При использовании SQLAlchemy ORM взаимодействие с базой данных происходит через объект Session. Он также захватывает соединение с базой данных и транзакции. Транзакция неявно стартует как только Session начинает общаться с базой данных и остается открытой до тех пор, пока Session не коммитится, откатывается или закрывается.
Для создания объекта session можно использовать класс Session из sqlalchemy.orm.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
Создавать объект Session нужно будет каждый раз при взаимодействии с базой.
Конструктор Session принимает определенное количество аргументов, которые определяют режим его работы. Если создать сессию таким способом, то в дальнейшем конструктор Session нужно будет вызывать с одним и тем же набором параметров.
Чтобы упростить этот процесс, SQLAlchemy предоставляет класс sessionmaker, который создает класс Session с аргументами для конструктора по умолчанию.
from sqlalchemy.orm import Session, sessionmaker
session = sessionmaker(bind=engine)
Нужно просто вызвать sessionmaker один раз в глобальной области видимости.
Получив доступ к этому классу Session раз, можно создавать его экземпляры любое количество раз, не передавая параметры.
session = Session()Обратите внимание на то, что объект Session не сразу устанавливает соединение с базой данных. Это происходит лишь при первом запросе.
Вставка(добавление) данных
Для создания новой записи с помощью SQLAlchemy ORM нужно выполнить следующие шаги:
- Создать объект
- Добавить его в сессию
- Сохранить сессию
Создадим два новых объекта Customer:
c1 = Customer(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com'
)
c2 = Customer(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com'
)
print(c1.first_name, c2.last_name)
session.add(c1)
session.add(c2)
print(session.new)
session.commit()
Первый вывод: Dmitriy Golyshkin.
Два объекта созданы. Получить доступ к их атрибутам можно с помощью оператора точки (.).
Дальше в сессию добавляются объекты.
session.add(c1)
session.add(c2)Но добавление объектов не влияет на запись в базу, а лишь готовит объекты к сохранению в следующем коммите. Проверить это можно, получив первичные ключи объектов.
Значение атрибута id обоих объектов — None. Это значит, что они еще не сохранены в базе данных.
Вместо добавления одного объекта за раз можно использовать метод add_all(). Он принимает список объектов, которые будут добавлены в сессию.
session.add_all([c1, c2])Добавление объекта в сессию несколько раз не приводит к ошибкам. В любой момент на имеющиеся объекты можно посмотреть с помощью session.new.
IdentitySet([<__main__.Customer object at 0x000001BD25928C40>, <__main__.Customer object at 0x000001BD25928C70>])Наконец, для сохранения данных используется метод commit():
session.commit()После сохранения транзакции ресурсы соединения, на которые ссылается объект Session, возвращаются в пул соединений. Последующие операции будут выполняться в новой транзакции.
Сейчас таблица Customer выглядит вот так:
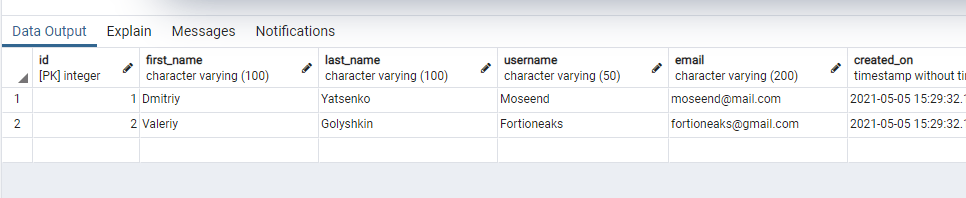
Пока что покупатели ничего не приобрели. Поэтому c1.orders и c2.orders вернут пустой список.
[] []Добавим еще потребителей в таблицу customers:
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
c3 = Customer(
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
)
c4 = Customer(
first_name = "Vladimir",
last_name = "Belousov",
username = "Andescols",
email = "andescols@mail.com",
)
c5 = Customer(
first_name = "Tatyana",
last_name = "Khakimova",
username = "Caltin1962",
email = "caltin1962@mail.com",
)
c6 = Customer(
first_name = "Pavel",
last_name = "Arnautov",
username = "Lablen",
email = "lablen@mail.com",
)
session.add_all([c3, c4, c5, c6])
session.commit()
Также добавим продукты в таблицу items:
i1 = Item(name = 'Chair', cost_price = 9.21, selling_price = 10.81, quantity = 5)
i2 = Item(name = 'Pen', cost_price = 3.45, selling_price = 4.51, quantity = 3)
i3 = Item(name = 'Headphone', cost_price = 15.52, selling_price = 16.81, quantity = 50)
i4 = Item(name = 'Travel Bag', cost_price = 20.1, selling_price = 24.21, quantity = 50)
i5 = Item(name = 'Keyboard', cost_price = 20.1, selling_price = 22.11, quantity = 50)
i6 = Item(name = 'Monitor', cost_price = 200.14, selling_price = 212.89, quantity = 50)
i7 = Item(name = 'Watch', cost_price = 100.58, selling_price = 104.41, quantity = 50)
i8 = Item(name = 'Water Bottle', cost_price = 20.89, selling_price = 25, quantity = 50)
session.add_all([i1, i2, i3, i4, i5, i6, i7, i8])
session.commit()
Создадим заказы:
o1 = Order(customer = c1)
o2 = Order(customer = c1)
line_item1 = OrderLine(order = o1, item = i1, quantity = 3)
line_item2 = OrderLine(order = o1, item = i2, quantity = 2)
line_item3 = OrderLine(order = o2, item = i1, quantity = 1)
line_item3 = OrderLine(order = o2, item = i2, quantity = 4)
session.add_all([o1, o2])
session.new
session.commit()
В данном случае в сессию добавляются только объекты Order (o1 и o2). Order и OrderLine связаны отношением один-ко-многим. Добавление объекта Order в сессию неявно добавляет также и объекты OrderLine. Но даже если добавить последние вручную, ошибки не будет.
Вместо передачи объекта Order при создании экземпляра OrderLine можно сделать следующее:
o3 = Order(customer = c1)
orderline1 = OrderLine(item = i1, quantity = 5)
orderline2 = OrderLine(item = i2, quantity = 10)
o3.line_items.append(orderline1)
o3.line_items.append(orderline2)
session.add_all([o3,])
session.new
session.commit()
После коммита таблицы orders и order_lines будут выглядеть вот так:
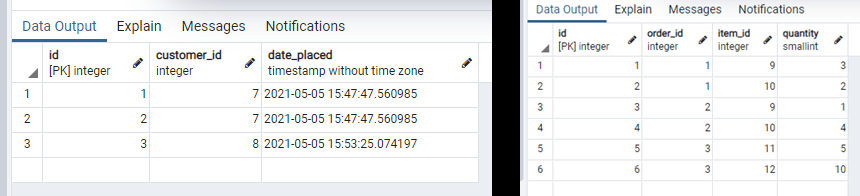
Если сейчас получить доступ к атрибуту orders объекта Customer, то вернется не-пустой список.
[<Order:1>, <Order:2>]С другой стороны отношения можно получить доступ к объекту Customer, которому заказ принадлежит через атрибут customer объекта Order — o1.customer.
Сейчас у покупателя c1 три заказа. Чтобы посмотреть все пункты в заказе нужно использовать атрибут line_items объекта Order.
c1.orders[0].line_items, c1.orders[1].line_items
([<OrderLine:1>, <OrderLine:2>], [<OrderLine:3>, <OrderLine:4>])Для получения элемента заказа используйте item.
for ol in c1.orders[0].line_items:
ol.id, ol.item, ol.quantity
print('-------')
for ol in c1.orders[1].line_items:
ol.id, ol.item, ol.quantity
Вывод:
(1, <Item:1-Chair>, 3)
(2, <Item:2-Pen>, 2)
-------
(3, <Item:1-Chair>, 1)
(4, <Item:2-Pen>, 4)
Все это возможно благодаря отношениям relationship() моделей.
Получение данных
Чтобы сделать запрос в базу данных используется метод query() объекта session. Он возвращает объект типа sqlalchemy.orm.query.Query, который называется просто Query. Он представляет собой инструкцию SELECT, которая будет использована для запроса в базу данных. В следующей таблице перечислены распространенные методы класса Query.
| Метод | Описание |
|---|---|
| all() | Возвращает результат запроса (объект Query) в виде списка |
| count() | Возвращает общее количество записей в запросе |
| first() | Возвращает первый результат из запроса или None, если записей нет |
| scalar() | Возвращает первую колонку первой записи или None, если результат пустой. Если записей несколько, то бросает исключение MultipleResultsFound |
| one | Возвращает одну запись. Если их несколько, бросает исключение MutlipleResultsFound. Если данных нет, бросает NoResultFound |
| get(pk) | Возвращает объект по первичному ключу (pk) или None, если объект не был найден |
| filter(*criterion) | Возвращает экземпляр Query после применения оператора WHERE |
| limit(limit) | Возвращает экземпляр Query после применения оператора LIMIT |
| offset(offset) | Возвращает экземпляр Query после применения оператора OFFSET |
| order_by(*criterion) | Возвращает экземпляр Query после применения оператора ORDER BY |
| join(*props, **kwargs) | Возвращает экземпляр Query после создания SQL INNER JOIN |
| outerjoin(*props, **kwargs) | Возвращает экземпляр Query после создания SQL LEFT OUTER JOIN |
| group_by(*criterion) | Возвращает экземпляр Query после добавления оператора GROUP BY к запросу |
| having(criterion) | Возвращает экземпляр Query после добавления оператора HAVING |
Метод all()
В базовой форме метод query() принимает в качестве аргументов один или несколько классов модели или колонок. Следующий код вернет все записи из таблицы customers.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
print(session.query(Customer).all())
[<Customer:1-Moseend>,
<Customer:2-Fortioneaks>,
<Customer:3-Antence73>,
<Customer:4-Andescols>,
<Customer:5-Caltin1962>,
<Customer:6-Lablen>]Так же можно получить записи из таблиц items и orders.
Чтобы получить сырой SQL, который используется для выполнения запроса в базу данных, примените sqlalchemy.orm.query.Query следующим образом: print(session.query(Customer)).
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customersВызов метода all() на большом объекте результата не очень эффективен. Вместо этого стоит использовать цикл for для перебора по объекту Query:
q = session.query(Customer)
for c in q:
print(c.id, c.first_name)
Предыдущие запросы вернули данные из всех колонок таблицы. Предотвратить это можно, передав названия колонок явно в метод query():
print(session.query(Customer.id, Customer.first_name).all())
Вывод:
[(1, 'Dmitriy'),
(2, 'Valeriy'),
(3, 'Vadim'),
(4, 'Vladimir'),
(5, 'Tatyana'),
(6, 'Pavel')]Обратите внимание на то, что каждый элемент списка — это кортеж, а не экземпляр модели.
Метод count()
count() возвращает количество элементов в результате.
session.query(Item).count()
# Вывод - 8
Метод first()
first() возвращает первый результат запроса или None, если последний не вернул данных.
session.query(Order).first()
# Вывод - Order:1
Метод get()
get() возвращает экземпляр с соответствующим первичным ключом или None, если такой объект не был найден.
session.query(Customer).get(1)
# Вывод - Customer:1-Moseend
Метод filter()
Этот метод позволяет отфильтровать результаты, добавив оператор WHERE. Он принимает колонку, оператор и значение. Например:
session.query(Customer).filter(Customer.first_name == 'Vadim').all()Этот запрос вернет всех покупателей, чье имя — Vadim. А вот SQL-эквивалент этого запроса:
print(session.query(Customer).filter(Customer.first_name == 'Vadim'))
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
WHERE
customers.first_name = %(first_name_1)sСтрока %(first_name_1)s в операторе WHERE — это заполнитель, который будет заменен на реальное значение (Vadim) при выполнении запроса.
Можно передать несколько фильтров в метод filter() и они будут объединены с помощью оператора AND. Например:
session.query(Customer).filter(Customer.id <= 5, Customer.last_name == "Arnautov").all()
Этот запрос вернет всех покупателей, чей первичный ключ меньше или равен 5, а фамилия начинается с "Ar".
session.query(Customer).filter(Customer.id <= 5, Customer.last_name.like("Ar%")).all()
Еще один способ комбинировать условия — союзы (and_(), or_() и not_()). Некоторые примеры:
# все клиенты с именем Vadim и Tatyana
session.query(Customer).filter(or_(
Customer.first_name == 'Vadim',
Customer.first_name == 'Tatyana'
)).all()
# найти всех с именем и Pavel фамилией НЕ Yatsenko
session.query(Customer).filter(and_(
Customer.first_name == 'Pavel',
not_(
Customer.last_name == 'Yatsenko',
)
)).all()
Следующий перечень демонстрирует, как использовать распространенные операторы сравнения с методом filter().
IS NULL
session.query(Order).filter(Order.date_placed == None).all()IS NOT NULL
session.query(Order).filter(Order.date_placed != None).all()
IN
session.query(Customer).filter(Customer.first_name.in_(['Pavel', 'Vadim'])).all()NOT INT
session.query(Customer).filter(Customer.first_name.notin_(['Pavel', 'Vadim'])).all()BETWEEN
session.query(Item).filter(Item.cost_price.between(10, 50)).all()NOT BETWEEN
session.query(Item).filter(not_(Item.cost_price.between(10, 50))).all()
LIKE
session.query(Item).filter(Item.name.like("%r")).all()
Метод like() выполняет поиск с учетом регистра. Для поиска совпадений без учета регистра используйте ilike().
session.query(Item).filter(Item.name.ilike("w%")).all()
NOT LIKE
session.query(Item).filter(not_(Item.name.like("W%"))).all()
Метод limit()
Метод limit() добавляет оператор LIMIT к запросу. Он принимает количество записей, которые нужно вернуть.
session.query(Customer).limit(2).all()
session.query(Customer).filter(Customer.username.ilike("%Andes")).limit(2).all()
SQL-эквивалент:
SELECT
customers. id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s Метод offset()
Метод offset() добавляет оператор OFFSET к запросу. Он принимает в качестве аргумента значение смещения. Часто используется с оператором limit().
session.query(Customer).limit(2).offset(2).all()
SQL-эквивалент:
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_addrees,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s OFFSET %(param_2)sМетод order_by()
Метод order_by() используется для сортировки результата с помощью оператора ORDER BY. Он принимает названия колонок, по которым необходимо сортировать результат. По умолчанию сортирует по возрастанию.
session.query(Item).filter(Item.name.ilike("wa%")).all()
session.query(Item).filter(Item.name.ilike("wa%")).order_by(Item.cost_price).all()
Чтобы сортировать по убыванию используйте функцию desc():
from sqlalchemy import desc
session.query(Item).filter(Item.name.ilike("wa%")).order_by(desc(Item.cost_price)).all()
Метод join()
Метод join() используется для создания SQL INNER JOIN. Он принимает название таблицы, с которой нужно выполнить SQL JOIN.
Используем join(), чтобы найти всех покупателей, у которых как минимум один заказ.
session.query(Customer).join(Order).all()
SQL-эквивалент:
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
JOIN orders ON customers.id = orders.customer_id
Этот оператор часто используется для получения данных из одной или нескольких таблиц в одном запросе. Например:
session.query(Customer.id, Customer.username, Order.id).join(Order).all()
Можно создать SQL JOIN для более чем двух таблиц, объединив несколько методов join() следующим образом:
session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Вот еще один пример, который использует 3 объединения для нахождения всех пунктов в первом заказе Dmitriy Yatsenko.
session.query(
Customer.first_name,
Item.name,
Item.selling_price,
OrderLine.quantity
).join(Order).join(OrderLine).join(Item).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
Order.id == 1,
).all()
Метод outerjoin()
Метод outerjoin() работает как join(), но создает LEFT OUTER JOIN.
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order).all()
В этом запросе левой таблицей является customers. Это значит, что он вернет все записи из customers и только те, которые соответствуют условию, из orders.
Создать FULL OUTER JOIN можно, передав в метод full=True. Например:
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order, full=True).all()
Метод group_by()
Результаты группируются с помощью group_by(). Этот метод принимает одну или несколько колонок и группирует записи в соответствии со значениями в колонке.
Следующий запрос использует join() и group_by() для подсчета количества заказов, сделанных Dmitriy Yatsenko.
from sqlalchemy import func
session.query(func.count(Customer.id)).join(Order).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
).group_by(Customer.id).scalar()
Метод having()
Чтобы отфильтровать результаты на основе значений, которые возвращают агрегирующие функции, используется метод having(), добавляющий оператор HAVING к инструкции SELECT. По аналогии с where() он принимает условие.
session.query(
func.count("*").label('username_count'),
Customer.town
).group_by(Customer.username).having(func.count("*") > 2).all()
Работа с дубликатами
Для работы с повторяющимися записями используется параметр DISTINCT. Его можно добавить к SELECT с помощью метода distinct(). Например:
from sqlalchemy import distinct
session.query(Customer.first_name).filter(Customer.id < 10).all()
session.query(Customer.first_name).filter(Customer.id < 10).distinct().all()
session.query(
func.count(distinct(Customer.first_name)),
func.count(Customer.first_name)
).all()
Приведение
Приведение (конвертация) данных от одного типа к другому — распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import cast, Date, distinct, union
session.query(
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
).all()
Объединения
Для объединения запросов используется метод union() объекта Query. Он принимает один или несколько запросов. Например:
s1 = session.query(Item.id, Item.name).filter(Item.name.like("Wa%"))
s2 = session.query(Item.id, Item.name).filter(Item.name.like("%e%"))
s1.union(s2).all()
[(2, 'Pen'),
(4, 'Travel Bag'),
(3, 'Headphone'),
(5, 'Keyboard'),
(7, 'Watch'),
(8, 'Water Bottle')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения используйте union_all().
s1.union_all(s2).all()Обновление данных
Для обновления объекта просто установите новое значение атрибуту, добавьте объект в сессию и сохраните ее.
i = session.query(Item).get(8)
i.selling_price = 25.91
session.add(i)
session.commit()
Таким образом можно обновлять только один объект за раз. Для обновления нескольких записей за раз используйте метод update() объекта Query. Он возвращает общее количество обновленных записей. Например:
session.query(Item).filter(
Item.name.ilike("W%")
).update({"quantity": 60}, synchronize_session='fetch')
session.commit()
Удаление данных
Для удаления объекта используйте метод delete() объекта сессии. Он принимает объект и отмечает его как удаленный для следующего коммита.
i = session.query(Item).filter(Item.name == 'Monitor').one()
session.delete(i)
session.commit()
<Item:6-Monitor>Этот коммит удаляет Monitor из таблицы items.
Для удаления нескольких записей за раз используйте метод delete() объекта Query.
session.query(Item).filter(
Item.name.ilike("W%")
).delete(synchronize_session='fetch')
session.commit()
Этот коммит удаляет все элементы, название которых начинается с W.
Сырые(raw) запросы
ORM предоставляет возможность использовать сырые SQL-запросы с помощью функции text(). Например:
from sqlalchemy import text
session.query(Customer).filter(text("first_name = 'Vladimir'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).order_by(text("first_name, id desc")).all()
Транзакции
Транзакция — это способ выполнения набора SQL-инструкций так, что выполняются или все вместе, или ни одна из них. Если хотя бы одна инструкция из транзакции была провалена, база данных возвращается к предыдущему состоянию.
В базе данных есть два заказа, в процессе отгрузки заказа есть такие этапы:
- В колонке
date_placedтаблицыordersустанавливается дата отгрузки. - Количество заказанных товаров вычитается из
items.
Оба действия должны быть выполнены как одно, чтобы убедиться, что данные в таблицах корректны.
В следующем коде определяем метод dispatch_order(), который принимает order_id в качестве аргумента и выполняет описанные выше задачи в одной транзакции.
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
order = session.query(Order).get(order_id)
if not order:
raise ValueError("Недействительный order_id: {}.".format(order_id))
try:
for i in order.line_items:
i.item.quantity = i.item.quantity - i.quantity
order.date_placed = datetime.now()
session.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
print("Возврат назад...")
session.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
В первом заказе 3 стула и 2 ручки. dispatch_order() с идентификатором заказа 1 даст следующий вывод:
Транзакция завершена.ORM построен на базе SQLAlchemy Core, поэтому имеющиеся знания должны пригодиться.
ORM позволяет быть более продуктивным, но также добавляет дополнительную сложность в запросы. Однако для большинства приложений преимущества перевешивают проигрыш в производительности.
Прежде чем двигаться дальше удалите все таблицы из sqlalchemy-tuts с помощью следующей команды: metadata.drop_all(engine).
Создание моделей
Модель — это класс Python, соответствующий таблице в базе данных, а его свойства — это колонки.
Чтобы класс был валидной моделью, нужно соответствовать следующим требованиям:
- Наследоваться от декларативного базового класса с помощью вызова функции
declarative_base(). - Объявить имя таблицы с помощью атрибута
__tablename__. - Объявить как минимум одну колонку, которая должна быть частью первичного ключа.
Последние два пункта говорят сами за себя, а вот для первого нужны детали.
Базовый класс управляет каталогом классов и таблиц. Другими словами, декларативный базовый класс — это оболочка над маппером и MetaData. Маппер соотносит подкласс с таблицей, а MetaData сохраняет всю информацию о базе данных и ее таблицах. По аналогии с Core в ORM методы create_all() и drop_all() объекта MetaData используются для создания и удаления таблиц.
Следующий код показывает, как создать модель Post, которая используется для сохранения постов в блоге.
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, unique=True)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
Разберем построчно:
- На 1-4 строках импортируются нужные классы и функции.
- В 6 строке создается базовый класс с помощью вызова функции
declarative_base(). - На 10-16 строках колонки объявляются как атрибуты класса.
Стоит обратить внимание на то, что для создания колонок используется тот же класс Column, что и для SQLAlchemy Core. Единственное отличие в том, что первым аргументом является тип, а не название колонки. Аргументы-ключевые слова, в свою очередь, переданные в Column(), работают одинаково в ORM и Core.
Поскольку ORM построен на базе Core, SQLAlchemy использует определение модели для создания объекта Table и связи его с моделью с помощью функции mapper(). Это завершает процесс маппинга модели Post с соответствующим экземпляром Table. Теперь модель Post можно использовать для управления базой данных и для осуществления запросов к ней.
Классический маппинг
После прошлого раздела может создаться впечатление, что для использования SQLAlchemy ORM нужно переписать все экземпляры Table в виде моделей. Но это не так.
Можно запросто мапить любые Python классы на экземпляры Table с помощью функции mapper(). Например:
from sqlalchemy import MetaData, Table, Integer, String, Column, Text, DateTime, Boolean
from sqlalchemy.orm import mapper
from datetime import datetime
metadata = MetaData()
post = Table('post', metadata,
Column('id', Integer(), primary_key=True),
Column('title', String(200), nullable=False),
Column('slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
class Post(object):
pass
mapper(Post, post)
Этот класс принимает два аргумента: класс для маппинга и объект Table.
После этого у класса Post будут атрибуты, соответствующие колонкам таблицы. Таким образом у Post сейчас следующие атрибуты:
post.idpost.titlepost.slugpost.contentpost.publishedpost.created_onpost.updated_on
Код в списке выше эквивалентен модели Post, которая была объявлена выше.
Теперь вы должны лучше понимать, что делает declarative_base().
Добавление ключей и ограничений
При использовании ORM ключи и ограничения добавляются с помощью атрибута __table_args__.
from sqlalchemy import Table, Index, Integer, String, Column, Text, \
DateTime, Boolean, PrimaryKeyConstraint, \
UniqueConstraint, ForeignKeyConstraint
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer)
username = Column(String(100), nullable=False)
email = Column(String(100), nullable=False)
password = Column(String(200), nullable=False)
__table_args__ = (
PrimaryKeyConstraint('id', name='user_pk'),
UniqueConstraint('username'),
UniqueConstraint('email'),
)
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, default=False)
user_id = Column(Integer(), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
__table_args__ = (
ForeignKeyConstraint(['user_id'], ['users.id']),
Index('title_content_index' 'title', 'content'), # composite index on title and content
)
Отношения
Один-ко-многим
Отношение один-ко-многим создается за счет передачи внешнего ключа в дочерний класс. Например:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
Строчка author_id = Column(Integer, ForeignKey('authors.id')) устанавливает отношение один-ко-многим между моделями Author и Book.
Функция relationship() добавляет атрибуты в модели для доступа к связанным данным. Как минимум — название класса, отвечающего за одну сторону отношения.
Строчка books = relationship("Book") добавляет атрибут books классу Author.
Имея объект a класса Author, получить доступ к его книгам можно через a.books. А если нужно получить автора книги через объект Book?
Для этого можно определить отдельное отношение relationship() в модели Author:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author")
Теперь через объект b класса Book можно получить автора b.author.
Как вариант можно использовать параметры backref для определения названия атрибута, который должен быть задан на другой стороне отношения.
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book", backref="book")
Relationship можно задавать на любой стороне отношений. Поэтому предыдущий код можно записать и так:
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", backref="books")
Один-к-одному
Установка отношения один-к-одному в SQLAlchemy почти не отличается от одного-ко-многим. Единственное отличие в том, что нужно передать дополнительный аргумент uselist=False в функцию relationship(). Например:
class Person(Base):
__tablename__ = 'persons'
id = Column(Integer(), primary_key=True)
name = Column(String(255), nullable=False)
designation = Column(String(255), nullable=False)
doj = Column(Date(), nullable=False)
dl = relationship('DriverLicense', backref='person', uselist=False)
class DriverLicense(Base):
__tablename__ = 'driverlicense'
id = Column(Integer(), primary_key=True)
license_number = Column(String(255), nullable=False)
renewed_on = Column(Date(), nullable=False)
expiry_date = Column(Date(), nullable=False)
person_id = Column(Integer(), ForeignKey('persons.id'))
Имея объект p класса Person, p.dl вернет объект DriverLicense. Если не передать uselist=False в функцию, то установится отношение один-ко-многим между Person и DriverLicense, а p.dl вернет список объектов DriverLicense вместо одного. При этом uselist=False никак не влияет на атрибут persons объекта DriverLicense. Он вернет объект Person как и обычно.
Многие-ко-многим
Для отношения многие-ко-многим нужна отдельная таблица. Она создается как экземпляр класса Table и затем соединяется с моделью с помощью аргумента secondary функции relationship().
author_book = Table('author_book', Base.metadata,
Column('author_id', Integer(), ForeignKey("authors.id")),
Column('book_id', Integer(), ForeignKey("books.id"))
)
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", secondary=author_book, backref="books")
Один автор может написать одну или несколько книг. Так и книга может быть написана одним или несколькими авторами. Поэтому здесь требуется отношение многие-ко-многим.
Для представления этого отношения была создана таблица author_book.
Через объект a класса Author можно получить все книги автора с помощью a.books. По аналогии через b класса Book можно вернуть список авторов b.authors.
В этом случае relationship() была объявлена в модели Book, но это можно было сделать и с другой стороны.
Может потребоваться хранить дополнительную информацию в промежуточной таблице. Для этого нужно определить эту таблицу как класс модели.
class Author_Book(Base):
__tablename__ = 'author_book'
id = Column(Integer, primary_key=True)
author_id = Column(Integer(), ForeignKey("authors.id"))
book_id = Column(Integer(), ForeignKey("books.id"))
extra_data = Column(String(100))
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Author_Book", backref='author')
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
authors = relationship("Author_Book", backref="book")
Создание таблиц
По аналогии с SQLAlchemy Core в ORM есть метод create_all() экземпляра MetaData, который отвечает за создание таблицы.
Base.metadata.create_all(engine)Для удаления всех таблиц есть drop_all.
Base.metadata.drop_all(engine)Пересоздадим таблицы с помощью моделей и сохраним их в базе данных, вызвав create_all(). Вот весь код для этой операции:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, SmallInteger
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from datetime import datetime
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer(), primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
username = Column(String(50), nullable=False)
email = Column(String(200), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
orders = relationship("Order", backref='customer')
class Item(Base):
__tablename__ = 'items'
id = Column(Integer(), primary_key=True)
name = Column(String(200), nullable=False)
cost_price = Column(Numeric(10, 2), nullable=False)
selling_price = Column(Numeric(10, 2), nullable=False)
quantity = Column(Integer())
class Order(Base):
__tablename__ = 'orders'
id = Column(Integer(), primary_key=True)
customer_id = Column(Integer(), ForeignKey('customers.id'))
date_placed = Column(DateTime(), default=datetime.now)
line_items = relationship("OrderLine", backref='order')
class OrderLine(Base):
__tablename__ = 'order_lines'
id = Column(Integer(), primary_key=True)
order_id = Column(Integer(), ForeignKey('orders.id'))
item_id = Column(Integer(), ForeignKey('items.id'))
quantity = Column(SmallInteger())
item = relationship("Item")
Base.metadata.create_all(engine)
Будем использовать таблицу созданную в предыдущей статье.
Вставка (добавление) записей
Есть несколько способов вставить записи в базу данных. Основной — метод insert() экземпляра Table. Его нужно вызвать, после чего использовать метод values() и передать значения для колонок в качестве аргументов-ключевых слов:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
print(ins)
Чтобы увидеть, какой SQL код будет сгенерирован в результате, достаточно вывести ins:
INSERT INTO customers (first_name, last_name, username, email, address, town, created_on, updated_on) VALUES (:first_name, :last_name, :username, :email, :address, :town, :created_on, :updated_on)Стоит обратить внимание на то, что внутри оператора VALUES находятся связанные параметры (параметры в формате :name), а не сами значения, переданные в метод values().
И только при выполнении запроса в базе данных диалект заменит их на реальные значения. Они также будут экранированы, что исключает вероятность SQL-инъекций.
Посмотреть на то, какие значения будут на месте связанных параметров, можно с помощью такой инструкции: ins.compile().params.
Вывод:
{'first_name': 'Dmitriy',
'last_name': 'Yatsenko',
'username': 'Moseend',
'email': 'moseend@mail.com',
'address': 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
'town': ' Vladivostok',
'created_on': None,
'updated_on': None}Инструкция создана, но не отправлена в базу данных. Для ее вызова нужно вызвать метод execute() на объекте Connection:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
conn = engine.connect()
r = conn.execute(ins)
Этот код вставляет следующую запись в таблицу customers:

Метод execute() возвращает объект типа ResultProxy. Последний предоставляет несколько атрибутов, один из которых называется inserted_primary_key. Он возвращает первичный ключ вставленной записи.
Еще один способ создания инструкции для вставки — использование функции insert() из библиотеки sqlalchemy.
from sqlalchemy import insert
ins = insert(customers).values(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com',
address = 'Narovchatova, bld. 8, appt. 37',
town = 'Magadan'
)
conn = engine.connect()
r = conn.execute(ins)
print(r.inserted_primary_key)
Вывод: (2,).
Вставка (добавление) нескольких записей
Вместо того чтобы передавать значения в метод values() в качестве аргументов-ключевых слов, их можно передать в метод execute().
from sqlalchemy import insert
conn = engine.connect()
ins = insert(customers)
r = conn.execute(ins,
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
address = 'Partizanskiy Prospekt, bld. 28/А, appt. 51',
town = ' Vladivostok'
)
Метод execute() достаточно гибкий, потому что он позволяет вставить несколько записей, передав значения в качестве списка словарей, где каждый — значения для одной строки:
r = conn.execute(ins, [
{
"first_name": "Vladimir",
"last_name": "Belousov",
"username": "Andescols",
"email":"andescols@mail.com",
"address": "Ul. Usmanova, bld. 70, appt. 223",
"town": " Naberezhnye Chelny"
},
{
"first_name": "Tatyana",
"last_name": "Khakimova",
"username": "Caltin1962",
"email":"caltin1962@mail.com",
"address": "Rossiyskaya, bld. 153, appt. 509",
"town": "Ufa"
},
{
"first_name": "Pavel",
"last_name": "Arnautov",
"username": "Lablen",
"email":"lablen@mail.com",
"address": "Krasnoyarskaya Ul., bld. 35, appt. 57",
"town": "Irkutsk"
},
])
print(r.rowcount)
Вывод: 3.
Прежде чем переходить к следующему разделу, добавим также записи в таблицы items, orders и order_lines:
items_list = [
{
"name":"Chair",
"cost_price": 9.21,
"selling_price": 10.81,
"quantity": 6
},
{
"name":"Pen",
"cost_price": 3.45,
"selling_price": 4.51,
"quantity": 3
},
{
"name":"Headphone",
"cost_price": 15.52,
"selling_price": 16.81,
"quantity": 50
},
{
"name":"Travel Bag",
"cost_price": 20.1,
"selling_price": 24.21,
"quantity": 50
},
{
"name":"Keyboard",
"cost_price": 20.12,
"selling_price": 22.11,
"quantity": 50
},
{
"name":"Monitor",
"cost_price": 200.14,
"selling_price": 212.89,
"quantity": 50
},
{
"name":"Watch",
"cost_price": 100.58,
"selling_price": 104.41,
"quantity": 50
},
{
"name":"Water Bottle",
"cost_price": 20.89,
"selling_price": 25.00,
"quantity": 50
},
]
order_list = [
{
"customer_id": 1
},
{
"customer_id": 1
}
]
order_line_list = [
{
"order_id": 1,
"item_id": 1,
"quantity": 5
},
{
"order_id": 1,
"item_id": 2,
"quantity": 2
},
{
"order_id": 1,
"item_id": 3,
"quantity": 1
},
{
"order_id": 2,
"item_id": 1,
"quantity": 5
},
{
"order_id": 2,
"item_id": 2,
"quantity": 5
},
]
r = conn.execute(insert(items), items_list)
print(r.rowcount)
r = conn.execute(insert(orders), order_list)
print(r.rowcount)
r = conn.execute(insert(order_lines), order_line_list)
print(r.rowcount)
Вывод:
8
2
5Получение записей
Для получения записей используется метод select() на экземпляре объекта Table:
s = customers.select()
print(s)
Вывод:
SELECT customers.id, customers.first_name, customers.last_name, customers.username, customers.email, customers.address, customers.town, customers.created_on, customers.updated_on
FROM customersТакой запрос вернет все записи из таблицы customers. Вместо этого можно также использовать функцию select(). Она принимает список или колонок, из которых требуется получить данные.
from sqlalchemy import select
s = select([customers])
print(s)
Вывод буде тот же.
Для отправки запроса нужно выполнить метод execute():
from sqlalchemy import select
conn = engine.connect()
s = select([customers])
r = conn.execute(s)
print(r.fetchall())
Вывод:
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109)),...)]Метод fetchall() на объекте ResultProxy возвращает все записи, соответствующие запросу. Как только результаты будут исчерпаны, последующие запросы к fetchall() вернут пустой список.
Метод fetchall() загружает все результаты в память сразу. В случае большого количества данных это не очень эффективно. Как вариант, можно использовать цикл для перебора по результатам:
s = select([customers])
rs = conn.execute(s)
for row in rs:
print(row)
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
...
(7, 'Pavel', 'Arnautov', 'Lablen', 'lablen@mail.com', 'Krasnoyarskaya Ul., bld. 35, appt. 57', 'Irkutsk', datetime.datetime(2021, 4, 22, 10, 32, 45, 364619), datetime.datetime(2021, 4, 22, 10, 32, 45, 364619))Дальше список часто используемых методов и атрибутов объекта ResultProxy:
| Метод/Атрибут | Описание |
| fetchone() | Извлекает следующую запись из результата. Если других записей нет, то последующие вызовы вернут None |
| fetchmany(size=None) | Извлекает набор записей из результата. Если их нет, то последующие вызовы вернут None |
| fetchall() | Извлекает все записи из результата. Если записей нет, то вернется None |
| first() | Извлекает первую запись из результата и закрывает соединение. Это значит, что после вызова метода first() остальные записи в результате получить не выйдет, пока не будет отправлен новый запрос с помощью метода execute() |
| rowcount | Возвращает количество строк в результате |
| keys() | Возвращает список колонок из источника данных |
| scalar() | Возвращает первую колонку первой записи и закрывает соединение. Если результата нет, то возвращает None |
Следующие сессии терминала демонстрируют рассмотренные выше методы и атрибуты в действии, где s = select([customers]).
fetchone()
r = conn.execute(s)
print(r.fetchone())
print(r.fetchone())
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
(2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))fetchmany()
r = conn.execute(s)
print(r.fetchmany(2))
print(len(r.fetchmany(5))) # вернется 4, потому что у нас всего 6 записей
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))]
4first()
r = conn.execute(s)
print(r.first())
print(r.first()) # вернется ошибка
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
Traceback (most recent call last):
...
sqlalchemy.exc.ResourceClosedError: This result object is closed.rowcount
r = conn.execute(s)
print(r.rowcount)
# вернется 6
keys()
r = conn.execute(s)
print(r.keys())
RMKeyView(['id', 'first_name', 'last_name', 'username', 'email', 'address', 'town', 'created_on', 'updated_on'])scalar()
r = conn.execute(s)
print(r.scalar())
# вернется 1
Важно отметить, что fetchxxx() и first() возвращают не кортежи или словари, а объекты типа LegacyRow, что позволяет получать доступ к данным в записи с помощью названия колонки, индекса или экземпляра Column. Например:
r = conn.execute(s)
row = r.fetchone()
print(row)
print(type(row))
print(row['id'], row['first_name']) # доступ к данным по названию колонки
print(row[0], row[1]) # доступ к данным по индексу
print(row[customers.c.id], row[customers.c.first_name]) # доступ к данным через объект класса
print(row.id, row.first_name) # доступ к данным, как к атрибуту
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
<class 'sqlalchemy.engine.row.LegacyRow'>
1 Dmitriy
1 Dmitriy
1 Dmitriy
1 DmitriyДля получения данных из нескольких таблиц нужно передать список экземпляров Table, разделенных запятыми в функцию select():
Этот код вернет Декартово произведение записей из обоих таблиц. О SQL JOIN поговорим позже отдельно.
Фильтр записей
Для фильтрования записей используется метод where(). Он принимает условие и добавляет оператор WHERE к SELECT:
s = select([items]).where(
items.c.cost_price > 20
)
print(s)
r = conn.execute(s)
print(r.fetchall())
Запрос вернет все элементы, цена которых выше 20.
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1
[(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50)]Дополнительные условия можно задать, просто добавив несколько вызовов метода where().
s = select([items]).\
where(items.c.cost_price + items.c.selling_price > 50).\
where(items.c.quantity > 10)
При использовании такого способа операторы просто объединяются при помощи AND. А как использовать OR или NOT?
Для этого есть:
- Побитовые операторы
- Союзы
Побитовые операторы
Побитовые операторы &, | и ~ позволяют объединять условия с операторами AND, OR или NOT из SQL.
Предыдущий запрос можно записать вот так с помощью побитовых операторов:
s = select([items]).\
where(
(items.c.cost_price + items.c.selling_price > 50) &
(items.c.quantity > 10)
)
Условия заключены в скобки. Это нужно из-за того, что побитовые операторы имеют более высокий приоритет по сравнению с операторами + и >.
s = select([items]).\
where(
(items.c.cost_price > 200 ) |
(items.c.quantity < 5)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50) &
(items.c.cost_price < 20)
)
print(s)
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1 OR items.quantity < :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1 AND items.cost_price < :cost_price_1Союзы
Условия можно объединять и с помощью функций-союзов and_(), or_() и not_(). Это предпочтительный способ добавления условий в SQLAlchemy.
from sqlalchemy import select, and_, or_, not_
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
or_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
not_(
items.c.name == 'Headphone'
),
)
)
Другие распространенные операторы сравнения
Следующий список демонстрирует как использовать остальные операторы сравнения при определении условий в SQLAlchemy
IS NULL
select([orders]).where(
orders.c.date_shipped == None
)
IS NOT NULL
select([orders]).where(
orders.c.date_shipped != None
)
IN
select([customers]).where(
customers.c.first_name.in_(["Valeriy", "Vadim"])
)
NOT IN
select([customers]).where(
customers.c.first_name.notin_(["Valeriy", "Vadim"])
)
BETWEEN
select([items]).where(
items.c.cost_price.between(10, 20)
)
NOT BETWEEN
from sqlalchemy import not_
select([items]).where(
not_(items.c.cost_price.between(10, 20))
)
LIKE
select([items]).where(
items.c.name.like("Wa%")
)
Метод like() выполняет сравнение с учетом регистра. Для сравнения без учета регистра используйте ilike().
NOT LIKE
select([items]).where(
not_(items.c.name.like("wa%"))
)
Сортировка результата c order_by
Метод order_by() добавляет оператор ORDER BY к инструкции SELECT. Он принимает одну или несколько колонок для сортировки. Для каждой колонки можно указать, выполнять ли сортировку по возрастанию (asc()) или убыванию (desc()). Если не указать ничего, то сортировка будет выполнена в порядке по возрастанию. Например:
s = select([items]).where(
items.c.quantity > 10
).order_by(items.c.cost_price)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity > :quantity_1 ORDER BY items.cost_price
[(3, 'Headphone', Decimal('15.52'), Decimal('16.81'), 50),
(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50)]Запрос возвращает записи, отсортированные по cost_price по возрастанию. Это эквивалентно следующему:
from sqlalchemy import asc
s = select([items]).where(
items.c.quantity > 10
).order_by(asc(items.c.cost_price))
rs = conn.execute(s)
rs.fetchall()
Для сортировки результатов по убыванию используйте функцию desc(). Пример:
from sqlalchemy import desc
s = select([items]).where(
items.c.quantity > 10
).order_by(desc(items.c.cost_price))
conn.execute(s).fetchall()
Вот еще один пример сортировки по двух колонкам: quantity по возрастанию и cost_price по убыванию.
s = select([items]).order_by(
items.c.quantity,
desc(items.c.cost_price)
)
conn.execute(s).fetchall()
Ограничение результатов c limit
Метод limit() добавляет оператор LIMIT в инструкцию SELECT. Он принимает целое число, определяющее число записей, которые должны вернуться. Например:
s = select([items]).order_by(
items.c.quantity
).limit(2)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items ORDER BY items.quantity
LIMIT :param_1
[(2, 'Pen', Decimal('3.45'), Decimal('4.51'), 3),
(1, 'Chair', Decimal('9.21'), Decimal('10.81'), 5)]Чтобы задавать «сдвиг» (начальное положение) в LIMIT, нужно использовать метод offset():
s = select([items]).order_by(
items.c.quantity
).limit(2).offset(2)
Ограничение колонок
Инструкции SELECT, созданные ранее, возвращают данные из всех колонок. Ограничить количество полей, возвращаемых запросом можно, передав название полей в виде списка в функцию select(). Например:
s = select([items.c.name, items.c.quantity]).where(
items.c.quantity == 50
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT items.name, items.quantity
FROM items
WHERE items.quantity = :quantity_1
RMKeyView(['name', 'quantity'])
[('Headphone', 50), ('Travel Bag', 50), ('Keyboard', 50), ('Monitor', 50), ('Watch', 50), ('Water Bottle', 50)]Запрос возвращает данные только из колонок name и quantity таблицы items.
По аналогии с SQL можно выполнять вычисления на вернувшихся строках до того, как они попадут в вывод. Например:
select([
items.c.name,
items.c.quantity,
items.c.selling_price * 5
]).where(
items.c.quantity == 50
)
Обратите внимание на то, что items.c.selling_price * 5 — это не реальная колонка, поэтому создается анонимное имя anon_1.
Колонке или выражению можно присвоить метку с помощью метода label(), который работает, добавляя оператор AS к SELECT.
select([
items.c.name,
items.c.quantity,
(items.c.selling_price * 5).label('price')
]).where(
items.c.quantity == 50
)
Доступ к встроенным функциям
Для доступа к встроенным функциям базы данных используется объект func. Следующий список показывает, как использовать функции для работы с датой/временем, математическими операциями и строками в базе данных PostgreSQL.
from sqlalchemy.sql import func
c = [
## функции даты/времени ##
func.timeofday(),
func.localtime(),
func.current_timestamp(),
func.date_part("month", func.now()),
func.now(),
## математические функции ##
func.pow(4,2),
func.sqrt(441),
func.pi(),
func.floor(func.pi()),
func.ceil(func.pi()),
## строковые функции ##
func.lower("ABC"),
func.upper("abc"),
func.length("abc"),
func.trim(" ab c "),
func.chr(65),
]
s = select(c)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
RMKeyView(['timeofday_1', 'localtime_1', 'current_timestamp_1', 'date_part_1', 'now_1', 'pow_1', 'sqrt_1', 'pi_1', 'floor_1', 'ceil_1', 'lower_1', 'upper_1', 'length_1', 'trim_1', 'chr_1'])
[('Thu Apr 22 12:33:07.655488 2021 EEST', datetime.time(12, 33, 7, 643174), datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 4.0, datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 16.0, 21.0, 3.14159265358979, 3.0, 4.0, 'abc', 'ABC', 3, 'ab c', 'A')]Также можно получить доступ к агрегирующим функциям из объекта object.
c = [
func.sum(items.c.quantity),
func.avg(items.c.quantity),
func.max(items.c.quantity),
func.min(items.c.quantity),
func.count(customers.c.id),
]
s = select(c)
rs = conn.execute(s)
print(rs.fetchall())
# вывод: [(1848, Decimal('38.5000000000000000'), 50, 3, 48)]
Группировка результатов с group_by
Группировка результатов выполняется с помощью оператора GROUP BY. Он часто используется в союзе с агрегирующими функциями. GROUP BY добавляется к SELECT с помощью метода group_by(). Последний принимает одну или несколько колонок и группирует строки по значениям в этих колонках. Например:
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town)
print(conn.execute(s).fetchall())
Вывод:
[(1, 'Ufa'), (1, 'Irkutsk'), (2, ' Vladivostok'), (1, 'Magadan'), (1, ' Naberezhnye Chelny')]Этот запрос возвращает количество потребителей в каждом городе.
Чтобы отфильтровать результат на основе значений агрегирующих функций, используется метод having(), добавляющий оператор HAVING к SELECT. По аналогии с where() он принимает условие.
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town).having(func.count("*") > 2)
Объединения (joins)
Экземпляр Table предоставляет два метода для создания объединений (joins):
join()— создает внутренний joinouterjoin()— создает внешний join (LEFT OUTER JOIN, если точнее)
Внутренний join возвращает только те колонки, которые соответствуют условию объединения, а внешний — также некоторые дополнительные.
Оба метода принимают экземпляр Table, определяют условие объединения на основе отношений во внешних ключах и возвращают конструкцию JOIN.
>>> print(customers.join(orders))
customers JOIN orders ON customers.id = orders.customer_idЕсли методы не могут определить условия объединения, или нужно предоставить другое условие, то это делается через передачу условия объединения в качестве второго аргумента.
customers.join(items,
customers.c.address.like(customers.c.first_name + '%')
)Когда в функции select() указываются таблицы или список колонок, SQLAlchemy автоматически размещает эти таблицы в операторе FROM. Но при использовании объединения таблицы, которые нужны во FROM, точно известны, поэтому используется select_from(). Этот же метод можно применять и для запросов, не использующих объединения. Например:
s = select([
customers.c.id,
customers.c.first_name
]).select_from(customers)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT customers.id, customers.first_name
FROM customers
RMKeyView(['id', 'first_name'])
[(1, 'Dmitriy'), (2, 'Valeriy'), (4, 'Vadim'), (5, 'Vladimir'), (6, 'Tatyana'), (7, 'Pavel')]Используем эти знания, чтобы найти все заказы, размещенные пользователем Dmitriy Yatsenko.
select([
orders.c.id,
orders.c.date_placed
]).select_from(
orders.join(customers)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
Последний запрос возвращает id и date_placed заказа. Было бы неплохо также знать товары и их общее количество.
Для этого нужно сделать 3 объединения вплоть до таблицы items.
s = select([
orders.c.id.label('order_id'),
orders.c.date_placed,
order_lines.c.quantity,
items.c.name,
]).select_from(
orders.join(customers).join(order_lines).join(items)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT orders.id AS order_id, orders.date_placed, order_lines.quantity, items.name
FROM orders JOIN customers ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id JOIN items ON items.id = order_lines.item_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1
RMKeyView(['order_id', 'date_placed', 'quantity', 'name'])
[(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 2, 'Pen'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 1, 'Headphone'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Pen')]
А вот как создавать внешнее объединение.
select([
customers.c.first_name,
orders.c.id,
]).select_from(
customers.outerjoin(orders)
)
Экземпляр Table, передаваемый в метод outerjoin(), располагается с правой стороны внешнего объединения. В результате последний запрос вернет все записи из таблицы customers (левой таблицы) и только те, которые соответствуют условию объединения из таблицы orders (правой).
Если нужны все записи из таблицы order, но лишь те, которые соответствуют условию, из orders, стоит использовать outerjoin():
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers)
)
Также можно создать FULL OUTER JOIN, передав full=True в метод outerjoin(). Например:
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers, full=True)
)
Обновление записей
Обновление данных выполняется с помощью функции update(). Например, следующий запрос обновляет selling_price и quantity для Water Bottle и устанавливает значения 30 и 60 соответственно.
from sqlalchemy import update
s = update(items).where(
items.c.name == 'Water Bottle'
).values(
selling_price = 30,
quantity = 60,
)
print(s)
rs = conn.execute(s)
Вывод:
UPDATE items SET selling_price=:selling_price, quantity=:quantity WHERE items.name = :name_1Удаление записей
Для удаления данных используется функция delete().
from sqlalchemy import delete
s = delete(customers).where(
customers.c.username.like('Vladim%')
)
print(s)
rs = conn.execute(s)
Вывод:
DELETE FROM customers WHERE customers.username LIKE :username_1Этот запрос удалит всех покупателей, чье имя пользователя начинается с Vladim.
Работа с дубликатами
Для обработки повторяющихся записей в результатах используется параметр DISTINCT. Его можно добавить в SELECT с помощью метода distinct(). Например:
# без DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
# с DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10).distinct()
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Magadan',), (' Vladivostok',), (' Naberezhnye Chelny',), ('Ufa',), ('Irkutsk',)]
SELECT DISTINCT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Ufa',), ('Irkutsk',), ('Magadan',), (' Naberezhnye Chelny',)]
Вот еще один пример использования distinct() с агрегирующей функцией count().Здесь считается количество уникальных городов в таблице customers.
select([
func.count(distinct(customers.c.town)),
func.count(customers.c.town)
])
Конвертация данных с cast
Приведение (конвертация) данных из одного типа в другой — это распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import func, cast, Date
s = select([
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
])
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT CAST(pi() AS INTEGER) AS pi, CAST(pi() AS NUMERIC(10, 2)) AS anon__1, CAST(:param_1 AS DATETIME) AS anon_1, CAST(:param_2 AS DATE) AS anon_2
[(3, Decimal('3.14'), datetime.datetime(2010, 12, 1, 0, 0), datetime.date(2010, 12, 1))]Union
Оператор UNION позволяет объединять результаты нескольких SELECT. Для добавления его к функции select() используется вызов union().
from sqlalchemy import union, desc
u = union(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
print(u)
rs = conn.execute(u)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_1 UNION SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_2 ORDER BY id DESC
[(8, 'Water Bottle'), (7, 'Watch'), (5, 'Keyboard'), (4, 'Travel Bag'), (3, 'Headphone'), (2, 'Pen')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения стоит использовать union_all().
from sqlalchemy import union_all, desc
union_all(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
Создание подзапросов
Данные можно получать и из нескольких таблиц с помощью подзапросов.
Следующий запрос возвращает идентификатор и название элементов, отсортированных по Dmitriy Yatsenko в его первом заказе:
s = select([items.c.id, items.c.name]).where(
items.c.id.in_(
select([order_lines.c.item_id]).select_from(customers.join(orders).join(order_lines)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
)
)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.id IN (SELECT order_lines.item_id
FROM customers JOIN orders ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1 AND orders.id = :id_1)
[(1, 'Chair'), (2, 'Pen'), (3, 'Headphone')]Тот же запрос можно написать и с использованием объединений:
select([items.c.id, items.c.name]).select_from(customers.join(orders).join(order_lines).join(items)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
«Сырые» запросы
SQLAlchemy предоставляет возможность выполнять сырые SQL-запросы с помощью функции text(). Например, следующая инструкция SELECT возвращает все заказы с товарами для Dmitriy Yatsenko.
from sqlalchemy.sql import text
s = text(
"""
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
"""
)
print(s)
rs = conn.execute(s, first_name='Dmitriy', last_name='Yatsenko')
print(rs.fetchall())
Вывод:
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
[(1, 1, 'Chair'), (1, 2, 'Pen'), (1, 3, 'Headphone'), (2, 1, 'Chair'), (2, 2, 'Pen')]Обратите внимание на то, что инструкция включает пару связанных параметров: first_name и last_name. Сами значения для них передаются уже в метод execute().
Эту же функцию можно встроить в select(). Например:
select([items]).where(
text("items.name like 'Wa%'")
).order_by(text("items.id desc"))
Выполнить сырой SQL можно и просто передав его прямо в execute(). Например:
rs = conn.execute("select * from orders;")
rs.fetchall()
Транзакции
Транзакция — это способ выполнять наборы SQL-инструкций так, чтобы выполнились или все, или ни одна из них. Если хотя бы одна из инструкций, участвующих в транзакции, проходит с ошибкой, база данных возвращается к состоянию, которое было до ее начала.
Сейчас в базе данных два заказа. Для совершения заказа нужно выполнить следующие два действия:
- Удалить заказанные товары из
items - Обновить колонку
date_shippedс датой
Оба действия должны быть выполнены как одно целое, чтобы быть уверенными в том, что данные корректные.
Объект Connection предоставляет метод begin(), который инициирует транзакцию и возвращает соответствующий объект Transaction. Последний в свою очередь предоставляет методы rollback() и commit() для отката до прежнего состояния или сохранения текущего состояния.
В следующем списке метод dispatch_order() принимает order_id в качестве аргумента и выполняет упомянутые выше действия с помощью транзакции.
from sqlalchemy import func, update
from sqlalchemy.exc import IntegrityError
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
r = conn.execute(select([func.count("*")]).where(orders.c.id == order_id))
if not r.scalar():
raise ValueError("Недействительный order_id: {}".format(order_id))
# брать товары в порядке очереди
s = select([order_lines.c.item_id, order_lines.c.quantity]).where(
order_lines.c.order_id == order_id
)
rs = conn.execute(s)
ordered_items_list = rs.fetchall()
# начало транзакции
t = conn.begin()
try:
for i in ordered_items_list:
u = update(items).where(
items.c.id == i.item_id
).values(quantity = items.c.quantity - i.quantity)
rs = conn.execute(u)
u = update(orders).where(orders.c.id == order_id).values(date_shipped=datetime.now())
rs = conn.execute(u)
t.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
t.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
Первый заказ включает 5 стульев и 2 ручки. Вызов функции dispatch_order() с идентификатором заказа 1 вернет такой результат.
Транзакция завершена.
Теперь items и order_lines должны выглядеть следующим образом:
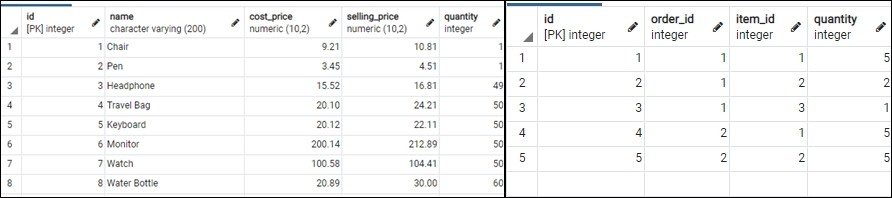
В следующем заказе 5 стульев и 4 ручки, но в запасе остались лишь 1 стул и 1 ручка.
Запустим dispatch_order(2) для второго заказа.
(psycopg2.errors.CheckViolation) ОШИБКА: новая строка в отношении "items" нарушает ограничение-проверку "quantity_check"
DETAIL: Ошибочная строка содержит (1, Chair, 9.21, 10.81, -4).
[SQL: UPDATE items SET quantity=(items.quantity - %(quantity_1)s) WHERE items.id = %(id_1)s]
[parameters: {'quantity_1': 5, 'id_1': 1}]
(Background on this error at: http://sqlalche.me/e/14/gkpj)
Транзакция не удалась.
Выполнение закончилось с ошибкой, потому что в запасе недостаточно ручек. В итоге база данных вернулась к состоянию до начала транзакции.
]]>Таблицы в SQLAlchemy представлены в виде экземпляров класса Table. Его конструктор принимает название таблицы, метаданные и одну или несколько колонок. Например:
from sqlalchemy import MetaData, Table, String, Integer, Column, Text, DateTime, Boolean
from datetime import datetime
metadata = MetaData()
blog = Table('blog', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
Разберем код построчно:
- Импортируем несколько классов из sqlalchemy, которые используются для создания таблицы.
- Импортируем класс datetime из модуля datetime.
- Создаем объекта
MetaData. Он содержит всю информацию о базе данных и таблицах. ЭкземплярMetaDataиспользуется для создания или удаления таблиц в базе данных. - Наконец, создается схема таблицы. Колонки создаются с помощью экземпляра
Column. Конструктор этого класса принимает название колонки и тип данных. Также можно передать дополнительные аргументы для обозначения ограничений (constraints) и конструкций SQL. Вот самые популярные ограничения:
| Ограничение | Описание |
primary_key | Булево. Если значение равно True, отмечает колонку как первичный ключ таблицы. Для создания составного ключа, нужно просто установить значение True для каждой колонки. |
nullable | Булево. Если False, то добавляет ограничение NOT NULL. Значение по умолчанию равно True. |
default | Определяет значение по умолчанию, если при вставке данных оно не было передано. Может быть как скалярное значение, так и вызываемое значение Python. |
onupdate | Значение по умолчанию для колонки, которое устанавливается, если ничего не было передано при обновлении записи. Может принимать то же значение, что и default. |
unique | Булево. Если True, следит за тем, чтобы значение было уникальным. |
index | Булево. Если True, создает индексируемую колонку. По умолчанию False. |
auto_increment | Добавляет параметр auto_increment для колонки. Значение по умолчанию равно auto. Это значит, что значение основного ключа будет увеличиваться каждый раз при добавлении новой записи. Если нужно увеличить значение для каждого элемента составного ключа, то этот параметр нужно задать как True для всех колонок ключа. Для отключения поведения нужно установить значение False |
Типы колонок
Тип определяет то, какие данные колонка сможет хранить. SQLAlchemy предоставляет абстракцию для большого количества типов. Однако всего есть три категории:
- Общие типы
- Стандартные SQL-типы
- Типы отдельных разработчиков
Общие типы
Тип Generic указывает на те типы, которые поддерживаются большинством баз данных. При использовании такого типа SQLAlchemy подбирает наиболее подходящий при создании таблицы. Например, в прошлом примере была определена колонка published. Ее тип — Boolean. Это общий тип. Для базы данных PostgreSQL тип будет boolean. А для MySQL — SMALLINT, потому что там нет Boolean. В Python же этот тип данных представлен типом bool (True или False).
Следующая таблица описывает основные типы в SQLAlchemy и ассоциации в Python и SQL.
| SQLAlchemy | Python | SQL |
|---|---|---|
BigInteger | int | BIGINT |
Boolean | bool | BOOLEAN или SMALLINT |
Date | datetime.date | DATE |
DateTime | datetime.datetime | DATETIME |
Integer | int | INTEGER |
Float | float | FLOAT или REAL |
Numeric | decimal.Decimal | NUMERIC |
Text | str | TEXT |
Получить эти типы можно из sqlalchemy.types или sqlalchemy.
Стандартные типы SQL
Типы в этой категории происходят из самого SQL. Их поддерживает небольшое количество баз данных.
from sqlalchemy import MetaData, Table, Column, Integer, ARRAY
metadata = MetaData()
employee = Table('employees', metadata,
Column('id', Integer(), primary_key=True),
Column('workday', ARRAY(Integer)),
)
Доступ к ним можно также получить из sqlalchemy.types или sqlalchemy. Однако для разделения стандартные типы записаны в верхнем регистре. Например, есть тип ARRAY, который пока поддерживается только PostgreSQL.
Типы производителей
В пакете sqlalchemy можно найти типы, которые используются в конкретных базах данных. Например, в PostgreSQL есть тип INET для хранения сетевых данных. Для его использования нужно импортировать sqlalchemy.dialects.
from sqlalchemy import MetaData, Table, Column, Integer
from sqlalchemy.dialects import postgresql
metadata = MetaData()
comments = Table('comments', metadata,
Column('id', Integer(), primary_key=True),
Column('ipaddress', postgresql.INET),
)
Реляционные отношения (связи)
Таблицы в базе данных редко существуют сами по себе. Чаще всего они связаны с другими через специальные отношения. Существует три типа отношений:
- Один-к-одному
- Один-ко-многим
- Многие-ко-многим
Разберемся, как определять эти отношения в SQLAlchemy.
Отношение один-ко-многим
Две таблицы связаны отношением один-ко-многим, если запись в первой таблице связана с одной или несколькими записями второй. На изображении ниже такая связь существует между таблицей users и posts.
Для создания отношения нужно передать объект ForeignKey, в котором содержится название колонки в функцию-конструктор Column.
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', ForeignKey("users.id")),
)
В этом коде определяется внешний ключ для колонки user_id таблицы posts. Это значит, что эта колонка может содержать только значения из колонки id таблицы users.
Вместо того чтобы передавать название колонки в качестве строки, можно передать объект Column прямо в конструктор ForeignKey. Например:
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey(user.c.id)),
)
user.c.id ссылается на колонку id таблицы users. Важно лишь запомнить, что определение колонки (user.c.id) должно идти до ссылки на нее (posts.c.user_id).
Отношение один-к-одному
Две таблицы имеют связь один-к-одному, если запись в одной таблице связана только с одной записью в другой. На изображении ниже таблица employees связана с employee_details. Первая включает публичные записи о сотрудниках, а вторая — частные.
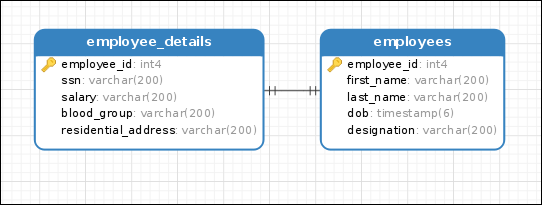
from sqlalchemy import MetaData, Table, Column, Integer, String, DateTime, ForeignKey
metadata = MetaData()
employees = Table('employees', metadata,
Column('employee_id', Integer(), primary_key=True),
Column('first_name', String(200), nullable=False),
Column('last_name', String(200), nullable=False),
Column('dob', DateTime(), nullable=False),
Column('designation', String(200), nullable=False),
)
employee_details = Table('employee_details', metadata,
Column('employee_id', ForeignKey('employees.employee_id'), primary_key=True),
Column('ssn', String(200), nullable=False),
Column('salary', String(200), nullable=False),
Column('blood_group', String(200), nullable=False),
Column('residential_address', String(200), nullable=False),
)
Для создания такой связи одна и та же колонка должна выступать одновременно основным и внешним ключом в employee_details.
Отношение многие-ко-многим
Две таблицы имеют связь многие-ко-многим, если запись в первой таблице связана с одной или несколькими таблицами во второй. Вместе с тем, запись во второй таблице связана с одной или несколькими в первой. Для таких отношений создается таблица ассоциаций. На изображении ниже отношение многие-ко-многим существует между таблицами posts и tags.
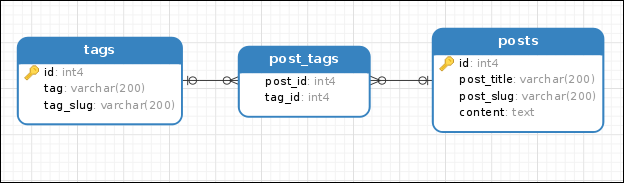
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
)
tags = Table('tags', metadata,
Column('id', Integer(), primary_key=True),
Column('tag', String(200), nullable=False),
Column('tag_slug', String(200), nullable=False),
)
post_tags = Table('post_tags', metadata,
Column('post_id', ForeignKey('posts.id')),
Column('tag_id', ForeignKey('tags.id'))
)
Процесс установки отношений почти не отличается от такового в SQL. Все потому что используется SQLAlchemy Core, который позволяет делать почти то же, что доступно в SQL.
Ограничения (constraint) на уровне таблицы
В прошлых разделах мы рассмотрели, как добавлять ограничения и индексы для колонки, передавая дополнительные аргументы в функцию-конструктор Column. По аналогии с SQL можно также определять ограничения с индексами и на уровне таблицы. В следующей таблице перечислены основные constraint и классы для их создания:
| Ограничения/индексы | Название класса |
| Основной ключ | PrimaryKeyConstraint |
| Внешний ключ | ForeignKeyConstraint |
| Уникальный ключ | UniqueConstraint |
| Проверочный ключ | CheckConstraint |
| Индекс | Index |
Получить доступ к этим классам можно через sqlalchemy.schema или sqlalchemy. Вот некоторые примеры использования:
Добавления Primary Key с помощью PrimaryKeyConstraint
parent = Table('parent', metadata,
Column('acc_no', Integer()),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', name='acc_no_pk')
)Здесь создается первичный ключ для колонки acc_no. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer(), primary=True),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
)Преимущественно PrimaryKeyConstraint используется для создания составного основного ключа (такого ключа, который использует несколько колонок). Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', 'acc_type', name='uniq_1')
)Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False, primary_key=True),
Column('acc_type', Integer, nullable=False, primary_key=True),
Column('name', String(16), nullable=False),
)Создание Foreign Key с помощью ForeignKeyConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', Integer, nullable=False),
Column('name', String(40), nullable=False),
ForeignKeyConstraint(['parent_id'],['parent.id'])
)Создаем внешний ключ в колонке parent_it, которая ссылается на колонку id таблицы parent. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', ForeignKey('parent.id'), nullable=False),
Column('name', String(40), nullable=False),
)Но реальную пользу ForeignKeyConstraint приносит при определении составного внешнего ключа (который также задействует несколько колонок). Например:
parent = Table('parent', metadata,
Column('id', Integer, nullable=False),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('id', 'ssn', name='uniq_1')
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(40), nullable=False),
Column('parent_id', Integer, nullable=False),
Column('parent_ssn', Integer, nullable=False),
ForeignKeyConstraint(['parent_id','parent_ssn'],['parent.id', 'parent.ssn'])
)Обратите внимание на то, что просто передать объект ForeignKey в отдельные колонки не получится — это приведет к созданию нескольких внешних ключей.
Создание Unique Constraint с помощью UniqueConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('ssn', name='unique_ssn')
)Определим ограничение уникальности для колонки ssn. Необязательное ключевое слово name позволяет задать имя для этого constraint. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, unique=True, nullable=False),
Column('name', String(16), nullable=False),
)UniqueConstraint часто используется для создания ограничения уникальности на нескольких колонках. Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, primary_key=True),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('acc_no', 'acc_type', name='uniq_1')
)В этом примере ограничения уникальности устанавливаются на acc_no и acc_type, в результате чего комбинация значений этих двух колонок всегда должна быть уникальной.
Создание ограничения проверки с помощью CheckConstraint
Ограничение CHECK позволяет создать условие, которое будет срабатывать при вставке или обновлении данных. Если проверка пройдет успешно, данные успешно сохранятся в базе данных. В противном случае возникнет ошибка.
Добавить это ограничение можно с помощью CheckConstraint.
employee = Table('employee', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(100), nullable=False),
Column('salary', Integer(), nullable=False),
CheckConstraint('salary < 100000', name='salary_check')
)Создание индексов с помощью Index
Аргумент-ключевое слово index также позволяет добавлять индекс для отдельных колонок. Для работы с ним есть класс Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name')
)В этом примере индекс создается для колонки first_name. Такой код эквивалентен следующему:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False, index=True),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
)Если запросы включают поиск по определенному набору полей, то увеличить производительность можно с помощью составного индекса (то есть, индекса для нескольких колонок). В этом основное назначение Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name', 'last_name')
)Связь с таблицами и колонками с помощью MetaData
Объект MetaData содержит всю информацию о базе данных и таблицах внутри нее. С его помощью можно получать доступ к объектам таблицы, используя такие два атрибута:
| Атрибут | Описание |
| tables | Возвращает объект-словарь типа immutabledict, где ключом выступает название таблицы, а значением — объект с ее данными |
| sorted_tables | Возвращает список объектов Table, отсортированных по порядку зависимости внешних ключей. Другими словами, таблицы с зависимостями располагаются перед самими зависимостями. Например, если у таблицы posts есть внешний ключ, указывающий на колонку id таблицы users, то таблица users будет расположена перед posts |
Вот два описанных атрибута в действии:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, Column, Text, DateTime, Boolean, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey("users.id")),
)
for t in metadata.tables:
print(metadata.tables[t])
print('-------------')
for t in metadata.sorted_tables:
print(t.name)
Ожидаемый вывод:
users
posts
-------------
users
postsПосле получения доступа к экземпляру Table можно получать доступ к любым деталям о колонках:
print(posts.columns) # вернуть список колонок
print(posts.c) # как и post.columns
print(posts.foreign_keys) # возвращает множество, содержащий внешние ключи таблицы
print(posts.primary_key) # возвращает первичный ключ таблицы
print(posts.metadata) # получим объект MetaData из таблицы
print(posts.columns.post_title.name) # возвращает название колонки
print(posts.columns.post_title.type) # возвращает тип колонки
Ожидаемый вывод:
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
{ForeignKey('users.id')}
PrimaryKeyConstraint(Column('id', Integer(), table=<posts>, primary_key=True, nullable=False))
MetaData()
post_title
VARCHAR(200)Создание таблиц
Для создания таблиц, хранящихся в экземпляре MetaData, вызовите метод MetaData.create_all() с объектом Engine.
metadata.create_all(engine)Этот метод создает таблицы только в том случае, если они не существуют в базе данных. Это значит, что его можно вызвать безопасно несколько раз. Также стоит отметить, что вызов метода после определения схемы не изменит ее. Для этого нужно использовать инструмент миграции под названием Alembic.
Удалить все таблицы можно с помощью MetaData.drop_all().
В дальнейшем будем работать с базой данных для приложения в сфере электронной коммерции. Она включает 4 таблицы:
- customers — хранит всю информацию о потребителях. Имеет следующие колонки:
- id — первичный ключ
- first_name — имя покупателя
- last_name — фамилия покупателя
- username — уникальное имя покупателя
- email — уникальный адрес электронной почты
- address — адрес
- town — город
- created_on — дата и время создания аккаунта
- updated_on — дата и время обновления аккаунта
- items — хранит информацию о товарах. Колонки:
- id — первичный ключ
- name — название
- cost_price — себестоимость товара
- selling_price — цена продажи
- quantity — количество товаров в наличии
- orders — информация о покупках потребителей. Колонки:
- id — первичный ключ
- customer_id — внешний ключ, указывающий на колонку
idтаблицы customers - date_placed — дата и время размещения заказа
- date_shipped — дата и время отгрузки заказа
- order_lines — подробности каждого товара в заказе. Колонки:
- id — первичный ключ
- order_id — внешний ключ, указывающий на
idтаблицы orders - item_id — внешний ключ, указывающий на
idтаблицы items - quantity — количество товаров в заказе
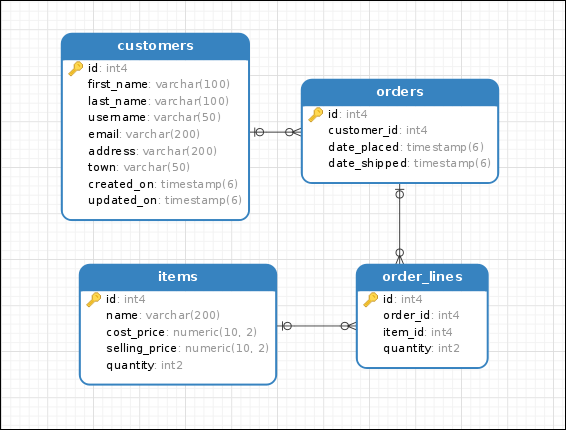
А вот и весь код для создания этих таблиц:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, CheckConstraint
from datetime import datetime
metadata = MetaData()
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
customers = Table('customers', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('last_name', String(100), nullable=False),
Column('username', String(50), nullable=False),
Column('email', String(200), nullable=False),
Column('address', String(200), nullable=False),
Column('town', String(50), nullable=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
items = Table('items', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(200), nullable=False),
Column('cost_price', Numeric(10, 2), nullable=False),
Column('selling_price', Numeric(10, 2), nullable=False),
Column('quantity', Integer(), nullable=False),
CheckConstraint('quantity > 0', name='quantity_check')
)
orders = Table('orders', metadata,
Column('id', Integer(), primary_key=True),
Column('customer_id', ForeignKey('customers.id')),
Column('date_placed', DateTime(), default=datetime.now),
Column('date_shipped', DateTime())
)
order_lines = Table('order_lines', metadata,
Column('id', Integer(), primary_key=True),
Column('order_id', ForeignKey('orders.id')),
Column('item_id', ForeignKey('items.id')),
Column('quantity', Integer())
)
metadata.create_all(engine)
Базу данных
sqlalchemy_tutsмы создали в предыдущем уроке: https://pythonru.com/biblioteki/ustanovka-i-podklyuchenie-sqlalchemy-k-baze-dannyh
В следующем материале рассмотрим, как выполнять CRUD-операции в базе данных с помощью SQL.
]]>Установка SQLAlchemy
Для установки SQLAlchemy введите следующее:
pip install sqlalchemyЧтобы проверить успешность установки введите следующее в командной строке:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.8'
Установка DBAPI
По умолчанию SQLAlchemy работает только с базой данных SQLite без дополнительных драйверов. Для работы с другими базами данных необходимо установить DBAPI-совместимый драйвер в соответствии с базой данных.
Что такое DBAPI?
DBAPI — это стандарт, который поощряет один и тот же API для работы с большим количеством баз данных. В следующей таблице перечислены все DBAPI-совместимые драйверы:
| База данных | DBAPI драйвер |
|---|---|
| MySQL | PyMySQL, MySQL-Connector, CyMySQL, MySQL-Python (по умолчанию) |
| PostgreSQL | psycopg2 (по умолчанию), pg8000, |
| Microsoft SQL Server | PyODBC (по умолчанию), pymssql |
| Oracle | cx-Oracle (по умолчанию) |
| Firebird | fdb (по умолчанию), kinterbasdb |
Все примеры в этом руководстве протестированы в PostgreSQL, но вы можете выбрать базу данных по вкусу. Для установки DBAPI psycopg2 для PostgreSQL введите следующую команду:
pip install psycopg2Подготовка к подключению
Первый шаг для подключения к базе данных — создания объекта Engine. Именно он отвечает за взаимодействие с базой данных. Состоит из двух элементов: диалекта и пула соединений.
Диалект SQLAlchemy
SQL — это стандартный язык для работы с базами данных. Однако и он отличается от базы к базе. Производители баз данных редко придерживаются одной и той же версии и предпочитают добавлять свои особенности. Например, если вы используете Firebird, то для получения id и name для первых 5 строк из таблицы employees нужна следующая команда:
select first 10 id, name from employeesА вот как получить тот же результат для MySQL:
select id, name from employees limit 10
Чтобы обрабатывать эти различия нужен диалект. Диалект определяет поведение базы данных. Другими словами он отвечает за обработку SQL-инструкций, выполнение, обработку результатов и так далее. После установки соответствующего драйвера диалект обрабатывает все отличия, что позволяет сосредоточиться на создании самого приложения.
Пул соединений SQLAlchemy
Пул соединений — это стандартный способ кэширования соединений в памяти, что позволяет использовать их повторно. Создавать соединение каждый раз при необходимости связаться с базой данных — затратно. А пул соединений обеспечивает неплохой прирост производительности.
При таком подходе приложение при необходимости обратиться к базе данных вытягивает соединение из пула. После выполнения запросов подключение освобождается и возвращается в пул. Новое создается только в том случае, если все остальные связаны.
Для создания движка (объекта Engine) используется функция create_engine() из пакета sqlalchemy. В базовом виде она принимает только строку подключения. Последняя включает информацию об источнике данных. Обычно это приблизительно следующий формат:
dialect+driver://username:password@host:port/databasedialect— это имя базы данных (mysql, postgresql, mssql, oracle и так далее).driver— используемый DBAPI. Этот параметр является необязательным. Если его не указать будет использоваться драйвер по умолчанию (если он установлен).usernameиpassword— данные для получения доступа к базе данных.host— расположение сервера базы данных.port— порт для подключения.database— название базы данных.
Вот код для создания движка некоторых популярных баз данных:
from sqlalchemy import create_engine
# Подключение к серверу MySQL на localhost с помощью PyMySQL DBAPI.
engine = create_engine("mysql+pymysql://root:pass@localhost/mydb")
# Подключение к серверу MySQL по ip 23.92.23.113 с использованием mysql-python DBAPI.
engine = create_engine("mysql+mysqldb://root:pass@23.92.23.113/mydb")
# Подключение к серверу PostgreSQL на localhost с помощью psycopg2 DBAPI
engine = create_engine("postgresql+psycopg2://root:pass@localhost/mydb")
# Подключение к серверу Oracle на локальном хосте с помощью cx-Oracle DBAPI.
engine = create_engine("oracle+cx_oracle://root:pass@localhost/mydb"))
# Подключение к MSSQL серверу на localhost с помощью PyODBC DBAPI.
engine = create_engine("oracle+pyodbc://root:pass@localhost/mydb")
Формат строки подключения для базы данных SQLite немного отличается. Поскольку это файловая база данных, для нее не нужны имя пользователя, пароль, порт и хост. Вот как создать движок для базы данных SQLite:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sqlite3.db') # используя относительный путь
engine = create_engine('sqlite:////path/to/sqlite3.db') # абсолютный путь
Подключение к базе данных
Но создание движка — это еще не подключение к базе данных. Для получения соединения нужно использовать метод connect() объекта Engine, который возвращает объект типа Connection.
from sqlalchemy import create_engine
# 1111 это мой пароль для пользователя postgres
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
engine.connect()
print(engine)
Но если запустить его, то будет следующая ошибка:
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError)
(Background on this error at: http://sqlalche.me/e/14/e3q8)Проблема в том, что предпринимается попытка подключиться к несуществующей базе данных. Для создания базы данных PostgreSQL нужно выполнить следующий код:
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
# Устанавливаем соединение с postgres
connection = psycopg2.connect(user="postgres", password="1111")
connection.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
# Создаем курсор для выполнения операций с базой данных
cursor = connection.cursor()
sql_create_database =
# Создаем базу данных
cursor.execute('create database sqlalchemy_tuts')
# Закрываем соединение
cursor.close()
connection.close()
Запустите скрипт еще раз, чтобы получить нужный вывод:
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Дополнительные аргументы
В следующей таблице перечислены дополнительные аргументы-ключевые слова, которые можно передать в функцию create_engine().
| Аргумент | Описание |
echo | Булево значение. Если задать True, то движок будет сохранять логи SQL в стандартный вывод. По умолчанию значение равно False |
pool_size | Определяет количество соединений для пула. По умолчанию — 5 |
max_overflow | Определяет количество соединений вне значения pool_size. По умолчанию — 10 |
encoding | Определяет кодировку SQLAlchemy. По умолчанию — UTF-8. Однако этот параметр не влияет на кодировку всей базы данных |
isolation_level | Уровень изоляции. Эта настройка контролирует степень изоляции одной транзакции. Разные базы данных поддерживают разные уровни. Для этого лучше ознакомиться с документацией конкретной базы данных |
Вот скрипт, в котором использованы дополнительные аргументы-ключевые слова при создании движка:
from sqlalchemy import create_engine
engine = create_engine(
"postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts",
echo=True, pool_size=6, max_overflow=10, encoding='latin1'
)
engine.connect()
print(engine)
Запустите его, чтобы получить следующий вывод:
2021-04-16 15:12:59,983 INFO sqlalchemy.engine.Engine select version()
2021-04-16 15:13:00,023 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,028 INFO sqlalchemy.engine.Engine select current_schema()
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine show standard_conforming_strings
2021-04-16 15:13:00,048 INFO sqlalchemy.engine.Engine [raw sql] {}
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Зачем использовать SQLAlchemy
Самая важная особенность SQLAlchemy — это ее ORM. ORM или Object Relational Mapper (объектно-реляционное отображение) позволяет работать с базой данных с помощью объектно-ориентированного кода, не используя SQL-запросы. Еще одна особенность SQLAlchemy — код приложения будет оставаться тем же вне зависимости от используемой базы данных. Это позволяет с легкостью мигрировать с одной базы данных на другую, не переписывая код.
У SQLAlchemy есть компонент, который называется SQLAlchemy Core. Это абстракция над традиционным SQL. Он предоставляет SQL Expression Language, позволяющий генерировать SQL-инструкции с помощью конструкций Python.
В отличие от ORM, который сосредоточен на моделях и объектах, Core фокусируется на таблицах, колонках, индексах и так далее (по аналогии с обычным SQL). SQL Expression Language очень похож на SQL, однако он стандартизирован, поэтому его можно использовать в разных базах данных. SQLAlchemy ORM и Core можно использовать независимо друг от друга. Под капотом SQLAlchemy ORM использует Core.
Так что использовать: Core или ORM?
Смысл ORM — упрощение процесса работы с базой данных. В процессе добавляется некая сложность, однако она незаметна, если работать с не очень большими объемами данных. Для большинства проектов ORM будет достаточно, однако там, где имеется много данных, стоит работать с чистым SQL.
Кто использует SQLAlchemy
- Hulu
- Fedora Project
- Dropbox
- OpenStack
- и многие другие.
Уроки по SQLAlchemy
Чтобы разобраться с руководством, нужно иметь базовые знания в Python и SQL.
]]>Для работы понадобится python 3.6+, библиотеки SQLAlchemy и Flask. Код урока здесь.
Версии библиотек в файлеrequirements.txt
В этом материале речь пойдет об основах SQLAlchemy. Создадим веб-приложение на Flask, фреймворке языка Python. Это будет минималистичное приложение, которое ведет учет книг.
С его помощью можно будет добавлять новые книги, читать уже существующие, обновлять и удалять их. Эти операции — создание, чтение, обновление и удаление — также известны как «CRUD» и составляют основу почти всех веб-приложений. О них отдельно пойдет речь в статье.
Но прежде чем переходить к CRUD, разберемся с отдельными элементами приложения, начиная с SQLAlchemy.
Что такое SQLAlchemy?
Стоит отметить, что существует расширение для Flask под названием flask-sqlalchemy, которое упрощает процесс использования SQLAlchemy с помощью некоторых значений по умолчанию и других элементов. Они в первую очередь облегчают выполнение базовых задач. Но в этом материале будет использоваться только чистый SQLAlchemy, чтобы разобраться в его основах без разных расширений.
Как написано на сайте библиотеки «SQLAlchemy — это набор SQL-инструментов для Python и инструмент объектно-реляционного отображения (ORM), который предоставляет разработчикам всю мощь и гибкость SQL».
При чтении этого определения в первую очередь возникает вопрос: а что же такое объектно-реляционное отображение? ORM — это техника, используемая для написания запросов к базам данных с помощью парадигм объектно-ориентированного программирования выбранного языка (Python в этом случае).
Если еще проще, ORM — это своеобразный переводчик, который переводит код с одного набора абстракций в другой. В этом случае — из Python в SQL.
Есть масса причин, почему стоит использовать ORM, а не вручную сооружать строки SQL. Вот некоторые из них:
- Ускорение веб-разработки, ведь пропадает необходимость переключаться между написанием кода Python и SQL
- Устранение повторяющегося кода
- Оптимизация рабочего процесса и более эффективные запросы к базе данных
- Абстрагирование системы базы данных, так что переключение между несколькими базами становится более плавным
- Генерация шаблонного кода для основных операций CRUD
Углубимся еще сильнее.
Зачем использовать ORM, когда можно писать сырой SQL? При написании запросов на сыром SQL, мы передаем их базе данных в виде строк. Следующий запрос написан на сыром SQL:
#импорт sqlite
import sqlite3
# подключаемся к базе данных коллекции книг
conn = sqlite3.connect('books-collection.db')
# создаем объект cursor, для работы с базой данных
c = conn.cursor()
# делаем запрос, который создает таблицу books с идентификатором и именем
c.execute('''
CREATE TABLE books
(id INTEGER PRIMARY KEY ASC,
name varchar(250) NOT NULL)
''' )
# выполняет запрос, который вставляет значения в таблицу
c.execute("INSERT INTO books VALUES(1, 'Чистый Python')")
# сохраняем работу
conn.commit()
# закрываем соединение
conn.close()
Нет ничего плохого в использовании чистого SQL для обращения к базам данных, только если вы не сделаете ошибку в запросе. Это может быть, например, опечатка в названии базы, к которой происходит обращение или неправильное название таблицы. Компилятор Python здесь ничем не поможет.
SQLAlchemy — один из множества ORM-инструментов для Python. При работе с маленькими приложения чистый SQL может сработать. Но если это большой сайт с массой данных, такой подход сильнее подвержен ошибкам и просто более сложен.
Создание базы данных с помощью SQLAlchemy
Создадим файл для настройки базы данных. Можете назвать его как угодно, но пусть это будет database_setup.py.
import sys
# для настройки баз данных
from sqlalchemy import Column, ForeignKey, Integer, String
# для определения таблицы и модели
from sqlalchemy.ext.declarative import declarative_base
# для создания отношений между таблицами
from sqlalchemy.orm import relationship
# для настроек
from sqlalchemy import create_engine
# создание экземпляра declarative_base
Base = declarative_base()
# здесь добавим классы
# создает экземпляр create_engine в конце файла
engine = create_engine('sqlite:///books-collection.db')
Base.metadata.create_all(engine)
В верхней части файла импортируем все необходимые модули для настройки и создания баз данных. Для определения колонок в таблицах импортируем Column, ForeignKey, Integer и String.
Далее импортируем расширение declarative_base. Base = declarative_base() создает базовый класс для определения декларативного класса и присваивает его переменной Base.
Согласно документации declarative_base() возвращает новый базовый класс, который наследуют все связанные классы. Это таблица, mapper() и объекты класса в пределах его определения.
Далее создаем экземпляр класса create_engine, который указывает на базу данных с помощью engine = create_engine('sqlite:///books-collection.db'). Можно назвать базу данных как угодно, но здесь пусть будет books-collection.
Последний этап настройки — добавление Base.metadata.create_all(engine). Это добавит классы (напишем их чуть позже) в виде таблиц созданной базы данных.
После настройки базы данных создаем классы. В SQLAlchemy классы являются объектно-ориентированными или декларативными представлениями таблицы в базе данных.
# мы создаем класс Book наследуя его из класса Base.
class Book(Base):
__tablename__ = 'book'
id = Column(Integer, primary_key=True)
title = Column(String(250), nullable=False)
author = Column(String(250), nullable=False)
genre = Column(String(250))
Для этого руководства достаточно одной таблицы: Book. Она будет содержать 4 колонки: id, title, author и genre. Integer и String используются для определения типа значений, которые будут храниться в колонках. Колонка с названием, именем автора и жанром — это строки, а id — число.
Есть много атрибутов класса, которые используются для определения колонок, но рассмотрим уже использованные:
primary_key: при значенииTrueуказывает на значение, используемое для идентификации каждой уникальной строки таблицы.String(250): String — тип значения, а значение в скобках — максимальная длина строки.Integer: указывает тип значения (целое число).nullable: еслиFalse, это значит, что для создания строки обязательно должно быть значение .
На этом процесс настройки заканчивается. Если сейчас использовать команду python database_setup.py в командной строке, будет создана пустая база данных books-collection.db. Теперь можно наполнять ее данными и пробовать обращаться.
CRUD с SQLAlchemy на примерах
В начале кратко была затронута тема операций CRUD. Пришло время их использовать.
Создадим еще один файл и назовем его populate.py (или любым другим именем).
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# импортируем классы Book и Base из файла database_setup.py
from database_setup import Book, Base
engine = create_engine('sqlite:///books-collection.db')
# Свяжим engine с метаданными класса Base,
# чтобы декларативы могли получить доступ через экземпляр DBSession
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
# Экземпляр DBSession() отвечает за все обращения к базе данных
# и представляет «промежуточную зону» для всех объектов,
# загруженных в объект сессии базы данных.
session = DBSession()
В первую очередь импортируем все зависимости и некоторые классы из файла database_setup.py.
Затем сообщим программе, с какой базой данных хотим взаимодействовать. Это делается с помощью функции create_engine.
Что бы создать соединение между определениями класса и таблицами в базе данных, используем команду Base.metadata.bind.
Для создания, удаления, чтения или обновления записей в базе данных SQLAlchemy предоставляет интерфейс под названием Session. Для выполнения запросов необходимо добавлять и фиксировать (делать комит) запроса. Используем метод flush(). Он переносит изменения из памяти в буфер транзакции базы данных без фиксации изменения.
CREATE:
Стандартный процесс создания записи следующий:
entryName = ClassName(property="value", property="value" ... )
# Чтобы сохранить наш объект ClassName, мы добавляем его в наш сессию:
session.add(entryName)
'''
Чтобы сохранить изменения в нашу базу данных и зафиксировать
транзакцию, мы используем commit(). Любое изменение,
внесенное для объектов в сессии, не будет сохранено
в базу данных, пока вы не вызовете session.commit().
'''
session.commit()
Создать первую книгу можно с помощью следующей команды:
bookOne = Book(title="Чистый Python", author="Дэн Бейде", genre="компьютерная литература")
session.add(bookOne)
session.commit()
READ:
В зависимости от того, что нужно прочитать, используются разные функции. Рассмотрим два варианты их использования в приложении.
session.query(Book).all() — вернет список всех книг
session.query(Book).first() — вернет первый результат или None, если строки нет
UPDATE:
Для обновления записей в базе данных, нужно проделать следующее:
- Найти запись
- Сбросить значения
- Добавить новую запись
- Зафиксировать сессию в базе данных (сделать комит)
Если еще не заметили, в записи bookOne есть ошибка. Книгу «Чистый Python» написал Дэн Бейдер, а не «Дэн Бейде». Обновим имя автора с помощью 4 описанных шагов.
Для поиска записи используется filter(), который фильтрует запросы на основе атрибутов записей. Следующий запрос выдаст книгу с id=1 (то есть, «Чистый Python»)
editedBook = session.query(Book).filter_by(id=1).one()
Чтобы сбросить и зафиксировать имя автора, нужны следующие команды:
editedBook.author = "Дэн Бейдер"
session.add(editedBook)
session.commit()
Можно использовать all(), one() или first() для поиска записи в зависимости от ожидаемого результата. Но есть несколько нюансов, о которых важно помнить.
all()— возвращает результаты запроса в виде спискаone()— возвращает один результат или вызывает исключение. Вызовет исключениеsqlaclhemy.orm.exc.NoResultFoud, если результат не найден илиsqlaclhemy.orm.exc.NoResultFoud, если были возвращены несколько результатовfirst()— вернет первый результат запроса илиNone, если он не содержит строк, но без исключения
DELETE:
Удаление значений из базы данных — это почти то же самое, что и обновление:
- Находим запись
- Удаляем запись
- Фиксируем сессию
bookToDelete = session.query(Book).filter_by(title='Чистый Python').one()
session.delete(bookToDelete)
session.commit()
Теперь когда база данных настроена и есть базовое понимание CRUD-операций, пришло время написать небольшое приложение Flask. Но в сам фреймворк не будем углубляться. О нем можно подробнее почитать в других материалах.
Создадим новый файл app.py в той же папке, что и database_setup.py и populate.py. Затем импортируем необходимые зависимости.
from flask import Flask, render_template, request, redirect, url_for
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from database_setup import Base, Book
app = Flask(__name__)
# Подключаемся и создаем сессию базы данных
engine = create_engine('sqlite:///books-collection.db?check_same_thread=False')
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
session = DBSession()
# страница, которая будет отображать все книги в базе данных
# Эта функция работает в режиме чтения.
@app.route('/')
@app.route('/books')
def showBooks():
books = session.query(Book).all()
return render_template("books.html", books=books)
# Эта функция позволит создать новую книгу и сохранить ее в базе данных.
@app.route('/books/new/', methods=['GET', 'POST'])
def newBook():
if request.method == 'POST':
newBook = Book(title=request.form['name'], author=request.form['author'], genre=request.form['genre'])
session.add(newBook)
session.commit()
return redirect(url_for('showBooks'))
else:
return render_template('newBook.html')
# Эта функция позволит нам обновить книги и сохранить их в базе данных.
@app.route("/books/<int:book_id>/edit/", methods=['GET', 'POST'])
def editBook(book_id):
editedBook = session.query(Book).filter_by(id=book_id).one()
if request.method == 'POST':
if request.form['name']:
editedBook.title = request.form['name']
return redirect(url_for('showBooks'))
else:
return render_template('editBook.html', book=editedBook)
# Эта функция для удаления книг
@app.route('/books/<int:book_id>/delete/', methods=['GET', 'POST'])
def deleteBook(book_id):
bookToDelete = session.query(Book).filter_by(id=book_id).one()
if request.method == 'POST':
session.delete(bookToDelete)
session.commit()
return redirect(url_for('showBooks', book_id=book_id))
else:
return render_template('deleteBook.html', book=bookToDelete)
if __name__ == '__main__':
app.debug = True
app.run(port=4996)
Наконец, нужно создать шаблоны: books.html, newBook.html, editBook.html и deleteBook.html. Для этого создадим папку с шаблонами во Flask templates на том же уровне, где находится файл app.py. Внутри него создадим четыре файла.
books.html
<html>
<body>
<h1>Books</h1>
<a href="{{url_for('newBook')}}">
<button>Добавить книгу</button>
</a>
<ol>
{% for book in books %}
<li> {{book.title}} by {{book.author}} </li>
<a href="{{url_for('editBook', book_id = book.id )}}">
Изменить
</a>
<a href="{{url_for('deleteBook', book_id = book.id )}}" style="margin-left: 10px;">
Удалить
</a>
<br> <br>
{% endfor %}
</ol>
</body>
</html>
Теперь newBook.html.
<h1>Add a Book</h1>
<form action="#" method="post">
<div class="form-group">
<label for="name">Название:</label>
<input type="text" maxlength="100" name="name" placeholder="Название книги">
<label for="author">Автор:</label>
<input maxlength="100" name="author" placeholder="Автор книги">
<label for="genre">Жанр:</label>
<input maxlength="100" name="genre" placeholder="Жанр книги">
<button type="submit">Добавить</button>
</div>
</form>
Дальше editBook.html.
<form action="{{ url_for('editBook',book_id = book.id)}}" method="post">
<div class="form-group">
<label for="name">Название:</label>
<input type="text" class="form-control" name="name" value="{{book.title }}">
<button type="submit">Обновить</button>
</div>
</form>
<a href='{{ url_for('showBooks') }}'>
<button>Отменить</button>
</a>
И deleteBook.html.
<h2>Вы уверены, что хотите удалить {{book.title}}?</h2>
<form action="#" method='post'>
<button type="submit">Удалить</button>
</form>
<a href='{{url_for('showBooks')}}'>
<button>Отменить</button>
</a>
Если запустить приложение app.py и перейти в браузере на страницу https://localhost:4996/books, отобразится список книг. Добавьте несколько и если все работает, это выглядит вот так:

Расширение приложения и выводы
Если вы добрались до этого момента, то теперь знаете чуть больше о том, как работает SQLAlchemy. Это важная и объемная тема, а в этом материале речь шла только об основных вещах, поэтому поработайте с другими CRUD-операциями и добавьте в приложение новые функции.
Можете добавить таблицу Shelf в базу данных, чтобы отслеживать свой прогресс чтения, или даже реализовать аутентификацию с авторизацией. Это сделает приложение более масштабируемым, а также позволит другим пользователям добавлять собственные книги.
Добавление данных
Чтобы создать новую запись с данными с помощью SQLAlchemy, нужно выполнить следующие шаги:
- Создать объект
- Добавить объект в сессию
- Загрузить (сделать коммит) сессию
В SAQLAlchemy взаимодействие с базой данных происходит с помощью сессии. К счастью, ее не нужно создавать вручную. Это делает Flask-SQLAlchemy. Доступ к объекту сессии можно получить с помощью db.session. Это объект сессии, которые отвечает за подключение к базе данных. Он же отвечает за процесс транзакции. По умолчанию транзакция запускается и остается открытой до тех пор, пока выполняются коммиты и откаты.
Запустим оболочку Python для создания некоторых объектов модели:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>>
>>> c1 = Category(name='Python', slug='python')
>>> c2 = Category(name='Java', slug='java')
>>>
Были созданы два объекта Category. Получить доступ к их атрибутам можно с помощью оператора точки (.):
>>>
>>> c1.name, c1.slug
('Python', 'python')
>>>
>>> c2.name, c2.slug
('Java', 'java')
>>>
Дальше необходимо добавить объекты в сессию.
>>>
>>> db.session.add(c1)
>>> db.session.add(c2)
>>>
Добавление объектов не записывает их в базу данных , этот процесс лишь готовит их для сохранения при следующей коммите. Удостовериться в этом можно, проверив первичный ключ объектов.
>>>
>>> print(c1.id)
None
>>>
>>> print(c2.id)
None
>>>
Значение атрибута id обоих объектов — None. Это значит, что объекты не сохранены в базе данных.
Вместо добавления по одному объекту в сессию каждый раз, можно использовать метод add_all(). Метод add_all() принимает список объектов, которые нужно добавить в сессию.
>>>
>>> db.session.add_all([c1, c1])
>>>
Если попытаться добавить объект в сессию несколько раз, ошибок не возникнет. В любой момент можно посмотреть все объекты сессии с помощью db.session.new.
>>>
>>> db.session.new
IdentitySet([<None:Python>, <None:java>])
>>>
Наконец, для сохранения объектов в базе данных нужно вызвать метод commit():
>>>
>>> db.session.commit()
>>>
Если обратиться к атрибуту id объекта Category сейчас, то он вернет первичный ключ, а не None.
>>>
>>> print(c1.id)
1
>>>
>>> print(c2.id)
2
>>>
На этом этапе таблица categories в HeidiSQL должна выглядеть примерно так:

Новые категории пока не связаны с постами. Поэтому c1.posts и c2.posts вернут пустой список.
>>>
>>> c1.posts
[]
>>>
>>> c2.posts
[]
>>>
Стоит попробовать создать несколько постов.
>>>
>>> p1 = Post(title='Post 1', slug='post-1', content='Post 1', category=c1)
>>> p2 = Post(title='Post 2', slug='post-2', content='Post 2', category=c1)
>>> p3 = Post(title='Post 3', slug='post-3', content='Post 3', category=c2)
>>>
Вместо того чтобы передавать категорию при создании объекта Post, можно выполнить следующую команду:
>>>
>>> p1.category = c1
>>>
Дальше нужно добавить объекты в сессию и сделать коммит.
>>>
>>> db.session.add_all([p1, p2, p3])
>>> db.session.commit()
>>>
Если сейчас попробовать получить доступ к атрибуту posts объекта Category, то он вернет не-пустой список:
>>>
>>> c1.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> c2.posts
[<3:Post 3>]
>>>
С другой стороны отношения, можно получить доступ к объекту Category, к которому относится пост, с помощью атрибута category у объекта Post.
>>>
>>> p1.category
<1:Python>
>>>
>>> p2.category
<1:Python>
>>>
>>> p3.category
<2:Java>
>>>
Стоит напомнить, что все это возможно благодаря инструкции relationship() в модели Category. Сейчас в базе данных есть три поста, но ни один из них не связан с тегами.
>>>
>>> p1.tags, p2.tags, p3.tags
([], [], [])
>>>
Пришло время создать теги. Это можно сделать в оболочке следующим образом:
>>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> db.session.add_all([t1, t2, t3])
>>> db.session.commit()
>>>
Этот код создает три объекта тегов и делает их коммит в базу данных. Посты все еще не привязаны к тегам. Вот как можно связать объект Post с объектом Tag.
>>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add_all([p1, p2, p3])
>>>
>>> db.session.commit()
>>>
Этот коммит добавляет следующие пять записей в таблицу post_tags.

Посты теперь связаны с одним или большим количеством тегов:
>>>
>>> p1.tags
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> p2.tags
[<2:snippet>]
>>>
>>> p3.tags
[<3:analytics>]
>>>
С другой стороны можно получить доступ к постам, которые относятся к конкретному тегу:
>>>
>>> t1.posts
[<1:Post 1>]
>>>
>>> t2.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> t3.posts
[<1:Post 1>, <3:Post 3>]
>>>
>>>
Важно отметить, что вместо изначального коммита объектов Tag и последующей их связи с объектами Post, все это можно сделать и таким способом:
>>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add(p1)
>>> db.session.add(p2)
>>> db.session.add(p3)
>>>
>>> db.session.commit()
>>>
Важно обратить внимание, что на строках 11-13 в сессию добавляются только объекты Post. Объекты Tag и Post связаны отношением многие-ко-многим. В результате, добавление объекта Post в сессию влечет за собой добавление связанных с ним объектов Tag. Но даже если сейчас вручную добавить объекты Tag в сессию, ошибки не будет.
Обновление данных
Для обновления объекта нужно всего лишь передать его атрибуту новое значение, добавить объект в сессию и сделать коммит.
>>>
>>> p1.content # начальное значение
'Post 1'
>>>
>>> p1.content = "This is content for post 1" # задаем новое значение
>>> db.session.add(p1)
>>>
>>> db.session.commit()
>>>
>>> p1.content # обновленное значение
'This is content for post 1'
>>>
Удаление данных
Для удаления объекта нужно использовать метод delete() объекта сессии. Он принимает объект и отмечает, что тот подлежит удалению при следующем коммите.
Создадим новый временный тег seo и свяжем его с постами p1 и p2:
>>>
>>> tmp = Tag(name='seo', slug='seo') # создание временного объекта Tag
>>>
>>> p1.tags.append(tmp)
>>> p2.tags.append(tmp)
>>>
>>> db.session.add_all([p1, p2])
>>> db.session.commit()
>>>
Этот коммит добавляет всего 3 строки: одну в таблицу table и еще две — в таблицу post_tags. В базе данных эти три строки выглядят следующим образом:


Теперь нужно удалить тег seo:
>>>
>>> db.session.delete(tmp)
>>> db.session.commit()
>>>
Этот коммит удаляет все три строки, добавленные в предыдущем шаге. Тем не менее он не удаляет пост, с которым тег был связан.
По умолчанию при удалении объекта в родительской таблице (например, categories) значение внешнего ключа объекта, который с ним связан в дочерней таблице (например, posts) становится NULL. Следующий код демонстрирует это поведение на примере создания нового объекта категории и объекта поста, который с ней связан, и дальнейшим удалением объекта категории:
>>>
>>> c4 = Category(name='css', slug='css')
>>> p4 = Post(title='Post 4', slug='post-4', content='Post 4', category=c4)
>>>
>>> db.session.add(c4)
>>>
>>> db.session.new
IdentitySet([<None:css>, <None:Post 4>])
>>>
>>> db.session.commit()
>>>
Этот коммит добавляет две строки. Одну в таблицу categories, и еще одну — в таблицу posts.


Теперь нужно посмотреть, что происходит при удалении объекта Category.
>>>
>>> db.session.delete(c4)
>>> db.session.commit()
>>>
Этот коммит удаляет категорию css из таблицы categories и устанавливает значение внешнего ключа (category_id) для поста, который с ней связан, на NULL.

В некоторых случаях может возникнуть необходимость удалить все дочерние записи при том, что родительские записи уже удалены. Это можно сделать, передав cascade=’all,delete-orphan’ инструкции db.relationship(). Откроем main2.py, чтобы изменить инструкцию db.relationship() в модели Catagory:
#...
class Category(db.Model):
#...
posts = db.relationship('Post', backref='category', cascade='all,delete-orphan')
#...
С этого момента удаление категории повлечет за собой удаление постов, которые с ней связаны. Чтобы это начало работать, нужно перезапустить оболочку. Далее импортируем нужные объекты и создаем категорию вместе с постом:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>> c5 = Category(name='css', slug='css')
>>> p5 = Post(title='Post 5', slug='post-5', content='Post 5', category=c5)
>>>
>>> db.session.add(c5)
>>> db.session.commit()
>>>
Вот как база данных выглядит после этого коммита.


Удалим категорию.
>>>
>>> db.session.delete(c5)
>>> db.session.commit()
>>>
После этого коммита база данных выглядит вот так:
Запрос данных
Чтобы выполнить запрос к базе данных, используется метод query() объекта session. Метод query() возвращает объект flask_sqlalchemy.BaseQuery, который является расширением оригинального объекта sqlalchemy.orm.query.Query. Объект flask_sqlalchemy.BaseQuery представляет собой оператор SELECT, который будет использоваться для осуществления запросов к базе данных. В этой таблице перечислены основные методы класса flask_sqlalchemy.BaseQuery.
| Метод | Описание |
|---|---|
| all() | Возвращает результат запроса (представленный flask_sqlalchemy.BaseQuery) в виде списка. |
| count() | Возвращает количество записей в запросе. |
| first() | Возвращает первый результат запроса или None, если в нем нет строк. |
| first_or_404() | Возвращает первый результат запроса или ошибку 404, если в нем нет строк. |
| get(pk) | Возвращает объект, который соответствует данному первичному ключу или None, если объект не найден. |
| get_or_404(pk) | Возвращает объект, который соответствует данному первичному ключу или ошибку 404, если объект не найден. |
| filter(*criterion) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором WHERE. |
| limit(limit) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором LIMIT. |
| offset(offset) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором OFFSET. |
| order_by(*criterion) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором OFFSET. |
| join() | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery после создания SQL JOIN. |
Метод all()
В своей простейшей форме метод query() принимает в качестве аргументов один или больше классов модели или колонки. Следующий код вернет все записи из таблицы posts.
>>>
>>> db.session.query(Post).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>, <4:Post 4>]
>>>
Похожим образом следующий код вернет все записи из таблиц categories и tags.
>>>
>>> db.session.query(Category).all()
[<1:Python>, <2:Java>]
>>>
>>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
Чтобы получить чистый SQL, использованный для запроса к базе данных, нужно просто вывести объект flask_sqlalchemy.BaseQuery:
>>>
>>> print(db.session.query(Post))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
>>>
В предыдущих примерах данные возвращались со всех колонок таблицы. Это можно поменять, передав методу query() названия колонок:
>>>
>>> db.session.query(Post.id, Post.title).all()
[(1, 'Post 1'), (2, 'Post 2'), (3, 'Post 3'), (4, 'Post 4')]
>>>
Метод count()
Метод count() возвращает количество результатов в запросе.
>>>
>>> db.session.query(Post).count() # получить общее количество записей в таблице Post
4
>>> db.session.query(Category).count() # получить общее количество записей в таблице Category
2
>>> db.session.query(Tag).count() # получить общее количество записей в таблице Tag
3
>>>
Метод first()
Метод first() вернет только первый запрос из запроса или None, если в запросе нет результатов.
>>>
>>> db.session.query(Post).first()
<1:Post 1>
>>>
>>> db.session.query(Category).first()
<1:Python>
>>>
>>> db.session.query(Tag).first()
<1:refactoring>
>>>
Метод get()
Метод get() вернет экземпляр объекта с соответствующим первичным ключом или None, если такой объект не был найден.
>>>
>>> db.session.query(Post).get(2)
<2:Post 2>
>>>
>>> db.session.query(Category).get(1)
<1:Python>
>>>
>>> print(db.session.query(Category).get(10)) # ничего не найдено по первичному ключу 10
None
>>>
Метод get_or_404()
То же самое, что и метод get(), но вместо None вернет ошибку 404, если объект не найден.
>>>
>>> db.session.query(Post).get_or_404(1)
<1:Post 1>
>>>
>>>
>>> db.session.query(Post).get_or_404(100)
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
>>>
Метод filter()
Метод filter() позволяет отсортировать результатов с помощью оператора WHERE, примененного к запросу. Он принимает колонку, оператор или значение. Например:
>>>
>>> db.session.query(Post).filter(Post.title == 'Post 1').all()
[<1:Post 1>]
>>>
Запрос вернет все посты с заголовком "Post 1". SQL-эквивалент запроса следующий:
>>>
>>> print(db.session.query(Post).filter(Post.title == 'Post 1'))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.title = % (title_1) s
>>>
>>>
Строка % (title_1) s в условии WHERE — это заполнитель. На ее месте будет реальное значение при выполнении запроса.
Методу filter() можно передать несколько значений и они будут объединены оператором AND в SQL. Например:
>>>
>>> db.session.query(Post).filter(Post.id >= 1, Post.id <= 2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>>
Этот запрос вернет все посты, первичный ключ которых больше 1, но меньше 2. SQL-эквивалент:
>>>
>>> print(db.session.query(Post).filter(Post.id >= 1, Post.id <= 2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
AND posts.id <= % (id_2) s
>>>
Метод first_or_404()
Делает то же самое, что и метод first(), но вместо None возвращает ошибку 404, если запрос без результата.
>>>
>>> db.session.query(Post).filter(Post.id > 1).first_or_404()
<2:Post 2>
>>>
>>> db.session.query(Post).filter(Post.id > 10).first_or_404().all()
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
>>>
Метод limit()
Метод limit() добавляет оператор LIMIT к запросу. Он принимает количество строк, которые нужно вернуть с запросом.
>>>
>>> db.session.query(Post).limit(2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>> db.session.query(Post).filter(Post.id >= 2).limit(1).all()
[<2:Post 2>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).limit(2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
LIMIT % (param_1) s
>>>
>>>
>>> print(db.session.query(Post).filter(Post.id >= 2).limit(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
LIMIT % (param_1) s
>>>
>>>
Метод offset()
Метод offset() добавляет условие OFFSET в запрос. В качестве аргумента он принимает смещение. Часто используется вместе с limit().
>>>
>>> db.session.query(Post).filter(Post.id > 1).limit(3).offset(1).all()
[<3:Post 3>, <4:Post 4>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).filter(Post.id > 1).limit(3).offset(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id > % (id_1) s
LIMIT % (param_1) s, % (param_2) s
>>>
Строки % (param_1) s и % (param_2) — заполнители для смещения и ограничения вывода, соответственно.
Метод order_by()
Метод order_by() используется, чтобы упорядочить результат, добавив к запросу оператор ORDER BY. Он принимает количество колонок, для которых нужно установить порядок. По умолчанию сортирует в порядке возрастания.
>>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> db.session.query(Tag).order_by(Tag.name).all()
[<3:analytics>, <1:refactoring>, <2:snippet>]
>>>
Для сортировки по убыванию нужно использовать функцию db.desc():
>>>
>>> db.session.query(Tag).order_by(db.desc(Tag.name)).all()
[<2:snippet>, <1:refactoring>, <3:analytics>]
>>>
Метод join()
Метод join() используется для создания JOIN в SQL. Он принимает имя таблицы, для которой нужно создать JOIN.
>>>
>>> db.session.query(Post).join(Category).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).join(Category))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
Метод join() широко используется, чтобы получить данные из одной или большего количества таблиц одним запросом. Например:
>>>
>>> db.session.query(Post.title, Category.name).join(Category).all()
[('Post 1', 'Python'), ('Post 2', 'Python'), ('Post 3', 'Java')]
>>>
Можно создать JOIN для большее чем двух таблиц с помощью цепочки методов join():
db.session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Закончить урок можно завершением контактной формы.
Стоит напомнить, что в уроке «Работа с формами во Flask» была создана контактная форма для получения обратной связи от пользователей. Пока что функция представления contact() не сохраняет отправленные данные. Она только выводит их в консоли. Для сохранения полученной информации сначала нужно создать новую таблицу. Откроем main2.py, чтобы добавить модель Feedback следом за моделью Tag:
#...
class Feedback(db.Model):
__tablename__ = 'feedbacks'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(1000), nullable=False)
email = db.Column(db.String(100), nullable=False)
message = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
#...
Дальше нужно перезапустить оболочку Python и вызвать метод create_all() объекта db для создания таблицы feedbacks:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db
>>>
>>> db.create_all()
>>>
Также нужно изменить функция представления contact():
#...
@app.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
print(name)
print(Post)
print(email)
print(message)
# здесь логика базы данных
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
print("\nData received. Now redirecting ...")
flash("Message Received", "success")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
#...
Запустим сервер и зайдем на https://127.0.0.1:5000/contact/, чтобы заполнить и отправить форму.

Отправленная запись в HeidiSQL будет выглядеть следующим образом:
