Делитель, также известный как фактор или множитель, — это такое целое число m, на которое n делится без остатка. Например, делителями числа 12 являются 1, 2, 3, 4, 6 и 12.
В итоге я написал кое-что с помощью itertools, и в моем коде используется несколько интересных моментов из теории чисел. Я не знаю, буду ли я возвращаться к нему снова, но я надумал написать эту статью, потому что мои попытки решить озвученный выше вопрос перетекли в довольно забавное упражнение.
Простейший подход
Если мы хотим найти все числа, которые делят n без остатка, мы можем просто перебрать числа от 1 до n:
def get_all_divisors_brute(n):
for i in range(1, int(n / 2) + 1):
if n % i == 0:
yield i
yield n
На деле нам нужно дойти только до n/2, потому что все, что больше этого значения, гарантировано не может быть делителем n — если вы разделите n на что-то большее, чем n/2, результат не будет целым числом.
Этот код очень прост, и для малых значений n он работает достаточно хорошо, но он довольно неэффективен и медлителен в других случаях. По мере увеличения n время выполнения линейно увеличивается. Можем ли мы сделать лучше?
Факторизация
В моем проекте я работал в основном с факториалами. Факториал числа n, обозначаемый n! — это произведение всех целых чисел от 1 до n включительно. Например:
8! = 8 × 7 × 6 × 5 × 4 × 3 × 2 × 1
Поскольку факториалы состоят преимущественно из небольших множителей, я решил попробовать получить список делителей, определив сначала наименьшие из них. В частности, я искал простые множители, то есть те, которые также являются простыми числами. (Простое число — это число, единственными делителями которого являются оно само и 1. Например, 2, 3 и 5 являются простыми, а 4 и 6 — нет).
Вот функция, которая находит простые делители числа n:
def get_prime_divisors(n):
i = 2
while i * i <= n:
if n % i == 0:
n /= i
yield i
else:
i += 1
if n > 1:
yield n
Это похоже на предыдущую функцию, использующую перебор делителей: мы продолжаем пробовать множители, и если находим подходящий, то делим на него. В противном случае мы проверяем следующее число. Это довольно стандартный подход к поиску простых множителей.
Теперь мы можем использовать этот метод для получения факторизации числа, то есть для его записи в виде произведения простых чисел. Например, факторизация числа 8! выглядит следующим образом:
8! = 2^7 × 3^2 × 5 × 7
Вычисление такой факторизации относительно эффективно, особенно для факториалов, так как, поскольку все простые множители очень малы, вам не нужно делать много делений.
В теории чисел есть утверждение, называемое основной теоремой арифметики, которое гласит, что простые факторизации (разложения) уникальны: для любого числа n существует только один способ представить его в виде произведения простых множителей. (Я не буду приводить здесь доказательство, но вы можете найти его в Википедии).
Это дает нам способ находить делители путем перебора всех комбинаций простых множителей. Простые множители любого m делителя числа n должны входить в подмножество простых множителей n, иначе m не делило бы число n.
Переход от факторизации к делителям
Для начала разложим исходное число на простые множители с указанием «кратности», то есть мы должны получить список всех множителей и количество раз, которое каждый из них встречается в факторизации:
import collections
def get_all_divisors(n):
primes = get_prime_divisors(n)
primes_counted = collections.Counter(primes)
...
Затем, давайте продолжим и возведем каждое простое число во все степени, которые могут появиться в возможном делителе n.
def get_all_divisors(n):
...
divisors_exponentiated = [
[div ** i for i in range(count + 1)]
for div, count in primes_counted.items()
]
Например, для 8! представленный код выдаст нам следующее:
[
[1, 2, 4, 8, 16, 32, 64, 128], // 2^0, 2^1, ..., 2^7
[1, 3, 9], // 3^0, 3^1, 3^2
[1, 5],
[1, 7],
]
Затем, чтобы получить делители, мы можем использовать довольно удобную функцию itertools.product, которая принимает на вход итерабельные объекты и возвращает все возможные упорядоченные комбинации их элементов. В нашем случае она выбирает по одному числу из каждого списка с возведениями в степень, а затем, перемножая их вместе, мы получаем очередной делитель n.
import itertools
def calc_product(iterable):
acc = 1
for i in iterable:
acc *= i
return acc
def get_all_divisors(n):
...
for prime_exp_combination in itertools.product(*divisors_exponentiated):
yield calc_product(prime_exp_combination)
Таким образом, мы находим все делители n (хотя, в отличие от предыдущих функций, они не отсортированы).
Собираем все вместе
Сложив все это, мы получим следующую функцию для вычисления делителей n:
import collections
import itertools
def get_prime_divisors(n):
i = 2
while i * i <= n:
if n % i == 0:
n /= i
yield i
else:
i += 1
if n > 1:
yield n
def calc_product(iterable):
acc = 1
for i in iterable:
acc *= i
return acc
def get_all_divisors(n):
primes = get_prime_divisors(n)
primes_counted = collections.Counter(primes)
divisors_exponentiated = [
[div ** i for i in range(count + 1)]
for div, count in primes_counted.items()
]
for prime_exp_combination in itertools.product(*divisors_exponentiated):
yield calc_product(prime_exp_combination)
print(list(get_all_divisors(40320))) # 8!
Такая реализация очень эффективна, особенно когда у вас много маленьких простых множителей, как в случае с факториалами, с которыми я работал. Я не знаю, насколько хорошо она покажет себя в общем случае, и, если вы занимаетесь серьезными научными вычислениями, я уверен, что вы легко найдете уже реализованные и оптимизированные алгоритмы для такого рода вещей.
]]>Сначала давайте вкратце рассмотрим, что такое список в Python и как найти в нем максимальное значение или просто наибольшее число.
Список в Python
В Python есть встроенный тип данных под названием список (list). По своей сути он сильно напоминает массив. Но в отличие от последнего данные внутри списка могут быть любого типа (необязательно одного): он может содержать целые числа, строки или значения с плавающей точкой, или даже другие списки.
Хранимые в списке данные определяются как разделенные запятыми значения, заключенные в квадратные скобки. Списки можно определять, используя любое имя переменной, а затем присваивая ей различные значения в квадратных скобках. Он является упорядоченным, изменяемым и допускает дублирование значений. Например:
list1 = ["Виктор", "Артем", "Роман"]
list2 = [16, 78, 32, 67]
list3 = ["яблоко", "манго", 16, "вишня", 3.4]
Далее мы рассмотрим возможные варианты кода на Python, реализующего поиск наибольшего элемента в списке, состоящем из сравниваемых элементов. В наших примерах будут использоваться следующие методы/функции:
- Встроенная функция
max() - Метод грубой силы (перебора)
- Функция
reduce() - Алгоритм Heap Queue (очередь с приоритетом)
- Функция
sort() - Функция
sorted() - Метод хвостовой рекурсии
№1 Нахождение максимального значения с помощью функции max()
Это самый простой и понятный подход к поиску наибольшего элемента. Функция Python max() возвращает самый большой элемент итерабельного объекта. Ее также можно использовать для поиска максимального значения между двумя или более параметрами.
В приведенном ниже примере список передается функции max в качестве аргумента.
list1 = [3, 2, 8, 5, 10, 6]
max_number = max(list1)
print("Наибольшее число:", max_number)
Наибольшее число: 10Если элементы списка являются строками, то сначала они упорядочиваются в алфавитном порядке, а затем возвращается наибольшая строка.
list1 = ["Виктор", "Артем", "Роман"]
max_string = max(list1, key=len)
print("Самая длинная строка:", max_string)
Самая длинная строка: Виктор№2 Поиск максимального значения перебором
Это самая простая реализация, но она немного медленнее, чем функция max(), поскольку мы используем этот алгоритм в цикле.
В примере выше для поиска максимального значения нами была определена функция large(). Она принимает список в качестве единственного аргумента. Для сохранения найденного значения мы используем переменную max_, которой изначально присваивается первый элемент списка. В цикле for каждый элемент сравнивается с этой переменной. Если он больше max_, то мы сохраняем значение этого элемента в нашей переменной. После сравнения со всеми членами списка в max_ гарантировано находится наибольший элемент.
def large(arr):
max_ = arr[0]
for ele in arr:
if ele > max_:
max_ = ele
return max_
list1 = [1,4,5,2,6]
result = large(list1)
print(result) # вернется 6
№3 Нахождение максимального значения с помощью функции reduce()
В функциональных языках reduce() является важной и очень полезной функцией. В Python 3 функция reduce() перенесена в отдельный модуль стандартной библиотеки под названием functools. Это решение было принято, чтобы поощрить разработчиков использовать циклы, так как они более читабельны. Рассмотрим приведенный ниже пример использования reduce() двумя разными способами.
В этом варианте reduce() принимает два параметра. Первый — ключевое слово max, которое означает поиск максимального числа, а второй аргумент — итерабельный объект.
from functools import reduce
list1 = [-1, 3, 7, 99, 0]
print(reduce(max, list1)) # вывод: 99
Другое решение показывает интересную конструкцию с использованием лямбда-функции. Функция reduce() принимает в качестве аргумента лямбда-функцию, а та в свою очередь получает на вход условие и список для проверки максимального значения.
from functools import reduce
list1 = [-1, 3, 7, 99, 0]
print(reduce(lambda x, y: x if x > y else y, list1)) # -> 99
№4 Поиск максимального значения с помощью приоритетной очереди
Heapq — очень полезный модуль для реализации минимальной очереди. Если быть более точным, он предоставляет реализацию алгоритма очереди с приоритетом на основе кучи, известного как heapq. Важным свойством такой кучи является то, что ее наименьший элемент всегда будет корневым элементом. В приведенном примере мы используем функцию heapq.nlargest() для нахождения максимального значения.
import heapq
list1 = [-1, 3, 7, 99, 0]
print(heapq.nlargest(1, list1)) # -> [99]
Приведенный выше пример импортирует модуль heapq и принимает на вход список. Функция принимает n=1 в качестве первого аргумента, так как нам нужно найти одно максимальное значение, а вторым аргументом является наш список.
№5 Нахождение максимального значения с помощью функции sort()
Этот метод использует функцию sort() для поиска наибольшего элемента. Он принимает на вход список значений, затем сортирует его в порядке возрастания и выводит последний элемент списка. Последним элементом в списке является list[-1].
list1 = [10, 20, 4, 45, 99]
list1.sort()
print("Наибольшее число:", list1[-1])
Наибольшее число: 99№6 Нахождение максимального значения с помощью функции sorted()
Этот метод использует функцию sorted() для поиска наибольшего элемента. В качестве входных данных он принимает список значений. Затем функция sorted() сортирует список в порядке возрастания и выводит наибольшее число.
list1=[1,4,22,41,5,2]
sorted_list = sorted(list1)
result = sorted_list[-1]
print(result) # -> 41
№7 Поиск максимального значения с помощью хвостовой рекурсии
Этот метод не очень удобен, и иногда программисты считают его бесполезным. Данное решение использует рекурсию, и поэтому его довольно сложно быстро понять. Кроме того, такая программа очень медленная и требует много памяти. Это происходит потому, что в отличие от чистых функциональных языков, Python не оптимизирован для хвостовой рекурсии, что приводит к созданию множества стековых фреймов: по одному для каждого вызова функции.
def find_max(arr, max_=None):
if max_ is None:
max_ = arr.pop()
current = arr.pop()
if current > max_:
max_ = current
if arr:
return find_max(arr, max_)
return max_
list1=[1,2,3,4,2]
result = find_max(list1)
print(result) # -> 4
Заключение
В этой статье мы научились находить максимальное значение из заданного списка с помощью нескольких встроенных функций, таких как max(), sort(), reduce(), sorted() и других алгоритмов. Мы написали свои код, чтобы попробовать метод перебора, хвостовой рекурсии и алгоритма приоритетной очереди.
Если вам просто нужно найти количество конкретных элементов с списке, используйте метод .count()
>>> list_numbers = [1, 2, 2, 5, 5, 7, 4, 2, 1]
>>> print(list_numbers.count(2))
3
Существует несколько способов такого подсчета, и мы изучим каждый из них с помощью примеров. Итак, давайте начнем.
1. Использование цикла for для подсчета в списке Python
В этом фрагменте кода мы используем цикл for для подсчета элементов списка Python, удовлетворяющих условиям или критериям. Мы перебираем каждый элемент списка и проверяем условие, если оно истинно, то мы увеличиваем счетчик на 1. Это простой процесс сопоставления и подсчета для получения интересующего нас количества.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
for item in list_numbers:
if item%5 == 0:
count += 1
print("количество элементов списка, удовлетворяющих заданному условию:", count)
количество элементов списка, удовлетворяющих заданному условию: 6
2. Применение len() со списковыми включениями для подсчета в списке Python
В представленном ниже фрагменте кода, мы используем списковые включения (list comprehension), чтобы создать новый список, элементы которого соответствует заданному условию, после чего мы получаем длину собранного списка. Это намного легче понять на примере, поэтому давайте перейдем к нему.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
element_count = len([item for item in list_numbers if item%5 == 0])
print(
"количество элементов списка, удовлетворяющих заданному условию:",
element_count
)
количество элементов списка, удовлетворяющих заданному условию: 6
Подсчет ненулевых элементов
В этом примере мы находим общее количество ненулевых элементов. Чтобы узнать число нулевых членов списка, мы можем просто изменить условие на if item == 0.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 0, 0, 0]
element_count = len([item for item in list_numbers if item != 0])
print(
"количество элементов списка, удовлетворяющих заданному условию:",
element_count
)
количество элементов списка, удовлетворяющих заданному условию: 7
3. sum() и выражение-генератор для подсчета в списке Python
В этом примере кода мы используем sum() с генераторным выражением. Каждый элемент списка проходит проверку условием и для тех элементов, которые ему удовлетворяют, возвращается значение True. Метод sum() в свою очередь подсчитывает общее число истинных значений.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
count = sum(True for i in list_numbers if i % 5 == 0)
print(
"количество элементов списка, удовлетворяющих заданному условию:",
count
)
количество элементов списка, удовлетворяющих заданному условию: 6
4. sum() и map() для подсчета элементов списка Python с условиями или критериями
Функция map(fun, iterable) принимает два аргумента: итерируемый объект (это может быть строка, кортеж, список или словарь) и функцию, которая применяется к каждому его элементу, — и возвращает map-объект (итератор). Для применения одной функции внутри другой идеально подходит лямбда-функция. Таким образом, map() примет первый аргумент в виде лямбда-функции.
Здесь sum() используется с функцией map(), чтобы получить количество всех элементов списка, которые делятся на 5.
Давайте разберемся на примере, в котором переданная лямбда-функция предназначена для фильтрации членов списка, не кратных 5.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
count = sum(map(lambda item: item % 5 == 0, list_numbers))
print(
"количество элементов списка, удовлетворяющих заданному условию:",
count
)
количество элементов списка, удовлетворяющих заданному условию: 6
5. reduce() с лямбда-функцией для подсчета элементов списка Python с условием или критериями
Lambda — это анонимная (без имени) функция, которая может принимать много параметров, но тело функции должно содержать только одно выражение. Лямбда-функции чаще всего применяют для передачи в качестве аргументов в другие функции или для написания более лаконичного кода. В этом примере мы собираемся использовать функции sum(), map() и reduce() для подсчета элементов в списке, которые делятся на 5.
Приведенный ниже код наглядно демонстрирует это.
from functools import reduce
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
result_count = reduce(
lambda count, item: count + (item % 5 == 0),
list_numbers,
0
)
print(
"количество элементов списка, удовлетворяющих заданному условию:",
result_count
)
количество элементов списка, удовлетворяющих заданному условию: 6Надеюсь, что вы узнали о различных подходах к подсчету элементов в списке Python с помощью условия или критериев для фильтрации данных.
Удачного обучения!
]]>Проще говоря, AJAX позволяет обновлять веб-страницы асинхронно, негласно обмениваясь данными с веб-сервером. Это означает, что обновление частей веб-страницы возможно без перезагрузки всей страницы.
Мы можем делать запросы AJAX из шаблонов Django, используя JQuery. AJAX методы библиотеки jQuery позволяют нам запрашивать текст, HTML, XML или JSON с удаленного сервера, используя как HTTP Get, так и HTTP Post. Полученные данные могут быть загружены непосредственно в выбранные HTML-элементы вашей веб-страницы.
В этом руководстве мы узнаем, как выполнять AJAX HTTP GET и POST запросы из шаблонов Django.
Требования к знаниям
Я предполагаю, что у вас есть базовые знания о Django. Поэтому я не буду вдаваться в настройку проекта. Это очень простой проект с приложением под названием AJAX, в котором я использую bootstrap и Django crispy form для стилизации.
Репозиторий Gitlab — https://gitlab.com/PythonRu/django-ajax
Выполнение AJAX GET запросов с помощью Django и JQuery
Метод HTTP GET используется для получения данных с сервера.
В этом разделе мы создадим страницу регистрации, где мы будем проверять доступность имени пользователя с помощью JQuery и AJAX в шаблонах Django. Это очень распространенное требование для большинства современных приложений.
# ajax/views.py
from django.contrib.auth.models import User
from django.contrib.auth.decorators import login_required
from django.http import JsonResponse
from django.contrib.auth.forms import UserCreationForm
from django.contrib.auth import login, authenticate
from django.shortcuts import render, redirect
from django.views.generic.edit import CreateView
from django.urls import reverse_lazy
@login_required(login_url='signup')
def home(request):
return render(request, 'home.html')
class SignUpView(CreateView):
template_name = 'signup.html'
form_class = UserCreationForm
success_url = reverse_lazy('home')
def form_valid(self, form):
valid = super().form_valid(form)
login(self.request, self.object)
return valid
def validate_username(request):
"""Проверка доступности логина"""
username = request.GET.get('username', None)
response = {
'is_taken': User.objects.filter(username__iexact=username).exists()
}
return JsonResponse(response)
Итак, у нас есть три представления, первым является home, которое отображает довольно простой шаблон домашней страницы.
Далее идет SignUpView, унаследованный от класса CreateView. Он нужен для создания пользователей с помощью встроенного Django-класса UserCreationForm, который предоставляет очень простую форму для регистрации. При успешном ее прохождении происходит вход в систему, и пользователь перенаправляется на домашнюю страницу.
Наконец, validate_username — это наше AJAX представление, которое возвращает объект JSON с логическим значением из запроса, проверяющего, существует ли введенное имя пользователя.
Класс JsonResponse возвращает HTTP-ответ с типом содержимого application/json, преобразуя переданный ему объект в формат JSON. Поэтому, если имя пользователя уже существует в базе данных, он вернет JSON-объект, показанный ниже.
{'is_taken': true}
# ajax/urls.py
from django.urls import path
from .views import home, SignUpView, validate_username
urlpatterns = [
path('', home, name='home'),
path('signup', SignUpView.as_view(), name='signup'),
path('validate_username', validate_username, name='validate_username')
]
# dj_ajax/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('ajax/', include('ajax.urls'))
]
{# home.html #}
<h1>Привет, {{ user.username }}!</h1>
{# signup.html #}
{% load crispy_forms_tags %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" crossorigin="anonymous">
</head>
<body>
<div class="container mt-5 w-50">
<form id="signupForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="signupSubmit" class="btn btn-success btn-lg" />
</form>
</div>
{% block javascript %}
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#id_username').keyup(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаяем данные формы
url: "{% url 'validate_username' %}",
// если успешно, то
success: function (response) {
if (response.is_taken == true) {
$('#id_username').removeClass('is-valid').addClass('is-invalid');
$('#id_username').after('<div class="invalid-feedback d-block" id="usernameError">This username is not available!</div>')
}
else {
$('#id_username').removeClass('is-invalid').addClass('is-valid');
$('#usernameError').remove();
}
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
{% endblock javascript %}
</body>
</html>
Для лучшего понимания давайте подробно разберем все части представленного шаблона.
Внутри тега head мы загружаем bootstrap, используя CDN. Вы также можете сохранить библиотеку себе на диск и отдавать ее клиенту из статических папок.
<form id="signupForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="signupSubmit" class="btn btn-success btn-lg" />
</form>
Затем мы создаем форму Django, используя для стилизации тег crispy.
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
Далее внутри блока javascript мы запрашиваем JQuery от google CDN, вы также можете загрузить ее локально.
$(document).ready(function () {
( .... )
})
Затем у нас есть еще один скрипт с методом ready(). Код, написанный внутри метода $(document).ready(), будет запущен, когда DOM страницы будет готов для выполнения JavaScript.
$('#id_username').keyup(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаяем данные формы
url: "{% url 'validate_username' %}",
// если успешно, то
success: function (response) {
if (response.is_taken == true) {
$('#id_username').removeClass('is-valid').addClass('is-invalid');
$('#id_username').after('<div class="invalid-feedback d-block" id="usernameError">Это имя пользователя недоступно!</div>')
}
else {
$('#id_username').removeClass('is-invalid').addClass('is-valid');
$('#usernameError').remove();
}
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
console.log(response.responseJSON.errors)
}
});
return false;
});
Метод ajax запускается функцией keyup. Он принимает на вход объект с параметрами запроса. После успешного завершения запросов запускается одна из колбэк-функций success или error. При успешном вызове мы используем условный оператор для добавления и удаления классов is-valid/is-invalid поля ввода. А return false в конце скрипта предотвращает отправку форм, таким образом останавливая перезагрузку страницы.
Сохраните файлы и запустите сервер, вы должны увидеть AJAX в действии.
Выполнение AJAX POST запросов с помощью Django и JQuery
Метод HTTP POST используется для отправки данных на сервер.
В этом разделе мы узнаем, как делать POST-запросы с помощью JQuery и AJAX в шаблонах Django.
Мы создадим контактную форму и сохраним данные, предоставленные пользователем, в базу данных с помощью JQuery и AJAX.
# ajax/models.py
from django.db import models
class Contact(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField()
message = models.TextField()
def __str__(self):
return self.name
# ajax/forms.py
from django import forms
from .models import Contact
class ContactForm(forms.ModelForm):
class Meta:
model = Contact
fields = '__all__'
# ajax/urls.py
...
from .views import home, SignUpView, validate_username, contact_form
urlpatterns = [
...
path('contact-form/', contact_form, name='contact_form')
]
# ajax/views.py
...
from .forms import ContactForm
...
def contact_form(request):
form = ContactForm()
if request.method == "POST" and request.is_ajax():
form = ContactForm(request.POST)
if form.is_valid():
name = form.cleaned_data['name']
form.save()
return JsonResponse({"name": name}, status=200)
else:
errors = form.errors.as_json()
return JsonResponse({"errors": errors}, status=400)
return render(request, "contact.html", {"form": form})
В представлении мы проверяем ajax-запрос с помощью метода request.is_ajax(). Если форма корректно заполнена, мы сохраняем ее в базе данных и возвращаем объект JSON с кодом состояния и именем пользователя. Для недопустимой формы мы отправим клиенту найденные ошибки с кодом 400, что означает неверный запрос (bad request).
{# contact.html #}
{% load crispy_forms_tags %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Contact us</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" crossorigin="anonymous">
</head>
<body>
<div class="container mt-5 w-50">
<form id="contactForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="contact-submit" class="btn btn-success btn-lg" />
</form>
</div>
{% block javascript %}
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#contactForm').submit(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаем данные формы
type: $(this).attr('method'), // GET или POST
url: "{% url 'contact_form' %}",
// если успешно, то
success: function (response) {
alert("Спасибо, что обратились к нам " + response.name);
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
alert(response.responseJSON.errors);
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
{% endblock javascript %}
</body>
</html>
Давайте разобьем шаблон на более мелкие модули, чтобы лучше понять его.
Сначала мы импортируем bootstrap в head, используя CDN. Затем внутри body мы создаем форму с тегом crispy для стилизации.
После этого в первом javascript-блоке мы загружаем JQuery из CDN. Далее внутри функции $(document).ready() мы добавили наш AJAX метод.
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#contactForm').submit(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаем данные формы
type: $(this).attr('method'), // GET или POST
url: "{% url 'contact_form' %}",
// если успешно, то
success: function (response) {
alert("Спасибо, что обратились к нам " + response.name);
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
alert(response.responseJSON.errors);
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
При отправке формы мы вызываем метод ajax(), который сериализует ее данные и отправляет их по заданному URL-адресу. В случае успеха мы показываем диалоговое окно с сообщением, сгенерированным на основе полученного имени пользователя.
Выполнение AJAX POST запросов с использованием представлений на основе классов
Нам нужно просто вернуть объект JSON из метода form_valid() класса FormView. Вы также можете использовать другие стандартные представления, основанные на классах, переопределив метод post().
# ajax/views.py
...
from django.views.generic.edit import CreateView, FormView
...
class ContactFormView(FormView):
template_name = 'contact.html'
form_class = ContactForm
def form_valid(self, form):
"""
Если форма валидна, вернем код 200
вместе с именем пользователя
"""
name = form.cleaned_data['name']
form.save()
return JsonResponse({"name": name}, status=200)
def form_invalid(self, form):
"""
Если форма невалидна, возвращаем код 400 с ошибками.
"""
errors = form.errors.as_json()
return JsonResponse({"errors": errors}, status=400)
Наличие готовых датасетов является огромным преимуществом, потому что вы можете сразу приступить к созданию моделей, не тратя время на получение, очистку и преобразование данных — на что специалисты по данным тратят много времени.
Даже после того, как вся подготовительная работа выполнена, применение выборок Scikit-Learn поначалу может показаться вам немного запутанным. Не волнуйтесь, через несколько минут вы точно узнаете, как использовать датасеты, и встанете на путь исследования мира искусственного интеллекта. В этой статье предполагается, что у вас установлены python, scikit-learn, pandas и Jupyter Notebook (или вы можете воспользоваться Google Collab). Давайте начнем.
Введение в Scikit-Learn datasets
Scikit-Learn предоставляет семь наборов данных, которые они называют игровыми датасетами. Не дайте себя обмануть словом «игровой». Эти выборки довольно объемны и служат хорошей отправной точкой для изучения машинного обучения (далее ML). Вот несколько примеров доступных наборов данных и способы их использования:
- Цены на жилье в Бостоне — используйте ML для прогнозирования цен на жилье на основе таких атрибутов, как количество комнат, уровень преступности в городе.
- Датасет диагностики рака молочной железы (Висконсин) — используйте ML для диагностики рака как доброкачественного (не распространяется на остальную часть тела) или злокачественного (распространяется).
- Распознавание вина — используйте ML для определения типа вина по химическим свойствам.
В этой статье мы будем работать с “Breast Cancer Wisconsin” (рак молочной железы, штат Висконсин) датасетом. Мы импортируем данные и разберем, как их читать. В качестве бонуса мы построим простую модель машинного обучения, которая сможет классифицировать сканированные изображения рака как злокачественные или доброкачественные.
Чтобы узнать больше о предоставленных выборках, нажмите здесь для перехода на документацию Scikit-Learn.
Как импортировать модуль datasets?
Доступные датасеты можно найти в sklearn.datasets. Давайте импортируем необходимые данные. Сначала мы добавим модуль datasets, который содержит все семь выборок.
from sklearn import datasets
У каждого датасета есть соответствующая функция, используемая для его загрузки. Эти функции имеют единый формат: «load_DATASET()», где DATASET — названием выборки. Для загрузки набора данных о раке груди мы используем load_breast_cancer(). Точно так же при распознавании вина мы вызовем load_wine(). Давайте загрузим выбранные данные и сохраним их в переменной data.
data = datasets.load_breast_cancer()
До этого момента мы не встретили никаких проблем. Но упомянутые выше функции загрузки (такие как load_breast_cancer()) не возвращают данные в табличном формате, который мы привыкли ожидать. Вместо этого они передают нам объект Bunch.
Не знаете, что такое Bunch? Не волнуйтесь. Считайте объект Bunch причудливым аналогом словаря от библиотеки Scikit-Learn.
Давайте быстро освежим память. Словарь — это структура данных, в которой данные хранятся в виде ключей и значений. Думайте о нем как о книге с аналогичным названием, к которой мы привыкли. Вы ищете интересующее вас слово (ключ) и получаете его определение (значение). У программистов есть возможность делать ключи и соответствующие значения какими угодно (могут быть словами, числами и так далее).
Например, в случае хранения персональных контактов ключами являются имена, а значениями — телефонные номера. Таким образом, словарь в Python не ограничивается его типичной репрезентацией, но может быть применен ко всему, что вам нравится.
Что в нашем Bunch-словаре?
Предоставленный Sklearn словарь Bunch — достаточно мощный инструмент. Давайте узнаем, какие ключи нам доступны.
print(data.keys())
Получаем следующие ключи:
data— это необходимые для предсказания данные (показатели, полученные при сканировании, такие как радиус, площадь и другие) в массиве NumPy.target— это целевые данные (переменная, которую вы хотите предсказать, в данном случае является ли опухоль злокачественной или доброкачественной) в массиве NumPy.
Значения этих двух ключей предоставляют нам необходимые для обучения данные. Остальные ключи (смотри ниже) имеют пояснительное предназначение. Важно отметить, что все датасеты в Scikit-Learn разделены на data и target. data представляет собой показатели, переменные, которые используются моделью для тренировки. target включает в себя фактические метки классов. В нашем случае целевые данные — это один столбец, в котором опухоль классифицируется как 0 (злокачественная) или 1 (доброкачественная).
feature_names— это названия показателей, другими словами, имена столбцов вdata.target_names— это имя целевой переменной или переменных, другими словами, название целевого столбца или столбцов.DESCR— сокращение от DESCRIPTION, представляет собой описание выборки.filename— это путь к файлу с данными в формате CSV.
Чтобы посмотреть значение ключа, вы можете ввести data.KEYNAME, где KEYNAME — интересующий ключ. Итак, если мы хотим увидеть описание датасета:
print(data.DESCR)
Вот небольшая часть полученного результата (полная версия слишком длинная для добавления в статью):
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
...Вы также можете узнать информацию о выборке, посетив документацию Scikit-Learn. Их документация намного более читабельна и точна.
Работа с датасетом
Теперь, когда мы понимаем, что возвращает функция загрузки, давайте посмотрим, как можно использовать датасет в нашей модели машинного обучения. Прежде всего, если вы хотите изучить выбранный набор данных, используйте для этого pandas. Вот так:
# импорт pandas
import pandas as pd
# Считайте DataFrame, используя данные функции
df = pd.DataFrame(data.data, columns=data.feature_names)
# Добавьте столбец "target" и заполните его данными.
df['target'] = data.target
# Посмотрим первые пять строк
df.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Вы загрузили обучающую выборку в Pandas DataFrame, которая теперь полностью готова к изучению и использованию. Чтобы действительно увидеть возможности этого датасета, запустите:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
30 target 569 non-null int32
dtypes: float64(30), int32(1)
memory usage: 135.7 KBНесколько вещей, на которые следует обратить внимание:
- Нет пропущенных данных, все столбцы содержат 569 значений. Это избавляет нас от необходимости учитывать отсутствующие значения.
- Все типы данных числовые. Это важно, потому что модели Scikit-Learn не принимают качественные переменные. В реальном мире, когда получаем такие переменные, мы преобразуем их в числовые. Датасеты Scikit-Learn не содержат качественных значений.
Следовательно, Scikit-Learn берет на себя работу по очистке данных. Эти наборы данных чрезвычайно удобны. Вы получите удовольствие от изучения машинного обучения, используя их.
Обучение на датесете из sklearn.datasets
Наконец, самое интересное. Далее мы построим модель, которая классифицирует раковые опухоли как злокачественные и доброкачественные. Это покажет вам, как использовать данные для ваших собственных моделей. Мы построим простую модель K-ближайших соседей.
Во-первых, давайте разделим выборку на две: одну для тренировки модели — предоставление ей данных для обучения, а вторую — для тестирования, чтобы посмотреть, насколько хорошо модель работает с данными (результаты сканирования), которые она раньше не видела.
X = data.data
y = data.target
# разделим данные с помощью Scikit-Learn's train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Это дает нам два датасета — один для обучения и один для тестирования. Приступим к тренировке модели.
from sklearn.neighbors import KNeighborsClassifier
logreg = KNeighborsClassifier(n_neighbors=6)
logreg.fit(X_train, y_train)
logreg.score(X_test, y_test)
Получили на выходе 0.923? Это означает, что модель точна на 92%! Всего за несколько минут вы создали модель, которая классифицирует результаты сканирования опухолей с точностью 90%. Конечно, в реальном мире все сложнее, но это хорошее начало.
Ноутбук с кодом вы можете скачать здесь.
Вы многому научитесь, пытаясь построить модели с использованием datasets из Scikit-Learn. Удачного обучения искусственному интеллекту!
]]>- Как настроить Celery с Django.
- Как протестировать Celery-задачу в Django-оболочке.
- Где контролировать работу Celery-приложения.
Вы можете использовать на исходный код проекта из этого репозитория.
Зачем приложению на Django нужен Celery
Celery нужен для запуска задач в отдельном рабочем процессе (worker), что позволяет немедленно отправить HTTP-ответ пользователю в веб-процессе (даже если задача в рабочем процессе все еще выполняется). Цикл обработки запроса не будет заблокирован, что повысит качество взаимодействия с пользователем.
Ниже приведены некоторые примеры использования Celery:
- Вы создали приложение с функцией отправки комментариев, в которых пользователь может использовать символ @, чтобы упомянуть другого пользователя, после чего последний получит уведомление по электронной почте. Если пользователь упоминает 10 человек в своем комментарии, веб-процессу необходимо обработать и отправить 10 электронных писем. Иногда это занимает много времени (сеть, сервер и другие факторы). В данном случае Celery может организовать отправку писем в фоновом режиме, что в свою очередь позволит вернуть HTTP-ответ пользователю без ожидания.
- Нужно создать миниатюру загруженного пользователем изображения? Такую задачу стоит выполнить в рабочем процессе.
- Вам необходимо делать что-то периодически, например, генерировать ежедневный отчет, очищать данные истекшей сессии. Используйте Celery для отправки задач рабочему процессу в назначенное время.
Когда вы создаете веб-приложение, постарайтесь сделать время отклика не более, чем 500мс (используйте New Relic или Scout APM), если пользователь ожидает ответа слишком долго, выясните причину и попытайтесь устранить ее. В решении такой проблемы может помочь Celery.
Celery или RQ
RQ (Redis Queue) — еще одна библиотека Python, которая решает вышеуказанные проблемы.
Логика работы RQ схожа с Celery (используется шаблон проектирования производитель/потребитель). Далее я проведу поверхностное сравнение для лучшего понимания, какой из инструментов более подходит для задачи.
- RQ (Redis Queue) проста в освоении, направлена на снижение барьера в использовании асинхронного рабочего процесса. В ней отсутствуют некоторые функции, и она работает только с Redis и Python.
- Celery предоставляет больше возможностей, поддерживает множество различных серверных конфигураций. Одним из минусов такой гибкости является более сложная документация, что довольно часто пугает новичков.
Я предпочитаю Celery, поскольку он замечательно подходит для решения многих проблем. Данная статья написана мной, чтобы помочь читателю (особенно новичку) быстро изучить Celery!
Брокер сообщений и бэкенд результатов
Брокер сообщений — это хранилище, которое играет роль транспорта между производителем и потребителем.
Из документации Celery рекомендуемым брокером является RabbitMQ, потому что он поддерживает AMQP (расширенный протокол очереди сообщений).
Так как во многих случаях нам не нужно использовать AMQP, другой диспетчер очереди, такой как Redis, также подойдет.
Бэкенд результатов — это хранилище, которое содержит информацию о результатах выполнения Celery-задач и о возникших ошибках.
Здесь рекомендуется использовать Redis.
Как настроить Celery
Celery не работает на Windows. Используйте Linux или терминал Ubuntu в Windows.
Далее я покажу вам, как импортировать Celery worker в ваш Django-проект.
Мы будем использовать Redis в качестве брокера сообщений и бэкенда результатов, что немного упрощает задачу. Но вы свободны в выборе любой другой комбинации, которая удовлетворяет требованиям вашего приложения.
Используйте Docker для подготовки среды разработки
Если вы работаете в Linux или Mac, у вас есть возможность использовать менеджер пакетов для настройки Redis (brew, apt-get install), однако я хотел бы порекомендовать вам попробовать применить Docker для установки сервера redis.
- Вы можете скачать Docker-клиент здесь.
- Затем попробуйте запустить службу Redis
$ docker run -p 6379: 6379 --name some-redis -d redis
Команда выше запустит Redis на 127.0.0.1:6379.
- Если вы намерены использовать RabbitMQ в качестве брокера сообщений, вам нужно изменить только приведенную выше команду.
- Закончив работу с проектом, вы можете закрыть Docker-контейнер — окружение вашей рабочей машины по-прежнему будет чистым.
Теперь импортируем Celery в наш Django-проект.
Создание Django-проекта
Рекомендую создать отдельное виртуальное окружение и работать в нем.
$ pip install django==3.1
$ django-admin startproject celery_django
$ python manage.py startapp pollsНиже представлена структура проекта.
├── celery_django
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── polls
├── __init__.py
├── admin.py
├── apps.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.pyФайл celery.py
Давайте приступим к установке и настройке Celery.
pip install celery==4.4.7 redis==3.5.3 flower==0.9.7
Создайте файл celery_django/celery.py рядом с celery_django/wsgi.py.
"""
Файл настроек Celery
https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html
"""
from __future__ import absolute_import
import os
from celery import Celery
# этот код скопирован с manage.py
# он установит модуль настроек по умолчанию Django для приложения 'celery'.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_django.settings')
# здесь вы меняете имя
app = Celery("celery_django")
# Для получения настроек Django, связываем префикс "CELERY" с настройкой celery
app.config_from_object('django.conf:settings', namespace='CELERY')
# загрузка tasks.py в приложение django
app.autodiscover_tasks()
@app.task
def add(x, y):
return x / y
Файл __init__.py
Давайте продолжим изменять проект, в celery_django/__init__.py добавьте.
from __future__ import absolute_import, unicode_literals
# Это позволит убедиться, что приложение всегда импортируется, когда запускается Django
from .celery import app as celery_app
__all__ = ('celery_app',)
Дополнение settings.py
Поскольку Celery может читать конфигурацию из файла настроек Django, мы внесем в него следующие изменения.
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0"
CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/0"
Есть кое-что, о чем следует помнить.
При изучении документации Celery вы вероятно увидите, что broker_url — это ключ конфигурации, который вы должны установить для диспетчера сообщений, однако в приведенном выше celery.py:
app.config_from_object('django.conf: settings', namespace = 'CELERY')сообщает Celery, чтобы он считывал значение из пространства именCELERY, поэтому, если вы установите простоbroker_urlв своем файле настроек Django, этот параметр не будет работать. Правило применяется для всех ключей конфигурации в документации Celery.- Некоторые конфигурационные ключи различаются между Celery 3 и Celery 4, так что, пожалуйста, загляните в документацию при настройке.
Отправка заданий Celery
После завершение работы с конфигурацией все готово к использованию Celery. Мы будем запускать некоторые команды в отдельном терминале, но я рекомендую вам взглянуть на Tmux, когда у вас будет время.
Сначала запустите Redis-клиент, потом celery worker в другом терминале, celery_django — это имя Celery-приложения, которое вы установили в celery_django/celery.py.
$ celery worker -A celery_django --loglevel=info
-------------- celery@DESKTOP-111111 v4.4.7 (cliffs)
--- ***** -----
-- ******* ---- Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.27 2021-03-15 15:03:44
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: celery_django:0x7ff07f818ac0
- ** ---------- .> transport: redis://127.0.0.1:6379/0
- ** ---------- .> results: redis://127.0.0.1:6379/0
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. celery_django.celery.add
Далее запустим приложение в новом терминале, которое поможет нам отслеживать Celery-задачу (я расскажу об этом чуть позже).
$ flower -A celery_django --port=5555
[I 210315 16:11:39 command:135] Visit me at http://localhost:5555
[I 210315 16:11:39 command:142] Broker: redis://127.0.0.1:6379/0
[I 210315 16:11:39 command:143] Registered tasks:
['celery.accumulate',
'celery.backend_cleanup',
'celery.chain',
'celery.chord',
'celery.chord_unlock',
'celery.chunks',
'celery.group',
'celery.map',
'celery.starmap',
'celery_django.celery.add']
[I 210315 16:11:39 mixins:229] Connected to redis://127.0.0.1:6379/0
Затем откройте http://localhost:5555/. Вы должны увидеть информационную панель, на которой отображаются детали выполнения рабочего процесса Celery.
Теперь войдем в Django shell и попробуем отправить Celery несколько задач.
$ python manage.py migrate
$ python manage.py shell
...
>>> from celery_django.celery import add
>>> task = add.delay(1, 2)Рассмотрим некоторые моменты:
- Мы используем
xxx.delayдля отправки сообщения брокеру. Рабочий процесс получает эту задачу и выполняет ее. - Когда вы нажимаете клавишу enter для ввода
task = add.delay(1, 2), кажется, что команда быстро завершает выполнение (отсутствие блокировки), но метод добавления все еще активен в рабочем процессе Celery. - Если вы проверите вывод терминала, где был запущен Celery, то увидите что-то вроде этого:
[2021-03-15 15:04:32,859: INFO/MainProcess] Received task: celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578de
de]
[2021-03-15 15:04:32,882: INFO/ForkPoolWorker-1] Task celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578dede] s
ucceeded in 0.013418699999988348s: 0.5
Рабочий процесс получил задачу в 15:04:32, и она была успешно выполнена.
Думаю, теперь у вас уже есть базовое представление об использовании Celery. Попробуем ввести еще один блок кода.
>>> print(task.state, task.result)
SUCCESS 0.5
Затем давайте попробуем вызвать ошибку в Celery worker и посмотрим, что произойдет.
>>> task = add.delay(1, 0)
>>> type(task)
celery.result.AsyncResult
>>> task.state
'FAILURE'
>>> task.result
ZeroDivisionError('division by zero')
Как видите, результатом вызова метода delay является экземпляр AsyncResult.
Мы можем использовать его следующим образом:
- Проверить состояние задачи.
- Узнать возвращенное значение (результат) или сведения об исключении.
- Получить другие метаданные.
Мониторинг Celery с помощью Flower
Flower позволяет отобразить информацию о работу Celery более наглядно на веб-странице с дружественным интерфейсом. Это значительно упрощает понимание происходящего, поэтому я хочу обратить внимание на Flower, прежде чем углубиться в дальнейшее рассмотрение Celery.
URL-адрес панели управления: http://127.0.0.1:5555/. Откройте страницу задач — Tasks.
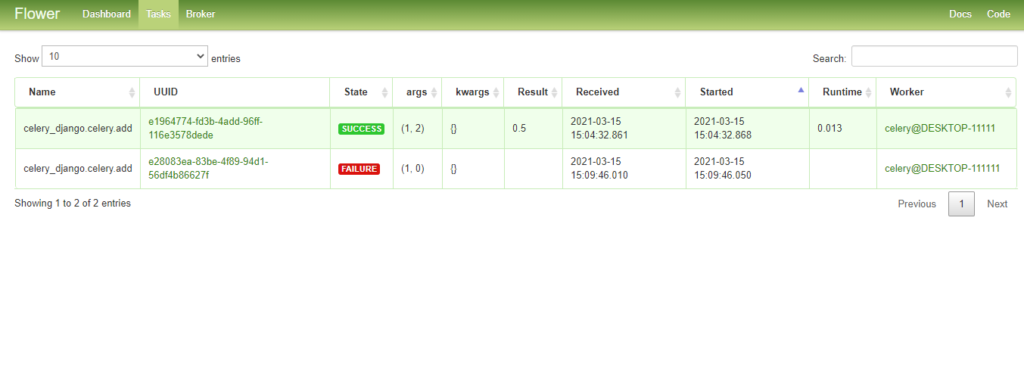
При изучении Celery довольно полезно использовать Flower для лучшего понимания деталей.
Когда вы развертываете свой проект на сервере, Flower не является обязательным компонентом. Я имею в виду, что вы можете напрямую использовать команды Celery, чтобы управлять приложением и проверять статус рабочего процесса.
Заключение
В этой статье я рассказал об основных аспектах Celery. Надеюсь, что после прочтения вы стали лучше понимать процесс работы с ним. Исходный код проекта доступен по ссылке в начале статьи.
]]>В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts, изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series, содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксисdf['your_column'].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df['your_column'], а не пару df[['your_column']].
Параметры:
normalize(bool, по умолчанию False) — еслиTrue, то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.sort(bool, по умолчанию True) — сортировка по частоте.ascending(bool, по умолчанию False) — сортировка по возрастанию.bins(int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
# импорт библиотеки
import pandas as pd
# Загрузка данных
df = pd.read_csv('Downloads/coursea_data.csv', index_col=0)
# проверка данных из csv
df.head(10)
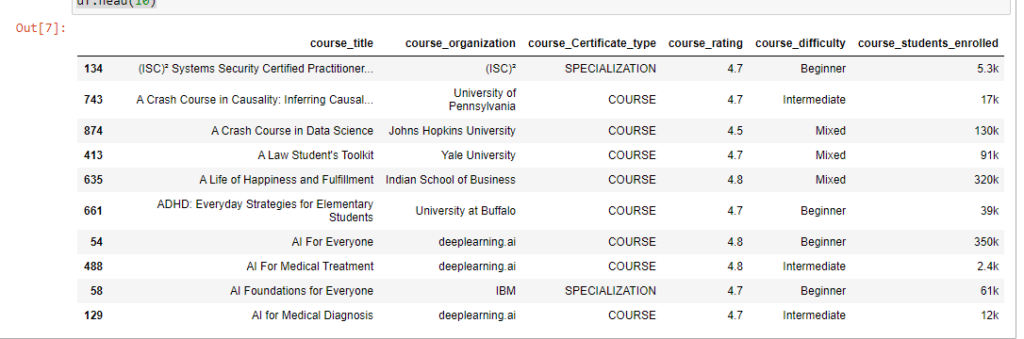
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 134 to 163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 course_title 891 non-null object
1 course_organization 891 non-null object
2 course_Certificate_type 891 non-null object
3 course_rating 891 non-null float64
4 course_difficulty 891 non-null object
5 course_students_enrolled 891 non-null object
dtypes: float64(1), object(5)
memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts. Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts().
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts()
---------------------------------------------------
Beginner 487
Intermediate 198
Mixed 187
Advanced 19
Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending.
Синтаксис: df['your_column'].value_counts(ascending=True).
df['course_difficulty'].value_counts(ascending=True)
---------------------------------------------------
Advanced 19
Mixed 187
Intermediate 198
Beginner 487
Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts().
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True)
---------------------------------------------------
Advanced 19
Beginner 487
Intermediate 198
Mixed 187
Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False).
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame({
'fruit':
['хурма']*5 + ['яблоки']*5 + ['бананы']*3 +
['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2
})
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False).
df_fruit['fruit'].value_counts()\
.sort_index(ascending=False)\
.sort_values(ascending=False)
-------------------------------------------------
хурма 5
яблоки 5
бананы 3
морковь 3
персики 3
манго 2
абрикосы 1
Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False.
Синтаксис: df['your_column'].value_counts(normalize=True).
df['course_difficulty'].value_counts(normalize=True)
-------------------------------------------------
Beginner 0.546577
Intermediate 0.222222
Mixed 0.209877
Advanced 0.021324
Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin. Это работает только с числовыми данными. Принцип напоминает pd.cut. Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп).
df['course_rating'].value_counts(bins=4)
-------------------------------------------------
(4.575, 5.0] 745
(4.15, 4.575] 139
(3.725, 4.15] 5
(3.297, 3.725] 2
Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna. Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False).
8. value_counts() как dataframe
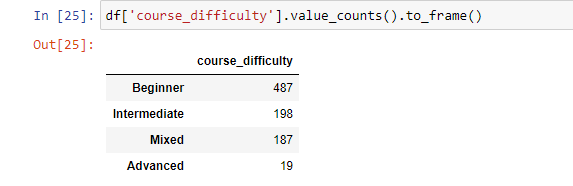
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts().
Синтаксис: df['your_column'].value_counts().to_frame().
Это будет выглядеть следующим образом:
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts()
# преобразование в df и присвоение новых имен колонкам
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty']
df_value_counts
Groupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts().
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts()
-------------------------------------------------
course_difficulty course_Certificate_type
Advanced SPECIALIZATION 10
COURSE 9
Beginner COURSE 282
SPECIALIZATION 196
PROFESSIONAL CERTIFICATE 9
Intermediate COURSE 104
SPECIALIZATION 91
PROFESSIONAL CERTIFICATE 3
Mixed COURSE 187
Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts().
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1].
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\
.value_counts().loc[lambda x: x > 4]
-------------------------------------------------
4.8 256
4.7 251
4.6 168
4.5 80
4.9 68
4.4 34
4.3 15
4.2 10
Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Во-первых, Heroku очень редко используют в продакшене. Его платные тарифы сильно выше стоимости аренды сервера.
Во-вторых, крупные кампании дают виртуальные машины бесплатно на год. Этого достаточно, что бы 4 года не платить за работу сервера.
Получение VPS
Как я уже написал, есть возможность получить VPS бесплатно на год. Выбирайте любой:
- AWS Amazon, продукт Amazon EC2.
- Azure Microsoft, продукт Виртуальные машины Linux.
- Google Cloud, продукт Compute Engine.
- Alibaba Cloud, продукт Elastic Compute Service.
Только не активируйте все сразу, это разовое предложение.
Не буду подробно описывать, как развернуть VPS, у этих платформ документации на высоком уровне. Если у вас трудности с английским и переводчиками, начинайте с Azure. У них много русской документации. Скажу только, что крайне желательно выбирать OS Ubuntu 18.04.
Процесс получения бесплатного периода и создание виртуальной машины достаточно тернист. Если вы никогда не делали это ранее, будьте готов потратить 1-2 часа на знакомство с облачными решениями.
Я буду использовать VPS с почасовой оплатой от reg.ru. Это дешевое и простое решение. Для обучения и демонстрации можно запускать на несколько часов по цене от 0,32 ₽/час. А постоянная работа подобного бота будет стоить 215 рублей в месяц.
Подключение к виртуальной машине
Для подключения к VPS нужно знать ip (IPv4), логин (обычно «root») и пароль.
С Linux и MacOS можно подключится из терминала. Введите команду, логин и ip сервера.
ssh root@123.123.123.23Для windows можно скачать терминал Ubuntu. Если такой вариант не подходит, используйте PuTTY (порт: 22). Вот так выглядит консоль. Для подключения требуется ввести «yes» и пароль.
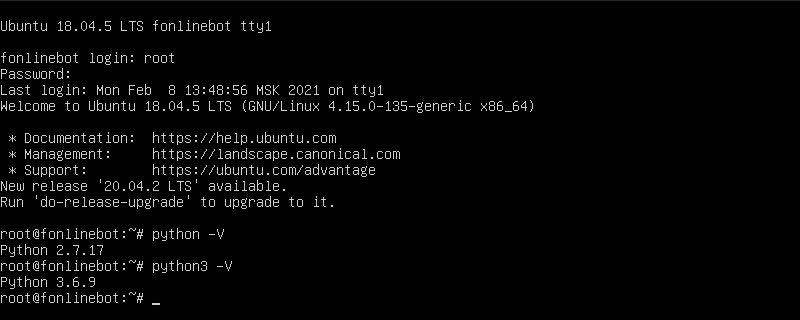
После входа я узнал какая версия python установлена командой python -V. Из коробки стоит 3.6.9, а проект на 3.8.5, нужно обновить.
Подготовка сервера
- Установим необходимую версию python. Внимательно вводите эти команды по очереди, это процесс кастомной установки.
$ sudo apt update
$ sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev
$ wget https://www.python.org/ftp/python/3.8.5/Python-3.8.5.tgz
$ tar -xf Python-3.8.5.tgz
$ cd Python-3.8.5
$ ./configure --enable-optimizations
$ make # ~15 минут
$ sudo make altinstall
$ cd /homeНемного деталей. Я скачал архив, распаковал и установил python 3.8.5. Будет готов подождать пока выполнится команды make. Введите python3.8 -V и убедитесь, что можно продолжать:
/home# python3.8 -V
Python 3.8.5 2. Создадим проект. Установим и создадим виртуально окружение. Выполняйте команды по очереди:
$ python3.8 -m pip install --upgrade pip
$ pip install virtualenv
$ mkdir fonlinebot
$ cd fonlinebot
$ virtualenv venv
$ source venv/bin/activate
$ python -V
$ deactivateМы установили pip и virtualenv. Затем создали папку «fonlinebot», создали в ней виртуальное окружение и проверили его.

3. Установим и запустим Redis-server. Для установки и проверки в Ubuntu введите эти команды:
$ sudo apt install redis-server
$ redis-cli
127.0.0.1:6379> pingПолучите PONG, значит redis запущен. Устанавливать удаленный доступ и пароль в этом руководстве я не буду. Эта служба доступна только конкретной машине, что полностью покрывает задачу.
4. Переменные окружения. Теперь нужно спрятать токен и API-ключ в переменные. Выполните команду nano /etc/environment и вставьте эти строки со своими значениями в кавычках.
fonlinebot_token="замените_на_токен"
fonlinebot_api_key="замените_на_ключ_апи"Затем нажмите CTRL+O -> Enter -> CTRL+X для сохранения. Перезапустите машину: sudo reboot, что бы переменить настройки.
5. Подготовка кода бота. Отредактируйте файл config.py. Раскомментируем настройки логирования и установим переменные окружения.
# fonlinebot/config.py
#...
import datetime
import os
formatter = '[%(asctime)s] %(levelname)8s --- %(message)s (%(filename)s:%(lineno)s)'
logging.basicConfig(
filename=f'bot-from-{datetime.datetime.now().date()}.log',
filemode='w',
format=formatter,
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.WARNING
)
TOKEN = os.environ.get("fonlinebot_token")
#...
'x-rapidapi-key': os.environ.get("fonlinebot_api_key"),
#...
Скрывать секретную информацию (токены, пароли) обязательно. Нельзя выкладывать файлы с паролями на гитхаб, stackoverflow или отправлять сторонним разработчикам.
Половина работы сделана. Теперь нужно загрузить файлы на сервер.
Загрузка файлов на VPS
Скачайте и установите WinSCP. Это программа для загрузки проекта на VPS. Альтернативный вариант Filezilla. Вариант для повышения скиллов — Git.
Откройте и установите соединение с сервером:
Далее перенесите файлы проекта (без venv и файлов Pycharm) в папку home/fonlinebot/.
Готово? Запустим бота с сервера.
$ cd /home/fonlinebot/ # перейдем в папку проекта
$ source venv/bin/activate # активируем окружение
$ pip install -r requirements.txt # установим зависимости
$ python main.py # запустим ботаТеперь перейдите в Телеграм и протестируйте работу. Отвечает? Хорошо, остановите его (ctrl+c) и деактивируйте виртуальное окружение (deactivate)
Финишная прямая проекта. После закрытия терминала, бот остановится. После перезапуска сервера, он не запустится. Настроем автономную работу.
Беспрерывная работа бота
Создадим собственную службу для постоянной работы бота и перезапуска в случае падения.
nano /lib/systemd/system/fonlinebot.serviceС настройками:
[Unit]
Description=Football online bot
After=network.target
[Service]
EnvironmentFile=/etc/environment
ExecStart=/home/fonlinebot/venv/bin/python main.py
ExecReload=/home/fonlinebot/venv/bin/python main.py
WorkingDirectory=/home/fonlinebot/
KillMode=process
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
Затем нажмите CTRL+O -> Enter -> CTRL+X для сохранения. Что это за настройки?
Настройки службы, нам важны эти:
Description— описание службы.EnvironmentFile— путь к файлу с переменными.ExecStartиExecReload— это команды для запуска и перезапуска бота.WorkingDirectory— путь к папке в которой файл запуска main.py.
Для запуска службы выполните эти 2 команды.
systemctl enable fonlinebot
systemctl start fonlinebotТеперь вернемся в бот и посмотрим как он отвечает.
Если бот не отвечает, проверьте статус и логи. Здесь сложно предвидеть ошибку:
systemctl status fonlinebot # статус
journalctl -u fonlinebot.service # логиПроект готов, отличная работа! Все этапы разработки на Gitlab.
Заключение
Мы проделали большую работу: создали бота, настроили его взаимодействие с внешним api и загрузили на сервера. В процессе затронули кнопки, меню, callback и ошибки.
Вот несколько идей для продолжения проекта:
- более детальная статистика матча,
- админка для получения ошибок и отправки сообщения всем пользователям,
- сбор статистики активности пользователей.
- переход на вебхук.
Удачи!
]]>Полный код бота из этого урока на gitlab.
Выбор API для результатов матчей
Обычно я использую Rapid API для получения данных, там много бесплатных предложений. Под нашу задачу хорошо подходит Football Pro. Они дают 100 запросов в день, и возможность получить все результаты за раз.
Зарегистрируйтесь на Rapid Api, создайте приложение и оформите подписку на базовый (бесплатный) план. Сервис бесплатный, но для продолжения требуется карта.
После подписки вы получите уникальный ключ, который мы позже добавим в настройки.
Бесплатно можно делать только 100 запросов в сутки. При превышении лимита с вас будут брать деньги. Хотя мы будем останавливать работу при достижении лимита, я не несу ответственность за возможные списания.
Обновление настроек для API
Добавим переменные для запросов. Ключ можно найти на вкладке «Endpoints» внизу в поле «X-RapidAPI-Key». Остальные строки можно копировать у меня. Мы будем запрашивать данные по указанному адресу с заголовками для авторизации и параметрами для фильтрации.
# fonlinebot/config.py
# ...
SOCCER_API_URL = "https://football-pro.p.rapidapi.com/api/v2.0/livescores"
SOCCER_API_HEADERS = {
'x-rapidapi-key': "ваш уникальный ключ",
'x-rapidapi-host': "football-pro.p.rapidapi.com"
}
SOCCER_API_PARAMS = {
"tz": "Europe/Moscow",
"include": "localTeam,visitorTeam"
}
# ...
В этом же файле нужно отредактировать данные лиг. Я предлагаю уже готовые, вы можете выбрать другие (Id здесь):
# fonlinebot/config.py
# ...
BOT_LEAGUES = {
"82": "Немецкая Бундеслига",
"384": "Итальянская Серия А",
"564": "Испанская Ла Лига",
"462": "Португальская Примейра Лига",
"72": "Чемпионат Нидерландов",
"2": "Лига Чемпионов",
"5": "Лига Европы",
"8": "Английская Премьер-лига",
"301": "Французская Лига 1",
"486": "Российская Премьер-лига"
}
# Флаги для сообщений, emoji-код
BOT_LEAGUE_FLAGS = {
"82": ":Germany:",
"384": ":Italy:",
"564": ":Spain:",
"462": ":Portugal:",
"72": ":Netherlands:",
"2": ":European_Union:",
"5": ":trophy:",
"8": ":England:",
"301": ":France:",
"486": ":Russia:"
}
# ...
Вместо тестовых 1,2,3 я добавил реальные id лиг. Вместе с этим обновились и некоторые лиги. Запустим и проверим:
Отлично, теперь можно следить за Лигой Чемпионов.
Получение данных с внешнего API
В прошлой части руководства я заложил будущую логику, хранение результатов по трем лигам в одном ключе. Так как у нас всего 10 лиг и нет разницы в запросе по трем лигам или всем сразу лучше результаты по каждой хранить отдельно. Это сэкономит запросы.
Посмотрим в каком виде приходят данные в ответе с помощью интерфейса сервиса. Во вкладке «Endpoints» слева выберем «Fixtures of Today» и нажмем «Test Endpoint». Ответ появится в правом столбце.
Вот эти строки мы будем использовать для каждого матча:
{
...
"league_id":998
...
"scores":{
...
"ht_score":"0-0"
"ft_score":"1-1"
...
}
"time":{
"status":"FT"
"starting_at":{
"time":"08:00:00"
...
}
"minute":90
...
"added_time":NULL
...
}
...
"localTeam":{
"data":{
...
"name":"Hadiya Hosaena"
...
}
}
"visitorTeam":{
"data":{
...
"name":"Kedus Giorgis"
...
}
}
}Для отправки запросов нужно установить библиотеку requests: pip install requests==2.25.1.
Напишем функцию, которая делает запрос к API. Иногда в ответ мы будем получать ошибки, нужно быть готовым. Отправим логи об ошибке и вернем ее.
TODO для вас. Настройте отправку сообщения админу, если fetch_results вернула словарь с ключом "error".
# fonlinebot/app/service.py
import requests
import logging
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS, MINUTE, \
SOCCER_API_URL, SOCCER_API_HEADERS, SOCCER_API_PARAMS
# ...
def limit_control(headers):
"""Контроль бесплатного лимита запросов"""
if headers.get("x-ratelimit-requests-remaining") is None:
logging.error(f"Invalid headers response {headers}")
if int(headers['x-ratelimit-requests-remaining']) <= 5:
cache.setex(
"limit_control",
int(headers['x-ratelimit-requests-reset']),
msg.limit_control
)
def fetch_results() -> dict:
SOCCER_API_PARAMS['leagues'] = ",".join(BOT_LEAGUES.keys())
try:
resp = requests.get(SOCCER_API_URL,
headers=SOCCER_API_HEADERS,
params=SOCCER_API_PARAMS)
except requests.ConnectionError:
logging.error("ConnectionError")
return {"error": "ConnectionError"}
limit_control(resp.headers)
if resp.status_code == 200:
return resp.json()
else:
logging.warning(f"Data retrieval error [{resp.status_code}]. Headers: {resp.headers} ")
return {"error": resp.status_code}
#...
Для контроля бесплатных запросов я добавил функцию limit_control. Когда останется меньше 6ти запросов, в кеш добавится соответствующая запись. Теперь бот будет проверять наличие этой записи в кеше, прежде чем отправлять запрос.
Проверку разместим в generate_results_answer. Если запись есть, мы вернем предупреждение.
# fonlinebot/app/service.py
#...
async def generate_results_answer(ids: list) -> str:
"""Функция создaет сообщение для вывода результатов матчей"""
limit = cache.get("limit_control")
if limit is not None:
return limit
results = await get_last_results(ids)
if results == [[]]*len(ids):
return msg.no_results
elif msg.fetch_error in results:
return msg.fetch_error
else:
text_results = results_to_text(results)
return msg.results.format(matches=text_results)
#...
А теперь обновите «bot.py» и «dialogs.py».
# fonlinebot/app/bot.py
#...
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results(callback_query: types.CallbackQuery):
"""Обновление сообщения результатов"""
if cache.get(f"last_update_{callback_query.from_user.id}") is None:
user_leagues = callback_query.data.split("#")[1:]
answer = await s.generate_results_answer(user_leagues)
if answer == msg.limit_control:
return await callback_query.answer(answer, show_alert=True)
else:
cache.setex(f"last_update_{callback_query.from_user.id}", MINUTE, "Updated")
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}")),
reply_markup=s.results_kb(user_leagues)
)
# игнорируем обновление, если прошло меньше минуты
await callback_query.answer(msg.cb_updated)
#...
Я дописал в функцию 2 строки для проверки answer. Если в ответе текст превышения лимита мы показываем предупреждение.
# fonlinebot/app/dialogs.py
#...
limit_control: str = "Лимит запросов исчерпан. Возвращайтесь завтра."
fetch_error: str = "Ошибка получения данных, попробуйте позже."
#...
Можете добавить такую запись на минуту и убедиться.
cache.setex("limit_control", 60, msg.limit_control)
На самом деле лимит начисляется каждые 24 часа с момента подписки. Если вы подписались в 13:00, значит это время обновления остатка. В заголовках ответа по ключу
x-ratelimit-requests-resetможно получить остаток времени в секундах.
Очистка данных API и сохранение
Теперь напишем функцию которая распарсит ответ для сохранения в кеш.
TODO для вас. Не всегда нужно обновлять матчи. Например, мы в 8 утра получили список и первый матч начнется в 19.00. До начала первого матча результаты не изменятся, здесь можно сэкономить запросы.
# fonlinebot/app/service.py
#...
async def parse_matches() -> dict:
"""Функция сбора матчей по API"""
data = {}
matches = fetch_results()
if matches.get("error", False):
return matches
for m in matches['data']:
if not data.get(str(m['league_id']), False):
data[str(m['league_id'])] = [m]
else:
data[str(m['league_id'])].append(m)
return data
#...
Эту функцию мы вызываем в get_last_results, если не нашли результатов в кеше. Давайте туда допишем сохранение последних результатов:
# fonlinebot/app/service.py
#...
async def save_results(matches: dict):
"""Сохранение результатов матчей"""
for lg_id in BOT_LEAGUES.keys():
cache.jset(lg_id, matches.get(lg_id, []), MINUTE)
async def get_last_results(league_ids: list) -> list:
last_results = [cache.jget(lg_id) for lg_id in league_ids]
if None in last_results:
all_results = await parse_matches()
if all_results.get("error", False):
return [msg.fetch_error]
else:
await save_results(all_results)
last_results = [all_results.get(lg_id, []) for lg_id in league_ids]
return last_results
#...
Если по какой-то лиге у нас нет записи, мы обращаемся к API и сохраняем результат на 1 минуту.
Запись логов в файл
Появились важные логи, которые помогут исправлять ошибки получения данных. Добавим настройки логирования: формат и запись в файл.
# fonlinebot/config.py
#...
formatter = '[%(asctime)s] %(levelname)8s --- %(message)s (%(filename)s:%(lineno)s)'
logging.basicConfig(
# TODO раскомментировать на сервере
# filename=f'bot-from-{datetime.datetime.now().date()}.log',
# filemode='w',
format=formatter,
datefmt='%Y-%m-%d %H:%M:%S',
# TODO logging.WARNING
level=logging.DEBUG
)
#...
Теперь строка будет выглядеть так. Появилось время и место лога:
[2021-02-05 11:38:29] INFO --- Database connection established (database.py:38)Для настройки логирования много вариантов, мы не будет подробно на этом останавливать. Уроки посвящены телеграм боту.
Красивый вывод сообщения пользователю
Хорошо, мы получили список словарей с множеством данных. Его нужно превратить в текст формата:
Английская Премьер-лига Окончен Тоттенхэм 0:1 (0:1) Челси
Форматирование реализуем в results_to_text.
# fonlinebot/app/service.py
#...
def add_text_time(time: dict) -> str:
"""Подбор текста в зависимости от статуса матча
Все статусы здесь:
https://sportmonks.com/docs/football/2.0/getting-started/a/response-codes/85#definitions
"""
scheduled = ["NS"]
ended = ["FT", "AET", "FT_PEN"]
live = ["LIVE", "HT", "ET", "PEN_LIVE"]
if time['status'] in scheduled and time['starting_at']['time'] is not None:
# обрезаем секунды
return time['starting_at']['time'][:-3]
elif time['status'] in ended:
return "Окончен"
elif time['status'] in live and time['minute'] is not None:
if time['extra_minute'] is not None:
return time['minute'] + time['extra_minute']
return time['minute']
else:
# для других статусов возвращаем заглушку
return "--:--"
def results_to_text(matches: list) -> str:
"""
Функция генерации сообщения с матчами
Получает list[list[dict]]]
Возвращает текст:
| Английская Премьер-лига |
| Окончен Тоттенхэм 0:1 (0:1) Челси |
...
"""
text = ""
for lg_matches in matches:
if not lg_matches:
continue
lg_flag = BOT_LEAGUE_FLAGS[str(lg_matches[0]['league_id'])]
lg_name = BOT_LEAGUES[str(lg_matches[0]['league_id'])]
text += f"{emojize(lg_flag)} {lg_name}\n"
for m in lg_matches:
text += f"{add_text_time(m['time']):>7} "
if m['localteam_id'] == m['winner_team_id']:
text += f"*{m['localTeam']['data']['name']}* "
else:
text += f"{m['localTeam']['data']['name']} "
if m['time']['minute'] is not None:
text += f"{m['scores']['localteam_score']}-{m['scores']['visitorteam_score']} "
else:
text += "— "
if m['scores']['ht_score'] is not None:
text += f"({m['scores']['ht_score']}) "
if m['visitorteam_id'] == m['winner_team_id']:
text += f"*{m['visitorTeam']['data']['name']}*\n"
else:
text += f"{m['visitorTeam']['data']['name']}\n"
text += "\n"
return text
#...
Функция циклом проходит по лигам и матчам, формирует читаемый вывод. Перед запуском нужно добавить параметр parse_mode в сообщения, для выделения жирным команд-победителей.
# fonlinebot/app/bot.py
#...
async def get_results(message: types.Message):
#...
await message.answer(answer,
reply_markup=s.results_kb(user_leagues),
parse_mode=types.ParseMode.MARKDOWN)
# ...
async def update_results(callback_query: types.CallbackQuery):
# ...
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}")),
parse_mode=types.ParseMode.MARKDOWN,
reply_markup=s.results_kb(user_leagues)
)
Запустим и проверим, как работает бот:
TODO для вас.
1. Получение данных может длится несколько секунд, добавьте chat_action. Это текст, который отображается сверху во время выполнения кода.
2. Не всегда обновление результатов меняет сообщение, это приводит к ошибке. Пусть сообщение не редактируется, если текст дублирует старый.
Теперь допишем немного тестов и пойдем деплоить.
Тестирование бота
Будем проверять работоспособность API и контроль лимита.
# fonlinebot/test.py
#...
import requests
import config
#...
class TestService(IsolatedAsyncioTestCase):
#...
def test_limit_control(self):
test_data = {'x-ratelimit-requests-reset': "60",
'x-ratelimit-requests-remaining': "0"}
service.limit_control(test_data)
self.assertIsNotNone(cache.get("limit_control"))
class TestAPI(unittest.TestCase):
def test_api_response(self):
result = service.fetch_results()
self.assertIsNotNone(result.get('data', None))
def test_api_headers(self):
config.SOCCER_API_PARAMS['leagues'] = ",".join(config.BOT_LEAGUES.keys())
resp = requests.get(
config.SOCCER_API_URL,
headers=config.SOCCER_API_HEADERS,
params=config.SOCCER_API_PARAMS
)
self.assertIsNotNone(resp.headers.get('x-ratelimit-requests-reset', None))
Бот готов! Код этого урока в начале статьи.
]]>«Рыба» кода бота
Сразу запишем функции в «bot.py», которые понадобятся. Предварительно удалите test_message:
# fonlinebot/app/bot.py
# ...
dp.middleware.setup(LoggingMiddleware())
@dp.message_handler(commands=['start'])
async def start_handler(message: types.Message):
"""Обработка команды start. Вывод текста и меню"""
...
@dp.message_handler(commands=['help'])
async def help_handler(message: types.Message):
"""Обработка команды help. Вывод текста и меню"""
...
@dp.callback_query_handler(lambda c: c.data == 'main_window')
async def show_main_window(callback_query: types.CallbackQuery):
"""Главный экран"""
...
@dp.message_handler(lambda message: message.text == msg.btn_online)
@dp.message_handler(commands=['online'])
async def get_results(message: types.Message):
"""Обработка команды online и кнопки Онлайн.
Запрос матчей. Вывод результатов"""
...
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results():
"""Обновление сообщения результатов"""
...
@dp.message_handler(lambda message: message.text == msg.btn_config)
async def get_config(message: types.Message):
"""Обработка кнопки Настройки.
Проверка выбора лиг. Вывод меню изменений настроек"""
...
@dp.callback_query_handler(lambda c: c.data.startswith('edit_config'))
async def set_or_update_config(user_id: str):
"""Получение или обновление выбранных лиг"""
...
@dp.callback_query_handler(lambda c: c.data[:6] in ['del_le', 'add_le'])
async def update_leagues_info(callback_query: types.CallbackQuery):
"""Добавление/удаление лиги из кеша, обновление сообщения"""
...
@dp.callback_query_handler(lambda c: c.data == 'save_config')
async def save_config(callback_query: types.CallbackQuery):
"""Сохранение пользователя в базу данных"""
....
@dp.callback_query_handler(lambda c: c.data == 'delete_config')
async def delete_config(user_id: str):
"""Удаление пользователя из базы данных"""
...
@dp.message_handler()
async def unknown_message(message: types.Message):
"""Ответ на любое неожидаемое сообщение"""
...
async def on_shutdown(dp):
# ...
Это не окончательная версия, я мог что-то упустить. В процессе добавим недостающие.
Каждая функция обернута декоратором, так мы общаемся с Телегармом:
@dp.message_handler(commands=['start'])— декоратор ожидает сообщения-команды (которые начинаются с/). В этом примере он ожидает команду/start.@dp.callback_query_handler(lambda c: c.data == 'main_window')— ожидает callback и принимает lambda-функцию для его фильтрации. Callback отправляется inline-кнопками. В примере мы ожидаем callback со значением'main_window'.@dp.message_handler(lambda message: message.text == msg.btn_config)— этот декоратор похож на предыдущий, но ожидает сообщение от пользователя. В примере мы будем обрабатывать сообщение с текстом изmsg.btn_config.
Итак. Пользователь нажимает команду старт, получает приветственное сообщение. В нем мы предлагаем выбрать 3 лиги и мониторить результаты по ним. Получить результаты можно командой или кнопкой меню. Так же мы даем возможность изменить выбранные соревнования или удалить свои данные из бота.
Полный код бота из этого урока на gitlab.
Добавление команд в бота
Изначально команды не настроены. Пользователи могут вводить их, но специально меню нет. Для добавления нужно снова написать https://t.me/botfather команду /setcommands. Выберите своего бота и добавьте этот текст:
start - Запуск и перезапуск бота
help - Возможности бота
online - Результаты матчей
В ответ получите «Success! Command list updated. /help». Теперь можно перейти в своего бота и проверить:
Ответы на команды
Взаимодействие с ботом начинается с команды /start. Нужно поприветствовать и предложить следующий шаг. Эта команда будет возвращать текст с клавиатурой. Точно так же работает и /help.
Добавим обработку этих команд в «bot.py», обновите start_handler help_handler:
# fonlinebot/app/bot.py
# ...
from config import TOKEN, YEAR, MINUTE
import app.service as s
# ...
@dp.message_handler(commands=['start'])
async def start_handler(message: types.Message):
"""Обработка команды start. Вывод текста и меню"""
# проверка, есть ли пользователь в базе
user_league_ids = await s.get_league_ids(message.from_user.id)
if not user_league_ids:
await message.answer(msg.start_new_user)
# добавление id сообщения настроек
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+2)
await set_or_update_config(user_id=message.from_user.id)
else:
await message.answer(msg.start_current_user,
reply_markup=s.MAIN_KB)
@dp.message_handler(commands=['help'])
async def help_handler(message: types.Message):
"""Обработка команды help. Вывод текста и меню"""
await message.answer(msg.help, reply_markup=s.MAIN_KB)
# ...
Я добавил импорт import app.service as s. В этом модуле клавиатура и функция проверки пользователя. start_handler проверяет есть ли пользователь в кеше или базе данных, и отправляет ему соответствующий текст.
Перед отправкой текста для выбора лиг, я сохранил его будущий id. Получил номер последнего сообщения (это сама команда «start») и добавил 2 пункта: +1 за наш ответ на команду и +1 за само сообщения выбора лиг. Зная id сообщения, его можно редактирвать.
Теперь напишем клавиатуру и get_league_ids в модуль «service».
# fonlinebot/app/service.py
from aiogram.types import ReplyKeyboardMarkup, KeyboardButton, \
InlineKeyboardMarkup, InlineKeyboardButton
from emoji import emojize
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS
from database import cache, database as db
from app.dialogs import msg
MAIN_KB = ReplyKeyboardMarkup(
resize_keyboard=True,
one_time_keyboard=True
).row(
KeyboardButton(msg.btn_online),
KeyboardButton(msg.btn_config)
)
async def get_league_ids(user_id: str) -> list:
"""Функция получает id лиг пользователя в базе данных"""
leagues = cache.lrange(f"u{user_id}", 0, -1)
if leagues is None:
leagues = await db.select_users(user_id)
if leagues is not None:
leagues = leagues.split(',')
[cache.lpush(f"u{user_id}", lg_id) for lg_id in leagues]
else:
return []
return leagues
MAIN_KB — основная клавиатура, как на скриншоте выше. Разберем подробнее:
ReplyKeyboardMarkup— объект, который создает клавиатуру.- Параметр
resize_keyboard=Trueуменьшает ее размер. - А с
one_time_keyboard=Trueклавиатура будет скрываться, после использования. .row— метод для группировки кнопок в строку.KeyboardButton(msg.btn_online)иKeyboardButton(msg.btn_config)— кнопки с заданным текстом.
Осталось только добавить текста сообщений в dialogs. Вставьте этот код в класс Messages.
# fonlinebot/app/dialogs.py
# ...
start_new_user: str = "Привет. Я могу сообщать тебе результаты матчей online."
start_current_user: str = "Привет. С возвращением! " \
"Используй команды или меню внизу для продолжения."
help: str = """
Этот бот получает результаты матчей за последние 48 часов.
Включая режим LIVE.
- Что бы выбрать/изменить лиги нажмите "Настройки".
- Для проверки результатов нажмите "Онлайн".
Бот создан в учебных целях, для сайта pythonru.com
"""
Выбор, изменение и удаление лиг

Сначала внесем правки в наши вспомогательные модули.
В «dababase» в класс Database добавим новый метод insert_or_update_users.
# fonlinebot/database.py
#...
async def insert_or_update_users(self, user_id: int, leagues: str):
user_leagues = await self.select_users(user_id)
if user_leagues is not None:
await self.update_users(user_id, leagues)
else:
await self.insert_users(user_id, leagues)
#...
В настройки добавим переменные метрик времени:
# fonlinebot/config.py
#...
MINUTE = 60
YEAR = 60*60*24*366
И допишем текста для блока настроек:
# fonlinebot/app/dialogs.py
# ...
league_row: str = "{i}. {flag} {name}"
config: str = "Сейчас выбраны:\n{leagues}"
btn_back: str = "<- Назад"
btn_go: str = "Вперед ->"
btn_save: str = "Сохранить"
config_btn_edit: str = "Изменить"
config_btn_delete: str = "Удалить данные"
data_delete: str = "Данные успешно удалены"
set_leagues: str = "Выбери 3 лиги для отслеживания.\nВыбраны:\n{leagues}"
main: str = "Что будем делать?"
db_saved: str = "Настройки сохранены"
cb_not_saved: str = "Лиги не выбраны"
cb_limit: str = "Превышен лимит. Максимум 3 лиги."
# ...
На этом подготовка окончена, пора написать логику добавления лиг. В модуль «service» добавим две inline-клавиатуры.
Inline-клавиатура привязана к конкретному сообщению. С их помощью можно отправлять и обрабатывать сигналы боту.
# fonlinebot/app/service.py
# ...
CONFIG_KB = InlineKeyboardMarkup().row(
InlineKeyboardButton(msg.btn_back, callback_data='main_window'),
InlineKeyboardButton(msg.config_btn_edit, callback_data='edit_config#')
).add(InlineKeyboardButton(msg.config_btn_delete, callback_data='delete_config'))
def leagues_kb(active_leagues: list, offset: int = 0):
kb = InlineKeyboardMarkup()
league_keys = list(BOT_LEAGUES.keys())[0+offset:5+offset]
for lg_id in league_keys:
if lg_id in active_leagues:
kb.add(InlineKeyboardButton(
f"{emojize(':white_heavy_check_mark:')} {BOT_LEAGUES[lg_id]}",
callback_data=f'del_league_#{offset}#{lg_id}'
))
else:
kb.add(InlineKeyboardButton(
BOT_LEAGUES[lg_id],
callback_data=f'add_league_#{offset}#{lg_id}'
))
kb.row(
InlineKeyboardButton(
msg.btn_back if offset else msg.btn_go,
callback_data="edit_config#0" if offset else "edit_config#5"),
InlineKeyboardButton(msg.btn_save, callback_data="save_config")
)
return kb
# ...
В клавиатуре CONFIG_KB 3 кнопки. Класс кнопки InlineKeyboardButton принимает текст и параметр callback_data. Именно callback нам отправит Телеграм после нажатия на кнопку. Вот так выглядит эта клавиатура:
А leagues_kb генерирует более сложную клавиатуру, с пагинацией. Мы выводим 5 лиг, кнопку «далее/назад» и «сохранить». Функция принимает выбранные лиги и отступ. Отступ нужен, для вывода лиг постранично.
Когда юзер нажимает на лигу, мы добавляем ее в кеш, нажимает повторно — удаляем. Обратите внимание, я генерирую динамическую строку в callback_data. Подставляю параметры offset и lg_id, что бы использовать при обработке.
Теперь напишем функцию красивого вывода списка лиг и обновления этого списка в кеше:
# fonlinebot/app/service.py
# ...
async def get_league_names(ids: list) -> str:
"""Функция собирает сообщение с названиями лиг из id"""
leagues_text = ""
for i, lg_id in enumerate(ids, start=1):
if i != 1:
leagues_text += '\n'
leagues_text += msg.league_row.format(
i=i,
flag=emojize(BOT_LEAGUE_FLAGS.get(lg_id, '-')),
name=BOT_LEAGUES.get(lg_id, '-')
)
return leagues_text
def update_leagues(user_id: str, data: str):
"""Функция добавляет или удаляет id лиги для юзера"""
league_id = data.split("#")[-1] # data ~ add_league_#5#345
if data.startswith("add"):
cache.lpush(f"u{user_id}", league_id)
else:
cache.lrem(f"u{user_id}", 0, league_id)
Настройка общения с Телеграмом
В файле бота допишем функции для меню настроек.
# fonlinebot/app/bot.py
@dp.callback_query_handler(lambda c: c.data == 'main_window')
async def show_main_window(callback_query: types.CallbackQuery):
"""Главный экран"""
await callback_query.answer()
await bot.send_message(callback_query.from_user.id, msg.main, reply_markup=s.MAIN_KB)
dp.message_handler(lambda message: message.text == msg.btn_config)
async def get_config(message: types.Message):
"""Обработка кнопки Настройки.
Проверка выбора лиг. Вывод меню изменений настроек"""
user_league_ids = await s.get_league_ids(message.from_user.id)
if user_league_ids:
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+2)
leagues = await s.get_league_names(user_league_ids)
await message.answer(msg.config.format(leagues=leagues),
reply_markup=s.CONFIG_KB)
else:
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+1)
await set_or_update_config(user_id=message.from_user.id)
@dp.callback_query_handler(lambda c: c.data == 'delete_config')
async def delete_config(callback_query: types.CallbackQuery):
"""Удаление пользователя из базы данных"""
await db.delete_users(callback_query.from_user.id)
cache.delete(f"u{callback_query.from_user.id}")
await callback_query.answer()
cache.incr(f"last_msg_{callback_query.from_user.id}")
await bot.send_message(callback_query.from_user.id,
msg.data_delete,
reply_markup=s.MAIN_KB)
Функция get_config вызывается после нажатия на «Настройки». Если у пользователя выбраны лиги, она возвращает стандартное сообщение и меню настроек. В другом случае будет вызвана set_or_update_config для выбора лиг.
Одновременно я добавил удаление данных и главный экран.
Создавать и редактировать список будем в одной функции. Ей понадобятся параметры из строки callback. Например, пользователь нажал «вперед ->» и Телеграм прислал "edit_config#5". Мы разделили строку по # и взяли последнее значение (‘5’). Так будут передаваться параметры между сообщениями.
# fonlinebot/app/bot.py
@dp.callback_query_handler(lambda c: c.data.startswith('edit_config'))
async def set_or_update_config(callback_query: types.CallbackQuery = None,
user_id=None, offset=""):
"""Получение или обновление выбранных лиг"""
# если пришел callback, получим данные
if callback_query is not None:
user_id = callback_query.from_user.id
offset = callback_query.data.split("#")[-1]
league_ids = await s.get_league_ids(user_id)
leagues = await s.get_league_names(league_ids)
# если это первый вызов функции, отправим сообщение
# если нет, отредактируем сообщение и клавиатуру
if offset == "":
await bot.send_message(
user_id,
msg.set_leagues.format(leagues=leagues),
reply_markup=s.leagues_kb(league_ids)
)
else:
msg_id = cache.get(f"last_msg_{user_id}")
await bot.edit_message_text(
msg.set_leagues.format(leagues=leagues),
user_id,
message_id=msg_id
)
await bot.edit_message_reply_markup(
user_id,
message_id=msg_id,
reply_markup=s.leagues_kb(league_ids, int(offset))
)
Не хватает еще реакции на нажатие по названию лиг и кнопке «сохранить».
# fonlinebot/app/bot.py
dp.callback_query_handler(lambda c: c.data[:6] in ['del_le', 'add_le'])
async def update_leagues_info(callback_query: types.CallbackQuery):
"""Добавление/удаление лиги из кеша, обновление сообщения"""
offset = callback_query.data.split("#")[-2]
s.update_leagues(callback_query.from_user.id, callback_query.data)
await set_or_update_config(user_id=callback_query.from_user.id, offset=offset)
await callback_query.answer()
@dp.callback_query_handler(lambda c: c.data == 'save_config')
async def save_config(callback_query: types.CallbackQuery):
"""Сохранение пользователя в базу данных"""
leagues_list = await s.get_league_ids(callback_query.from_user.id)
if len(leagues_list) > 3:
# не сохраняем, если превышен лимит лиг
await callback_query.answer(msg.cb_limit, show_alert=True)
elif leagues_list:
await db.insert_or_update_users(
callback_query.from_user.id,
",".join(leagues_list)
)
await callback_query.answer()
await bot.send_message(
callback_query.from_user.id,
msg.db_saved,
reply_markup=s.MAIN_KB
)
else:
# не сохраняем если список пустой
await callback_query.answer(msg.cb_not_saved)
Готово. Теперь можете запустить бота и добавить лиги в настройках.
Сообщение с результатами матчей
Так как работа с API еще не настроена, напишем заглушку для этих процессов.
# fonlinebot/app/bot.py
@dp.message_handler(lambda message: message.text == msg.btn_online)
@dp.message_handler(commands=['online'])
async def get_results(message: types.Message):
"""Обработка команды online и кнопки Онлайн.
Запрос матчей. Вывод результатов"""
user_leagues = await s.get_league_ids(message.from_user.id)
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+1)
if not user_leagues:
await set_or_update_config(user_id=message.from_user.id)
else:
answer = await s.generate_results_answer(user_leagues)
cache.setex(f"last_update_{message.from_user.id}", MINUTE, "Updated")
await message.answer(answer, reply_markup=s.results_kb(user_leagues))
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results(callback_query: types.CallbackQuery):
"""Обновление сообщения результатов"""
if cache.get(f"last_update_{callback_query.from_user.id}") is None:
user_leagues = callback_query.data.split("#")[1:]
answer = await s.generate_results_answer(user_leagues)
cache.setex(f"last_update_{callback_query.from_user.id}", MINUTE, "Updated")
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}"))
)
# игнорируем обновление, если прошло меньше минуты
await callback_query.answer(msg.cb_updated)
get_results получает лиги и фиксирует id сообщения для редактирования. Если у пользователя нет сохраненных лиг — вызывает set_or_update_config, в другом случает генерируем ответ с матчами и кнопкой «обновить».

Функция обновления результатов выполняет логику только если прошло больше минуты с момента последнего обновления. Для этого после каждого получения ответа с результатами мы добавляем запись в кеш со сроком хранения 1 минута.
Допишем зависимости:
# fonlinebot/app/dialogs.py
#...
results: str = "Все результаты за сегодня\n{matches}"
no_results: str = "Сегодня нет матчей"
update_results: str = "Обновить результаты"
cb_updated: str = f"{emojize(':white_heavy_check_mark:')} Готово"
#...
Кнопку обновления и генерацию ответа в «service.py».
# fonlinebot/app/service.py
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS, MINUTE
#...
def results_kb(leagues: list):
params = [f"#{lg}" for lg in leagues]
kb = InlineKeyboardMarkup()
kb.add(InlineKeyboardButton(
msg.update_results,
callback_data=f"update_results{''.join(params)}"
))
return kb
async def generate_results_answer(ids: list) -> str:
"""Функция создaет сообщение для вывода результатов матчей"""
results = await get_last_results(ids)
if results:
text_results = results_to_text(results)
return msg.results.format(matches=text_results)
else:
return msg.no_results
def ids_to_key(ids: list) -> str:
"""Стандартизация ключей для хранения матчей"""
ids.sort()
return ",".join(ids)
async def parse_matches(ids: list) -> list:
"""Функция получения матчей по API"""
# логику напишем в следующей части
return []
async def get_last_results(league_ids: list) -> list:
lg_key = ids_to_key(league_ids)
last_results = cache.jget(lg_key)
if last_results is None:
last_results = await parse_matches(league_ids)
if last_results:
# добавляем новые матчи, если они есть
cache.jset(lg_key, last_results, MINUTE)
return last_results
def results_to_text(matches: list) -> str:
"""
Функция генерации сообщения с матчами
"""
# логику напишем в следующей части
...
#...
Функция generate_results_answer получает матчи, преобразовывает данные в текст и возвращает его. Если матчей нет, возвращает соответствующий текст.
Что бы сэкономить ресурсы мы проверяем наличие матчей в кеше и только потом обращаемся к API.
Обработка неизвестных сообщений
Люди будут писать текст, который мы не обрабатываем. Обновите класс Messages:
# fonlinebot/app/dialogs.py
#...
unknown_text: str = "Ничего не понятно, но очень интересно.\nПопробуй команду /help"
#...
И unknown_message.
# fonlinebot/app/bot.py
#...
@dp.message_handler()
async def unknown_message(message: types.Message):
"""Ответ на любое неожидаемое сообщение"""
await message.answer(msg.unknown_text, reply_markup=s.MAIN_KB)
#...
Убедимся, что все работает:
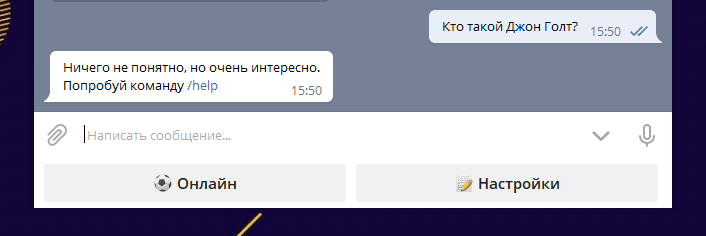
Отлично. Мы написали бота с клавиатурами, кешированием и базой данных. Теперь пора добавить тестов.
Обновление тестов
Добавим класс TestService для контроля функции get_league_ids и get_last_results.
# fonlinebot/test.py
from app import bot, service
#...
class TestService(IsolatedAsyncioTestCase):
async def test_get_league_ids(self):
ids = await service.get_league_ids("1111")
self.assertEqual(type(ids), list)
async def test_get_last_results(self):
results = await service.get_last_results(["1", "2", "3"])
self.assertEqual(type(results), list)
#...
Ссылка на репозиторий с кодом в начале статьи. Удачи!
Что дальше?
Осталась малая часть работы. В следующей части мы найдем подходящий API и настроем обработку получения результатов: добавление внешнего API.
]]>Когда локальная версия будет готова, разместим бота на сервере. Вместо Heroku, я выбрал отдельную виртуальную машину, что бы бот не засыпал. Это ближе к реальности.
Вся разработка разбита на этапы:
- Локальная установка библиотек и Redis.
- Регистрация и получение токена.
- Настройка , подключение к базам данных.
- Написание основной функциональности бота.
- Регистрации, выбор и настройка внешнего апи футбольных матчей.
- Добавление сбора результатов матчей и интеграция в бота.
- Деплой, публикация на сервере:
- Регистрация дешевого или бесплатного VPS.
- Запуск Редис-клиента.
- Запуск и настройка бота на сервере.
Рабочая версия бота запущена в телеграме до конца февраля @FonlineBOT. Бот отключен.
Вводные данные
Материал рассчитан на уровень Начинающий+, нужно понимать как работают классы и функции, знать основы базы данных и async/await. Если знаний мало, крайне желательно писать код в Pycharm, бесплатная версия подходит.
Используйте указанные версии библиотек, что бы проект работал без изменений. При установке иных версий вы можете получать ошибки, связанные с совместимостью.
Версия Python - 3.8+
aiogram==2.11.2
emoji==1.1.0
redis==3.5.3
ujson==4.0.1
uvloop==0.14.0 # не работает и не требуется на WindowsРепозиторий с кодом этой для этой части бота:
https://gitlab.com/PythonRu/fonlinebot/-/tree/master/first_step
Локальная установка библиотек для бота и Redis
Для начала нужно создать проект «fonlinebot» с виртуальным окружение. В Pycharm это делается так:
Затем установить библиотеки в виртуальном окружении. Сразу понадобятся 4: для бота, работы с redis, ускорения и emoji в сообщениях.
pip install aiogram==2.11.2 redis==3.5.3 ujson==4.0.1 emoji==1.1.0Установка Redis локально
Redis — это резидентная база данных (такая, которая хранит записи прямо в оперативной памяти) в виде пар ключ-значение. Чтение и запись в память происходит намного быстрее, чем в случае с дисками, поэтому такой подход отлично подходит для хранения второстепенных данных.
Из недавней статьи — Redis для приложений на Python
Для установки Redis на Linux/Mac следуйте этим инструкциям: https://redis.io/download#from-source-code. Для запуска достаточно ввести src/redis-server.
Что бы установить на Windows скачайте и распакуйте архив отсюда. Для запуска откройте «redis-server.exe».
Теперь нужно убедиться, что все работает. Создайте файл «main.py» в корне проекта и выполните этот код:
# fonlinebot/main.py
import redis
r = redis.StrictRedis()
print(r.ping())
Вывод будет True, в другом случае ошибка.
Регистрация бота и получение токена
Для регистрации напишем https://t.me/botfather команду /newbot. Далее он просит ввести имя и адрес бота. Если данные корректны, выдает токен. Учтите, что адрес должен быть уникальным, нельзя использовать «fonlinebot» снова.
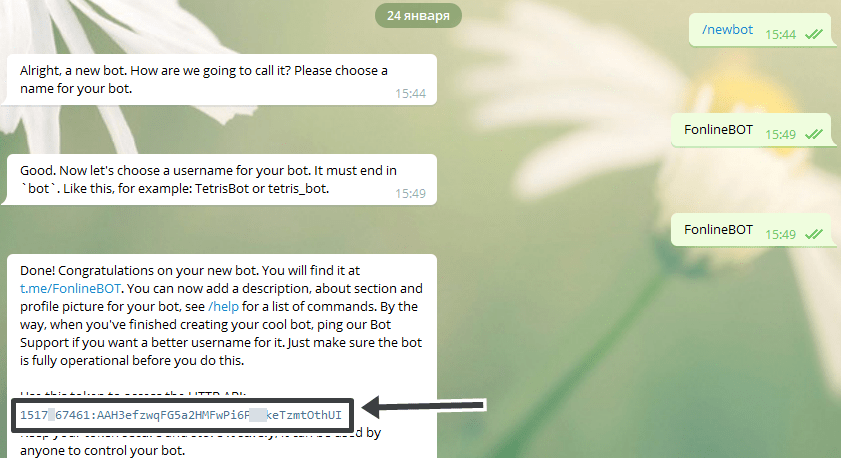
На время разработки сохраним токен в файл. Создайте «config.py» в папке проекта для хранения настроек и запишите токен TOKEN = "ВАШ ТОКЕН"
Настройка бота
Теперь нужно связать бота с redis и базой данных, проверить работоспособность.
Создадим необходимые модули и файлы. В папке «fonlinebot» к созданным ранее «main.py» и «config.py» добавим: «database.py», «requirements.txt» и папку «app». В папку «app» добавьте: «bot.py», «dialogs.py», «service.py». Вот такая структура получится:

Разделив бот на модули, его удобнее поддерживать и дорабатывать.
- «main.py» — для запуска бота.
- «config.py» — хранит настройки, ключи доступов и другую статическую информацию.
- «database.py» — для работы с базой данных и кешем(redis).
- «requirements.txt» — хранит зависимости проекта, для запуска на сервере.
- «app» — папка самого бота.
- «bot.py» — для взаимодействия бота с юзерами, ответы на сообщения.
- «dialogs.py» — все текстовые ответы бота.
- «service.py» — бизнес логика, получение и обработка данных о матчах.
Пришло время перейти к программированию. Запишем в «requirements.txt» наши зависимости:
aiogram==2.11.2
emoji==1.1.0
redis==3.5.3
ujson==4.0.1
uvloop==0.14.0Так как большая часть программирует на Windows, uvloop мы не устанавливали локально. Установим его на сервере.
В «config.py» к токену добавим данные бота и подключения к redis.
# fonlinebot/config.py
import ujson
import logging
logging.basicConfig(level=logging.INFO)
TOKEN = "здесь должен быть токен"
BOT_VERSION = 0.1
# База данных хранит выбранные юзером лиги
BOT_DB_NAME = "users_leagues"
# Тестовые данные поддерживаемых лиг
BOT_LEAGUES = {
"1": "Бундеслига",
"2": "Серия А",
"3": "Ла Лига",
"4": "Турецкая Суперлига",
"5": "Чемпионат Нидерландов",
"6": "Про-лига Бельгии",
"7": "Английская Премьер-лига",
"8": "Лига 1",
}
# Флаги для сообщений, emoji-код
BOT_LEAGUE_FLAGS = {
"1": ":Germany:",
"2": ":Italy:",
"3": ":Spain:",
"4": ":Turkey:",
"5": ":Netherlands:",
"6": ":Belgium:",
"7": ":England:",
"8": ":France:",
}
# Данные redis-клиента
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# По умолчанию пароля нет. Он будет на сервере
REDIS_PASSWORD = None
Информацию о лигах в будущем можно будет вынести в отдельный json файл. Эта версия бота будет поддерживать не более 10 вариантов, я явно их записал.
Добавление базы данных
Теперь добавим классы для работы с базой данных sqlite и redis. База данных нужна для сохранения предпочтений по лигам юзеров.
Юзер будет выбирать 3 чемпионата для отслеживания, бот сохранит их в БД и использует для запроса результатов.
Кеш(redis) будет сохранять результаты матчей, что бы уменьшить количество запросов к API и ускорить время ответов. Как правило, бесплатные API лимитирует запросы.
# fonlinebot/database.py
import os
import logging
import sqlite3
import redis
import ujson
import config
# класс наследуется от redis.StrictRedis
class Cache(redis.StrictRedis):
def __init__(self, host, port, password,
charset="utf-8",
decode_responses=True):
super(Cache, self).__init__(host, port,
password=password,
charset=charset,
decode_responses=decode_responses)
logging.info("Redis start")
def jset(self, name, value, ex=0):
"""функция конвертирует python-объект в Json и сохранит"""
r = self.get(name)
if r is None:
return r
return ujson.loads(r)
def jget(self, name):
"""функция возвращает Json и конвертирует в python-объект"""
return ujson.loads(self.get(name))
Класс Cache наследуется от StrictRedis. Мы добавляем 2 метода jset, jget для сохранения списков и словарей python в хранилище redis. Изначально он не работает с ними.
Теперь добавим класс, который будет создавать базы данных и выполнять функции CRUD.
# fonlinebot/database.py
#...
class Database:
""" Класс работы с базой данных """
def __init__(self, name):
self.name = name
self._conn = self.connection()
logging.info("Database connection established")
def create_db(self):
connection = sqlite3.connect(f"{self.name}.db")
logging.info("Database created")
cursor = connection.cursor()
cursor.execute('''CREATE TABLE users
(id INTEGER PRIMARY KEY,
leagues VARCHAR NOT NULL);''')
connection.commit()
cursor.close()
def connection(self):
db_path = os.path.join(os.getcwd(), f"{self.name}.db")
if not os.path.exists(db_path):
self.create_db()
return sqlite3.connect(f"{self.name}.db")
def _execute_query(self, query, select=False):
cursor = self._conn.cursor()
cursor.execute(query)
if select:
records = cursor.fetchone()
cursor.close()
return records
else:
self._conn.commit()
cursor.close()
async def insert_users(self, user_id: int, leagues: str):
insert_query = f"""INSERT INTO users (id, leagues)
VALUES ({user_id}, "{leagues}")"""
self._execute_query(insert_query)
logging.info(f"Leagues for user {user_id} added")
async def select_users(self, user_id: int):
select_query = f"""SELECT leagues from leagues
where id = {user_id}"""
record = self._execute_query(select_query, select=True)
return record
async def update_users(self, user_id: int, leagues: str):
update_query = f"""Update leagues
set leagues = "{leagues}" where id = {user_id}"""
self._execute_query(update_query)
logging.info(f"Leagues for user {user_id} updated")
async def delete_users(self, user_id: int):
delete_query = f"""DELETE FROM users WHERE id = {user_id}"""
self._execute_query(delete_query)
logging.info(f"User {user_id} deleted")
Sqlite подходит для тестовых проектов. В будущем потребуется переход на внешнюю базу данных и асинхронная работа. Что бы не переписывать всю логику работы с базой, я сразу добавил асинхронный синтаксис.
Файл базы данных будет создаваться один раз, автоматически. Теперь нужно создать экземпляры классов:
# fonlinebot/database.py
#...
# создание объектов cache и database
cache = Cache(
host=config.REDIS_HOST,
port=config.REDIS_PORT,
password=config.REDIS_PASSWORD
)
database = Database(config.BOT_DB_NAME)
Добавление текстовых сообщений
Для шаблонов сообщений создадим неизменяемый dataclass. Здесь будут все текстовые ответы. А dataclass удобно использовать при вызове аргументов.
# fonlinebot/app/dialogs.py
from dataclasses import dataclass
@dataclass(frozen=True)
class Messages:
test: str = "Привет {name}. Работаю..."
msg = Messages()
Создание бота
В файле «bot.py» создадим бота. Импортируем зависимости, создадим объект бота и первое сообщение.
# fonlinebot/app/bot.py
from aiogram import Bot, types
from aiogram.contrib.middlewares.logging import LoggingMiddleware
from aiogram.dispatcher import Dispatcher
from config import TOKEN
from app.dialogs import msg
from database import database as db
# стандартный код создания бота
bot = Bot(token=TOKEN)
dp = Dispatcher(bot)
dp.middleware.setup(LoggingMiddleware())
@dp.message_handler()
async def test_message(message: types.Message):
# имя юзера из настроек Телеграма
user_name = message.from_user.first_name
await message.answer(msg.test.format(name=user_name))
Функция test_message принимает любое сообщение и отвечает на него. Кроме этого, нужно закрывать соединение с базой данных перед завершением работы. Добавим в конец файла on_shutdown.
# fonlinebot/app/bot.py
# ...
async def on_shutdown(dp):
logging.warning('Shutting down..')
# закрытие соединения с БД
db._conn.close()
logging.warning("DB Connection closed")
Первый запуск бота
Для запуска используем файл «main.py». Импортируем бота и настроим пулинг:
# fonlinebot/main.py
from aiogram import executor
from app import bot
executor.start_polling(bot.dp,
skip_updates=True,
on_shutdown=bot.on_shutdown)
Теперь запустим проект. Если вы в Pycharm, откройте вкладку «Terminal» и введите python main.py. Что бы запустить бота без Pycharm:
- перейдите в папку проекта,
- активируйте виртуальное окружение,
- запустите скрипт (
python main.py).
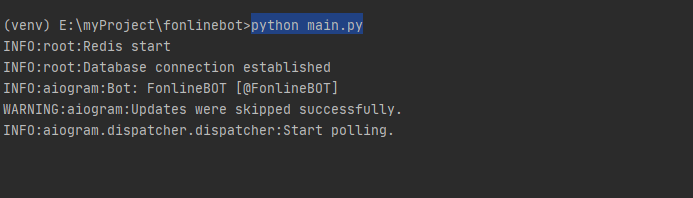
Теперь откроем телеграм и проверим.
Отлично, работает! Теперь самое время написать несколько базовых тестов, что бы избежать проблем в будущем.
Тестирование бота
В процессе написания проекта код будем изменяться. Что бы избежать появления новых ошибок после размещения на сервере, нужно сразу написать несколько тестов.
Добавьте модуль «test.py» в папку fonlinebot. На этом этапе достаточно 4 теста, вы можете добавить свои.
# fonlinebot/test.py
import unittest
import aiohttp
from unittest import IsolatedAsyncioTestCase
from database import cache, database
from app import bot
class TestDatabase(IsolatedAsyncioTestCase):
async def test_crud(self):
await database.insert_users(1111, "1 2 3")
self.assertEqual(await database.select_users(1111), ('1 2 3',))
await database.delete_users(1111)
self.assertEqual(await database.select_users(1111), None)
class TestCache(unittest.TestCase):
def test_connection(self):
self.assertTrue(cache.ping())
def test_response_type(self):
cache.setex("test_type", 10, "Hello")
response = cache.get("test_type")
self.assertEqual(type(response), str)
class TestBot(IsolatedAsyncioTestCase):
async def test_bot_auth(self):
bot.bot._session = aiohttp.ClientSession()
bot_info = await bot.bot.get_me()
await bot.bot._session.close()
self.assertEqual(bot_info["username"], "FonlineBOT")
if __name__ == '__main__':
unittest.main()
Мы проверим CRUD функции базы данных, запишем тестовые данные и удалим. Проверим соединение с redis и ботом.
Запуск теста такой же как и бота, изменяется только имя файла python main.py.

На скриншоте видно уведомление об ошибке после завершения тестирования. Это известная проблема aiohttp на windows, можно игнорировать.
Ошибки, которые можно встретить
aiogram.utils.exceptions.Unauthorized: Unauthorized— неверный токен бота. Токен нужно сохранить как строку, его структура «цифры:буквы-и-цифры», проверьте.redis.exceptions.ConnectionError: Error 10061 connecting to ...— redis-server не запущен.sqlite3.IntegrityError: UNIQUE constraint failed: ...— вы пытаетесь добавить значение в базу данных, которое уже существует.
На этом подготовка проекта окончена. Переходите ко второй части: Написание ядра бота.
]]>datetime включает различные компоненты. Так, он состоит из объектов следующих типов:
date— хранит датуtime— хранит времяdatetime— хранит дату и время
Как получить текущие дату и время?
С помощью модуля Python это сделать очень просто. Сначала нужно импортировать класс datetime из модуля datetime, после чего создать объект datetime. Модуль предоставляет метод now(), который возвращает текущие дату и время с учетом локальных настроек.
import datetime
dt_now = datetime.datetime.now()
print(dt_now)
А вот результат:
2020-11-14 15:43:32.249588Получить текущую дату в Python
Класс date можно использовать для получения или изменения объектов даты. Например, для получения текущей с учетом настроек подойдет следующее:
from datetime import date
current_date = date.today()
print(current_date)
Результат:
2020-11-14Текущая дата — 2020-11-14 в формате год-месяц-день соответственно.
Получить текущее время
Для получения текущего локального времени сперва нужно получить текущие дату и время, а затем достать из этого объекта только время с помощью метода time():
import datetime
current_date_time = datetime.datetime.now()
current_time = current_date_time.time()
print(current_time)
Результат:
15:51:05.627643Компоненты datetime в Python
Модуль datetime в Python может использоваться для получения разных версий времени. Для этого нужно ознакомиться с атрибутами модуля. Используем для этого функцию dir().
import datetime
attr = dir(datetime)
print(attr)
# ['MAXYEAR', 'MINYEAR', '__doc__', '__name__', '__package__', 'date', 'datetime',
# 'datetime_CAPI', 'time', 'timedelta', 'tzinfo']
В этом руководстве речь пойдет о следующих элементах:
date— объекты датыdatetime— объекты даты и времениtime— объекты времениtimedelta— этот атрибут покрывает интервалы и используется для определения прошлых или будущих событийTzinfo— этот атрибут отвечает за часовые пояса
Как создавать объекты даты и времени
Для создания объекта времени используется класс time из модуля datetime в Python. Синтаксис следующий: datetime.time(hour, minutes, seconds).
В этом примере создается объект времени представленный следующим образом (8, 48, 45).
import datetime
timeobj= datetime.time(8,48,45)
print(timeobj)
Результат такой:
08:48:45Сначала импортируется модуль datetime. После этого создается экземпляр класса (объект time). Затем ему присваивается значение datetime.time(8, 48, 45), где параметры 8, 48 и 45 представляют собой часы, минуты и секунды соответственно.
Для создания объекта даты нужно передать дату с использованием следующего синтаксиса:
datetime.datetime(year,month,day))Такой пример:
import datetime
date_obj = datetime.datetime(2020,10,17)
print(date_obj)
Вернет вот такой результат:
2020-10-17 00:00:00Timedelta
timedelta представляет длительность (даты или времени). Модуль datetime включает атрибут timedelta(), который используется для управления датой в Python. Объект timedelta выглядит следующим образом:
td_object =timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
td_object
datetime.timedelta(0)
Все аргументы опциональные и их значения по умолчанию равно 0. Они могут быть целыми или числами с плавающей точкой, как положительными, так и отрицательными. Благодаря этому можно выполнять математические операции, такие как сложение, вычитание и умножение.
Как вычислить разницу для двух дат
Посмотрим на несколько примеров вычисления разницы во времени. Предположим, есть два объекта datetime:
first_date = date(2020, 10, 2)
second_date = date(2020, 10, 30)Для получения разницы нужно лишь вычесть значение одного объекта из второго:
from datetime import date
first_date = date(2020, 10, 2)
second_date = date(2020, 10, 30)
delta = second_date - first_date
print(delta)
Результат:
28 days,0:00:00Таким образом между 2 и 30 октября 2020 года 28 дней.
Как вычислить разницу двух объектов datetime.time
С помощью timedelta нельзя выполнять манипуляции над объектами time. Например:
from datetime import datetime, timedelta
current_datetime = datetime.now()
current_time = current_datetime.time()
print("Текущее время:", current_time)
tm_after_1_hr = current_time + timedelta(hours=1)
print(tm_after_1_hr)
Такой код вернет следующую ошибку:
Traceback (most recent call last):
File "C:\Users\alex\AppData\Local\Programs\Python\Python38\sg_verify.py", line 6, in <module>
tm_after_1_hr = current_time + timedelta(hours=1)
TypeError: unsupported operand type(s) for +: 'datetime.time' and 'datetime.timedelta'Как получать прошлые и будущие даты с помощью timedelta
Поскольку timedelta — это длительность, то для получения прошлой или будущей даты нужно добавить объект timedelta к существующему или вычесть из него же. Вот пример нескольких уравнений, где n — это целое число, представляющее количество дней:
import datetime
current_date = datetime.datetime.today()
past_date = datetime.datetime.today() – datetime.timedelta(days=n)
future_date = datetime.datetime.today() – datetime.timedelta(days=n)
Если нужно, например, получить дату за прошлые две недели, то достаточно вычесть 14 дней из текущей даты:
import datetime
past_date = datetime.datetime.today() - datetime.timedelta(days=14)
print(past_date)
Результат:
2020-10-31 16:12:09.142258Предположим, вы задумали практиковать определенный навык в течение 21 дня. Для получения будущей даты нужно добавить 21 день к текущей дате:
import datetime
future_date = datetime.datetime.today() + datetime.timedelta(days=21)
print(future_date)
Результат:
2020-12-05 16:14:09.718325Другие арифметические операции с timedelta
Значения даты и времени могут сравниваться для определения того, какая из них была раньше или позже. Например:
import datetime
now = datetime.time(9, 31, 0)
next_hour = datetime.time(10, 31, 0)
print('now < next_hour:', now < next_hour)
today = datetime.date.today()
next_week = datetime.date.today() + datetime.timedelta(days=7)
print('today > next_week:', today > next_week)
Результат:
now < next_hour: True
today > next_week: FalseЧасовые пояса
Пока что мы работали с datetime без учета часовых поясов и летнего времени. Но прежде чем переходить к следующим пунктам, нужно разобраться с разницей в абсолютных (naive) и относительных (aware) датах.
Абсолютные даты не содержат информацию, которая бы могла определить часовой пояс или летнее время. Однако с такими намного проще работать.
Относительные же содержат достаточно информации для определения часового пояса или отслеживания изменений из-за летнего времени.
Разница между DST, GMT и UTC
- GMT
Официальный часовой пояс, используемый в некоторых странах Европы и Африки. Он может быть представлен как в 24, так и в 12-часовом форматах. GMT используется для того, чтобы задавать местное время. Например, местное время для Берлина 2020–10–17 09:40:33.614581+02:00 GMT. Для Найроби же это — 2020–10–17 10:40:33.592608+03:00 GMT. - DST (летнее время)
Страны, которые переходят на летнее время, делают это для того, чтобы дневное время длилось как можно дольше. Во время летнего времени они переводят стрелки своих часов на час вперед и возвращаются обратно осенью. - UTC (всемирное координированное время)
Временной стандарт для часовых поясов во всем мире. Он позволяет синхронизировать время во всем мире и служит отправной точкой для остальных.
Как работать с часовыми поясами
Рассмотрим, как создать простой относительный объект datetime:
import datetime
dt_now = datetime.datetime.utcnow()
print(dt_now)
Эта программа возвращает объект с абсолютным значением datetime. Если же нужно сделать его абсолютным, то нужно явно указать часовой пояс. Как это сделать? В библиотеке datetime в Python нет модуля для работы с часовыми поясами. Для этого нужно использовать другие библиотеки. Одна из таких — pytz.
Предположим, нужно получить текущее время для Найроби. Для этого нужно использовать конкретный часовой пояс. Для начала можно с помощью pytz получить все существующие часовые пояса.
import pytz
pytz.all_timezones
Вот некоторые из них:
['Africa/Abidjan', 'Africa/Accra', 'Africa/Addis_Ababa', 'Africa/Nairobi']Для получения времени в Найроби:
import pytz
import datetime
tz_nairobi = pytz.timezone("Africa/Nairobi")
dt_nairobi =datetime.datetime.now(tz_nairobi)
print(dt_nairobi)
Результат:
2020-11-14 17:27:31.141255+03:00А вот так можно получить время Берлина:
import pytz
import datetime
tz_berlin = pytz.timezone("Europe/Berlin")
dt_berlin =datetime.datetime.now(tz_berlin)
print(dt_berlin)
Результат:
2020-11-14 15:28:20.977529+01:00Здесь можно увидеть разницу в часовых поясах разных городов, хотя сама дата одна и та же.
Конвертация часовых поясов
При конвертации часовых поясов в первую очередь нужно помнить о том, что все атрибуты представлены в UTC. Допустим, нужно конвертировать это значение в America/New_York:
import datetime
import pytz
timezone_berlin = '2019-06-29 17:08:00'
tz_ber_obj = datetime.datetime.strptime(timezone_berlin, '%Y-%m-%d %H:%M:%S')
timezone_newyork = pytz.timezone('America/New_York')
timezone_newyork_obj = timezone_newyork.localize(tz_ber_obj)
print(timezone_newyork_obj)
print(timezone_newyork_obj.tzinfo)
Результат:
2019-06-29 17:08:00-04:00
America/New_YorkДругие практические примеры
Всегда храните даты в UTC. Вот примеры:
import datetime
import pytz
time_now = datetime.datetime.now(pytz.utc)
print(time_now)
Результат для этого кода — 2020-11-14 14:38:46.462397+00:00, хотя локальное время может быть, например, таким 2020-11-14 16:38:46.462397+00:00. А уже при демонстрации даты пользователю стоит использовать метод localize с местными настройками:
import datetime
import pytz
now = datetime.datetime.today()
now_utc = pytz.utc.localize(now)
Вернет текущее локальное время — 2020-11-14 16:42:38.228528+00:00.
Как конвертировать строки в datetime
strptime() в Python — это метод из модуля datetime. Вот его синтаксис:
dateobj = datetime.strptime(date_string, format)Аргументы формата необязательные и являются строками. Предположим, нужно извлечь текущие дату и время:
import datetime
current_dt = datetime.datetime.now()
print(current_dt)
Результат:
2020-11-14 16:50:45.049229Результат будет в формате ISO 8601, то есть YYYY-MM-DDTHH:MM:SS.mmmmmm — формат по умолчанию, что позволяет получать строки в едином формате.
Таблица форматов:
| Символ | Описание | Пример |
|---|---|---|
| %a | День недели, короткий вариант | Wed |
| %A | Будний день, полный вариант | Wednesday |
| %w | День недели числом 0-6, 0 — воскресенье | 3 |
| %d | День месяца 01-31 | 31 |
| %b | Название месяца, короткий вариант | Dec |
| %B | Название месяца, полное название | December |
| %m | Месяц числом 01-12 | 12 |
| %y | Год, короткий вариант, без века | 18 |
| %Y | Год, полный вариант | 2018 |
| %H | Час 00-23 | 17 |
| %I | Час 00-12 | 05 |
| %p | AM/PM | PM |
| %M | Минута 00-59 | 41 |
| %S | Секунда 00-59 | 08 |
| %f | Микросекунда 000000-999999 | 548513 |
| %z | Разница UTC | +0100 |
| %Z | Часовой пояс | CST |
| %j | День в году 001-366 | 365 |
| %U | Неделя числом в году, Воскресенье первый день недели, 00-53 | 52 |
| %W | Неделя числом в году, Понедельник первый день недели, 00-53 | 52 |
| %c | Локальная версия даты и времени | Mon Dec 31 17:41:00 2018 |
| %x | Локальная версия даты | 12/31/18 |
| %X | Локальная версия времени | 17:41:00 |
| %% | Символ “%” | % |
import datetime
date_string = "11/17/20"
date_obj = datetime.datetime.strptime(date_string, '%m/%d/%y')
print(date_obj)
Результат:
2020-11-17 00:00:00Примеры конвертации строки в объект datetime с помощью strptime
Предположим, что есть следующая строка с датой: «11/17/20 15:02:34», и ее нужно конвертировать в объект datetime.
from datetime import datetime
datetime_string = "11/17/20 15:02:34"
datetime_obj = datetime.strptime(datetime_string, '%m/%d/%y %H:%M:%S')
print(datetime_obj)
Результат:
2020-11-17 15:02:34Даты могут быть записаны в разных форматах. Например, следующие даты отличаются лишь представлением:
- Friday, November 17, 2020;
- 11/17/20;
- 11–17–2020.
Вот как это работает:
from datetime import datetime
# создадим даты как строки
ds1 = 'Friday, November 17, 2020'
ds2 = '11/17/20'
ds3 = '11-17-2020'
# Конвертируем строки в объекты datetime и сохраним
dt1 = datetime.strptime(ds1, '%A, %B %d, %Y')
dt2 = datetime.strptime(ds2, '%m/%d/%y')
dt3 = datetime.strptime(ds3, '%m-%d-%Y')
print(dt1)
print(dt2)
print(dt3)
Результат будет одинаковым для всех форматов:
2020-11-17 00:00:00
2020-11-17 00:00:00
2020-11-17 00:00:00Практические примеры
Если строка представлена в формате «Oct 17 2020 9:00PM», то ее можно конвертировать следующим образом:
date_string = 'Oct 17 2020 9:00PM'
date_object = datetime.strptime(date_string, '%b %d %Y %I:%M%p')
print(date_object)
Результат — 2020-10-17 21:00:00.
Функцию strptime() можно использовать для конвертации строки в объект даты:
from datetime import datetime
date_string = '10-17-2020'
date_object = datetime.strptime(date_string, '%m-%d-%Y').date()
print(type(date_object))
print(date_object)
Результат:
<type 'datetime.date'>
2020-10-17Как конвертировать объект datetime в строку
Модуль datetime в Python содержит метод strftime(), который делает обратное (то есть, конвертирует объект datetime и time в строки). Вот его синтаксис:
datetime_string = datetime_object.strftime(format_string)
time_string = datetime_object.strftime(format_string[,time_object])Примеры конвертации datetime в строку с помощью strftime()
Предположим, нужно конвертировать текущий объект datetime в строку. Сначала нужно получить представление объекта datetime и вызвать на нем метод strftime().
import datetime
current_date = datetime.datetime.now()
current_date_string = current_date.strftime('%m/%d/%y %H:%M:%S')
print(current_date_string)
Результат — 11/14/20 17:15:03.
Как получить строковое представление даты и времени с помощью функции format()
Пример №1. Конвертация текущей временной метки в объекте datetime в строку в формате «DD-MMM-YYYY (HH:MM:SS:MICROS)»:
import datetime
dt_obj =datetime.datetime.now()
dt_string = dt_obj.strftime("%d-%b-%Y (%H:%M:%S.%f)")
print('Текущее время : ', dt_string)
Результат:
Текущее время : 14-Nov-2020 (17:18:09.890960)Пример №2. Конвертация текущей временной метки объекта datetime в строку в формате «HH:MM:SS.MICROS – MMM DD YYYY».
import datetime
dt_obj =datetime.datetime.now()
dt_string = dt_obj.strftime("%H:%M:%S.%f - %b %d %Y")
print('Текущее время : ', dt_string)
Результат:
Текущее время : 17:20:28.841390 - Nov 14 2020Другие datetime-библиотеки в Python
В Python есть и другие библиотеки, которые упрощают процесс манипуляций с объектами datetime. В некоторых из них есть поддержка часовых поясов.
Arrow
Arrow — еще один популярный модуль, который делает более простым процесс создания, управления и форматирования дат и времени. Получить его можно с помощью pip. Для установки достаточно ввести pip install arrow.
Arrow можно использовать для получения текущего времени по аналогии с модулем datetime:
import arrow
current_time = arrow.now()
print(current_time)
print(current_time.to('UTC'))
Результат:
2020-11-14T15:52:58.921198+00:00
2020-11-14T15:52:58.921198+00:00Maya
Maya упрощает процесс парсинга строк и конвертации часовых поясов. Например:
import maya
dt = maya.parse('2019-10-17T17:45:25Z').datetime()
print(dt.date())
print(dt)
print(dt.time())
Результат:
2019-10-17
2019-10-17 17:45:25+00:00
17:45:25Dateutil
Dateutil — это мощная библиотека, которая используется для парсинга дат и времени в разных форматах. Вот некоторые примеры.
from dateutil import parser
dt_obj = parser.parse('Thu Oct 17 17:10:28 2019')
print(dt_obj)
dt_obj1=parser.parse('Thursday, 17. October 2019 5:10PM')
print(dt_obj1)
dt_obj2=parser.parse('10/17/2019 17:10:28')
print(dt_obj2)
t_obj=parser.parse('10/17/2019')
print(t_obj)
Результат:
2019-10-17 17:10:28
2019-10-17 17:10:00
2019-10-17 17:10:28
2010-10-17 00:00:00Важно, что в этом случае не нужны регулярные выражения при определении формата. Парсер ищет узнаваемые токены и либо возвращает корректный результат, либо выдает ошибку.
Важные нюансы
Вот о чем важно помнить при работе с datetime в Python:
- Рекомендуется всегда работать с UTC. Это позволяет не думать о часовых поясах, что часто приводит к ошибкам из-за разницы во времени в разных регионах.
- Дату и время стоит конвертировать в локальную только при выводе пользователю.
Выводы
Есть масса сценариев работы с датой и временем в реальных приложениях. Например:
- Запланировать работу скрипта на определенное время.
- Отфильтровать даты.
- Извлечь дату из определенных API каждый день, в определенное время.
- Приложения для отслеживания событий, записей, бронирования и так далее.
В этом материале разберемся с этой функцией и рассмотрим более продвинутые вещи.
Как выводить текст в Python 3
Выводить текст в Python очень просто. Достаточно лишь написать:
print("Текст для вывода")
Но все становится чуть сложнее, учитывая, что существуют две популярные версии Python. Этот пример сработает с Python 3+ (поддерживаемой сегодня версией), однако стоит убрать скобки в том случае, если это Python 2:
print "Текст для вывода"
Вывод строк и других переменных
Размещая текст внутри кавычек, вы создаете строку. Строка в программировании — это любая последовательность букв или цифр.
Строки могут храниться и в виде переменных. Это значит, что слово будет использоваться для представления строки, и к нему можно будет ссылаться позже в коде.
Например:
hello_world = "Hello world!"
print(hello_world)
Этот код хранит строку "Hello world!" в переменной hello_world. Позже ее можно будет использовать для вывода текста, указав в скобках без кавычек.
Зачем может понадобиться выводить такой текст? Это может быть полезно в тех ситуациях, когда показываемый контент потенциально может поменяться во время работы программы. Это также удобно для получения информации: например, за счет ввода от пользователя.
name = input("Введите ваше имя пожалуйста: ")
print("Привет " + name)
Если запустить этот код и ввести «Витя» получим:
Введите ваше имя пожалуйста: Витя
Привет ВитяКак можно понять, этот код запрашивает пользователя сделать ввод и затем приветствует лично его. Также этот пример демонстрирует, как выводить текст, объединяя его с текстом из переменной. Достаточно заключить текст в кавычки и добавить знак плюса. Обратите внимание на пробел. Однако есть и другой способ разделения элементов — для этого используется запятая. Например:
Некоторые приемы вывода
Если при выводе текста в Python после него нужна пустая строка, то для этого используется символ \n.:
print("Привет\n")
print(name)
Привет
ВитяТакже обратите внимание на то, что разрешается использовать как одинарные, так и двойные кавычки. Благодаря этому можно использовать кавычки как часть выводимого текста:
print('Он "умеет" кодить!')
А если нужно вывести два типа кавычек, то тут на помощь приходят тройные кавычки:
print("""Я сказал "Привет" и все еще жду, когда 'они' ответят мне""")
Вот и все что нужно знать о выводе текста в Python.
Краткий итог
Что бы вывести текст в python достаточно вызвать функцию print(). Например: print("Ваш текст").
В этом материале речь пойдет о следующем:
- Как определять символ новой строки в Python.
- Как использовать символ новой строки в строках и инструкциях вывода.
- Вывод текста без добавления символа новой строки в конце.
Символ новой строки
Символ новой строки в Python выглядит так \n. Он состоит из двух символов:
- Обратной косой черты.
- Символа n (в нижнем регистре).
Если встретили этот символ в строке, то знайте, что он указывает на то, что текущая строка заканчивается здесь, а новая начинается сразу после нее.
>>> print("Hello\nWorld!")
Hello
World!Его же можно использовать в f-строках: print(f"Hello\nWorld!").
Символ новой строки в print
По умолчанию инструкции вывода добавляют символ новой строки «за кулисами» в конце строки. Вот так:

Это поведение описано в документации Python. Значение параметра end встроенной функции print по умолчанию — \n. Именно таким образом символ новой строки добавляется в конце строки.
Вот определение функции:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)Значением end='\n', поэтому именно этот символ будет добавлен к строке.
Если использовать только одну инструкцию print, то на такое поведение можно и не обратить внимание, потому что будет выведена лишь одна строка. Но если использовать сразу несколько таких инструкций:
print("Hello, World 1!")
print("Hello, World 2!")
print("Hello, World 3!")
print("Hello, World 4!")
Вывод будет разбит на несколько строк, потому что символ \n добавится «за кулисами» в конце каждой строки:
Hello, World 1!
Hello, World 2!
Hello, World 3!
Hello, World 4!Как использовать print без символа новой строки
Изменить поведение по умолчанию можно, изменив значение параметра end в функции print. В этом примере настройки по умолчанию приведут к такому результату:
>>> print("Hello")
>>> print("World")
Hello
World
Но если указать значением end пробел (" "), то этот он будет добавлен в конце строки вместо \n, поэтому вывод отобразится на одной строке:
>>> print("Hello", end=" ")
>>> print("World")
Hello World
Это можно использовать, например, для вывода последовательности значений в одной строке, как здесь:
for i in range(15):
if i < 14:
print(i, end=", ")
else:
print(i)
Вывод будет такой:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14Примечание: условная конструкция нужна, чтобы не добавлять запятую после последнего символа.
Таким же образом можно использовать print для вывода значений итерируемого объекта в одну строку:
data = [1, 2, 3, 4, 5]
for num in range(len(data)):
print(data[num], end=" ")
Вывод:
1 2 3 4 5 Для вывода всех элементов списка списка , лучше использовать join: " ".join([str(i) for i in data])
Символ новой строки в файлах
Символ новой строки можно найти и в файлах, но он «скрыт». Создадим файл с именами. Каждое имя будет на новой строке.
names = ['Petr', 'Dima', 'Artem', 'Ivan']
with open("names.txt", "w") as f:
for name in names[:-1]:
f.write(f"{name}\n")
f.write(names[-1])
Если в текстовом файле есть разделение на несколько строк, то это значит, что в конце предыдущей символ \n. Проверить это можно с помощью функции .readlines():
with open("names.txt", "r") as f:
print(f.readlines())
Вывод:
['Petr\n', 'Dima\n', 'Artem\n', 'Ivan']Так, первые три строки текстового файла заканчиваются символом новой строки \n, которая работает «за кулисами».
Выводы
- Символ новой строки в Python — это
\n. Он используется для обозначения окончания строки текста. - Вывести текст без добавления новой строки можно с помощью параметра
end ="<character>", где<character>— это символ, который дальше будет использоваться для разделения строк.
numbers = [1, 1, 2, 3, 3, 4]Но нужен список с уникальными числами:
numbers = [1, 2, 3, 4]Есть несколько вариантов, как можно получить уникальные значения. Разберем их.
Вариант №1. Использование множества (set) для получения элементов
Использование множества (set) — один из вариантов. Он удобен тем, что включает только уникальные элементы. После этого множество можно обратно превратить в список.
Посмотрим на два способа использования множества и списка. Первый — достаточно подробный, но он позволяет увидеть происходящее на каждом этапе.
numbers = [1, 2, 2, 3, 3, 4, 5]
def get_unique_numbers(numbers):
list_of_unique_numbers = []
unique_numbers = set(numbers)
for number in unique_numbers:
list_of_unique_numbers.append(number)
return list_of_unique_numbers
print(get_unique_numbers(numbers))
Разберем, что происходит на каждом этапе. Есть список чисел numbers. Передаем его в функцию get_unique_numbers.
Внутри этой функции создается пустой список, который в итоге будет включать все уникальные числа. После этого используется set для получения уникальных чисел из списка numbers.
unique_numbers = set(numbers)
В итоге имеется перечень из уникальных чисел. Осталось сделать из него список. Для этого можно использовать цикл, перебирая каждый из элементов.
for number in unique_numbers:
list_of_unique_numbers.append(number)
На каждой итерации текущее число добавляется в список list_of_unique_numbers. Наконец, именно этот список возвращается в конце программы.
Есть и более короткий способ использования множества для получения уникальных значений в Python. О нем и пойдет речь дальше.
Короткий вариант с set
Весь код выше можно сжать в одну строку с помощью встроенных в Python функций.
numbers = [1, 2, 2, 3, 3, 4, 5]
unique_numbers = list(set(numbers))
print(unique_numbers)
Хотя этот код сильно отличается от первого примера, идея та же. Сперва множество используется для получения уникальных значений. После этого множество превращается в список.
unique_numbers = list(set(numbers))
Проще всего думать «изнутри наружу» при чтении этого кода. Самый вложенный код выполняется первым: set(numbers). Затем — внешний блок: list(set(numbers)).
Вариант №2. Использование цикла for
Также стоит рассмотреть подход с использованием цикла.
Для начала нужно создать пустой список, который будет включать уникальные числа. После этого можно задействовать цикл для итерации по каждому числу в переданном списке. Если число из него есть в уникальном, то можно переходить к следующему элементу. В противном случае — добавить это число.
Рассмотрим два способа использования цикла. Начнем с более подробного.
numbers = [20, 20, 30, 30, 40]
def get_unique_numbers(numbers):
unique = []
for number in numbers:
if number in unique:
continue
else:
unique.append(number)
return unique
print(get_unique_numbers(numbers))
Вот что происходит на каждом этапе. Сначала есть список чисел numbers. Он передается в функцию get_unique_numbers.
Внутри этой функции создается пустой список unique. В итоге он будет включать все уникальные значения.
Цикл будет использоваться для перебора по числам в списке numbers.
for number in numbers:
if number in unique:
continue
else:
unique.append(number)
Условные конструкции в цикле проверяют, есть ли число текущей итерации в списке unique. Если да, то цикл переходит на следующую итерации. Если нет — число добавляется в список.
Важно отметить, что добавляются только уникальные числа. Когда цикл завершен, список unique с уникальными числами возвращается.
Короткий способ с циклом
Есть и другой способ использования варианта с циклом, который короче на несколько строк.
numbers = [20, 20, 30, 30, 40]
def get_unique_numbers(numbers):
unique = []
for number in numbers:
if number not in unique:
unique.append(number)
return unique
Разница в условной конструкции. В этот раз она следующая — если числа нет в unique, то его нужно добавить.
if number not in unique:
unique.append(number)
В противном случае цикл перейдет к следующему числу в списке numbers.
Результат будет тот же. Но иногда подобное читать сложнее, когда булево значение опускается.
Есть еще несколько способов поиска уникальных значений в списке Python. Но достаточно будет тех, которые описаны в этой статье.
]]>Архив с проектом contact.rar
Первоначальная настройка
Если вы уже знаете как создавать джанго-приложение, этот шаг можно пропустить. Создайте проект —
config, приложение —sendemailи виртуальное окружениеcontact.
Первый шаг — создание отдельной папки для проекта. Создайте ее в ручную или с помощью терминала. В командной строке (Mаc или Linux, для Windows некоторые команды отличаются) выполните следующие команды, чтобы перейти в нужную директорию и создать новую папку «contact».
$ cd ~/ПУТЬ_К_ПАПКЕ
$ mkdir contact && cd contactТеперь можно установить Django и активировать виртуальную среду.
Примечание:
Естьpipenvу вас не установлен, начните сpip install pipenv
$ pipenv install django==3.0.5
$ pipenv shellДалее создадим новый проект Django под названием config в приложении sendemail:
(contact) $ django-admin startproject config .
(contact) $ python manage.py startapp sendemailЧтобы убедиться, что все работает, запустим migrate и runserver.
(contact) $ python manage.py migrate
(contact) $ python manage.py runserverЕсли теперь открыть ссылку 127.0.0.1:8000, то должно появиться приблизительно следующее:
Обновление settings.py
Созданное приложение теперь нужно явно добавить в проект Django. В файле settings.py следует записать sendemail в разделе INSTALLED_APPS.
# config/settings.py
INSTALLED_APPS [
'sendemail.apps.SendemailConfig', # новая строка
...
]
Затем в этом же файле нужно создать DEFAULT_FROM_EMAIL — ваша@почта.com и RECIPIENTS_EMAIL — список почт получателей по уполчанию. Также стоит обновить EMAIL_BACKEND, указав, какой бэкенд email используется — в данном случае это console. Это нужно, чтобы почта выводилась в командной строке.
# config/settings.py
RECIPIENTS_EMAIL = ['manager@mysite.com'] # замените на свою почту
DEFAULT_FROM_EMAIL = 'admin@mysite.com' # замените на свою почту
EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
Обновление urls.py
После добавления приложения в проект Django нужно обновить корневой файл config/urls.py, добавив include в верхней строке, а также новый urlpattern в приложении:
# config/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('sendemail.urls')),
]
Дальше создайте файл sendemail/urls.py в приложении вручную или:
touch sendemail/urls.pyТеперь — этот код. Благодаря ему основная контактная форма будет доступна по ссылке email/, а удачная отправка — перенаправлять на success/.
# sendemail/urls.py
from django.contrib import admin
from django.urls import path
from .views import contact_view, success_view
urlpatterns = [
path('contact/', contact_view, name='contact'),
path('success/', success_view, name='success'),
]
Создание forms.py
Внутри приложения sendemail теперь нужно создать новый файл forms.py.
touch sendemail/forms.pyОн будет содержать все поля для самой формы. Потребуются три: from_email, subject и message.
# sendemail/forms.py
from django import forms
class ContactForm(forms.Form):
from_email = forms.EmailField(label='Email', required=True)
subject = forms.CharField(label='Тема', required=True)
message = forms.CharField(label='Сообщение', widget=forms.Textarea, required=True)
Будем использовать встроенный в Django Forms API для быстрого создания трех полей.
Создание views.py
Создадим представление, которое будет выполнять основную работу для контактной формы. Обновим существующий файл sendemail/views.py:
from django.shortcuts import render
from django.core.mail import send_mail, BadHeaderError
from django.http import HttpResponse, HttpResponseRedirect
from django.shortcuts import render, redirect
from .forms import ContactForm
from config.settings import RECIPIENTS_EMAIL, DEFAULT_FROM_EMAIL
def contact_view(request):
# если метод GET, вернем форму
if request.method == 'GET':
form = ContactForm()
elif request.method == 'POST':
# если метод POST, проверим форму и отправим письмо
form = ContactForm(request.POST)
if form.is_valid():
subject = form.cleaned_data['subject']
from_email = form.cleaned_data['from_email']
message = form.cleaned_data['message']
try:
send_mail(f'{subject} от {from_email}', message,
DEFAULT_FROM_EMAIL, RECIPIENTS_EMAIL)
except BadHeaderError:
return HttpResponse('Ошибка в теме письма.')
return redirect('success')
else:
return HttpResponse('Неверный запрос.')
return render(request, "email.html", {'form': form})
def success_view(request):
return HttpResponse('Приняли! Спасибо за вашу заявку.')
Сначала импортируем send_email и BadHeaderError для безопасности. После этого добавим ссылку на класс ContactForm, который был создан в файле forms.py.
Создание шаблонов
В качестве финального шага нужно создать шаблоны для сообщения и страницы с информацией об успешной отправке. Для этого используем новую папку templates в директории с проектом.
(contact) $ mkdir templates
(contact) $ touch templates/email.htmlТеперь обновим файл settings.py, чтобы Django знал, где искать папку с шаблонами. Обновим настройку DIRS в TEMPLATES.
# config/settings.py
TEMPLATES = [
{
...
'DIRS': [os.path.join(BASE_DIR, 'templates')],
...
},
]
Далее обновим сами файлы шаблонов, используя следующий код:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Пример отправки сообщений</title>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/twitter-bootstrap/3.3.7/css/bootstrap.min.css">
</head>
<body>
<h1 class="text-center">Оставьте заявку</h1>
<div class="container text-center">
<div id="form_container">
<form method="post">
{% csrf_token %}
{{ form.as_p }}
<div class="form-actions form-group ">
<button type="submit" class="form-control btn btn-success">Отправить</button>
</div>
</form>
</div>
</div>
</body>
</html>Отправка первого сообщения
Убедитесь, что сервер запущен с помощью команды python manage.py runserver и откройте http://127.0.0.1:8000/contact в браузере. Заполните форму и нажмите кнопку Отправить.
Программа перенаправит на страницу http://127.0.0.1:8000/success, если сообщение отправилось.
А в консоли должно отобразиться, что сообщение отправилось:
Content-Type: text/plain; charset="utf-8"
MIME-Version: 1.0
Content-Transfer-Encoding: 8bit
Subject: =?utf-8?b?0J/RgNC40LLQtdGC?=
From: admin@mysite.com
To: manager@mysite.com
Date: Sat, 03 Oct 2020 11:10:29 -0000
Message-ID: <160172342967.9128.15896163902795968694@DESKTOP-4G7VN>Email-сервис
Для реальной отправки сообщений нужно настроить сервис: SendGrid, mailgun или SES. К счастью, в Django их очень легко использовать.
Для использования SendGrid нужно создать бесплатный аккаунт и выбрать вариант SMTP. Его легче настраивать при работе с Web API.
Необходимо выполнить верификацию отправителя. Инструкции доступны по этой ссылке. Если раньше можно было отправлять сообщения с бесплатных адресов (gmail.com или yahoo.com), но теперь это не будет работать из-за протокола email-аутентификации DMARC. Поэтому для реальной отправки сообщений нужно почту на своем домене, владение которой придется подтвердить.
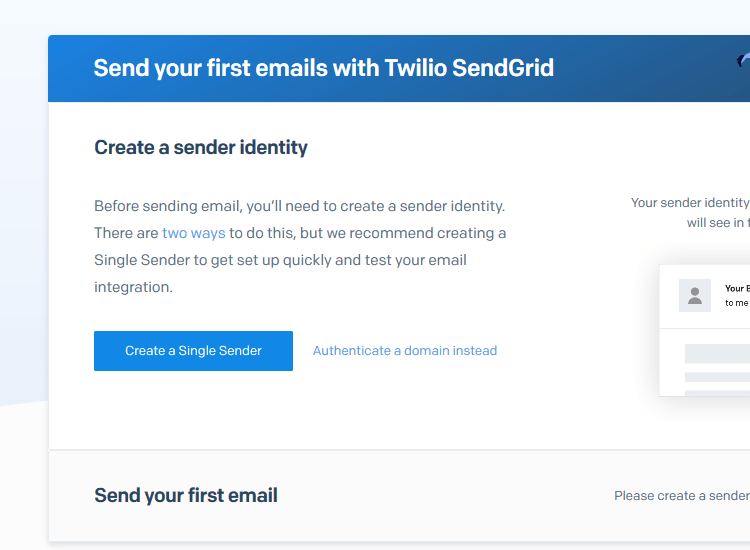
После добавления отправителя на странице https://app.sendgrid.com/settings/sender_auth/senders/new, подтвердите почту и переходите к настройке Web API https://app.sendgrid.com/guide/integrate/langs/python.
Следующее окно требует указать название для API-ключа. После этого нужно нажать на Create Key.
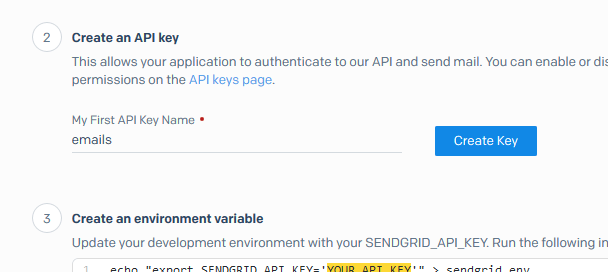
Следуйте инструкциям. На момент написания нужно установить библиотеку sendgrid и отправить тестовое письмо. Можете воспользоваться этим файлом sg_verify.py. Пройдя все этапы вы увидите сообщение об успешном подключении:
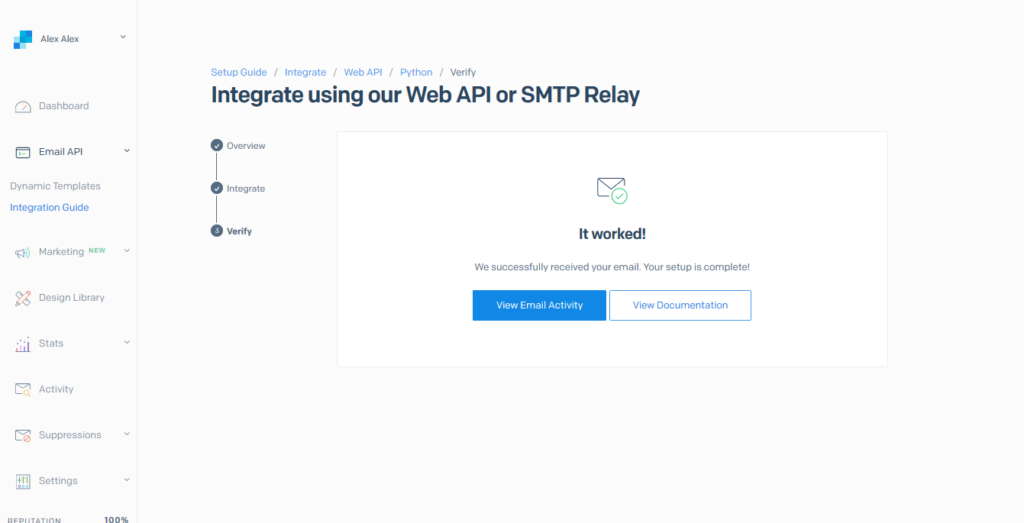
Дальше обновим файл settings.py, поменяв значение console на smtp в переменной EMAIL_BACKEND. Также добавим еще несколько полей. А также EMAIL_HOST_PASSWORD с ключем аккаунта SendGrid.
# config/settings.py
# почты для получения писем
RECIPIENTS_EMAIL = ['manager@mysite.com']
# почта отправителя по умолчанию, та что верифицирована
DEFAULT_FROM_EMAIL = 'admin@myiyte.com'
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
EMAIL_HOST = 'smtp.sendgrid.net'
EMAIL_HOST_USER = 'apikey'
# ваш уникальный апи-ключ с сайта sendgrid
EMAIL_HOST_PASSWORD = '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'
EMAIL_PORT = 587
EMAIL_USE_TLS = True
Вернемся на http://127.0.0.1:8000/contact/, заполним и отправим форму еще раз. Работает!
Выводы
После всех этих этапов у вас будет рабочее приложение с функцией отправки реальных сообщений из Django. Часто это нужно при регистрации пользователей, сбросе пароля, быстрых ответов и так далее.
]]>Напишем функции повара и официанта, используя традиционный синхронный Python-код. Вот как он будет выглядеть:
import time
def waiter():
cook('Паста', 8)
cook('Салат Цезарь', 3)
cook('Отбивные', 16)
def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
time.sleep(time_to_prepare)
print(order, '- готово')
if __name__ == '__main__':
waiter()
Сохраним файл sync.py.
Здесь повар симулируется в виде функции. Он принимает заказ и время на его приготовление. Затем с помощью функции time.sleep симулируется сам процесс готовки. А по завершении выводится сообщение о том, что заказ готов.
Есть еще одна функция официанта. По внутренней логике официант принимает заказы от посетителей и синхронно передает их повару.
Убедитесь, что установлена версия Python 3.7+ с помощью команды python3 --version на Mac или python --version — на Windows. Если версия меньше 3.7, обновите.
Запустите пример, чтобы убедиться, что все заказы медленно, но верно подаются.
Новый заказ: Паста
Паста - готово
Новый заказ: Салат Цезарь
Салат Цезарь - готово
Новый заказ: Отбивные
Отбивные - готовоПервая асинхронная программа
Теперь конвертируем программу так, чтобы она использовала библиотеку asyncio. Это будет первый шаг для того, чтобы разобраться с тем, как писать асинхронный код. Скопируем файл sync.py в новый файл coros.py со следующим кодом:
import asyncio
import time
async def waiter() -> None:
cook('Паста', 8)
cook('Салат Цезарь', 3)
cook('Отбивные', 16)
async def cook(order: str, time_to_prepare: int) -> None:
print(f'Новый заказ: {order}')
time.sleep(time_to_prepare)
print(order, '- готово')
asyncio.run(waiter())
В первую очередь нужно импортировать стандартную библиотеку Python под названием asyncio. Это нужно для получения асинхронных возможностей.
В конце программы заменим if __name__ == '__main__' на новый метод run из модуля asyncio. Что именно делает run?
По сути, run берет низкоуровневый псевдо-сервер asyncio, который называется рабочим циклом. Этот цикл является координатором, который следит за приостановкой и возобновлением задач из кода. В примере с поваром и официантом вызов «cook(»Паста’)» — это задача, которая выполнится, но также будет приостановлена на 8 секунд. Таким образом после получения запроса он отмечается, а программа переходит к выполнению следующего. После завершения заказа на приготовление пасты цикл продолжит выполнение на следующей строке, где готовится салат «Цезарь».
Команде run нужна функция, которую она будет выполнять, поэтому передаем waiter, которая является основной функцией в этом коде.
Run также отвечает за очистку, поэтому когда весь код проработает, он отключится от цикла.
Однако этих изменений недостаточно, чтобы код был асинхронным. Нужно сообщить asyncio, какие функции и задачи будут работать асинхронно. Поэтому поменяем функцию waiter, чтобы она выглядела следующим образом.
async def waiter() -> None:
await cook('Паста', 8)
await cook('Салат Цезарь', 3)
await cook('Отбивные', 16)
Функция waiter объявляется асинхронной за счет добавления приставки async в начале. После этого появляется возможность сообщать asyncio, какие из задач будут асинхронными внутри. Для этого к ним добавляется ключевое слово await.
Такой код можно читать следующим образом: «вызвать функцию cook и дождаться (await) ее результата, прежде чем переходить к следующей строке». Но это не процесс с блокировкой потока. Наоборот, он сообщает циклу следующее: «если есть другие запросы, можешь переходить к их выполнению, пока мы ждем, а мы дадим знать, когда текущий запрос завершится».
Достаточно лишь запомнить, что если есть задачи с await, то сама функция должна быть объявлена с async.
А как же функция cook? Ее тоже нужно сделать асинхронной, поэтому перепишем ее вот так.
async def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
await time.sleep(time_to_prepare)
print(order, '- готово')
Но здесь есть одна проблема. Если использовать стандартную функцию time.sleep, то она заблокирует весь процесс выполнения, сделав асинхронную программу бесполезной. В этом случае нужно использовать функцию sleep из модуля asyncio.
async def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
await asyncio.sleep(time_to_prepare)
print(order, '- готово')
Это гарантирует, что пока функция cook находится в состоянии сна до завершения таймера, программа сможет начать выполнение других запросов.
Если сейчас запустить программу, то результат будет таким:
Новый заказ: Паста
Паста - готово
Новый заказ: Салат Цезарь
Салат Цезарь - готово
Новый заказ: Отбивные
Отбивные - готовоНо разницы с асинхронной версией нет. Возможно, казалось, что этот вариант исполнится быстрее. На самом деле, это одно из главных заблуждений касательно асинхронного кода. Некоторые ошибочно считают, что он работает быстрее. Но это программа уже лучше, хотя этого нельзя явно сказать на основе опыта работы с ней.
Если запустить эту программу как часть сайта, то будет возможность обслуживать сотни тысяч посетителей одновременно на одном сервере без каких-либо проблем. Когда вместо этого использовать синхронный код, то максимум можно рассчитывать на пару десятков пользователей. Если же их будет больше, то процессор сервера не сможет выдерживать нагрузку.
Сопрограммы и задачи (coroutines and tasks)
Сопрограммы (coroutines)
Функции waiter и cook трансформируются именно в тот момент, когда перед их определением ставится ключевое слово async. С этого момент их можно считать сопрограммами.
Если попытаться запустить одну из таких прямо, то вернется сообщение с информацией о ней, но сама программа не будет запущена. Попробуем запустить терминал Python и импортировать туда функцию cook из файла coros. Во-первых, нужно закомментировать команду asyncio.run так, чтобы код не выполнялся. После этого файл можно сохранить.
# asyncio.run(waiter())Затем откроем терминал и сделаем следующее:
>>> from coros import cook
>>> cook('Паста', 8)
Сопрограммы могут выполняться только в пределах рабочего цикла или их ожидания (awaiting) внутри других сопрограмм.
Но есть и третий способ выполнения сопрограммы. Продемонстрируем его в следующем разделе.
Задачи (tasks)
С помощью задач можно запустить несколько сопрограмм одновременно. Скопируем файл coros.py в файл tasks.py и допишем следующее:
import asyncio
async def waiter():
task1 = asyncio.create_task(cook('Паста', 8))
task2 = asyncio.create_task(cook('Салат Цезарь', 3))
task3 = asyncio.create_task(cook('Отбивные', 16))
await task1
await task2
await task3
async def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
await asyncio.sleep(time_to_prepare)
print(order, '- готово')
asyncio.run(waiter())
Здесь мы создаем задачи с тремя разными заказами. Задачи дают два преимущества, которых не получить при добавлении await:
- Они используются для планирования последовательного выполнения сопрограмм;
- Задачи могут быть отменены при ожидании завершения их выполнения.
Так, в коде выше при ожидании трех задач три сопрограммы cook работают одновременно, поэтому результат довольно сильно отличается. Запустите код.
Новый заказ: Паста
Новый заказ: Салат Цезарь
Новый заказ: Отбивные
Салат Цезарь - готово
Паста - готово
Отбивные - готовоЭто уже больше похоже на то, чего многие ждали: официант забирает заказы в том порядке, в котором их возвращает повар.
Частые ошибки с asyncio
При переходе к асинхронному коду нужно помнить о некоторых вещах:
Вызов блокирующей функции из сопрограммы
Одна из самых распространенных проблем — использование синхронной функции внутри асинхронной.
Один из примеров такого — использование синхронной функции time.sleep внутри асинхронной функции cook. Использование обычного метода sleep из стандартной библиотеки заблокировало бы весь код.
Попробуйте. Добавьте import time в верхней части файла coros.py и синхронную функцию sleep:
async def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
await time.sleep(time_to_prepare)
print(order, '- готово')
При попытке выполнить такой код вернется следующая ошибка:
...
File "coros.py", line 7, in waiter
await cook('Pasta', 8)
File "coros.py", line 13, in cook
await time.sleep(time_to_prepare)
TypeError: object NoneType can't be used in 'await' expressionНа первый взгляд эта ошибка кажется странной. Дело в том, что time.sleep() — это не объект, выполнения которого можно дождаться (await). Таким образом он возвращает вызвавшей его функции None. И даже исключение появляется не сразу, а только через 8 секунд.
С другой стороны, asyncio.sleep — это тоже сопрограмма. Это значит, что она возвращает соответствующий объект (выполнения которого можно дождаться). Такой объект может быть отмечен в цикле, после чего программа перейдет к следующим запросам до тех пор, пока функция sleep не будет завершена.
Но это крайне удачный пример. Опасность синхронных или блокирующих функций в том, что порой они тихо блокируют код так, что даже ошибок не видно. Это происходит из-за того, что они не возвращаются вызвавшей их функции.
Поэтому важно запомнить, что внутри сопрограммы нужно вызывать только другие сопрограммы.
Не дожидаться завершения выполнения сопрограммы
Во-первых, уберем time.sleep и вернем на место asyncio.sleep. После этого поменяем второй вызов функции cook, забрав у нее ключевое слово await:
import asyncio
import time
async def waiter() -> None:
await cook('Паста', 8)
cook('Салат Цезарь', 3)
await cook('Отбивные', 16)
async def cook(order, time_to_prepare):
print(f'Новый заказ: {order}')
await asyncio.sleep(time_to_prepare)
print(order, '- готово')
asyncio.run(waiter())
При попытке запустить этот код вернется следующая ошибка:
coros.py:5: RuntimeWarning: coroutine 'cook' was never awaitedОна появляется в тех случаях, когда функция была вызвана без await. Иногда это не так очевидно, и придется покопаться, чтобы понять, где именно это произошло.
Неполученные результаты
Еще одна ловушка — завершение сопрограммы в тот момент, когда внутренняя сопрограмма продолжает выполняться. Что с ней происходит в этот момент? Можно получить ошибку от сборщика мусора Python.
Например, возьмем следующий код:
import asyncio
async def executed():
asyncio.sleep(15)
print("Функция executed")
async def main():
asyncio.create_task(executed())
asyncio.run(main())
После его запуска вернется следующая ошибка:
RuntimeWarning: coroutine 'sleep' was never awaited
asyncio.sleep(15)
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Функция executedВ этой ситуации сопрограмма main выполняется, но поскольку результат внутренней сопрограммы не ожидается, выполнение заканчивается, а у asyncio.sleep и не было возможности запуститься.
Теперь вы знаете, на что обращать внимание при получении ошибки not consumed.
С этими проблемами куда легче разбираться при наличии практики работы с асинхронным кодом, поэтому не стоит его бояться. Все-таки его преимущества значительно перевешивают недостатки и потенциальные ловушки.
]]>Играли ли вы когда-нибудь в игры, где проверяется скорость набора текста? Это очень полезное развлечение, поскольку оно позволяет не только отслеживать значение, но и улучшает навык со временем. Если заинтересовались, то ее вполне можно создать самостоятельно.
О проекте
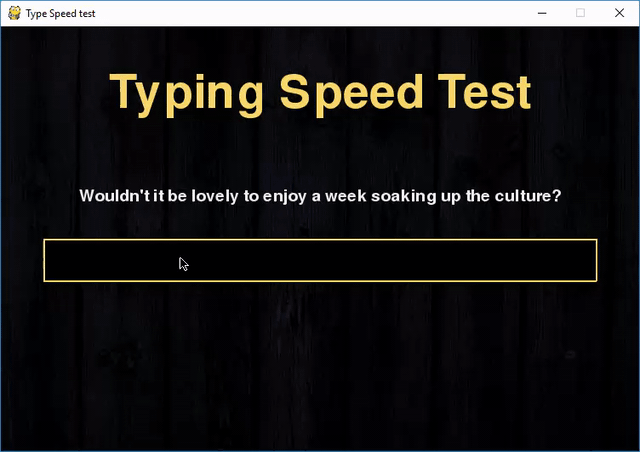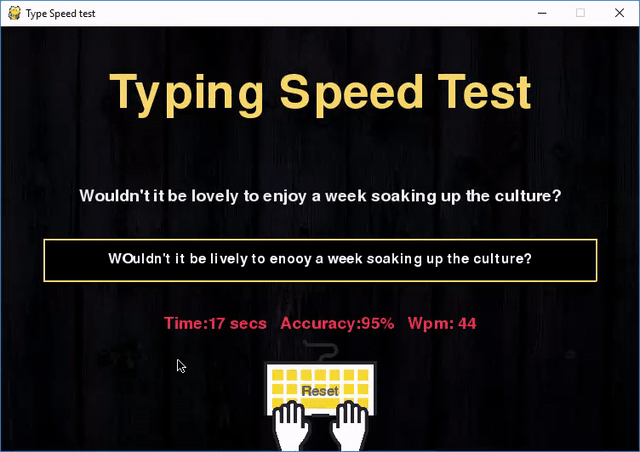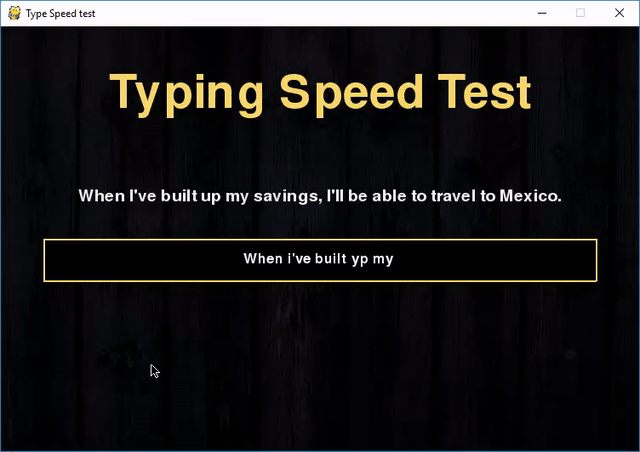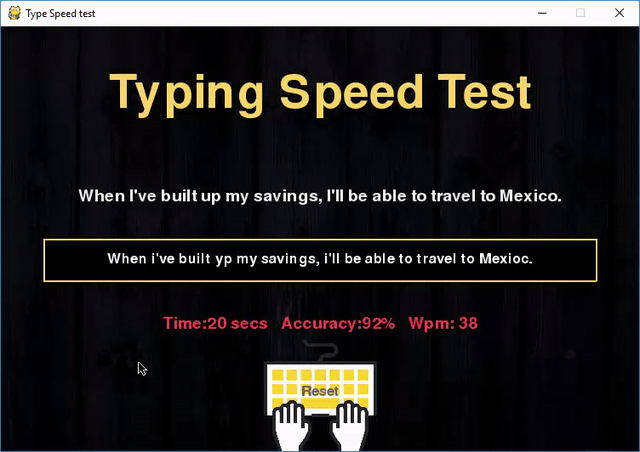
В этом проекте создадим приложение на Python, с помощью которого можно будет проверять и увеличивать собственную скорость набора текста. Для графического интерфейса используем библиотеку pygame, которая для этих целей и предназначена. Также нарисуем изображения, которые будут отображаться на экране.
Требования
Для работы над проектом требуются базовые знания программирования на Python и библиотеки pygame.
Для установки библиотеки используйте в терминале следующую команду.
pip install pygame
Шаги для создания проекта
По этой ссылке можно загрузить весь исходный код проекта: typing-speed-game.rar
Для начала разберемся с файловой структурой проекта:
- background.jpg — фоновое изображение для программы
- icon.jpg — иконка для кнопки сброса
- sentences.txt — текстовый файл со списком предложений
- speed_typing.py — файл со всем кодом программы
- typing-speed-open.png — иконка для отображения при запуске игры
Создадим файл sentences.txt, в котором на каждой строке добавим по предложению.
При создании проекта будем использовать принципы объектно-ориентированного программирования.
Импортируем библиотеки
Для этого проекта будем использовать библиотеку pygame. Ее нужно импортировать вместе с другими встроенными модулями Python, такими как time и random.
import pygame
from pygame.locals import *
import sys
import time
import random
Создадим класс игры
Дальше создаем класс игры, который будет содержать функции для старта, сброса и несколько дополнительных, отвечающих за вычисления.
Создадим конструктор класса, в котором будет определены все переменные проекта.
class Game:
def __init__(self):
self.w=750
self.h=500
self.reset=True
self.active = False
self.input_text=''
self.word = ''
self.time_start = 0
self.total_time = 0
self.accuracy = '0%'
self.results = 'Time:0 Accuracy:0 % Wpm:0 '
self.wpm = 0
self.end = False
self.HEAD_C = (255,213,102)
self.TEXT_C = (240,240,240)
self.RESULT_C = (255,70,70)
pygame.init()
self.open_img = pygame.image.load('type-speed-open.png')
self.open_img = pygame.transform.scale(self.open_img, (self.w,self.h))
self.bg = pygame.image.load('background.jpg')
self.bg = pygame.transform.scale(self.bg, (500,750))
self.screen = pygame.display.set_mode((self.w,self.h))
pygame.display.set_caption('Type Speed test')
В этом конструкторе инициализируем ширину и высоту окна, а также переменные, которые нужны для вычислений. Наконец, инициализируем саму pygame и загрузим изображения. Самое важное — переменная экрана, на котором будет выводиться интерфейс.
Метод draw_text()
Метод draw_text() — это вспомогательная функция для класса Game, которая выводит текст на экран. В качестве аргумента она принимает экран, выводимое сообщение, координату y экрана, где нужно нарисовать текст, а также размер и цвет шрифта. В этом случае все должно выводиться по центру. После прорисовки pygame нужно обновить экран.
def draw_text(self, screen, msg, y ,fsize, color):
font = pygame.font.Font(None, fsize)
text = font.render(msg, 1,color)
text_rect = text.get_rect(center=(self.w/2, y))
screen.blit(text, text_rect)
pygame.display.update()
Метод get_sentence()
В файле sentences.txt хранится список предложений. Метод get_sentence() будет открывать его и возвращать случайное предложение из списка. Целая строка будет разбиваться с помощью символа новой строки.
def get_sentence(self):
f = open('sentences.txt').read()
sentences = f.split('\n')
sentence = random.choice(sentences)
return sentence
Метод show_results()
В методе show_results() рассчитывается скорость набора. Таймер запускается в тот момент, когда пользователь нажимает на поле ввода, а останавливается в момент нажатия Enter. Затем рассчитывается разница и определяется время в секундах.
Для вычисления точности используется математика. Подсчитываются правильно введенные символы за счет сравнения введенного текста с тем, который нужно было ввести.
Формула следующая:
(правильные символы) х 100 / (всего символов в предложении)
WPM (words per minute) — это количество слов в минуту. Типичное слово состоит приблизительно из 5 символов, поэтому рассчитываем показатель, разделяя общее количество слов на 5. Затем результат делится на общее время, которое потребовалось для набора. Поскольку общее время указано в секундах, его сначала нужно конвертировать в минуты, разделив значение на 60.
Наконец, в нижней части есть иконка, выступающая кнопкой сброса. Когда пользователь нажимает на нее, игра сбрасывается. Речь о методе reset_game() пойдет дальше.
def show_results(self, screen):
if(not self.end):
# Расчет времени
self.total_time = time.time() - self.time_start
# Расчет точности
count = 0
for i,c in enumerate(self.word):
try:
if self.input_text[i] == c:
count += 1
except:
pass
self.accuracy = count/len(self.word)*100
# Расчет количества слов в минуту
self.wpm = len(self.input_text)*60/(5*self.total_time)
self.end = True
print(self.total_time)
self.results = 'Time:'+str(round(self.total_time)) +" secs Accuracy:"+ str(round(self.accuracy)) + "%" + ' Wpm: ' + str(round(self.wpm))
# Загрузка иконки
self.time_img = pygame.image.load('icon.png')
self.time_img = pygame.transform.scale(self.time_img, (150,150))
# screen.blit(self.time_img, (80,320))
screen.blit(self.time_img, (self.w/2-75,self.h-140))
self.draw_text(screen,"Reset", self.h - 70, 26, (100,100,100))
print(self.results)
pygame.display.update()
Метод run()
Это основной метод класса, отвечающий за обработку всех событий. Метод reset_game() вызывается в начале метода, который сбрасывает все переменные. Затем выполняется бесконечный цикл, который захватывает все события мыши и клавиатуры. После этого на экране рисуются заголовок и поле ввода.
Другой цикл ждет событий мыши и клавиатуры. Когда кнопка мыши нажимается, проверяется ее положение. Если она над полем ввода, то таймер запускается, а переменная active становится True. Если над кнопкой сброса — игра сбрасывается.
Когда значение active равняется True, а набор текста не завершен, ожидаются события с клавиатуры. Если пользователь нажимает любую клавишу, то нужно обновить сообщение поля ввода. Клавиша Enter завершает ввод, после чего происходят вычисления. Еще одно событие — для клавиши Backspace, которая удаляет последний символ введенного текста.
def run(self):
self.reset_game()
self.running=True
while(self.running):
clock = pygame.time.Clock()
self.screen.fill((0,0,0), (50,250,650,50))
pygame.draw.rect(self.screen,self.HEAD_C, (50,250,650,50), 2)
# Обновление текста пользовательского ввода
self.draw_text(self.screen, self.input_text, 274, 26,(250,250,250))
pygame.display.update()
for event in pygame.event.get():
if event.type == QUIT:
self.running = False
sys.exit()
elif event.type == pygame.MOUSEBUTTONUP:
x,y = pygame.mouse.get_pos()
# Расположение окна ввода
if(x>=50 and x<=650 and y>=250 and y<=300):
self.active = True
self.input_text = ''
self.time_start = time.time()
# Расположение кнопки сброса
if(x>=310 and x<=510 and y>=390 and self.end):
self.reset_game()
x,y = pygame.mouse.get_pos()
elif event.type == pygame.KEYDOWN:
if self.active and not self.end:
if event.key == pygame.K_RETURN:
print(self.input_text)
self.show_results(self.screen)
print(self.results)
self.draw_text(self.screen, self.results,350, 28, self.RESULT_C)
self.end = True
elif event.key == pygame.K_BACKSPACE:
self.input_text = self.input_text[:-1]
else:
try:
self.input_text += event.unicode
except:
pass
pygame.display.update()
clock.tick(60)
Метод reset_game()
Метод reset_game() сбрасывает все переменные, так что проверить скорость набора можно снова. Еще раз выбирается случайное предложение с помощью метода get_sentence(). В конце определение класса закрывается. Создаем объект класса Game и запускаем программу.
def reset_game(self):
self.screen.blit(self.open_img, (0,0))
pygame.display.update()
time.sleep(1)
self.reset=False
self.end = False
self.input_text=''
self.word = ''
self.time_start = 0
self.total_time = 0
self.wpm = 0
# Получаем случайное предложение
self.word = self.get_sentence()
if (not self.word): self.reset_game()
# Загрузка окна
self.screen.fill((0,0,0))
self.screen.blit(self.bg,(0,0))
msg = "Typing Speed Test"
self.draw_text(self.screen, msg,80, 80,self.HEAD_C)
# Отрисовка поля ввода
pygame.draw.rect(self.screen,(255,192,25), (50,250,650,50), 2)
# Отрисовка строки предложения
self.draw_text(self.screen, self.word,200, 28,self.TEXT_C)
pygame.display.update()
Game().run()
Вывод:
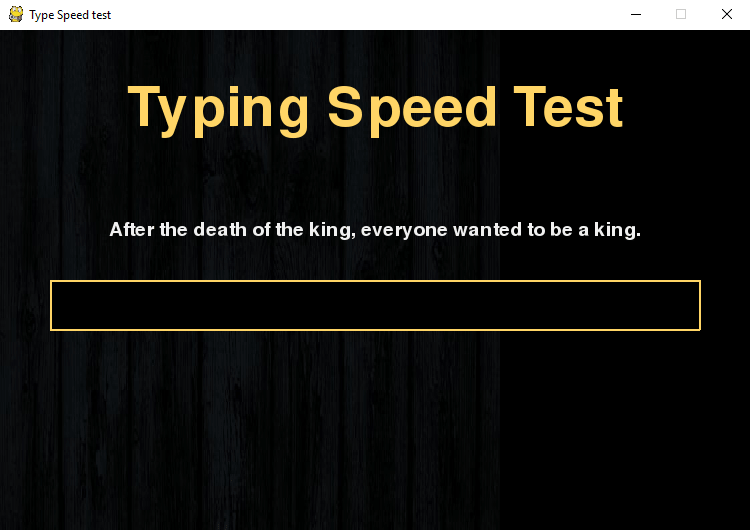
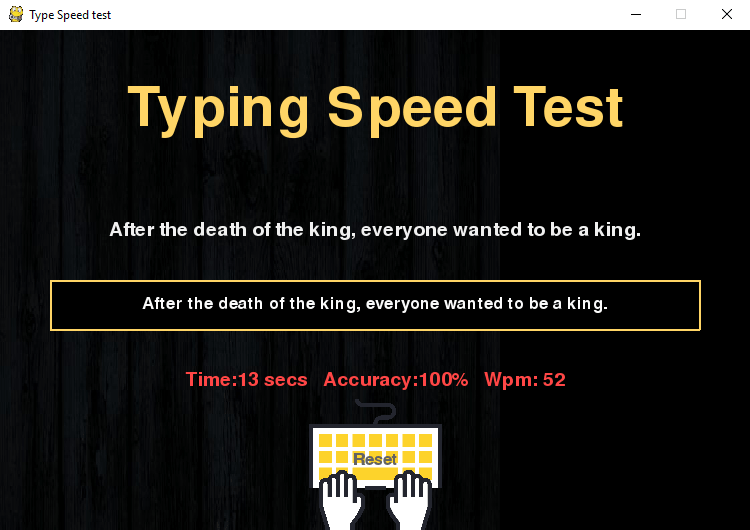
Выводы
В этом проекте мы создали игру на Python с использованием pygame, которая отслеживает скорость набора текста пользователем.
]]>Разработчики используют машинное обучение и глубокое обучение, чтобы делать компьютеры более умными. Человек учится, выполняя определенную задачу, практикуясь и повторяя ее раз за разом, запоминая, как именно это делается. После этого нейроны в мозге срабатывают автоматически и могут быстро выполнить выученную задачу.
Глубокое обучение работает по похожему принципу. В нем используются разные типы архитектуры нейронной сети в зависимости от типов проблем. Например, распознавание объектов, классификация изображений и звуков, определение объектов, сегментация изображений и так далее.
Что такое распознавание рукописных цифр?
Распознавание рукописных цифр — это способность компьютера узнавать написанные от руки цифры. Для машины это не самая простая задача, ведь каждая написанная цифра может отличаться от эталонного написания. В случае с распознаванием решением является то, что машина способна узнавать цифру на изображении.
О Python-проекте
В этом материале реализуем приложение для распознавания написанных от руки цифр с помощью набора данных MNIST. Используем специальный тип глубокой нейронной сети, которая называется сверточной нейронной сетью. А в конце создадим графический интерфейс, в котором можно будет рисовать цифру и тут же ее узнавать.
Требования
Для этого проекта нужны базовые знания программирования на Python, библиотеки Keras для глубокого обучения и библиотеки Tkinter для создания графического интерфейса.
Установим требуемые библиотеки для проекта с помощью pip install.
Библиотеки: numpy, tensorflow, keras, pillow.
Набор данных MNIST
Это, наверное, один из самых популярных наборов данных среди энтузиастов, работающих в сфера машинного обучения и глубокого обучения. Он содержит 60 000 тренировочных изображений написанных от руки цифр от 0 до 9, а также 10 000 картинок для тестирования. В наборе есть 10 разных классов. Изображения с цифрами представлены в виде матриц 28 х 28, где каждая ячейка содержит определенный оттенок серого.
Создание проекта на Python для распознавания рукописных цифр
Скачайте файлы проекта
1. Импорт библиотек и загрузка набор данных
Сначала нужно импортировать все модули, которые потребуются для тренировки модели. Библиотека Keras уже включает некоторые из них. В их числе и MNIST. Таким образом можно запросто импортировать набор и начать работать с ним. Метод mnist.load_data() возвращает тренировочные данные, их метки и тестовые данные с метками.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
# скачиваем данные и разделяем на надор для обучения и тесовый
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
2. Предварительная обработка данных
Данные с изображения нельзя прямо передать в модель, поэтому сперва нужно выполнить определенные операции, обработав данные, чтобы нейронная сеть с ними работала. Размерность тренировочных данных — (60000, 28, 28). Модель сверточной нейронной сети требует одну размерность, поэтому потребуется перестроить форму (60000, 28, 28, 1).
num_classes = 10
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
# преобразование векторных классов в бинарные матрицы
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('Размерность x_train:', x_train.shape)
print(x_train.shape[0], 'Размер train')
print(x_test.shape[0], 'Размер test')
3. Создание модели
Следующий этап – создание модели сверточной нейронной сети. Она преимущественно состоит из сверточных и слоев подвыборки. Модель лучше работает с данными, представленными в качестве сеточных структур. Вот почему такая сеть отлично подходит для задач с классификацией изображений. Слой исключения используется для отключения отдельных нейронов и во время тренировки. Он уменьшает вероятность переобучения. Затем происходит компиляция модели с помощью оптимизатора Adadelta.
batch_size = 128
epochs = 10
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,optimizer=keras.optimizers.Adadelta(),metrics=['accuracy'])
4. Тренировка модели
Функция model.fit() в Keras начнет тренировку модели. Она принимает тренировочные, валидационные данные, эпохи (epoch) и размер батча (batch).
Тренировка модели занимает некоторое время. После этого веса и определение модели сохраняются в файле mnist.h5.
hist = model.fit(x_train, y_train, batch_size = batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
print("Модель успешно обучена")
model.save('mnist.h5')
print("Модель сохранена как mnist.h5")
5. Оценка модели
В наборе данных есть 10 000 изображений, которые используются для оценки качества работы модели. Тестовые данные не используются во время тренировки, поэтому являются новыми для модели. Набор MNIST хорошо сбалансирован, поэтому можно рассчитывать на точность около 99%.
score = model.evaluate(x_test, y_test, verbose=0)
print('Потери на тесте:', score[0])
print('Точность на тесте:', score[1])
6. Создание графического интерфейса для предсказания цифр
Для графического интерфейса создадим новый файл, в котором будет интерактивное окно для рисования цифр на полотне и кнопка, отвечающая за процесс распознавания. Библиотека Tkinter является частью стандартной библиотеки Python. Функция predict_digit() принимает входящее изображение и затем использует натренированную сеть для предсказания.
Затем создаем класс App, который будет отвечать за построение графического интерфейса приложения. Создаем полотно, на котором можно рисовать, захватывая события мыши. Кнопка же будет активировать функцию predict_digit() и отображать результат.
Дальше весь код из файла gui_digit_recognizer.py:
from keras.models import load_model
from tkinter import *
import tkinter as tk
import win32gui
from PIL import ImageGrab, Image
import numpy as np
model = load_model('mnist.h5')
def predict_digit(img):
# изменение рзмера изобржений на 28x28
img = img.resize((28,28))
# конвертируем rgb в grayscale
img = img.convert('L')
img = np.array(img)
# изменение размерности для поддержки модели ввода и нормализации
img = img.reshape(1,28,28,1)
img = img/255.0
# предстказание цифры
res = model.predict([img])[0]
return np.argmax(res), max(res)
class App(tk.Tk):
def __init__(self):
tk.Tk.__init__(self)
self.x = self.y = 0
# Создание элементов
self.canvas = tk.Canvas(self, width=300, height=300, bg = "white", cursor="cross")
self.label = tk.Label(self, text="Думаю..", font=("Helvetica", 48))
self.classify_btn = tk.Button(self, text = "Распознать", command = self.classify_handwriting)
self.button_clear = tk.Button(self, text = "Очистить", command = self.clear_all)
# Сетка окна
self.canvas.grid(row=0, column=0, pady=2, sticky=W, )
self.label.grid(row=0, column=1,pady=2, padx=2)
self.classify_btn.grid(row=1, column=1, pady=2, padx=2)
self.button_clear.grid(row=1, column=0, pady=2)
# self.canvas.bind("<Motion>", self.start_pos)
self.canvas.bind("<B1-Motion>", self.draw_lines)
def clear_all(self):
self.canvas.delete("all")
def classify_handwriting(self):
HWND = self.canvas.winfo_id()
rect = win32gui.GetWindowRect(HWND) # получаем координату холста
im = ImageGrab.grab(rect)
digit, acc = predict_digit(im)
self.label.configure(text= str(digit)+', '+ str(int(acc*100))+'%')
def draw_lines(self, event):
self.x = event.x
self.y = event.y
r=8
self.canvas.create_oval(self.x-r, self.y-r, self.x + r, self.y + r, fill='black')
app = App()
mainloop()
Получится:
Выводы
Проект для распознавания рукописных цифр на Python готов. Была создана и натренирована сверточная нейронная сеть, которая идеально подходит для классификации изображений. Наконец, был реализован графический интерфейс, который используется для рисования и представления результата предсказания цифры.
]]>В предыдущем материале был написан код для симуляции игры в блэкджек. С помощью симуляции большого количества игр можно было четко отследить, какое преимущество есть у казино. Вот что удалось обнаружить:
- Казино получает конкурентное преимущество, заставляя игроков совершать действия до дилера (действовать в условиях неполной информации). Это создает риск получить перебор (таким образом игроки теряют все еще до того, как дилер совершает хоть какое-нибудь действие).
- Особую опасность представляют ситуации, когда карты на руках игроков стоят от 12 до 16 очков (в таком случае вероятность получить перебор со следующей картой максимальная), а дилер показывает старшую карту. В таких случаях можно предположить, что у дилера будет более высокое значение, так что игрокам остается только брать еще или проигрывать. Это можно увидеть даже визуально на графике с шансами на победу или ничью (промежуток значений от 12 до 16 называется “долиной отчаяния”).

- Наконец, простейшая «наивная» стратегия брать карты в случае нулевой вероятности получить перебор значительно увеличивает шансы на победу, ведь в таком случае растет вероятность того, что проиграет казино.
Также в том материале были описаны и правила игры.
Способно ли глубокое обучение справиться лучше?
Задача этого материала — определить, можно ли с помощью глубокого обучения получить более эффективную стратегию. Для этого:
- Сгенерируем данные с помощью симулятора блэкджека из прошлого материала (с некоторыми исправлениями, чтобы он лучше подходил для тренировки алгоритмов).
- Напишем код для тренировки нейронной сети игре в блэкджек (желательно оптимальной).

Прежде чем переходить к самому процессу тренировки, вернемся и быстро рассмотрим достоинства и недостатки использования нейронной сети в этой ситуации. Нейронные сети — это очень эффективные алгоритмы, которые можно, грубо говоря, сравнить с глиной. Они подстраиваются под очертания доступной информации, при это минимально или вообще не изменяясь. Данные, например, с линейной регрессией запросто поддаются обработке с помощью нейронной сети. А слои и нейроны в сети способны находить заложенные глубоко внутри нелинейные отношения данных.
Тем не менее за такую гибкость приходится платить: нейронная сеть — это модель черного ящика. В отличие от регрессии, когда можно увидеть, как именно модель принимает решения, посмотрев на коэффициенты, нейронная сеть такой прозрачностью не обладает. Она также подвержена риску переобучения, при котором данные из выборки уже не обобщаются. Об этих недостатках нужно помнить и предпринимать дополнительные меры для работы с ними. Тем не менее это не повод отказываться от использования нейронных сетей.
Генерация тренировочных данных
Перед началом тренировки нейронной сети сперва нужно определить, как структурировать данные так, чтобы построенная модель была полезной.
Что нужно предсказать? Есть два кандидата на роль целевой переменной:
- Вероятность поражения. Но это полезно только в том случае, если бы была возможность увеличить или уменьшить ставку, однако в блэкджеке такого варианта нет.
- Оптимальное действие: взять еще карту или спасовать. Поэтому целевой переменной будет решение о том, какое действие идеально в конкретной ситуации: взять еще или сделать пас.
Нет необходимости в том, чтобы сеть вообще не делала ошибок. Достаточно добиться того, чтобы она в большинстве случаев предсказывала правильно. Вот какой способ для этого можно использовать:
- раздать карты игроку и дилеру;
- проверить, нет ли у одного из них 21;
- выполнить одно действие (взять карту или спасовать);
- симулировать игру до конца и записать результат.
Поскольку симулируемый игрок принимает лишь одно решение, можно оценить его качество на основе того, выиграл ли он партию или проиграл:
- Если игрок взял карту и выиграл, тогда карта (Y=1) была правильным решением
- Если игрок взял карту и проиграл, тогда пас (Y=0) был правильным решением
- Если игрок спасовал и выиграл, тогда пас (Y=1) был правильным решением
- Если игрок спасовал и проиграл, тогда карта (Y=0) была правильным решением
Это позволяет тренировать модель так, чтобы вывод представлял собой предсказание правильного действия: карта или пас. Код похож на тот, что использовался в прошлый раз. Вот основные признаки:
- Открытая карта лидера (вторая закрыта от игроков)
- Общая стоимость карт в руках игрока
- Проверка, есть ли у игрока туз
- Действие игрока (карта или пас)
Цель — выявить правильно решение на основе описанный выше логики.
Тренировка нейронной сети
ВАЖНО! Весь код статьи в этом архиве
Для нейронной сети будет использоваться библиотека Keras. Сначала добавим все необходимые импорты:
from keras.models import Sequential
from keras.layers import Dense, LSTM, Flatten, Dropout
Теперь настроим переменные ввода для тренировки сети. feature_list — это переменная с колонками, представляющими перечисленные выше признаки. В dataframe model_rf хранятся данные запущенных симуляций.
# Задаем переменные для нейронной сети
feature_list = [i for i in model_df.columns if i not in
['dealer_card','Y','lose','correct_action']
]
train_X = np.array(model_df[feature_list])
train_Y = np.array(model_df['correct_action']).reshape(-1,1)
Код, запускающий и тренирующий нейронную сеть, довольно простой. Первая строка создает нейронную сеть последовательного типа, которая является линейной последовательностью слоев нейронной сети. Следующие строки друг за другом добавляют слои (Dense — простейший тип слоя, представляющий собой набор нейронов), а числа 16, 128 и т. д. обозначают количество нейронов в каждом слое.
Наконец, для последнего слоя нужно выбрать функцию активации. Она конвертирует сырой вывод в более осмысленный вид. Обратите внимание на две вещи: во-первых, финальный слой включает лишь один нейрон, потому что предсказание делается на основе двух возможных выводов (двухклассовая проблема). Во-вторых, используется сигмоидная функция, потому что необходимо, чтобы нейронная сеть действовала по принципу логистической регрессии и предсказывала, что является корректным действием: карта (Y=1) или пас (Y=0). Другими словами, необходимо знать вероятность того, что карта — это правильный вариант.
Последние две строчки сообщают, какую функцию потерь использовать (перекрестная функция — это функция потерь, используемая классификационными моделями, которые предсказывают вероятности) и сопоставляют данные с моделью. Если поэкспериментировать с количеством нейронов чуть дольше, то можно получить еще более эффективную сеть.
# Настройка нейронной сети с 5 слоями
model = Sequential()
model.add(Dense(16))
model.add(Dense(128))
model.add(Dense(32))
model.add(Dense(8))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='sgd')
model.fit(train_X, train_Y, epochs=20, batch_size=256, verbose=1)
pred_Y_train = model.predict(train_X)
actuals = train_Y[:,-1]
Предсказание производительности модели
Простой способ оценить, насколько эффективнее оказывается модель — использовать ROC-кривую. ROC-кривая показывает, насколько хороша модель в плане отношения между пользой (общим количеством носителей признака, верно классифицированных как несущие признак) и затратами (долей объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак). Чем больше площадь под кривой, тем лучше модель.
График показывает ROC-кривую для нейронной сети, играющей в блэкджек. Судя по всему, она все-таки дает обеспечивает полезность относительно случайного угадывания (красная пунктирная линия). Площадь под кривой, AUC, — 0,73, в то время как показатель AUC для случайного предсказывания равен 0,5.

Для составления ROC-кривой здесь использовались тренировочные данные. Обычно для этого нужны тестовые данные, но в этом случае, поскольку известно, что набор довольно большой, то он является репрезентативным (если продолжать играть по тем же правилам). И можно предположить, что модель будет хорошо обобщать данные (любые новые данные будут обладать теми же характеристиками, что и тренировочные).
Время играть!
Прежде чем нейронная сеть начнет играть, ей нужно передать правило принятия решения. Здесь нужно напомнить, что сигмоидная активация (из финального слоя нейронной сети) показывает вывод в виде вероятности того, что карта — это правильный ход. Теперь нужно задать правила, когда в соответствии с вероятностью необходимо брать карту или делать пас.
Функция mode_decision принимает в качестве признаков то, что необходимо нейронной сети, делает на их основе предсказание и сравнивает его с заданным порогом, чтобы решить, брать или еще карту или пасовать. Используем значение 0,52, потому что нам известно, что перебор в блэкджеке представляет куда большую опасность. Таким образом такая вероятность слегка уменьшает вероятность действия карта и уменьшает риск перебора.
# Учитывая входные данные, функция использует нейронную сеть, чтобы сделать прогноз
# а затем на основе этого прогноза решает, взять или пропустить
def model_decision(model, player_sum, has_ace, dealer_card_num):
input_array = np.array([player_sum, 0, has_ace, dealer_card_num]).reshape(1,-1)
predict_correct = model.predict(input_array)
if predict_correct >= 0.52:
return 1
else:
return 0
Осталось лишь добавить эту функцию в код в то место, где решается, брать ли еще карту или пасовать. Теперь нейронная сеть будет принимать решение на основе того, какую карту показывает дилер, общей стоимости карт и наличия туза в руке.
А модель хороша!
Теперь сравним показатели нейронной сети со случайной и наивной стратегиями.
- Всего было запущено 300 000 симуляций для каждой стратегии
- При наивной стратегии карта берется только в том случае, если на руках меньше 12 очков
- При случайной стратегии подбрасывается монетка: если орел, тогда берем карту, если решка — пас. Если карта взята и нет перебора, тогда процесс продолжается снова и снова.
Посмотрим, получилась ли стратегия нейронной сети более выгодной. Следующая таблица показывает распределение результата для каждой стратегии. Нейронная сеть проиграла чуть меньше половины сыгранных игр. В этом случае вы все еще не обыгрываете казино, но это неплохой результат для игры, где все шансы против игрока. При этом ей не удалось одержать намного больше побед, чем в случае наивной стратегии — зато получилось больше ничьих.

Также можно взглянуть на то, как показали себя стратегии в отношении ключевых признаков (карты дилера и стоимости карт на руках). Во-первых, проверим, как карта дилера влияет на вероятность победы или ничьей в трех стратегиях. Если у дилера карта с маленьким значением, результаты нейронной сети такие же, как и у наивной стратегии. Но если у него больше 7, то она показывает себя намного лучше.

Также можно взглянуть на вероятность победы или ничьей в зависимости от стартовой руки игрока. Нам всем диапазоне нейронная сеть показывает себя намного эффективнее. И в отличие от наивной, которая работает даже хуже угадывания в долине отчаяния (когда на руках значения от 12 до 16), нейронная сеть выступает очень неплохо.

Следующий график показывает, насколько нейронная сеть эффективнее наивной стратегии. Последняя (из-за используемого алгоритма) даже не предпринимает попыток, когда есть хоть какая-то вероятность перебора. Нейронная сеть же регулярно берет еще карту, когда у нее 12, 13, 14 или 15. В данном случае речь идет о принятии решений с большим количество деталей и способностью учитывать некоторые риски.

Можно взглянуть на то, что делает нейронная сеть, когда у игрока на руках между 12 и 16 очками, чтобы улучшить наивную стратегию (и не проигрывать так много денег казино).
Похоже, что сеть часто берет карту, когда дилер показывает старшую карту (8, 9 или 10). Но даже когда у него на руках что-то низкое, например 3, нейронная сеть берет карту в 60% случаев. Это связано с тем, что она учитывает все признаки. На основе этого можно было бы разработать несколько простых правил.

Выводы
Теперь вы должны чуть лучше представлять, как машинное обучение используется для помощи в принятии решений из реальной жизни. Вот что важно запомнить для тренировки моделей (будь то деревья решений, регрессии или нейронные сети):
- Структурирована ли целевая переменная так, что если ее можно предсказать, то она решит проблему? Прежде чем переходить к сбору данных и построению модели, важно убедиться, что вы предсказываете нужные вещи.
- Как могут новые данные отличаться от тех, на которых производилась тренировка? Если они будут отличаться значительно, тогда статистическая модель может и вовсе не подойти. И по крайней мере это нужно осознавать и встраивать проверки, такие как регуляризация или строгая валидация, а также проводить тестирование модели.
- Если вы не можете понять, как модель принимает решения, то не поймете качество этих решений, сделанных вне тестовых данных.
Напоследок пара напутственных слов о том, как вы сможете улучшить представленный код самостоятельно:
- Попробуйте улучшить модель с помощью оптимизированной структуры нейронной сети, кода для разделения тузов (здесь он не использовался) или, наконец, выбора лучших признаков.
- Научите модель считать карты и смотрите, как это влияет на производительность в случае игры с одной колодой и шестью (стандарт Вегаса).
Возможно, вам удастся добиться более впечатляющих результатов. Удачи!
]]>Познакомьтесь с реализацией популярной карточной игры блэкджек, которая предоставит возможность осознать все риски поездки в Лас-Вегас.
Это руководство не ставит за цель рекламу блэкджека или любых других азартных игр. В казино все ставки всегда против вас, так что со временем вы ВСЕГДА теряете деньги. Никогда не рискуйте тем, что не готовы потерять.
Один из классических видов приложений на тему вероятности и статистики — это изучение азартных игр. Они так любимы среди специалистов по статистике, потому что содержат элементы как случайности, так и определенной неизбежности:
- Случайность в том, что вы никогда не знаете, чего ждать от игры.
- Неизбежность — знание среднего результата для большого количества сыгранных партий.
В этом материале будем разбираться с блэкджеком, написав симулятор на Python. Потом проведем несколько симуляций и изучим, как себя вел игрок. Если вдруг не помните правила этой игры, то вот ключевые моменты:
- Игроки делают ставки
- Им выдают по 2 карты в закрытом виде
- Дилер также получает 2 карты, но одна из них видна игрокам.
- Цель игры — набрать больше очков, чем у дилера (но не больше 21, больше 21 — это автоматическое поражение, которое называется перебор). Если удалось набрать больше очков, чем у дилера, то выигрышем является ставка (победа также присуждается, если у дилера перебор). Тузы оцениваются в 1 или 11 очков, а все остальные карты — согласно их значениям (валет, дама и король — их называют “картинками” — в 10 очков).
- Лучшая стартовая комбинация — туз и картинка. Она называется блэкджек.
- После первого раунда у каждого игрока есть возможность взять больше карт или спасовать (не брать карт). Если игрок набрал больше 21 очка, то его ставка сгорает.
- Когда все игроки решили, что не будут больше брать карты, дилер переворачивает свою скрытую карту. Если у него меньше 17 очков, то он обязан взять еще. Так продолжается до тех пор, пока он не наберет 17 или больше.
- После этого подводятся итоги. Если у дилера перебор, тогда игроки без перебора получают свои ставки. Если нет — тогда набранные значения сравниваются. Каждый, кто набрал больше дилера, выигрывает сумму равную ставке. Тот, у кого меньше, теряет поставленное. В случае ничьей деньги остаются на местах.
А теперь пришло время программирования
Для удобства и избежания ошибок используйте этот black_jack.ipynb
Создание симулятора
Неплохо было бы использовать ООП, но не в этот раз. Вы сами можете попробовать сделать рефакторинг и реализовать финальный код по правилам в ООП.
Для начала добавим необходимые импорты:
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
import seaborn as sns
Теперь создадим кое-какие функции. Во-первых, нужна та, что будет создавать новую колоду карт. За эту операцию будет отвечать make_decks. Она должна добавлять 4 масти каждой карты (туза, двойки, тройки, четверки и так далее) в список new_deck, перемешивать его и возвращать новый список, с которым предстоит играть. В функции можно указать и количество колод (num_decks), которые должна создавать функция.
# Создаем колоду
def make_decks(num_decks, card_types):
new_deck = []
for i in range(num_decks):
for j in range(4):
new_deck.extend(card_types)
random.shuffle(new_deck)
return new_deck
Также нужна функция, которая будет прибавлять значения карт в руке. Это сложнее базовой операции прибавления, потому что, например, туз может быть равен 1 или 11 в зависимости от того, что выгодно владельцу. Поэтому в первую очередь функция подсчитывает значение всех карт в руке за исключением туза (все картинки могут быть представлены в виде 10, поскольку в блэкджеке они работают идентично). Затем она подсчитывает количество тузов. Наконец, определяет, сколько должен «стоить» туз в зависимости от значений остальных карт в руке.
Вспомогательная функция ace_values принимает в качестве аргумента количество тузов в руке и выдает список уникальных значений стоимости тузов:
# Эта функция перечисляет все комбинации значений туза в
# массив sum_array.
# Например, если у вас 2 туза, есть 4 комбинации:
# [[1,1], [1,11], [11,1], [11,11]]
# Эти комбинации приводят к 3 уникальным суммам: [2, 12, 22]
# Из этих 3 только 2 являются <= 21, поэтому они возвращаются: [2, 12]+
def get_ace_values(temp_list):
sum_array = np.zeros((2**len(temp_list), len(temp_list)))
# Этот цикл получает комбинации
for i in range(len(temp_list)):
n = len(temp_list) - i
half_len = int(2**n * 0.5)
for rep in range(int(sum_array.shape[0]/half_len/2)):
sum_array[rep*2**n : rep*2**n+half_len, i]=1
sum_array[rep*2**n+half_len : rep*2**n+half_len*2, i]=11
# Только значения, которые подходят (<=21)
return list(set([int(s) for s in np.sum(sum_array, axis=1)\
if s<=21])) # Конвертация num_aces, int в list
# Например, если num_aces = 2, вывод должен быть [[1,11],[1,11]]
# Нужен этот формат для функции get_ace_values
def ace_values(num_aces):
temp_list = []
for i in range(num_aces):
temp_list.append([1,11])
return get_ace_values(temp_list)Эти две функции могут быть использованы функцией total_up, которая рассчитывает стоимость всех карт в руке (включая правильную обработку любого количества тузов):
# Сумма на руках
def total_up(hand):
aces = 0
total = 0
for card in hand:
if card != 'A':
total += card
else:
aces += 1
# Вызовите функцию ace_values, чтобы получить список возможных значений для тузов на руках.
ace_value_list = ace_values(aces)
final_totals = [i+total for i in ace_value_list if i+total<=21]
if final_totals == []:
return min(ace_value_list) + total
else:
return max(final_totals)Когда со вспомогательными функциями покончено, можно переходить к основному циклу. Сначала определяют ключевые переменные:
- stacks — количество стеков карт (где каждый стек может состоять из одной или большего количества колод), которые будут симулироваться
- players — количество игроков в одной партии
- num_decks — количество колод в каждом стеке
- card_types — список всех 13 типов карт
stacks = 50000
players = 1
num_decks = 1
card_types = ['A',2,3,4,5,6,7,8,9,10,10,10,10]Дальше начинаются основные циклы симулятора. Всего их два:
- Цикл for перебирает 50 000 симулируемых стеков карт
- Цикл while, по одному для каждого стека, играет в блэкджек до тех пор, пока в стеке не осталось 20 или меньше карт. В этот момент он переходит к следующему стеку
Массив numpy, curr_player_results, — это важная переменная, где хранятся результаты каждого игрока: 1 — победа, 0 — ничья, -1 — поражение. Каждый элемент массива соответствует одному игроку за столом.
В цикле while каждый игрок и дилер получают по карте (фрагмент с комментарием # Получение ПЕРВОЙ карты). После этого все получают еще по одной карте. Для этого используется функция pop с аргументом 0 — она возвращает первый элемент списка, удаляя его из списка (идеально подходит для работы с картами в стеке). Когда в стеке дилера меньше 20 карт, новый стек заменяет предыдущий (переходит к следующей итерации цикла for).
for stack in range(stacks):
blackjack = set(['A',10])
dealer_cards = make_decks(num_decks, card_types)
while len(dealer_cards) > 20:
curr_player_results = np.zeros((1,players))
dealer_hand = []
player_hands = [[] for player in range(players)]
# Получение ПЕРВОЙ карты
for player, hand in enumerate(player_hands):
player_hands[player].append(dealer_cards.pop(0))
dealer_hand.append(dealer_cards.pop(0))
# Получение ВТОРОЙ карты
for player, hand in enumerate(player_hands):
player_hands[player].append(dealer_cards.pop(0))
dealer_hand.append(dealer_cards.pop(0))Дальше дилер проверяет, нет ли у него блэкджека (туз и 10). Обратите внимание, что блэкджек определен как множество, включающее туз (ace) и десятку.
Если у дилера блэкджек, тогда игроки проиграли (они получают соответствующее значение -1 в curr_player_results). Это касается только тех, у кого также не выпало 21 очков (в этом случае объявляется ничья).
# Дилер проверяется на 21
if set(dealer_hand) == blackjack:
for player in range(players):
if set(player_hands[player]) != blackjack:
curr_player_results[0,player] = -1
else:
curr_player_results[0,player] = 0Если дилер не получил блэкджек, тогда игра продолжается. Теперь игроки проверяют, нет ли у них победной комбинации. Если есть — они автоматически одерживают победу (в некоторых казино это подразумевает выплату 1,5 к 1, то есть вы можно получить $150 в ответ на ставку $100). Выигрыш записывается с помощью значения 1 в массиве curr_player_results соответствующего игрока.
Игроки без блэкджека получают возможность взять новые карты или спасовать. В этой симуляции цель была в том, чтобы захватить все виды решений игрока — умные, глупые и удачные. Поэтому решение основывается на броске монетки (если random.random() генерирует значение больше 0,5, тогда игрок берет еще карту, в противном случае — пасует).
Такой подход может показаться глупым, но именно за счет того, что решение не связано с происходящим в игре, можно изучить все ситуации и сгенерировать богатый набор данных для анализа.
Прямо сейчас нет необходимости определять оптимальную стратегию. Задача симулятора — сгенерировать тренировочные данные, с помощью которых можно тренировать нейронную сеть играть в блэкджек оптимально.
В Python символ \ обозначает продолжение строки. Он используется для создания длинных строк кода и улучшения читаемости. Символ есть в следующем блоке кода.
else:
for player in range(players):
# Игроки проверяются на 21
if set(player_hands[player]) == blackjack:
curr_player_results[0,player] = 1
else:
# Игроки случайным образом, проверяются на перебор
while (random.random() >= 0.5) and (total_up(player_hands[player]) != 21):
player_hands[player].append(dealer_cards.pop(0))
if total_up(player_hands[player]) > 21:
curr_player_results[0,player] = -1
breakВ финальном разделе цикла очередь дилера. Он должен брать карты до тех пор, пока не получит перебор или не наберет как минимум 17. Так что пока дилер получает карты общей суммой до 17 нужно лишь проверять, не перебор ли у него. Если он взял больше 21, тогда каждый игрок без перебора побеждает и получает 1 в curr_player_results.
# Дилер добирает карты, если нужно
while total_up(dealer_hand) < 17:
dealer_hand.append(dealer_cards.pop(0))
# Сравнение очков дилера с очками игрока, но сначала проверка, не перебрал ли дилер
if total_up(dealer_hand) > 21:
for player in range(players):
if curr_player_results[0,player] != -1:
curr_player_results[0,player] = 1Если у дилера не перебор, тогда каждый игрок сравнивает свои карты с картами дилера — более высокое значение побеждает.
else:
for player in range(players):
if total_up(player_hands[player]) > total_up(dealer_hand):
if total_up(player_hands[player]) <= 21:
curr_player_results[0,player] = 1
elif total_up(player_hands[player]) == total_up(dealer_hand):
curr_player_results[0,player] = 0
else:
curr_player_results[0,player] = -1В итоге результаты игры с остальными переменными добавляются в списки, которые используются для отслеживания общих результатов симуляции:
# Отслеживание результатов симуляции
dealer_card_feature.append(dealer_hand[0])
player_card_feature.append(player_hands)
player_results.append(list(curr_player_results[0]))Результаты симуляции
Теперь можно изучить результаты. Симуляция была проведена для 50 000 стеков. Вот что получилось в итоге:
- Сыграно 312 459 партий в блэкджек
- Игрок проиграл в 199 403 играх (64% всех случаев)
- Игрок победил в 99 324 играх (32% всех случаев)
- Ничья в 13 732 играх (4% всех случаев)
Можно взглянуть на то, как меняется вероятность выигрыша/ничьей (вероятность не проиграть деньги казино) от ключевых наблюдаемых факторов. Например, вот вероятность победы/ничьей для всех возможных карт дилера (стоит напомнить, что игроки могут видеть только одну из них):
Вероятность выигрыша или ничьей к показанной карты дилера

При наличии у дилера карты от 2 до 6 вероятность победы/ничьей увеличивается. Но после 6 она резко падает. Почему так происходит?
- Если дилер показывает карту с маленьким значением, тогда при прочих равных вполне вероятно, что у него невысокая общая сумма. В таком случае игроку проще одержать победу. Это частично объясняет, почему вероятности от 2 до 6 в среднем выше, чем от 7 до туза.
- Также нужно напомнить правило дилера — если общее значение у него в руке меньше 17, он должен брать еще карту. В этом случае увеличивается вероятность того, что у него будет перебор. Это объясняет, почему вероятность растет от 2 до 6. Подумайте, какое значение самое распространенное в колоде? Конечно, 10, ведь так оценены аж 16 из 52 карт (валеты, дамы и короли). Так что если дилер показывает 6 (при условии что мы не считаем карты) наиболее вероятное предсказание — что у него на руках 16 очков. 16 меньше 17, поэтому он вынужден брать еще. А в колоде достаточно много карт, которые приведут к тому, что у дилера будет перебор: от 6 и выше. То же касается и 5, только здесь на одну карту меньше, которая приведет к перебору (7 или выше).
- Теперь подумайте о том, что происходит, когда дилер показывает 7. В этом случае велики шансы, что у него 10. Тогда игроки с 16 очками или меньше будут вынуждены брать еще. В таком случае высока вероятность перебора. В противном — недобрать достаточно очков.
Это, если обобщить, и является главным преимуществом казино перед игроками в блэкджек — скрывая одну из карт дилера (и заставляя игроков принимать решение раньше него) они заставляют игроков предполагать худший расклад и рисковать перебором (а риск значителен).
Поэтому если вы в казино и у вас на руках значение между 12 и 16, удачи, потому что шансы против вас. Теперь посмотрим на то, как начальное значение на руках у игрока (его двух стартовых карт) влияет на вероятность победы/ничьей:
Вероятность выигрыша или ничьей к сумме карт игрока

Как и следовало ожидать, вероятность победы/ничьей самая низкая для значений на руках у игрока между 12 и 16. Именно с таким количеством очков он оказывается перед ситуацией: «если я спасую, то не доберу, а если возьму еще — будет перебор». Есть смысл и в том, что 4 или 5 очков дают невысокую вероятность. Если у вас такое низкое значение и вы берете новую карту, то с большой долей вероятности на руках образуется 15, а это возвращает к ранее описанной дилемме.
Доработка алгоритма
Теперь попробуем разобраться, как с помощью простейшего эвристического алгоритма повысить шансы. Вспомните два момента:
- Основная проблема — необходимость делать ход первым (что создает риск получить перебор до дилера). Стратегия казино в том, чтобы заставить игроков действовать в условиях неопределенности в надежде на то, что они возьмут карту и получат перебор.
- Игрок в симуляторе принимает решение на основе броска монетки вне зависимости от руки (только если у него не выпало сразу 21). Поэтому даже при наличии 20 очков, есть вероятность в 50%, что он возьмет еще карту.
Попробуем увеличить шансы, сделав так, чтобы симулятор решал, брать ли новую карту только в случае нулевой вероятности перебора. Вместо броска монетки будем проверять, чтобы значение было 11 или меньше. Это не оптимальная, но простая стратегия. И поскольку она препятствует возможному перебору, то снижает риск перебора до дилера.
Следующий график сравнивает новую «умную» стратегию (синий цвет) с оригинальной (красный):
весь код в этом ноутбуке

Простейшее решение не рисковать, чтобы не получить перебор, значительно увеличивает шансы на победу. Тенденция никуда не делась, но увеличились шансы не потерять деньги.
А теперь стоит взглянуть, как новая стратегия влияет на шансы на основе собственной руки:

Шансы на победу значительно увеличились для всех ситуаций кроме значений от 12 до 16. Вероятности с этими руками почти не изменились, потому что решая остаться (и не набрать перебор) игрок увеличивает вероятность того, что дилер наберет больше (ведь он останавливается как минимум с 17 очками).
Но для остальных ситуаций новая стратегия работает прекрасно.
Понравилось? Читайте вторую часть: Учим нейронную сеть играть в блэкджек
И еще раз — никогда не ставьте то, что не готовы потерять!
]]>Что такое машинное обучение и почему это важно?
Машинное обучение — это область искусственного интеллекта, использующая статистические методы, чтобы предоставить компьютерным системам способность «учиться». То есть постепенно улучшать производительность в конкретной задаче, с помощью данных без явного программирования. Хороший пример — то, насколько эффективно (или не очень) Gmail распознает спам или насколько совершеннее стали системы распознавания голоса с приходом Siri, Alex и Google Home.
С помощью машинного обучения решаются следующие задачи:
- Распознавание мошенничества — отслеживание необычных шаблонов в транзакциях кредитных карт или банковских счетов
- Предсказание — предсказание будущей цены акций, курса обмена валюты или криптовалюты
- Распознавание изображений — определение объектов и лиц на картинках
Машинное обучение — огромная область, и сегодня речь пойдет лишь об одной из ее составляющих.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
- В регрессионных проблемах мы пытаемся предсказать непрерывный вывод. Например, предсказание цены дома на основе данных о его размере
- В классификационных — предсказываем дискретное число качественных меток. Например, попытка предсказать, является ли письмо спамом на основе количества слов в нем.

Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
- Случайный лес (random forest)
- Наивный байесовский классификатор (naive Bayes)
- Логистическая регрессия (logistic regression)
- Метод k-ближайших соседей (k nearest neighbors)
В этом материале в качестве модели будет использоваться нейронная сеть.
Понимание работы нейронных сетей
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.

- Эта диаграмма иллюстрирует процесс активации, через который проходит каждый нейрон. Рассмотрим схему слева направо.
- Все вводные данные (числовые значения) из входящих нейронов считываются. Они определяются как x1…xn.
- Каждый ввод умножается на взвешенную сумму, ассоциированную с этим соединением. Ассоциированные веса обозначены как W1j…Wnj.
- Все взвешенные вводы суммируются и передаются активирующей функции. Она читает этот ввод и трансформирует его в числовое значение k-ближайших соседей.
- В итоге числовое значение, которое возвращает эта функция, будет вводом для другого нейрона в другом слое.
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
- Слой ввода является точкой входа в нейронную сеть. В рамках программировании его можно воспринимать как аргумент функции.
- Вывод — это результат работы нейронной сети. В терминах программирования это возвращаемое функцией значение.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.

Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Если вы еще не работали с Jupyter Notebook, сначало изучите Руководство по Jupyter Notebook для начинающих
Список необходимых библиотек:
- numpy
- matplotlib
- sklearn
- tensorflow
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
!pip install matplotlib
!pip install sklearn
!pip install tensorflow
Если эти модули установлены, то теперь можно запускать весь код в проекте.
Импортируем модули и библиотеки:
import numpy as np
import matplotlib.pyplot as plt
import gzip
from typing import List
from sklearn.preprocessing import OneHotEncoder
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
%matplotlib inline
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. MNIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Цель
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:
%%bash
rm -Rf train-images-idx3-ubyte.gz
rm -Rf train-labels-idx1-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz

Чтение меток
Есть 10 цифр: (0-9), поэтому каждая метка должна быть цифрой от 0 до 9. Загруженный файл, train-labels-idx1-ubyte.gz, кодирует метки следующим образом:
Файл ярлыка тренировочного набора (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | label |
Значения меток от 0 до 9.
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
- Открыть файл с помощью библиотеки gzip, чтобы его можно было распаковать
- Прочитать весь массив байтов в память
- Пропустить первые 8 байт
- Перебирать каждый байт и приводить его к целому числу
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
with gzip.open('train-labels-idx1-ubyte.gz') as train_labels:
data_from_train_file = train_labels.read()
# Пропускаем первые 8 байт
label_data = data_from_train_file[8:]
assert len(label_data) == 60000
# Конвертируем каждый байт в целое число.
# Это будет число от 0 до 9
labels = [int(label_byte) for label_byte in label_data]
assert min(labels) == 0 and max(labels) == 9
assert len(labels) == 60000
Чтение изображений
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | pixel |
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
SIZE_OF_ONE_IMAGE = 28 ** 2
images = []
# Перебор тренировочного файла и читение одного изображения за раз
with gzip.open('train-images-idx3-ubyte.gz') as train_images:
train_images.read(4 * 4)
ctr = 0
for _ in range(60000):
image = train_images.read(size=SIZE_OF_ONE_IMAGE)
assert len(image) == SIZE_OF_ONE_IMAGE
# Конвертировать в NumPy
image_np = np.frombuffer(image, dtype='uint8') / 255
images.append(image_np)
images = np.array(images)
images.shape
Вывод: (60000, 784)
В списке 60000 изображений. Каждое из них представлено битовым вектором размером SIZE_OF_ONE_IMAGE. Попробуем построить изображение с помощью библиотеки matplotlib:
def plot_image(pixels: np.array):
plt.imshow(pixels.reshape((28, 28)), cmap='gray')
plt.show()
plot_image(images[25])

Кодирование меток изображения с помощью One-hot encoding
Будем использовать one-hot encoding для превращения целевых меток в вектор.
labels_np = np.array(labels).reshape((-1, 1))
encoder = OneHotEncoder(categories='auto')
labels_np_onehot = encoder.fit_transform(labels_np).toarray()
labels_np_onehot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])
Были успешно созданы входные данные и векторный вывод, который будет поступать на входной и выходной слои нейронной сети. Вектор ввода с индексом i будет отвечать вектору вывода с индексом i.
Вводные данные:
labels_np_onehot[999]
Вывод:
array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0.])
Вводные данные:
plot_image(images[999])
Вывод:

В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Вводные данные:
X_train, X_test, y_train, y_test = train_test_split(images, labels_np_onehot)
print(y_train.shape)
print(y_test.shape)
(45000, 10)
(15000, 10)
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
model = keras.Sequential()
model.add(keras.layers.Dense(input_shape=(SIZE_OF_ONE_IMAGE,), units=128, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
Вывод:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
Для обучения нейронной сети, выполним этот код.
model.fit(X_train, y_train, epochs=20, batch_size=128)
Вывод:
Train on 45000 samples
Epoch 1/20
45000/45000 [==============================] - 2s 54us/sample - loss: 1.3391 - accuracy: 0.6710
Epoch 2/20
45000/45000 [==============================] - 2s 39us/sample - loss: 0.6489 - accuracy: 0.8454
...
Epoch 20/20
45000/45000 [==============================] - 2s 40us/sample - loss: 0.2584 - accuracy: 0.9279
Проверяем точность на тренировочных данных.
model.evaluate(X_test, y_test)
Вывод:
[0.2567395991722743, 0.9264]
Посмотрим результаты
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
y_test[1010]
Вывод:
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Построим изображения соответствующей картинки
plot_image(X_test[1010])

Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вводные данные:
predicted_results = model.predict(X_test[1010].reshape((1, -1)))
Вывод слоя softmax — это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
predicted_results.sum()
1.0000001
Чтение вывода слоя softmax для конкретной цифры
Как можно видеть дальше, 5-ой индекс действительно близок к 1 (0,99), а это значит, что он с большой долей вероятности является
4… а это так и есть!
predicted_results
array([[1.2202066e-06, 3.4432333e-08, 3.5151488e-06, 1.2011528e-06, 9.9889344e-01, 3.5855610e-05, 1.6140550e-05, 7.6822333e-05, 1.0446112e-04, 8.6736667e-04]], dtype=float32)
Просмотр матрицы ошибок
predicted_outputs = np.argmax(model.predict(X_test), axis=1)
expected_outputs = np.argmax(y_test, axis=1)
predicted_confusion_matrix = confusion_matrix(expected_outputs, predicted_outputs)
predicted_confusion_matrix
array([[1402, 0, 4, 3, 1, 6, 20, 2, 21, 2],
[ 1, 1684, 9, 5, 4, 9, 1, 3, 9, 3],
[ 13, 8, 1280, 9, 19, 5, 12, 15, 17, 8],
[ 6, 8, 37, 1404, 1, 53, 3, 17, 33, 15],
[ 4, 7, 8, 0, 1345, 1, 18, 3, 8, 54],
[ 17, 8, 9, 31, 25, 1157, 25, 3, 24, 12],
[ 9, 6, 10, 0, 10, 12, 1431, 0, 6, 1],
[ 3, 11, 17, 4, 23, 2, 1, 1484, 5, 40],
[ 11, 16, 24, 40, 9, 25, 13, 3, 1348, 25],
[ 5, 5, 6, 16, 31, 6, 0, 43, 7, 1381]],
dtype=int64)
# это код из https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Compute confusion matrix
class_names = [str(idx) for idx in range(10)]
cnf_matrix = confusion_matrix(expected_outputs, predicted_outputs)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
plt.show()

Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
- Кодировать и декодировать изображения в наборе данных MNIST
- Кодировать категориальные значения с помощью “one-hot encoding”
- Определять нейронную сеть с двумя скрытыми слоями, а также слой вывода, использующий функцию активации softmax
- Изучать результаты вывода функции активации softmax
- Строить матрицу ошибок классификатора
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы. С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Попробуйте сами
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python:
- Поэкспериментируйте с количеством нейронов в скрытом слое. Сможете ли вы увеличить точность?
- Попробуйте добавить больше слоев. Тренируется ли сеть от этого медленнее? Понимаете ли вы, почему?
- Попробуйте RandomForestClassifier (нужна библиотека scikit-learn) вместо нейронной сети. Увеличилась ли точность?
Сокращение и ранжирование результатов
Django предлагает класс SearchQuery для перевода запросов в объект поискового запроса. По умолчанию запросы проходят через алгоритмы сокращения, что позволяет лучше находить совпадения. Также можно отсортировать результаты по релевантности. PostgreSQL предоставляет функцию ранжирования, которая сортирует результаты на основе того, как часто текст запроса появляется и как близко они расположены относительно друг друга. Отредактируйте файл views.py приложения blog и добавьте следующие импорты:
from django.contrib.postgres.search import SearchVector, SearchQuery, SearchRank
Затем взгляните на эти строки:
results = Post.objects.annotate(
search=SearchVector('title', 'body'),
).filter(search=query)Замените их этими:
search_vector = SearchVector('title', 'body') search_query = SearchQuery(query)
results = Post.objects.annotate(
search=search_vector,
rank=SearchRank(search_vector, search_query)
).filter(search=search_query).order_by('-rank')В этом коде создается объект SeatchQuery, после этого результаты фильтруются, а SearchRank используется для их ранжирования. Можете открыть https://127.0.0.1:8000/blog/search/ в браузере и провести несколько тестов, чтобы увидеть, как работает сокращение и ранжирование.
Вес запросов
Можно сделать так, чтобы у определенных направлений было больше веса при сортировке по релевантности. Например, такой код подойдет, чтобы ранжировать результаты в первую очередь по заголовкам, а не по телу. Отредактируйте предыдущие строки файла views.py приложения blog, чтобы он выглядел так:
search_vector = SearchVector('title', weight='A') + SearchVector('body', weight='B')
search_query = SearchQuery(query)
results = Post.objects.annotate(
rank=SearchRank(search_vector, search_query)
).filter(rank__gte=0.3).order_by('-rank')В этом коде используется дополнительный «вес» для направлений поиска в полях title и body. Вес по умолчанию — D, C, B и A. Они соответствуют числам 0.1, 0.2, 0.4 и 1.0 соответственно. Применим вес 1.0 к полю title и 0.4 — body: совпадения в заголовке будут преобладать над таковыми в теле. Отфильтруем результаты для отображения только тех, у которых вес больше 0.3.
Поиск по схожести триграмм
Еще один поисковый алгоритм — схожесть триграмм. Триграмма — это группа из трех символов. Можно измерить схожесть двух строк, посчитав количество общих триграмм. Этот подход часто используется для измерения схожести слов во многих языках.
Для использования триграмм в PostgreSQL нужно сперва установить pg_trgm. Используйте следующую команду, чтобы подключиться к базе данных:
psql blog
Затем эту, чтобы установить расширение pg_trgm:
CREATE EXTENSION pg_trgm;Отредактируйте представление и измените его для поиска триграм. Отредактируйте файл views.py приложения blog и добавьте следующий импорт:
from django.contrib.postgres.search import TrigramSimilarity
Затем замените поисковый запрос Post на следующие строки:
results = Post.objects.annotate(
similarity=TrigramSimilarity('title', query),
).filter(similarity__gt=0.3).order_by('-similarity')Откройте https://127.0.0.1:8000/blog/search/ в браузере и проверьте разные варианты поиска триграмм. Например, введите yango и получите результаты включающие слово django (есть в блоге есть статьи с таким словом).
Теперь у проекта мощный поисковый движок. Еще больше информации о полнотекстовом поиске можно найти здесь https://docs.djangoproject.com/en/2.0/ref/contrib/postgres/search/.
]]>Теперь нужно создать представление для того, чтобы пользователи могли осуществлять поиск по постам. В первую очередь нужна форма поиска. Отредактируйте файл forms.py приложения blog и добавьте следующую форму:
class SearchForm(forms.Form):
query = forms.CharField()
Будем использовать поле query, чтобы пользователи могли ввести поисковые запросы. Отредактируйте файл views.py и добавьте следующий код:
from django.contrib.postgres.search import SearchVector
from .forms import EmailPostForm, CommentForm, SearchForm
def post_search(request):
form = SearchForm()
query = None
results = []
if 'query' in request.GET:
form = SearchForm(request.GET)
if form.is_valid():
query = form.cleaned_data['query']
results = Post.objects.annotate(
search=SearchVector('title', 'body'),
).filter(search=query)
return render(request,
'blog/post/search.html',
{'form': form,
'query': query,
'results': results})
В этом представлении в первую очередь создается экземпляр формы SearchForm. Она будет приниматься с помощью метода GET, так, чтобы итоговый URL включал параметр query. Чтобы проверить, принята ли форма, проверяем параметр query в словаре request.GET. Когда форма принимается, создаем ее экземпляр с принятыми данными GET и верифицируем. Если она проходит проверку, проводим поиск с помощью SearchVector по полям title и body.
Представление поиска готово. Нужно создать шаблон для отображения формы и результатов поиска. Создайте файл в папке с шаблонами /blog/post/, назовите его search.html и добавьте следующий код:
{% extends "blog/base.html" %}
{% block title %}Search{% endblock %}
{% block content %}
{% if query %}
<h1>Posts containing "{{ query }}"</h1>
<h3>
{% with results.count as total_results %}
Found {{ total_results }} result{{ total_results|pluralize }}
{% endwith %}
</h3>
{% for post in results %}
<h4><a href="{{ post.get_absolute_url }}">{{ post.title }}</a></h4>
{{ post.body|truncatewords:5 }}
{% empty %}
<p>There are no results for your query.</p>
{% endfor %}
<p><a href="{% url "blog:post_search" %}">Search again</a></p>
{% else %}
<h1>Search for posts</h1>
<form action="." method="get">
{{ form.as_p }}
<input type="submit" value="Search">
</form>
{% endif %}
{% endblock %}
Как и в представлении поиска, узнать, была ли форма проверена, можно по присутствию параметра query. Перед проверкой отображаем форму и кнопку подтверждения. После проверки, отображаем проведенный поиск и общее количество результатов, а также список постов.
Наконец, отредактируйте файл urls.py приложения blog и добавьте следующий шаблон URL:
path('search/', views.post_search, name='post_search'),
Теперь откройте https://127.0.0.1:8000/blog/search/ в браузере. Вы увидите форму. Введите запрос и нажмите на кнопку «Search».
Теперь у блога есть базовая поисковая система.
]]>Добавим поисковые возможности в блог. Django ORM позволяет проводить базовые операции по поиску совпадений с помощью, например, фильтра contains (или его версии, учитывающей регистр, icontains). Следующий запрос можно использовать для поиска постов, содержащих слово framework в теле:
from blog.models import Post Post.objects.filter(body__contains='framework')
Но если планируется осуществлять сложный поиск с получением результатов, учитывающих схожесть или разный вес у полей, потребуется полнотекстовый поисковый движок.
Django предлагает мощный поиск, созданный на основе полнотекстового поиска из PostgreSQL. Модуль django.contrib.postgres включает функции, которые есть в PostgreSQL, но которых лишены другие базы данных, поддерживаемые Django. Больше об этом поиске можно узнать здесь: https://www.postgresql.org/docs/10/static/textsearch.html.
Хотя Django и способен работать с любой базой данных, он включает модуль, поддерживающий широкий набор возможностей из PostgreSQL, которых нет в других базах данных, поддерживаемых Django.
Простой поиск
Отредактируйте файл settings.py проекта и добавьте в пункт INSTALLED_APP строку django.contrib.postgres:
INSTALLED_APPS = [
# ...
'django.contrib.postgres',
]
Теперь с помощью search можно проводить поиск:
from blog.models import Post Post.objects.filter(body__search='django')
Этот запрос использует PostgreSQL для создания направления поиска поля body и поискового запроса «django». Результаты основаны на сопоставлении направления и запроса.
Поиск в нескольких полях
Иногда может потребоваться искать в нескольких полях. В этом случае нужно определить SearchVector. Построим вектор, который позволит искать в полях title и body модели Post:
from django.contrib.postgres.search import SearchVector
from blog.models import Post
Post.objects.annotate(
search=SearchVector('title', 'body'),
).filter(search='django')
С помощью annotate и SearchVector для обоих полей получается функциональность, которая будет искать совпадения в заголовке и теле постов.
]]>Полнотекстовый поиск — это интенсивный процесс. Если он будет осуществляться в более чем нескольких сотнях строк, нужно определить функциональный индекс, который совпадает с используемым поисковым направлением. Django предлагает поле
SearchVectorFieldдля моделей. Подробно об этом можно почитать здесь: https://docs.djangoproject.com/en/2.0/ref/contrib/postgres/search/#perfomance.
Сейчас для проекта используется SQLite. Это необходимо для процесса разработки. Но для развертывания потребуется более мощная база данных: PostgreSQL, MySQL или Oracle. Сделаем выбор в пользу первой, чтобы получить ее функции полнотекстового поиска.
Если вы используете Linux, установите компоненты, необходимые для работы PostgreSQL следующим образом:
sudo apt-get install libpq-dev python-dev
Затем установите саму базу данных:
sudo apt-get install postgresql postgresql-contrib
Если у вас macOS или Windows, загрузите PostgreSQL с сайта https://www.postgresql.org/download/ и установите.
Также потребуется адаптер PostgreSQL под названием Psycopg2 для Python. Эта команда установит его:
pip install psycopg2==2.7.7
Создадим базу данных PostgreSQL. Откройте консоль и введите следующие команды:
su postgres
createuser -dP blog
Дальше нужно будет ввести пароль для нового пользователя. Введите его и создайте базу данных blog, сделав ее владельцем того пользователя, что только что был создан с помощью команды:
createdb -E utf8 -U blog blog
Отредактируйте файл settings.py и измените настройку DATABASES, чтобы она выглядела вот так:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'blog',
'USER': 'blog',
'PASSWORD': '*****', # пароль
}
}
Замените данные выше названием новой базы данных и данными нового пользователя. Новая база данных пустая. Запустите следующую команду, чтобы применить все миграции базы данных:
python manage.py migrate
Наконец, создайте нового суперпользователя:
python manage.py createsuperuser
Можете запустить сервер разработки и перейти на административный сайт https://127.0.0.1:8000/admin/ с помощью новых данных.
Поскольку база данных поменялась, постов здесь нет. Заполните ее с помощью базовых постов так, чтобы можно было осуществлять поиск.
]]>Строка — это последовательность символов. Встроенный строковый класс в Python представляет собой строки, основанные на наборе символов Юникод — международного стандарта кодирования символов. Строки работают с базовыми операциями Python и некоторыми дополнительными эксклюзивными методами.
В этом материале изучим самые используемые. Здесь важно отметить, что все строковые методы всегда возвращают новые значения, а не меняют оригинальную строку.
1. Выравнивание строки по центру
Метод center() выравнивает строку по центру. Выравнивание происходит за счет определенного символа (по умолчанию — это пробел).
Синтаксис
str.center(length, fillchar), где:
- length — длина строки (обязательно);
- fillchar — символ, который определяет выравнивание (необязательно);
Пример кода
sentence = 'алгоритм'
sentence.center(14,'-')
'---алгоритм---'
2. Сколько раз символ встречается в строке
Метод count() возвращает, сколько раз конкретное значение встречалось в строке.
Синтаксис
str.count(value, start, end), где:
- value — подстрока, которую нужно искать в строке (обязательно);
- start — начальный индекс строки, откуда нужно начинать поиск (необязательно);
- end — конечный индекс строки, где поиск значения должен завершиться (необязательно);
Пример кода
sentence = 'Она продает ракушки на берегу моря. Товары, которые она продает, безусловно, ракушки.'
sentence.count('ракушки')
sentence.count('ракушки',9,25)
2
1
3. Поиск подстроки в строке
Метод find() возвращает наименьший индекс позиции, где указанная подстрока встречается в строке. Если она не найдена, возвращает -1.
Синтаксис
str.find(value, start, end), где:
- value — подстрока, которую нужно искать в строке (обязательно);
- start — начальный индекс строки, откуда нужно начинать поиск (необязательно);
- end — конечный индекс строки, где поиск значения должен завершиться (необязательно);
Типы
rfind()— методrfind()похож наfind(), но он возвращает самый большой индекс.
Пример кода
sentence = 'Она продает ракушки на берегу моря. Товары, которые она продает, безусловно, ракушки.'
sentence.find('ракушки')
sentence.find('ракушки',0,9)
sentence.find('р',5,10)
sentence.rfind('ракушки')
10
-1
8
69
4. Зеркальное изменение регистра строки
Метод swapcase() возвращает копию строки, где все буквы в нижнем регистре написаны в верхнем и наоборот.
Синтаксис
string.swapcase()
Пример кода
sentence = 'Queue - это еще одна ФУНДАМЕНТАЛЬНАЯ СТРуктура данных'
sentence.swapcase()
'qUEUE - ЭТО ЕЩЕ ОДНА фундаментальная стрУКТУРА ДАННЫХ'
5. Поиск в начале или в конце строки
Метод startswith() возвращает True, если строка начинается с заданного значения; в противном случае — False.
Метод endswith() возвращает False, если строка заканчивается конкретным значением; в противном случае — False.
Синтаксис
string.startswith(value, start, end)
string.endsswith(value, start, end)
- value — это значение, которое нужно искать в строке (обязательно);
- start — начальный индекс строки, откуда нужно начинать поиск (необязательно);
- end — конечный индекс строки, где поиск значения должен завершиться (необязательно);
Пример кода
#string.startswith()
sentence = 'Бинарный поиск - классический рекурсивный алгоритм'
sentence.startswith("Бинарный")
sentence.startswith("поиск",7,20)
True
True
#string.endswith()
sentence.endswith('классический')
False
6. Превращение строки в список
Метод split() возвращает список из слов строки, где разделителем по умолчанию выступает пробел.
Синтаксис
string.split(sep, maxsplit)
- sep — разделитель, которые используется для разделения строки. Если ничего не указано, то им выступает пробел (необязательно);
- maxsplit() — обозначает количество разделений. Значение по умолчанию (-1) означает «во всех случаях» (необязательно);
Типы
rsplit()— разбивает строку, начиная с правой стороны.
Пример кода
#string.split()
fruits = 'яблоки, манго, бананы, виноград'
fruits.split()
fruits.split(",",maxsplit = 2)
['яблоки,', 'манго,', 'бананы,', 'виноград']
['яблоки', ' манго', ' бананы, виноград']
#string.rsplit()
fruits.rsplit(",",maxsplit = 1)
['яблоки, манго, бананы', ' виноград']
7. Изменение регистра строки
7.1. Первый символ в верхний регистр
Метод capitalize() делает заглавным только первый символ строки.
Синтаксис
string.capitalize()
"сан-Франциско".capitalize()
'Сан-франциско'
7.2. Все символы в верхний регистр
Метод upper() делает все символы строки в верхнем регистре.
Синтаксис
string.upper()
"сан-Франциско".upper()
'САН-ФРАНЦИСКО'
7.3. Все первые буквы слов в верхний регистр
Метод title() делает заглавными все первые буквы в словах заданной строки.
Синтаксис
string.title()
"сан-Франциско".title()
'Сан-Франциско'
8. Выравнивание строк по левому или правому краю
Метод ljust() возвращает выровненную по левому краю строку с помощью заданного символа (пробел по умолчанию). Метод rjust() выравнивает строку по правому краю.
Синтаксис
string.rjust/ljust(length, character)
- length — длина строки, которую нужно вернуть (обязательно);
- character — символ, используемый для заполнения пустого пространства, пробел по умолчанию (необязательно);
Пример кода
#str.rjust
text = 'Бинарный поиск — '
print(text.rjust(25),"классический рекурсивный алгоритм")
Бинарный поиск — классический рекурсивный алгоритм
#str.ljust
text = 'Бинарный поиск — '
print(text.ljust(25),"классический рекурсивный алгоритм")
Бинарный поиск — классический рекурсивный алгоритм
9. Удаление пробелов вокруг строки
Метод strip() возвращает копию строки, в которой удалены определенные символы в начале и конце строки. Пробел — символ по умолчанию.
Синтаксис
string.strip(character)
Типы
rstrip()— убирает символы с правой части строки.lstrip()— удаляет символы с левой стороны строки.
Пример
#str.strip
string = '#.......Раздел 3.2.1 Вопрос #32......'
string.strip('.#!')
'Раздел 3.2.1 Вопрос #32'
#str.rstrip
string.rstrip('.#!')
string.lstrip('.#!')
'#.......Раздел 3.2.1 Вопрос #32'
'Раздел 3.2.1 Вопрос #32......'
10. Добавление нулей в начале строки
Метод zfill() добавляет нули (0) в начале строки. Длина возвращаемой строки зависит от указанной ширины.
Синтаксис
string.zfill(width)
- width — определяет длину возвращаемой строки. Нули не добавляются, если параметр ширины меньше длины оригинальной строки.
Пример
'7'.zfill(3)
'-21'.zfill(5)
'Python'.zfill(10)
'Python'.zfill(3)
'007'
'-0021'
'0000Python'
'Python'
Выводы
Это лишь некоторые полезные встроенные в Python строковые методы. Есть и другие, не менее важные. Статья Строки в python 3: методы, функции, форматирование — отличный ресурс для углубления во все подробности.
]]>В Django есть встроенный фреймворк для синдикации ленты, которую можно использовать для того, чтобы динамически генерировать ленты RSS или Atom по принципу создания карты сайта. Веб-ленты — это формат данных (обычно XML), который предлагает пользователям часто обновляемый контент. Они могут подписаться на ленту с помощью агрегатора — софта, используемого для чтения лент и получения уведомления о новом контенте.
Создайте новый файл в папке приложения blog и назовите его feeds.py. Добавьте следующие строки:
from django.contrib.syndication.views import Feed
from django.template.defaultfilters import truncatewords
from .models import Post
class LatestPostsFeed(Feed):
title = 'My blog'
link = '/blog/'
description = 'New posts of my blog.'
def items(self):
return Post.published.all()[:5]
def item_title(self, item):
return item.title
def item_description(self, item):
return truncatewords(item.body, 30)
Во-первых, нужно подкласс класса Feed фреймворка синдикации. Атрибуты title, link и description связаны с соответствующими элементами RSS: <title>, <link>, <description>.
Метод items() получает объекты, которые нужно включить в ленту. Здесь их будет 5. Методы item_title() и item_description() получают каждый объект, который возвращает items() и возвращают заголовок и описание соответственно. Встроенный фильтр truncatewords используется для создания описания из первых 30 слов.
Теперь отредактируйте файл blog/urls.py, импортируйте созданный LatestPostsFeed и создайте экземпляр ленты в шаблоне URL:
from .feeds import LatestPostsFeed
urlpatterns = [
# ...
path('feed/', LatestPostsFeed(), name='post_feed'),
]
Откройте https://127.0.0.1:8000/blog/feed/ в браузере. Должна появиться лента RSS из последних пяти постов.
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0"
xmlns:atom="https://www.w3.org/2005/Atom">
<channel>
<title>My blog</title>
<link>https://localhost:8000/blog/</link>
<description>New posts of my blog.</description>
<atom:link href="https://localhost:8000/blog/feed/" rel="self"></atom:link>
<language>en-us</language>
<lastBuildDate>Sun, 02 Feb 2020 14:59:07 +0000</lastBuildDate>
<item>
<title>Markdown post</title>
<link>https://localhost:8000/blog/2020/2/2/markdown-post/</link>
<description>This is a post formatted with markdown
--------------------------------------
*This is emphasized* and **this is more emphasized**.
Here is a list: * One * Two * Three And a [link to ...
</description>
<guid>https://localhost:8000/blog/2020/2/2/markdown-post/</guid>
</item>
<item>
<title>The AI Community Needs to Take Responsibility for Its Technology and Its Actions</title>
<link>https://localhost:8000/blog/2019/12/14/ai-community-needs-take-responsibility-its-technology-and-its-actions/</link>
<description>At the opening keynote of a prominent AI research conference,
Celeste Kidd, a cognitive psychologist, challenged the audience
to think critically about the future they want to build.
</description>
<guid>https://localhost:8000/blog/2019/12/14/ai-community-needs-take-responsibility-its-technology-and-its-actions/</guid>
</item>
</channel>
</rss>
Если открыть эту же ссылку в RSS-клиенте, лента будет отображаться в человекочитаемом виде с интерфейсом.
Финальный шаг — добавить ссылку для подписки в ленту в сайдбаре блога. Откройте шаблон blog/base.html и добавьте следующую строку под общим количеством постов в блоке div сайдбара:
<p><a href="{% url "blog:post_feed" %}">Subscribe to my RSS feed</a></p>
Теперь откройте https://127.0.0.1:8000/blog/ в браузере и посмотрите на сайдбар. Ссылка должна вести на ленту блога:

В Django есть фреймворк для карты сайта, который позволяет генерировать ее динамически. Карта сайта — это файл в формате XML, который сообщает поисковым системам о том, какие страницы имеются на сайте, их релевантность и частоту обновления. С ее помощью можно помочь поисковым роботом индексировать весь контент.
Этот фреймворк опирается на django.contrib.sites, который позволяет делать объектами отдельные сайты целого проекта. Это очень удобно, если нужно запустить несколько сайтов с помощью одного проекта Django. Для установки фреймворка нужно активировать приложения sites и sitemap в проекте. Отредактируйте файл settings.py проекта и добавьте в INSTALLED_APPS пункты django.contrib.sites и django.contrib.sitemaps. Также определите новую настройку с SITE_ID:
SITE_ID = 1
# Application definition
INSTALLED_APPS = [
# ...
'django.contrib.sites',
'django.contrib.sitemaps',
]
Теперь запустите эту команду для создания таблиц приложения сайта Django в базе данных:
python manage.py migrate
Вывод должен быть следующим:
Applying sites.0001_initial... OK
Applying sites.0002_alter_domain_unique... OK
Приложение sites теперь синхронизировано с базой данных. Создайте новый файл в папке приложения blog и назовите его sitemap.py. Откройте файл и добавьте следующий код:
from django.contrib.sitemaps import Sitemap
from .models import Post
class PostSitemap(Sitemap):
changefreq = 'weekly'
priority = 0.9
def items(self):
return Post.published.all()
def lastmod(self, obj):
return obj.updated
Создадим собственную карту сайта, наследуя класс Sitemap модуля sitemaps. Атрибуты changefreq и priotiy указывают на частоту изменения страниц с постами и их релевантность на сайте (максимальное значение — 1). Метод items() возвращает QuerySet объектов для включения в базу данных. По умолчанию Django вызывает метод get_absolute_url() для каждого объекта для получения URL. Вспомните о созданном методе для получения канонических URL для постов. Если необходимо определить URL для каждого объекта, можно добавить метод location к классу карты сайта. Метод lastmod получает каждый объект, который вернул метод items() и в свою очередь возвращает дату, когда тот последний раз изменился. И changefreq, и priority могут быть как методами, так и атрибутами. Полностью фреймворк карты сайта описан в документации Django https://docs.djangoproject.com/en/2.0/ref/contrib/sitemaps/.
Осталось лишь добавить URL карты сайта. Отредактируйте главный файл urls.py проекта и добавьте ссылку.
# mysite/urls.py
from django.urls import path, include
from django.contrib import admin
from django.contrib.sitemaps.views import sitemap
from blog.sitemap import PostSitemap
sitemaps = {
'posts': PostSitemap,
}
urlpatterns = [
path('admin/', admin.site.urls),
path('blog/', include('blog.urls', namespace='blog')),
path('sitemap.xml', sitemap, {'sitemaps': sitemaps},
name='django.contrib.sitemaps.views.sitemap')
]
В этом коде были включены необходимые импорты, а также определен словарь карт сайта. Также определен шаблон URL, который ведет на sitemap.xml и использует представление карты сайта. Запустите сервер разработки и введите в браузере https://127.0.0.1:8000/sitemap.xml. Должен появиться следующий XML-вывод:
<urlset>
<url>
<loc>https://example.com/blog/2020/2/2/markdown-post/</loc>
<lastmod>2020-02-02</lastmod>
<changefreq>weekly</changefreq>
<priority>0.9</priority>
</url>
<url>
<loc>
https://example.com/blog/2019/12/14/ai-community-needs-take-responsibility-its-technology-and-its-actions/
</loc>
<lastmod>2019-12-28</lastmod>
<changefreq>weekly</changefreq>
<priority>0.9</priority>
</url>
...
</urlset>
URL для каждого поста создается с помощью метода get_absolute_url().
Атрибут lastmod соответствует полю updated поста, как было определено в карте сайта. А атрибуты changefreq и priority берутся из класса PostSitemap. Домен, используемый для создания URL — example.com. Он исходит из объекта Site, который хранится в базе данных. Этот объект по умолчанию создается при синхронизации структуры сайта с базой данных. Откройте https://127.0.0.1:8000/admin/sites/site/ в браузере. Отобразится следующее:

На этом скриншоте изображено представление для отображения списка структуры сайта. Здесь можно назначить домен или хост, чтобы они использовались структуры сайта и приложениями, которые с ним работают. Для генерации URL в локальной среде нужно изменить доменное имя на localhost:8000, как показано на предыдущем скриншоте и сохранить:

URL, отображаемые в ленте, теперь будут строиться с помощью имени хоста. При развертывании сайта нужно будет использовать доменное имя.
]]>В Django есть много разных встроенных фильтров, которые позволяют модифицировать переменные в шаблонах. Это функции Python, принимающие один или два параметра: значение переменной, к которой она будет применена и опциональный аргумент. Они возвращают значение, которое может быть отображено или стать еще одним фильтром. Фильтр выглядит следующим образом {{ variable|my_filter }}. А фильтры с аргументом так — {{ variable|my_filter:"foo" }}. К переменной можно применять сколько угодно фильтров, например, {{ variable|filter1|filter2 }}. Каждый из них будет применен в выводу, который сгенерирует предыдущий.
Создадим собственный фильтр, который позволит использовать разметку Markdown в постах блога и затем конвертировать содержимое в код HTML в шаблонах. Markdown — это синтаксис для форматирования обычного текста, который затем превращается в HTML. С основами этого формата можно ознакомиться по ссылке https://daringfireball.net/project/markdown/basics.
Сперва установите модуль Markdown в Python с помощью pip:
pip install Markdown==2.6.11
Затем отредактируйте файл blog_tags.py и добавьте следующий код:
from django.utils.safestring import mark_safe
import markdown
@register.filter(name='markdown')
def markdown_format(text):
return mark_safe(markdown.markdown(text))
Фильтры шаблона регистрируются так же, как и шаблонные теги. Чтобы избежать конфликта имени функции с модулем markdown первую нужно назвать markdown_format, а фильтр для шаблонов — markdown: {{ variable|markdown }}. Django исключает HTML-код, сгенерированный фильтрами. Функция mark_sage из Django используется, чтобы отметить, какой HTML-код нужно отрендерить стандартным путем. По умолчанию, Django будет исключать любой HTML-код перед выводом. Единственные исключения — отмеченные переменные. Такое поведение предотвращает возможный вывод потенциально опасного кода и позволяет создавать исключения для возврата безопасного HTML-кода.
Теперь загрузите шаблонные теги в шаблоны со списком постов и страницей поста. Добавьте следующую строку в верхней части шаблонов blog/post/list.html и blog/post/detail.html после тега {% extends %}:
{% load blog_tags %}
В шаблоне post/detail.html взгляните на следующую строку:
{{ post.body|linebreaks }}
Замените ее на эту:
{{ post.body|markdown }}
Затем в файле post/list.html замените эту строку:
{{ post.body|truncatewords:30|linebreaks }}
На эту:
{{ post.body|markdown|truncatewords_html:30 }}
Фильтр truncatewords_html обрезает строку после определенного количества слов, избегая незакрытых HTML-тегов.
Теперь откройте https://127.0.0.1:8000/admin/blog/post/add в браузере и добавьте пост со следующим тегом.
This is a post formatted with markdown
--------------------------------------
*This is emphasized* and **this is more emphasized**.
Here is a list:
* One
* Two
* Three
And a [link to the Django website](https://www.djangoproject.com/)
Откройте браузер и посмотрите, как он отрендерился. Должно выглядеть вот так:

Как можно видеть на скриншоте, собственные фильтры шаблонов очень удобны для форматирования. Больше об этой теме здесь: https://docs.djangoproject.com/en/2.0/howto/custom-template-tags/#writing-custom-template-filters.
]]>Это небольшая аналитика, чтобы получить некоторое представление о хаосе, вызванном коронавирусом. Немного графики и статистики для общего представления.
Данные — Novel Corona Virus 2019 Dataset
Импортируем необходимые библиотеки.
import numpy as np # линейная алгебра
import pandas as pd # обработка данных, CSV afqk I/O (например pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('paper')
import random
def random_colours(number_of_colors):
'''
Простая функция для генерации случайных цветов.
Входные данные:
number_of_colors - целочисленное значение, указывающее
количество цветов, которые будут сгенерированы.
Выход:
Цвет в следующем формате: ['#E86DA4'].
'''
colors = []
for i in range(number_of_colors):
colors.append("#"+''.join([random.choice('0123456789ABCDEF') for j in range(6)]))
return colors
Статистический анализ
data = pd.read_csv('/novel-corona-virus-2019-dataset/2019_nCoV_data.csv')
data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Anhui | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 1 | 2 | Beijing | China | 1/22/2020 12:00 | 14.0 | 0.0 | 0.0 |
| 2 | 3 | Chongqing | China | 1/22/2020 12:00 | 6.0 | 0.0 | 0.0 |
| 3 | 4 | Fujian | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 4 | 5 | Gansu | China | 1/22/2020 12:00 | 0.0 | 0.0 | 0.0 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 497 entries, 0 to 496
Data columns (total 7 columns):
Sno 497 non-null int64
Province/State 393 non-null object
Country 497 non-null object
Last Update 497 non-null object
Confirmed 497 non-null float64
Deaths 497 non-null float64
Recovered 497 non-null float64
dtypes: float64(3), int64(1), object(3)
memory usage: 27.3+ KB
Растет метрик по числовым колонкам.
data.describe()
| Sno | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|
| count | 434.000000 | 434.000000 | 434.000000 | 434.000000 |
| mean | 217.500000 | 80.762673 | 1.847926 | 1.525346 |
| std | 125.429263 | 424.706068 | 15.302792 | 9.038054 |
| min | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 109.250000 | 2.000000 | 0.000000 | 0.000000 |
| 50% | 217.500000 | 7.000000 | 0.000000 | 0.000000 |
| 75% | 325.750000 | 36.000000 | 0.000000 | 0.000000 |
| max | 434.000000 | 5806.000000 | 204.000000 | 116.000000 |
Растет метрик по не числовым колонкам.
data.describe(include="O")
| Province/State | Country | Last Update | |
|---|---|---|---|
| count | 393 | 497 | 497 |
| unique | 45 | 31 | 13 |
| top | Ningxia | Mainland China | 1/31/2020 19:00 |
| freq | 10 | 274 | 63 |
Преобразуем данные Last Update в datetime
data['Last Update'] = pd.to_datetime(data['Last Update'])
Добавляем колонки Day и Hour
data['Day'] = data['Last Update'].apply(lambda x:x.day)
data['Hour'] = data['Last Update'].apply(lambda x:x.hour)
Данные только за 30 день января.
data[data['Day'] == 30]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
| 380 | 381 | Jiangxi | Mainland China | 2020-01-30 21:30:00 | 240.0 | 0.0 | 7.0 | 30 | 21 |
| 381 | 382 | Anhui | Mainland China | 2020-01-30 21:30:00 | 237.0 | 0.0 | 3.0 | 30 | 21 |
| 382 | 383 | Chongqing | Mainland China | 2020-01-30 21:30:00 | 206.0 | 0.0 | 1.0 | 30 | 21 |
| 383 | 384 | Shandong | Mainland China | 2020-01-30 21:30:00 | 178.0 | 0.0 | 2.0 | 30 | 21 |
| 384 | 385 | Sichuan | Mainland China | 2020-01-30 21:30:00 | 177.0 | 1.0 | 1.0 | 30 | 21 |
| 385 | 386 | Jiangsu | Mainland China | 2020-01-30 21:30:00 | 168.0 | 0.0 | 2.0 | 30 | 21 |
| 386 | 387 | Shanghai | Mainland China | 2020-01-30 21:30:00 | 128.0 | 1.0 | 9.0 | 30 | 21 |
| 387 | 388 | Beijing | Mainland China | 2020-01-30 21:30:00 | 121.0 | 1.0 | 5.0 | 30 | 21 |
| 388 | 389 | Fujian | Mainland China | 2020-01-30 21:30:00 | 101.0 | 0.0 | 0.0 | 30 | 21 |
| 389 | 390 | Guangxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 2.0 | 30 | 21 |
| 390 | 391 | Hebei | Mainland China | 2020-01-30 21:30:00 | 82.0 | 1.0 | 0.0 | 30 | 21 |
| 391 | 392 | Yunnan | Mainland China | 2020-01-30 21:30:00 | 76.0 | 0.0 | 0.0 | 30 | 21 |
| 392 | 393 | Shaanxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 0.0 | 30 | 21 |
| 393 | 394 | Heilongjiang | Mainland China | 2020-01-30 21:30:00 | 59.0 | 2.0 | 0.0 | 30 | 21 |
| 394 | 395 | Hainan | Mainland China | 2020-01-30 21:30:00 | 50.0 | 1.0 | 1.0 | 30 | 21 |
| 395 | 396 | Liaoning | Mainland China | 2020-01-30 21:30:00 | 45.0 | 0.0 | 1.0 | 30 | 21 |
| 396 | 397 | Shanxi | Mainland China | 2020-01-30 21:30:00 | 39.0 | 0.0 | 1.0 | 30 | 21 |
| 397 | 398 | Tianjin | Mainland China | 2020-01-30 21:30:00 | 32.0 | 0.0 | 0.0 | 30 | 21 |
| 398 | 399 | Gansu | Mainland China | 2020-01-30 21:30:00 | 29.0 | 0.0 | 0.0 | 30 | 21 |
| 399 | 400 | Ningxia | Mainland China | 2020-01-30 21:30:00 | 21.0 | 0.0 | 1.0 | 30 | 21 |
| 400 | 401 | Inner Mongolia | Mainland China | 2020-01-30 21:30:00 | 20.0 | 0.0 | 0.0 | 30 | 21 |
| 401 | 402 | Xinjiang | Mainland China | 2020-01-30 21:30:00 | 17.0 | 0.0 | 0.0 | 30 | 21 |
| 402 | 403 | Guizhou | Mainland China | 2020-01-30 21:30:00 | 15.0 | 0.0 | 1.0 | 30 | 21 |
| 403 | 404 | Jilin | Mainland China | 2020-01-30 21:30:00 | 14.0 | 0.0 | 1.0 | 30 | 21 |
| 404 | 405 | Hong Kong | Hong Kong | 2020-01-30 21:30:00 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| 405 | 406 | Taiwan | Taiwan | 2020-01-30 21:30:00 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| 406 | 407 | Qinghai | Mainland China | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 407 | 408 | Macau | Macau | 2020-01-30 21:30:00 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| 408 | 409 | Tibet | Mainland China | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 409 | 410 | Washington | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 410 | 411 | Illinois | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 411 | 412 | California | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 412 | 413 | Arizona | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 413 | 414 | NaN | Japan | 2020-01-30 21:30:00 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| 414 | 415 | NaN | Thailand | 2020-01-30 21:30:00 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| 415 | 416 | NaN | South Korea | 2020-01-30 21:30:00 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| 416 | 417 | NaN | Singapore | 2020-01-30 21:30:00 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| 417 | 418 | NaN | Vietnam | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 418 | 419 | NaN | France | 2020-01-30 21:30:00 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| 419 | 420 | NaN | Nepal | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 420 | 421 | NaN | Malaysia | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 421 | 422 | Ontario | Canada | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 422 | 423 | British Columbia | Canada | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 423 | 424 | NaN | Cambodia | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 424 | 425 | NaN | Sri Lanka | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 425 | 426 | New South Wales | Australia | 2020-01-30 21:30:00 | 4.0 | 0.0 | 2.0 | 30 | 21 |
| 426 | 427 | Victoria | Australia | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 427 | 428 | Queensland | Australia | 2020-01-30 21:30:00 | 3.0 | 0.0 | 0.0 | 30 | 21 |
| 428 | 429 | Bavaria | Germany | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 429 | 430 | NaN | Finland | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 430 | 431 | NaN | United Arab Emirates | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 431 | 432 | NaN | Philippines | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 432 | 433 | NaN | India | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 433 | 434 | NaN | Italy | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
data[data['Day'] == 30].sum()
Sno 23895
Country Mainland ChinaMainland ChinaMainland ChinaMain...
Confirmed 9776
Deaths 213
Recovered 187
Day 1770
Hour 1239
dtype: object
Мы можем видеть, что число подтвержденных случаев для провинции Хубэй в Китае — 5806 на 30-е число. Количества смертей, выздоровевших и пострадавших, соответствует официальным на 30 января. Это означает, что в Confirmed уже включены люди, затронуте в предыдущие даты.
Создаем датасета с данными только за 30 января.
latest_data = data[data['Day'] == 30]
latest_data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
print('Подтвержденные случаи (весь мир): ', latest_data['Confirmed'].sum())
print('Смерти (весь мир): ', latest_data['Deaths'].sum())
print('Выздоровления (весь мир): ', latest_data['Recovered'].sum())
Подтвержденные случаи (весь мир): 9776.0
Смерти (весь мир): 213.0
Выздоровления (весь мир): 187.0
Данные датасета соответствуют официальным данным.
Посмотрим как коронавирус распространялся с течением времени.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Confirmed'].plot();

Со временем наблюдается экспоненциальный рост числа жертв короновируса.
plt.figure(figsize=(16,6))
sns.barplot(x='Day',y='Confirmed',data=data);

Глубокий разведочный анализ данных (EDA)
latest_data.groupby('Country').sum()
| Sno | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|
| Country | ||||||
| Australia | 1281 | 9.0 | 0.0 | 2.0 | 90 | 63 |
| Cambodia | 424 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Canada | 845 | 3.0 | 0.0 | 0.0 | 60 | 42 |
| Finland | 430 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| France | 419 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| Germany | 429 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Hong Kong | 405 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| India | 433 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Italy | 434 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| Japan | 414 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| Macau | 408 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| Mainland China | 12126 | 9658.0 | 213.0 | 179.0 | 930 | 651 |
| Malaysia | 421 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| Nepal | 420 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Philippines | 432 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Singapore | 417 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| South Korea | 416 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| Sri Lanka | 425 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Taiwan | 406 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| Thailand | 415 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| US | 1646 | 6.0 | 0.0 | 0.0 | 120 | 84 |
| United Arab Emirates | 431 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Vietnam | 418 | 2.0 | 0.0 | 0.0 | 30 | 21 |
- Материковый Китай имеет ненулевые значения выздоровлений и смертей, которые можно изучить позже, создав отдельный набор данных
Провинции и регионы в которых нет зарегистрированных случаев заболевания.
data[data['Confirmed']==0]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | Gansu | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 10 | 11 | Heilongjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 12 | 13 | Hong Kong | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 15 | 16 | Inner Mongolia | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 18 | 19 | Jilin | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 22 | 23 | Qinghai | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 23 | 24 | Shaanxi | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 30 | 31 | Tibet | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 32 | 33 | Xinjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 53 | 54 | Inner Mongolia | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 60 | 61 | Qinghai | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 68 | 69 | Tibet | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 77 | 78 | NaN | Philippines | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 78 | 79 | NaN | Malaysia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 80 | 81 | NaN | Australia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 81 | 82 | NaN | Mexico | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 82 | 83 | NaN | Brazil | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 115 | 116 | Qinghai | Mainland China | 2020-01-24 12:00:00 | 0.0 | 0.0 | 0.0 | 24 | 12 |
| 263 | 264 | NaN | Ivory Coast | 2020-01-27 20:30:00 | 0.0 | 0.0 | 0.0 | 27 | 20 |
- Интересно, что есть части материкового Китая, которые еще не были затронуты вирусом.
- Есть страны без подтвержденных случаев заражения, и мы отбросим их.
Провинции и регионы в которых есть минимум 1 зарегистрированный случай заболевания.
data = data[data['Confirmed'] != 0]
Количество зараженных в разных странах.
plt.figure(figsize=(18,8))
sns.barplot(x='Country',y='Confirmed',data=data)
plt.tight_layout()

- На графике показано то, что мы все знаем. Вирус больше всего затронул материковый Китай, однако есть сообщения о жертвах в соседних странах, что говорит о распространении вируса.
- Есть также случаи, подтвержденные в странах, которые далеко, таких как США, Таиланд, Япония и т. Д. Интересно, как вирус попал туда. Я предполагаю, что кто-то был в Ухане или близлежащем районе во время распространения вируса и увез его с собой домой, эта вспышка действительно опасна.
Количество зараженных в разных регионах.
import plotly.express as px
fig = px.bar(data, x='Province/State', y='Confirmed')
fig.show()

Анализ роста коронавируса в каждой стране
pivoted = pd.pivot_table(data, values='Confirmed', columns='Country', index='Day')
pivoted.plot(figsize=(16,10));

Визуализация вспышки в провинциях/регионах
pivoted = pd.pivot_table(data, values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

- Hubei, наиболее пострадавшая провинция.
- Также в подтвержденных случаях наблюдается тенденция к росту, и кажется, что состояние ухудшается.
Теперь давайте посмотрим на страны, которые были затронуты изначально, и страны, в которые сейчас проник коронный вирус.
data[data['Day'] == 22]['Country'].unique()
array(['China', 'US', 'Japan', 'Thailand', 'South Korea'], dtype=object)
Итак, в первый день, 22 января заражения были обнаружены в Китае, США, Японии, Таиланде
temp = data[data['Day'] == 22]
temp.groupby('Country').sum()['Confirmed'].plot.bar()

Посмотрим на последние данные.
data[data['Day'] == 30]['Country'].unique()
array(['Mainland China', 'Hong Kong', 'Taiwan', 'Macau', 'US', 'Japan',
'Thailand', 'South Korea', 'Singapore', 'Vietnam', 'France',
'Nepal', 'Malaysia', 'Canada', 'Cambodia', 'Sri Lanka',
'Australia', 'Germany', 'Finland', 'United Arab Emirates',
'Philippines', 'India', 'Italy'], dtype=object)
Здесь мы видим, что вспышка распространилась в 23 странах к 30 января.
Рассмотрим только материковый Китай
data_main_china = latest_data[latest_data['Country']=='Mainland China']
Рассчитаем процент смертей.
(data_main_china['Deaths'].sum() / data_main_china['Confirmed'].sum())*100
2.205425553944916
Теперь процент выздоровлений.
(data_main_china['Recovered'].sum() / data_main_china['Confirmed'].sum())*100
1.8533857941602818
- Мы можем видеть, что процент смертности от коронавируса — 2%, поэтому он не такой смертоносный, как другие вирусные вспышки.
- Поскольку зарегистрировано мало случаев излечения, процент выздоровления составляет 1,87, это страшно. Хотя цифра может сильно вырасти, ведь 96% сейчас не попадают ни в одну из групп.

Где произошло большинство смертей
data_main_china.groupby('Province/State')['Deaths'].sum().reset_index(
).sort_values(by=['Deaths'],ascending=False).head()
| Province/State | Deaths | |
|---|---|---|
| 12 | Hubei | 204.0 |
| 10 | Heilongjiang | 2.0 |
| 11 | Henan | 2.0 |
| 9 | Hebei | 1.0 |
| 1 | Beijing | 1.0 |
Количество смертей по дням.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Deaths'].plot();

График заболеваний в материковом Китае.
pivoted = pd.pivot_table(data[data['Country']=='Mainland China'] , values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15))

pivoted = pd.pivot_table(data, values='Deaths', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

Что дальше
Скачайте coronavirus.ipynb и данные по ссылке в начале статьи. Попробуйте построить свои графики и таблицы.
]]>Django предлагает множество встроенных тегов, таких как {% if %} или {% block %}. Некоторые из них были использованы в ранее рассмотренных шаблонах. С полным списком можно ознакомиться по ссылке: https://docs.djangoproject.com/en/2.0/ref/templates/builtins/.
Тем не менее Django дает возможность создавать собственные шаблонные теги для осуществления любых действий. Они пригодятся в тех случаях, когда требуемая функциональность не найдется среди базового набора Django.
Создание тега
Django предлагает следующие вспомогательные функции, которые позволят с легкостью создавать собственные шаблонные теги:
simple_tag: обрабатывает данные и возвращает строку.inclusion_tag: обрабатывает данные и возвращает отрисованный шаблон.
Шаблонные теги могут использоваться только внутри приложений Django.
В папке приложения blog создайте новую папку, назовите ее templatetags и добавьте пустой файл __init__.py. Создайте еще один файл blog_tags.py. Файловая структура приложения блога должна быть следующей:
blog/
__init__.py
models.py
...
templatetags/
__init__.py
blog_tags.py
Важно выбирать правильные названия, поскольку они будут использоваться для загрузки тегов в шаблонах.
Начнем с создания простого тега, который будет получать общее количество опубликованных в блоге постов. Отредактируйте файл blog_tags.py и добавьте следующий код:
from django import template
from ..models import Post
register = template.Library()
@register.simple_tag
def total_posts():
return Post.published.count()
Этот тег возвращает количество опубликованных постов. Каждый модуль с шаблонными тегами, чтобы являться действительной библиотекой тегов, должен включать переменную register. Эта переменная — экземпляр template.Library. Она используется для регистрации собственных шаблонных тегов и фильтров. Дальше нужно определить тег total_posts с помощью функции Python и использовать декоратор @register.simple_tag для регистрации его в качестве простого тега. Django использует имя функции в качестве имени тега. Если хочется выбрать другое имя, это можно сделать с помощью атрибута name, например, @register.simple_tag(name='my_tag').
После добавления нового модуля шаблонных тегов нужно перезагрузить сервер разработки Django, чтобы изменения вступили в силу, а новые теги и фильтры можно было использовать.
Перед тем как начинать использовать собственные шаблонные теги, их нужно сделать доступными с помощью тега {% load %}. Как упоминалось ранее, необходимо использовать имя модуля Python, включающего шаблонные теги и фильтры. Откройте шаблон и добавьте сверху {% load blog_tags %} для загрузки модуля тегов шаблона. Затем используйте созданный тег для отображения общего количества опубликованных постов. Просто добавьте тег {% total_posts %} в шаблон. Он будет выглядеть вот так:
{% load blog_tags %}
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>{% block title %}{% endblock %}</title>
<link href="{% static 'css/blog.css' %}" rel="stylesheet">
</head>
<body>
<div id="content">
{% block content %}
{% endblock %}
</div>
<div id="sidebar">
<h2>My blog</h2>
<p>This is my blog. I've written {% total_posts %} posts so far.</p>
</div>
</body>
</html>
Нужно перезагрузить сервер, чтобы проект отслеживал все новые файлы. Остановите его комбинацией Ctrl + C и запустите снова с помощью:
python manage.py runserver
Откройте https://127.0.0.1:8000/blog/ в браузере. Отобразится общее количество опубликованных постов:

Преимущество собственных тегов в том, что с их помощью можно обрабатывать любые данные и добавлять в любой шаблон вне зависимости от представления. Можно использовать QuerySet или обрабатывать любые данные для отображения результатов в шаблонах.
Теперь создадим еще один тег для отображения последних постов в сайдбаре. Будем использовать тег inclusion (включения). С его помощью можно рендерить шаблон с контекстными переменными, которые шаблонный тег возвращает. Отредактируйте файл blog_tags.py и добавьте следующий код:
@register.inclusion_tag('blog/post/latest_posts.html')
def show_latest_posts(count=5):
latest_posts = Post.published.order_by('-publish')[:count]
return {'latest_posts': latest_posts}
В этом коде тег шаблона был зарегистрирован с помощью @register.inclusion_tag. Также был определен шаблон, который тег вернет вместе со значениями с помощью blog/post/latest_posts.html. Тег будет принимать опциональный параметр count со значением по умолчанию 5. Он позволяет определять количество постов, которые необходимо выводить. Используем переменную для ограничения результатов запроса Post.published.order_by('-publish')[:count]. Обратите внимание, что функция возвращает словарь, а не одно значение. Включенный тег должен возвращать словарь значений, который используется как контекст для рендеринга определенного шаблона. Созданный тег шаблона позволяет определять количество постов для отображения по желанию: {% show_latest_posts 3 %}.
Теперь нужно создать новый файл шаблона в папке blog/post/ и назвать его latest_posts.html. Добавьте туда следующий код:
<ul>
{% for post in latest_posts %}
<li>
<a href="{{ post.get_absolute_url }}">{{ post.title }}</a>
</li>
{% endfor %}
</ul>
Этот код отображает неупорядоченный список постов с помощью переменной latest_posts, которую возвращает тег шаблона. Теперь нужно отредактировать шаблон blog/base.html и добавить в него тег шаблона для отображения последних трех постов. Код сайдбара должен выглядеть следующим образом:
<div id="sidebar">
<h2>My blog</h2>
<p>This is my blog. I've written {% total_posts %} posts so far.</p>
<h3>Latest posts</h3>
{% show_latest_posts 3 %}
</div>
Тег шаблона вызывается, передавая количество постов для отображения, а шаблон отрисовывается в нужной позиции с указанным контекстом.
Вернитесь в браузер и обновите странице. Сайдбар будет выглядеть так:

Наконец, создадим просто тег шаблона, который сохраняет результат в переменной так, чтобы его можно было использовать в дальнейшем. Создадим тег для отображения наиболее комментируемых постов. Отредактируйте файл blog_tags.py и добавьте следующий импорт и шаблонный тег:
from django.db.models import Count
# ...
@register.simple_tag
def get_most_commented_posts(count=5):
return Post.published.annotate(
total_comments=Count('comments')
).order_by('-total_comments')[:count]
В нем с помощью функции annotate() создаем QuerySet, который агрегирует общее количество комментариев под постов. Сейчас используются функция агрегации Count для сохранения количества комментариев и поле total_comments каждого объекта Post. Отсортируем QuerySet по значению этого поля в убывающем порядке. Используем переменную count для ограничения общего количество возвращаемых объектов.
В дополнение к Count в Django есть такие функции агрегации, как Avg, Max, Min и Sum. О них можно почитать здесь https://docs.djangoproject.com/en/2.0/topics/db/aggregation/.
Отредактируйте шаблон blog/base.html и добавьте следующий код к элементу сайдбара <div> (после {% show_latest_posts 3 %}):
<h3>Most commented posts</h3>
{% get_most_commented_posts as most_commented_posts %}
<ul>
{% for post in most_commented_posts %}
<li>
<a href="{{ post.get_absolute_url }}">{{ post.title }}</a>
</li>
{% endfor %}
</ul>
Сохраним результат в переменной с помощью аргумента as и имени переменной. Для тега шаблона используем {% get_most_commented_posts as most_commented_posts %} для сохранения результата шаблонного тега в новой переменной most_commented_posts. Затем отобразим посты в виде неотсортированного списка.
Откройте браузер и перезагрузите страницу, чтобы увидеть финальный результат:

Теперь вы знаете, как самостоятельно создавать шаблонные теги. Подробно о них можно почитать здесь https://docs.djangoproject.com/en/2.0/howto/custom-template-tags/.
]]>Теперь, когда теги реализованы, с ними можно многое делать. С их помощью легко классифицировать посты. Материалы на схожие темы будут содержать общие теги. Создадим функциональность, которая будет отображать похожие посты, отталкиваясь от количества одинаковых тегов. Так, когда пользователь прочтет один материал, ему можно будет порекомендовать другой, связанный с ним тематически.
Для получения похожих постов нужно совершить следующие шаги:
- Получить все теги текущего поста.
- Получить все посты, к которым проставлены любые из этих же тегов.
- Исключить текущий материал, чтобы не рекомендовать его же.
- Отсортировать результаты по количеству общих тегов с текущим постом.
- Если тегов два или более, рекомендовать самый последний.
- Ограничить количество рекомендуемых постов.
Эти шаги превращаются в сложный QuerySet, который будет включать представление post_detail. Откройте файл views.py приложения блога и добавьте следующий импорт в верхней его части:
from django.db.models import Count
Это функция агрегации Count из ORM Django. Она позволяет осуществлять совокупный подсчет тегов. django.db.models включает следующие функции агрегации:
Avg: среднее значениеMax: максимальное значениеMin: минимальное значениеCount: подсчет объектов
Узнать больше об агрегации можно здесь: https://docs.djangoproject.com/en/2.0/topics/db/aggregation/.
Добавьте следующие строки в представление post_detail перед функцией render() со следующим уровнем отступа:
# Список похожих постов
post_tags_ids = post.tags.values_list('id', flat=True)
similar_posts = Post.published.filter(tags__in=post_tags_ids) \
.exclude(id=post.id)
similar_posts = similar_posts.annotate(same_tags=Count('tags')) \
.order_by('-same_tags', '-publish')[:4]
Этот код выполняет следующее:
- Получаем список Python с ID тегов текущего поста. QuerySet
values_list()возвращает кортеж со значениями для заданных полей. Передаемflat=True, чтобы получить список в формате[1, 2, 3, ...]. - Получаем все посты с одним из этих тегов, не включая текущий.
- Используем функцию агрегации
Countдля генерации поляsame_tags, которое содержит количество общих тегов. - Сортируем результаты по количество общих тегов (в порядке убывания) по
publish, чтобы отображать последние [по дате публикации] посты в числе первых, если у нескольких одинаковое количество общих тегов. Обрезаем результаты, чтобы получить только первые четыре поста.
Добавьте объект similar_posts в словарь контекста для функции render():
return render(request,
'blog/post/detail.html',
{'post': post,
'comments': comments,
'new_comment': new_comment,
'comment_form': comment_form,
'similar_posts': similar_posts})
Теперь нужно отредактировать шаблон blog/post/detail.html и добавить следующий код перед списком комментариев к посту:
<h2>Similar posts</h2>
{% for post in similar_posts %}
<p>
<a href="{{ post.get_absolute_url }}">{{ post.title }}</a>
</p>
{% empty %}
There are no similar posts yet.
{% endfor %}
Теперь страница поста должна выглядеть так:

Теперь можно рекомендовать похожие посты пользователям. django-taggit также включает менеджер similar_objects(), который можно использовать для получения постов с общими тегами. Посмотреть на все менеджеры django-taggit можно здесь: https://django-taggit.readthedocs.io/en/latest/api.html.
Также можно добавить список тегов на страницу поста по принципу шаблона blog/post/list.html.
После создания системы комментариев пришло время реализовать теги для постов. Сделаем это с помощью интеграции стороннего приложения Django. Модуль django-taggit — это приложение, состоящее из модели Tag и менеджера для добавления тегов к любой модели. Вот его исходный код: https://github.com/jazzband/django-taggit.
Сперва нужно установить django-taggit с помощью pip, воспользовавшись следующей командой:
pip install django_taggit==0.22.2
Затем откройте файл settings.py проекта mysite и добавьте taggit к настройке INSTALLED_APPS:
INSTALLED_APPS = [
# ...
'blog.apps.BlogConfig',
'taggit',
]
Откройте файл models.py приложения blog и добавьте менеджер TaggableManager из django-taggit к модели Post с помощью следующего кода:
from taggit.managers import TaggableManager
class Post(models.Model):
# ...
tags = TaggableManager()
Менеджер tags позволяет добавлять, удалять и получать теги от объектов Post.
Используйте следующую команду для создания миграции для изменений модели:
python manage.py makemigrations blog
Должен появиться следующий вывод:
Migrations for 'blog':
blog\migrations\0003_post_tags.py
- Add field tags to post
Теперь запустите следующую команду для создания требуемых таблиц базы данных для моделей django-taggit и синхронизации изменений модели:
python manage.py migrate
Появится вывод, подтверждающий примененные миграции:
Applying taggit.0001_initial... OK
Applying taggit.0002_auto_20150616_2121... OK
Applying blog.0003_post_tags... OK
База данных теперь готова использовать модели django-taggit. Но сперва нужно разобраться, как работает менеджер tags. Откройте терминал с помощью команды python manage.py shell и введите следующий код. В первую очередь нужно получить один из постов (с ID 1):
>>> from blog.models import Post
>>> post = Post.objects.get(id=1)
Затем добавьте некоторые теги и попробуйте вернуть их, чтобы проверить, были ли они добавлены:
>>> post.tags.add('music', 'jazz', 'django')
>>> post.tags.all()
<QuerySet [<Tag: jazz>, <Tag: music>, <Tag: django>]>
Наконец, удалите их и проверьте список еще раз:
>>> post.tags.remove('django')
>>> post.tags.all()
<QuerySet [<Tag: jazz>, <Tag: music>]>
Это было легко, не так ли? Запустите команду python manage.py runserver для запуска сервера разработки и откройте https://127.0.0.1:8000/admin/taggit/tag в браузере. Отобразится административная страница со списком объектов Tag приложения taggit:

Перейдите на https://127.0.0.1:8000/admin/blog/post/ и кликните по посту, чтобы отредактировать его. Посты теперь включают поле Tags, с помощью которого можно легко их редактировать:

Отредактируем посты в блоге для отображения тегов. Откройте шаблон blog/post/list.html и добавьте следующий код HTML под названием поста:
<p class="tags">Tags: {{ post.tags.all|join:", " }}</p>
Фильтр шаблона join работает так же, как и метод строки join() для объединения элементов с выбранной строкой. Откройте https://127.0.0.1:8000/blog/ в браузере. Теперь под каждым названием поста будет отображаться список тегов:

Отредактируем представление post_list, чтобы пользователи могли посмотреть все посты, связанные с конкретным тегом. Откройте файл views.py приложения blog, импортируйте модель Tag из django-taggit и измените представление post_list, чтобы опционально фильтровать посты по тегу:
from taggit.models import Tag
def post_list(request, tag_slug=None):
object_list = Post.published.all()
tag = None
if tag_slug:
tag = get_object_or_404(Tag, slug=tag_slug)
object_list = object_list.filter(tags__in=[tag])
paginator = Paginator(object_list, 3) # 3 поста на каждой странице
# ...
Представление post_list работает следующим образом:
- Оно принимает опциональный параметр
tag_slugсо значением по умолчаниюNone. Он будет в URL. - В представлении создается первый QuerySet, который получает все опубликованные посты. Если
slugуказан, то объектTagможно получить через него с помощьюget_object_or_404(). - Затем список фильтруется, чтобы остались только те, что включают тег. Это отношение многое-ко-многим, поэтому фильтровать нужно по тегам в списке, который в этом случае содержит всего один элемент.
Стоит напомнить, что QuerySet ленивы. Они будут выполнены только при итерации по списку постов при рендеринге шаблона.
Наконец, нужно изменить функцию render() в нижней части представления для передачи тега tag шаблону. В итоге представление будет выглядеть вот так:
def post_list(request, tag_slug=None):
object_list = Post.published.all()
tag = None
if tag_slug:
tag = get_object_or_404(Tag, slug=tag_slug)
object_list = object_list.filter(tags__in=[tag])
paginator = Paginator(object_list, 3) # 3 поста на каждой странице
page = request.GET.get('page')
try:
posts = paginator.page(page)
except PageNotAnInteger:
# Если страница не является целым числом, поставим первую страницу
posts = paginator.page(1)
except EmptyPage:
# Если страница больше максимальной, доставить последнюю страницу результатов
posts = paginator.page(paginator.num_pages)
return render(request,
'blog/post/list.html',
{'page': page,
'posts': posts,
'tag': tag})
Откройте файл urls.py приложения blog, закомментируйте URL-шаблон PostListView, основанный на классе и раскомментируйте представление post_list:
path('', views.post_list, name='post_list'),
# path('', views.PostListView.as_view(), name='post_list'),
Добавьте следующий дополнительный URL-шаблон для перечисления постов по тегу:
path('tag/<slug:tag_slug>/',
views.post_list, name='post_list_by_tag'),
Оба шаблона указывают на одно представление, но называются они по-разному. Первое будет вызывать представление post_list без дополнительных параметров, а второй использует tag_slug. Здесь используется конвертер пути slug для сопоставления параметра в качестве строки в нижнем регистре, состоящей из символов ASCII, дефиса и нижнего подчеркивания.
Поскольку используется представление post_list, нужно отредактировать шаблон blog/post/list.html и изменить пагинацию так, чтобы она использовала объект posts:
{% include "../pagination.html" with page=posts %}
Добавьте следующие строки над циклом {% for %}:
{% if tag %}
<h2>Posts tagged with "{{ tag.name }}"</h2>
{% endif %}
Если пользователь будет заходить в блог, он увидит список постов. Если попробует отфильтровать материалы по конкретному тегу — тег, по которому проходит фильтрация. Измените способ отображения тегов:
<p class="tags">
Tags:
{% for tag in post.tags.all %}
<a href="{% url "blog:post_list_by_tag" tag.slug %}">
{{ tag.name }}
</a>
{% if not forloop.last %}, {% endif %}
{% endfor %}
</p>
Теперь переберите все теги поста, отображая кастомную ссылку в URL для фильтра постов по этому тегу. URL будет построен с помощью {% url "blog:post_list_by_tag" tag.slug %} с URL и slug в качестве параметров. Теги разделяются запятыми.
Откройте https://127.0.0.1:8000/blog/ в браузере и нажмите на ссылку тега. Появится список постов с этим тегом:

Функциональность для управления комментариями поста уже готова. Теперь нужно адаптировать шаблон post/detail.html, чтобы он делал следующие вещи:
- Отображал общее количество комментариев для поста.
- Отображал список комментариев.
- Отображал форму для добавления нового комментария.
Сначала нужно добавить все комментарии. Откройте шаблон post/detail.html и добавьте следующий код в блок content:
{% with comments.count as total_comments %}
<h2>
{{ total_comments }} comment{{ total_comments|pluralize }}
</h2>
{% endwith %}
Здесь в шаблоне используется ORM Django — она исполняет QuerySet comments.count(). Важно отметить, что язык шаблонов Django не использует скобки для вызова методов. Тег {% with %} позволяет присвоить значение новой переменной. Она будет доступна вплоть до тега {% endwith %}.
Тег шаблона
{% with %}полезен, поскольку позволяет избежать риска изменения базы данных или доступа к методам по несколько раз.
Фильтр шаблона pluralize используется для отображения суффикса множественного числа в слове comment в зависимости от значения total_comments. Фильтры принимают значение переменной, к которой их применяли, в качестве ввода и возвращают вычисленное значение. Фильтрам шаблона будет посвящена отдельная тема.
Фильтр pluralize возвращает строку с символом «s», если значение отличается от 1. Текст отрендерится как 0 comments, 1 comment или N comments. Django включает множество тегов и фильтров шаблона, с помощью которых можно отображать желаемую информацию.
Теперь включим список комментариев. Добавьте следующие строки в шаблон post/detail.html перед предыдущим кодом:
{% for comment in comments %}
<div class="comment">
<p class="info">
Comment {{ forloop.counter }} by {{ comment.name }}
{{ comment.created }}
</p>
{{ comment.body|linebreaks }}
</div>
{% empty %}
<p>There are no comments yet.</p>
{% endfor %}
Тег шаблона {% for %} используется, чтобы перебирать комментарии. Сообщение по умолчанию отображается в том случае, если список comments пустой. Оно говорит о том, что к посту комментарии не оставляли. Перечисляются они с помощью переменной {{ forloop.counter }}, которая содержит счетчик цикла в каждой итерации. Затем отображаются имя автора, дата и тело комментария.
Наконец, нужно отрендерить форму или отобразить сообщение об успехе, если сообщение было проверено. Добавьте следующие строки под предыдущим кодом:
{% if new_comment %}
<h2>Your comment has been added.</h2>
{% else %}
<h2>Add a new comment</h2>
<form action="." method="post">
{{ comment_form.as_p }}
{% csrf_token %}
<p><input type="submit" value="Add comment"></p>
</form>
{% endif %}
Он должен быть понятен: если объект new_comment существует, отображается сообщение об успехе. В противном случае рендерится элемент абзаца <p> для каждого поля с включенным CSRF-токеном, который обязателен для запросов POST. Откройте https://127.0.0.1:8000/blog/ в браузере и кликните на пост, чтоб открыть его. Появится следующее:

Добавьте несколько комментариев с помощью формы. Они должны появится под постом в хронологическом порядке:

Откройте https://127.0.0.1:8000/admin/blog/comment/ в браузере. Вы увидите админ-панель со списком созданных комментариев. Нажмите на один из них для редактирования, уберите галочку с Active и нажмите Save. Программа снова перенаправит на список комментариев, и колонка Active покажет неактивную иконку для следующего комментария. Он будет выглядеть как первое сообщение на следующем скриншоте.

Если вернуться на страницу поста, то будет видно, что удаленный комментарий не отображается и не учитывается в общем количестве. Благодаря полю active можно отключать неприемлемые сообщения и не показывать их в постах.
Все еще нужна форма, чтобы пользователи могли оставлять комментарии к записям. В Django есть два базовых класса для построения форм: Form и ModelForm. Первый уже использовался для того, чтобы пользователи могли делиться постами через электронную почту. Сейчас нужно использовать ModelForm, потому что форму необходимо создавать динамически на основе Comment. Отредактируйте файл forms.py приложения blog и добавьте следующие строки:
from .models import Comment
class CommentForm(forms.ModelForm):
class Meta:
model = Comment
fields = ('name', 'email', 'body')
Для создания формы на основе модели нужно просто указать, какую модель взять за основу в классе формы Meta. Django исследует модель и строит форму динамически. Каждое поле модели имеет соответствующий тип поля формы по умолчанию. Способ, которым были определены поля модели, учитывается при проверке формы. По умолчанию Django создает поле формы для каждого поля модели. Но можно явно указать фреймворку, какие поля нужны в форме с помощью списка fields или определения того, какие поля нужно исключить с помощью списка полей exclude. Для формы CommentForm будут использоваться name, email и body, потому что это единственное, что нужно заполнять.
Обработка ModelForms в представлениях
Для простоты представление поста будет использоваться для создания экземпляра формы и ее обработки. Отредактируйте файл views.py, добавьте импорты для модели Comment и формы CommentForm и отредактируйте представление post_detail, чтобы оно выглядело вот так:
from .models import Post, Comment
from .forms import EmailPostForm, CommentForm
def post_detail(request, year, month, day, post):
post = get_object_or_404(Post, slug=post,
status='published',
publish__year=year,
publish__month=month,
publish__day=day)
# Список активных комментариев к этой записи
comments = post.comments.filter(active=True)
new_comment = None
if request.method == 'POST':
# Комментарий был опубликован
comment_form = CommentForm(data=request.POST)
if comment_form.is_valid():
# Создайте объект Comment, но пока не сохраняйте в базу данных
new_comment = comment_form.save(commit=False)
# Назначить текущий пост комментарию
new_comment.post = post
# Сохранить комментарий в базе данных
new_comment.save()
else:
comment_form = CommentForm()
return render(request,
'blog/post/detail.html',
{'post': post,
'comments': comments,
'new_comment': new_comment,
'comment_form': comment_form})
Разберем, что есть в представлении. Представление post_detail используется для отображения поста и комментариев. С помощью QuerySet можно получить все активные комментарии:
comments = post.comments.filter(active=True)
Начинается этот QuerySet с объекта post. Менеджер для связанных объектов, определенный в comments, используется при помощи атрибута related_name отношения в модели Comment.
То же представление используется для того, чтобы пользователи могли оставлять комментарии. Переменная new_comment инициализируется при передаче ей значения None. Она создается при создании комментария. Экземпляр формы создается с помощью comment_form = CommentForm(), если представление вызывается посредством запроса GET. Если он делается через POST, форма экземпляра создается с помощью отправленных данных и проверяется через метод is_valid(). Если форма неверна, рендерится шаблон с ошибками проверки. Если правильная — выполняются следующие действия:
- Создается новый объект
Commentпосредством вызова метода формыsave()и присваивания его переменнойnew_commentследующим образом:new_comment = comment_form.save(commit=False)Метод
save()создает экземпляр модели, к которой привязана форма и сохраняет ее в базу данных. Если ее вызвать с помощьюcommit=False, то экземпляр будет создан, но сохранение в базу данных не состоится. Это удобно, когда нужно изменить объект перед сохранением. А это следующий этап.Метод
save()доступен дляModelForm, но не для экземпляровForm, потому что они не привязаны ни к одной модели. - Текущий пост присваивается созданному комментарию:
new_comment.post = postТаким образом отмечается, что этот комментарий принадлежит этому посту.
- Наконец, новый комментарий сохраняется в базу данных через метод
save():new_comment.save()
Представление готово отображать и обрабатывать новые комментарии.
]]>Пришло время создать систему комментариев для блога, с помощью которой пользователи смогут делиться мыслями о прочитанных материалах. Для этого понадобится проделать следующие шаги:
- Создать модель для сохранения комментариев.
- Создать форму для отправки комментариев и проверки введенных данных.
- Добавить представление, которое будет обрабатывать форму и сохранять комментарий в системе.
- Отредактировать шаблон поста для отображения списка комментариев и формы для добавления нового.
Сначала создадим модель для сохранения комментариев. Откройте файл models.py приложения blog и добавьте следующий код:
class Comment(models.Model):
post = models.ForeignKey(Post,
on_delete=models.CASCADE,
related_name='comments')
name = models.CharField(max_length=80)
email = models.EmailField()
body = models.TextField()
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
active = models.BooleanField(default=True)
class Meta:
ordering = ('created',)
def __str__(self):
return 'Comment by {} on {}'.format(self.name, self.post)
Это модель Comment. Она содержит внешний ключ ForeignKey для ассоциации с конкретным постом. Это отношение многое к одному определено в модели Comment, потому что каждый комментарий предназначен для одной записи, но у поста может быть несколько комментариев. Атрибут related_name позволяет назвать атрибут, используемый для связи объектов. После его определения можно будет получать пост, для которого оставлен комментарий, с помощью comment.post. Все комментарии можно будет получить с помощью post.comments.all(). Если этот атрибут не определить, Django будет использовать имя модели маленькими буквами и __set (например, comment_set). Так будет называться менеджер связанного объекта.
Больше о связи много к одному можно почитать здесь: https://docs.djangoproject.com/en/2.0/topics/db/examples/many_to_one/.
Есть булево поле active, которое используется для ручного отключения неприемлемых комментариев. А поле created нужно для сортировки комментариев в хронологическом порядке по умолчанию.
Новая модель comment не синхронизирована с базой данных. Запустите следующую команду для создания миграции, которая отметит создание новой модели:
python manage.py makemigrations blog
Появится следующий вывод:
Migrations for 'blog':
blog/migrations/0002_comment.py
- Create model Comment
Django сгенерировал файл 0002_comment.py в папке migrations/ приложения blog. Теперь нужно создать схему связанной базы данных и применить изменения к базе данных. Воспользуйтесь командой для применения существующих миграций:
python manage.py migrate
Вывод будет включать следующую строку:
Applying blog.0002_comment... OK
Миграция была применена, а таблица blog_comment существует в базе данных.
Теперь можно добавить новую модель в административный сайт, чтобы управлять комментариями через простой интерфейс. Откройте admin.py приложения blog, импортируйте модель Comment и добавьте следующий класс ModelAmdin:
@admin.register(Comment)
class CommentAdmin(admin.ModelAdmin):
list_display = ('name', 'email', 'post', 'created', 'active')
list_filter = ('active', 'created', 'updated')
search_fields = ('name', 'email', 'body')
Запустите сервер разработки с помощью python manage.py runserver и откройте ссылку https://127.0.0.1:8000/admin/ в браузере. Вы увидите, что новая модель отображается в разделе BLOG, как на скриншоте:

Модель зарегистрирована в административном сайте, а это значит, что экземплярами Comment можно управлять с помощью простого интерфейса.
После создания формы и представления, а также добавления URL-шаблона не хватает только шаблона для этого представления. Создайте новый файл в папке blog/templates/blog/post/ и назовите его share.html. После этого добавьте следующий код:
{% extends "blog/base.html" %}
{% block title %}Share a post{% endblock %}
{% block content %}
{% if sent %}
<h1>E-mail successfully sent</h1>
<p>
"{{ post.title }}" was successfully sent to {{ form.cleaned_data.to }}.
</p>
{% else %}
<h1>Share "{{ post.title }}" by e-mail</h1>
<form action="." method="post">
{{ form.as_p }}
{% csrf_token %}
<input type="submit" value="Send e-mail">
</form>
{% endif %}
{% endblock %}
Это шаблон для отображения формы или сообщения об успешной отправке. Как можно заметить, создается HTML-элемент form. Отправка его происходит с помощью метода POST:
<form action="." method="post">
Затем включается актуальный экземпляр формы. Django сообщается, что он должен рендерить поля в HTML-абзацах — элементах <p> с помощью метода as_p. Также формы можно отрендерить в виде ненумерованного списка с помощью as_ul или как HTML-таблицу с помощью as_table. Если нужно отрендерить каждое поле, можно перебрать поля как в этом примере:
{% for field in form %}
<div>
{{ field.errors }}
{{ field.label_tag }} {{ field }}
</div>
{% endfor %}
Ярлык шаблона {% csrf_token %} представляет собой скрытое поле с автоматически генерируемым токеном, который позволяет избежать атак cross-site request forgery (CSRF, «межсайтовая подделка запроса»). Такие атаки представляют собой сайты или программы злоумышленников, выполняющие нежелательные действия за пользователя на сайте. Подробно этом написано по ссылке https://www.owasp.org/index.php/Cross-Site_Request_Forgery_(CSRF).
Этот ярлык генерирует скрытое поля, которые выглядит вот так:
<input type='hidden' name='csrfmiddlewaretoken'
value='26JjKo2lcEtYkGoV9z4XmJIEHLXN5LDR' />
По умолчанию Django проверяет CSRF — токен для всех запросов
POST. Не забывайте включить ярлык_csrf_tokenво все формы, отправляемые с помощьюPOST.
Отредактируйте шаблон blog/post/detail.html и добавьте следующую ссылку в URL поста, которым будут делиться, после переменной {{ post.body|linebreaks }}:
<p>
<a href="{% url 'blog:post_share' post.id %}">
Share this post
</a>
</p>
URL создаются динамически с помощью ярлыка шаблона {% url %} из Django. Используется пространство имен blog и URL post_share. ID поста передается в качестве параметра для создания абсолютного URL.
Запустите сервер разработки с помощью команды python manage.py runserver и откройте https://127.0.0.1:8000/blog/ в браузере. Нажмите на название любого поста, под ним будет добавленная ссылка:

Кликните на «Share this post». Откроется страница с формой для того, чтобы поделиться этим постом через email:

CSS-стили есть в коде примера в static/css/blog.css. После нажатия на SEND E-MAIL форма отправляется и проверяется. Если данные в полях правильные, отобразится сообщение об успехе E-mail successfully sent.
Если данные неверные, форма отрендерится заново с ошибками проверки.
Некоторые современные браузеры не дадут отправлять формы с пустыми или некорректными полями. Это происходит из-за того, что проверка форм браузерами основывается на типах полей и их ограничениях. В этом случае форма не будет отправлена, а браузер отобразит ошибку для некорректных полей.

Форма чтобы делиться постами через email готова. Дальше создадим систему комментариев для блога.
]]>Отправлять электронные письма с помощью Django очень просто. В первую очередь нужен локальный SMTP-сервер или определенная конфигурация внешнего в соответствующих настройках в файле settings.py проекта:
EMAIL_HOST: хост SMTP-сервера, по умолчанию —localhost.EMAIL_PORT: порт SMTP, по умолчанию —25.EMAIL_HOST_USER: имя пользователя SMTP-сервера.EMAIL_HOST_PASSWORD: пароль SMTP-сервера.EMAIL_USE_TLS: использовать ли безопасное TLS-соединение.EMAIL_USE_SSL: использовать ли безопасное SSL-соединение.
Если SMTP-сервер использовать не получается, можно задать Django, чтобы он выводил письма в оболочку. Это удобно для тестирования приложения без сервера.
Если нужно отправлять письма, но локального SMTP-сервера нет, можно использовать сервер провайдера. Следующая конфигурация подойдет для отправки через Gmail с помощью Google-аккаунта:
EMAIL_HOST = 'smtp.gmail.com'
EMAIL_HOST_USER = 'your_account@gmail.com' EMAIL_HOST_PASSWORD = 'your_password'
EMAIL_PORT = 587
EMAIL_USE_TLS = True
Запустите команду python manage.py shell для открытия оболочки и отправьте письма следующим образом:
>>> from django.core.mail import send_mail
>>>> send_mail('Django mail', 'This e-mail was sent with Django.',
'your_account@gmail.com', ['your_account@gmail.com'], fail_silently=False)
Функция send_mail() принимает тему, сообщение, отправителя и список получателей в качестве аргументов. С помощью необязательного аргумента fail_silent=False можно сделать так, чтобы при неудачной попытке отправки было вызвано исключение. Если вывод — 1, значит письмо было отправлено.
Если будет использоваться аккаунт Gmail, в настройках по ссылке https://myaccount.google.com/lesssecureapps нужно активировать следующий пункт:

Теперь необходимо добавить функциональность представлению:
Отредактируйте представление post_share в файле views.py приложения blog:
from django.core.mail import send_mail
def post_share(request, post_id):
# Получить пост по id
post = get_object_or_404(Post, id=post_id, status='published')
sent = False
if request.method == 'POST':
# Форма была отправлена
form = EmailPostForm(request.POST)
if form.is_valid():
# Поля формы прошли проверку
cd = form.cleaned_data
post_url = request.build_absolute_uri(post.get_absolute_url())
subject = '{} ({}) recommends you reading " {}"'.format(cd['name'], cd['email'], post.title)
message = 'Read "{}" at {}\n\n{}\'s comments: {}'.format(post.title, post_url, cd['name'], cd['comments'])
send_mail(subject, message, 'admin@myblog.com', [cd['to']])
sent = True
else:
form = EmailPostForm()
return render(request, 'blog/post/share.html', {'post': post,
'form': form,
'sent': sent})
Объявляем переменную sent и задаем для нее значение True, когда пост отправлен. Эта переменная будет использоваться позже в шаблоне, чтобы отображать сообщение об успешной отправке. Поскольку нужно включать ссылку на пост в email, с помощью метода get_absolute_url() можно будет получить абсолютный путь. Он будет использоваться как ввод для request.build_absolute_uri() для построения URL со схемой HTTP и именем хоста. Тема и тело письма создаются на основе очищенных данных из отправленной формы. Наконец, email отправляется по адресу указанному в поле to формы.
Когда представление готово, нужно добавить новый URL-шаблон. Откройте файл urls.py приложения blog и добавьте URL-шаблон post_share:
urlpatterns = [
# ...
path('<int:post_id>/share/',
views.post_share, name='post_share'),
]
Необходимо создать новое представление, которое обрабатывает форму и отправляет email при успешном принятии. Отредактируйте файл views.py приложения blog и добавьте следующий код:
from .forms import EmailPostForm
def post_share(request, post_id):
# Получить пост по id
post = get_object_or_404(Post, id=post_id, status='published')
if request.method == 'POST':
# Форма была отправлена
form = EmailPostForm(request.POST)
if form.is_valid():
# Поля формы прошли проверку
cd = form.cleaned_data
# ... отправить письмо
else:
form = EmailPostForm()
return render(request, 'blog/post/share.html', {'post': post,
'form': form})
Представление работает следующим образом:
- Определяется представление
post_share, которое принимает объектrequestи переменнуюpost_idв качестве параметров - Ярлык
get_object_or_404используется для получения ID поста. Также ярлык проверяет что статус поста —published. - Одно и то же представление используется для отображения изначальной формы и обработки отправленных данных. На основе метода
requestможно понять, были ли данные отправлены с помощью формы или еще нет, а принятие происходит с помощьюPOST. Предполагаем, что если запросGET, то форма будет отображаться пустой, а еслиPOST— форма отправляется и обрабатывается. Таким образом для поиска отличий в сценариях используетсяrequest.method == 'POST'.
Дальше процесс отображения и обработки формы:
- Когда представление изначально загружается с запросом
GET, создается новый экземплярform, который будет использоваться для отображения пустой формы в шаблоне:form = EmailPostForm() - Пользователь заполняет форму и отправляет ее с помощью
POST. Затем создается экземпляр формы с помощью отправленных данных, которые хранятся вrequest.POST:if request.method == 'POST': # Форма была отправлена form = EmailPostForm(request.POST) - После этого отправленные данные проверяются с помощью метода формы
is_valid(). Он проверяет данные и возвращаетTrue, если все поля содержат прошедшие проверку данные. Если где-то указана неправильная информация, методis_valid()возвращаетFalse. Список ошибок проверки можно посмотреть, получив доступ кform.errors. - Если форма не прошла проверку, то она снова рендерится в шаблоне с новыми данными. Ошибки проверки отображаются в шаблоне.
- Если проверка пройдена, доступ к данным можно получить с помощью
form.cleaned_data. Этот атрибут является словарем, где его значения — это поля формы.
Если форма не прошла проверку, в
cleaned_dataбудут только те поля, данные которых подошли.
Теперь нужно узнать, как с помощью Django отправлять email.
]]>В прошлом разделе было создано базовое приложение блога. Теперь пришло время превратить его в полнофункциональный блог с продвинутыми функциями, такими как возможность делиться постами по email, добавлять комментарии, проставлять теги и получать похожие посты. Дальше речь пойдет о следующих темах:
- Отправка email с помощью Django
- Создание форм и обработка их в представлениях
- Создание форм из моделей
- Интеграция сторонних приложений
- Построение сложных QuerySet
Делиться постами
В первую очередь нужно предоставить пользователям возможность делиться постами с помощью email. Подумайте о том, как использовать представления, URL и шаблоны для создания такой функциональности. Теперь необходимо разобраться с тем, что понадобится для того, чтобы у пользователей была возможность делиться постами по email. Требуется следующее:
- Создать форму для пользователей, где они будут указывать свои имя и электронный адрес, email получателя и дополнительные комментарии.
- Создать представление в файле
views.py, которое будет обрабатывать данные и отправлять сообщение. - Добавить URL-шаблон для нового представления в файле
urls.pyприложения блога. - Создать шаблон для отображения формы.
Создание форм в Django
Начнем с создания формы, используемой чтобы делиться постами. В Django есть встроенный фреймворк форм, который позволяет легко их создавать. С его помощью достаточно лишь определить поля, выбрать тип их отображения и указать, как они будут проверять полученные данные. Этот фреймворк обеспечивает гибкий рендеринг форм и обработку данных.
В Django есть два базовых класса для построения форм:
Form: используется для построения стандартных форм.ModelForm: позволяет создавать формы, привязанные к экземплярам модели.
Сперва нужно создать файл forms.py в папке приложения blog и добавить следующий код:
from django import forms
class EmailPostForm(forms.Form):
name = forms.CharField(max_length=25)
email = forms.EmailField()
to = forms.EmailField()
comments = forms.CharField(required=False,
widget=forms.Textarea)
Это ваша первая форма Django. Ознакомьтесь с кодом. Форма была создана посредством наследования класса Form. Здесь были использованы другие типы полей, чтобы Django правильно их проверял.
Формы могут быть где угодно в проекте Django. Но принято сохранять их в файле
forms.pyдля каждого приложения.
Тип поля name — CharField. Он отрисовывается как HTML-элемент <input type="text">. У каждого типа поля есть виджет по умолчанию, определяющий, как поле рендерится в HTML. Виджет по умолчанию может быть перезаписан с помощью атрибута widget. В поле comments используется виджет Textarea для отображения HTML-элемента <textarea> вместо стандартного <input>.
Проверка поля зависит от его типа. Например, поля email и to — это поля EmailField. Обе требуют действительной электронной почты. В противном случае будет вызвано исключение forms.ValidationError, и проверка не пройдет. Другие параметры тоже учитываются: максимальная длина поля name может быть 25 символов, а поле comments можно сделать опциональным с помощью required=False. Все это учитывается при проверке. Типы полей в этой форме — это лишь часть из общей массы. С целым списком можно ознакомиться здесь: https://docs.djangoproject.com/en/2.0/ref/forms/fields/.
Представления, основанные на классах, — это альтернативный способ внедрять представления в виде объектов, а не функций Python. Поскольку представление — это вызываемый объект, принимающий веб-запрос и возвращающий ответ, его можно определить в виде методов класса. Django предоставляет базовые классы представлений для этого. Они все наследуют класс View, который обрабатывает HTTP метод направления и другие функции.
Представления, основанные на классах, предлагают свои преимущества над представлениями, основанными на функциях в определенных случаях. У них есть следующие особенности:
- Код, связанный с методами HTTP, такими как
GET,POSTилиPUT, в отдельных методах, а не в ветках условий. - Использование наследования для создания классов представлений, которые можно использовать неоднократно (известны как
mixins).
Подробно о представлениях, основанных на классах, можно почитать здесь: https://docs.djangoproject.com/en/2.0/topics/class-based-views/intro/.
Поменяем представление post_list на «классовое», чтобы использовать общий ListView из Django. Это базовое представление позволяет отображать объекты любого вида.
Отредактируйте файл views.py приложения blog и добавьте следующий код.
from django.views.generic import ListView
class PostListView(ListView):
queryset = Post.published.all()
context_object_name = 'posts'
paginate_by = 3
template_name = 'blog/post/list.html'
Это классовое представление аналогично ранее используемому post_list. В коде выше ListView сообщается, что он должен:
- Использовать конкретный QuerySet, а не получать все объекты. Вместо определения атрибута
queryset, можно использовать определенныйmodel = Post, и Django построит общий QuerySetPost.objects.all()автоматически. - Использовать контекстную переменную
postsдля запроса результатов. Еслиcontext_object_nameне определена, то переменная по умолчанию —object_list. - Разбить результат на страницы по три объекта на каждой.
- Использовать кастомный шаблон для рендеринга. Если шаблон по умолчанию не указан,
ListViewиспользуетblog/post_list.html.
Теперь откройте файл urls.py приложения blog, закомментируйте предыдущий URL-шаблона post_list и добавьте новый с помощью класса PostListView:
urlpatterns = [
# post views
# path('', views.post_list, name='post_list'), path('', views.PostListView.as_view(), name='post_list'),
path('<int:year>/<int:month>/<int:day>/<slug:post>/',
views.post_detail,
name='post_detail'),
]
Чтобы пагинация работала, нужно использовать правильный объект страницы, который передается шаблону. Общее представление Django ListView передает выбранную страницу переменной page_obj, поэтому нужно отредактировать шаблон post/list.html. Это необходимо, чтобы пагинатор использовать правильную переменную:
{% include "pagination.html" with page=page_obj %}
Откройте https://127.0.0.1:8000/blog/ в бразуере и проверьте, чтобы все работало так же, как и с прошлым представлением post_list. Это простой пример представления, основанного на классах, использующего общий класс Django.
Итого
Вы узнали основы веб-фреймворка Django и создали базовое приложение блога. Разработали модели данных и применили миграции. Создали представления, шаблоны и URL для проекта, включая пагинацию.
Дальше речь пойдет об улучшении приложения с помощью системы комментариев и функции проставления тегов, а также возможности пользователям делиться постами через электронную почту.
]]>Список Python — это последовательность значений любого типа: строки, числа, числа с плавающей точкой или даже смешанного типа. В этом материале речь пойдет о функциях списков, о том, как создавать их, добавлять элементы, представлять в обратном порядке и многих других.
Создать списки Python
Для создания списка Python нужно заключить элементы в квадратные скобки:
my_list = [1, 2, 3, 4, 5]
Список может выглядеть так:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
Можно смешивать типы содержимого:
my_list = ['один', 10, 2.25, [5, 15], 'пять']
Поддерживаются вложенные списки как в примере выше.
Получать доступ к любому элементу списка можно через его индекс. В Python используется система индексации, начиная с нуля.
third_elem = my_list[2]
Принцип похож на строки.
Изменение списка
Списки — это изменяемые объекты, поэтому их элементы могут изменяться, или же может меняться их порядок.
Если есть такой список:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
То его третий элемент можно изменить следующим образом:
my_list[2] = 'ноль'
Если сейчас вывести его на экран, то он будет выглядеть вот так:
['один', 'два', 'ноль', 'четыре', 'пять']
Если индекс — отрицательное число, то он будет считаться с последнего элемента.
my_list = ['один', 'два', 'три', 'четыре', 'пять']
elem = my_list[-1]
print(elem)
Вывод этого кода — ‘пять’.
Проход (итерация) по списку
Читать элементы списка можно с помощью следующего цикла:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
for elem in my_list:
print(elem)
Таким образом можно читать элементы списка. А вот что касается их обновления:
my_list = [1, 2, 3, 4, 5]
for i in range(len(my_list)):
my_list[i]+=5
print(my_list)
Результат будет следующим:
[6, 7, 8, 9, 10]
Функция len() используется для возврата количества элементов, а range() — списка индексов.
Стоит запомнить, что вложенный список — это всегда один элемент вне зависимости от количества его элементов.
my_list = ['один', 10, 2.25, [5, 15], 'пять']
print(len(my_list))
Результат кода выше — 5.
Срез списка
Можно получить срез списка с помощью оператора (:):
my_list = ['один', 'два', 'три', 'четыре', 'пять']
print(my_list[1:3])
Результат кода выше — ['два', 'три']
Если убрать первое число, от срез будет начинаться с первого элемента, а если второе — с последнего.
Если убрать числа и оставить только двоеточие, то скопируется весь список.
my_list = ['один', 'два', 'три', 'четыре', 'пять']
print(my_list[1:3])
print(my_list[1:])
print(my_list[:3])
print(my_list[:])
Результат этого года:
['два', 'три']
['два', 'три', 'четыре', 'пять']
['один', 'два', 'три']
['один', 'два', 'три', 'четыре', 'пять']
Поскольку списки изменяемые, менять элементы можно с помощью оператора среза:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
my_list[1:3] = ['Привет', 'Мир']
print(my_list)
Результат:
['один', 'Привет', 'Мир', 'четыре', 'пять']
Вставить в список
Метод insert можно использовать, чтобы вставить элемент в список:
my_list = [1, 2, 3, 4, 5]
my_list.insert(1,'Привет')
print(my_list)
Результат:
[1, 'Привет', 2, 3, 4, 5]
Индексы для вставляемых элементов также начинаются с нуля.
Добавить в список
Метод append можно использовать для добавления элемента в список:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
my_list.append('ещё один')
print(my_list)
Результат:
['один', 'два', 'три', 'четыре', 'пять', 'ещё один']
Можно добавить и больше одного элемента таким способом:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
list_2 = ['шесть', 'семь']
my_list.extend(list_2)
print(my_list)
Результат:
['один', 'два', 'три', 'четыре', 'пять', 'шесть', 'семь']
При этом list_2 не поменяется.
Отсортировать список
Для сортировки списка нужно использовать метод sort.
my_list = ['cde', 'fgh', 'abc', 'klm', 'opq']
list_2 = [3, 5, 2, 4, 1]
my_list.sort()
list_2.sort()
print(my_list)
print(list_2)
Вывод:
['abc', 'cde', 'fgh', 'klm', 'opq']
[1, 2, 3, 4, 5]
Перевернуть список
Можно развернуть порядок элементов в списке с помощью метода reverse:
my_list = [1, 2, 3, 4, 5]
my_list.reverse()
print(my_list)
Результат:
[5, 4, 3, 2, 1]
Индекс элемента
Метод index можно использовать для получения индекса элемента:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
print(my_list.index('два'))
Результат 1.
Если в списке больше одного такого же элемента, функция вернет индекс первого.
Удалить элемент
Удалить элемент можно, написав его индекс в методе pop:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
removed = my_list.pop(2)
print(my_list)
print(removed)
Результат:
['один', 'два', 'четыре', 'пять']
три
Если не указывать индекс, то функция удалит последний элемент.
my_list = ['один', 'два', 'три', 'четыре', 'пять']
removed = my_list.pop()
print(my_list)
print(removed)
Результат:
['один', 'два', 'три', 'четыре']
пять
Элемент можно удалить с помощью метода remove.
my_list = ['один', 'два', 'три', 'четыре', 'пять']
my_list.remove('два')
print(my_list)
Результат:
['один', 'три', 'четыре', 'пять']
Оператор del можно использовать для тех же целей:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
del my_list[2]
print(my_list)
Результат:
['один', 'два', 'четыре', 'пять']
Можно удалить несколько элементов с помощью оператора среза:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
del my_list[1:3]
print(my_list)
Результат:
['один', 'четыре', 'пять']
Функции агрегации
В Python есть некоторые агрегатные функции:
my_list = [5, 3, 2, 4, 1]
print(len(my_list))
print(min(my_list))
print(max(my_list))
print(sum(my_list))
sum() работает только с числовыми значениями.
А max(), len() и другие можно использовать и со строками.
Сравнить списки
В Python 2 сравнить элементы двух списком можно с помощью функции cmp:
my_list = ['один', 'два', 'три', 'четыре', 'пять']
list_2 = ['три', 'один', 'пять', 'два', 'четыре']
print(cmp(my_list,list_2))
Она вернет -1, если списки не совпадают, и 1 в противном случае.
В Python 3 для этого используется оператор (==):
my_list = ['один', 'два', 'три', 'четыре', 'пять']
list_2 = ['три', 'один', 'пять', 'два', 'четыре']
if (my_list == list_2):
print('cовпадают')
else:
print('не совпадают')
Результат не совпадают.
Математические операции на списках:
Для объединения списков можно использовать оператор (+):
list_1 = [1, 2, 3]
list_2 = [4, 5, 6]
print(list_1 + list_2)
Результат:
[1, 2, 3, 4, 5, 6]
Список можно повторить с помощью оператора умножения:
list_1 = [1, 2, 3]
print(list_1 * 2)
Результат:
[1, 2, 3, 1, 2, 3]
Списки и строки
Для конвертации строки в набор символов, можно использовать функцию list:
my_str = 'Monty Python'
my_list = list(my_str)
print(my_list)
Результат:
['M', 'o', 'n', 't', 'y', ' ', 'P', 'y', 't', 'h', 'o', 'n']
Функция list используется для того, чтобы разбивать строку на отдельные символы.
Можно использовать метод split для разбития строки на слова:
my_str = 'Monty Python'
my_list = my_str.split()
print(my_list)
Результат:
['Monty', 'Python']
Она возвращает обычный список, где с каждым словом можно взаимодействовать через индекс.
Символом разбития может служить любой знак, а не только пробел.
my_str = 'Monty-Python'
my_list = my_str.split('-')
print(my_list)
Результат будет аналогичен:
['Monty', 'Python']
Объединить список в строку
Обратный процесс — объединение элементов списка в строку.
Это делается с помощью метода join:
my_list = ['Monty', 'Python']
delimiter = ' '
output = delimiter.join(my_list)
print(output)
Результат Monty Python.
Алиасинг (псевдонимы)
Когда две переменные ссылаются на один и тот же объект:
my_list = ['Monty', 'Python']
list_2 = my_list
Алиасинг значит, что на объект ссылается больше одного имени.
Следующий пример показывает, как меняются изменяемые списки:
my_list = ['Monty', 'Python']
list_2 = my_list
list_2[1] = 'Java:)'
print(my_list)
Результат:
['Monty', 'Java:)']
Изменился список list_2, но поскольку он ссылается на один и тот же объект, то оригинальный список тоже поменялся.
Использовать “псевдонимы” при работе со списками не рекомендуется.
В целом, работать со списками в Python очень просто.
Добавляя контент на блог, вы быстро придете к выводу, что список постов лучше делить на несколько страниц. В Django есть встроенный класс пагинации, который позволяет сделать это очень быстро.
Отредактируйте файл views.py приложения blog, чтобы импортировать класс Paginator и измените представление post_list следующим образом:
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger
def post_list(request):
object_list = Post.published.all()
paginator = Paginator(object_list, 3) # 3 поста на каждой странице
page = request.GET.get('page')
try:
posts = paginator.page(page)
except PageNotAnInteger:
# Если страница не является целым числом, поставим первую страницу
posts = paginator.page(1)
except EmptyPage:
# Если страница больше максимальной, доставить последнюю страницу результатов
posts = paginator.page(paginator.num_pages)
return render(request,
'blog/post/list.html',
{'page': page,
'posts': posts})
Вот как работает этот класс:
- Создается экземпляр класса
Paginatorс количеством объектов, которые нужно отображать на одной странице. - Получаем параметр
page GET, который указывает на текущую страницу. - Получаем объекты для нужной страницы, вызывая метод page() метода
Paginator. - Если параметр
page— это не целое число, возвращаем первую страницу результатов. Если оно больше последней страницы результатов, возвращаем последнюю. - Передаем шаблону номер страницы и полученные объекты.
Теперь нужно создать шаблон для отображения пагинатора так, чтобы он мог использоваться в любом шаблоне с пагинацией. В папке templates/ приложения blog создайте новый файл и назовите его pagination.html. Добавьте туда следующий код:
<div class="pagination">
<span class="step-links">
{% if page.has_previous %}
<a href="?page={{ page.previous_page_number }}">Previous</a>
{% endif %}
<span class="current">
Page {{ page.number }} of {{ page.paginator.num_pages }}.
</span>
{% if page.has_next %}
<a href="?page={{ page.next_page_number }}">Next</a>
{% endif %}
</span>
</div>
Шаблон пагинации ожидает получить объект Page, чтобы отрисовать ссылки «Previous» и «Next», а также для отображения текущей страницы и общее количество страниц результата. Вернемся к шаблону blog/post/list.html и добавим шаблон pagination.html в нижней части блока {% content %}:
{% block content %}
...
{% include "../pagination.html" with page=posts %}
{% endblock %}
Поскольку объект Page, который передается шаблону, называется posts, передадим шаблон пагинации в шаблон списка постов вместе с параметрами для корректного рендеринга. Этот способ можно применять, чтобы использовать шаблон пагинации в постраничных представлениях разных моделей.
Теперь откройте https://127.0.0.1:8000/blog/ в браузере. Вы увидите элементы навигации по страницам в нижней части и сможете перемещаться по ним.

Итак, представления и URL-шаблоны для приложения blog были созданы. Теперь нужно добавить шаблоны для отображения постов так, чтобы их было удобно читать пользователям.
Создайте следующие директории и файлы в папке приложения blog:
blog/
templates/
blog/
base.html
post/
list.html
detail.html
Эта файловая структура для шаблонов. Файл base.html включает основной HTML-код сайта. В нем содержимое разделено между главной областью с контентом и сайдбаром. Файлы list.html и detail.html будут наследовать base.html для отрисовки списка постов и представления поста соответственно.
В Django есть мощный язык шаблонов, который позволяет обознаиать, как именно данные будут отображаться. Он основан на тегах, переменных и фильтрах шаблона:
- Теги управляют рендерингом шаблона и выглядят так
{% tag %}. - Переменные шаблона заменяются значениями при отрисовке и выглядят так
{{ variable }}. - Фильтры позволяют изменять отображаемые переменные и выглядят так
{{ variable|filter }}.
Все встроенные теги и фильтры шаблона перечислены здесь https://doc.djangoproject.com/en/2.0/ref/templates/builtins/.
Отредактируем файл base.html и добавим следующий код:
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>{% block title %}{% endblock %}</title>
<link href="{% static 'css/blog.css' %}" rel="stylesheet">
</head>
<body>
<div id="content">
{% block content %}
{% endblock %}
</div>
<div id="sidebar">
<h2>My blog</h2>
<p>This is my blog.</p>
</div></body>
</html>
{% load static %} сообщает Django, что нужно загрузить теги шаблона static, предоставленные приложением django.contrliv.staticfiles, которое можно найти в INSTALLED_APPS. После загрузки фильтр шаблон {% static %} можно использовать во всем шаблоне. С помощью фильтра можно включать статичные файлы, например файл blog.css. Он находится в коде в папке static/. Скопируйте стили из кода внизу в то же место, где хранится проект, чтобы применить стили CSS.
blog/
static/
css/
blog.css
blog.css
* {
box-sizing:border-box;
}
a {
text-decoration: none;
}
body,
html {
height: 100%;
margin: 0;
}
h1 {
border-bottom: 1px solid lightgrey;
padding-bottom: 10px;
}
.date,
.info {
color: grey;
}
.comment:nth-child(even) {
background-color: whitesmoke;
}
#content,
#sidebar {
display: inline-block;
float: left;
padding: 20px;
height: 100%;
}
#content {
width: 70%;
}
#sidebar {
width: 30%;
background-color: lightgrey;
}
Также используются два тега {% block %}. Они сообщают Django, что в этой области нужно определить блок. Наследуемые шаблоны могут заполнять эти блоки контентом. С их помощью определены блоки title и content.
Отредактируем файл post/list.html, чтобы он выглядел следующим образом:
{% extends "blog/base.html" %}
{% block title %}My Blog{% endblock %}
{% block content %}
<h1>My Blog</h1>
{% for post in posts %}
<h2>
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>
</h2>
<p class="date">
Published {{ post.publish }} by {{ post.author }}
</p>
{{ post.body|truncatewords:30|linebreaks }}
{% endfor %}
{% endblock %}
Тег шаблона {% extends %} сообщает Django, чтобы он наследовал шаблон blog/base.html. Затем контентом заполняются блоки title и content базового шаблона. Происходит перебор по постам, в результате чего отображаются их название, дата, автор и тело, включая ссылку в названии к каноническому URL поста. В теле применяются два фильтра шаблона: truncateword обрезает значение до заданного количества слов, а linebreaks конвертирует вывод в строки HTML с переносами. Можно объединять сколько угодно фильтров шаблона. Каждый будет применяться к выводу предыдущего.
Откройте терминал и выполните команду python manage.py runserver для запуска сервера разработки. Откройте https://127.0.0.1:8000/blog/ в бразуере, чтобы увидеть, как все работает. Для отображения постов здесь они должны быть со статусом Published. Появится следующее:

Теперь нужно отредактировать файл post/detail.html:
{% extends "blog/base.html" %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
<h1>{{ post.title }}</h1>
<p class="date">
Published {{ post.publish }} by {{ post.author }}
</p>
{{ post.body|linebreaks }}
{% endblock %}
Наконец, можно вернуться в браузер и кликнуть по названию любого поста, чтобы посмотреть, как он выглядит:

И посмотрите на URL — его структура должны быть приблизительно такой /blog/2019/11/23/who-was-django-reinhardt/. Это значит, что ссылки подходят для SEO-оптимизации.
URL-шаблоны позволяют связывать URL с представлениями. Шаблон URL состоит из шаблона строки, представления и имени (опционально), с помощью которого можно задать имя для URL всего проекта. Django перебирает каждый шаблон и останавливается на первом, который соответствует запрошенному URL. Затем библиотека импортирует представление совпавшего URL-шаблона и исполняет его, передавая экземпляр класса HttpRequest и ключевое слово или позиционные аргументы.
Создайте файл urls.py в папке приложение blog и добавьте следующие строки:
from django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [
# post views
path('', views.post_list, name='post_list'),
path('<int:year>/<int:month>/<int:day>/<slug:post>/',
views.post_detail,
name='post_detail'),
]
В этом коде было определено пространство имен приложения с помощью переменной app_name. Это позволяет организовать URL по приложениям и использовать имена, ссылаясь на них. В примере два шаблона были определены с помощью функции path(). Первый URL-шаблон не принимает аргументов и привязан к представлению post_list. Второй — принимает следующие 4 аргумента и связан с представлением post_detail:
year: требует целое числоmonth: требует целое числоday: требует целое числоpost: может быть составлен из слов и дефисов
Угловые скобки используются для захвата значений из URL. Любое значение, определенное в URL-шаблоне как <parameter>, захватывается как строка. Для точного совпадения и возврата целого числа применяются конвертеры пути, такие как <int:year>. А <slug:post> нужен для совпадения ссылки (строки, состоящей из символов ASCII и чисел, плюс дефис и нижнее подчеркивание). Все конвертеры перечислены здесь: https://docs.djangoproject.com/en/2.0/topics/urls/#path-converters.
Если способ с использованием path() и конвертеров не подходит, можно рассмотреть re_path(). Она применяется для определения сложных URL-шаблонов с помощью регулярных выражений Python. Узнать больше об определении URL-шаблонов с помощью регулярных выражений можно по ссылке https://docs.djangoproject.com/en/2.0/ref/urls/#django.urls.re_path. Если вы не работали с ними раньше, рассмотрите эту тему в разделе HOWTO: https://docs.python.org/3/howto/regex/html_
Создавать файл
urls.pyдля каждого приложения — лучший способ добиться того, чтобы их можно было использовать в других проектах.
Теперь нужно включить URL-шаблоны приложения blog в основные URL-шаблоны проекта. Отредактируйте файл urls.py в папке mysite проекта, чтобы он выглядел следующим образом:
from django.urls import path, include
from django.contrib import admin
urlpatterns = [
path('admin/', admin.site.urls),
path('blog/', include('blog.urls', namespace='blog')),
]
Новый URL-шаблон, определенный с помощью include, ссылается на URL-шаблоны, определенные в приложении блога. Таким образом они относятся к пути blog/ и включены под пространством имен blog. Пространства имен должны быть уникальными во всем проекте. Позже на URL блога можно будет ссылаться с помощью пространства имен, создавая их, например вот так blog:post_list или blog:post_detail. Больше о пространствах имен URL можно узнать по ссылке https://docs.djangoproject.com/en/2.0/topics/http/urls/#url-namespaces.
Канонические URL для моделей
Для построения канонических URL для объектов post можно использовать URL post_detail, определенные в предыдущем разделе. По правилам Django нужно добавить метод get_absolute_url() в модель. Он вернет канонический URL объекта. Для этого метода будет использоваться метод reverse(), который позволяет создавать URL согласно их названиям и передаваемым опциональным параметрам. Отредактируйте файл models.py и добавьте следующее:
from django.urls import reverse
class Post(models.Model):
# ...
def get_absolute_url(self):
return reverse('blog:post_detail',
args=[self.publish.year,
self.publish.month,
self.publish.day,
self.slug])
В шаблонах будет использоваться метод get_absolute_url() для связи с конкретными постами.
Начнем с создания представления для отображения списка постов. Отредактируйте файл views.py приложения blog, чтобы он выглядел следующим образом:
from django.shortcuts import render, get_object_or_404
from .models import Post
def post_list(request):
posts = Post.published.all()
return render(request,
'blog/post/list.html',
{'posts': posts})
Это первое представление Django. Представление post_list принимает объект request в качестве единственного параметра. Он обязателен для всех представлений. В этом представлении можно получить все посты с помощью статуса published из менеджера published, который был создан ранее.
Наконец, используется ярлык render(). Она представляется Django для рендеринга списка постов с заданным шаблоном. Эта функция принимает объект request, путь шаблона и контекстные переменные для отрисовки выбранного шаблона. Она возвращает объект HttpResponce с отрисованным текстом (обычно это код HTML). Ярлык render() учитывает контекст запроса, поэтому любая переменная из контекстного процессора шаблона может использоваться для заданного шаблона. Процессоры контекста для шаблонов — это всего лишь вызываемые объекты, которые назначают переменные для контекста.
Создадим второе представление для отображения одного поста. Добавьте следующую функцию в файл views.py:
def post_detail(request, year, month, day, post):
post = get_object_or_404(Post, slug=post,
status='published',
publish__year=year,
publish__month=month,
publish__day=day)
return render(request,
'blog/post/detail.html',
{'post': post})
Это представление поста. Оно принимает year, month, day и параметры post для получения опубликованного поста с заданным slug и датой. Стоит обратить внимание, что при создании модели Post в поле slug было добавлено поле unique_for_date. Таким образом можно удостовериться, что будет только один пост с такой ссылкой в указанную дату, а это значит, что с помощью даты и ссылки (slug) всегда можно получить один конкретный пост. В этом представлении используется ярлык get_object_or_404() для получения нужной записи. Функция возвращает объект, параметры которого совпадают с запросом или запускает исключение HTTP 404 (не найдено), если такой не был найдет. В конце используется ярлык render() для отрисовки полученного поста с помощью шаблона.
Как уже упоминалось, objects — это менеджер по умолчанию для каждой модели. Он получает объекты из базы данных. Но можно определять и собственные менеджеры для моделей. Попробуем создать собственный менеджер для получения постов со статусом published.
Их можно добавить двумя способами: добавив дополнительные методы менеджера или изменив оригинальные. Первый предоставляет API QuerySet, такие как Post.objects.my_manager(), а второй — Post.my_manager.all(). Менеджер позволит получать посты с помощью Post.published.all().
Отредактируйте файл models.py приложения blog для добавления кастомного менеджера:
class PublishedManager(models.Manager):
def get_queryset(self):
return super(PublishedManager,
self).get_queryset()\
.filter(status='published')
class Post(models.Model):
# ...
objects = models.Manager() # Менеджер по умолчанию
published = PublishedManager() # Собственный менеджер
Метод менеджера get_queryset() возвращает QuerySet, который и будет исполнен. Перезапишем его, чтобы включить кастомный фильтр в финальный QuerySet. Кастомный менеджер уже определен и добавлен к модели Post; теперь его можно использовать и для осуществления запросов. Проверим.
Запустите сервер разработки с помощью этой команды:
python manage.py shell
Теперь вы можете получить все посты, названия которых начинаются с Who:
Post.published.filter(title__startswith='Who')
ORM в Django основан на QuerySet. QuerySet — это набор объектов из базы данных, который может использовать фильтры для ограничения результатов. Уже известно, как получать один объект из базы данных с помощью метода get(). Получить к нему доступ можно с помощью Post.objects.get(). Каждая модель Django имеет как минимум один менеджер, а менеджер по умолчанию называется objects. Сделать запрос к объекту (QuerySet) можно с помощью менеджера модели. Для получения всех объектов из таблицы нужно просто использовать метод all() в менеджере объектов по умолчанию:
>>> all_posts = Post.objects.all()
Таким образом можно создать QuerySet, который вернет все объекты базы данных. Но важно обратить внимание на то, что он не еще исполнился. QuerySet в Django ленивые. Они исполняются только в том случае, если их заставить. Это поведение делает инструмент крайне эффективным. Если не сохранить QuerySet в переменную, а написать его прямо в оболочку Python, выражение SQL в QuerySet исполнится автоматически, потому что такой была команда:
>>> Post.objects.all()
Метод filter()
Чтобы отфильтровать QuerySet, можно использовать метод filter() менеджера. Например, можно получить все посты за 2017 год с помощью такого запроса:
Post.objects.filter(publish__year=2017)
Можно фильтровать и по нескольким полям одновременно. Так, чтобы получить все посты за 2017 год, написанные автором admin, следует использовать команду:
Post.objects.filter(publish__year=2017, author__username='admin')
Это то же самое, что писать QuerySet с цепочкой фильтров:
Post.objects.filter(publish__year=2017) \
.filter(author__username='admin')
Запросы с методами поиска по полям пишутся с двумя нижними подчеркиваниями, например
publish__year, _но такое же написание используется для получения доступа к полям связанных моделей, напримерauthor__username.
Метод exclude()
Можно исключить некоторые результаты из запроса с помощью метода менеджера exclude(). Например, можно получить все посты за 2017 год, названия которых не начинаются с Why:
Post.objects.filter(publish__year=2017) \
.exclude(title__startswith='Why')
Метод order_by()
Результаты можно отсортировать по полям с помощью метода менеджера order_by(). Например, можно получить все объекты, отсортированные согласно их названию (title) с помощью такой команды:
Post.objects.order_by('title')
Подразумевается расположение по возрастанию. Чтобы разместить элементы по убыванию необходимо использовать минус в качестве префикса:
Post.objects.order_by('-title')
Удаление объектов
Если нужно удалить объект, это можно сделать из экземпляра с помощью метода delete():
post = Post.objects.get(id=1)
post.delete()
Обратите внимание, что удаление объектов также удалит все зависимые отношения для объектов
ForeignKey, для которых вCASCADEопределеноon_delete.
Когда исполняется QuerySet
Для QuerySet можно объединить несколько фильтров, но они не коснутся базы данных, до тех пор пока QuerySet не будет выполнен. А он исполняется в следующих условиях:
- При первой итерации по QuerySet.
- При получении среза, например
Post.objects.all()[:3]. - При сериализации или кэшировании объектов.
- При вызове
repr()илиlen(). - При прямом вызове
list(). - При проверке QuerySet в других выражениях, например
bool(),or,andилиif.
Теперь, когда есть полноценный административный сайт для управления контентом из блога, пришло время узнать, как получать информацию из базы данных и взаимодействовать с ней. В Django есть мощный встроенный API для создания, получения, обновления и удаления объектов. Инструмент ORM (объектно-реляционное отображение) в Django совместим с MySQL, PostgreSQL, SQLite и Oracle. Определить базу данных своего проекта можно в настройке DATABASES в файле settings.py проекта. Django умеет работать с несколькими базами данных одновременно, а вы можете создать роутеры для создания собственным схем роутинга.
После создания моделей данных Django предоставляет бесплатный API для взаимодействия с ними. Вот ссылка на информацию о нем в официальной документации: https://docs.djangoproject.com/en/2.0/ref/models/.
Создание объектов
Откройте командную строку и введите следующую команду для открытия оболочки Python:
python manage.py shell
Попробуйте ввести следующие строки:
>>> from django.contrib.auth.models import User
>>> from blog.models import Post
>>> user = User.objects.get(username='admin')
>>> post = Post(title='Another post', slug='another-post', body='Post body.', author=user)
>>> post.save()
Разберем по порядку, за что отвечает этот код. Сначала нужно получить объект user, имя пользователя которого — admin.
user = User.objects.get(username='admin')
Метод get() позволяет получить один объект из базы данных. Он рассчитывает на результат, который бы соответствовал запросу. Если база данных не вернет результат, метод вернет исключение DoesNotExist, а если вернет несколько, то — исключение MultipleObjectsReturned. Оба исключения — атрибуты класса модели, к которой и был направлен запрос.
Затем создается экземпляр Post с названием, текстом ссылки и телом. Добавленный же в прошлом шаге пользователь будет автором поста:
post = Post(title='Another post',
slug='another-post',
body='Post body.',
author=user)
Этот объект хранится в памяти и не представлен в базе данных.
Дальше сохраняется объект Post с помощью метода save():
post.save()
Предыдущее действие отвечает за выражение INSERT в SQL. Вы уже знаете, как сначала создать объект в памяти, а потом перенести его в базу данных, но это же можно сделать и с помощью одной операции — create():
Post.objects.create(title='One more post',
slug='one-more-post',
body='Post body.',
author=user)
Обновление объектов
Попробуйте поменять название поста и снова сохраните объект:
>>> post.title = 'New title'
>>> post.save()
В этот раз метод save() исполнит выражение UPDATE в SQL.
]]>Сделанные изменения не сохранятся в базе данных до вызова метода
save().
Рассмотрим, как изменить внешний вид списка объектов модели в админ-панели. Отредактируйте файл admin.py приложения блога и измените его следующим образом:
from django.contrib import admin
from .models import Post
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish', 'status')
Таким образом административная панель Django понимает, что модель зарегистрирована с помощью пользовательского класса, наследуемого из ModelAdmin. В него можно включить информацию о том, как отображать модель и как взаимодействовать с ней. Атрибут list_display позволяет настроить поля модели, которые необходимо показывать на странице со списком объектов на сайте. Декоратор @admin.register() выполняет ту же функцию, что и замененная admin.site.register(), регистрируя класс ModeAdmin, который он же и декорирует.
Отредактируем административную панель с помощью следующих настроек:
from django.contrib import admin
from .models import Post
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish', 'status')
list_filter = ('status', 'created', 'publish', 'author')
search_fields = ('title', 'body')
prepopulated_fields = {'slug': ('title',)}
raw_id_fields = ('author',)
date_hierarchy = 'publish'
ordering = ('status', 'publish')
Вернемся в браузер и перезагрузим страницу. Теперь она будет выглядеть вот так:

Можно увидеть, что поля, отображаемые на странице со списком постов — это те, что были определены в атрибуте list_display. Она включает правый сайдбар, с помощью которого можно фильтровать результаты по полям, которые указаны в атрибуте list_filter. На странице появилось и поле поиска. Это потому что был определен список полей, по которым можно осуществлять поиск с помощью search_fields. Под ним есть навигационные ссылки для просмотра разных дат. Также посты упорядочены по умолчанию согласно данным в колонках «Status» (Статус) или «Publish» (Опубликовано). Порядок по умолчанию задан с помощью атрибута ordering.
Теперь кликните по кнопке «Add Post» (Добавить пост). Здесь тоже есть кое-какие изменения. При вводе названия нового поста поле slug будет заполняться автоматически. Django использует для этого атрибут prepopulated_fields и данные из поля title. Также поле author теперь отображается с виджетом поиска, который с большим объемом данных работает лучше чем выпадающее меню.

Всего парой строк кода удалось изменить способ отображения модели в административной панели. Есть еще много способов изменения внешнего вида и расширения возможностей списка объектов модели в админ-панели Django.
]]>Добавим модели блога на административный сайт. Отредактируйте файл admin.py приложения blog, чтобы он выглядел так:
from django.contrib import admin
from .models import Post
admin.site.register(Post)
Теперь перезагрузите сайт в браузере. Там появится модель Post:

Это было просто, не так ли? При регистрации модели в административном сайте Django пользователь получает интуитивный интерфейс, созданный посредством анализа моделей. Это позволяет легко создавать, удалять и редактировать их.
Нажмите на ссылку Add около Posts, чтобы добавить новую запись. Появится форма создания, которую Django сгенерировал динамически для этой модели:

Django использует разные виджеты форм для каждого типа поля. Даже сложные поля, такие как DateTimeField, отображаются с простым интерфейсомt.
Заполните форму и нажмите кнопку Save. Вы должны быть перенаправлены на страницу списка постов с подтверждением добавления поста, как показано ниже:

Теперь, когда модель Post определена, нужно создать простую админ-панель для постов в блоге. В Django есть встроенный административный интерфейс, который подходит для работы с контентом. Он создается динамически с помощью чтения мета-данных модели. Это приводит к появлению готового интерфейса, который используется для редактирования контента. Можно сразу начинать использовать его, настроив лишь способ отображения моделей.
Приложение django.contrib.admin уже включено в INSTALLED_APPS, поэтому отдельно его не нужно добавлять.
Создание супер-пользователя
В первую очередь нужно создать пользователя, который сможет управлять админ-панелью. Для этого необходимо использовать команду:
python manage.py createsuperuser
Отобразится следующий вывод. Потребуется ввести имя пользователя, email и пароль:
Username (leave blank to use 'admin'):
admin Email address:
admin@admin.com
Password: ********
Password (again): ********
Superuser created successfully.
Админ-панель Django
Запустить сервер разработки можно с помощью команды python manage.py runserver. Дальше нужно открыть https://127.0.0.1:8000/admin/ в браузере. Отобразится страница авторизации как на скриншоте:

Необходимо зайти на сайт с помощью имени пользователя и пароли, созданных в прошлом шаге. Отобразится стартовая страница админ-панели как на скриншоте:

Модели Group и User — это элементы фреймворка аутентификации Django, которые расположены в django.contrib.auth. Если нажать на Users, вы увидите созданного пользователя. Модель Post приложения blog связана с моделью User. Запомните, что отношение определяется полем author.
Теперь, когда есть модель данных для постов в блоге, нужна таблица базы данных. В Django есть система миграции, которая отслеживает изменения в моделях и позволяет передавать их в базу данных. Команда migrate применяет миграции для всех приложений в INSTALLED_APPS. Она синхронизирует базу данных с текущими моделями и существующими миграциями.
В первую очередь нужно создать стартовую миграцию для модели Post. В корневой директории проекта необходимо ввести следующую команду:
python manage.py makemigrations blog
Появится следующий вывод:
Migrations for 'blog':
blog/migrations/0001_initial.py
- Create model Post
Django только что создал файл 0001_initial.py в папке migrations приложения blog. Можно открыть его, чтобы увидеть, как появилась миграция. Миграция определяет зависимости от других миграций и операций, которые нужно провести в базе данных, чтобы синхронизировать ее с изменениями модели.
Посмотрим на код SQL, который исполнится в базе данных для создания таблицы для модели. Команда sqlmigrate возьмет названия миграций и вернет их SQL без исполнения. Выполните следующую команду, чтобы увидеть вывод SQL от первой миграции:
python manage.py sqlmigrate blog 0001
Он должен выглядеть следующим образом:
BEGIN;
--
-- Create model Post
--
CREATE TABLE "blog_post" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"title" varchar(250) NOT NULL, "slug" varchar(250) NOT NULL, "body" text NOT
NULL, "publish" datetime NOT NULL, "created" datetime NOT NULL, "updated"
datetime NOT NULL, "status" varchar(10) NOT NULL, "author_id" integer NOT
NULL REFERENCES "auth_user" ("id") DEFERRABLE INITIALLY DEFERRED
);
CREATE INDEX "blog_post_slug_b95473f2" ON "blog_post" ("slug");
CREATE INDEX "blog_post_author_id_dd7a8485" ON "blog_post" ("author_id");
COMMIT;
Точный вывод зависит от используемой базы данных. Этот пример основан на SQLite. Как можно видеть в этом выводе, Django генерирует имена таблицы объединяя название приложения и название модели в нижнем регистре (blog_post), но можно указать и собственное имя базы данных в классе модели Meta с помощью атрибута db_table. Django создает основной ключ автоматически для каждой модели, но его можно перезаписать, указав primary_key = True в одной из полей модели. Основной ключ по умолчанию — это колонка id. Она состоит из целого числа, которое автоматически инкрементируется. Эта колонка соотносится с полем id, которое автоматически добавляется моделям.
Синхронизируем базу данных с новой моделью. Для этого нужно ввести следующую команду:
python manage.py migrate
Вывод будет такой:
Applying blog.0001_initial... OK
Это применило миграции для приложений в INSTALLED_APPS, включая приложение blog. После применения база данных отображает текущее состояние моделей.
Если отредактировать файл models.py для добавления, удаления или изменения полей существующих моделей или при добавлении новых моделей нужно будет создавать новую миграцию с помощью команды makemigrations. Миграция позволит Django отслеживать изменения модели. Затем нужно будет использовать команду migrate, чтобы синхронизировать базу данных с моделями.
Начинать разработку дизайна схемы блога необходимо с определения моделей данных блога. Модель — это класс в Python, представляющий собой подкласс django.db.models.Model,_ в котором каждый атрибут — это поле базы данных. Django создаст таблицу для каждой модели, определенной в файле models.py. При создании модели Django предоставляет практический API, с помощью которого легко делать запросы к объектам в базе данных.
В первую очередь необходимо определить модель Post. Для этого в файл models.py приложения blog нужно добавить следующие строки:
from django.db import models
from django.utils import timezone
from django.contrib.auth.models import User
class Post(models.Model):
STATUS_CHOICES = (
('draft', 'Draft'),
('published', 'Published'),
)
title = models.CharField(max_length=250)
slug = models.SlugField(max_length=250,
unique_for_date='publish')
author = models.ForeignKey(User,
on_delete=models.CASCADE,
related_name='blog_posts')
body = models.TextField()
publish = models.DateTimeField(default=timezone.now)
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
status = models.CharField(max_length=10,
choices=STATUS_CHOICES,
default='draft')
class Meta:
ordering = ('-publish',)
def __str__(self):
return self.title
Это модель данных для постов блога. Рассмотрим подробно каждый из полей в этой модели:
-
title— поле для заголовка поста. Это полеCharField, которое переводится в колонкуVARCHARв базе данных SQL. -
slug— это поле используется в URL. Это короткий маркер, включающий только буквы, числа, нижние подчеркивания и дефисы. Он нужен для создания красивых URL, подходящих для SEO. Для этого поля также добавлен параметрunique_for_date, так что для постов будет использоваться дата их публикации вместе соslug. Django не позволит использовать один и тот жеslugдля нескольких постов в один день. -
author— это поле представлено внешним ключом, определенным отношением многие к одному. Мы сообщаем Django, что каждый пост написан пользователем, и пользователь может написать любое количество постов. Для этого поля Django создаст внешний ключ в базе данных, основываясь на основном ключе связанной модели. В этом случае опираемся на модельUserиз системы аутентификации Django. Параметрon_deleteопределяет поведение, когда объект, на который ссылаются, оказывается удален. Это из стандартов SQL. С помощьюCASCADEможно указать, что если пользователь удаляется, система удалит и все связанные с ним записи из блога. Все возможные варианты представлены здесь https://docs.djangoproject.com/en/2.0/ref/models/fields/#django.db.models.ForeignKey.on_delete. Определить обратное отношение, отUserкPostможно с помощью атрибутаrelated_name. Это позволит легко получать доступ к связанным объектам. Речь об этом в подробностях пойдет дальше. -
body— тело поста. Это текстовое поле, которое переводится в колонкуTEXTв базе данных SQL. -
publish— datetime определяет, когда пост был опубликован. По умолчанию используется методnowиз timezone Django. Возвращаются текущие дата и время с учетом часового пояса. Этот подход напоминает методdatetime.nowстандартной версии Python. -
created— datetime указывает, когда пост был создан. Поскольку используетсяauto_now_add, дата сохранится автоматически при создании объекта. -
updated— datetime указывает, когда пост был обновлен в последний раз. Поскольку используетсяauto_now, дата сохранится автоматически при обновлении объекта. -
status— показывает статус поста. Используется параметрchoices, поэтому значение поля может быть одним из представленных вариантов.
В Django есть несколько типов полей, которые можно использовать для моделей. Все эти типы полей перечислены здесь: https://docs.djangoproject.com/en/2.0/ref/models/fields/.
Класс Meta в модели содержит мета-данные. По умолчанию Django будет сортировать результаты в поле publish в обратном хронологическом порядке при запросе к базе данных. Обратный хронологический порядок задается с помощью отрицательного индекса. В таком случае новые посты будут появляться первыми.
Метод __str__() — это версия объекта в человекочитаемой форме. Django будет использовать ее во многих местах, например в административном сайте.
Если ранее вы пользовались Python 2.X, обратите внимание, что в_ Python 3 все строки по умолчанию закодированы в Unicode, поэтому используется метод __str__(). Метод __unicode__() устарел.
В руководствах по этому фреймворку вы будете встречать слова «проект» и «приложение». В Django проектом называется установка Django с определенными настройками. Приложение — это группа моделей, представлений, шаблонов и URL.
Приложение взаимодействует с фреймворком для предоставления различных возможностей. Его можно задействовать и в других наработках. Проектом можно считать сайт, которые включает приложения: блог, справочник или форум, которые найдут применение и в других проектах.
Создание приложения
Создадим приложение блога на Django. В командной строке из корневого каталога проекта нужно ввести следующее:
python manage.py startapp blog
Это создаст стандартную структуру:
blog/
__init__.py
admin.py
apps.py
migrations/
__init__.py
models.py
tests.py
views.py
Файлы в нем выполняют такие задачи:
admin.py— здесь регистрируются модели, которые будут использоваться в административном сайте Django (его необязательно использовать).apps.py— включает настройкуblog.migrations— этот каталог включает миграции базы данных приложения. С их помощью Django сохраняет информацию об изменении моделей и соответственно синхронизирует базу данных.models.py— модели данных приложения. Все приложения Django должны иметь файлmodels.py, но он может оставаться пустым.tests.py— здесь можно добавлять тесты для приложения.views.py— здесь находится логика приложения. Каждое представление получает HTTP-запрос, обрабатывает его и возвращает ответ.
Активация приложений
Чтобы Django имел возможность отслеживать приложение и мог создавать для моделей базы данных, приложение нужно активировать. Для этого требуется отредактировать файл settings.py и добавить в INSTALLED_APP пункт blog.apps.BlogConfig. Теперь он должен выглядеть так:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blog.apps.BlogConfig',
]
Класс BlogConfig — это настройка целого приложения. Теперь Django знает, что оно активно и сможет загружать его модели.
Запустим файл settings.py, чтобы ознакомиться с настройками. Там содержатся только некоторые из настроек Django. Все, включая их значения по умолчанию можно найти по ссылке https://docs.djangoproject.com/en/2.0/ref/settings/.
Вот на какие пункты рекомендуется обратить внимание в первую очередь:
-
DEBUG— это булево значение, которое активирует режим отладки. Django будет показывать страницы с детальным описанием ошибок при определенных исключениях. При переходу к рабочей среде обязательно нужно установить значениеFalse. Нельзя разворачивать сайт с активированным режимом отладки, потому что это сделает общедоступными важные для проекта данные. -
ALLOWED_HOSTSне работает с активированным режимом отладки или работающих тестах. Когда сайт в рабочем режиме, а значениеDEBUGравняетсяFalse, этой настройке нужно передать домен/хост, чтобы он взаимодействовал с сайтом. -
INSTALLED_APPS— раздел, который обязательно нужно редактировать. Он сообщает Django, какие приложения работают для конкретного сайта. Изначально Django включает следующие:django.contrib.admin: административный сайтdjango.contrib.auth: фреймворк для аутентификацииdjango.contrib.contenttypes: фреймворк для обработки типов контентаdjango.contrib.sessions: фреймворк для работы с сессиямиdjango.contrib.messages: фреймворк сообщенийdjango.contrib.staticfiles: фреймворк для управления статичными файлами.
-
MIDDLEWARE— список микропрограммных средств, которые будут запущены. -
ROOT_URLCONF— указывает на модуль URL, где определены корневые URL-паттерны приложения. -
DATABASES— Python-словарь с настройками баз данных проекта. Одна стандартная всегда должна присутствовать. Конфигурация по умолчанию использует SQLite3. -
LANGUAGE_CODE— отвечает за настройку кода языка сайта Django по умолчанию. -
USE_TZ— сообщает Django, что нужно включить/выключить поддержку часовых поясов. В Django есть встроенная поддержка модуля для работы с датой и временем, которая работает и с часовыми зонами. Она получает значениеTrue, когда новый проект создается командойstartproject.
Не волнуйтесь, если многое здесь покажется непонятным. Все пункты будут рассмотрены детально в других материалах.
]]>В Django есть веб-сервер, который нужен для быстрой проверки кода. Благодаря ему не нужно заниматься наладкой полноценного рабочего решения. При его запуске сервер продолжает проверять изменения в коде и самостоятельно перезагружается. Но некоторые вещи он не замечает: такие как появление новых файлов в проекте. В таком случае нужно перезагрузить сервер вручную.
Запустить сервер можно с помощью следующей команды в корневом каталоге:
python manage.py runserver
Появятся приблизительно такие строки:
Performing system checks...
System check identified no issues (0 silenced).
November 16, 2019 - 15:20:27
Django version 2.0.5, using settings 'mysite.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
Теперь нужно открыть https://127.0.0.1:8000/ в браузере. Страница сообщит, что проект работает. Как на следующем скриншоте:

Это изображение сообщает, что Django работает. Если взглянуть на консоль, то можно увидеть запрос GET от браузера:
[16/Nov/2019 15:22:45] "GET / HTTP/1.1" 200 16348
Каждый HTTP-запрос регистрируется отдельно. В командной строке будут отображаться все ошибки, которые появятся в процессе работы.
Можно запустить сервер на другом порте или использовать другой файл настроек с помощью таких команд:
python manage.py runserver 127.0.0.1:8001 --settings=mysite.settings
Работая с разными средами, требующими разных настроек, можно создать несколько файлов для каждой из них.
Этот сервер стоит использовать только для разработки, но не для полноценного использования. Чтобы развернуть Django в производственной среде (production) его нужно запустить в качестве WSGI-приложения с помощью реального инструмента: Apache, Gunicorn или uWSGI.
]]>В Django есть команда, которая позволяет создать базовую файловую структуру проекта. Напишите следующее в командной строке:
django-admin startproject mysite
Это создаст проект Django с именем mysite.
Не называйте проекты именами встроенных модулей
PythonилиDjango, чтобы избежать конфликтов.
Рассмотрим структуру проекта:
mysite/
manage.py
mysite/
__init__.py
settings.py
urls.py
wsgi.py
Она включает следующие файлы:
manage.py— это утилита для командной строки, которая используется для взаимодействия с проектом. Это тонкая оболочка дляdjango-admin.py. Редактировать этот файл нельзя.mysite/— это директория проекта, состоящая из следующих файлов:__init__.py— пустой файл, который сообщает Python, чтоmysiteнужно воспринимать как модуль Python.settings.py— включает настройки проекта с параметрами по умолчанию.urls.py— место хранения URL паттернов. Каждый определенный здесь URL используется для представления.wsgi.py— конфигурация для запуска проекта в виде приложения Web Server Gateway Interface (WSGI)
Сгенерированный файл settings.py содержит настройки проекта, включая базовую конфигурацию для использования базы данных SQLite 3 и список INSTALLED_APPS, с основными приложениями Django. Они добавляются в проект по умолчанию. О них будет рассказано позже в статье “Настройки проекта”.
Чтобы завершить установку проекта, нужно создать таблицы базы данных, которые нужны для приложений, перечисленных в INSTALLED_APPS. Откройте командную строку и используйте следующие команды:
cd mysite
python manage.py migrate
Появится следующий вывод:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK
Эти строки обозначают миграции базы данных Django. Благодаря им создаются таблицы для базовых приложений в базе данных. О команде migrate речь пойдет в статье “Создание и использование миграций”.
Если Django уже установлен, можете пропустить этот раздел и переходить к части «Создание первого проекта». Django — это пакет Python, поэтому он может быть установлен в любой среде Python. Вот как установить фреймворк для локальной разработки.
Для Django 2.0 обязательны Python 3.4 или старше. Дальше будет использоваться Python 3.6.5. Для Linux или macOS, то Python, вероятно уже установлен. Если Windows — то инструкция по установке здесь.
Проверить установлен ли Python на компьютере можно, введя python в командной строке. Если в ответ отобразится что-то подобное, то Python установлен:
Python 3.7.3 (default, Mar 27 2019, 17:13:21)
[MSC v.1915 64 bit (AMD64)] :: Anaconda custom (64-bit) on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
Если он не установлен или установлена версия Python 3.4 или младше, то нужно перейти в раздел “Скачать и установить Python”, найти руководство под свою OS и следовать инструкциям.
Для Python 3 не нужна база данных. Эта версия Python поставляется со встроенной базой данных SQLite. Это облегченная база данных, которая подходит для разработки на Django. Если же нужно будет разворачивать приложение в производственной среде, то понадобится более продвинутое решение: PostgreSQL, MySQL или Oracle. Больше узнать о том, как заставить базу данных работать с Django, можно по этой ссылке: https://docs.djangoproject.com/en/2.0/topics/install/#database-installation.
Создание виртуальной среды Python
Рекомендуется использовать virtualenv для создания виртуальной среды Python так, чтобы можно было спокойно использовать разные версии пакетов для разных проектов. Это практичнее, чем устанавливать пакеты в Python напрямую в систему. Еще одно преимущество virtualenv — для установки пакетов Python не нужны права администратора. Запустите следующую команду в командной строке для установки virtualenv:
pip install virtualenv
После установки virtualenv, создайте виртуальную среду с помощью следующей команды:
virtualenv my_env
Это создаст папку my_env вместе со средой Python. Любые библиотеки Python, установленные с активированной виртуальной средой Python, будут установлены в папку my_env/lib/python3.7/site-packages.
Если в системе была предустановлена Python 2.X, а вы установили Python 3.X, то нужно указать
virtualenv, чтобы он работал с последней версией.
Можно указать путь, по которому установлен Python 3 и использовать его для создания виртуальной среды с помощью следующих команд:
$ which python3 /Library/Frameworks/Python.framework/Versions/3.7/bin/python3
$ virtualenv my_env -p
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3
Используйте следующую команду для активации виртуальной среды:
source my_env/bin/activate
Командная строка будет включать название активной виртуальной среды в скобках:
(my_env) username:~$
Отключить виртуальную среду можно с помощью команды deactivate.
Больше о virtualenv можно узнать по ссылке https://virtualenv.pypa.io/en/latest/.
Поверх virtualenv можно также использовать virtualenvwrapper. Этот инструмент предоставляет оболочки, с помощью которых проще создавать и управлять виртуальной средой. Загрузить его можно здесь: https://virtualenvwrapper.readthedocs.io/en/latest/.
Установка Django с помощью pip
Система управления пакетами pip — рекомендуемый способ установки Django. В Python 3.6+ она предустановлена, а инструкции для установки можно найти по ссылке https://pythonru.com/baza-znanij/ustanovka-pip-dlja-python-i-bazovye-komandy.
Используйте следующую команду в оболочке, чтобы установить Django с помощью pip:
pip install Django==2.0.5
Django установится в папку Python под названием site-packages/ активной виртуальной среды.
Теперь нужно проверить, успешно ли прошла установка. Для этого в командной строке необходимо ввести python, импортировать Django и проверить его версию следующим образом:
>>> import django
>>> django.get_version()
'2.0.5'
Если вывод такой, как вверху, значит Django был успешно установлен на компьютере:
]]>Django можно установить и другими способами. Полный гайд по установке можно найти здесь: https://docs.djangoproject.com/en/2.0/topics/install/.
Четырнадцатая проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз закончим игру с помощью экрана «Игра закончена» и добавим возможность начать сначала.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Игра закончена
Сейчас, если у игрока заканчиваются жизни, программа просто резко обрывается. Выглядит не очень приятно, поэтому добавим экран «Игра закончена» и дадим возможность игрокам начать сначала, если они хотят.
Причина остановки программы в том, что игровой цикл управляется переменной running (значение которой может быть только True или False), и в момент смерти игрока он становится False. Вместо этого сделаем так, чтобы отслеживалось состояние игры (state). Оно может быть следующим: демонстрация экрана с законченной игрой или непосредственно игра. Создадим в начале переменную game_over:
# Цикл игры
game_over = True
running = True
while running:
if game_over:
show_go_screen()
Дальше нужно будет создать и show_go_screen, но сперва необходимо подумать еще кое о чем. Когда игра заканчивается и переходит к соответствующему экрану, а игрок выбирает начать сначала, нужно сбросить все: очки, астероиды, жизни игрока и так далее. Сейчас эти элементы настраиваются перед началом игрового цикла, но их нужно переместить в позицию после show_go_screen(), так, чтобы они происходили, когда игрок уже покидает этот экран.
# Цикл игры
game_over = True
running = True
while running:
if game_over:
show_go_screen()
game_over = False
all_sprites = pygame.sprite.Group()
mobs = pygame.sprite.Group()
bullets = pygame.sprite.Group()
powerups = pygame.sprite.Group()
player = Player()
all_sprites.add(player)
for i in range(8):
newmob()
score = 0
Также необходимо переключить значение game_over на False при старте новой игры. Теперь можно менять и то, что происходит, когда у игрока заканчиваются жизни.
# Если игрок умер, игра окончена
if player.lives == 0 and not death_explosion.alive():
game_over = True
Экран «Игра закончена»
Осталось определить, что будет делать экран show_go_screen. Поскольку в этом примере достаточно будет лишь одного «экрана», ограничимся названием игры и инструкциями для игроков:
def show_go_screen():
screen.blit(background, background_rect)
draw_text(screen, "SHMUP!", 64, WIDTH / 2, HEIGHT / 4)
draw_text(screen, "Arrow keys move, Space to fire", 22,
WIDTH / 2, HEIGHT / 2)
draw_text(screen, "Press a key to begin", 18, WIDTH / 2, HEIGHT * 3 / 4)
pygame.display.flip()
waiting = True
while waiting:
clock.tick(FPS)
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
if event.type == pygame.KEYUP:
waiting = False
Игра будет просить «Нажать клавишу для старта». Это поведение нужно обрабатывать с помощью цикла while. Его можно воспринимать как миниатюрный игровой цикл, который проверяет всего два события. Первое — pygame.QUIT, которое происходит при нажатии на крестик окна программы. Второе — нажатие клавиши для старта. Важно отметить, что pygame.KEYDOWN здесь не используется.
Вместо этого указана KEYUP. Это нужно для того, чтобы игра не начиналась до тех пор, пока игрок не отпустит клавишу.
Это простейший способ сделать игровой экран. Есть масса других вариантов, но об этом — в следующих уроках.
Код урока — shmup-14.py
Итого
Вот и все, ваша первая игра на Pygame готова. Если вы следовали инструкциям и выполняли все задания, то это неплохой старт для начинающего программиста.
При этом есть еще много вещей, которые можно было бы добавить в игру:
- Увеличивающуюся сложность
- Больше улучшений
- Врагов (отстреливающихся)
- Систему очков
- Уровни с боссами
И это только самые очевидные идеи.
Спасибо за то, что читали эти уроки и выполняли задания.
]]>Тринадцатая проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз добавим в игру улучшения, которые будут время от времени появляться на экране.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Улучшения оружия
В прошлой части был создан спрайт улучшения, который появляется на месте уничтоженного астероида с определенной долей вероятности. Улучшение «здоровье» уже готово, а вот улучшению «оружие» нужно уделить еще немного внимания.
Есть множество параметров, которые можно улучшить в оружии: скорость стрельбы, урон (хотя сейчас астероиды и так уничтожаются с одного попадания), тип оружия и так далее. В этой части поработаем над улучшением, увеличивающим темп стрельбы. Но можно оставить некую свободу действий, чтобы легко настраивать его в будущем. Для этого необходимо создать новый метод для Player, который будет вызываться, когда игрок подбирает улучшение «оружия»:
if hit.type == 'gun':
player.powerup()
Сперва нужно добавить новые свойства в спрайт Player: power будет отслеживать «уровень силы» (увеличивающийся с каждым выстрелом), а power_time — снижать его спустя некоторое время:
self.power = 1
self.power_time = pygame.time.get_ticks()
В методе powerup будут следующие свойства:
def powerup(self):
self.power += 1
self.power_time = pygame.time.get_ticks()
Теперь можно изменить метод shoot, чтобы игрок выстреливал двумя пулями, если значение power выше 1. Появляться они будут на кончиках крыльев:
def shoot(self):
now = pygame.time.get_ticks()
if now - self.last_shot > self.shoot_delay:
self.last_shot = now
if self.power == 1:
bullet = Bullet(self.rect.centerx, self.rect.top)
all_sprites.add(bullet)
bullets.add(bullet)
shoot_sound.play()
if self.power >= 2:
bullet1 = Bullet(self.rect.left, self.rect.centery)
bullet2 = Bullet(self.rect.right, self.rect.centery)
all_sprites.add(bullet1)
all_sprites.add(bullet2)
bullets.add(bullet1)
bullets.add(bullet2)
shoot_sound.play()
Теперь необходимо проверять время с помощью power_time. Его необходимо добавить в update игрока:
# тайм-аут для бонусов
if self.power >= 2 and pygame.time.get_ticks() - self.power_time > POWERUP_TIME:
self.power -= 1
self.power_time = pygame.time.get_ticks()
Важно не забыть установить значение 5000 (5 секунд) у POWERUP_ TIME сверху.
Звуки
Чтобы закончить с функцей улучшений, нужно добавить приятные звуки в те моменты, когда игрок их подбирает. Это вы можете сделать самостоятельно. Используйте «bgxr», чтобы найти звуки, которые подойдут для игры. Назвать их можно как-то так: shield_sound и power_sound. Например:
shield_sound = pygame.mixer.Sound(path.join(snd_dir, 'pow4.wav'))
power_sound = pygame.mixer.Sound(path.join(snd_dir, 'pow5.wav'))
После этого нужно просто запускать их при столкновении игрока с соответствующим улучшением. Код для реализации этой функции есть ниже, но попробуйте реализовать его самостоятельно.
Код урока — shmup-13.py
Следующий урок будет последним. В нем создадим экран «Игра закончена».
]]>Это дополнение к «Основы Pandas». Вместо теоретического вступления в миллион особенностей Pandas — 2 примера:
- Данные с космического телескопа «Хаббл».
- Датасет о заработной плате экономически активного населения США.
Данные «Хаббла»
Начнем с данных «Хаббла». В первую очередь речь пойдет о том, как читать простой csv-файл и строить данные:
Начнем с данных с космического телескопа «Хаббл», одного из известнейших телескопов.
Данные очень простые. Файл называется hubble_data.csv. Его можно открыть даже в Microsoft Excel или OpenOffice. Вот как он будет выглядеть в этих программах:

Данные в формате CSV. Это очень популярный формат в первую очередь из-за своей простоты. Его можно открыть в любом текстовом редакторе. Попробуйте.
Будет видно, что CSV-файлы — это всего лишь разные значения, разделенные запятой (что, собственно, и подразумевается в названии — comma-separated values).
Это основная причина популярности формата. Для него не нужно никакое специальное ПО, даже Excel. Это также значит, что данные можно будет прочесть и через 10 лет, когда появятся новые версии электронных таблиц.
Начнем. Откройте экземпляр Ipython (Jupyter) и запустите следующий код.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
Это импортирует pandas — основную библиотеку в Python для анализа данных. Также импортируется matplotlib для построения графиков.
%pylan inline — это команда Ipython, которая позволяет использовать графики в работе.
data = pd.read_csv("hubble_data.csv")
data.head()
Pandas значительно упрощает жизнь. Прочесть файл csv можно с помощью одной функции: read_csv().
Теперь можно вызвать функцию head(), чтобы вывести первые пять строк.
| distance | recession_velocity | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas — довольно умная библиотека. Это проявляется в том, что она понимает, что первая строка файла — это заголовок. Вот как выглядят первые 3 строки CSV-файла:
distance,recession_velocity
.032,170
.034,290
Теперь можно увидеть, что заголовок в верхней части действительно есть. Он называет две колонки: distance и recession_velocity.
Pandas корректно распознает это.
А что делать, если заголовка нет? Можно прочесть файл, вручную указав заголовки. Есть еще один файл hubble_data_no_headers.csv без заголовков. Он не отличается от предыдущего за исключением отсутствующих заголовков.
Вот как читать такой файл:
headers = ["dist","rec_vel"]
data_no_headers = pd.read_csv("hubble_data_no_headers.csv", names=headers)
data_no_headers.head()
Здесь объявляются собственные заголовки (headers). У них другие имена (dist и rec_vel), чтобы было явно видно, что это другой файл.
Данные читаются таким же способом, но в этот раз передаются новые переменные names=headers. Это сообщает Pandas, что нужно использовать их, поскольку в файле заголовков нет. Затем выводятся первые пять строк.
| dist | rec_vel | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas позволяет увидеть только одну колонку:
data_no_headers["dist"]
0 0.032
1 0.034
2 0.214
3 0.263
4 0.275
Теперь, когда данные есть, на их основе нужно построить график.
Проще всего добиться этого, избавившись от индексов. Pandas по умолчанию добавляет номера (как и Excel). Если посмотреть на структуру данных, будет видно, что левая строка имеет значения 0,1,2,3,4....
Если заменить номера на distance, тогда построение графиков станет еще проще. distance станет осью x, а velocity — осью y.
Но как заменить индексы?
data.set_index("distance", inplace=True)
data.head()
| distance | recession_velocity |
|---|---|
| 0.032 | 170 |
| 0.034 | 290 |
| 0.214 | -130 |
| 0.263 | -70 |
| 0.275 | -185 |
При сравнении с прошлым примером можно увидеть, что номера пропали. Более того, данные теперь расположены в соотношении x — y.
Создать график теперь еще проще:
data.plot()
plt.show()

Данные о заработной плате
Теперь данные о заработной плате. Этот пример построен на предыдущем и показывает, как добавлять собственные заголовки, работать с файлами, разделенными отступами, и извлекать колонки из данных:
Этот пример посложнее.
Откройте ноутбук. Начнем, как и раньше, с импорта необходимых модулей и чтения CSV-файла. В данном случае речь идет о файле wages_hours.csv.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
data = pd.read_csv("wages_hours.csv")
data.head()
Все как раньше. Нужно ведь просто прочесть файл? Но результат получается следующий:
| HRS RATE ERSP ERNO NEIN ASSET AGE DEP RACE SCHOOL | |
|---|---|
| 0 | 2157\t2.905\t1121\t291\t380\t7250\t38.5\t2.340… |
| 1 | 2174\t2.970\t1128\t301\t398\t7744\t39.3\t2.335… |
| 2 | 2062\t2.350\t1214\t326\t185\t3068\t40.1\t2.851… |
| 3 | 2111\t2.511\t1203\t49\t117\t1632\t22.4\t1.159\… |
| 4 | 2134\t2.791\t1013\t594\t730\t12710\t57.7\t1.22… |
Выглядит непонятно. И совсем не похоже на оригинальный файл.
Что же случилось?
В CSV-файле нет запятых
Хотя название подразумевает «Значения, Разделенные Запятыми», данные могут быть разделены чем угодно. Например, отступами.
\t в тексте означает отступы. Pandas не может разобрать файл, потому что библиотека рассчитывала на запятые, а не на отступы.
Нужно прочитать файл еще раз, в этот раз передав новую переменную sep='\t'. Это сообщит, что разделителями выступают отступы, а не запятые.
data = pd.read_csv("wages_hours.csv", sep="\t")
data.head()
| HRS | RATE | ERSP | ERNO | NEIN | ASSET | AGE | DEP | RACE | SCHOOL | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2157 | 2.905 | 1121 | 291 | 380 | 7250 | 38.5 | 2.340 | 32.1 | 10.5 |
| 1 | 2174 | 2.970 | 1128 | 301 | 398 | 7744 | 39.3 | 2.335 | 31.2 | 10.5 |
| 2 | 2062 | 2.350 | 1214 | 326 | 185 | 3068 | 40.1 | 2.851 | * | 8.9 |
| 3 | 2111 | 2.511 | 1203 | 49 | 117 | 1632 | 22.4 | 1.159 | 27.5 | 11.5 |
| 4 | 2134 | 2.791 | 1013 | 594 | 730 | 12710 | 57.7 | 1.229 | 32.5 | 8.8 |
Сработало.
Но тут довольно много данных. Нужны ли они все?
В этом проекте необходимы только AGE (возраст) и RACE (ставка заработной платы). В первую очередь необходимо извлечь только эти две колонки.
data2 = data[["AGE", "RATE"]]
data2.head()
| AGE | RATE | |
|---|---|---|
| 0 | 38.5 | 2.905 |
| 1 | 39.3 | 2.970 |
| 2 | 40.1 | 2.350 |
| 3 | 22.4 | 2.511 |
| 4 | 57.7 | 2.791 |
Чтобы составить грамотный график, необходимо расположить возраст по порядку: возрастания или убывания.
Сделаем в порядке убывания (потому что это поведение по умолчанию для функции sort()).
data_sorted = data2.sort(["AGE"])
data_sorted.head()
Как и в прошлый раз, нужно убрать числа, а вместо них использовать значения возраста, чтобы упростить процесс построения графика.
data_sorted.set_index("AGE", inplace=True)
data_sorted.head()
| AGE | RATE |
|---|---|
| 22.4 | 2.511 |
| 37.2 | 3.015 |
| 37.4 | 1.901 |
| 37.5 | 1.899 |
| 37.5 | 3.009 |
И сам график:
data_sorted.plot()
plt.show()

Можно увидеть, что ставка повышается до 35 лет, а потом начинает сильно меняться.
Конечно, это общий универсальный показатель. Из этого набора данных можно сделать лишь отдельные выводы.
]]>Двенадцатая проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз добавим в игру бонусы, которые будут появляться случайным образом.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Улучшения
В нашем шутере уже много чего, но кое-чего важного не хватает — возможности для игрока делать свой корабль сильнее. Можно придумать массу улучшений, но начнем с двух:
- Здоровье — объект, который будет восстанавливать здоровье игрока
- Оружие — объект, увеличивающий огневую мощь
Спрайт улучшения
Для начала нужно добавить еще один спрайт, который будет представлять собой объект улучшения. Чтобы упростить этот процесс, можно скопировать класс Bullet() и добавить пару изменений. Это сработает, потому что их поведение очень похоже: появиться в определенном месте (месте астероида, который был уничтожен) и двигаться вниз, а затем — убрать спрайт, если он уйдет за пределы экрана. При отображении улучшения будем случайным образом выбирать между «здоровьем» и «оружием».
class Pow(pygame.sprite.Sprite):
def __init__(self, center):
pygame.sprite.Sprite.__init__(self)
self.type = random.choice(['shield', 'gun'])
self.image = powerup_images[self.type]
self.image.set_colorkey(BLACK)
self.rect = self.image.get_rect()
self.rect.center = center
self.speedy = 2
def update(self):
self.rect.y += self.speedy
# убить, если он сдвинется с нижней части экрана
if self.rect.top > HEIGHT:
self.kill()
Нужно загрузить изображения в раздел с уже имеющимися. Это делается с помощью словаря, который содержит картинки улучшений в виде ключей.
powerup_images = {}
powerup_images['shield'] = pygame.image.load(path.join(img_dir, 'shield_gold.png')).convert()
powerup_images['gun'] = pygame.image.load(path.join(img_dir, 'bolt_gold.png')).convert()
Такие изображения будут использоваться в игре (можно нажать для скачивания):
![]()
![]()
Появление
Для создания спрайтов необходима единая группа (которая будет обрабатывать столкновения):
powerups = pygame.sprite.Group()
Затем, когда пуля уничтожает астероид, необходим случайный (маленький) шанс на выпадение улучшения:
# проверьте, не попала ли пуля в моб
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
score += 50 - hit.radius
random.choice(expl_sounds).play()
expl = Explosion(hit.rect.center, 'lg')
all_sprites.add(expl)
if random.random() > 0.9:
pow = Pow(hit.rect.center)
all_sprites.add(pow)
powerups.add(pow)
newmob()
random.random() выберет случайное десятичное число от 0 до 1, а улучшение будет появляться только в том случае, если значение окажется выше 0.9. То есть, шанс всего 10%.
Столкновение с игроком
Теперь нужна еще одна проверка столкновений. На этот раз — между игроком и группой улучшений. Ее стоит добавить после уже имеющихся:
# Проверка столкновений игрока и улучшения
hits = pygame.sprite.spritecollide(player, powerups, True)
for hit in hits:
if hit.type == 'shield':
player.shield += random.randrange(10, 30)
if player.shield >= 100:
player.shield = 100
if hit.type == 'gun':
pass
Сначала обрабатывается улучшение «здоровья», которое возвращает игроку случайное значение здоровья. С «оружием» все несколько сложнее, поэтому ему будет посвящен следующий материал.
Код урока — shmup-12.py
]]>Одиннадцатая проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части.
В этот раз у игрока появятся дополнительные жизни и анимация взрыва при смерти.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Взрыв игрока
В случае смерти игрока будет использоваться другая анимация из набора Kenny Game Art.
Скачать архив изображений можно по этой ссылке.
После этого их нужно загрузить в виде кадров, как это было с прошлыми взрывами. Добавим еще один тип взрыва 'player' и загрузим его в тот же цикл, поскольку у этой анимации столько же кадров, сколько было у предыдущей. Теперь код загрузки выглядит следующим образом:
explosion_anim = {}
explosion_anim['lg'] = []
explosion_anim['sm'] = []
explosion_anim['player'] = []
for i in range(9):
filename = 'regularExplosion0{}.png'.format(i)
img = pygame.image.load(path.join(img_dir, filename)).convert()
img.set_colorkey(BLACK)
img_lg = pygame.transform.scale(img, (75, 75))
explosion_anim['lg'].append(img_lg)
img_sm = pygame.transform.scale(img, (32, 32))
explosion_anim['sm'].append(img_sm)
filename = 'sonicExplosion0{}.png'.format(i)
img = pygame.image.load(path.join(img_dir, filename)).convert()
img.set_colorkey(BLACK)
explosion_anim['player'].append(img)
В спрайте класса Explosion не нужно ничего менять — достаточно просто сделать взрыв игрока, когда его здоровье падает до нуля. Этот пункт можно добавить в игру там же, где проверяются столкновения игрока с астероидами:
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, True, pygame.sprite.collide_circle)
for hit in hits:
player.shield -= hit.radius * 2
expl = Explosion(hit.rect.center, 'sm')
all_sprites.add(expl)
newmob()
if player.shield <= 0:
death_explosion = Explosion(player.rect.center, 'player')
all_sprites.add(death_explosion)
running = False
Но если запустить программу сейчас, то будет одна проблема: после смерти игрока значение running становится False, игра заканчивается, и нет возможности увидеть анимацию.
Чтобы это исправить, нужно не заканчивать игру до тех пор, пока не завершится анимация взрыва. Так, игрока нужно удалять, но не менять значение running до завершения анимации взрыва:
if player.shield <= 0:
death_explosion = Explosion(player.rect.center, 'player')
all_sprites.add(death_explosion)
player.kill()
# Если игрок умер, игра окончена
if not player.alive() and not death_explosion.alive():
running = False
Функция alive() просто сообщает, является ли конкретный спрайт живым. Поскольку взрыв был убит (функцией kill()), после завершения анимации игра заканчивается.
Жизни
Теперь нужно добавить несколько жизней игроку. Их можно отслеживать с помощью переменной, но также необходимо выводить их на экран. Вместо чисел также можно использовать миниатюрные изображения корабля игрока. Для начала нужно создать уменьшенное изображение:
player_img = pygame.image.load(path.join(img_dir, "playerShip1_orange.png")).convert()
player_mini_img = pygame.transform.scale(player_img, (25, 19))
player_mini_img.set_colorkey(BLACK)
Дальше — добавить несколько параметров в __init__() класса Player: счетчик жизней, флажок (переменная, которая может принимать значения True или False), чтобы показывать/скрывать игрока и таймер для определения того, сколько времени игрока нужно скрывать.
self.lives = 3
self.hidden = False
self.hide_timer = pygame.time.get_ticks()
Теперь, в случае смерти игрока, вместо использования kill() игрок будет скрываться, а от lives будет отниматься 1. Также на следующей жизни сбрасывается здоровье:
if player.shield <= 0:
death_explosion = Explosion(player.rect.center, 'player')
all_sprites.add(death_explosion)
player.hide()
player.lives -= 1
player.shield = 100
# Если игрок умер, игра окончена
if player.lives == 0 and not death_explosion.alive():
running = False
Дальше нужно проработать, как работает скрытие игрока. В классе Player() необходимо добавить соответствующий метод, который будет переключать флажок hidden на значение True и запускать таймер. Также нужно удостовериться в том, что пока игрок скрыт, он не может столкнуться с астероидом. Есть несколько вариантов, как этого можно добиться, но в самом простом не нужно добавлять/удалять его из групп или делать что-то подобное. Достаточно убрать игрока с нижней части экрана на короткое время:
def hide(self):
# временно скрыть игрока
self.hidden = True
self.hide_timer = pygame.time.get_ticks()
self.rect.center = (WIDTH / 2, HEIGHT + 200)
А в методе update() необходимо снова вернуть игрока, если прошло достаточно времени (начать можно с 1 секунды):
def update(self):
# показать, если скрыто
if self.hidden and pygame.time.get_ticks() - self.hide_timer > 1000:
self.hidden = False
self.rect.centerx = WIDTH / 2
self.rect.bottom = HEIGHT - 10
Отображение счетчика жизней
Для отображения жизней нужно создать функцию, похожую на draw_shield_bar(), которая позволит размещать счетчик в конкретном месте:
def draw_lives(surf, x, y, lives, img):
for i in range(lives):
img_rect = img.get_rect()
img_rect.x = x + 30 * i
img_rect.y = y
surf.blit(img, img_rect)
Дальше необходим цикл с количеством, соответствующем количеству жизней и пространством в 30 пикселей для каждого изображения (ширина player_mini_img — 25 пикселей, так что между ними как раз останется достаточно места).
Далее нужно добавить вызов функции в раздел отрисовки игрового цикла:
draw_lives(screen, WIDTH - 100, 5, player.lives,
player_mini_img)
А вот и финальный результат:

Код урока — shmup-11.py
В следующем уровне добавим в игру улучшения.
]]>Десятаячасть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз добавим анимацию для взрывов астероидов.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Авто-огонь
В первую очередь можно поменять сам принцип стрельбы. Сейчас для выстрелов нужно постоянно нажимать на пробел. Таким образом легко можно даже сломать клавишу. Но вместо этого можно сделать так, чтобы огонь велся до тех пор, пока кнопка нажата.
Для этого игроку нужно добавить несколько свойств:
self.shoot_delay = 250
self.last_shot = pygame.time.get_ticks()
shmup_delay будет измерять, сколько времени должно пройти между появлением пуль (в миллисекундах). last_shot — отслеживать, сколько прошло с момента последней пули так, чтобы в нужный момент выстрелить снова.
Теперь нужно добавить кнопку огня к проверке нажатий на клавиатуре. Она находится в функции обновления игрока:
def update(self):
self.speedx = 0
keystate = pygame.key.get_pressed()
if keystate[pygame.K_LEFT]:
self.speedx = -8
if keystate[pygame.K_RIGHT]:
self.speedx = 8
if keystate[pygame.K_SPACE]:
self.shoot()
Всю механику стрельбы также можно перенести в отдельный метод:
def shoot(self):
now = pygame.time.get_ticks()
if now - self.last_shot > self.shoot_delay:
self.last_shot = now
bullet = Bullet(self.rect.centerx, self.rect.top)
all_sprites.add(bullet)
bullets.add(bullet)
Теперь, если пробел нажат, игра будет проверять, сколько времени прошло после вылета последней пули. Если прошло shoot_delay миллисекунд, тогда вылетит следующая пуля, а параметр last_shot обновится. В конце концов, можно удалить следующие строки из игрового цикла.
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_SPACE:
player.shoot()
Анимированные взрывы
Следующий шаг — сделать взрывы более привлекательными в визуальном плане. Этого можно добиться, заставив астероиды по-настоящему взрываться, а не просто пропадать с экрана. Для этого нужен набор кадров анимации, которые будут воспроизводиться на месте уничтожения астероида. Вот эта последовательность:

Нажмите здесь, чтобы загрузить архив с этими изображениями.
Сначала нужно загрузить графику в игру и добавить ее в список. Как и в случае со спрайтом игрока, необходимо поменять размер этих изображений, сделав две версии. Крупная будет воспроизводиться в месте подрыва астероида игроком, а маленькая — там, где астероид врезается в корабль игрока. Для этого используется словарь explosion_anim c двумя списками lg и sm. Поскольку все файлы называются одинаково (с номерами от 0 до 8), можно использовать цикл для их загрузки, изменения размера и добавления в списки:
explosion_anim = {}
explosion_anim['lg'] = []
explosion_anim['sm'] = []
for i in range(9):
filename = 'regularExplosion0{}.png'.format(i)
img = pygame.image.load(path.join(img_dir, filename)).convert()
img.set_colorkey(BLACK)
img_lg = pygame.transform.scale(img, (75, 75))
explosion_anim['lg'].append(img_lg)
img_sm = pygame.transform.scale(img, (32, 32))
explosion_anim['sm'].append(img_sm)
Спрайт взрыва
Дальше требуется создать спрайт, представляющий собой взрыв на экране. Изображение спрайта будет быстро меняться, переходя от одного изображения к другому в наборе. Добравшись до последнего, спрайт исчезнет.
При его появлении спрайту нужно указать, где появляться (местоположение астероида) и какого быть размера. Как и в случае с функцией авто-огня, здесь можно использовать параметр frame_rate, который будет контролировать скорость воспроизведения анимации — если менять изображение с каждым обновлением игрового цикла (1/60 секунды), то взрыв произойдет очень быстро (1/10 секунды). Поэтому вот код спрайта Explosion:
class Explosion(pygame.sprite.Sprite):
def __init__(self, center, size):
pygame.sprite.Sprite.__init__(self)
self.size = size
self.image = explosion_anim[self.size][0]
self.rect = self.image.get_rect()
self.rect.center = center
self.frame = 0
self.last_update = pygame.time.get_ticks()
self.frame_rate = 50
def update(self):
now = pygame.time.get_ticks()
if now - self.last_update > self.frame_rate:
self.last_update = now
self.frame += 1
if self.frame == len(explosion_anim[self.size]):
self.kill()
else:
center = self.rect.center
self.image = explosion_anim[self.size][self.frame]
self.rect = self.image.get_rect()
self.rect.center = center
Теперь нужно сделать так, чтобы этот спрайт появлялся при уничтожении астероида:
# проверьте, не попала ли пуля в моб
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
score += 50 - hit.radius
random.choice(expl_sounds).play()
expl = Explosion(hit.rect.center, 'lg')
all_sprites.add(expl)
newmob()
и при попадании по игроку:
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, True, pygame.sprite.collide_circle)
for hit in hits:
player.shield -= hit.radius * 2
expl = Explosion(hit.rect.center, 'sm')
all_sprites.add(expl)
newmob()
if player.shield <= 0:
running = False
А вот и финальный результат:

Код урока — shmup-10.py
В следующей части игра станет дольше благодаря тому, что у игрока появятся жизни.
]]>Девятая часть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз дадим игроку здоровье и добавим полоску, которая будет показывать его уровень.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Добавление здоровья
Пока что игрока уничтожает одно попадание астероида. Так играть не очень интересно, поэтому добавим свойство shield, которое будет всего лишь числом от 0 до 100.
class Player(pygame.sprite.Sprite):
def __init__(self):
self.speedx = 0
self.shield = 100
Теперь, каждый раз, когда астероид будет попадать в игрока, можно отнимать определенный уровень здоровья. Когда уровень упадет до 0, игра заканчивается. Чтобы было интереснее, можно сделать, чтобы крупные астероиды наносили больше урона. Для этого стоит использовать свойство radius астероида.
Урон игроку
Пока что столкновение моб-против-игрока обрабатывается на простейшем уровне:
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, False, pygame.sprite.collide_circle)
if hits:
running = False
Нужно добавить несколько изменений:
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, True, pygame.sprite.collide_circle)
for hit in hits:
player.shield -= hit.radius * 2
if player.shield <= 0:
running = False
В spritecollide изменим значение с False на True, потому что нужно, чтобы астероид исчезал после попадания. Если этого не сделать, то по мере продвижения он будет снова сталкиваться с игроком в следующих кадрах. Возможно и то, что сразу несколько астероидов ударят по игроку, поэтому значений hit должно быть несколько. Необходимо перебирать hits и отнимать определенное количество уровня здоровья, основываясь на радиусе астероида. В конце концов, когда значение упадет до 0, игра закончится.
Вы могли заметить, что при удалении астероида, столкнувшегося с игроком, уменьшается их общее количество. Чтобы не изменять его, необходимо создавать новый при удалении. Мобы появлялись с помощью этого кода:
for i in range(8):
m = Mob()
all_sprites.add(m)
mobs.add(m)
Можно было бы добавить кое-какие изменения, но это вызовет повторение в коде, что не очень хорошо. Вместо этого лучше поместить логику создания мобов в функцию и использовать ее везде, где это потребуется:
def newmob():
m = Mob()
all_sprites.add(m)
mobs.add(m)
Теперь можно использовать эту же функцию в начале игры, когда астероиды только появляются и в том месте, где они пропадают после столкновения:
for i in range(8):
newmob()
# проверка, попала ли пуля в моб
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
score += 50 - hit.radius
random.choice(expl_sounds).play()
newmob()
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, True, pygame.sprite.collide_circle)
for hit in hits:
player.shield -= hit.radius * 2
newmob()
if player.shield <= 0:
running = False
Полоска здоровья
Имеется значение здоровья, но оно во многом бесполезно, если игроку неизвестно это значение. Нужно создать дисплей, но вместо показа просто цифр лучше вывести полоску, по которой будет видно, насколько она заполнена:
def draw_shield_bar(surf, x, y, pct):
if pct < 0:
pct = 0
BAR_LENGTH = 100
BAR_HEIGHT = 10
fill = (pct / 100) * BAR_LENGTH
outline_rect = pygame.Rect(x, y, BAR_LENGTH, BAR_HEIGHT)
fill_rect = pygame.Rect(x, y, fill, BAR_HEIGHT)
pygame.draw.rect(surf, GREEN, fill_rect)
pygame.draw.rect(surf, WHITE, outline_rect, 2)
Эта функция будет работать по аналогии с draw_text. Она создаст полоску с размерами BAR_LENGHT и BAR_HEIGHT, которая будет находиться в (x, y) и заполнена на следующее значение pct. Нарисуем два прямоугольника: первый — белый контур, второй — уровень здоровья. Добавим вызов этой функции в раздел отрисовки игрового цикла:
draw_text(screen, str(score), 18, WIDTH / 2, 10)
draw_shield_bar(screen, 5, 5, player.shield)
Теперь можно видеть, сколько здоровья у игрока, и как он меняется при попадании астероидов.
Код урока — shmup-9.py
]]>Восьмая часть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части.
В этом уроке в игре появятся музыка и звуки.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Сила звука
Хороший звук (музыка и звуковые эффекты) — это один из самых эффективных способов добавить в игру «энергии». Это неофициальный термин из геймдизайна, который применяется по отношению к элементам, делающим игры более веселыми и захватывающими. Его часто называют «чувством игры» (game feel).
Как и в случае с графикой, найти подходящие звуки может быть непросто. OpenGameArt — отличное место для поиска аудио-ассетов, но в этот раз попробуем другой подход — создать звуковые эффекты самостоятельно.
Создание собственных звуков
Для этого будет использоваться инструмент под названием Bfxr. Он выглядит следующим образом:

Но не стоит пугаться этого многообразия слайдеров и жаргонизмов. Кнопки слева случайным образом генерируют звук выбранного типа. Попробуйте нажать «Shoot» несколько раз. Сгенерированные звуки сохранятся в списке ниже.
Для Стрелялки нужны звуки «выстрела» и «взрыва». После получения подходящего звука, нужно нажать на кнопку «Export Wav» (НЕ «Save to Disk»).
Дальше необходимо создать папку «snd» (как и для изображений) и переместить WAV-файлы туда. Можете использовать, например, эти звуки:
Обратите внимание, что здесь два звука взрыва. Можно сделать так, чтобы они воспроизводились случайным образом, и таким образом добавить разнообразия в игру.
Теперь нужна музыка. Ее можно поискать на OpenGameArt или использовать следующую:
Обратите внимание, что автор указал «Attribution Instructions» (модель атрибуции). Это условия, которые выбрал музыкант, чтобы лицензировать свое произведение. Это значит, что его нужно упомянуть. Для этого достаточно скопировать и вставить текст со страницы в верхнюю часть программы.
Добавление звука в игру
Теперь можно добавлять звуки в игру. Во-первых, нужно указать, в какой папке они находятся:
# Frozen Jam by tgfcoder <https://twitter.com/tgfcoder> licensed under CC-BY-3
# Art from Kenney.nl
import pygame
import random
from os import path
img_dir = path.join(path.dirname(__file__), 'img')
snd_dir = path.join(path.dirname(__file__), 'snd')
Дальше файлы необходимо загрузить. Это стоит сделать в том же месте, где загружалась графика. Сначала звук выстрелов:
# Загрузка мелодий игры
shoot_sound = pygame.mixer.Sound(path.join(snd_dir, 'pew.wav'))
Теперь, когда звук загружен и присвоен переменной shoot_sound, на него можно ссылаться. Важно, чтобы он воспроизводился каждый раз, когда игрок стреляет, поэтому его нужно добавить в метод shoot():
def shoot(self):
bullet = Bullet(self.rect.centerx, self.rect.top)
all_sprites.add(bullet)
bullets.add(bullet)
shoot_sound.play()
Это все, что требуется. Стрелять теперь будет приятнее!
Дальше нужны звуки взрывов. Загрузим оба и добавим их в список:
# Загрузка мелодий игры
shoot_sound = pygame.mixer.Sound(path.join(snd_dir, 'pew.wav'))
expl_sounds = []
for snd in ['expl3.wav', 'expl6.wav']:
expl_sounds.append(pygame.mixer.Sound(path.join(snd_dir, snd)))
Для воспроизведения взрывов нужно будет случайным образом выбирать один и включать его при разрушении астероида.
# проверка, попала ли пуля в моб
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
score += 50 - hit.radius
random.choice(expl_sounds).play()
m = Mob()
all_sprites.add(m)
mobs.add(m)
Музыка
Наконец, необходимо добавить фоновую музыку, которая сделает игру более эмоциональной. Здесь необходим другой подход, потому что музыка играет непрерывно.
Сначала загружаем файл:
expl_sounds = []
for snd in ['expl3.wav', 'expl6.wav']:
expl_sounds.append(pygame.mixer.Sound(path.join(snd_dir, snd)))
pygame.mixer.music.load(path.join(snd_dir, 'tgfcoder-FrozenJam-SeamlessLoop.ogg'))
pygame.mixer.music.set_volume(0.4)
Музыка довольно громкая, поэтому, чтобы она не перекрывала звуки, необходимо опустить ее максимальную громкость до 40%.
Чтобы музыка играла, нужно просто выбрать в каком месте кода она будет стартовать. В случае Стрелялки это будет позиция перед началом игрового цикла.
score = 0
pygame.mixer.music.play(loops=-1)
# Цикл игры
running = True
Параметр loops определяет, как часто трек будет повторяться. Если установить значение на -1, то он будет воспроизводиться бесконечно.
Игра теперь ощущается совсем по-другому. Геймплей не поменялся, но с музыкой и звуками все воспринимается живее. Осталось поэкспериментировать с разными звуками и понять, какие подходят лучше.
Код урока — shmup-8.py
В следующем уроке добавим игроку щиты, чтобы он не умирал так быстро.
]]>Седьмая часть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз начнем вести счет и научимся выводить текст на экран.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Ведение счета
Ведение счет игрока — простая задача. Нужно переменная с начальным значением 0, к которой будет добавляться +1 при каждом уничтожении астероида. Поскольку астероиды разные, а в крупные попасть легче, чем в маленькие, есть смысл в том, чтобы давать больше очков за уничтожение тех, что поменьше.
Назовем переменную score и объявим ее до игрового цикла:
for i in range(8):
m = Mob()
all_sprites.add(m)
mobs.add(m)
score = 0
# Цикл игры
running = True
Чтобы назначать очки в зависимости от размера астероида, можно использовать свойство radius. У самых крупных астероидов изображение больше 100 пикселей, а радиус 100 * 0.85 / 2 = 43 пикселя. В то же время радиус самого маленького астероида — всего 8 пикселей. Можно вычитать радиус из большего числа, например 50, чтобы получать количество очков. Так, большой будет давать всего 7 очков, а маленький — 42 очка.
# проверка, попала ли пуля в моб
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
score += 50 - hit.radius
m = Mob()
all_sprites.add(m)
mobs.add(m)
Рендеринг текста
Теперь, когда есть переменная со счетом, нужно отрисовывать ее на экране, и вот это уже посложнее. Делается все в несколько этапов. Если вы планируете выводить текст не один раз, тогда есть смысла создать функцию, которая будет называться draw_text. Ее параметры:
surf— поверхность, на которой текст будет написанtext— строка, которую нужно отображатьx, y— положение
Также нужно выбрать шрифт. Проблема может возникнуть, если выбрать тот шрифт, который не установлен на компьютере. Решить это можно с помощью pygame.font.match_font(), которая ищет наиболее подходящий шрифт в системе.
Вот вся функция draw_text:
font_name = pygame.font.match_font('arial')
def draw_text(surf, text, size, x, y):
font = pygame.font.Font(font_name, size)
text_surface = font.render(text, True, WHITE)
text_rect = text_surface.get_rect()
text_rect.midtop = (x, y)
surf.blit(text_surface, text_rect)
Отрисовка текста на экране — это, фактически, вычисление необходимой структуры пикселей. В компьютерной графике это называется «рендерингом». За это будет отвечать функция font.render(). В функции есть неизвестный параметр True, который отвечает за включение и отключение сглаживания.
Сглаживание
Если вы когда-нибудь пытались нарисовать что-нибудь пикселями (или, например, блоками в Minecraft), то знаете, насколько сложно изображать изогнутые линии на квадратной сетке. Максимум, что выходит, — зубчатая форма. Такая зубчатость называется «алиасингом». Вот как она выглядит:

Первая «a» выглядит чересчур угловатой из-за алиасинга. Сглаживание (анти-алиасинг) — это то, как современные компьютеры работают с текстом, чтобы он не был настолько зубчатым. Это происходит с помощью смешивания пикселей с фоном на границах объектов. В уменьшенном масштабе такой шрифт выглядит чисто и аккуратно.
Отображение счета
Теперь можно показывать счет на экране. Нужно лишь добавить его в раздел отрисовки в верхней части экрана по центру.
# Рендеринг
screen.fill(BLACK)
screen.blit(background, background_rect)
all_sprites.draw(screen)
draw_text(screen, str(score), 18, WIDTH / 2, 10)

Код урока — shmup-7.py
Вот и все. В следующей раз будем работать с музыкой и звуками.
]]>Шестая часть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этом уроке астероиды будут выглядеть интереснее благодаря анимациям.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Анимированные астероиды
Все астероиды выглядят одинаково, что не очень-то впечатляет:

Добавить разнообразия и привлекательности можно, заставив их вращаться. Благодаря этому будет создаваться впечатление, что они действительно летят в космосе. Это довольно легко сделать. Так же, как и с функцией pygame.transform.scale(), используемой для изменения размера спрайта Игрока, для вращения нужно задействовать pygame.transform.rotate(). Но чтобы сделать это правильно, нужно ознакомиться с парой нюансов.
В первую очередь необходимо добавить свойства спрайту Mob:
class Mob(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = meteor_img
self.image.set_colorkey(BLACK)
self.rect = self.image.get_rect()
self.radius = int(self.rect.width * .85 / 2)
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-150, -100)
self.speedy = random.randrange(1, 8)
self.speedx = random.randrange(-3, 3)
self.rot = 0
self.rot_speed = random.randrange(-8, 8)
self.last_update = pygame.time.get_ticks()
Первое свойство rot (сокращенно от «rotation» (вращение)) будет измерять, на сколько градусов должен вращаться астероид. Начальное значение — 0, но оно будет меняться со временем. rot_speed измеряет, на сколько градусов астероид будет поворачиваться каждый раз — чем больше число, тем быстрее будет происходить вращение. Подойдет любое значение: положительное задаст вращение по часовой стрелке, а отрицательное — против.
Последнее свойство необходимо для контроля скорости анимации. Для игры не нужно каждый раз менять изображение спрайта в каждом кадре. При анимации изображения спрайта нужно лишь определить время — как часто оно будет меняться.
В библиотеке есть объект pygame.time.Clock(), который называется clock (часы). Он позволяет контролировать FPS (количество кадров в секунду). Вызывая pygame.time.get_ticks(), можно узнать, сколько миллисекунд прошло с тех пор, как часы были запущены. Так можно будет сказать, прошло ли достаточно времени, что в очередной раз менять изображение спрайта.
Вращение изображения
Для этой операции потребуется еще несколько строк кода. Используем новый метод self.rotate(), который можно добавить в метод update():
def update(self):
self.rotate()
Благодаря этому можно будет добиться того, что в методе не будет лишней информации, а вращение можно убрать, закомментировав всего одну строку. Вот начало метода вращения:
def rotate(self):
now = pygame.time.get_ticks()
if now - self.last_update > 50:
self.last_update = now
# вращение спрайтов
Сначала проверяется текущее время, затем вычитается время последнего обновления. Если прошло более 50 миллисекунд, нужно обновлять изображение. Добавляем значение now в last_update и можно делать вращение. Кажется, что осталось лишь применить его к спрайту — как-то так:
self.image = pygame.transform.rotate(self.image, self.rot_speed)
Но в таком случае возникнет проблема:

Вращение разрушительно!
Это происходит, потому что изображение представляет собой сетку пикселей. При перемещении их в новое положение пиксели не выравниваются, и некоторая информация просто пропадает. Если повернуть изображение один раз, то ничего страшного не случится. Но при постоянном вращении астероид превращается в кашу.
Решение состоит в том, чтобы использовать переменную rot для отслеживания общей степени вращения (добавляя rot_speed с каждым обновлением) и вращать оригинальное изображение с таким шагом. Таким образом спрайт каждый раз будет представлять собой чистое изображение, которое повернется всего один раз.
Сначала нужно скопировать оригинальную картинку:
class Mob(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image_orig = random.choice(meteor_images)
self.image_orig.set_colorkey(BLACK)
self.image = self.image_orig.copy()
self.rect = self.image.get_rect()
self.radius = int(self.rect.width * .85 / 2)
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-150, -100)
self.speedy = random.randrange(1, 8)
self.speedx = random.randrange(-3, 3)
self.rot = 0
self.rot_speed = random.randrange(-8, 8)
self.last_update = pygame.time.get_ticks()
Затем в методе rotate нужно обновить значение rot и применить вращение к исходному изображению:
def rotate(self):
now = pygame.time.get_ticks()
if now - self.last_update > 50:
self.last_update = now
self.rot = (self.rot + self.rot_speed) % 360
self.image = pygame.transform.rotate(self.image_orig, self.rot)
Стоит отметить, что был использован оператор остатка, %, чтобы значение rot не было больше 360.
Изображения уже выглядят хорошо, но все еще есть одна проблема:

Кажется, что астероиды прыгают, а не плавно вращаются.
Обновление прямоугольника (rect)
После поворота изображения, размер rect может оказаться неправильным. В качестве примера стоит рассмотреть процесс вращения корабля:

Здесь видно, что при вращении rect остается одинаковым. Но важно каждый раз вычислять размеры прямоугольника при изменении изображения:

Можно увидеть, как меняется прямоугольник при повороте изображения. Для исправления «прыгающего» эффекта нужно убедиться, чтобы центр прямоугольника всегда находится в одном и том же месте, а не привязываться к верхнему левому углу:

Для этого необходимо указать положение центра прямоугольника, вычислить новый размер и сохранить координаты центра в обновленный прямоугольник:
def rotate(self):
now = pygame.time.get_ticks()
if now - self.last_update > 50:
self.last_update = now
self.rot = (self.rot + self.rot_speed) % 360
new_image = pygame.transform.rotate(self.image_orig, self.rot)
old_center = self.rect.center
self.image = new_image
self.rect = self.image.get_rect()
self.rect.center = old_center
Случайные размеры астероида
Последнее, что можно сделать, чтобы астероиды выглядели интереснее, — задавать их размеры случайным образом.
Сперва необходимо загрузить их и добавить в список:
meteor_images = []
meteor_list =['meteorBrown_big1.png','meteorBrown_med1.png',
'meteorBrown_med1.png','meteorBrown_med3.png',
'meteorBrown_small1.png','meteorBrown_small2.png',
'meteorBrown_tiny1.png']
for img in meteor_list:
meteor_images.append(pygame.image.load(path.join(img_dir, img)).convert())
Далее нужно просто каждый раз выбирать случайный астероид для появления в кадре:
class Mob(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image_orig = random.choice(meteor_images)
self.image_orig.set_colorkey(BLACK)
self.image = self.image_orig.copy()
Так гораздо лучше!

Код урока — shmup-6.py
Итого
Анимированные спрайты делают игру визуально более привлекательной, вне зависимости от того, что именно происходит на экране. Но чем больше анимаций, тем больше изображений нужно отслеживать. Поэтому важно организовывать их и использовать такие инструменты, как pygame.transform(помня об их ограничениях).
В следующий раз разберем, как вести счет, и узнаем, как выводить текст на экран.
]]>Пятая часть проекта «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начните с первой части. В этот раз будем менять то, как Pygame обрабатывает столкновения спрайтов.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Что происходит со столкновениями?
После прошлого урока в игре появилась графика, а спрайты превратились из простых прямоугольников в приятные PNG-изображения. Тем не менее появилась и новая проблема: игра начала засчитывать столкновения даже тогда, когда визуально их не видно. Чтобы увидеть это визуально, нужно рассмотреть схему:

Тип столкновения по умолчанию в Pygame — функция collide_rect(), которая высчитывает атрибуты rect спрайтов, чтобы понять, пересекаются ли они. Это столкновения AABB, которые работают быстро и надежно. Однако если изображения спрайтов не являются прямоугольниками, то происходит ситуация как на изображении выше. Прямоугольники пересекаются, функция collide_rect возвращает True, но игрок разочарован, потому что он-то на самом деле избежал столкновения.
Вот как можно избежать этой ситуации.

Используя collide_rect_ratio(), можно сделать прямоугольник меньшего размера, уменьшив количество «пустого» места, которое в противном случае воспринималось бы как пересечение. Но это не всегда сработает. На изображении выше крылья космического корабля все равно оказываются за пределами прямоугольника. Это значит, что иногда астероид будет проходить сквозь крыло, не нанося урона. Но это не так уж и плохо! На той скорости, на которой работает игра, игрок не заметит, но почувствует, что был очень близок к столкновению. Вместо разочарования он почувствует, что неплохо справляется.

Другой вариант — использовать ограничивающий круг. Он идеально вписывается в форму астероида. Не так хорошо подходит для крыльев корабля, но самой игре это не навредит.
Установка радиуса спрайта
Опираясь на возможности, описанные выше, для функции столкновения игрока с астероидом будут использоваться круги. В Pygame это сделать проще простого с помощью атрибута self.radius для каждого из спрайтов.
Сначала игрок. Какого размера должен быть круг? Придется поэкспериментировать, чтобы определить нужный радиус. Вот как сделать это в спрайте игрока __init()__:
self.rect = self.image.get_rect()
self.radius = 25
pygame.draw.circle(self.image, RED, self.rect.center, self.radius)
Нарисуем красный круг поверх изображения, чтобы видеть, как он работет. То же самое нужно сделать и для астероида:
self.rect = self.image.get_rect()
self.radius = int(self.rect.width / 2)
pygame.draw.circle(self.image, RED, self.rect.center, self.radius)
Здесь удалось пойти на небольшую хитрость. Если со временем будет решено использовать астероиды разных размеров, то указав радиус как 1/2 ширины изображения, можно будет не возвращаться к редактированию кода.
Вот как это выглядит:

Здесь видно, что для игрока радиус выбран чересчур большой —круг даже больше чем размер корабля по оси y. Лучше установить радиус self.radius = 20.
Для астероида хорошо было бы, чтобы его края выглядывали из-под круга, поэтому при расчете нужно уменьшить ширину астероида до 85% от оригинальной.
self.radius = int(self.rect.width * .85 / 2)
Изменение типа столкновения
Чтобы игра начала использовать этот тип столкновений, нужно поменять команду spritecollide c AABB на ограничивающий круг:
# проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, False, pygame.sprite.collide_circle)
if hits:
running = False

Если все работает так, как хотелось, красные круги можно убрать. Лучше их просто закомментировать, если нужно будет поэкспериментировать с ними в будущем.
Код урока — shmup-5.py
Итого
Тип столкновений влияет на то, как будет восприниматься игра. Так, в этот раз изменился тип столкновений астероидов и игрока, но не поменялось взаимодействие астероидов с пулями. Последним лучше оставаться прямоугольниками.
В следующий раз речь пойдет о том, как добавить спрайтам анимацию.
]]>Четвертая часть проект «Стрелялка с Pygame». Если пропустили, обязательно вернитесь и начините с первой части. В этот раз речь пойдет об использовании заготовленной графики.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Выбор графики
В уроке, посвященном спрайтами, затрагивалась тема Opengameart.org — источника бесплатного арта для игр; и популярного местного автора, Kenney. Kenney создал набор арта, который прекрасно подойдет для этой стрелялки. Он называется «Space Shooter Pack». Найти его можно здесь:
https://opengameart.org/content/space-shooter-redux
Он включает массу качественных изображений с космическими кораблями, лазерами, астероидами и так далее.
Архив содержит несколько папок. Для этого проекта нужно папка PNG со всеми изображениями по отдельности. Для спрайтов пока что нужно только три, а также изображение звездного неба для фона.

![]()
![]()

Изображения необходимо скопировать туда, где игра сможет их найти. Лучше всего создать новую папку в том же месте, где хранится код игры. Назовем ее «img».
Загрузка изображений
Чтобы быть уверенными в том, что код будет работать в любой операционной системе, нужно использовать функцию os.path, которая определяет правильный путь к файлам вне зависимости от ОС.
В верхней части программы необходимо определить местоположение папки img:
from os import path
img_dir = path.join(path.dirname(__file__), 'img')
Прорисовка фона
Теперь можно приступать к загрузке фонового изображения. Загрузку ассетов необходимо производить до игрового цикла и кода запуска:
# Загрузка всей игровой графики
background = pygame.image.load(path.join(img_dir, 'starfield.png')).convert()
background_rect = background.get_rect()
Теперь можно прорисовать фон в разделе Draw игрового цикла до прорисовки любого из спрайтов:
# Рендеринг
screen.fill(BLACK)
screen.blit(background, background_rect)
all_sprites.draw(screen)
blit — это олдскульный термин из компьютерной графики, который обозначает прорисовку пикселей одного изображения на другом. В этом случае — прорисовку фона на экране. Теперь фон выглядит намного лучше:

Изображения спрайтов:
Теперь можно загрузить изображения спрайтов:
# Загрузка всей игровой графики
background = pygame.image.load(path.join(img_dir, 'starfield.png')).convert()
background_rect = background.get_rect()
player_img = pygame.image.load(path.join(img_dir, "playerShip1_orange.png")).convert()
meteor_img = pygame.image.load(path.join(img_dir, "meteorBrown_med1.png")).convert()
bullet_img = pygame.image.load(path.join(img_dir, "laserRed16.png")).convert()
Начнем с игрока — необходимо заменить зеленый прямоугольник, то есть self.image и не забыть убрать параметр image.fill(GREEN), который больше не нужен:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = player_img
self.rect = self.image.get_rect()

Тем не менее имеется пара проблем. Во-первых, картинка чуть больше, чем требуется. Есть два варианта: 1) открыть ее в графическом редакторе (Photoshop, GIMP) и отредактировать; 2) поменять размер прямо в коде. Выбираем второй вариант. Для этого понадобится функция Pygame под названием transform.scale(). Уменьшим изображение вдвое — до размера 50х30 пикселей.
Вторая проблема — черный прямоугольник вокруг корабля. Чтобы это исправить, нужно назначить прозрачный цвет с помощью set_colorkey:
self.image = pygame.transform.scale(player_img, (50, 38))
self.image.set_colorkey(BLACK)
Если повторить то же самое для классов Bullet и Mob (хотя их размер менять не нужно), игра будет выглядеть намного лучше:
Код урока — shmup-4.py
Итого
Теперь в игре есть графика, и это помогает заметить новую проблему: астероиды уничтожают корабль, даже когда не касаются его. В следующем уроке поработаем над тем, чтобы столкновения работали корректно.
]]>Третья часть проекта «Стрелялка с Pygame». В этот раз в игре появятся столкновения между игроком и врагами, а также пули, которыми игрок будет стрелять.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Она будет особенно интересна начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Столкновения
Столкновения — важная часть разработки игр. Обнаружение столкновений подразумевает необходимость распознать, когда один объект в игре касается другого. Ответ на столкновение — это то, что случится в момент столкновения: когда Марио подберет монетку, когда меч Линка нанесет урон врагу и так далее.
В этой стрелялке есть спрайты врагов, которые летят сверху вниз по направлению к игроку, и хотелось бы понимать, когда они сталкиваются с игроком. На этом этапе предположим, что момент столкновения означает завершение игры.
Ограничивающая рамка
У каждого спрайта в Pygame есть атрибут rect, определяющий его координаты и размер. Объект rect в Pygame представлен в формате [x, y, width, height], где x и y представляют собой верхний левый угол прямоугольника. Другое название для этого прямоугольника — ограничивающая рамка, потому что она является границей объекта.
Обнаружение столкновений называется AABB (axis-aligned bounding box или «параллельный осям ограничивающий параллелепипед»). Такое название объясняется тем, что прямоугольник выравнивается в соответствии с осями экрана, которые не наклоняются. Обнаружение столкновений AABB столь популярно, потому что работает быстро — компьютер молниеносно сравнивает координаты прямоугольников, что особенно удобно, когда на экране много объектов.
Чтобы обнаружить столкновение, необходимо сравнить прямоугольник игрока с прямоугольниками остальных мобов. Это можно сделать, пройдя циклом по всем мобам и сравнить каждый из них следующим образом:

На изображении видно, что только прямоугольник №3 сталкивается с большим черным прямоугольником. №1 пересекается с осью x, а №2 — с осью y. Но для пересечения двух прямоугольников, должны пересекаться обе их оси. Вот как это преподнести в коде:
if mob.rect.right > player.rect.left and \
mob.rect.left < player.rect.right and \
mob.rect.bottom > player.rect.top and \
mob.rect.top < player.rect.bottom:
collide = True
К счастью, в Pygame есть встроенная функция spritecollide() для выполнения того же самого.
Столкновение мобов с игроком
В раздел «update» игрового цикла необходимо добавить следующую команду:
# Обновление
all_sprites.update()
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.spritecollide(player, mobs, False)
if hits:
running = False
spritecollide() принимает 3 аргумента: название спрайта, который нужно проверять, название группы для сравнения и значения True или False для параметра dokill. Последний параметр позволяет указать, должен ли объект удаляться при столкновении. Если нужно было, например, проверить, подобрал ли игрок монетку, необходимо указать значение True так, чтобы монетка пропала.
Результат команды spritecollide() — это список спрайтов, которые столкнулись с игроком (он может быть не один). Присвоим его переменной hits.
Если список hits будет непустым, значение инструкции if окажется True. В результате значение running изменится на False, и игра закончится.
Стрельба
Спрайт пули
Пришло время добавить еще один спрайт — пули. Это будет спрайт, который появляется в момент выстрела над спрайтом игрока и двигается вверх с большой скоростью. Определение спрайта вам знакомо, поэтому вот сразу готовый класс Bullet:
class Bullet(pygame.sprite.Sprite):
def __init__(self, x, y):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((10, 20))
self.image.fill(YELLOW)
self.rect = self.image.get_rect()
self.rect.bottom = y
self.rect.centerx = x
self.speedy = -10
def update(self):
self.rect.y += self.speedy
# убить, если он заходит за верхнюю часть экрана
if self.rect.bottom < 0:
self.kill()
В метод __init__() спрайта пули нужно передать значения x и y, чтобы указать спрайту, где появляться. Поскольку спрайт игрока может двигаться, то место появления будет соответствовать местоположению игрока. Значение speedy будет отрицательным, чтобы он спрайт двигался наверх.
Наконец, нужно проверить оказался ли спрайт за пределами экрана. Если да — его можно удалять.
Событие keypress
Чтобы было легко хотя бы вначале, нужно сделать так, чтобы каждый раз при нажатии пробела вылетала пуля. Это нужно добавить к проверке событий:
for event in pygame.event.get():
# проверка для закрытия окна
if event.type == pygame.QUIT:
running = False
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_SPACE:
player.shoot()
Новый код проверяет событие KEYDOWN, и если таковое наблюдается, проверяет нажата ли кнопка K_SPACE. Если да — запускается метод игрока shoot().
Появление пули
В первую очередь необходимо добавить группу для пуль:
bullets = pygame.sprite.Group()
Теперь можно создавать следующий метод в классе Player:
def shoot(self):
bullet = Bullet(self.rect.centerx, self.rect.top)
all_sprites.add(bullet)
bullets.add(bullet)
Все что делает метод shoot() — создает пулю, используя в качестве места появления верхнюю центральную часть игрока. После этого нужно убедиться, что пуля добавлена в all_sptires (чтобы она отрисовалась и обновилась) и в bullets, которая будет использоваться для столкновений.
Столкновения пуль
Теперь нужно проверить, задела ли пуля моба. Отличие в том, что есть несколько пуль (в группе bullets) и несколько мобов (в группе mobs), поэтому нельзя использовать spritecollide() как в прошлый раз, потому что в этой функции сравнивается только один спрайт с группой. Вместо этого нужно использовать groupcollide():
# Обновление
all_sprites.update()
# Проверка, не ударил ли моб игрока
hits = pygame.sprite.groupcollide(mobs, bullets, True, True)
for hit in hits:
m = Mob()
all_sprites.add(m)
mobs.add(m)
Функция groupcollide() похожа на spritecollide() за исключением того, что нужно указывать две группы для сравнения, а возвращать функция будет список задетых мобов. Также есть два значения dokill для каждой из групп.
Если просто удалять мобов, то появится проблема: они закончатся. Поэтому нужно просто проходить циклом по hits и для каждого уничтоженного моба создавать один новый.
Теперь это начинает напоминать реальную игру:

Код урока — shmup-3.py
В следующем уроке вы узнаете, как добавить графику в игре вместо того, чтобы использовать цветные прямоугольники.
]]>Вторая часть проекта «Стрелялка с Pygame». В этот раз в игре появятся враги, от которых должен будет уклоняться игрок.
В этой серии уроков будет создана полноценная игра на языке Python с помощью библиотеки Pygame. Это будет особенно интересно начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Спрайты врагов
Пока что можно не думать о том, какими именно будут спрайты врагов. Главное, чтобы они просто отображались на экране. Можно сделать проект, в котором космический корабль будет уклоняться от метеоритов, или единорог — от пицц. Это никак не затронет код, поэтому внешний вид не столь важен на данном этапе.
Учитывая это, нужно дать спрайту врага в коде какое-то общее название. Почти идеальным именем для такого рода объектов (которые двигаются в игре) является моб (вы могли слышать это выражение раньше).
Начнем с определения свойств спрайта:
class Mob(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((30, 40))
self.image.fill(RED)
self.rect = self.image.get_rect()
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-100, -40)
self.speedy = random.randrange(1, 8)
Важно определить хорошую стартовую точку для появления мобов. Не хочется, чтобы они возникали из ниоткуда, поэтому нужно просто выбрать значение, которое бы размещало объект сверху за пределами экрана (y < 0), а значение x должно быть в пределах двух сторон.
Дальше для функции обновления нужно задать движения спрайта с определенной скоростью, но что с ним будет, когда он доберется до нижней части экрана? Его можно удалить и создать новый или же можно перенести этот же спрайт в случайное место в верхней части экрана.
def update(self):
self.rect.y += self.speedy
if self.rect.top > HEIGHT + 10:
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-100, -40)
self.speedy = random.randrange(1, 8)
Появление врагов
Врагов будет много, поэтому нужно создать группу mobs для них всех. Это также упростит работу с ними в дальнейшем. После этого нужно вызвать определенное количество мобов и добавить их в группы.
player = Player()
all_sprites.add(player)
for i in range(8):
m = Mob()
all_sprites.add(m)
mobs.add(m)
Должен получиться поток мобов, которые опускаются вниз по экрану:

Пока что все отлично, но мобы, двигающиеся ровно вниз, смотрятся скучно. Нужно добавить движение по координате x:
class Mob(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((30, 40))
self.image.fill(RED)
self.rect = self.image.get_rect()
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-100, -40)
self.speedy = random.randrange(1, 8)
self.speedx = random.randrange(-3, 3)
def update(self):
self.rect.x += self.speedx
self.rect.y += self.speedy
if self.rect.top > HEIGHT + 10 or self.rect.left < -25 or self.rect.right > WIDTH + 20:
self.rect.x = random.randrange(WIDTH - self.rect.width)
self.rect.y = random.randrange(-100, -40)
self.speedy = random.randrange(1, 8)
Также нужно изменить инструкцию if, которая создает новых мобов в тот момент, когда те пропадают с экрана. Моб, который двигается по диагонали, пропадет с экрана задолго до того как доберется до нижней части, поэтому нужно перезагрузить его быстрее.
Теперь игра должна выглядеть следующим образом:

Код урока — shmup-2.py
В следующем уроке научимся определять, когда два моба сталкиваются и дадим игроку возможность отстреливаться.
]]>В этой серии уроков будет создана полноценная игру с помощью Python и Pygame. Это будет особенно интересно начинающим программистам, которые уже знакомы с основами языка и хотят углубить знания, а также узнать, что лежит в основе создания игр.
Перед стартом
Если вы еще не знакомы с pygame, вернитесь и закончите первый урок в водной части «Библиотека Pygame / Часть 1. Введение». Дальше будет использоваться программа pygame template.py, которая была создана в том уроке, как основа для этого.
В этой серии мы будем работать над игрой в жанре «Shmup» или «Shoot ’em up» (или, если еще проще, «Стрелялка»). Игрок будет пилотом маленького космического корабля, который пытается выжить среди метеоритов и прочих предметов, летящих на него.
Для начала нужно сохранить файл pygame template.py с новым именем. Таким образом вы сможете использовать этот шаблон в будущем для других игр. Можно назвать файл просто как shmup.py.
В первую очередь, необходимо отредактировать настройки, добавив некоторые значения в игру:
WIDTH = 480
HEIGHT = 600
FPS = 60
Игра будет выполнена в «портретном режиме» — это значит, что высота окна больше, чем его ширина. Игра будет экшеном, поэтому важно задать высокое значение кадров в секунду. В таком случае спрайты будут двигаться максимально плавно. 60 — идеальное значение.
Спрайт игрока
Первое, что необходимо добавить — спрайт, который олицетворяет собой игрока. В итоге это будет космический корабль, но на начальных этапах можно просто игнорировать графику и использовать прямоугольники вместо спрайтов. Важно добиться того, чтобы они отображались на экране и двигались так, как требуется. Заменить их потом артами не составит труда.
Это начало спрайта игрока:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 40))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.centerx = WIDTH / 2
self.rect.bottom = HEIGHT - 10
self.speedx = 0
Для игрока выбран размер 50х40 пикселей. Он будет находится по центру в нижней части экрана. Также есть свойство speedx, которое будет отслеживать, с какой скоростью двигается игрок по оси x (со стороны в сторону). Если вы не до конца понимаете, как это все работает, вернитесь к уроку «Работа со спрайтами».
Метод update() спрайта запускается в каждом кадре. Он будет перемещать спрайт с конкретной скоростью:
def update(self):
self.rect.x += self.speedx
Теперь нужно показать спрайт, чтобы убедиться, что он отображается на экране:
all_sprites = pygame.sprite.Group()
player = Player()
all_sprites.add(player)
Не забывайте, что каждый созданный спрайт должен быть добавлен в группу all_sprites, так чтобы он обновлялся и прорисовывался на экране.
Движение/управление
Управлять в этой игре нужно будет с помощью клавиатуры, поэтому игрок должен будет двигаться при нажатии кнопок Влево или Вправо (это могут быть a или d).
Когда речь заходит об использовании кнопок в игре, есть выбор, а это значит, что речь идет о Событиях:
1 вариант: в этой очереди событий можно определить два события (по одному для каждой кнопки), каждое из которых будет менять скорость игрока, соответственно:
for event in pygame.event.get():
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_LEFT:
player.speedx = -8
if event.key == pygame.K_RIGHT:
player.speedx = 8
Проблема с этим методом в том, что после нажатия кнопки Игрок двигается, но не останавливается. Нужно также добавить два события KEYUP, которые будут возвращать скорость к значению 0.
2 вариант: установить скорость спрайта по умолчанию на значение 0, за исключением случаев, когда нажимаются кнопки Влево или Вправо. В результате движение будет более плавным, а код проще.
def update(self):
self.speedx = 0
keystate = pygame.key.get_pressed()
if keystate[pygame.K_LEFT]:
self.speedx = -8
if keystate[pygame.K_RIGHT]:
self.speedx = 8
self.rect.x += self.speedx
Этот код устанавливает скорость speedx на значении 0 для каждого кадра, а затем проверяет, не нажата ли кнопка. pygame.key.get_pressed() возвращает словарь со всеми клавишами клавиатуры и значениями True или False, которые указывают на то, нажата ли какая-то из них. Если одна из кнопок нажимается, скорость меняется соответственно.
В пределах экрана
Наконец, нужно сделать так, чтобы спрайт не пропадал с экрана. Для этого нужно добавить этот код к update() игрока:
if self.rect.right > WIDTH:
self.rect.right = WIDTH
if self.rect.left < 0:
self.rect.left = 0
Теперь если rect попробует двигаться за пределы экрана, он остановится. Второй вариант — телепортировать спрайт с одного края экрана ко второму, когда он туда доберется. Но в этой игре предпочтительнее тормозить игрока.
Итог
Вот весь код этого шага:
# Игра Shmup - 1 часть
# Cпрайт игрока и управление
import pygame
import random
WIDTH = 480
HEIGHT = 600
FPS = 60
# Задаем цвета
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
YELLOW = (255, 255, 0)
# Создаем игру и окно
pygame.init()
pygame.mixer.init()
screen = pygame.display.set_mode((WIDTH, HEIGHT))
pygame.display.set_caption("Shmup!")
clock = pygame.time.Clock()
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 40))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.centerx = WIDTH / 2
self.rect.bottom = HEIGHT - 10
self.speedx = 0
def update(self):
self.speedx = 0
keystate = pygame.key.get_pressed()
if keystate[pygame.K_LEFT]:
self.speedx = -8
if keystate[pygame.K_RIGHT]:
self.speedx = 8
self.rect.x += self.speedx
if self.rect.right > WIDTH:
self.rect.right = WIDTH
if self.rect.left < 0:
self.rect.left = 0
all_sprites = pygame.sprite.Group()
player = Player()
all_sprites.add(player)
# Цикл игры
running = True
while running:
# Держим цикл на правильной скорости
clock.tick(FPS)
# Ввод процесса (события)
for event in pygame.event.get():
# проверка для закрытия окна
if event.type == pygame.QUIT:
running = False
# Обновление
all_sprites.update()
# Рендеринг
screen.fill(BLACK)
all_sprites.draw(screen)
# После отрисовки всего, переворачиваем экран
pygame.display.flip()
pygame.quit()
В следующем уроке в игру будут добавлены спрайты врагов, от которых игрок будет уклоняться.
]]>Это пошаговое руководство по созданию бота для Telegram. Бот будет показывать курсы валют, разницу между курсом раньше и сейчас, а также использовать современные встроенные клавиатуры.
Время переходить к делу и узнать наконец, как создавать ботов в Telegram.
Шаг №0: немного теории об API Telegram-ботов
Начать руководство стоит с простого вопроса: как создавать чат-ботов в Telegram?
Ответ очень простой: для чтения сообщений отправленных пользователями и для отправки сообщений назад используется API HTML. Это требует использования URL:
https://api.telegram.org/bot/METHOD_NAME
Токен — уникальная строка из символов, которая нужна для того, чтобы установить подлинность бота в системе. Токен генерируется при создании бота. METHOD_NAME — это метод, например, getUpdates, sendMessage, getChat и так далее.
Токен выглядит приблизительно так:
123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11
Для выполнения запросов используются как GET, так и POST запросы. Многие методы требуют дополнительных параметров (методу sendMessage, например, нужно передать chat_id и текст). Эти параметры могут быть переданы как строка запроса URL, application/x-www-form-urlencoded и application-json (кроме загрузки файлов). Еще одно требование — кодировка UTF-8.
После отправки запроса к API, вы получаете ответ в формате JSON. Например, если извлечь данные с помощью метода getME, ответ будет такой:
GET https://api.telegram.org/bot<token>/getMe
{
ok: true,
result: {
id: 231757398,
first_name: "Exchange Rate Bot",
username: "exchangetestbot"
}
}
Если значение ‘ok’ — true, значит запрос был успешным и результат отобразится в поле ‘field’. Если false — в поле ‘description’ будет сообщение об ошибке.
Список всех типов данных и методов API Telegram-бота можно найти здесь (ENG) или с переводом здесь (ру) .
Следующий вопрос: как получать пользовательские сообщения?
Есть два варианта.
Первый — вручную создавать запросы с помощью метода getUpdates. В качестве объекта вы получите массив объектов Update. Этот метод работает как технология длинных опросов (long polling), когда вы отправляете запрос, обрабатываете данные и начинаете повторяете процесс. Чтобы избежать повторной обработки одних и тех же данных рекомендуется использовать параметр offset.
Второй вариант — использовать webhooks. Метод setWebhook нужно будет применить только один раз. После этого Telegram будет отправлять все обновления на конкретный URL-адрес, как только они появятся. Единственное ограничение — необходим HTTPS, но можно использовать и сертификаты, заверенные самостоятельно.
Как выбрать оптимальный метод? Метод getUpdates лучше всего подходит, если:
- Вы не хотите или не можете настраивать HTTPS во время разработки.
- Вы работаете со скриптовыми языками, которые сложно интегрировать в веб-сервер.
- У бота высокая нагрузка.
- Вы меняете сервер бота время от времени.
Метод с Webhook лучше подойдет в таких случаях:
- Вы используете веб-языки (например, PHP).
- У бота низкая нагрузка, и нет смысла делать запросы вручную.
- Бот на постоянной основе интегрирован в веб-сервер.
В этом руководстве будет использоваться метод getUpdates.
Еще один вопрос: как создать зарегистрировать бота?
@BotFather используется для создания ботов в Telegram. Он также отвечает за базовую настройку (описание, фото профиля, встроенная поддержка и так далее).
Существует масса библиотек, которые облегчают процесс работы с API Telegram-бота. Вот некоторые из них:
- Python
pyTelegramBotAPI (TeleBot)
Telepot
Aiogram - PHP
Telegram Bot API — PHP SDK + Laravel Integration - Java
TelegramBots - NodeJS
Telegram Node Bot - Ruby
Telegram Bot - C#
Telegram Bot API LIbrary
По своей сути, все эти библиотеки — оболочки HTML-запросов. Большая часть из них написана с помощью принципов ООП. Типы данных Telegram Bot API представлены в виде классов.
В этом руководстве будет использоваться библиотека pyTelegramBotApi.
Шаг №1: реализовать запросы курсов валют
Весь код был проверен на версии Python==3.7 c использование библиотек:
pyTelegramBotAPI==3.6.6
pytz==2019.1
requests==2.7.0
Начать стоит с написания Python-скрипта, который будет реализовывать логику конкретных запросов курсов валют. Использовать будем PrivatBank API. URL: https://api.privatbank.ua/p24api/pubinfo?json&exchange&coursid=5.
Пример ответа:
[
{
ccy:"USD",
base_ccy:"UAH",
buy:"25.90000",
sale:"26.25000"
},
{
ccy:"EUR",
base_ccy:"UAH",
buy:"29.10000",
sale:"29.85000"
},
{
ccy:"RUR",
base_ccy:"UAH",
buy:"0.37800",
sale:"0.41800"
},
{
ccy:"BTC",
base_ccy:"USD",
buy:"11220.0384",
sale:"12401.0950"
}
]
Создадим файл pb.py со следующим кодом:
import re
import requests
import json
URL = 'https://api.privatbank.ua/p24api/pubinfo?json&exchange&coursid=5'
def load_exchange():
return json.loads(requests.get(URL).text)
def get_exchange(ccy_key):
for exc in load_exchange():
if ccy_key == exc['ccy']:
return exc
return False
def get_exchanges(ccy_pattern):
result = []
ccy_pattern = re.escape(ccy_pattern) + '.*'
for exc in load_exchange():
if re.match(ccy_pattern, exc['ccy'], re.IGNORECASE) is not None:
result.append(exc)
return result
Были реализованы три метода:
load_exchange: загружает курсы валют по указанному URL-адресу и возвращает их в формате словаря(dict).get_exchange: возвращает курсы валют по запрошенной валюте.get_exchanges: возвращает список валют в соответствии с шаблоном (требуется для поиска валют во встроенных запросах).
Шаг №2: создать Telegram-бота с помощью @BotFather
Необходимо подключиться к боту @BotFather, чтобы получить список чат-команд в Telegram. Далее нужно набрать команду /newbot для инструкций выбора название и имени бота. После успешного создания бота вы получите следующее сообщение:
Done! Congratulations on your new bot. You will find it at telegram.me/<username>.
You can now add a description, about section and profile picture for your bot, see /help for a list of commands.
By the way, when you've finished creating your cool bot, ping our Bot Support if you want a better username for it.
Just make sure the bot is fully operational before you do this.
Use this token to access the HTTP API:
<token> (here goes the bot’s token)
For a description of the Bot API, see this page: https://core.telegram.org/bots/api
Его нужно сразу настроить. Необходимо добавить описание и текст о боте (команды /setdescription и /setabouttext), фото профиля (/setuserpic), включить встроенный режим (/setinline), добавить описания команд (/setcommands). Потребуется использовать две команды: /help и /exchange. Стоит описать их в /setcommands.
Теперь, когда настройка закончена, можно переходить к написанию кода. Прежде чем двигаться дальше, рекомендуется почитать об API и ознакомиться с документацией библиотеки, чтобы лучше понимать то, о чем пойдет речь дальше.
Шаг №3: настроить и запустить бота
Начнем с создания файла config.py для настройки:
TOKEN = '<bot token>' # заменить на токен своего бота
TIMEZONE = 'Europe/Kiev'
TIMEZONE_COMMON_NAME = 'Kiev'
В этом файле указаны: токен бота и часовой пояс, в котором тот будет работать (это понадобится в будущем для определения времени обновления сообщений. API Telegram не позволяет видеть временную зону пользователя, поэтому время обновления должно отображаться с подсказкой о часовом поясе).
Создадим файл bot.py. Нужно импортировать все необходимые библиотеки, файлы с настройками и предварительно созданный pb.py. Если каких-то библиотек не хватает, их можно установить с помощью pip.
import telebot
import config
import pb
import datetime
import pytz
import json
import traceback
P_TIMEZONE = pytz.timezone(config.TIMEZONE)
TIMEZONE_COMMON_NAME = config.TIMEZONE_COMMON_NAME
Создадим бота с помощью библиотеки pyTelegramBotAPI. Для этого конструктору нужно передать токен:
bot.py
bot = telebot.TeleBot(config.TOKEN)
bot.polling(none_stop=True)
Шаг №4: написать обработчик команды /start
Теперь чат-бот на Python работает и постоянно посылает запросы с помощью метода getUpdates. Параметр none_stop отвечает за то, чтобы запросы отправлялись, даже если API возвращает ошибку при выполнении метода.
Из переменной бота возможно вызывать любые методы API Telegram-бота.
Начнем с написания обработчика команды /start и добавим его перед строкой bot.polling(none_stop=True):
@bot.message_handler(commands=['start'])
def start_command(message):
bot.send_message(
message.chat.id,
'Greetings! I can show you exchange rates.\n' +
'To get the exchange rates press /exchange.\n' +
'To get help press /help.'
)
Как можно видеть, pyTelegramBotApi использует декораторы Python для запуска обработчиков разных команд Telegram. Также можно перехватывать сообщения с помощью регулярных выражений, узнавать тип содержимого в них и лямбда-функции.
В нашем случае если условие commands=['start'] равно True, тогда будет вызвана функция start_command. Объект сообщения (десериализованный тип Message) будет передан функции. После этого вы просто запускаете send_message в том же чате с конкретным сообщением.
Это было просто, не так ли?
Шаг №5: создать обработчик команды /help
Давайте оживим обработчик команды /help с помощью встроенной кнопки со ссылкой на ваш аккаунт в Telegram. Кнопку можно озаглавить “Message the developer”.
@bot.message_handler(commands=['help'])
def help_command(message):
keyboard = telebot.types.InlineKeyboardMarkup()
keyboard.add(
telebot.types.InlineKeyboardButton(
'Message the developer', url='telegram.me/artiomtb'
)
)
bot.send_message(
message.chat.id,
'1) To receive a list of available currencies press /exchange.\n' +
'2) Click on the currency you are interested in.\n' +
'3) You will receive a message containing information regarding the source and the target currencies, ' +
'buying rates and selling rates.\n' +
'4) Click “Update” to receive the current information regarding the request. ' +
'The bot will also show the difference between the previous and the current exchange rates.\n' +
'5) The bot supports inline. Type @<botusername> in any chat and the first letters of a currency.',
reply_markup=keyboard
)
Как видно в примере выше, был использован дополнительный параметр (reply_markup) для метода send_message. Метод получил встроенную клавиатуру (InlineKeyboardMarkup) с одной кнопкой (InlineKeyboardButton) и следующим текстом: “Message the developer” и url='telegram.me/artiomtb'.
Код выше выглядит вот так:

Шаг №6: добавить обработчик команды /exchange
Обработчик команды /exchange отображает меню выбора валюты и встроенную клавиатуру с 3 кнопками: USD, EUR и RUR (это валюты, поддерживаемые API банка).
@bot.message_handler(commands=['exchange'])
def exchange_command(message):
keyboard = telebot.types.InlineKeyboardMarkup()
keyboard.row(
telebot.types.InlineKeyboardButton('USD', callback_data='get-USD')
)
keyboard.row(
telebot.types.InlineKeyboardButton('EUR', callback_data='get-EUR'),
telebot.types.InlineKeyboardButton('RUR', callback_data='get-RUR')
)
bot.send_message(
message.chat.id,
'Click on the currency of choice:',
reply_markup=keyboard
)
Вот как работает InlineKeyboardButton. Когда пользователь нажимает на кнопку, вы получаете CallbackQuery (в параметре data содержится callback-data) в getUpdates. Таким образом вы знаете, какую именно кнопку нажал пользователь, и как ее правильно обработать.
Вот как работает ответ /exchange:

Шаг №7: написать обработчик для кнопок встроенной клавиатуры
В библиотеке pyTelegramBot Api есть декоратор @bot.callback_query_handler, который передает объект CallbackQuery во вложенную функцию.
@bot.callback_query_handler(func=lambda call: True)
def iq_callback(query):
data = query.data
if data.startswith('get-'):
get_ex_callback(query)
Давайте реализуем метод get_ex_callback:
def get_ex_callback(query):
bot.answer_callback_query(query.id)
send_exchange_result(query.message, query.data[4:])
Метод answer_callback_query нужен, чтобы убрать состояние загрузки, к которому переходит бот после нажатия кнопки. Отправим сообщение send_exchange_query. Ему нужно передать Message и код валюты (получить ее можно из query.data. Если это, например, get-USD, передавайте USD).
Реализуем send_exchange_result:
def send_exchange_result(message, ex_code):
bot.send_chat_action(message.chat.id, 'typing')
ex = pb.get_exchange(ex_code)
bot.send_message(
message.chat.id, serialize_ex(ex),
reply_markup=get_update_keyboard(ex),
parse_mode='HTML'
)
Все довольно просто.
Сперва отправим состояние ввода в чат, так чтобы бот показывал индикатор «набора текста», пока API банка получает запрос. Теперь вызовем метод get_exchange из файла pb.py, который получит код валюты (например, USD). Также нужно вызвать два новых метода в send_message: serialize_ex, сериализатор валюты и get_update_keyboard (который возвращает клавиатуре кнопки “Update” и “Share”).
def get_update_keyboard(ex):
keyboard = telebot.types.InlineKeyboardMarkup()
keyboard.row(
telebot.types.InlineKeyboardButton(
'Update',
callback_data=json.dumps({
't': 'u',
'e': {
'b': ex['buy'],
's': ex['sale'],
'c': ex['ccy']
}
}).replace(' ', '')
),
telebot.types.InlineKeyboardButton('Share', switch_inline_query=ex['ccy'])
)
return keyboard
Запишем в get_update_keyboard текущий курс валют в callback_data в форме JSON. JSON сжимается, потому что максимальный разрешенный размер файла равен 64 байтам.
Кнопка t значит тип, а e — обмен. Остальное выполнено по тому же принципу.
У кнопки Share есть параметр switch_inline_query. После нажатия кнопки пользователю будет предложено выбрать один из чатов, открыть этот чат и ввести имя бота и определенный запрос в поле ввода.
Методы serialize_ex и дополнительный serialize_exchange_diff нужны, чтобы показывать разницу между текущим и старыми курсами валют после нажатия кнопки Update.
def serialize_ex(ex_json, diff=None):
result = '<b>' + ex_json['base_ccy'] + ' -> ' + ex_json['ccy'] + ':</b>\n\n' + \
'Buy: ' + ex_json['buy']
if diff:
result += ' ' + serialize_exchange_diff(diff['buy_diff']) + '\n' + \
'Sell: ' + ex_json['sale'] + \
' ' + serialize_exchange_diff(diff['sale_diff']) + '\n'
else:
result += '\nSell: ' + ex_json['sale'] + '\n'
return result
def serialize_exchange_diff(diff):
result = ''
if diff > 0:
result = '(' + str(diff) + ' <img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt=" " src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/72x72/2197.png">" src="https://s.w.org/images/core/emoji/72x72/2197.png">)'
elif diff < 0:
result = '(' + str(diff)[1:] + ' <img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="
" src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2197.svg">" src="https://s.w.org/images/core/emoji/72x72/2197.png">" src="https://s.w.org/images/core/emoji/72x72/2197.png">)'
elif diff < 0:
result = '(' + str(diff)[1:] + ' <img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt="<img draggable="false" data-mce-resize="false" data-mce-placeholder="1" data-wp-emoji="1" class="emoji" alt=" " src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/72x72/2198.png">" src="https://s.w.org/images/core/emoji/72x72/2198.png">)'
return result
" src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/2.3/svg/2198.svg">" src="https://s.w.org/images/core/emoji/72x72/2198.png">" src="https://s.w.org/images/core/emoji/72x72/2198.png">)'
return result
Как видно, метод serialize_ex получает необязательный параметр diff. Ему будет передаваться разница между курсами обмена в формате {'buy_diff': <float>, 'sale_diff': <float>}. Это будет происходить во время сериализации после нажатия кнопки Update. Когда курсы валют отображаются первый раз, он нам не нужен.
Вот как будет выглядеть бот после нажатия кнопки USD:

Шаг №8: реализовать обработчик кнопки обновления
Теперь можно создать обработчик кнопки Update. После дополнения метода iq_callback_method он будет выглядеть следующим образом:
@bot.callback_query_handler(func=lambda call: True)
def iq_callback(query):
data = query.data
if data.startswith('get-'):
get_ex_callback(query)
else:
try:
if json.loads(data)['t'] == 'u':
edit_message_callback(query)
except ValueError:
pass
Если данные обратного вызова начинаются с get- (get-USD, get-EUR и так далее), тогда нужно вызывать get_ex_callback, как раньше. В противном случае стоит попробовать разобрать строку JSON и получить ее ключ t. Если его значение равно u, тогда нужно вызвать метод edit_message_callback. Реализуем это:
def edit_message_callback(query):
data = json.loads(query.data)['e']
exchange_now = pb.get_exchange(data['c'])
text = serialize_ex(
exchange_now,
get_exchange_diff(
get_ex_from_iq_data(data),
exchange_now
)
) + '\n' + get_edited_signature()
if query.message:
bot.edit_message_text(
text,
query.message.chat.id,
query.message.message_id,
reply_markup=get_update_keyboard(exchange_now),
parse_mode='HTML'
)
elif query.inline_message_id:
bot.edit_message_text(
text,
inline_message_id=query.inline_message_id,
reply_markup=get_update_keyboard(exchange_now),
parse_mode='HTML'
)
Как это работает? Очень просто:
- Загружаем текущий курс валюты (
exchange_now = pb.get_exchange(data['c'])). - Генерируем текст нового сообщения путем сериализации текущего курса валют с параметром
diff, который можно получить с помощью новых методов (о них дальше). Также нужно добавить подпись —get_edited_signature. - Вызываем метод
edit_message_text, если оригинальное сообщение не изменилось. Если это ответ на встроенный запрос, передаем другие параметры.
Метод get_ex_from_iq_data разбирает JSON из callback_data:
def get_ex_from_iq_data(exc_json):
return {
'buy': exc_json['b'],
'sale': exc_json['s']
}
Метод get_exchange_diff получает старое и текущее значение курсов валют и возвращает разницу в формате {'buy_diff': <float>, 'sale_diff': <float>}:
def get_exchange_diff(last, now):
return {
'sale_diff': float("%.6f" % (float(now['sale']) - float(last['sale']))),
'buy_diff': float("%.6f" % (float(now['buy']) - float(last['buy'])))
}
get_edited_signature генерирует текст “Updated…”:
def get_edited_signature():
return '<i>Updated ' + \
str(datetime.datetime.now(P_TIMEZONE).strftime('%H:%M:%S')) + \
' (' + TIMEZONE_COMMON_NAME + ')</i>'
Вот как выглядит сообщение после обновления, если курсы валют не изменились:

И вот так — если изменились:

Шаг №9: реализовать встроенный режим
Реализация встроенного режима значит, что если пользователь введет @ + имя бота в любом чате, это активирует поиск введенного текста и выведет результаты. После нажатия на один из них бот отправит результат от вашего имени (с пометкой “via bot”).
@bot.inline_handler(func=lambda query: True)
def query_text(inline_query):
bot.answer_inline_query(
inline_query.id,
get_iq_articles(pb.get_exchanges(inline_query.query))
)
Обработчик встроенных запросов реализован.
Библиотека передаст объект InlineQuery в функцию query_text. Внутри используется функция answer_line, которая должна получить inline_query_id и массив объектов (результаты поиска).
Используем get_exchanges для поиска нескольких валют, подходящих под запрос. Нужно передать этот массив методу get_iq_articles, который вернет массив из InlineQueryResultArticle:
def get_iq_articles(exchanges):
result = []
for exc in exchanges:
result.append(
telebot.types.InlineQueryResultArticle(
id=exc['ccy'],
title=exc['ccy'],
input_message_content=telebot.types.InputTextMessageContent(
serialize_ex(exc),
parse_mode='HTML'
),
reply_markup=get_update_keyboard(exc),
description='Convert ' + exc['base_ccy'] + ' -> ' + exc['ccy'],
thumb_height=1
)
)
return result
Теперь при вводе “@exchangetestbost + пробел” вы увидите следующее:

Попробуем набрать usd, и результат мгновенно отфильтруется:

Проверим предложенный результат:

Кнопка “Update” тоже работает:

Отличная работа! Вы реализовали встроенный режим!
Выводы
Поздравляем! Теперь вы знаете, как сделать бота для Telegram, добавить встроенную клавиатуру, обновление сообщений и встроенный режим. Можете похлопать себя по спине и поднять тост за нового бота.
Источник: How to make a bot: a guide to your first Python chat bot for Telegram
]]>Регулярные выражения, также называемые regex, синтаксис или, скорее, язык для поиска, извлечения и работы с определенными текстовыми шаблонами большего текста. Он широко используется в проектах, которые включают проверку текста, NLP (Обработка естественного языка) и интеллектуальную обработку текста.
Введение в регулярные выражения
Регулярные выражения, также называемые regex, используются практически во всех языках программирования. В python они реализованы в стандартном модуле re.
Он широко используется в естественной обработке языка, веб-приложениях, требующих проверки ввода текста (например, адреса электронной почты) и почти во всех проектах в области анализа данных, которые включают в себя интеллектуальную обработку текста.
Эта статья разделена на 2 части.
Прежде чем перейти к синтаксису регулярных выражений, для начала вам лучше понять, как работает модуль re.
Итак, сначала вы познакомитесь с 5 основными функциями модуля re, а затем посмотрите, как создавать регулярные выражения в python.
Узнаете, как построить практически любой текстовый шаблон, который вам, скорее всего, понадобится при работе над проектами, связанными с поиском текста.
Что такое шаблон регулярного выражения и как его скомпилировать?
Шаблон регулярного выражения представляет собой специальный язык, используемый для представления общего текста, цифр или символов, извлечения текстов, соответствующих этому шаблону.
Основным примером является \s+.
Здесь \ s соответствует любому символу пробела. Добавив в конце оператор +, шаблон будет иметь не менее 1 или более пробелов. Этот шаблон будет соответствовать даже символам tab \t.
В конце этой статьи вы найдете больший список шаблонов регулярных выражений. Но прежде чем дойти до этого, давайте посмотрим, как компилировать и работать с регулярными выражениями.
>>> import re
>>> regex = re.compile('\s+')
Вышеупомянутый код импортирует модуль re и компилирует шаблон регулярного выражения, который соответствует хотя бы одному или нескольким символам пробела.
Как разбить строку, разделенную регулярным выражением?
Рассмотрим следующий фрагмент текста.
>>> text = """100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский"""
У меня есть три курса в формате “[Номер курса] [Код курса] [Название курса]”. Интервал между словами разный.
Передо мной стоит задача разбить эти три предмета курса на отдельные единицы чисел и слов. Как это сделать?
Их можно разбить двумя способами:
- Используя метод
re.split. - Вызвав метод
splitдля объектаregex.
# Разделит текст по 1 или более пробелами
>>> re.split('\s+', text)
# или
>>> regex.split(text)
['100', 'ИНФ', 'Информатика', '213', 'МАТ', 'Математика', '156', 'АНГ', 'Английский']
Оба эти метода работают. Но какой же следует использовать на практике?
Если вы намерены использовать определенный шаблон несколько раз, вам лучше скомпилировать регулярное выражение, а не использовать re.split множество раз.
Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
#найти все номера в тексте
>>> print(text)
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
>>> regex_num = re.compile('\d+')
>>> regex_num.findall(text)
['100', '213', '156']
В приведенном выше коде специальный символ \ d является регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах.
Добавление к нему символа + означает наличие по крайней мере 1 числа.
Подобно +, есть символ *, для которого требуется 0 или более чисел. Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.
В итоге, метод findall извлекает все вхождения 1 или более номеров из текста и возвращает их в список.
re.search() против re.match()
Как понятно из названия, regex.search() ищет шаблоны в заданном тексте.
Но, в отличие от findall, который возвращает согласованные части текста в виде списка, regex.search() возвращает конкретный объект соответствия. Он содержит первый и последний индекс первого соответствия шаблону.
Аналогично, regex.match() также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.
>>> # создайте переменную с текстом
>>> text2 = """ИНФ Информатика
213 МАТ Математика 156"""
>>> # скомпилируйте regex и найдите шаблоны
>>> regex_num = re.compile('\d+')
>>> s = regex_num.search(text2)
>>> print('Первый индекс: ', s.start())
>>> print('Последний индекс: ', s.end())
>>> print(text2[s.start():s.end()])
Первый индекс: 17
Последний индекс: 20
213
В качестве альтернативы вы можете получить тот же результат, используя метод group() для объекта соответствия.
>>> print(s.group())
205
>>> m = regex_num.match(text2)
>>> print(m)
None
Как заменить один текст на другой, используя регулярные выражения?
Для изменения текста, используйте regex.sub().
Рассмотрим следующую измененную версию текста курсов. Здесь добавлена табуляция после каждого кода курса.
# создайте переменную с текстом
>>> text = """100 ИНФ \t Информатика
213 МАТ \t Математика
156 АНГ \t Английский"""
>>> print(text)
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Для этого нужно просто использовать regex.sub для замены шаблона \s+ на один пробел .
# заменить один или больше пробелов на 1
>>> regex = re.compile('\s+')
>>> print(regex.sub(' ', text))
или
>>> print(re.sub('\s+', ' ', text))
101 COM Computers 205 MAT Mathematics 189 ENG English
Предположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Это можно сделать, используя отрицательное соответствие (?!\n). Шаблон проверяет наличие символа новой строки, в python это \n, и пропускает его.
# убрать все пробелы кроме символа новой строки
>>> regex = re.compile('((?!\n)\s+)')
>>> print(regex.sub(' ', text))
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
>>> text = """100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский"""
# извлечь все номера курсов
>>> re.findall('[0-9]+', text)
# извлечь все коды курсов (для латиницы [A-Z])
>>> re.findall('[А-ЯЁ]{3}', text)
# извлечь все названия курсов
>>> re.findall('[а-яА-ЯёЁ]{4,}', text)
['100', '213', '156']
['ИНФ', 'МАТ', 'АНГ']
['Информатика', 'Математика', 'Английский']
Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон [0-9]+ указывает на соответствие всем числам от 0 до 9. Добавление символа + в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть [0-9] {3}.
Для кода курса, как вы могли догадаться, [А-ЯЁ]{3} будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).
Для названий курса, [а-яА-ЯёЁ]{4,} будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.
Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().
# создайте группы шаблонов текста курса и извлеките их
>>> course_pattern = '([0-9]+)\s*([А-ЯЁ]{3})\s*([а-яА-ЯёЁ]{4,})'
>>> re.findall(course_pattern, text)
[('100', 'ИНФ', 'Информатика'), ('213', 'МАТ', 'Математика'), ('156', 'АНГ', 'Английский')]
Обратите внимание на шаблон номера курса: [0-9]+, код: [А-ЯЁ]{3} и название: [а-яА-ЯёЁ]{4,} они все помещены в круглую скобку (), для формирования группы.
Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
>>> text = "<body>Пример жадного соответствия регулярных выражений</body>"
>>> re.findall('<.*>', text)
['<body>Пример жадного соответствия регулярных выражений</body>']
Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
С другой стороны, ленивое соответствие “берет как можно меньше”. Это можно задать добавлением ? в конец шаблона.
>>> re.findall('<.*?>', text)
['<body>', '</body>']
Если вы хотите получить только первое совпадение, используйте вместо этого метод поиска search.
re.search('<.*?>', text).group()
'<body>'
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
| . | Один символ кроме новой строки |
| \. | Просто точка ., обратный слеш \ убирает магию всех специальных символов. |
| \d | Одна цифра |
| \D | Один символ кроме цифры |
| \w | Один буквенный символ, включая цифры |
| \W | Один символ кроме буквы и цифры |
| \s | Один пробельный (включая таб и перенос строки) |
| \S | Один не пробельный символ |
| \b | Границы слова |
| \n | Новая строка |
| \t | Табуляция |
Модификаторы
| $ | Конец строки |
| ^ | Начало строки |
| ab|cd | Соответствует ab или de. |
| [ab-d] | Один символ: a, b, c, d |
| [^ab-d] | Любой символ, кроме: a, b, c, d |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| [ab]{2} | 2 непрерывных появления a или b |
| [ab]{2,5} | от 2 до 5 непрерывных появления a или b |
| [ab]{2,} | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
Примеры регулярных выражений
Любой символ кроме новой строки
>>> text = 'python.org'
>>> print(re.findall('.', text)) # Любой символ кроме новой строки
['p', 'y', 't', 'h', 'o', 'n', '.', 'o', 'r', 'g']
>>> print(re.findall('...', text))
['pyt', 'hon', '.or']
Точки в строке
>>>text = 'python.org'
>>> print(re.findall('\.', text)) # соответствует точке
['.']
>>> print(re.findall('[^\.]', text)) # соответствует всему кроме точки
['p', 'y', 't', 'h', 'o', 'n', 'o', 'r', 'g']
Любая цифра
>>> text = '01, Янв 2018'
>>> print(re.findall('\d+', text)) # Любое число (1 и более цифр подряд)
['01', '2018']
Все, кроме цифры
>>> text = '01, Янв 2018'
>>> print(re.findall('\D+', text)) # Любая последовательность, кроме цифр
[', Янв ']
Любая буква или цифра
>>> text = '01, Янв 2018'
>>> print(re.findall('\w+', text)) # Любой символ(1 или несколько подряд)
['01', 'Янв', '2018']
Все, кроме букв и цифр
>>> text = '01, Янв 2018'
>>> print(re.findall('\W+', text)) # Все кроме букв и цифр
[', ', ' ']
Только буквы
>>> text = '01, Янв 2018'
>>> print(re.findall('[а-яА-ЯёЁ]+', text)) # Последовательность букв русского алфавита
['Янв']
Соответствие заданное количество раз
>>> text = '01, Янв 2018'
>>> print(re.findall('\d{4}', text)) # Любые 4 цифры подряд
['2018']
>>> print(re.findall('\d{2,4}', text))
['01', '2018']
1 и более вхождений
>>> print(re.findall(r'Co+l', 'So Cooool')) # 1 и более буква 'o' в строке
['Cooool']
Любое количество вхождений (0 или более раз)
>>> print(re.findall(r'Pi*lani', 'Pilani'))
['Pilani']
0 или 1 вхождение
>>> print(re.findall(r'colou?r', 'color'))
['color']
Граница слова
Границы слов \b обычно используются для обнаружения и сопоставления началу или концу слова. То есть, одна сторона является символом слова, а другая сторона является пробелом и наоборот.
Например, регулярное выражение \btoy совпадает с ‘toy’ в ‘toy cat’, но не в ‘tolstoy’. Для того, чтобы ‘toy’ соответствовало ‘tolstoy’, используйте toy\b.
Можете ли вы придумать регулярное выражение, которое будет соответствовать только первой ‘toy’в ‘play toy broke toys’? (подсказка: \ b с обеих сторон)
Аналогично, \ B будет соответствовать любому non-boundary( без границ).
Например, \ Btoy \ B будет соответствовать ‘toy’, окруженной словами с обеих сторон, как в ‘antoynet’.
>>> re.findall(r'\btoy\b', 'play toy broke toys') # соедини toy с ограничениями с обеих сторон
['toy']
Практические упражнения
Давайте немного попрактикуемся. Пришло время открыть вашу консоль. (Варианты ответов здесь)
1. Извлеките никнейм пользователя, имя домена и суффикс из данных email адресов.
emails = """zuck26@facebook.com
page33@google.com
jeff42@amazon.com"""
# требуеый вывод
[('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]
2. Извлеките все слова, начинающиеся с ‘b’ или ‘B’ из данного текста.
text = """Betty bought a bit of butter, But the butter was so bitter, So she bought some better butter, To make the bitter butter better."""
# требуеый вывод
['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'bought', 'better', 'butter', 'bitter', 'butter', 'better']
3. Уберите все символы пунктуации из предложения
sentence = """A, very very; irregular_sentence"""
# требуеый вывод
A very very irregular sentence
4. Очистите следующий твит, чтобы он содержал только одно сообщение пользователя. То есть, удалите все URL, хэштеги, упоминания, пунктуацию, RT и CC.
tweet = '''Good advice! RT @TheNextWeb: What I would do differently if I was learning to code today https://t.co/lbwej0pxOd cc: @garybernhardt #rstats'''
# требуеый вывод
'Good advice What I would do differently if I was learning to code today'
- Извлеките все текстовые фрагменты между тегами с HTML страницы: https://raw.githubusercontent.com/selva86/datasets/master/sample.html
Код для извлечения HTML страницы:
import requests
r = requests.get("https://raw.githubusercontent.com/selva86/datasets/master/sample.html")
r.text # здесь хранится html
# требуеый вывод
['Your Title Here', 'Link Name', 'This is a Header', 'This is a Medium Header', 'This is a new paragraph! ', 'This is a another paragraph!', 'This is a new sentence without a paragraph break, in bold italics.']
Ответы
# 1 задание
>>> pattern = r'(\w+)@([A-Z0-9]+)\.([A-Z]{2,4})'
>>> re.findall(pattern, emails, flags=re.IGNORECASE)
[('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]
Есть больше шаблонов для извлечения домена и суфикса. Это лишь один из них.
# 2 задание
>>> import re
>>> re.findall(r'\bB\w+', text, flags=re.IGNORECASE)
['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'bought', 'better', 'butter', 'bitter', 'butter', 'better']
\b находится слева от ‘B’, значит слово должно начинаться на ‘B’.
Добавьте flags=re.IGNORECASE, что бы шаблон был не чувствительным к регистру.
# 3 задание
>>> import re
>>> " ".join(re.split('[;,\s_]+', sentence))
'A very very irregular sentence'
# 4 задание
>>> import re
>>> def clean_tweet(tweet):
tweet = re.sub('http\S+\s*', '', tweet) # удалит URL
tweet = re.sub('RT|cc', '', tweet) # удалит RT и cc
tweet = re.sub('#\S+', '', tweet) # удалит хештеги
tweet = re.sub('@\S+', '', tweet) # удалит упоминани
tweet = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""), '', tweet) # удалит символы пунктуации
tweet = re.sub('\s+', ' ', tweet) # заменит пробельные символы на 1 пробел
return tweet
>>> print(clean_tweet(tweet))
'Good advice What I would do differently if I was learning to code today'
# 5 задание
>>> re.findall('<.*?>(.*)</.*?>', r.text)
['Your Title Here', 'Link Name', 'This is a Header', 'This is a Medium Header', 'This is a new paragraph! ', 'This is a another paragraph!', 'This is a new sentence without a paragraph break, in bold italics.']
]]>Надеемся, информация была вам полезна. Стояла цель — познакомить вас с примерами регулярных выражений легким и доступным для запоминания способом.
Во время запуска проекта на python вы можете дойти до места, где даже отладчик не сможет найти ошибку. В этот момент вы поймете, что создание лог-файла с записями действий программы, действительно полезно. Как только вы получите рабочую версию программы, нужно понять, что происходит при последующих ее запусках.
Простейший (обратите внимание: не лучший) способ сделать это — использовать много операторов вывода (print) своем коде. Это плохая идея, так как вы получите много вывода в консоли, и, скорее всего, удалите инструкции для вывода, как только исправите ошибку.
Как отслеживать ошибки правильно? Логгирование!
Python имеет встроенную библиотеку logging, отличный инструмент для записи действий программы в файл.
Эта статья для «ведения лога» разбирает множество примеров из базового и более расширенного использования библиотеки.
Пример #1 – Приложение для одного файла
Первый пример — простая программа, которая поможет проиллюстрировать основные возможности модуля logging. Эта программа состоит из одного файла под именем app.py, который содержит один класс:
class FirstClass:
def __init__(self):
self.current_number = 0
def increment_number(self):
self.current_number += 1
def decrement_number(self):
self.current_number -= 1
def clear_number(self):
self.current_number = 0
number = FirstClass()
number.increment_number()
number.increment_number()
print("Текущее значение: %s" % str(number.current_number))
number.clear_number()
print("Текущее значение: %s" % str(number.current_number))
Вы можете запустить эту программу, выполнив:
$ python app.py
Текущее значение: 2
Текущее значение: 0
Эта программа использует два оператора вывода в консоль. Это нормально для того, чтобы программа работала, а переход на логгирование сообщений — лучший долгосрочный подход.
Настройка модуля логгирования
Конфигурация модуля логгирования может показаться сложной, поскольку вы начинаете указывать все больше и больше сведений о том, как вести лог. Следующая последовательность обеспечивает хорошую конфигурацию для:
- установки уровня строгости ведения лога
- указания файла для записи сообщений
- установки формата сообщений
Измените конструктор класса FirstClass, чтобы настроить модуль logging:
def __init__(self):
self.current_number = 0
# Создайте Logger
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.WARNING)
# Создайте обработчик для записи данных в файл
logger_handler = logging.FileHandler('python_logging.log')
logger_handler.setLevel(logging.WARNING)
# Создайте Formatter для форматирования сообщений в логе
logger_formatter = logging.Formatter('%(name)s - %(levelname)s - %(message)s')
# Добавьте Formatter в обработчик
logger_handler.setFormatter(logger_formatter)
# Добавьте обработчик в Logger
self.logger.addHandler(logger_handler)
self.logger.info('Настройка логгирования окончена!')
Не забудьте добавить
import logging
Конструктор настраивает использование модуля logging и заканчивается записью о том, что настройка завершена.
Добавление лог-сообщений
Чтобы добавить сообщения лога, вы можете использовать один из методов модуля логгирования python для вывода в логе:
def increment_number(self):
self.current_number += 1
self.logger.warning('Число увеличивается!')
self.logger.info('Число еще увеличивается!!')
def decrement_number(self):
self.current_number -= 1
def clear_number(self):
self.current_number = 0
self.logger.warning('Очистка значения!')
self.logger.info('Значение еще не очищено!!')
Если вы снова запустите программу, вы все равно увидите тот же вывод консоли.
$ python app.py
Текущее значение: 2
Текущее значение: 0
Уровень серьёзности логгирования
Чтобы узнать, что делает модуль logging, проверьте файл лога, который был создан:
$ cat python_logging.log
__main__ - WARNING - Число увеличивается!
__main__ - WARNING - Число увеличивается!
__main__ - WARNING - Очистка значения!
Интересно, это то, чего вы ждали? Должно было быть еще две записи «Число еще увеличивается!!», но они не отобразились. Почему? Ну, дело в том, что у модуля logging 5 уровней серьезности:
- DEBUG (низший)
- INFO
- WARNING
- ERROR
- CRITICAL (высший)
Наша программа использует настройку по умолчанию (WARNING) для серьезности ведения лога, это означает, что любое сообщение журнала с меньшей степенью серьезности, чем WARNING, не будет отображаться. Следовательно, сообщения INFO так же не отображаются.
Поменяйте следующие строки в __init__():
# Создайте Logger
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.INFO)
# Создайте обработчик для записи данных в файл
logger_handler = logging.FileHandler('python_logging.log')
logger_handler.setLevel(logging.INFO)
Теперь проверьте файл лога, сообщения уровня INFO отображаются:
$ cat python_logging.log
__main__ - WARNING - Число увеличивается!
__main__ - WARNING - Число увеличивается!
__main__ - WARNING - Очистка значения!
__main__ - INFO - Настройка логгирования окончена!
__main__ - WARNING - Число увеличивается!
__main__ - INFO - Число еще увеличивается!!
__main__ - WARNING - Число увеличивается!
__main__ - INFO - Число еще увеличивается!!
__main__ - WARNING - Очистка значения!
__main__ - INFO - Значение еще не очищено!!
Пример #2 – Logging в модуле
Второй пример немного сложнее, так как он обновляет структуру программы для включения пакета с одним модулем:
python_logging
python_logging
__init__.py
first_class.py
app.py
Файл first_class.py содержит класс FirstClass, который был создан в первом примере:
import logging
class FirstClass:
def __init__(self):
self.current_number = 0
# Создайте Logger
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.INFO)
# Создайте обработчик для записи данных в файл
logger_handler = logging.FileHandler('python_logging.log')
logger_handler.setLevel(logging.INFO)
# Создайте Formatter для форматирования сообщений в логе
logger_formatter = logging.Formatter('%(name)s - %(levelname)s - %(message)s')
# Добавьте Formatter в обработчик
logger_handler.setFormatter(logger_formatter)
# Добавте обработчик в Logger
self.logger.addHandler(logger_handler)
self.logger.info('Настройка логгирования окончена!')
def increment_number(self):
self.current_number += 1
self.logger.warning('Число увеличивается!')
self.logger.info('Число еще увеличивается!!')
def decrement_number(self):
self.current_number -= 1
def clear_number(self):
self.current_number = 0
self.logger.warning('Очистка значения!')
self.logger.info('Значение еще не очищено!!')
Чтобы использовать этот модуль, обновите файл app.py в каталоге верхнего уровня и импортируйте класс FirstClass для его использования:
from python_logging.first_class import FirstClass
number = FirstClass()
number.increment_number()
number.increment_number()
print("Текущее значение: %s" % str(number.current_number))
number.clear_number()
print("Текущее значение: %s" % str(number.current_number))
Запустим app.py и проверим файл лога:
$ python app.py
Текущее значение: 2
Текущее значение: 0
$ cat python_logging.log
...
__main__ - WARNING - Очистка значения!
__main__ - INFO - Значение еще не очищено!!
python_logging - INFO - Настройка логгирования окончена!
python_logging.first_class - WARNING - Число увеличивается!
python_logging.first_class - INFO - Число еще увеличивается!!
python_logging.first_class - WARNING - Число увеличивается!
python_logging.first_class - INFO - Число еще увеличивается!!
python_logging.first_class - WARNING - Очистка значения!
python_logging.first_class - INFO - Значение еще не очищено!!
Пример #3: Logging в пакетах
В третьем примере добавлен второй класс в пакет python_logging, чтобы показать, как настроить модуль ведения журнала для всего пакета. Вот структура этого примера:
python_logging
python_logging
__init__.py
first_class.py
second_class.py
app.py
Вот базовая версия файла second_class.py:
class SecondClass:
def __init__(self):
self.enabled = False
def enable_system(self):
self.enabled = True
def disable_system(self):
self.enabled = False
Можно дублировать настройки logger в конструктор этого класса (копия из first_class.py). Это приведет к большому количеству ненужного повторяющегося кода.
Лучше всего переместить настройку logger в файл __init__.py:
from os import path, remove
import logging
import logging.config
from .first_class import FirstClass
from .second_class import SecondClass
# Удалите существующий файл лога, если он есть, чтобы создавать новый файл во время каждого выполнения
if path.isfile("python_logging.log"):
remove("python_logging.log")
# Создайте Logger
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# Создайте обработчик для записи данных в файл
logger_handler = logging.FileHandler('python_logging.log')
logger_handler.setLevel(logging.INFO)
# Создайте Formatter для форматирования сообщений в логе
logger_formatter = logging.Formatter('%(name)s - %(levelname)s - %(message)s')
# Добавьте Formatter в обработчик
logger_handler.setFormatter(logger_formatter)
# Добавте обработчик в Logger
logger.addHandler(logger_handler)
logger.info('Настройка логгирования окончена!')
В зависимости от типа создаваемой программы вам может быть полезно удалить любые существующие файлы лога до записи любых новых сообщений во время выполнения этой программы. Один из вариантов, если вы хотите сохранить текущий лог приложения, воспользоваться RotatingFileHandler из модуля Logging.
Теперь, когда настройка модуля логгирования выполняется в __init__.py, файл second_class.py можно значительно упростить и не беспокоиться о его настройке:
import logging
class SecondClass(object):
def __init__(self):
self.enabled = False
self.logger = logging.getLogger(__name__)
def enable_system(self):
self.enabled = True
self.logger.warning('Включение системы!')
self.logger.info('Система все еще включается!!')
def disable_system(self):
self.enabled = False
self.logger.warning('Выключение системы!')
self.logger.info('Система все еще выключается!!')
Так же нужно упростить def __init__() в first_class.py:
def __init__(self):
self.current_number = 0
self.logger = logging.getLogger(__name__)
Наконец, обновления в __init__.py приводят к необходимости следующих обновлений в app.py:
from python_logging import FirstClass, SecondClass
number = FirstClass()
number.increment_number()
number.increment_number()
print("Текущее значение: %s" % str(number.current_number))
number.clear_number()
print("Текущее значение: %s" % str(number.current_number))
system = SecondClass()
system.enable_system()
system.disable_system()
print("Текущее состояние системы: %s" % str(system.enabled))
Попробуйте снова запустить программу и посмотрите файл лога:
$ cat python_logging.log
python_logging - INFO - Настройка логгирования окончена!
python_logging.first_class - WARNING - Число увеличивается!
python_logging.first_class - INFO - Число еще увеличивается!!
python_logging.first_class - WARNING - Число увеличивается!
python_logging.first_class - INFO - Число еще увеличивается!!
python_logging.first_class - WARNING - Очистка значения!
python_logging.first_class - INFO - Значение еще не очищено!!
python_logging.second_class - WARNING - Включение системы!
python_logging.second_class - INFO - Система все еще включается!!
python_logging.second_class - WARNING - Выключение системы!
python_logging.second_class - INFO - Система все еще выключается!!
Обратите внимание, как выводятся имена модулей! Это очень удобная функция, позволяющая быстро определить, где происходят конкретные операции.
Пример #4: Logging в пакетах с JSON
Четвертый (и последний) пример расширяет возможности логгирования, добавив входной файл (JSON) для настройки логгера.
Первое изменение для этого примера в __init__.py, чтобы изменить настройки логгера для использования входного файла JSON:
from os import path, remove
import logging
import logging.config
import json
from .first_class import FirstClass
from .second_class import SecondClass
# Удалите существующий файл лога, если он есть, чтобы создавать новый файл во время каждого выполнения
if path.isfile("python_logging.log"):
remove("python_logging.log")
with open("python_logging_configuration.json", 'r') as logging_configuration_file:
config_dict = json.load(logging_configuration_file)
logging.config.dictConfig(config_dict)
# Запись о том, что logger настроен
logger = logging.getLogger(__name__)
logger.info('Настройка логгирования окончена!')
Теперь, когда у нас есть код для обработки входного файла, давайте определим входной файл (python_logging_configuration.json). Обязательно добавьте этот файл в папку верхнего уровня, чтобы он мог быть легко идентифицирован интерпретатором python. Вы должны запустить эту программу из папки верхнего уровня, чтобы сделать входной файл JSON доступным интерпретатору python, поскольку он находится в текущем / рабочем каталоге.
Вот файл конфигурации:
{
"version": 1,
"disable_existing_loggers": false,
"formatters": {
"simple": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
}
},
"handlers": {
"file_handler": {
"class": "logging.FileHandler",
"level": "DEBUG",
"formatter": "simple",
"filename": "python_logging.log",
"encoding": "utf8"
}
},
"root": {
"level": "DEBUG",
"handlers": ["file_handler"]
}
}
Запустите программу еще раз и посмотрите файл лога:
$ cat python_logging.log
2019-01-05 20:13:40,636 - python_logging - INFO - Настройка логгирования окончена!
2019-01-05 20:13:40,636 - python_logging.first_class - WARNING - Число увеличивается!
2019-01-05 20:13:40,636 - python_logging.first_class - INFO - Число еще увеличивается!!
2019-01-05 20:13:40,636 - python_logging.first_class - WARNING - Число увеличивается!
2019-01-05 20:13:40,636 - python_logging.first_class - INFO - Число еще увеличивается!!
2019-01-05 20:13:40,636 - python_logging.first_class - WARNING - Очистка значения!
2019-01-05 20:13:40,636 - python_logging.first_class - INFO - Значение еще не очищено!!
2019-01-05 20:13:40,636 - python_logging.second_class - WARNING - Включение системы!
2019-01-05 20:13:40,636 - python_logging.second_class - INFO - Система все еще включается!!
2019-01-05 20:13:40,636 - python_logging.second_class - WARNING - Выключение системы!
2019-01-05 20:13:40,636 - python_logging.second_class - INFO - Система все еще выключается!!
Файл лога почти такой же, но строка даты и времени добавлена в каждое сообщение. Этот формат сообщений логгирования очень удобный: дата / время — package.module — сообщение журнала
Если Вам не нравится работать с JSON, входной файл также может быть определен как файл YAML. Вот пример: Good Logging Practice in Python
]]>Идея перехода от операторов вывода к фактическому протоколированию сообщений стала простой благодаря модулю logging, который встроен в python. Модуль logging требует некоторой настройки, но это небольшая плата за такой простой в использовании модуль.
Наличие файла лога для программы, особенно приложений с командной строкой, дает отличный способ понять, что делает программа.
Python — объектно-ориентированный язык с начала его существования. Поэтому, создание и использование классов и объектов в Python просто и легко. Эта статья поможет разобраться на примерах в области поддержки объектно-ориентированного программирования Python. Если у вас нет опыта работы с объектно-ориентированным программированием (OOП), ознакомьтесь с вводным курсом или учебным пособием, чтобы понять основные понятия.
Создание классов
Оператор class создает новое определение класса. Имя класса сразу следует за ключевым словом class, после которого ставиться двоеточие:
class ClassName:
"""Необязательная строка документации класса"""
class_suite- У класса есть строка документации, к которой можно получить доступ через
ClassName.__doc__. class_suiteсостоит из частей класса, атрибутов данных и функции.
Пример создания класса на Python:
class Employee:
"""Базовый класс для всех сотрудников"""
emp_count = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.emp_count += 1
def display_count(self):
print('Всего сотрудников: %d' % Employee.empCount)
def display_employee(self):
print('Имя: {}. Зарплата: {}'.format(self.name, self.salary))
- Переменная
emp_count— переменная класса, значение которой разделяется между экземплярами этого класса. Получить доступ к этой переменной можно черезEmployee.emp_countиз класса или за его пределами. - Первый метод
__init__()— специальный метод, который называют конструктором класса или методом инициализации. Его вызывает Python при создании нового экземпляра этого класса. - Объявляйте другие методы класса, как обычные функции, за исключением того, что первый аргумент для каждого метода
self. Python добавляет аргументselfв список для вас; и тогда вам не нужно включать его при вызове этих методов.
Создание экземпляров класса
Чтобы создать экземпляры классов, нужно вызвать класс с использованием его имени и передать аргументы, которые принимает метод __init__.
# Это создаст первый объект класса Employee
emp1 = Employee("Андрей", 2000)
# Это создаст второй объект класса Employee
emp2 = Employee("Мария", 5000)
Доступ к атрибутам
Получите доступ к атрибутам класса, используя оператор . после объекта класса. Доступ к классу можно получить используя имя переменой класса:
emp1.display_employee()
emp2.display_employee()
print("Всего сотрудников: %d" % Employee.emp_count)
Теперь, систематизируем все.
class Employee:
"""Базовый класс для всех сотрудников"""
emp_count = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.emp_count += 1
def display_count(self):
print('Всего сотрудников: %d' % Employee.emp_count)
def display_employee(self):
print('Имя: {}. Зарплата: {}'.format(self.name, self.salary))
# Это создаст первый объект класса Employee
emp1 = Employee("Андрей", 2000)
# Это создаст второй объект класса Employee
emp2 = Employee("Мария", 5000)
emp1.display_employee()
emp2.display_employee()
print("Всего сотрудников: %d" % Employee.emp_count)
При выполнении этого кода, мы получаем следующий результат:
Имя: Андрей. Зарплата: 2000
Имя: Мария. Зарплата: 5000
Всего сотрудников: 2
Вы можете добавлять, удалять или изменять атрибуты классов и объектов в любой момент.
emp1.age = 7 # Добавит атрибут 'age'
emp1.age = 8 # Изменит атрибут 'age'
del emp1.age # Удалит атрибут 'age'
Вместо использования привычных операторов для доступа к атрибутам вы можете использовать эти функции:
getattr(obj, name [, default])— для доступа к атрибуту объекта.hasattr(obj, name)— проверить, есть ли вobjатрибутname.setattr(obj, name, value)— задать атрибут. Если атрибут не существует, он будет создан.delattr(obj, name)— удалить атрибут.
hasattr(emp1, 'age') # возвращает true если атрибут 'age' существует
getattr(emp1, 'age') # возвращает значение атрибута 'age'
setattr(emp1, 'age', 8) #устанавливает атрибут 'age' на 8
delattr(empl, 'age') # удаляет атрибут 'age'
Встроенные атрибуты класса
Каждый класс Python хранит встроенные атрибуты, и предоставляет к ним доступ через оператор ., как и любой другой атрибут:
__dict__— словарь, содержащий пространство имен класса.__doc__— строка документации класса.Noneесли, документация отсутствует.__name__— имя класса.__module__— имя модуля, в котором определяется класс. Этот атрибут__main__в интерактивном режиме.__bases__— могут быть пустые tuple, содержащие базовые классы, в порядке их появления в списке базового класса.
Для вышеуказанного класса давайте попробуем получить доступ ко всем этим атрибутам:
class Employee:
"""Базовый класс для всех сотрудников"""
emp_count = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def display_count(self):
print('Всего сотрудников: %d' % Employee.empCount)
def display_employee(self):
print('Имя: {}. Зарплата: {}'.format(self.name, self.salary))
print("Employee.__doc__:", Employee.__doc__)
print("Employee.__name__:", Employee.__name__)
print("Employee.__module__:", Employee.__module__)
print("Employee.__bases__:", Employee.__bases__)
print("Employee.__dict__:", Employee.__dict__)
Когда этот код выполняется, он возвращает такой результат:
Employee.__doc__: Базовый класс для всех сотрудников
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: (<class 'object'>,)
Employee.__dict__: {'__module__': '__main__', '__doc__': 'Базовый класс для всех сотрудников', 'emp_count': 0, '__init__': <function Employee.__init__ at 0x03C7D7C8>, 'display_count': <function Employee.display_count at 0x03FA6AE0>, 'display_employee': <function Employee.display_employee at 0x03FA6B28>, '__dict__': <attribute '__dict__' of 'Employee' objects>, '__weakref__': <attribute '__weakref__' of 'Employee' objects>}
Удаление объектов (сбор мусора)
Python автоматически удаляет ненужные объекты (встроенные типы или экземпляры классов), чтобы освободить пространство памяти. С помощью процесса ‘Garbage Collection’ Python периодически восстанавливает блоки памяти, которые больше не используются.
Сборщик мусора Python запускается во время выполнения программы и тогда, когда количество ссылок на объект достигает нуля. С изменением количества обращений к нему, меняется количество ссылок.
Когда объект присваивают новой переменной или добавляют в контейнер (список, кортеж, словарь), количество ссылок объекта увеличивается. Количество ссылок на объект уменьшается, когда он удаляется с помощью del, или его ссылка выходит за пределы видимости. Когда количество ссылок достигает нуля, Python автоматически собирает его.
a = 40 # создали объект <40>
b = a # увеличивает количество ссылок <40>
c = [b] # увеличивает количество ссылок <40>
del a # уменьшает количество ссылок <40>
b = 100 # уменьшает количество ссылок <40>
c[0] = -1 # уменьшает количество ссылок <40>
Обычно вы не заметите, когда сборщик мусора уничтожает экземпляр и очищает свое пространство. Но классом можно реализовать специальный метод __del__(), называемый деструктором. Он вызывается, перед уничтожением экземпляра. Этот метод может использоваться для очистки любых ресурсов памяти.
Пример работы __del__()
Деструктор __del__() выводит имя класса того экземпляра, который должен быть уничтожен:
class Point:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print('{} уничтожен'.format(class_name))
pt1 = Point()
pt2 = pt1
pt3 = pt1
print(id(pt1), id(pt2), id(pt3)) # выведите id объектов
del pt1
del pt2
del pt3
Когда вышеуказанный код выполняется и выводит следующее:
17692784 17692784 17692784
Point уничтоженВ идеале вы должны создавать свои классы в отдельном модуле. Затем импортировать их в основной модуль программы с помощью
import SomeClass.
Наследование класса в python
Наследование — это процесс, когда один класс наследует атрибуты и методы другого. Класс, чьи свойства и методы наследуются, называют Родителем или Суперклассом. А класс, свойства которого наследуются — класс-потомок или Подкласс.
Вместо того, чтобы начинать с нуля, вы можете создать класс, на основе уже существующего. Укажите родительский класс в круглых скобках после имени нового класса.
Класс наследник наследует атрибуты своего родительского класса. Вы можете использовать эти атрибуты так, как будто они определены в классе наследнике. Он может переопределять элементы данных и методы родителя.
Синтаксис наследования класса
Классы наследники объявляются так, как и родительские классы. Только, список наследуемых классов, указан после имени класса.
class SubClassName(ParentClass1[, ParentClass2, ...]):
"""Необязательная строка документации класса"""
class_suiteПример наследования класса в Python
class Parent: # объявляем родительский класс
parent_attr = 100
def __init__(self):
print('Вызов родительского конструктора')
def parent_method(self):
print('Вызов родительского метода')
def set_attr(self, attr):
Parent.parent_attr = attr
def get_attr(self):
print('Атрибут родителя: {}'.format(Parent.parent_attr))
class Child(Parent): # объявляем класс наследник
def __init__(self):
print('Вызов конструктора класса наследника')
def child_method(self):
print('Вызов метода класса наследника')
c = Child() # экземпляр класса Child
c.child_method() # вызов метода child_method
c.parent_method() # вызов родительского метода parent_method
c.set_attr(200) # еще раз вызов родительского метода
c.get_attr() # снова вызов родительского метода
Когда этот код выполняется, он выводит следующий результат:
Вызов конструктора класса наследника
Вызов метода класса наследника
Вызов родительского метода
Атрибут родителя: 200Аналогичным образом вы можете управлять классом с помощью нескольких родительских классов:
class A: # объявите класс A
...
class B: # объявите класс B
...
class C(A, B): # C наследуется от A и B
...Вы можете использовать функции issubclass() или isinstance() для проверки отношений двух классов и экземпляров.
- Логическая функция
issubclass(sub, sup)возвращает значениеTrue, если данный подклассsubдействительно является подклассомsup. - Логическая функция
isinstance(obj, Class)возвращаетTrue, еслиobjявляется экземпляром классаClassили является экземпляром подкласса класса.
Переопределение методов
Вы всегда можете переопределить методы родительского класса. В вашем подклассе могут понадобиться специальные функции. Это одна из причин переопределения родительских методов.
Пример переопределения методов:
class Parent: # объявите родительский класс
def my_method(self):
print('Вызов родительского метода')
class Child(Parent): # объявите класс наследник
def my_method(self):
print('Вызов метода наследника')
c = Child() # экземпляр класса Child
c.my_method() # метод переопределен классом наследником
Когда этот код выполняется, он производит следующий результат:
Вызов метода наследникаПопулярные базовые методы
В данной таблице перечислены некоторые общие функции. Вы можете переопределить их в своих собственных классах.
| № | Метод, описание и пример вызова |
|---|---|
| 1 | __init__(self [, args...]) — конструктор (с любыми необязательными аргументами)obj = className(args) |
| 2 | __del__(self) — деструктор, удаляет объектdel obj |
| 3 | __repr__(self) — программное представление объектаrepr(obj) |
| 4 | __str__(self) — строковое представление объектаstr(obj) |
Пример использования __add__
Предположим, вы создали класс Vector для представления двумерных векторов. Что происходит, когда вы используете дополнительный оператор для их добавления? Скорее всего, Python будет против.
Однако вы можете определить метод __add__ в своем классе для добавления векторов и оператор + будет вести себя так как нужно.
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector ({}, {})'.format(self.a, self.b)
def __add__(self, other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2, 10)
v2 = Vector(5, -2)
print(v1 + v2)
При выполнении этого кода, мы получим:
Vector(7, 8)Приватные методы и атрибуты
Атрибуты класса могут быть не видимыми вне определения класса. Вам нужно указать атрибуты с __ вначале, и эти атрибуты не будут вызваны вне класса.
Пример приватного атрибута:
class JustCounter:
__secret_count = 0
def count(self):
self.__secret_count += 1
print(self.__secret_count)
counter = JustCounter()
counter.count()
counter.count()
print(counter.__secret_count)
При выполнении данного кода, имеем следующий результат:
1
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print(counter.__secret_count)
AttributeError: 'JustCounter' object has no attribute '__secret_count'Вы можете получить доступ к таким атрибутам, так object._className__attrName. Если вы замените свою последнюю строку следующим образом, то она будет работать.
...
print(counter._JustCounter__secret_count)
При выполнении кода, получаем результат:
1
2
2