки try-except? Добавим следующее в код. Если запустить его, ввести 1 и 0, будет следующий вывод:
a,b=int(input()),int(input())
try:
if b==0:
raise ZeroDivisionError
except:
print("Деление на 0")
print("Будет ли это напечатано?")
1
0
Деление на 0
Будет ли это напечатано?
Рассмотрим еще несколько примеров, прежде чем двигаться дальше:
raise KeyError
Traceback (most recent call last):
File “<pyshell#180>”, line 1, in <module>
raise KeyError
KeyError
a. Raise без определенного исключения в Python
Можно использовать ключевое слово raise и не указывая, какое исключение вызвать. Оно вызовет исключение, которое произошло. Поэтому его можно использовать только в блоке except.
try:
print('1'+1)
except:
raise
Traceback (most recent call last):
File “<pyshell#152>”, line 2, in <module>
print(‘1’+1)
TypeError: must be str, not int
b. Raise с аргументом в Python
Также можно указать аргумент к определенному исключению в raise. Делается это с помощью дополнительных деталей исключения.
raise ValueError("Несоответствующее значение")
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
raise ValueError("Несоответствующее значение")
ValueError: Несоответствующее значение
6. assert в Python
Утверждение (assert) — это санитарная проверка для вашего циничного, параноидального «Я». Оно принимает инструкцию в качестве аргумента и вызывает исключение Python, если возвращается значение False. В противном случае выполняет операцию No-operation (NOP).
assert(True)
# код работает дальше
Если бы инструкция была False?
assert(1==0)
Traceback (most recent call last):
File “<pyshell#157>”, line 1, in <module>
assert(1==0)
AssertionError
Возьмем другой пример:
try:
print(1)
assert 2+2==4
print(2)
assert 1+2==4
print(3)
except:
print("assert False.")
raise
finally:
print("Хорошо")
print("Пока")
Вывод следующий:
1
2
assert False.
Хорошо
Traceback (most recent call last):
File “<pyshell#157>”, line 5, in <module>
assert 1+2==4
AssertionError
Утверждения можно использовать для проверки валидности ввода и вывода в функции.
a. Второй аргумент для assert
Можно предоставить второй аргумент, чтобы дать дополнительную информацию о проблеме.
assert False,"Это проблема"
Traceback (most recent call last):
File “<pyshell#173>”, line 1, in <module>
assert False,”Это проблема”
AssertionError: Это проблема
7. Объявление собственных исключений Python
Наконец, рассмотрим процесс создания собственных исключений. Для этого создадим новый класс из класса Exception. Потом его можно будет вызывать как любой другой тип исключения.
class MyError(Exception):
print("Это проблема")
raise MyError("ошибка MyError")
Traceback (most recent call last):
File “<pyshell#179>”, line 1, in <module>
raise MyError(“ошибка MyError”)
MyError: ошибка MyError
Вот и все, что касается обработки исключений в Python.
8. Вывод: обработка исключений Python
Благодаря этой статье вы сможете обеспечить дополнительную безопасность своему коду. Все благодаря возможности обработки исключений Python, их вызова и создания собственных.
]]>Строковый метод format() форматирует строки python для более красивого вывода.
Синтаксис метода:
template.format(p0, p1, ..., k0=v0, k1=v1, ...)
Здесь p0, p1,... — это позиционные аргументы, а k0, k1,... — аргументы-ключевые слова со значениями v0, v1,... соответственно.
А template — это набор строк с заполнителями для аргументов.
Параметры format()
Метод format() принимает любое количество параметров. Но они делятся на два вида:
- Позиционные аргументы — список параметров, доступ к которым можно получить по индексу параметра в фигурных скобках {индекс}.
- Параметры — ключевые слова — список параметров типа ключ=значение, доступ к которым можно получить с помощью ключа параметра в фигурных скобках {ключ}.
Возвращаемое значение format()
Метода format() возвращает отформатированную строку.
Как работает format()?
Формат читает тип переданных аргументов и форматирует строку в соответствии с кодами форматирования в строке.
Для позиционных аргументов
 для позиционных аргументов")
Здесь Аргумент 0 — это строка “Adam”, а Аргумент 1 — число с плавающей точкой 230.2346.
Список аргументов в Python начинается с 0.
Строка Hello {0}, your balance is {1:9.3f} — это шаблон строки. Он содержит коды форматирования.
Фигурные скобки — это всего лишь заполнители, которые будут заменены аргументами. В примере выше {0} — это заполнитель для "Adam", а {1:9.3f} — для 230.2346.
Поскольку шаблон строки ссылается на аргументы format() ({0} и {1}), они являются позиционными аргумента. На них можно ссылаться без использования чисел, а Python конвертирует {} в числа автоматически.
Что происходит:
- Поскольку
"Adam"— это нулевой аргумент, он располагается в позиции {0}. Поскольку {0} не содержит других кодов форматирования, дополнительные операции не осуществляются. - Но в случае с первым аргументом,
230.2346, ситуация другая.{1:9.3f}размещает230.2346на нужно месте и выполняет операцию9.3f. fопределяет, что это формат числа с плавающей точкой. Если указать неправильно, будет ошибка.- Часть до точки (9) определяет минимальную ширину, которую может занимать число 230.2346. В этом случае числу 230.2346 выделены 9 мест с точкой.
Если параметр выравнивания не указан, то он выравнивается вправо до оставшихся позиций (для строк — влево). - Часть после точки (3) урезает десятичную часть (2346) до указанной числа. В этом случае 2346 может занимать три места. Остаток (46) округляется и выходит 235.
Для аргументов-ключевых слов
 для аргументов-ключевых слов")
В этом примере используется то же выражение, чтобы продемонстрировать разницу в использовании позиционных и аргументов-ключевых слов.
Здесь вместо просто параметров использованы сочетания ключ-значение. А именно: name="Adam" и blc=230.2346.
Поскольку ссылка на эти параметры происходит через ключи ({name} и {blc:9.3f}) — это именованные аргументы.
Что происходит внутри:
- Заполнитель
{name}заменяется значением ключаname— “Adam”. Никаких дополнительных операций здесь нет. - В случае с аргументом
blc=230.2346заполнитель{blc:9.3f}заменяется на значение230.2346. Но перед заменой производится операция9.3f.
Вывод — “230.235”. Десятичная часть обрезается после трех позиций, а оставшиеся цифры округляются. Общая ширина — 9, а два символа остаются справа.
Базовое форматирование с format()
Метод format() позволяет использовать простые заполнители для форматирования.
Пример №1: базовое форматирование для аргументов по умолчанию, позиционных и аргументов-ключевых слов.
# аргументы по умолчанию
print("Hello {}, your balance is {}.".format("Adam", 230.2346))
# позиционные аргументы
print("Hello {0}, your balance is {1}.".format("Adam", 230.2346))
# аргументы ключевые слова
print("Hello {name}, your balance is {blc}.".format(name="Adam", blc=230.2346))
# смешанные аргументы
print("Hello {0}, your balance is {blc}.".format("Adam", blc=230.2346))
При запуске программы вывод будет одинаковым:
Hello Adam, your balance is 230.2346.
Hello Adam, your balance is 230.2346.
Hello Adam, your balance is 230.2346.
Hello Adam, your balance is 230.2346.
При использовании смешанных аргументов аргументы-ключевые слова должны идти после позиционных аргументов.
Форматирование чисел с format()
С помощью спецификаторов формата можно форматировать и числа:
Типы форматирования чисел
| Тип | Значение |
|---|---|
| d | Десятичное число |
| c | Соответствующий символ Unicode |
| b | Двоичный формат |
| o | Восьмеричный формат |
| x | Шестнадцатеричный формат (в нижнем регистре) |
| X | Шестнадцатеричный формат (в верхнем регистре) |
| n | То же, что и d, но использует местную настройку для разделения числа |
| e | Экспоненциальная запись (e в нижнем регистре) |
| E | Экспоненциальная запись (E в верхнем регистре) |
| f | Отображать фиксированное количество знаков (по умолчанию 6) |
| F | То же, что и f, только отображает inf как INF, а nan как NAN |
| g | Общий формат. Округляет число до p значащих цифр (Точность по умолчанию: 6) |
| G | То же, что и g. Но переключается к E, если число очень большое |
| % | Проценты. Делит на 100 и добавляет % в конце |
Пример №2: простое форматирование чисел.
# целочисленные аргументы
print("The number is:{:d}".format(123))
# аргументы с плавающей точкой
print("The float number is:{:f}".format(123.4567898))
# восьмеричный, двоичный и шестнадцатеричный формат
print("bin: {0:b}, oct: {0:o}, hex: {0:x}".format(12))
При запуске этой программы вывод будет следующий:
The number is: 123
The number is:123.456790
bin: 1100, oct: 14, hex: c
Пример №3: форматирование чисел с полями для целых и чисел с плавающей точкой.
# целые числа с минимальной шириной
print("{:5d}".format(12))
# ширина не работает для чисел длиннее заполнения
print("{:2d}".format(1234))
# заполнение для чисел с плавающей точкой
print("{:8.3f}".format(12.2346))
# целые числа с минимальной шириной, заполненные нулями
print("{:05d}".format(12))
# заполнение для чисел с плавающей запятой, заполненных нулями
print("{:08.3f}".format(12.2346))
Эта программа выдаст следующее:
12
1234
12.235
00012
0012.235
Здесь:
- В первой инструкции
{:5d}принимает целое число в качестве аргумента и задает минимальную ширину 5. Поскольку настройка выравнивания не задана, оно выравнивается к правому краю. - Во втором ширина (2) меньше, чем размер числа (1234), поэтому слева не появляется свободное пространство, но число и не обрезается.
- В отличие от целых чисел у чисел с плавающей точкой есть целая и десятичная части. Минимальная ширина в этом случае включает обе из них и точку.
- В третьем выражении
{:8.3f}обрезает десятичную часть, округляя ее до 2 цифр. И число, теперь 12.235, занимает 8 позиций, оставляя 2 пустых местах слева. - Если нужно заполнить оставшиеся места нулями, спецификатор может сделать и это. Это работает как для целых чисел, так и для чисел с плавающей точкой:
{:05d}и{:08.3f}.
Пример №4: форматирование чисел со знаками.
# показать знак +
print("{:+f} {:+f}".format(12.23, -12.23))
# показать знак -
print("{:-f} {:-f}".format(12.23, -12.23))
# показать место для знака +
print("{: f} {: f}".format(12.23, -12.23))
Вывод будет следующий:
+12.230000 -12.230000
12.230000 -12.230000
12.230000 -12.230000
Форматирование чисел с выравниванием
Операторы <, ^, > и = используются для выравнивания в том случае, если указана конкретная ширина.
Форматирование чисел с выравниванием
| Тип | Значение |
|---|---|
| < | Выравнивается по левому краю |
| ^ | Выравнивается по центру |
| > | Выравнивается по правому краю |
| = | Сдвигает знаки (+ или -) к левой позиции |
Пример №5: форматирование чисел с выравниванием по центру, левому и правому краю.
# целые числа с выравниванием по правому краю
print("{:5d}".format(12))
# числа с плавающей точкой с выравниванием по центру
print("{:^10.3f}".format(12.2346))
# выравнивание целого числа по левому краю заполнено нулями
print("{:<05d}".format(12))
# числа с плавающей точкой с выравниванием по центру
print("{:=8.3f}".format(-12.2346))
Вывод этой программы:
12
12.235
12000
- 12.235
Выравнивание по левому краю с нулями для целых чисел может создать проблемы, как в случае с третьим примером, который возвращает 12000 вместо 12.
Форматирование строк с format()
Как и числа, строки можно форматировать с помощью format().
Пример №6: форматирование строк с полями и выравниванием.
# отступ строки с выравниванием по левому краю
print("{:5}".format("cat"))
# отступ строки с выравниванием по правому краю
print("{:>5}".format("cat"))
# заполнение строк с выравниванием по центру
print("{:^5}".format("cat"))
# заполнение строк с выравниванием по центру
# и '*' - символ заполнения
print("{:*^5}".format("cat"))
При запуске программы вывод будет следующим:
cat
cat
cat
*cat*
Пример №7: обрезание строк.
# обрезание строк до 3 букв
print("{:.3}.".format("caterpillar"))
# обрезание строк до 3 букв и заполнение
print("{:5.3}.".format("caterpillar"))
# обрезание строк до 3 букв,
# заполнение и выравнивание по центру
print("{:^5.3}.".format("caterpillar"))
Вывод будет следующим:
cat.
cat .
cat .
Форматирование элементов классов и словарей с format()
Python использует getattr() для элементов класса в форме “.age”. А __getitem__() — для элементов словаря в форме “[index]”.
Пример №8: форматирование элементов класса с format().
# определяем класс Person
class Person:
age = 23
name = "Adam"
# форматирование возраста
print("{p.name}'s age is: {p.age}".format(p=Person()))
Вывод этой программы:
Adam's age is: 23
Здесь объект Person передается как аргумент-ключевое слово p.
В шаблоне строки получают доступ к значениям name и age с помощью .name и .age.
Пример №9: форматирование элементов словаря с format().
# объявляем словарь person
person = {'age': 23, 'name': 'Adam'}
# форматирование возраста
print("{p[name]}'s age is: {p[age]}".format(p=person))
Вывод:
Adam's age is: 23
По аналогии с классом словарь person передается в качестве аргумента-ключевого слова p.
В шаблоне строки доступ к name и age получают с помощью [name] и [age].
Есть и более простой способ форматировать словари в Python с помощью str.fromat(**mapping).
# объявляем словарь person
person = {'age': 23, 'name': 'Adam'}
# форматирование возраста
print("{name}'s age is: {age}".format(**person))
Вывод:
Adam's age is: 23
* — это параметр формата (минимальная ширина поля).
Аргументы как параметры в format()
Параметры, такие как точность, выравнивание или символы заполнения можно передавать в качестве позиционных аргументов-ключевых слов.
Пример №10: динамическое форматирование.
# динамический шаблон формата строки
string = "{:{fill}{align}{width}}"
# передача кодов формата в качестве аргументов
print(string.format('cat', fill='*', align='^', width=5))
# динамический шаблон формата float
num = "{:{align}{width}.{precision}f}"
# передача кодов формата в качестве аргументов
print(num.format(123.236, align='<', width=8, precision=2))
Вывод:
*cat*
123.24
Здесь:
- В первом пример “cat” — это позиционный аргумент, который будет отформатирован. Аналогично
fill='*',align='^'иwidth=5являются аргументами-ключевыми словами. - В шаблоне строки эти аргументы извлекаются не как обычные строки для вывода, а как коды форматирования:
fill,alignиwidth.
Эти аргументы заменяют соответствующие заполнители, а строка “cat” соответствующим образом форматируется. - Во втором примере 123.236 — это позиционный аргумент, а
align,withиprecisionпередаются в шаблон в качестве параметров форматирования.
Дополнительные параметры форматирования с format()
format() также поддерживает форматирования по типам, например, для datetime или форматирование сложных чисел. Он внутренне вызывает __format__() для datetime и получает доступ к атрибутам сложных чисел.
Можно запросто переопределить метод __format__() для любого объекта для создания собственного форматирования.
Пример №11: форматирование по типу с format() и переопределение метода _format().
import datetime
# datetime форматирование
date = datetime.datetime.now()
print("It's now: {:%Y/%m/%d %H:%M:%S}".format(date))
# форматирование комплексных чисел
complexNumber = 1+2j
print("Real part: {0.real} and Imaginary part: {0.imag}".format(complexNumber))
# пользовательский метод __format__()
class Person:
def __format__(self, format):
if(format == 'age'):
return '23'
return 'None'
print("Adam's age is: {:age}".format(Person()))
Вывод:
It's now: 2020/01/18 12:19:24
Real part: 1.0 and Imaginary part: 2.0
Adam's age is: 23
Здесь
- Для datetime:
Текущий объектdatetimeпередается в качестве позиционного аргумента методуformat(). С помощью метода__format__()format()получает доступ к году, месяцу, дню, часу, минутам и секундам. - Для сложны чисел:
1+2j конвертируется в объект ComplexNumber.
Затем через доступ к атрибутамrealиimagчисла форматируются. - Переопределение format():
Как и сdatetimeможно перезаписать метод__format__()для собственного форматирования, которое вернет возраст при попытке получить доступ через{:age}.
Также можно использовать функциональность __str__() и __repr__() объекта с условными обозначениями и format().
Как и __format__() можно запросто переопределять метода __str__() и __repr__() объекта.
Пример №12: условные обозначения str() и repr() (!r и !s) с format().
# __str__() и __repr__() сокращенно !r и !s
print("Quotes: {0!r}, Without Quotes: {0!s}".format("cat"))
# реализация для класса __str__() и __repr__()
class Person:
def __str__(self):
return "STR"
def __repr__(self):
return "REPR"
print("repr: {p!r}, str: {p!s}".format(p=Person()))
Вывод:
Quotes: 'cat', Without Quotes: cat
repr: REPR, str: STR
В этом руководстве вы узнаете и увидите на примерах, какие преимущества для форматирования дает использование f-строк в Python.
Вступление
Что такое форматирование строк?
Форматирование строк — это оформление строк с помощью методов форматирования, предложенных конкретным языком программирования. В Python таких несколько, но речь пойдет только об одном: f-строках.
f-строки исполняются при исполнении самой программы. Это работает быстрее других методов.
У f-строк более простой синтаксис в сравнении с другими техниками форматирования Python. Эта особенность будет рассмотрена на примерах.
Синтаксис
Каждая инструкция f-строки состоит из двух частей: символа f (или F) и строки, которую нужно форматировать. Строка должна быть в одинарных, двойных или тройных кавычках.
Синтаксис следующий.
# мы также можем использовать F, '', ''''', """"""
f"string"
На месте string нужно написать предложение, которое требуется отформатировать.
Отображение переменных
Раньше для форматирования использовался метод str.format(). Новый подход делает все вдвое быстрее.
Переменные в фигурных {} скобках отображаются в выводе как обычно в print. Стоит посмотреть на примере.
# объявление переменных
name = "Pythonru"
type_of_site = "Блог"
# заключите переменную в {}, чтобы отобразить ее значение в выводе
print(f"{name} это {type_of_site}.")
Pythonru это Блог.
Все значения переменных отобразились в выводе. С этим все понятно. Вместо f можно написать F.
# объявление переменных
name = "Pythonru"
type_of_site = "Блог"
# заключите переменную в {}, чтобы отобразить ее значение в выводе
print(F"{name} это {type_of_site}?")
Pythonru это Блог?
Выражения
Что, если можно было бы выполнять арифметические выражения или вызовы функций в строке? Это удобно. И f-строки позволяют делать это.
Просто вставьте выражение в {} для исполнения. Оно выполнится при запуске программы. Экономит время и код.
Вот примеры отдельных выражений.
# объявление переменных
print(f"{2 * 2}") # вывод: 4
Также в {} можно вызвать функцию. Определим функцию greet() и вызовем ее в f-строке.
def greet(name):
return "Привет, " + name
# вызов функции с использованием f-строки
name = "Олег"
print(f"{greet(name)}")
Привет, Олег
Также можно вызвать определенные заранее методы.
# метод title, делает первую букву каждого слова заглавной
string = "pythonru это блог."
print(f"{string.title()}")
Pythonru Это Блог.
Что еще умеет f-строка? Отображать объект? Да. Работает это так же, как и при выводе переменных.
class Sample:
def __init__(self, name, age):
self.name = name
self.age = age
# этот метод будет вызываться при выводе объекта
def __str__(self):
return f'Имя: {self.name}. Возвраст: {self.age}.'
user= Sample("Игорь", 19)
# это вызовет метод __str__()
print(f"{user}")
Имя: Игорь. Возвраст: 19.
Специальные символы
Что делать, если нужно отобразить специальные символы, такие как {}, \', \"? Они ведь используются в Python для определенных целей. Можно ли использовать экранирование внутри f-строки? Вот ответы на все вопросы.
Кавычки
Можно использовать любые кавычки (одинарные, двойные или тройные) в f-строке. Для их вывода потребуется использовать экранирование. Выражение f-строки не позволяет использовать обратную косую черту. Ее нужно размещать вне {}.
Рассмотрим на примерах.
name = "Pythonru"
# отображение одинарных кавычек
print(f"Привет, \'{name}\'")
print()
# отображение двойных кавычек
print(f"Привет, \"{name}\"")
Привет, 'Pythonru'
Привет, "Pythonru"
Другие кавычки в f-строках.
f'{"Привет, Pythonru"}' # 'Привет, Pythonru'
f"{'Привет, Pythonru'}" # 'Привет, Pythonru'
f"""Привет, Pythonru""" # 'Привет, Pythonru'
f'''Привет, Pythonru''' # 'Привет, Pythonru'
{} также можно включать в тройные кавычки.
В f-строках нельзя использовать обратную косую черту в {}. Если попробовать, то будет ошибка.
print(f"{\"Pythonru\"}") # SyntaxError
Скобки
Двойные скобки нужны, чтобы вывести одни фигурные скобки в f-строке.
print(f"{{Pythonru}}")
{Pythonru}
Если нужно вывести две пары скобок, то в выражении потребуется указать по четыре.
print(f"{{{{Pythonru}}}}")
{{Pythonru}}
Словари
Нужно быть осторожным, работая с ключами словаря в f-строке. Необходимо использовать другие кавычки по отношению к ключам. Они не должны быть теми же, которыми окружена f-строка.
person = {"name": "Игорь", "age": 19}
print(f"{person['name']}, {person['age']} лет.")
Игорь, 19 лет.
Со словарями так нельзя.
person = {"name": "Игорь", "age": 19}
print(f'{person['name']}, {person['age']} лет.')
File "<ipython-input-65-6849ff0810ae>", line 2
print(f'{person['name']}, {person['age']} лет.')
^
SyntaxError: invalid syntax
В Python есть модуль time, который используется для решения задач, связанных со временем. Для использования определенных в нем функций необходимо сначала его импортировать:
import time
Дальше перечислены самые распространенные функции, связанные со временем.
Python time.time()
Функция time() возвращает число секунд, прошедших с начала эпохи. Для операционных систем Unix 1 января 1970, 00:00:00 (UTC) — начало эпохи (момент, с которого время пошло).
import time
seconds = time.time()
print("Секунды с начала эпохи =", seconds)
Python time.ctime()
Функция time.ctime() принимает в качестве аргумента количество секунд, прошедших с начала эпохи, и возвращает строку, представляющую собой местное время.
import time
# секунды прошли с эпох
seconds = 1575721830.711298
local_time = time.ctime(seconds)
print("Местное время:", local_time)
Если запустить программу, то вывод будет выглядеть так:
Местное время: Sat Dec 7 14:31:36 2019
Python time.sleep()
Функция sleep() откладывает исполнение текущего потока на данное количество секунд.
import time
print("Сейчас.")
time.sleep(2.4)
print("Через 2.4 секунды.")
Прежде чем переходить к другим функциям, связанных со временем, нужно вкратце разобраться с классом time.struct_time.
Класс time.struct_time
Некоторые функции в модуле time, такие как gmtime(), asctime() и другие, принимают объект time.struct_time в качестве аргумента или возвращают его.
Вот пример объекта time.struct_time.
| Индекс | Атрибут | Значения |
|---|---|---|
| 0 | tm_year | 0000, …, 2019, …, 9999 |
| 1 | tm_mon | 1, 2, …, 12 |
| 2 | tm_mday | 1, 2, …, 31 |
| 3 | tm_hour | 0, 1, …, 23 |
| 4 | tm_min | 0, 1, …, 59 |
| 5 | tm_sec | 0, 1, …, 61 |
| 6 | tm_wday | 0, 1, …, 6; Monday is 0 |
| 7 | tm_yday | 1, 2, …, 366 |
| 8 | tm_isdst | 0, 1 or -1 |
К значениям (элементам) объекта time.struct_time доступ можно получить как с помощью индексов, так и через атрибуты.
Python time.localtime()
Функция localtime() принимает в качестве аргумента количество секунд, прошедших с начала эпохи, и возвращает stuct_time в локальном времени.
import time
result = time.localtime(1575721830)
print("результат:", result)
print("\nгод:", result.tm_year)
print("tm_hour:", result.tm_hour)
Вывод этой программы будет следующим:
result: time.struct_time(tm_year=2019, tm_mon=12, tm_mday=7, tm_hour=14, tm_min=30, tm_sec=30, tm_wday=5, tm_yday=341, tm_isdst=0)
year: 2019
tm_hour: 14
Если localtime() передан аргумент None, то вернется значение из time().
Python time.gmtime()
Функция gmtime() принимает в качестве аргумента количество секунд, прошедших с начала эпохи и возвращает struct_time в UTC.
import time
result = time.gmtime(1575721830)
print("результат:", result)
print("\nгод:", result.tm_year)
print("tm_hour:", result.tm_hour)
Вывод этой программы будет следующим:
result: time.struct_time(tm_year=2019, tm_mon=12, tm_mday=7, tm_hour=12, tm_min=30, tm_sec=30, tm_wday=5, tm_yday=341, tm_isdst=0)
year: 2019
tm_hour: 12
Если gmtime() передан аргумент None, то вернется значение time().
Python time.mktime()
Функция mktime() принимает struct_time (или кортеж, содержащий 9 значений, относящихся к struct_time) в качестве аргумента и возвращает количество секунд, прошедших с начала эпохи, в местном времени. Это функция, обратная localtime().
import time
t = (2019, 12, 7, 14, 30, 30, 5, 341, 0)
local_time = time.mktime(t)
print("Местное время:", local_time)
Следующий пример показывает, как связаны mktime() и localtime().
import time
seconds = 1575721830
# возвращает struct_time
t = time.localtime(seconds)
print("t1: ", t)
# возвращает секунды из struct_time
s = time.mktime(t)
print("\ns:", seconds)
Вывод будет следующий:
t1: time.struct_time(tm_year=2019, tm_mon=12, tm_mday=7, tm_hour=14, tm_min=30, tm_sec=30, tm_wday=5, tm_yday=341, tm_isdst=0)
s: 1575721830
Python time.asctime()
Функция asctime() принимает struct_time (или кортеж, содержащий 9 значений, относящихся к struct_time) в качестве аргумента и возвращает строку, представляющую собой дату.
Например:
import time
t = (2019, 12, 7, 14, 30, 30, 5, 341, 0)
result = time.asctime(t)
print("Результат:", result)
Вывод:
Результат: Sat Dec 7 14:30:30 2019
Python time.strftime()
Функция strftime принимает stuct_time (или соответствующий кортеж) в качестве аргумента и возвращает строку с датой в зависимости от использованного формата. Например:
import time
named_tuple = time.localtime() # получить struct_time
time_string = time.strftime("%m/%d/%Y, %H:%M:%S", named_tuple)
print(time_string)
Вывод будет следующий:
12/07/2019, 15:01:09
Здесь %Y, %m, %d, %H и другие — элементы форматирования.
%Y— год [0001,…, 2019, 2020,…, 9999]%m— месяц [01, 02, …, 11, 12]%d— день [01, 02, …, 30, 31]%H— час [00, 01, …, 22, 23%M— минута [00, 01, …, 58, 59]%S— секунда [00, 01, …, 58, 61]
Python time.strptime()
Функция strptime() делает разбор строки python, в которой упоминается время и возвращает struct_time.
import time
time_string = "15 June, 2019"
result = time.strptime(time_string, "%d %B, %Y")
print(result)
Вывод:
time.struct_time(tm_year=2019, tm_mon=6, tm_mday=15, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=166, tm_isdst=-1)
Из этого материала вы узнаете, что такое циклы while, как они могут становиться бесконечными, как использовать инструкцию else в цикле while и как прерывать исполнение цикла.
Управление потоком инструкций: цикл While в Python
Как и другие языки программирования Python включает несколько инструкций для управления потоком. Одна из таких — if else. Еще одна — циклы. Циклы используются в тех случаях, когда нужно повторить блок кода определенное количество раз.
Что такое цикл while в Python?
Цикл while используется в Python для неоднократного исполнения определенной инструкции до тех пор, пока заданное условие остается истинным. Этот цикл позволяет программе перебирать блок кода.
while test_expression:
body of while
Сначала программа оценивает условие цикла while. Если оно истинное, начинается цикл, и тело while исполняется. Тело будет исполняться до тех пор, пока условие остается истинным. Если оно становится ложным, программа выходит из цикла и прекращает исполнение тела.
Рассмотрим пример, чтобы лучше понять.
a = 1
while a < 10:
print('Цикл выполнился', a, 'раз(а)')
a = a+1
print('Цикл окончен')
Вывод:
Цикл выполнился 1 раз
Цикл выполнился 2 раз
Цикл выполнился 3 раз
Цикл выполнился 4 раз
Цикл выполнился 5 раз
Цикл выполнился 6 раз
Цикл выполнился 7 раз
Цикл выполнился 8 раз
Цикл выполнился 9 раз
Цикл окончен
Бесконечный цикл while в Python
Бесконечный цикл while — это цикл, в котором условие никогда не становится ложным. Это значит, что тело исполняется снова и снова, а цикл никогда не заканчивается.
Следующий пример — бесконечный цикл:
a = 1
while a==1:
b = input('Как тебя зовут?')
print('Привет', b, ', Добро пожаловать')
Если запустить этот код, то программа войдет в бесконечный цикл и будет снова и снова спрашивать имена. Цикл не остановится до тех пор, пока не нажать Ctrl + C.
Else в цикле while
В Python с циклами while также можно использовать инструкцию else. В этом случае блок в else исполняется, когда условие цикла становится ложным.
a = 1
while a < 5:
print('условие верно')
a = a + 1
else:
print('условие неверно')
Этот пример демонстрирует принцип работы else в цикле while.
Вывод:
условие верно
условие верно
условие верно
условие верно
условие неверно
Программа исполняет код цикла while до тех, пока условие истинно, то есть пока значение a меньше 5. Поскольку начальное значение a равно 1, а с каждым циклом оно увеличивается на 1, условие станет ложным, когда программа доберется до четвертой итерации — в этот момент значение a изменится с 4 до 5. Программа проверит условие еще раз, убедится, что оно ложно и исполнит блок else, отобразив «условие неверно».
Прерывания цикла while в Python
В Python есть два ключевых слова, с помощью которых можно преждевременно остановить итерацию цикла.
- Break — ключевое слово
breakпрерывает цикл и передает управление в конец циклаa = 1 while a < 5: a += 1 if a == 3: break print(a) # 2 - Continue — ключевое слово
continueпрерывает текущую итерацию и передает управление в начало цикла, после чего условие снова проверяется. Если оно истинно, исполняется следующая итерация.
a = 1
while a < 5:
a += 1
if a == 3:
continue
print(a) # 2, 4, 5
Эта статья посвящена работе с файлами (вводу/выводу) в Python: открытие, чтение, запись, закрытие и другие операции.
Файлы Python
Файл — это всего лишь набор данных, сохраненный в виде последовательности битов на компьютере. Информация хранится в куче данных (структура данных) и имеет название «имя файла» (filename).
В Python существует два типа файлов:
- Текстовые
- Бинарные
Текстовые файлы
Это файлы с человекочитаемым содержимым. В них хранятся последовательности символов, которые понимает человек. Блокнот и другие стандартные редакторы умеют читать и редактировать этот тип файлов.
Текст может храниться в двух форматах: (.txt) — простой текст и (.rtf) — «формат обогащенного текста».
Бинарные файлы
В бинарных файлах данные отображаются в закодированной форме (с использованием только нулей (0) и единиц (1) вместо простых символов). В большинстве случаев это просто последовательности битов.
Они хранятся в формате .bin.
Любую операцию с файлом можно разбить на три крупных этапа:
- Открытие файла
- Выполнение операции (запись, чтение)
- Закрытие файла
Открытие файла
Метод open()
В Python есть встроенная функция open(). С ее помощью можно открыть любой файл на компьютере. Технически Python создает на его основе объект.
Синтаксис следующий:
f = open(file_name, access_mode)
Где,
file_name= имя открываемого файлаaccess_mode= режим открытия файла. Он может быть: для чтения, записи и т. д. По умолчанию используется режим чтения (r), если другое не указано. Далее полный список режимов открытия файла
| Режим | Описание |
|---|---|
| r | Только для чтения. |
| w | Только для записи. Создаст новый файл, если не найдет с указанным именем. |
| rb | Только для чтения (бинарный). |
| wb | Только для записи (бинарный). Создаст новый файл, если не найдет с указанным именем. |
| r+ | Для чтения и записи. |
| rb+ | Для чтения и записи (бинарный). |
| w+ | Для чтения и записи. Создаст новый файл для записи, если не найдет с указанным именем. |
| wb+ | Для чтения и записи (бинарный). Создаст новый файл для записи, если не найдет с указанным именем. |
| a | Откроет для добавления нового содержимого. Создаст новый файл для записи, если не найдет с указанным именем. |
| a+ | Откроет для добавления нового содержимого. Создаст новый файл для чтения записи, если не найдет с указанным именем. |
| ab | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для записи, если не найдет с указанным именем. |
| ab+ | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для чтения записи, если не найдет с указанным именем. |
Пример
Создадим текстовый файл example.txt и сохраним его в рабочей директории.

Следующий код используется для его открытия.
f = open('example.txt','r') # открыть файл из рабочей директории в режиме чтения
fp = open('C:/xyz.txt','r') # открыть файл из любого каталога
В этом примере f — переменная-указатель на файл example.txt.
Следующий код используется для вывода содержимого файла и информации о нем.
>>> print(*f) # выводим содержимое файла
This is a text file.
>>> print(f) # выводим объект
<_io.TextIOWrapper name='example.txt' mode='r' encoding='cp1252'>
Стоит обратить внимание, что в Windows стандартной кодировкой является cp1252, а в Linux — utf-08.
Закрытие файла
Метод close()
После открытия файла в Python его нужно закрыть. Таким образом освобождаются ресурсы и убирается мусор. Python автоматически закрывает файл, когда объект присваивается другому файлу.
Существуют следующие способы:
Способ №1
Проще всего после открытия файла закрыть его, используя метод close().
f = open('example.txt','r')
# работа с файлом
f.close()
После закрытия этот файл нельзя будет использовать до тех пор, пока заново его не открыть.
Способ №2
Также можно написать try/finally, которое гарантирует, что если после открытия файла операции с ним приводят к исключениям, он закроется автоматически.
Без него программа завершается некорректно.
Вот как сделать это исключение:
f = open('example.txt','r')
try:
# работа с файлом
finally:
f.close()
Файл нужно открыть до инструкции
try, потому что если инструкцияopenсама по себе вызовет ошибку, то файл не будет открываться для последующего закрытия.
Этот метод гарантирует, что если операции над файлом вызовут исключения, то он закроется до того как программа остановится.
Способ №3
Инструкция with
Еще один подход — использовать инструкцию with, которая упрощает обработку исключений с помощью инкапсуляции начальных операций, а также задач по закрытию и очистке.
В таком случае инструкция close не нужна, потому что with автоматически закроет файл.
Вот как это реализовать в коде.
with open('example.txt') as f:
# работа с файлом
Чтение и запись файлов в Python
В Python файлы можно читать или записывать информацию в них с помощью соответствующих режимов.
Функция read()
Функция read() используется для чтения содержимого файла после открытия его в режиме чтения (r).
Синтаксис
file.read(size)
Где,
file= объект файлаsize= количество символов, которые нужно прочитать. Если не указать, то файл прочитается целиком.
Пример
>>> f = open('example.txt','r')
>>> f.read(7) # чтение 7 символов из example.txt
'This is '
Интерпретатор прочитал 7 символов файла и если снова использовать функцию read(), то чтение начнется с 8-го символа.
>>> f.read(7) # чтение следующих 7 символов
' a text'
Функция readline()
Функция readline() используется для построчного чтения содержимого файла. Она используется для крупных файлов. С ее помощью можно получать доступ к любой строке в любой момент.
Пример
Создадим файл test.txt с нескольким строками:
This is line1.
This is line2.
This is line3.
Посмотрим, как функция readline() работает в test.txt.
>>> x = open('test.txt','r')
>>> x.readline() # прочитать первую строку
This is line1.
>>> x.readline(2) # прочитать вторую строку
This is line2.
>>> x.readlines() # прочитать все строки
['This is line1.','This is line2.','This is line3.']
Обратите внимание, как в последнем случае строки отделены друг от друга.
Функция write()
Функция write() используется для записи в файлы Python, открытые в режиме записи.
Если пытаться открыть файл, которого не существует, в этом режиме, тогда будет создан новый.
Синтаксис
file.write(string)
Пример
Предположим, файла xyz.txt не существует. Он будет создан при попытке открыть его в режиме чтения.
>>> f = open('xyz.txt','w') # открытие в режиме записи
>>> f.write('Hello \n World') # запись Hello World в файл
Hello
World
>>> f.close() # закрытие файла
Переименование файлов в Python
Функция rename()
Функция rename() используется для переименовывания файлов в Python. Для ее использования сперва нужно импортировать модуль os.
Синтаксис следующий.
import os
os.rename(src,dest)
Где,
src= файл, который нужно переименоватьdest= новое имя файла
Пример
>>> import os
>>> # переименование xyz.txt в abc.txt
>>> os.rename("xyz.txt","abc.txt")
Текущая позиция в файлах Python
В Python возможно узнать текущую позицию в файле с помощью функции tell(). Таким же образом можно изменить текущую позицию командой seek().
Пример
>>> f = open('example.txt') # example.txt, который мы создали ранее
>>> f.read(4) # давайте сначала перейдем к 4-й позиции
This
>>> f.tell() # возвращает текущую позицию
4
>>> f.seek(0,0) # вернем положение на 0 снова
Методы файла в Python
file.close() |
закрывает открытый файл |
file.fileno() |
возвращает целочисленный дескриптор файла |
file.flush() |
очищает внутренний буфер |
file.isatty() |
возвращает True, если файл привязан к терминалу |
file.next() |
возвращает следующую строку файла |
file.read(n) |
чтение первых n символов файла |
file.readline() |
читает одну строчку строки или файла |
file.readlines() |
читает и возвращает список всех строк в файле |
| file.seek(offset[,whene]) | устанавливает текущую позицию в файле |
file.seekable() |
проверяет, поддерживает ли файл случайный доступ. Возвращает True, если да |
file.tell() |
возвращает текущую позицию в файле |
file.truncate(n) |
уменьшает размер файл. Если n указала, то файл обрезается до n байт, если нет — до текущей позиции |
file.write(str) |
добавляет строку str в файл |
file.writelines(sequence) |
добавляет последовательность строк в файл |
Введение
Определение
Вот пример простой функции:
def compute_surface(radius):
from math import pi
return pi * radius * radius
Для определения функции нужно всего лишь написать ключевое слово def перед ее именем, а после — поставить двоеточие. Следом идет блок инструкций.
Последняя строка в блоке инструкций может начинаться с return, если нужно вернуть какое-то значение. Если инструкции return нет, тогда по умолчанию функция будет возвращать объект None. Как в этом примере:
i = 0
def increment():
global i
i += 1
Функция инкрементирует глобальную переменную i и возвращает None (по умолчанию).
Вызовы
Для вызова функции, которая возвращает переменную, нужно ввести:
surface = compute_surface(1.)
Для вызова функции, которая ничего не возвращает:
increment()
Еще
Функцию можно записать в одну строку, если блок инструкций представляет собой простое выражение:
def sum(a, b): return a + b
Функции могут быть вложенными:
def func1(a, b):
def inner_func(x):
return x*x*x
return inner_func(a) + inner_func(b)
Функции — это объекты, поэтому их можно присваивать переменным.
Инструкция return
Возврат простого значения
Аргументы можно использовать для изменения ввода и таким образом получать вывод функции. Но куда удобнее использовать инструкцию return, примеры которой уже встречались ранее. Если ее не написать, функция вернет значение None.
Возврат нескольких значений
Пока что функция возвращала только одно значение или не возвращала ничего (объект None). А как насчет нескольких значений? Этого можно добиться с помощью массива. Технически, это все еще один объект. Например:
def stats(data):
"""данные должны быть списком"""
_sum = sum(data) # обратите внимание на подчеркивание, чтобы избежать переименования встроенной функции sum
mean = _sum / float(len(data)) # обратите внимание на использование функции float, чтобы избежать деления на целое число
variance = sum([(x-mean)**2/len(data) for x in data])
return mean,variance # возвращаем x,y — кортеж!
m, v = stats([1, 2, 1])
Аргументы и параметры
В функции можно использовать неограниченное количество параметров, но число аргументов должно точно соответствовать параметрам. Эти параметры представляют собой позиционные аргументы. Также Python предоставляет возможность определять значения по умолчанию, которые можно задавать с помощью аргументов-ключевых слов.
Параметр — это имя в списке параметров в первой строке определения функции. Он получает свое значение при вызове. Аргумент — это реальное значение или ссылка на него, переданное функции при вызове. В этой функции:
def sum(x, y):
return x + y
x и y — это параметры, а в этой:
sum(1, 2)
1 и 2 — аргументы.
При определении функции параметры со значениями по умолчанию нужно указывать до позиционных аргументов:
def compute_surface(radius, pi=3.14159):
return pi * radius * radius
Если использовать необязательный параметр, тогда все, что указаны справа, должны быть параметрами по умолчанию.
Выходит, что в следующем примере допущена ошибка:
def compute_surface(radius=1, pi):
return pi * radius * radius
Для вызовов это работает похожим образом. Сначала нужно указывать все позиционные аргументы, а только потом необязательные:
S = compute_surface(10, pi=3.14)
На самом деле, следующий вызов корректен (можно конкретно указывать имя позиционного аргумента), но этот способ не пользуется популярностью:
S = compute_surface(radius=10, pi=3.14)
А этот вызов некорректен:
S = compute_surface(pi=3.14, 10)
При вызове функции с аргументами по умолчанию можно указать один или несколько, и порядок не будет иметь значения:
def compute_surface2(radius=1, pi=3.14159):
return pi * radius * radius
S = compute_surface2(radius=1, pi=3.14)
S = compute_surface2(pi=3.14, radius=10.)
S = compute_surface2(radius=10.)
Можно не указывать ключевые слова, но тогда порядок имеет значение. Он должен соответствовать порядку параметров в определении:
S = compute_surface2(10., 3.14)
S = compute_surface2(10.)
Если ключевые слова не используются, тогда нужно указывать все аргументы:
def f(a=1,b=2, c=3):
return a + b + c
Второй аргумент можно пропустить:
f(1,,3)
Чтобы обойти эту проблему, можно использовать словарь:
params = {'a':10, 'b':20}
S = f(**params)
Значение по умолчанию оценивается и сохраняется только один раз при определении функции (не при вызове). Следовательно, если значение по умолчанию — это изменяемый объект, например, список или словарь, он будет меняться каждый раз при вызове функции. Чтобы избежать такого поведения, инициализацию нужно проводить внутри функции или использовать неизменяемый объект:
def inplace(x, mutable=[]):
mutable.append(x)
return mutable
res = inplace(1)
res = inplace(2)
print(inplace(3))
[1, 2, 3]
def inplace(x, lst=None):
if lst is None: lst=[]
lst.append()
return lst
Еще один пример изменяемого объекта, значение которого поменялось при вызове:
def change_list(seq):
seq[0] = 100
original = [0, 1, 2]
change_list(original)
original
[100, 1, 2]
Дабы не допустить изменения оригинальной последовательности, нужно передать копию изменяемого объекта:
original = [0, 1, 2]
change_list(original[:])
original
[0, 1, 2]
Указание произвольного количества аргументов
Позиционные аргументы
Иногда количество позиционных аргументов может быть переменным. Примерами таких функций могут быть max() и min(). Синтаксис для определения таких функций следующий:
def func(pos_params, *args):
block statememt
При вызове функции нужно вводить команду следующим образом:
func(pos_params, arg1, arg2, ...)
Python обрабатывает позиционные аргументы следующим образом: подставляет обычные позиционные аргументы слева направо, а затем помещает остальные позиционные аргументы в кортеж (*args), который можно использовать в функции.
Вот так:
def add_mean(x, *data):
return x + sum(data)/float(len(data))
add_mean(10,0,1,2,-1,0,-1,1,2)
10.5
Если лишние аргументы не указаны, значением по умолчанию будет пустой кортеж.
Произвольное количество аргументов-ключевых слов
Как и в случае с позиционными аргументами можно определять произвольное количество аргументов-ключевых слов следующим образом (в сочетании с произвольным числом необязательных аргументов из прошлого раздела):
def func(pos_params, *args, **kwargs):
block statememt
При вызове функции нужно писать так:
func(pos_params, kw1=arg1, kw2=arg2, ...)
Python обрабатывает аргументы-ключевые слова следующим образом: подставляет обычные позиционные аргументы слева направо, а затем помещает другие позиционные аргументы в кортеж (*args), который можно использовать в функции (см. предыдущий раздел). В конце концов, он добавляет все лишние аргументы в словарь (**kwargs), который сможет использовать функция.
Есть функция:
def print_mean_sequences(**kwargs):
def mean(data):
return sum(data)/float(len(data))
for k, v in kwargs.items():
print k, mean(v)
print_mean_sequences(x=[1,2,3], y=[3,3,0])
y 2.0
x 2.0
Важно, что пользователь также может использовать словарь, но перед ним нужно ставить две звездочки (**):
print_mean_sequences(**{'x':[1,2,3], 'y':[3,3,0]})
y 2.0
x 2.0
Порядок вывода также не определен, потому что словарь не отсортирован.
Документирование функции
Определим функцию:
def sum(s,y): return x + y
Если изучить ее, обнаружатся два скрытых метода (которые начинаются с двух знаков нижнего подчеркивания), среди которых есть __doc__. Он нужен для настройки документации функции. Документация в Python называется docstring и может быть объединена с функцией следующим образом:
def sum(x, y):
"""Первая срока - заголовок
Затем следует необязательная пустая строка и текст
документации.
"""
return x+y
Команда docstring должна быть первой инструкцией после объявления функции. Ее потом можно будет извлекать или дополнять:
print(sum.__doc__)
sum.__doc__ += "some additional text"
Методы, функции и атрибуты, связанные с объектами функции
Если поискать доступные для функции атрибуты, то в списке окажутся следующие методы (в Python все является объектом — даже функция):
sum.func_closure sum.func_defaults sum.func_doc sum.func_name
sum.func_code sum.func_dict sum.func_globals
И несколько скрытых методов, функций и атрибутов. Например, можно получить имя функции или модуля, в котором она определена:
>>> sum.__name__
"sum"
>>> sum.__module
"__main__"
Есть и другие. Вот те, которые не обсуждались:
sum.__call__ sum.__delattr__ sum.__getattribute__ sum.__setattr__
sum.__class__ sum.__dict__ sum.__globals__ sum.__new__ sum.__sizeof__
sum.__closure__ sum.__hash__ sum.__reduce__ sum.__str__
sum.__code__ sum.__format__ sum.__init__ sum.__reduce_ex__ sum.__subclasshook__
sum.__defaults__ sum.__get__ sum.__repr__
Рекурсивные функции
Рекурсия — это не особенность Python. Это общепринятая и часто используемая техника в Computer Science, когда функция вызывает сама себя. Самый известный пример — вычисление факториала n! = n * n — 1 * n -2 * … 2 *1. Зная, что 0! = 1, факториал можно записать следующим образом:
def factorial(n):
if n != 0:
return n * factorial(n-1)
else:
return 1
Другой распространенный пример — определение последовательности Фибоначчи:
f(0) = 1
f(1) = 1
f(n) = f(n-1) + f(n-2)
Рекурсивную функцию можно записать так:
def fibbonacci(n):
if n >= 2:
else:
return 1
Важно, чтобы в ней было была конечная инструкция, иначе она никогда не закончится. Реализация вычисления факториала выше, например, не является надежной. Если указать отрицательное значение, функция будет вызывать себя бесконечно. Нужно написать так:
def factorial(n):
assert n > 0
if n != 0:
return n * factorial(n-1)
else:
return 1
Важно!
Рекурсия позволяет писать простые и элегантные функции, но это не гарантирует эффективность и высокую скорость исполнения.
Если рекурсия содержит баги (например, длится бесконечно), функции может не хватить памяти. Задать максимальное значение рекурсий можно с помощью модуля sys.
Глобальная переменная
Вот уже знакомый пример с глобальной переменной:
i = 0
def increment():
global i
i += 1
Здесь функция увеличивает на 1 значение глобальной переменной i. Это способ изменять глобальную переменную, определенную вне функции. Без него функция не будет знать, что такое переменная i. Ключевое слово global можно вводить в любом месте, но переменную разрешается использовать только после ее объявления.
За редкими исключениями глобальные переменные лучше вообще не использовать.
Присвоение функции переменной
С существующей функцией func синтаксис максимально простой:
variable = func
Переменным также можно присваивать встроенные функции. Таким образом позже есть возможность вызывать функцию другим именем. Такой подход называется непрямым вызовом функции.
Менять название переменной также разрешается:
def func(x): return x
a1 = func
a1(10)
10
a2 = a1
a2()
10
В этом примере a1, a2 и func имеют один и тот же id. Они ссылаются на один объект.
Практический пример — рефакторинг существующего кода. Например, есть функция sq, которая вычисляет квадрат значения:
def sq(x): return x*x
Позже ее можно переименовать, используя более осмысленное имя. Первый вариант — просто сменить имя. Проблема в том, что если в другом месте кода используется sq, то этот участок не будет работать. Лучше просто добавить следующее выражение:
square = sq
Последний пример. Предположим, встроенная функция была переназначена:
dir = 3
Теперь к ней нельзя получить доступ, а это может стать проблемой. Чтобы вернуть ее обратно, нужно просто удалить переменную:
del dir
dir()
Анонимная функция: лямбда
Лямбда-функция — это короткая однострочная функция, которой даже не нужно имя давать. Такие выражения содержат лишь одну инструкцию, поэтому, например, if, for и while использовать нельзя. Их также можно присваивать переменным:
product = lambda x,y: x*y
В отличие от функций, здесь не используется ключевое слово return. Результат работы и так возвращается.
С помощью type() можно проверить тип:
>>> type(product)
function
На практике эти функции редко используются. Это всего лишь элегантный способ записи, когда она содержит одну инструкцию.
power = lambda x=1, y=2: x**y
square = power
square(5.)
25
power = lambda x,y,pow=2: x**pow + y
[power(x,2, 3) for x in [0,1,2]]
[2, 3, 10]
Изменяемые аргументы по умолчанию
>>> def foo(x=[]):
... x.append(1)
... print x
...
>>> foo()
[1]
>>> foo()
[1, 1]
>>> foo()
[1, 1, 1]
Вместо этого нужно использовать значение «не указано» и заменить на изменяемый объект по умолчанию:
>>> def foo(x=None):
... if x is None:
... x = []
... x.append(1)
... print x
>>> foo()
[1]
>>> foo()
[1]
Объектно-ориентированное программирование в Python
Python — это процедурно-ориентированный и одновременно объектно-ориентированный язык программирования.
Процедурно-ориентированный
«Процедурно-ориентированный» подразумевает наличие функций. Программист может создавать функции, которые затем используются в сторонних скриптах.
Объектно-ориентированный
«Объектно-ориентированный» подразумевает наличие классов. Есть возможность создавать классы, представляющие собой прототипы для будущих объектов.
Создание класса в Python
Синтаксис для написания нового класса:
class ClassName:
'Краткое описание класса (необязательно)'
# Код ...
- Для создания класса пишется ключевое слово
class, его имя и двоеточие (:). Первая строчка в теле класса описывает его. (По желанию) получить доступ к этой строке можно с помощьюClassName.__doc__ - В теле класса допускается объявление атрибутов, методов и конструктора.
Атрибут:
Атрибут — это элемент класса. Например, у прямоугольника таких 2: ширина (width) и высота (height).
Метод:
- Метод класса напоминает классическую функцию, но на самом деле — это функция класса. Для использования ее необходимо вызывать через объект.
- Первый параметр метода всегда
self(ключевое слово, которое ссылается на сам класс).
Конструктор:
- Конструктор — уникальный метод класса, который называется
__init__. - Первый параметр конструктора во всех случаях
self(ключевое слово, которое ссылается на сам класс). - Конструктор нужен для создания объекта.
- Конструктор передает значения аргументов свойствам создаваемого объекта.
- В одном классе всегда только один конструктор.
- Если класс определяется не конструктором, Python предположит, что он наследует конструктор родительского класса.
# Прямоугольник.
class Rectangle :
'Это класс Rectangle'
# Способ создания объекта (конструктор)
def __init__(self, width, height):
self.width= width
self.height = height
def getWidth(self):
return self.width
def getHeight(self):
return self.height
# Метод расчета площади.
def getArea(self):
return self.width * self.height
Создание объекта с помощью класса Rectangle:

# Создаем 2 объекта: r1 & r2
r1 = Rectangle(10,5)
r2 = Rectangle(20,11)
print("r1.width = ", r1.width)
print("r1.height = ", r1.height)
print("r1.getWidth() = ", r1.getWidth())
print("r1.getArea() = ", r1.getArea())
print("-----------------")
print("r2.width = ", r2.width)
print("r2.height = ", r2.height)
print("r2.getWidth() = ", r2.getWidth())
print("r2.getArea() = ", r2.getArea())

Что происходит при создании объекта с помощью класса?
При создании объекта класса Rectangle запускается конструктор выбранного класса, и атрибутам нового объекта передаются значения аргументов. Как на этом изображении:

Конструктор с аргументами по умолчанию
В других языках программирования конструкторов может быть несколько. В Python — только один. Но этот язык разрешает задавать значение по умолчанию.
Все требуемые аргументы нужно указывать до аргументов со значениями по умолчанию.
class Person:
# Параметры возраста и пола имеют значение по умолчанию.
def __init__(self, name, age=1, gender="Male"):
self.name = name
self.age = age
self.gender= gender
def showInfo(self):
print("Name: ", self.name)
print("Age: ", self.age)
print("Gender: ", self.gender)
Например:
from person import Person
# Создать объект Person.
aimee = Person("Aimee", 21, "Female")
aimee.showInfo()
print(" --------------- ")
# возраст по умолчанию, пол.
alice = Person( "Alice" )
alice.showInfo()
print(" --------------- ")
# Пол по умолчанию.
tran = Person("Tran", 37)
tran.showInfo()

Сравнение объектов
В Python объект, созданный с помощью конструктора, занимает реальное место в памяти. Это значит, что у него есть точный адрес.
Если объект AA — это просто ссылка на объект BB, то он не будет сущностью, занимающей отдельную ячейку памяти. Вместо этого он лишь ссылается на местоположение BB.

Оператор == нужен, чтобы узнать, ссылаются ли два объекта на одно и то же место в памяти. Он вернет True, если это так. Оператор != вернет True, если сравнить 2 объекта, которые ссылаются на разные места в памяти.
from rectangle import Rectangle
r1 = Rectangle(20, 10)
r2 = Rectangle(20 , 10)
r3 = r1
# Сравните r1 и r2
test1 = r1 == r2 # --> False
# Сравните r1 и r3
test2 = r1 == r3 # --> True
print ("r1 == r2 ? ", test1)
print ("r1 == r3 ? ", test2)
print (" -------------- ")
print ("r1 != r2 ? ", r1 != r2)
print ("r1 != r3 ? ", r1 != r3)

Атрибуты
В Python есть два похожих понятия, которые на самом деле отличаются:
- Атрибуты
- Переменные класса
Стоит разобрать на практике:
class Player:
# Переменная класса
minAge = 18
maxAge = 50
def __init__(self, name, age):
self.name = name
self.age = age
Атрибут
Объекты, созданные одним и тем же классом, будут занимать разные места в памяти, а их атрибуты с «одинаковыми именами» — ссылаться на разные адреса. Например:

from player import Player
player1 = Player("Tom", 20)
player2 = Player("Jerry", 20)
print("player1.name = ", player1.name)
print("player1.age = ", player1.age)
print("player2.name = ", player2.name)
print("player2.age = ", player2.age)
print(" ------------ ")
print("Assign new value to player1.age = 21 ")
# Присвойте новое значение атрибуту возраста player1.
player1.age = 21
print("player1.name = ", player1.name)
print("player1.age = ", player1.age)
print("player2.name = ", player2.name)
print("player2.age = ", player2.age)

Python умеет создавать новые атрибуты для уже существующих объектов. Например, объект player1 и новый атрибут address.
from player import Player
player1 = Player("Tom", 20)
player2 = Player("Jerry", 20)
# Создайте новый атрибут с именем «address» для player1.
player1.address = "USA"
print("player1.name = ", player1.name)
print("player1.age = ", player1.age)
print("player1.address = ", player1.address)
print(" ------------------- ")
print("player2.name = ", player2.name)
print("player2.age = ", player2.age)
# player2 е имеет атрибута 'address' (Error!!)
print("player2.address = ", player2.address)
Вывод:
player1.name = Tom
player1.age = 20
player1.address = USA
-------------------
player2.name = Jerry
player2.age = 20
Traceback (most recent call last):
File "C:/Users/gvido/class.py", line 27, in <module>
print("player2.address = ", player2.address)
AttributeError: 'Player' object has no attribute 'address'
Атрибуты функции
Обычно получать доступ к атрибутам объекта можно с помощью оператора «точка» (например, player1.name). Но Python умеет делать это и с помощью функции.
| Функция | Описание |
|---|---|
getattr (obj, name[,default]) |
Возвращает значение атрибута или значение по умолчанию, если первое не было указано |
hasattr (obj, name) |
Проверяет атрибут объекта — был ли он передан аргументом «name» |
setattr (obj, name, value) |
Задает значение атрибута. Если атрибута не существует, создает его |
delattr (obj, name) |
Удаляет атрибут |
from player import Player
player1 = Player("Tom", 20)
# getattr(obj, name[, default])
print("getattr(player1,'name') = " , getattr(player1,"name"))
print("setattr(player1,'age', 21): ")
# setattr(obj,name,value)
setattr(player1,"age", 21)
print("player1.age = ", player1.age)
# Проверка, что player1 имеет атрибут 'address'?
hasAddress = hasattr(player1, "address")
print("hasattr(player1, 'address') ? ", hasAddress)
# Создать атрибут 'address' для объекта 'player1'
print("Create attribute 'address' for object 'player1'")
setattr(player1, 'address', "USA")
print("player1.address = ", player1.address)
# Удалить атрибут 'address'.
delattr(player1, "address")
Вывод:
getattr(player1,'name') = Tom
setattr(player1,'age', 21):
player1.age = 21
hasattr(player1, 'address') ? False
Create attribute 'address' for object 'player1'
player1.address = USA
Встроенные атрибуты класса
Объекты класса — дочерние элементы по отношению к атрибутам самого языка Python. Таким образом они заимствуют некоторые атрибуты:
| Атрибут | Описание |
|---|---|
__dict__ |
Предоставляет данные о классе коротко и доступно, в виде словаря |
__doc__ |
Возвращает строку с описанием класса, или None, если значение не определено |
__class__ |
Возвращает объект, содержащий информацию о классе с массой полезных атрибутов, включая атрибут __name__ |
__module__ |
Возвращает имя «модуля» класса или __main__, если класс определен в выполняемом модуле. |
class Customer:
'Это класс Customer'
def __init__(self, name, phone, address):
self.name = name
self.phone = phone
self.address = address
john = Customer("John",1234567, "USA")
print ("john.__dict__ = ", john.__dict__)
print ("john.__doc__ = ", john.__doc__)
print ("john.__class__ = ", john.__class__)
print ("john.__class__.__name__ = ", john.__class__.__name__)
print ("john.__module__ = ", john.__module__)
Вывод:
john.__dict__ = {'name': 'John', 'phone': 1234567, 'address': 'USA'}
john.__doc__ = Это класс Customer
john.__class__ = <class '__main__.Customer'>
john.__class__.__name__ = Customer
john.__module__ = __main__
Переменные класса
Переменные класса в Python — это то же самое, что Field в других языках, таких как Java или С#. Получить к ним доступ можно только с помощью имени класса или объекта.
Для получения доступа к переменной класса лучше все-таки использовать имя класса, а не объект. Это поможет не путать «переменную класса» и атрибуты.
У каждой переменной класса есть свой адрес в памяти. И он доступен всем объектам класса.

from player import Player
player1 = Player("Tom", 20)
player2 = Player("Jerry", 20)
# Доступ через имя класса.
print ("Player.minAge = ", Player.minAge)
# Доступ через объект.
print("player1.minAge = ", player1.minAge)
print("player2.minAge = ", player2.minAge)
print(" ------------ ")
print("Assign new value to minAge via class name, and print..")
# Новое значение minAge через имя класса
Player.minAge = 19
print("Player.minAge = ", Player.minAge)
print("player1.minAge = ", player1.minAge)
print("player2.minAge = ", player2.minAge)
Вывод:
Player.minAge = 18
player1.minAge = 18
player2.minAge = 18
------------
Assign new value to minAge via class name, and print..
Player.minAge = 19
player1.minAge = 19
player2.minAge = 19
Составляющие класса или объекта
В Python присутствует функция dir, которая выводит список всех методов, атрибутов и переменных класса или объекта.
from player import Player
# Вывести список атрибутов, методов и переменных объекта 'Player'
print(dir(Player))
print("\n\n")
player1 = Player("Tom", 20)
player1.address ="USA"
# Вывести список атрибутов, методов и переменных объекта 'player1'
print(dir(player1))
Вывод:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__gt__',
'__hash__', '__init__', '__init_subclass__', '__le__', '__lt__',
'__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '__weakref__', 'maxAge', 'minAge']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__gt__',
'__hash__', '__init__', '__init_subclass__', '__le__', '__lt__',
'__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '__weakref__', 'address', 'age', 'maxAge',
'minAge', 'name']
В предыдущих материалах этого руководства мы обсудили базовые концепции Python: переменные, структуры данных, встроенные функции и методы, циклы for и инструкции if. Это все — семантическое ядро языка. Но это лишь основа того, что есть в Python. Самое интересное ждет впереди. У Python есть море модулей и пакетов, которые можно импортировать в свой проект. Что это значит? Об этом вы узнаете в статье: о том, как использовать инструкцию import и о самых важных встроенных модулях для работы в сфере data science.
Инструкция import в Python
Итак, что такое инструкция import, и почему она так важна?
Представьте LEGO.
Пока что в руководствах использовались только базовые элементы набора LEGO. Но если нужно построить что-то более сложное, необходимо задействовать более сложные инструменты.
С помощью import можно получить доступ к «инструментам» Python, которые называются модулями.
Они делятся на три группы:
- Модули стандартной библиотеки Python:
Получить к ним доступ проще простого, потому что они поставляются с языком Python3 по умолчанию. Все что нужно — ввестиimportи название модуля. С этого момента выбранный модуль можно использовать в коде. О том, как это делать, дальше в статье. - Другие более продвинутые и специализированные модули:
Эти модули не являются частью стандартной библиотеки. Для их использования нужно установить новыепакетына сервер данных. В проектах data science такие «внешние» пакеты будут использоваться часто. (Вы могли слышать, например, о pandas, numpy, matplotlib, scikit-learn и так далее). Этой теме будет посвящен отдельный материал - Собственные модули:
Да, их можно писать и самостоятельно (об этом в более продвинутых руководствах по Python)
import — очень мощный элемент Python, потому что именно с его помощью можно постоянно и почти бесконечно расширять свой набор инструментов, особенно в процессе работы с особенно сложными задачами.
Самые важные встроенные модули Python для специалистов Data Science
Теперь, когда вы понимаете, о чем идет речь, можно переходить к практике. В стандартной библиотеке Python есть десятки встроенных модулей. Одними из самых важных для проектов data science являются следующие:
- random
- statistics
- math
- datetime
- csv
Импортировать их можно, используя следующий синтаксис:
import [module_name]
Например: import random
Примечание: это импортирует весь модуль целиком со всеми его элементами. Можно взять и отдельную его часть: from [module_name] import [item_name]. Но пока лучше не переусложнять.
Разберем эти пять модулей.
Встроенный модуль №1: random
Рандомизация (случайности) очень важна в data science… например, A/B тестирование. С помощью модуля random можно генерировать случайные числа, следуя разным правилам:
Введем следующее в Jupyter Notebook:
import random
Затем в отдельную ячейку:
random.random()
Это сгенерирует случайное число с плавающей точкой от 0 до 1.
Стоит попробовать и так тоже:
random.randint(1, 10)
Это создаст случайное целое число от 1 до 10.

Больше о random можно узнать здесь.
Встроенный модуль №2: statistics
Если рандомизация важна, то статистика неизбежна. К счастью, в библиотеке есть встроенный модуль со следующими функциями: среднее значение, медиана, деление с остатком, среднеквадратичное отклонение, дисперсия и многие другие…
Начинаем стандартно:
import statistics
Дальше нужно создать список:
a = [0, 1, 1, 3, 4, 9, 15]
Теперь посчитать все значения для этого списка:

Больше о statistics можно узнать здесь.
Встроенный модуль №3: math
Есть несколько функций, которые относятся больше к математике, чем к статистике. Для них есть отдельный модуль. Он включает факториал, возведение в степень, логарифмические функции, а также тригонометрию и константы.
import math
И сам код:
math.factorial(5)
math.pi
math.sqrt(5)
math.log(256, 2)

Больше о math можно узнать здесь.
Встроенный модуль №4: datetime
Планируете работать в интернет-стартапе? Тогда вы наверняка столкнетесь с журналами данных. В их основе лежат дата и время. По умолчанию Python 3 не работает с датой и временем, но если импортировать модуль datatime, то эти функции тоже станут доступны.
import datetime
На самом деле, модуль datetime слегка переусложнен. Как минимум для новичков. Чтобы разобраться с ним, нужен отдельный материал. Но начать можно с этих двух функций:
datetime.datetime.now()
datetime.datetime.now().strftime("%F")

Встроенный модуль №5: csv
«csv» расшифровывается как «comma-separated values». Это один из самых распространенных форматов файлов для хранения журналов данных в виде текстовых данных (простого текста). Поэтому очень важно знать, как открыть файл с расширением .csv в Python. Есть конкретный способ, как это можно сделать.
Предположим, имеется маленький .csv-файл (его даже в Jupyter можно создать) под названием fruits.csv:
2018-04-10;1001;banana
2018-04-11;1002;orange
2018-04-12;1003;apple
Чтобы открыть его в Jupyter Notebook, нужно использовать следующий код:
import csv
with open('fruits.csv') as csvfile:
my_csv_file = csv.reader(csvfile, delimiter=';')
for row in my_csv_file:
print(row)

Он возвращает списки Python. С помощью функций выбора списков и методами списка, изученными раньше, можно реорганизовать набор данных.
Больше о модуле csv можно узнать здесь.
Больше встроенных модулей
Неплохое начало, но полный список встроенных модулей Python намного объемнее. С их помощью можно запаковывать и распаковывать файлы, собирать сетевые данные, отправлять email, декодировать файлы JSON и многое другое. Чтобы взглянуть на этот список, нужно перейти на страницу стандартной библиотеки Python — это часть официальной документации языка.
Есть и другие библиотеки и пакеты, не являющиеся частью стандартной библиотеки (pandas, numpy, scipy и другие). О них чуть позже.
Синтаксис
При обсуждении синтаксиса нужно выделить три вещи:
- В скриптах Python все инструкции
importнужно оставлять в начале. Почему? Чтобы видеть, какие модули нужны коду. Это также гарантирует, что импорт произойдет до того, как отдельные части модуля будут использованы. Поэтому просто запомните: инструкцииimportдолжны находиться в начале.
- В статье функции модуля использовались с помощью такого синтаксиса:
module_name.function_name(parameters)
Например,statistics.median(a)
или
csv.reader(csvfile, delimiter=';')Это логично. Перед использованием функции нужно сообщить Python, в каком модуле ее можно найти. Иногда бывают даже более сложные выражения, как функции класса в модуле (например,datetime.datetime.now()), но сейчас об этом можно не думать. Лучше просто составить список любимых модулей и функций и изучать, как они работают. Если нужен новый — посмотрите в документации Python, как создать его вместе с определенными функциями. - При использовании модуля (или пакета) его можно переименовать с помощью ключевого слова
as:
Если ввести:
import statistics as stat, в дальнейшем ссылаться на модуль можно с помощью «stat». Например,stat.median(a), а неstatistics.median(a). По традиции две библиотеки, используемые почти во всех проектах Data Science, импортируются с укороченными именами: numpy (import numpy as np) и pandas (import pandas as pd). Об этом также будет отдельный материал.
Так что это? Пакет? Модуль? Функция? Библиотека?
Поначалу вам может быть сложно даже понять, что именно импортируете. Иногда эти элементы называют «модулями», иногда — «пакетами», «функциями» или даже «библиотеками».
Примечание: даже если проверить сайты numpy и pandas, можно обнаружить, что один из них называют библиотекой, а второй — пакетом.
Не все любят теорию в программировании. Но если вы хотите участвовать в осмысленных беседах с другими разработчиками (или как минимум задавать грамотные вопросы на Stackoverflow), нужно хотя бы иметь представление о том, что и как называется.
Вот как можно попытаться классифицировать эти вещи:
- Функция: это блок кода, который можно использовать по несколько раз, вызывая его с помощью ключевого слова. Например,
print()— это функция. - Модуль: это файл с расширением .py, который содержит список функций (также — переменных и классов). Например, в
statisctics.mean(a),mean— это функция, которую можно найти в модулеstatistics. - Пакет: это коллекция модулей Python. Например,
numpy.random.randint(2, size=10).randint()— это функция в модулеrandomв пакете numpy. - Библиотека: это обобщенное название для определенной коллекции кода в Python.
Эта информация взята из вопроса на Stackoverflow.
Выводы
import — это важная составляющая Python. Чем больше вы будете узнавать о data science, тем лучше будете понимать, как постоянно расширять собственный набор инструментов в зависимости от поставленной задачи. import — это основной инструмент для этих целей. Он открывает тысячи дверей.
Для новичков в программировании синтаксис оказывается одной из самых сложных вещей. Он очень строг и может казаться противоречивым. Поэтому в этом материале собраны основы синтаксиса Python, которые важны даже для профессионалов. Здесь же упомянуты лучшие практики форматирования, которые помогут делать код опрятным.
Это основы. Ссылки на более сложные вещи будут в конце материала.
3 важных правила о синтаксисе Python
#1. Разрывы строк имеют значение
В отличие от SQL, в Python разрывы имеют значение. В 99% случаев если добавить разрыв туда, где его быть не должно, появится ошибка. Странно? Зато точку с запятой в конце каждой строки добавлять не нужно.
Поэтому вот правило №1 в Python: одно выражение на строку.
Есть и исключения. Выражения могут быть разбиты на несколько строк, если они записаны:
- в скобках (например, функции или методы),
- в квадратных скобках (например, списки),
- в фигурных скобках (например, словари).
Это называется неявным объединением строк и очень помогает при работе с более крупными структурами данных.

Также можно разбивать любое выражение на несколько строк, если написать обратную черту (\) в конце строки. Обратное также допустимо — ввести несколько выражений на одной строке, добавляя точку с запятой (;) после каждого. Но эти способы не используются слишком часто. Применять их нужно только при сильной необходимости. (Например, с выражениями, которые состоят из более чем 80 символов).


#2. Отступы важны
Ненавидите отступы? Вы не одиноки в этом. Многие начинающие Python-программисты не любят это понятие. У людей, которые только знакомятся с азами программирования, именно из-за отступов возникает больше всего ошибок в коде. Но вы привыкнете. А если ответственно проходили примеры из прошлых частей руководства, то, возможно, уже привыкли.
Зачем нужны отступы? Простыми словами, это способ показать, какие части кода связаны между собой — например, где начало и конец инструкции if или цикла for. В других языках, где отступов нет, для этих целей используются другие методы: в Javascript блоки кода окружают дополнительные скобки, а в bash — ключевые слова. В Python используются отступы и по мнению многих — это самый элегантный способ решения проблемы.
И это правило №2 в Python: убедитесь, что используете отступы правильно и последовательно.
Примечание: об этих же правилах речь шла в руководствах, посвященных циклам for и инструкциям if.

И вот еще: если вы смотрели сериал «Кремниевая долина», то наверняка слышали о споре «отступы против пробелов»:
Так отступы или пробелы? Вот что говорится в Руководстве по стилю Python:
Табы или пробелы?
Пробелы являются предпочтительным методом отступа.
Табы должны использоваться исключительно для соответствия с кодом, который уже имеет отступы табуляцией.
Все понятно!
#3. Чувствительность к регистру
Python чувствителен к регистру. Есть разница в том, чтоб ввести and (правильно) или AND (не сработает). Как показывает практика, большинство ключевых слов в Python пишутся с маленькой буквы. Известное исключение (из-за которого у многих новичков возникают проблемы) — булевы значения. Их нужно вводить только так: True и False. (Не TRUE или true).
Правило №3 в Python: Python чувствителен к регистру.
Другие практики Python
Есть и другие необязательные особенности Python, которые сделают код более приятным и читаемым.
1. Используйте комментарии
В код Python можно добавлять комментарии. Для этого нужно всего лишь добавить символ #. Все, что будет написано после символа #, не исполнится.
# Это комментарий перед циклом for.
for i in range(0, 100, 2):
print(i)
#2. Названия переменных
Традиционно переменные нужно писать буквами в нижнем регистре, разделяя их символами нижнего подчеркивания (_). Также не рекомендуется использовать переменные длиной в один символ. Понятные и легко различимые переменные помогают и другим программистам, когда те разбираются в вашем коде.
my_meaningful_variable = 100
#3. Используйте пустые строки
Если вы хотите визуально разделить блоки кода (например, есть скрипт на 100 строк, состоящий из 10-12 блоков), используйте пустые строки. Или даже несколько. Это никак не повлияет на сам код.

#4. Добавляйте пробелы вокруг операторов и оператора присваивания
Чтобы получить более чистый код, рекомендуется использовать пробелы вокруг знаков =, математических и операторов сравнения (>, <, +, - и так далее). Без этих пробелов код все равно будет работать: но чем он чище, тем проще его читать и тем проще использовать повторно.
number_x = 10
number_y = 100
number_mult = number_x * number_y
#5. Максимальная длина строки — 79 символов
Если в вашей строке больше 79 символов, рекомендуется разбить код на несколько с помощью знака \. Python его проигнорирует и прочитает так, будто бы это одна строка.
(В некоторых же случаях можно использовать неявное объединение строк).
#6. Будьте последовательны
Одно из самых важных правил — оставайтесь последовательны. Даже если всегда следовать правилам выше, в определенных ситуациях придется придумывать собственные. Главное — неукоснительно придерживаться уже их. При идеальном сценарии спустя 6 месяцев вы откроете код и быстро поймете, для чего он нужен. Если вы будете без причины менять правила оформления или способ именования переменных, создадите ненужную головную боль для будущего себя.
Дзен Python — приятное пасхальное яйцо
Что еще могло бы быть в конце этой статьи, как не пасхальное яйцо?
Если ввести import this в Jupyter Notebook, то выведутся 19 «заповедей» Python:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Используйте их с умом!
Выводы
Следуйте этим советам, а если хотите узнать еще больше о синтаксисе Python и лучших практиках, обратитесь к следующим материалам:
В последней части речь пойдет о библиотеках Python.
]]>В прошлый раз вы узнали, как работают инструкции if и циклы for в Python. В этот раз стоит поговорить о том, как объединять их. На практических примерах вы узнаете, как совмещать несколько циклов for, а также — один цикл for с инструкцией if.
Это практическое руководство! Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам.
Цикл for внутри цикла for — или просто вложенный цикл for
Чем сложнее проект, над которым ведется работа, тем больше вероятность, что придется работать с вложенным циклом for. Это значит, что будет одна итерация с другой итерацией внутри нее.
Предположим, что есть 9 сериалов в трех категориях: комедии, мультфильмы и драмы. Они представлены во вложенном списке Python («списки в списке»):
my_movies = [['How I Met Your Mother', 'Friends', 'Silicon Valley'],
['Family Guy', 'South Park', 'Rick and Morty'],
['Breaking Bad', 'Game of Thrones', 'The Wire']]
Необходимо посчитать символы в этих названиях и вывести результаты один за одним на экране в таком формате:
"The title [movie_title] is [X] characters long."
Как это можно сделать? Поскольку в основном списке есть три списка, чтобы получить их названия нужно перебрать элементы my_movies. Это нужно сделать и в основном списке, и в каждом вложенном:
for sublist in my_movies:
for movie_name in sublist:
char_num = len(movie_name)
print("The title " + movie_name + " is " + str(char_num) + " characters long.")
Примечание:
len()— это функция Python, которая выводит целое число. Чтобы сделать его «выводимым», нужно превратить число в строку. О том, как это сделать, говорилось в прошлом руководстве.

Циклы for в Python может быть сложно понять вначале, а с вложенными циклами все еще сложнее. Поэтому чтобы разобраться с тем, что происходит, нужно взять ручку и бумагу и попробовать воспроизвести скрипт так, будто вы компьютер — пройти через каждый шаг и выписать результаты.
И еще кое-что:
Синтаксис! Правила те же, что были при изучении простых циклов for. Единственное, на чем важно сделать акцент — отступы. Только используя корректные отступы в Python, вы сможете сообщить языку, в каком именно блоке цикла (внешнем или внутреннем) нужно применить тот или иной код. Попробуйте сделать следующее и обнаружить отличия в этих примерах:

Инструкции if в цикле for
Внутри цикла for также можно использовать инструкции if.
В качестве примера можно привести известное упражнение, которое предлагают junior-специалистам в сфере data science:
Переберите числа до 99. Выводите «fizz» для каждого числа, которое делится на 3, «buzz» — для тех, что делятся на 5 и «fizzbuzz» — для тех, что делятся на 3 и на 5! Если число не делится, выводите тире (’-’)
Вот решение:
for i in range(100):
if i % 3 == 0 and i % 5 == 0:
print('fizzbuzz')
elif i % 3 == 0:
print('fizz')
elif i % 5 == 0:
print('buzz')
else:
print('-')
Как видно в примере, инструкция if в цикле for отлично подходит, чтобы оценить диапазон чисел (или, например, элементы списка) и разбить их по категориям. Таким же образом к ним можно применить функции или просто вывести.
Важно: при использовании инструкции if в цикле for будьте особенно внимательно с отступами, потому что если что-то упустить, то программа работать не будет.
Break
В Python есть удобный инструмент потока, который идеально подходит для управления инструкциями if в циклах for. Это инструкция break.
Найдете первое 7-значное число, которое делится на 137? (Только одно — первое).
Решение:
for i in range(0, 10000000, 137):
if len(str(i)) == 7:
print(i)
break
Этот цикл берет каждое 137-е число (for i in range (0, 10000000, 137)) и проверяет, используется ли в нем 7 цифр или нет (if len(str(i) == 7). Как только он получит первое 7-значное число, инструкция if станет истинной (True), и произойдут две вещи:
print(i)— число выведется на экранbreakпрервет цикл, чтобы первое 7-значное число было также и последним на экране.
Узнать больше о break (и его брате близнеце, continue) можно в статье: Синтаксис, возможности и подводные камни цикла for Python 3.
Примечание: эту задачу можно решить еще проще с помощью цикла
while. Но поскольку руководства по этому циклу еще нет, здесь был использован подход цикл for +break.
Проверьте себя!
Пришло время узнать, насколько вы разобрались с инструкцией if, циклами for и их объединением. Попробуйте решить следующее задание.
Создайте скрипт на Python, который узнает ваш возраст максимум с 8 попыток. Он должен задавать только один вопрос: угадывать возраст (например, «Вам 67 лет?»). Отвечать же можно одним из трех вариантов:
- correct
- less
- more
Основываясь на ответе, компьютер должен делать новые попытки до тех пор, пока не узнает корректный возраст.
Примечание: для решения задачи нужно изучить новую функцию
input(). Больше о ней здесь.
Готовы? Вперед!
Решение
Вот код решения.
Примечание: решить задачу можно и с помощью цикла while. Но поскольку он еще не рассматривался, был выбран вариант с for.
down = 0
up = 100
for i in range(1,10):
guessed_age = int((up + down) / 2)
answer = input('Are you ' + str(guessed_age) + " years old?")
if answer == 'correct':
print("Nice")
break
elif answer == 'less':
up = guessed_age
elif answer == 'more':
down = guessed_age
else:
print('wrong answer')
Логика решения следующая:
- Устанавливаем диапазон от 0 до 100, предполагая, что возраст «игрока» будет где-то посередине.
down = 0 up = 100 - Скрипт всегда спрашивает среднее значение диапазона (первой попыткой будет 50):
guessed_age = int((up + down) / 2) answer = input('Are you ' + str(guessed_age) + " years old?") - После получения ответа от «игрока» могут быть 4 возможных сценария:
- Если возраст угадан, скрипт заканчивается и возвращает определенный ответ.
if answer == 'correct': print("Nice") break- Если ответ «меньше», тогда цикл начинается сначала, но перед этим максимальное значение диапазона устанавливается на уровне последнего предположения (Так, вторая итерация будет искать середину между 0 и 50).
elif answer == 'less': up = guessed_age - То же самое для «больше» — только в этом случае меняется минимум:
elif answer == 'more': down = guessed_age - И в конце обрабатываются ошибки или опечатки:
else: print('wrong answer')
Итого
Теперь вы знаете о:
- Вложенных циклах for в Python
- Объединении циклов for и инструкций if
Это уже не базовый уровень Python, а переход к среднему. Использование этих инструментов предполагает понимание логики Python 3 и постоянной практики.
В серии этих руководств осталось всего два урока. Продолжайте, чтобы узнать все об основах синтаксиса Python.
]]>Помните, как в предыдущей части инструкции if в Python сравнивались с тем, как принимает решения мозг человека, основываясь на неких условиях в повседневной жизни? В случае с циклами for ситуация та же. Человек перебирает весь список покупок, пока не купит все, что в нем указано. Дилер раздает карты до тех пор, пока каждый игрок не получит 5 штук. Спортсмен делает отжимания, пока не доберется до сотни… Циклы повсюду. Касательно циклов for в Python — они нужны для выполнения повторяющихся задач. В этот статье вы узнаете все, что нужно знать об этих циклах: синтаксис, логику и лучшие примеры.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
- #1 Python для Data Science – Руководство для начинающих
- #2 Python для Data Science — Структуры данных
- #3 Python для Data Science — встроенные функции и методы Python
- #4 Python для Data Science — инструкции if в Python
Циклы for в Python — два простых примеры
Перво-наперво: циклы for нужны для перебора (итерации) итерируемых объектов. В большинстве случаев ими будут выступать уже знакомые списки, строки и словари. Иногда это могут быть объекты range() (об этом в конце статьи).
Начнем с простейшего примера — списка!
В прошлых руководствах неоднократно использовался пес Фредди. И вот он снова здесь для иллюстрации примера. Создадим список:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Теперь, когда есть готовый список, можно перебрать все его элементы, выводя их один за одним с помощью простейшего цикла for:
for i in dog:
print(i)

Результатом будут элементы списка, выведенные один за одним на разных строках:
Freddie
9
True
1.1
2001
['bone', 'little ball']
Но в чем преимущество такого способа? Используем другой пример — список чисел:
numbers = [1, 5, 12, 91, 102]
Предположим, что нужно возвести в квадрат каждое из них.
Примечание: к сожалению, формула
numbers * numbersне сработает… Это кажется логичным, но, узнав Python лучше, станет понятно, что это совсем не логично.
Нужно сделать следующее:
for i in numbers:
print(i * i)
Результат будет такой:

Вот что происходит по шагам:
- Есть список (
numbers) с 5 элементами. - Берем первый элемент (из-за индексации с нуля, это будет 0 (нулевой) элемент) списка (
1) и сохраняем его в переменнуюi. - Исполняем функцию
print(i * i), которая возвращает значение1в квадрате. Это1. - Затем весь процесс начинается заново…
- Берем новый элемент и присваиваем его переменной
i. - Снова исполняем функцию
print (i * i)и получаем значение второго элемента в квадрате:25 - Повторяем процесс…
… пока не получим последний элемент, возведенный в квадрат.
Это базовый пример работы цикла в Python, но сильно сложнее он не будет становиться — только комплекснее.
Логика, лежащая в основе циклов for в Python
Теперь, когда стала понятна польза циклов for, нужно разобраться с логикой в их основе.
Примечание: это одна из важнейших частей руководства. Многие люди без проблем используют базовые циклы, но затрудняются применять те что посложнее. Проблема в том, что они изучают синтаксис, но забывают разобраться в логике. Поэтому желательно перечитывать этот раздел до тех пор, пока не станет понятно что к чему. В будущем вы поблагодарите себя за то, что когда-то потратили на это время.
Это блок-схема с визуализацией процесса работы цикла:

Разобьем ее и изучим все в деталях. В качестве примера будем использовать предыдущий код со списком numbers и их значениями, возведенными в квадрат:
numbers = [1, 5, 12, 91, 102]
for i in numbers:
print(i * i)
- Определяем итерируемый объект (то есть, уже имеющийся список
numbers = [1, 5, 12, 91, 102]). - При создании цикла for первая строка всегда будет выглядеть как-то так:
for i in numbers:forиin— это ключевые слова Python, аnumber— название списка. Но куда важнее переменнаяi. Это «временная» переменная, и ее единственная роль заключается в хранении конкретного элемента списка, который будет работать в момент каждой отдельной итерации цикла. Хотя в большинстве случаев эта переменная обозначается какi(в онлайн-курсах и даже книгах), важно знать, что можно выбрать любое имя. Это может быть не толькоi(for i in numbers), но, напримерx(for x in numbers) илиhello(for hello in numbers). Или любое другое значение. Суть в том, что это переменная и нужно не забывать ссылаться на нее внутри цикла. - Продолжаем использовать числа в качестве примеров. Берем первый элемент итерируемого объекта (технически, из-за индексации с нуля — это 0 (нулевой) объект. Запустится первая итерация цикла. Нулевой элемент — это
1. Значением переменнойiбудет1. - Функция в цикле была
print(i * i). Поскольку i = 1, результатомi * iбудет1.1выведется на экран. - Цикл начинается заново.
- Берется следующий элемент, и начинается вторая итерация цикла. Первый элемент
number— это5. iравняется5. Снова запуститсяprint(i * i), а на экран выведется25.- Цикл начнется заново. Следующий элемент.
- Еще один элемент. Это уже третья итерация. Второй элемент —
12. print(i * i)выведет144.- Цикл стартует заново. Следующий элемент присутствует. Новая итерация.
- Третий элемент —
91. Значение в квадрате —8281. - Цикл стартует заново. Следующий элемент присутствует. Новая итерация.
iравняется102. Значение в квадрате —10404.- Цикл стартует заново. Но «следующего элемента» нет. Цикл завершается.
Это очень-очень подробное объяснение третьей строки. Но такой разбор нужен лишь первый раз. Уже в следующий раз вся логика будет у вас в голове. Но важно было рассмотреть все таким вот образом, потому что у начинающих специалистов именно этой логики и не достает, а такой недостаток прямо влияет на качество кода.
Итерация по строкам
Для цикла можно использовать и другие последовательности, а не только списки. Попробуем строку:
my_list = "Hello World!"
for i in my_list:
print(i)

Все просто. Буквы выводятся одна за одной. Важно запомнить, что строки всегда обрабатываются как последовательности символов, поэтому цикл for и работает с ними так же, как и со списками.
Итерация по объектам range()
range() — это встроенная функция Python и она используется почти всегда только в циклах for. Но для чего? Если говорить простым языком — она генерирует список чисел. Вот как это работает:
my_list = range(0,10)
for i in my_list:
print(i)
")
Она принимает три аргумента:
")
- the first element: первый элемент диапазона
- the last element: можно было бы предположить, что это последний элемент диапазона, но это не так. На самом деле здесь определяется элемент, который будет идти после последнего. Если ввести 10, то диапазон будет от 0 до 9. Если 11 — от 0 до 10 и так далее.
- the step: это разница между элементами диапазона. Если это 2, то будет выводиться только каждый второй элемент.
Можете теперь угадать, каким будет результат диапазона сверху?
Вот он:

Примечание: атрибуты first element и step опциональны. Если их не определить, тогда первым элементом будет 0, а шаг по умолчанию — это 1. Попробуйте следующее в Jupyter Notebook и проверьте результат:
my_list = range(10)
for i in my_list:
print(i)
Зачем нужна range()? В двух случаях:
- Необходимо перебрать числа. Например, нужно возвести в куб нечетные числа между 1 и 9. Без проблем:
my_list = range(1, 10, 2) for i in my_list: print(i * i * i) - Необходимо перебрать список, сохранив индексы элементов.
my_list = [1, 5, 12, 91, 102] my_list_length = len(my_list) for i in range(0,my_list_length): print(i, my_list[i] * my_list[i])В этом случае
i— это индекс, а элементами списка будутmy_list[i].
В любом случае, range() упростит работу с циклами в Python.
Лучшие примеры и распространенные ошибки
- Циклы for — это не самая простая тема для начинающих. Чтобы работать с ними, нужно алгоритмическое мышление. Но с практикой понимание приходит… Если же попалась действительно сложна задача, лучше нарисовать схему а бумаге. Просто пройти первые итерации на бумаге и записать результаты. Так будет понятнее.
- Как и в случае с инструкциями if, нужно быть внимательными с синтаксисом. Двоеточие обязательно в конце строки
for. А перед строкой в теле цикла должны быть 4 отступа. - Нельзя выводить строки и числа в функции
print()с помощью знака+. Это больше особенность функцииprint, а не цикла for, но чаще всего такая проблема будет встречать в циклах. Например:
Если встречается такое, лучше всего превратить числа в строки с помощью функции str(). Вот предыдущий пример с правильным синтаксисом:

Вот и все. Пришло время упражнений.
Проверьте себя
Вот отличное упражнение для цикла for:
Возьмите переменную и присвойте ей случайную строку.
Затем выведите пирамиду из элементов строки как в этом примере:
my_string = "python"
Вывод:
p
py
pyt
pyth
pytho
python
pytho
pyth
pyt
py
p
Напишите код, который бы делал подобное для любого значения my_string.
Решение
Примечание: есть несколько способов решения этой задачи. Дальше будет относительно простое, но вы можете использовать и посложнее.
my_string = "python"
x = 0
for i in my_string:
x = x + 1
print(my_string[0:x])
for i in my_string:
x = x - 1
print(my_string[0:x])

Решение говорит само за себя. Единственная хитрость заключается в использовании переменной-счетчика «x», которая показывает количество символов, необходимых для вывода в этой итерации. В первом цикле for значение увеличивается, пока не доберется до значения количества символов в слове. Во втором — опускается до нуля, пока на экране не останется ни одного символа.
Итого
Циклы for в Python очень важны. Они широко используются в data science. Синтаксис довольно простой, но для понимания логики нужно постараться. Этой статьи должно быть достаточно, чтобы разобраться в основах, поэтому все, что остается, — практиковаться.
В следующем материале вы узнаете, как объединять циклы for между собой и циклы for с инструкциями if.
]]>Инструкции if (если) используются в повседневной жизни постоянно, пусть она и не написана на Python. Если горит зеленый, тогда можно переходить дорогу; в противном случае нужно подождать. Если солнце встало, тогда нужно выбираться из постели; в противном случае можно продолжать спать. Возможно, все не настолько строго, но когда действия выполняются на основе условий, мозг делает то же самое, что и компьютер — оценивает условия и действует в зависимости от результата.
Однако у компьютера нет подсознания, поэтому для занятий data science нужно понимать, как работает инструкция if, и как ее использовать в Python!
Это практическое руководство! Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними:
- #1 Python для Data Science – Руководство для начинающих
- #2 Python для Data Science — Структуры данных
- #3 Python для Data Science — встроенные функции и методы Python
Основы инструкций if в Python
Логика инструкции if очень проста.

Предположим, что есть два значения: a = 10 и b = 20. Сравниваем эти два значения. Сравнение даст один из двух выводов: True или False. (Проверьте в своем Jupyter Notebook)

Можно пойти дальше и написать условие: if a == b вернет True, тогда вывести 'yes'. Если False — тогда 'no'. И это все — это логика инструкций if в Python. Синтаксис следующий:
a = 10
b = 20
if a == b:
print('yes')
else:
print('no')

Запустите этот скрипт в Jupyter Notebook. Очевидно, что результат будет 'no'.
Теперь попробуйте то же самое, но со значением b равным 10.
a = 10
b = 10
if a == b:
print('yes')
else:
print('no')
На этот раз сообщение будет 'yes'.
Синтаксис инструкции if в Python
Нужно рассмотреть синтаксис подробно, потому что в нем есть строгие правила. Основы просты:

Имеются:
- ключевое слово
if - условие
- инструкция
- ключевое слово
else - другая инструкция
Но есть две вещи, о которых нужно всегда помнить:
- Никогда не пропускать двоеточие в конце строк
ifиelse!

- Никогда не пропускать отступы в начале строк с инструкциями!

Если что-то из этого пропустить, вернется сообщение об ошибке с текстом «invalid syntax», а скрипт не будет работать.
Инструкции if в Python — 2-й уровень
Теперь, когда вы знаете основы, пришло время сделать условия более сложными: с помощью арифметики, сравнений и логических операторов. (Примечание: если слово «оператор» ни о чем не говорит, лучше вернуться к первому материалу из серии).
Вот пример:
a = 10
b = 20
c = 30
if (a + b) / c == 1 and c - b - a == 0:
print('yes')
else:
print('no')
Код вернет yes, поскольку оба условия, (a + b) / c == 1 и c - b - a == 0 вернут True, а логический оператор между ними — это and.

Конечно, код можно сделать еще более сложным, но суть в том, что в инструкции if легко можно использовать несколько операторов — подобное часто встречается на практике.
Инструкции if в Python — 3-й уровень
Можно перейти на еще один уровень выше, используя ключевое слово elif (это короткая форма фразы «else if») для создания последовательностей условий. «Последовательность условий» звучит красиво, но на самом деле — это всего лишь инструкция if, вложенная в другую инструкцию if:

Другой пример:
a = 10
b = 11
c = 10
if a == b:
print('first condition is true')
elif a == c:
print('second condition is true')
else:
print('nothing is true. existence is pain.')
Очевидно, что результат будет "second condition is true".

Это можно делать миллионы раз и построить огромную последовательность if-elif-elif-elif, если хочется, конечно.
И это более-менее все, что нужно знать об инструкциях if в Python. А теперь:
Проверьте себя
Вот случайное целое число: 918652728452151.
Нужно узнать две вещи о нем:
- Делится ли оно на 17 без остатка?
- В нем больше 12 цифр?
Если оба условия верны, тогда вернем super17.
Если одно из них ложно, тогда стоит запустить второй тест:
- Делится ли оно без остатка на 13?
- В нем больше 10 цифр?
Если оба условия верны, тогда вернем awesome13.
Если оригинальное число не определяется ни как super17, ни как awesome13, тогда выведем просто meh, this is just an average random number.
Итак: является ли число 918652728452151 super 17 или awesome13 или это просто случайное число?
Решение
918652728452151 — это число super17.

Рассмотрим подробнее код:
my_number = 918652728452151
if my_number % 17 == 0 and len(str(my_number)) > 12:
print("super17")
elif my_number % 13 == 0 and len(str(my_number)) > 10:
print("awesome13")
else:
print("meh, this is just a random number")
В первой строке число 918652728452151 сохраняется в переменную, так что его не придется записывать каждый раз, а код будет смотреться изящнее: my_number = 918652728452151.
После этого создается последовательность условия if-elif-else.
В строке if есть два условия. Первое — проверка, делится ли my_number на 17 без остатка. Это часть my_number % 17 == 0. Во втором нужно подсчитать количество цифр в my_number. Из-за ограничений языка сделать это нельзя, поэтому нужно преобразовать число в строку с помощью функции str(). После этого необходимо использовать функцию len() и узнать количество символов. Это часть len(str(my_number)).
Выходит, что оба оригинальных условия были верны, потому что на экран вывелось super17. Но если бы это было не так, следующая строка elif проделала бы то же самое, но проверяла, делится ли число на 13 (а не 17), а символов должно было быть больше 10 (не 12).
Если бы и это условие оказалось ложным, инструкция else запустила бы print("meh, this is just an average random number").
Не так уж и сложно, не правда ли?
Итого
Инструкции if широко используются в каждом языке программирования. Теперь вы тоже знаете, как пользоваться ими. Логика их работы проста, а синтаксис можно даже пересказать обычными словами.
В следующий раз речь пойдет о циклах for в Python.
]]>Функции — одно из главных преимуществ языка Python как минимум при использовании их в проектах Data Science. Это третья часть серии материалов «Python для Data Science», в которой речь пойдет о функциях и методах.
Из нее вы узнаете не только о базовых концепциях, но познакомитесь с наиболее важными функциями и методами, которые будете использовать в будущем.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
Что такое функции и методы Python?
Начнем с основ. Предположим, что существует переменная:
a = 'Hello!'
Вот простейший пример функции Python:
len(a)
# Результат: 6
А вот пример метода Python:
a.upper()
# Результат: HELLO!

Так что такое функции и методы Python? По сути, они превращают что-то в нечто другое. В случае этого примера ввод 'Hello!' дал вывод длины строки (6) и версию строки, переписанную с большой буквы: 'HELLO!'. Конечно, это не единственные функции. Их намного больше. Их комбинация пригодится в разных частях проекта — от очистки данных до машинного обучения.
Встроенные vs. пользовательские методы и функции
Круто то, что помимо огромного списка встроенных функций/методов, пользователи могут создавать собственные. Также они поставляются с различными Python-библиотеками. Для доступа к ним библиотеку нужно скачать и импортировать. Выходит, что возможности безграничны. Но к этому стоит вернуться позже, а сейчас сосредоточимся на встроенных элементах.
Самые важные встроенные функции Python для проектов Data Science
Функция в Python работают очень просто — ее нужно вызвать с заданными аргументами, а она вернет результат. Тип аргумента (например, строка, число, логическое значение и так далее) может быть ограничен (например, иногда нужно, чтобы это было именно целое число), но чаще аргументом может выступать значение любого типа. Рассмотрим самые важные встроенные функции Python:
print()
Эта функция уже использовалась в прошлых статьях. Она выводит различные значения на экран.
print("Hello, World!")

abs()
Возвращает абсолютную величину числа (то есть, целое число или число с плавающей точкой). Результат не может быть строкой, а только числовым значением.
abs(-4/3)

round()
Возвращает округленное значение числа
round(-4/3)

min()
Возвращает наименьший объект в списке или из общего числа введенных аргументов. Это может быть в том числе и строка.
min(3,2,5)
min('c','a','b')

max()
Несложно догадаться, что это противоположность min().
sorted()
Сортирует список по возрастанию. Он может содержать и строки и числа.
a = [3, 2, 1]
sorted(a)

sum()
Суммирует значения списка. Он может содержать разные типы числовых значений, но стоит понимать, что с числами с плавающей запятой функция справляется не всегда корректно.
a = [3, 2, 1]
sum(a)
b = [4/3 , 2/3, 1/3, 1/3, 1/3]
sum(b)

len()
Возвращает количество элементов в списке или количество символов в строке.
len('Hello!')
type()
Возвращает тип переменной
a = True
type(a)
b = 2
type(b)

Это встроенные функции Python, которые придется использовать регулярно. Со всем списком можно ознакомиться здесь: https://docs.python.org/3/library/functions.html
С многими другими вы познакомитесь в следующих руководствах.
Самые важные встроенные методы Python
Большую часть методов Python необходимо применять по отношению к конкретному типу. Например, upper() работает со строками, но не с целыми числами. А append() можно использовать на списках, но со строками, числами и логическими значениями он бесполезен. Поэтому дальше будет список методов, разбитый по типам.
Методы для строк Python
Строковые методы используются на этапе очистки данных проекта. Например, представьте, что вы собираете информацию о том, что ищут пользователи на сайте, и получили следующие строки: 'mug', 'mug ', 'Mug'. Человеку известно, что речь идет об одном и том же, но для Python это три уникальные строки. И здесь ему нужно помочь. Для этого используются самые важные строковые методы Python:
a.lower()
Возвращает версию строки с символами в нижнем регистре.
a = 'MuG'
a.lower()

a.upper()
Противоположность lower()
a.strip()
Если в строке есть пробелы в начале или в конце, метод их удалит.
a = ' Mug '
a.strip()

a.replace(‘old’, ‘new’)
Заменяет выбранную строку другой строкой. Метод чувствителен к регистру.
a = 'muh'
a.replace('h', 'g')

a.split(‘delimiter’)
Разбивает строку и делает из нее список. Аргумент выступает разделителем.
a = 'Hello World'
a.split(' ')
Примечание: в этом случае разделителем выступает пробел.

’delimeter’.join(a)
Объединяет элементы списка в строку. Разделитель можно указать заново.
a = ['Hello', 'World']
' '.join(a)

Это были самые важные методы, для работы со строками в Python.
Методы Python для работы со списками
В прошлом материале речь шла о структурах данных Python. И вот к ним нужно вернуться снова. Вы уже знаете, как создавать списки и получать доступ к их элементам. Теперь узнаете, как менять их.
Используем уже знакомую собаку Freddie:
[dog] = ['Freddie', 9 , True, 1.1, 2001, ['bone', 'little ball']]
Теперь посмотрим, как можно изменять список.
a.append(arg)
Метод append добавляет элемент к концу списка. Предположим, что нужно добавить количество лап Freddie (4).
dog.append(4)
dog

a.remove(arg)
Удалить любой из элементов можно с помощью метода .remove(). Для этого нужно указать элемент, который необходимо удалить, а Python уберет первый такой элемент в списке.
dog.remove(2001)
dog

a.count(arg)
Возвращает количество указанных элементов в списке.
dog.count('Freddie')

a.clear()
Удаляет все элементы списка. По сути, он полностью удалит Freddie. Но не стоит волноваться, потом его можно вернуть.
dog.clear()
dog

Список всех методов для работы с Python можно найти здесь: https://docs.python.org/3/tutorial/datastructures.html
Методы Python для работы со словарями
Как и в случае со списками, есть набор важных методов для работы со словарями, о которых нужно знать.
И снова Freddie:
dog_dict = {'name': 'Freddie',
'age': 9,
'is_vaccinated': True,
'height': 1.1,
'birth_year': 2001,
'belongings': ['bone', 'little ball']}
dog_dict.keys()
Вернет все ключи словаря.

dog_dict.values()
Вернет все значения словаря.

dog_dict.clear()
Удалит все из словаря.

Для добавления элемента в словарь не обязательно использовать метод; достаточно просто указать пару ключ-значение следующим образом:
dog_dict['key'] = 'value'
dog_dict['name'] = 'Freddie'

Это все методы на сегодня.
Проверьте себя
В этом задании вам нужно использовать не только то, что узнали сегодня, но и знания о структурах данных из прошлого материала, а также о переменных — из первого.
- Есть список:
test_yourself = [1, 1, 2, 2, 3, 3, 3, 3, 4, 5, 5] - Посчитайте среднее значение элементов списка, используя знания, полученные из прошлых частей руководства.
- Посчитайте медиану, следуя тем же условиям.
.
.
.
.
.
.
Решение
sum(test_yourself) / len(test_yourself)
sum() суммирует значения элементов, а len() подсчитывает их количество. Если поделить одно значение на другое, то выйдет среднее. Результат: 2.909090

test_yourself[round(len(test_yourself) / 2) - 1]
Повезло, что в списке нечетное количество элементов.
Примечание: эта формула не сработает, если элементов будет четное количество.
len(test_yourself) / 2 подскажет, где в списке искать среднее число — это и будет медиана. Результат равен 5,5, но результат len() / 2 всегда будет на 0,5 меньше, чем реальное число, если в списке нечетное количество элементов (можете проверить на списке с 3 или 5 элементами). Округлим 5,5 до 6 с помощью round(len(test_yourself) / 2). Все верно — в данном случае внутри функции используется другая функция. Затем нужно вычесть единицу, потому что индексация начинается с нуля: round(len(test_yourself) / 2) - 1.
В конце концов результат можно подставить в качестве индекса для поиска его в списке: test_yourself[round(len(test_yourself) / 2 - 1]; или взять полученное число: test_yourself[5]. Результат — 3.

В чем разница между функциями и методами в Python?
После прочтения этой статьи у вас наверняка появился вопрос: «Зачем нужны и функции и методы, если они делают одно и то же?»
Это один из самых сложных вопросов для тех, кто только знакомится с Python, а ответ включает много технических деталей, поэтому вот некоторые подсказки, чтобы начать разбираться.
Сперва очевидное. Отличается синтаксис. Функция выглядит вот так: function(something), а метод вот так: something.method().
Так зачем и методы и функции нужны в Python? Официальный ответ заключается в том, что между ними есть небольшие отличия. Так, метод всегда относится к объекту (например, в dog.append(4) методу append() нужно объект dog). В функции объект не нужно использовать. Если еще проще, метод — это определенная функция. Все методы — это функции, но не все функции являются методами.
Если все равно не понятно, но стоит волноваться. Работая с Python и дальше, вы разберетесь в различиях, особенно, когда начнете создавать собственные методы и функции.
Вот еще один дополнительный совет: функции и методы — это как артикли (der, die, das) в немецком языке. Нужно просто выучить синтаксис и использовать их по правилам.
Как и в немецком, есть эмпирические правила, которые также должны помочь. Так, функции можно применять к разным типам объектов, а методы — нет. Например, sorted() — это функция, которая работает со строками, списками, числами и так далее. Метод upper() работает исключительно со строками.
Но главный совет в том, чтобы не пытаться понять различия, а учиться их использовать.
Итого
Теперь вы знакомы более чем с 20 методами и функциями Python. Неплохое начало, но это только основы. В следующих руководствах их количество будет расти в том числе за счет функций и методов из сторонних библиотек.
Далее нужно будет разобраться с циклами и инструкциями if.
В предыдущей статье речь шла о переменных в Python. Теперь нужно обсудить вторую важную тему, без которой невозможно работать с этим языком в Data Science — структуры данных в Python.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
Почему структуры данных в Python так важны?
Представьте книгу. Пусть это будет «Практическая статистика для специалистов Data Science» П. Брюса и Э. Брюса. Сохранить эту информацию можно, поместив ее в переменную.
my_book = "Практическая статистика для специалистов Data Science"
Готово!
А если рядом лежат также «Цифровая крепость» Дэна Брауна и «Игра престолов» Джорджа Мартина? Как сохранить их? Можно снова воспользоваться переменными:
my_book2 = "Цифровая крепость"
my_book3 = "Игра престолов"
А если позади целый книжный шкаф? Вот здесь и появляется проблема. Иногда в Python нужно хранить релевантную информацию в одном объекте, а не разбивать ее по переменным.
Вот зачем нужны структуры данных!
Структуры данных Python
В Python 3 основные структуры данных:
- Списки
book_list = ['Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science'] - Кортежи
book_tuple = ('Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science') - Словари
book_dictionary = {'Джордж Мартин': 'Игра престолов', 'Дэн Браун': 'Цифровая крепость', 'П. & Э. Брюсы': 'Практическая статистика для специалистов Data Science'}
Все три нужны для разных ситуаций и использовать их необходимо по-разному.
Перейдем к деталям!
Первая структура данных Python: Список
Начнем с самого простого — списков в Python.
Список — это последовательность значений. Это данные, заключенные в квадратные скобки и разделенные запятыми. Простой пример — список целых чисел:
[3, 4, 1, 4, 5, 2, 7]
Важно понимать, что в Python список является объектом, поэтому работать с ним можно так же, как и с любыми другими типами данных (например, целыми числами, строками, булевыми операторами и так далее). Это значит, что список можно присвоить переменной, чтобы хранить ее таким образом и получать доступ в дальнейшем более простым способом:
my_first_list = [3, 4, 1, 4, 5, 2, 7]
my_first_list

Список может содержать другие типы данных, включая строки, логические значения и даже другие списки. Помните собаку Freddie из прошлой статьи?

Ее параметры можно сохранить в одном списке, а не разбивать на 5 разных переменных:
dog = ['Freddie', 9, True, 1.1, 2001]

Теперь предположим, что Freddie принадлежит две вещи: кость и маленький мяч. Их можно сохранить внутри списка отдельным списком.
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
На самом деле, вот так углубляться в дерево списков можно бесконечно. Этот прием (официально он называется «вложенными списками») будет важен при работе с Data Science в Python — например, при создании многомерных массивов numpy для запуска корреляционных анализов… но сейчас не об этом! Главное, что нужно запомнить — списки можно хранить внутри других списков.
Попробуйте:
sample_matrix = [[1, 4, 9], [1, 8, 27], [1, 16, 81]]

Чувствуете себя ученым? Стоило бы, потому что вы создали двухмерный массив размерами 3-на-3.
Как получить доступ к конкретному элементу в списке Python?
Теперь, когда значения сохранены, нужно разобраться, как получать к ним доступ в будущем. Вернуть целый список можно с помощью имени переменной. Например dog
Но как вызвать один элемент из списка? Сперва подумайте, как можно обратиться к одному из элементов в теории? Единственное, что приходит в голову, — положение значения. Так, если нужно вернуть первый элемент из списка dog, необходимо ввести его название и номер элемента в скобках: [1]. Попробуйте: dog[1]

Что??? Цифра 9 была вторым элементом списка, а не первым. Однако в Python это работает иначе. Python использует так называемое «индексирование с нуля». Это значит, что номер первого элемента — это всегда [0], второго — [1], третьего — [2] и так далее. Это важно помнить, работая со структурами данных в Python.
Если вам кажется, что это слишком сложно, просто почитайте открытое письмо известного ученого Дейкстра, написанное в 1982 году: https://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html. А теперь просто перестаньте думать об этом и запомните, что так будет всегда!
Вот подробный пример!
Собака Freddie:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]

Попробуйте вывести все элементы списка один за одним:
dog[0]
dog[1]
dog[2]
dog[3]
dog[4]
dog[5]

Запутанно… Но к этому можно привыкнуть.
Как получить доступ к определенному элементу вложенного списка в Python
Еще один важный момент о Freddie. Нужно вывести его вещи друг за другом
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Догадаетесь, как получить элемент bone, заключенный во вложенный список? Это максимально интуитивно.
Он будет нулевым элементом пятого элемента:
dog[5][0]Если на 100% не понятно, почему все работает именно так, поиграйтесь с этим набором данных и вы разберетесь: sample_matrix = [[1, 4, 9], [1, 8, 27], [1, 16, 81]].
Как получить доступ к нескольким элементам списка Python
Вот еще один трюк. Можно использовать двоеточие между двумя числами в скобках, чтобы получить последовательность значений.
dog[1:4]

Пока это все, что вам нужно знать о списках Python.
Вторая структура данных Python: Кортежи
Что такое кортеж в Python? Во-первых, начинающий специалист Data Science не должен много думать об этой структуре. Можете и вовсе пропустить этот раздел.
Если все-таки остались:
Кортеж в Python — почти то же самое, что и список в Python с небольшими отличиями.
- Синтаксис: при объявлении используются не квадратные скобки, а круглые.
Список:book_list = ['Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science']Кортежи
book_tuple = ('Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science') - Список — изменяемый тип данных, поэтому в нем можно добавлять, удалять или изменять элементы. Кортеж — неизменяемый тип данных. Он остается таким, каким был и объявлен. Это строгость пригодится, чтобы сделать код безопаснее.
- Кортежи работают быстрее, чем списки в Python в одних и тех же операциях.
В остальном кортежи можно использовать так же, как и списки. Даже возвращать отдельный элемент нужно с помощью квадратных скобок. (Попробуйте book_tuple[1] на новом кортеже).
book_tuple[1]
'Цифровая крепость'
Еще раз: ничего из вышесказанного не будет вас заботить первое время, но хорошо знать хотя бы что-нибудь о кортежах.
Третья структура данных Python: Словари
Словари — это совсем другая история. Они сильно отличаются от списков и очень часто используются в проектах data science.
Особенность словарей в том, что у каждого значения есть уникальный ключ. Взглянем еще раз на собаку Freddie:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Это значения с параметрами собаки, которые нужно сохранить. В словаре для каждого значения можно назначить свой ключ так, чтобы понимать, что они обозначают.
`dog_dict = {'name': 'Freddie', 'age': 9, 'is_vaccinated': True, 'height': 1.1, 'birth_year': 2001, 'belongings': ['bone', 'little ball']}`

Вывод заранее форматируется Python. Чтобы лучше разобраться, то же самое можно сделать изначально, перенеся каждое значение на новую строку:
dog_dict = {'name': 'Freddie',
'age': 9,
'is_vaccinated': True,
'height': 1.1,
'birth_year': 2001,
'belongings': ['bone', 'little ball']}
Как можно видеть, вложенный список (в этом примере belongings) как значение словаря не является проблемой.
Это что касается внешнего вида словарей в Python.
Как получить доступ к конкретному элементу словаря Python
Самое важное, что нужно запомнить о получении доступа к элементу любого типа в любой структуре данных Python, это то, что вне зависимости от структуры (список, кортеж или словарь), нужно всего лишь ввести название структуры и универсальный идентификатор элемента в квадратных скобках (например, [1]).
То же касается и словарей.
Единственное отличие в том, что для списков и кортежей идентификатором выступает номер элемента, а здесь ключ. Попробуйте:
dog_dict['name']

Примечание: наверняка возникает вопрос, а можно ли использовать число для доступа к значению словаря. Нет, потому что словари в Python по умолчанию не упорядочены — это значит, что ни у одной пары ключ-значение нет своего номера.
Примечание: нельзя также вывести ключ с помощью значения. Python попросту не предназначен для этого.
Проверьте себя
Вы многое узнали о структурах данных. Даже если вы не выполняли прошлые уроки в конце статей, сделайте исключение для этой. Структуры — это то, что придется использовать постоянно, поэтому сделайте себе одолжение и попробуйте разобраться во всем на 100%
Упражнение:
- Скопируйте этот супер-вложенный список-словарь Python в Jupyter Notebook и присвойте его переменной
test.test = [{'Arizona': 'Phoenix', 'California': 'Sacramento', 'Hawaii': 'Honolulu'}, 1000, 2000, 3000, ['hat', 't-shirt', 'jeans', {'socks1': 'red', 'socks2': 'blue'}]] - Выполните эти 6 небольших заданий, выводя конкретные значения из списка-словаря! Каждое следующее будет немного сложнее.2.1. Верните
20002.2. Верните словарь с городами и штатами{'Arizona': 'Phoenix', 'California': 'Sacramento', 'Hawaii': 'Honolulu'}2.3. Верните список вещей['hat', 't-shirt', 'jeans', {'socks1': 'red', 'socks2': 'blue'}]2.4. Верните слово'Phoenix'2.5. Верните слово'jeans'2.6. Верните слово
'blue'
.
.
.
.
.
.
Решения
test[2]— главная сложность в том, чтобы запомнить, что индексирование начинается с нуля, а это значит, что2000— второй элемент.test[0]— это выведет весь словарь из основного списка.test[4]— как и в предыдущих примерах, будет выведен вложенный список.test[0]['Arizona"]— следующий этап для второго задания. Здесь с помощью ключа'Arizona'вызывается значение'Phoenix'.test[4][2]— это решение связано с третьим заданием. Обращаемся к'jeans'по номеру. Главное не забыть об индексировании с нуля.test[4][3]['socks2']— последний шаг — вызов элемента из словаря в списке, вложенного в другой список

Итог
Итак, вы справились с еще одним руководством по Python! Это почти все, что нужно знать о структурах данных. Впереди будет еще много небольших, но важных деталей (например, о том, как добавлять, удалять и изменять элементы в списке или словаре)… но до этого необходимо разобраться с функциями и методами.
]]>Если вы изучаете Data Science (науку о данных), то довольно быстро встретитесь с Python. Почему? Потому что это один из самых используемых языков программирования для работы с данными. Он популярен по 3 основным причинам:
- Его легко изучать, с ним легко работать
- Python прекрасно работает с разными структурами данных
- Существуют мощные библиотеки языка для визуализации данных и статистики
В этом руководстве речь пойдет обо всем, что нужно знать, начиная с основ. Даже если вы никогда не работали с кодом, то точно оказались в нужном месте. Затрагиваться будет только та часть языка, которая имеет отношение к data science — ненужные и непрактичные нюансы пропустим. А в конце обязательно создадим что-то интересное, например, прогнозную аналитику.
Это практическое руководство!
Делать что-то, следуя инструкциям, всегда полезнее, чем просто читать. Если те части, в которых есть код, вы будете повторять самостоятельно, набирая его на своем ПК, то разберетесь и запомните все в 10 раз лучше. А в конце статьи обязательно будет одно-два упражнения для проверки!
Это значит, что для практики нужна некоторая подготовка. Установите:
- Python 3.6+
- Jupyter (с iPython)
- Библиотеки: pandas, numpy, scikit, matplotlib
Зачем учить Python для Data Science?
Когда настает время изучать код для работы с данными, стоит сосредоточиться на этих 4 языках:
- SQL
- Python
- R
- Bash
Конечно, хорошо бы изучить все четыре. Но если вы только начинаете, то стоит начать с одного или двух. Чаще всего рекомендуют выбирать Python и SQL. С их помощью удастся охватить 99% процесса работы с данными и аналитических проблем.
Но почему стоит изучать Python для Data Science?
- Это легко и весело.
- Есть много библиотек для простых аналитических проектов (например, сегментация, групповой анализ, исследовательская аналитика и так далее) и более сложных (например, построение моделей машинного обучения).
- Рынок труда требует профессионалов в сфере работы с данными, у которых хорошие знания Python. Это значит, что Python в резюме будет чрезвычайно конкурентоспособным пунктом.
Что такое Python? Он подходит только для Data Science?
Теоретическая часть будет короткой. Но вам нужно знать две вещи о языке, прежде чем начинать использовать его.
- Python — язык общего назначения и он используется не только для Data Science. Это значит, что его не нужно знать идеально, чтобы быть экспертом в сфере работы с данными. В то же время даже основ будет достаточно, чтобы понимать и другие языки, а это очень удобно для работы в IT.
- Python — высокоуровневый язык. Это значит, что в отношении процессорного времени он не самый эффективный. С другой же стороны, он был создан очень простым, «удобным для использования» и понятным. Так, пусть вы и проиграете в процессорном времени, но сможете отыграться в процессе разработки.
Python 2 vs Python 3 – какой выбрать для Data Science?
Многие слышали о противостоянии Python 2.x и Python 3.x. Суть его в том, что Python 3 существует с 2008 года, и 95% функций и библиотек для data science уже перекочевали из Python 2. Также Python 2 перестанет поддерживаться после 2020 года. Учить его — то же самое, что учить латынь — иногда полезно, но будущее все равно за Python 3.
По этой причине все эти руководства написаны на Python 3.
Примечание: тем не менее почти всегда используется код, который будет работать в обеих версиях.
Достаточно теории! Пора программировать!
Как открыть Jupyter Notebook
Когда Jupyter Notebook установлен, следуйте этим 4 шагам каждый раз, когда нужно будет его запустить:
Есть вы работаете локально, достаточно запустить программу Jupyter Notebook и перейти к пункту 4.
- Войти на сервер! Для этого нужно открыть терминал и ввести следующее в командную строку:
ssh [ваш_логин]@[ваш ip-адрес]
и пароль.
(Например:ssh dataguy@178.62.1.214)

- Запустить Jupyter Notebeook на сервере с помощью команды:
jupyter notebook --browser any

- Получить доступ к Jupyter из браузера! Для этого нужно открыть Google Chrome (или любой другой) и ввести следующее в адресную строку:
[IP адрес удаленного сервера]:8888
(Например: 178.62.1.214:8888)
На экране отобразится следующее:

Нужно будет ввести “password” (пароль) или “token” (токен). Поскольку пароля пока нет, сначала нужно использовать токен, который можно найти в окне терминала:

- Готово! Теперь нужно создать новый Jupyter Notebook! (Если он создан, осталось его открыть).

Важно! Во время работы в браузере окно терминал сдолжен работать в фоне. Если его закрыть, Jupyter в браузере тоже закроется.
Вот и все. Запомните порядок действий, потому что их придется повторять часто в этом руководстве по Python для Data Science.
Как использовать Jupyter Notebeook
Теперь разберем, как пользоваться Jupyter Notebook!

- Введите команду Python! Это может быть команда на несколько строк — если нажать Enter, ничего не запустится, а в этой же ячейке появится новая строка!

- Для запуска команды Python нужно нажать
SHIFT + ENTER!

- Введите что-то и нажмите
TAB. Если это возможно, Jupyter автоматически закончит выражение (для команд Python и указанных переменных). Если вариантов несколько, появится выпадающее меню.

Основы Python
Прекрасно! Вы знаете все, что может понадобиться с технической стороны. Дальше речь пойдет об основных концепциях, которые нужно изучить, прежде чем переходить к использованию Python в Data Science. Вот эти 6 концепций:
- Переменные и типы данных
- Структуры данных в Python
- Функции и методы
- Инструкция (оператор) if
- Циклы
- Основы синтаксиса Python
Чтобы упростить процесс изучения и практики, эти 6 тем разбиты на 6 статей. Вот первая.
Основы Python №1: переменные и типы данных
В Python значения присваиваются переменным. Почему? Потому что это улучшает код — делает его более гибким, понятным и позволяет легко использовать повторно. В то же время «концепция присваивания» является одной из самых сложных в программировании. Когда код ссылается на элемент, который в свою очередь ссылается на другой элемент… это непросто. Но как только привыкаете, это начинает нравиться!
Посмотрим, как это работает!
Предположим, что есть собака (“Freddie”), и нужно сохранить ее черты (name, age, is_vaccinated, birth_year и так далее) в переменных Python. В ячейке Jupyter Notebook нужно ввести следующее:
dog_name = 'Freddie'
age = 9
is_vaccinated = True
height = 1.1
birth_year = 2001
Примечание: это же можно сделать по одной переменной для каждой ячейки. Но такое решение все-в-одном проще и изящнее.
С этого момент если вводить названия переменных, то те будут возвращать соответствующие значения:

Как и в SQL в Python есть несколько типов данных.
Например, переменная dog_name хранит строку: 'Freddie'. В Python 3 строка — это последовательность символов в кодировке Unicode (например, цифры, буквы, знаки препинания и так далее), поэтому она может содержать цифры, знаки восклицания и почти все что угодно (например, ‘R2-D2’ — допустимая строка). В Python легко определить строку — она записывается в кавычках.
age и birth_year хранят целые числа (9 и 2001) — это числовой тип данных Python. Другой тип данных — числа с плавающей точкой (float). В примере это height со значением 1.1.
Значение True переменной is_vaccinated — это логический тип (или булевый тип). В этом типе есть только два значения: True и False.
Резюме в таблице:
| Имя переменной | Значение | Тип данных |
|---|---|---|
dog_name |
'Freddie' |
str (сокр. от ‘string’ — строка) |
age |
9 |
int (сокр. от ‘integer’ — целое число) |
is_vaccinated |
True |
bool (сокр. от Boolean — булев тип) |
height |
1.1 |
float (сокр. от floating — с плавающей запятой) |
birth_year |
2001 |
int (сокр. от integer) |
Есть и другие типы данных, но для начала этих четырех будет достаточно.
Важно знать, что любую переменную Python можно перезаписать. Например, если запустить:
_dog_name = 'Eddie'
в Jupyter Notebook, тогда имя пса больше не будет ‘Freddie’…

Переменные Python — основные операторы
Вы знаете, что такое переменные. Пора поэкспериментировать с ними! Определим две переменные: a и b:
a = 3
b = 4
Что можно сделать с a и b? В первую очередь, есть набор арифметических операций! Ничего необычного, но вот список:
| Оператор | Что делает? | Результат |
|---|---|---|
a + b |
Складывает a и b | 7 |
a - b |
Вычитает b из a | -1 |
a * b |
Умножает a на b | 12 |
a / b |
Делит a на b | 0.75 |
b % a |
Делит b на a и возвращает остаток | 1 |
a ** b |
Возводит a в степень b | 81 |
Вот как это выглядит в Jupyter:

Примечание: попробуйте самостоятельно со своими переменными в Jupyter Notebook.
Можно использовать переменные с операторами сравнения. Результатом всегда будут логические True или False. a и b все еще 3 и 4.
| Оператор | Что делает? | Результат |
|---|---|---|
a > b |
Оценивает, больше ли a чем b |
False |
a < b |
Оценивает, меньше ли a чем b |
True |
a == b |
Оценивает, равны ли a и b |
False |
В Jupyter Notebook:

В итоге, переменные сами могут быть логическими операторами. Определим c и d:
c = True
d = False
| Оператор | Что делает? | Результат |
|---|---|---|
c and d |
True, если c и d — True |
False |
c or d |
True, если c или d — True |
True |
not c |
Противоположное c |
False |

Это легко и, возможно, не так интересно, но все-таки: попробуйте ввести все это в Jupyter Notebook, запустите команды и начните соединять элементы — будет интереснее.
Время переходить к заданиям.
Проверьте себя №1
Вот несколько переменных:
a = 1
b = 2
c = 3
d = True
e = 'cool'
Какой тип данных вернется, и каким будет результат всей операции?
a == e or d and c > b
Примечание: сперва попробуйте ответить на этот вопрос без Python — а затем проверьте, правильно ли вы определили!
.
.
.
Ответ: это будет логический тип данных со значением True.
Почему? Потому что:
- Значение
a == eравноFalse, поскольку 1 не равняется ‘cool’ - Значение
dравноTrueпо определению - Значение
c > bравноTrue, потому что 3 больше 2
Таким образом, a == e or d and c > b превращается в False or True and True, что в итоге приводит к True.
Проверьте себя №2
Используйте переменные из прошлого задания:
a = 1
b = 2
c = 3
d = True
e = 'cool'
Но в этот раз попробуйте определить результат слегка измененного выражения:
not a == e or d and not c > b
Чтобы правильно решить эту задачку, нужно знать порядок исполнения логических операторов:
- not
- and
- or
.
.
.
Ответ: True.
Почему? Разберем.
Пользуясь логикой прошлого задания, можно прийти к выводу, что выражение равняется: not False or True and not True.
Первым исполняется оператор not. После того как все not оценены, остается: True or True and False.
Второй шаг — определить оператор and. Переводим и получаем True or (True and False), что приводит к True or False.
И финальный шаг — or:
True or False → True
Выводы
Осознали ли вы, что программировали на Python 3? Не правда ли, что было легко и весело?
Хорошие новости в том, что в остальном Python настолько же прост. Сложность появляется от объединения простых вещей… Именно поэтому так важно знать основы!
В следующей части «Python для Data Science» вы узнаете о самых важных структурах данных в Python.
]]>При изучении программирования в качестве практики часто приходится создавать «идеальные программы», которые в реальном мире работают совсем не так.
Иногда, например, нужно исполнить ряд инструкций только в том случае, если соблюдаются определенные условия. Для обработки таких ситуаций в языках программирования есть операторы управления. В дополнение к управлению потоком выполнения программы эти операторы используются для создания циклов или пропуска инструкций, когда какое-то условие истинно.
Операторы управления бывают следующих типов:
- Оператор-выражение if
- Оператор-выражение if-else
- Оператор-выражение if-elif-else
- Цикл while
- Цикл for
- Оператор-выражение break
- Оператор-выражение continue
В этом уроке речь пойдет о первых трех операторах управления.
Оператор if
Синтаксис оператора if следующий:
if condition:
<indented statement 1>
<indented statement 2>
<non-indented statement>
Первая строчка оператора, то есть if condition: — это условие if, а condition — это логическое выражение, которое возвращает True или False. В следующей строке блок инструкций. Блок представляет собой одну или больше инструкций. Если он идет следом за условием if, такой блок называют блоком if.
Стоит обратить внимание, что у каждой инструкции в блоке if одинаковый отступ от слова if. Многие языки, такие как C, C++, Java и PHP, используют фигурные скобки ({}), чтобы определять начало и конец блока, но в Python используются отступы.
Каждая инструкция должна содержать одинаковое количество пробелов. В противном случае программа вернет синтаксическую ошибку. В документации Python рекомендуется делать отступ на 4 пробела. Такая рекомендация актуальная для и для этого .
Как это работает:
Когда выполняется инструкция if, проверяется условие. Если условие истинно, тогда все инструкции в блоке if выполняются. Но если условие оказывается неверным, тогда все инструкции внутри этого блока пропускаются.
Инструкции следом за условием if, у которых нет отступов, не относятся к блоку if. Например, <non-intenden statement> — это не часть блока if, поэтому она будет выполнена в любом случае.
Например:
number = int(input("Введите число: "))
if number > 10:
print("Число больше 10")
Первый вывод:
Введите число: 100
Число больше 10
Второй вывод:
Введите число: 5
Стоит обратить внимание, что во втором случае, когда условие не истинно, инструкция внутри блока if пропускается. В этом примере блок if состоит из одной инструкции, но их может быть сколько угодно, главное — делать отступы.
Рассмотрим следующий код:
number = int(input("Введите число: "))
if number > 10:
print("первая строка")
print("вторая строка")
print("третья строка")
print("Выполняется каждый раз, когда вы запускаете программу")
print("Конец")
Первый вывод:
Введите число: 45
первая строка
вторая строка
третья строка
Выполняется каждый раз, когда вы запускаете программу
Конец
Второй вывод:
Введите число: 4
Выполняется каждый раз, когда вы запускаете программу
Конец
Здесь важно обратить внимание, что только выражения на строках 3, 4 и 5 относятся к блоку if. Следовательно, они будут исполнены только в том случае, когда условие if будет истинно. Но инструкции на строках 7 и 8 выполнятся в любом случае.
Консоль Python реагирует иначе при использовании операторов управления прямо в ней. Стоит напомнить, что для разбития выражения на несколько строк используется оператор продолжение (\). Но в этом нет необходимости с операторами управления. Интерпретатор Python автоматически активирует мультистрочный режим, если нажать Enter после условия if. Например:
>>>
>>> n = 100
>>> if n > 10:
...
После нажатия Enter на строке с условием if командная строка преобразуется с >>> на …. Консоль Python показывает … для многострочных инструкций. Это значит, что начатая инструкция все еще не закончена.
Чтобы закончить инструкцию if, нужно добавить еще одну инструкцию в блок if:
>>>
>>> n = 100
>>> if n > 10:
... print("n v 10")
...
Python не будет автоматически добавлять отступ. Это нужно сделать самостоятельно. Закончив ввод инструкции, нужно дважды нажать Enter, чтобы исполнить инструкцию. После этого консоль вернется к изначальному состоянию.
>>>
>>> n = 100
>>> if n > 10:
... print("n больше чем 10")
...
n больше чем 10
>>>
Все эти программы заканчиваются внезапно, не показывая ничего, если условие не истинно. Но в большинстве случаев пользователю нужно показать хотя бы что-нибудь. Для этого используется оператор-выражение if-else.
Оператор if-else
Оператор if-else исполняет одну порцию инструкций, если условие истинно и другое — если нет. Таким образом этот оператор предлагает два направления действий. Синтаксис оператора if-else следующий:
if condition:
# блок if
statement 1
statement 2
and so on
else:
# блок else
statement 3
statement 4
and so on:
Как это работает:
Когда оператор if-else исполняется, условие проверяется, и если оно возвращает True, когда инструкции в блоке if исполняются. Но если возвращается False, тогда исполняются инструкции из блока else.
Пример 1: программа для расчета площади и длины окружности круга.
radius = int(input("Введите радиус: "))
if radius >= 0:
print("Длина окружности = ", 2 * 3.14 * radius)
print("Площадь = ", 3.14 * radius ** 2)
else:
print("Пожалуйста, введите положительное число")
Первый вывод:
Введите радиус: 4
Длина окружности = 25.12
Площадь = 50.24
Второй вывод:
Введите радиус: -12
Пожалуйста, введите положительное число
Теперь программа показывает корректный ответ пользователю, даже если условие if не является истинным. Это и требуется.
В инструкциях if-else нужно следить за тем, чтобы условия if и else находились на одном уровне. В противном случае программа вернет синтаксическую ошибку. Например:
radius = int(input("Введите радиус: "))
if radius >= 0:
print("Длина окружности = ", 2 * 3.14 * radius)
print("Площадь = ", 3.14 * radius ** 2)
else:
print("Пожалуйста, введите положительное число")
Если попробовать запустить эту программу, то появится следующая ошибка:
$ python3 if_and_else_not_aligned.py
File "if_and_else_not_aligned.py", line 6
else:
^
SyntaxError: invalid syntax
$
Для исправления проблемы нужно вертикально выровнять if и else
Другой пример:
Пример 2: программа для проверки пароля, введенного пользователем.
password = input("Введите пароль: ")
if password == "sshh":
print("Добро пожаловать")
else:
print("Доступ запрещен")
Первый вывод:
Введите пароль: sshh
Добро пожаловать
Второй вывод:
Введите пароль: abc
Доступ запрещен
Вложенные операторы if и if-else
Использовать операторы if-else можно внутри других инструкций if или if-else. Это лучше объяснить на примерах:
Оператор if внутри другого if-оператора
Пример 1: программа, проверяющая, имеет ли студент право на кредит.
gre_score = int(input("Введите текущий лимит: "))
per_grad = int(input("Введите кредитный рейтинг: "))
if per_grad > 70:
# внешний блок if
if gre_score > 150:
# внутренний блок if
print("Поздравляем, вам выдан кредит")
else:
print("Извините, вы не имеете права на кредит")
Здесь оператор if используется внутри другого if-оператора. Внутренним называют вложенный оператором if. В этом случае внутренний оператор if относится к внешнему блоку if, а у внутреннего блока if есть только одна инструкция, которая выводит “Поздравляем, вам выдан кредит”.
Как это работает:
Сначала оценивается внешнее условие if, то есть per_grad > 70. Если оно возвращает True, тогда управление программой происходит внутри внешнего блока if. Там же проверяется условие gre_score > 150. Если оно возвращает True, тогда в консоль выводится "Congratulations you are eligible for loan". Если False, тогда программа выходит из инструкции if-else, чтобы исполнить следующие операции. Ничего при этом не выводится в консоль.
При этом если внешнее условие возвращает False, тогда выполнение инструкций внутри блока if пропускается, и контроль переходит к блоку else (9 строчка).
Первый вывод:
Введите текущий лимит: 160
Введите кредитный рейтинг: 75
Поздравляем, вам выдан кредит
Второй вывод:
Введите текущий лимит: 160
Введите кредитный рейтинг: 60
Извините, вы не имеете права на кредит
У этой программы есть одна маленькая проблема. Запустите ее заново и введите gre_score меньше чем 150, а per_grade — больше 70:
Вывод:
Введите текущий лимит: 140
Введите кредитный рейтинг: 80
Программа не выводит ничего. Причина в том, что у вложенного оператора if нет условия else. Добавим его в следующем примере.
Пример 2: инструкция if-else внутри другого оператора if.
gre_score = int(input("Введите текущий лимит: "))
per_grad = int(input("Введите кредитный рейтинг: "))
if per_grad > 70:
if gre_score > 150:
print("Поздравляем, вам выдан кредит")
else:
print("У вас низкий кредитный лимит")
else:
print("Извините, вы не имеете права на кредит")
Вывод:
Введите текущий лимит: 140
Введите кредитный рейтинг: 80
У вас низкий кредитный лимит
Как это работает:
Эта программа работает та же, как и предыдущая. Единственное отличие — у вложенного оператора if теперь есть инструкция else. Теперь если ввести балл GRE меньше, чем 150, программа выведет: “У вас низкий кредитный лимит”
При создании вложенных операторов if или if-else, всегда важно помнить об отступах. В противном случае выйдет синтаксическая ошибка.
Оператор if-else внутри условия else
Пример 3: программа для определения оценки студента на основе введенных баллов.
score = int(input("Введите вашу оценку: "))
if score >= 90:
print("Отлично! Ваша оценка А")
else:
if score >= 80:
print("Здорово! Ваша оценка - B")
else:
if score >= 70:
print("Хорошо! Ваша оценка - C")
else:
if score >= 60:
print("Ваша оценка - D. Стоит повторить материал.")
else:
print("Вы не сдали экзамен")
Первый вывод:
Введите вашу оценку: 92
Отлично! Ваша оценка А
Второй вывод:
Введите вашу оценку: 72
Хорошо! Ваша оценка - C
Третий вывод:
Введите вашу оценку: 56
Вы не сдали экзамен
Как это работает:
Когда управление программой переходит к оператору if-else, проверяется условие на строке 3 (score >= 90). Если оно возвращает True, в консоль выводится “Отлично! Ваша оценка А”. Если значение неверное, управление переходит к условию else на 5 строке. Теперь проверяется условие score >= 80 (6 строка). Если оно верное, тогда в консоли выводится “Здорово! Ваша оценка — B”.
В противном случае управление программой переходит к условию else на 8 строке. И здесь снова имеется вложенный оператор if-else. Проверяется условие (score >= 70). Если оно истинно, тогда в консоль выводится “Хорошо! Ваша оценка — C”. В противном случае управление переходит к блоку else на 11 строке. В конце концов, проверяется условие (score >= 60). Если оно возвращает True, тогда в консоль выводится “Ваша оценка — D. Стоит повторить материал.” Если же False, тогда в консоли будет “Вы не сдали экзамен”. На этом этапе управление переходит к следующим инструкциям, написанным после внешнего if-else.
Хотя вложенные операторы if-else позволяют проверять несколько условий, их довольно сложно читать и писать. Эти же программы можно сделать более читабельными и простыми с помощью if-elif-else.
Оператор if-elif-else
Оператор if-elif-else — это альтернативное представление оператора if-else, которое позволяет проверять несколько условий, вместо того чтобы писать вложенные if-else. Синтаксис этого оператора следующий:
if condition_1:
# блок if
statement
statement
more statement
elif condition_2:
# первый блок elif
statement
statement
more statement
elif condition_3:
# второй блок elif
statement
statement
more statement
...
else
statement
statement
more statement
Примечание: … означает, что можно писать сколько угодно условий eilf.
Как это работает:
Когда исполняется инструкция if-elif-else, в первую очередь проверяется condition_1. Если условие истинно, тогда исполняется блок инструкций if. Следующие условия и инструкции пропускаются, и управление переходит к операторам вне if-elif-else.
Если condition_1 оказывается ложным, тогда управление переходит к следующему условию elif, и проверяется condition_2. Если оно истинно, тогда исполняются инструкции внутри первого блока elif. Последующие инструкции внутри этого блока пропускаются.
Этот процесс повторяется, пока не находится условие elif, которое оказывается истинным. Если такого нет, тогда исполняется блок else в самом конце.
Перепишем программу с помощью if-elif-else.
score = int(input("Введите вашу оценку: "))
if score >= 90:
print("Отлично! Ваша оценка А")
elif score >= 80:
print("Здорово! Ваша оценка - B")
elif score >= 70:
print("Хорошо! Ваша оценка - C")
elif score >= 60:
print("Ваша оценка - D. Стоит повторить материал.")
else:
print("Вы не сдали экзамен")
Первый вывод:
Введите вашу оценку: 78
Хорошо! Ваша оценка - C
Второй вывод:
Введите вашу оценку: 91
Отлично! Ваша оценка А
Третий вывод:
Введите вашу оценку: 55
Вы не сдали экзамен
Такую программу намного легче читать, чем в случае с вложенными if-else.
]]>В Python есть много встроенных структур данных, используемых для хранения разных типов информации. Словарь (dict) — одна из таких структур, которая хранит данные в формате пар ключ-значение. Получить доступ к значениям словаря Python можно с помощью ключей. Этот материал посвящен подробному обсуждению словаря.
Создание словаря
Для создания словаря в Python необходимо передать последовательность элементов внутри фигурных скобок {}, разделив их запятыми (,). Каждый элемент имеет ключ и значение, выраженное парой «ключ: значение».
Значения могут быть представлять собой любые типы данных и повторяться, но ключи обязаны быть уникальными.
Следующие примеры показывают, как создавать словари Python:
Создание пустого словаря:
dict_sample = {}
Cловарь, где ключи являются целыми числами:
dict_sample = {1: 'mango', 2: 'pawpaw'}
Создание словаря с ключами разных типов:
dict_sample = {'fruit': 'mango', 1: [4, 6, 8]}
Можно также создать словарь, явно вызвав метод dict():
dict_sample = dict({1:'mango', 2:'pawpaw'})
Словарь можно создать с помощью последовательности, как в примере внизу:
dict_sample = dict([(1,'mango'), (2,'pawpaw')])
Словари могут быть вложенными. Это значит, что можно создавать словари внутри существующего словаря. Например:
dict_sample = {
1: {'student1': 'Nicholas', 'student2': 'John', 'student3': 'Mercy'},
2: {'course1': 'Computer Science', 'course2': 'Mathematics', 'course3': 'Accounting'}
}
Чтобы вывести содержимое словаря, можно использовать функцию print() и передать название словаря в качестве аргумента. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
print(dict_sample)
Вывод:
{'Company': 'Toyota', 'model': 'Premio', 'year': 2012}
Доступ к элементами
Чтобы получить доступ к элементам словаря, нужно передать ключ в квадратных скобках []. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample["model"]
print(x)
Вывод:
Premio
Был создан словарь dict_sample. Затем была создана переменная x. Ее значение — это значение ключа ["model"] из словаря.
Вот другой пример:
dict = {'Name': 'Mercy', 'Age': 23, 'Course': 'Accounting'}
print("Student Name:", dict['Name'])
print("Course:", dict['Course'])
print("Age:", dict['Age'])
Вывод:
Student Name: Mercy
Course: Accounting
Age: 23
Объект словаря также имеет функцию get(), которой можно пользоваться для доступа к элементам словаря. Ее нужно добавлять к словаря через точку и затем передавать название ключа как аргумент функции. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.get("model")
print(x)
Вывод:
Premio
Теперь вы знаете, как получать доступ к элементам словаря с помощью разных методов. В следующем разделе речь пойдет о добавлении новых элементов в уже существующий словарь.
Добавление элементов
Существует множество способов для добавления новых элементов в словарь. Можно использовать новый ключ и присвоить ему значение. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
dict_sample["Capacity"] = "1800CC"
print(dict_sample)
Вывод:
{'Capacity': '1800CC', 'year': 2012, 'Company': 'Toyota', 'model': 'Premio'}
У нового элемента ключ "Capacity" и значение — "180CC". Он был добавлен в качестве первого элемента словаря.
Вот другой пример. Для начала нужно создать пустой словарь:
MyDictionary = {}
print("An Empty Dictionary: ")
print(MyDictionary)
Вывод:
An Empty Dictionary:
Словарь ничего не возвращает, потому что в нем ничего не хранится. Добавим в нему элементы, один за одним:
MyDictionary[0] = 'Apples'
MyDictionary[2] = 'Mangoes'
MyDictionary[3] = 20
print("\n3 elements have been added: ")
print(MyDictionary)
Вывод:
3 elements have been added: {0: 'Apples', 2: 'Mangoes', 3: 20}
Для добавления элементов были отдельно указаны ключи и соответствующие значения. Например:
MyDictionary[0] = 'Apples'
В этом примере 0 является ключом, а "Apples" — значение.
Можно даже добавить несколько значений для одного ключа. Например:
MyDictionary['Values'] = 1, "Pairs", 4
print("\n3 elements have been added: ")
print(MyDictionary)
Вывод:
3 elements have been added: {'Values': (1, 'Pairs', 4)}
В этом примере название ключа — "Value", а все что после знака = — его значения в формате множества (Set).
Помимо добавления новых элементов в словарь, их можно обновлять или изменять. Об этом в следующем разделе.
Обновление элементов
После добавления значения в словарь существующий элемент словаря можно изменить. Для изменения значения используется соответствующий ключ. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
dict_sample["year"] = 2014
print(dict_sample)
Вывод:
{'year': 2014, 'model': 'Premio', 'Company': 'Toyota'}
В этом примере видно, что было обновлено значение ключа "year" с 2012 на 2014.
Удаление элементов
Удалить элемент из словаря можно несколькими способами. В этом разделе они будут рассмотрены по одному:
Ключевое слово del можно использовать для удаления элемента с конкретным ключом. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
del dict_sample["year"]
print(dict_sample)
Вывод:
{'Company': 'Toyota', 'model': 'Premio'}
Вызывается ключевое слово del, а следом за ним — название словаря. В квадратных скобках следом за словарем идет ключ элемента, который требуется удалить. В этом примере это "year". Запись "year" удаляется из словаря.
Другой способ удалить пару ключ-значение — функция pop() с ключом записи в виде аргумента. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
dict_sample.pop("year")
print(dict_sample)
Вывод:
{'Company': 'Toyota', 'model': 'Premio'}
Функция pop() была вызвана добавлением ее к названию словаря. В этом случае будет удалена запись с ключом "year".
Функция popitem() удаляет последний элемент в словаре. Для нее не нужно указывать конкретный ключ. Примеры:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
dict_sample.popitem()
print(dict_sample)
Вывод:
{'Company': 'Toyota', 'model': 'Premio'}
Последней записью в словаре была "year". Она пропала из словаря после вызова функции popitem().
Что делать, если нужно удалить целый словарь? Это будет сложно и займет много времени, если пользоваться этими методами к каждому ключу. Вместо этого можно использовать ключевое слово del для целого словаря. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
del dict_sample
print(dict_sample)
Вывод:
NameError: name 'dict_sample' is not defined
Код вернет ошибку, потому что функция print() пытается получить доступ к словарю, который уже не существует.
В определенных случаях может потребоваться удалить все элементы словаря, оставив его пустым. Этого можно добиться, воспользовавшись функцией clear():
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
dict_sample.clear()
print(dict_sample)
Вывод:
{}
Код вернет пустой словарь, поскольку все его элементы уже удалены.
Другие распространенные методы словарей
Метод len()
С помощью этого метода можно посчитать количество элементов в словаре. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
print(len(dict_sample))
Вывод:
3
В этом словаре три записи, поэтому метод вернет 3.
Метод copy()
Этот метод возвращает копию существующего словаря. Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.copy()
print(x)
Вывод:
{'Company': 'Toyota', 'year': 2012, 'model': 'Premio'}
Была создана копия словаря dict_sample. Она присвоена переменной x. Если вывести x в консоль, то в ней будут те же элементы, что и в словаре dict_sample.
Это удобно, потому что изменения в скопированном словаре не затрагивают оригинальный словарь.
Метод items()
Этот метод возвращает итерируемый объект. Такой объект содержит пары ключ-значение для словаря по аналогии с кортежами в списке. Метод используется, когда нужно перебрать значения словаря.
Этот метод нужно вызывать вместе со словарем, как в примере ниже:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
for k, v in dict_sample.items():
print(k, v)
Вывод:
('Company', 'Toyota')
('model', 'Premio')
('year', 2012)
Объект, который возвращает items(), можно использовать, чтобы показать изменения в словаре. Вот как это работает.
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.items()
print(x)
dict_sample["model"] = "Mark X"
print(x)
Вывод:
dict_items([('Company', 'Toyota'), ('model', 'Premio'), ('year', 2012)])
dict_items([('Company', 'Toyota'), ('model', 'Mark X'), ('year', 2012)])
Вывод демонстрирует, что когда вы меняете значение в словаре, объекты элементов также обновляются.
Метод fromkeys()
Этот метод возвращает словарь с указанными ключами и значениями. У него следующий синтаксис:
dictionary.fromkeys(keys, value)
Значение требуемого параметра keys — итерируемые объекты. Оно отвечает за ключи нового словаря. Значение для параметра value указывать необязательно. Оно отвечает за значение по умолчанию для всех ключей. По умолчанию — None.
Предположим, что нужно создать словарь с тремя ключами и одинаковым значением. Это можно сделать следующим образом:
name = ('John', 'Nicholas', 'Mercy')
age = 25
dict_sample = dict.fromkeys(name, age)
print(dict_sample)
Вывод:
{'John': 25, 'Mercy': 25, 'Nicholas': 25}
В коде вверху определены ключи и одно значение. Метод fromkeys() перебирает ключи и объединяет их со значением для создания заполненного словаря.
Значение для параметра keys является обязательным. В следующем примере показано, что происходит, если параметр values не определен:
name = ('John', 'Nicholas', 'Mercy')
dict_sample = dict.fromkeys(name)
print(dict_sample)
Вывод:
{'John': None, 'Mercy': None, 'Nicholas': None}
Используется значение по умолчанию, None.
Метод setdefault()
Этот метод используется, когда нужно получить значение элемента с конкретным ключом. Если ключ не найден, он будет вставлен в словарь вместе с указанным значением.
У метода следующий синтаксис:
dictionary.setdefault(keyname, value)
В этой функции параметр keyname является обязательным. Он обозначает название ключа, значение которого нужно вернуть. Параметр value необязательный. Если в словаре уже есть ключ, параметр не будет иметь никакого эффекта. Если ключ не существует, тогда значение функции станет значением ключа. Значение по умолчанию — None.
Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.setdefault("color", "Gray")
print(x)
Вывод:
Gray
В словаре нет ключа color. Метод setdefault() вставляет этот ключ вместе со значением "Gray".
Следующий пример показывает, как работает метод, если такой ключ уже есть:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.setdefault("model", "Allion")
print(x)
Вывод:
Premio
Значение "Allion" не повлияло на словарь, потому что у ключа уже есть значение.
Метод keys()
Этот метод также возвращает итерируемый объект. Он является списком всех ключей в словаре. Как и метод items(), этот отображает изменения в самом словаре.
Для использования метода нужно всего лишь использовать его с именем словаря, как показано ниже:
dictionary.keys()
Например:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
x = dict_sample.keys()
print(x)
Вывод:
dict_keys(['model', 'Company', 'year'])
Часто этот метод используется, чтобы перебрать все ключи в словаре:
dict_sample = {
"Company": "Toyota",
"model": "Premio",
"year": 2012
}
for k in dict_sample.keys():
print(k)
Вывод:
Company
model
year
Выводы
Это все, что нужно знать о словарях Python. Они хранят информацию в парах «ключ: значение». «Ключ» выступает идентификатором объекта, а «значение» — это определенные данные. В Python много функций, которые могут быть использовать для извлечения и обработки данных. В этой статье были рассмотрены способы создания, изменения и удаления словаря, а также самые распространенные методы для работы с этим типом данных.
]]>В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Вы уже видели операторы + и * в применении их к числовым значениям в уроке по операторам в Python . Эти два оператора применяются и к строкам.
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
>>> s = 'py'
>>> t = 'th'
>>> u = 'on'
>>> s + t
'pyth'
>>> s + t + u
'python'
>>> print('Привет, ' + 'Мир!')
Go team!!!
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s:
s * n
n * s
Вот примеры умножения строк:
>>> s = 'py.'
>>> s * 4
'py.py.py.py.'
>>> 4 * s
'py.py.py.py.'
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
>>> 'py' * -6
''
Если вы создадите строковую переменную и превратите ее в пустую строку, с помощью 'py' * -6, кто-нибудь будет справедливо считать вас немного глупым. Но это сработает.
Оператор принадлежности подстроки in
Python также предоставляет оператор принадлежности, который можно использоваться для манипуляций со строками. Оператор in возвращает True, если подстрока входит в строку, и False, если нет:
>>> s = 'Python'
>>> s in 'I love Python.'
True
>>> s in 'I love Java.'
False
Есть также оператор not in, у которого обратная логика:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
Встроенные функции строк в python
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
Самая простая схема в повседневном использовании называется ASCII . Она охватывает латинские символы, с которыми мы чаще работает. Для этих символов ord(c) возвращает значение ASCII для символа c:
>>> ord('a')
97
>>> ord('#')
35
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
>>> ord('€')
8364
>>> ord('∑')
8721
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() действует обратно ord(). Если задано числовое значение n, chr(n) возвращает строку, представляющую символ n:
>>> chr(97)
'a'
>>> chr(35)
'#'
chr() также обрабатывает символы Юникода:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s:
>>> s = 'Простоя строка.'
>>> len(s)
15
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('py')
'py'
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
В Python строки являются упорядоченными последовательностями символьных данных и могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [].
Индексация строк начинается с нуля: у первого символа индекс 0, следующего 1 и так далее. Индекс последнего символа в python — ‘‘длина строки минус один’’.
Например, схематическое представление индексов строки 'foobar' выглядит следующим образом:

Отдельные символы доступны по индексу следующим образом:
>>> s = 'foobar'
>>> s[0]
'f'
>>> s[1]
'o'
>>> s[3]
'b'
>>> s[5]
'r'
Попытка обращения по индексу большему чем len(s) - 1, приводит к ошибке IndexError:
>>> s[6]
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
s[6]
IndexError: string index out of range
Индексы строк также могут быть указаны отрицательными числами. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее. Вот такая же диаграмма, показывающая как положительные, так и отрицательные индексы строки 'foobar':

Вот несколько примеров отрицательного индексирования:
>>> s = 'foobar'
>>> s[-1]
'r'
>>> s[-2]
'a'
>>> len(s)
6
>>> s[-len(s)] # отрицательная индексация начинается с -1
'f'
Попытка обращения по индексу меньшему чем -len(s), приводит к ошибке IndexError:
>>> s[-7]
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, код s[len(s)-1] и s[-1] возвращают последний символ. Нет индекса, который применим к пустой строке.
Срезы строк
Python также допускает возможность извлечения подстроки из строки, известную как ‘‘string slice’’. Если s это строка, выражение формы s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая позицию:
>>> s = 'python'
>>> s[2:5]
'tho'
Помните: индексы строк в python начинаются с нуля. Первый символ в строке имеет индекс
0. Это относится и к срезу.
Опять же, второй индекс указывает символ, который не включен в результат. Символ 'n' в приведенном выше примере. Это может показаться немного не интуитивным, но дает результат: выражение s[m:n] вернет подстроку, которая является разницей n - m, в данном случае 5 - 2 = 3.
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m]:
>>> s = 'python'
>>> s[:4]
'pyth'
>>> s[0:4]
'pyth'
Аналогично, если опустить второй индекс s[n:], срез длится от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкой s[n:len(s)]:
>>> s = 'python'
>>> s[2:]
'thon'
>>> s[2:len(s)]
'thon'
Для любой строки s и любого целого n числа (0 ≤ n ≤ len(s)), s[:n] + s[n:]будет s:
>>> s = 'python'
>>> s[:4] + s[4:]
'python'
>>> s[:4] + s[4:] == s
True
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
>>> s = 'python'
>>> t = s[:]
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
>>> s[2:2]
''
>>> s[4:2]
''
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
>>> s = 'python'
>>> s[-5:-2]
'yth'
>>> s[1:4]
'yth'
>>> s[-5:-2] == s[1:4]
True
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
Например , для строки 'python' срез 0:6:2 начинается с первого символа и заканчивается последним символом (всей строкой), каждый второй символ пропускается. Это показано на следующей схеме:

Иллюстративный код показан здесь:
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::5]
'11111'
>>> s[4::5]
'55555'
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'python'
>>> s[5:0:-2]
'nhy'
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::-5]
'55555'
Это общая парадигма для разворота (reverse) строки:
>>> s = 'Если так говорит товарищ Наполеон, значит, так оно и есть.'
>>> s[::-1]
'.ьтсе и оно кат ,тичанз ,ноелопаН щиравот тировог кат илсЕ'
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале (f'string'), и python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора ,, разделяющего числовые значения и строковые:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('Произведение', n, 'на', m, 'равно', prod)
Произведение 20 на 25 равно 500
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
- Напишите
fилиFперед кавычками строки. Это укажет python, что это f-строка вместо стандартной. - Укажите любые переменные для воспроизведения в фигурных скобках (
{}).
Код с использованием f-string, приведенный ниже выглядит намного чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'Произведение {n} на {m} равно {prod}')
Произведение 20 на 25 равно 500
Любой из трех типов кавычек в python можно использовать для f-строки:
>>> var = 'Гав'
>>> print(f'Собака говорит {var}!')
Собака говорит Гав!
>>> print(f"Собака говорит {var}!")
Собака говорит Гав!
>>> print(f'''Собака говорит {var}!''')
Собака говорит Гав!
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError:
>>> s = 'python'
>>> s[3] = 't'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 't'
TypeError: 'str' object does not support item assignment
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
>>> s = s[:3] + 't' + s[4:]
>>> s
'pytton'
Есть встроенный метод string.replace(x, y):
>>> s = 'python'
>>> s = s.replace('h', 't')
>>> s
'pytton'
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
obj.foo(<args>)
Этот код вызывает метод .foo() объекта obj. <args> — аргументы, передаваемые методу (если есть).
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ([]), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
>>> s = 'everyTHing yoU Can IMaGine is rEAl'
>>> s.capitalize()
'Everything you can imagine is real'
Не алфавитные символы не изменяются:
>>> s = 'follow us @PYTHON'
>>> s.capitalize()
'Follow us @python'
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'everyTHing yoU Can IMaGine is rEAl'.lower()
'everything you can imagine is real'
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
>>> 'everyTHing yoU Can IMaGine is rEAl'.swapcase()
'EVERYthING YOu cAN imAgINE IS ReaL'
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
>>> 'the sun also rises'.title()
'The Sun Also Rises'
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
>>> 'follow us @PYTHON'.title()
'Follow Us @Python'
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
>>> 'follow us @PYTHON'.upper()
'FOLLOW US @PYTHON'
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы <start> и <end> аргументы. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа <start> и продолжающейся вплоть до позиции символа <end>, но не включая его. Если <start> указано, а <end> нет, метод применяется к части строки от <start> конца.
string.count(<sub>[, <start>[, <end>]]) подсчитывает количество вхождений подстроки в строку.
s.count(<sub>) возвращает количество точных вхождений подстроки <sub> в s:
>>> 'foo goo moo'.count('oo')
3
Количество вхождений изменится, если указать <start> и <end>:
>>> 'foo goo moo'.count('oo', 0, 8)
2
string.endswith(<suffix>[, <start>[, <end>]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith(<suffix>) возвращает, True если s заканчивается указанным <suffix> и False если нет:
>>> 'python'.endswith('on')
True
>>> 'python'.endswith('or')
False
Сравнение ограничено подстрокой, между <start> и <end>, если они указаны:
>>> 'python'.endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
string.find(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку.
s.find(<sub>) возвращает первый индекс в s который соответствует началу строки <sub>:
>>> 'Follow Us @Python'.find('Us')
7
Этот метод возвращает, -1 если указанная подстрока не найдена:
>>> 'Follow Us @Python'.find('you')
-1
Поиск в строке ограничивается подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'.find('Us', 4)
7
>>> 'Follow Us @Python'.find('Us', 4, 7)
-1
string.index(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку.
Этот метод идентичен .find(), за исключением того, что он вызывает исключение ValueError, если <sub> не найден:
>>> 'Follow Us @Python'.index('you')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'Follow Us @Python'.index('you')
ValueError: substring not found
string.rfind(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку, начиная с конца.
s.rfind(<sub>) возвращает индекс последнего вхождения подстроки <sub> в s, который соответствует началу <sub>:
>>> 'Follow Us @Python'.rfind('o')
15
Как и в .find(), если подстрока не найдена, возвращается -1:
>>> 'Follow Us @Python'.rfind('a')
-1
Поиск в строке ограничивается подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'.rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
string.rindex(<sub>[, <start>[, <end>]]) ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение ValueError, если <sub> не найден:
>>> 'Follow Us @Python'.rindex('you')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'Follow Us @Python'.rindex('you')
ValueError: substring not found
string.startswith(<prefix>[, <start>[, <end>]]) определяет, начинается ли строка с заданной подстроки.
s.startswith(<suffix>) возвращает, True если s начинается с указанного <suffix> и False если нет:
>>> 'Follow Us @Python'.startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
Сравнение ограничено подстрокой, между <start> и <end>, если они указаны:
>>> 'Follow Us @Python'.startswith('Us', 7)
True
>>> 'Follow Us @Python'.startswith('Us', 8, 16)
False
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
s.isalnum() возвращает True, если строка s не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра). В другом случае False :
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
string.isalpha() определяет, состоит ли строка только из букв.
s.isalpha() возвращает True, если строка s не пустая, а все ее символы буквенные. В другом случае False:
>>> 'ABCabc'.isalpha()
True
>>> 'abc123'.isalpha()
False
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
s.isidentifier() возвращает True, если s валидный идентификатор (название переменной, функции, класса и т.д.) python, а в False если нет:
>>> 'foo32'.isidentifier()
True
>>> '32foo'.isidentifier()
False
>>> 'foo$32'.isidentifier()
False
Важно: .isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову python, даже если его нельзя использовать:
>>> 'and'.isidentifier()
True
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword. Один из возможных способов сделать это:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор python, вы должны проверить, что .isidentifier() = True и iskeyword() = False.
string.islower() определяет, являются ли буквенные символы строки строчными.
s.islower() возвращает True, если строка s не пустая, и все содержащиеся в нем буквенные символы строчные, а False если нет. Не алфавитные символы игнорируются:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
>>> 'a\tb'.isprintable() # \t - символ табуляции
False
>>> 'a b'.isprintable()
True
>>> ''.isprintable()
True
>>> 'a\nb'.isprintable() # \n - символ перевода строки
False
Важно: Это единственный .is****() метод, который возвращает True, если s пустая строка. Все остальные возвращаются False.
string.isspace() определяет, состоит ли строка только из пробельных символов.
s.isspace() возвращает True, если s не пустая строка, и все символы являются пробельными, а False, если нет.
Наиболее часто встречающиеся пробельные символы — это пробел ' ', табуляция '\t' и новая строка '\n':
>>> ' \t \n '.isspace()
True
>>> ' a '.isspace()
False
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
>>> '\f\u2005\r'.isspace()
True
'\f' и '\r' являются escape-последовательностями для символов ASCII; '\u2005' это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
s.istitle() возвращает True когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Возвращает False, если нет:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
string.isupper() определяет, являются ли буквенные символы строки заглавными.
s.isupper() возвращает True, если строка s не пустая, и все содержащиеся в ней буквенные символы являются заглавными, и в False, если нет. Не алфавитные символы игнорируются:
>>> 'ABC'.isupper()
True
>>> 'ABC1$D'.isupper()
True
>>> 'Abc1$D'.isupper()
False
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center(<width>[, <fill>]) выравнивает строку по центру.
s.center(<width>) возвращает строку, состоящую из s выровненной по ширине <width>. По умолчанию отступ состоит из пробела ASCII:
>>> 'py'.center(10)
' py '
Если указан необязательный аргумент <fill>, он используется как символ заполнения:
>>> 'py'.center(10, '-')
'----py----'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'.center(2)
'python'
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ('\t') пробелами. По умолчанию табуляция заменяются на 8 пробелов:
>>> 'a\tb\tc'.expandtabs()
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs()
'aaa bbb c'
tabsize необязательный параметр, задающий количество пробелов:
>>> 'a\tb\tc'.expandtabs(4)
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs(tabsize=4)
'aaa bbb c'
string.ljust(<width>[, <fill>]) выравнивание по левому краю строки в поле.
s.ljust(<width>) возвращает строку s, выравненную по левому краю в поле шириной <width>. По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.ljust(10)
'python '
Если указан аргумент <fill> , он используется как символ заполнения:
>>> 'python'.ljust(10, '-')
'python----'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'.ljust(2)
'python'
string.lstrip([<chars>]) обрезает пробельные символы слева
s.lstrip()возвращает копию s в которой все пробельные символы с левого края удалены:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> '\t\nfoo\t\nbar\t\nbaz'.lstrip()
'foo\t\nbar\t\nbaz'
Необязательный аргумент <chars>, определяет набор символов, которые будут удалены:
>>> 'https://www.pythonru.com'.lstrip('/:pths')
'www.pythonru.com'
string.replace(<old>, <new>[, <count>]) заменяет вхождения подстроки в строке.
s.replace(<old>, <new>) возвращает копию s где все вхождения подстроки <old>, заменены на <new>:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love')
'I love python! I love python! I love python!'
Если указан необязательный аргумент <count>, выполняется количество <count> замен:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love', 2)
'I love python! I love python! I hate python!'
string.rjust(<width>[, <fill>]) выравнивание по правому краю строки в поле.
s.rjust(<width>) возвращает строку s, выравненную по правому краю в поле шириной <width>. По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.rjust(10)
' python'
Если указан аргумент <fill> , он используется как символ заполнения:
>>> 'python'.rjust(10, '-')
'----python'
Если s больше или равна <width>, строка возвращается без изменений:
>>> 'python'.rjust(2)
'python'
string.rstrip([<chars>]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'foo\t\nbar\t\nbaz\t\n'.rstrip()
'foo\t\nbar\t\nbaz'
Необязательный аргумент <chars>, определяет набор символов, которые будут удалены:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
string.strip([<chars>]) удаляет символы с левого и правого края строки.
s.strip() эквивалентно последовательному вызову s.lstrip()и s.rstrip(). Без аргумента <chars> метод удаляет пробелы в начале и в конце:
>>> s = ' foo bar baz\t\t\t'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
Как в .lstrip() и .rstrip(), необязательный аргумент <chars> определяет набор символов, которые будут удалены:
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
>>> ' foo bar baz\t\t\t'.lstrip().rstrip()
'foo bar baz'
>>> ' foo bar baz\t\t\t'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
string.zfill(<width>) дополняет строку нулями слева.
s.zfill(<width>) возвращает копию s дополненную '0' слева для достижения длины строки указанной в <width>:
>>> '42'.zfill(5)
'00042'
Если s содержит знак перед цифрами, он остается слева строки:
>>> '+42'.zfill(8)
'+0000042'
>>> '-42'.zfill(8)
'-0000042'
Если s больше или равна <width>, строка возвращается без изменений:
>>> '-42'.zfill(3)
'-42'
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
>>> 'foo'.zfill(6)
'000foo'
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( []), а кортеж заключен в простые (()).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join(<iterable>) объединяет список в строку.
s.join(<iterable>) возвращает строку, которая является результатом конкатенации объекта <iterable> с разделителем s.
Обратите внимание, что .join() вызывается строка-разделитель s . <iterable> должна быть последовательностью строковых объектов.
Примеры кода помогут вникнуть. В первом примере разделителем s является строка ', ', а <iterable> список строк:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере <iterable> указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, результатом ':'.join('corge') является строка, состоящая из каждого символа в 'corge', разделенного символом ':'.
Этот пример завершается с ошибкой TypeError, потому что один из объектов в <iterable> не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Это можно исправить так:
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
Как вы скоро увидите, многие объекты в Python можно итерировать, и .join() особенно полезен для создания из них строк.
string.partition(<sep>) делит строку на основе разделителя.
s.partition(<sep>) отделяет от s подстроку длиной от начала до первого вхождения <sep>. Возвращаемое значение представляет собой кортеж из трех частей:
- Часть
sдо<sep> - Разделитель
<sep> - Часть
sпосле<sep>
Вот пара примеров .partition()в работе:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если <sep> не найден в s, возвращаемый кортеж содержит s и две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition(<sep>) делит строку на основе разделителя, начиная с конца.
s.rpartition(<sep>) работает как s.partition(<sep>), за исключением того, что s делится при последнем вхождении <sep> вместо первого:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
>>> 'foo bar baz qux'.rsplit()
['foo', 'bar', 'baz', 'qux']
>>> 'foo\n\tbar baz\r\fqux'.rsplit()
['foo', 'bar', 'baz', 'qux']
Если <sep> указан, он используется в качестве разделителя:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
Если <sep> = None, строка разделяется пробелами, как если бы <sep> не был указан вообще.
Когда <sep> явно указан в качестве разделителя s, последовательные повторы разделителя будут возвращены как пустые строки:
>>> 'foo...bar'.rsplit(sep='.')
['foo', '', '', 'bar']
Это не работает, когда <sep> не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'foo\t\t\tbar'.rsplit()
['foo', 'bar']
Если указан необязательный параметр <maxsplit>, выполняется максимальное количество разделений, начиная с правого края s:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=1)
['www.pythonru', 'com']
Значение по умолчанию для <maxsplit> — -1. Это значит, что все возможные разделения должны быть выполнены:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=-1)
['www', 'pythonru', 'com']
>>> 'www.pythonru.com'.rsplit(sep='.')
['www', 'pythonru', 'com']
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
s.split() ведет себя как s.rsplit(), за исключением того, что при указании <maxsplit>, деление начинается с левого края s:
>>> 'www.pythonru.com'.split('.', maxsplit=1)
['www', 'pythonru.com']
>>> 'www.pythonru.com'.rsplit('.', maxsplit=1)
['www.pythonru', 'com']
Если <maxsplit> не указано, между .rsplit() и .split() в python разницы нет.
string.splitlines([<keepends>]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
>>> 'foo\nbar\r\nbaz\fqux\u2028quux'.splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
>>> 'foo\f\f\fbar'.splitlines()
['foo', '', '', 'bar']
Если необязательный аргумент <keepends> указан и его булевое значение True, то символы границы строк сохраняются в списке подстрок:
>>> 'foo\nbar\nbaz\nqux'.splitlines(True)
['foo\n', 'bar\n', 'baz\n', 'qux']
>>\> 'foo\nbar\nbaz\nqux'.splitlines(8)
['foo\n', 'bar\n', 'baz\n', 'qux']
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:
]]>По мере того, как приложения меняются и усложняются, наличие лог-журнала будет полезным при отладке и для понимания проблем, анализа производительности приложений.
Стандартная библиотека логгирования в Python поставляется модулем logging , который предлагает большинство главных функций для ведения лога. При правильной настройке сообщения лога, мы получим много полезной информации. О том, когда и где запускается логгирование, о контексте лог-журнала, например: запущенном процессе или потоке.
Несмотря на преимущества, модуль logging часто упускается из виду, так как для правильной настройки требуется некоторое время. На мой взгляд, полная официальная документация logging на самом деле не показывает лучших методов ведения лог-журнала и не выделяет некоторые сюрпризы ведения лог-журнала.
Обратите внимание, что фрагменты кода в статье предполагают, что вы уже импортировали модуль logging:
import logging
Концепции Python Logging
В этом разделе представлен обзор некоторых концепций, которые часто встречаются в модуле logging.
Уровни Python Logging
Уровень лога соответствует его важности: лог ERROR важнее, чем WARNING. Тогда как лог DEBUG следует использовать только при отладке приложения.
Python предлагает шесть уровней лога; каждый уровень связан с числом, которое указывает на важность лога: NOTSET=0, DEBUG=10, INFO=20, WARNING=30, ERROR=40 и CRITICAL=50.
Иерархия уровней интуитивно понятна: DEBUG < INFO < WARNING. Кроме NOTSET, со спецификой которого, ознакомимся позднее.
Форматирование лога в Python
Форматирование лога дополняет сообщение, добавляя к нему контекстную информацию. Полезно знать, когда отправляется лог, где (файл Python, номер строки, метод и т. д.), а так же дополнительный контекст, такой как поток и процесс. Чрезвычайно полезные данные при отладке многопоточного приложения.
"%(time)s — %(log_name)s — %(level)s — %(func_name)s:%(line_no)d — %(message)s"
Он превращается в:
2019-01-16 10:35:12,468 - keyboards - ERROR - <module>:1 - привет мир
Обработчик ведения лога в Python
Обработчик лога — компонент, который записывает и отображает данные лога. Он отображает лог в консоли (через StreamHandler), в файле (через FileHandler), с помощью отправки электронного письма (через SMTPHandler) и других методов.
В каждом обработчике лога 2 важных поля:
- Форматировщик, который добавляет контекстную информацию в лог.
- Уровень важности лога, который отфильтровывает логи, уровни которых ниже. Поэтому обработчик лога с уровнем INFO не будет обрабатывать логи DEBUG.
Стандартная библиотека содержит несколько обработчиков, которых достаточно для большинства случаев: https://docs.python.org/3/library/logging.handlers.html#module-logging.handlers. Наиболее распространенные — StreamHandler и FileHandler:
console_handler = logging.StreamHandler()
file_handler = logging.FileHandler("MyLogFile.txt")
Python Logger
Логгер будет использоваться чаще всего в коде и будет самым сложным. Новый Logger получим следующим образом:
toto_logger = logging.getLogger("Privacy")
У логгера три основных поля:
- Propagate: определяет, должен ли лог распространяться на родителя журнала. По умолчанию равен
True. - Level: как и уровень обработчика лога, уровень логгера используется для фильтрации “менее важных” логов. Кроме того, в отличие от обработчика лога, уровень проверяется только на “детях” логгера; и после того, как лог распространился среди его родителей, уровень не будет проверятся. Это скорее не интуитивное поведение.
- Handlers: список обработчиков, на которые отправит лог, когда поступит в логгер. Это делает обработку логов гибкой, например, вы создадите обработчик лога для записи в файл, который регистрирует логи DEBUG и обработчик лога для отправки электронной почты, который будет использоваться только для логов CRITICAL. Таким образом, отношение обработчика-логгера становится похожим на издатель-потребитель: где лог будет передаваться всем обработчикам после проверки уровня лога.
Logger определяется по имени, это означает, что если создан лог с именем foo, последующие вызовы logging.getLogger (" foo") будут возвращать один и тот же объект:
assert id(logging.getLogger("foo")) == id(logging.getLogger("foo"))
Как вы могли догадаться, у логгеров есть иерархия. В верхней части иерархии корневой лог, к которому можно получить доступ через logging.root. Этот лог вызывается, когда используются такие методы, как logging.debug(). По умолчанию, уровень корневого лога — WARNING, поэтому каждый лог с уровнем ниже игнорируется (например, через logging.info("info")).
Другая особенность корневого логгера заключается в том, что его обработчик, по умолчанию, создается при первом входе в лог с уровнем, выше WARNING.
Использование корневого логгера с помощью таких методов, как logging.debug(), не рекомендуется
lab = logging.getLogger("f.r")
assert lab.parent == logging.root # lab.parent действительно корневой логгер
Тем не менее логгер использует “точечную запись”, значит логгер с именем f.r будет потомком логгерра f. Однако это справедливо только в том случае, когда создан лог f, иначе родитель fr по прежнему будет корнем.
la = logging.getLogger("f")
assert lab.parent == la # родитель lab теперь la вместо корня
Эффективный уровень логгера
Когда логгер решает, должен ли лог выводится в соответствии с уровнем важности (например, если уровень лога ниже уровня логгера, сообщение будет проигнорировано), он использует свой “эффективный уровень” вместо фактического уровня.
Эффективный уровень совпадает с уровнем логгера, если уровень не равен NOTSET. Однако, если уровень логгера равен NOTSET, эффективным уровнем будет первый уровень родителя, у которого уровень не NOTSET.
По умолчанию, новый логгер имеет уровень NOTSET. Поскольку корневой логгер с уровнем WARNING, эффективный уровень логгера будет WARNING.
Поэтому, даже если новый логгер подключен к некоторым обработчикам, эти обработчики не будут вызываться, если уровень лога не превысит WARNING:
foo_logger = logging.getLogger("foo")
assert foo_logger.level == logging.NOTSET # у нового логгера уровень NOTSET
assert foo_logger.getEffectiveLevel() == logging.WARNING # и его эффективный уровень не является уровнем корневого логгера
# прикрепите консольный обработчик к foo_logger
console_handler = logging.StreamHandler()
foo_logger.addHandler(console_handler)
foo_logger.debug("debug level") # ничего не отображается, так как уровень лога DEBUG меньше чем эффективный уровень foo
foo_logger.setLevel(logging.DEBUG)
foo_logger.debug("debug message") # теперь вы увидите на экране "debug message"
По умолчанию, уровень логгера будет использоваться для решения о выводе лога. Если уровень лога ниже уровня логгера, лог не будет брать во внимание.
Рекомендации по работе с Python Logging
Модуль logging действительно удобен, но со своими особенностями, которые оборачиваются часами головной боли даже для опытных разработчиков Python. Вот рекомендации по использованию этого модуля:
- Настройте корневой логгер, но никогда не используйте его в своем коде, никогда не вызывайте функцию типа
logging.info(), которая оставляет корневой логгер без дела. Если хотите убрать сообщения об ошибках из используемых библиотек, обязательно настройте корневой лог для записи в файл, например, чтобы облегчить отладку. По умолчанию корневой логгер выводит только наstderr, поэтому журнал может легко потеряться. - Чтобы использовать логгирование, создайте новый логгер с помощью
logging.getLogger(имя логгера). Я использую__name__в качестве имени логгера, но вы можете подобрать и другие варианты. Чтобы добавить больше одного обработчика, есть метод, который возвращает логгер.
import logging
import sys
from logging.handlers import TimedRotatingFileHandler
FORMATTER = logging.Formatter("%(time)s — %(name)s — %(level)s — %(message)s")
LOG_FILE = "my_app.log"
def get_console_handler():
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(FORMATTER)
return console_handler
def get_file_handler():
file_handler = TimedRotatingFileHandler(LOG_FILE, when='midnight')
file_handler.setFormatter(FORMATTER)
return file_handler
def get_logger(logger_name):
logger = logging.getLogger(logger_name)
logger.setLevel(logging.DEBUG) # лучше иметь больше логов, чем их нехватку
logger.addHandler(get_console_handler())
logger.addHandler(get_file_handler())
logger.propagate = False
return logger
После этого, вы можете создать новый логгер и пользоваться им:
my_logger = get_logger("Имя модуля например")
my_logger.debug("debug сообщение")
- Используйте классы
RotatingFileHandler, такие, какTimedRotatingFileHandler, из примера вместоFileHandler, так как он автоматически меняет файл для, когда тот достигает максимального размера или делает это каждый день. - Используйте такие инструменты, как Sentry, Airbrake, Raygun и т.д., чтобы автоматически ловить сообщения об ошибке. Это полезно при работе с приложениями. Там лог бывает очень многословным, а логи ошибок могут легко потеряться. Другое преимуществом использования этих инструментов это возможность получить подробную информацию о значениях переменных которые связанны с ошибкой: какой URL-адрес вызывает ошибку, какой пользователь и т. д.
Регулярные выражения — специальная последовательность символов, которая помогает сопоставлять или находить строки python с использованием специализированного синтаксиса, содержащегося в шаблоне. Регулярные выражения распространены в мире UNIX.
Модуль re предоставляет полную поддержку выражениям, подобным Perl в Python. Модуль re поднимает исключение re.error, если возникает ошибка при компиляции или использовании регулярного выражения.
Давайте рассмотрим две функции, которые будут использоваться для обработки регулярных выражений. Важно так же заметить, что существуют символы, которые меняют свое значение, когда используются в регулярном выражении.Чтобы избежать путаницы при работе с регулярными выражениями, записывайте строку как r'expression'.
Функция match
Эта функция ищет pattern в string и поддерживает настройки с помощью дополнительного flags.
Ниже можно увидеть синтаксис данной функции:
re.match(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения (r'g.{3}le') |
| 2 | string — строка, в которой мы будем искать соответствие с шаблоном в начале строки ('google') |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.match возвращает объект match при успешном завершении, или None при ошибке. Мы используем функцию group(num) или groups() объекта match для получения результатов поиска.
| № | Метод совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — этот метод возвращает полное совпадение (или совпадение конкретной подгруппы) |
| 2 | groups() — этот метод возвращает все найденные подгруппы в tuple |
Пример функции re.match
import re
title = "Error 404. Page not found"
exemple = re.match( r'(.*)\. (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group() : ", exemple.group())
print("exemple.group(1) : ", exemple.group(1))
print("exemple.group(2) : ", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Когда вышеуказанный код выполняется, он производит следующий результат:
exemple.group(): Error 404. Page not found
exemple.group(1): Error 404
exemple.group(2): Page
exemple.groups(): ('Error 404', 'Page')
Функция search
Эта функция выполняет поиск первого вхождения pattern внутри string с дополнительным flags.
Пример синтаксиса для этой функции:
re.search(pattern, string, flags=0)
Описание параметров:
| № | Параметр & Описание |
|---|---|
| 1 | pattern — строка регулярного выражения |
| 2 | string — строка, в которой мы будем искать первое соответствие с шаблоном |
| 3 | flags — модификаторы, перечисленными в таблице ниже. Вы можете указать разные флаги с помощью побитового OR |
Функция re.search возвращает объект match если совпадение найдено, и None, когда нет совпадений. Используйте функцию group(num) или groups() объекта match для получения результата функции.
| № | Способы совпадения объектов и описание |
|---|---|
| 1 | group(num=0) — метод, который возвращает полное совпадение (или же совпадение конкретной подгруппы) |
| 2 | groups() — метод возвращает все сопоставимые подгруппы в tuple |
Пример функции re.search
import re
title = "Error 404. Page not found"
# добавим пробел в начало паттерна
exemple = re.search( r' (.*)\. (.*?) .*', title, re.M|re.I)
if exemple:
print("exemple.group():", exemple.group())
print("exemple.group(1):", exemple.group(1))
print("exemple.group(2):", exemple.group(2))
print("exemple.groups():", exemple.groups())
else:
print("Нет совпадений!")
Запускаем скрипт и получаем следующий результат:
exemple.group(): 404. Page not found
exemple.group(1): 404
exemple.group(2): Page
exemple.groups(): ('404', 'Page')
Match и Search
Python предлагает две разные примитивные операции, основанные на регулярных выражениях: match выполняет поиск паттерна в начале строки, тогда как search выполняет поиск по всей строке.
Пример разницы re.match и re.search
import re
title = "Error 404. Page not found"
match_exemple = re.match( r'not', title, re.M|re.I)
if match_exemple:
print("match --> match_exemple.group():", match_exemple.group())
else:
print("Нет совпадений!")
search_exemple = re.search( r'not', title, re.M|re.I)
if search_exemple:
print("search --> search_exemple.group():", search_exemple.group())
else:
print("Нет совпадений!")
Когда этот код выполняется, он производит следующий результат:
Нет совпадений!
search --> search_exemple.group(): not
Метод Sub
Одним из наиболее важных методов модуля re, которые используют регулярные выражения, является re.sub.
Пример синтаксиса sub:
re.sub(pattern, repl, string, max=0)
Этот метод заменяет все вхождения pattern в string на repl, если не указано на max. Он возвращает измененную строку.
Пример
import re
born = "05-03-1987 # Дата рождения"
# Удалим комментарий из строки
dob = re.sub(r'#.*$', "", born)
print("Дата рождения:", dob)
# Заменим дефисы на точки
f_dob = re.sub(r'-', ".", born)
print(f_dob)
Запускаем скрипт и получаем вывод:
Дата рождения: 05-03-1987
05.03.1987 # Дата рождения
Модификаторы регулярных выражений: flags
Функции регулярных выражений включают необязательный модификатор для управления изменения условий поиска. Модификаторы задают в необязательном параметре flags. Несколько модификаторов задают с помощью побитового ИЛИ (|), как показано в примерах выше.
| № | Модификатор & Описание |
|---|---|
| 1 | re.I — делает поиск нечувствительным к регистру |
| 2 | re.L — ищет слова в соответствии с текущим языком. Эта интерпретация затрагивает алфавитную группу (\w и \W), а также поведение границы слова (\b и \B). |
| 3 | re.M — символ $ выполняет поиск в конце любой строки текста (не только конце текста) и символ ^ выполняет поиск в начале любой строки текста (не только в начале текста). |
| 4 | re.S — изменяет значение точки (.) на совпадение с любым символом, включая новую строку |
| 5 | re.U— интерпретирует буквы в соответствии с набором символов Unicode. Этот флаг влияет на поведение \w, \W, \b, \B. В python 3+ этот флаг установлен по умолчанию. |
| 6 | re.X— позволяет многострочный синтаксис регулярного выражения. Он игнорирует пробелы внутри паттерна (за исключением пробелов внутри набора [] или при экранировании обратным слешем) и обрабатывает не экранированный “#” как комментарий. |
Шаблоны регулярных выражений
За исключением символов (+?. * ^ $ () [] {} | ), все остальные соответствуют самим себе. Вы можете избежать экранировать специальный символ с помощью бэкслеша (/).
В таблицах ниже описаны все символы и комбинации символов для регулярных выражений, которые доступны в Python:
| № | Шаблон & Описание |
|---|---|
| 1 | ^ — соответствует началу строки. |
| 2 | $— соответствует концу строки. |
| 3 | . — соответствует любому символу, кроме новой строки. Использование флага re.M позволяет также соответствовать новой строке. |
| 4 | [4fw] — соответствует любому из символов в скобках. |
| 5 | [^4fw] — соответствует любому символу, кроме тех, что в квадратных скобках. |
| 6 | foo* — соответствует 0 или более вхождений “foo”. |
| 7 | bar+ —- соответствует 1 или более вхождениям “bar”. |
| 8 | foo? —- соответствует 0 или 1 вхождению “foo”. |
| 9 | bar{3} —- соответствует трем подряд вхождениям “bar”. |
| 10 | foo{3,} — соответствует 3 или более вхождениям “foo”. |
| 11 | bar{2,5} —- соответствует от 2 до 5 вхождениям “bar”. |
| 12 | a|b — соответствует либо a, либо b. |
| 13 | (foo) — группирует регулярные выражения. |
| 14 | (?imx) — временно включает параметры i, m или x в регулярное выражение. Если используются круглые скобки — затрагивается только эта область. |
| 15 | (?-imx) — временно отключает опции i, m или x в регулярном выражении. Если используются круглые скобки — затрагивается только эта область. |
| 16 | (?: foo) — Группирует регулярные выражения без сохранения совпадающего текста. |
| 17 | (?imx: re) — Временно включает параметры i, m или x в круглых скобках. |
| 18 | (?-imx: re) — временно отключает опции i, m или x в круглых скобках. |
| 19 | (?#…) — комментарий. |
| 20 | (?= foo) — совпадает со всеми словами после которых » foo». |
| 21 | (?! foo) — совпадает со всеми словами после которых нет » foo». |
| 22 | (?> foo) — совпадает со всеми словами перед которыми » foo». |
| 23 | \w — совпадает с буквенным символом. |
| 24 | \W — совпадает с не буквенным символом. |
| 25 | \s — совпадает с пробельными символами (\t, \n, \r, \f и пробелом). |
| 26 | \S — все кроме пробельных символов. |
| 27 | \d — соответствует цифрам (0-9). |
| 28 | \D — все кроме цифры. |
| 29 | \A — соответствует началу строки. |
| 30 | \Z – соответствует концу строки. Включая перевод на новую строку, если такая есть. |
| 31 | \z — соответствует концу строки. |
| 32 | \G — соответствует месту, где закончилось последнее соответствие. |
| 33 | \b — соответствует границам слов, когда поставлены внешние скобки. |
| 34 | \B — все кроме границы слова. |
| 35 | **\n,\t,\r,\f ** — соответствует новым строкам, подстрокам. |
| 36 | \1…\9 — соответствует подгруппе n-й группы. |
| 37 | \10 — соответсвуйет номеру группы. В противном случае относится к восьмеричному представлению символьного кода. |
Примеры регулярных выражений
Поиск по буквам
python – находит “python”. |
Поиск по наборам символов
| № | Паттерн & Результаты |
|---|---|
| 1 | [Pp]ython соответствует “Python” и “python” |
| 2 | rub[ye] соответствует “ruby” и “rube” |
| 3 | [aeiou] Соответствует любой гласной нижнего регистра английского алфавита ([ауоыиэяюёе] для русского) |
| 4 | [0-9] соответствует любой цифре; так же как и [0123456789] |
| 5 | [a-z] соответствует любой строчной букве ASCII (для кириллицы [а-яё]) |
| 6 | [A-Z] соответствует любой прописной букве ASCII (для кириллицы [А-ЯЁ]) |
| 7 | [a-zA-Z0-9] соответствует всем цифрам и буквам |
| 8 | [^aeiou] соответствует всем символам, кроме строчной гласной |
| 9 | [^0-9] Соответствует всем символам, кроме цифр |
Специальные классы символов
| № | Пример & Описание |
|---|---|
| 1 | . соответствует любому символу, кроме символа новой строки |
| 2 | \d соответствует цифрам: [0-9] |
| 3 | \D не соответствует цифрам: [^0-9] |
| 4 | \s соответствует пробельным символам: [\t\r\n\f] |
| 5 | \S не соответствует пробельным символам: [^ \t\r\n\f] |
| 6 | \w соответствует одному из буквенных символов: [A-Za-z0-9_] |
| 7 | \W не соответствует ни одному из буквенных символов: [^A-Za-z0-9_] |
Случаи повторения
| № | Примеры |
|---|---|
| 1 | ruby? совпадает с “rub” и “ruby”: “y” необязателен |
| 2 | ruby* совпадает с “rub” и “rubyyyyy”: “y” необязателен и может повторятся несколько раз |
| 3 | ruby+ совпадает с “ruby”: “y” обязателен |
| 4 | \d{3} совпадает с тремя цифрами подряд |
| 5 | \d{3,} совпадает с тремя и более цифрами подряд |
| 6 | \d{3,5} совпадает с 3,4,5 цифрами подряд |
Жадный поиск
| № | Пример & Описание |
|---|---|
| 1 | <.*> Жадное повторение: соответствует “perl>” |
| 2 | <.*?> Ленивый поиск: соответствует “” в “perl>” |
Группирование со скобками
| № | Пример & Описание |
|---|---|
| 1 | \D\d+ Нет группы: + относится только к \d |
| 2 | (\D\d)+ Группа: + относится к паре \D\d |
| 3 | ([Pp]ython(, )?)+ соответствует “Python”, “Python, python, python”. |
Ссылки на группы
| № | Пример & Описание |
|---|---|
| 1 | ([Pp])ython&\1ails совпадает с python&pails и Python&Pails |
| 2 | ([’»])[^\1]*\1 Строка с одним или двумя кавычками. \1 соответствует 1-й группе. \2 соответствует второй группе и т. д. |
Или
| № | Пример & Описание |
|---|---|
| 1 | python|perl соответствует “python” или “perl” |
| 2 | rub(y|le)) соответствует “ruby” или “ruble” |
| 3 | Python(!+|?) после «Python» следует 1 и более “!” или один “?” |
Границы слов и строк
| № | Пример & Описание |
|---|---|
| 1 | ^Python соответствует “Python” в начале текста или новой строки текста. |
| 2 | Python$ соответствует “Python” в конце текста или строки текста. |
| 3 | \APython соответствует “Python” в начале текста |
| 4 | Python\Z соответствует “Python” в конце текста |
| 5 | \bPython\b соответствует “Python” как отдельному слову |
| 6 | \brub\B соответствует «rub» в начале слова: «rube» и «ruby». |
| 7 | Python(?=!) соответствует “Python”, если за ним следует восклицательный знак. |
| 8 | Python(?!!) соответствует “Python”, если за ним не следует восклицательный знак |
Специальный синтаксис в группах
| № | Пример & Описание |
|---|---|
| 1 | R(?#comment) соответствует «R». Все, что следует дальше — комментарий |
| 2 | R(?i)uby нечувствительный к регистру при поиске “uby” |
| 3 | R(?i:uby) аналогично указанному выше |
| 4 | rub(?:y le)) группируется только без создания обратной ссылки (\1) |
Циклы python — for и while представляют собой операторы языка программирования, то есть операторы итерации, которые позволяют повторять код определенное количество раз.
Синтаксис цикла For
Как уже упоминалось ранее, цикл for в Python является итератором, основанным на цикле. Он проходит по элементам list и tuple, строкам, ключам словаря и другим итерируемым объектам.
В Python цикл начинается с ключевого слова for, за которым следует произвольное имя переменной, которое будет хранить значения следующего объекта последовательности. Общий синтаксис for...in в python выглядит следующим образом:
for <переменная> in <последовательность>:
<действие>
else:
<действие>Элементы «последовательности» перебираются один за другим «переменной» цикла; если быть точным, переменная указывает на элементы. Для каждого элемента выполняется «действие».
Пример простого цикла for в Python:
>>> languages = ["C", "C++", "Perl", "Python"]
>>> for x in languages:
... print(x)
...
C
C++
Perl
Python
>>>
Блок else является особенным; в то время как программист, работающий на Perl знаком с ним, это неизвестная конструкция для программистов, которые работают на C и C++. Семантически он работает точно так же, как и в цикле while.
Он будет выполнен только в том случае, если цикл не был «остановлен» оператором break. Таким образом, он будет выполнен только после того, как все элементы последовательности будут пройдены.
Оператор прерывания в python — break
Если в программе цикл for должен быть прерван оператором break, цикл будет завершен, и поток программы будет продолжен без выполнения действий из else.
Обычно фразы break в pyton связаны с условными операторами.
edibles = ["отбивные", "пельмени", "яйца", "орехи"]
for food in edibles:
if food == "пельмени":
print("Я не ем пельмени!")
break
print("Отлично, вкусные " + food)
else:
print("Хорошо, что не было пельменей!")
print("Ужин окончен.")
Если мы запустим этот код, получим следующий результат:
Отлично, вкусные отбивные
Я не ем пельмени!
Ужин окончен.Удалим «пельмени» из нашего списка еды и получим следующее:
Отлично, вкусные отбивные
Отлично, вкусные яйца
Отлично, вкусные орехи
Хорошо, что не было пельменей!
Ужин окончен.
Оператор пропуска python — continue
Предположим, нам «пельмени» нам нужно просто пропустить и продолжить прием пищи. Тогда нужно использовать оператор continue, для перехода к следующему элементу.
В следующем маленьком скрипте python мы используем continue, чтобы продолжить, итерацию по списку, когда мы сталкиваемся с пельменями.
edibles = ["отбивные", "пельмени", "яйца", "орехи"]
for food in edibles:
if food == "пельмени":
print("Я не ем пельмени!")
continue
print("Отлично, вкусные " + food)
else:
print("Ненавижу пельмени!")
print("Ужин окончен.")
Результат будет следующим:
Отлично, вкусные отбивные
Я не ем пельмени!
Отлично, вкусные яйца
Отлично, вкусные орехи
Ненавижу пельмени!
Ужин окончен.Итерация по спискам с функцией range()
Если вам нужно получить доступ к индексам списка, не очевидно как использовать цикл for для этой задачи. Мы можем получить доступ ко всем элементам, но индекс элемента остается недоступным. Есть способ получить доступ как к индексу элемента, так и к самому элементу. Для этого используйте функцию range() в сочетании с функцией длины len():
fibonacci = [0,1,1,2,3,5,8,13,21]
for i in range(len(fibonacci)):
print(i,fibonacci[i])
Вы получите следующий вывод:
0 0
1 1
2 1
3 2
4 3
5 5
6 8
7 13
8 21Примечание. Если вы примените
len()кlistилиtuple, получите соответствующее количество элементов этой последовательности.
Подводные камни итераций по спискам
Если вы перебираете список, лучше избегать изменения списка в теле цикла. Чтобы наглядно увидеть, что может случиться, посмотрите на следующий пример:
colours = ["красный"]
for i in colours:
if i == "красный":
colours += ["черный"]
if i == "черный":
colours += ["белый"]
print(colours)
Что выведет print(colours)?
['красный', 'черный', 'белый']Чтобы избежать этого, лучше всего работать с копией с помощью срезов, как сделано в следующем примере:
colours = ["красный"]
for i in colours[:]:
if i == "красный":
colours += ["черный"]
if i == "черный":
colours += ["белый"]
print(colours)
В результате вы получите следующее:
['красный', 'черный']Мы изменили список colours, но данное изменение не повлияло на цикл. Элементы, которые должны быть итерированы, остаются неизменными во выполнения цикла.
Enumerate в python 3
Enumerate — встроенная функция Python. Большинство новичков и даже некоторые продвинутые программисты не знают о ней. Она позволяет нам автоматически считать итерации цикла. Вот пример:
for counter, value in enumerate(some_list):
print(counter, value)
Функция enumerate также принимает необязательный аргумент (значение начала отсчета, по умолчанию 0), который делает ее еще более полезной.
my_list = ['яблоко', 'банан', 'вишня', 'персик']
for c, value in enumerate(my_list, 1):
print(c, value)
# Результат:
# 1 яблоко
# 2 банан
# 3 вишня
# 4 персик
Этот модуль реализует генераторы псевдослучайных чисел под различные потребности.
- Для целых чисел есть выбор одного из диапазона.
- Для последовательностей — выбор случайного элемента, функция случайной сортировки списка и функция случайного выбора нескольких элементов из последовательности.
- Есть функции для вычисления однородных, нормальных (Гауссовских), логнормальных, отрицательных экспоненциальных, гамма и бета распределений.
- Для генерации распределений углов доступно распределение фон Мизеса.
Почти все функции модуля зависят от основной функции random(), которая генерирует случайным образом чисто с плавающей точкой(далее float) равномерно в полуоткрытом диапазоне [0.0, 1.0).
Python использует Mersenne Twister в качестве основного генератора. Он производит 53-битные точные float и имеет период 2**19937-1. Основная его реализация в C быстрая и многопоточная. Mersenne Twister один из наиболее широко протестированных генераторов случайных чисел. Однако, будучи полностью детерминированным, он подходит не для любых целей, особенно для криптографических.
Модуль random так же предоставляет класс SystemRandom. Этот класс использует системную функцию os.urandom() для генерации случайных чисел из источников, которые предоставляет операционная система.
Псевдослучайные генераторы этого модуля не должны использоваться в целях безопасности. Для обеспечения безопасности или для криптографического использования ознакомьтесь с модулем secrets.
Функции для целых чисел
random.randrange(stop)
random.randrange(start, stop[, step])
Возвращает случайно выбранный элемент из range(start, stop, step). Это эквивалентно choice(range(start, stop, step)), но не создает объект диапазона.
>>> random.randrange(0, 101, 2)
26
Шаблон позиционного аргумента совпадает с шаблоном range(). Аргументы не должны использоваться как ключевого слова(start, stop, step), потому что функция может использовать их неожиданными способами.
random.randint(a, b)
Возвращает случайное целое число N так, чтобы a <= N <= b.
>>> random.randint(0, 101)
44
Функции для последовательностей
random.choice(seq)
Возвращает случайный элемент из непустой последовательности seq. Если seq пуст, возникает ошибка IndexError.
>>> choice(['win', 'lose', 'draw'])
'draw'
random.choices(population, weights=None, *, cum_weights=None, k=1)
Возвращает список элементов размером k, выбранных из population с заменой. Если population пуст, возникает ошибка IndexError.
>>> random.choices(["яблоки", "бананы", "вишня"], weights = [10, 1, 1], k = 5)
['яблоки', 'вишня', 'яблоки', 'яблоки', 'яблоки']
Если задана последовательность weights, выбор производится в соответствии с относительным весом. В качестве альтернативы, если задана последовательность cum_weights, выбор производится в соответствии с совокупными весами (возможно, вычисляется с использованием itertools.accumulate()).
Например, относительный вес [10, 5, 30, 5] эквивалентны кумулятивному весу [10, 15, 45, 50]. Внутренне относительные веса преобразуются в кумулятивные перед выбором, поэтому поставка кумулятивного веса экономит время.
Если ни weights, ни cum_weights не указаны, выбор производится с равной вероятностью. Если задана последовательность веса, она должна быть такой же, как и последовательность population. TypeError возникает, если не правильно указан аргумент weights или cum_weights.
Weights или cum_weights могут использовать любой тип чисел, который взаимодействует со значением float, возвращаемым функцией random() (который включает целые числа, числа с плавающей точкой и фракции, но исключает десятичные числа).
random.shuffle(x[, random])
Перемешивает последовательность x на месте.
Необязательный аргумент random — функция 0-аргумента, возвращающая случайное значение float в [0.0, 1.0]; по умолчанию это функция random().
>>> fruits = ["яблоки", "бананы", "вишня"]
>>> random.shuffle(fruits)
>>> fruits
['бананы', 'вишня', 'яблоки']
Чтобы перемешать неизменяемую последовательность и вернуть новый перемешанный список, используйте sample(x, k=len(x)).
Обратите внимание, что даже для небольшого len(x) общее количество перестановок x может увеличиваться сильнее, чем период большинства генераторов случайных чисел.
Это означает, что большинство перестановок длинной последовательности никогда не могут быть выполнены. Например, последовательность длиной 2080 элементов является самой большой, которая может вписываться в период генератора случайных чисел «Мерсин Твистер».
random.sample(population, k)
Возвращает список длиной k из уникальных элементов, выбранных из последовательности или множества. Используется для случайной выборки без замены.
>>> random.sample([0, 1, 2, 3, 4, 5, 6], 3)
[5, 6, 4]
Это новый список, содержащий элементы из последовательности, оставляя исходную последовательности неизменной. Новый список находится в порядке выбора, так что все суб-срезы будут также случайными последовательностями.
Это позволяет победителям розыгрышей (при выборке) делиться на главный приз, второе место и далее.
Участники не должны быть hashable или уникальными. Если последовательность содержит повторы, то каждое вхождение является возможным выбором в выборке.
Что бы выбрать одно число из ряда чисел, используйте объект range() в качестве аргумента. Это простое решение для выборки из большой последовательности: sample(range(10000000), k=60).
Если размер выборки больше длины последовательности, возникает ошибка ValueError.
Функции управления генератором
random.seed(a=None, version=2)
Инициализирует (запускает) генератор случайных чисел.
Если a не задан или None, используется текущее системное время. Если источники случайности предоставляются операционной системой, они используются вместо системного времени (см. функцию os.urandom() для получения подробной информации).
Используется значение a, если оно int (целое число).
>>> random.seed(10)
>>> random.random()
0.5714025946899135
При version=2 (по умолчанию), объекты str, bytes, или bytearray преобразуются в int и все его биты используются.
При version=1 (для воспроизведения случайных последовательностей из более старых версий Python), алгоритм для str и bytes
вырабатывает более узкий диапазон посева.
random.getstate()
Возвращает объект, фиксирующий текущее внутреннее состояние генератора. Этот объект может быть передан в setstate() для возобновления состояния.
>>> random.getstate()
(3, (2910518045, 2919558713, 592432859, 1634426085,
....
2194693540, 2), None)
random.setstate(state)state должен быть получен из предыдущего вызоваgetstate(). И setstate() восстановит внутреннее состояние генератора до такого, которое было получено из вызова getstate().
random.getrandbits(k)
Возвращает Python int со случайными битами k. Этот метод поставляется вместе с генератором MersenneTwister, в то время как другие генераторы могут также предоставлять его как необязательную часть API.
>>> random.getrandbits(8)
109
При возможности, getrandbits() включает randrange() для обработки диапазонов величины.
Другие функции генерации распределений
Функциональные параметры появляются после соответствующих переменных в уравнении распределения, которые используются в общей математической практике; большинство этих уравнений можно найти в любом статистическом тексте.
random.random()
Возвращает случайное число с плавающей точкой в диапазоне [0.0, 1.0).
>>> random.random()
0.48256167455085586
random.uniform(a, b)
Возвращает случайное число с плавающей точкой N таким образом, чтобы a <= N <= b для a <= b и b <= N <= a для b < a.
>>> random.uniform(2.5, 10.0)
2.611243345184153
Конечное значение b будет или не будет включено в диапазон в зависимости от округления float в уравнении a + (b-a) * random().
random.triangular(low, high, mode)
Возвращает случайное число с плавающей точкой N, так, что low <= N <= high и с указанным mode между этими границами. Границы low и high по умолчанию равны 0 и 1.
>>> random.triangular(20, 60, 30)
34.605051874664895
Аргумент mode по умолчанию совпадает с серединой между границами, предоставляя симметричное распределение.
random.betavariate(alpha, beta)
Бета-распределение. Условиями для аргументов являются alpha > 0 и beta > 0. Возвращаемые значения варьируются от 0 до 1.
>>> random.betavariate(5, 10)
0.33277653214797026
random.expovariate(lambd)
Экспоненциальное распределение. lambd равно 1.0, деленное на желаемое среднее значение. Оно должно быть отличным от нуля (Параметр будет называться «лямбда», но это зарезервированное слово в Python). Возвращаемые значения варьируются от 0 до положительной бесконечности, если lambd положительный, и от отрицательной бесконечности до 0, если lambd отрицателен.
>>> random.expovariate(1.5)
2.0299375769298558
random.gammavariate(alpha, beta)
Гамма-распределение (Не гамма-функция!). Условиями для параметров являются alpha > 0 и beta > 0.
>>> random.gammavariate(5, 10)
71.54713670428183
Функция распределения вероятности:
x ** (alpha - 1) * math.exp(-x / beta)
pdf(x) = --------------------------------------
math.gamma(alpha) * beta ** alpha
random.gauss(mu, sigma)
Гауссовское распределение. mu — среднее значение, а sigma — стандартное отклонение. Она немного быстрее, чем функция normalvariate(), обозначенная ниже.
>>> random.gauss(100, 50)
76.0247266799225
random.lognormvariate(mu, sigma)
Нормальное распределение логарифма. Если вы берете натуральный логарифм этого распределения, вы получите нормальное распределение со средним mu и стандартным отклонением sigma. mu может иметь любое значение, а sigma должно быть больше нуля.
>>> random.lognormvariate(0, 0.5)
0.8067122423139358
random.normalvariate(mu, sigma)
Нормальное распределение. mu — среднее значение, а sigma — стандартное отклонение.
>>> random.normalvariate(100, 50)
138.00550761929435
random.vonmisesvariate(mu, kappa)mu — средний угол, выраженный в радианах от 0 до 2pi, а kappa — параметр концентрации, который должен быть больше или равен нулю.
>>> random.vonmisesvariate(1, 4)
0.8597679422468718
Если kappa равен нулю, это распределение сводится к равномерному случайному углу в диапазоне от 0 до 2pi.
random.paretovariate(alpha)
Распределение Парето. alpha — параметр формы.
>>> random.paretovariate(3)
1.2256909386811103
random.weibullvariate(alpha, beta)
Распределение Вейбулла. alpha — параметр масштаба, а beta — параметр формы.
>>> random.weibullvariate(1, 1.5)
1.56960602898881
Альтернативный генератор
random.Random([seed])
Класс, реализующий генератор псевдослучайных чисел по умолчанию, используемый модулем случайных чисел.
Доступен с версии python 3.9: В будущем seed должен быть одного из типов: None, int, float, str, bytes или bytearray.
random.SystemRandom([seed])
Класс, который использует функцию os.urandom() для генерации случайных чисел из источников, предоставляемых операционной системой. Не на всех OS доступен. Не полагается на состояние программного обеспечения, последовательности не воспроизводятся.
Следовательно метод seed() не имеет эффекта и игнорируется. При вызове методов getstate() и setstate() получите ошибку NotImplementedError.
Примеры и инструкции
Базовые примеры:
>>> fro random inport *
>>> random() # Случайное float: 0.0 <= x < 1.0
0.37444887175646646
>>> uniform(2.5, 10.0) # Случайное float: 2.5 <= x < 10.0
3.1800146073117523
>>> expovariate(1 / 5) # Интервал между прибытием в среднем 5 секунд
5.148957571865031
>>> randrange(10) # Целое число от 0 до 9 включительно
7
>>> randrange(0, 101, 2) # Четное целое число от 0 до 100 включительно
26
>>> choice(["победа", "поражение", "ничья"]) # Случайный элемент из последовательности
'ничья'
>>> deck = 'раз два три четыре'.split()
>>> shuffle(deck) # Перемешать список
>>> deck
["четыре", "два", "раз", "три"]
>>> sample([10, 20, 30, 40, 50], k=4) # Четыре элемента без замены
[40, 10, 50, 30]
Симуляторы:
>>> # Шесть результатов рулетки (взвешенная выборка с заменой)
>>> choices(['red', 'black', 'green'], [18, 18, 2], k=6)
['red', 'green', 'black', 'black', 'red', 'black']
>>> # Задействуйте 20 карт без замены колоды из 52 игральных карт
>>> # и определите долю карт с десятизначным значением
>>> # (десятка, валет, королева или король).
>>> deck = collections.Counter(tens=16, low_cards=36)
>>> seen = sample(list(deck.elements()), k=20)
>>> seen.count('tens') / 20
0.15
>>> # Оцените вероятность получения 5 или более побед из 7 спинов
>>> # смещенной монеты, которая располагается наверху в 60% случаев.
>>> trial = lambda: choices('HT', cum_weights=(0.60, 1.00), k=7).count('H') >= 5
>>> sum(trial() for i in range(10000)) / 10000
0.4169
>>> # Вероятность медианы 5 образцов, находящихся в средних двух квартилях
>>> trial = lambda : 2500 <= sorted(choices(range(10000), k=5))[2] < 7500
>>> sum(trial() for i in range(10000)) / 10000
0.7958
Тест на знание модуля Python Random
json предоставляет API, знакомый пользователям стандартных библиотечных модулей marshal и pickle.
Преобразование базовых объектов в Python в json:
>>> import json
>>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print(json.dumps("\"foo\bar"))
"\"foo\bar"
>>> print(json.dumps('\u1234'))
"\u1234"
>>> print(json.dumps('\\'))
"\\"
>>> print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True))
{"a": 0, "b": 0, "c": 0}
>>> from io import StringIO
>>> io = StringIO()
>>> json.dump(['streaming API'], io)
>>> io.getvalue()
'["streaming API"]'
Компактное преобразование:
>>> import json
>>> json.dumps([1, 2, 3, {'4': 5, '6': 7}], separators=(',', ':'))
'[1,2,3,{"4":5,"6":7}]'
Красивый вывод:
>>> import json
>>> print(json.dumps({'4': 5, '6': 7}, sort_keys=True, indent=4))
{
"4": 5,
"6": 7
}
Декодирование JSON, преобразование json в объект Python:
>>> import json
>>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]')
['foo', {'bar': ['baz', None, 1.0, 2]}]
>>> json.loads('"\\"foo\\bar"')
'"foo\x08ar'
>>> from io import StringIO
>>> io = StringIO('["streaming API"]')
>>> json.load(io)
['streaming API']
Специализированное декодирование объектов в JSON:
>>> import json
>>> def as_complex(dct):
... if '__complex__' in dct:
... return complex(dct['real'], dct['imag'])
... return dct
...
>>> json.loads('{"__complex__": true, "real": 1, "imag": 2}',
... object_hook=as_complex)
(1+2j)
>>> import decimal
>>> json.loads('1.1', parse_float=decimal.Decimal)
Decimal('1.1')
Расширение JSONEncoder:
>>> import json
>>> class ComplexEncoder(json.JSONEncoder):
... def default(self, obj):
... if isinstance(obj, complex):
... return [obj.real, obj.imag]
... # Let the base class default method raise the TypeError
... return json.JSONEncoder.default(self, obj)
...
>>> json.dumps(2 + 1j, cls=ComplexEncoder)
'[2.0, 1.0]'
>>> ComplexEncoder().encode(2 + 1j)
'[2.0, 1.0]'
>>> list(ComplexEncoder().iterencode(2 + 1j))
['[2.0', ', 1.0', ']']
Рекомендуется использование json.tool для проверки и красивого вывода:
$ echo '{"json":"obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)JSON является подмножеством YAML 1.2 JSON создан с помощью стандартных настроек этого модуля и также является подмножеством YAML 1.0 and 1.1. Этот модуль может использоваться в качестве сериализатора YAML.
До Python 3.7 порядок ключей словаря не сохранялся, поэтому входные и выходные данные, как правило, отличались. Начиная с Python 3.7, порядок ключей стал сохраняться, поэтому больше нет необходимости использовать
collections.OrderedDictдля парсинга JSON.
Основные методы
Метод json dump
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)Сериализует obj в JSON-подобный формат записывая его в fp (который поддерживает .write()) используя эту таблицу.
Если skipkeys=True (по умолчанию: False), тогда ключи словаря не базового типа (str, int, float, bool, None) будут пропущены, вместо того, чтобы вызывать исключение TypeError.
Модуль json всегда создает объекты str, не bytes. Следовательно, fp.write() должен поддерживать ввод str.
Когда ensure_ascii=True (по умолчанию), все не-ASCII символы в выводе будут экранированы последовательностями \uXXXX,. Если ensure_ascii=False, эти символы будут записаны как есть.
Когда check_circular=False (по умолчанию: True), тогда проверка циклических ссылок для типов контейнера будет пропущена, а такие ссылки будут вызывать OverflowError (или ошибку серьёзнее).
Если allow_nan=False (по умолчанию: True), при каждой попытке сериализировать значение float, выходящее за допустимые пределы (nan, inf, -inf), будет возникать ValueError, в соответствии с сертификацией JSON. В случае если allow_nan=True, будут использованы JavaScript аналоги (NaN, Infinity, -Infinity).
Когда indent является неотрицательным целым числом или строкой, то объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или "", будут использоваться новые строки без отступов. None (по умолчанию) отражает наиболее компактное представление. Если indent строка (например, "\t"), эта строка используется в качестве отступа.
Изменения в версии 3.2: Допускаются строки для отступа в дополнение к целым числам.
Separators должны быть tuple (item_separator, key_separator). По умолчанию используется значение (', ', ': ') если indent=None и (',', ': ') при другом значении. Чтобы получить наиболее компактное представление JSON, вы должны указать (',', ':').
Изменения в версии 3.4: Используйте
(',', ': ')при отступеNone.
Значение default должно быть функцией. Он вызывается для объектов, которые не могут быть сериализованы. Функция должна вернуть кодируемую версию объекта JSON или вызывать TypeError. Если default не указано, возникает ошибка TypeError.
Если sort_keys=True (по умолчанию: False), ключи выводимого словаря будут отсортированы.
Чтобы использовать собственный подкласс JSONEncoder (например, тот который переопределяет метод default() для сериализации дополнительных типов), укажите его с помощью аргумента cls; в противном случае используется JSONEncoder.
Метод json dumps
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)Сериализирует obj в строку str формата JSON с помощью таблицы конвертации. Аргументы имеют то же значение, что и для dump().
Ключи в парах ключ/значение всегда являются строками. Когда словарь конвертируется в JSON, все ключи словаря преобразовываются в строки. Если в результате, сначала конвертировать его в JSON, а потом обратно, новый в словарь может отличаться от, то можно получить словарь идентичный исходному. Другими словами, loads(dumps(x)) != x если x имеет не строковые ключи.
Метод json load
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)Десериализует из fp (текстовый или бинарный файл, который поддерживает метод .read() и содержит JSON документ) в объект Python используя эту таблицу конвертации.
object_hook — опциональная функция, которая применяется к результату декодирования объекта. Использоваться будет значение, возвращаемое этой функцией, а не полученный словарь dict. Эта функция используется для реализации пользовательских декодеров (например JSON-RPC).
object_pair_shook — опциональная функция, которая применяется к результату декодирования объекта с определенной последовательностью пар ключ/значение. Вместо исходного словаря dict будет использоваться результат, возвращаемый функцией. Эта функция используется для реализации пользовательских декодеров. Если задан object_hook, object_pairs_hook будет в приоритете.
В случае определения parse_float, он будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str). Можно использовать другой тип данных или парсер для этого значения (например decimal.Decimal)
В случае определения parse_int, он будет вызван для декодирования строк JSON int. По умолчанию, эквивалентен int(num_str). Можно использовать другой тип данных или парсер для этого значения (например float).
В случае определения parse_constant, он будет вызван для строк: -Infinity, Infinit, NaN. Может быть использован для вызова исключений при обнаружении недопустимых чисел JSON. parse_constant больше не вызывается при null, true, fasle.
Чтобы использовать собственный подкласс JSONDecoder, укажите его с помощью аргумента cls; в противном случае используется JSONDecoder. Дополнительные аргументы ключевого слова будут переданы конструктору класса.
Если десериализованные данные не являются допустимым документом JSON, возникнет JSONDecodeError.
Метод json loads
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)Десериализует s (экземпляр str, bytes или bytearray, содержащий JSON документ) в объект Python используя таблицу конвертации.
Остальные аргументы аналогичны аргументам в load(), кроме кодировки, которая устарела либо игнорируется.
Если десериализованные данные не являются допустимым документом JSON, возникнет ошибка JSONDecodeError.
Кодировщики и декодировщики
JSONDecoder
Класс json.JSONDecoder(*, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
Простой декодер JSON. При декодировании выполняет следующие преобразования:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
Он также понимает NaN, Infinity, и -Infinity как соответствующие значения float, которые находятся за пределами спецификации JSON.
object_hook будет вызван для каждого значения декодированного объекта JSON, а его возвращаемое значение будет использовано в указанном месте dict. Может быть использовано для обеспечения десериализации (например, для поддержки JSON-RPC class hinting).
object_pairs_hook будет вызван для каждого значения декодированного объекта JSON с упорядоченным списком пар. Возвращаемое значение object_pairs_hook будет использовано вместо dict. Эта функция может использоваться для запуска стандартного декодера. Если object_hook так же определён, в приоритете будет object_pairs_hook.
parse_float будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str). Может быть использован для другого типа данных или парсера JSON float. (например, decimal.Decimal).
parse_int будет вызван для строки JSON int. По умолчанию, эквивалентно int(num_str). Может быть использован для других типов данных и парсеров целых чисел JSON (например, float).
parse_constant будет вызван для строк: '-Infinity', 'Infinity', 'NaN'. Можно использовать для вызова исключений при обнаружении недопустимых чисел JSON.
Если strict=False (True по умолчанию), тогда использование управляющих символов внутри строк будет разрешено. В данном контексте управляющие символы — это символы с кодами в диапазоне 0–31, включая \t (tab), \n, \r и \0.
Если десериализованные данные не являются допустимым документом JSON, будет вызвана ошибка JSONDecodeError.
decode(s)
Возвращает представление s в Python (str — содержащий документ JSON). JSONDecodeError будет вызвана, если документ JSON не валидный (или не действительный).
raw_decode(s)
Декодирует документ JSON из s (str начинающийся с JSON документа) и возвращает кортеж из 2-х элементов (представление Python и индекс строки в s, на которой закончился документ). Может использоваться для декодирования документа JSON из строки, которая имеет дополнительные данные в конце.
JSONEncoder
Класс json.JSONEncoder(*, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None)
Расширяемый кодировщик JSON для структур данных Python.
Поддерживает следующие типы данных и объекты по умолчанию:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
Для того, чтобы можно было распознавать и другие объекты, подкласс должен выполнить метод default(), который вернет сериализуемый объект для o, если это возможно, в противном случае он должен вызвать реализацию родительского класса (для вызова TypeError).
Если skipkeys=False (по умолчанию), вызывается TypeError при попытке кодировать ключи, которые не являются str, int, float или None. В случае если skipkeys=True, такие элементы просто пропускаются.
Если ensure_ascii=True (по умолчанию), на выходе гарантируется, что все входящие не ASCII символы экранируются последовательностями \uXXXX. Но если ensure_ascii=False, эти символы будут выводиться как есть.
Если check_circular=True (по умолчанию), тогда списки, словари и самостоятельно закодированные объекты будут проверяться на циклические ссылки во время кодировки, чтобы предотвратить бесконечную рекурсию (что вызовет OverflowError). В другом случае, такая проверка не выполняется.
Если allow_nan=True (по умолчанию), тогда NaN, Infinity, и -Infinity будут кодированы как таковые. Это не соответствует спецификации JSON, но соответствует большинству кодировщиков и декодеров на основе JavaScript. В другом случае такие значения вызовут ValueError.
Если sort_keys=True (по умолчанию: False), выводимый словарь будет отсортирован по именам ключей; это полезно для регрессивного тестирования, чтобы сравнивать сериализацию JSON ежедневно.
Если indent является неотрицательным целым числом или строкой, то объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или "", будут использоваться новые строки без отступов. None (по умолчанию) отражает наиболее компактное представление. Если indent строка (например, "\t"), эта строка используется в качестве отступа.
Если указан separator (должен быть tuple типа (item_separator, key_separator)). По умолчанию используется (', ', ': ') если indent=None и (',', ': ') если нет. Для получения наиболее компактного представления JSON , вам следует использовать (',', ':'), чтобы уменьшить количество пробелов.
Значение default должно быть функцией. Она вызывается для объектов, которые не могут быть сериализованы. Функция должна вернуть кодируемую версию объекта JSON или вызывать TypeError. Если default не указано, возникает ошибка TypeError.
default(o)
Внедрите этот метод в подкласс таким образом, чтобы он возвращал сериализуемый объект для o или вызывал базовую реализацию (для повышения TypeError).
Например, чтобы поддерживать произвольные итераторы, вы можете реализовать default следующим образом:
def default(self, o):
try:
iterable = iter(o)
except TypeError:
pass
else:
return list(iterable)
# Пусть базовый класс вызовет исключение TypeError
return json.JSONEncoder.default(self, o)
encode(o)
Возвращает строковое представление JSON структуры данных Python. Пример:
>>> json.JSONEncoder().encode({"foo": ["bar", "baz"]})
'{"foo": ["bar", "baz"]}'
iterencode(o)
Кодирует переданный объект o и выдаёт каждое строковое представление, как только оно становится доступным. Например:
for chunk in json.JSONEncoder().iterencode(bigobject):
mysocket.write(chunk)
Исключение JSONDecodeError
Исключение json.JSONDecodeError(msg, doc, pos)
Подкласс ValueError с дополнительными атрибутами:
msg — не отформатированное сообщение об ошибке.doc — парсинг JSON документа.pos — первый индекс doc, если парсинг неудачный.lineno — строка, соответствующая pos.colno — колонка, соответствующая pos.
Стандартное соответствие и совместимость
Формат JSON указан в RFC 7159 и ECMA-404. В этом разделе описывается уровень соответствия этого модуля с RFC. Для упрощения, подклассы JSONEncoder и JSONDecoder, и параметры, которые отличаются от указанных, не берутся во внимание.
Этот модуль не соответствует RFC, устанавливая некоторые расширения, которые являются рабочими для JavaScript, но недействительными для JSON. В частности:
InfiniteиNaNпринимаются и выводятся;- Повторяемые имена внутри объекта принимаются и выводятся, но только последнее значение дублируемого ключа.
Поскольку RFC разрешает синтаксическим анализаторам, совместимым с RFC, принимать входные тексты, которые не соответствуют требованиям RFC, десериализатор этого модуля технически соответствует стандартным настройкам RFC.
Декодировка символов
RFC требует, чтобы JSON был представлен с использованием UTF-8, UTF-16 или UTF-32, при том, что UTF-8 является рекомендуемым по умолчанию для максимальной совместимости.
Возможно, но не обязательно для RFC, сериализаторы этого модуля устанавливают ensure_ascii=True по умолчанию, таким образом строки содержат только символы ASCII.
Кроме параметра ensure_ascii, этот модуль напрямую не затрагивает проблему кодировки символов.
RFC запрещает маркер последовательности байтов (BOM) в начало текста JSON и сериализатор этого модуля не добавляет BOM. RFC позволет, не не требует десериализаторы JSON игнорировать BOM на входе. Десериализатор этого модуля вызывает ValueError при наличии BOM.
RFC явно не запрещает строки JSON, содержащие последовательность байт, которая не соответствует валидным символам Unicode (например, непарные UTF-16 заменители), он отмечает — они могут вызывать проблемы совместимости. По умолчанию этот модуль принимает и выводит (если есть в исходной строке) специальные последовательности кода.
Infinite и NaN
RFC не допускает представления для значений infinite или NaN. Несмотря на это, по умолчанию этот модуль принимает и выводит Infinity, -Infinity, и NaN, как если бы они были действительно буквальными значениями числа в JSON:
>>> # Ни один из этих вызовов не будет исключением, но результаты не являются JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # То же самое при дезериализации
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
В сериализаторе параметр allow_nan используется для изменения этого поведения. В десериализаторе параметр этот переметр — parse_constant.
Повторяющиеся имена внутри объекта
RFC указывает, что имена в объекте JSON должны быть уникальными, но не указывает, как должны обрабатываться повторяющиеся имена в объектах JSON. По умолчанию этот модуль не вызывает исключения; вместо этого он игнорирует все, кроме последней пары ключ/значение для данного ключа:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json)
{'x': 3}
Параметр object_pairs_hook может использоваться для изменения этого.
Значение верхнего уровня Non-Object, Non-Array
Старая версия JSON указанная устаревшим RFC 4627 требовала, чтобы значение верхнего уровня текста JSON было объектом JSON или массивом (Python dict или list), или не было JSON null, boolean, number, string value. RFC 7159 убрало это ограничение, поэтому этот модуль не выполнял и никогда не применял это ограничение ни в своем сериализаторе, ни в десериализаторе.
Тем не менее, для максимальной совместимости, вы можете добровольно придерживаться этого ограничения.
Ограничения реализации
Некоторые реализации десериализатора JSON имеют лимиты на:
- размер принимаемого текста JSON
- максимальный уровень вложенности объектов и массивов JSON
- диапазон и точность чисел JSON
- содержание и максимальная длина строк JSON
Этот модуль не ставит никаких ограничений, кроме тех, которые относятся к соответствующим типам Python или самому интерпретатору Python.
При сериализации в JSON будьте осторожны с такими ограничениями в приложениях, которые могут потреблять ваш JSON. В частности, числа в JSON часто десериализуются в числа двойной точности IEEE 754 и подвержены ограничениям диапазона и точности этого представления. Это особенно актуально при сериализации значений Python int чрезвычайно большой величины или при сериализации экземпляров «необычных» числовых типов, таких как decimal.Decimal.
Интерфейс командной строки
Исходный код: Lib/json/tool.py
Модуль json.tool обеспечивает простой интерфейс командной строки для проверки и вывода объектов JSON.
Если не обязательные аргументы infile и outfile не указаны, sys.stdin и sys.stdout будут соответственно:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)Возможности командной строки
infile
Проверки и красивого вывод файла JSON:
$ python -m json.tool mp_films.json
[
{
"title": "And Now for Something Completely Different",
"year": 1971
},
{
"title": "Monty Python and the Holy Grail",
"year": 1975
}
]
$ python -m json.tool mp_films.json
[
{
"title": "And Now for Something Completely Different",
"year": 1971
},
{
"title": "Monty Python and the Holy Grail",
"year": 1975
}
]$ python -m json.tool mp_films.json
[
{
"title": "And Now for Something Completely Different",
"year": 1971
},
{
"title": "Monty Python and the Holy Grail",
"year": 1975
}
]Если infile не указан, чтение из sys.stdin.
outfile
Запишет вывод из infile в данный outfile. В противном случае, запишет его в sys.stdout.
--sort-keys
Сортировка выводимых словарей в алфавитном порядке по ключам.
-h, --help
Показать справку.
Тест на знание модуля Json

Если вы опытный разработчик, или даже новичок, вы, несомненно, слышали о функции Python range(). Но что же она делает? В двух словах, она генерирует список чисел, который обычно используется для работы с циклом for. Существует много вариантов использования. Зачастую, ее используют, когда нужно выполнить действие X раз, где вы можете использовать индекс. В других случаях вам, возможно, понадобится сделать итерацию по списку (или по другому итерируемому объекту), имея доступ к индексу.
Функция range() имеет небольшие отличия в работе на версии Python 2.x и 3.x , тем не менее у них остается одинаковая концепция. К этому вопросу мы доберемся немного позже.
Параметры range: star, stop, шаг
Функция range() принимает три параметра, например:
range(stop)- stop: количество целых чисел для генерации, начиная с нуля. Например,
range(3) == [0, 1, 2].
range([start], stop[, step])- start: число начала последовательности.
- stop: генерирует число до данного числа, но не включая его.
- step: разница между каждым числом из последовательности.
Обратите внимание:
- Все параметры должны быть целыми числами.
- Каждый из параметров может быть положительным или отрицательным.
range()(и Python в целом) основана на индексе 0, означая, что список индексов начинается с 0, а не 1, например. Синтаксис, предоставляющий доступ к первому элементу в списке —mylist[0]. Поэтому, последнее целое число, сгенерированное функциейrange()зависит отstop, но не будет включать его. Например,range(0, 5)генерирует целые числа 0, 1, 2, 3, 4, но не включая 5.
Примеры функции range()
Простое применение с циклом for:
>>> # 5 чисел начиная с 0
>>> for i in range(5):
print(i)
0
1
2
3
4
>>> # числа с 3 до 6 (не включая его)
>>> for i in range(3, 6):
print(i)
3
4
5
>>> # числа с 4 до 10 (не включая его) с шагом 2
>>> for i in range(4, 10, 2):
print(i)
4
6
8
>>> # числа с 0 до -10 (не включая его) с шагом -2
>>> for i in range(0, -10, -2):
print(i)
0
-2
-4
-6
-8
А это пример итерации по списку.
>>> my_list = ['один', 'два', 'три', 'четыре', 'пять']
>>> my_list_len = len(my_list)
>>> for i in range(0, my_list_len):
print(my_list[i])
один
два
три
четыре
пять
В качестве параметра stop мы передали длину списка (5).
Range полезна в итерации с условиями. Рассмотрим примере песни “99 Bottles of Beer on the Wall…” со следующим кодом:
for i in range(99, 0, -1):
if i == 1:
print('1 bottle of beer on the wall, 1 bottle of beer!')
print('So take it down, pass it around, no more bottles of beer on the wall!')
elif i == 2:
print('2 more bottles of beer on the wall, 2 more bottles of beer!')
print('So take one down, pass it around, 1 more bottle of beer on the wall!')
else:
print('{0} bottles of beer on the wall, {0} bottles of beer!'.format(i))
print('So take it down, pass it around, {0} more bottles of beer on the wall!'.format(i - 1))
Мы получаем следующий результат:
99 bottles of beer on the wall, 99 bottles of beer!
So take one down, pass it around, 98 more bottles of beer on the wall!
98 bottles of beer on the wall, 98 bottles of beer!
So take one down, pass it around, 97 more bottles of beer on the wall!
97 bottles of beer on the wall, 97 bottles of beer!
So take one down, pass it around, 96 more bottles of beer on the wall!
...
3 bottles of beer on the wall, 3 bottles of beer!
So take one down, pass it around, 2 more bottles of beer on the wall!
2 more bottles of beer on the wall, 2 more bottles of beer!
So take one down, pass it around, 1 more bottle of beer on the wall!
1 bottle of beer on the wall, 1 bottle of beer!
So take it down, pass it around, no more bottles of beer on the wall!Прекрасно! Наконец-то вы видите настоящую силу Python. Если вы еще немного в замешательстве, рекомендую прочитать статью 99 бутылок пива (Википедия).
range против функций xrange в python
Вы должно быть слышали о функции, известной как xrange(). Эта функция представлена в Python 2.x, и была переименована в range() в Python 3.x. Так в чем же разница? В Python 2.x range() создавала список, а xrange() возвращала итератор — объект последовательности. Мы можем увидеть это в следующем примере:
# Python 3.x
>>> range(1)
range(0, 1)
>>> type(range(1))
<class 'range'>
# Python 2.x
>>> range(1)
[0]
>>> type(range(1))
<class 'list'>В Python 3.x. у функции range() есть свой собственный тип. Говоря языком простых терминов, если вы хотите воспользоваться range() в цикле for, вы сделаете это с легкостью. Однако вы не можете использовать его как объект списка. Например, вы не можете разбить на срезы тип range.
Когда вы используете итератор, каждый цикл оператора for выдает мгновенно последующий номер на лету. В то время как исходная функция range() производит все числа мгновенно, прежде чем цикл for начнет выполняться.
Проблема с исходной функцией range() (в Python 2.x) заключалась в том, что она требовала очень большой объем памяти при создании большого количества чисел. Однако в нем, как правило, можно работать быстрее с небольшим количеством чисел.
Обратите внимание, что в Python 3.x вы все равно можете создать список, передав генератор, возвращенный функции list(). Следующим образом:
>>> list_of_ints = list(range(3))
>>> list_of_ints
[0, 1, 2]
Чтобы увидеть разницу в скорости действия в функции range() и xrange(), посмотрите эту статью (english).
Использование float с функцией range()
К сожалению, функция range() не поддерживает тип float. Тем не менее, не спешите расстраиваться! Мы можем легко использовать его с помощью данной функции. Есть несколько способов сделать это, вот один из них.
>>> # все аргументы обязательны
>>> def frange(start, stop, step):
i = start
while i < stop:
yield i
i += step
>>> for i in frange(0.5, 1.0, 0.1):
print(i)
0.5
0.6
0.7
0.8
0.9
1.0
Тест на знание функции Range
Списки объявляются в квадратных скобках [ ].
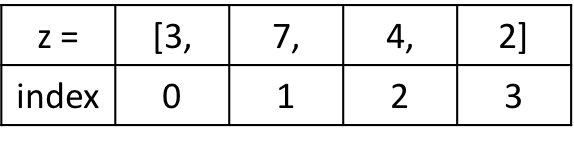
z = [3, 7, 4, 2] # Создание спискаВ python списки хранят упорядоченный набор элементов, которые могут быть разных типов. В примере, указанном выше элементы имеют один и тот же тип int. Не обязательно все элементы должны быть одного типа.
# Создание списка с разными типам данных
heterogenousElements = [3, True, 'Витя', 2.0]
Этот список содержит int, bool, string и float.
Доступ к элементам списка
Каждый элемент имеет присвоенный ему индекс. Важно отметить, в python индекс первого элемента в списке — 0.
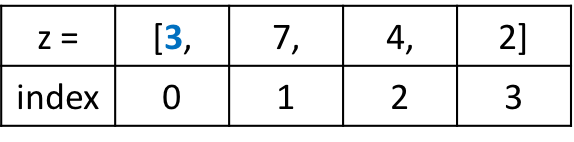
z = [3, 7, 4, 2] # создаем список
# обращение к первому элементу списка с индексом 0
print(z[0])
# элемент с индексом 0 -> 3
Также поддерживается отрицательная индексация. Отрицательная индексация начинается с конца. Иногда её удобнее использовать для получения последнего элемента в списке, потому что не нужно знать длину списка, чтобы получить доступ к последнему элементу.
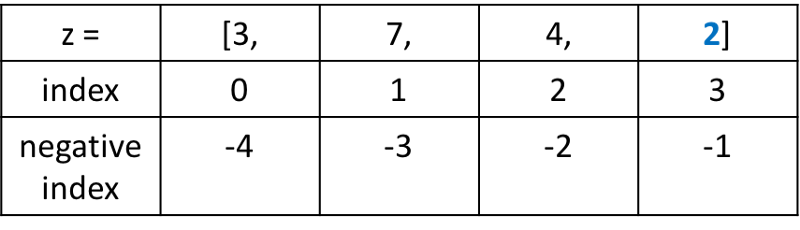
# выведите последний элемент списка
>>> print(z[-1])
2
Вы также можете получить доступ к одному и тому же элементу с использованием положительных индексов (как показано ниже). Альтернативный способ доступа к последнему элементу в списке z.
>>> print(z[3])
2
Срезы(slice) списка
Срезы хороши для получения подмножества значений с вашего списка. На примере кода, приведенного ниже, он вернет список с элементами из индекса 0 и не включая индекс 2.
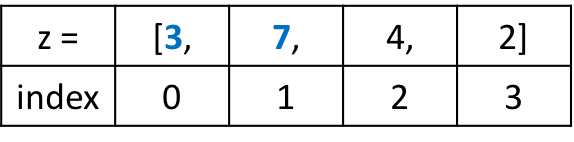
# Создайте список
z = [3, 7, 4, 2]
# Вывод элементов с индексом от 0 до 2 (не включая 2)
print(z[0:2])
# вывод: [3, 7]
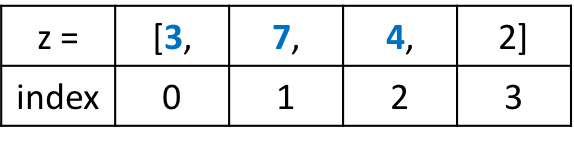
# Все, кроме индекса 3
>>> print(z[:3])
[3, 7, 4]
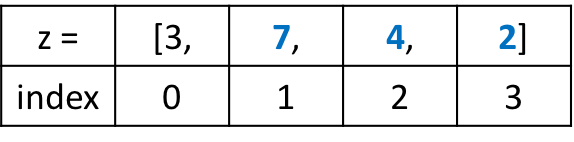
Код, указанный ниже возвращает список с элементами начиная с индекса 1 до конца.
# начиная с индекса 1 до конца списка
>>> print(z[1:])
[7, 4, 2]
Изменение элементов в списке
Списки в Python изменяемы. Это означает, что после создания списка можно обновить его отдельные элементы.
z = [3, 7, 4, 2] # Создание списка
# Изменяем элемент с индексом 1 на строку 'fish'
z[1] = 'fish'
print(z)
[3, 'fish', 4, 2]Методы и функции списков python
У списков Python есть разные методы, которые помогают в программировании. В этом разделе рассматриваются все методы списков.
Метод Index
Метод index возвращает положение первого индекса, со значением х. В указанном ниже коде, он возвращает назад 0.
# Создайте список
>>> z = [4, 1, 5, 4, 10, 4]
>>> print(z.index(4))
0

Вы также можете указать, откуда начинаете поиск.
>>> print(z.index(4, 3))
3

Метод Count
Метод count работает так, как звучит. Он считает количество раз, когда значение появляется в списке.
>>> random_list = [4, 1, 5, 4, 10, 4]
>>> print(random_list.count(4))
3
Метод Sort

Метод sort сортирует и меняет исходный список.
z = [3, 7, 4, 2]
z.sort()
print(z)
[2, 3, 4, 7]
Вышеуказанный код сортирует список чисел от наименьшего к наибольшему. Код, указанный ниже, показывает, как вы можете сортировать список от наибольшего к наименьшему.
# Сортировка и изменение исходного списка от наивысшего к наименьшему
z.sort(reverse = True)
print(z)
[7, 4, 3, 2]Следует отметить, что вы также можете отсортировать список строк от А до Я (или A-Z) и наоборот.
# Сортировка списка строками
names = ["Стив", "Рейчел", "Майкл", "Адам", "Джессика", "Лестер"]
names.sort()
print(names)
['Адам', 'Джессика', 'Лестер', 'Майкл', 'Рейчел', 'Стив']Метод Append

Метод append добавляет элемент в конец списка. Это происходит на месте.
z = [7, 4, 3, 2]
z.append(3)
print(z)
[7, 4, 3, 2, 3]Метод Remove

z = [7, 4, 3, 2, 3]
z.remove(2)
print(z)
Код удаляет первое вхождение значения 2 из списка z.
[7, 4, 3, 3]Метод Pop
Метод pop удаляет элемент в указанном индексе. Этот метод также вернет элемент, который был удален из списка. В случае, если вы не указали индекс, он по умолчанию удалит элемент по последнему индексу.
z = [7, 4, 3, 3]
print(z.pop(1))
print(z)
4
[7, 3, 3]Метод Extend

Метод extend расширяет список, добавляя элементы. Преимущество над append в том, что вы можете добавлять списки.
Добавим [4, 5] в конец z:
z = [7, 3, 3]
z.extend([4,5])
print(z)
[7, 3, 3, 4, 5]То же самое можно было бы сделать, используя +.
>>> print([1,2] + [3,4])
[7, 3, 3, 4, 5]
Метод Insert
Метод insert вставляет элемент перед указанным индексом.
z = [7, 3, 3, 4, 5]
z.insert(4, [1, 2])
print(z)
[7, 3, 3, 4, [1, 2], 5]Простые операции над списками
| Метод | Описаниее |
|---|---|
x in s | True если элемент x находится в списке s |
x not in s | True если элемент x не находится в списке s |
s1 + s2 | Объединение списков s1 и s2 |
s * n , n * s | Копирует список s n раз |
len(s) | Длина списка s, т.e. количество элементов в s |
min(s) | Наименьший элемент списка s |
max(s) | Наибольший элемент списка s |
sum(s) | Сумма чисел списка s |
for i in list() | Перебирает элементы слева направо в цикле for |
Примеры использование функций со списками:
>>> list1 = [2, 3, 4, 1, 32]
>>> 2 in list1 # 2 в list1?
True
>>> 33 not in list1 # 33 не в list1?
True
>>> len(list1) # количество элементов списка
5
>>> max(list1) # самый большой элемент списка
32
>>> min(list1) # наименьший элемент списка
1
>>> sum(list1) # сумма чисел в списке
42
# генератор списков python (list comprehension)
>>> x = [i for i in range(10)]
>>> print(x)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> print(list1.reverse()) # разворачивает список
[32, 1, 4, 3, 2]
Операторы + и * для списков
+ объединяет два списка.
list1 = [11, 33]
list2 = [1, 9]
list3 = list1 + list2
print(list3)
[11, 33, 1, 9]* копирует элементы в списке.
list4 = [1, 2, 3, 4]
list5 = list4 * 3
print(list5)
[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]Оператор in и not in
Оператор in проверяет находится ли элемент в списке. При успешном результате он возвращает True, в случае неудачи, возвращает False .
>>> list1 = [11, 22, 44, 16, 77, 98]
>>> 22 in list1
True
Аналогично not in возвращает противоположный от оператора in результат.
>>> 22 not in list1
False
Итерация по списку с использованием цикла for
Список — последовательность. Ниже способ, которые вы можете использовать для цикла, чтобы перебрать все элементы списка.
list1 = [1,2,3,4,5]
for i in list1:
print(i, end=" ")
1 2 3 4 5Преобразование списка в строку
Как преобразовать список в строку?
Для преобразования списка в строку используйте метод join(). В Python это выглядит так: ",".join(["a", "b", "c"]) -> "a,b,c".
Разделитель пишут в кавычках перед join, в список должен состоять из строк.
Вот несколько полезных советов для преобразования списка в строку (или любого другого итерабельного, такого как tuple).
Во-первых, если это список строк, вы можете просто использовать join() следующим образом.
mylist = ['spam', 'ham', 'eggs']
print(', '.join(mylist))
spam, ham, eggsИспользуя тот же метод, вы можете также сделать следующее:
>>> print('\n'.join(mylist))
spam
ham
eggs
Однако этот простой метод не работает, если список содержит не строчные объекты, такие как целые числа. Если вы просто хотите получить строку с разделителями-запятыми, вы можете использовать этот шаблон:
list_of_ints = [80, 443, 8080, 8081]
print(str(list_of_ints).strip('[]'))
80, 443, 8080, 8081Или же этот, если ваши объекты содержат квадратные скобки:
>>> print(str(list_of_ints)[1:-1])
80, 443, 8080, 8081
В конце концов, вы можете использовать map() чтобы преобразовать каждый элемент в список строки и затем присоединиться к ним:
>>> print(', '.join(map(str, list_of_ints)))
80, 443, 8080, 8081
>>> print('\n'.join(map(str, list_of_ints)))
80
443
8080
8081