- Виртуализация
- Контейнеризация (с помощью Docker)
- Docker
- Создание Dockerfile
- Docker Compose
- Настройка Django приложения в среде Docker с помощью Dockerfile и docker-compose
Условия
Чтобы справиться с этим руководством вам нужно иметь следующее:
- Git/GitHub
- PyCharm (или любой другой редактор кода)
- Опыт работы с Django
Готовый репозиторий с Django-приложением, как всегда на GitLab: https://gitlab.com/PythonRu/django-docker.
Что такое виртуализация
Обычно при развертывании веб-приложения в хостинге (например, DigitalOcean или Linode) вы настраиваете виртуальную машину или виртуальный компьютер, куда будет перенесен весь код с помощью git, FTP или другими средствами. Это называется виртуализацией.
Со временем разработчики начали видеть недостатки такого процесса — как минимум затраты на приспосабливание к изменениям в операционной системе. Им хотелось объединить среды разработки и производственную, вследствие чего и появилась идея контейнеризации.
Что такое контейнеры, и что в них такого особенного?
Контейнер, если говорить простыми словами, — это место для среды разработки, то есть, вашего приложения и тех зависимостей, которые требуются для его работы.
Контейнеры позволяют разработчику упаковывать приложение со всеми зависимостями и передавать его между разными средами без каких-либо изменений.
Поскольку контейнеризация — куда более портативное, масштабируемое и эффективное решение, такие платформы, как Docker, становятся популярным выбором разработчиков.
Введение в Docker
Docker — это набор инструментов, с помощью которого можно создавать, управлять и запускать приложения в контейнерах. Он позволяет запросто упаковывать и запускать приложения в виде портативных, независимых и легких контейнеров, которые способны работать где угодно.
Установка Docker
Для установки Docker на компьютере, воспользуйтесь инструкцией с официального сайта. У каждой операционной системы есть своя версия приложения.
Настройка приложения
Для этого руководства используем репозиторий приложения для опросов, написанного на Django. По мере продвижения в этом руководстве настроим Dockerfile, в котором будут обозначены инструкции для контейнера, внутри которого приложение и будет работать. После этого же настроим и файл docker-compose.yml для упрощения всего процесса.
На ПК с установленным git перейдите в выбранную папку и клонируйте следующий репозиторий из GitLab:
git clone https://gitlab.com/PythonRu/django-docker.gitПосле этого перейдите в корень этой папки и откройте ее в редакторе с помощью такой команды:
cd django-docker && code .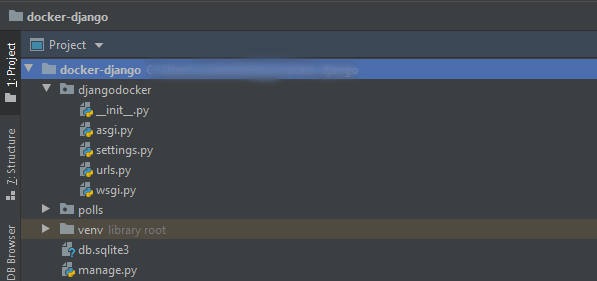
В этой папке создайте файл Dockerfile (регистр играет роль) без формата. Внутри него будут находиться настройки контейнера. Инструкции из него компьютер будет выполнять каждый раз при запуске команды docker build.
Следующий этап — создание файла requirements.txt, в котором перечислены все зависимости. Позже он будет использован для Dockerfile, в котором также требуется указывать все требуемые зависимости.
В файле requirements.txt добавьте Django версии 3.1.2 в таком формате:
Django==3.1.2Что такое Dockerfile
Идея написания Dockerfile может показаться сложной, но не забывайте, что это всего лишь инструкция (набор шагов) для создания собственных образов (images). Dockerfile будет содержать следующее:
- Базовый образ, на основе которого требуется построить свой. Он выступает своего рода фундаментом для вашего приложения. Это может быть операционная система, язык программирования (Python в нашем случае) или фреймворк.
- Пакеты и дополнительные инструменты для образа.
- Скрипты и файлы, которые требуется скопировать в образ. Обычно это и есть исходный код приложения.
При чтении или написании такого файла удобно держать в голове следующее:
- Строки с инструкциями обычно начинаются с ключевого слова, например:
RUN,FROM,COPY,WORKDIRи так далее. - Комментарии начинаются с символа
#. При выполнении инструкций из файла такие комментарии обычно игнорируются.
Создание Dockerfile
Приложение будет работать на основе официального образа Python. Напишем следующие инструкции:
# Указывает Docker использовать официальный образ python 3 с dockerhub в качестве базового образа
FROM python:3
# Устанавливает переменную окружения, которая гарантирует, что вывод из python будет отправлен прямо в терминал без предварительной буферизации
ENV PYTHONUNBUFFERED 1
# Устанавливает рабочий каталог контейнера — "app"
WORKDIR /app
# Копирует все файлы из нашего локального проекта в контейнер
ADD ./app
# Запускает команду pip install для всех библиотек, перечисленных в requirements.txt
RUN pip install -r requirements.txtФайл Docker Compose
Docker Compose — это отличный инструмент, помогающий определять и запускать приложения, для которых требуются несколько сервисов.
Обычно Docker Compose использует файл docker-compose.yml для настройки сервисов, которые приложение будет использовать. Запускаются эти сервисы с помощью команды docker-compose up. Это создает и запускает все сервисы из файла. В большинстве веб-приложений нужны, веб-сервер (такой как nginx) и база данных (например, PostgreSQL). В этом приложении будем использовать SQLite, поэтому внешняя база данных не потребуется.
Для использования особенностей Docker Compose нужно создать файл docker-compose.yml в той же папке, где находится Dockerfile и добавить туда следующий код:
version: '3.8'
services:
web:
build: .
command: python manage.py runserver localhost:8000
ports:
- 8000:8000Дальше разберем содержимое файла построчно:
version: '3.8'Эта строка сообщает Docker, какая версия docker-compose должна быть использована для запуска файла. На момент написания руководства последняя версия — 3.8, но обычно синтаксис не сильно меняется по мере выхода последующих.
После настройки docker-compose откройте терминал и запустите команду docker-compose up -d для запуска приложения. Дальше открывайте ссылку localhost:8000 в браузере, чтобы увидеть приложение в действии:
Для закрытия контейнера используется команда docker-compose down.
Выводы
Репозиторий проекта: https://gitlab.com/PythonRu/django-docker.
В этом руководстве вы познакомились с виртуализацией, контейнеризацией и другими терминами из мира Docker. Также вы теперь знаете, что такое Dockerfile, как его создавать для запуска контейнеризированного Django-приложения. Наконец, разобрались с настройкой docker-compose с помощью файла docker-compose.yml для сервисов, от которых зависит самое приложения.
Не существует единого правильного способа использовать Docker в Django-приложении, но считается хорошей практикой следовать официальным инструкциями, чтобы максимально обезопасить свое приложение.
]]>Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris().
from sklearn import datasets
# загрузка датасета
iris = datasets.load_iris()
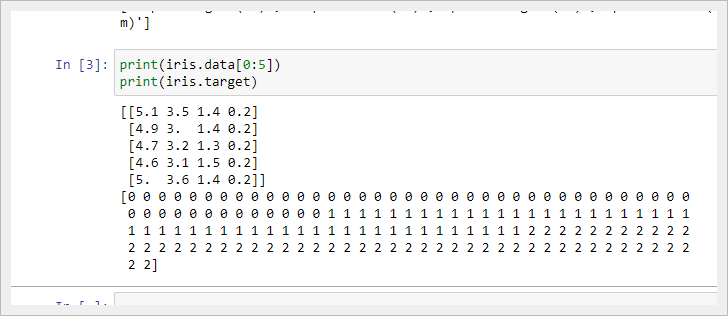
Вы можете отобразить имена целевого класса и признаков, чтобы убедиться, что это нужный вам датасет:
print(iris.target_names)
print(iris.feature_names)
['setosa' 'versicolor' 'virginica']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']Рекомендуется всегда хотя бы немного изучить свои данные, чтобы знать, с чем вы работаете. Здесь вы можете увидеть результат вывода первых пяти строк используемого набора данных, а также всех значений целевой переменной датасета.
Ниже мы создаем dataframe из нашего набора данных об ирисах.
import pandas as pd
data=pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
data.head()
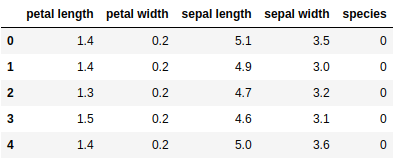
Далее мы разделяем столбцы на зависимые и независимые переменные (признаки и метки целевых классов). Затем давайте создадим выборки для обучения и тестирования из исходных данных.
from sklearn.model_selection import train_test_split
X = data[['sepal length', 'sepal width', 'petal length', 'petal width']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=85)
После этого мы сгенерируем модель случайного леса на обучающем наборе и выполним предсказания на тестовом.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
После создания модели стоит проверить ее точность, используя фактические и спрогнозированные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
Accuracy: 0.9333333333333333Вы также можете сделать предсказание для единственного наблюдения. Предположим, sepal length=3, sepal width=5, petal length=4, petal width=2.
Мы можем определить, к какому типу цветка относится выбранный, следующим образом:
clf.predict([[3, 5, 4, 2]])
# результат - 2
Выше цифра 2 указывает на класс цветка «virginica».
Поиск важных признаков с помощью scikit-learn
В этом разделе вы определяете наиболее значимые признаки или выполняете их отбор в датасете iris. В scikit-learn мы можем решить эту задачу, выполнив перечисленные шаги:
- Создадим модель случайного леса.
- Используем переменную
feature_importances_, чтобы увидеть соответствующие оценки значимости показателей. - Визуализируем полученные оценочные значения с помощью библиотеки seaborn.
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)
feature_imp
petal width (cm) 0.470224
petal length (cm) 0.424776
sepal length (cm) 0.075913
sepal width (cm) 0.029087Вы также можете визуализировать значимость признаков. Такое графическое отображение легко понять и интерпретировать. Кроме того, визуальное представление информации является самым быстрым способом ее усвоения человеческим мозгом.
Для построения необходимых диаграмм вы можете использовать библиотеки matplotlib и seaborn совместно, потому что seaborn, построенная поверх matplotlib, предлагает множество специальных тем и дополнительных графиков. Matplotlib — это надмножество seaborn, и обе библиотеки одинаково необходимы для хорошей визуализации.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.barplot(x=feature_imp, y=feature_imp.index)
plt.xlabel('Важность признаков')
plt.ylabel('Признаки')
plt.title('Визуализация важных признаков')
plt.show()
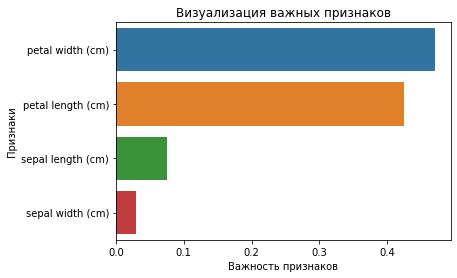
Повторная генерация модели с отобранными признаками
Далее мы удаляем показатель «sepal width» и используем оставшиеся 3 признака, поскольку ширина чашелистика имеет очень низкую важность.
from sklearn.model_selection import train_test_split
X = data[['petal length', 'petal width','sepal length']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=85)
После разделения вы сгенерируете модель случайного леса для выбранных признаков обучающей выборки, выполните прогноз на тестовом наборе и сравните фактические и предсказанные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
from sklearn import metrics
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.9619047619047619
Вы можете заметить, что после удаления наименее важных показателей (ширины чашелистика) точность увеличилась, поскольку мы устранили вводящие в заблуждение данные и уменьшили шум. Кроме того, ограничив количество значимых признаков, мы сократили время обучения модели.
Преимущества Random Forest:
- Случайный лес считается высокоточным и надежным методом, поскольку в процессе прогнозирования участвует множество деревьев решений.
- Random forest не страдает проблемой переобучения. Основная причина в том, что случайный лес использует среднее значение всех прогнозов, что устраняет смещения.
- RF может использоваться в обоих типах задач (задачах классификации и регрессии).
- Случайный лес также может работать с отсутствующими значениями. Есть два способа решения такой проблемы в Random forest. В первом используется медианное значение для заполнения непрерывных переменных, а во втором вычисляется среднее взвешенное пропущенных значений.
- RF также рассчитывает относительную важность показателей, которая помогает в выборе наиболее значимых признаков для классификатора.
Недостатки Random Forest:
- Случайный лес довольно медленный, так как для работы алгоритм использует множество деревьев: каждому дереву в лесу передаются одни и те же входные данные, на основании которых оно должно вернуть свое предсказание. После чего также происходит голосование на полученных прогнозах. Весь этот процесс занимает много времени.
- Модель случайного леса сложнее интерпретировать по сравнению с деревом решений, где вы легко определяете результат, следуя по пути в дереве.
Заключение
Вы узнали об алгоритме Random forest и принципе его работы, о поиске важных признаков, о главных отличиях случайного леса от дерева решений, о преимуществах и недостатках данного метода. Также научились создавать и оценивать модели, находить наиболее значимые показатели в scikit-learn. Не останавливайся на этом!
Я рекомендую вам попробовать RF на разных наборах данных и прочитать больше о матрице ошибок.
]]>Известный пример — спам-фильтр для электронной почты. Gmail использует методы машинного обучения с учителем, чтобы автоматически помещать электронные письма в папку для спама в зависимости от их содержания, темы и других характеристик.
Две модели машинного обучения выполняют большую часть работы, когда дело доходит до задач классификации:
- Метод K-ближайших соседей
- Метод К-средних
Из этого руководства вы узнаете, как применять алгоритмы K-ближайших соседей и K-средних в коде на Python.
Модели K-ближайших соседей
Алгоритм K-ближайших соседей является одним из самых популярных среди ML-моделей для решения задач классификации.
Обычным упражнением для студентов, изучающих машинное обучение, является применение алгоритма K-ближайших соседей к датасету, категории которого неизвестны. Реальным примером такой ситуации может быть случай, когда вам нужно делать предсказания, используя ML-модели, обученные на секретных правительственных данных.
В этом руководстве вы изучите алгоритм машинного обучения K-ближайших соседей и напишите его реализацию на Python. Мы будем работать с анонимным набором данных, как в описанной выше ситуации.
Используемый датасет
Первое, что вам нужно сделать, это скачать набор данных, который мы будем использовать в этом руководстве. Вы можете скачать его на Gitlab.
Далее вам нужно переместить загруженный файл с датасетом в рабочий каталог. После этого откройте Jupyter Notebook — теперь мы можем приступить к написанию кода на Python!
Необходимые библиотеки
Чтобы написать алгоритм K-ближайших соседей, мы воспользуемся преимуществами многих Python-библиотек с открытым исходным кодом, включая NumPy, pandas и scikit-learn.
Начните работу, добавив следующие инструкции импорта:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Импорт датасета
Следующий шаг — добавление файла classified_data.csv в наш код на Python. Библиотека pandas позволяет довольно просто импортировать данные в DataFrame.
Поскольку датасет хранится в файле csv, мы будем использовать метод read_csv:
raw_data = pd.read_csv('classified_data.csv')
Отобразив полученный DataFrame в Jupyter Notebook, вы увидите, что представляют собой наши данные:
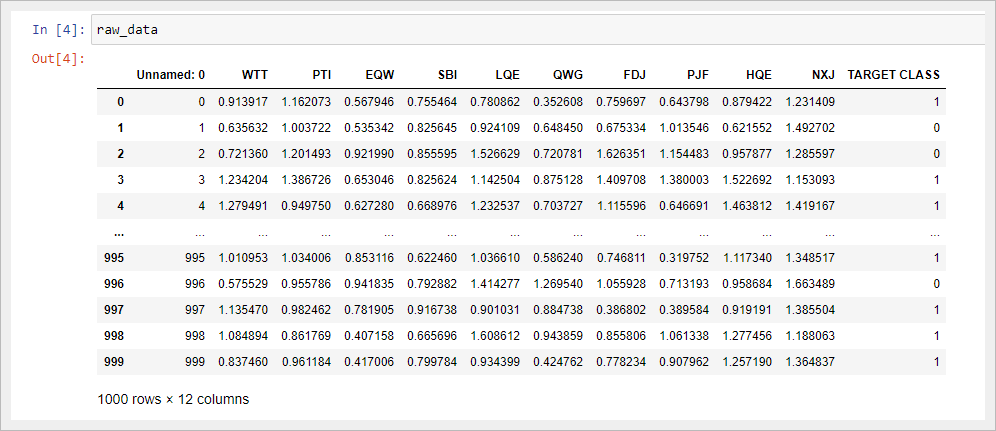
Стоит заметить, что таблица начинается с безымянного столбца, значения которого равны номерам строк DataFrame. Мы можем исправить это, немного изменив команду, которая импортировала наш набор данных в скрипт Python:
raw_data = pd.read_csv('classified_data.csv', index_col = 0)
Затем давайте посмотрим на показатели (признаки), содержащиеся в этом датасете. Вы можете вывести список имен столбцов с помощью следующей инструкции:
raw_data.columns
Получаем:
Index(['WTT', 'PTI', 'EQW', 'SBI', 'LQE', 'QWG', 'FDJ', 'PJF', 'HQE', 'NXJ',
'TARGET CLASS'],
dtype='object')Поскольку этот набор содержит секретные данные, мы понятия не имеем, что означает любой из этих столбцов. На данный момент достаточно признать, что каждый столбец является числовым по своей природе и поэтому хорошо подходит для моделирования с помощью методов машинного обучения.
Стандартизация датасета
Поскольку алгоритм K-ближайших соседей делает прогнозы относительно точки данных (семпла), используя наиболее близкие к ней наблюдения, существующий масштаб показателей в датасете имеет большое значение.
Из-за этого специалисты по машинному обучению обычно стандартизируют набор данных, что означает корректировку каждого значения x так, чтобы они находились примерно в одном диапазоне.
К счастью, библиотека scikit-learn позволяет сделать это без особых проблем.
Для начала нам нужно будет импортировать класс StandardScaler из scikit-learn. Для этого добавьте в свой скрипт Python следующую команду:
from sklearn.preprocessing import StandardScaler
Этот класс во многом похож на классы LinearRegression и LogisticRegression, которые мы использовали ранее в этом курсе. Нам нужно создать экземпляр StandardScaler, а затем использовать этот объект для преобразования наших данных.
Во-первых, давайте создадим экземпляр класса StandardScaler с именем scaler следующей инструкцией:
scaler = StandardScaler()
Теперь мы можем обучить scaler на нашем датасете, используя метод fit:
scaler.fit(raw_data.drop('TARGET CLASS', axis=1))
Теперь мы можем применить метод transform для стандартизации всех признаков, чтобы они имели примерно одинаковый масштаб. Мы сохраним преобразованные семплы в переменной scaled_features:
scaled_features = scaler.transform(raw_data.drop('TARGET CLASS', axis=1))
В качестве результата мы получили массив NumPy со всеми точками данных из датасета, но нам желательно преобразовать его в формат DataFrame библиотеки pandas.
К счастью, сделать это довольно легко. Мы просто обернем переменную scaled_features в метод pd.DataFrame и назначим этот DataFrame новой переменной scaled_data с соответствующим аргументом для указания имен столбцов:
scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop('TARGET CLASS', axis=1).columns)
Теперь, когда мы импортировали наш датасет и стандартизировали его показатели, мы готовы разделить этот набор данных на обучающую и тестовую выборки.
Разделение датасета на обучающие и тестовые данные
Мы будем использовать функцию train_test_split библиотеки scikit-learn в сочетании с распаковкой списка для создания обучающих и тестовых датасетов из нашего набора секретных данных.
Во-первых, вам нужно импортировать train_test_split из модуля model_validation библиотеки scikit-learn:
from sklearn.model_selection import train_test_split
Затем нам необходимо указать значения x и y, которые будут переданы в функцию train_test_split.
Значения x представляют собой DataFrame scaled_data, который мы создали ранее. Значения y хранятся в столбце "TARGET CLASS" нашей исходной таблицы raw_data.
Вы можете создать эти переменные следующим образом:
x = scaled_data
y = raw_data['TARGET CLASS']
Затем вам нужно запустить функцию train_test_split, используя эти два аргумента и разумный test_size. Мы будем использовать test_size 30%, что дает следующие параметры функции:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3)
Теперь, когда наш датасет разделен на данные для обучения и данные для тестирования, мы готовы приступить к обучению нашей модели!
Обучение модели K-ближайших соседей
Начнем с импорта KNeighborsClassifier из scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
Затем давайте создадим экземпляр класса KNeighborsClassifier и назначим его переменной model.
Для этого требуется передать параметр n_neighbors, который равен выбранному вами значению K алгоритма K-ближайших соседей. Для начала укажем n_neighbors = 1:
model = KNeighborsClassifier(n_neighbors = 1)
Теперь мы можем обучить нашу модель, используя метод fit и переменные x_training_data и y_training_data:
model.fit(x_training_data, y_training_data)
Теперь давайте сделаем несколько прогнозов с помощью полученной модели!
Делаем предсказания с помощью алгоритма K-ближайших соседей
Способ получения прогнозов на основе алгоритма K-ближайших соседей такой же, как и у моделей линейной и логистической регрессий, построенных нами ранее в этом курсе: для предсказания достаточно вызвать метод predict, передав в него переменную x_test_data.
В частности, вот так вы можете делать предсказания и присваивать их переменной predictions:
predictions = model.predict(x_test_data)
Давайте посмотрим, насколько точны наши прогнозы, в следующем разделе этого руководства.
Оценка точности нашей модели
В руководстве по логистической регрессии мы видели, что scikit-learn поставляется со встроенными функциями, которые упрощают измерение эффективности классификационных моделей машинного обучения.
Для начала импортируем в наш отчет две функции classification_report и confusion_matrix:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
Теперь давайте поработаем с каждой из них по очереди, начиная с classification_report. С ее помощью вы можете создать отчет следующим образом:
print(classification_report(y_test_data, predictions))
Полученный вывод:
precision recall f1-score support
0 0.92 0.91 0.91 148
1 0.91 0.92 0.92 152
accuracy 0.91 300
macro avg 0.91 0.91 0.91 300
weighted avg 0.91 0.91 0.91 300Точно так же вы можете сгенерировать матрицу ошибок:
print(confusion_matrix(y_test_data, predictions))
# Вывод:
# [[134 14]
# [ 12 140]]
Глядя на такие метрики производительности, похоже, что наша модель уже достаточно эффективна. Но ее еще можно улучшить.
В следующем разделе будет показано, как мы можем повлиять на работу модели K-ближайших соседей, выбрав более подходящее значение для K.
Выбор оптимального значения для K с помощью метода «Локтя»
В этом разделе мы будем использовать метод «локтя», чтобы выбрать оптимальное значение K для нашего алгоритма K-ближайших соседей.
Метод локтя включает в себя итерацию по различным значениям K и выбор значения с наименьшей частотой ошибок при применении к нашим тестовым данным.
Для начала создадим пустой список error_rates. Мы пройдемся по различным значениям K и добавим их частоту ошибок в этот список.
error_rates = []
Затем нам нужно создать цикл Python, который перебирает различные значения K, которые мы хотим протестировать, и на каждой итерации выполняет следующее:
- Создает новый экземпляр класса
KNeighborsClassifierиз scikit-learn. - Тренирует эту модель, используя наши обучающие данные.
- Делает прогнозы на основе наших тестовых данных.
- Вычисляет долю неверных предсказаний (чем она ниже, тем точнее наша модель).
Реализация описанного цикла для значений K от 1 до 100:
for i in np.arange(1, 101):
new_model = KNeighborsClassifier(n_neighbors = i)
new_model.fit(x_training_data, y_training_data)
new_predictions = new_model.predict(x_test_data)
error_rates.append(np.mean(new_predictions != y_test_data))
Давайте визуализируем, как изменяется частота ошибок при различных K, используя matplotlib — plt.plot(error_rates):
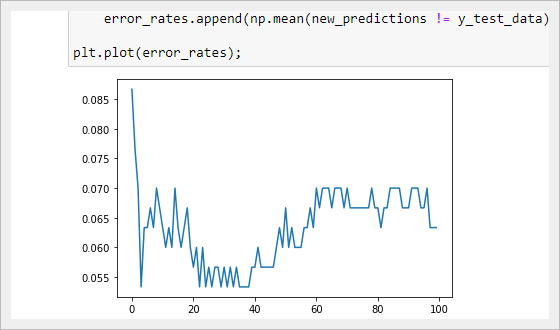
Как видно из графика, мы достигаем минимальной частоты ошибок при значении K, равном приблизительно 35. Это означает, что 35 является подходящим выбором для K, который сочетает в себе простоту и точность предсказаний.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
from sklearn.datasets import make_blobs
Теперь давайте воспользуемся функцией make_blobs, чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
raw_data = make_blobs(
n_samples = 200,
n_features = 2,
centers = 4,
cluster_std = 1.8
)
Если вы выведите объект raw_data, то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs).
Теперь, когда наши данные созданы, мы можем перейти к импорту других необходимых библиотек с открытым исходным кодом в наш скрипт Python.
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter, передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y:
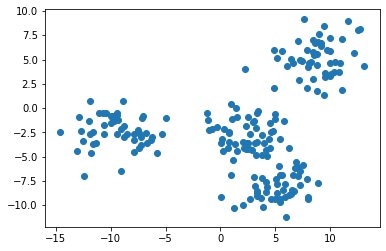
Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Чтобы исправить это, нужно сослаться на второй элемент кортежа raw_data, представляющий собой массив NumPy: он содержит индекс кластера, которому принадлежит каждое наблюдение.
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:
plt.scatter(raw_data[0][:,0], raw_data[0][:,1], c=raw_data[1]);
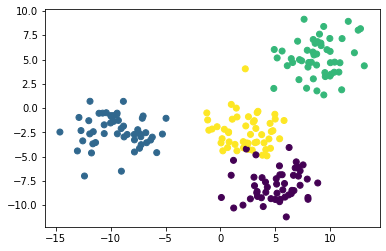
Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
from sklearn.cluster import KMeans
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model:
model = KMeans(n_clusters=4)
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data:
model.fit(raw_data[0])
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
- К какому кластеру принадлежит каждая точка данных.
- Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
model.labels_
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
array([3, 2, 1, 1, 3, 2, 1, 0, 0, 0, 0, 0, 3, 2, 1, 2, 1, 3, 3, 3, 3, 1,
1, 1, 2, 2, 3, 1, 3, 2, 1, 0, 1, 3, 1, 1, 3, 2, 0, 1, 3, 2, 3, 3,
0, 3, 2, 2, 3, 0, 0, 0, 1, 1, 2, 1, 2, 0, 1, 2, 2, 1, 2, 3, 0, 3,
0, 2, 0, 0, 1, 1, 0, 3, 2, 3, 2, 0, 1, 2, 0, 2, 0, 3, 3, 0, 3, 3,
0, 3, 2, 3, 2, 1, 2, 1, 3, 3, 2, 2, 0, 2, 0, 2, 0, 2, 1, 0, 0, 2,
3, 2, 1, 2, 3, 0, 1, 1, 1, 3, 2, 2, 3, 3, 2, 1, 3, 0, 0, 3, 0, 1,
1, 3, 1, 0, 1, 1, 0, 3, 2, 0, 3, 0, 1, 2, 1, 2, 1, 2, 2, 3, 2, 1,
0, 2, 3, 3, 2, 0, 1, 3, 3, 2, 0, 0, 0, 3, 1, 2, 0, 2, 3, 3, 2, 2,
3, 1, 0, 1, 2, 3, 1, 3, 1, 1, 0, 2, 1, 0, 2, 1, 3, 1, 3, 3, 1, 3,
0, 3])Чтобы узнать, где находится центр каждого кластера, аналогичным способом обратитесь к атрибуту cluster_centers_:
model.cluster_centers_
Получаем двумерный массив NumPy, содержащий координаты центра каждого кластера. Он будет выглядеть так:
array([[ 5.2662658 , -8.20493969],
[-9.39837945, -2.36452588],
[ 8.78032251, 5.1722511 ],
[ 2.40247618, -2.78480268]])Визуализация точности предсказаний модели
Последнее, что мы сделаем в этом руководстве, — это визуализируем точность нашей модели. Для этого можно использовать следующий код:
f, (ax1, ax2) = plt.subplots(1, 2, sharey=True,figsize=(10,6))
ax1.set_title('Наши предсказания')
ax1.scatter(raw_data[0][:,0], raw_data[0][:,1],c=model.labels_)
ax2.set_title('Реальные значения')
ax2.scatter(raw_data[0][:,0], raw_data[0][:,1],c=raw_data[1]);
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:
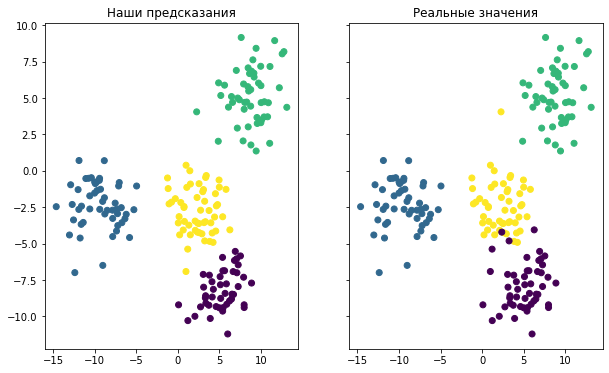
Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
- Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
- Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
- Как разделить датасет на обучающую и тестирующую выборки с помощью функции
train_test_split. - Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
- Как оценить эффективность модели K-ближайших соседей.
- Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
- Как сгенерировать фиктивные данные в scikit-learn с помощью функции
make_blobs. - Как создать и обучить модель кластеризации K-средних.
- То, что ML-методы без учителя не требуют, чтобы вы разделяли датасет на данные для обучения и данные для тестирования.
- Как создать и обучить модель кластеризации K-средних с помощью scikit-learn.
- Как визуализировать эффективность алгоритма K-средних, если вы изначально владеете информацией о кластерах.
В бой. Импортируем рабочие библиотеки и датасет:
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import learning_curve
from sklearn.metrics import make_scorer
%matplotlib inline
np.random.seed(42)
boston_data = load_boston()
boston_df = pd.DataFrame(boston_data.data, columns=boston_data.feature_names)
target = boston_data.target
Вот краткое описание нашего датасета:
- CRIM — уровень преступности на душу населения по городам.
- ZN — доля земли под жилую застройку, разделенная на участки площадью более 25 000 кв. футов.
- INDUS — доля акров, которые принадлежат предприятиям, не связанным с розничной торговлей, на город.
- CHAS — фиктивная переменная реки Чарльз (1, если участок соединен с рекой; 0 в противном случае).
- NOX — концентрация оксидов азота (в десятимиллионных долях).
- RM — среднее количество комнат в доме.
- AGE — доля занимаемых зданий, построенных до 1940 г.
- DIS — взвешенные расстояния до пяти бостонских центров занятости.
- RAD — индекс доступности радиальных автомобильных дорог.
- TAX — полная ставка налога на имущество за каждые 10000 долларов стоимости.
- PTRATIO — соотношение учеников и учителей по городам.
- B — 1000 (Bk — 0,63) , где Bk — доля граждан афроамериканского происхождения по городам.
- LSTAT — процент более низкого статуса населения.
- TARGET —медианное значение стоимости занимаемых домов в тысячах долларов США.
Задача данной выборки сводится к прогнозированию целевого показателя (медианной стоимости недвижимости), используя приведенные выше показатели (все, кроме TARGET).
Полный ноутбук с кодом статьи: https://gitlab.com/PythonRu/notebooks/-/blob/master/linear_regression_sklearn.ipynb
Линейная регрессия
Как мы можем подойти к этой проблеме?
Для нашего первого прохода давайте упростим задачу. Допустим, мы просто хотим использовать признак LSAT для прогнозирования TARGET.
plt.scatter(boston_df['LSTAT'], target);

По оси X у нас есть LSTAT, а по оси Y — TARGET. Просто взглянув на это, можно увидеть отрицательную взаимосвязь: когда LSTAT растет, TARGET падает.
Функция оценки/стоимости
Как мы можем решить проблему предсказания TARGET на основе LSTAT? Хорошая отправная точка для размышлений: допустим, мы разрабатываем множество моделей для прогнозирования целевого показателя, как нам выбрать лучшую из них? Как только мы найдем подходящее для сравнения значение, наша задача — минимизировать/максимизировать его.
Это чрезвычайно полезно, если вы можете свести проблему к единственной оценочной метрике. Тогда это очень упрощает цикл разработки модели. Однако в реальном мире прийти к такому упрощению может быть непросто. Иногда не совсем понятно, что вы хотите, чтобы ваша модель максимизировала/минимизировала. Но это проблема для другой статьи.
Поэтому для нашей задачи предлагаю использовать среднюю квадратическую ошибку (mean squared error) в качестве оценочной метрики. Для лучшего понимания смысла MSE, давайте определимся с терминологией:

Таким образом, MSE:

По сути, для каждой точки мы вычитаем предсказанное нами значение из фактического. Затем, поскольку нас не волнует направление ошибки, мы возводим разницу в квадрат. Наконец, мы вычисляем среднее всех этих значений. Таким образом, мы хотим, чтобы среднее расстояние между предсказанными и фактическими показателями было минимальным.
Вам может быть интересно, почему мы возводили разницу в квадрат вместо того, чтобы брать абсолютное значение. Оказывается, что для некоторых из представленных ниже математических операций возведение в квадрат работает лучше. Кроме того, это метод максимального правдоподобия. Тем не менее, такой подход приводит к тому, что крупные ошибки имеют более сильное влияние на среднее значение, поскольку мы возводим в квадрат каждое отклонение.
Наша модель
Теперь, когда у нас есть функция оценки, как найти способ ее минимизировать? В этом посте мы рассмотрим модель линейной регрессии. Она выглядит следующим образом:

Где j — количество имеющихся у нас предсказателей (независимых переменных), значения бета — это наши коэффициенты. А бета 0 является смещением (intercept). По сути, данная модель представляет собой линейную комбинацию наших предсказателей с intercept.
Теперь, когда у нас есть модель и функция оценки, наша задача состоит в том, чтобы найти бета-значения, которые минимизируют MSE для наших данных. Для линейной регрессии на самом деле существует решение в замкнутой форме, называемое нормальным уравнением. Однако в этом посте мы собираемся использовать другую технику — градиентный спуск.
Градиентный спуск
Градиентный спуск — это метод, который мы позаимствовали из оптимизации. Очень простой, но мощный алгоритм, который можно использовать для поиска минимума функции.
- Выберите случайное начальное значение.
- Делайте шаги, пропорциональные отрицательному градиенту в текущей точке.
- Повторяйте, пока не достигните предела.
Этот метод найдет глобальный минимум, если функция выпуклая. В противном случае мы можем быть уверены только в том, что достигнем локальный минимум.
Первый вопрос, на который нам нужно ответить: является ли наша функция оценки выпуклой? Давайте посмотрим:
mses = []
lstat_coef = range(-20, 23)
for coef in lstat_coef:
pred_values = np.array([coef * lstat for lstat in boston_df.LSTAT.values])
mses.append(np.sum((target - pred_values)**2))
plt.plot(lstat_coef, mses);
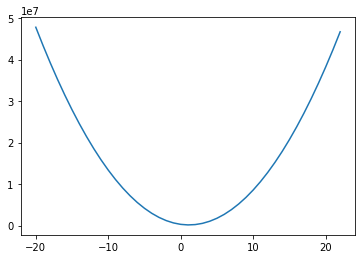
Для построения графика выше мы взяли диапазон значений коэффициентов для LSTAT, и для каждого из них рассчитали MSE на основе наших данных. Если мы затем отобразим полученные значения, мы получим приведенную выше кривую — выглядит довольно выпуклой! И оказывается, что наша функция MSE с нашей моделью линейной регрессии всегда будет выпуклой! Это означает: мы можем использовать градиентный спуск, чтобы найти оптимальные коэффициенты для нашей модели!
Одна из причин того, что градиентный спуск более распространен, чем нормальное уравнение для машинного обучения, заключается в том, что он намного лучше масштабируется по мере увеличения количества показателей. Это также стандартный метод оптимизации, который используется повсюду в машинном обучении. Поэтому понимание того, как он работает, чрезвычайно важно.
Градиенты
Если вы снова посмотрите на наш псевдокод для градиентного спуска, вы увидите, что на самом деле все, что нам нужно сделать, это вычислить градиенты. Итак, что такое градиенты? Это просто частные производные по коэффициентам. Для каждого имеющегося коэффициента нам нужно будет вычислить производную MSE по этому коэффициенту. Давайте начнем!
Для начала запишем выражение для MSE, подставив функцию оценки со смещением и единственной переменной LSTAT:
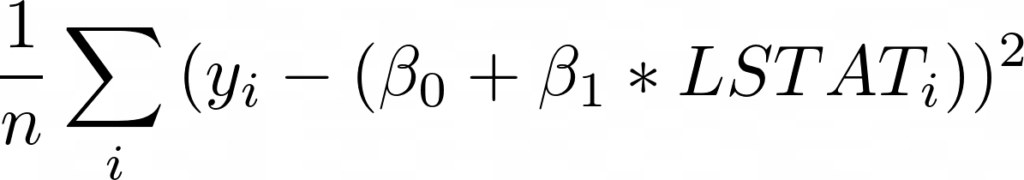
Теперь, взяв производную по бета 0, мы получим (умноженное на -1):

И для бета 1:
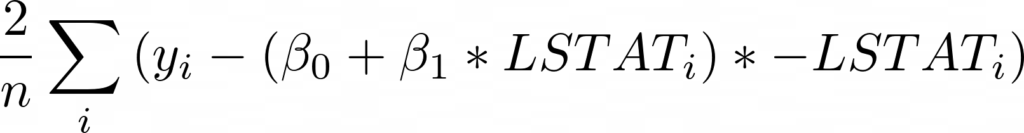
Теперь давайте запустим наш алгоритм градиентного спуска и убедимся, что MSE действительно уменьшается:
beta_0 = 0
beta_1 = 0
learning_rate = 0.001
lstat_values = boston_df.LSTAT.values
n = len(lstat_values)
all_mse = []
for _ in range(10000):
predicted = beta_0 + beta_1 * lstat_values
residuals = target - predicted
all_mse.append(np.sum(residuals**2))
beta_0 = beta_0 - learning_rate * ((2/n) * np.sum(residuals) * -1)
beta_1 = beta_1 - learning_rate * ((2/n) * residuals.dot(lstat_values) * -1)
plt.plot(range(len(all_mse)), all_mse);
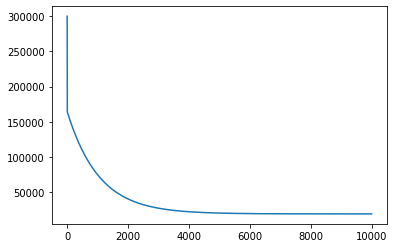
Первый график, представленный выше, показывает значение MSE, когда мы запускаем градиентный спуск. Как и следовало ожидать, MSE уменьшается со временем по мере выполнения алгоритма. Это означает, что мы постоянно приближаемся к оптимальному решению.
На графике видно, что мы вполне могли завершить работу раньше. MSE переходит в прямую (почти не изменяется) примерно после 4000 итераций.
print(f"Beta 0: {beta_0}")
print(f"Beta 1: {beta_1}")
plt.scatter(boston_df['LSTAT'], target)
x = range(0, 40)
plt.plot(x, [beta_0 + beta_1 * l for l in x]);
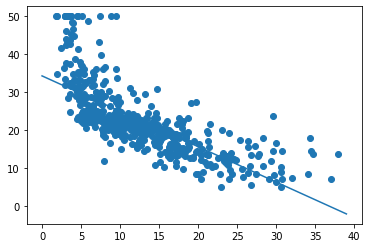
Итак, запуск градиентного спуска показал, что оптимальное смещение составляет 34.55, а оптимальный наклон равен -0,95. На приведенном выше графике эта линия показана поверх наших данных, она выглядит как аппроксимирующая прямая.
Скорость обучения
Один параметр, который нам еще предстоит обсудить, — это скорость обучения. Эта скорость — гиперпараметр, используемый для определения того, насколько большие шаги мы делаем от направления градиента. Как узнать, какое значение выбрать? Как правило, можно попробовать множество вариантов. Вот некоторые из них, которые были предложены Andrew Ng: .001, .003, .01, .03, .1, .3, 1, 3.
Выбор слишком малого значения приводит к более медленной сходимости. Выбор слишком большого значения может привести к перешагиванию через минимум и расхождению.
Существуют также другие оптимизаторы градиентного спуска, которые более сложны и адаптируют скорость обучения за вас. Это также то, что вы можете делать самостоятельно, постепенно снижая скорость обучения.
Когда прекратить итерацию?
В моем коде я просто выполняю наш цикл 10000 раз. Почему 10000? Никакой реальной причины, кроме моей уверенности в том, что этого достаточно, чтобы достичь минимума. Такой подход точно нельзя назвать лучшей практикой. Вот несколько более разумных идей:
- Следите за оценкой после каждого цикла, и когда ее очередное изменение меньше некоторого граничного значения — скажем, 0.001 — останавливайтесь.
- Используйте проверочный датасет (validation set) и отслеживайте число ошибок, например, с помощью MSE. Когда метрика перестанет уменьшаться, остановитесь.
Нормализация данных
При работе с градиентным спуском вы хотите, чтобы все ваши данные были нормализованы. Вычтите среднее значение и разделите на стандартное отклонение для всех ваших тренировочных показателей. Обычно это ускоряет обучение и снижает вероятность застревания в локальном оптимуме, если функция оценки не является выпуклой.
Другие виды градиентного спуска
Показанный здесь градиентный спуск представляет собой классическую форму, что означает: каждое обновление коэффициента использует все данные для вычисления градиентов. Существует также стохастический градиентный спуск. Ему необходима только 1 строка данных (1 наблюдение) для пересчета коэффициентов в каждом цикле.
Такой способ намного лучше масштабируется, так как нужно обработать только одну строку данных за раз перед обновлением. Также он является более неопределенным, поскольку вы пытаетесь перемещаться с использованием градиента, рассчитанного на основе единственного наблюдения.
Другой тип градиентного спуска — это мини-пакетный градиентный спуск. Эта форма представляет собой компромисс между двумя, где вы выбираете размер пакета. Скажем, 32 (или, что еще лучше, пакетный график, который начинается с небольших пакетов и увеличивается с увеличением количества эпох), и каждая итерация вашего градиентного спуска использует 32 случайные строки данных для вычисления градиента (алгоритм воспользуется всеми строками перед повторной выборкой раннее обработанных). В результате мы получаем некоторую масштабируемость, но и некоторую неопределенность.
Такое случайное поведение оказывается полезным для функций оценки, которые не являются выпуклыми (глубокое обучение), поскольку оно может помочь модели избежать локального минимума. Это наиболее распространенный метод для невыпуклых функций оценки.
Допущения нашей модели
Всякий раз, когда вы имеете дело с моделью, хорошо знать, какие допущения она делает. Университет Дьюка написал об этом целую статью:
https://people.duke.edu/~rnau/testing.htm
Реализация линейной регрессии в Scikit-Learn
Теперь, когда мы немного разбираемся в теории и реализации, давайте обратимся к библиотеке scikit-learn, чтобы на самом деле использовать линейную регрессию на наших данных. Написание моделей с нуля довольно полезно для обучения, но на практике вам, как правило, гораздо лучше использовать проверенную и широко используемую библиотеку.
Для начала нужно нормализовать данные:
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(boston_df)
scaled_df = scaler.transform(boston_df)
У Scikit-learn довольно удобный API. Он предоставляет множество моделей, и все они имеют функции fit и predict. Вы можете вызвать fit с вашими X и y данными для обучения модели, а затем использовать predict для получения предсказанных значений на основе новых данных. Scikit-learn также предоставляет множество метрик, которые вы можете использовать для оценки, такие как MSE. Здесь я вычисляю среднеквадратическую ошибку (RMSE). Так мы можем использовать шкалу нашего целевого показателя, что, легче для понимания.
SGDRegressor выполняет линейную регрессию с использованием градиентного спуска и принимает следующие аргументы: tol(сообщает модели, когда следует прекратить итерацию) и eta0(начальная скорость обучения).
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(scaled_df, target)
predictions = linear_regression_model.predict(scaled_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
RMSE в итоге составила 4.68… для нашей обучающей выборки с использованием scikit-learn.
Полиномиальные переменные
Рассматривая построенный выше график стоимости от LSTAT, вы могли заметить, что между данными показателями существует полиномиальная связь. Линейная регрессия хорошо подходит в случае линейной зависимости, но, если вы добавите полиномиальные показатели, такие как LSTAT, вы сможете установить более сложные отношения. SKLearn упрощает данный процесс:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2, include_bias=False)
poly_df = poly.fit_transform(boston_df)
scaled_poly_df = scaler.fit_transform(poly_df)
print(f"shape: {scaled_poly_df.shape}")
linear_regression_model.fit(scaled_poly_df, target)
predictions = linear_regression_model.predict(scaled_poly_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
shape: (506, 104)
RMSE: 3.243477309312183Функция PolynomialFeatures сгенерировала новую матрицу показателей, состоящую из всех их полиномиальных комбинаций со степенью меньше или равной указанной (в нашем примере 2). Затем мы нормализовали эти данные и скормили их нашей модели. Так мы получили улучшенную тренировочную RMSE, равную 3.24. Однако обратите внимание, что эти результаты, представленные в иллюстративных целях, используют только тренировочную выборку.
Категориальные переменные
Линейная регрессия — одна из моделей, с которой нужно быть осторожным, когда у вас есть качественные данные. Если у вас переменные со значениями 1, 2 и 3, которые на самом деле означают «Мужской», «Женский», «Нет ответа», не передавайте их модели таким образом, даже если они являются числами.
Если бы вы это сделали, модель присвоила бы такому показателю коэффициент — возможно, 0.1. Это будет означать, что принадлежность к женскому полу увеличивает предсказанное значение на 0.1. А отсутствие ответа — на 0.2. Но, возможно, метка «Женский» должна повысить результат на 1.2, а «Нет ответа» — всего на 0.001. Чтобы решить данную проблему, вы должны преобразовать такие значения в фиктивные переменные, чтобы каждая категория имела свой собственный вес. Вы можете узнать, как это сделать с помощью scikit-learn, здесь.
Интерпретация вашей модели
Линейная регрессия — это отличная статистическая модель, которая существует уже давно. Есть много статистических методов, которые можно использовать для ее оценки и интерпретации. Мы не будем рассматривать их все и на самом деле сосредоточимся на очень простых подходах, которые, возможно, более распространены в машинном обучении, чем в статистике.
Во-первых, давайте посмотрим на коэффициенты, которым научилась наша модель (по всем показателям):
linear_regression_model.fit(scaled_df, target)
sorted(list(zip(boston_df.columns, linear_regression_model.coef_)),
key=lambda x: abs(x[1]))
[('AGE', -0.09572161737815363),
('INDUS', -0.21745291834072922),
('CHAS', 0.7410105153873195),
('B', 0.8435653632801421),
('CRIM', -0.850480180062872),
('ZN', 0.9500420835249525),
('TAX', -1.1871976153182786),
('RAD', 1.7832553590229068),
('NOX', -1.8352515775847786),
('PTRATIO', -2.0059298125382456),
('RM', 2.8526547965775757),
('DIS', -2.9865347158079887),
('LSTAT', -3.724642983604627)]Что они означают? Каждый коэффициент представляет собой среднее изменение цены на жилье при изменении соответствующего показателя на единицу с условием, что все остальные показатели остаются неизменными. Например, если значения других показателей не затрагиваются, то увеличение LSTAT на единицу снижает наш целевой показатель (цену на жилье) на 3.72, а увеличение RM увеличивает его на 2.85.
Таким образом, если вы хотите повысить стоимость дома, то может быть стоит начать с увеличения RM и уменьшения LSTAT. Я говорю «может быть», потому что линейная регрессия рассматривает корреляции. Судя по нашим данным, такая взаимосвязь имеет место быть, что само по себе не означает обязательное наличие причинно-следственной связи между показателями.
Доверительные интервалы
Часто в машинном обучении очень полезно иметь доверительный интервал вокруг ваших оценок. Есть разные способы сделать это, но одним довольно общим методом является использование bootstrap.
Bootstrap — это случайная выборка на основе наших данных, и эта выборка того же размера, что и исходные данные. Так мы можем создать несколько представлений одних и тех же данных. Давайте создадим 1000 bootstrap-семплов наших данных.
from sklearn.utils import resample
n_bootstraps = 1000
bootstrap_X = []
bootstrap_y = []
for _ in range(n_bootstraps):
sample_X, sample_y = resample(scaled_df, target)
bootstrap_X.append(sample_X)
bootstrap_y.append(sample_y)
Затем мы обучим модель на каждом из полученных датасетов и получим следующие коэффициенты:
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
coeffs = []
for i, data in enumerate(bootstrap_X):
linear_regression_model.fit(data, bootstrap_y[i])
coeffs.append(linear_regression_model.coef_)
coef_df = pd.DataFrame(coeffs, columns=boston_df.columns)
coef_df.plot(kind='box')
plt.xticks(rotation=90);
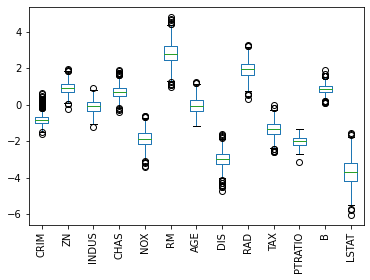
На представленной диаграмме размаха показан диапазон значений коэффициентов, которые мы получили для каждого показателя для всех моделей, которые мы обучили. AGE — особенно интересен, потому что значения коэффициентов были как положительными, так и отрицательными, что является хорошим признаком того, что, вероятно, нет никакой связи между возрастом и стоимостью.
Кроме того, мы можем увидеть, что LSTAT имеет большой разброс в значениях коэффициентов, в то время как PTRATIO имеет относительно небольшую дисперсию, что повышает доверие к нашей оценке этого коэффициента.
Мы даже можем немного углубиться в полученные коэффициенты для LSTAT:
print(coef_df['LSTAT'].describe())
coef_df['LSTAT'].plot(kind='hist');
count 1000.000000
mean -3.686064
std 0.713812
min -6.032298
25% -4.166195
50% -3.671628
75% -3.202391
max -1.574986
Name: LSTAT, dtype: float64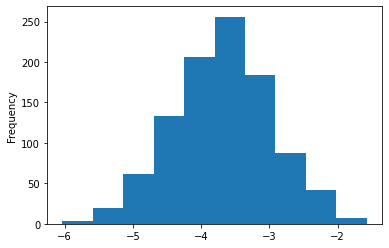
Теперь мы можем с большой уверенностью сказать, что фактический коэффициент LSTAT отрицателен и почти наверняка находится между -2 и -5.5.
Разделение на обучающий/тестовый датасеты и кросс-валидация
До этого момента мы тренировались на всех имеющихся данных. Это может иметь смысл, потому что мы хотим максимизировать их полезность, используя как можно больше данных для обучения. С другой стороны, из-за такого подхода нам становится труднее оценивать, насколько хорошо работает наша модель. Причина этого в том, что, если мы продолжим рассчитывать MSE, используя тренировочные данные, мы можем обнаружить, что при применении модели на незнакомых ей данных, она работает довольно плохо.
Эта идея называется переобучением (overfitting). По сути, такая модель работает намного лучше с обучающими данными, чем с новыми. Она была чрезмерно натренирована на обнаружение уникальных характеристик обучающего множества, которые не являются общими закономерностями, присущими генеральной совокупности.
Другая сторона проблемы называется bias. Модель имеет высокий bias, когда она плохо обучена. В этом случае MSE будет высокой как для тренировочных данных, так и для данных, не показанных во время обучения.
В ML всегда существует компромисс между смещением (bias) и дисперсией (overfitting). По мере того, как ваши модели становятся более сложными, возрастает риск переобучения на тренировочных данных.
Теперь, когда мы знаем о проблемах с вычислением MSE, используя только обучающее множество, что мы можем сделать, чтобы лучше судить о способности модели к обобщению? А также диагностировать overfitting и bias? Типичным решением является разделение наших данных на две части: обучающий и тестовый датасеты.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_df,
target,
test_size=0.33,
random_state=42)
Теперь, когда у нас есть два отдельных набора данных, мы можем тренировать модель на обучающем множестве и вычислять метрики, используя оба датасета (лучше всего использовать ваши тестовые данные после настройки модели):
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(X_train, y_train)
train_predictions = linear_regression_model.predict(X_train)
test_predictions = linear_regression_model.predict(X_test)
train_mse = mean_squared_error(y_train, train_predictions)
test_mse = mean_squared_error(y_test, test_predictions)
print("Train MSE: {}".format(train_mse))
print("Test MSE: {}".format(test_mse))
Train MSE: 23.068773005090424
Test MSE: 21.243935754712375Отлично! Теперь у нас есть MSE как для тренировочных данных, так и для данных тестирования. И оба значения довольно близки, что говорит об отсутствии проблемы с переобучением. Но достаточно ли они низкие? Большие значения предполагают наличие высокого bias.
Один из способов разобраться в этом — построить график обучения. Кривая обучения отображает нашу функцию ошибок (MSE) с различными объемами данных, используемых для тренировки. Вот наш график:
# Источник: http://scikit-learn.org/0.15/auto_examples/plot_learning_curve.html
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Train примеры")
plt.ylabel("Оценка")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring=make_scorer(mean_squared_error))
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Train score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="C-V score")
plt.legend(loc="best")
return plt
plot_learning_curve(linear_regression_model,
"Кривая обучения",
X_train,
y_train,
cv=5);

Вы можете видеть, что с менее чем 50 обучающими примерами тренировочная MSE неплохая, а кросс-валидация оставляет желать лучшего — довольно плохая (мы еще не говорили о кросс-валидации, так что пока думайте об этом как о тестировании). Если бы у нас было только такое количество данных, это выглядело бы как явная проблема высокой дисперсии (переобучения).
По мере увеличения наших данных мы начинаем улучшать оба результата, и они становятся очень похожими, что говорит о том, что у нас нет проблемы переобучения. Как правило, при высокой дисперсии на этом графике две линии будут находится довольно далеко друг от друга, и кажется, что, если мы продолжим добавлять больше данных, они могут сойтись.
Этот график больше похож на проблему с большим смещением (bias), поскольку две наши кривые очень близки и сглаживаются. Однако трудно сказать наверняка, потому что, возможно, мы только что достигли наилучшего возможного MSE. В таком случае это не будет проблемой высокого смещения. Такой результат был бы ей только в том случае, если бы наши кривые выровнялись при значении MSE выше оптимального. В реальной жизни вы не знаете, какова оптимальная MSE, поэтому вам нужно немного поразмышлять, считаете ли вы, что уменьшение bias улучшит ваш результат — но лучше просто попробуйте!
Устранение проблем высоких bias/variance
Итак, теперь, когда вы диагностировали проблему смещения или дисперсии, как ее исправить?
Для высокой дисперсии:
- Получите больше данных для обучения
- Попробуйте меньший набор показателей
- Используйте менее сложную модель
- Добавьте регуляризацию
Для высокого смещения:
- Попробуйте увеличить число показателей
- Перейдите на более сложную модель
Кросс-валидация и настройка гиперпараметров
Ранее мы упоминали этот термин: кросс-валидация. Давайте поговорим об этом сейчас. На данный момент мы узнали, что неплохо разделить данные на наборы для обучения и тестирования, чтобы лучше понять, насколько хорошо работает модель. Это замечательно, но представьте, что мы хотим протестировать несколько разных моделей или протестировать разные параметры нашей модели — например, другую скорость обучения или толерантность. Как бы нам решить, какая модель или какой параметр лучше? Будем ли мы обучать все на тренировочных данных и тестировать все на наших тестовых данных?
Надеюсь, вы понимаете, что это не имеет смысла, потому что тогда мы, по сути, оказались бы в том же месте, что и раньше, без возможности проверить, насколько хорошо мы справляемся с ранее неизвестными данными. Итак, мы хотим сохранить датасет для тестирования незапятнанным в том смысле, что в идеальном мире мы бы запускали наши тесты на нем только после того, как провели все необходимые эксперименты и были уверены в том, что нашли самую лучшую модель.
Похоже, нам нужен третий набор данных – датасет для валидации. По сути, мы можем разбить наши обучающие данные на две части: обучающий и проверочный датасеты. Все модели будут обучены на тренировочном множестве, а затем протестированы на нашем проверочном наборе. Затем мы выберем модель, которая лучше всего справляется с проверкой, и посмотрим, насколько удачно она пройдет тестирование. Результаты тестирования покажут, как хорошо наша модель будет работать с незнакомыми данными, и на этом мы завершим процесс разработки.
Примечание: в статье предполагается, что используемые тестовые и проверочные датасеты представляют собой репрезентативные выборки из нашей совокупности. Например, если средняя цена дома в вашем проверочном множестве составляет 1 миллион, а для генеральной совокупности соответствующее значение равно 300 тысячам, у вас плохая выборка. Часто мы случайным образом делим имеющиеся данные на три выборки, но всегда полезно подтвердить, что эти наборы являются репрезентативными. В противном случае вы обнаружите, что ваша модель, которая хорошо зарекомендовала себя при проверке и тестировании, плохо работает на реальных данных.
На практике вместо создания единого множества для проверки мы часто используем k-блочную кросс-валидацию.
Это означает, что мы выбираем значение k, скажем 3. Затем мы берем наши обучающие данные и делим их на 3 части. Мы случайным образом выбираем 2 блока для тренировки, а затем используем оставшийся для тестирования. Повторяем этот процесс еще 2 раза, так чтобы все наблюдения были использованы как для обучения, так и для проверки, и каждое из них применялось для валидации только один раз. После этого усредняем все три оценки (в нашем случае MSE), чтобы получить общую оценку для конкретной модели. Затем мы можем повторить этот процесс для других моделей, чтобы найти лучшую.
Вот видео, которое более наглядно описывает этот подход (с русскими субтитрами): https://www.youtube.com/watch?v=TIgfjmp-4BA
Этот процесс довольно просто реализуется с помощью sklearn:
from sklearn.model_selection import RandomizedSearchCV
param_dist = {"eta0": [ .001, .003, .01, .03, .1, .3, 1, 3]}
linear_regression_model = SGDRegressor(tol=.0001)
n_iter_search = 8
random_search = RandomizedSearchCV(linear_regression_model,
param_distributions=param_dist,
n_iter=n_iter_search,
cv=3,
scoring='neg_mean_squared_error')
random_search.fit(X_train, y_train)
print("Лучшие параметры: {}".format(random_search.best_params_))
print("Лучшая оценка MSE: {}".format(random_search.best_score_))
Лучшие параметры: {'eta0': 0.001}
Лучшая оценка MSE: -25.64219216972172Здесь мы фактически использовали рандомизированный поиск (RandomizedSearchCV), который обычно лучше, чем поиск по всем возможным значениям. Часто вы хотите попробовать много разных параметров для множества различных регуляторов, и сеточный поиск (перебор всех возможных комбинаций) вам не подходит.
Обычно вы хотите использовать рандомизированный поиск (случайный выбор комбинаций), как мы сделали выше. Хотя, поскольку у нас было только небольшое количество значений, мы заставили его работать как сеточный поиск, установив n_iter_search равным числу вариантов, которые мы хотели попробовать.
Мы также установили cv=3, чтобы иметь 3 блока и использовали отрицательную MSE, потому что функции CV в scikit-learn пытаются максимизировать значение.
Вы можете узнать больше о случайном и «сеточном» вариантах поиска здесь: https://scikit-learn.org/stable/modules/grid_search.html.
Кроме того, в scikit-learn есть много других CV функций, которые полезны, особенно если вы хотите протестировать разные модели с одинаковыми блоками. Вот некоторая документация: https://scikit-learn.org/stable/modules/cross_validation.html.
Регуляризация
В качестве средства борьбы с высокой дисперсией я упомянул регуляризацию. Вы можете думать о ней как о методе, который используется для наказания модели за обучение сложным взаимосвязям. Для линейной регрессии она принимает форму трех популярных подходов. Все эти методы сосредоточены на идее ограничения того, насколько большими могут быть коэффициенты наших показателей.
Идея состоит в том, что если мы переоцениваем влияние предсказателя (большое значение коэффициента), то, вероятно, мы переобучаемся. Примечание: у нас все еще могут быть просто большие коэффициенты. Регуляризация говорит о том, что уменьшение MSE должно оправдывать увеличение значений коэффициентов.
- Регуляризация L1 (Lasso): вы добавляете сумму абсолютных значений коэффициентов к функции оценки. Этот метод может принудительно обнулить коэффициенты, что затем может быть средством выбора показателей.
- Регуляризация L2 (Ridge): вы добавляете сумму квадратов значений коэффициентов к функции оценки.
- Эластичная сетка: вы добавляете обе и выбираете, как их утяжелить.
Каждый из этих методов принимает весовой множитель, который говорит вам, насколько сильное влияние регуляризация будет иметь на функцию оценки. В scikit-learn такой параметр называется альфа. Альфа равный 0 не добавит штрафа, в то время как высокое его значение будет сильно наказывать модель за наличие больших коэффициентов. Вы можете использовать кросс-валидацию, чтобы найти хорошее значение для альфа.
Sklearn упрощает это:
from sklearn.linear_model import ElasticNetCV
clf = ElasticNetCV(l1_ratio=[.1, .5, .7, .9, .95, .99, 1], alphas=[.1, 1, 10])
clf.fit(X_train, y_train)
train_predictions = clf.predict(X_train)
test_predictions = clf.predict(X_test)
print("Train MSE: {}".format(mean_squared_error(y_train, train_predictions)))
print("Test MSE: {}".format(mean_squared_error(y_test, test_predictions)))
Train MSE: 23.58766002758097
Test MSE: 21.54591803491954Здесь мы использовали функцию ElasticNetCV, которая имеет встроенную кросс-валидацию, чтобы выбрать лучшее значение для альфы. l1_ratio — это вес, который придается регуляризации L1. Оставшийся вес применяется к L2.
Итог
Если вы зашли так далеко, поздравляю! Это была тонна информации, но я обещаю, что, если вы потратите время на ее усвоение, у вас будет очень твердое понимание линейной регрессии и многих вещей, которые она может делать!
Кроме того, здесь вы можете найти весь код статьи.
]]>Django REST Framework — это набор инструментов для создания REST API с помощью Django. В этом руководстве рассмотрим, как правильно его использовать. Создадим эндпоинты(точки доступа к ресурсам) для пользователей, постов в блоге, комментариев и категорий.
Также рассмотрим аутентификацию, чтобы только залогиненный пользователь мог изменять данные приложения.
Вот чему вы научитесь:
- Добавлять новые и существующие модели Django в API.
- Сериализовать модели с помощью встроенных сериализаторов для распространенных API-паттернов.
- Создавать представления и URL-паттерны.
- Создавать отношения многие-к-одному и многие-ко-многим.
- Аутентифицировать пользовательские действия.
- Использовать созданный API Django REST Framework.
Код урока можно скачать в репозитории https://gitlab.com/PythonRu/blogapi.
Требования
У вас в системе должен быть установлен Python 3, желательно 3.8. Также понадобится опыт работы с REST API. Вы должны быть знакомы с реляционными базами данными, включая основные и внешние ключи, модели баз данных, миграции, а также отношения многие-к-одному и многие-ко-многим.
Наконец, потребуется опыт работы с Python и Django.
Настройка проекта
Для создания нового API-проекта для начала создайте виртуальную среду Python в своей рабочей директории. Для этого запустите следующую команду в терминале:
python3 -m venv env
source env/bin/activateВ Windows это будет source env\Scripts\activate.
Не забывайте запускать все команды из этого руководства в виртуальной среде. Убедиться в том, что она активирована можно благодаря надписи (env) в начале строки приглашения к вводу в терминале.
Чтобы деактивировать среду, введите deactivate.
После этого установите Django и REST Framework в среду:
pip install django==3.1.7 djangorestframework==3.12.4Создайте новый проект «blog» и новое приложение «api»:
django-admin startproject blog
cd blog
django-admin startapp api
Из корневой директории «blog» (там где находится файл «manage.py»), синхронизируйте базу данных. Это запустит миграции для admin, auth, contenttypes и sessions.
python manage.py migrateВам также понадобится пользователь admin для взаимодействия с панелью управления Django и API. Из терминала запустите следующее:
python manage.py createsuperuser --email admin@example.com --username admin
Установите любой пароль (у него должно быть как минимум 8 символов). Если вы введете слишком простой пароль, то можете получить ошибку.
Для настройки, добавьте rest_framework и api в файл конфигурации (blog/blog/settings.py):
INSTALLED_APPS = [
...
'rest_framework',
'api.apps.ApiConfig',
]
Добавление ApiConfig позволит добавлять параметры конфигурации в приложение. Другие настройки для этого руководства не потребуются.
Наконец, запустите локальный сервер с помощью команды python manage.py runserver.
Перейдите по ссылке http://127.0.0.1:8000/admin и войдите в админ-панель сайта. Нажмите на «Users», чтобы увидеть пользователя и добавить новых при необходимости.

Создание API для пользователей
Теперь с пользователем «admin» можно переходить к созданию самого API. Это предоставит доступ только для чтения списку пользователей из списка API-эндпоинтов.
Сериализатор для User
REST Framework Django использует сериализаторы, чтобы переводить наборы запросов и экземпляры моделей в JSON-данные. Сериализация также определяет, какие данные вернет API в ответ на запрос клиента.
Пользователи Django создаются из модели User, которая определена в django.contrib.auth. Для создания сериализатора для модели добавьте следующее в blog/api/serializers.py (файл нужно создать):
from rest_framework import serializers
from django.contrib.auth.models import User
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'username']
По примеру импортируйте модель User из Django вместе с набором сериализаторов из REST Framework Django.
Теперь создайте класс UserSerializer, который должен наследоваться от класса ModelSerializer.
Определите модель, которая должна ассоциироваться с сериализатором (model = User). Массив fields определяет, какие поля модели должны быть включены. Например, можно добавлять поля first_name и last_name.
Класс ModelSerializer генерирует поля сериализатора, которые основаны на соответствующих свойствах модели. Это значит, что не нужно вручную указывать все атрибуты для поля сериализации, поскольку они вытягиваются напрямую из модели.
Этот сериализатор также создает простые методы create() и update(). При необходимости их можно переписать.
Ознакомиться подробнее с работой ModelSerializer можно на официальном сайте.
Представления для User
Есть несколько способов создавать представления в REST Framework Django. Чтобы получить возможность повторного использования кода и избегать повторений, используйте классовые представления.
REST Framework предоставляет несколько обобщенных представлений, основанных на классе APIView. Они представляют собой самые распространенные паттерны.
Например, ListAPIView используется для эндпоинтов с доступом только для чтения. Он предоставляет метод-обработчик get. ListCreateAPIView используется для эндпоинтов с разрешением чтения-записи, а также обработчики get и post.
Для создания эндпоинта только для чтения, который возвращал бы список пользователей, добавьте следующее в blog/api/views.py:
from rest_framework import generics
from . import serializers
from django.contrib.auth.models import User
class UserList(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = serializers.UserSerializer
class UserDetail(generics.RetrieveAPIView):
queryset = User.objects.all()
serializer_class = serializers.UserSerializer
В первую очередь здесь импортируется generics коллекция представлений, а также модель User и UserSerialized из предыдущего шага. Представление UserList предоставляет доступ только для чтения (через get) к списку пользователей, а UserDetails — к одному пользователю.
Названия представлений должны быть в следующем формате: {ModelName}List и {ModelName}Details для коллекции объектов и одного объекта соответственно.
Для каждого представления переменная queryset содержит коллекцию экземпляров модели, которую возвращает User.objects.all(). Значением serializer_class должно быть UserSerializer, который и сериализует данные модели User.
Пути к эндпоинтам будут настроены на следующем шаге.
URL-паттерны
С моделью, сериализатором и набором представлений для User финальным шагом будет создание эндпоинтов (которые в Django называются URL-паттернами) для каждого представления.
В первую очередь добавьте следующее в blog/api/urls.py (этот файл тоже нужно создать):
from django.urls import path
from rest_framework.urlpatterns import format_suffix_patterns
from . import views
urlpatterns = [
path('users/', views.UserList.as_view()),
path('users/<int:pk>/', views.UserDetail.as_view()),
]
urlpatterns = format_suffix_patterns(urlpatterns)
Здесь импортируется функция path и также коллекция представлений приложения api.
Функция path создает элемент, который Django использует для показа страницы приложения. Для этого Django в первую очередь ищет нужный элемент с соответствующим URL (например, users/) для запрошенного пользователем. После этого он импортирует и вызывает соответствующее представление (то есть, UserList)
Последовательность <int:pk> указывает на целочисленное значение, которое является основным ключом (pk). Django захватывает эту часть URL и отправляет в представление в виде аргумента-ключевого слова.
В этом случае основным ключом для User является поле id, поэтому http://127.0.0.1:8000/users/1 вернет id со значением 1.
Прежде чем можно будет взаимодействовать с этими URL-паттернами (и теми, которые будут созданы позже) их нужно добавить в проект. Добавьте следующее в blog/blog/urls.py:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('api.urls')),
]
Чтобы убедиться, что все элементы работают корректно, перейдите по ссылке http://127.0.0.1:8000/users, чтобы увидеть список пользователей приложения.
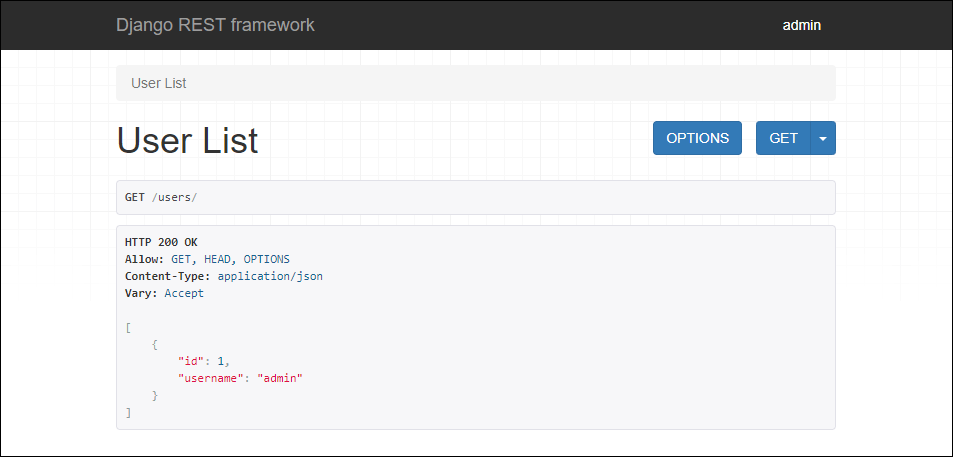
В этом руководстве используется графическое представление API из Django REST Framework для демонстрации эндпоинтов. Интерфейс предоставляет элементы аутентификации и формы, имитирующие фронтенд-клиент. Для тестирования API также можно использовать cURL или httpie.
Обратите внимание на то, что значение пользователя admin равно 1. Можете перейти к нему, открыв для этого http://127.0.0.1:8000/users/1.
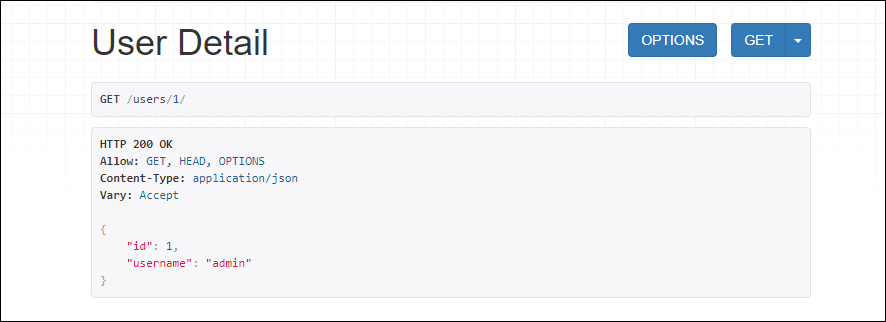
В итоге класс модели Django сериализуется с помощью UserSerializaer. Он предоставляет данные представлениям UserList и UserDetail, доступ к которым можно получить с помощью паттернов users/ и users/<int:pk>.
Создание API для Post
После базовой настройки можно приступать к созданию полноценного API для блога с эндпоинтами для постов, комментариев и категорий. Начнем с API для Post.
Модель Post
В blog/api/models.py создайте модель Post, которая наследуется от класса Model из Django и определите ее поля:
from django.db import models
class Post(models.Model):
created = models.DateTimeField(auto_now_add=True)
title = models.CharField(max_length=100, blank=True, default='')
body = models.TextField(blank=True, default='')
owner = models.ForeignKey('auth.User', related_name='posts', on_delete=models.CASCADE)
class Meta:
ordering = ['created']
Типы полей соответствуют таковым в реляционных базах данные. Можете ознакомиться со страницей Models на официальном сайте фреймворка.
Обратите внимание на то, что тип ForeignKey создает отношение многие-к-одному между текущей моделью и моделью, указанной в первом аргументе (auth.User — то есть, модель User, с которой вы работаете).
В этом случае пользователь может иметь много статей, но у поста может быть всего один владелец. Поле owner может быть использовано во фронтенд-приложении для получения пользователя и отображения его имени в качестве автора поста.
Аргумент related_name позволяет задать другое имя доступа к текущей модели (posts) вместо стандартного (post_set). Список постов будет добавлен в сериализатор User на следующем шаге для завершения отношения многие-к-одному.
Каждый раз при обновлении модели запускайте следующие команды для обновления базы данных:
python manage.py makemigrations api
python manage.py migrateПоскольку мы работаем с моделями Django, таким как User, посты можно изменить из административной панели Django, зарегистрировав ее в blog/api/admin.py:
from django.contrib import admin
from .models import Post
admin.site.register(Post)
Позже их можно будет создавать и через графическое представление API.
Перейдите на http://127.0.0.1:8000/admin, кликните на Posts и добавьте новые посты. Вы заметите, что поля title и body в форме соответствуют типам CharField и TextField из модели Post.
Также можно выбрать owner среди существующих пользователей. При создании поста в API пользователя выбирать не нужно. Owner будет задан автоматически на основе данных залогиненного пользователя. Это настроим в следующем шаге.
Сериализатор Post
Чтобы добавить модель Post в API, нужно повторить шаги добавления модели User.
Сначала нужно сериализовать данные модели Post. В blog/api/serializers.py добавьте следующее:
from rest_framework import serializers
from django.contrib.auth.models import User
from .models import Post
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts']
Импортируйте модель Post из приложения api и создайте PostSerializer, который будет наследоваться от класса ModelSerializer. Задайте модель и поля, которые будут использоваться сериализатором.
ReadOnlyField — это класс, возвращающий данные без изменения. В этом случае он используется для возвращения поля username вместо стандартного id.
Дальше добавьте поле posts в UserSerializer. Отношение многие-к-одному между постами и пользователями определено моделью Post в прошлом шаге. Название поля (posts) должно быть равным аргументу related_field поля Post.owner. Замените posts на post_set (значение по умолчанию), если вы не задали значение related_field в прошлом шаге.
PrimaryKeyRelatedField представляет список публикаций в этом отношении многие-к-одному (many=True указывает на то, что постов может быть больше чем один).
Если не задать read_only=True поле posts будет иметь права записи по умолчанию. Это значит, что будет возможность вручную задавать список статей, принадлежащих пользователю при его создании. Вряд ли это желаемое поведение.
Перейдите по ссылке http://127.0.0.1:8000/users, чтобы увидеть поле posts каждого пользователя.
Обратите внимание на то, что список
posts— это, по сути, список id. Вместо этого можно возвращать список URL с помощьюHyperLinkModelSerializer.
Представления Post
Следующий шаг — создать набор представлений для Post API. Добавьте следующее в blog/api/views.py:
...
from .models import Post
...
class PostList(generics.ListCreateAPIView):
queryset = Post.objects.all()
serializer_class = serializers.PostSerializer
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class PostDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Post.objects.all()
serializer_class = serializers.PostSerializer
ListCreateAPIView и RetrieveUpdateDestroyAPIView предоставляют самые распространенные обработчики API-методов: get и post для списка (ListCreateAPIView) и get, update и delete для одной сущности (RetrieveUpdateDestroyAPIView).
Также нужно перезаписать функцию по умолчанию perform_create, чтобы задать поле owner текущего пользователя (значение self.request.user).
URL-паттерны Post
Чтобы закончить с эндпоинтами для Post API создайте URL-паттерны Post. Добавьте следующее в массив urlpatterns в blog/api/urls.py:
urlpatterns = [
...
path('posts/', views.PostList.as_view()),
path('posts/<int:pk>/', views.PostDetail.as_view()),
]
Объединение представлений с этими URL-паттернами создает эндпоинты:
get posts/,post posts/,get posts/<int:pk>/,put posts/<int:pk>/- и
delete posts/<int:pk>/.
Чтобы протестировать их, перейдите на http://127.0.0.1:8000/posts и создайте публикации. Я взял несколько статей из Медиума.
Перейдите на один пост (например, http://127.0.0.1:8000/posts/1 и нажмите DELETE. Чтобы поменять название поста, обновите поле «title» и нажмите PUT.
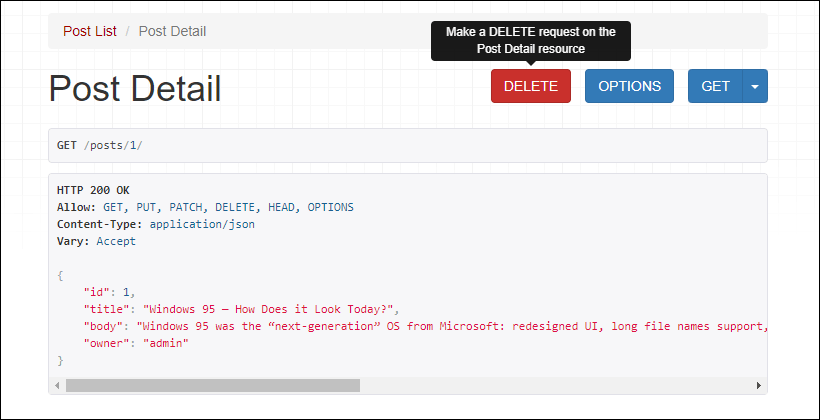
После этого перейдите на http://127.0.0.1:8000/posts, чтобы увидеть список существующих публикаций или создать новый. Убедитесь, что вы залогинены, потому что при создании поста его автор создается на основе данных текущего пользователя.

Настройка разрешений
Для удобства добавим кнопку «Log in» в графическое представление API с помощью следующего кода в blog/urls.py:
urlpatterns = [
...
path('api-auth/', include('rest_framework.urls')),
]
Теперь можно заходить под разными аккаунтами, чтобы проверять работу разрешений и изменять посты через интерфейс.
Сейчас можно создать пост, будучи зарегистрированным, но для удаления или изменения данных этого не требуется — даже если пост вам не принадлежит. Попробуйте зайти под другим аккаунтом, и вы сможете удалить посты, принадлежащие admin.
Чтобы аутентифицировать пользователя и быть уверенным в том, что только владелец поста может обновлять и удалять его, нужно добавить разрешения.
Начните с этого кода в blog/api/permisisions.api (файл необходимо создать):
from rest_framework import permissions
class IsOwnerOrReadOnly(permissions.BasePermission):
def has_object_permission(self, request, view, obj):
if request.method in permissions.SAFE_METHODS:
return True
return obj.owner == request.user
Разрешение IsOwnerOrReadOnly проверяет, является ли пользователь владельцем этого объекта. Таким образом только при этом условии можно будет обновлять или удалять пост. Не-владельцы смогут получать пост, потому что это действие только для чтения.
Также есть встроенное разрешение IsAuthenticatedOrReadOnly. С ним любом аутентифицированный пользователь может выполнять любой запрос, а остальные — только на чтение.
Добавьте эти разрешения в представления Post:
from rest_framework import generics, permissions
...
from .serializers import PostSerializer
from .permissions import IsOwnerOrReadOnly
...
class PostList(generics.ListCreateAPIView):
queryset = Post.objects.all()
serializer_class = PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class PostDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Post.objects.all()
serializer_class = PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
Представлению PostList требуется разрешение IsAuthenticatedOrReadOnly, потому что пользователь должен аутентифицироваться, чтобы создать пост, а вот просматривать список может любой пользователь.
Для PostDetails нужны оба разрешения, поскольку обновлять или удалять пост должен только залогиненный пользователь, а также его владелец. Для получения поста прав не нужно. Вернитесь на http://127.0.0.1:8000/posts. Зайдите в учетную запись admin и другие, чтобы проверить, какие действия доступны аутентифицированным и анонимным пользователям.
Будучи разлогиненным, вы не должны иметь возможность создавать, удалять или обновлять посты. При аутентификации вы не должны иметь право удалять или редактировать чужие посты.
Создание API для Comments
Теперь у вас есть базовый API для постов. Можно добавить в систему комментарии.
Комментарий — это текст, который пользователь добавляет в ответ на пост другого пользователя. К одному можно оставить несколько комментариев, а у поста может быть несколько комментариев от разных пользователей. Это значит, что нужно настроить две пары отношений многие-к-одному: между комментариями и пользователями, а также между комментариями и постами.
Модель Comment
Сначала создайте модель в blog/api/models.py:
...
class Comment(models.Model):
created = models.DateTimeField(auto_now_add=True)
body = models.TextField(blank=False)
owner = models.ForeignKey('auth.User', related_name='comments', on_delete=models.CASCADE)
post = models.ForeignKey('Post', related_name='comments', on_delete=models.CASCADE)
class Meta:
ordering = ['created']
Модель Comment похожа на Post и имеет отношение многие-к-одному с пользователями через поле owner. У комментария есть отношение многие-к-одному с одним постом через поле post.
Запустите миграции базы данных:
python manage.py makemigrations api
python manage.py migrateСериализатор Comment
Для создания API комментариев нужно добавить модель Comment в PostSerializer и UserSerializer, чтобы убедиться, что связанные комментарии отправляются вместе с данными о пользователе и посте.
Обновите код в blog/api/serializers.py:
...
from .models import Post, Comment
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner', 'comments']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts', 'comments']
Процесс напоминает добавление posts в UserSerializer. Это настраивает часть «многие» отношения многие-к-одному между комментариями и пользователем, а также между комментариями и постом. Список комментариев должен быть доступен только для чтения (read_only=True)
Теперь добавим CommentSerializer в тот же файл:
...
class CommentSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
class Meta:
model = Comment
fields = ['id', 'body', 'owner', 'post']
Обратите внимание на то, что поле post не меняется. После добавления поля post в массив fields он будет сериализоваться по умолчанию (согласно ModelSerializer). Это эквивалентно post=serializers.PrimaryKeyRelatedField(queryset=Post.objects.all()).
Это значит, что у поля post есть право на запись по умолчанию: при создании комментария настраивается, какому посту он принадлежит.
Представления комментариев
Наконец, создадим представления и паттерны для комментариев. Процесс похож на тот, что был при настройке API Post.
Добавьте этот код в blog/api/views.py:
...
from .models import Post, Comment
...
class CommentList(generics.ListCreateAPIView):
queryset = Comment.objects.all()
serializer_class = serializers.CommentSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class CommentDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Comment.objects.all()
serializer_class = serializers.CommentSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
Представления похожи на PostList и PostDetails.
URL-Паттерны комментариев
Чтобы закончить API комментариев, определите URL-паттерны в blog/api/urls.py:
urlpatterns = [
...
path('comments/', views.CommentList.as_view()),
path('comments/<int:pk>/', views.CommentDetail.as_view()),
]
Теперь по ссылке http://127.0.0.1:8000/comments можете увидеть список существующих комментариев и создавать новые.
Также обратите внимание на то, что при создании нужно выбрать пост из списка существующих.
Создание API для Category
Финальный элемент блога — система категорий.
Пост может принадлежать к одной или нескольким категориям. Также одна категория может принадлежать нескольким постам, значит это отношение многие-ко-многим.
Модель категории
Создайте модель Category в blog/api/models.py:
urlpatterns = [
...
path('comments/', views.CommentList.as_view()),
path('comments/<int:pk>/', views.CommentDetail.as_view()),
]
Здесь класс ManyToManyField создает отношение многие-ко-многим между текущей моделью и моделью из первого аргумента. Как и в случае с классом ForeignKey отношение завершает сериализатор.
Обратите внимание на то, что verbose_name_plural определяет, как правильно писать название модели во множественном числе. Это нужно, например, для административной панели. Так, вы можете указать, что во множественном числе правильно писать categories, а не categorys.
Запустите миграции базы данных:
python manage.py makemigrations api
python manage.py migrateСериализатор Category
Процесс создания похож на описанный в прошлых шагах. Сперва создайте сериализатор для Category, добавив код в blog/api/serializers.py:
...
from .models import Post, Comment, Category
...
class CategorySerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Category
fields = ['id', 'name', 'owner', 'posts']
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner', 'comments', 'categories']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
categories = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts', 'comments', 'categories']
Не забудьте добавить имя поля categories в список полей PostSerializer и UserSerializer. Обратите внимание на то, что UserSerializer.categories можно отметить как read_only=True. Это поле представляет список всех созданных категорий.
С другой стороны, поле PostSerializer.categories будет иметь право на запись по умолчанию. То же самое, что указать categories = serializers.PrimaryKeyRelatedField(many=True, queryset=Category.objects.all()). Это позволит пользователю выбирать одну или нескольких категорий для поста.
Представления для категории
Дальше создайте представления в blog/api/views.api:
...
from .models import Post, Comment, Category
...
class CategoryList(generics.ListCreateAPIView):
queryset = Category.objects.all()
serializer_class = serializers.CategorySerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class CategoryDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Category.objects.all()
serializer_class = serializers.PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
По аналогии с прошлыми.
URL-паттерны категорий
Наконец, добавьте этот код в blog/api/urls.py:
...
from .models import Post, Comment, Category
urlpatterns = [
...
path('categories/', views.CategoryList.as_view()),
path('categories/<int:pk>/', views.CategoryDetail.as_view()),
]
Теперь отправляйтесь на http://127.0.0.1:8000/categories и создайте пару категорий. А на http://127.0.0.1:8000/posts создайте пост и выберите для него категории.
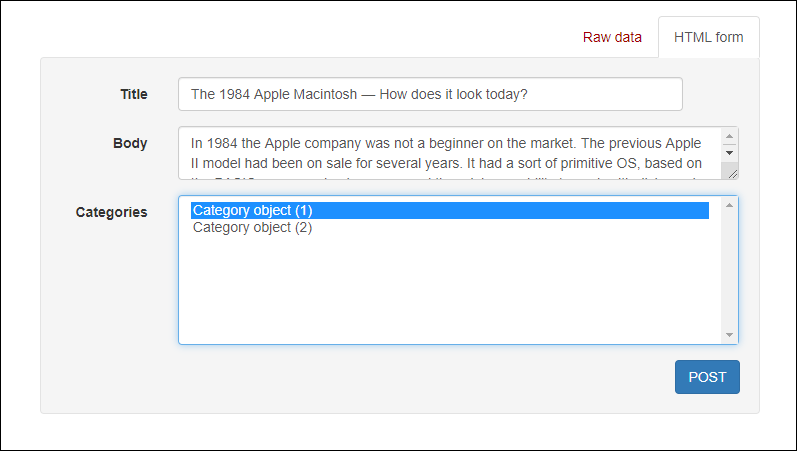
Выводы
Теперь у вас есть API блога с аутентификацией и многими распространенными паттернами API. Есть эндпоинты для получения, создания, обновления и удаления постов, категорий и комментариев. Также настроены отношения многие-к-одному и многие-ко-многим между этими ресурсами.
Чтобы расширить возможности своего API, переходите к официальной документации Django REST Framework. А ссылку на код этого урока можно найти в начале статьи.
]]>Что такое статические файлы в Django?
Изображения, JS и CSS-файлы называются статическими файлами или ассетами проекта Django.
Код из урока: https://gitlab.com/PythonRu/django_static
1. Создадим папку для статических файлов
В папке проекта Django создайте новую папку «static». В примере выше она находится в директории «dstatic».
2. Укажите статический URL Django в настройках
Теперь убедитесь, что статические файлы Django django.contrib.staticfiles указаны в списке установленных приложений в settings.py.
# dstatic > dstatic > settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
Они должны быть там по умолчанию.
После этого пролистайте в нижнюю часть файла настроек и укажите статический URL, если такого еще нет. Вы также можете указать статическую папку, чтобы Django знал, где искать статические файлы.
# dstatic > dstatic > settings.py
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static"),
]
Не забудьте импортировать библиотеку os после добавления кода выше.
После завершения базовой настройки рассмотрим, как добавлять и показывать изображения в шаблонах, а также как подключить свои JavaScript и CSS файлы.
3. Создайте папку для изображений
Создайте папку в «static» специально для изображений. Назовите ее «img». Главное после этого правильно ссылаться на нее в шаблонах.
4. Загрузите статический файл в свой HTML-шаблон
Теперь в выбранном шаблоне (например, в «home.html») загрузите статический файл в верхней части страницы.
Важно добавить
{% load static %}до того, как добавлять изображение. В противном случае оно не будет загружено.
Использование тега static в шаблоне
После этого вы можете использовать тег «static» в шаблоне для работы с источником изображения.
dstatic > templates > home.html
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<div class="container">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
Стоит отметить, что этот файл использует также Bootstrap CDN. Результат:

5. Создание папки и файла JavaScript
Если нужно добавить кастомные JS-файлы в проект, создайте папку «js» внутри «static».
Можно также использовать элемент <script> внутри шаблона, но создание отдельного JS-файла улучшит организацию проекта и поможет проще находить все скрипты в одном месте.
Создание файла script.js
В папке static > js создайте файл «script.js», в котором будут храниться все функции JavaScript.
$(window).scroll(function() {
if ($(document).scrollTop() > 600 && $("#myModal").attr("displayed") === "false") {
$('#myModal').modal('show');
$("#myModal").attr("displayed", "true");
}
});
6. Загрузите скрипт в шаблон
Теперь для подключения JS-файла к проекту добавьте файл в «header.html». Файл должен вызываться так же, как и в случае с изображениями.
Не забудьте и о {% load static %} в верхней части страницы для корректной работы тегов.
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="{% static 'js/script.js' %}"></script>
</head>
<body>
<div class="container">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
7. Создание папки и файла для CSS
Также можно подключить CSS-файлы. Для этого создайте папку «css» внутри «static». Вы также можете использовать элемент <style> и вложить все стили туда.
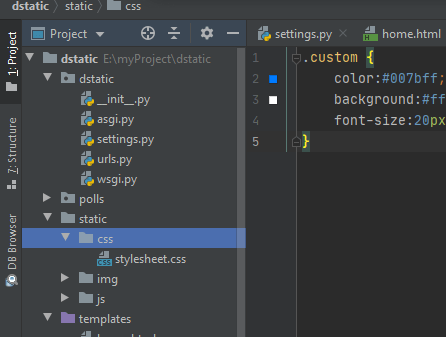
Но в случае создания отдельных классовых атрибутов, которые затем используются в разных шаблонах, лучше создавать отдельные папки и файлы.
Создание файла стилей css
Создайте файл «stylesheet.css» в static > css. Там будут храниться все ваши стили.
.custom {
color:#007bff;
background:#000000;
font-size:20px;
}
8. Загрузите ссылку на CSS в шаблон
Для подключения собственных стилей к проекту, добавьте HTML-элемент <link> в «header.html». Файл вызывается так же, как изображения и JS-файлы.
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
<link rel="stylesheet" href="{% static 'css/stylesheet.css'%}" type="text/css">
<script src="{% static 'js/script.js' %}"></script>
</head>
<body>
<div class="container custom">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
И снова не забудьте о {% load static %} в верхней части страницы. Если не добавить эту строку, то будет ошибка.
Если класс custom добавить к container вы увидите изменения:

Ошибки, связанные с загрузкой статических файлов Django
Если вы получили ошибку «Invalid block tag on line 8: ‘static’, expected ‘endblock’. Did you forget to register or load this tag?», то вы наверняка забыли добавить тег загрузки статических файлов в верхней части страницы: {% load static %} до вызова самого изображения.
{% load static %}
<img src="{% static 'img/photo.jpg' %}">
Такая ошибка «Could not parse the remainder: ‘/photo.jpg’ from ‘img/photo.jpg’» значит, что вы забыли добавить кавычки вокруг ссылки на изображения. В этом случае нужно использовать две пары кавычек: одни для всего содержимого src, а вторые — для ссылки на изображение.
<img src="{% static img/photo.jpg %}"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
«Invalid block tag on line 9: »static/img/photo.jpg», expected ‘endblock’. Did you forget to register or load this tag?» говорит о том, что вы случайно добавили тег static в URL.
<img src="{% 'static/img/photo.jpg' %}"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
Если страница не загружается, и появляется следующая ошибка: «django.core.exceptions.ImproperlyConfigured: You’re using the staticfiles app without having set the required STATIC_URL setting», то это указывает на то, что вы забыли указать статический URL в файле настроек. Его нужно задать в settings.py и сохранить документ.
STATIC_URL = '/static/'Наконец, если вы не получаете ошибку, но изображение не отображается, то убедитесь, что вы правильно используете тег.
<img src="{ static img/photo.jpg }"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
Где используется?
Словари — распространенная структура данных в Python. Они используются в самых разных ситуациях. Вот некоторые из методов и функций словарей:
.keys()— используется для вывода ключей словаря..items()— используется для создания кортежей с ключами и значениями..get()— метод для получения значения по ключу..clear()— очистить словарь..copy()— скопировать весь словарь.len()— получить длину словаря.type()— узнать тип.min()— получить ключ с минимальным значением.max()— получить ключ с максимальным значением.
Рекомендации по работе со словарями
- Словари создаются с помощью фигурных скобок.
- Пары из ключа и значения разделяются запятыми.
- Ключи и значения разделяются между собой двоеточием
- Ключи в словаре могут быть только строками, целыми числами или числами с плавающей точкой. А вот значения могут быть любого типа
- Важно не забывать использовать кавычки для строки-ключа
Дальше пример словаря, где в качестве ключей используются строки, а в качестве значений — целые числа.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages)
{"Андрей": 32, "Виктор": 29, "Максим": 18}
Все строки в словаре заключены в кавычки. В следующем примере ключами уже являются целые числа, а значениями — строки.
>>> p_ages = {32: "Андрей", 29: "Виктор", 18: "Максим"}
>>> print(p_ages)
{32: "Андрей", 29: "Виктор", 18: "Максим"}
В этот раз кавычки нужно использовать для значений, которые тут представлены в виде строк. Доступ к значениям словаря можно получить по его ключам.
Так, для получения значения ключа «Виктор» нужно использовать такой синтаксис:
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> p_ages["Максим"]
18
>>> p_ages["Андрей"]
32
Merge и Update
Начиная с версии Python 3.9, в языке появились новые операторы, которые облегчают процесс слияния словарей.
- Merge (
|): этот оператор позволяет объединять два словаря с помощью одного символа |. - Update (
|=): с помощью такого оператора можно обновить первый словарь значением второго (с типом dict)
Вот основные отличия этих двух операторов:
- «|» создает новый словарь, объединяя два, а «|=» обновляет первый словарь.
- Оператор merge (|) упрощает процесс объединения словарей и работы с их значениями.
- Оператор update (|=) используется для обновления словарей.
>>> dict1 = {"x": 1, "y":2}
>>> dict2 = {"a":11, "b":22}
>>> dict3 = dict1 | dict2
>>> print(dict3)
{"x":1, "y":2, "a":11, "b":22}
>>> dict1 = {"x": 1, "y":2}
>>> dict2 = {"a":11, "b":22}
>>> dict2 |= dict1
>>> print(dict2)
{"x":1, "y":2, "a":11, "b":22}
Примечание: при наличии пересекающихся ключей (а в словарях Python может быть только один уникальный ключ) останется ключ второго словаря, а первый просто заменится.
Функция №1: .keys()
.keys() — это удобный метод, который возвращает все ключи в словаре. Дальше посмотрим на пример с использованием метода keys.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.keys())
dict_keys(['Андрей', 'Виктор', 'Максим'])
Функция №2: .items()
.items() возвращает список кортежей, каждый из которых является парой из ключа и значения. Полезность этой функции станет понятна на более поздних этапах работы в качестве программиста, а пока достаточно просто запомнить эту функцию.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> a = p_ages.items()
>>> print(a)
dict_items([('Андрей', 32), ('Виктор', 29), ('Максим', 18)])
Метод .items() пригодится при необходимости использовать индексацию для доступа к данным.
Функция №3: .get()
.get() — полезный метод для получения значений из словаря по ключу. Получим доступ к возрасту с помощью метода .get().
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.get("Андрей"))
32
Функция №4: .clear()
Метод .clear() очищает словарь ото всех элементов.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> p_ages.clear()
>>> print(p_ages)
{}
Функция №5: .copy()
Метод .copy() возвращает копию словаря.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.copy())
{"Андрей": 32, "Виктор": 29, "Максим": 18}
Функция №6: len()
Метод len() возвращает количество элементов словаря.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(len(p_ages))
3
Полезно знать
- Метод
get()— более продвинутый по сравнению с подходом получения значения по ключу.
Если добавить в метод второй параметр, то он вернет переданное значение в случае, когда ключ не будет найден. Если второй параметр не указывать, получитеNone. - Если попробовать использовать новые операторы (| и |=) в старых версиях python, то вернется ошибка TypeError. Это касается в том числе и dict comprehension.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.get("Михаил", "Не найдено"))
Не найдено
>>> print(p_ages.get("Андрей", "Не найдено"))
32
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Выведите значение возраста из словаря person.
# данный код
person = {"name": "Kelly", "age":25, "city": "New york"}
# требуемый вывод:
# 252. Значениями словаря могут быть и списки. Допишите словарь с ключами BMW, ВАЗ, Tesla и списками из 3х моделей в качестве значений.
# данный код
models_data = {..., "Tesla": ["Modes S", ...]}
print(models_data["Tesla"][0])
# требуемый вывод:
# Modes S- Исправьте ошибки в коде, что бы получить требуемый вывод.
# данный код
d1 = {"a": 100. "b": 200. "c":300}
d2 = {a: 300, b: 200, d:400}
print(d1["b"] == d2["b"])
# требуемый вывод:
# TrueФайл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_8.py.
Тест по словарям
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
Конец. Что делать дальше?
Это краткая серия знакомит с программированием на python. Если вы решали задачи, проходили тесты, справлялись с ошибками и не потеряли мотивацию стать разработчиком — стоит продолжать!
Вы можете учится основам, например на бесплатных курсах от Нетологии или практиковаться на вебинарах Skillbox.
Для перехода на следующий уровень напишите свою программу: калькулятор, игру, api. Самостоятельно или с поддержкой менторов из Twitter и EPAM на программе Профессия Python-разработчик.
]]>Отображение панелей с вкладками с помощью Notebook
Класс ttk.Notebook — еще один новый виджет из модуля ttk. Он позволяет добавлять разные виды отображения приложения в одном окне, предлагая после этого выбрать желаемый с помощью клика по соответствующей вкладке.
Панели с вкладками — это удобный вариант повторного использования графического интерфейса для тех ситуаций, когда содержимое нескольких областей не должно отображаться одновременно.
Следующее приложение показывает список дел, разбитый по категориям. В этом примере данные доступны только для чтения (для упрощения):
Создаем ttk.Notebook с фиксированными размерами, и затем проходимся по словарю с заранее определенными данными. Он выступит источником вкладок и названий для каждой области:
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Ttk Notebook")
todos = {
"Дом": ["Постирать", "Сходить за продуктами"],
"Работа": ["Установить Python", "Учить Tkinter", "Разобрать почту"],
"Отпуск": ["Отдых!"]
}
self.notebook = ttk.Notebook(self, width=250, height=100, padding=10)
for key, value in todos.items():
frame = ttk.Frame(self.notebook)
self.notebook.add(frame, text=key, underline=0,
sticky=tk.NE + tk.SW)
for text in value:
ttk.Label(frame, text=text).pack(anchor=tk.W)
self.label = ttk.Label(self)
self.notebook.pack()
self.label.pack(anchor=tk.W)
self.notebook.enable_traversal()
self.notebook.bind("<<NotebookTabChanged>>", self.select_tab)
def select_tab(self, event):
tab_id = self.notebook.select()
tab_name = self.notebook.tab(tab_id, "text")
text = "Ваш текущий выбор: {}".format(tab_name)
self.label.config(text=text)
if __name__ == "__main__":
app = App()
app.mainloop()
При клике по вкладке метка в нижней части экрана обновляет содержимое, показывая название текущей вкладки.
Как работает этот виджет
Виджет ttk.Notebook создается с фиксированными шириной, высотой и внешними отступами.
Каждый ключ из словаря todos используется в качестве названия вкладки, а список значений добавляется в виде меток в ttk.Frame, который представляет собой область окна:
self.notebook = ttk.Notebook(self, width=250, height=100, padding=10)
for key, value in todos.items():
frame = ttk.Frame(self.notebook)
self.notebook.add(frame, text=key,
underline=0, sticky=tk.NE+tk.SW)
for text in value:
ttk.Label(frame, text=text).pack(anchor=tk.W)
После этого у виджета ttk.Notebook вызывается метод enable_traversal(). Это позволяет пользователям переключаться между вкладками с помощью Ctrl + Shift + Tab и Ctrl + Tab соответственно.
Благодаря этому также можно переключиться на определенную вкладку, зажав Alt и подчеркнутый символ: Alt + H для вкладки Home, Alt + W — для Work, а Alt + V — для Vacation.
Виртуальное событие "<<NotebookTabChanged>>" генерируется автоматически при изменении выбора. Оно связывается с методом select_tab(). Стоит отметить, что это событие автоматически срабатывает при добавлении вкладки в ttk.Notebook:
self.notebook.pack()
self.label.pack(anchor=tk.W)
self.notebook.enable_traversal()
self.notebook.bind("<<NotebookTabChanged>>", self.select_tab)
При упаковке элементов необязательно размещать дочерние элементы ttk.Notebook, поскольку это делается автоматически с помощью вызова geometry manager:
def select_tab(self, event):
tab_id = self.notebook.select()
tab_name = self.notebook.tab(tab_id, "text")
self.label.config(text=f"Ваш текущий выбор: {tab_name}")
Если нужно получить текущий дочерний элемент ttk.Notebook, то для этого не нужно использовать дополнительные структуры данных для маппинга индекса вкладки и окна виджета.
Метод nametowidget() доступен для всех классов виджетов, так что с его помощью можно легко получить объект виджета, соответствующий определенному имени:
def select_tab(self, event):
tab_id = self.notebook.select()
frame = self.nametowidget(tab_id)
# ...
Применение стилей Ttk
У тематических виджетов есть отдельный API для изменения внешнего вида. Прямо задавать параметры нельзя, потому что они определены в классе ttk.Style.
В этом разделе разберем, как изменять виджеты и добавлять им стили.
Для добавления дополнительных настроек нужен объект ttk.Style, который предоставляет следующие методы:
configure(style, opts)— меняет внешний видoptsдляstyleвиджета. Именно здесь задаются такие параметры, как фон, отступы и анимации.map(style, query)— меняет динамический видstyleвиджета. Аргументquery— аргумент-ключевое слово, где каждый ключ отвечает за параметр стиля, а значение — список кортежей в виде(state, value). Это значит, что значение каждого параметра определяется его текущим состоянием.
Например, отметим следующие примеры для двух ситуаций:
import tkinter as tk
import tkinter.ttk as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Tk themed widgets")
style = ttk.Style(self)
style.configure("TLabel", padding=10)
style.map("TButton",
foreground=[("pressed", "grey"), ("active", "white")],
background=[("pressed", "white"), ("active", "grey")]
)
# ...
Теперь каждый ttk.Label отображается с внутренним отступом 10, а у ttk.Button динамические стили: серая заливка с белым фоном, когда состояние кнопки — pressed и белая заливка с серым фоном — когда active.
Как работают стили
Создавать ttk.Style довольно просто. Нужно лишь создать экземпляр с родительским виджетом в качестве первого параметра.
После этого можно задать настройки стиля для виджетов с помощью символа T в верхнем регистре и названия виджета: Tbutton для ttk.Button, Tlabel для ttk.Label и так далее. Однако есть и исключения, поэтому рекомендуется сверяться с помощью интерпретатора Python, вызывая winfo_class() для экземпляра виджета.
Также можно добавить префикс, чтобы указать, что этот стиль должен быть не по умолчанию, а явно задаваться для определенных виджетов:
style.configure("My.TLabel", padding=10)
# ...
label = ttk.Label(master, text="Какой-то текст", style="My.TLabel")
Создание виджета выбора даты
Если нужно позволить пользователям выбирать дату в приложении, то можно попробовать оставить текстовую подсказку, которая бы побудила их написать строку в формате даты. Еще одно решение — добавить несколько числовых полей для ввода дня, месяца и года, но в этом случае понадобятся несколько правил валидации.
В отличие от других фреймворков для создания графических интерфейсов, в Tkinter нет класса для этих целей, но можно воспользоваться знаниями тематических виджетов для создания виджета календаря.
В этом материале пошагово разберем процесс создания виджета выбора даты с помощью виджетов Ttk:
Это рефакторинг решения https://svn.python.org/projects/sandbox/trunk/t tk-gsoc/samples/ttkcalendar.py, который не требует внешних зависимостей.
Помимо модулей tkinter также нужны модули calendar и datetime из стандартной библиотеки. Это поможет моделировать данные виджета и взаимодействовать с ними.
Заголовок виджета показывает стрелки для перемещения между месяцами. Их внешний вид зависит от текущих выбранных стилей Tk. Тело виджета состоит из таблицы ttk.Treeview с экземпляром Canvas, который подсвечивает ячейку выбранной даты:
import calendar
import datetime
import tkinter as tk
import tkinter.ttk as ttk
import tkinter.font as tkfont
from itertools import zip_longest
class TtkCalendar(ttk.Frame):
def __init__(self, master=None, **kw):
now = datetime.datetime.now()
fwday = kw.pop('firstweekday', calendar.MONDAY)
year = kw.pop('year', now.year)
month = kw.pop('month', now.month)
sel_bg = kw.pop('selectbackground', '#ecffc4')
sel_fg = kw.pop('selectforeground', '#05640e')
super().__init__(master, **kw)
self.selected = None
self.date = datetime.date(year, month, 1)
self.cal = calendar.TextCalendar(fwday)
self.font = tkfont.Font(self)
self.header = self.create_header()
self.table = self.create_table()
self.canvas = self.create_canvas(sel_bg, sel_fg)
self.build_calendar()
# ...
def main():
root = tk.Tk()
root.title('Календарь Tkinter')
ttkcal = TtkCalendar(firstweekday=calendar.SUNDAY)
ttkcal.pack(expand=True, fill=tk.BOTH)
root.mainloop()
if __name__ == '__main__':
main()
Полный код в файле lesson_23/creating_widget.py на Gitlab.
Как создается виджет
Этот класс TtkCalendar можно кастомизировать, передавая параметры в виде аргументов-ключевых слов. Их можно получать при инициализации, указав кое-какие значения по умолчанию, например, текущие месяц и год:
def __init__(self, master=None, **kw):
now = datetime.datetime.now()
fwday = kw.pop('firstweekday', calendar.MONDAY)
year = kw.pop('year', now.year)
month = kw.pop('month', now.month)
sel_bg = kw.pop('selectbackground', '#ecffc4')
sel_fg = kw.pop('selectforeground', '#05640e')
super().__init__(master, **kw)
После этого задаются атрибуты для хранения информации:
selected— хранит значение выбранной даты.date— дата, представляющая текущий месяц, который показывается на календаре.calendar— григорианский календарь с информацией о неделях и названиями месяцев.
Визуальные элементы виджета внутри создаются с помощью методов create_header() и create_table(), речь о которых пойдет дальше.
Также используется экземпляр tkfont.Font для определения размера шрифта.
После инициализации этих атрибутов визуальные элементы календаря выравниваются с помощью вызова метода build_calendar():
self.selected = None
self.date = datetime.date(year, month, 1)
self.cal = calendar.TextCalendar(fwday)
self.font = tkfont.Font(self)
self.header = self.create_header()
self.table = self.create_table()
self.canvas = self.create_canvas(sel_bg, sel_fg)
self.build_calendar()
Метод create_header() использует ttk.Style для отображения стрелок, которые нужны для переключения между месяцами. Он возвращает метку названия текущего месяца:
def create_header(self):
left_arrow = {'children': [('Button.leftarrow', None)]}
right_arrow = {'children': [('Button.rightarrow', None)]}
style = ttk.Style(self)
style.layout('L.TButton', [('Button.focus', left_arrow)])
style.layout('R.TButton', [('Button.focus', right_arrow)])
hframe = ttk.Frame(self)
btn_left = ttk.Button(hframe, style='L.TButton',
command=lambda: self.move_month(-1))
btn_right = ttk.Button(hframe, style='R.TButton',
command=lambda: self.move_month(1))
label = ttk.Label(hframe, width=15, anchor='center')
hframe.pack(pady=5, anchor=tk.CENTER)
btn_left.grid(row=0, column=0)
label.grid(row=0, column=1, padx=12)
btn_right.grid(row=0, column=2)
return label
Колбек move_month() скрывает текущий выбор, выделенный с помощью поля полотна и добавляет параметр offset текущему месяцу, чтобы задать атрибут date с предыдущим или следующим месяцем. После этого календарь снова перерисовывается, показывая уже дни нового месяца:
def move_month(self, offset):
self.canvas.place_forget()
month = self.date.month - 1 + offset
year = self.date.year + month // 12
month = month % 12 + 1
self.date = datetime.date(year, month, 1)
self.build_calendar()
Тело календаря создается в create_table() с помощью виджета ttk.Treeview, который показывает каждую неделю текущего месяца в одной строке:
def create_table(self):
cols = self.cal.formatweekheader(3).split()
table = ttk.Treeview(self, show='', selectmode='none',
height=7, columns=cols)
table.bind('<Map>', self.minsize)
table.pack(expand=1, fill=tk.BOTH)
table.tag_configure('header', background='grey90')
table.insert('', tk.END, values=cols, tag='header')
for _ in range(6):
table.insert('', tk.END)
width = max(map(self.font.measure, cols))
for col in cols:
table.column(col, width=width, minwidth=width, anchor=tk.E)
return table
Полотно, подсвечивающее выбор, создается с помощью метода create_canvas(). Поскольку оно выравнивает размер в зависимости от размеров выбранного элемента, то оно же скрывается при изменении размеров окна:
def create_canvas(self, bg, fg):
canvas = tk.Canvas(self.table, background=bg,
borderwidth=0, highlightthickness=0)
canvas.text = canvas.create_text(0, 0, fill=fg, anchor=tk.W)
handler = lambda _: canvas.place_forget()
canvas.bind('<ButtonPress-1>', handler)
self.table.bind('<Configure>', handler)
self.table.bind('<ButtonPress-1>', self.pressed)
return canvas
Календарь строится за счет перебора недель и позиций элементов таблицы ttk.Treeview. С помощью функции zip_longest() из модуля itertools перебираем коллекцию, оставляя на месте недостающих дней пустые строки.
Это поведение нужно для первой и последней недель месяца, ведь именно там часто можно найти пустые слоты:
def build_calendar(self):
year, month = self.date.year, self.date.month
month_name = self.cal.formatmonthname(year, month, 0)
month_weeks = self.cal.monthdayscalendar(year, month)
self.header.config(text=month_name.title())
items = self.table.get_children()[1:]
for week, item in zip_longest(month_weeks, items):
week = week if week else []
fmt_week = ['%02d' % day if day else '' for day in week]
self.table.item(item, values=fmt_week)
При клике по элементу таблицы обработчик события pressed() задает выделение и меняет полотно для выделения выбора:
def pressed(self, event):
x, y, widget = event.x, event.y, event.widget
item = widget.identify_row(y)
column = widget.identify_column(x)
items = self.table.get_children()[1:]
if not column or not item in items:
# клик на заголовок или за пределами столбцов
return
index = int(column[1]) - 1
values = widget.item(item)['values']
text = values[index] if len(values) else None
bbox = widget.bbox(item, column)
if bbox and text:
self.selected = '%02d' % text
self.show_selection(bbox)
Метод show_selection() размещает полотно в пределах выбранного элемента, так что текст помещается внутри:
def show_selection(self, bbox):
canvas, text = self.canvas, self.selected
x, y, width, height = bbox
textw = self.font.measure(text)
canvas.configure(width=width, height=height)
canvas.coords(canvas.text, width - textw, height / 2 - 1)
canvas.itemconfigure(canvas.text, text=text)
canvas.place(x=x, y=y)
Наконец, параметр selection позволяет получить выбранную дату в виде объекта datetime.date. Он не используется в примере, но нужен для работы API в классе TtkCalendar:
@property
def selection(self):
if self.selected:
year, month = self.date.year, self.date.month
return datetime.date(year, month, int(self.selected))
Индекс начинается с нуля, как и в случае списков, а отрицательный индекс — с -1. Этот индекс указывает на последний элемент кортежа.
Где используется?
Кортежи — распространенная структура данных для хранения последовательностей в Python.
.index()— используется для вывода индекса элемента..count()— используется для подсчета количества элементов в кортеже.sum()— складывает все элементы кортежа.min()— показывает элемент кортежа с наименьшим значением.max()— показывает элемент кортежа с максимальным значением.len()— показывает количество элементов кортежа.
Рекомендации по работе с кортежами
- Кортежи создаются с помощью круглых скобок:
(); - Элементы внутри кортежей разделяются запятыми;
- Важно соблюдать особенности синтаксиса, характерные для каждого отдельного типа данных в кортеже — кавычки для строк, числа и булевые значения без кавычек и так далее.
Дальше — кортеж, включающий элементы разных типов:
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup)
('Лондон', 'Пекин', 44, True)
Доступ к элементам: получить элементы кортежа можно с помощью соответствующего индекса в квадратных скобках.
Например, для получения элемента «Лондон» нужно использовать следующий индекс: p_tup[0]
А для 44: p_tup[2]
Последний элемент следующего кортежа — булево True. Доступ к нему мы получаем с помощью функции print.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[3])
True
Пример получения первого элемента кортежа.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[0])
'Лондон'
Советы:
- Обратное индексирование: по аналогии с элементами списка элементы кортежа также можно получить с помощью обратного индексирования. Оно начинается с -1. Это значение указывает на последний элемент.
Так, для получения последнего элементp_tupнужно писатьp_tup[-1].p_tup[-2]вернет второй элемент с конца и так далее. - Главное отличие кортежей от списков — они неизменяемые. Кортежам нельзя добавлять или удалять элементы.
Поэтому эта структура используется, когда известно, что элементы не будут меняться в процессе работы программы.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[-1])
True
Функция .index()
.index() — полезный метод, используемый для получения индекса конкретного элемента в кортеже.
Посмотрим на примере.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup.index("Лондон"))
0
Функция .count()
Метод .count() подходит для определения количества вхождений определенного элемента в кортеже.
В примере ниже можно увидеть, что считается количество вхождений числа 101 в списке p_cup. Результат — 2.
>>> p_tup = (5, 101, 42, 3, 101)
>>> print(p_tup.count(101))
2
Функция sum()
Функция sum() возвращает общую сумму чисел внутри кортежа.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(sum(lucky_numbers))
210
Функция min()
Функция min() вернет элемент с самым маленьким значением в кортеже.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(min(lucky_numbers))
5
Функция max()
Функция max() вернет элемент с максимальным значением в кортеже.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(max(lucky_numbers))
101
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Создайте кортеж с цифрами от 0 до 9 и посчитайте сумму.
# данный код
numbers =
print(sum(numbers))
# требуемый вывод:
# 452. Введите статистику частотности букв в кортеже.
# данный код
long_word = (
'т', 'т', 'а', 'и', 'и', 'а', 'и',
'и', 'и', 'т', 'т', 'а', 'и', 'и',
'и', 'и', 'и', 'т', 'и'
)
print("Количество 'т':", )
print("Количество 'a':", )
print("Количество 'и':", )
# требуемый вывод:
# Колличество 'т': 5
# Колличество 'а': 3
# Колличество 'и': 11- Допишите скрипт для расчета средней температуры.
Постарайтесь посчитать количество дней на основеweek_temp. Так наш скрипт сможет работать с данными за любой период.
# данный код
week_temp = (26, 29, 34, 32, 28, 26, 23)
sum_temp =
days =
mean_temp = sum_temp / days
print(int(mean_temp))
# требуемый вывод:
# 28Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_7.py.
Тест по кортежам
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>В этом материале рассмотрим класс ttk.Treeview, с помощью которого можно выводить информацию в иерархической или форме таблицы.
Каждый элемент, добавленный к классу ttk.Treeview разделяется на одну или несколько колонок. Первая может содержать текст и иконку, которые показывают, может ли элемент быть раскрыт, чтобы показать вложенные элементы. Оставшиеся колонки показывают значения для каждой строки.
Первая строка класса ttk.Treeview состоит из заголовков, которые определяют каждую колонку с помощью имени. Их можно скрыть.
С помощью ttk.Treeview создадим таблицу из списка контактов, которые хранятся в CSV-файле:
Создадим виджет ttk.Treeview с тремя колонками, в каждой из которых будут поля каждого из контактов: имя, фамилия и адрес электронной почты.
Контакты загружаются из CSV-файла с помощью модуля csv, и после этого добавляется связывание для виртуального элемента <<TreeviewSelect>>, который генерируется при выборе одного или большего количества элементов:
import csv
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
super().__init__()
self.title("Ttk Treeview")
columns = ("#1", "#2", "#3")
self.tree = ttk.Treeview(self, show="headings", columns=columns)
self.tree.heading("#1", text="Фамилия")
self.tree.heading("#2", text="Имя")
self.tree.heading("#3", text="Почта")
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL, command=self.tree.yview)
self.tree.configure(yscroll=ysb.set)
with open("../lesson_13/contacts.csv", newline="") as f:
for contact in csv.reader(f):
self.tree.insert("", tk.END, values=contact)
self.tree.bind("<<TreeviewSelect>>", self.print_selection)
self.tree.grid(row=0, column=0)
ysb.grid(row=0, column=1, sticky=tk.N + tk.S)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
def print_selection(self, event):
for selection in self.tree.selection():
item = self.tree.item(selection)
last_name, first_name, email = item["values"][0:3]
text = "Выбор: {}, {} <{}>"
print(text.format(last_name, first_name, email))
if __name__ == "__main__":
app = App(path=".")
app.mainloop()
Если запустить эту программу, то каждый раз при выборе контакта данные о нем будут выводиться в стандартный вывод.
Как работает виджет Treeview
Для создания ttk.Treeview с несколькими колонками нужно указать идентификатор каждой с помощью параметра columns. После этого можно настроить текст заголовка с помощью метода heading().
Используем идентификаторы #1, #2 и #3, поскольку первая колонка, включающая иконку раскрытия и текст, всегда генерируется с идентификатором #0.
Также параметру show передается значение «headings», чтобы обозначить, что нужно скрыть колонку #0, потому что вложенных элементов тут не будет.
Следующие значения являются валидными для параметра show:
tree— отображает колонку #0;headings— отображает строку заголовка;tree headings— отображает и колонку #0, и строку заголовка (является значением по умолчанию);""— не отображает ни колонку #0, ни строку заголовка.
После этого к виджету ttk.Treeview добавляется вертикальный скроллбар:
columns = ("#1", "#2", "#3")
self.tree = ttk.Treeview(self, show="headings", columns=columns)
self.tree.heading("#1", text="Фамилия")
self.tree.heading("#2", text="Имя")
self.tree.heading("#3", text="Почта")
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL, command=self.tree.yview)
self.tree.configure(yscroll=ysb.set)
Для загрузки контактов в таблицу файл нужно обработать с помощью функции render() из модуля CSV. В процессе строка, прочтенная на каждой итерации, добавляется к ttk.Treeview.
Это делается с помощью метода insert(), который получает родительский узел и положение для размещения элемента.
Поскольку все контакты показываются как элементы верхнего уровня, передаем пустую строку в качестве первого параметра и константу END, чтобы обозначить, что каждый элемент добавляется на последнюю позицию.
Также можно использовать другие аргументы-ключевые слова для метода insert(). Здесь используется параметр values, который принимает последовательность значений — они и отображаются в каждой колонке Treeview:
with open("../lesson_13/contacts.csv", newline="") as f:
for contact in csv.reader(f):
self.tree.insert("", tk.END, values=contact)
self.tree.bind("<<TreeviewSelect>>", self.print_selection)
<<TreeviewSelect>> — это виртуальное событие, которое генерируется при выборе одного или нескольких элементов из таблицы. В обработчике print_selection() получаем текущее выделение с помощью метода selection(), и для каждого результата выполняем следующие шаги:
- С помощью метода
item()получаем словарь параметров и значений выбранного элемента. - Получаем первые три значения словаря
item, которые соответствуют фамилии, имени и адресу электронной почты контакта. - Значения форматируются и выводятся в стандартный вывод:
def print_selection(self, event):
for selection in self.tree.selection():
item = self.tree.item(selection)
last_name, first_name, email = item["values"][0:3]
text = "Выбор: {}, {} <{}>"
print(text.format(last_name, first_name, email))
Это были базовые особенности класса ttk.Treeview, поскольку работа велась с обычной таблицей. Однако приложение можно расширить и с помощью более продвинутых особенностей этого класса.
Использование тегов в элементах Treeview
Тэги доступны для элементов ttk.Treeview, благодаря чему существует возможность связать последовательности события с конкретными строками таблицы Contacts.
Предположим, что есть необходимость открывать новое окно для добавления информации об электронной почте по двойному клику. Однако это должно работать только для записей, в которых поле email уже заполнено.
Это можно реализовать, добавляя тег с условием при вставке. После этого нужно вызывать tag_bind() на экземпляре виджета с последовательностью "<Double-Button-1>" — здесь можно просто сослаться на реализацию функции-обработчика send_email_to_contact() по имени:
columns = ("Фамилия", "Имя", "Почта")
tree = ttk.Treeview(self, show="headings", columns=columns)
for contact in csv.reader(f):
email = contact[2]
tags = ("dbl-click",) if email else ()
self.tree.insert("", tk.END, values=contact, tags=tags)
tree.tag_bind("dbl-click", "<Double-Button-1>", send_email_to_contact)
По аналогии с тем, что происходит при связывании событий с элементами Canvas, важно не забывать добавлять элементы с тегами к ttk.Treeview до вызова tag_bind(), потому что связывания добавляются только к существующим совпадающим элементам.
Заполнение вложенных элементов в Treeview
ttk.Treeview может использоваться и как обычная таблица, но также — содержать структуры с определенной иерархией. Визуально это напоминает дерево, у которого можно раскрывать определенные узлы.
Это удобно для отображения результатов рекурсивных вызовов и нескольких уровней вложенных элементов. В этом материале рассмотрим сценарий работы с такой структурой.
Для демонстрации рекурсивного добавления элементов в виджет ttk.Treeview создадим базовый браузер файловой системы. Раскрываемые узлы будут представлять собой папки, а после раскрытия они будут показывать вложенные файлы и папки:
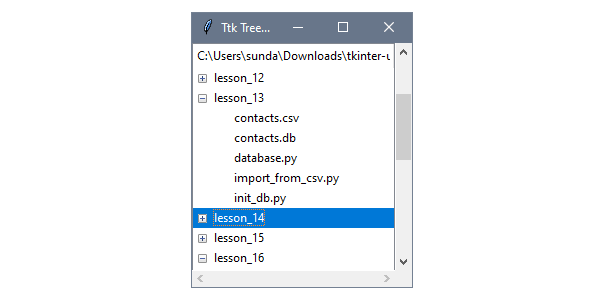
Дерево изначально будет заполняться с помощью метода populate_node(), который содержит записи текущей директории. Если запись сама является директорией, то она добавляет дочерний раскрываемый узел.
Когда такой узел раскрывается, он «лениво» загружает содержимое с помощью еще одного вызова populate_node(). В этот раз, вместо добавления элементов в качестве узлов верхнего уровня, они вкладываются внутрь открытого узла:
import os
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
super().__init__()
self.title("Ttk Treeview")
abspath = os.path.abspath(path)
self.nodes = {}
self.tree = ttk.Treeview(self)
self.tree.heading("#0", text=abspath, anchor=tk.W)
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL,
command=self.tree.yview)
xsb = ttk.Scrollbar(self, orient=tk.HORIZONTAL,
command=self.tree.xview)
self.tree.configure(yscroll=ysb.set, xscroll=xsb.set)
self.tree.grid(row=0, column=0, sticky=tk.N + tk.S + tk.E + tk.W)
ysb.grid(row=0, column=1, sticky=tk.N + tk.S)
xsb.grid(row=1, column=0, sticky=tk.E + tk.W)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
self.tree.bind("<<TreeviewOpen>>", self.open_node)
self.populate_node("", abspath)
def populate_node(self, parent, abspath):
for entry in os.listdir(abspath):
entry_path = os.path.join(abspath, entry)
node = self.tree.insert(parent, tk.END, text=entry, open=False)
if os.path.isdir(entry_path):
self.nodes[node] = entry_path
self.tree.insert(node, tk.END)
def open_node(self, event):
item = self.tree.focus()
abspath = self.nodes.pop(item, False)
if abspath:
children = self.tree.get_children(item)
self.tree.delete(children)
self.populate_node(item, abspath)
if __name__ == "__main__":
app = App(path="../")
app.mainloop()
Запуск предыдущего примера выведет иерархию файловой системы в зависимости от того, где запустить этот файл. Однако можно явно указать директорию с помощью аргумента path конструктора App.
Как работают выпадающие элементы
В этом примере будем использовать модуль os, который является частью стандартной библиотеки Python и предоставляет удобный способ для выполнения запросов к операционной системе.
Первый раз модуль используется для перевода начального пути в абсолютный, а также для инициализации словаря nodes, который будет хранить соответствия между расширяемыми элементами и путями к директориям, которые те представляют:
import os
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
# ...
abspath = os.path.abspath(path)
self.nodes = {}
Например, os.path.abspath(".") вернет абсолютную версию пути к папке, откуда был запущен скрипт. Этот подход лучше использования относительных путей, потому что он помогает не думать о возможных проблемах при работе с путями.
Дальше инициализируется экземпляр ttk.Treeview с вертикальным и горизонтальным скроллбарами. Параметр text иконки заголовка будет тем самым абсолютным путем:
self.tree = ttk.Treeview(self)
self.tree.heading("#0", text=abspath, anchor=tk.W)
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL,
command=self.tree.yview)
xsb = ttk.Scrollbar(self, orient=tk.HORIZONTAL,
command=self.tree.xview)
self.tree.configure(yscroll=ysb.set, xscroll=xsb.set)
После этого виджеты размещаются с помощью geometry manager Grid. Экземпляр ttk.Treeview нужно сделать автоматически изменяемым горизонтально и вертикально.
После этого выполняется связывание виртуального события "<<TreeviewOpen>>", которое генерируется при открытии раскрываемого элемента в обработчике open_node(). populate_node() вызывается для загрузки записей конкретной директории:
self.tree.bind("<<TreeviewOpen>>", self.open_node)
self.populate_node("", abspath)
Стоит обратить внимание на то, что первый вызов этого метода выполняется с пустой строкой для родительской директории, что значит, что у нее не будет родителей, и ее стоит отображать как элемент верхнего уровня.
В методе populate_node() перечисляем названия записей директорий с помощью вызова os.listdir(). Для каждого названия после этого выполняем следующие действия:
- Вычисляем абсолютный путь к записи. В UNIX-системах это делается за счет объединения строк слэшем, а в Windows используются обратные слэши. Благодаря
os.path.join()с путями можно работать безопасно, не думая об особенностях платформ. - Вставляем строку
entryкак последний дочерний элемент конкретного узлаparent. Всегда отмечаем их закрытыми, чтобы «лениво» загружать вложенные элементы только тогда, когда те потребуются. - Если абсолютный путь записи указывает на директорию, то добавляется связь для узла и пути в атрибут
nodes, а также добавляется пустой дочерний элемент, позволяющий раскрывать его:
def populate_node(self, parent, abspath):
for entry in os.listdir(abspath):
entry_path = os.path.join(abspath, entry)
node = self.tree.insert(parent, tk.END, text=entry, open=False)
if os.path.isdir(entry_path):
self.nodes[node] = entry_path
self.tree.insert(node, tk.END)
При нажатии на такой элемент обработчик open_node() получает выбранный элемент с помощью вызова метода focus() экземпляра ttk.Treeview.
Идентификатор элемента используется для получения абсолютного пути, который был добавлен до этого в атрибут nodes. Чтобы ошибка KeyError не появлялась, если узел не существует в словаре, используем метод pop(), который возвращает второй параметр в качестве значения по умолчанию — False.
Если узел существует, очищаем «фейковый» элемент расширяемого узла. Вызов self.tree.get_children(item) возвращает идентификаторы дочерних элементов item. После этого они удаляются с помощью вызова self.tree.delete(children).
После очистки элемента добавляем реальные дочерние элементы с помощью метода populate_node() и item в качестве родителя:
def open_node(self, event):
item = self.tree.focus()
abspath = self.nodes.pop(item, False)
if abspath:
children = self.tree.get_children(item)
self.tree.delete(children)
self.populate_node(item, abspath)
В отличие от словарей у списков есть индексный порядок. Это значит, что каждый элемент в списке имеет индекс, который не поменяется, если его не изменить вручную. В случае других структур, таких как словари, это может быть иначе. Например, у словарей нет индексов для их ключей, поэтому нельзя просто указать на второй или третий элемент, ведь такого порядка не существует. Эту структуру данных стоит воспринимать как мешок перемешанных вещей без конкретного порядка.
Индексация: важно отметить, что индексация списков начинается с 0 (нуля). Это значит, что первый элемент в списке на самом деле является нулевым в мире Python. Об этом очень важно помнить.
Изменяемость: списки являются изменяемым типом, что значит, что можно добавлять или удалять их элементы. Посмотрим на примерах.
Где используется?
Списки — распространенная структура данных в Python. Они используются для самых разных целей.
| Метод | Действие |
|---|---|
| .append() | метод для добавления элементов в список |
| .insert() | для добавления элементов в конкретное место в списке |
| .index() | для получения индекса элемента |
| .clear() | для очистки списка |
| .remove() | для удаления элемента списка |
| .reverse() | чтобы развернуть список в обратном порядке |
| .count() | для подсчета количества элементов в списке |
| sum() | для сложения элементов списка |
| min() | показывает элемент с самым низким значением в списке |
| max() | элемент с самым высоким значением в списке |
Рекомендации по работе со списками
- Списки создаются с помощью квадратных скобок [].
- Элементы списка нужно разделять запятыми.
- Правила синтаксиса, характерные для определенных типов данных, нужно соблюдать внутри списка. Так, если у строки должны быть кавычки, то их нужно использовать и внутри списка, а для чисел и значений булево типа их не нужно использовать.
Дальше идет список, включающий значения разных типов. Это отличный пример, демонстрирующий нюансы списков. Посмотрим.
>>> p_datatypes = ["Python", "апельсин", 23, 51, False, "False", "22"]
>>> print(p_datatypes)
"Python", "апельсин", 23, 51, False, "False", "22"
- Во-первых, видно, что внутри находятся значения разных типов. Это строка, целое число, булево значение и снова строка.
- Последние два элемента списка — это строки, хотя они могут напоминать булев тип и целое число. Однако использование кавычек прямо указывает на то, что это строки в Python.
- Наконец, если посмотреть на индексы элементов, то можно увидеть, что нулевой элемент — это «Python», а шестой — «22». Оба являются строками. Хотя элементов 7, последним индексом является 6.
Доступ к элементам: доступ к элементам списка можно получить с помощью их индекса, указанного в квадратных скобках.
Например, для получения первого элемента («Python») нужно написать следующим образом: p_datatypes[0]. Для получения элемента 23: p_datatypes[2].
Посмотрим на другие примеры. Последний элемент следующего списка — булево значение False. Получим доступ к нему внутри функции print.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[3])
False
А вот получение первого элемента из списка.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[0])
'Python'
Обратное индексирование
- Обратное индексирование. Элементы списка также можно вызывать, начиная с конца — это называется обратным индексированием. В отличие от обычного индексирования, обратное начинается не с 0, а с -1.
Для получения последнего элемента списка p_datatypes:p_datatypes[-1]. - Аналогично
p_datatypes[-2]вернет второй элемент с конца и так далее.
Этот подход имеет свои преимущества в определенных ситуациях. Куда практичнее и эффективнее использовать обратное индексирование, ведь благодаря этому можно не считать количество элементов в списке. Еще одно преимущество становится заметным при изменяемой длине списка. В этом случае снова не придется считать элементы с самого начала, чтобы добраться до финального.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[-1])
False
Методы и функции списков
Метод №1: .append()
append() — это, наверное, самый используемый метод списков. Он используется для добавления элементов к списку. Теперь посмотрим на пример, где метод .append() используется для добавления нового элемента в конец списка.
>>> p_datatypes = ["Python", "апельсин"]
>>> p_datatypes.append("BMW")
>>> print(p_datatypes)
["Python", "апельсин", "BMW"]
Метод №2: .insert()
.insert() — еще один полезный метод для списков. Он используется для вставки элемента в список по индексу.
Посмотрим на примере — .insert() принимает два аргумента: индекс, куда нужно вставить новый элемент, и сам элемент.
>>> p_datatypes = ["Python", "апельсин"]
>>> p_datatypes.insert(1, “BMW”)
>>> print(p_datatypes)
["Python", "BMW", "апельсин"]
Метод №3 .index()
.index() помогает определить индекс элемента. Дальше идет пример получения индекса конкретного элемента.
>>> lst = [1, 33, 5, 55, 1001]
>>> a = lst.index(55)
>>> print(a)
3
Метод №4: .clear()
Метод .clear() удаляет все элементы списка.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.clear()
>>> print(lucky_numbers)
[]
Метод №5: .remove()
Метод .remove() удаляет конкретный элемент списка.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.remove(101)
>>> print(lucky_numbers)
[5, 55, 4, 3, 42]
Метод №6: .reverse()
Метод .reverse() разворачивает порядок элементов в списке.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.reverse()
>>> print(lucky_numbers)
[42, 101, 3, 4, 55, 5]
Метод №7: .count()
Метод .count() используется, чтобы подсчитать, как часто конкретный элемент встречается в списке.
В следующем примере мы считаем, как часто в списке встречается число 5. Результат — 1, что значит, что число 5 встретилось всего один раз.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(lucky_numbers.count(5))
1
В этом же случае в списке нет 1, поэтому и вывод будет 0.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(lucky_numbers.count(1))
0
Функция №8: sum()
Функция sum() вернет общую сумму всех чисел в списке.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(sum(lucky_numbers))
210
Функция №9: min()
Функция min() покажет элемент с минимальным значением в списке. Посмотрим пример.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(min(lucky_numbers))
3
Функция №10: max()
Функция max() покажет элемент с максимальным значением в списке. Пример:
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(max(lucky_numbers))
101
Продвинутые рекомендации
Вот еще некоторые функции и методы списков, особенности которых мы рассмотрим позже:
- .sort()
- .find()
- .pop()
- len() — используется и в других структурах данныхю.
- zip()
- map()
- filter()
- List Comprehension (очень практичный и удобный способ работы со списками)
Как перемешать элементы списка
Перемешать элементы в списке можно с помощью библиотеки random.
Это стандартная библиотека Python, которая предлагает разные полезные элементы (среди самых используемых — randrange и randint).
В этой библиотеке также есть метод shuffle, который можно использовать после импорта random: random.shuffle(список).
>>> import random
>>> lst = [1,2,3,4,5,6,7,8,9,10]
>>> random.shuffle(lst)
>>> print(lst)
[7,3,5,2,6,8,4,1,9]
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Допишите код, что бы вывести последний элемент списка.
# данный код
sample = ["abc", "xyz", "aba", 1221]
# требуемый вывод:
# 12212. Допишите код, что бы вывести расширенный список.
# данный код
sample = ["Green", "White", "Black"]
print(sample)
# требуемый вывод:
# ["Red", "Green", "White", "Black", "Pink", "Yellow"]3. Исправьте ошибки в коде, что бы посчитать сумму элементов в списке.
# данный код
sample = ["11", "33", "50"]
print(sample.sum())
# требуемый вывод:
# 94Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_6.py.
Тест по спискам
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>Тематические виджеты Tk — это отдельная коллекция виджетов Tk, которые выглядят и ощущаются как нативные, и могут быть кастомизированы с помощью API.
Эти классы определены в модуле tkinter.ttk. Помимо новых виджетов, таких как Treeview и Notebook, этот модуль предлагает альтернативную реализацию классических виджетов Tk: Button, Label и Frame.
В этом материале рассмотрим, как использовать эти классы, как их стилизовать и как применять новые классы виджетов.
Набор тематических виджетов Tk был представлен в Tk 8.5, что не должно быть проблемой, ведь установка Python как минимум версии 3.6 добавляет интерпретатор Tcl/Tk версии 8.6.
Убедиться в этом можно, набрав на любой платформе в командной строке python –mtkinter. После этого запустится следующая программа с указанием текущей версии Tcl/Tk:
Замена классов базовых виджетов
В качестве первого пункта знакомства с тематическими виджетами Tkinter посмотрим, как использовать уже знакомые (Button, Label, Entry и так далее), но взятые из другого модуля, сохраняя то же поведение в приложении.
Хотя это не даст аналогичных возможностей в плане настройки стилей, достаточно обратить внимание на визуальные отличия, которые привносят нативные дизайн и «ощущения» этих тематических виджетов.
На следующем скриншоте можно увидеть различия между тематическим виджетом и стандартным виджетом Tkinter:
Создадим приложение с первого скриншота, но рассмотрим, как легко переключаться между разными стилями.
Стоит отметить, что это поведение сильно зависит от платформы. В этом конкретном случае тематический виджет повторяет внешний вид виджетов с Windows 10.
Чтобы начать использовать тематические виджеты нужны импортировать модуль tkinter.ttk и привычным образом использовать виджеты из него в приложении:
import tkinter as tk
import tkinter as ttk
class App(tk.Tk):
greetings = ("Привет", "Ciao", "Hola")
def __init__(self):
super().__init__()
self.title("Тематические виджеты Tk")
var = tk.StringVar()
var.set(self.greetings[0])
label_frame = ttk.LabelFrame(self, text="Выберите приветствие")
for greeting in self.greetings:
radio = ttk.Radiobutton(label_frame, text=greeting,
variable=var, value=greeting)
radio.pack()
frame = ttk.Frame(self)
label = ttk.Label(frame, text="Введите ваше имя")
entry = ttk.Entry(frame)
command = lambda: print("{}, {}!".format(var.get(), entry.get()))
button = ttk.Button(frame, text="Приветствовать", command=command)
label.grid(row=0, column=0, padx=5, pady=5)
entry.grid(row=0, column=1, padx=5, pady=5)
button.grid(row=1, column=0, columnspan=2, pady=5)
label_frame.pack(side=tk.LEFT, padx=10, pady=10)
frame.pack(side=tk.LEFT, padx=10, pady=10)
if __name__ == "__main__":
app = App()
app.mainloop()
Если же в будущем потребуется переключиться к обычным виджетам Tkinter, то достаточно заменить все ttk. на tk..
Как работает замена виджетов
Чтобы начать использовать тематически виджеты нужно импортировать модуль tkinter.ttk с помощь синтаксиса import … as. Это позволит быстро отличать стандартные виджеты благодаря имени tk и тематические — с именем ttk:
import tkinter as tk
import tkinter as ttk
Вы могли заметить, что для замены виджетов из модуля tkinter на аналогичные им из tkinter.ttk достаточно просто поменять алиас:
import tkinter as tk
import tkinter as ttk
# ...
entry_1 = tk.Entry(root)
entry_2 = ttk.Entry(root)
В этом примере мы делаем это с помощью виджетов ttk.Frame, ttk.Label, ttk.Entry, ttk.LabelFrame и ttk.Radiobutton. Эти классы принимают почти те же базовые параметры, что и эквиваленты из Tkinter. На самом деле, они являются их подклассами.
Тем не менее эта смена довольно простая, потому что в этом случае не переносятся никакие особенности стиля: например, foreground и background. В тематических виджетах эти ключевые слова используются в классе ttk.Style, речь о котором пойдет дальше.
Создание редактируемого выпадающего списка с Combobox
Выпадающие списки — это удобный способ выбора значения с помощью отображения вертикального списка значений только тогда, когда они нужны. Традиционно пользователям также позволяют добавить свой вариант, которого нет в списке.
Эта функциональность комбинируется с классом ttk.Combobox, который выглядит и ощущается как нативные (для конкретной платформы) выпадающие списки.
Следующее приложение будет состоять из простого выпадающего списка с парой кнопок для подтверждения или сброса содержимого.
Если одно из имеющихся значений выбирается и нажимается кнопка Submit, то текущее значение Combobox выводится в стандартный вывод:
Это приложение создает экземпляр ttk.Combobox при инициализации, передавая заранее определенную последовательность значений, которые можно будет выбирать из списка:
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Ttk Combobox")
colors = ("Purple", "Yellow", "Red", "Blue")
self.label = ttk.Label(self, text="Пожалуйста, выберите цвет")
self.combo = ttk.Combobox(self, values=colors)
btn_submit = ttk.Button(self, text="Разместить",
command=self.display_color)
btn_clear = ttk.Button(self, text="Очистить",
command=self.clear_color)
self.combo.bind("<>", self.display_color)
self.label.pack(pady=10)
self.combo.pack(side=tk.LEFT, padx=10, pady=5)
btn_submit.pack(side=tk.TOP, padx=10, pady=5)
btn_clear.pack(padx=10, pady=5)
def display_color(self, *args):
color = self.combo.get()
print("Ваш выбор", color)
def clear_color(self):
self.combo.set("")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает виджет Combobox
Традиционно виджет ttk.Combobox добавляется в приложение через передачу экземпляра Tk в качестве первого параметра в конструктор. Параметр values определяет список выбираемых вариантов, которые будут отображаться по клику.
Также выполняется связывание виртуального события <<ComboboxSelected>> при выборе одного из значений списка:
self.label = ttk.Label(self, text="Пожалуйста, выберите цвет")
self.combo = ttk.Combobox(self, values=colors)
btn_submit = ttk.Button(self, text="Разместить",
command=self.display_color)
btn_clear = ttk.Button(self, text="Очистить",
command=self.clear_color)
self.combo.bind("<<ComboboxSelected>>", self.display_color)
Тот же метод вызывается при клике по кнопке Submit, так что она получает значение, введенное пользователем.
display_color() принимает переменный список аргументов с помощью синтаксиса *, что позволяет безопасно обрабатывать опциональные аргументы. Это происходит, потому что событие передается внутрь при вызове через связывание. Однако функция не получает параметры при вызове через колбек кнопки.
Внутри этого метода мы получаем текущее значение Combobox с помощью метода get() и выводим его:
def display_color(self, *args):
color = self.combo.get()
print("Ваш выбор", color)
Наконец, clear_color() очищает содержимое Combobox с помощью вызова set() с пустой строкой:
def clear_color(self):
self.combo.set("")
С помощью этих методов вы знаете, как взаимодействовать с выбранным значением в экземпляре Combobox.
Класс ttk.Combobox расширяет ttk.Entry, который, в свою очередь, расширяет класс Entry из модуля tkinter.
Это значит, что можно использовать уже рассмотренные методы из класса Entry, если потребуется:
combobox.insert(0, "Добавьте это в начало: ")
Вот этот код более понятен чем combobox.set("Добавьте это в начало: " + combobox.get()).
Инициализировать список, кортеж и словарь можно несколькими способами. Один из наиболее распространенных — присвоить соответствующие символы переменной. Для списка эти символы — [], для кортежа — (), а для словаря — {}. Если присвоить эти символы без значений внутри, то будут созданы соответствующие пустые структуры данных.
Функции, которые будут использоваться дальше, являются альтернативными способами создания списков, кортежей и словарей. Их необязательно знать, но лучше запомнить, ведь они могут встретиться в коде других разработчиков.
Где используется
Структуры данных используются во всех аспектах программирования.
- Списки: содержат значения. Ими могут быть числа, строки, имена и так далее:
- Модели автомобилей;
- Имена собак;
- Посещенные страны;
- Посетители магазина и так далее;
- Кортежи: этот тип данных очень похож на список, но с одним исключением. После создания кортежа его значения нельзя менять. Списки — изменяемые, а кортежи — нет. Это может понадобиться в определенных случаях для достижения безопасности или просто удобства. В кортежах могут, например, храниться:
- Все месяцы года;
- Дисциплины Олимпийских игр;
- Штаты США;
Важно только отметить, что кортежи не являются вообще неизменяемыми, ведь вы всегда можете переписать код, поменяв или удалив определенные значения. Речь идет о том, что значения не могут быть изменены после создания — во время работы программы.
- Словари — это пары из ключа и значения. Словари также являются изменяемыми. Это удобная структура данных, которая подходит для сохранения значения с определенными дополнительными параметрами, например:
- Данные клиента включая список его покупок
- Названия стран + их количество олимпийских медалей
- Автомобильные бренды и их модели
- Страны с количеством ДТП с летальным исходом
- Функции
list()иdict()очень простые. Они помогают создавать соответствующие структуры данных.
Рекомендации по работе со структурами данных
- List(), dict() и float() используют круглые скобки, потому что они являются функциями;
- Скобки сами по себе представляют кортеж, и их не стоит путать со скобками в функциях, например, list();
- При создании пустого списка нужно использовать квадратные, а не круглые скобки:
[].
Функция №1: list()
У функции list() очень простой сценарий применения.
C помощью скобок создается список. После этого выводится переменная с присвоенным ей пустым списком. Выводится «[]», что указывает пусть и на пустой, но список. После этого выводится подтверждение того, что это действительно список.
>>> my_first_list = []
>>> print(my_first_list )
>>> print(type(my_first_list ))
[]
<class 'list'>
В следующем примере можно добиться того же результата, что и в первом, но уже с помощью функции list().
>>> my_first_list = list()
>>> print(my_first_list)
>>> print(type(my_first_list))
[]
<class 'list'>
Функция №2: dict()
Рассмотрим функцию dict(), с помощью которой можно создать словарь Python.
>>> my_first_dictionary = {}
>>> print(my_first_dictionary)
>>> print(type(my_first_dictionary))
{}
<class 'dict'>
И вот еще один пример создания пустого словаря. Тот же результат, но с помощью функции dict().
>>> my_first_dictionary = dict()
>>> print(my_first_dictionary)
>>> print(type(my_first_dictionary))
{}
<class 'dict'>
Функция №3: tuple()
Функция tuple() для создания кортежа Python. Пример с присваиванием переменной пустого кортежа.
>>> my_first_tuple = ()
>>> print(my_first_tuple)
>>> print(type(my_first_tuple))
()
<class 'tuple'>
И снова тот же результат, но уже с помощью функции tuple().
>>> my_first_tuple = tuple()
>>> print(my_first_tuple)
>>> print(type(my_first_tuple))
()
<class 'tuple'>
Советы:
- Кортеж — отличная альтернатива списку для тех ситуаций, когда в дальнейшем не требуется менять значения внутри этой структуры данных.
- Словари — идеальная структура для хранения пар ключ-значение.
Создадим список со значениями внутри.
>>> mylist = ["лыжные ботинки", "лыжи", "перчатки"]
>>> print(mylist)
>>> print(type(mylist))
["лыжные ботинки", "лыжи", "перчатки"]
<class 'list'>
В этом примере список состоит из 3 строковых значений. Но все три типа — списки, словари и кортежи — могут включать разные типы данных.
Теперь создадим словарь с этими значениями.
>>> mydict = {"лыжные ботинки": 3, "лыжи": 2, "перчатки": 5}
>>> print(mydict)
>>> print(type(mydict))
{"лыжные ботинки": 3, "лыжи": 2, "перчатки": 5}
<class 'dict'>
В этом примере создается словарь. Он присвоен переменной mydict, которая состоит из 3 ключей: “лыжные ботинки”, “лыжи” и “перчатки”. Каждому ключу присвоено свое значение: 3, 2 и 5 соответственно.
Теперь создадим список со значениями разных типов.
>>> mylist = ["карабины", False, "порошок", 666, 25.25]
>>> print(mylist)
>>> print(type(mylist))
["карабины", False, "порошок", 666, 25.25]
<class 'list'>
В этом примере список включает 5 значений четырех разных типов: строка, булев тип, строка, целое число и число с плавающей точкой.
Наконец, создадим пример кортежа.
>>> mytuple = ("карабины", False, "порошок", 666, 25.25)
>>> print(mytuple)
>>> print(type(mytuple))
("карабины", False, "порошок", 666, 25.25)
<class 'tuple'>
Единственное отличие здесь в том, что используются круглые (), а не квадратные [] скобки.
Мы кратко рассмотрели структуры данных, в следующих уроках разберем каждый подробно.
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Создайте пустой список, определите его тип и выведите в консоль.
# данный код
gift_list=
answer_1=
print(answer_1)
# требуемый вывод:
# <class 'list'>2. Допишите код, чтобы gift_list был заполненным кортежем. Порядок элементов значения не имеет.
gifts=
print(gifts)
# требуемый вывод:
# ("Камера", "Наушники", "Часы")3. Исправьте ошибки в коде, для получения требуемого вывода.
stats = {1 - 10, 220, 3 - 30, 4 - 40, 5 - 50 6 - 60}
print(stat)
# требуемый вывод:
# {1: 10, 2: 20, 3: 30, 4: 40, 5: 50, 6: 60}Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_5.py.
Тест по конвертации типов данных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>Определение пересечений между элементами
В продолжение предыдущего материала о поиске ближайшего элемента стоит отметить, что существует также возможность определять, пересекается ли один прямоугольник с другим. Этого можно добиться благодаря тому, что все элементы заключены в прямоугольные контейнеры. А для определения пересечений используется метод find_overlapping() из класса Canvas.
Это приложение расширяет возможности предыдущего за счет четырех новых прямоугольников, добавленных на полотно. Подсвечиваться будет тот, с которым пересечется синий. Управлять последним можно с помощью клавиш стрелок:

Поскольку код во многом повторяет предыдущий, отметим лишь те части кода, которые отвечают за создание новых прямоугольников и вызов метода canvas.find_overlapping():
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Обнаружение пересечений между предметами")
self.canvas = tk.Canvas(self, bg="white")
self.canvas.pack()
self.update()
self.width = w = self.canvas.winfo_width()
self.height = h = self.canvas.winfo_height()
pos = (w / 2 - 15, h / 2 - 15, w / 2 + 15, h / 2 + 15)
self.item = self.canvas.create_rectangle(*pos, fill="blue")
positions = [(60, 60), (w - 60, 60), (60, h - 60), (w - 60, h - 60)]
for x, y in positions:
self.canvas.create_rectangle(x - 10, y - 10, x + 10, y + 10,
fill="green")
self.pressed_keys = {}
self.bind("<KeyPress>", self.key_press)
self.bind("<KeyRelease>", self.key_release)
self.process_movements()
def key_press(self, event):
self.pressed_keys[event.keysym] = True
def key_release(self, event):
self.pressed_keys.pop(event.keysym, None)
def process_movements(self):
all_items = self.canvas.find_all()
for item in filter(lambda i: i is not self.item, all_items):
self.canvas.itemconfig(item, fill="green")
x0, y0, x1, y1 = self.canvas.coords(self.item)
items = self.canvas.find_overlapping(x0, y0, x1, y1)
for item in filter(lambda i: i is not self.item, items):
self.canvas.itemconfig(item, fill="yellow")
off_x, off_y = 0, 0
speed = 3
if 'Right' in self.pressed_keys:
off_x += speed
if 'Left' in self.pressed_keys:
off_x -= speed
if 'Down' in self.pressed_keys:
off_y += speed
if 'Up' in self.pressed_keys:
off_y -= speed
pos_x = x0 + (x1 - x0) / 2 + off_x
pos_y = y0 + (y1 - y0) / 2 + off_y
if 0 <= pos_x <= self.width and 0 <= pos_y <= self.height:
self.canvas.move(self.item, off_x, off_y)
self.after(10, self.process_movements)
if __name__ == "__main__":
app = App()
app.mainloop()
Как определяются пересечения
До пересечения цвет заполнения всех прямоугольников на полотне, кроме управляемого пользователем, будет зеленым. Идентификаторы этих элементов можно получить с помощью метода canvas.find_all():
def process_movements(self):
all_items = self.canvas.find_all()
for item in filter(lambda i: i is not self.item, all_items):
self.canvas.itemconfig(item, fill="green")
Когда цвета элемента сброшены, вызываем canvas.find_overlapping() для получения всех элементов, которые пересекаются с двигающимся. Он, в свою очередь, из цикла исключен, а цвет остальных пересекающихся элементов (если такие имеются) меняется на желтый:
def process_movements(self):
# ...
x0, y0, x1, y1 = self.canvas.coords(self.item)
items = self.canvas.find_overlapping(x0, y0, x1, y1)
for item in filter(lambda i: i is not self.item, items):
self.canvas.itemconfig(item, fill="yellow")
Метод продолжает выполнение, перемещая синий прямоугольник на заданный показатель сдвига, и планируя себя же снова с помощью process_movements().
Если нужно определить, когда движущийся элемент полностью перекрывает другой (а не частично), то стоит воспользоваться методом canvas.find_enclosed() вместо canvas.find_overlapping() с теми же параметрами.
Удаление элементов с полотна
Помимо добавления и изменения элементов полотна их также можно удалять с помощью метода delete() класса Canvas. Хотя в принципах его работы нет каких-либо особенностей, существуют кое-какие паттерны, которые будут рассмотрены дальше.
Стоит учитывать, что чем больше элементов на полотне, тем дольше Tkinter будет рендерить виджет. Таким образом важно удалять неиспользуемые для улучшения производительности.
В этом примере создадим приложение, которое случайным образом выбирает несколько кругов на полотне. Каждый кружок будет удаляться по клику. Одна кнопка в нижней части виджета сбрасывает состояние полотна, а вторая — удаляет все элементы.

Чтобы случайным образом размещать элементы на полотне, будем генерировать координаты с помощью функции randint модуля random. Цвет элемента будет выбираться случайным образом с помощью вызова choice и определенного набора цветов.
После генерации элементы можно будет удалить с помощью обработчика on_click или кнопки Clearitems, которая, в свою очередь, вызывает функцию обратного вызова clear_all. Внутри этот метод вызывает canvas.delete() с нужными параметрами:
import random
import tkinter as tk
class App(tk.Tk):
colors = ("red", "yellow", "green", "blue", "orange")
def __init__(self):
super().__init__()
self.title("Удаление элементов холста")
self.canvas = tk.Canvas(self, bg="white")
frame = tk.Frame(self)
generate_btn = tk.Button(frame, text="Создавать элементы",
command=self.generate_items)
clear_btn = tk.Button(frame, text="Удалить элементы",
command=self.clear_items)
self.canvas.pack()
frame.pack(fill=tk.BOTH)
generate_btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
clear_btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
self.update()
self.width = self.canvas.winfo_width()
self.height = self.canvas.winfo_height()
self.canvas.bind("<Button-1>", self.on_click)
self.generate_items()
def on_click(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.canvas.delete(item)
def generate_items(self):
self.clear_items()
for _ in range(10):
x = random.randint(0, self.width)
y = random.randint(0, self.height)
color = random.choice(self.colors)
self.canvas.create_oval(x, y, x + 20, y + 20, fill=color)
def clear_items(self):
self.canvas.delete(tk.ALL)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает удаление элементов
Метод canvas.delete() принимает один аргумент, который может быть идентификатором элемента или тегом, и удаляет один или несколько соответствующих элементов (поскольку тег может быть использован несколько раз).
В обработчике on_click() можно увидеть пример удаления элемента по идентификатору:
def on_click(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.canvas.delete(item)
Стоит также отметить, что если сейчас кликнуть по пустой точке, то canvas.find_withtag(tk.CURRENT) вернет None, но когда это значение будет передано в canvas.delete(), то ошибки не будет. Это объясняется тем, что параметр None не совпадает ни с одним идентификатором или тегом. Таким образом это валидный параметр, хоть в результате никакое действие и не выполняется.
В функции обратного вызова clear_items() можно найти другой пример удаления элементов. Здесь вместо передачи идентификатора элемента используется тег ALL, который соответствует всем элементам и удаляет их с полотна:
def clear_items(self):
self.canvas.delete(tk.ALL)
Можно обратить внимание на то, что тег ALL работает «из коробки», поэтому его не нужно добавлять каждому элементу полотна.
Связывание событий с элементами полотна
Вы уже знаете, как связывать события с виджетами, но то же самое можно делать и с элементами. Это помогает писать более специфичные и простые обработчики событий. Такой намного удобнее, чем связывать все события с экземпляром Canvas и потом определять, какое из них нужно в текущий момент.
Следующее приложение показывает, как реализовать функциональность drag and drop для элементов полотна. Это распространенная особенность, которая способна значительно упростить программы.
Создадим несколько элементов (прямоугольник и овал), которые можно будет перетаскивать с помощью мыши. Разная форма поможет заметить, как события кликов корректно применяются к элементам, даже когда они пересекаются между собой:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Drag and drop")
self.dnd_item = None
self.canvas = tk.Canvas(self, bg="white")
self.canvas.pack()
self.canvas.create_rectangle(30, 30, 60, 60, fill="green",
tags="draggable")
self.canvas.create_oval(120, 120, 150, 150, fill="red",
tags="draggable")
self.canvas.tag_bind("draggable", "<ButtonPress-1>",
self.button_press)
self.canvas.tag_bind("draggable", "<Button1-Motion>",
self.button_motion)
def button_press(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.dnd_item = (item, event.x, event.y)
def button_motion(self, event):
x, y = event.x, event.y
item, x0, y0 = self.dnd_item
self.canvas.move(item, x - x0, y - y0)
self.dnd_item = (item, x, y)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает drag and drop
Для связывания событий с элементами используется метод tag_bind() из класса Canvas. Это добавляет связывание для всех элементов, которые соответствуют конкретному элементу — тегу draggable в этом случае.
И хотя метод называется tag_bind() вместо тега в него можно передавать также идентификатор:
self.canvas.tag_bind("draggable", "<ButtonPress-1>",
self.button_press)
self.canvas.tag_bind("draggable", "<Button1-Motion>",
self.button_motion)
Также стоит отметить, что новое поведение затронет только уже существующие элементы, поэтому если позже добавить новые с тегом draggable, то к ним связывание применено не будет.
Метод button_press() — это обработчик, который запускается после нажатия на элемент. Традиционный паттерн для получения соответствующего элемента — вызов canvas.find_withtag(tk.CURRENT).
Идентификатор элемента, а также координаты x и y события click хранятся в поле dnd_item. Эти значения позже будут использованы для перемещения элемента в соответствии с движением мыши:
def button_press(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.dnd_item = (item, event.x, event.y)
Метод button_motion() обрабатывает события движения мыши до тех пор, пока зажата основная кнопка.
Для определения дистанции, на которую должен быть перемещен элемент, нужно вычислить разницу текущей позиции с предыдущими координатами. Эти значения передаются в метод canvas.move() и снова сохраняются в поле dnd_item:
def button_motion(self, event):
x, y = event.x, event.y
item, x0, y0 = self.dnd_item
self.canvas.move(item, x - x0, y - y0)
self.dnd_item = (item, x, y)
Существуют вариации этой drag & drop функциональности, которые также задействуют обработчик последовательности <ButtonRelease-1>. Она сбрасывает текущий элемент.
Однако использовать его необязательно, потому что после того как это событие происходит, связывание <Button1-Motion> не запустится до очередного клика по элементу. Это также помогает избежать проверки того, не является ли None значением dnd_item в начале обработчика button_motion().
Также этот пример можно улучшить, добавив базовую валидацию. Например, можно проверять, чтобы пользователь не мог вытащить элемент за пределы видимой области полотна.
Для этого используются паттерны, которые рассматривались в прошлых примерах. С их помощью можно вычислять ширину и высоту полотна и убедиться, что финальное положение элемента находится в пределах валидного диапазона с помощью цепочки операторов сравнения. В качестве шаблона для этого можно использовать следующий код:
final_x, final_y = pos_x + off_x, pos_y + off_y
if 0 <= final_x <= canvas_width and 0 <= final_y <= canvas_height:
canvas.move(item, off_x, off_y)
Рендер полотна в файл PostScript
Класс Canvas нативно поддерживает сохранение содержимого с помощью языка PostScript и метода postscript(). Он сохраняет графическое представление элементов полотна (линий, прямоугольников, овалов и так далее), но не его виджетов или изображений.
Изменим прошлый пример, который динамически генерирует этот тип простых элементов, и добавим функциональность для сохранения полотна в файл PostScript.
Возьмем уже знакомый код и добавим в него кусок для вывода содержимого полотна в файл PostScript:
import tkinter as tk
from lesson_18.drawing import LineForm
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Базовый холст")
self.line_start = None
self.form = LineForm(self)
self.render_btn = tk.Button(self, text="Render canvas",
command=self.render_canvas)
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("<Button-1>", self.draw)
self.form.grid(row=0, column=0, padx=10, pady=10)
self.render_btn.grid(row=1, column=0)
self.canvas.grid(row=0, column=1, rowspan=2)
def draw(self, event):
x, y = event.x, event.y
if not self.line_start:
self.line_start = (x, y)
else:
x_origin, y_origin = self.line_start
self.line_start = None
line = (x_origin, y_origin, x, y)
arrow = self.form.get_arrow()
color = self.form.get_color()
width = self.form.get_width()
self.canvas.create_line(*line, arrow=arrow,
fill=color, width=width)
def render_canvas(self):
self.canvas.postscript(file="output.ps", colormode="color")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает рендеринг в .ps
Основное нововведение — это кнопка Render canvas с функцией обратного вызова render_canvas().
Она вызывает метод postscript() для экземпляра canvas с аргументами file и colormode. Эти параметры определяют путь к расположению файла, а также информацию о цвете. Вторым параметром может быть color для полностью цветного вывода, gray — для использования оттенков серого или mono — для конвертации цветов в черный и белый:
def render_canvas(self):
self.canvas.postscript(file="output.ps", colormode="color")
Все параметры, которые можно передать в postscript(), стоит искать в официальной документации Tk/Tcl по ссылке https://www.tcl.tk/m an/tcl8.6/TkCmd/canvas.htm#M61. Стоит напомнить, что PostScript — язык печати, поэтому большая часть его параметров касается настроек страницы.
Поскольку файлы PostScript не так популярны, как другие форматы файлов, возможно, возникнет необходимость конвертировать готовый файл во что-то более знакомое — например, PDF.
Для этого нужен сторонний софт, такой как, например, Ghostscript, который распространяется по лицензии GNU APGL. Интерпретатор и инструмент рендеринга можно вызвать из программы для автоматической конвертации результатов PostScript в PDF.
Установить программу можно с сайта https://w ww.ghostscript.com/download/gsdnld.html. Дальше нужно только добавить папки bin и lib из установки в переменную path операционной системы.
Затем остается изменить приложение Tkinter для вызова программы ps2pdf в качестве подпроцеса и удалить файл output.ps после завершения выполнения:
import os
import subprocess
import tkinter as tk
class App(tk.Tk):
# ...
def render_canvas(self):
output_filename = "output.ps"
self.canvas.postscript(file=output_filename, colormode="color")
process = subprocess.run(["ps2pdf", output_filename, "output.pdf"],
shell=True)
os.remove(output_filename)
type() возвращает тип объекта. Ее назначение очевидно, и на примерах можно понять, зачем эта функция нужна.
Также в этом материале рассмотрим другие функции, которые могут помочь в процессе конвертации типа данных. Некоторые из них — это int(), float() или str().
type() — это базовая функция, которая помогает узнать тип переменной. Получившееся значение можно будет выводить точно так же, как обычные значения переменных с помощью print.
Где используется
- Функция
type()используется для определения типа переменной. - Это очень важная информация, которая часто нужна программистам.
- Например, программа может собирать данные, и будет необходимость знать тип этих данных.
- Часто требуется выполнять определенные операции с конкретными типами данных: например, арифметические вычисления на целых или числах с плавающей точкой или поиск символа в строках.
- Иногда будут условные ситуации, где с данными нужно будет обращаться определенным образом в зависимости от их типа.
- Будет и много других ситуаций, где пригодится функция
type().
Рекомендации по работе с типами данных
- Типы
intиfloatможно конвертировать вstr, потому что строка может включать не только символы алфавита, но и цифры. - Значения типа
strвсегда представлены в кавычках, а дляint,floatиboolони не используются. - Строку, включающую символы алфавита, не выйдет конвертировать в целое или число с плавающей точкой.
Примеры конвертации типов данных
>>> game_count = 21
>>> print(type(game_count))
<class 'int'>
В следующих материалах речь пойдет о более сложных типах данных, таких как списки, кортежи и словари. Их обычно называют составными типами данных, потому что они могут состоять из значений разных типов. Функция type() может использоваться для определения их типов также.
>>> person1_weight = 121.25
>>> print(type(person1_weight))
<class 'float'>
Функция int()
С помощью функции int() можно попробовать конвертировать другой тип данных в целое число.
В следующем примере можно увидеть, как на первой строке переменной inc_count присваивается значение в кавычках.
Из-за этих кавычек переменная регистрирует данные как строку. Дальше следуют команды print для вывода оригинального типа и значения переменной, а затем — использование функции int() для конвертации переменной к типу int.
После этого две функции print показывают, что значение переменной не поменялось, но тип данных — изменился.
Можно обратить внимание на то, что после конвертации выведенные данные не отличаются от тех, что были изначально. Так что без использования type() вряд ли удастся увидеть разницу.
>>> inc_count = "2256"
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = int(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'str'>
2256
<class 'int'>
2256
Функция float()
Функция float() используется для конвертации данных из других типов в тип числа с плавающей точкой.
>>> inc_count = "2256"
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = float(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'str'>
2256
<class 'float'>
2256.0
Функция str()
Как и int() с float() функция str() помогает конвертировать данные в строку из любого другого типа.
>>> inc_count = 2256
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = str(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'int'>
2256
<class 'str'>
2256
Советы:
- Не любой тип можно конвертировать в любой другой. Например, если строка состоит только из символов алфавита, то при попытке использовать с ней
int()приведет к ошибке. - Зато почти любой символ или число можно привести к строке. Это будет эквивалентно вводу цифр в кавычках, поскольку именно так создаются строки в Python.
Как можно увидеть в следующем примере, поскольку переменная состоит из символов алфавита, Python не удается выполнить функцию int(), и он возвращает ошибку.
>>> my_data = "Что-нибудь"
>>> my_data = int(my_data)
ValueError: invalid literal for int() with base 10: 'Что-нибудь'
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Измените и дополните код, что бы переменная salary_type хранила результат функции type() со значением int.
# данный код
salary = "50000"
salary_type =
print(salary_type)
# требуемый вывод:
# <class 'int'>2. Исправьте ошибку в коде, что бы получить требуемый вывод.
# данный код
mark = int("5+")
print(mark, "баллов")
# требуемый вывод:
# 5+ баллов3. Конвертируйте переменные и введите только целые числа через дефис.
# данный код
score1 = 50.5648
score2 = 23.5501
score3 = 96.560
print()
# требуемый вывод:
# 50-23-96Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_4.py.
Тест по конвертации типов данных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>Добавление геометрических фигур на полотно
В этом примере рассмотрим три основных элемента полотна: прямоугольники, овалы и дуги. Они все отображаются в пределах собственного контейнера, поэтому для определения их положения достаточно координат двух точек: верхнего левого и правого нижнего углов контейнера.
Следующее приложение позволяет пользователям свободно рисовать определенные элементы полотна, выбирая их тип с помощью трех соответствующих кнопок.
Положение элементов определяется двумя кликами: первый указывает на верхний левый угол контейнера, в который будет заключен элемент, а второй – на правый нижний. Также по умолчанию задаются определенные параметры:
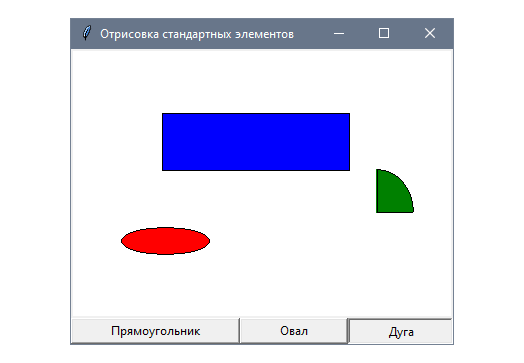
Приложение сохраняет текущий выбранный тип элемента, который задается с помощью одной из трех кнопок, расположенных в нижней части полотна.
Клик левой кнопкой мыши по полотну вызывает обработчик, который сохраняет положение первого угла нового элемента, а после второго клика считывает значение выбранной формы для условного рисования соответствующего элемента:
import tkinter as tk
from functools import partial
class App(tk.Tk):
shapes = ("прямоугольник", "овал", "дуга")
def __init__(self):
super().__init__()
self.title("Отрисовка стандартных элементов")
self.start = None
self.shape = None
self.canvas = tk.Canvas(self, bg="white")
frame = tk.Frame(self)
for shape in self.shapes:
btn = tk.Button(frame, text=shape.capitalize())
btn.config(command=partial(self.set_selection, btn, shape))
btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
self.canvas.bind("<Button-1>", self.draw_item)
self.canvas.pack()
frame.pack(fill=tk.BOTH)
def set_selection(self, widget, shape):
for w in widget.master.winfo_children():
w.config(relief=tk.RAISED)
widget.config(relief=tk.SUNKEN)
self.shape = shape
def draw_item(self, event):
x, y = event.x, event.y
if not self.start:
self.start = (x, y)
else:
x_origin, y_origin = self.start
self.start = None
bbox = (x_origin, y_origin, x, y)
if self.shape == "прямоугольник":
self.canvas.create_rectangle(*bbox, fill="blue",
activefill="yellow")
elif self.shape == "овал":
self.canvas.create_oval(*bbox, fill="red",
activefill="yellow")
elif self.shape == "дуга":
self.canvas.create_arc(*bbox, fill="green",
activefill="yellow")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает рисование фигур
Для сохранения возможности динамически выбирать тип элемента создаются кнопки для каждого из представленных. Они создаются за счет перебора кортежа shapes.
Каждая функция обратного вызова определяется с помощью функции partial из модуля functools. Это позволяет заморозить экземпляр Button и текущую форму цикла в качестве аргументов функции обратного вызова для каждой кнопки:
for shape in self.shapes:
btn = tk.Button(frame, text=shape.capitalize())
btn.config(command=partial(self.set_selection, btn, shape))
btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
Функция обратного вызова set_section() помечает нажатую кнопку с помощью SUNKEN и сохраняет выбор в поле shape.
Остальные кнопки настраиваются со стандартным рельефом RAISED. Это делается с помощью перехода к родителю, который доступен в поле master текущего виджета. Из него и можно получить все дочерние виджеты, используя метод winfo_children():
def set_selection(self, widget, shape):
for w in widget.master.winfo_children():
w.config(relief=tk.RAISED)
widget.config(relief=tk.SUNKEN)
self.shape = shape
Обработчик draw_item() сохраняет координаты первого клика каждой пары событий, чтобы нарисовать элемент при повторном клике по полотну.
В зависимости от типа поля shape вызывается один из следующих методов для отображения соответствующего элемента:
canvas.create_rectangele(x0, y0, x1, y,1 **options)– рисует прямоугольник, чей левый верхний угол расположен по координатам (x0, y0), а правый нижний – (x1, y1).
canvas.create_oval(x0, y0, x1, y1, **options)– рисует эллипс, который вписывается в прямоугольник с координатами (x0, y0) и (x1, y1).
canvas.create_arc(x0, y0, x1, y1, **options)– рисует четверть эллипса, который поместится в прямоугольник с координатами (x0, y0) и (x1, y1).
Поиск элементов по их положению
Класс Canvas включает методы для получения идентификаторов элементов, которые находятся рядом с координатами полотна.
Это удобно, потому что позволяет не хранить каждую ссылку на элемент полотна с последующим вычислением текущего положения. Тем не менее это нужно для определения того, какие из них расположены рядом с конкретной точкой.
Следующее приложение создает полотно с четырьмя прямоугольниками и меняет цвет в зависимости от того, к какому из них ближе всего расположен курсор:

Для нахождения ближайшего к курсору элемента координаты мыши передаются методу canvas.find_closest(), который и определяют идентификатор ближайшего элемента.
Если в пределах полотна есть хотя бы один элемент, можно быть уверенным в том, что метод всегда вернет валидный идентификатор элемента:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Поиск предметов на canvas")
self.current = None
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("<Motion>", self.mouse_motion)
self.canvas.pack()
self.update()
w = self.canvas.winfo_width()
h = self.canvas.winfo_height()
positions = [(60, 60), (w-60, 60), (60, h-60), (w-60, h-60)]
for x, y in positions:
self.canvas.create_rectangle(x-10, y-10, x+10, y+10,
fill="blue")
def mouse_motion(self, event):
self.canvas.itemconfig(self.current, fill="blue")
self.current = self.canvas.find_closest(event.x, event.y)
self.canvas.itemconfig(self.current, fill="yellow")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает поиск элементов
При инициализации приложения создается полотно и определяется поле current для сохранения ссылки на текущий подсвеченный элемент. Также обрабатываются события "<Motion>" с помощью метода mouse_motion():
self.current = None
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("<Motion>", self.mouse_motion)
self.canvas.pack()
После этого создаются четыре элемента с определенным положением так, что можно запросто отобразить ближайший из них к указателю:
self.update()
w = self.canvas.winfo_width()
h = self.canvas.winfo_height()
positions = [(60, 60), (w-60, 60), (60, h-60), (w-60, h-60)]
for x, y in positions:
self.canvas.create_rectangle(x-10, y-10, x+10, y+10,
fill="blue")
Обработчик mouse_motion() задает цвет текущего элемента обратно в синий и сохраняет идентификатор нового. Наконец, цвет fill этого элемента становится желтым:
def mouse_motion(self, event):
self.canvas.itemconfig(self.current, fill="blue")
self.current = self.canvas.find_closest(event.x, event.y)
self.canvas.itemconfig(self.current, fill="yellow")
Изначально при вызове mouse_motion() ошибок нет, а поле current равно None, поскольку это также валидное значение для параметра itemconfig. Просто в таком случае действия не выполняются.
Перемещение элементов в canvas
После размещения элементы полотна могут быть перемещены – для этого им не нужно задавать абсолютные координаты.
При перемещении элементов полотна обычно нужно вычислить текущее положение, чтобы определить, находятся ли они в пределах определенной области полотна и ограничить перемещение за пределы этой области.
Следующий пример будет включать простое полотно с прямоугольным элементом, который можно перемещать горизонтально и вертикально с помощью клавиш стрелок.
Чтобы элемент не ушел за пределы экрана, ограничим перемещение в пределах полотна:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Перемещение элементов холста")
self.canvas = tk.Canvas(self, bg="white")
self.canvas.pack()
self.update()
self.width = self.canvas.winfo_width()
self.height = self.canvas.winfo_height()
self.item = self.canvas.create_rectangle(30, 30, 60, 60,
fill="blue")
self.pressed_keys = {}
self.bind("<KeyPress>", self.key_press)
self.bind("<KeyRelease>", self.key_release)
self.process_movements()
def key_press(self, event):
self.pressed_keys[event.keysym] = True
def key_release(self, event):
self.pressed_keys.pop(event.keysym, None)
def process_movements(self):
off_x, off_y = 0, 0
speed = 3
if 'Right' in self.pressed_keys:
off_x += speed
if 'Left' in self.pressed_keys:
off_x -= speed
if 'Down' in self.pressed_keys:
off_y += speed
if 'Up' in self.pressed_keys:
off_y -= speed
x0, y0, x1, y1 = self.canvas.coords(self.item)
pos_x = x0 + (x1 - x0) / 2 + off_x
pos_y = y0 + (y1 - y0) / 2 + off_y
if 0 <= pos_x <= self.width and 0 <= pos_y <= self.height:
self.canvas.move(self.item, off_x, off_y)
self.after(10, self.process_movements)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает перемещение элементов
Для обработки клавиш стрелок на клавиатуре свяжем "<KeyPress>" и "<KeyRelease>" с экземпляром приложения. Нажатые сейчас клавиши сохраняются в словарь pressed_keys:
def __init__(self):
# ...
self.pressed_keys = {}
self.bind("<KeyPress>", self.key_press)
self.bind("<KeyRelease>", self.key_release)
def key_press(self, event):
self.pressed_keys[event.keysym] = True
def key_release(self, event):
self.pressed_keys.pop(event.keysym, None)
Такой подход лучше отдельного связывания клавиш "<Up>", "<Down>", "<Right>" и "<Left>", потому что они вызывали бы каждый из обработчиков только при обработке событий клавиатуры. В результате элементы бы «перепрыгивали» с одного положения на другое, а не плавно перемещались.
Последний элемент инициализации экземпляра App – вызов process_movements(), который запускает обработку движения элемента полотна.
Этот метод вычисляет сдвиг по каждой из осей. В зависимости от содержания словаря pressed_keys, скорость speed добавляется или вычисляется из координат компонентов:
def process_movements(self):
off_x, off_y = 0, 0
speed = 3
if 'Right' in self.pressed_keys:
off_x += speed
if 'Left' in self.pressed_keys:
off_x -= speed
if 'Down' in self.pressed_keys:
off_y += speed
if 'Up' in self.pressed_keys:
off_y -= speed
После этого мы получаем положение текущего элемента с помощью вызова canvas.coords() и распаковки пары точек, которые формируют контейнер из четырех переменных.
Центр каждого элемента вычисляется за счет сложения x и y верхнего левого угла с половиной ширины и высоты. Результат, плюс сдвиг по каждой оси, соответствует финальному положению элемента после перемещения:
x0, y0, x1, y1 = self.canvas.coords(self.item)
pos_x = x0 + (x1 - x0) / 2 + off_x
pos_y = y0 + (y1 - y0) / 2 + off_y
После этого мы проверяем, находимся ли мы в пределах полотна. Для этого используем встроенную в Python поддержку связанных операторов сравнения:
if 0 <= pos_x <= self.width and 0 <= pos_y <= self.height:
self.canvas.move(self.item, off_x, off_y)
Наконец, этот метод планирует сам себя с задержкой в 10 миллисекунд с помощью вызова self.after(10, self.process_movements). Таким образом достигается эффект собственного основного цикла внутри реального цикла Tkinter.
Вас может заинтересовать, почему в этом примере использовался after(), а не after_idle() для планирования метода process_movements().
Это может казаться корректным подходом, поскольку других событий для обработки помимо перерисовки полотна и обработки событий клавиатуры нет, и нет необходимости добавлять задержку между вызовами process_movements(), если нет событий интерфейса в процессе ожидания.
Однако при использовании after_idle элементы бы перемещались со скоростью, зависящей от скорости компьютера. Это значит, что более быстрая система вызывала бы process_movements() больше раз за один и тот же промежуток времени.
С помощью минимальной фиксированной задержки есть возможность одинаково обрабатывать элементы на разных машинах.
]]>int— этот тип данных состоит из целых чисел.float— этот тип используется для работы с десятичными числами.str— переменная с типом str (от string — строка) хранит данные в виде текстовых строк.
Где используется
- Данные используются в программирования повсеместно, поэтому важно понимать, с какими именно вы сейчас работаете, и какие последствия это накладывает на процесс взаимодействия. Существует множество типов данных, но только некоторые из них используются каждым программистом.
int— тип данных для работы с целыми числами, аfloat— для работы с числами с плавающей точкой.strхранит данные в строковом формате и может включать буквы, символы и цифры. В то же время вintиfloatиспользовать символы нельзя — только числа.- тип
boolсостоит всего из двух значений:TrueилиFalse. Важно отметить, что при инициализации или присваивании значения типаboolTrueилиFalseнужно вводить без кавычек. Строковые же значения наоборот всегда заключены в кавычки.
Рекомендации по работе с типами данных
- Нужно всегда помнить о следующих особенностях типов данных: их форматах, областях применения и возможностях.
- Строковые значения всегда заключены в кавычки, тогда как
int,floatилиboolзаписываются без них.
Примеры работы с разными типами данных
>>> my_сars_number = 3
>>> my_сars_color = "Бронза, зеленый, черный"
>>> print(my_сars_number)
>>> print(my_сars_color)
3
Бронза, зеленый, черный
В этом примере были созданы переменные двух типов данных, после чего они были выведены на экран. my_сars_number — это целое число (int), а my_сars_color — строка (str).
Рассмотрим порядок выполнения этого года:
- В первой строке создается переменная
my_сars_number, и ей присваивается значение 3. Это внутренний процесс, поэтому увидеть результат этой операции не выйдет, только если не попробовать вывести значение переменной. - На второй строке создается еще одна переменная, которой присваивается свое значение.
- На 3 и 4 строках ранее созданные переменные выводятся на экран.
Советы:
А зачем типы данных вообще нужны в Python? Этот вопрос наверняка будет интересовать в первую очередь начинающих программистов.
- Если подумать о внутреннем устройстве компьютера, то память в нем занимается распределением, а центральный процессор отвечает за вычисления. Благодаря типам данных компьютер знает, как распределять память, для чего ее использовать и какие операции выполнять с каким типом данных.
- Отличное сравнение в данном случае — контейнеры для продуктов. Типы данных можно воспринимать как разные контейнеры. В зависимости от типа еды, ее нужно размещать в соответствующих емкостях.
- С другой стороны, если конкретные данные — это целое число, то компьютер может не думать о конвертации их в нижний или верхний регистр, поиске гласных и так далее. Если строка — то здесь уже арифметические операции, поиск квадратного корня, конвертация и прочие команды становятся нерелевантными.
Создадим число с плавающей точкой.
>>> miami_temp_today = 103.40
>>> print(miami_temp_today)
103.4
В этом примере создаем число с плавающей точкой и выводим его на экране.
Продвинутые концепции
В Python есть и много других типов данных, например:
- байты;
- комплексные числа;
- булевые значения.
Есть даже и другие значения в других областях: дата, время, GPS-координаты и так далее. В будущем полезно использовать их особенно в крупных проектах. Но пока что остановимся на базовых.
Посмотрим на булевый тип. Это довольно простая концепция, но более сложный тип данных. Основная сложность в том, что мы не сталкиваемся с таким типом в реальном мире, и поэтому порой его сложновато воспринимать. Булевый тип можно воспринимать как переключатель. Он может быть либо включенным, либо выключенным. В Python это либо True, либо False.
Важно запомнить, что значения этого типа не должны быть заключены в кавычки. Это их основное отличие от строк. По сути, True и "True" — это два разных типа данных в Python: булевое и строка.
В более продвинутых примерах булевые типы окажутся очень полезными.
В следующем примере может показаться, что используется строка, но на самом деле это значение булевого типа. Оно может быть либо True, либо False.
>>> hungry_or_not = True
>>> print(hungry_or_not)
True
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Присвойте переменной целое число и получите вывод <class 'int'>.
Функция
type()возвращает тип объекта. Для решения задачи изменять нужно только первую строку.
# данный код
current_month =
type_var = type(current_month)
print(type_var)
# требуемый вывод:
# <class 'int'>2. Исправьте ошибки в коде, что бы получить требуемый вывод.
# данный код
polar_radius_title = "Радиус" "Земли"
polar_radius_float = 6378,1
print(polar_radius_title, polar_radius_float)
# требуемый вывод:
# Радиус Земли 6378.13. Создайте переменные, что бы получить требуемый вывод.
# данный код
str_type, int_type, float_type, bool_type =
print("Типы данных: ", end="")
print(type(str_type), type(int_type, type(float_type), type(bool_type), sep=",")
# требуемый вывод:
# Типы данных: <class 'str'>, <class 'int'>, <class 'float'>, <class 'bool'>Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_3.py.
Тест по типам данных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>В предыдущих материалах основное внимание было уделено стандартному виджету Tkinter. Однако вне внимания остался виджет Canvas. Причина в том, что он предоставляет массу графических возможностей и заслуживает отдельного рассмотрения.
Canvas (полотно) — это прямоугольная область, в которой можно выводить не только текст или геометрические фигуры, такие как линии, прямоугольники или овалы, но также другие виджеты Tkinter. Все вложенные объекты называются элементами Canvas, и у каждого есть свой идентификатор, с помощью которого ими можно манипулировать еще до момента отображения.
Рассмотрим методы класса Canvas на реальных примерах, что поможет познакомиться с распространенными паттернами, которые в дальнейшем помогут при создании приложений.
Понимание системы координат
Для рисования графических элементов на полотне, нужно обозначать их положение с помощью системы координат. Поскольку Canvas — это двумерная область, то точки будут обозначаться координатами горизонтальной и вертикальной осей — традиционными x и y соответственно.
На примере простого приложения можно легко изобразить, как именно стоит располагать эти точки по отношению к основанию системы координат, которая находится в верхнем левом углу области полотна.
Следующая программа содержит пустое полотно, а также метку, которая показывает положение курсора на нем. Можно перемещать курсор и видеть, в каком положении он находится. Это явно показывает, как изменяются координаты x и y в зависимости от положения курсора:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Базовый canvas")
self.canvas = tk.Canvas(self, bg="white")
self.label = tk.Label(self)
self.canvas.bind("", self.mouse_motion)
self.canvas.pack()
self.label.pack()
def mouse_motion(self, event):
x, y = event.x, event.y
text = "Позиция курсора: ({}, {})".format(x, y)
self.label.config(text=text)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает система координат
Экземпляр Canvas создается по аналогии с любым другим виджетом Tkinter. В него передаются родительский контейнер, а также все настройки в виде ключевых слов:
def __init__(self):
# ...
self.canvas = tk.Canvas(self, bg="white")
self.label = tk.Label(self)
self.canvas.bind("", self.mouse_motion)
Следующий скриншот показывает точку, составленную из перпендикулярных проекций двух осей:
- Координата x соответствует расстоянию по горизонтальной оси и увеличивается по мере движения слева направо;
- Координата y соответствует расстоянию по вертикальной оси и увеличивается по мере движения снизу вверх;
Можно обратить внимание на то, что эти координаты точно соответствуют атрибутам x и y экземпляра event, который был передан обработчику:
def mouse_motion(self, event):
x, y = event.x, event.y
text = "Позиция курсора: ({}, {})".format(x, y)
self.label.config(text=text)
Так происходит из-за того, что атрибуты рассчитываются относительно виджета, к которому прикреплено событие — в этом случае это последовательность <Motion>.
Площадь полотна также способна отображать элементы с отрицательными значениями их координат. В зависимости от размера элемента, он может быть частично виден у левой или верхней границ полотна.
Аналогично если расположить элемент так, что его координаты будут лежать за пределами полотна, то часть его будет видна у правого и нижнего краев.
Рисование линий и стрелок
Одно из базовых действий, которое можно выполнить на полотне — рисование сегментов от одной точки к другой. Хотя есть другие способы рисовать многоугольники, метод create_line класса Canvas предлагает достаточное количество опций для понимания основ отображения элементов.
В этом примере создадим приложение, которое позволит рисовать линии с помощью кликов по полотну. Каждая из них будет отображаться после двух кликов: первый будет указывать на начало линии, а второй — на ее конец.
Также можно будет задавать определенные элементы внешнего вида, например, толщину и цвет:
Класс App будет отвечать за создание пустого полотна и обработку кликов мышью.
Информация о линии будет идти из класса LineForm. Такой подход с выделением компонента в отдельный класс позволит абстрагировать детали его реализации и сфокусироваться на работе с виджетом Canvas.
Говоря простым словами, мы пропускаем реализацию класса LineForm в следующем коде:
import tkinter as tk
class LineForm(tk.LabelFrame):
# ...
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Базовый canvas")
self.line_start = None
self.form = LineForm(self)
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("", self.draw)
self.form.pack(side=tk.LEFT, padx=10, pady=10)
self.canvas.pack(side=tk.LEFT)
def draw(self, event):
x, y = event.x, event.y
if not self.line_start:
self.line_start = (x, y)
else:
x_origin, y_origin = self.line_start
self.line_start = None
line = (x_origin, y_origin, x, y)
arrow = self.form.get_arrow()
color = self.form.get_color()
width = self.form.get_width()
self.canvas.create_line(*line, arrow=arrow,
fill=color, width=width)
if __name__ == "__main__":
app = App()
app.mainloop()
Весь код целиком можно найти в отдельном файле lesson_18/drawing.py.
Как рисовать линии в Tkinter
Поскольку нужно обрабатывать клики мышью на полотне, свяжем метод draw() с этим типом события. Также определим поле line_start, чтобы отслеживать начальное положение каждой линии:
def __init__(self):
# ...
self.line_start = None
self.form = LineForm(self)
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("", self.draw)
Метод draw() содержит основную логику приложения. Первый клик служит для определения начала для каждой линии и ничего не рисует. Координаты он получает из объекта event, который передается обработчику:
def draw(self, event):
x, y = event.x, event.y
if not self.line_start:
self.line_start = (x, y)
else:
# ...
Если у line_start уже есть значение, то мы получаем его и передаем координаты текущего события, чтобы нарисовать линию:
def draw(self, event):
x, y = event.x, event.y
if not self.line_start:
# ...
else:
x_origin, y_origin = self.line_start
self.line_start = None
line = (x_origin, y_origin, x, y)
self.canvas.create_line(*line)
text = "Линия проведена из ({}, {}) к ({}, {})".format(*line)
Метод canvas.create_line() принимает четыре аргумента, где первые два — это горизонтальная и вертикальная координаты начала линии, а вторые два — ее конечной точки.
Вывод текста в canvas
В некоторых случаях появляется необходимость вывести на полотне текст. Для этого нет нужды использовать дополнительный виджет, такой как Label. Класс Canvas включает метод create_text для отображения строки, которой можно управлять точно так же, как и любым другим элементом полотна.
При этом есть возможность использовать те же параметры форматирования, что позволит задавать стиль текста: цвет, размер и семейство шрифтов.
В этом примере объединим виджет Entry с содержимым текстового элемента полотна. И если у первого будет стандартный стиль, то текст на полотне можно будет стилизовать:
Текстовый элемент по умолчанию будет отображаться с помощью canvas.create_text() и дополнительными параметрами, которые позволят добавить семейство шрифтов Consolas и синий цвет.
Динамическое поведение текстового элемента реализовано с помощью StringVar. Отслеживая эту переменную Tkinter, можно менять содержимое элемента:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Текстовые элементы Canvas")
self.geometry("300x100")
self.var = tk.StringVar()
self.entry = tk.Entry(self, textvariable=self.var)
self.canvas = tk.Canvas(self, bg="white")
self.entry.pack(pady=5)
self.canvas.pack()
self.update()
w, h = self.canvas.winfo_width(), self.canvas.winfo_height()
options = {"font": "courier", "fill": "blue",
"activefill": "red"}
self.text_id = self.canvas.create_text((w / 2, h / 2), **options)
self.var.trace("w", self.write_text)
def write_text(self, *args):
self.canvas.itemconfig(self.text_id, text=self.var.get())
if __name__ == "__main__":
app = App()
app.mainloop()
Можно ознакомиться с этой программой, введя любой текст в поле ввода, что автоматически обновит его на полотне.
Как работает вывод текста на полотно
В первую очередь создается экземпляр Entry с переменной StringVar и виджетом Canvas:
self.var = tk.StringVar()
self.entry = tk.Entry(self, textvariable=self.var)
self.canvas = tk.Canvas(self, bg="white")
После этого виджеты размещаются с помощью вызовов методов geometry manager Pack. Важно отметить, что update() нужно вызывать в корневом окне, благодаря чему Tkinter будет вынужден обрабатывать все изменения, в данном случае — рендеринг виджетов до того, как метод __init__ продолжит выполнение:
self.entry.pack(pady=5)
self.canvas.pack()
self.update()
Это делается, потому что на следующем шаге будут выполняться вычисления размеров полотна, и до тех пор пока geometry manager не разместит виджет, у него не будет реальных значений высоты и ширины.
После этого можно безопасно получить размеры полотна. Поскольку текст нужно выровнять относительно центра полотна, достаточно поделить значения ширины и длины пополам.
Эти координаты будут определять положение элемента, и вместе с параметрами стиля их нужно передать в метод create_text(). Аргумент-ключевое слово text — это стандартный параметр, но его можно пропустить, потому что он будет задаваться динамически при изменении значения StringVar:
w, h = self.canvas.winfo_width(), self.canvas.winfo_height()
options = { "font": "courier", "fill": "blue",
"activefill": "red" }
self.text_id = self.canvas.create_text((w/2, h/2), **options)
self.var.trace("w", self.write_text)
Идентификатор, который возвращает create_text(), будет сохранен в поле text_id. Он будет использоваться в методе write_text() для ссылки на элемент. А этот метод будет вызван за счет механизма отслеживания операции записи в экземпляре var.
Для обновления параметра text в обработчике write_text() вызывается метод canvas.itemconfig() с идентификатором элемента в качестве первого аргумента и настройки — как второго.
В этой программе используем поле field_id, сохраненное при создании экземпляра App, а также содержимое StringVar с помощью метода get():
Метод write_text() определен таким образом, что он может получать переменное число аргументов, хотя они не нужны, потому что метод trace() переменных Tkinter передает их в функции обратного вызова.
В методе canvas.create_text() есть много других параметров для изменения внешнего вида элементов полотна.
Размещение текста в левом верхнем углу
Параметр anchor позволяет контролировать положение элемента относительно координат, переданных в качестве первого аргумента в canvas.create_text(). По умолчанию это значение равно tk.CENTER, что значит, что текст будет отцентрирован в этих координатах.
Если же его нужно разместить в верхнем левом углу, то достаточно передать (0, 0) и задать значение tk.NW для anchor, что выровняет его в северо-западном положении прямоугольной области, в которой находится текст:
# ...
options = { "font": "courier", "fill": "blue",
"activefill": "red", "anchor": tk.NW }
self.text_id = self.canvas.create_text((0, 0), **options)
Этот код обеспечит такой результат:
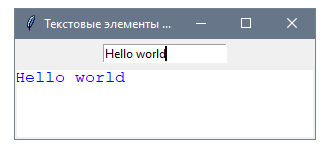
Перенос строк
По умолчанию содержимое текстового элемента будет выводиться в одну строку. Параметр width же позволяет задать максимальную ширину строки. В результате если она окажется больше, то содержимое перенесется на новую строку:
# ...
options = { "font": "courier", "fill": "blue",
"activefill": "red", "width": 70 }
self.text_id = self.canvas.create_text((w/2, h/2), **options)
Теперь если написать Hello World, часть текста выйдет за пределы заданной ширины и перенесется на новую строку:
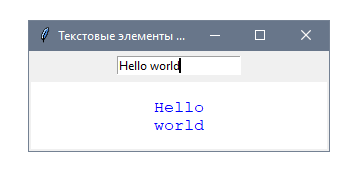
Понимать переменные важно для работы с любой логикой в программировании. Это то, что знает любой программист вне зависимости от языка программирования, и поэтому это так важно для начинающих.
Простейшее определение переменной — это именованный контейнер для данных, к которым нужно обращаться в программе. Есть 2 основные причины для этого:
- Зачастую данные — это больше чем 2 символа.
- Обычно к ним нужно обращаться по несколько раз.
Где используется?
- Сложно представить программирование без переменных. Это как обращаться к людям, не используя их имена и фамилии. Можно только представить, насколько это было бы неудобно.
- В программировании переменные используются для определения и обращения к данным разных размеров, типов и форм.
Правила использования
- При присвоении значения переменная всегда находится слева, а данные — справа.
- Имя переменной может начинаться с символа или нижнего подчеркивания (
_). - Для вывода значения переменной с помощью функции
printнужно передавать ее без кавычек.
Частые ошибки
- Начинать имя переменной с цифры.
- Использовать символы (кроме нижнего подчеркивания) в имени переменной.
- Использовать в переменной пробелы.
Примеры использования переменных
Предположим, что есть большое число: 149597970. Оно обозначает расстояние между Солнцем и Землей в километрах.
Предположим, что к этому значению нужно обратиться для выполнения вычислений. Вместо того, чтобы каждый раз вводить его, можно просто использовать переменную. Вот так:
>>> sun_to_earth = 149597970
>>> sun_to_earth = sun_to_earth + 1
>>> print(sun_to_earth)
149597971
Эти данные могли бы быть и куда объемнее. В них, например, могло бы быть 100 цифр, а обращаться к данным, возможно, нужно было бы в 100 разных местах. Таким образом польза от присваивания имени значению очевидна.
Разберем код примера:
- Сначала создается переменная
sun_to_earth, и ей присваивается значение 149597970. - Переменной
sun_to_earthприсваивается новое значение — 149597971. - Выполняется функция
print, которая выводит текущее значение переменной, то есть, 149597971.
Советы:
- Название переменной всегда расположено слева при присваивании. А значение, которое нужно присвоить, располагается справа.
- В Python (и любом другом языке программирования) очень важно правильно выбирать название переменной, ведь к ней придется часто обращаться:
- Кое-какие названия являются зарезервированными в Python, поэтому их использовать нельзя: print, true, false, count, sum и так далее. Со временем вы все их узнаете.
- Названия переменных должны начинаться с символа алфавита или нижнего подчеркивания.
- Если начать переменную с символа или нижнего подчеркивания, то после в нее можно включать и цифры.
- Названия переменных чувствительны к регистру. Если был использован символ в верхнем регистре, то именно так и нужно обращаться к переменой в будущем.
- Практические соглашения именования переменных:
- Можно добавлять небольшой суффикс, чтобы не путать переменную с ключевым словом Python: var_number , var_true , v_start , v_close, the_class, the_one, the_name. Креативность разрешена, главное, чтобы система оставалась понятной.
- Лучше не использовать переменную в один символ, только если это цикл или любая другая короткая операция. Такие имена как a, x, y, z начинают путать уже спустя пару минут после того, как их впервые использовали.
- Слова рекомендуется разделять нижним подчеркиванием: cars_сounted, doors_сlosed, dogs_saved, ships_fixed и так далее. Это повышает читаемость переменных. Сравните: timeinmoscow и time_in_moscow.
- Рекомендуется (часто требуется) использовать латиницу и английские слова. Так ваш код будут понимать больше разработчиков.
>>> dogs_name = "Шарик"
>>> dogs_kind = "Сенбернар"
>>> print("Его зовут " , dogs_name , ". Он ", dogs_kind, ".", sep="")
Его зовут Шарик. Он Сенбернар.
Это отличный пример применения не только переменной, но и функции print, ведь в последней используются сразу текст и значение переменной. Плюс, названия переменных выбраны очень удачно. Названия для переменных — тема субъективная, поэтому достаточно использовать то, что удобно для вас.
В одной строке можно присвоить сразу несколько переменных. Вот пример:
>>> i, j, k = "Hello", 55, 21.0765
>>> print(i, j, k)
Hello 55 21.0765
>>> dogs_name = "Шарик"
>>> dogs_kind = "Сенбернар"
>>> print("Его зовут " , dogs_name , ". Он ", dogs_kind, ".", sep="")
Его зовут Шарик. Он Сенбернар.
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Отредактируйте код, что бы он выводил заданный текст.
# данный код
apple_stocks =
print("", apple_stocks, "")
# требуемый вывод:
# Запасы яблок на складе: 356 кг.2. Допишите код, что бы получить требуемый вывод.
# данный код
a, b = 45, 54
c = a + 1
d = c +
print(d)
# требуемый вывод:
# 563. Создайте переменные, что бы вывести требуемый текст.
# данный код
print("Мой стек:", programming_lang_1, programming lang_2, programming_lang_3)
# требуемый вывод:
# Мой стек: python, javascript, phpФайл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_2.py.
Тест на понимание переменных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
Эти уроки подразумевают, что у вас уже установлен python и вы знаете как открыть IDLE. Рекомендую использовать python 3.7+.
Если он не установлен, посмотрите руководства здесь: https://pythonru.com/tag/skachat-i-ustanovit-python
Вывод «Hello World!» — это, наверное, один из самых распространенных ритуалов для всех языков программирования, поэтому при изучения основ функции print можно и взять его за основу.
Print — это как первая буква в алфавите программирования. В Python она отвечает за вывод данных пользователю.
print() используется для показа информации пользователю или программисту. Она не меняет значения, переменные или функции, а просто показывает данные.
Функция очень полезна для программиста, ведь помогает проверять значения, устанавливать напоминания или показывать сообщения на разных этапах процесса работы программы.
Правила использования
- Print работает с круглыми скобками. Вот корректный синтаксис:
print(). - Если нужно вывести текст, то его необходимо заключить в скобки:
print("Hello World"). - Символ
#используется для добавления комментариев в текст. Эти комментарии не выполняются и не выводятся. Они выступают всего лишь заметками для тех, кто работает с кодом.
Частые ошибки
- Нельзя выводить текст без скобок. Хотя такой подход и работает с Python 2, в Python 3 возникнет ошибка.
- Внутри функции print не нужно использовать кавычки при выводе значений переменных. Они нужны только для строк.
Переменная — сущность, которая хранит записанное значение. Например, в контакты телефона мы сохраняем номер под именем, что бы не запоминать его и не вводить каждый раз. В python мы сохраняем такие значения в переменные: pavel = "8 800 123 45 67"
Примеры функции print()
>>> print("Hello, World!")
Hello, World!
Важные моменты:
- Текст для вывода должен быть заключен в скобки. Это правило синтаксиса, которому нужно следовать.
- Если выводится переменная, то кавычки не нужны, достаточно ввести название самой переменной. Как в следующем примере:
>>> my_message = "Этот текст выводим"
>>> print(my_message)
Этот текст выводим
Советы:
- Используйте запятую. Можно вывести несколько значений, разделив их запятыми.
print("Привет" , "меня зовут" , "Иван") - Параметр
sep. Помимо того, что можно увидеть, есть еще и параметрsep, который разделяет каждое значение указанным разделителем.print("Model S" , "Model 3" , sep="--") - Параметр
end. По умолчанию функция добавляет символ новой строки после каждого выполнения. Этого можно избежать с помощью параметраend. Ему также можно присвоить любое значение.print("Model S" , "Model 3" , end="|")print("100" , "200" , end="|")print("USA" , "France" , end="|")
>>> print("Привет" , "меня зовут" , "Иван")
Привет меня зовут Иван
>>># Это комментарий. Обычно здесь пишут пояснения своего кода. Эта строка не выполняется.
>>> print("Привет" , "меня зовут" , "Иван")
Привет меня зовут Иван
Можно увидеть, что в коде есть строка комментария, которая начинается с символа #. Она полностью игнорируется программой — ее можно воспринимать как заметку относительно содержания кода.
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Отредактируйте код, что бы он выводил текст Добро пожаловать!.
# данный код
print("Hello world")
# требуемый вывод:
# Добро пожаловать!2. Допишите код, что бы получить вывод: Функция print().
# данный код
my_text=""
print(my_text)
# требуемый вывод:
# Функция print()3. Даны переменные name, surname и salary. Выведите требуемый текст.
# данный код
name = "Иван"
surname = "Петров"
salary = "90 000"
# требуемый вывод:
# Иван Петров зарабатывает 90 000 рублейФайл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_1.py.
Тест по функции print()
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>Есть ситуации, когда определенная операция приводит к небольшому перерыву в работе программы. Он может занимать меньше секунды, но все равно будет заметен пользователю, ведь приведет к тому, что в это время графический интерфейс перестанет отвечать.
В этом материале рассмотрим, как справляться с такими ситуациями без необходимости обрабатывать целую задачу на отдельном потоке.
Возьмем пример из материала о «Запланированных действиях», но с паузой в 1, а не 5 секунд.
При изменении состояния кнопки на DISABLED функция обратного вызова продолжает выполнение, поэтому состояние кнопки не меняется до тех пор, пока система находится в состоянии ожидания. Это значит, что она будет ждать завершения time.sleep().
Однако можно сделать так, чтобы Tkinter принудительно обновил все элементы графического интерфейса в режиме ожидания в конкретный момент:
import time
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.button = tk.Button(self, command=self.start_action,
text="Ждать секунды")
self.button.pack(padx=30, pady=20)
def start_action(self):
self.button.config(state=tk.DISABLED)
self.update_idletasks()
time.sleep(1)
self.button.config(state=tk.NORMAL)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает обработка задач
Главная фишка здесь — вызов self.update_idletasks(). Благодаря этому изменение состояния кнопки обрабатывается Tkinter до вызова time.sleep(). И в ту секунду, пока функция обратного вызова приостановлена, кнопка выглядит так, как нужно, потому что Tkinter задает это состояние еще до вызова функции обратного вызова.
Для иллюстрации примера был использован метод time.sleep(), но в реальных ситуациях стоит ожидать куда более сложные вычисления.
Создание отдельных процессов
В определенных ситуациях невозможно добиться нужного результата, просто используя потоки. Например, может потребоваться вызвать отдельную программу, написанную на другом языке.
В таком случае нужно использовать модуль subprocess для вызова определенной программы из процесса Python.
Следующий пример выполняет запрос на обозначенный DNS или IP адрес:
Обычно определяется метод AsyncAction, но в этот раз вызовем subprocess.run() со значением в виджете Entry.
Эта функция запускает отдельный подпроцесс, который, в отличие от потоков, использует другую область памяти. Это значит, что для получения результата команды ping потребуется перенаправить его в стандартный вывод и прочесть в Python-программе:
import threading
import subprocess
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.entry = tk.Entry(self)
self.button = tk.Button(self, text="Пинг!",
command=self.do_ping)
self.output = tk.Text(self, width=80, height=15)
self.entry.grid(row=0, column=0, padx=5, pady=5)
self.button.grid(row=0, column=1, padx=5, pady=5)
self.output.grid(row=1, column=0, columnspan=2,
padx=5, pady=5)
def do_ping(self):
self.button.config(state=tk.DISABLED)
thread = AsyncAction(self.entry.get())
thread.start()
self.poll_thread(thread)
def poll_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.poll_thread(thread))
else:
self.button.config(state=tk.NORMAL)
self.output.delete(1.0, tk.END)
self.output.insert(tk.END, thread.result)
class AsyncAction(threading.Thread):
def __init__(self, ip):
super().__init__()
self.ip = ip
def run(self):
self.result = subprocess.run(["ping", self.ip], shell=True,
stdout=subprocess.PIPE).stdout.decode("CP866")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает создание новых процессов
Функция run() выполняет подпроцесс, заданный в массиве аргументов. По умолчанию результат включает только код процесса, поэтому нужно также передать параметр stdout с константой PIPE, чтобы обозначить, что стандартный вывод следует передать.
Эта функция вызывается с аргументом-ключевым словом shell и значением True, чтобы для процесса ping не открывалось новое окно терминала:
def run(self):
self.result = subprocess.run(["ping", self.ip], shell=True,
stdout=subprocess.PIPE).stdout.decode("CP866")
Наконец, когда основной поток подтверждает, что операция завершилась, он выводит результат в виджете Text:
def poll_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.poll_thread(thread))
else:
self.button.config(state=tk.NORMAL)
self.output.delete(1.0, tk.END)
self.output.insert(tk.END, thread.result)
Выполнение HTTP-запросов
Общение приложения с удаленным сервером с помощью HTTP — это распространенный случай в асинхронном программирования. Клиент делает запрос, который передается по сети по протоколу TCP/IP. После этого сервер обрабатывает информацию и отправляет клиенту ответ.
Время выполнения операции может варьироваться от нескольких миллисекунд до секунд, но в большинстве случаев стоит предполагать, что пользователи способны заметить задержку.
Есть много сторонних веб-сервисов, которые можно использовать на этапе разработки в целях прототипирования. Однако лучше этого не делать, ведь их API может поменяться или же они вообще станут недоступны.
В этом примере реализуем HTTP-сервер, который генерирует случайный ответ в формате JSON и выведем его в приложении с графическим интерфейсом.
import time
import json
import random
from http.server import HTTPServer, BaseHTTPRequestHandler
class RandomRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# Имитация задержки
time.sleep(3)
# Добавляем заголовки ответа
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
# Добавляем тело ответа
body = json.dumps({'random': random.random()})
self.wfile.write(bytes(body, "utf8"))
def main():
"""Запускает HTTP-сервер на порту 8090"""
server_address = ('', 8090)
httpd = HTTPServer(server_address, RandomRequestHandler)
httpd.serve_forever()
if __name__ == "__main__":
main()
Для запуска сервера нужно выполнить скрипт server.py и оставить процесс запущенным для получения запросов на локальном порте 8090.
Клиентское приложение состоит из метки для показа информации пользователям и кнопки для выполнения нового HTTP-запроса на локальный сервер:
import json
import threading
import urllib.request
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Выполнение HTTP-запросов")
self.label = tk.Label(self, text="Нажмите 'Старт', чтобы получить случайное значение.")
self.button = tk.Button(self, text="Старт",
command=self.start_action)
self.label.pack(padx=60, pady=10)
self.button.pack(pady=10)
def start_action(self):
self.button.config(state=tk.DISABLED)
thread = AsyncAction()
thread.start()
self.check_thread(thread)
def check_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.check_thread(thread))
else:
text = "Случайное значение: {}".format(thread.result)
self.label.config(text=text)
self.button.config(state=tk.NORMAL)
class AsyncAction(threading.Thread):
def run(self):
self.result = None
url = "http://localhost:8090"
with urllib.request.urlopen(url) as f:
obj = json.loads(f.read().decode("utf-8"))
self.result = obj["random"]
if __name__ == "__main__":
app = App()
app.mainloop()
После завершения запроса метка покажем случайное значение, которое было сгенерировано на сервере:
При выполнении асинхронной операции кнопка традиционно будет становиться неактивной, что не позволит сделать новый запрос до выполнения текущего.
Как работают HTTP-запросы
В этом примере класс Thread был расширен для реализации логики, которая должна работать на отдельном потоке с применением более объектно-ориентированного подхода. Это делается за счет переопределения метода run(), который будет отвечать за выполнение HTTP-запроса на локальный сервер:
class AsyncAction(threading.Thread):
def run(self):
# ...
Существует множество клиентских HTTP-библиотек, но в этом примере используем модуль urllib.request из стандартной библиотеки. Он включает функцию urlopen(), которая принимает URL в виде строки и возвращает HTTP-ответ, который может работать как контекстный менеджер. Это позволит безопасно прочитать информацию и закрыть его с помощью with.
Сервер возвращает приблизительной такой JSON-документ (увидеть его можно, открыв http://localhost:8080 в бразуере):
{"random": 0.0915826359180778}Чтобы декодировать строку в объект, нужно передать содержимое ответа функции loads() из модуля json. Благодаря этому можно получить доступ к случайному значению с помощью словаря и сохранить его в атрибуте result, экземпляр которого создается со значением None. Благодаря этому основной поток не будет считывать этот атрибут в случае ошибки:
def run(self):
self.result = None
url = "http://localhost:8090"
with urllib.request.urlopen(url) as f:
obj = json.loads(f.read().decode("utf-8"))
self.result = obj["random"]
После этого приложение с графическим интерфейсом периодически опрашивает статус потока, как было видно в прошлом примере:
def check_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.check_thread(thread))
else:
text = "Random value: {}".format(thread.result)
self.label.config(text=text)
self.button.config(state=tk.NORMAL)
Основное отличие в том, что когда поток не активен, можно получить значение result, потому что оно было задано до завершения выполнения.
Соединение потоков прогрессбаром
Шкалы прогресса — это удобные индикаторы статуса фоновых задач, которые показывают пропорционально заполняемую часть шкалы относительно общего прогресса. Обычно они используются в тех операциях, выполнение которых занимает много времени. Распространенная практика — объединять их с потоками, которые выполняют эти задачи для предоставления визуальной обратной связи для конечных пользователей.
Приложение будет состоять из горизонтальной шкалы прогресса, которая будет постепенно увеличивать количество прогресса после нажатия на кнопку Старт:
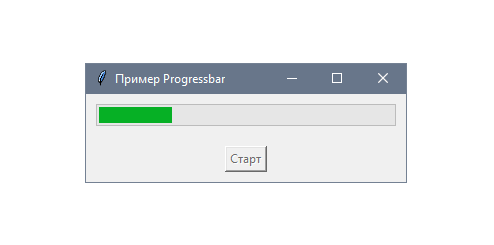
Для симуляции выполнения фоновой задачи инкремент шкалы будет генерироваться в другом потоке, который должен приостанавливать выполнение на 1 секунду для каждого шага.
Коммуникация будет настроена с помощью синхронизированной очереди, которая позволяет обмениваться информации, сохраняя потокобезопасность:
import time
import queue
import threading
import tkinter as tk
import tkinter.ttk as ttk
import tkinter.messagebox as mb
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Пример Progressbar")
self.queue = queue.Queue()
self.progressbar = ttk.Progressbar(self, length=300,
orient=tk.HORIZONTAL)
self.button = tk.Button(self, text="Старт",
command=self.start_action)
self.progressbar.pack(padx=10, pady=10)
self.button.pack(padx=10, pady=10)
def start_action(self):
self.button.config(state=tk.DISABLED)
thread = AsyncAction(self.queue, 20)
thread.start()
self.poll_thread(thread)
def poll_thread(self, thread):
self.check_queue()
if thread.is_alive():
self.after(100, lambda: self.poll_thread(thread))
else:
self.button.config(state=tk.NORMAL)
mb.showinfo("Готово!", "Асинхронное действие завершено")
def check_queue(self):
while self.queue.qsize():
try:
step = self.queue.get(0)
self.progressbar.step(step * 100)
except queue.Empty:
pass
class AsyncAction(threading.Thread):
def __init__(self, queue, steps):
super().__init__()
self.queue = queue
self.steps = steps
def run(self):
for _ in range(self.steps):
time.sleep(1)
self.queue.put(1 / self.steps)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает прогрессбар с потоками
Progressbar — это тематический виджет из модуля tkinter.ttk.
Также нужно импортировать модуль queue, который определяет синхронизированные коллекции, такие как Queue. Синхронность — важная тема в средах с несколькими потоками, потому что если к ресурсам с общим доступом попытаться получить доступ одновременно, результат будет непредсказуемым. Такие маловероятные, но все равно возможные сценарии называются состоянием гонки.
Теперь класс App включает такие новые инструкции:
# ...
import queue
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Пример Progressbar")
self.queue = queue.Queue()
self.progressbar = ttk.Progressbar(self, length=300,
orient=tk.HORIZONTAL)
Как и в предыдущих примерах метод start_action() запускает поток, передавая queue и количество шагов, которые будут симулировать долгоиграющую задачу:
def start_action(self):
self.button.config(state=tk.DISABLED)
thread = AsyncAction(self.queue, 20)
thread.start()
self.poll_thread(thread)
Подкласс AsyncAction определяет конструктор для получения этих параметров, которые позже будут использованы в методе run():
class AsyncAction(threading.Thread):
def __init__(self, queue, steps):
super().__init__()
self.queue = queue
self.steps = steps
def run(self):
for _ in range(self.steps):
time.sleep(1)
self.queue.put(1 / self.steps)
Цикл приостанавливает выполнение потока на 1 секунду и добавляет инкремент в очередь в зависимости от значения атрибута steps.
Элемент, добавленный в очередь, считывается из экземпляра приложения с помощью чтения очереди из check_queue():
def check_queue(self):
while self.queue.qsize():
try:
step = self.queue.get(0)
self.progressbar.step(step * 100)
except queue.Empty:
pass
Следующий метод периодически вызывается из poll_thread(), который опрашивает статус потока и планирует сам себя с помощью after(), пока поток не завершит выполнение:
def poll_thread(self, thread):
self.check_queue()
if thread.is_alive():
self.after(100, lambda: self.poll_thread(thread))
else:
self.button.config(state=tk.NORMAL)
mb.showinfo("Готово!", "Асинхронное действие завершено")
Отмена запланированных действий
Механизм планирования Tkinter не только предоставляет методы для откладывания выполнения функций обратного вызова, но дает возможность отменять те, которые еще не были выполнены. Это может быть операция, которая занимает много времени. И можно разрешить пользователям остановить ее, нажав на кнопку или закрыв приложение.
Возьмем пример из первого приложения и добавим кнопку Stop, которая позволяет остановить запланированное действие.
Она будет активной только при наличии запланированного действия. Это значит, что после нажатия кнопки слева пользователь может подождать 5 секунд или нажать на Stop, чтобы снова сделать ее доступной:
Метод after_cancel() отменяет выполнение запланированного действия, используя идентификатор, который вернулся после вызова after(). В этом примере это значение хранится в атрибуте scheduled_id:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.button = tk.Button(self, command=self.start_action,
text="Подождите 5 секунд")
self.cancel = tk.Button(self, command=self.cancel_action,
text="Стоп", state=tk.DISABLED)
self.button.pack(padx=30, pady=20, side=tk.LEFT)
self.cancel.pack(padx=30, pady=20, side=tk.LEFT)
def start_action(self):
self.button.config(state=tk.DISABLED)
self.cancel.config(state=tk.NORMAL)
self.scheduled_id = self.after(5000, self.init_buttons)
def init_buttons(self):
self.button.config(state=tk.NORMAL)
self.cancel.config(state=tk.DISABLED)
def cancel_action(self):
print("Отмена событий", self.scheduled_id)
self.after_cancel(self.scheduled_id)
self.init_buttons()
if __name__ == "__main__":
app = App()
app.mainloop()
Как происходит отмена событий
Чтобы отменить запланированное действие для функции обратного вызова сперва нужен идентификатор, который возвращает after(). Сохраним его в атрибуте scheduled_id, поскольку он понадобится в отдельном методе:
def start_action(self):
self.button.config(state=tk.DISABLED)
self.cancel.config(state=tk.NORMAL)
self.scheduled_id = self.after(5000, self.init_buttons)
Затем это поле передается в after_callback() обратного вызова кнопки Стоп:
def cancel_action(self):
print("Отмена событий", self.scheduled_id)
self.after_cancel(self.scheduled_id)
self.init_buttons()
Важно отключить кнопку Старт после клика, ведь если нажать ее дважды, переменная scheduled_id будет перезаписана, и кнопка Стоп сможет отменить только последнее запланированное действие.
Также стоит отметить, что after_cancel() не сработает, если вызвать ее без идентификатора действия, которое уже было выполнено.
В этом разделе было рассмотрено, как отменить запланированное действие, но если эта функция опрашивала статус фонового потока, важно знать, как остановить и его тоже.
К сожалению, не существует официального API для остановки экземпляра Thread. При определении кастомного подкласса может потребоваться добавить флаг, который периодически проверяется в методе run():
class MyAsyncAction(threading.Thread):
def __init__(self):
super().__init__()
self.do_stop = False
def run(self):
# Начать выполнение...
if not self.do_stop:
# Продолжить выполнение...
Затем этот флаг может быть изменен внешне с помощью thread.do_stop = True при вызове after_cancel() для остановки и потока.
Этот подход зависит от операций в методе run — например, его проще будет реализовать при наличии цикла, ведь будет возможность выполнять проверку между итерациями.
А с Python 3.4 можно использовать модуль asyncio, который включает классы и функции для управления асинхронными операциями, включая отмены. Хотя он и не касается этого материала, на него обязательно стоит обратить внимание.
]]>Планирование действий
Базовый метод предотвращения блокировки основного потока в Tkinter — это планирование действий, которые будут выполнены после истечения заданного времени.
В этом материале разберемся с тем, как реализовать этот подход в Tkinter с помощью метода after(), который может быть вызван во всех классах виджетов.
Следующий код показывает пример того, как функция обратного вызова может блокировать основной цикл.
Это приложение состоит из одной кнопки, которая становится неактивной после нажатия. Через 5 секунд ее снова можно нажать. Простейшая реализация будет выглядеть следующим образом:
import time
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.button = tk.Button(self, command=self.start_action,
text="Ждать 5 секунд")
self.button.pack(padx=50, pady=20)
def start_action(self):
self.button.config(state=tk.DISABLED)
time.sleep(5)
self.button.config(state=tk.NORMAL)
if __name__ == "__main__":
app = App()
app.mainloop()
Если запустить эту программу, то можно заметить, что не кнопка становится неактивной, а весь графический интерфейс зависает на 5 секунд. Это понятно по внешнему виду кнопки, которая в течение 5 секунд выглядит нажатой, а не выключенной. Более того, строка заголовка не будет реагировать на клики мыши все это время:
Если активировать дополнительные виджеты, например, Entry и Scroll, то это поведение задело бы и их.
А теперь посмотрим, как добиться нужного поведения вместо того, чтобы блокировать выполнение потока.
Как работает планирование действий
Метод after() позволяет регистрировать функцию обратного вызова, которая вызывается после задержки, заданной в миллисекундах в основном цикле Tkinter. По сути, они представляют собой зарегистрированные сигналы-события, которые обрабатываются в те моменты, когда система находится в состоянии ожидания.
Таким образом заменим вызов time.sleep(5) на self.after(5000,callback). Используем экземпляр self, потому что метод after() также доступен в корневом экземпляре Tk, и нет разницы в том, чтобы вызывать его из дочернего виджета:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.button = tk.Button(self, command=self.start_action,
text="Ждать 5 секунд")
self.button.pack(padx=50, pady=20)
def start_action(self):
self.button.config(state=tk.DISABLED)
self.after(5000, lambda: self.button.config(state=tk.NORMAL))
if __name__ == "__main__":
app = App()
app.mainloop()
Благодаря этому приложение будет реагировать вплоть до запланированного действия. Кнопка станет неактивной, но со строкой заголовка можно продолжать взаимодействовать привычным образом:
По последнему примеру можно предположить, что метод after() исполняется после заданной в миллисекундах длительности.
Однако на самом деле метод просит Tkinter зарегистрировать событие, что гарантирует, что оно не выполнится ранее намеченного времени. И если основной поток занят, то верхнего предела того, когда оно все-таки выполнится, нет.
Нужно также помнить о том, что выполнение метода продолжается сразу же после планирования действия. Следующий пример иллюстрирует такое поведение:
print("Первый")
self.after(1000, lambda: print("Третий"))
print("Второй")
Этот код выведет «Первый», «Второй» и, наконец, «Третий» спустя секунду. Все это время графический интерфейс будет оставаться доступным, а пользователи смогут продолжать взаимодействовать с ним.
Обычно нужно также не допустить, чтобы одно и то же фоновое задание выполнялось более одного раза, поэтому хорошей практикой считается отключение виджета, запустившего выполнение.
Не стоит забывать, что любая запланированная функция будет выполнена в основном потоке, поэтому одного только after() недостаточно, чтобы предотвратить зависание интерфейса. Нужно также не выполнять методы, выполнение которых занимает много времени в качестве обратного вызова.
В следующем примере рассмотрим, как можно сделать так, чтобы эти блокирующие действия выполнялись в отдельных потоках.
Метод after() возвращает идентификатор запланированного события, который можно передать в метод after_cancel() для отмены выполнения функции обратного вызова.
Дальше рассмотрим, как реализовать остановку запланированного события с помощью этого метода.
Работа в потоках
Поскольку основной поток отвечает только за обновление графического интерфейса и обработку событий, оставшаяся часть фоновых событий должна выполняться на разных потоках.
Стандартная библиотека Python включает модуль threading для создания и контроля несколько потоков с помощью высокоуровневого интерфейса, который позволяет работать с простыми классами и методами.
Стоит отметить, что CPython — «эталонная реализация» Python — ограничена GIL (Global Interpreter Lock), механизмом, который не дает нескольким потокам запускать байт-код Python одновременно. Из-за этого невозможно пользоваться преимуществами многопроцессорных систем. Об этом важно помнить при попытке улучшить производительность приложения.
В следующем примере объединены приостановка потока с помощью time.sleep(), а также действие, запланированное с помощью after():
import time
import threading
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.button = tk.Button(self, command=self.start_action,
text="Ждать 5 секунд")
self.button.pack(padx=50, pady=20)
def start_action(self):
self.button.config(state=tk.DISABLED)
thread = threading.Thread(target=self.run_action)
print(threading.main_thread().name)
print(thread.name)
thread.start()
self.check_thread(thread)
def check_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.check_thread(thread))
else:
self.button.config(state=tk.NORMAL)
def run_action(self):
print("Запуск длительного действия...")
time.sleep(5)
print("Длительное действие завершено!")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работают треды
Для создания нового объекта Thread можно использовать конструктор и аргумент-ключевое слово target. Он будет вызван на отдельном потоке при использовании его же метода start().
В прошлом примере использовалась ссылка на метод run_action, примененная экземпляру текущего приложения:
thread = threading.Thread(target=self.run_action)
thread.start()
После этого периодически опрашивается статус потока после after(), который планирует тот же метод до завершения потока:
def check_thread(self, thread):
if thread.is_alive():
self.after(100, lambda: self.check_thread(thread))
else:
self.button.config(state=tk.NORMAL)
В прошлом примере задержка была 100 миллисекунд, потому что чаще проверять статус нет необходимости. Хотя это всегда зависит от типа действия на потоке.
Это процесс может быть представлен в виде такой диаграммы:
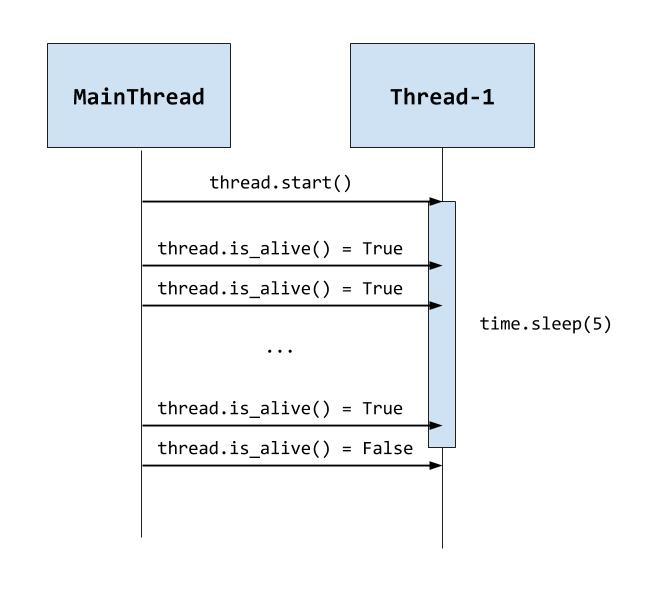
Прямоугольник Thread-1 представляет время, во время которого поток занят выполнением time.sleep(5). В то же время MainThread только проверяет статус, и нет ни одной операции, которая приводила бы к зависанию всего интерфейса.
В этом материале мы познакомились с классом Thread, но важно остановиться на некоторых деталях создания их экземпляров и использования в программах на Python.
Методы Thread — start, run и join
start() в этом примере вызывался для выполнения метода в отдельном потоке, чтобы основной продолжал выполняться.
Если же вызвать join(), то основной был бы заблокирован до остановки нового. Это привело бы к тому же «зависанию», которого мы пытались избежать, даже при использовании нескольких потоков.
Наконец, метод run() — это то, где поток выполняет операцию. В будущем его нужно перезаписывать.
Важно запомнить, что нужно всегда вызывать start() из основного потока, чтобы не блокировать его.
Параметры для метода
При использовании конструктора класса Thread можно задать аргументы для передаваемого метода с помощью параметра args:
def start_action(self):
self.button.config(state=tk.DISABLED)
thread = threading.Thread(target=self.run_action, args=(5,))
thread.start()
self.check_thread(thread)
def run_action(self, timeout):
# ...
Параметр self передается автоматически, поскольку используется текущий экземпляр для ссылки на переданный метод. Это удобно в тех ситуациях, когда новому потоку нужен доступ к информации из экземпляра вызвавшего его.
Теперь, когда вся функциональность приложения готова, можно обратить внимание на проблемы в его дизайне. Например, класс App имеет несколько обязанностей: от создания экземпляров виджетов Tkinter до выполнения инструкций SQL.
Хотя кажется довольно простым и очевидным писать методы, которые бы выполняли операции от начала и до конца, этот подход приводит к тому, что код становится все сложнее поддерживать. Определить этот недостаток можно, предположив кое-какие архитектурные изменения, как например, замену реляционной базы данных на REST-бэкенд, связываться с которым приложение будет по HTTP.
Начнем с определения паттерна MVC и того, как он соотносится с разными частями приложения, которое было создано в прошлых материалах.
Паттерн отвечает за разделение приложение на три компонента, каждый из которых инкапсулирует отдельную зону ответственности, формируя троицу MVC:
model(модель) представляет доменные данные и содержит бизнес-правила для взаимодействия с ними. В этом примере это классContactи конкретный код SQLite.view(представление) — графическое представление данных модели. В нашем приложении это виджеты Tkinter, которые и представляют собой графический интерфейс.controller(контроллер) связывает представление и модель, получая пользовательский ввод и обновляя данные. Это — функции обратного вызова и обработчики событий, а также некоторые атрибуты.
Выполним рефакторинг приложения, чтобы добиться разделения зон ответственности. Это потребует дополнительного кода, но поможет четче разграничить разные части.
В первую очередь нужно извлечь весь код, который отвечает за взаимодействие с базой данных, и поместить его в отдельный класс. Это позволит скрыть детали реализации слоя данных, оставив всего лишь 4 метода: get_contacts, add_contact, update_contact и delete_contact:
class ContactsRepository(object):
def __init__(self, conn):
self.conn = conn
def to_values(self, c):
return c.last_name, c.first_name, c.email, c.phone
def get_contacts(self):
sql = """SELECT rowid, last_name, first_name, email, phone
FROM contacts"""
for row in self.conn.execute(sql):
contact = Contact(*row[1:])
contact.rowid = row[0]
yield contact
def add_contact(self, contact):
sql = "INSERT INTO contacts VALUES (?, ?, ?, ?)"
with self.conn:
cursor = self.conn.cursor()
cursor.execute(sql, self.to_values(contact))
contact.rowid = cursor.lastrowid
return contact
def update_contact(self, contact):
sql = """UPDATE contacts
SET last_name = ?, first_name = ?, email = ?, phone = ?
WHERE rowid = ?"""
with self.conn:
self.conn.execute(sql, self.to_values(contact) + (contact.rowid,))
return contact
def delete_contact(self, contact):
sql = "DELETE FROM contacts WHERE rowid = ?"
with self.conn:
self.conn.execute(sql, (contact.rowid,))
Это, вместе с классом Contact, станет моделью приложения.
Представление будет включать лишь код, необходимый для отображения графического интерфейса, и методы контроллера для обновления. Переименуем класс в ContactsView, что лучше выразит его назначение:
class ContactsView(tk.Tk):
def __init__(self):
super().__init__()
self.title("Список контактов")
self.list = ContactList(self, height=15)
self.form = UpdateContactForm(self)
self.btn_new = tk.Button(self, text="Добавить контакт")
self.list.pack(side=tk.LEFT, padx=10, pady=10)
self.form.pack(padx=10, pady=10)
self.btn_new.pack(side=tk.BOTTOM, pady=5)
def set_ctrl(self, ctrl):
self.btn_new.config(command=ctrl.create_contact)
self.list.bind_doble_click(ctrl.select_contact)
self.form.bind_save(ctrl.update_contact)
self.form.bind_delete(ctrl.delete_contact)
def add_contact(self, contact):
self.list.insert(contact)
def update_contact(self, contact, index):
self.list.update(contact, index)
def remove_contact(self, index):
self.form.clear()
self.list.delete(index)
def get_details(self):
return self.form.get_details()
def load_details(self, contact):
self.form.load_details(contact)
Также стоит обратить внимание, что пользовательский ввод обрабатывается контроллером. Для этого добавлен метод set_ctrl, который связывается с функциями обратного вызова Tkinter.
Класс ContactsController теперь будет включать весь оставшийся код — взаимодействие интерфейса и слоя с данными с атрибутами selection и contacts:
class ContactsController(object):
def __init__(self, repo, view):
self.repo = repo
self.view = view
self.selection = None
self.contacts = list(repo.get_contacts())
def create_contact(self):
new_contact = NewContact(self.view).show()
if new_contact:
contact = self.repo.add_contact(new_contact)
self.contacts.append(contact)
self.view.add_contact(contact)
def select_contact(self, index):
self.selection = index
contact = self.contacts[index]
self.view.load_details(contact)
def update_contact(self):
if not self.selection:
return
rowid = self.contacts[self.selection].rowid
update_contact = self.view.get_details()
update_contact.rowid = rowid
contact = self.repo.update_contact(update_contact)
self.contacts[self.selection] = contact
self.view.update_contact(contact, self.selection)
def delete_contact(self):
if not self.selection:
return
contact = self.contacts[self.selection]
self.repo.delete_contact(contact)
self.view.remove_contact(self.selection)
def start(self):
for c in self.contacts:
self.view.add_contact(c)
self.view.mainloop()
Создадим скрипт __main__.py, который позволит не только загружать приложение, но также запускать его из запакованного файла с помощью названия папки, где он сохранен:
# Предположим, что __main__.py находится в lesson_14
$ python lesson_14
# Или, если мы сжимаем содержимое каталога
$ python lesson_14.zipКак работает реализация MVC
Оригинальная реализация MVC была представлена в языке программирования Smalltalk. Ее можно представить следующей схемой:
На ней можно увидеть, что представление передает пользовательские события контроллеру, который, в свою очередь, обновляет модель. Чтобы показать эти изменения, вводится понятие паттерна наблюдателя. Это значит, что представления подписываются на то, чтобы получать уведомления при обновлении. Таким образом они запрашивают состояние модели и меняют отображаемые данные.
Существует вариация этого дизайна, где нет коммуникации между представлением и моделью. Вместо этого изменения применяются контроллером после обновления модели:
Такой подход называется пассивной моделью и является самым распространенным в современных MVC-приложениях, особенно веб-фреймворках. Он использовался и в этом материале, потому что он упрощает ContactsRepository и не требует серьезных изменений в классе ContactsController.
Можно было обратить внимание, что операции обновления и удаления работают благодаря полю rowid, например, в случае с методом update_contact из класса ContactsController:
def update_contact(self):
if not self.selection:
return
rowid = self.contacts[self.selection].rowid
update_contact = self.view.get_details()
update_contact.rowid = rowid
Поскольку это — особенность реализации для базы данных SQLite, ее нужно скрыть от остальных компонентов.
Решение — добавить другое поле классу Contact с именем id или contact_id (важно не забыть, что id — это еще и встроенная функция Python, поэтому некоторые редакторы могут неправильно ее подсветить).
Затем можно предположить, что это поле — полноценная часть данных и представляет собой уникальный идентификатор. А уже детали генерации можно оставить модели.
]]>Необходимые файлы есть в папке «lesson_13» из репозитория по ссылке выше.
Чтение записей из CSV-файла
В качестве первой попытки загрузки данных для чтения в приложение используем файл CSV (comma-separated value, то есть — значения, разделенные запятыми). Этот формат сводит в таблицу данные в обычных текстовых файлах. Каждый файл соответствует полю записи, разделенному запятыми, например, вот так:
Gauford,Albertine,agauford0@acme.com,(614) 7171720
Greger,Bryce,bgreger1@acme.com,(616) 3543513
Wetherald,Rickey,rwetherald2@acme.com,(379) 3652495Такое решение легко реализовать для простых сценариев, особенно если текстовые поля не содержат разрывов строк. Используем модуль csv из стандартной библиотеки, а после загрузки данных заполним ими виджеты из прошлых материалов.
Соберем все виджеты, созданные ранее. После загрузки записей из CSV-файла приложение будет выглядеть как на следующем скриншоте:
Помимо импорта класса Contact также импортируем виджеты ContactForm и ContactList:
import csv
import tkinter as tk
from lesson_12.structuring_data import Contact
from lesson_12.widgets import ContactForm, ContactList
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Контакты из CSV")
self.list = ContactList(self, height=12)
self.form = ContactForm(self)
self.contacts = self.load_contacts()
for contact in self.contacts:
self.list.insert(contact)
self.list.pack(side=tk.LEFT, padx=10, pady=10)
self.form.pack(side=tk.LEFT, padx=10, pady=10)
self.list.bind_doble_click(self.show_contact)
def load_contacts(self):
with open("contacts.csv", encoding="utf-8", newline="") as f:
return [Contact(*r) for r in csv.reader(f)]
def show_contact(self, index):
contact = self.contacts[index]
self.form.load_details(contact)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает загрузка данных из CSV
Функция load_contacts отвечает за чтение файла CSV и трансформацию всех записей в список экземпляров Contact.
Каждая строка, считанная csv.reader, возвращается в виде кортежа строк, созданного с помощью разделения соответствующей строки по запятым. Поскольку кортеж использует тот же порядок, что и параметры в методе __init__ класса Contact, можно запросто распаковать его с помощью оператора *. Весь этот код можно собрать в одну строку с помощью «list comprehension»:
def load_contacts(self):
with open("contacts.csv", encoding="utf-8", newline="") as f:
return [Contact(*r) for r in csv.reader(f)]
Нет никаких проблем с возвратом списка с помощью блока with, поскольку менеджер контекста автоматически закрывает файл, когда метод выполнения заканчивает выполнение.
Сохранение данных в базе данных SQLite
Поскольку есть необходимость сохранять изменения данных в приложении, можно реализовать такое решение, которое будет работать как с записью, так и с чтением.
Можно сохранять все записи в тот же текстовый файл после каждого изменения, но это не очень эффективно, особенно когда речь идет об изменении нескольких отдельных строк.
Поскольку вся информация будет храниться локально, для этих целей можно использовать базу данных SQLite. Модуль sqlite3 — это часть стандартной библиотеки, поэтому для ее использования не нужны дополнительные зависимости.
Конечно, этот подход — не исчерпывающее руководство по SQLite, а лишь практическое введение по тому, как интегрировать базу данных в свое приложение.
Перед использованием базы данных в приложении нужно создать ее и заполнить начальными данными. Все контакты хранятся в файле CSV, поэтому используем скрипт миграции для чтения записей и добавления их в базу.
Сначала создадим соединение с файлом contacts.db, где данные будут храниться. После этого создадим таблицу contacts с текстовыми полями last_name, first_name, email и phone.
Поскольку csv.reader возвращает итерируемый объект, состоящий из кортежей, чьи поля следуют порядку, определенному в CREATE TALE, их можно прямо передать в метод executemany. Это выполнит инструкцию INSERT для каждого кортежа, заменяя вопросительные знаки на реальные значения каждой записи:
import csv
import sqlite3
def main():
with open("contacts.csv", encoding="utf-8", newline="") as f, \
sqlite3.connect("contacts.db") as conn:
conn.execute("""CREATE TABLE contacts (
last_name text,
first_name text,
email text,
phone text
)""")
conn.executemany("INSERT INTO contacts VALUES (?,?,?,?)",
csv.reader(f))
if __name__ == "__main__":
main()
Инструкция with автоматически подтверждает транзакцию и закрывает файл и SQLite-соединение в конце выполнения.
Как работать с базой данных
Для добавления новых контактов в базу данных определим подкласс Toplevel, который будет переиспользовать ContactForm для создания экземпляров новых контактов:
class NewContact(tk.Toplevel):
def __init__(self, parent):
super().__init__(parent)
self.contact = None
self.form = ContactForm(self)
self.btn_add = tk.Button(self, text="Подтвердить", command=self.confirm)
self.form.pack(padx=10, pady=10)
self.btn_add.pack(pady=10)
def confirm(self):
self.contact = self.form.get_details()
if self.contact:
self.destroy()
def show(self):
self.grab_set()
self.wait_window()
return self.contact
Следующее окно верхнего уровня будет отображаться поверх основного и вернет фокус после подтверждения и закрытия диалогового:
Также расширим класс ContactForm двумя дополнительными кнопками: одна будет использоваться для обновления информации, а вторая — для удаления выбранного контакта:
class UpdateContactForm(ContactForm):
def __init__(self, master, **kwargs):
super().__init__(master, **kwargs)
self.btn_save = tk.Button(self, text="Сохранить")
self.btn_delete = tk.Button(self, text="Удалить")
self.btn_save.pack(side=tk.RIGHT, ipadx=5, padx=5, pady=5)
self.btn_delete.pack(side=tk.RIGHT, ipadx=5, padx=5, pady=5)
def bind_save(self, callback):
self.btn_save.config(command=callback)
def bind_delete(self, callback):
self.btn_delete.config(command=callback)
Методы bind_save и bind_delete позволят связать функцию обратного вызова с соответствующей кнопкой command.
Для интеграции всех этих изменений добавим соответствующий код в класс App:
class App(tk.Tk):
def __init__(self, conn):
super().__init__()
self.title("Контакты из SQLite")
self.conn = conn
self.selection = None
self.list = ContactList(self, height=15)
self.form = UpdateContactForm(self)
self.btn_new = tk.Button(self, text="Добавить контакт",
command=self.add_contact)
self.contacts = self.load_contacts()
for contact in self.contacts:
self.list.insert(contact)
self.list.pack(side=tk.LEFT, padx=10, pady=10)
self.form.pack(padx=10, pady=10)
self.btn_new.pack(side=tk.BOTTOM, pady=5)
self.list.bind_doble_click(self.show_contact)
self.form.bind_save(self.update_contact)
self.form.bind_delete(self.delete_contact)
Также нужно поменять метод load_contacts для создания контактов из результата запроса:
def load_contacts(self):
contacts = []
sql = "SELECT rowid, last_name, first_name, email, phone FROM contacts"
for row in self.conn.execute(sql):
contact = Contact(*row[1:])
contact.rowid = row[0]
contacts.append(contact)
return contacts
def show_contact(self, index):
self.selection = index
contact = self.contacts[index]
self.form.load_details(contact)
Для добавления контакта в список нужно создавать экземпляр диалога NewContact и вызывать его метод show для получения всех данных. Если значения валидны, то сохраним их в кортеже в том же порядке, что и в инструкции INSERT:
def to_values(self, c):
return (c.last_name, c.first_name, c.email, c.phone)
def add_contact(self):
new_contact = NewContact(self)
contact = new_contact.show()
if not contact:
return
values = self.to_values(contact)
with self.conn as c:
cursor = c.cursor()
cursor.execute("INSERT INTO contacts VALUES (?,?,?,?)", values)
contact.rowid = cursor.lastrowid
self.contacts.append(contact)
self.list.insert(contact)
После выбора контактов их детали можно обновить, получив текущие значения форм. Если они валидны, выполним UPDATE, чтобы задать колонки записей с указанным rowid.
Поскольку поля находятся в том же порядке, что и в INSERT, можем заново использовать метод to_values для создания кортежа из экземпляра контакта. Единственным отличием будет то, что нужно добавить параметр замены для rowid:
def update_contact(self):
if self.selection is None:
return
rowid = self.contacts[self.selection].rowid
contact = self.form.get_details()
if contact:
values = self.to_values(contact)
with self.conn as c:
sql = """UPDATE contacts SET
last_name = ?,
first_name = ?,
email = ?,
phone = ?
WHERE rowid = ?"""
c.execute(sql, values + (rowid,))
contact.rowid = rowid
self.contacts[self.selection] = contact
self.list.update(contact, self.selection)
Для удаления выбранного контакта получаем его rowid и подставляем в DELETE. Когда транзакция подтверждена, контакт удаляется из графического представления: он пропадает из формы и удаляется из списка. Значением атрибута selection становится None, что позволяет не выполнять операции над элементами, которые уже не являются валидными:
def delete_contact(self):
if self.selection is None:
return
rowid = self.contacts[self.selection].rowid
with self.conn as c:
c.execute("DELETE FROM contacts WHERE rowid = ?", (rowid,))
self.form.clear()
self.list.delete(self.selection)
self.selection = None
Наконец, оборачиваем код для создания экземпляра приложения в функцию main:
def main():
with sqlite3.connect("contacts.db") as conn:
app = App(conn)
app.mainloop()
if __name__ == "__main__":
main()
Со всеми этими изменениями приложение будет выглядеть следующим образом:
Как работают SQL запросы
Такой тип приложения часто называют CRUD (Create, Read, Update Delete — Создание, Чтение, Обновление, Удаление). Эти операции соответствуют SQL-инструкциям, таким как INSERT, SELECT, UPDATE и DELETE.
Теперь посмотрим, как реализовать каждую из операций с помощью класса sqlite3.Connection.
INSERT добавляет новые записи в таблицу, указывая названия колонок и соответствующие значения. Вместо этого можно использовать и порядок колонок.
При создании таблицы в SQLite по умолчанию создается колонка rowid, которой автоматически присваивается уникальное значение для идентификации каждой строки. Поскольку это значение часто требуется для последующих операций, получить его можно с помощью атрибута lastrowid, которое есть у класса Cursor:
sql = "INSERT INTO my_table (col1, col2, col3) VALUES (?, ?, ?)"
with connection:
cursor = connection.cursor()
cursor.execute(sql, (value1, value2, value3))
rowid = cursor.lastrowid
SELECT получает значения одной или нескольких колонок из таблицы. Также можно добавить условие WHERE для фильтрации записей. Это пригодится для реализации поиска и разбиения на страницы, но можно обойтись без этого в простом приложении:
sql = "SELECT rowid, col1, col2, col3 FROM my_table"
for row in connection.execute(sql):
# do something with row
UPDATE обновляет значение одной или нескольких колонок из таблицы. Обычно добавляется WHERE для обновления только тех строк, которые соответствуют определенным критериям — в данном случае можно использовать rowid:
sql = "UPDATE my_table SET col1 = ?, col2 = ?, col3 = ?
WHERE rowid = ?"
with connection:
connection.execute(sql, (value1, value2, value3, rowid))
Наконец, DELETE удаляет одну или несколько записей из таблицы. В данном случае еще важнее использовать WHERE, потому что без условия можно удалить сразу все записи:
sql = "DELETE FROM my_table WHERE rowid = ?"
with connection:
connection.execute(sql, (rowid,))
Структурирование данных с помощью класса
Для иллюстрации того, как можно использовать классы Python для моделирования данных, возьмем в качестве примера приложение списка контактов. Хотя пользовательский интерфейс и будет отличаться, все равно нужно будет определить доменную модель, в этом случае — каждый из контактов.
Каждый контакт будет содержать следующую информацию:
- Имя и фамилию. Эти значения не могут быть пустыми;
- Адрес электронной почты, например, alex123@example.com;
- Номер телефона в формате (123) 4567890.
С этой абстракцией можно приступать к написанию кода для класса Contact.
Сначала определим несколько служебных функций, которые будут использоваться для валидации полей, которые являются обязательными или предполагают специальный формат:
def required(value, message):
if not value:
raise ValueError(message)
return value
def matches(value, regex, message):
if value and not regex.match(value):
raise ValueError(message)
return value
После этого определим класс Contact и его метод __init__. В нем зададим все параметры соответствующих полей. Также сохраним скомпилированные регулярные выражения, поскольку они будут использоваться для каждого экземпляра при валидации полей:
import re
class Contact(object):
email_regex = re.compile(r"[^@]+@[^@]+\.[^@]+")
phone_regex = re.compile(r"\([0-9]{3}\)\s[0-9]{7}")
def __init__(self, last_name, first_name, email, phone):
self.last_name = last_name
self.first_name = first_name
self.email = email
self.phone = phone
Однако этого определения недостаточно чтобы инициировать валидацию каждого поля. Для этого нужно использовать декоратор @property. С его помощью можно будет получить доступ к внутренним атрибутам:
@property
def last_name(self):
return self._last_name
@last_name.setter
def last_name(self, value):
self._last_name = required(value, "Фамилия обязательна")
Та же техника применяется и к first_name, поскольку и это поле является обязательным. Атрибуты email и phone также используют этот подход и функцию matches с соответствующим регулярным выражением:
@property
def email(self):
return self._email
@email.setter
def email(self, value):
self._email = matches(value, self.email_regex, "Invalid email format")
Готовый код в — structuring_data.py, позже его нужно будет использовать.
Как уже говорилось ранее, property — это механизм, который запускает вызовы функции, получая доступ к атрибутам объекта.
В этом примере они получают доступ к внутренним атрибутам с нижним подчеркиванием в начале названия:
contact.first_name = "John" # Сохраняется "John" в contact._first_name
print(contact.first_name) # Читается "John" из contact._first_name
contact.last_name = "" # ValueError вызвано функцией проверки данных
Дескриптор property обычно используется с синтаксисом @decorated — важно не забывать использовать одно и то же имя для декорируемых функций:
@property
def last_name(self):
# ...
@last_name.setter
def last_name(self, value):
# ...
Полная реализация класса contact может показаться перегруженной, ведь каждый атрибут нужно присвоить в методе __init__ и задать для него соответствующие методы получения и установки значения (геттеры и сеттеры).
К счастью, существуют способы, которые позволяют уменьшить количество шаблонного кода. Функция namedtuple из стандартной библиотеки позволяет создавать простые подклассы кортежей с именованными полями:
from collections import namedtuple
Contact = namedtuple("Contact", ["last_name", "first_name",
"email", "phone"])
Однако все еще нужно добавить обходной путь реализации валидации полей. Для этого используется пакет attrs, доступный в Python Package Index.
Установить его можно с помощью командной строки и pip:
pip install attrsПосле этого все свойства можно заменить на attr.ib. Это также позволяет задавать функцию обратного вызова validator, которая принимает экземпляр класса, атрибут, который будет изменен, и значение, которое нужно задать.
С минимумом изменений можно переписать класс Contact, уменьшив количество строк кода вдвое:
import re
import attr
def required(message):
def func(self, attr, val):
if not val: raise ValueError(message)
return func
def match(pattern, message):
regex = re.compile(pattern)
def func(self, attr, val):
if val and not regex.match(val):
raise ValueError(message)
return func
@attr.s
class Contact(object):
last_name = attr.ib(validator=required("Фамилия обязательна"))
first_name = attr.ib(validator=required("Имя обезательно"))
email = attr.ib(validator=match(r"[^@]+@[^@]+\.[^@]+",
"Ошибка в поле email"))
phone = attr.ib(validator=match(r"\([0-9]{3}\)\s[0-9]{7}",
"Ошибка в поле phone"))
С внешними зависимостями в коде нужно обращать внимание не только на преимущества в плане продуктивности, но также на документацию, лицензирование и поддержку.
Больше информации о пакете attrs можно найти на сайте https://www.atrs.org/en/stable/.
Создание виджетов для отображения информации
Сложно создавать крупные приложения, если весь код содержится в одном классе. Разбив графический интерфейс на отдельные классы, можно сделать структуру программы модульной и создавать виджеты для определенных задач.
Помимо пакета Tkinter импортируем класс Contact из прошлого примера:
import tkinter as tk
import tkinter.messagebox as mb
from with_attr import Contact
Нужно убедиться, что файл with_attr.py находится в той же папке. В противном случае инструкция import-from вернет ошибку ImportError.
Создадим список со скроллингом, в котором будут перечислены все контакты. Чтобы каждый элемент был представлен в виде строки, отобразим имя и фамилию каждого контакта:
class ContactList(tk.Frame):
def __init__(self, master, **kwargs):
super().__init__(master)
self.lb = tk.Listbox(self, **kwargs)
scroll = tk.Scrollbar(self, command=self.lb.yview)
self.lb.config(yscrollcommand=scroll.set)
scroll.pack(side=tk.RIGHT, fill=tk.Y)
self.lb.pack(side=tk.LEFT, fill=tk.BOTH, expand=1)
def insert(self, contact, index=tk.END):
text = "{}, {}".format(contact.last_name, contact.first_name)
self.lb.insert(index, text)
def delete(self, index):
self.lb.delete(index, index)
def update(self, contact, index):
self.delete(index)
self.insert(contact, index)
def bind_doble_click(self, callback):
handler = lambda _: callback(self.lb.curselection()[0])
self.lb.bind("", handler)
Для просмотра и редактирования деталей контакта также создадим специальную форму. Возьмем в качестве базового класса LabelFrame с Label и Entry для каждого поля:
class ContactForm(tk.LabelFrame):
fields = ("Фамилия", "Имя", "Email", "Телефон")
def __init__(self, master, **kwargs):
super().__init__(master, text="Contact", padx=10, pady=10, **kwargs)
self.frame = tk.Frame(self)
self.entries = list(map(self.create_field, enumerate(self.fields)))
self.frame.pack()
def create_field(self, field):
position, text = field
label = tk.Label(self.frame, text=text)
entry = tk.Entry(self.frame, width=25)
label.grid(row=position, column=0, pady=5)
entry.grid(row=position, column=1, pady=5)
return entry
def load_details(self, contact):
values = (contact.last_name, contact.first_name,
contact.email, contact.phone)
for entry, value in zip(self.entries, values):
entry.delete(0, tk.END)
entry.insert(0, value)
def get_details(self):
values = [e.get() for e in self.entries]
try:
return Contact(*values)
except ValueError as e:
mb.showerror("Ошибка валидации", str(e), parent=self)
def clear(self):
for entry in self.entries:
entry.delete(0, tk.END)
Как работает создание виджета
Важная особенность класса ContactList — то, что он предоставляет возможность добавить функцию обратного вызова для двойного клика. Он также передает индекс, по которому был осуществлен клик в качестве аргумента функции. Это нужно, чтобы скрыть детали реализации внутреннего класса Listbox:
def bind_doble_click(self, callback):
handler = lambda _: callback(self.lb.curselection()[0])
self.lb.bind("<Double-Button-1&rt;", handler)
У ContactForm также есть абстракция для создания экземпляра контакта на основе значений, введенных в Entry:
def get_details(self):
values = [e.get() for e in self.entries]
try:
return Contact(*values)
except ValueError as e:
mb.showerror("Ошибка валидации", str(e), parent=self)
Поскольку в классе Contact есть валидация полей, создание экземпляра контакта вернет ошибку ValueError, если текст будет содержать невалидное значение. Для уведомления пользователя об этом выведем диалоговое окно с сообщением об ошибке.
Предыдущий урок: Функция __main__
Функция zip() в Python создает итератор, который объединяет элементы из нескольких источников данных. Эта функция работает со списками, кортежами, множествами и словарями для создания списков или кортежей, включающих все эти данные.
В Python есть несколько встроенных функций, которые позволяют перебирать данные. Одна из них — zip. Функция zip() в Python создает итератор, который объединяет элементы из нескольких источников данных.
У функции zip() множество сценариев применения. Например, она пригодится, если нужно создать набор словарей из двух массивов, каждый из которых содержит имя и номер сотрудника.
В этом материале разберемся с основами этой функции, познакомимся с отличиями в Python 2 и Python 3, а также узнаем, в каких ситуациях zip() может быть полезна.
Обновление итератора Python
В Python итерация — это процесс прохождения программы по списку. Например, если есть цикл for, который выводит название каждой сферы, которой занимается компания, можно сказать, что программа выполняет итерацию (перебирает) списка названий.
Итерируемый объект же — это объект, который может возвращать отдельные элементы. Таким образом массивы — это итерируемые объекты, потому что можно вывести каждый отдельный элемент с помощью цикла for. Основы итерации в Python вспомнили — теперь можно переходить и к функции zip().
Пример работы функция zip() в Python
Функция zip() принимает итерируемый объект, например, список, кортеж, множество или словарь в качестве аргумента. Затем она генерирует список кортежей, которые содержат элементы из каждого объекта, переданного в функцию.
Предположим, что есть список имен и номером сотрудников, и их нужно объединить в массив кортежей. Для этого можно использовать функцию zip(). Вот пример программы, которая делает именно это:
employee_numbers = [2, 9, 18, 28]
employee_names = ["Дима", "Марина", "Андрей", "Никита"]
zipped_values = zip(employee_names, employee_numbers)
zipped_list = list(zipped_values)
print(zipped_list)
Функция zip возвращает следующее:
[('Дима', 2), ('Марина', 9), ('Андрей', 18), ('Никита', 28)]Эта программа создала массив из кортежей, каждый из которых содержит имя и номер сотрудника. Здесь много составляющих, поэтому разберем по порядку. На первых двух строках объявляются переменные, которые хранят номера и имена сотрудников. На следующей — функция zip() объединяет два списка вместе, создавая новый массив кортежей.
На следующей строке zip-элемент конвертируется в список так, чтобы его можно было выводить и использовать как список. И на финальной строке он уже и выводится.
Можно убедиться в том, что zipped_values — это элемент zip(), воспользовавшись следующим кодом:
print(type(zipped_values))
Он вернет класс zip:
<class 'zip'>В предыдущем примере были объединены два элемента. Но их может быть и больше. Нужно просто передать их в функцию zip().
Использование одного аргумента (или ни одного)
Пока что функция zip() использовалась для объединения двух итерируемых объектов. Но ее же можно использовать с одним или без единого аргумента. В таком случае она вернет пустой zip-объект. Вот пример:
zipped_object = zip()
print(list(zipped_object))
Этот код возвращает пустой итератор []. Результат не содержит никаких значений, потому что в функцию не были переданы аргументы. С другой стороны, если передать один аргумент, можно использовать следующий код:
employee_names = ["Дима", "Марина", "Андрей", "Никита"]
zipped_object = zip(employee_names)
print(list(zipped_object))
Эта программа возвращает следующее:
[('Дима',), ('Марина',), ('Андрей',), ('Никита',)]Но передача одного аргумента в zip() редко используется — можно использовать существующий список и конвертировать его в кортеж. Здесь просто демонстрируется возможность подобного.
Функция zip с циклом for
Работа с несколькими итерируемыми объектами — один из основных сценариев использования функции zip() в Python. Она даже может быть итератором кортежей или любых других итерируемых объектов, что часто используется в разработке ПО.
Вот пример использования zip() для итерации по массивам:
employee_numbers = [2, 9, 18, 28]
employee_names = ["Дима", "Марина", "Андрей", "Никита"]
for name, number in zip(employee_names, employee_numbers):
print(name, number)
Этот код вернет следующее:
[('Дима', 2), ('Марина', 9), ('Андрей', 18), ('Никита', 28)]В этом примере программа перебирает список кортежей, которые возвращает zip() и делит их на два: имена и номера. Это упрощает процесс перебора нескольких итерируемых объектов за раз. Если необходимо, можно перебирать три и больше объектов.
Как сделать «unzip»
В последнем коде были объединены разные типы данных. Но как восстановить их прежнюю форму? Если есть список кортежей (упакованных), которые нужно разделить, можно использовать специальный оператор функции zip(). Это оператор-звездочка (*).
Вот пример работы оператора распаковки в zip():
employees_zipped = [('Дима', 2), ('Марина', 9), ('Андрей', 18), ('Никита', 28)]
employee_names, employee_numbers = zip(*employees_zipped)
print(employee_names)
print(employee_numbers)
Этот код вернет такой результат:
("Дима", "Марина", "Андрей", "Никита")
(2, 9, 18, 28)Это может казаться сложным, поэтому разберем по шагам. На первой строке определяется переменная, которая включает список кортежей. Затем еще две переменные: employee_names и employee_numbers. Им присваиваются значения функции распаковки.
Функция распаковки — это просто zip-функция, которая принимает переменную employee_zipped и использует оператор распаковки *. После этого выводятся две новые переменные, которые включают имена и номера сотрудников.
Выводы
В этом материале были рассмотрены принципы работы функции zip(). Она принимает итерируемые объекты и возвращает итератор, который может создавать кортежи, соединяя элементы из каждого входящего элемента. Это может быть полезно при необходимости собрать в один несколько массивов или кортежей.
Рассмотрели, как использовать zip() с одним или без входящих элементов, как использовать zip() для перебора итерируемых объектов и как распаковывать zip-объекты с помощью специального оператора.
Открытие дополнительного окна
Корневой экземпляр Tk представляет собой основное окно графического интерфейса. Когда он уничтожается, приложение закрывается, а основной цикл завершается.
Но есть в Tkinter и другой класс, который используется для создания дополнительных окон верхнего уровня. Он называется Toplevel. Этот класс можно использовать для отображения любого типа окна: от диалоговых до мастер форм.
Начнем с создания простого окна, которое открывается по нажатию кнопки в основном. Дополнительное окно будет включать кнопку, которая закрывает его и возвращает фокус в основное:
Класс виджета Toplevel создает новое окно верхнего уровня, которое выступает в качестве родительского контейнера по аналогии с экземпляром Tk. В отличие от класса Tk можно создавать неограниченное количество окон верхнего уровня:
import tkinter as tk
class About(tk.Toplevel):
def __init__(self, parent):
super().__init__(parent)
self.label = tk.Label(self, text="Это всплывающее окно")
self.button = tk.Button(self, text="Закрыть", command=self.destroy)
self.label.pack(padx=20, pady=20)
self.button.pack(pady=5, ipadx=2, ipady=2)
class App(tk.Tk):
def __init__(self):
super().__init__()
self.btn = tk.Button(self, text="Открыть новое окно",
command=self.open_window)
self.btn.pack(padx=50, pady=20)
def open_window(self):
about = About(self)
about.grab_set()
if __name__ == "__main__":
app = App()
app.mainloop()
Как работают всплывающие окна
Определяем подкласс Toplevel, который будет представлять собой кастомное окно. Его отношение с родительским будет определено в методе __init__. Виджеты добавляются в это окно привычным образом:
class Window(tk.Toplevel):
def __init__(self, parent):
super().__init__(parent)
Окно открывается за счет создания нового экземпляра, но чтобы оно получало все события, нужно вызвать его метод grab_set. Благодаря этому пользователи не будут взаимодействовать с основным окном, пока дополнительное не закроется:
def open_window(self):
window = Window(self)
window.grab_set()
Обработка закрытия окна
При определенных условиях может потребоваться выполнить определенное действие до закрытия окно верхнего уровня: например, чтобы пользователь не потерял несохраненную работу. Tkinter позволяет перехватывать этот тип событий, что позволяет уничтожать окно только при определенном условии.
Будем заново использовать класс App из прошлого примера, но изменим класс Window, чтобы он показывал диалоговое окно для подтверждения перед закрытием:
В Tkinter можно определить, когда окно готовится закрыться с помощью функции-обработчика для протокола WM_DELETE_WINDOW. Его можно запустить, нажав на иконку «x» в верхней панели в большинстве настольных программ.
import tkinter as tk
import tkinter.messagebox as mb
class Window(tk.Toplevel):
def __init__(self, parent):
super().__init__(parent)
self.protocol("WM_DELETE_WINDOW", self.confirm_delete)
self.label = tk.Label(self, text="Это всплывающее окно")
self.button = tk.Button(self, text="Закрыть", command=self.destroy)
self.label.pack(padx=20, pady=20)
self.button.pack(pady=5, ipadx=2, ipady=2)
def confirm_delete(self):
message = "Вы уверены, что хотите закрыть это окно?"
if mb.askyesno(message=message, parent=self):
self.destroy()
class App(tk.Tk):
def __init__(self):
super().__init__()
self.btn = tk.Button(self, text="Открыть новое окно",
command=self.open_about)
self.btn.pack(padx=50, pady=20)
def open_about(self):
window = Window(self)
window.grab_set()
if __name__ == "__main__":
app = App()
app.mainloop()
Этот метод-обработчик показывает диалоговое окно для подтверждения удаления окна. В более сложных программах логика обычно включает дополнительную валидацию.
Как работает проверка закрытия окна
Метод bind() используется для регистрации обработчиков событий виджетов, а метод protocol делает то же самое для протоколов менеджеров окна.
Обработчик WM_DELETE_WINDOW вызывается, когда окно верхнего уровня должно уже закрываться, и по умолчанию Tk уничтожает окно, для которого оно было получено. Поскольку это поведение перезаписывается с помощью обработчика confirm_delete, нужно явно уничтожить окно при подтверждении.
Еще один полезный протокол — WM_TAKE_FOCUS. Он вызывается, когда окно получает фокус.
Стоит запомнить, что для сохранения фокуса в дополнительном окне при открытом диалоговом нужно передать ссылку экземпляру верхнего уровня в параметре parent диалоговой функции:
if mb.askyesno(message=message, parent=self):
self.destroy()
В противном случае диалоговое окно будет считать родительским корневое, и оно будет возникать над вторым. Это может запутать пользователей, поэтому хорошей практикой считается правильное указание родителя для каждого экземпляра верхнего уровня или диалогового окна.
Передача переменных между окнами
Два разных окна иногда нуждаются в том, чтобы передавать информацию прямо во время работы программы. Ее можно сохранять на диск и читать в нужном окне, но в определенных случаях удобнее обрабатывать ее в памяти и передавать в качестве переменных.
Основное окно будет включать три кнопки-переключателя для выбора типа пользователя, а второе — форму для заполнения его данных:
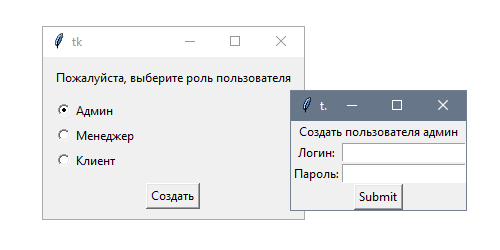
Для сохранения пользовательских данных создаем namedtuple с полями, которые представляют собой экземпляр каждого пользователя. Эта функция из модуля collections получает имя типа и последовательность имен полей, а возвращает подкласс кортежа для создания простого объекта с заданными полями:
import tkinter as tk
from collections import namedtuple
User = namedtuple("User", ["username", "password", "user_type"])
class UserForm(tk.Toplevel):
def __init__(self, parent, user_type):
super().__init__(parent)
self.username = tk.StringVar()
self.password = tk.StringVar()
self.user_type = user_type
label = tk.Label(self, text="Создать пользователя " + user_type.lower())
entry_name = tk.Entry(self, textvariable=self.username)
entry_pass = tk.Entry(self, textvariable=self.password, show="*")
btn = tk.Button(self, text="Submit", command=self.destroy)
label.grid(row=0, columnspan=2)
tk.Label(self, text="Логин:").grid(row=1, column=0)
tk.Label(self, text="Пароль:").grid(row=2, column=0)
entry_name.grid(row=1, column=1)
entry_pass.grid(row=2, column=1)
btn.grid(row=3, columnspan=2)
def open(self):
self.grab_set()
self.wait_window()
username = self.username.get()
password = self.password.get()
return User(username, password, self.user_type)
class App(tk.Tk):
def __init__(self):
super().__init__()
user_types = ("Админ", "Менеджер", "Клиент")
self.user_type = tk.StringVar()
self.user_type.set(user_types[0])
label = tk.Label(self, text="Пожалуйста, выберите роль пользователя")
radios = [tk.Radiobutton(self, text=t, value=t,
variable=self.user_type) for t in user_types]
btn = tk.Button(self, text="Создать", command=self.open_window)
label.pack(padx=10, pady=10)
for radio in radios:
radio.pack(padx=10, anchor=tk.W)
btn.pack(pady=10)
def open_window(self):
window = UserForm(self, self.user_type.get())
user = window.open()
print(user)
if __name__ == "__main__":
app = App()
app.mainloop()
Когда поток выполнения возвращается в основное окно, пользовательские данные выводятся в консоль.
Как работает передача данных между окнами
Большая часть кода в этом примере рассматривалась и ранее, а основное отличие — в методе open() класса UserForm, куда перемещен вызов grab_set(). Однако именно метод wait_windows() отвечает за остановку исполнения и гарантирует, что данные не вернутся, пока форма не будет изменена:
def open(self):
self.grab_set()
self.wait_window()
username = self.username.get()
password = self.password.get()
return User(username, password, self.user_type)
Важно отметить, что wait_windows() запускает локальный цикл событий, который завершается после уничтожения окна. Хотя и существует возможность передать виджет, который должен быть удален, этот момент можно пропустить. В таком случае ссылка будет выполнена неявно на экземпляр, который вызвал метод.
Когда экземпляр UserForm уничтожается, выполнение метода open() продолжается, и он возвращает объект User, который теперь может быть использован в классе App:
def open_window(self):
window = UserForm(self, self.user_type.get())
user = window.open()
print(user)
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.
Сложные графические интерфейсы обычно используют строки меню для организации действий и навигации по приложению. Этот подход также применяется для группировки тесно связанных операций. Например, в большинстве текстовых редакторов есть пункт «Файл».
Tkinter поддерживает такие меню, которые отображаются и ощущаются в соответствии с окружением конкретной операционной системы. Это позволяет не симулировать все с помощью фреймов, ведь из-за этого пропадет возможность пользоваться встроенными кроссплатформенными особенностями Tkinter.
Добавим меню в корневое окно со вложенным выпадающим меню. В Windows 10 это отображается следующим образом:
В Tkinter есть класс виджета Menu, который можно использовать для разных меню, включая основную строку. По аналогии с другими классами виджетов экземпляры меню создаются с помощи передачи родительского контейнера в виде первого аргумента и опциональных параметров — в качестве второго:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
menu = tk.Menu(self)
file_menu = tk.Menu(menu, tearoff=0)
file_menu.add_command(label="Новый файл")
file_menu.add_command(label="Открыть")
file_menu.add_separator()
file_menu.add_command(label="Сохранить")
file_menu.add_command(label="Сохранить как...")
menu.add_cascade(label="Файл", menu=file_menu)
menu.add_command(label="О программе")
menu.add_command(label="Выйти", command=self.destroy)
self.config(menu=menu)
if __name__ == "__main__":
app = App()
app.mainloop()
Если запустить это скрипт, то вы увидите, что элемент Файл показывает дополнительное меню, а с помощью кнопки Выйти приложение можно закрыть.
Как работает создание верхнего меню
Сначала создаем экземпляр каждого меню, указывая родительский контейнер. Значение 1 у параметра tearoff указывает на то, что меню можно открепить с помощью пунктирной линии на границе. Это поведение не характерно для верхнего меню, но если его нужно отключить, то стоит задать значение 0 для этого параметра:
def __init__(self):
super().__init__()
menu = tk.Menu(self)
file_menu = tk.Menu(menu, tearoff=0)
Элементы меню организованы в том же порядке, в котором они добавляются с помощью методов: add_command, app_separator и add_cascade:
menu.add_cascade(label="Файл", menu=file_menu)
menu.add_command(label="О программе")
menu.add_command(label="Выйти", command=self.destroy)
Обычно add_command вызывается с параметром command, который является функцией обратного вызова, срабатывающей при нажатии. Аргументы ей не передаются — то же характерно и для виджета Button.
Для демонстрации добавим параметр элементу Выйти, который будет уничтожать экземпляр Tk и закрывать приложение.
Наконец, прикрепляем меню к основному окну с помощью вызова self.config(menu=menu). Стоит отметить, что у этого окна может быть только одна строка меню.
Использование переменных в меню
Помимо вызова команд и вложенных встроенных меню также можно подключать переменные Tkinter к элементам меню.
Добавим кнопку-флажок и три переключателя в подменю «Опции», разделив их между собой. Внутри будет две переменных Tkinter, которые сохранят выбранные значения так, что их можно будет получить в других методах приложения:
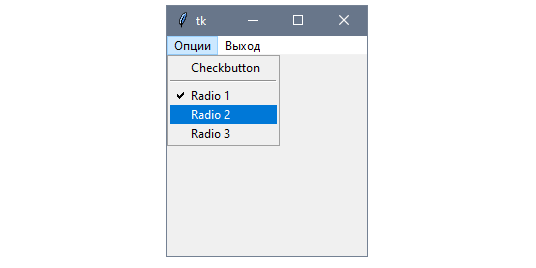
Эти типы элементов добавляются с помощью методов add_checkbutton и add_radiobutton из класса виджета Menu. Как и в случае с обычными переключателями все связаны с одной переменной Tkinter, но имеют разные значения:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.checked = tk.BooleanVar()
self.checked.trace("w", self.mark_checked)
self.radio = tk.StringVar()
self.radio.set("1")
self.radio.trace("w", self.mark_radio)
menu = tk.Menu(self)
submenu = tk.Menu(menu, tearoff=0)
submenu.add_checkbutton(label="Checkbutton", onvalue=True,
offvalue=False, variable=self.checked)
submenu.add_separator()
submenu.add_radiobutton(label="Radio 1", value="1",
variable=self.radio)
submenu.add_radiobutton(label="Radio 2", value="2",
variable=self.radio)
submenu.add_radiobutton(label="Radio 3", value="3",
variable=self.radio)
menu.add_cascade(label="Опции", menu=submenu)
menu.add_command(label="Выход", command=self.destroy)
self.config(menu=menu)
def mark_checked(self, *args):
print(self.checked.get())
def mark_radio(self, *args):
print(self.radio.get())
if __name__ == "__main__":
app = App()
app.mainloop()
Будем отслеживать изменения переменной так, чтобы можно было выводить значения в консоли во время работы приложения.
Как работает создание переменных в меню
Для добавления булевой переменной элементу Checkbutton сначала нужно определить BooleanVar и затем создать элемент с помощью вызова add_checkbutton и параметра variable.
Стоит запомнить, что параметры onvalue и offvalue должны совпадать с типами переменных Tkinter как и в случае с виджетами RadioButton и Checkbutton:
self.checked = tk.BooleanVar()
self.checked.trace("w", self.mark_checked)
# ...
submenu.add_checkbutton(label="Checkbutton", onvalue=True,
offvalue=False, variable=self.checked)
Элементы Radiobutton создаются похожим образом с помощью метода add_radiobutton, и лишь один параметр value может быть задан для переменной Tkinter при нажатии на переключатель. Поскольку изначально в StringVar хранится пустая строка, зададим значение для первого переключателя, чтобы был отмечен как выбранный:
self.radio = tk.StringVar()
self.radio.set("1")
self.radio.trace("w", self.mark_radio)
# ...
submenu.add_radiobutton(label="Radio 1", value="1",
variable=self.radio)
submenu.add_radiobutton(label="Radio 2", value="2",
variable=self.radio)
submenu.add_radiobutton(label="Radio 3", value="3",
variable=self.radio)
Обе переменные отслеживают изменения с помощью методов mark_checked и mark_radio, которые просто выводят значения в консоль.
Отображение контекстных меню
Меню Tkinter не обязательно должны быть расположены в строке меню. Их можно размещать в любом месте. Такие меню называются контекстными, и обычно они отображаются при нажатии правой кнопкой по элементу.
Контекстные меню широко распространены в приложениях с графическим интерфейсом. Например, файловые менеджеры позволяют показывать все доступные операции для выбранного файла так, что для пользователей это будет ощущаться интуитивно.
Создадим контекстное меню для виджета Text, которое будет отображать некоторые распространенные действия в редакторах текста: Вырезать, Копировать, Вставить и Удалить:
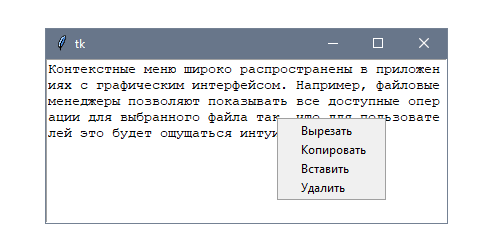
Вместо настройки экземпляра меню в качестве контейнера можно явно задать положение с помощью метода post.
Все команды в элементах меню вызывают метод, использующий текст для получения текущего выделения или позиции для вставки:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.menu = tk.Menu(self, tearoff=0)
self.menu.add_command(label="Вырезать", command=self.cut_text)
self.menu.add_command(label="Копировать", command=self.copy_text)
self.menu.add_command(label="Вставить", command=self.paste_text)
self.menu.add_command(label="Удалить", command=self.delete_text)
self.text = tk.Text(self, height=10, width=50)
self.text.bind("", self.show_popup)
self.text.pack()
def show_popup(self, event):
self.menu.post(event.x_root, event.y_root)
def cut_text(self):
self.copy_text()
self.delete_text()
def copy_text(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
self.clipboard_clear()
self.clipboard_append(self.text.get(*selection))
def paste_text(self):
self.text.insert(tk.INSERT, self.clipboard_get())
def delete_text(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
self.text.delete(*selection)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает контекстное меню
Связываем событие нажатия правой кнопки мыши с обработчиком show_popup для экземпляра текста. Оно будет выводить меню, чей левый верхний угол находится над положением, где был произведен клик. Каждый раз при срабатывании события заново отображается одно и то же меню:
def show_popup(self, event):
self.menu.post(event.x_root, event.y_root)
Следующие методы доступны для всех классов виджетов, что позволяет взаимодействовать с буфером обмена:
clipboard_clear()— очищает данные в буфере обменаclipboard_append(string)— добавляет строку в буфер обменаclipboard_get()— получает данные из буфера обмена
Метод обратного вызова для действия copy получает текущее выделение и добавляет его в буфер обмена:
def copy_text(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
self.clipboard_clear()
self.clipboard_append(self.text.get(*selection))
Действие action вставляет содержимое буфера на место курсора, которое определено индексом INSERT. Его нужно обернуть в блок try...except, поскольку вызов clipboard_get вызывает ошибку TclError, если буфер пуст:
def paste_text(self):
try:
self.text.insert(tk.INSERT, self.clipboard_get())
except tk.TclError:
pass
Действие delete не взаимодействует с буфером обмена, но удаляет содержимое текущего выделения:
def delete_text(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
self.text.delete(*selection)
Поскольку действие Вырезать — это комбинация копирования и удаления, эти методы заново используются для составления функции обратного вызова.
Параметр postcommand позволяет настраивать меню каждый раз, когда оно отображается в методe post. Для демонстрации этого отключим элементы Вырезать, Копировать, Удалить в том случае, если в виджете Text нет выделения, а элемент Вставить — при отсутствии содержимого в буфере обмена.
По аналогии с другими функциями обратного вызова передаем ссылку на метод в класс для добавления параметра:
Затем проверяем существует ли диапазон SEL для определения того, должно ли состояние элементов быть ACTIVE или DISABLED. Это значение передается методу entryconfig, который принимает индекс элемента для настройки в качестве первого аргумента и список параметров для обновления. Элементы меню также начинаются с индекса 0:
def enable_selection(self):
state_selection = tk.ACTIVE if self.text.tag_ranges(tk.SEL) else tk.DISABLED
state_clipboard = tk.ACTIVE
try:
self.clipboard_get()
except tk.TclError:
state_clipboard = tk.DISABLED
self.menu.entryconfig(0, state=state_selection) # Вырезать
self.menu.entryconfig(1, state=state_selection) # Копировать
self.menu.entryconfig(2, state=state_clipboard) # Вставить
self.menu.entryconfig(3, state=state_selection) # Удалить
Например, все элементы должны быть серого цвета, если нет выделения или содержимого в буфере обмена:
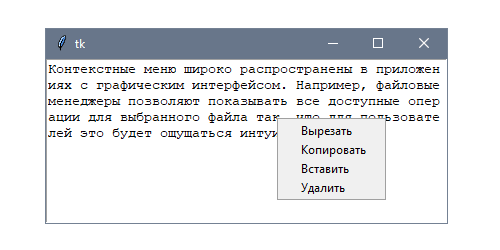
С помощью entryconfig также можно настроить другие параметры: метку, шрифт или фон. По ссылке https://www.tcl.tk/man/tcl8.6/TkCmd/menu.htm#M48 доступен весь список параметров.
Предыдущий урок: Namedtuple
В различных руководствах по Python часто используется функция main(). Но иногда это может быть и лишним.
Лаконичность — важный элемент программирования. И вполне логично задавать вопрос о том, зачем разработчику добавлять лишние строки в программу. Функция main() требует дополнительных строк, но она служит определенной цели.
В этом материале речь пойдет о функции main(), о том, какую пользу она приносит, а также о том, как правильно использовать ее в коде.
Что такое функция main()?
Main — это специальная функция, которая позволяет добавить больше логики в структуру программ. В Python можно вызвать функцию в нижней части программы, которая и будет запущена. Рассмотрим такой пример:
def cookies():
print("Печенье вкусное!")
print("Дайте печенье.")
cookies()
Запустим этот код:
Дайте печенье.
Печенье вкусное!Можно увидеть, что выражение «Дайте печенье.» выводится до «Печенье вкусное!», потому что метод cookies() не вызывается вплоть до последней строки, а именно в этой функции хранится предложение «Печенье вкусное!».
Такой код работает, но его довольно сложно читать. В таких языках программирования, как C++ и Java весь основной код программы хранится внутри основной функции. Это хороший способ для распределения всего кода программы. Те, кто только знакомится с Python, но уже работал, например, с C++ будут благодарны за использование функции main().
Как создать функцию main
Есть две части основной функции Python. Первая — сама функция main(). В ней хранится код основной программы. Вызовем функцию cookies() и выведем выражение «Дайте печенье.» из функции main():
def cookies():
print("Печенье вкусное!")
def main():
print("Дайте печенье.")
cookies()
Теперь вызовем функцию в конце программы:
main()
Можно запустить код:
Дайте печенье.
Печенье вкусное!Результат не поменялся. Но теперь сам код читать легче. Пусть в нем и больше строк (и одна дополнительная строка), вполне очевидно, что именно происходит:
Cookies()— функция, которая выводит «Печенье вкусное!».- Когда программа запускается, определяются две функции:
cookies()иmain(). - Затем функция
main()вызывается. - «Дайте печенье.» выводится в консоли.
- Затем вызывается функция
cookies(), которая выводит в консоль «Печенье вкусное!».
Код не только чище, но и логичнее. Если вы пришли из другого языка, например, Java, но знаете, насколько это удобно.
Значение __name__
Прежде чем переходить к инструкциям __name__ и __main__, которые часто используются вместе, нужно обсудить __name__. __name__ хранит название программы.
Если запустить файл прямо, то значением __name__ будет __main__. Предположим, что файл называется print_name.py:
print(__name__)
Этот код можно запустить следующим образом:
$ python print_name.pyОн вернет __main__.
Предположим, что этот код был импортирован в качестве модуля в файл main.py:
import print_name
Запустим его:
$ python main.pyКод вернет:
print_nameКод внутри print_name.py исполняется потому что он был импортирован в качестве модуля в основной программе. Файл print_name выводит __name__ в консоль. Поскольку print_name был импортирован в качестве модуля, то и значением __name__ является print_name.
if __name__ == __main__ в Python
Вы наверняка встречали следующую конструкцию в программах на Python в функции main:
if __name__ == "__main__":
Что она значит? В Python любая переменная, начинающаяся с двух символов нижнего подчеркивания (__), является специальной. Это зарезервированные значения, которые выполняют определенную роль в программе.
__main__ указывает на область видимости, где будет выполняться код. Если запустить Python-файл прямо, то значением __name__ будет __main__. Если же его запустить в качестве модуля, то значением будет уже не __main__, а название модуля.
Это значит, что строка выше вернет True только в том случае, если программа будет запущена прямо.
Если же ссылаться на файл как на модуль, то содержимое конструкции if не будет выполнено. Рассмотрим на примере.
Как использовать __name__ и __main__
Создадим новый скрипт на Python под названием username.py. В коде будем просить пользователя ввести его имя и проверять, не является ли его длина больше 5. Если символов не больше 5, то попросим ввести имя снова.
Начнем с определения глобальной переменной для хранения имени пользователя:
username = ""
После этого определим две функции. Первая будет просить пользователя ввести имя пользователя и проверять, не больше ли 5 символов в нем. Вторая будет выводить значение в оболочке Python:
def choose_username():
global username
username = input("Введите логин: ")
if len(username) > 5:
print("Ваш логин сохранен.")
else:
print("Пожалуйста, выберите имя пользователя длиной более пяти символов.")
choose_username()
def print_username():
print(username)
В этом примере использовалось ключевое слово global, чтобы содержимое, присвоенное в методе choose_username(), было доступно глобально. После определения функций нужно создать main, которая и будет их вызывать:
def main():
choose_username()
print_username()
После этого нужно добавить if __name__="__main__" в инструкцию if. Это значит, что при запуске файла прямо, интерпретатор Python исполнит две функции. Если же запустить код в качестве модуля, то содержимое внутри main() исполнено не будет.
if __name__ == "__main__":
main()
Запустим код:
$ python username.pyОн вернет следующее:
Введите логин: mylogin
Ваш логин сохранен.
myloginЭтот код запускает функцию choose_username(), а затем — print_username(). Если указать имя длиной меньше 4 символов, то ответ будет таким:
Введите логин: Li
Ваш логин сохранен.
Пожалуйста, выберите имя пользователя длиной более пяти символов.
Введите логин:Будет предложено ввести другое имя. Если импортировать этот код в качестве модуля, то функция main() не запустится.
Выводы
Функция main() используется для разделения блоков кода в программе. Использование функции main() обязательно в таких языках, как Java, потому что это упрощает понимание того, в каком порядке код запускается в программе. В Python функцию main() писать необязательно, но это улучшает читаемость кода.
]]>Далее: Функция zip()
Предыдущий урок: Инструкция assert
Именованные кортежи (namedtuple) — это подкласс кортежей в Python. У них те же функции, что и у обычных, но их значения можно получать как с помощью имени (через точку, например, .name), так и с помощью индекса (например [0]). В этом материале на примерах разберем синтаксис и функции этих кортежей.
Зачем нужны именованные кортежи?
Именованные кортежи улучшают читаемость кода и отдельных функций.
Разберемся на примере. Предположим, что есть программа, которая сохраняет оценки студента в кортеже под названием marks. Но с этим кодом комфортно работать, если помнить назначение кортежа. Однако, скорее всего, оно забудется уже через несколько дней.
marks = (98, 80, 95)
print(marks)
print(marks[0])
print(marks[2])
(98, 80, 95)
98
95Namedtuple — это замена обычных кортежей. Они выполняют те же функции, но улучшают читаемость кода. Даже если программист приостановит работу над программой на несколько месяцев, синтаксис или значение самого кортежа будут говорить сами за себя. Теперь время поговорить о самом синтаксисе таких кортежей.
Импорт именованных кортежей в Python
По сравнению с другими структурами данных в Python (список, словарь, кортеж и множество) именованный кортеж — не часть стандартной библиотеки. Он доступен в модуле collections. Последний включает и другие альтернативы встроенных структур в Python.
from collections import namedtuple
Когда namedtuple импортирован, можно переходить к его использованию.
Синтаксис namedtuple в Python
collections.namedtuple(typename, field_names, *,
rename=False, defaults=None, module=None)Создание именованного кортежа
Мы уже импортировали именованный кортеж, теперь рассмотрим синтаксис.
from collections import namedtuple
Marks = namedtuple('Marks', 'Physics Chemistry Math English')
marks = Marks(90, 85, 95, 100)
print(marks)
Marks(Physics=90, Chemistry=85, Math=95, English=100)В первую очередь объявляется сигнатура кортежа, где первый параметр принимает имя типа, а второй — названия полей. Имя типа — это строка с типом, который нужно сделать именованным кортежем.
В качестве второго параметра можно использовать итерируемую структуру данных: список, словарь, кортеж или множество.
Если же это строка, то разные имена нужно разделить с помощью отдельного символа.
marks = Marks(90, 85, 95, 100) — эта строка создает именованный кортеж. «Marks» — это объявление именованного кортежа, которое может использоваться для создания бесконечного количества аналогичных структур. Это еще называется фабрикой именованных кортежей.
Позиционные аргументы соответствуют определению кортежа.
Для улучшения читабельности можно создавать именованные кортежи с помощью ключевых слов: marks = Marks(Physics=90, Chemistry=85, Math=95, English=100).
Создание namedtuple с помощью списка
from collections import namedtuple
lst = ['Physics', 'Chemistry', 'Math', 'English']
Marks = namedtuple('Marks', lst)
marks = Marks(90, 85, 95, 100)
print(marks)
Создание namedtuple с помощью словаря
Стартовое значение словаря — 0, поскольку значение поля игнорируется кортежем.
from collections import namedtuple
dct = {'Physics': 0, 'Chemistry': 0, 'Math': 0, 'English': 0}
Marks = namedtuple('Marks', dct)
marks = Marks(90, 85, 95, 100)
print(marks)
Создание namedtuple с помощью кортежа
from collections import namedtuple
tupl = ('Physics', 'Chemistry', 'Math', 'English')
Marks = namedtuple('Marks', tupl)
marks = Marks(90, 85, 95, 100)
print(marks)
Создание namedtuple с помощью множества
from collections import namedtuple
subject_set = {'Physics', 'Chemistry', 'Math', 'English'}
Marks = namedtuple('Marks', subject_set)
marks = Marks(90, 85, 95, 100)
print(marks)
Вывод во всех примерах будет одинаковый:
Marks(Physics=90, Chemistry=85, Math=95, English=100)Именованный кортеж можно создать с помощью любой структуры данных, поддерживающей итерацию.
Создание namedtuple с помощью функции _make
В предыдущем разделе речь шла о том, как создавать именованный кортеж с помощью итерируемой структуры данных. Теперь стоит разобрать, как добиться того же с помощью функции _make.
from collections import namedtuple
lst = ['Physics', 'Chemistry', 'Math', 'English']
Marks = namedtuple('Marks', lst)
marks = Marks._make([55, 78, 98, 90])
print(marks)
Marks(Physics=55, Chemistry=78, Math=98, English=90)Функция _make также принимает итерируемый объект (в случае со словарем — значение).
marks = Marks._make({55: 'Physics', 78: 'Chemistry', 98: 'Math', 90: 'English'})
print(marks)
Доступ к именам полей namedtuple в python
Дальше рассмотрим, как получать доступ к полям в именованном кортеже. Для этого есть несколько способов:
- Через смещение.
- Через точку.
getattr().
Доступ к полям можно получить тем же способом, что и в кортежах — с помощью индекса.
print(marks[0])
print(marks[3])
Также можно использовать названия полей по аналогии с атрибутами экземпляра класса.
print(marks.Physics)
print(marks.English)
Наконец, поля можно получить и с помощью функции getattr().
Именованные кортежи неизменяемые
Как и стандартные кортежи в Python именованные является неизменяемыми. Это значит, что после объявления значения кортежа не могут быть изменены.
>>> marks.Physics = 99
File ".\main.py", line 6, in
marks.Physics = 99
AttributeError: can't set attribute
Изменение значения поля namedtuple
Несмотря на неизменяемость есть способ, с помощью которого можно менять значение поля. Для этого используется функция _replace.
marks = marks._replace(Physics=99)
print(marks)
Marks(Physics=99, Chemistry=78, Math=98, English=90)Функция _replace() принимает имя поля и значение, которое нужно заменить, а возвращает именованный кортеж с измененным значением. Таким образом этот тип оказывается изменяемым с помощью одного простого трюка.
]]>Далее: Функция __main__
Окна уведомлений
Распространенный сценарий применения диалоговых окон — уведомление пользователей о событиях, которые происходят в приложении: сделана новая запись или произошла ошибка при попытке открыть файл. Рассмотрим базовые функции Tkinter, предназначенные для отображения диалоговых окон.
В этой программе будет три кнопки, где каждая показывает определенное окно со своим статическим названием и сообщением. Сам по себе этот тип окон имеет лишь кнопку для подтверждения о прочтении и закрытия:
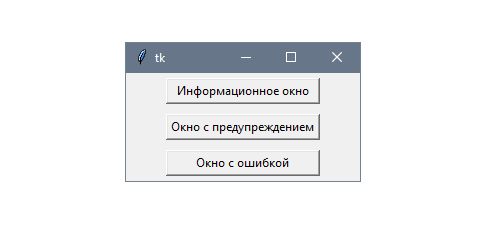
При запуске этого примера стоит обратить внимание на то, что каждое окно воспроизводит соответствующий платформе звук и показывает перевод метки в зависимости от языка системы:
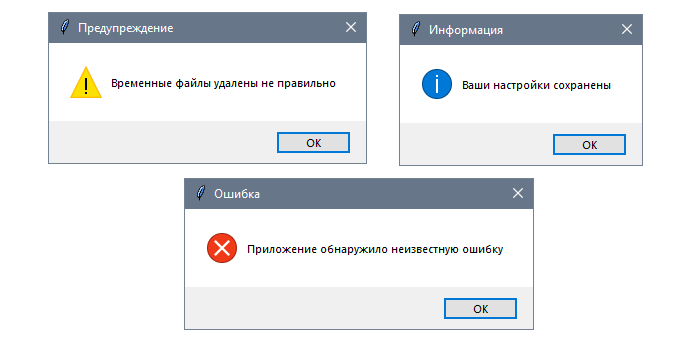
Эти диалоговые окна открываются с помощью функций showinfo, showwarning и showerror из модуля tkinter.messagebox:
import tkinter as tk
import tkinter.messagebox as mb
class App(tk.Tk):
def __init__(self):
super().__init__()
btn_info = tk.Button(self, text="Информационное окно",
command=self.show_info)
btn_warn = tk.Button(self, text="Окно с предупреждением",
command=self.show_warning)
btn_error = tk.Button(self, text="Окно с ошибкой",
command=self.show_error)
opts = {'padx': 40, 'pady': 5, 'expand': True, 'fill': tk.BOTH}
btn_info.pack(**opts)
btn_warn.pack(**opts)
btn_error.pack(**opts)
def show_info(self):
msg = "Ваши настройки сохранены"
mb.showinfo("Информация", msg)
def show_warning(self):
msg = "Временные файлы удалены не правильно"
mb.showwarning("Предупреждение", msg)
def show_error(self):
msg = "Приложение обнаружило неизвестную ошибку"
mb.showerror("Ошибка", msg)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работают окна с уведомлениями
В первую очередь нужно импортировать модуль tkinter.messagebox, задав для него алиас mb. В Python2 этот модуль назывался tkMessageBox, поэтому такой синтаксис позволит изолировать проблемы совместимости.
Каждое окно обычно выбирается в зависимости от информации, которую нужно показать пользователю:
showinfo— операция была завершена успешно,showwarning— операция была завершена, но что-то пошло не так, как планировалось,showerror— операция не была завершена из-за ошибки.
Все три функции получают две строки в качестве входящих аргументов: заголовок и сообщение.
Сообщение может быть выведено на нескольких строках с помощью символа новой строки \n.
Окна выбора ответа
Другие типы диалоговых окон в Tkinter используются для запроса подтверждения от пользователя. Это нужно, например, при сохранении файла или перезаписывании существующего.
Эти окна отличаются от ранее рассмотренных тем, что значения, возвращаемые функцией, зависят от кнопки, по которой кликнул пользователь. Это позволяет взаимодействовать с программой: продолжать или же отменять действие.
В этой программе рассмотрим остальные диалоговые функции из модуля tkinter.messagebox. Каждая кнопка включает метки с описанием типа окна, которое откроется при нажатии:
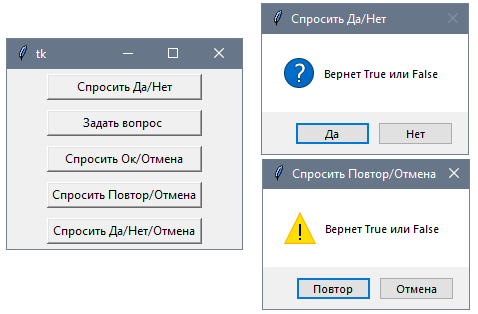
У них есть кое-какие отличия, поэтому стоит попробовать каждое из окон, чтобы разобраться в них.
Как и в прошлом примере сначала нужно импортировать tkinter.messagebox с помощью синтаксиса import … as и вызывать каждую из функций вместе с title и message:
import tkinter as tk
import tkinter.messagebox as mb
class App(tk.Tk):
def __init__(self):
super().__init__()
self.create_button(mb.askyesno, "Спросить Да/Нет",
"Вернет True или False")
self.create_button(mb.askquestion, "Задать вопрос ",
"Вернет 'yes' или 'no'")
self.create_button(mb.askokcancel, "Спросить Ок/Отмена",
"Вернет True или False")
self.create_button(mb.askretrycancel, "Спросить Повтор/Отмена",
"Вернет True или False")
self.create_button(mb.askyesnocancel, "Спросить Да/Нет/Отмена",
"Вернет True, False или None")
def create_button(self, dialog, title, message):
command = lambda: print(dialog(title, message))
btn = tk.Button(self, text=title, command=command)
btn.pack(padx=40, pady=5, expand=True, fill=tk.BOTH)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работают вопросительные окна
Чтобы избежать повторений при создании экземпляра кнопки и функции обратного вызова определим метод create_button, который будет переиспользоваться для каждой кнопки с диалогами. Команды всего лишь выводят результат функции dialog, переданной в качестве параметра, что позволит видеть значение, которое она возвращает в зависимости от нажатой пользователем кнопки.
Выбор файлов и папок
Диалоговые окна для выбора файлов позволяют выбирать один или несколько файлов из файловой системы. В Tkinter эти функции объявлены в модуле tkinter.filedialog, который также включает окна для выбора папок. Он также позволяет настраивать поведение нового окна: например, фильтрация по расширению или выбор папки по умолчанию.
В этом приложении будет две кнопки. Первая, «Выбрать файл», откроет диалоговое окно для выбора файла. По умолчанию в окне будут только файлы с расширением .txt:
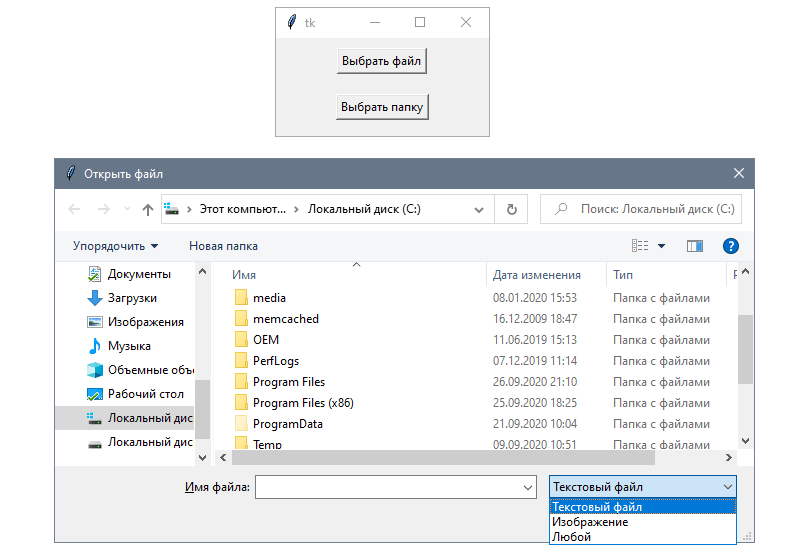
Вторая — «Выбор папки». Она будет открывать похожее диалоговое окно для выбора папки.
Обе кнопки будут выводить полный путь к выбранным файлу или папке и не делать ничего, если пользователь выберет вариант Отмена.
Первая кнопка будет вызывать функцию askopenfilename, а вторая — askdirectory:
import tkinter as tk
import tkinter.filedialog as fd
class App(tk.Tk):
def __init__(self):
super().__init__()
btn_file = tk.Button(self, text="Выбрать файл",
command=self.choose_file)
btn_dir = tk.Button(self, text="Выбрать папку",
command=self.choose_directory)
btn_file.pack(padx=60, pady=10)
btn_dir.pack(padx=60, pady=10)
def choose_file(self):
filetypes = (("Текстовый файл", "*.txt"),
("Изображение", "*.jpg *.gif *.png"),
("Любой", "*"))
filename = fd.askopenfilename(title="Открыть файл", initialdir="/",
filetypes=filetypes)
if filename:
print(filename)
def choose_directory(self):
directory = fd.askdirectory(title="Открыть папку", initialdir="/")
if directory:
print(directory)
if __name__ == "__main__":
app = App()
app.mainloop()
Поскольку пользователь может отменить выбор, также добавим условные инструкции, которые перед выводом в консоль будут проверять, не возвращает ли окно пустую строку. Такая валидация нужна для любого приложения, которое в дальнейшем будет работать с вернувшимся путем, считывая и копируя файлы или изменяя разрешения.
Как работают окна выбора файлов и папок
Создадим первое диалоговое окно с помощью функции askopenfilename, которая возвращает строку с полным путем к файлу. Она принимает следующие опциональные аргументы:
title— название для диалогового окна.initialdir— начальная папка.filetypes— последовательность из двух строк. Первая — метка с типом файла в читаемом формате, а вторая — шаблон для поиска совпадения с названием файла.multiple— булево значение для определения того, может ли пользователь выбирать несколько файлов.defaultextension— расширение, добавляемое к файлу, если оно не было указано явно.
В этом примере задаем корневую папку в качестве начальной, а также название. В кортеже типов файлов есть следующие три варианта: текстовые файлы, сохраненные с расширением .txt, изображения с .jpg, .gif и .png, а также подстановочный знак («*») для всех файлов.
Стоит обратить внимание на то, что эти шаблоны не обязательно соответствуют формату данных в файле, поскольку есть возможность переименовать его с другим расширением:
filetypes = (("Текстовый файл", "*.txt"),
("Изображение", "*.jpg *.gif *.png"),
("Любой", "*"))
filename = fd.askopenfilename(title="Открыть файл", initialdir="/",
filetypes=filetypes)
Функция askdirectory также принимает параметры title и initialdir, а также булев параметр mustexist для определения того, должны ли пользователи выбирать существующую папку:
directory = fd.askdirectory(title="Открыть папку", initialdir="/")
Модуль tkinter.filedialog включает вариации этих функций, которые позволяют прямо получать объекты файлов.
Например, askopenfile возвращает объект файла, который соответствует выбранному вместо того чтобы вызывать open с путем возвращающим askopenfilename. Но при этом все еще придется проверять, не было ли окно отклонено перед вызовом файловых методов:
import tkinter.filedialog as fd
filetypes = (("Текстовый файл", "*.txt"),)
my_file = fd.askopenfile(title="Открыть файл", filetypes=filetypes)
if my_file:
print(my_file.readlines())
my_file.close()
Сохранение данных в файл
Помимо выбора существующих файлов и папок также есть возможность создавать новые, используя диалоговые окна Tkinter. Они позволят сохранять данные, сгенерированные приложением, позволяя пользователям выбирать название и местоположение нового файла.
Будем использовать диалоговое окно «Сохранить файл» для записи содержимого виджета Text в текстовый файл:
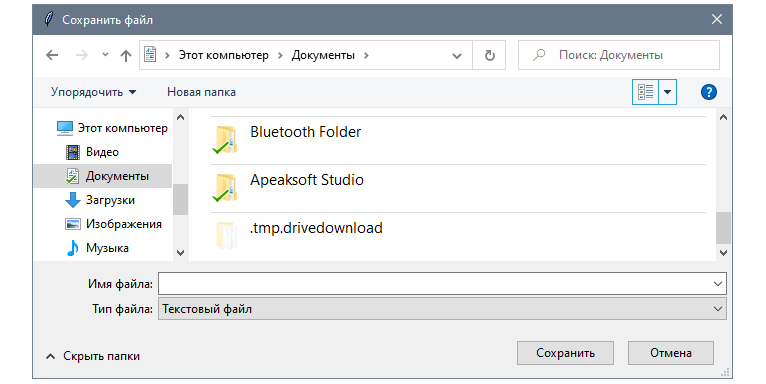
Для открытия такого диалогового окна используется функция asksavefile из модуля tkinter.filedialog. Она создает объект файла с режимом записи ('w') или None, если окно было закрыто:
import tkinter as tk
import tkinter.filedialog as fd
class App(tk.Tk):
def __init__(self):
super().__init__()
self.text = tk.Text(self, height=10, width=50)
self.btn_save = tk.Button(self, text="Сохранить", command=self.save_file)
self.text.pack()
self.btn_save.pack(pady=10, ipadx=5)
def save_file(self):
contents = self.text.get(1.0, tk.END)
new_file = fd.asksaveasfile(title="Сохранить файл", defaultextension=".txt",
filetypes=(("Текстовый файл", "*.txt"),))
if new_file:
new_file.write(contents)
new_file.close()
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает сохранение фалов
Функция asksavefile принимает те же опциональные параметры, что и askopenfile, но также позволяет добавить расширение файла по умолчанию с помощью параметра defaultextension.
Чтобы пользователи случайно не перезаписывали существующие файлы, это окно автоматически предупреждает, если они пытаются сохранить новый файл с тем же названием, что и у существующего.
С помощью объекта файла можно записать содержимое виджета Text. Нужно лишь не забывать закрывать файл для освобождения ресурсов, которые использовал объект:
contents = self.text.get(1.0, tk.END)
new_file.write(contents)
new_file.close()
Благодаря последней программе стало понятно, что askopenfile возвращает объект файла, а не его название. Также есть функция asksaveasfilename, которая возвращает путь к выбранному файлу. Ее можно использовать для изменения пути или выполнения валидации перед открытием файла для записи.
Изменение иконки курсора
Tkinter позволяет менять внешний вид иконки курсора при наведении на виджет. Это поведение иногда включается по умолчанию, как, например, в случае с виджетом Entry, который показывает курсор текстового выделения.
Следующее приложение демонстрирует, как показывать курсор загрузки, а также курсор со знаком вопроса, который часто используется во вспомогательных меню.
Иконку можно поменять с помощью параметра cursor. В этом примере используется значение watch для демонстрации нативной иконки загрузки, а также question_arrow — для обычной стрелки со знаком вопроса:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо иконки курсора")
self.resizable(0, 0)
self.label = tk.Label(self, text="Нажмите для старта")
self.btn_launch = tk.Button(self, text="Старт !",
command=self.perform_action)
self.btn_help = tk.Button(self, text="Помощь",
cursor="question_arrow")
btn_opts = {"side": tk.LEFT, "expand": True, "fill": tk.X,
"ipadx": 30, "padx": 20, "pady": 5}
self.label.pack(pady=10)
self.btn_launch.pack(**btn_opts)
self.btn_help.pack(**btn_opts)
def perform_action(self):
self.btn_launch.config(state=tk.DISABLED)
self.btn_help.config(state=tk.DISABLED)
self.label.config(text="Запуск...")
self.after(3000, self.end_action)
self.config(cursor="watch")
def end_action(self):
self.btn_launch.config(state=tk.NORMAL)
self.btn_help.config(state=tk.NORMAL)
self.label.config(text="Готово!")
self.config(cursor="arrow")
def set_watch_cursor(self, widget):
widget._old_cursor = widget.cget("cursor")
widget.config(cursor="watch")
for w in widget.winfo_children():
self.set_watch_cursor(w)
def restore_cursor(self, widget):
widget.config(cursor=widget.old_cursor)
for w in widget.winfo_children():
self.restore_cursor(w)
if __name__ == "__main__":
app = App()
app.mainloop()
Полный список валидных значений для cursor( включая те, которые характерны для определенной ОС) можно посмотреть в официальной документации Tcl/TK на сайте https://www.tcl.tk/man/tcl/TkCmd/cursors.htm.
Как работает изменение курсора
Если виджет не определяет параметр cursor, он берет значение из родительского контейнера. Таким образом можно запросто задать нужную иконку для всех виджетов, определив значение на уровне root. Это делается с помощью вызова set_watch_cursor() внутри метода perform_action():
def perform_action(self):
self.config(cursor="watch")
# ...
Исключением здесь является кнопка Помощь, которая явно задает значение question_arrow для курсора. Это же можно сделать при создании экземпляра виджета:
self.btn_help = tk.Button(self, text="Помощь",
cursor="question_arrow")
Стоит также обратить внимание на то, что если нажать на кнопку Старт и разместить курсор над кнопкой Помощь до вызова запланированного метода, то значение будет help, а не watch. Это происходит из-за того что, если параметр cursor виджета задан, то у него более высокая приоритетность по сравнению со значением в родительском контейнере.
Чтобы избежать этого, можно сохранить текущее значение cursor и поменять его на watch, вернув позже. Функцию, которая будет выполнять эту операцию, можно вызывать рекурсивно в дочернем виджете, перебирая список winfo_children():
def perform_action(self):
self.set_watch_cursor(self)
# ...
def end_action(self):
self.restore_cursor(self)
# ...
def set_watch_cursor(self, widget):
widget._old_cursor = widget.cget("cursor")
widget.config(cursor="watch")
for w in widget.winfo_children():
self.set_watch_cursor(w)
def restore_cursor(self, widget):
widget.config(cursor=widget.old_cursor)
for w in widget.winfo_children():
self.restore_cursor(w)
В этом коде свойство _old_cursor было добавлено каждому виджету. При использовании такого же подхода важно помнить, что нельзя вызывать restore_cursor() до set_watch_cursor().
Виджет Text
Виджет Text предлагает расширенную функциональность по сравнению с другими классами виджетов. Он отображает несколько строк редактируемого текста, который можно индексировать по строкам и колонкам. Также на них можно ссылаться с помощью тегов, которые определяют измененные внешний вид и поведение.
Следующее приложение демонстрирует базовый пример использования виджета Text, где можно динамически добавлять и удалять выбранный текст:
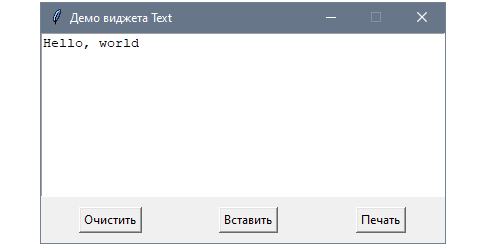
Помимо виджета Text это приложение содержит три кнопки, которые вызывают методы для очистки всего содержимого, вставки строки «Hello, world!» в месте, где сейчас находится курсор, и вывода выделения, сделанного с помощью мыши или клавиатуры:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо виджета Text")
self.resizable(0, 0)
self.text = tk.Text(self, width=50, height=10)
self.btn_clear = tk.Button(self, text="Очистить",
command=self.clear_text)
self.btn_insert = tk.Button(self, text="Вставить",
command=self.insert_text)
self.btn_print = tk.Button(self, text="Печать",
command=self.print_selection)
self.text.pack()
self.btn_clear.pack(side=tk.LEFT, expand=True, pady=10)
self.btn_insert.pack(side=tk.LEFT, expand=True, pady=10)
self.btn_print.pack(side=tk.LEFT, expand=True, pady=10)
def clear_text(self):
self.text.delete("1.0", tk.END)
def insert_text(self):
self.text.insert(tk.INSERT, "Hello, world")
def print_selection(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
content = self.text.get(*selection)
print(content)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает текстовый виджет
Изначально виджет Text пустой и имеет ширину на 50 символов, а высоту на 10 строк. Помимо добавления возможности для пользователей вводить любой текст, разберем также методы каждой кнопки, чтобы понимать, как взаимодействовать с виджетом.
Метод delete(start, end) удаляет содержимое с индексами от start до end. Если второй параметр не указан, то удаляются только символы с индексом start.
В этом примере будем удалять весь текст от индекса 1.0 (нулевая колонка первой строчки) до tk.END, которая ссылается на последний символ:
def clear_text(self):
self.text.delete("1.0", tk.END)
Метод insert(index, text) вставляет выбранный текст в положении index. Вызываем его с помощью индекса INDEX, который соответствует позиции курсора:
def insert_text(self):
self.text.insert(tk.INSERT, "Hello, world")
Метод tag_ranges(tag) возвращает кортеж с первым и последним индексами всех диапазонов конкретного tag. Здесь был использован тег tk.SEL, который указывает на текущую позицию. Если ничего не было выбрано, то вызов вернет пустой кортеж. Этот метод объединен с get(start, end), который возвращает текст в заданном диапазоне:
Поскольку тег SEL соответствует лишь одному диапазону, его можно с легкостью извлечь с помощью метода get.
Добавление HTML тегов в виджет Text
В этом разделе разберем, как настраивать поведение последовательности символов с проставленными тегами в виджете Text.
Эти принципы не отличаются от тех, что применяются к обычным виджетам, таким как последовательности событий или параметры, которые рассматривались в прошлых материалах. Основное отличие в том, что нужно работать с текстовыми индексами для определения контента с тегами вместо того, чтобы использовать ссылки на объекты.
Для демонстрации принципов работы с тегами, создадим виджет Text, который симулирует добавление гиперссылок. При нажатии по таким в браузере по умолчанию будет открываться выбранный URL.
Например, если пользователь введет следующий текст, то python.org можно отметить тегом как гиперссылку:
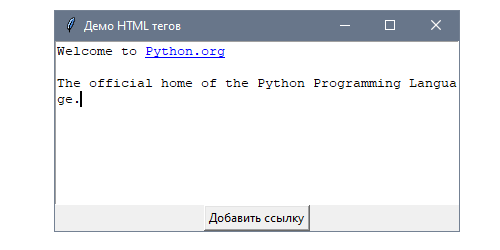
Определим тег «link», который представляет собой кликабельную гиперссылку. Этот тег будет добавляться к текущему выбранному тексту с помощью кнопки, а клик мышью запустит событие для открытия ссылки в браузере:
import tkinter as tk
import webbrowser
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо HTML тегов")
self.text = tk.Text(self, width=50, height=10)
self.btn_link = tk.Button(self, text="Добавить ссылку",
command=self.add_hyperlink)
self.text.tag_config("link", foreground="blue", underline=1)
self.text.tag_bind("link", "", self.open_link)
self.text.tag_bind("link", "",
lambda _: self.text.config(cursor="hand2"))
self.text.tag_bind("link", "",
lambda e: self.text.config(cursor=""))
self.text.pack()
self.btn_link.pack(expand=True)
def add_hyperlink(self):
selection = self.text.tag_ranges(tk.SEL)
if selection:
self.text.tag_add("link", *selection)
def open_link(self, event):
position = "@{},{} + 1c".format(event.x, event.y)
index = self.text.index(position)
prevrange = self.text.tag_prevrange("link", index)
url = self.text.get(*prevrange)
webbrowser.open(url)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает добавление тега
Изначально создается экземпляр тега с помощью настройки цвета и стиля подчеркивания. Добавим событие для открытия ссылок по нажатию и поменяем внешний вид курсора, когда тот находится над текстом с тегом:
def __init__(self):
super().__init__()
self.title("Демо HTML тегов")
self.text = tk.Text(self, width=50, height=10)
self.btn_link = tk.Button(self, text="Добавить ссылку",
command=self.add_hyperlink)
self.text.tag_config("link", foreground="blue", underline=1)
self.text.tag_bind("link", "", self.open_link)
self.text.tag_bind("link", "",
lambda _: self.text.config(cursor="hand2"))
self.text.tag_bind("link", "",
lambda e: self.text.config(cursor=""))
Внутри метода open_link поменяем положение клика на соответствующую строку и колонку с помощью метода index класса Text:
position = "@{},{} + 1c".format(event.x, event.y)
index = self.text.index(position)
prevrange = self.text.tag_prevrange("link", index)
Стоит обратить внимание на то, что положение, соответствующее индексу, по которому был совершен клик, — «@x,y», но оно сдвинут на один символ. Это сделано из-за того, что tag_prevrange возвращает предшествующий диапазон конкретного индекса. В таком случае он бы не возвращал текущий диапазон при клике по первому символу.
Наконец, получаем текст из диапазона и открываем его с помощью браузера по умолчанию, используя для этого функцию open из модуля webbrowser:
url = self.text.get(*prevrange)
webbrowser.open(url)
Поскольку функция webbrowser.open не проверяет, является ли URL валидным, то приложение можно улучшить, добавив базовую валидацию гиперссылки. Например, можно использовать функцию urlparse, чтобы убедиться, что у ссылки есть сетевое положение:
Хотя этот подход не является идеальным, он подойдет на первых этапах, чтобы отбрасывать невалидные ссылки.
В целом, можно использовать теги для создания сложных программ, основанных на тексте: например, IDE с подсветкой синтаксиса. На самом деле, IDLE, которая идет в составе Python, основана на Tkinter.
]]>Предыдущий урок: Потоки и многопоточность
Инструкции assert в Python — это булевы выражения, которые проверяют, является ли условие истинным (True). Они определяют факты (утверждения) в программе. Assertion — это проверка, которую можно включить, а затем выключить, завершив тестирование программы.
Возьмем простой пример функции деления. Можно быть уверенным в том, что делитель не должен быть нолем. Это и указывается при тестировании. Разберем этот пример позже.
Что такое Assertion (утверждение)
Assertions (утверждения) — это инструкции, которые «утверждают» определенный кейс в программе. В Python они выступают булевыми выражениями, которые проверяют, является ли условие истинным или ложным. Если оно истинно, то программа ничего не делает и переходит к выполнению следующей строчки кода.
Но если оно ложно, то программа останавливается и возвращает ошибку.
Следующий синтаксис — это базовая структура инструкций утверждения в Python.
assert conditionЕсли же нужно добавить сообщение для вывода при ложном условии, то синтаксис будет таким.
assert condition, messageЭто сообщение позволит лучше понять, почему код не сработал.
Пример assert
Если нужно симулировать или выполнить отладку кода, чтобы узнать, что именно происходит на определенном этапе, то «утверждения» в Python отлично для этого подходят.
Именно инструмент отладки останавливает программу, как только возникает какая-то ошибка. Он также показывает, где именно она произошла.
- Инструкция assert принимает выражение и необязательное сообщение;
- Она используется для проверки типов, значений аргумента и вывода функции;
- А также для отладки, поскольку приостанавливает программу в случае ошибки.
Вот пример работы утверждений в Python.
def avg(ranks):
assert len(ranks) != 0
return round(sum(ranks)/len(ranks), 2)
ranks = [62, 65, 75]
print("Среднее значение:", avg(ranks))
В этом примере нужно, чтобы пользователь не оставлял параметры пустыми. Если этого не сделать, вернется ошибка Assertion Error. Вот пример вывода:
Среднее значение: 67.33В этом случае параметры были переданы, поэтому функция вернула нужный результат.
Теперь попробуем ничего не передавать.
def avg(ranks):
assert len(ranks) != 0
return round(sum(ranks)/len(ranks), 2)
ranks = []
print("Среднее значение:", avg(ranks))
Длина массива ranks оказалась 0, и python вернул ошибку Assertion Error.
Traceback (most recent call last):
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 6, in <module>
print("Среднее значение:", avg(ranks))
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 2, in avg
assert len(ranks) != 0
AssertionErrorИсключения Assertion Error можно перехватывать и обрабатывать как и любые другие исключения с помощью try-except. Но если их обработать неправильно, то программа остановится и вернет traceback.
Однако в примере выше она не возвращает ошибку с нужным сообщением. Ее можно написать самостоятельно. Вот как это делается.
def avg(ranks):
assert len(ranks) != 0, 'Список ranks не должен быть пустым'
return round(sum(ranks)/len(ranks), 2)
ranks = []
print("Среднее значение:", avg(ranks))
Вторым аргументом к assert в примере выше было передано сообщение, которое позже появится в выводе.
Traceback (most recent call last):
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 6, in <module>
print("Среднее значение:", avg(ranks))
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 2, in avg
assert len(ranks) != 0, 'Список ranks не должен быть пустым'
AssertionError: Список ranks не должен быть пустымAssert с сообщением об ошибки
Рассмотрим еще один пример с делением на 0.
def divide(x, y):
assert y != 0 , 'Нельзя делить на 0'
return round(x/y, 2)
z = divide(21,3)
print(z)
a = divide(21,0)
print(a)
В этом примере, если делителем будет ноль, то assert вернет сообщение с ошибкой. Посмотрим на вывод.
7.0
Traceback (most recent call last):
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 8, in <module>
a = divide(21,0)
File "C:/Users/asd/AppData/Local/Programs/Python/Python38/wb.py", line 2, in divide
assert y != 0 , 'Нельзя делить на 0'
AssertionError: Нельзя делить на 0
На третьей сверху строчке написана сама инструкция assert. Именно здесь проверяется, не является ли переменная y равной 0. Если она больше 0, то условие истинно, и код возвращает требуемый результат.
Но если вызвать метод division() со вторым аргументом 0, то условие assert будет ложным.
По этой причине и возникает исключение Assertion Error. Именно оно возвращает ошибку с сообщением «Нельзя делить на 0».
Методы assert
Метод | Проверка на | Работает с |
|---|---|---|
assertEqual(x, y) | x == y | |
assertNotEqual(x, y) | x != y | |
assertTrue(x) | bool(x) равно True | |
assertFalse(x) | bool(x) равно False | |
assertIs(x, y) | x это y | 3.1 |
assertIsNot(x, y) | x это не y | 3.1 |
assertIsNone(x) | x это None | 3.1 |
assertIsNotNone(x) | x это не None | 3.1 |
assertIn(x, y) | x в y | 3.1 |
assertNotIn(x, y) | x не в y | 3.1 |
assertIsInstance(x, y) | isinstance(x, y) | 3.2 |
assertNotIsInstance(x,y) | не isinstance(x, y) | 3.2 |
Как проверить, что функция возвращает исключение
Можно использовать TestCase.assertRaises (или TestCase.failUnlessRaises) из модуля unittest.
import unittest
def broken_function():
raise Exception('Это ошибка')
class MyTestCase(unittest.TestCase):
def test(self):
with self.assertRaises(Exception) as context:
broken_function()
self.assertTrue('Это ошибка' in str(context.exception))
if __name__ == '__main__':
unittest.main()
Вывод:
.
----------------------------------------------------------------------
Ran 1 test in 0.051s
OKРаспространенные ошибки
Есть два важных момента касательно утверждений в Python, о которых нужно помнить.
- Не стоит использовать assert для валидации данных, ведь это приводит к появлению проблем с безопасностью и багов.
- Важно не писать такие утверждения, которые всегда будут истинными.
Ключевые моменты assert в Python
- Утверждение (Assertion) — это условие или булево выражение, которое должно быть истинным.
- Инструкция assert принимает выражение и необязательное сообщение.
- Инструкция assert используется для проверки типов, значений аргументов и вывода функций.
- Это также инструмент для отладки, ведь он останавливает программу при появлении ошибки.
- В первую очередь утверждения используются для уведомления разработчиков о неотслеживаемых ошибках. Они не должны сообщать об условия ошибок, таких как «файл не был найден», где пользователь может попытаться исправиться и повторить действия.
- Утверждения — это внутренняя проверка для программы. Они работают за счет объявления невозможных условий в коде. Если эти условия не проходят, значит имеется баг.
]]>Предыдущий урок: Namedtuple
Работа с цветами
В примерах из прошлых материалов цвета задавались с помощью их названий: например, white, blue или yellow. Эти значения передаются в виде строк параметрам foreground и background, которые изменяют цвет текста и фона виджета соответственно.
Названия цветов дальше уже привязываются к RGB-значениям (аддитивной модели, которая представляет цвета за счет комбинации интенсивности красного, зеленого и синего цветов). Этот перевод делается на основе таблицы, которая отличается от платформы к платформе. Если же нужно отображать один и тот же цвет на разных платформах, то можно передавать RGB-значение в параметры виджета.
Следующее приложение показывает, как можно динамически менять параметры foreground и background у метки, которая демонстрирует зафиксированный текст:
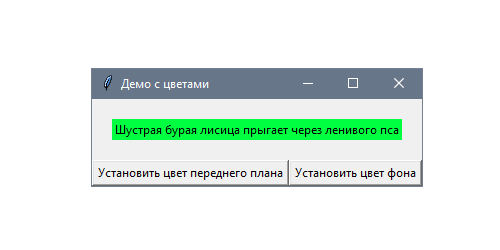
Цвета определены в формате RGB и выбираются с помощью нативного модального окна. На следующем скриншоте представлено диалоговое окно из Windows 10:
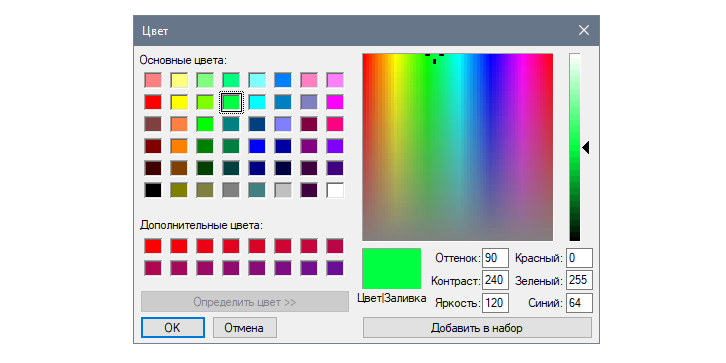
Традиционно будем работать с настройками виджета с помощью кнопок — по одной для каждого параметра. Основное отличие по сравнению с предыдущими примерами в том, что значения могут быть прямо выбраны с помощью диалогового окна askcolor из модуля tkinter.colorchooser:
from functools import partial
import tkinter as tk
from tkinter.colorchooser import askcolor
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо с цветами")
text = "Шустрая бурая лисица прыгает через ленивого пса"
self.label = tk.Label(self, text=text)
self.fg_btn = tk.Button(self, text="Установить цвет текста",
command=partial(self.set_color, "fg"))
self.bg_btn = tk.Button(self, text="Установить цвет фона",
command=partial(self.set_color, "bg"))
self.label.pack(padx=20, pady=20)
self.fg_btn.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.bg_btn.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
def set_color(self, option):
color = askcolor()[1]
print("Выбрать цвет:", color)
self.label.config(**{option: color})
if __name__ == "__main__":
app = App()
app.mainloop()
Если нужно проверить RGB-значение выбранного цвета, то его можно вывести в консоль при подтверждении выбора. Если же ничего не было выбрано, то и консоль останется пустой.
Как работает настройка цвета
Обе кнопки используют функцию partial в качестве обратного вызова. Это инструмент из модуля functools, который создает новый вызываемый объект. Он ведет себя как оригинальная функция, но с некоторыми зафиксированными аргументами. Возьмем в качестве примера такую инструкцию:
tk.Button(self, command=partial(self.set_color, "fg"), ...)
Предыдущая инструкция выполняет то же действие, что и следующая:
tk.Button(self, command=lambda: self.set_color("fg"), ...)
Так делается для того, чтобы переиспользовать метод set_color() из модуля functools. Это особенно полезно в более сложных сценариях, например, когда нужно создать несколько функций, и очевидно, что некоторые аргументы заданы заранее.
Нужно лишь помнить тот нюанс, что foreground и background кратко записаны как fg и bg. Эти строки распаковываются с помощью ** при настройке виджета в инструкции:
def set_color(self, option):
color = askcolor()[1]
print("Выбрать цвет:", color)
self.label.config(**{option: color}) # same as (fg=color)
or (bg=color)
askcolor возвращает кортеж с двумя элементами, которые представляют собой выбранный цвет. Первый — кортеж цветов из RGB-значений, а второй — шестнадцатеричное представление в виде строки. Поскольку первый вариант не может быть прямо передан в параметры виджета, используется второй.
Если нужно преобразовать название цвета в RGB-формат, можно использовать метод winfo_rgb() из предыдущего виджета. Поскольку он возвращает кортеж целых чисел от 0 до 65535, которые представляют 16-битные RGB-значения, их можно конвертировать в более привычное представление #RRGGBB, сдвинув вправо 8 битов:
rgb = widget.winfo_rgb("lightblue")
red, green, blue = [x>>8 for x in rgb]
print("#{:02x}{:02x}{:02x}".format(red, green, blue))
В предыдущем коде использовался {:02x} для форматирования каждого целого числа в два шестнадцатеричных.
Задание шрифтов виджета
В Tkinter можно менять шрифт виджета на кнопках, метках и записях. По умолчанию он соответствует системному, но его можно поменять с помощью параметра font.
Следующее приложение позволяет пользователю динамически менять тип шрифта и его размер для статического текста. Попробуйте разные значения, чтобы увидеть результаты настройки:
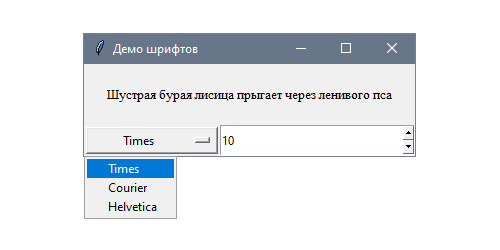
В данном случае для настройки используются два вида виджетов: выпадающее меню со списком шрифтов и поле ввода с предустановленными вариантами Spinbox для выбора размера:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо шрифтов")
text = "Шустрая бурая лисица прыгает через ленивого пса"
self.label = tk.Label(self, text=text)
self.family = tk.StringVar()
self.family.trace("w", self.set_font)
families = ("Times", "Courier", "Helvetica")
self.option = tk.OptionMenu(self, self.family, *families)
self.size = tk.StringVar()
self.size.trace("w", self.set_font)
self.spinbox = tk.Spinbox(self, from_=8, to=18,
textvariable=self.size)
self.family.set(families[0])
self.size.set("10")
self.label.pack(padx=20, pady=20)
self.option.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.spinbox.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
def set_font(self, *args):
family = self.family.get()
size = self.size.get()
self.label.config(font=(family, size))
if __name__ == "__main__":
app = App()
app.mainloop()
Стоит обратить внимание, что у переменных Tkinter есть некоторые значения по умолчанию, которые привязаны к каждому полю.
Как работает настройка шрифтов?
Кортеж FAMILIES включает три типа шрифтов, которые Tk гарантированно поддерживает на всех платформах: Times (Times New Roman), Courier и Helvetica. Между ними можно переключаться с помощью виджета OptionMenu, который привязан к переменной self.family.
Подобный подход используется также для того, чтобы задать размер шрифта в Spinbox. Обе переменных вызывают метод, который меняет шрифт метки:
def set_font(self, *args):
family = self.family.get()
size = self.size.get()
self.label.config(font=(family, size))
Кортеж, который передается в font, также может определять один или несколько следующих параметров шрифта: полужирный, стандартный, курсивный, подчеркнутый или перечеркнутый:
widget1.config(font=("Times", "20", "bold"))
widget2.config(font=("Helvetica", "16", "italic underline"))
Полный список всех доступных шрифтов, которые доступны для платформы, можно получить с помощью метода families() из модуля tkinter.font. Поскольку сперва нужно создать экземпляр окна root, можно использовать следующий скрипт:
import tkinter as tk
from tkinter import font
root = tk.Tk()
print(font.families())
Tkinter не вернет ошибку при попытке использовать шрифт не из списка, но попробует подобрать похожий.
Модуль tkinter.font включает класс Font, который можно переиспользовать в нескольких виджетах. Основное преимущество изменения экземпляра font в том, что в таком случае он затрагивает все виджеты, в которых был использован.
Работа с классом Font напоминает работу с дескрипторами шрифтов. Например, этот скрипт создает полужирный шрифт Courier размером 18 пикселей:
from tkinter import font
courier_18 = font.Font(family="Courier", size=18, weight=font.BOLD)
Чтобы получить или изменить значение, можно использовать методы cget и configure:
family = courier_18.cget("family")
courier_18.configure(underline=1)
Использование параметров базы данных
В Tkinter есть понятие базы данных параметров. Этот механизм используется для настройки внешнего вида приложения без определения параметров для каждого виджета. Это позволяет отделить некоторые параметры виджета от индивидуальной настройки, предоставив стандартизированные значения по умолчанию на основе иерархии виджетов.
В этом примере построим приложение, включающее несколько виджетов с разными стилями, которые будут определены в базе данных параметров:
Добавим кое-какие параметры с помощью метода option_add(), который доступен из всех классов виджетов:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Демо опции")
self.option_add("*font", "helvetica 10")
self.option_add("*header.font", "helvetica 18 bold")
self.option_add("*subtitle.font", "helvetica 14 italic")
self.option_add("*Button.foreground", "blue")
self.option_add("*Button.background", "white")
self.option_add("*Button.activeBackground", "gray")
self.option_add("*Button.activeForeground", "black")
self.create_label(name="header", text="Это 'header'")
self.create_label(name="subtitle", text="Это 'subtitle'")
self.create_label(text="Это параграф")
self.create_label(text="Это следующий параграф")
self.create_button(text="Больше...")
def create_label(self, **options):
tk.Label(self, **options).pack(padx=20, pady=5, anchor=tk.W)
def create_button(self, **options):
tk.Button(self, **options).pack(padx=5, pady=5, anchor=tk.E)
if __name__ == "__main__":
app = App()
app.mainloop()
Вместо настройки шрифтов, foreground и background и других параметров Tkinter будет использовать значения по умолчанию из базы.
Как работают стили для виджетов
Начнем с объяснения каждого вызова option_add. Первый из них добавляет параметр, который задает атрибут font для всех виджетов — звездочка представляет любое название приложения:
self.option_add("*font", "helvetica 10")
Следующий вызов ограничивает вызов для элементов с именем header. Чем он конкретнее, тем выше приоритет. Это же имя позже используется при создании экземпляра с меткой name="header":
self.option_add("*header.font", "helvetica 18 bold")
То же применимо и к self.option_add("*subtitle.font", "helvetica 14 italic"), где каждый параметр соответствует своему экземпляру виджета.
Следующие параметры используют имя класса Button вместе имени экземпляра. Таким образом можно ссылаться на все виджеты конкретного класса, чтобы задать для них значения по умолчанию:
self.option_add("*Button.foreground", "blue")
self.option_add("*Button.background", "white")
self.option_add("*Button.activeBackground", "gray")
self.option_add("*Button.activeForeground", "black")
База параметров использует иерархию виджетов для определения параметров, которые будут применяться к каждому экземпляру, поэтому в случае вложенных контейнеров они также могут быть использованы для ограничения параметров, у которых выше приоритет.
Эти параметры не применяются к существующим виджетам, а лишь к тем, которые были созданы после изменения базы данных. Таким образом всегда рекомендуется вызывать option_add() в начале приложения.
Есть несколько примеров, где один приоритетнее предыдущего:
*Frame*background: работает для фона всех виджетов во фрейме.*Frame.background: фон всех фреймов.*Frame.myButton.background: фон виджетаmyButton.*myFrame.myButton.background: фон виджетаmyButtonвнутри контейнераmyFrame.
Чтобы не добавлять параметры в коде, их можно определить в отдельном текстовом файле в таком формате:
*font: helvetica 10
*header.font: helvetica 18 bold
*subtitle.font: helvetica 14 italic
*Button.foreground: blue
*Button.background: white
*Button.activeBackground: gray
*Button.activeForeground: black
Этот файл затем загружается в приложение с помощью метода option_readfile() и заменяет все вызовы к option_add(). В этом примере предположим, что файл называется my_options_file и что находится он в одной папке с кодом:
def __init__(self):
super().__init__()
self.title("Options demo")
self.option_readfile("my_options_file")
# ...
Если такого файла не существует или его формат неверный, Tkinter вернет ошибку TclError.
В Tkinter geometry manager занимают все необходимое место в родительском контейнере для размещения виджетов. Но если у этого контейнера фиксированный размер или же он превышает размеры экрана, то появляется область, которая не будет видна пользователям.
Скроллбары в Tkinter автоматически не добавляются, поэтому их нужно создать и добавить как и любой другой виджет. Также нужно учесть, что лишь у некоторых классов виджетов есть параметры, с помощью которых к ним можно добавить скроллбары.
Чтобы это обойти, можно воспользоваться преимуществами виджета Canvas, который позволяет добавить скроллинг в любой контейнер.
Для демонстрации совместной работы классов Canvas и Scrollbar с целью создания изменяемого фрейма со скроллбарами, создадим приложение, которое будет динамически менять размер за счет загрузки изображения.
После нажатия на кнопку «Загрузить изображение» сама она пропадает, а в Canvas загружается изображение, которое больше контейнера. Это может быть любой графический файл.
Это активирует горизонтальный и вертикальный скроллбары, которые будут автоматически подстраиваться при изменении основного окна:

У виджета Canvas есть стандартный интерфейс скроллинга, а также метод create_window(). Важно обратить внимание на то, что этот скрипт предполагает размещение файла python.gif в той же директории:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.scroll_x = tk.Scrollbar(self, orient=tk.HORIZONTAL)
self.scroll_y = tk.Scrollbar(self, orient=tk.VERTICAL)
self.canvas = tk.Canvas(self, width=300, height=100,
xscrollcommand=self.scroll_x.set,
yscrollcommand=self.scroll_y.set)
self.scroll_x.config(command=self.canvas.xview)
self.scroll_y.config(command=self.canvas.yview)
self.frame = tk.Frame(self.canvas)
self.btn = tk.Button(self.frame, text="Загрузить изображение",
command=self.load_image)
self.btn.pack()
self.canvas.create_window((0, 0), window=self.frame,
anchor=tk.N + tk.W)
self.canvas.grid(row=0, column=0, sticky="nswe")
self.scroll_x.grid(row=1, column=0, sticky="we")
self.scroll_y.grid(row=0, column=1, sticky="ns")
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
self.bind("", self.resize)
self.update_idletasks()
self.minsize(self.winfo_width(), self.winfo_height())
def resize(self, event):
region = self.canvas.bbox(tk.ALL)
self.canvas.configure(scrollregion=region)
def load_image(self):
self.btn.destroy()
self.image = tk.PhotoImage(file="python.gif")
tk.Label(self.frame, image=self.image).pack()
if __name__ == "__main__":
app = App()
app.mainloop()
Как работают скроллбары в Tkinter
Первые строчки приложения создают скроллбары и присоединяют их к объекту Canvas с помощью параметров xscrollcommand и yscrollcommand, которые ссылаются на метод set() объектов scroll_x и scroll_y соответственно. Этот метод отвечает за перемещение слайдера.
Также нужно настроить параметр command каждого из скроллбаров после определения Canvas:
self.scroll_x = tk.Scrollbar(self, orient=tk.HORIZONTAL)
self.scroll_y = tk.Scrollbar(self, orient=tk.VERTICAL)
self.canvas = tk.Canvas(self, width=300, height=100,
xscrollcommand=self.scroll_x.set,
yscrollcommand=self.scroll_y.set)
self.scroll_x.config(command=self.canvas.xview)
self.scroll_y.config(command=self.canvas.yview)
Есть возможность сначала создать Canvas и настроить его параметры позже, когда уже будут созданы экземпляры скроллбаров.
Следующий шаг — добавить фрейм с помощью метода create_window(). Первый аргумент — положение, где нужно разместить виджет, который в свою очередь передается в аргументе window. Поскольку оси x и y виджета размещаются в верхнем левом углу, разместим виджет в положении (0, 0) и выровняем его в этом углу с помощью anchor=tk.NW (северо-запад):
self.frame = tk.Frame(self.canvas)
# ...
self.canvas.create_window((0, 0), window=self.frame, anchor=tk.NW)
Затем зададим переменный размер для первых строки и колонки с помощью методов rowconfigure() и columnconfigure(). Параметр weight обозначает относительную ширину, для распределения дополнительного пространства. Однако в этом примере нет колонок или рядков для изменения размера.
Связывание с событием <Configure> поможет правильно перенастроить Canvas, когда размер основного окна меняется. Обработка такого типа события работает по тому же принципу, что и события мыши и клавиатуры:
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
self.bind("<Configure>", self.resize)
В итоге задаем минимальный размер основного окна с текущими шириной и высотой, которые можно получить с помощью методов winfo_width() или winfo_height().
Для получения реального размера контейнера нужно сделать так, чтобы geometry manager прорисовывал все дочерние виджеты в первую очередь с помощью вызова update_idletasks(). Этот виджет доступен во всех классах виджета и он отвечает за то, чтобы Tkinter обработал все события в процессе ожидания: например, перерисовку или новые вычисления размеров:
self.update_idletasks()
self.minsize(self.winfo_width(), self.winfo_height())
Метод resize обрабатывает событие изменения размера окна и обновляет параметр scrollregion, определяющий область Canvas, которую можно скроллить. Чтобы провести вычисления заново, можно использовать метода bbox() с константой ALL. Он возвращает окружающий размер всего виджета Canvas:
def resize(self, event):
region = self.canvas.bbox(tk.ALL)
self.canvas.configure(scrollregion=region)
Tkinter автоматически вызывает несколько событий <Configure> при старте приложения, поэтому нет необходимости вызывать self.resize() в конце метода __init__.
Лишь несколько классов виджетов поддерживают стандартные параметры скроллинга: Listbox, Text и Canvas поддерживают xscrollcommand и yscrollcommand, а Entry — только xscrollcommand. На примере было разобрано, как использовать этот паттерн с Canvas, поскольку это может быть общее решение, но та же структура применима для любых виджетов.
Также нужно отметить, что в данном случае не вызывался geometry manager для прорисовки кадра, поскольку create_window() делает это автоматически. Для лучшей организации класса приложения, можно переместить всю функциональность фрейма и внутренние виджеты в отдельный подкласс Frame.
Виджеты определяют, какие действия смогут выполнять пользователи с помощью графического интерфейса. Однако важно обращать внимание на их взаимное и индивидуальное расположение. Эффективные макеты позволяют интуитивно определять значение и приоритетность каждого графического элемента, так что пользователь способен быстро разобраться, как нужно взаимодействовать с программой.
Макет также определяет внешний вид, который должен прослеживаться во всем приложении. Например, если кнопки расположены в правом верхнем углу, то они должны находиться там всегда. Хотя это может казаться очевидным для разработчиков, конечные пользователи будут путаться, если не провести их по приложению.
В этом материале погрузимся в разные механизмы, которые Tkinter предлагает для формирования макета, группировки виджетов и управления другими атрибутами, например, размером и отступами.
Группировка виджетов с фреймами
Фрейм представляет собой прямоугольную область окна, обычно используемую в сложных макетах. В них содержатся другие виджеты. Поскольку у фреймов есть собственные внутренние отступы, рамки и фон, то нужно отметить, что группа виджетов связана логически.
Еще одна распространенная особенность фреймов — инкапсуляция части функциональности приложения таким образом, что с помощью абстракции можно спрятать детали реализации дочерних виджетов.
Дальше будут рассмотрены оба сценария на примере создания компонента, который наследует класс Frame и раскрывает определенную информацию о включенных виджетах.
Создадим приложение, которое будет включать два списка, где первый — это список элементов, а второй изначально пустой. Оба можно пролистывать. Также есть возможность перемещать элементы между ними с помощью двух кнопок по центру:
Определим подкласс Frame, который представляет собой список с возможностью скроллинга и два его экземпляра. Также в основное окно будут добавлены две кнопки:
import tkinter as tk
class ListFrame(tk.Frame):
def __init__(self, master, items=[]):
super().__init__(master)
self.list = tk.Listbox(self)
self.scroll = tk.Scrollbar(self, orient=tk.VERTICAL,
command=self.list.yview)
self.list.config(yscrollcommand=self.scroll.set)
self.list.insert(0, *items)
self.list.pack(side=tk.LEFT)
self.scroll.pack(side=tk.LEFT, fill=tk.Y)
def pop_selection(self):
index = self.list.curselection()
if index:
value = self.list.get(index)
self.list.delete(index)
return value
def insert_item(self, item):
self.list.insert(tk.END, item)
class App(tk.Tk):
def __init__(self):
super().__init__()
months = ["Январь", "Февраль", "Март", "Апрель",
"Май", "Июнь", "Июль", "Август", "Сентябрь",
"Октябрь", "Ноябрь", "Декабрь"]
self.frame_a = ListFrame(self, months)
self.frame_b = ListFrame(self)
self.btn_right = tk.Button(self, text=">",
command=self.move_right)
self.btn_left = tk.Button(self, text="<",
command=self.move_left)
self.frame_a.pack(side=tk.LEFT, padx=10, pady=10)
self.frame_b.pack(side=tk.RIGHT, padx=10, pady=10)
self.btn_right.pack(expand=True, ipadx=5)
self.btn_left.pack(expand=True, ipadx=5)
def move_right(self):
self.move(self.frame_a, self.frame_b)
def move_left(self):
self.move(self.frame_b, self.frame_a)
def move(self, frame_from, frame_to):
value = frame_from.pop_selection()
if value:
frame_to.insert_item(value)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает группировка виджетов
У класса ListFrame есть только два метода для взаимодействия с внутренним списком: pop_selection() и insert_item(). Первый возвращает и удаляет текущий выделенный элемент, или не делает ничего, если элемент не был выбран. Второй — вставляет элемент в конец списка.
Эти методы используются в родительском классе для перемещения элемента из одного списка в другой:
def move(self, frame_from, frame_to):
value = frame_from.pop_selection()
if value:
frame_to.insert_item(value)
Также можно воспользоваться особенностями контейнеров родительского фрейма, чтобы правильно размещать их с нужными внутренними отступами:
# ...
self.frame_a.pack(side=tk.LEFT, padx=10, pady=10)
self.frame_b.pack(side=tk.RIGHT, padx=10, pady=1
Благодаря фреймам вызовы управлять геометрией макетов проще.
Еще одно преимущество такого подхода — возможность использовать geometry manager в контейнерах каждого виджета. Это могут быть grid() для виджетов во фрейме или pack() для укладывания фрейма в основном окне.
Однако смешивать эти менеджеры в одном контейнере в Tkinter запрещено. Из-за этого приложение просто не будет работать.
Geometry manager Pack
В прошлых материалах можно было обратить внимание на то, что после создания виджета он не отображается на экране автоматически. Для каждого нужно было вызывать метод pack(). Это подразумевает использование соответствующего geometry manager.
Это один из трех доступных в Tkinter менеджеров и он отлично подходит для простых макетов, как в случае, когда, например, нужно разместить все друг над другом или рядом.
Предположим, что нужно получить следующий макет для приложения:
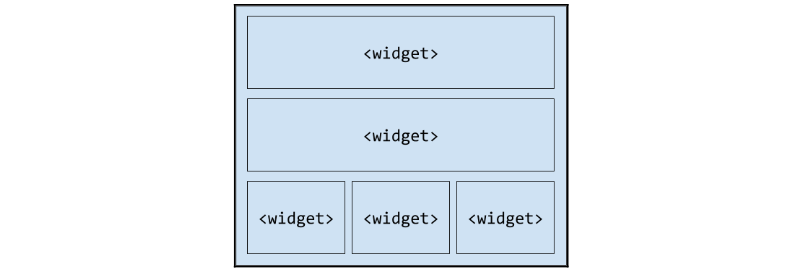
Он состоит из трех строк, где в последней есть три виджета, расположенных рядом друг с другом. В таком случае Pack сможет добавить виджеты как требуется без использования дополнительных фреймов.
Для этого будут использоваться пять виджетов Label с разными текстом и фоном, что поможет различать каждую прямоугольную область:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
label_a = tk.Label(self, text="Label A", bg="yellow")
label_b = tk.Label(self, text="Label B", bg="orange")
label_c = tk.Label(self, text="Label C", bg="red")
label_d = tk.Label(self, text="Label D", bg="green")
label_e = tk.Label(self, text="Label E", bg="blue")
opts = { 'ipadx': 10, 'ipady': 10, 'fill': tk.BOTH }
label_a.pack(side=tk.TOP, **opts)
label_b.pack(side=tk.TOP, **opts)
label_c.pack(side=tk.LEFT, **opts)
label_d.pack(side=tk.LEFT, **opts)
label_e.pack(side=tk.LEFT, **opts)
if __name__ == "__main__":
app = App()
app.mainloop()
Также были добавлены параметры в словаре opts. Они делают яснее размеры каждой области:
Как работает Pack
Чтобы лучше понимать принципы работы Pack, разберем пошагово, как виджеты добавляются в родительский контейнер. Стоит обратить особое внимание на значение параметра side, который определяет относительное положение виджета по отношению к следующему в этом же контейнере.
Сначала добавляются две метки в верхней части экрана. Пусть значение параметра side по умолчанию является tk.TOP,все равно зададим его явно, чтобы отличать от тех случаев, где используется tk.LEFT:
Дальше добавляем еще три метки со значением tk.LEFT у параметра side, в результате чего они размещаются рядом друг рядом с другом:
Определение стороны label_e особой роли не играет, поскольку это последний виджет, который добавляется в контейнер.
Важно запомнить, что это основная причина, почему порядок так важен при работе с Pack. Чтобы не столкнутся с непредвиденными результатами в сложных макетах распространенной практикой считается их расположение в пределах фрейма так, что бы они не пересекались.
В таких случаях рекомендуется использовать geometry manager Grid, поскольку он позволяет прямо задавать положение каждого виджета с помощью вызова geometry manager и избегать использования дополнительных фреймов.
В side можно передать не только tk.TOP и tk.LEFT, но также tk.BOTTOM и tk.RIGHT. Они разместят виджеты в другом порядке, но это может быть не интуитивно, ведь мы естественным путем следим сверху вниз и слева направо.
Например, если заменить значение tk.LEFT на tk.RIGHT в последних трех виджетах, их порядок будет следующим: label_e, label_d и label_c.
Geometry manager Grid
Grid — самый гибкий из всех доступных geometry manager. Он полностью переосмысливает концепцию сетки (grid), которая традиционно используется при дизайне пользовательских интерфейсов. Сетка — это двумерная таблица, разделенная на строки и колонки, где каждая ячейка представляет собой пространство, которое доступно для виджета.
Продемонстрируем работу Grid с помощью следующего макета:
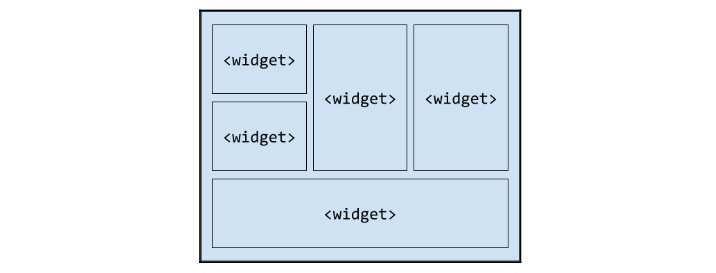
Его можно представить в виде таблицы 3×3, где виджеты во второй и третьей колонках растягиваются на две строки, а виджет в третьей строке занимает все три колонки.
Как и в предыдущем варианте используем 5 меток с разным фоном, чтобы проиллюстрировать распределение ячеек:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
label_a = tk.Label(self, text="Label A", bg="yellow")
label_b = tk.Label(self, text="Label B", bg="orange")
label_c = tk.Label(self, text="Label C", bg="red")
label_d = tk.Label(self, text="Label D", bg="green")
label_e = tk.Label(self, text="Label E", bg="blue")
opts = { 'ipadx': 10, 'ipady': 10 , 'sticky': 'nswe' }
label_a.grid(row=0, column=0, **opts)
label_b.grid(row=1, column=0, **opts)
label_c.grid(row=0, column=1, rowspan=2, **opts)
label_d.grid(row=0, column=2, rowspan=2, **opts)
label_e.grid(row=2, column=0, columnspan=3, **opts)
if __name__ == "__main__":
app = App()
app.mainloop()
Также будем передавать словарь параметров, включающий внутренний отступ, который растянет виджеты на все доступное пространство внутри ячеек.
Как работает Grid
Расположение label_a и label_b говорит само за себя: они занимают первую и вторую строки первой колонки соответственно (важно не забывать, что индексация начинается с нуля):
Чтобы растянуть label_c и label_d на несколько ячеек, зададим значение 2 для параметра rowspan. Таким образом они будут занимать две ячейки, начиная с положения, отмеченного опциями row и column. Наконец, значение columnspan для label_e будет 3.
Важно запомнить, что в отличие от Pack есть возможность менять порядок вызовов к grid() для каждого виджета без изменения финального макета.
Параметр sticky определяет границы, к которым виджет должен крепиться. Он выражается в координатах сторон света: север, юг, запад и восток. В Tkinter эти значения выражены константами tk.N, tk.S, tk.W и tk.E, а также их комбинациями: tk.NW, tk.NE, tk.SW и tk.SE.
Например, sticky=tk.N выравнивает виджет у верхней границы ячейки (north – север), а sticky=tk.SE — в правом нижнем углу (south-ease – юго-восток).
Поскольку эти константы представляют соответствующие символы в нижнем регистре, выражение tk.N + tk.S + tk.W + tk.E можно записать в виде строки nwse. Это значит, что виджет должен расширяться одновременно горизонтально и вертикально — по аналогии с работой fill=tk.BOTH из Pack.
Если параметру sticky значение не передается, виджет располагается по центру ячейки.
Geometry manager Place
Менеджер Place позволяет задать положение и размер виджета в абсолютном или относительном значении.
Из трех менеджеров этот является наименее используемым. С другой стороны, он может работать со сложными сценариями, где есть необходимость свободно разместить виджет или перекрыть другой.
Для демонстрации работы Place повторим следующий макет, смешав абсолютные и относительные положения и размеры:
Метки, которые будут отображаться, имеют разный фон и определены в том порядке, в котором они будут расположены слева направо и сверху вниз:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
label_a = tk.Label(self, text="Label A", bg="yellow")
label_b = tk.Label(self, text="Label B", bg="orange")
label_c = tk.Label(self, text="Label C", bg="red")
label_d = tk.Label(self, text="Label D", bg="green")
label_e = tk.Label(self, text="Label E", bg="blue")
label_a.place(relwidth=0.25, relheight=0.25)
label_b.place(x=100, anchor=tk.N,
width=100, height=50)
label_c.place(relx=0.5, rely=0.5, anchor=tk.CENTER,
relwidth=0.5, relheight=0.5)
label_d.place(in_=label_c, anchor=tk.N + tk.W,
x=2, y=2, relx=0.5, rely=0.5,
relwidth=0.5, relheight=0.5)
label_e.place(x=200, y=200, anchor=tk.S + tk.E,
relwidth=0.25, relheight=0.25)
if __name__ == "__main__":
app = App()
app.mainloop()
Если запустить эту программу, то можно будет увидеть наложение label_c и label_d в центре экрана. Этого не удастся добиться с помощью других менеджеров.
Как работает Place
Первая метка располагается со значением 0.25 у параметров relwidth и relheight. Это значит, что виджет будет занимать 25% ширины и высоты родительского. По умолчанию виджеты расположены в положениях x=0 и y=0, а также выравнены к северо-западу, то есть, верхнему левому углу экрана.
Вторая метка имеет абсолютное положение — x=100. Она выравнена по верхней границе с помощью параметра anchor, который имеет значение tk.N. Тут также определен абсолютный размер с помощью width и height.
Третья метка расположена по центру окна с помощью относительного позиционирования и параметра anchor для tk.CENTER. Важно запомнить, что значение 0.5 для relx и relwidth обозначает половину родительской ширины, а 0.5 для rely и relheight — половину родительской высоты.
Четвертая метка расположена в верхней части label_c. Это делается с помощью переданного аргумента in_ (суффикс используется из-за того, что in — зарезервированное ключевое слово в Python). При использовании in_ можно обратить внимание на то, что выравнивание не является геометрически точным. В этом примере нужно добавить смещение на 2 пикселя в каждом направлении, чтобы идеально перекрыть правый нижний угол label_c.
Наконец, пятая метка использует абсолютное позиционирование и относительный размер. Как можно было заметить, эти размеры легко переключаются, поскольку значение размера родительского контейнера предполагается (200 х 200 пикселей). Однако при изменении размера основного окна будут работать только относительные величины. Это поведение легко проверить.
Еще одно важное преимущество Place — возможность совмещать его с Pack и Grid.
Например, представьте, что есть необходимость динамически отобразить текст на виджете при нажатии правой кнопкой мыши на нем. Его можно представить в виде виджета Label, который располагается в относительном положении при нажатии:
Лучше всего использовать другие менеджеры в своих приложениях Tkinter, а специализированные оставить для случаев, когда нужно кастомное позиционирование.
Группировка полей ввода с помощью виджета LabelFrame
Класс LabelFrame может быть использован для группировки нескольких виджетов ввода. Он представляет собой логическую сущность с соответствующей меткой. Обычно он используется в формах и сильно напоминает виджет Frame.
Создадим форму с парой экземпляров LabelFrame, каждый из которых будет включать соответствующие виджеты ввода:
Поскольку цель этого примера — показать финальный макет, добавим некоторые виджеты без сохранения их ссылок в виде атрибутов:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
group_1 = tk.LabelFrame(self, padx=15, pady=10,
text="Персональная информация")
group_1.pack(padx=10, pady=5)
tk.Label(group_1, text="Имя").grid(row=0)
tk.Label(group_1, text="Фамилия").grid(row=1)
tk.Entry(group_1).grid(row=0, column=1, sticky=tk.W)
tk.Entry(group_1).grid(row=1, column=1, sticky=tk.W)
group_2 = tk.LabelFrame(self, padx=15, pady=10,
text="Адрес")
group_2.pack(padx=10, pady=5)
tk.Label(group_2, text="Улица").grid(row=0)
tk.Label(group_2, text="Город").grid(row=1)
tk.Label(group_2, text="Индекс").grid(row=2)
tk.Entry(group_2).grid(row=0, column=1, sticky=tk.W)
tk.Entry(group_2).grid(row=1, column=1, sticky=tk.W)
tk.Entry(group_2, width=8).grid(row=2, column=1,
sticky=tk.W)
self.btn_submit = tk.Button(self, text="Отправить")
self.btn_submit.pack(padx=10, pady=10, side=tk.RIGHT)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает группировка полей ввода
Виджет LabelFrame принимает параметр labelWidget для задания виджета, который будет использоваться как метка. Если его нет, отображается строка, переданная в параметре text. Например, вместо создания экземпляра с tk.LabelFrame(master, text="Инфо") можно заменить это на следующие инструкции:
label = tk.Label(master, text="Инфо", ...)
frame = tk.LabelFrame(master, labelwidget=label)
# ...
frame.pack()
Это позволит делать любые изменения, например, добавить изображение. Стоит обратить внимание, что здесь не используются geometry manager, поскольку метка располагается сама при размещении фрейма.
Динамическое расположение виджетов
Grid легко использовать как для простых, так и для более продвинутых макетов. Он также является мощным инструментом для объединения со списком виджетов.
Рассмотрим, как можно уменьшить количество строк и вызовем geometry manager с помощью всего нескольких строк благодаря «list comprehension», а также встроенным функциям zip и enumerate.
Приложение, которое будет создавать, включает четыре виджета Entry, каждый из которых имеет соответствующую метку, указывающую на значение поля. Также добавим кнопку для вывода всех значений.
Вместо того чтобы создавать и присваивать каждый виджет отдельному атрибуту, будем работать со списками виджетов. Поскольку при итерации по списку идет отслеживание индекса, можно легко вызвать метод grid() с помощью соответствующего параметра column.
Выполним агрегацию списка меток и виджетов с помощью функции zip. Кнопка будет создана и расположена отдельно, поскольку у нее нет общих с другими виджетами параметров:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
fields = ["Имя", "Фамилия", "Телефон", "Email"]
labels = [tk.Label(self, text=f) for f in fields]
entries = [tk.Entry(self) for _ in fields]
self.widgets = list(zip(labels, entries))
self.submit = tk.Button(self, text="Распечатать",
command=self.print_info)
for i, (label, entry) in enumerate(self.widgets):
label.grid(row=i, column=0, padx=10, sticky=tk.W)
entry.grid(row=i, column=1, padx=10, pady=5)
self.submit.grid(row=len(fields), column=1, sticky=tk.E,
padx=10, pady=10)
def print_info(self):
for label, entry in self.widgets:
print("{} = {}".format(label.cget("text"), entry.get()))
if __name__ == "__main__":
app = App()
app.mainloop()
Можно ввести разный текст в каждое из полей и нажать кнопку «Распечатать», чтобы убедиться, что каждый кортеж содержит соответствующие метку и текст.
Как работает динамическое расположение
Каждый генератор списка выполняет итерацию по строкам списка полей. Поскольку метки используют каждый элемент как отображаемый текст, ссылки нужны только на родительский контейнер — нижнее подчеркивание подразумевает, что значение переменной игнорируется.
Начиная с Python 3, функция zip возвращает итератор вместо списка, поэтому результат — агрегация с функцией списка. В результате атрибут widgets содержит список кортежей, по которому можно пройти несколько раз:
fields = ["Имя", "Фамилия", "Телефон", "Email"]
labels = [tk.Label(self, text=f) for f in fields]
entries = [tk.Entry(self) for _ in fields]
self.widgets = list(zip(labels, entries))
Теперь нужно вызвать geometry manager для каждого кортежа виджетов. С помощью функции enumerate можно отслеживать индекс каждой итерации и передавать его в виде числа row:
for i, (label, entry) in enumerate(self.widgets):
label.grid(row=i, column=0, padx=10, sticky=tk.W)
entry.grid(row=i, column=1, padx=10, pady=5)
Стоит обратить внимание, что был использован синтаксис for i, (label, entry) in …, потому что нужно распаковать кортеж, сгенерированный с помощью enumerate и затем распаковать каждый кортеж атрибута widgets.
Внутри функции обратного вызова print_info() пройдем по виджетам для вывода текста каждой метки с соответствующими значениями поля. Для получения text из меток используем метод cget(), который позволяет получить значение параметра виджета по его имени.
Обработка событий с мыши и клавиатуры
Возможность реагировать на события — одна из базовых, но важных тем в приложениях с графическим интерфейсом. Именно она определяет, как пользователи смогут взаимодействовать с программой.
Нажимание клавиш на клавиатуре и клики по элементам мышью — базовые примеры событий, все из которых автоматически обрабатываются в некоторых классах Tkinter. Например, это поведение уже реализовано в параметре command класса виджета Button, который вызывает определенную функцию.
Некоторые события можно вызвать и без участия пользователя. Например, фокус ввода можно сместить с одного виджета на другой.
Выполнить привязку события к виджету можно с помощью метода bind. Следующий пример привязывает некоторые события мыши к экземпляру Frame:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
frame = tk.Frame(self, bg="green",
height=100, width=100)
frame.bind("<Button-1>", self.print_event)
frame.bind("<Double-Button-1>", self.print_event)
frame.bind("<ButtonRelease-1>", self.print_event)
frame.bind("<B1-Motion>", self.print_event)
frame.bind("<Enter>", self.print_event)
frame.bind("<Leave>", self.print_event)
frame.pack(padx=50, pady=50)
def print_event(self, event):
position = "(x={}, y={})".format(event.x, event.y)
print(event.type, "event", position)
if __name__ == "__main__":
app = App()
app.mainloop()
Все события обрабатываются методом класса print_event(), который выводит тип события и положение мыши в консоли. Можете поэкспериментировать, нажимая на зеленую рамку мышью и двигая ею, пока она будет выводить сообщения события.
Следующий пример содержит виджет поля ввода и несколько привязок. Одна из них срабатывает в тот момент, когда фокус оказывается в виджете, а вторая — при нажатии кнопки:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
entry = tk.Entry(self)
entry.bind("<FocusIn>", self.print_type)
entry.bind("<Key>", self.print_key)
entry.pack(padx=20, pady=20)
def print_type(self, event):
print(event.type)
def print_key(self, event):
args = event.keysym, event.keycode, event.char
print("Знак: {}, Код: {}, Символ: {}".format(*args))
if __name__ == "__main__":
app = App()
app.mainloop()
В первую очередь программа выведет сообщение события FocusIn. Это произойдет в тот момент, когда фокус окажется в виджете Entry. Можно убедиться также в том, что события срабатывают и в случае с непечатаемыми символами, такими как клавиши стрелок или Backspace.
Как работает отслеживание событий
Метод bind определен в классе widget и принимает три аргумента: событие sequence, функцию callback и опциональную строку add:
widget.bind(sequence, callback, add='')
Строка sequence использует синтаксис <modifier-type-detail>.
Модификаторы являются опциональными и позволяют задать дополнительные комбинации для общего типа события:
- Shift – когда пользователь нажимает клавишу Shift.
- Alt – когда пользователь нажимает клавишу Alt.
- Control – когда пользователь нажимает клавишу Control.
- Lock – когда пользователь нажимает клавишу Lock.
- Shift – когда пользователь нажимает клавишу Shift.
- Shift – когда пользователь нажимает клавишу Shift lock.
- Double – когда событие происходит дважды подряд.
- Triple – когда событие происходит трижды подряд.
Типы события определяют общий тип события:
- ButtonPress или Button – события, которые генерируются при нажатии кнопки мыши.
- ButtonRelease – событие, когда кнопка мыши отпускается.
- Enter – событие при перемещении мыши на виджет.
- Leave – событие, когда мышь покидает область виджета.
- FocusIn – событие, когда фокус ввода попадает в виджет.
- FocusOut – событие, когда виджет теряет фокус ввода.
- KeyPress или Key – событие для нажатия кнопки.
- KeyRelease – событие для отпущенной кнопки.
- Motion – событие при перемещении мыши.
detail – также опциональный параметр, который отвечает за определение конкретной клавиши или кнопки:
- Для событий мыши 1 — это левая кнопка, 2 — средняя, а 3 — правая
- Для событий клавиатуры используются сами клавиши. Если это специальные клавиши, то используется специальный символ: enter, Tab, Esc, up, down, right, left, Backspace и функциональные клавиши (от F1 до F12).
Функция callback принимает параметр события. Для событий мыши это следующие атрибуты:
xиy– текущее положение мыши в пикселяхx_rootиy_root— то же, что и x или y, но относительно верхнего левого угла экранаnum– номер кнопки мыши
Для клавиш клавиатуры это следующие атрибуты:
char– нажатая клавиша в виде строкиkeysym– символ нажатой клавишиkeycode– код нажатой клавиши
В обоих случаях у события есть атрибут widget, ссылающийся на экземпляр, который сгенерировал событие и type, определяющий тип события.
Рекомендуется определять метод для функции
callback, поскольку всегда будет иметься ссылка на экземпляр класса, и таким образом можно будет легко получить доступ к атрибутамwidget.
Наконец, параметр add может быть пустым ("") для замены функции callback, если до этого была привязка или + для добавления функции обратного вызова и сохранения старых.
Помимо описанных типов событий есть и другие, которые оказываются полезными в определенных сценариях: например, <Destroy> генерируется при уничтожении виджета, а <Configure> — при изменении размера или положения.
Полный список событий доступен в документации Tcl/Tk.
Настройка иконки, названия и размера основного окна
Экземпляр Tk отличается от обычных виджетов тем, как он настраивается. Рассмотрим основные методы, которые позволяют настраивать внешний вид.
Этот кусок кода создает основное окно с заданными названием и иконкой. Его ширина — 400 пикселей, а высота — 200. Плюс, есть разделение в 10px по каждой оси к левому верхнему углу экрана.
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Моя программа")
self.iconbitmap("python.ico")
self.geometry("400x200+10+10")
if __name__ == "__main__":
app = App()
app.mainloop()
Программа предполагает, что есть валидный ICO-файл python.ico в той же директории, где находится и сам скрипт. Вот результат:
Как работает настройка окна
Названия методов title() и iconbitmap() класса Tk говорят сами за себя. Первый настраивает название окна, а второй — принимает путь к иконке для него.
Метод geometry() настраивает размер окна с помощью строки со следующим шаблоном:
{width}x{height}+{of set_x}+{of set_y}
Если в приложении есть дополнительные окна, то эти же методы доступны в классе Toplevel.
Чтобы сделать приложение полноэкранным, нужно заменить вызов метода geometry() на self.state("zoomed").
Предыдущий урок: Приватные переменные
Модуль threading в Python используется для реализации многопоточности в программах. В этом материале разберемся с Thread и разными функциями этого модуля.
Что такое поток?
В информатике поток — это минимальная единица работы, запланированная для выполнения операционной системой.
О потоках нужно знать следующее:
- Они существуют внутри процесса;
- В одном процессе может быть несколько потоков;
- Потоки в одном процессе разделяют состояние и память родительского процесса.
Модуль threading в Python можно представить таким простым примером:
import time
from threading import Thread
def sleepMe(i):
print("Поток %i засыпает на 5 секунд.\n" % i)
time.sleep(5)
print("Поток %i сейчас проснулся.\n" % i)
for i in range(10):
th = Thread(target=sleepMe, args=(i, ))
th.start()
После запуска скрипта вывод будет следующий:
Поток 0 засыпает на 5 секунд.
Поток 3 засыпает на 5 секунд.
Поток 1 засыпает на 5 секунд.
Поток 4 засыпает на 5 секунд.
Поток 2 засыпает на 5 секунд.
Поток 5 засыпает на 5 секунд.
Поток 6 засыпает на 5 секунд.
Поток 7 засыпает на 5 секунд.
Поток 8 засыпает на 5 секунд.
Поток 9 засыпает на 5 секунд.
Поток 0 сейчас проснулся.
Поток 3 сейчас проснулся.
Поток 1 сейчас проснулся.
Поток 4 сейчас проснулся.
Поток 2 сейчас проснулся.
Поток 5 сейчас проснулся.
Поток 6 сейчас проснулся.
Поток 7 сейчас проснулся.
Поток 8 сейчас проснулся.
Поток 9 сейчас проснулся.У вас он может отличаться, потому что у параллельных потоков нет определенного порядка.
Функции threading в Python
Возьмем программу из первого примера и воспользуемся ею для демонстрации разных функций модуля.
threading.active_count()
Эта функция возвращает количество исполняемых на текущий момент потоков. Изменим последнюю программу, чтобы она выглядела вот так:
import time
import threading
from threading import Thread
def sleepMe(i):
print("Поток %i засыпает на 5 секунд." % i)
time.sleep(5)
print("Поток %i сейчас проснулся." % i)
for i in range(10):
th = Thread(target=sleepMe, args=(i, ))
th.start()
print("Запущено потоков: %i." % threading.active_count())
Теперь в выводе будет показываться количество активных на текущий момент потоков:
Поток 0 засыпает на 5 секунд.Запущено потоков: 3.
Запущено потоков: 4.Поток 1 засыпает на 5 секунд.
Запущено потоков: 5.Поток 2 засыпает на 5 секунд.
Поток 3 засыпает на 5 секунд.Запущено потоков: 6.
Запущено потоков: 7.Поток 4 засыпает на 5 секунд.
Поток 5 засыпает на 5 секунд.Запущено потоков: 8.
Поток 6 засыпает на 5 секунд.Запущено потоков: 9.
Запущено потоков: 10.Поток 7 засыпает на 5 секунд.
Поток 8 засыпает на 5 секунд.Запущено потоков: 11.
Поток 9 засыпает на 5 секунд.Запущено потоков: 12.
Поток 0 сейчас проснулся.
Поток 1 сейчас проснулся.
Поток 2 сейчас проснулся.
Поток 3 сейчас проснулся.
Поток 4 сейчас проснулся.
Поток 5 сейчас проснулся.
Поток 6 сейчас проснулся.
Поток 7 сейчас проснулся.
Поток 8 сейчас проснулся.
Поток 9 сейчас проснулся.Также обратите внимание, что после запуска всех потоков счетчик показывает число 11, а не 10. Причина в том, что основной поток также учитывается наравне с 10 остальными.
threading.current_thread()
Эта функция возвращает исполняемый прямо сейчас поток. С ее помощью можно выполнять определенные действия с ним. Поменяем все тот же скрипт:
import time
import threading
from threading import Thread
def sleepMe(i):
print("Поток %s засыпает на 5 секунд.\n" % threading.current_thread())
time.sleep(5)
print("Поток %s сейчас проснулся." % threading.current_thread())
# Cоздаем только четыре потока
for i in range(10):
th = Thread(target=sleepMe, args=(i, ))
th.start()
Теперь вывод будет таким:
Поток <Thread(Thread-4, started 13324)> засыпает на 5 секунд.
Поток <Thread(Thread-1, started 15748)> засыпает на 5 секунд.
Поток <Thread(Thread-5, started 12164)> засыпает на 5 секунд.
Поток <Thread(Thread-2, started 15972)> засыпает на 5 секунд.
Поток <Thread(Thread-6, started 13540)> засыпает на 5 секунд.
Поток <Thread(Thread-3, started 14396)> засыпает на 5 секунд.
Поток <Thread(Thread-7, started 15620)> засыпает на 5 секунд.
Поток <Thread(Thread-8, started 7644)> засыпает на 5 секунд.
Поток <Thread(Thread-9, started 15424)> засыпает на 5 секунд.
Поток <Thread(Thread-10, started 15852)> засыпает на 5 секунд.
Поток <Thread(Thread-4, started 13324)> сейчас проснулся.
Поток <Thread(Thread-1, started 15748)> сейчас проснулся.
Поток <Thread(Thread-5, started 12164)> сейчас проснулся.Поток <Thread(Thread-2, started 15972)> сейчас проснулся.
Поток <Thread(Thread-6, started 13540)> сейчас проснулся.
Поток <Thread(Thread-3, started 14396)> сейчас проснулся.Поток <Thread(Thread-7, started 15620)> сейчас проснулся.
Поток <Thread(Thread-8, started 7644)> сейчас проснулся.Поток <Thread(Thread-9, started 15424)> сейчас проснулся.
Поток <Thread(Thread-10, started 15852)> сейчас проснулся.threading.main_thread()
Эта функция возвращает основной поток программы. Именно из него создаются новые потоки.
import threading
print(threading.main_thread())
Запустим:
<_MainThread(MainThread, started 10476)>
threading.enumerate()
Эта функция возвращает список всех активных потоков. Пользоваться ею проще простого:
import threading
for thread in threading.enumerate():
print("Имя потока %s." % thread.getName())
Запустим скрипт:
Имя потока MainThread.
Имя потока SockThread.
Сейчас работает только 2 потока, поэтому в выводе есть только они.
threading.Timer()
Эта функция модуля threading используется для создания нового потока и указания времени, через которое он должен запуститься. После запуска поток вызывает определенную функцию. Разберем на примере:
import threading
def delayed():
print("Вывод через 5 секунд!")
thread = threading.Timer(5, delayed)
thread.start()
Запустим скрипт:
Вывод через 5 секунд!
Многопоточность в Python
В этом материале были разобраны некоторые функции модуля threading. Они предоставляют удобные методы для управления потоками в многопоточной среде.
]]>Далее: Assert
Преимущества Scrapy
- Имеется встроенный механизм под названием Selector, который отвечает за поиск и извлечение данные со страниц с помощью Xpath и CSS.
- Для работы Scrapy не нужно много дополнительного кода как в случае с остальными фреймворками. Достаточно лишь указать сайт и данные, которые требуется получить. Scrapy сделает все остальное.
- Scrapy — это бесплатный, кроссплатформенный проект с открытым исходным кодом.
- Он является быстрым, мощным и легко расширяемым за счет асинхронной обработки запросов.
- Используется для создания скраперов для крупных проектов.
- С помощью Scrapy можно извлекать данные с любых страниц вне зависимости от их доступности.
- Куда меньшее потребление памяти и мощности процессора в сравнении с другими библиотеками.
- Поддерживает экспорт данных в разные форматы, включая CSV, XML, JSON и JSON Line.
- Отличное сообщество для разработчиков.
Установка Scrapy
Scrapy работает в обеих версиях Python (2 и 3), но в этом руководстве будет использоваться Python 3. Есть два способа установки. Если имеется Anaconda, то нужно использовать канал conda-forge. Сама платформа доступна по ссылке.
Второй вариант — использовать пакетный менеджер pip. С его помощью можно установить Scrapy прямо на компьютер.
conda install -c conda-forge scrapy
pip install scrapy
В обоих случаях будет загружена и установлена последняя версия.
Создание проекта Scrapy
Архив с кодом проекта. Весь код протестирован на: python 3.8 / scrapy 2.3.0 / ubuntu 16.04
Для создания проекта нужно переместиться в папку с ним. Дальше создается проект Scrapy. В этом руководстве он будет называться scrapy_tutorial.
scrapy startproject scrapy_tutorial
Есть вы получили ошибку No module named ‘_cffi_backend’, установите cffi — pip install cffi
Когда проект создан, появляются папка и конфигурационный файл. Новая директория содержит различные компоненты поискового роботы, который будут созданы позже. Внутри проекта следующая структура.

Рассмотрим в подробностях.
| Файл | Описание |
| spiders | Эта папка содержит всех Spider в формате класса Python. Если запустить Scrapy, то он выполнит поиск именно в этой папке |
| items.py | Содержит контейнер, который будет загружаться вместе с извлеченными данными |
| middleware.py | Содержит механизм обработки для работы с запросами и ответами |
| pipeline.py | Набор классов Python для последующей обработки классов |
| settings.py | Здесь находятся все настройки |
Создание Spider
Spider — это класс, содержащий методологию извлечения данных с указанного сайта. Другими словами, он определяет, как именно должен проходить процесс.
Для создания Spider используется такая команда.
scrapy genspider spidername your-link-here
В качестве spidername можно задать любое название, а на месте ссылки — URL сайта или домена, с которого требуется извлечь данные. В этом руководстве попробуем достать пользовательские обзоры на Apple iPhone XS Max с сайта Amazon.com.
Поэтому Spider будет называться reviewspider.
scrapy genspider reviewspider amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S
Scrapy Shell
Scrapy Shell — это интерактивная оболочка, напоминающая Python Shell, где можно проверять свой код. С помощью нее можно протестировать выражения Xpath и CSS, убедившись, что данные извлекаются. Spider при этом даже не будет запускаться. Это быстрый и важный инструмент для разработки и отладки.
scrapy shell https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S
Определение структуры HTML
Прежде чем переходить к написанию кода самого Spider нужно проанализировать структуру страницы.
На изображении видно, что у каждого обзора есть текст и оценка в звездах. Будет извлекать оба элемента.
Для просмотра структуры нужно кликнуть правой кнопкой по странице и нажать «Посмотреть код» или посмотреть код с помощью инструментов разработчика в браузере.
Согласно структуре все отзывы заключены в блок с id cm_cr-review_list, у которого есть внутренние блоки для каждого отзыва.
Если раскрывать их, то можно увидеть отдельные блоки для каждого компонента обзора. Однако сейчас важны только рейтинг в звездочках и текст.
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-2 review-rating">
<span class="a-icon-alt">2.0 out of 5 stars</span>
</i>Здесь рейтинг определяется классом a-icon-alt.
<span data-hook="review-body" class="a-size-base review-text review-text-content">
<span>
I know is use phones but for the price of $700 it looks in
a bad condition unfortunately you take a risk when you buy
phones with out been able to see them and are used and I am
not happy with this purchase.
</span>
</span>Текст же заключен в класс a-size-base. Эта информация пригодится для создания Spider.
Создание парсера Scrapy
Если открыть Spider, который был создан раньше, то внутри будет такой класс.
import scrapy
class ReviewspiderSpider(scrapy.Spider):
name = 'reviewspider'
allowed_domains = ['amazon.com']
start_urls = ['https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/']
def parse(self, response):
pass
Это базовый шаблон, а allowed_domains и start_urls определены на основе переданных ссылок.
Логика извлечения данных будет прописана в функции parse, которая начнет работу после перехода на страницу, указанную в start_urls.
Scrapy предоставляет возможность поиска по нескольким URL одновременно. Для этого нужно определить базовый URL и те части, которые нужны присоединить к нему. Делается это с помощью urljoin(). Однако в этом примере достаточно будет лишь одной ссылки.
Далее код, который будет извлекать отзывы пользователей.
import scrapy
class ReviewspiderSpider(scrapy.Spider):
name = 'reviewspider'
allowed_domains = ['amazon.com']
start_urls = ['https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/']
def parse(self, response):
pass
В Scrapy есть собственный механизм, селекторы, для извлечения данных. Они используют выражения Xpath и CSS для выбора разных элементов в HTML-документах. В этом коде в качестве селектора используется Xpath.
star_rating=response.xpath('//span[@class="a-icon-alt"]/text()').extract()В последней строке Scrapy использует Xpath для получения узла в ответе и извлечения его данных в текстовом формате.
for item in zip(star_rating, comments):
# создаем словарь для хранения собранной информации
scraped_data = {
'Рейтинг': item[0],
'Отзыв': item[1],
}Здесь каждый элемент добавляется в словарь Python.
yield scraped_dataYield возвращает извлеченные данные для обработки и сохранения.
Обработка нескольких страниц
В примере выше функция parse работала для одной страницы. Но это неэффективно, когда обзоры расположены на нескольких. Поэтому нужно расширить код так, чтобы была возможность перемещаться по всем доступным страницам и извлекать данные тем же способом.
Перемещение по страницам происходит с помощью кнопки Next Page, и вот HTML-код для нее.
<li class="a-last">
<a href="/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/ref=cm_cr_arp_d_paging_btm_2?ie=UTF8&pageNumber=2">
Next page
<span class="a-letter-space"></span>
<span class="a-letter-space"></span>
→
</a>
</li>Теперь осталось изменить Spider так, чтобы он мог определять кнопку и проверять, существует ли она. Если да, то он будет переходить по ней и снова вызывать парсер. Для этого достаточно добавить следующее в конец функции parse.
def parse(self, response):
star_rating = response.xpath('//span[@class="a-icon-alt"]/text()').extract()
comments = response.xpath('//span[@class="a-size-base review-text review-text-content"]/span/text()').extract()
count = 0
for item in zip(star_rating, comments):
# создаем словарь для хранения собранной информации
scraped_data = {
'Рейтинг': item[0],
'Отзыв': item[1],
}
# возвращаем собранную информацию
yield scraped_data
Здесь в качестве селектора для Next Page использовался CSS. После определения extract_first() ищет первое совпадение и проверяет, существует ли оно. Если да, то для нового URL вызывается метод self.parse.
Работа Spider
После создания Spider его нужно запустить с помощью следующей команды.
next_page = response.css('.a-last a ::attr(href)').extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse
)
Команда runspider принимает reviewspider.py в качестве входящего файла и возвращает CSV-файл scraped_data.csv с собранными результатами.
Экспорт данных Scrapy
Scrapy предоставляет возможность экспорта для сохранения извлеченных данных в разных форматах или методах сериализации. Поддерживаются форматы CSV, XML и JSON.
Например, для получения вывода в формате CSV нужно перейти в settings.py и ввести следующие строки.
scrapy runspider scrapy_tutorial/spiders/reviewspider.py -o scraped_data.csv
После этого сохраните файл и снова запустите Spider. Сгенерированный файл окажется в папке проекта.
Если нужны временная метка или имя, то их можно передать в FEED_URI так: %(time)s или %(name)s.
Например:
FEED_URI = "scraped_data_%(time)s.json"Выводы
Scrapy — это мощный фреймворк для веб-скрапинга. На примере из материала можно было увидеть, насколько просто с ним работать. Он предназначен в первую очередь для парсинга HTML-документов, но быстро и легко изучается для самых разных сценариев примнения. Все подробности есть в официальной документации.
]]>Выбор числовых значений
В предыдущем материале речь шла о работе с вводом текста, но иногда есть необходимость ограничить поле для работы исключительно с числовыми значениями. Это нужно для классов Spinbox и Scale, которые позволяют пользователям выбирать числовое значение из диапазона или списка валидных вариантов. Однако есть отличия в том, как они отображаются и настраиваются.
У этой программы есть Spinbox и Scale для выбора целого числа от 0 до 5:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.spinbox = tk.Spinbox(self, from_=0, to=5)
self.scale = tk.Scale(self, from_=0, to=5,
orient=tk.HORIZONTAL)
self.btn = tk.Button(self, text="Вывести значения",
command=self.print_values)
self.spinbox.pack()
self.scale.pack()
self.btn.pack()
def print_values(self):
print("Spinbox: {}".format(self.spinbox.get()))
print("Scale: {}".format(self.scale.get()))
if __name__ == "__main__":
app = App()
app.mainloop()
Для отладки также была добавлена кнопка, которая выводит значение при нажатии:
Как работает выбор значений
Оба класса принимают параметры from_ и to, которые обозначают диапазон подходящих значений — нижнее подчеркивание в конце является обязательным, потому что параметр from изначально определен в Tck/Tk, хотя является зарезервированным ключевым словом в Python.
Удобная особенность класса Scale — параметр resolution, который настраивает точность округления. Например, значение «0.2» позволит выбирать такие: 0.0, 0.2, 0.4 и так далее. По умолчанию установлено значение 1, поэтому виджет округляет все введенные числа до ближайшего целого.
Также значение каждого виджета можно получить с помощью метода get(). Важное отличие в том, что Spinbox возвращает число в виде строки, а Scale — целое число или число с плавающей точкой, если округление принимает десятичные значения.
Класс Spinbox имеет настройки, которые похожи на те, что есть у Entry: параметры textvariable и validate. Разница лишь в том, что правила будут ограничены числовыми значениями.
Создание полей с радиокнопками (переключателями)
С помощью виджета Radiobutton можно разрешить пользователю выбирать среди нескольких вариантов. Это работает для относительно небольшого количества взаимоисключающих вариантов.
Несколько экземпляров Radiobutton можно подключить с помощью переменной Tkinter. Таким образом при выборе варианта, который до этого не был выбран, он будет отменять выбор предыдущего.
В следующем примере создаются три кнопки для параметров Red, Green и Blue. При каждом нажатии выводится название соответствующего цвета в нижнем регистре:
import tkinter as tk
COLORS = [("Red", "red"), ("Green", "green"), ("Blue", "blue")]
class ChoiceApp(tk.Tk):
def __init__(self):
super().__init__()
self.var = tk.StringVar()
self.var.set("red")
self.buttons = [self.create_radio(c) for c in COLORS]
for button in self.buttons:
button.pack(anchor=tk.W, padx=10, pady=5)
def create_radio(self, option):
text, value = option
return tk.Radiobutton(self, text=text, value=value,
command=self.print_option,
variable=self.var)
def print_option(self):
print(self.var.get())
if __name__ == "__main__":
app = ChoiceApp()
app.mainloop()
Если запустить скрипт, он покажет приложение, где вариант Red уже выбран.
Как работают радиокнопки
Чтобы не повторять код для инициализации Radiobutton, нужно определить служебный метод, вызываемый из сгенерированного списка. Так, значения каждого кортежа в списке COLORS распаковываются, а локальные переменные передаются в качестве опций в Radiobutton. Очень важно при возможности избегать повторений.
Поскольку StringVar является общим для всех Radiobutton, они автоматически соединяются, а пользователь может выбрать лишь один вариант.
Значением по умолчанию в программе является «red». Но что произойдет, если эту строку пропустить, а значение StringVar не будет соответствовать значению ни одной из кнопок? В таком случае оно будет совпадать со значением по умолчанию опции tristatevalue, то есть, пустой строкой. Из-за этого виджет отображается в неопределенном режиме «tri-state». Это можно изменить с помощью метода config(), но еще лучше — задавать правильное значение по умолчанию, чтобы переменная инициализировалась в валидном состоянии.
Реализация чекбоксов
Выбор из двух вариантов обычно реализуется с помощью чекбоксов с перечислением вариантов, где каждый из них не зависит от остальных. В следующем примере можно увидеть, как эта концепция реализуется с помощью Checkbutton.
Следующее приложение демонстрирует, как создавать чекбоксы, которые должны быть связаны с переменной IntVar для отслеживания состояния кнопки:
import tkinter as tk
class SwitchApp(tk.Tk):
def __init__(self):
super().__init__()
self.var = tk.IntVar()
self.cb = tk.Checkbutton(self, text="Активно?",
variable=self.var,
command=self.print_value)
self.cb.pack()
def print_value(self):
print(self.var.get())
if __name__ == "__main__":
app = SwitchApp()
app.mainloop()
В этом примере значение виджета просто выводится каждый раз при нажатии.
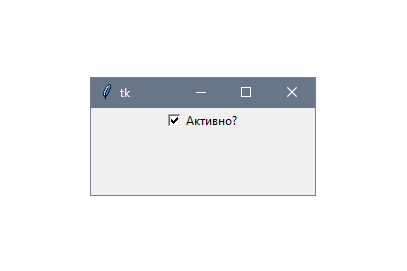
Как работают чекбоксы
По аналогии с Button Checkbutton принимает параметры Command и text.
С помощью опций onvalue и offvalue можно определить значения для отмеченного и пустого чекбоксов. Используется целочисленная переменная, потому что значения по умолчанию — это 1 и 0. Но это могут быть любые другие целые числа.
С Checkbuttons можно использовать даже другие типы переменных:
var = tk.StringVar()
var.set("OFF")
checkbutton_active = tk.Checkbutton(master, text="Активно?", variable=self.var,
onvalue="ON", offvalue="OFF",
command=update_value)
Единственное ограничение в том, что onvalue и offvalue должны совпадать с типом переменной Tkinter. В таком случае, поскольку «ON» и «OFF» — это строки, то и переменная должна быть StringVar. В противном случае интерпретатор Tcl вернет ошибку при попытке задать соответствующее значение другому типу.
Отображение списка элементов
Виджет Listbox содержит текстовые элементы, которые пользователь может выбрать с помощью мыши или клавиатуры. Есть возможность настроить, будут ли для выбора доступны один или несколько элементов.
Следующая программа создает такой селектор, где вариантами являются дни недели. Есть кнопка для вывода текущего выбора, а также ряд кнопок для изменения способа выбора:
import tkinter as tk
DAYS = ["Понедельник", "Вторник", "Среда", "Четверг",
"Пятница", "Суббота", "Воскресенье"]
MODES = [tk.SINGLE, tk.BROWSE, tk.MULTIPLE, tk.EXTENDED]
class ListApp(tk.Tk):
def __init__(self):
super().__init__()
self.list = tk.Listbox(self)
self.list.insert(0, *DAYS)
self.print_btn = tk.Button(self, text="Вывести выбор",
command=self.print_selection)
self.btns = [self.create_btn(m) for m in MODES]
self.list.pack()
self.print_btn.pack(fill=tk.BOTH)
for btn in self.btns:
btn.pack(side=tk.LEFT)
def create_btn(self, mode):
cmd = lambda: self.list.config(selectmode=mode)
return tk.Button(self, command=cmd,
text=mode.capitalize())
def print_selection(self):
selection = self.list.curselection()
print([self.list.get(i) for i in selection])
if __name__ == "__main__":
app = ListApp()
app.mainloop()
Попробуйте менять режимы и смотреть на вывод:
Как работает выбор элементов из списка
Можно создать пустой объект Listbox и добавить все элементы с помощью метода insert(). Индекс 0 обозначает, что элементы должны добавляться в начале списка. В следующей строке список DAYS распаковывается, но отдельные элементы можно добавить в конец с помощью константы END:
self.list.insert(tk.END, "Новый пункт")
Текущая выборка извлекается с помощью метода curselection(). Он возвращает индексы выбранных элементов. А для последующей трансформации их в соответствующие текстовые элементы для каждого элемента в списке вызывается метод get(). В итоге список выводится в STDOUT для отладки.
В этом примере параметр selectmode можно изменить для получения разного поведения:
SINGLE— один вариант;BROWSE— один вариант, который можно перемещать с помощью клавиш со стрелками;MULTIPLE— несколько вариантов;EXTENDED— несколько вариантов с диапазонами, которые выбираются кнопкамиShiftиCtrl.
Если элементов много, то может возникнуть необходимость добавить вертикальный скроллбар. Для этого нужно задействовать опцию yscrollcommand. В этом примере оба виджета оборачиваются в одно окно. Нужно только не забыть указать параметр fill, чтобы скроллбар занимал все место по оси y.
def __init__(self):
self.frame = tk.Frame(self)
self.scroll = tk.Scrollbar(self.frame, orient=tk.VERTICAL)
self.list = tk.Listbox(self.frame, yscrollcommand=self.scroll.set)
self.scroll.config(command=self.list.yview)
# ...
self.frame.pack()
self.list.pack(side=tk.LEFT)
self.scroll.pack(side=tk.LEFT, fill=tk.Y)
Также существует параметр xscrollcommand для горизонтальной оси.
Создание текстовых элементов
Виджет Entry представляет собой текстовый элемент на одной строке. Вместе с классами Label и Button он является одним из самых используемых в Tkinter.
Как создать текстовый элемент
Следующий пример демонстрирует, как создать форму логина с двумя экземплярами для полей username и password. Каждый символ password отображается в качестве звездочки. Кнопка Войти выводит значения в консоли, а Очистить — удаляет содержимое обоих полей, возвращая фокус в username:
import tkinter as tk
class LoginApp(tk.Tk):
def __init__(self):
super().__init__()
self.username = tk.Entry(self)
self.password = tk.Entry(self, show="*")
self.login_btn = tk.Button(self, text="Войти",
command=self.print_login)
self.clear_btn = tk.Button(self, text="Очистить",
command=self.clear_form)
self.username.pack()
self.password.pack()
self.login_btn.pack(fill=tk.BOTH)
self.clear_btn.pack(fill=tk.BOTH)
def print_login(self):
print("Логин: {}".format(self.username.get()))
print("Пароль: {}".format(self.password.get()))
def clear_form(self):
self.username.delete(0, tk.END)
self.password.delete(0, tk.END)
self.username.focus_set()
if __name__ == "__main__":
app = LoginApp()
app.mainloop()
Как работают экземпляры
Экземпляры виджетов Entry создаются в родительском окне или фрейме, будучи переданными в качестве первого аргумента. С помощью опциональных ключевых слов можно задать дополнительные свойства. У username в этом примере таких нет, а у password — аргумент show со строкой «*», который будет выводить каждый символ как звездочку.
С помощью метода get() текущий текст можно будет получить в виде строки. Это используется в методе print_login(), который выводит содержимое Entry в стандартном выводе (stdout).
Метод delete() принимает два аргумента, которые представляют собой диапазон символов для удаления. Важно только помнить, что индексы начинаются с 0 и не включают последний символ. Если передать только один аргумент, то удалится символ на этой позиции.
В методе clear_form() удаляется содержимое от индекса 0 до константы END, в результате чего весь контент очищается. После этого фокус возвращается в поле username.
Содержимое виджета Entry можно модифицировать с помощью метода insert(), который принимает два аргумента:
index— позиция, куда нужно вставить текст (индекс первого — 0)string— строка, которая будет вставлена
Стандартный шаблон сброса содержимого на значение по умолчанию — комбинация методов delete() и insert():
Еще один паттерн — добавление текста туда, где находится курсор. Для этого используется константа INSERT:
Как и Button класс Entry также принимает параметры relief и state для изменения стиля контура и состояния. Также стоит отметить, что вызовы delete() и insert() игнорируются, когда состояние равно «disabled» или «readonly».
Отслеживание изменений текста
Переменные Tk позволяют отправлять уведомления приложениям, когда входящие значения меняются. Есть 4 класса переменных в Tkinter: BooleanVar, DoubleVar, IntVar и StringVar. Каждый из них оборачивает значение соответствующего типа Python, который должен соответствовать типу виджета, прикрепленного к переменной.
Эта особенность особенно полезна в том случае, если нужно автоматически обновить отдельные части приложения на основе текущего состояния виджетов.
Как отслеживать изменения текста
В следующем примере экземпляр StringVar ассоциирован с Entry, у которого есть параметр textvariable. Такие переменные отслеживают операции записи с помощью метода обратного вызова show_message():
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.var = tk.StringVar()
self.var.trace("w", self.show_message)
self.entry = tk.Entry(self, textvariable=self.var)
self.btn = tk.Button(self, text="Очистить",
command=lambda: self.var.set(""))
self.label = tk.Label(self)
self.entry.pack()
self.btn.pack()
self.label.pack()
def show_message(self, *args):
value = self.var.get()
text = "Привет, {}!".format(value) if value else ""
self.label.config(text=text)
if __name__ == "__main__":
app = App()
app.mainloop()
Когда что-то вводится в этот виджет, текст метки обновляется на тот, что был составлен с помощью значения переменной Tk. Например, если ввести слово «Мир», то метка выведет Привет, Мир!. Если текст не вводить совсем, то ничего и не будет выводиться. Для демонстрации возможностей интерактивной настройки содержимого переменной была добавлена кнопка, которая очищает поле по нажатию.
Как работает изменение текста
Первые строки конструктора приложения создают экземпляр StringVar и прикрепляют функцию обратного вызова для режима записи. Валидные значения этого режима:
w— вызывается, когда переменная пишетсяr— вызывается, когда переменная читаетсяu(от unset) — вызывается, когда переменная удаляется
При вызове функция обратного вызова получает три аргумента: внутреннее имя переменной, пустую строку (она используется в других типах переменных Tk) и режим, который запустил операцию. При объявлении его с *args эти аргументы становятся опциональными, потому что при обратном вызове значения уже не используются.
Метод get() оберток Tk возвращает текущее значение переменной, а метод set() — обновляет его. Они также уведомляют все методы прослушки (trace). Поэтому изменение содержимого поля с помощью графического интерфейса и нажатие кнопки Очистить запускают вызов метода show_message().
Переменные Tk являются опциональными для виджетов поля, но они обязательны для работы других классов виджетов, таких как классы Checkbutton и Radiobutton.
Валидация текста в полях
Чаще всего поля для ввода текста представляют собой поля, которые следуют определенным правилам валидации, например, максимальная длина или определенный формат. Некоторые приложения предоставляют возможность ввода содержимого любого вида и выполняют валидацию уже после того как вся форма целиком была отправлена.
При определенных условиях нужно предотвратить возможность ввода невалидного содержимого в поле текста. Следующие примеры рассмотрят, как реализовать такое поведение с помощью параметров валидации в виджете Entry.
Как валидировать текст
Следующее приложение демонстрирует, как валидировать текст в поле ввода с помощью регулярных выражений:
import re
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.pattern = re.compile("^\w{0,10}$")
self.label = tk.Label(self, text="Введите логин")
vcmd = (self.register(self.validate_username), "%i", "%P")
self.entry = tk.Entry(self, validate="key",
validatecommand=vcmd,
invalidcommand=self.print_error)
self.label.pack()
self.entry.pack(anchor=tk.W, padx=10, pady=10)
def validate_username(self, index, username):
print("Проверка символа" + index)
return self.pattern.match(username) is not None
def print_error(self):
print("Запрещенный символ в логине")
if __name__ == "__main__":
app = App()
app.mainloop()
Если запустить этот скрипт и ввести не букву алфавита или цифру, то содержимое не изменится, а вместо этого будет выведено сообщение об ошибке в консоль. Это же будет происходить, если попытаться ввести больше 10 символов, поскольку регулярное выражение ограничивает общее количество.
Как работает валидация текста
Когда параметром validate является key, то валидация запускается при любом изменении содержимого. Значение по умолчанию — none, что значит, что валидации не будет.
Также значениями могут быть focusin или focusout, когда валидация выполняется при получении или потере фокуса. Значение focus выполняет проверку в обоих случаях. Во всех ситуациях валидация проходит, если установить значение all.
Функция validatecommand вызывается каждый раз при запуске валидации. Она должна возвращать true, если введенное содержимое прошло проверку. В противном случае — false.
Поскольку нужно больше информации, чтобы определить, является ли контент валидным, над функцией Python создается обертка Tcl с помощью метода register класса Widget. Затем добавляется замещение для каждого параметра, который будет передаться в функцию. В итоге эти значения группируются в кортеж. Описанное соответствует следующей строке из примера:
vcmd = (self.register(self.validate_username), "%i", "%P")
Можно использовать следующие замещения:
- %d — тип действия. 1 — добавление, 0 — удаление, -1 — остальное;
- %i — индекс вставляемой или удаляемой строки;
- %p — сущность содержимого, если изменение разрешено;
- %s — строковое содержимое до изменения;
- %s — строка, которая вставляется или удаляется;
- %v — тип текущей валидации;
- %V— тип валидации, которая запускает действие;
- %w — название виджета Entry.
Параметр invalidcommand принимает функцию, которая вызывается, когда validatecommand возвращает false. Те же замещения могут быть применены и к нему, но в данном примере классу был прямо передан метод print_error().
Документация Tcl/Tk предполагает, что не нужно смешивать параметры validatecommand и textvariable, поскольку невалидое значение переменной Tk вообще отключит проверку. То же самое произойдет, если функция validatecommand не вернет булевое значение.
Подробное введение в регулярные выражения доступно в официальной документации Python по ссылке https://docs.python.org/3.7/howto/regex.html.
]]>Предыдущий урок: Функция round()
Приватные переменные — это те переменные, которые видны и доступны только в пределах класса, которому они принадлежат. В Java приватные переменные объявляются с помощью ключевого слова private, которое дает к ним доступ только переменным и методам внутри этого же класса. Такие методы не могут быть перезаписаны извне. В Python такого нет — вместо этого используются два символа нижнего подчеркивания (__) для любых переменной или метода, которые должны считаться приватными.
Как работают приватные переменные в Python?
На практике в Python нет приватных методов и переменных, как в Java. Здесь задействованы два символа нижнего подчеркивания в начале любой переменной или метода, которые нужно сделать приватными. Когда переменные объявляются приватными, подразумевается, что их нельзя будет изменять, как в случае с публичными. Последние доступны из любого класса, поэтому их значения могут меняться, что часто приводит к различным конфликтам. Рассмотрим на примере, как в Python используются приватные переменные.
Примеры реализации приватных переменных
Пример №1
class Mainclass:
__private_variable = 2020;
def __private_method(self):
print("Это приватный метод")
def insideclass(self):
print("Приватная переменная:", Mainclass.__private_variable)
self.__private_method()
foo = Mainclass()
foo.insideclass()
Вывод:
Приватная переменная: 2020
Это приватный метод
В программе выше есть класс Mainclass, внутри которого имеются приватные переменные методы, объявленные с помощью двух подчеркиваний: __private_variable и __private_method. Получить к ним доступ можно только в пределах этого класса. Если же попробовать сделать это из другого класса, то вернется ошибка, сообщающая, что в классе нет такого атрибута. Это же можно продемонстрировать и на другом примере.
Пример №2
class Mainclass:
__private_variable = 2020
def __private_method(self):
print("Это приватный метод")
def insideclass(self):
print("Приватная переменная:", Mainclass.__private_variable)
foo = Mainclass()
foo.insideclass()
foo.__private_method()
Вывод:
Private Variable: 2020
Traceback (most recent call last):
File «C:\Python37\da.py», line 13, in
foo.__private_method()
AttributeError: ‘Mainclass’ object has no attribute ‘__private_method’
В этой программе можно обратить внимание на то, что метод приватный, но доступ к нему пытаются получить вне класса Mainclass, поэтому возвращается ошибка, которая сообщает, что у класса нет экземпляра этого атрибута. Таким образом по умолчанию все методы и переменные внутри класса являются публичными, но методы с двумя подчеркиваниями в названии становятся приватными, и получить к ним доступ можно только внутри того же класса.
Процесс превращения переменных или методов в локальные называется «искажением данных» или «искажением имен» (data/name mangling). Он используется для избежания неоднозначности при определении имен подклассов. Это же помогает перезаписывать методы подклассов без прерывания вызовов методов внутри класса.
Настоящая приватность в Python не поддерживается, а ту, что есть, называют «слабым индикатором внутреннего использования». Для нее есть один символ нижнего подчеркивания (_), который используется для объявления приватных переменных, методов, функций и классов в модуле.
Пример №3
class Vehicle:
def _start_engine(self):
return "Создаем мотоцикл."
def run(self):
return self._start_engine()
if __name__ == '__main__':
bike = Vehicle()
print(bike._start_engine())
print("Мотоцикл создан.")
bike.run()
print("Мотоцикл запущен.")
Вывод:
Создаем мотоцикл.
Мотоцикл создан.
Мотоцикл запущен.
В последнем примере нижнее подчеркивание используется для метода _start_engine чтобы сделать его приватным. Но такое подчеркивание применяется не часто, потому что оно лишь подразумевает, что к этому объекту нельзя будет получить доступ извне, а двойное подчеркивание означает то же, но соблюдается строже.
Одиночное подчеркивание используется не очень часто, потому что если метод с одним подчеркиванием изменяют любую переменную класса и при этом вызывается, то возможны конфликты в работе класса. Двойное подчеркивание же (__) широко используется для объявления приватных переменных и избежания неоднозначности при определении имен подклассов. В Python не таких приватных переменных, как в C++ или Java.
Выводы
В большей части языков программирования есть 3 модификатора доступа: публичный, приватный и защищенный. В Python они тоже есть, но работают и поддерживаются не совсем так.
Приватные переменные — это те переменные, к которым можно получить доступ внутри класса, где они были объявлены. В Python для этого есть одиночные и двойные подчеркивания, хотя вторые используются куда чаще. С их помощью можно получать доступ изнутри класса и выполнять «искажение имен».
]]>Далее: Потоки и многопоточность
Предыдущий урок: Функция Filter()
Round — встроенная функция Python. Ее задача — округлять число с плавающей точкой до той цифры, которую задает пользователь. Если ее не задать, то возвращается ближайшее целое число, ведь значением по умолчанию является 0. Функция round помогает «улучшать» числа с плавающей точкой.
Например, если округлить 4,5 до ближайшего целого, то вернется 5. Однако 4,7 будет результатом, если округлить до одной цифры 4,74. Быстрое округление — важный инструмент работы с такими числами.
Синтаксис:
round(float_number, number_of_decimals)
- Число с плавающей точкой (
float_number) представляет собой число, которое нужно округлить - Количество дробей (
number_of_decimals) определяет, до какой цифры будет округлено число. Функция возвращает float. - Если количество цифр не указано, то по умолчанию там стоит ноль. В таком случае округление происходит до ближайшего целого и возвращается тоже целое число.
Основные правила:
- Если >= 5, то добавляется +1.
- Если <5, то финальное значение такое же, как и до десятых.
Примеры работы функции round в Python
Пример №1 — один параметр
# Целые числа
a = 12
round (a)
print (a)
# Десятичные числа
b = 21.7
c = 21.4
print(round(b))
print(round(c))
Вывод:
12
22
21
Здесь возвращается целое число, до которого и округляется число с плавающей точкой.
Пример №2 — оба параметра
# когда последняя цифра 5
a = 5.465
print(round(a, 2))
# когда последняя цифра >=5
b = 5.476
print(round(b, 2))
# когда последняя цифра меньше 5
c = 5.473
print(round(c, 2))
Вывод:
5.46
5.48
5.47
Практические примеры
Пример №1 — функция round помогает при работе с дробями
Когда дроби нельзя конвертировать в десятичные дроби, в дело вступает функция round. После десятичной точки обычно много цифр, как например в случае с 22/7 (Pi). Но обычно используется не больше 2-4 цифр. Вспомогательный встроенный в round тип будет округлять до ближайшего кратного 10.
round(3.675, 2) вернет 3,67, а не 3,68. Удивительно, но это не баг. Результат указывает на то, что большая часть дробей не могут считаться точными числами с плавающей точкой.
a = 1/6
print(a)
print(round(a, 2))
Вывод:
0.16666666666666666
0.17
Пример №2 — исключения и ошибки
Функция round округлит 2, 2,5 и 1,5 до 2. Это тоже не баг, а нормальное поведение функции.
a = 1.5
b = 2
c = 2.5
print(round(a))
print(round(b))
print(round(c))
Вывод:
2
2
2
Если смотреть в целом, то работает функция вот так:
tup = (-40.95, 50.85, 10.98, 20.26, 30.05) # Создание кортежа
lis = [-39.29, -42.15 , -39.97, -10.98, 32.65] # Создание списка
print('Округление отрицательного десятичного числа = %.2f' %round(-19.48476))
print('Округление положительного десятичного числа = %.2f' %round(15.98763))
print('Округление со вторым параметром при положительном значении = %.3f' %round(11.98763, 3))
print('Округление со вторым параметром при отрицательном значении = %.3f' %round(-18.48476, 3))
print('Округление элементов в списке = %d' %round(lis[2]))
print('Округление элементов в списке = %d' %round(lis[4]))
print('Округление элементов в кортеже = %d' %round(tup[2]))
print('Округление элементов в кортеже = %d' %round(tup[4]))
print('Округление сумы чисел = %.2f' %round(20 + 40 - 20.6578, 2))
Вывод:
Округление отрицательного десятичного числа = -19.00
Округление положительного десятичного числа = 16.00
Округление со вторым параметром при положительном значении = 11.988
Округление со вторым параметром при отрицательном значении = -18.485
Округление элементов в списке = -40
Округление элементов в списке = 33
Округление элементов в кортеже = 11
Округление элементов в кортеже = 30
Округление сумы чисел = 39.34
Есть разные метода функции округления в Python. Одна из них — это сокращение.
Сокращение
Сокращение используется для уменьшения размеров элементов. Это самый простой способ округления до конкретного числа. Для положительных чисел функция округляет их до ближайшего целого в меньшую сторону, а для отрицательных — в большую.
Например, round(565.5556, -2) используется как функция сокращения. Она вернет 600.
Выводы
Функция round позволяет упростить работу с крупными объемами данных. Ее задача — возвращать число с определенным количеством цифр после точки.
]]>Далее: Приватные переменные
Предыдущий урок: Генераторы
Функция filter() в Python применяет другую функцию к заданному итерируемому объекту (список, строка, словарь и так далее), проверяя, нужно ли сохранить конкретный элемент или нет. Простыми словами, она отфильтровывает то, что не проходит и возвращает все остальное.
Объект фильтра — это итерируемый объект. Он сохраняет те элементы, для которых функция вернула True. Также можно конвертировать его в list, tuple или другие типы последовательностей с помощью фабричных методов.
В этом руководстве разберемся как использовать filter() с разными типами последовательностей. Также рассмотрим примеры, которые внесут ясность в принцип работы.
Функция filter() принимает два параметра. Первый — имя созданной пользователем функции, а второй — итерируемый объект (список, строка, множество, кортеж и так далее).
Она вызывает заданную функцию для каждого элемента объекта как в цикле. Синтаксис следующий:
# Синтаксис filter()
filter(in_function|None, iterable)
|__filter object
Первый параметр — функция, содержащая условия для фильтрации входных значений. Она возвращает True или False. Если же передать None, то она удалит все элементы кроме тех, которые вернут True по умолчанию.
Второй параметр — итерируемый объект, то есть последовательность элементов, которые проверяются на соответствие условию. Каждый вызов функции использует один из объектов последовательности для тестирования.
Возвращаемое значение — объект filter, который представляет собой последовательность элементов, прошедших проверку.
Примеры функции filter()
Фильтр нечетных чисел
В этом примере в качестве итерируемого объекта — список числовых значений
# список чисел
numbers = [1, 2, 4, 5, 7, 8, 10, 11]
И есть функция, которая отфильтровывает нечетные числа. Она передается в качестве первого аргумента вызову filter().
# функция, которая фильтрует нечетные числа
def filter_odd_num(in_num):
if(in_num % 2) == 0:
return True
else:
return False
Теперь соединим эти части и посмотрим на финальный код.
"""
Программа Python для фильтрации нечетных чисел
в списке, используя функцию filter()
"""
# список чисел
numbers = [1, 2, 4, 5, 7, 8, 10, 11]
# функция, которая проверяет числа
def filter_odd_num(in_num):
if(in_num % 2) == 0:
return True
else:
return False
# Применение filter() для удаления нечетных чисел
out_filter = filter(filter_odd_num, numbers)
print("Тип объекта out_filter: ", type(out_filter))
print("Отфильтрованный список: ", list(out_filter))
Вот на что стоит обратить внимание в примере:
- Функция filter() возвращает
out_filter, а для проверки типа данных использоваласьtype(); - Конструктор
list()был вызван для конвертации объектаfilterв список Python.
После запуска примера выйдет следующий результат:
Тип объекта out_filter: <class ‘filter’>
Отфильтрованный список: [2, 4, 8, 10]
Он показывает только четные числа, отфильтровывая нечетные.
Фильтр повторяющихся значений из двух списков
Функцию можно использовать для получения разницы двух последовательностей. Для этого нужно отфильтровывать повторяющиеся элементы.
Предположим, что существует два списка строк.
# Список строк с похожими элементами
list1 = ["Python", "CSharp", "Java", "Go"]
list2 = ["Python", "Scala", "JavaScript", "Go", "PHP", "CSharp"]
Видно, что в них есть одинаковые названия языков программирования. Задача заключается в том, чтобы написать функцию, которая бы проверяла повторяющиеся значения.
# функция, которая проверяет строки на вхождение
def filter_duplicate(string_to_check):
if string_to_check in ll:
return False
else:
return True
Теперь соберем все это вместе.
"""
Программа для поиска совпадений между
двумя списками, используя функцию filter()
"""
# Список строк с похожими элементами
list1 = ["Python", "CSharp", "Java", "Go"]
list2 = ["Python", "Scala", "JavaScript", "Go", "PHP", "CSharp"]
# функция, которая проверяет строки на вхождение
def filter_duplicate(string_to_check):
if string_to_check in ll:
return False
else:
return True
# Применение filter() для удаления повторяющихся строк
ll = list2
out_filter = list(filter(filter_duplicate, list1))
ll = list1
out_filter += list(filter(filter_duplicate, list2))
print("Отфильтрованный список:", out_filter)
После выполнения результат будет следующий:
Отфильтрованный список: [‘Java’, ‘Scala’, ‘JavaScript’, ‘PHP’]
Как и ожидалось, код вывел разницу двух списков. Однако это лишь примеры работы функции.
Использование лямбда-выражений с filter()
Лямбда-выражение в Python также работает как встроенная функция. Таким образом ее можно указать вместо функции в качестве аргумента при вызове filter() и избавиться от необходимости написания отдельной функции для фильтрации.
Рассмотрим некоторые примеры того, как использовать лямбда.
Отфильтровать стоп-слова из строки
В этом примере удалим стоп-слова из строки. Они перечислены в следующем списке.
list_of_stop_words = ["в", "и", "по", "за"]
А вот строка, включающая некоторые из слов.
string_to_process = "Сервис по поиску работы и сотрудников HeadHunter опубликовал подборку высокооплачиваемых вакансий в России за август."
Теперь код целиком.
"""
Программа для удаления стоп-слов
из строки используя функцию filter()
"""
# Список стоп-слов
list_of_stop_words = ["в", "и", "по", "за"]
# Строка со стоп-словами
string_to_process = "Сервис по поиску работы и сотрудников HeadHunter опубликовал подборку высокооплачиваемых вакансий в России за август."
# lambda-функция, фильтрующая стоп-слова
split_str = string_to_process.split()
filtered_str = ' '.join((filter(lambda s: s not in list_of_stop_words, split_str)))
print("Отфильтрованная строка:a", filtered_str)
Поскольку нужно убрать целое слово, строка разбивается на слова. После этого стоп-слова отфильтровываются, а все остальное объединяется.
Результат будет следующий:
Отфильтрованная строка: Сервис поиску работы сотрудников HeadHunter опубликовал подборку высокооплачиваемых вакансий России август.
Пересечение двух массивов
В этом примере создадим лямбда-выражение, а затем применим функцию фильтрации для поиска общих элементов в них.
Вот входные данные для теста.
# Два массива, имеющие общие элементы
arr1 = ['p','y','t','h','o','n',' ','3','.','0']
arr2 = ['p','y','d','e','v',' ','2','.','0']
Создадим lambda-функцию, которая будет отфильтровывать разницу и возвращать общие элементы.
# Лямбда с использованием filter() для поиска общих значений
out = list(filter(lambda it: it in arr1, arr2))
А вот полная реализация:
"""
Программа для поиска общих элементов в двух списках
с использованием функции lambda и filter()
"""
# Два массива, имеющие общие элементы
arr1 = ['p','y','t','h','o','n',' ','3','.','0']
arr2 = ['p','y','d','e','v',' ','2','.','0']
# Лямбда с использованием filter() для поиска общих значений
def interSection(arr1, arr2): # find identical elements
out = list(filter(lambda it: it in arr1, arr2))
return out
# функция main
if __name__ == "__main__":
out = interSection(arr1, arr2)
print("Отфильтрованный список:", out)
Такой будет результат выполнения:
Отфильтрованный список: [‘p’, ‘y’, ‘ ‘, ‘.’, ‘0’]
Функция filter без функции
Да, можно вызывать функцию filter() без передачи ей функции в качестве первого аргумента. Вместо этого нужно указать None.
В таком случае фильтр уберет те элементы, результат исполнения которых равен False. Возьмем в качестве примера следующую последовательность.
# Список значений, которые могут быть True или False
bools = ['bool', 0, None, True, False, 1-1, 2%2]
Дальше код целиком для анализа поведения filter() с None в качестве функции-аргумента.
"""
Вызов функции filter() без функции
"""
# Список значений, которые могут быть True или False
bools = ['bool', 0, None, True, False, 1, 1-1, 2%2]
# Передали None вместо функции в filter()
out = filter(None, bools)
# Вывод результата
for iter in out:
print(iter)
А вот результат исполнения:
bool
True
1
Теперь вы должны лучше понимать принцип работы функции filter() в Python.
]]>Далее: Функция round()
Предыдущий урок: Приоритетность операторов
В этой статье вы научитесь создавать и использовать функции и выражения генераторов в Python. Также узнаете, зачем и когда их стоит использовать в программах. Будут рассмотрены основные отличия от итераторов и обычных функций.
Отдельное внимание будет уделено инструкции yield. Она является частью генератора и заменяет ключевое слово return. Когда программа доходит до yield, то функция переходит в состояние ожидания и продолжает работу с того же места при повторном вызове.
Генератор в Python — это функция с уникальными возможностями. Она позволяет приостановить или продолжить работу. Генератор возвращает итератор, по которому можно проходить пошагово, получая доступ к одному значению с каждой итерацией.
Генератор предоставляет способ создания итераторов, решая следующую распространенную проблему.
Создание итератора в Python — достаточно громоздкая операция. Для этого нужно написать класс и реализовать методы __iter__() и __next__(). После этого требуется настроить внутренние состояния и вызывать исключение StopIteration, когда больше нечего возвращать.
Как создать генератор в Python?
Генератор — это альтернативный и более простой способ возвращать итераторы. Процедура создания не отличается от объявления обычной функции.
Есть два простых способа создания генераторов в Python.
Функция генератора
Генератор создается по принципу обычной функции.
Отличие заключается в том, что вместо return используется инструкция yield. Она уведомляет интерпретатор Python о том, что это генератор, и возвращает итератор.
Синтаксис функции генератора:
def gen_func(args):
...
while [cond]:
...
yield [value]
Return всегда является последней инструкцией при вызове функции, в то время как yield временно приостанавливает исполнение, сохраняет состояние и затем может продолжить работу позже.
Дальше простейший пример функции генератора Python, которая определяет следующее значение в последовательности Фибоначчи.
Демонстрация функции генератора Python:
def fibonacci(xterms):
# первые два условия
x1 = 0
x2 = 1
count = 0
if xterms <= 0:
print("Укажите целое число больше 0")
elif xterms == 1:
print("Последовательность Фибоначчи до", xterms, ":")
print(x1)
else:
while count < xterms:
xth = x1 + x2
x1 = x2
x2 = xth
count += 1
yield xth
fib = fibonacci(5)
print(next(fib))
print(next(fib))
print(next(fib))
print(next(fib))
print(next(fib))
print(next(fib))
В этом примере в функции генератора есть цикл while, который вычисляет следующее значение Фибоначчи. Инструкция yield является частью цикла.
После создания функции генератора вызываем ее, передав 5 в качестве аргумента. Она вернет только объект итератора.
Такая функция не будет выполняться до тех пор, пока не будет вызван метод next() с вернувшимся объектом в качестве аргумента (то есть fib). Для итерации повторим все шаги шесть раз.
Первые пять вызовов next() были успешными и возвращали соответствующий элемент последовательности Фибоначчи. А вот последний вернул исключение StopIteration, поскольку элементов, которые можно было бы вернуть, больше не осталось.
Вот что будет выведено после выполнения.
1
2
3
5
8
Traceback (most recent call last):
File «C:/Python/Python3/python_generator.py», line 29, in
print(next(fib))
StopIteration
Выражение генератора
Python позволяет писать выражения генератора для создания анонимных функций генератора. Процесс напоминает создание лямбда-функций для создания анонимных функций.
Синтаксис похож на используемый для создания списков с помощью цикла for. Однако там применяются квадратные скобки, а здесь — круглые.
# Синтаксис выражения генератора
gen_expr = (var**(1/2) for var in seq)
Еще одно отличие между «list comprehension» и «выражением генератора» в том, что при создании списков возвращается целый список, а в случае с генераторами — только одно значение за раз.
Пример выражение генератора Python:
# Создаем список
alist = [4, 16, 64, 256]
# Вычислим квадратный корень, используя генерацию списка
out = [a**(1/2) for a in alist]
print(out)
# Используем выражение генератора, чтобы вычислить квадратный корень
out = (a**(1/2) for a in alist)
print(out)
print(next(out))
print(next(out))
print(next(out))
print(next(out))
print(next(out))
В примере выше out вернет список со значениями, возведенными в квадрат. То есть, сразу готовый результат.
Выражение генератора вернет итератор, который будет выдавать по одному значению за раз. В списке 4 элемента. Таким образом четыре последовательных вызова метода next() напечатают квадратные корни соответствующих элементов списка.
Но поскольку метод был вызван 5 раз, то вернулось также исключение StopIteration.
[2.00, 4.0, 8.00, 16.0]
at 0x000000000359E308>
2.0
4.0
8.0
16.0
Traceback (most recent call last):
File «C:/Python/Python3/python_generator.py», line 17, in
print(next(out))
StopIteration
Как использовать генератор в Python?
Теперь пришло время разобраться с тем, как использовать генератор в программах. В прошлых примерах метод next() применялся по отношению к итератору, который возвращала функция генератора.
С помощью метода next()
Метод next() — самый распространенный способ для получения значения из функции генератора. Вызов метода приводит к выполнению, что возвращает результат тому, кто делал вызов.
В примере ниже значения выводятся с помощью генератора.
Демонстрация генератора next():
alist = ['Python', 'Java', 'C', 'C++', 'CSharp']
def list_items():
for item in alist:
yield item
gen = list_items()
iter = 0
while iter < len(alist):
print(next(gen))
iter += 1
Этот пример не отличается от предыдущих, но каждый элемент здесь возвращается генератором с помощью метода next(). Для этого сперва создается объект генератора gen, который является идентификатором, хранящим состояние генератора.
Каждый вызов next() объекта генератора приводит к выполнению вплоть до инструкции yield. Затем Python возвращает значение и сохраняет состояние для последующего использования.
Использование цикла for
Также можно использовать цикл for для итерации по объекту генератора. В этом случае вызов next() происходит неявно, но элементы все равно возвращаются один за одним.
Генератор для демонстрации цикла:
alist = ['Python', 'Java', 'C', 'C++', 'CSharp']
def list_items():
for item in alist:
yield item
gen = list_items()
for item in gen:
print(item)
Return vs. yield
Ключевое слово return — это финальная инструкция в функции. Она предоставляет способ для возвращения значения. При возвращении весь локальный стек очищается. И новый вызов начнется с первой инструкции.
Ключевое слово yield же сохраняет состояние между вызовами. Выполнение продолжается с момента, где управление было передано в вызывающую область, то есть, сразу после последней инструкции yield.
Генератор vs. функция
Дальше перечислены основные отличия между генератором и обычной функцией.
- Генератор использует
yieldдля отправления значения пользователю, а у функции для этого естьreturn; - При использовании генератора вызовов yield может быть больше чем один;
- Вызов yield останавливает исполнение и возвращает итератор, а return всегда выполняется последним;
- Вызов метода
next()приводит к выполнению функции генератора; - Локальные переменные и состояния сохраняются между последовательными вызовами метода
next(); - Каждый дополнительный вызов
next()вызывает исключениеStopIteration, если нет следующих элементов для обработки.
Дальше пример функции генератора с несколькими yield.
def testGen():
x = 2
print('Первый yield')
yield x
x *= 1
print('Второй yield')
yield x
x *= 1
print('Последний yield')
yield x
# Вызов генератора
iter = testGen()
# Вызов первого yield
next(iter)
# Вызов второго yield
next(iter)
# Вызов последнего yield
next(iter)
Вывод будет такой.
Первый yield
Второй yield
Последний yield
Когда использовать генератор?
Есть много ситуаций, когда генератор оказывается полезным. Вот некоторые из них:
- Генераторы помогают обрабатывать большие объемы данных. Они позволяют производить так называемые ленивые вычисления. Подобным образом происходит потоковая обработка.
- Генераторы можно устанавливать друг за другом и использовать их как Unix-каналы.
- Генераторы позволяют настроить одновременное исполнение
- Они часто используются для чтения крупных файлов. Это делает код чище и компактнее, разделяя процесс на более мелкие сущности.
- Генераторы особенно полезны для веб-скрапинга и увеличения эффективности поиска. Они позволяют получить одну страницу, выполнить какую-то операцию и двигаться к следующей. Этот подход куда эффективнее чем получение всех страниц сразу и использование отдельного цикла для их обработки.
Зачем использовать генераторы?
Генераторы предоставляют разные преимущества для программистов и расширяют особенности, которые проявляются во время выполнения.
Удобные для программистов
Генератор кажется сложной концепцией, но его легко использовать в программах. Это хорошая альтернатива итераторам.
Рассмотрим следующий пример реализации арифметической прогрессии с помощью класса итератора.
Создание арифметической прогрессии с помощью класса итератора:
class AP:
def __init__(self, a1, d, size):
self.ele = a1
self.diff = d
self.len = size
self.count = 0
def __iter__(self):
return self
def __next__(self):
if self.count >= self.len:
raise StopIteration
elif self.count == 0:
self.count += 1
return self.ele
else:
self.count += 1
self.ele += self.diff
return self.ele
for ele in AP(1, 2, 10):
print(ele)
Ту же логику куда проще написать с помощью генератора.
Генерация арифметической прогрессии с помощью функции генератора:
def AP(a1, d, size):
count = 1
while count <= size:
yield a1
a1 += d
count += 1
for ele in AP(1, 2, 10):
print(ele)
Экономия памяти
Есть использовать обычную функцию для возвращения списка, то она сформирует целую последовательность в памяти перед отправлением. Это приведет к использованию большого количества памяти, что неэффективно.
Генератор же использует намного меньше памяти за счет обработки одного элемента за раз.
Обработка больших данных
Генераторы полезны при обработке особенно больших объемов данных, например, Big Data. Они работают как бесконечный поток данных.
Такие объемы нельзя хранить в памяти. Но генератор, выдающий по одному элементы за раз и представляет собой этот бесконечный поток.
Следующий код теоретически может выдать все простые числа.
Стоит отметить, что он запустит бесконечный цикл, для остановки которого нужно нажать Ctrl + C.
Найдем все простые числа с помощью генератора:
def find_prime():
num = 1
while True:
if num > 1:
for i in range(2, num):
if (num % i) == 0:
break
else:
yield num
num += 1
for ele in find_prime():
print(ele)
Последовательность генераторов
С помощью генераторов можно создать последовательность разных операций. Это более чистый способ разделения обязанностей между всеми компонентами и последующей интеграции их для получения нужного результата.
Цепочка нескольких операций с использованием pipeline генератора:
def find_prime():
num = 1
while num < 100:
if num > 1:
for i in range(2, num):
if (num % i) == 0:
break
else:
yield num
num += 1
def find_odd_prime(seq):
for num in seq:
if (num % 2) != 0:
yield num
a_pipeline = find_odd_prime(find_prime())
for a_ele in a_pipeline:
print(a_ele)
В примере ниже связаны две функции. Первая находит все простые числа от 1 до 100, а вторая — выбирает нечетные.
Выводы
Генераторы создают последовательность на лету, что позволяет получать доступ к одному элементу в любой момент. Это не требует большого количества памяти и оставляет возможность работать с бесконечными потоками данных. Это довольна сложная концепция, которую все равно стоит попробовать внедрить в реальные проекты.
]]>Далее: filter() в python
Структурирование приложения Tkinter
Одно из главных преимуществ создания приложения с Tkinter в том, что с его помощью очень просто настроить интерфейс всего в несколько строк. И если программа становится сложнее, то и сложнее логически разделять ее на части, а организованная структура помогает сохранять код в чистом виде.
Простой пример
Возьмем в качестве примера следующую программу:
from tkinter import *
root = Tk()
btn = Button(root, text="Нажми!")
btn.config(command=lambda: print("Привет, Tkinter!"))
btn.pack(padx=120, pady=30)
root.title("Мое приложение Tkinter")
root.mainloop()
Она создает окно с кнопкой, которая выводит Привет, Tkinter! каждый раз при нажатии. Кнопка расположена с внутренним отступом 120px по горизонтальной оси и 30px – по вертикальной. Последняя строка запускает основной цикл, который обрабатывает все пользовательские события и обновляет интерфейс до закрытия основного окна.
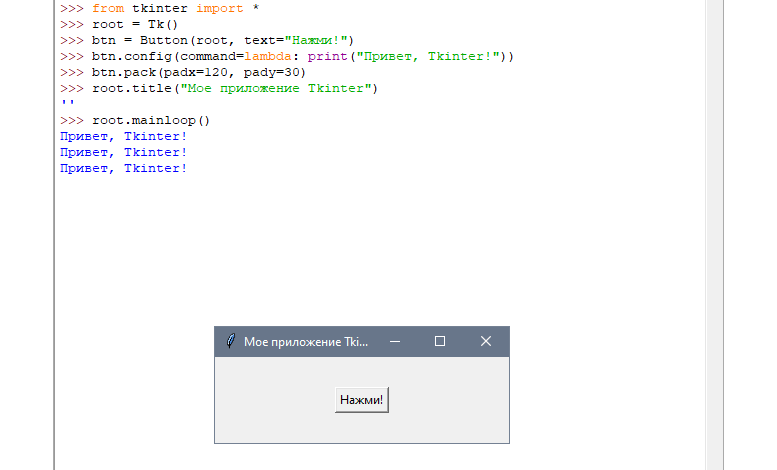
Программу можно запустить, чтобы убедиться, что она работает. Все переменные определяются в глобальном пространстве имен, и чем больше виджетов добавляется, тем сложнее разобраться в том, какие части они используют.
Wildcard-импорты (
from … import *) считаются плохой практикой, поскольку они загрязняют глобальное пространство имен. Здесь они используются для иллюстрации анти-паттерна, который часто встречается в примерах онлайн.
Эти проблемы настройки решаются с помощью базовых техник объектно-ориентированного программирования, что считается хорошей практикой для любых типов программ на Python.
Правильный пример
Чтобы улучшить модуль простой программы, стоит определить несколько классов, которые станут обертками вокруг глобальных переменных:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.btn = tk.Button(self, text="Нажми!",
command=self.say_hello)
self.btn.pack(padx=120, pady=30)
def say_hello(self):
print("Привет, Tkinter!")
if __name__ == "__main__":
app = App()
app.title("Мое приложение Tkinter")
app.mainloop()
Теперь каждая переменная хранится в конкретной области видимости, включая функцию command, которая находится в отдельном методе.
Как работает это приложение?
Во-первых нужно заменить wildcard-импорт на импорт в формате import … as для лучшего контроля над глобальным пространством имен.
Затем класс App определяется как подкласс Tk, который теперь ссылается на пространство имен tk. Для правильной инициализации базового класса, вызывается метод __init__() класса Tk с помощью встроенной функции super(). За это отвечают следующие строки:
class App(tk.Tk):
def __init__(self):
super().__init__()
# ...
Теперь есть ссылка на экземпляр App с переменной self. Так что виджет кнопки будет добавлен как атрибут класса.
Это может казаться излишним для такой простой программы, но подобный рефакторинг помогает работать с каждой отдельной частью. Создание кнопки отделено от обратного вызова, которые исполняется при нажатии. А генерация приложения перемещена в if __name__ == "main", что является стандартной практикой для исполняемых скриптов в Python.
Такой же принцип будет использовать в примерах и дальше, поэтому его можно взять как шаблон-стартовая точка для крупных приложений.
Дополнение о структуре приложения
Класс Tk вынесен в отдельный класс в примере, но распространенной практикой считается выделять так же другие классы виджетов. Это делается для воссоздания тех же инструкций, которые были до рефакторинга.
Однако может быть более удобно разделять классы Frame или Toplevel особенно для больших программ, где, например, есть несколько окон. Это все потому что у приложения Tkinter должен быть один экземпляр Tk, а система создает их автоматически при создании экземпляра виджета до создания экземпляра самого Tk.
Помните, что это не влияет на структуру класса App, поскольку у всех классов виджетов есть метод mainloop, который запускает основной цикл Tk.
Работа с кнопками
Виджеты кнопок представляют собой кликабельные элементы графического интерфейса приложений. Они обычно используют текст или изображение, указывающие на то, какое действие будет выполнено при нажатии. Tkinter позволяет легко настраивать их функциональность с помощью стандартных настроек класса виджета Button.
Как создать кнопку
Следующий блок содержит кнопку с изображением, которая выключается при нажатии, а также список кнопок с разными типами анимации после нажатия:
import tkinter as tk
RELIEFS = [tk.SUNKEN, tk.RAISED, tk.GROOVE, tk.RIDGE, tk.FLAT]
class ButtonsApp(tk.Tk):
def __init__(self):
super().__init__()
self.img = tk.PhotoImage(file="python.gif")
self.btn = tk.Button(self, text="Кнопка с изображением",
image=self.img, compound=tk.LEFT,
command=self.disable_btn)
self.btns = [self.create_btn(r) for r in RELIEFS]
self.btn.pack()
for btn in self.btns:
btn.pack(padx=10, pady=10, side=tk.LEFT)
def create_btn(self, relief):
return tk.Button(self, text=relief, relief=relief)
def disable_btn(self):
self.btn.config(state=tk.DISABLED)
if __name__ == "__main__":
app = ButtonsApp()
app.mainloop()
Цель программы — показать разные варианты настройки, которые могут быть использованы при создании виджета кнопки.
После выполнения кода выше, возвращается следующее:

Простейший способ создания экземпляра Button — использование параметра text для настройки метки кнопки и command, который ссылается на вызываемую функцию при нажатии кнопки.
В этом примере также добавляется PhotoImage с помощью параметра image, который имеет приоритет над строкой text. Этот параметр используется для объединения изображения и текста на одной кнопке, определяя местоположение, где будет находиться картинка. Он принимает следующие константы: CENTER, BOTTOM, LEFT, RIGHT и TOP.
Второй ряд кнопок создается с помощью сгенерированного списка и списка значений RELIEF. Метка каждой кнопки соответствует константе, так что можно заметить разницу во внешнем виде.
Для сохранения ссылки на экземпляр PhotoImage использовался атрибут, хотя его и нет вне метода __init__. Причина в том, что изображения удаляются при сборке мусора. Это и происходит, если объявить их в качестве локальных переменных.
Для избежания этого нужно помнить о сохранении ссылки на каждый объект PhotoImage до тех пор, пока окно, где он показывается, не закрыто.
Следующий урок: Работа с текстом (в разработке)
]]>Предыдущий урок: Комментарии
В этом материале рассмотрим приоритетность и ассоциативность операторов в Python. Тема очень важна для понимания семантики операторов Python.
После прочтения вы должны понимать, как Python определяет порядок исполнения операторов. У некоторых из них более высокий уровень приоритета. Например, оператор умножения более приоритетный по сравнению с операторами сложения или вычитания.
В выражении интерпретатор Python выполняет операторы с более высоким уровнем приоритета первыми. И за исключением оператора возведения в степень (**) они выполняются слева направо.
Приоритетность операторов в Python
Как работает приоритетность операторов в Python?
Выражение — это процесс группировки наборов значений, переменных, операторов и вызовов функций. При исполнении таких выражений интерпретатор Python выполняет их.
Вот простейший пример.
>>> 3 + 4
7
Здесь «3 + 4» — это выражение Python. Оно содержит один оператор и пару операндов. Но в более сложных инструкциях операторов может быть и несколько.
Для их выполнения Python руководствуется правилом приоритетности. Оно указывает на порядок операторов.
Примеры приоритетов операторов
В следующих примерах в сложных выражениях объединены по несколько операторов.
# Сначала выполняется умножение
# потом операция сложения
# Результат: 17
5 + 4 * 3
Однако порядок исполнения можно поменять с помощью скобок (). Они переопределяют приоритетность арифметический операций.
# Круглые скобки () переопределяют приоритет арифметических операторов
# Вывод: 27
(5 + 4) * 3
Следующая таблица демонстрирует приоритетность операторов от высокой до самой низкой.
| Операторы | Применение |
|---|---|
| { } | Скобки (объединение) |
| f(args…) | Вызов функции |
| x[index:index] | Срез |
| x[index] | Получение по индексу |
| x.attribute | Ссылка на атрибут |
| ** | Возведение в степень |
| ~x | Побитовое нет |
| +x, -x | Положительное, отрицательное число |
| *, /, % | Умножение, деление, остаток |
| +, — | Сложение, вычитание |
| <<, >> | Сдвиг влево/вправо |
| & | Побитовое И |
| ^ | Побитовое ИЛИ НЕ |
| | | Побитовое ИЛИ |
| in, not in, is, is not, <, <=, >, >=, <>, !=, == | Сравнение, принадлежность, тождественность |
| not x | Булево НЕ |
| and | Булево И |
| or | Булево ИЛИ |
| lambda | Лямбда-выражение |
Ассоциативность операторов
В таблице выше можно увидеть, что некоторые группы включают по несколько операторов python. Это значит, что все представители одной группы имеют один уровень приоритетности.
При наличии двух или более операторов с одинаковым уровнем в дело вступает ассоциативность, определяющая порядок.
Что такое ассоциативность в Python?
Ассоциативность — это порядок, в котором Python выполняет выражения, включающие несколько операторов одного уровня приоритетности. Большая часть из них (за исключением оператора возведения в степень **) поддерживают ассоциативность слева направо.
Примеры
Например, у операторов умножения и деления приоритетность одинаковая. В одном выражении тот, что находится слева, будет выполняться первым.
# Тестирование ассоциативности слева направо
print(4 * 7 % 3)
# Результат: 1
print(2 * (10 % 5))
# Результат: 0
Единственное исключение — оператор возведения в степень **. Вот пример с ним:
# Проверка ассоциативности с оператором степени
print(4 ** 2 ** 2)
# Вывод: 256
print((4 ** 2) ** 2)
# Вывод: 256
Обратите внимание на то , что print(4 ** 2 ** 2) дает такой же результат, как и ((4 ** 2) ** 2).
Неассоциативные операторы
В Python есть такие операторы (например, присваивания и сравнения), которые не поддерживают ассоциативность. Для них применяются специальные правила порядка, в которых ассоциативность не принимает участия.
Например, выражение 5 < 7 < 9 — это не то же самое, что и (5 < 7) < 9 или 5 < (7 < 9). Зато 5 < 7 < 9 — то же самое, что 5 < 7 и 7 < 9. Исполняется слева направо.
Так же работает связывание операторов присваивания (например, a=b=c), а вот a = b += c вернет ошибку.
# Установите значения
x = 11
y = 12
# Выражение неверно
# Неассоциативные операторы
# Ошибка -> SyntaxError: invalid syntax
x = y += 12
Выводы
Приоритетность и ассоциативность операторов в Python — важная тема. Зная ее, легче работать со сложными выражениями.
]]>Далее: Генераторы
Предыдущий урок: Инструкции и выражения
Добавление комментариев считается хорошей практикой. Это неисполняемые, но все равно важные части кода. Они не только помогают программистам, работающим над одним и тем же проектом, но также тестировщикам, которые могут обращаться к ним для ясности при тестировании белого ящика.
Куда лучше добавлять комментарии при создании или обновлении программы, иначе можно утратить контекст. Комментарии, добавленные позже, могут быть далеко не настолько эффективными.
Комментарии — это способ выражения того, что делает программа на самом высоком уровне. Это отмеченные строчки, которые комментируют код. В Python они бывают двух типов: одно- и многострочные.
Однострочные комментарии в Python
Такой тип комментариев нужен для написания простых, быстрых комментариев во время отладки. Такие комментарии начинаются с символа решетки # и автоматически заканчиваются символом окончания строки (EOL).
# Хороший код документируется
print("Изучите Python шаг за шагом!")
При добавлении комментария важно убедиться, что у него тот же уровень отступа, что и у кода под ним. Например, нужно оставить комментарий к строке объявления функции, у которой нет отступа. Однако они имеются у блоков кода внутри нее. Поэтому учитывайте выравнивание при комментировании внутренних блоков кода.
# Создадим список месяцев
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul','Aug','Sep','Oct','Nov','Dec']
# Функция вывода календарных месяцев
def showCalender(months):
# Цикл for проходит по списку и вводит название каждого месяца
for month in months:
print(month)
showCalender(months)
Многострочные комментарии в Python
Python позволяет писать комментарии на нескольких строках. Они называются многострочными или блочными. Такой тип комментирования подходит для описания чего-то более сложного.
Этот тип комментариев нужен для описания всего последующего кода. Дальше примеры многострочных комментариев в Python.
С помощью символа #
Для добавления многострочного комментария нужно начинать каждую строку с символа решетки и одного пробела. Такой комментарий можно разбить на абзацы. Для этого достаточно добавлять пустые строки с символом перед каждым из них.
Примечание: в оригинале этот символ (#) называется octothorpe, что переводится с латинского как «восемь концов». Термин придумала группа инженеров в Bell Labs, которая работала над проектом первой сенсорной клавиатуры.
# Чтобы выучить любой язык, вы должны следовать этим правилам.
# 1. Знать синтаксис, типы данных, структуры и условные операторы.
# 2. Изучить обработку ошибок и ввод/вывод.
# 3. Читайте о продвинутых структурах данных.
# 4. Пишите функции и следуйте концепциям ООП.
def main():
print("Начнем изучать Python.")
Docstring в Python
В Python есть такая особенность, как задокументированные строки (docstring). С их помощью программисты могут быстро добавлять комментарии для каждого модуля, функции, метода или класса в Python.
Задать docstring можно с помощью строковой константы. Она обязана быть первой инструкцией в определении объекта.
У docstring более широкая область применения, чем у комментария. Она должна описывать, что делает функция, а не как. Хорошей практикой считается добавление таких строк в каждую функцию программы.
Как задать docstring в Python?
Задать docstring в Python можно с помощью тройных кавычек Нужно добавить один набор в начале и еще один – в конце. Docstring также могут занимать по несколько строк.
Примечание: строки с тремя кавычками также являются docstring в Python, пусть они и могут казаться обычными комментариями.
В чем отличие между комментарием и docstring?
Строки, начинающиеся с тройной кавычки, — это все еще обычные строки, которые могут быть написаны в несколько строк. Это значит, что они все еще являются исполняемыми инструкциями. Если же у них нет метки, значит сборщик мусора уничтожит их после исполнения.
Интерпретатор Python не будет игнорировать их так же, как комментарии. Но если такая строка расположена сразу же после объявления функции или класса в верхней части модуля, то она станет docstring. Получить к ним доступ можно следующим образом — myobj.__doc__.
def theFunction():
'''
Эта функция демонстрирует использование docstring в Python.
'''
print("docstring python не являются комментариями.")
print("\nВыведем docstring функции...")
print(theFunction.__doc__)
Выводы
Комментарии и docstring добавляют ценности программе. Они делают программы более читаемыми и пригодными для последующей поддержки. Даже при рефакторинге сделать это будет намного проще с комментариями.
Разработка программного обеспечения — это лишь на 10% написание кода. Остальные 90% — поддержка.
Поэтому всегда добавляйте осмысленные комментарии и docstring, потому что они упрощают процесс взаимодействия и ускоряют процесс рефакторинга.
]]>Далее: Приоритетность операторов
Предыдущий урок: Try…Except
Этот материал посвящен инструкциям и выражениям в Python, а также отличиям между ними. Также речь пойдет об инструкциях, занимающих несколько строк, и отступах в Python. Попробуем ответить на вопрос: «Почему отступы так важны в Python?»
Инструкции в Python
Что такое инструкция?
Инструкция в Python — это логическая инструкция, которую интерпретатор Python может прочесть и выполнить. Она может являться выражением или оператором присваивания в Python.
Присваивание — фундаментальный элемент этого языка. Он определяет способ создания и сохранения объектов с помощью выражений.
Что такое выражение?
Выражение — один из типов инструкции, который содержит логическую последовательность чисел, строк, объектов и операторов python. Значение и переменная являются выражениями сами по себе.
С помощью выражений можно выполнять такие операции, как сложение, вычитание, конкатенация и другие. Они также могут представлять собой вызовы функций, которые возвращают результат.
# Использование арифметических выражений
>>> ((20 + 2) * 10 / 5 - 20)
24.0
# Использование функций в выражении
>>> pow(2, 10)
1024
# Использование eval в выражении
>>> eval("2.5+2.5")
5.0
Простая операция присваивания
В случае простого присваивания создаются новые переменные, которым присваиваются значения. Их можно менять. Инструкция предоставляет выражение и имя переменной в качестве метки для сохранения значения выражения.
# Синтаксис
variable = expression
Рассмотрим типы выражений присваивания в Python и посмотрим, как они работают внутри.
Пример 1. С правой стороны — выражение со значением
Это базовая форма присваивания в Python.
>>> test = "Изучение python"
Python создаст в памяти строку "Изучение python" и присвоит ей имя test. Узнать адрес в памяти можно с помощью встроенной функции id().
>>> test = "Изучение python"
>>> id(test)
6589040
Номер — это адрес места, где значение хранится в памяти. Дальше несколько интересных вещей, о которых нужно помнить.
- Если создать другую строку с тем же значением, Python создаст новый объект и присвоит его другому местоположению в памяти. Это работает в большинстве случаев.
- Однако в двух следующих случаях он использует то же место в памяти:
- Строки без пробелов с менее чем 20 символами;
- Целые числа от -5 до 255.
Это называется интернированием и делается для сохранения памяти.
Пример 2. С правой стороны — существующая переменная Python
Теперь другой пример инструкции присваивания. С правой стороны находится ранее объявленная переменная python.
>>> another_test = test
Инструкция выше не приведет к выделению нового места в памяти. Обе переменных будут ссылаться на один и тот же объект в памяти. Это как создание псевдонима для существующего объекта. Убедиться в этом можно с помощью все той же функции id().
>>> test = "Изучение python"
>>> id(test)
6589424
>>> another_test = test
>>> id(another_test)
6589424
Пример 3. С правой стороны — операция
В случае такой инструкции результат зависит от исхода операции. Возьмем такой пример.
>>> test = 2 * 2 / 4
>>> print(test)
1.0
>>> type(test)
В примере выше присваивание приведет к созданию переменной типа float. А в этом — к появлению переменной типа int.
>>> test = 3 * 3
>>> print(test)
9
>>> type(test)
Дополненная инструкция присваивания
Арифметические операторы можно объединять для формирования инструкций дополненного присваивания.
Рассмотрим такой пример: x += y. Он является аналогичным этой инструкции — x = x + y.
Следующий пример с добавлением новых элементов в кортеж чуть яснее демонстрирует принцип.
>>> my_tuple = (5, 10, 20)
>>> my_tuple += (40, 80,)
>>> print(my_tuple)
(5, 10, 20, 40, 80)
Следующий пример — список гласных. В нем в список добавляются недостающие значения.
>>> list_vowels = ['a','e','i']
>>> list_vowels += ['o', 'u',]
>>> print(list_vowels)
['a', 'e', 'i', 'o', 'u']
Инструкция в несколько строк
Каждая инструкция в Python заканчивается символом новой строки. Но это поведение можно расширить на несколько строк с помощью символа продолжения строки \.
В Python есть два варианта работы с инструкциями, занимающими несколько строк.
1. Явное продолжение строки
Когда сразу используется символ продолжения строки \ для разбития инструкции на несколько строчек.
# Инициализация списка с помощью многострочной инструкции
>>> my_list = [1, \
... 2, 3\
... ,4,5 \
... ]
>>> print(my_list)
[1, 2, 3, 4, 5]
# Вычислить выражение, используя многострочную инструкцию
>>> eval ( \
... " 2.5 \
... + \
... 3.5")
6.0
2. Неявное продолжение строки
Неявное продолжение строки работает в тех случаях, когда инструкция разбивается с помощью круглых (), квадратных [] или фигурных {} скобок. В таком случае инструкцию нужно заключить внутрь скобок для переноса.
>>> result = (10 + 100
... * 5 - 5
... / 100 + 10
... )
>>> print(result)
519.95
>>> subjects = [
... 'Метематика',
... 'Английский',
... 'Химия'
... ]
>>> print(subjects)
['Метематика', 'Английский', 'Химия']
>>> type(subjects)
Отступы в Python
Большая часть высокоуровневых языков программирования, таких как C, C++, C# используют фигурные скобки для выделения блоков кода. Python делает это с помощью отступов.
Блок кода, представляющий тело функции или цикл, начинается с отступа и заканчивается первой строкой без отступа.
Сколько места занимает один отступ
Согласно правилам стиля Python (PEP8), размер отступа — 4 символа. Однако у Google есть собственные правила, ограничивающие этот размер 2 символами. Так что можно руководствоваться и собственным стилем, но лучше следовать PEP8.
Почему отступы так важны в Python?
В большинстве языков программирования отступы используются для улучшения читабельности, но добавлять их необязательно. Но в Python их обязательно нужно использовать. Обычно каждую строку предваряет отступ в 4 символа для одного блока кода.
В примерах прошлых разделов были блоки без отступов. Однако в более сложных выражениях без них не обойтись.
def demo_routine(num):
print('Демо функция')
if num % 2 == 0:
return True
else:
return False
num = int(input('Введи число:'))
if demo_routine(num) is True:
print(num, 'четное число')
else:
print(num, 'нечетное число')
Также стоит рассмотреть пример, когда ненужный отступ вызывает ошибку.
>>> 6*5-10
File "", line 1
6*5-10
^
IndentationError: unexpected indent
Выводы
Если вы планируете стать профессиональным программистом, который верит в понятие чистого кода, тогда важно знать о выражениях, инструкциях и отступах в Python. Чтобы получить максимум от этого урока, повторите все представленные примеры в консоли. Для работы с ранее введенными командами можно использовать стрелку вверх на клавиатуре.
]]>Далее: Комментарии
Это третья часть руководства по pandas, в которой речь пойдет о методах форматирования данных, часто используемых в проектах data science: merge, sort, reset_index и fillna. Конечно, есть и другие, поэтому в конце статьи будет шпаргалка с функциями и методами, которые также могут пригодиться.
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.
Суть в том, что при работе с данными довольно часто придется вытаскивать данные из двух и более разных страниц. Это делается с помощью merge.
Примечание: хотя в pandas это называется merge, метод почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo (из предыдущих частей руководства), в котором есть разные животные. Но в этот раз нужен еще один DataFrame — zoo_eats, в котором будет описаны пищевые требования каждого вида.

Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:

В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?
В первую очередь нужно создать DataFrame zoo_eats, потому что zoo уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
animal;food
elephant;vegetables
tiger;meat
kangaroo;vegetables
zebra;vegetables
giraffe;vegetables
О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в Jupyter Notebook pandas_tutorial_1, который был создан еще в первой части руководства.
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food'])
И вот готов DataFrame zoo_eats.

Теперь пришло время метода merge:
zoo.merge(zoo_eats)
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame (zoo). Потом к нему применен метод .merge(). В качестве его параметра выступает новый DataFrame (zoo_eats). Можно было сделать и наоборот:
zoo_eats.merge(zoo)
Это то же самое, что и:
zoo.merge(zoo_eats)
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.

В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в zoo_eats нет значения lion. А в zoo нет значения giraffe. По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
zoo.merge(zoo_eats, how='outer')

В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск (NaN).
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: vegetables, meat и NaN (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром how='left' при объединении.
Вот так:
zoo.merge(zoo_eats, how='left')
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = 'left' заберет все значения из левой таблицы (zoo), но из правой (zoo_eats) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Для использования merge библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка animal). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры left_on и right_on.
Например, последний merge мог бы выглядеть следующим образом:
zoo.merge(zoo_eats, how = 'left', left_on='animal', right_on='animal')
Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о
left_onиright_onне стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:
zoo.sort_values('water_need')

Примечание: в прошлых версиях pandas была функция
sort(), работающая подобным образом. Но в новых версиях ее заменили наsort_values(), поэтому пользоваться нужно именно новым вариантом.
Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by:
zoo.sort_values(by=['animal', 'water_need'])

Примечание: ключевое слово
byможно использовать и для одной колонкиzoo.sort_values(by = ['water_need'].
sort_values сортирует в порядке возрастания, но это можно поменять на убывание:
zoo.sort_values(by=['water_need'], ascending=False)

reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?

Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.
В случае изменения DataFrame нужно переиндексировать строки. Для этого можно использовать метод reset_index(). Например:
zoo.sort_values(by=['water_need'], ascending=False).reset_index()

Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True)

Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:
zoo.merge(zoo_eats, how='left')
Это все животные. Проблема только в том, что для львов есть значение NaN. Само по себе это значение может отвлекать, поэтому лучше заменять его на что-то более осмысленное. Иногда это может быть 0, в других случаях — строка. Но в этот раз обойдемся unknown. Функция fillna() автоматически найдет и заменит все значения NaN в DataFrame:
zoo.merge(zoo_eats, how='left').fillna('unknown')

Примечание: зная, что львы едят мясо, можно было также написать
zoo.merge(zoo_eats, how='left').fillna('meat').
Проверьте себя
Вернемся к набору данных article_read.
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Скачайте еще один набор данных: blog_buy. Это можно сделать с помощью следующих двух строк в Jupyter Notebook:
!wget https://pythonru.com/downloads/pandas_tutorial_buy.csv
blog_buy = pd.read_csv('pandas_tutorial_buy.csv', delimiter=';', names=['my_date_time', 'event', 'user_id', 'amount'])
Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
Два вопроса:
- Какой средний доход в период с
2018-01-01по2018-01-07от пользователей изarticle_read? - Выведите топ-3 страны по общему уровню дохода за период с
2018-01-01по2018-01-07. (Пользователей изarticle_readздесь тоже нужно использовать).
Решение задания №1
Средний доход — 1,0852
Для вычисления использовался следующий код:
step_1 = article_read.merge(blog_buy, how='left', left_on='user_id', right_on='user_id')
step_2=step_1.amount
step_3=step_2.fillna(0)
result=step_3.mean()
result

Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
Краткое объяснение:
- На скриншоте также есть две строки с импортом pandas и numpy, а также чтением файлов csv в Jupyter Notebook.
- На шаге №1 объединены две таблицы (
article_readиblog_buy) на основе колонкиuser_id. В таблицеarticle_readхранятся все пользователи, даже если они ничего не покупают, потому что ноли (0) также должны учитываться при подсчете среднего дохода. Из таблицы удалены те, кто покупали, но кого нет в набореarticle_read. Все вместе привело к left-merge. - Шаг №2 — удаление ненужных колонок с сохранением только
amount. - На шаге №3 все значения
NaNзаменены на0. - В конце концов проводится подсчет с помощью
.mean().
Решение задания №2
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id')
step_2 = step_1.fillna(0)
step_3 = step_2.groupby('country').sum()
step_4 = step_3.amount
step_5 = step_4.sort_values(ascending = False)
step_5.head(3)

Найдите топ-3 страны на скриншоте.
Краткое объяснение:
- Тот же метод
merge, что и в первом задании. - Замена всех
NaNна0. - Суммирование всех числовых значений по странам.
- Удаление всех колонок кроме
amount. - Сортировка результатов в убывающем порядке так, чтобы можно было видеть топ.
- Вывод только первых 3 строк.
Итого
Это был третий эпизод руководства pandas с важными и часто используемыми методами: merge, sort, reset_index и fillna.
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
…простейший метод агрегации для него — суммирование water_needs, то есть 100 + 350 + 670 + 200 = 1320. Как вариант, можно посчитать количество животных — 4. Теория не так сложна. Но пора переходить к практике.
Агрегация данных — практика
Где мы остановились в последний раз? Открыли Jupyter Notebook, импортировали pandas и numpy и загрузили два набора данных: zoo.csv и article_reads. Продолжим с этого же места. Если вы не прошли первую часть, вернитесь и начните с нее.
Начнем с набора zoo. Он был загружен следующим образом:
pd.read_csv('zoo.csv', delimiter = ',')

Дальше сохраним набор данных в переменную zoo.
zoo = pd.read_csv('zoo.csv', delimiter = ',')
Теперь нужно проделать пять шагов:
- Посчитать количество строк (количество животных) в
zoo. - Посчитать общее значение
water_needживотных. - Найти наименьшее значение
water_need. - И самое большое значение
water_need. - Наконец, среднее
water_need.
Агрегация данных pandas №1: .count()
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo:
zoo.count()

А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
zoo[['animal']].count()
В этом случае результат будет даже лучше, если написать следующим образом:
zoo.animal.count()
Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Агрегация данных pandas №2: .sum()
Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:
zoo.water_need.sum()

Просто из любопытства можно попробовать найти сумму во всех колонках:
zoo.sum()

Примечание: интересно, как
.sum()превращает слова из колонкиanimalв строку названий животных. (Кстати, это соответствует всей логике языка Python).
Агрегация данных pandas №3 и №4: .min() и .max()
Какое наименьшее значение в колонке water_need? Определить это несложно:
zoo.water_need.min()

То же и с максимальным значением:
zoo.water_need.max()

Агрегация данных pandas №5 и №6: .mean() и .median()
Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:
zoo.water_need.mean()

zoo.water_need.median()

Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды (water_need) для всех животных (это 347,72). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
Функция .groupby в действии
Проделаем эту же группировку с DataFrame zoo.
Между переменной zoo и функцией .mean() нужно вставить ключевое слово groupby:
zoo.groupby('animal').mean()

Как и раньше, pandas автоматически проведет расчеты .mean() для оставшихся колонок (колонка animal пропала, потому что по ней проводилась группировка). Можно или игнорировать колонку uniq_id или удалить ее одним из следующих способов:
zoo.groupby('animal').mean()[['water_need']] — возвращает объект DataFrame.
zoo.groupby('animal').mean().water_need — возвращает объект Series.
Можно поменять метод агрегации с .mean() на любой изученный до этого.
Пришло время…
Проверить себя №1
Вернемся к набору данных article_read.
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
.
.
.
.
.
.
Правильный ответ:
Reddit!
Получить его можно было с помощью кода:
article_read.groupby('source').count()
Взять набор данных article_read, создать сегменты по значениям колонки source (groupby('source')) и в конце концов посчитать значения по источникам (.count()).

Также можно удалить ненужные колонки и сохранить только user_id:
article_read.groupby('source').count()[['user_id']]
Проверить себя №2
Вот еще одна, более сложная задача:
Какие самые популярные источник и страна для пользователей country_2? Другими словами, какая тема из какого источника принесла больше всего просмотров из country_2?
.
.
.
.
.
.
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count()

Вот краткое объяснение:
В первую очередь отфильтровали пользователей из country_2 (article_read[article_read.country == 'country_2']). Затем для этого подмножества был использован метод groupby. (Да, группировку можно осуществлять для нескольких колонок. Для этого их названия нужно собрать в список. Поэтому квадратные скобки используются между круглыми. Это что касается части groupby(['source', 'topic'])).
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
В следующем материале вы узнаете о четырех распространенных методах форматирования данных: merge, sort, reset_index и fillna.
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».

- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть
as pd, Jupyter Notebook понимает, что в будущем, при вводеpdподразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv().
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need
elephant,1001,500
elephant,1002,600
elephant,1003,550
tiger,1004,300
tiger,1005,320
tiger,1006,330
tiger,1007,290
tiger,1008,310
zebra,1009,200
zebra,1010,220
zebra,1011,240
zebra,1012,230
zebra,1013,220
zebra,1014,100
zebra,1015,80
lion,1016,420
lion,1017,600
lion,1018,500
lion,1019,390
kangaroo,1020,410
kangaroo,1021,430
kangaroo,1022,410
Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',')

Готово! Это файл zoo.csv, перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';')
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';',
names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл
.csvчерез URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv(
'https://pythonru.com/downloads/pandas_tutorial_read.csv',
delimiter=';',
names=['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head()

Или последние 5 строк:
article_read.tail()

Или 5 случайных строк:
article_read.sample(5)

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']]

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO']
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source? Результат всегда будет булевым значением (True или False).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read.

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']]
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head()
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']
)[['country', 'user_id']].head()
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2. Выведите первые 5 строк!
Вперед!
.
.
.
.
.
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head()
Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2']
ar_filtered_cols = ar_filtered[['user_id','topic', 'country']]
ar_filtered_cols.head()
В любом случае, логика не отличается. Сначала берется оригинальный dataframe (article_read), затем отфильтровываются строки со значением для колонки country — country_2 ([article_read.country == 'country_2']). Потому берутся три нужные колонки ([['user_id', 'topic', 'country']]) и в конечном итоге выбираются только первые пять строк (.head()).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
]]>Третья часть серии руководств «Разработка игр с помощью Pygame». Она предназначена для программистов начального и среднего уровней, которые заинтересованы в создании игр и улучшении собственных навыков кодирования на Python. Начать стоит с урока: «Библиотека Pygame / Часть 1. Введение».
Графические спрайты
Разноцветные прямоугольники вполне можно использовать на старте разработки, чтобы убедиться, что игра работает, но рано или поздно захочется задействовать изображение космического корабля или персонажа для спрайта. Это подводит к первому вопросу: где брать графику для игры?
Где искать арт
Когда вам нужен арт для игры, у вас есть 3 варианта:
- Нарисовать его самостоятельно
- Найти художника
- Использовать готовые арты из интернета
Первый и второй варианты подходят для творческих людей или тех, у кого есть талантливые друзья, но у большинства программистов рисование не входит в набор навыков. Поэтому остается интернет. Но здесь важно помнить, что нельзя использовать изображения, на которые у вас нет прав. Вы без проблем найдете изображение с Марио или любимым Покемоном, но их нельзя использовать, особенно если планируется выкладывать игру в интернет для других пользователей.
К счастью, есть хорошее решение — OpenGameArt.org. На этом сайте полно изображений, звуков, музыки и другого контента. Весь он лицензирован так, что его можно свободно использовать в играх. Один из лучших создателей контента на этом сайте — Kenney. Его можно найти, просто введя это имя в строку поиска или зайти на его сайт.
Особенность арта Kenney (помимо отличного качества) — он выпускает контент в коллекциях. Это значит, что разработчик получает различные изображения, выполненные в едином стиле, и нет необходимости брать картинки в разных источниках.
В этом уроке будет использоваться набор Platformer Art Complete Pack от Kenney, в котором полно графики для создания игры в жанре платформера. Нужно всего лишь скачать его и распаковать. Начнем с изображения p1_jump.png.

Или же можете просто скачать картинку отсюда.
Организация игровых ассетов
В первую очередь нужна папка для хранения ассетов. В играх так называют, например, арты или звук. Назовем папку “img” и перенесем туда изображение игрока.
Чтобы использовать изображение в игре, нужно сообщить библиотеке Pygame, чтобы она загружала файл. Для этого необходимо указать его местоположение. В зависимости от используемого компьютера этот процесс может отличаться, но поскольку нужно сделать так, чтобы игра работала на любом устройстве, необходимо загрузить библиотеку Python под название os и указать, где находится игра:
import pygame
import random
import os
# настройка папки ассетов
game_folder = os.path.dirname(__file__)
Специальная переменная __file__ относится к папке, в которой сохранен код игры, а команда os.path.dirname указывает путь к папке. Например, путь к коду на компьютере с macOS может быть такой:
/Users/gvido/Documents/gamedev/tutorials/1_3_sprite_example.py
Если используется Windows, тогда он будет выглядеть приблизительно вот так:
C:\Users\gvido\Documents\python\game.py
Разные операционные системы по-разному подходят к поиску местоположения файлов. С помощью команды os.path можно позволить ПК самостоятельно определять правильный путь (вне зависимости от того, используется “/” или “”).
Теперь можно точно указать местоположение папки “img”:
import pygame
import random
import os
# настройка папки ассетов
game_folder = os.path.dirname(__file__)
img_folder = os.path.join(game_folder, 'img')
player_img = pygame.image.load(os.path.join(img_folder, 'p1_jump.png')).convert()
Изображение загружается с помощью pygame.image.load(), а convert() ускорит прорисовку в Pygame, конвертируя изображение в тот формат, который будет быстрее появляться на экране. Теперь можно заменить зеленый квадрат на изображение персонажа:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = player_img
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
Обратите внимание, что команды self.image.fill(GREEN) больше нет, потому что заливка одним цветом больше не нужна. get_rect() работает так же — теперь она будет окружать прямоугольником любое изображение self.image.
Если сейчас запустить программу, вы увидите маленького инопланетянина, который двигается по экрану. Но осталась одна проблема, которой не видно из-за черного фона. С помощью команды screen.fill() нужно поменять цвет фона, например, на синий. Теперь понятно, в чем проблема.

Файл изображения на компьютере — это всегда сетка пикселей. Вне зависимости от нарисованной формы, имеются дополнительные пиксели, заполняющие «фон». Нужно сообщить Pygame, чтобы она игнорировала пиксели, которые не нужны. В случае этого изображения речь идет о черном цвете, поэтому в код необходимо добавить следующее:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = player_img
self.image.set_colorkey(BLACK)
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
set_colorkey() говорит Pygame игнорировать любые пиксели конкретного цвета. Так выглядит намного лучше:

Вы освоили основы работы с Python! Время переходить к созданию настоящей игры. У нас есть руководство с процессом создания игры Shoot ’em up от начала и до конца.
]]>Вторая часть серии руководств «Разработка игр с помощью Pygame». Она предназначена для программистов начального и среднего уровней, которые заинтересованы в создании игр и улучшении собственных навыков кодирования на Python. Начать стоит с урока: «Библиотека Pygame / Часть 1. Введение».
Что такое спрайт?
Спрайт — это элемент компьютерной графики, представляющий объект на экране, который может двигаться. В двухмерной игре все, что вы видите на экране, является спрайтами. Спрайты можно анимировать, заставлять их взаимодействовать между собой или передавать управление ими игроку.
Для загрузки и отрисовки спрайтов в случай этой игры их нужно добавить в разделы “Обновление” и “Визуализация” игрового цикла. Несложно представить, что если в игре много спрайтов, то цикл довольно быстро станет большим и запутанным. В Pygame для этого есть решение: группировка спрайтов.
Набор спрайтов — это коллекция спрайтов, которые могут отображаться одновременно. Вот как нужно создавать группу спрайтов в игре:
clock = pygame.time.Clock()
all_sprites = pygame.sprite.Group()
Теперь этой возможностью можно воспользоваться, добавив группу целиком в цикл:
# Обновление
all_sprites.update()
# Отрисовка
screen.fill(BLACK)
all_sprites.draw(screen)
Теперь при создании каждого спрайта, главное убедиться, что он добавлен в группу all_sprites. Такой спрайт будет автоматически отрисован на экране и обновляться в цикле.
Создание спрайта
Можно переходить к созданию первого спрайта. В Pygame все спрайты выступают объектами. Если вы не работали с этим типом данных в Python, то для начала достаточно знать, что это удобный способ группировки данных и кода в единую сущность. Поначалу это может путать, но спрайты Pygame — отличная возможность попрактиковаться в работе с объектами и понять, как они работают.
Начнем с определения нового спрайта:
class Player(pygame.sprite.Sprite):
class сообщает Python, что определяется новый объект, который будет спрайтом игрока. Его тип pygame.sprite.Sprite. Это значит, что он будет основан на заранее определенном в Pygame классе Sprite.
Первое, что нужно в определении class — специальная функция __init__(), включающая код, который будет запущен при создании нового объекта этого типа. Также у каждого спрайта в Pygame должно быть два свойства: image и rect.
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 50))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
Первая строка, Pygame.sprite.Sprite.__init__(self) требуется в Pygame — она запускает инициализатор встроенных классов Sprite. Далее необходимо определить свойство image. Сейчас просто создадим квадрат размером 50х50 и заполним его зеленым (GREEN) цветом. Чуть позже вы узнаете, как сделать image спрайта красивее, используя, например, персонажа или космический корабль, но сейчас достаточно сплошного квадрата.
Дальше необходимо определить rect спрайта. Это сокращенное от rectangle (прямоугольник). Прямоугольники повсеместно используются в Pygame для отслеживания координат объектов. Команда get_rect() оценивает изображение image и высчитывает прямоугольник, способный окружить его.
rect можно использовать для размещения спрайта в любом месте. Начнем с создания спрайта по центру:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 50))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
Теперь, после определения спрайта игрока Player, нужно отрисовать (создать) его, инициализировав экземпляр (instance) класса Player. Также нужно обязательно добавить спрайт в группу all_sprites.
all_sprites = pygame.sprite.Group()
player = Player()
all_sprites.add(player)
Сейчас, если запустить программу, по центру окна будет находиться зеленый квадрат. Увеличьте значения WIDTH и HEIGHT в настройках программы, чтобы создать достаточно пространства для движения спрайта в следующем шаге.

Движение спрайта
В игровом цикле есть функция all_sprites.update(). Это значит, что для каждого спрайта в группе Pygame ищет функцию update() и запускает ее. Чтобы спрайт двигался, нужно определить его правила обновления:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 50))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
def update(self):
self.rect.x += 5
Это значит, что при каждом игровом цикле x-координата спрайта будет увеличиваться на 5 пикселей. Запустите программу, чтобы посмотреть, как он скрывается за пределами экрана, достигая правой стороны.

Исправить это можно, заставив спрайт двигаться по кругу — когда он добирается до правой стороны экрана, просто переносить его влево. Это легко сделать, используя элемент управления rect спрайта:

Так, если левая сторона rect пропадает с экрана, просто задаем значение правого края равное 0:
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 50))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
def update(self):
self.rect.x += 5
if self.rect.left > WIDTH:
self.rect.right = 0
Теперь можно видеть, как спрайт будто бы двигается по кругу.

На этом все. Отправляйтесь изучать и экспериментировать, но не забывайте, что все, что вы помещаете в метод update(), будет происходить в каждом кадре. Попробуйте научить спрайт двигаться сверху вниз (изменив координату y) или заставить его отталкиваться от стен (изменяя направлении по достижении края).
Код урока:
# Pygame шаблон - скелет для нового проекта Pygame
import pygame
import random
WIDTH = 800
HEIGHT = 650
FPS = 30
# Задаем цвета
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
class Player(pygame.sprite.Sprite):
def __init__(self):
pygame.sprite.Sprite.__init__(self)
self.image = pygame.Surface((50, 50))
self.image.fill(GREEN)
self.rect = self.image.get_rect()
self.rect.center = (WIDTH / 2, HEIGHT / 2)
def update(self):
self.rect.x += 5
if self.rect.left > WIDTH:
self.rect.right = 0
# Создаем игру и окно
pygame.init()
pygame.mixer.init()
screen = pygame.display.set_mode((WIDTH, HEIGHT))
pygame.display.set_caption("My Game")
clock = pygame.time.Clock()
all_sprites = pygame.sprite.Group()
player = Player()
all_sprites.add(player)
# Цикл игры
running = True
while running:
# Держим цикл на правильной скорости
clock.tick(FPS)
# Ввод процесса (события)
for event in pygame.event.get():
# check for closing window
if event.type == pygame.QUIT:
running = False
# Обновление
all_sprites.update()
# Рендеринг
screen.fill(BLACK)
all_sprites.draw(screen)
# После отрисовки всего, переворачиваем экран
pygame.display.flip()
pygame.quit()
В следующем уроке речь пойдет о том, как использовать арт в спрайтах — перейти от обычного квадрата к анимированному персонажу.
]]>
Это первая часть серии руководств «Разработка игр с помощью Pygame». Она предназначена для программистов начального и среднего уровней, которые заинтересованы в создании игр и улучшении собственных навыков кодирования на Python.
Код в уроках был написан на Python 3.7 и Pygame 1.9.6
Что такое Pygame?
Pygame — это «игровая библиотека», набор инструментов, помогающих программистам создавать игры. К ним относятся:
- Графика и анимация
- Звук (включая музыку)
- Управление (мышь, клавиатура, геймпад и так далее)
Игровой цикл
В сердце каждой игры лежит цикл, который принято называть «игровым циклом». Он запускается снова и снова, делая все, чтобы работала игра. Каждый цикл в игре называется кадром.
В каждом кадре происходит масса вещей, но их можно разбить на три категории:
- Обработка ввода (события)
Речь идет обо всем, что происходит вне игры — тех событиях, на которые она должна реагировать. Это могут быть нажатия клавиш на клавиатуре, клики мышью и так далее.
- Обновление игры
Изменение всего, что должно измениться в течение одного кадра. Если персонаж в воздухе, гравитация должна потянуть его вниз. Если два объекта встречаются на большой скорости, они должны взорваться.
- Рендеринг (прорисовка)
В этом шаге все выводится на экран: фоны, персонажи, меню. Все, что игрок должен видеть, появляется на экране в нужном месте.
Время
Еще один важный аспект игрового цикла — скорость его работы. Многие наверняка знакомы с термином FPS, который расшифровывается как Frames Per Second (или кадры в секунду). Он указывает на то, сколько раз цикл должен повториться за одну секунду. Это важно, чтобы игра не была слишком медленной или быстрой. Важно и то, чтобы игра не работала с разной скоростью на разных ПК. Если персонажу необходимо 10 секунд на то, чтобы пересечь экран, эти 10 секунд должны быть неизменными для всех компьютеров.
Создание шаблона Pygame
Теперь, зная из каких элементов состоит игра, можно переходить к процессу написания кода. Начать стоит с создания простейшей программы pygame, которая всего лишь открывает окно и запускает игровой цикл. Это отправная точка для любого проекта pygame.
В начале программы нужно импортировать необходимые библиотеки и задать базовые переменные настроек игры:
# Pygame шаблон - скелет для нового проекта Pygame
import pygame
import random
WIDTH = 360 # ширина игрового окна
HEIGHT = 480 # высота игрового окна
FPS = 30 # частота кадров в секунду
Дальше необходимо открыть окно игры:
# создаем игру и окно
pygame.init()
pygame.mixer.init() # для звука
screen = pygame.display.set_mode((WIDTH, HEIGHT))
pygame.display.set_caption("My Game")
clock = pygame.time.Clock()
pygame.init() — это команда, которая запускает pygame. screen — окно программы, которое создается, когда мы задаем его размер в настройках. Дальше необходимо создать clock, чтобы убедиться, что игра работает с заданной частотой кадров.
Теперь необходимо создать игровой цикл:
# Цикл игры
running = True
while running:
# Ввод процесса (события)
# Обновление
# Визуализация (сборка)
Игровой цикл — это цикл while, контролируемый переменной running. Если нужно завершить игру, необходимо всего лишь поменять значение running на False. В результате цикл завершится. Теперь можно заполнить каждый раздел базовым кодом.
Раздел рендеринга (отрисовки)
Начнем с раздела отрисовки. Персонажей пока нет, поэтому экран можно заполнить сплошным цветом. Чтобы сделать это, нужно разобраться, как компьютер обрабатывает цвета.
Экраны компьютеров сделаны из пикселей, каждый из которых содержит 3 элемента: красный, зеленый и синий. Цвет пикселя определяется тем, как горит каждый из элементов:

Каждый из трех основных цветов может иметь значение от 0 (выключен) до 255 (включен на 100%), так что для каждого элемента есть 256 вариантов.
Узнать общее количество отображаемых компьютером цветов можно, умножив:
>>> 256 * 256 * 256
16,777,216
Теперь, зная, как работают цвета, можно задать их в начале программ:
# Цвета (R, G, B)
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
А после этого — заполнить весь экран.
# Рендеринг
screen.fill(BLACK)
Но этого недостаточно. Дисплей компьютера работает не так. Изменить пиксель — значит передать команду видеокарте, чтобы она передала соответствующую команду экрану. По компьютерным меркам это очень медленный процесс. Если нужно нарисовать на экране много всего, это займет много времени. Исправить это можно оригинальным способом, который называется — двойная буферизация. Звучит необычно, но вот что это такое.
Представьте, что у вас есть двусторонняя доска, которую можно поворачивать, показывая то одну, то вторую сторону. Одна будет дисплеем (то, что видит игрок), а вторая — оставаться скрытой, ее сможет «видеть» только компьютер. С каждым кадром рендеринг будет происходить на задней части доски. Когда отрисовка завершается, доска поворачивается и ее содержимое демонстрируется игроку.

А это значит, что процесс отрисовки происходит один раз за кадр, а не при добавлении каждого элемента.
В pygame это происходит автоматически. Нужно всего лишь сказать доске, чтобы она перевернулась, когда отрисовка завершена. Эта команда называется flip():
# Рендеринг
screen.fill(BLACK)
# после отрисовки всего, переворачиваем экран
pygame.display.flip()
Главное — сделать так, чтобы функция flip() была в конце. Если попытаться отрисовать что-то после поворота, это содержимое не отобразится на экране.
Раздел ввода (событий)
Игры еще нет, поэтому пока сложно сказать, какие кнопки или другие элементы управления понадобятся. Но нужно настроить одно важное событие. Если попытаться запустить программу сейчас, то станет понятно, что нет возможности закрыть окно. Нажать на крестик в верхнем углу недостаточно. Это тоже событие, и необходимо сообщить программе, чтобы она считала его и, соответственно, закрыла игру.
События происходят постоянно. Что, если игрок нажимает кнопку прыжка во время отрисовки? Это нельзя игнорировать, иначе игрок будет разочарован. Для этого pygame сохраняет все события, произошедшие с момента последнего кадра. Даже если игрок будет лупить по кнопкам, вы не пропустите ни одну из них. Создается список, и с помощью цикла for можно пройтись по всем из них.
for event in pygame.event.get():
# проверить закрытие окна
if event.type == pygame.QUIT:
running = False
В pygame много событий, на которые он способен реагировать. pygame.QUIT — событие, которое стартует после нажатия крестика и передает значение False переменной running, в результате чего игровой цикл заканчивается.
Контроль FPS
Пока что нечего поместить в раздел Update (обновление), но нужно убедиться, что настройка FPS контролирует скорость игры. Это можно сделать следующим образом:
while running:
# держим цикл на правильной скорости
clock.tick(FPS)
Команда tick() просит pygame определить, сколько занимает цикл, а затем сделать паузу, чтобы цикл (целый кадр) длился нужно время. Если задать значение FPS 30, это значит, что длина одного кадра — 1/30, то есть 0,03 секунды. Если цикл кода (обновление, рендеринг и прочее) занимает 0,01 секунды, тогда pygame сделает паузу на 0,02 секунды.
Итог
Наконец, нужно убедиться, что когда игровой цикл завершается, окно игры закрывается. Для этого нужно поместить функцию pygame.quit() в конце кода. Финальный шаблон pygame будет выглядеть вот так:
# Pygame шаблон - скелет для нового проекта Pygame
import pygame
import random
WIDTH = 360
HEIGHT = 480
FPS = 30
# Задаем цвета
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
# Создаем игру и окно
pygame.init()
pygame.mixer.init()
screen = pygame.display.set_mode((WIDTH, HEIGHT))
pygame.display.set_caption("My Game")
clock = pygame.time.Clock()
# Цикл игры
running = True
while running:
# Держим цикл на правильной скорости
clock.tick(FPS)
# Ввод процесса (события)
for event in pygame.event.get():
# check for closing window
if event.type == pygame.QUIT:
running = False
# Обновление
# Рендеринг
screen.fill(BLACK)
# После отрисовки всего, переворачиваем экран
pygame.display.flip()
pygame.quit()
Ура! У вас есть рабочий шаблон Pygame. Сохраните его в файле с понятным названием, например, pygame_template.py, чтобы можно было использовать его каждый раз при создании нового проекта pygame.
В следующем руководстве этот шаблон будет использован как отправная точка для изучения процесса отрисовки объектов на экране и их движения.
]]>
До этого момента все приложение хранилось в одном файле main2.py. Это нормально для маленьких программ, но когда масштабы растут, ими становится сложно управлять. Если разбить крупный файл на несколько, код в каждом из них становится читабельнее и предсказуемее.
У Flask нет никаких ограничений в плане структурирования приложений. Тем не менее существуют советы (гайдлайны) о том, как делать их модульными.
Мы будем использовать следующую структуру приложения.
/app_dir
/app
__init__.py
/static
/templates
views.py
config.py
runner.py
Ниже описание каждого файла и папки:
| Файл | Описание |
|---|---|
app_dir |
Корневая папка проекта |
app |
Пакет Python с файлами представления, шаблонами и статическими файлами |
__init__.py |
Этот файл сообщает Python, что папка app — пакет Python |
static |
Папка со статичными файлами проекта |
templates |
Папка с шаблонами |
views.py |
Маршруты и функции представления |
config.py |
Настройки приложения |
runner.py |
Точка входа приложения |
Оставшаяся часть урока будет посвящена преобразованию проекта к такой структуре. Начнем с создания config.py.
Настройки на основе классов
Проект по созданию ПО обычно работает в трех разных средах:
- Разработка
- Тестирование
- Рабочий режим
При развитии проекта понадобится определить разные параметры для разных сред. Некоторые также будут оставаться неизменными вне зависимости от среды. Внедрить такую систему конфигурации можно с помощью классов.
Начать стоит с определения настроек по умолчанию в базовом классе и только потом — создавать классы для отдельных сред, которые будут наследовать параметры из базового. Специальные классы могут перезаписывать или дополнять настройки, необходимые для конкретной среды.
Создадим файл config.py внутри папки flask_app и добавим следующий код:
import os
app_dir = os.path.abspath(os.path.dirname(__file__))
class BaseConfig:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'A SECRET KEY'
SQLALCHEMY_TRACK_MODIFICATIONS = False
##### настройка Flask-Mail #####
MAIL_SERVER = 'smtp.googlemail.com'
MAIL_PORT = 587
MAIL_USE_TLS = True
MAIL_USERNAME = os.environ.get('MAIL_USERNAME') or 'YOU_MAIL@gmail.com'
MAIL_PASSWORD = os.environ.get('MAIL_PASSWORD') or 'password'
MAIL_DEFAULT_SENDER = MAIL_USERNAME
class DevelopementConfig(BaseConfig):
DEBUG = True
SQLALCHEMY_DATABASE_URI = os.environ.get('DEVELOPMENT_DATABASE_URI') or \
'mysql+pymysql://root:pass@localhost/flask_app_db'
class TestingConfig(BaseConfig):
DEBUG = True
SQLALCHEMY_DATABASE_URI = os.environ.get('TESTING_DATABASE_URI') or \
'mysql+pymysql://root:pass@localhost/flask_app_db'
class ProductionConfig(BaseConfig):
DEBUG = False
SQLALCHEMY_DATABASE_URI = os.environ.get('PRODUCTION_DATABASE_URI') or \
'mysql+pymysql://root:pass@localhost/flask_app_db'
Стоит обратить внимание, что в этом коде значения некоторых настроек впервые берутся у переменных среды. Также здесь есть некоторые значения по умолчанию, если таковые для сред не будут указаны. Этот метод особенно полезен, когда имеется конфиденциальная информацию, и ее не хочется вписывать напрямую в приложение.
Считывать настройки из класса будет метод from_object():
app.config.from_object('config.Create')
Создание пакета приложения
В папке flask_app нужно создать новую папку под названием app и переместить все файлы и папки в нее (за исключением env и migrations, а также созданного только что файла config.py). Внутри папки app нужно создать файл __init__.py со следующим кодом:
from flask import Flask
from flask_migrate import Migrate, MigrateCommand
from flask_mail import Mail, Message
from flask_sqlalchemy import SQLAlchemy
from flask_script import Manager, Command, Shell
from flask_login import LoginManager
import os, config
# создание экземпляра приложения
app = Flask(__name__)
app.config.from_object(os.environ.get('FLASK_ENV') or 'config.DevelopementConfig')
# инициализирует расширения
db = SQLAlchemy(app)
mail = Mail(app)
migrate = Migrate(app, db)
login_manager = LoginManager(app)
login_manager.login_view = 'login'
# import views
from . import views
# from . import forum_views
# from . import admin_views
__init__.py создает экземпляр приложения и запускает расширения. Если переменная среды FLASK_ENV не задана, приложение запустится в режиме отладки (то есть, app.debug = True). Чтобы перевести приложение в рабочий режим, нужно установить для переменной среды FLASK_ENV значение config.ProductionConfig.
После запуска расширений инструкция import на 21 строке импортирует все функции представления. Это нужно, что подключить экземпляр приложение к этим функциям, иначе Flask не будет о них знать.
Необходимо переименовать файл main2.py на views.py и обновить его так, чтобы он содержал только маршруты и функции представления. Это полный код обновленного файла views.py.
from app import app
from flask import render_template, request, redirect, url_for, flash, make_response, session
from flask_login import login_required, login_user,current_user, logout_user
from .models import User, Post, Category, Feedback, db
from .forms import ContactForm, LoginForm
from .utils import send_mail
@app.route('/')
def index():
return render_template('index.html', name='Jerry')
@app.route('/user/<int:user_id>/')
def user_profile(user_id):
return "Profile page of user #{}".format(user_id)
@app.route('/books/<genre>/')
def books(genre):
return "All Books in {} category".format(genre)
@app.route('/login/', methods=['post', 'get'])
def login():
if current_user.is_authenticated:
return redirect(url_for('admin'))
form = LoginForm()
if form.validate_on_submit():
user = db.session.query(User).filter(User.username == form.username.data).first()
if user and user.check_password(form.password.data):
login_user(user, remember=form.remember.data)
return redirect(url_for('admin'))
flash("Invalid username/password", 'error')
return redirect(url_for('login'))
return render_template('login.html', form=form)
@app.route('/logout/')
@login_required
def logout():
logout_user()
flash("You have been logged out.")
return redirect(url_for('login'))
@app.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
# здесь логика БД
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
send_mail("New Feedback", app.config['MAIL_DEFAULT_SENDER'], 'mail/feedback.html',
name=name, email=email)
flash("Message Received", "success")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
@app.route('/cookie/')
def cookie():
if not request.cookies.get('foo'):
res = make_response("Setting a cookie")
res.set_cookie('foo', 'bar', max_age=60*60*24*365*2)
else:
res = make_response("Value of cookie foo is {}".format(request.cookies.get('foo')))
return res
@app.route('/delete-cookie/')
def delete_cookie():
res = make_response("Cookie Removed")
res.set_cookie('foo', 'bar', max_age=0)
return res
@app.route('/article', methods=['POST', 'GET'])
def article():
if request.method == 'POST':
res = make_response("")
res.set_cookie("font", request.form.get('font'), 60*60*24*15)
res.headers['location'] = url_for('article')
return res, 302
return render_template('article.html')
@app.route('/visits-counter/')
def visits():
if 'visits' in session:
session['visits'] = session.get('visits') + 1
else:
session['visits'] = 1
return "Total visits: {}".format(session.get('visits'))
@app.route('/delete-visits/')
def delete_visits():
session.pop('visits', None) # удаление посещений
return 'Visits deleted'
@app.route('/session/')
def updating_session():
res = str(session.items())
cart_item = {'pineapples': '10', 'apples': '20', 'mangoes': '30'}
if 'cart_item' in session:
session['cart_item']['pineapples'] = '100'
session.modified = True
else:
session['cart_item'] = cart_item
return res
@app.route('/admin/')
@login_required
def admin():
return render_template('admin.html')
views.py содержит не только функции представления. Сюда перемещен код моделей, классов форм и другие функции для соответствующих файлов:
models.py
from app import db, login_manager
from datetime import datetime
from flask_login import (LoginManager, UserMixin, login_required,
login_user, current_user, logout_user)
from werkzeug.security import generate_password_hash, check_password_hash
class Category(db.Model):
__tablename__ = 'categories'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False, unique=True)
slug = db.Column(db.String(255), nullable=False, unique=True)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
posts = db.relationship('Post', backref='category', cascade='all,delete-orphan')
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
post_tags = db.Table('post_tags',
db.Column('post_id', db.Integer, db.ForeignKey('posts.id')),
db.Column('tag_id', db.Integer, db.ForeignKey('tags.id'))
)
class Post(db.Model):
__tablename__ = 'posts'
id = db.Column(db.Integer(), primary_key=True)
title = db.Column(db.String(255), nullable=False)
slug = db.Column(db.String(255), nullable=False)
content = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onudate=datetime.utcnow)
category_id = db.Column(db.Integer(), db.ForeignKey('categories.id'))
def __repr__(self):
return "<{}:{}>".format(self.id, self.title[:10])
class Tag(db.Model):
__tablename__ = 'tags'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
slug = db.Column(db.String(255), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
posts = db.relationship('Post', secondary=post_tags, backref='tags')
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
class Feedback(db.Model):
__tablename__ = 'feedbacks'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(1000), nullable=False)
email = db.Column(db.String(100), nullable=False)
message = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
class Employee(db.Model):
__tablename__ = 'employees'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
designation = db.Column(db.String(255), nullable=False)
doj = db.Column(db.Date(), nullable=False)
@login_manager.user_loader
def load_user(user_id):
return db.session.query(User).get(user_id)
class User(db.Model, UserMixin):
__tablename__ = 'users'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(100))
username = db.Column(db.String(50), nullable=False, unique=True)
email = db.Column(db.String(100), nullable=False, unique=True)
password_hash = db.Column(db.String(100), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onupdate=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.username)
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
forms.py
from flask_wtf import FlaskForm
from wtforms import Form, ValidationError
from wtforms import StringField, SubmitField, TextAreaField, BooleanField
from wtforms.validators import DataRequired, Email
class ContactForm(FlaskForm):
name = StringField("Name: ", validators=[DataRequired()])
email = StringField("Email: ", validators=[Email()])
message = TextAreaField("Message", validators=[DataRequired()])
submit = SubmitField()
class LoginForm(FlaskForm):
username = StringField("Username", validators=[DataRequired()])
password = StringField("Password", validators=[DataRequired()])
remember = BooleanField("Remember Me")
submit = SubmitField()
utils.py
from . import mail, db
from flask import render_template
from threading import Thread
from app import app
from flask_mail import Message
def async_send_mail(app, msg):
with app.app_context():
mail.send(msg)
def send_mail(subject, recipient, template, **kwargs):
msg = Message(subject, sender=app.config['MAIL_DEFAULT_SENDER'], recipients=[recipient])
msg.html = render_template(template, **kwargs)
thrd = Thread(target=async_send_mail, args=[app, msg])
thrd.start()
return thrd
Наконец, для запуска приложения нужно добавить следующий код в файл runner.py:
import os
from app import app, db
from app.models import User, Post, Tag, Category, Employee, Feedback
from flask_script import Manager, Shell
from flask_migrate import MigrateCommand
manager = Manager(app)
# эти переменные доступны внутри оболочки без явного импорта
def make_shell_context():
return dict(app=app, db=db, User=User, Post=Post, Tag=Tag, Category=Category, Employee=Employee, Feedback=Feedback)
manager.add_command('shell', Shell(make_context=make_shell_context))
manager.add_command('db', MigrateCommand)
if __name__ == '__main__':
manager.run()
runner.py — это точка входа проекта. В первую очередь файл создает экземпляр объекта Manager(). Затем он определяет функцию make_shell_context(). Объекты, которые вернет make_shell_context(), будут доступны в оболочке без импорта соответствующих инструкций. Наконец, метод run() экземпляра Manager будет вызван для запуска сервера.
Порядок выполнения
В этом уроке было создано немало файлов, и достаточно легко запутаться в том, за что отвечает каждый из них, а также в порядке, в котором они запускаются. Этот раздел создан для разъяснения всего процесса.
Все начинается с исполнения файла runner.py. Вторая строка в файле runner.py импортирует app и db из пакета app. Когда интерпретатор Python доходит до этой строки, управление программой передается файлу __init__.py, который в этот момент начинает исполняться. На 7 строке __init__.py импортирует модуль config, который передает управление config.py. Когда исполнение config.py завершается, управление снова возвращается к __init__.py. На 21 строке __init__.py импортирует модуль views, который передает управление views.py. Первая строка views.py снова импортирует экземпляр приложения app из пакета app. Экземпляр приложения app уже в памяти, поэтому снова он не будет импортирован. На строках 4, 5 и 6 views.py импортирует модели, формы и функцию send_mail и временно передает управление соответствующим файлам. Когда исполнение views.py завершается, управление программой возвращается к __init__.py. Это завершает исполнение __init__.py. Управление возвращается к runner.py и начинается исполнения инструкции на строке 3.
Третья строка runner.py импортирует классы, определенные в модуле models.py. Поскольку модели уже доступны в файле views.py, файл models.py не будет исполняться.
Поскольку runner.py работает как основной модуль, условие на 17 строке выполнено, и manager.run() запускает приложение.
Запуск проекта
Теперь можно запускать проект. В терминале для запуска сервера нужно ввести следующую команду.
(env) gvido@vm:~/flask_app$ python runner.py runserver
* Restarting with stat
* Debugger is active!
* Debugger PIN: 391-587-440
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Если переменная среды FLASK_ENV не установлена, предыдущая команда запустит приложение в режиме отладки. Если зайти на https://127.0.0.1:5000/, откроется домашняя страница со следующим содержанием:
Name: Jerry
Также необходимо проверить остальные страницы приложения, чтобы убедиться, что все работает.
Приложение теперь является гибким. Оно может получить совсем иной набор настроек с помощью всего лишь одной переменной среды. Предположим, нужно перевести приложение в рабочий режим. Для нужно всего лишь создать переменную среды FLASK_ENV со значением config.ProductionConfig.
В терминале нужно вести следующую команду для создания переменной среды FLASK_ENV:
(env) gvido@vm:~/flask_app$ export FLASK_ENV=config.ProductionConfig
Эта команда создает переменную среды в Linux и macOS. Пользователи Windows могут использовать следующую команду:
(env) C:\Users\gvido\flask_app>set FLASK_ENV=config.ProductionConfig
Снова запустим приложение.
(env) gvido@vm:~/flask_app$ python runner.py runserver
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Теперь приложение работает в рабочем режиме. Если сейчас Python вызовет исключения, то вместо трассировки стека отобразится ошибка 500.
Поскольку сейчас все еще этап разработки, переменную среды FLASK_ENV следует удалить. Она будет удалена автоматически при закрытии терминала. Чтобы сделать это вручную, нужно ввести следующую команду:
(env) gvido@vm:~/flask_app$ unset FLASK_ENV
Пользователи Windows могут использовать следующую команду:
(env) C:\Users\gvido\flask_app>set FLASK_ENV=
Проект теперь в лучшей форме. Его элементы организованы более логично. Использованный здесь подход подойдет для маленьких и средних по масштабу проектов. Тем не менее у Flask есть еще несколько козырей для тех, кто хочет быть еще продуктивнее.
Blueprints (чертежы/схемы/планы/эскизы)
Эскизы — еще один способ организации приложений. Они предполагают разделение на уровне представления. Как и приложение Flask, эскиз может иметь собственные функции представления, шаблоны и статические файлы. Для них даже можно выбрать собственные URI. Предположим, ведется работа над блогом и административной панелью. Чертеж для блога будет включать функцию представления, шаблоны и статические файлы, необходимые только блогу. В то же время эскиз административной панели будет содержать файлы, которые нужны ему. Их можно использовать в виде модулей или пакетов.
Пришло время добавить эскиз к проекту.
Создание эскиза
Сначала нужно создать папку main в папке flask_app/app и переместить туда views.py и forms.py. Внутри папки main необходимо создать файл __init__.py со следующим кодом:
from flask import Blueprint
main = Blueprint('main', __name__)
from . import views
Здесь создается объект эскиза с помощью класса Blueprint. Конструктор Blueprint() принимает два аргумента: имя эскиза и имя пакета, где он расположен; для большинства приложений достаточно будет передать __name__.
По умолчанию функции представления в эскизе будут искать шаблоны и статические файлы в папках приложения templates и static.
Изменить это можно, задав местоположение шаблонов и статических файлов при создании объекта Blueprint:
main = Blueprint('main', __name__,
template_folder='templates_dir')
static_folder='static_dir')
В этом случае Flask будет искать шаблоны и статические файлы в папках templates_dir и static_dir, которые находятся в папке эскиза.
Путь шаблона, добавленный в эскизе, имеет более низкий приоритет по сравнению с папкой шаблонов приложения. Это значит, что если есть два шаблона с одинаковыми именами в папках templates_dir и templates, Flask использует шаблон из папки templates.
Вот некоторые вещи, которые важно помнить, когда речь заходит о эскизах:
- При использовании эскизов маршруты определяется с помощью декоратора
route, а не экземпляра приложения (app). - Для создания URL при использовании эскизов нужно в качестве префикса указать название эскиза, а через оператор точки (
.) — конечную точку. Это необходимо для создания URL и в Python, и в шаблонах. Например:url_for("main.index")Этот код вернет URL маршрута index эскиза main.
Можно не указывать название эскиза, если работа ведется в том же эскизе, для которого создается URL. Например:url_for(".index")
Этот код вернет URL маршрута index для эскиза main в том случае, если код редактируется в функции представления или шаблоне эскиза main.
Чтобы приспособить изменения, нужно обновить инструкции import, вызовы url_for() и маршруты во views.py. Это обновленная версия файла views.py.
from app import app, db
from . import main
from flask import Flask, request, render_template, redirect, url_for, flash, make_response, session
from flask_login import login_required, login_user, current_user, logout_user
from app.models import User, Post, Category, Feedback, db
from .forms import ContactForm, LoginForm
from app.utils import send_mail
@main.route('/')
def index():
return render_template('index.html', name='Jerry')
@main.route('/user/<int:user_id>/')
def user_profile(user_id):
return "Profile page of user #{}".format(user_id)
@main.route('/books/<genre>/')
def books(genre):
return "All Books in {} category".format(genre)
@main.route('/login/', methods=['post', 'get'])
def login():
if current_user.is_authenticated:
return redirect(url_for('.admin'))
form = LoginForm()
if form.validate_on_submit():
user = db.session.query(User).filter(User.username == form.username.data).first()
if user and user.check_password(form.password.data):
login_user(user, remember=form.remember.data)
return redirect(url_for('.admin'))
flash("Invalid username/password", 'error')
return redirect(url_for('.login'))
return render_template('login.html', form=form)
@main.route('/logout/')
@login_required
def logout():
logout_user()
flash("You have been logged out.")
return redirect(url_for('.login'))
@main.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
print(name)
print(email)
print(message)
# здесь логика БД
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
send_mail("New Feedback", app.config['MAIL_DEFAULT_SENDER'], 'mail/feedback.html',
name=name, email=email)
print("\nData received. Now redirecting ...")
flash("Message Received", "success")
return redirect(url_for('.contact'))
return render_template('contact.html', form=form)
@main.route('/cookie/')
def cookie():
if not request.cookies.get('foo'):
res = make_response("Setting a cookie")
res.set_cookie('foo', 'bar', max_age=60*60*24*365*2)
else:
res = make_response("Value of cookie foo is {}".format(request.cookies.get('foo')))
return res
@main.route('/delete-cookie/')
def delete_cookie():
res = make_response("Cookie Removed")
res.set_cookie('foo', 'bar', max_age=0)
return res
@main.route('/article/', methods=['POST', 'GET'])
def article():
if request.method == 'POST':
print(request.form)
res = make_response("")
res.set_cookie("font", request.form.get('font'), 60*60*24*15)
res.headers['location'] = url_for('.article')
return res, 302
return render_template('article.html')
@main.route('/visits-counter/')
def visits():
if 'visits' in session:
session['visits'] = session.get('visits') + 1 # чтение и обновление данных сессии
else:
session['visits'] = 1 # настройка данных сессии
return "Total visits: {}".format(session.get('visits'))
@main.route('/delete-visits/')
def delete_visits():
session.pop('visits', None) # удаление посещений
return 'Visits deleted'
@main.route('/session/')
def updating_session():
res = str(session.items())
cart_item = {'pineapples': '10', 'apples': '20', 'mangoes': '30'}
if 'cart_item' in session:
session['cart_item']['pineapples'] = '100'
session.modified = True
else:
session['cart_item'] = cart_item
return res
@main.route('/admin/')
@login_required
def admin():
return render_template('admin.html')
Стоит обратить внимание, что в файле views.py URL создаются без определения названия эскиза, потому что работа ведется в этом же эскизе.
Также нужно следующим образом обновить вызов url_for() в admin.html:
#...
<p><a href="{{ url_for('.logout') }}">Logout</a></p>
#...
Функции представления во views.py теперь ассоциируются с эскизом main. Дальше нужно зарегистрировать эскизы в приложении Flask. Необходимо открыть app/__init__.py и изменить его следующим образом:
#...
# создать экземпляр приложения
app = Flask(__name__)
app.config.from_object(os.environ.get('FLASK_ENV') or 'config.DevelopementConfig')
# инициализирует расширения
db = SQLAlchemy(app)
mail = Mail(app)
migrate = Migrate(app, db)
login_manager = LoginManager(app)
login_manager.login_view = 'main.login'
# регистрация blueprints
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
#from .admin import main as admin_blueprint
#app.register_blueprint(admin_blueprint)
Метод register_blueprint() экземпляра приложения используется для регистрации эскиза. Можно зарегистрировать несколько эскизов, вызвав register_bluebrint() для каждого. Важно обратить внимание, что на 11 строке login_manager.login_view присваивается main.login. В этом случае важно указать, о каком эскизе идет речь, иначе Flask не сможет понять, на какой эскиз ссылается код.
Сейчас структура приложения выглядит так:
├── flask_app/
├── app/
│ ├── __init__.py
│ ├── main/
│ │ ├── forms.py
│ │ ├── __init__.py
│ │ └── views.py
│ ├── models.py
│ ├── static/
│ │ └── style.css
│ ├── templates/
│ │ ├── admin.html
│ │ ├── article.html
│ │ ├── contact.html
│ │ ├── index.html
│ │ ├── login.html
│ │ └── mail/
│ │ └── feedback.html
│ └── utils.py
├── migrations/
│ ├── alembic.ini
│ ├── env.py
│ ├── README
│ ├── script.py.mako
│ └── versions/
│ ├── 0f0002bf91cc_adding_users_table.py
│ ├── 6e059688f04e_adding_employees_table.py
├── runner.py
├── config.py
├── env/
Фабрика приложения
В приложении уже используются пакеты и эскизы (blueprints). Его можно улучшать и дальше, передав функцию создания экземпляров приложения Фабрике приложения. Это всего лишь функция, создающая объект.
Что это даст:
- Упростит процесс тестирования, потому что можно будет создать экземпляр приложения с разными настройками
- Можно будет запускать несколько экземпляров одного приложения в одном и том же процессе. Это удобно, когда используется балансировка нагрузки трафика между разными серверами.
Для внедрения фабрики приложения нужно обновить app/__init__.py:
from flask import Flask
from flask_migrate import Migrate, MigrateCommand
from flask_mail import Mail, Message
from flask_sqlalchemy import SQLAlchemy
from flask_script import Manager, Command, Shell
from flask_login import LoginManager
import os, config
db = SQLAlchemy()
mail = Mail()
migrate = Migrate()
login_manager = LoginManager()
login_manager.login_view = 'main.login'
# Фабрика приложения
def create_app(config):
# создание экземпляра приложения
app = Flask(__name__)
app.config.from_object(config)
db.init_app(app)
mail.init_app(app)
migrate.init_app(app, db)
login_manager.init_app(app)
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
#from .admin import main as admin_blueprint
#app.register_blueprint(admin_blueprint)
return app
Теперь за создание экземпляров приложения ответственна функция create_app. Она принимает один аргумент config и возвращает экземпляр приложения.
Фабрика приложений разделяет процесс создания экземпляров расширений и их настройки. Создание экземпляров происходит до того, как create_app() вызывается, а настройка происходит внутри функции create_app() с помощью метода init_app().
Дальше нужно обновить runner.py для фабрики приложения:
import os
from app import db, create_app
from app.models import User, Post, Tag, Category, Employee, Feedback
from flask_script import Manager, Shell
from flask_migrate import MigrateCommand
app = create_app(os.getenv('FLASK_ENV') or 'config.DevelopementConfig')
manager = Manager(app)
def make_shell_context():
return dict(app=app, db=db, User=User, Post=Post, Tag=Tag, Category=Category,
Employee=Employee, Feedback=Feedback)
manager.add_command('shell', Shell(make_context=make_shell_context))
manager.add_command('db', MigrateCommand)
if __name__ == '__main__':
manager.run()
Стоит заметить, что при использовании фабрик приложения пропадает доступ к экземпляру приложения в эскизе во время импорта. Для получения доступа к экземплярам в эскизе нужно использовать прокси current_app из пакета flask. Необходимо обновить проект для использования переменной current_app:
from app import db
from . import main
from flask import (render_template, request, redirect, url_for, flash,
make_response, session, current_app)
from flask_login import login_required, login_user, current_user, logout_user
from app.models import User, Feedback
from app.utils import send_mail
from .forms import ContactForm, LoginForm
@main.route('/')
def index():
return render_template('index.html', name='Jerry')
@main.route('/user/<int:user_id>/')
def user_profile(user_id):
return "Profile page of user #{}".format(user_id)
@main.route('/books/<genre>/')
def books(genre):
return "All Books in {} category".format(genre)
@main.route('/login/', methods=['post', 'get'])
def login():
if current_user.is_authenticated:
return redirect(url_for('.admin'))
form = LoginForm()
if form.validate_on_submit():
user = db.session.query(User).filter(User.username == form.username.data).first()
if user and user.check_password(form.password.data):
login_user(user, remember=form.remember.data)
return redirect(url_for('.admin'))
flash("Invalid username/password", 'error')
return redirect(url_for('.login'))
return render_template('login.html', form=form)
@main.route('/logout/')
@login_required
def logout():
logout_user()
flash("You have been logged out.")
return redirect(url_for('.login'))
@main.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
# логика БД здесь
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
send_mail("New Feedback", current_app.config['MAIL_DEFAULT_SENDER'], 'mail/feedback.html',
name=name, email=email)
flash("Message Received", "success")
return redirect(url_for('.contact'))
return render_template('contact.html', form=form)
@main.route('/cookie/')
def cookie():
if not request.cookies.get('foo'):
res = make_response("Setting a cookie")
res.set_cookie('foo', 'bar', max_age=60*60*24*365*2)
else:
res = make_response("Value of cookie foo is {}".format(request.cookies.get('foo')))
return res
@main.route('/delete-cookie/')
def delete_cookie():
res = make_response("Cookie Removed")
res.set_cookie('foo', 'bar', max_age=0)
return res
@main.route('/article', methods=['POST', 'GET'])
def article():
if request.method == 'POST':
res = make_response("")
res.set_cookie("font", request.form.get('font'), 60*60*24*15)
res.headers['location'] = url_for('.article')
return res, 302
return render_template('article.html')
@main.route('/visits-counter/')
def visits():
if 'visits' in session:
session['visits'] = session.get('visits') + 1
else:
session['visits'] = 1
return "Total visits: {}".format(session.get('visits'))
@main.route('/delete-visits/')
def delete_visits():
session.pop('visits', None) # удаление посещений
return 'Visits deleted'
@main.route('/session/')
def updating_session():
res = str(session.items())
cart_item = {'pineapples': '10', 'apples': '20', 'mangoes': '30'}
if 'cart_item' in session:
session['cart_item']['pineapples'] = '100'
session.modified = True
else:
session['cart_item'] = cart_item
return res
@main.route('/admin/')
@login_required
def admin():
return render_template('admin.html')
utils.py
from . import mail, db
from flask import render_template, current_app
from threading import Thread
from flask_mail import Message
def async_send_mail(app, msg):
with app.app_context():
mail.send(msg)
def send_mail(subject, recipient, template, **kwargs):
msg = Message(subject, sender=current_app.config['MAIL_DEFAULT_SENDER'], recipients=[recipient])
msg.html = render_template(template, **kwargs)
thr = Thread(target=async_send_mail, args=[current_app._get_current_object(), msg])
thr.start()
return thr
В этих уроках речь шла о многих вещах, которые дают необходимые знания о Flask, его составляющих и том, как они сочетаются между собой.
]]>Аутентификация — один из самых важных элементов веб-приложений. Этот процесс предотвращает попадание неавторизованных пользователей на непредназначенные для них страницы. Собственную систему аутентификации можно создать с помощью куки и хэширования паролей. Такой миниатюрный проект станет отличной проверкой полученных навыков.
Как можно было догадаться, уже существует расширение, которое может значительно облегчить жизнь. Flask-Login — это расширение, позволяющее легко интегрировать систему аутентификации в приложение Flask. Установить его можно с помощью следующей команды:
(env) gvido@vm:~/flask_app$ pip install flask-login
Создание модели пользователя
Сейчас информация о пользователях, которые являются администраторами или редакторами сайта, нигде не хранится. Первая задача — создать модель User для хранения пользовательских данных. Откроем main2.py, чтобы добавить модель User после модели Employee:
#..
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(100))
username = db.Column(db.String(50), nullable=False, unique=True)
email = db.Column(db.String(100), nullable=False, unique=True)
password_hash = db.Column(db.String(100), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onupdate=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.username)
#...
Для обновления базы данных нужно создать новую миграцию. В терминале для создания нового скрипта миграции необходимо ввести следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py db migrate -m "Adding users table"
Запустить миграцию необходимо с помощью команды upgrade:
(env) gvido@vm:~/flask_app$ python main2.py db upgrade
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 6e059688f04e -> 0f0002bf91cc,
Adding users table
(env) gvido@vm:~/flask_app$
Это создаст таблицу users в базе данных.
Хэширование паролей
Пароли никогда не должны храниться в виде чистого текста в базе данных. Если так делать, злоумышленник, способный взломать базу данных, получит возможность узнать и пароли, и электронные адреса. Известно, что люди используют один и тот же пароль для разных сайтов, а это значит, что одна комбинация откроет злоумышленнику доступ к остальным аккаунтам пользователей.
Вместо хранения паролей прямо в базе данных, нужно сохранять их хэши. Хэш — это строка символов, которые смотрятся так, будто бы были подобраны случайно.
pbkdf2:sha256:50000$Otfe3YgZ$4fc9f1d2de2b6beb0b888278f21a8c0777e8ff980016e043f3eacea9f48f6dea
Хэш создается с помощью односторонней функции хэширования. Она принимает длину переменной и возвращает вывод фиксированной длины, которую мы и называем хэшем. Безопасным хэш делает тот факт, что его нельзя использовать для получения изначальной строки (поэтому функция и называется односторонней). Тем не менее для одного ввода односторонняя функция хэширования будет возвращать один и тот же результат.
Вот процессы, которые задействованы при создании хэша пароля:
Когда пользователь передает пароль (на этапе регистрации), необходимо его хэшировать и сохранить хэш в базу данных. Когда пользователь будет снова авторизоваться, функция повторно создаст хэш и сравнит его с тем, что хранится в базе данных. Если они совпадают, пользователь получит доступ к аккаунту. В противном случае, возникнет ошибка.
Flask поставляется с пакетом Werkzeug, в котором есть две вспомогательные функции для хэширования паролей.
| Метод | Описание |
|---|---|
generate_password_hash(password) |
Принимает пароль и возвращает хэш. По умолчанию использует одностороннюю функцию pbkdf2 для создания хэша. |
check_password_hash(password_hash, password) |
Принимает хэш и пароль в чистом виде, затем сравнивает password и password_hash. Если они одинаковые, возвращает True. |
Следующий код демонстрирует, как работать с этими функциями:
>>>
>>> from werkzeug.security import generate_password_hash, check_password_hash
>>>
>>> hash = generate_password_hash("secret password")
>>>
>>> hash
'pbkdf2:sha256:50000$zB51O5L3$8a43788bc902bca96e01a1eea95a650d9d5320753a2fbd16bea984215cdf97ee'
>>>
>>> check_password_hash(hash, "secret password")
True
>>>
>>> check_password_hash(hash, "pass")
False
>>>
>>>
Стоит обратить внимание, что когда check_password_hash() вызывается с правильными паролем (“secret password”), возвращается True, а если с неправильными — False.
Дальше нужно обновить модель User, и добавить в нее хэширование паролей:
#...
from werkzeug.security import generate_password_hash, check_password_hash
#...
#...
class User(db.Model):
#...
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onupdate=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.username)
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
#...
Создадим пользователей, чтобы проверить хэширование паролей.
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, User
>>>
>>> u1 = User(username='spike', email='spike@example.com')
>>> u1.set_password("spike")
>>>
>>> u2 = User(username='tyke', email='tyke@example.com')
>>> u2.set_password("tyke")
>>>
>>> db.session.add_all([u1, u2])
>>> db.session.commit()
>>>
>>> u1, u2
(<1:spike>, <2:tyke>)
>>>
>>>
>>> u1.check_password("pass")
False
>>> u1.check_password("spike")
True
>>>
>>> u2.check_password("foo")
False
>>> u2.check_password("tyke")
True
>>>
>>>
Вывод демонстрирует, что все работает как нужно, и в базе данных теперь есть два пользователя.
Интеграция Flask-Login
Для запуска Flask-Login нужно импортировать класс LoginManager из пакета flask_login и создать новый экземпляр LoginManager:
#...
from werkzeug.security import generate_password_hash, check_password_hash
from flask_login import LoginManager
app = Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:pass@localhost/flask_app_db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['MAIL_SERVER'] = 'smtp.googlemail.com'
app.config['MAIL_PORT'] = 587
app.config['MAIL_USE_TLS'] = True
app.config['MAIL_USERNAME'] = 'youmail@gmail.com'
app.config['MAIL_DEFAULT_SENDER'] = 'youmail@gmail.com'
app.config['MAIL_PASSWORD'] = 'password'
manager = Manager(app)
manager.add_command('db', MigrateCommand)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
mail = Mail(app)
login_manager = LoginManager(app)
#...
Для проверки пользователей Flask-Login требует добавления нескольких методов в класс User. Эти методы перечислены в следующей таблице:
| Метод | Описание |
|---|---|
is_authenticated() |
Возвращает True, если пользователь проверен (то есть, зашел с корректным паролем). В противном случае — False. |
is_active() |
Возвращает True, если действие аккаунта не приостановлено. |
is_anonymous() |
Возвращает True для неавторизованных пользователей. |
get_id() |
Возвращает уникальный идентификатор объекта User. |
Flask-Login предлагает реализацию этих методов по умолчанию с помощью класса UserMixin. Так, вместо определения их вручную, можно настроить их наследование из класса UserMixin. Откроем main2.py, чтобы изменить заголовок модели User:
#...
from flask_login import LoginManager, UserMixin
#...
class User(db.Model, UserMixin):
__tablename__ = 'users'
#...
Осталось только добавить обратный вызов user_loader. Соответствующий метод можно добавить над моделью User.
#...
@login_manager.user_loader
def load_user(user_id):
return db.session.query(User).get(user_id)
#...
Функция, принимающая в качестве аргумента декоратор user_loader, будет вызываться с каждым запросом к серверу. Она загружает пользователя из идентификатора пользователя в куки сессии. Flask-Login делает загруженного пользователя доступным с помощью прокси current_user. Для использования current_user его нужно импортировать из пакета flask_login. Он ведет себя как глобальная переменная и доступен как в функциях представления, так и в шаблонах. В любой момент времени current_user ссылается либо на вошедшего в систему, либо на анонимного пользователя. Различать их можно с помощью атрибута is_authenticated прокси current_user. Для анонимных пользователей is_authenticated вернет False. В противном случае — True.
Ограничение доступа к просмотру
Пока что на сайте нет никакой административной панели. В этом уроке она будет представлена обычной страницей. Чтобы не допустить неавторизованных пользователей к защищенным страница у Flask-Login есть декоратор login_required. Добавим следующий код в файле main2.py сразу за функцией представления updating_session():
#...
from flask_login import LoginManager, UserMixin, login_required
#...
@app.route('/admin/')
@login_required
def admin():
return render_template('admin.html')
#...
Декоратор login_required гарантирует, что функция представления admin() вызовется только в том случае, если пользователь авторизован. По умолчанию, если анонимный пользователь попытается зайти на защищенную страницу, он получит ошибку 401 «Не авторизован».
Необходимо запустить сервер и зайти на https://localhost:5000/login, чтобы проверить, как это работает. Откроется такая страница:

Вместо того чтобы показывать пользователю ошибку 401, лучше перенаправить его на страницу авторизации. Чтобы сделать это, нужно передать атрибуту login_view экземпляра LoginManager значение функции представления login():
#...
migrate = Migrate(app, db)
mail = Mail(app)
login_manager = LoginManager(app)
login_manager.login_view = 'login'
class Faker(Command):
'A command to add fake data to the tables'
#...
Сейчас функция login() определена следующим образом (но ее нужно будет поменять):
#...
@app.route('/login/', methods=['post', 'get'])
def login():
message = ''
if request.method == 'POST':
print(request.form)
username = request.form.get('username')
password = request.form.get('password')
if username == 'root' and password == 'pass':
message = "Correct username and password"
else:
message = "Wrong username or password"
return render_template('login.html', message=message)
#...
Если теперь зайти на https://localhost:5000/admin/, произойдет перенаправление на страницу авторизации:

Flask-Login также настраивает всплывающее сообщение, когда пользователя перенаправляют на страницу авторизации, но сейчас никакого сообщения нет, потому что шаблон авторизации (template/login.html) не отображает никаких сообщений. Нужно открыть login.html и добавить следующий код перед тегом <form>:
#...
{% endif %}
{% for category, message in get_flashed_messages(with_categories=true) %}
<spam class="{{ category }}">{{ message }}</spam>
{% endfor %}
<form action="" method="post">
#...
Если снова зайти на https://localhost:5000/admin/, на странице отобразится сообщение.

Чтобы изменить содержание сообщения, нужно передать новый текст атрибуту login_message экземпляра LoginManager.
Заодно почему бы не создать шаблон для функции представления admin(). Создадим новый шаблон admin.html со следующим кодом:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h2>Logged in User details</h2>
<ul>
<li>Username: {{ current_user.username }}</li>
<li>Email: {{ current_user.email }}</li>
<li>Created on: {{ current_user.created_on }}</li>
<li>Updated on: {{ current_user.updated_on }}</li>
</ul>
</body>
</html>
Здесь используется переменная current_user для отображения подробностей о авторизованном пользователе.
Создание формы авторизации
Перед авторизацией нужно создать форму. В ней будет три поля: имя пользователя, пароль и запомнить меня. Откроем forms.py, чтобы добавить класс LoginForm под классом ContactForm:
#...
from wtforms import StringField, SubmitField, TextAreaField, BooleanField, PasswordField
#...
#...
class LoginForm(FlaskForm):
username = StringField("Username", validators=[DataRequired()])
password = PasswordField("Password", validators=[DataRequired()])
remember = BooleanField("Remember Me")
submit = SubmitField()
Авторизация пользователей
Для авторизации пользователя Flask-Login предоставляет функцию login_user(). Она принимает объект пользователя. В случае успеха возвращает True и устанавливает сессию. В противном случае — False. По умолчанию сессия, установленная login_user(), заканчивается при закрытии браузера. Чтобы позволить пользователям оставаться авторизованными на дольше, нужно передать remember=True функции login_user() при авторизации пользователя. Откроем main2.py, чтобы изменить функцию представления login():
#...
from forms import ContactForm, LoginForm
#...
from flask_login import LoginManager, UserMixin, login_required, login_user, current_user
#...
@app.route('/login/', methods=['post', 'get'])
def login():
form = LoginForm()
if form.validate_on_submit():
user = db.session.query(User).filter(User.username == form.username.data).first()
if user and user.check_password(form.password.data):
login_user(user, remember=form.remember.data)
return redirect(url_for('admin'))
flash("Invalid username/password", 'error')
return redirect(url_for('login'))
return render_template('login.html', form=form)
#...
Дальше нужно обновить login.html, чтобы использовать класс LoginForm(). Нужно добавить в файл следующие изменения:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
</head>
<body>
{% for category, message in get_flashed_messages(with_categories=true) %}
<spam class="{{ category }}">{{ message }}</spam>
{% endfor %}
<form action="" method="post">
{{ form.csrf_token }}
<p>
{{ form.username.label() }}
{{ form.username() }}
{% if form.username.errors %}
{% for error in form.username.errors %}
{{ error }}
{% endfor %}
{% endif %}
</p>
<p>
{{ form.password.label() }}
{{ form.password() }}
{% if form.password.errors %}
{% for error in form.password.errors %}
{{ error }}
{% endfor %}
{% endif %}
</p>
<p>
{{ form.remember.label() }}
{{ form.remember() }}
</p>
<p>
{{ form.submit() }}
</p>
</form>
</body>
</html>
Теперь можно авторизоваться. Если зайти https://localhost:5000/admin, произойдет перенаправление на страницу авторизации.

Необходимо ввести корректное имя пользователя и пароль и нажать sumbit. Произойдет перенаправление на страницу администратора, которая должна выглядеть следующим образом.

Если не кликнуть “Remember Me” при авторизации, после закрытия браузера сайт выйдет из аккаунта. Если кликнуть, то логин останется.
Если ввести неправильные имя пользователя или пароль, произойдет перенаправление на страницу авторизации со всплывающим сообщением:

Завершение сеансов пользователей (выход из аккаунтов)
Функция logout_user() во Flask-Login завершает сеанс пользователя, удаляя его идентификатор из сессии. В файле main2.py нужно добавить следующий код под функцией представления login():
#...
from flask_login import LoginManager, UserMixin, login_required, login_user, current_user, logout_user
#...
@app.route('/logout/')
@login_required
def logout():
logout_user()
flash("You have been logged out.")
return redirect(url_for('login'))
#...
Далее необходимо обновить шаблон admin.html, чтобы добавить ссылку на маршрут logout:
#...
<ul>
<li>Username: {{ current_user.username }}</li>
<li>Email: {{ current_user.email }}</li>
<li>Created on: {{ current_user.created_on }}</li>
<li>Updated on: {{ current_user.updated_on }}</li>
</ul>
<p><a href="{{ url_for('logout') }}">Logout</a></p>
</body>
</html>
Если сейчас зайти на https://localhost:5000/admin/ (будучи авторизованным), то в нижней части страницы должны быть ссылка для выхода из аккаунта.

Если ее нажать, произойдет перенаправление на страницу авторизации.

Финальные штрихи
Есть одна маленькая проблема со страницей авторизации. Сейчас если авторизованный пользователь зайдет на https://localhost:5000/login/, то он снова увидит страницу авторизации. Нет смысла в демонстрации формы авторизованному пользователю. Для разрешения этой проблемы нужно добавить следующие изменения в функцию представления login():
#...
@app.route('/login/', methods=['post', 'get'])
def login():
if current_user.is_authenticated:
return redirect(url_for('admin'))
form = LoginForm()
if form.validate_on_submit():
#...
После этих изменений если авторизованный пользователь зайдет на страницу авторизации, он будет перенаправлен на страницу администратора.
]]>Веб-приложения отправляют электронные письма постоянно, и в этом уроке речь пойдет о том, как добавить инструмент для отправки email в приложение Flask.
В стандартной библиотеке Python есть модуль smtplib, который можно использовать для отправки сообщений. Хотя сам модуль smtplib не является сложным, он все равно требует кое-какой работы. Для облегчения процесса работы с ним было создано расширение Flask-Mail. Flask-Mail построен на основе модуля Python smtplib и предоставляет простой интерфейс для отправки электронных писем. Он также предоставляет возможности по массовой рассылке и прикрепленным к сообщениям файлам. Установить Flask-Mail можно с помощью следующей команды:
(env) gvido@vm:~/flask_app$ pip install flask-mail
Чтобы запустить расширение, нужно импортировать класс Mail из пакета flask_mail и создать экземпляр класса Mail:
#...
from flask_mail import Mail, Message
app = Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:pass@localhost/flask_app_db'
manager = Manager(app)
manager.add_command('db', MigrateCommand)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
mail = Mail(app)
#...
Дальше нужно указать некоторые параметры настройки, чтобы Flask-Mail знал, к какому SMTP-серверу подключаться. Для этого в файл main2.py нужно добавить следующий код:
#...
app.config['SECRET_KEY'] = 'a really really really really long secret key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:pass@localhost/flask_app_db'
app.config['MAIL_SERVER'] = 'smtp.googlemail.com'
app.config['MAIL_PORT'] = 587
app.config['MAIL_USE_TLS'] = True
app.config['MAIL_USERNAME'] = 'test@gmail.com' # введите свой адрес электронной почты здесь
app.config['MAIL_DEFAULT_SENDER'] = 'test@gmail.com' # и здесь
app.config['MAIL_PASSWORD'] = 'password' # введите пароль
manager = Manager(app)
manager.add_command('db', MigrateCommand)
db = SQLAlchemy(app)
mail = Mail(app)
#...
В данном случае используется SMTP-сервер Google. Стоит отметить, что Gmail позволяет отправлять только 100-150 сообщений в день. Если этого недостаточно, то стоит обратить внимание на альтернативы: SendGrid или MailChimp.
Вместо того чтобы напрямую указывать email и пароль в приложении, как это было сделано ранее, лучше хранить их в переменных среды. В таком случае, если почта или пароль поменяются, не будет необходимости обновлять код. О том, как это сделать, будет рассказано в следующих уроках.
Основы Flask-Mail
Для составления электронного письма, нужно создать экземпляр класса Message:
msg = Message("Subject", sender="sender@example.com", recipients=['recipient_1@example.com'])
Если при настройке параметров конфигурации MAIL_DEFAULT_SENDER был указан, то при создании экземпляра Message передавать значение sender не обязательно.
msg = Message("Subject", recipients=['recipient@example.com'])
Для указания тела письма необходимо использовать атрибут body экземпляра Message:
msg.body = "Mail body"
Если оно состоит из HTML, передавать его следует атрибуту html.
msg.html = "<p>Mail body</p>"
Наконец, отправить сообщение можно, передав экземпляр Message метод send() экземпляра Mail:
mail.send(msg)
Пришло время проверить настройки, отправив email с помощью командной строки.
Отправка тестового сообщения
Откроем терминал, чтобы ввести следующие команды:
(env) overiq@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import mail, Message
>>> # введите свою почту
>>> msg = Message("Subject", recipients=["you@mail.com"])
>>> msg.html = "<h2>Email Heading</h2>\n<p>Email Body</p>"
>>>
>>> mail.send(msg)
>>>
Если операция прошла успешно, то на почту должно прийти следующее сообщение с темой “Subject”:
Email Heading
Email Body
Стоит заметить, что отправка через SMTP-сервер Gmail не сработает, если не отключить двухфакторную аутентификацию и не разрешить небезопасным приложениям получать доступ к аккаунту.
Интеграция email в приложение
Сейчас когда пользователь отправляет обратную связь, она сохраняется в базу данных, сам пользователь получает уведомление о том, что его сообщение было отправлено, и на этом все. Но в идеале приложение должно уведомлять администраторов о полученной обратной связи. Это можно сделать. Откроем main2.py, чтобы изменить функцию представления contact() так, чтобы она отправляла сообщения:
#...
@app.route('/contact/', methods=['get', 'post'])
def contact():
#...
db.session.commit()
msg = Message("Feedback", recipients=[app.config['MAIL_USERNAME']])
msg.body = "You have received a new feedback from {} <{}>.".format(name, email)
mail.send(msg)
print("\nData received. Now redirecting ...")
#...
Дальше нужно запустить сервер и зайти на https://localhost:5000/contact/. Заполним и отправим форму. Если все прошло успешно, должен прийти email.
Можно было обратить внимание на задержку между отправкой обратной связи и появлением уведомления о том, что она была отправлена успешно. Проблема в том, что метод mail.send() блокирует исполнение функции представления на несколько секунд. В результате, код с перенаправлением страницы не будет исполнен до тех пор, пока не вернется метод mail.send(). Решить это можно с помощью потоков (threads).
Также прямо сейчас можно слегка изменить код отправки сообщений. На данный момент если email потребуется отправить в любом другом месте кода, нужно будет копировать и вставлять те самые строки. Но можно сохранить несколько строк, заключив логику отправки сообщений в функцию.
Откроем main2.py, чтобы добавить следующий код перед index:
#...
from threading import Thread
#...
def shell_context():
import os, sys
return dict(app=app, os=os, sys=sys)
manager.add_command("shell", Shell(make_context=shell_context))
def async_send_mail(app, msg):
with app.app_context():
mail.send(msg)
def send_mail(subject, recipient, template, **kwargs):
msg = Message(subject, sender=app.config['MAIL_DEFAULT_SENDER'], recipients=[recipient])
msg.html = render_template(template, **kwargs)
thr = Thread(target=async_send_mail, args=[app, msg])
thr.start()
return thr
@app.route('/')
def index():
return render_template('index.html', name='Jerry')
#...
Было сделано несколько изменений. Функция send_mail() теперь включает в себя всю логику отправки email. Она принимает тему письма, получателя и шаблон сообщения. Ей также можно передать дополнительные аргументы в виде аргументов-ключевых слов. Почему именно так? Дополнительные аргументы представляют собой данные, которые нужно передать шаблону. На 17 строке рендерится шаблон, а его результат передается атрибуту msg.html. На строке 18 создается объект Thread. Это делается с помощью передачи названия функции и аргументов функции, с которыми она должна быть вызвана. Следующая строка запускает потоки. Когда поток запускается, вызывается async_send_mail(). Теперь самое интересное. Впервые в коде работа происходит вне приложения (то есть, вне функции представления) в новом потоке. with app.app_context(): создает контекст приложения, а mail.send() отправляет email.
Дальше нужно создать шаблон для сообщения обратной связи. В папке templates необходимо создать папку mail. Она будет хранить шаблоны для электронных писем. Внутри папки необходимо создать шаблон feedback.html со следующим кодом:
<p>You have received a new feedback from {{ name }} <{{ email }}> </p>
Теперь нужно изменить функцию представления contact(), чтобы использовать функцию send_mail():
После этого нужно снова зайти на https://localhost:5000/contact, заполнить форму и отправить ее. В этот раз задержки не будет.
Alembic — это инструмент для миграции базы данных, используемый в SQLAlchemy. Миграция базы данных — это что-то похожее на систему контроля версий для баз данных. Стоит напомнить, что метод create_all() в SQLAlchemy лишь создает недостающие таблицы из моделей. Когда таблица уже создана, он не меняет ее схему, основываясь на изменениях в модели.
При разработке приложения распространена практика изменения схемы таблицы. Здесь и приходит на помощью Alembic. Он, как и другие подобные инструменты, позволяет менять схему базы данных при развитии приложения. Он также следит за изменениями самой базы, так что можно двигаться туда и обратно. Если не использовать Alembic, то за всеми изменениями придется следить вручную и менять схему с помощью Alter.
Flask-Migrate — это расширение, которое интегрирует Alembic в приложение Flask. Установить его можно с помощью следующей команды.
(env) gvido@vm:~/flask_app$ pip install flask-migrate
Для интеграции Flask-Migrate с приложением нужно импортировать классы Migrate и MigrateCommand из пакета flask_package, а также создать экземпляр класса Migrate, передав экземпляр приложения (app) и объект SQLAlchemy (db):
#...
from flask_migrate import Migrate, MigrateCommand
app = Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:pass@localhost/flask_app_db'
manager = Manager(app)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
manager.add_command('db', MigrateCommand)
#...
Класс MigrateCommand определяет некоторые команды миграции базы данных, доступные во Flask-Script. На 12 строке эти команды выводятся с помощью аргумента командной строки db. Чтобы посмотреть созданные команды, нужно вернуться обратно в терминал и ввести следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py
positional arguments:
{db,faker,foo,shell,runserver}
db Perform database migrations
faker A command to add fake data to the tables
foo Just a simple command
shell Runs a Python shell inside Flask application context.
runserver Runs the Flask development server i.e. app.run()
optional arguments:
-?, --help show this help message and exit
(env) gvido@vm:~/flask_app$
Так, можно видеть, что новая команда db используется для миграций базы данных. Чтобы посмотреть полный список подкоманд для dv, нужно ввести следующее:
(env) gvido@vm:~/flask_app$ python main2.py db -?
Perform database migrations
positional arguments:
{init,revision,migrate,edit,merge,upgrade,downgrade,show,history,heads,branche
s,current,stamp}
init Creates a new migration repository
revision Create a new revision file.
migrate Alias for 'revision --autogenerate'
edit Edit current revision.
merge Merge two revisions together. Creates a new migration
file
upgrade Upgrade to a later version
downgrade Revert to a previous version
show Show the revision denoted by the given symbol.
history List changeset scripts in chronological order.
heads Show current available heads in the script directory
branches Show current branch points
current Display the current revision for each database.
stamp 'stamp' the revision table with the given revision;
don't run any migrations
optional arguments:
-?, --help show this help message and exit
Это реальные команды, которые будут использоваться для миграций базы данных.
Перед тем как Alembic начнет отслеживать изменения, нужно установить репозиторий миграции. Репозиторий миграции — это всего лишь папка, которая содержит настройки Alembic и скрипты миграции. Для создания репозитория нужно исполнить команду init:
(env) gvido@vm:~/flask_app$ python main2.py db init
Creating directory /home/gvido/flask_app/migrations ... done
Creating directory /home/gvido/flask_app/migrations/versions ... done
Generating /home/gvido/flask_app/migrations/README ... done
Generating /home/gvido/flask_app/migrations/env.py ... done
Generating /home/gvido/flask_app/migrations/alembic.ini ... done
Generating /home/gvido/flask_app/migrations/script.py.mako ... done
Please edit configuration/connection/logging settings in
'/home/gvido/flask_app/migrations/alembic.ini' before proceeding.
(env) gvido@vm:~/flask_app$
Эта команда создаст папку “migrations” внутри папки flask_app. Структура папки migrations следующая:
migrations
├── alembic.ini
├── env.py
├── README
├── script.py.mako
└── versions
Краткое описание каждой папки и файла:
alembic.ini— файл с настройки Alembic.env.py— файл Python, который запускается каждый раз, когда вызывается Alembic. Он соединяется с базой данных, запускает транзакцию и вызывает движок миграции.README— файл README.script.py.mako— файл шаблона Mako, который будет использоваться для создания скриптов миграции.version— папка для хранения скриптов миграции.
Создание скрипта миграции
Alembic хранит миграции базы данных в скриптах миграции, которые представляют собой обычные файлы Python. Скрипт миграции определяет две функции: upgrade() и downgrade(). Задача upgrade() — применить изменения к базе данных, а downgrade() — откатить их обратно. Когда миграция применяется, вызывается функция upgrade(). При возврате обратно — downgrade().
Alembic предлагает два варианта создания миграций:
- Вручную с помощью команды
revision. - Автоматически с помощью команды
migrate.
Ручная миграция
Ручная или пустая миграция создает скрипт миграции с пустыми функциями upgrade() и downgrade(). Задача — заполнить их с помощью инструкций Alembic, которые и будет применять изменения к базе данных. Ручная миграция используется тогда, когда нужен полный контроль над процессом миграции. Для создания пустой миграции нужно ввести следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py db revision -m "Initial migration"
Эта команда создаст новый скрипт миграции в папке migrations/version. Название файла должно быть в формате someid_initial_migration.py. Файл должен выглядеть вот так:
"""Initial migration
Revision ID: 945fc7313080
Revises:
Create Date: 2019-06-03 14:39:27.854291
"""
from alembic import op
import sqlalchemy as sa
# идентификаторы изменений, используемые Alembic.
revision = '945fc7313080'
down_revision = None
branch_labels = None
depends_on = None
def upgrade():
pass
def downgrade():
pass
Он начинается с закомментированной части, которая содержит сообщение, заданное с помощью метки -m, ID изменения и времени, когда файл был создан. Следующая важная часть — идентификаторы изменения. Каждый скрипт миграции получает уникальный ID изменения, который хранится в переменной revision. На следующей строке есть переменная down_revision со значением None. Alembic использует переменную down_revision, чтобы определить, какую миграцию запускать и в каком порядке. Переменная down_revision указывает на идентификатор изменения родительской миграции. В этом случае его значение — None, потому что это только первый скрипт миграции. В конце файла есть пустые функции upgrade() и downgrade().
Теперь нужно отредактировать файл миграции, чтобы добавить операции создания и удаления таблицы для функций upgrade() и downgrade(), соответственно.
В функции upgrade() используется инструкция create_table() Alembic. Инструкция create_table() использует оператор CREATE TABLE.
В функции downgrade() инструкция drop_table() задействует оператор DROP TABLE.
При первом запуске миграции будет создана таблица users, а при откате — эта же миграция удалит таблицу users.
Теперь можно выполнить первую миграцию. Для этого нужно ввести следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py db upgrade
]
Эта команда исполнит функцию upgrade() скрипта миграции. Команда db upgrade вернет базу данных к последней миграции. Стоит заметить, что db upgrade не только запускает последнюю миграции, но все, которые еще не были запущены. Это значит, что если миграций было создано несколько, то db upgrade запустит их все вместе в порядке создания.
Вместо запуска последней миграции можно также передать идентификатор изменения нужной миграции. В таком случае db upgrade остановится после запуска конкретной миграции и не будет выполнять последующие.
(env) gvido@vm:~/flask_app$ python main2.py db upgrade 945fc7313080
Поскольку миграция запускается первый раз, Alembic также создаст таблицу alembic_version. Она состоит из одной колонки version_num, которая хранит идентификатор изменения последней запущенной миграции. Именно так Alembic знает текущее состояние миграции, и откуда ее нужно исполнять. Сейчас таблица alembic_version выглядит вот так:

Определить последнюю примененную миграцию можно с помощью команды db current. Она вернет идентификатор изменения последней миграции. Если таковой не было, то ничего не вернется.
(env) gvido@vm:~/flask_app$ python main2.py db current
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
945fc7313080 (head)
(env) gvido@vm:~/flask_app$
Вывод показывает, что текущая миграция — 945fc7313080. Также нужно обратить внимание на строку (head) после идентификатора изменения, которая указывает на то, что 945fc7313080 — последняя миграция.
Создадим еще одну пустую миграцию с помощью команды db revision:
(env) gvido@vm:~/flask_app$ python main2.py db revision -m "Second migration"
Дальше нужно снова запустить команду db current. В этот раз идентификатор изменения будет отображаться без строки (head), потому что миграция 945fc7313080 — не последняя.
(env) gvido@vm:~/flask_app$ python main2.py db current
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
945fc7313080
(env) gvido@vm:~/flask_app$
Чтобы посмотреть полный список миграций (запущенных и нет), нужно использовать команду db history. Она вернет список миграций в обратном хронологическом порядке (последняя миграция будет отображаться первой).
(env) gvido@vm:~/flask_app$ python main2.py db history
945fc7313080 -> b0c1f3d3617c (head), Second migration
<base> -> 945fc7313080, Initial migration
(env) gvido@vm:~/flask_app$
Вывод показывает, что 945fc7313080 — первая миграция, а следом за ней идет b0c1f3d3617 — последняя миграция. Как и обычно, (head) указывает на последнюю миграцию.
Таблица users был создана исключительно в целях тестирования. Вернуть базу данных к исходному состоянию, которое было до исполнения команды db upgrade, можно с помощью отката миграции. Чтобы откатиться к последней миграции, используется команда db downgrade.
(env) gvido@vm:~/flask_app$ python main2.py db downgrade
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running downgrade 945fc7313080 -> , Initial mi
gration
(env) gvido@vm:~/flask_app$
Она выполнит метод downgrade() миграции 945fc7313080, которая удалит таблицу users из базы данных. Как и в случае с командой db upgrade, можно передать идентификатор изменения миграции, к которому нужно откатиться. Например, чтобы откатиться к миграции 645fc5113912, нужно использовать следующую команду.
(env) gvido@vm:~/flask_app$ python main2.py db downgrade 645fc5113912
Чтобы вернуть все принятые миграции, нужно использовать следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py db downgrade base
Сейчас к базе данных не применено ни единой миграции. Убедиться в этом можно, запустив команду db current:
(env) gvido@vm:~/flask_app$ python main2.py db current
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
(env) gvido@vm:~/flask_app$
Как видно, вывод не возвращает идентификатор изменения. Стоит обратить внимание, что откат миграции лишь отменяет изменения базы данных, но не удаляет сам скрипт миграции. В результате команда db history покажет два скрипта миграции.
(env) gvido@vm:~/flask_app$ python main2.py db history
945fc7313080 -> b0c1f3d3617c (head), Second migration
<base> -> 945fc7313080, Initial migration
(env) gvido@vm:~/flask_app$
Что будет, если сейчас запустить команду db upgrade?
Команда db upgrade в первую очередь запустит миграцию 945fc7313080, а следом за ней — b0c1f3d3617.
База данных снова в изначальном состоянии, а поскольку изменения в скриптах миграции не требуются, их можно удалить.
Автоматическая миграция
Примечание: перед тем как двигаться дальше, нужно убедиться, что миграции из прошлого раздела удалены.
Автоматическая миграция создает код для функций upgrade() и downgrade() после сравнения моделей с текущей версией базы данных. Для создания автоматической миграции используется команда migrate, которая по сути повторяет то, что делает revision --autogenerate. В терминале нужно ввести команду migrate:
Важно обратить внимание, что на последней строчке вывода написано ”No changes in schema detected.”. Это значит, что модели синхронизированы с базой данных.
Откроем main2.py, чтобы добавить модель Employee после модели Feedback:
#...
class Employee(db.Model):
__tablename__ = 'employees'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
designation = db.Column(db.String(255), nullable=False)
doj = db.Column(db.Date(), nullable=False)
#...
Дальше нужно снова запустить команду db migrate. В этот раз Alembic определит, что была добавлена новая таблица employees и создаст скрипт миграции с функциями для последующего создания и удаления таблицы employees.
(env) gvido@vm:~/flask_app$ python main2.py db migrate -m "Adding employees table"
Скрипт миграции, созданный с помощью предыдущей команды, должен выглядеть вот так:
"""Adding employees table
Revision ID: 6e059688f04e
Revises:
Create Date: 2019-06-03 16:01:28.030320
"""
from alembic import op
import sqlalchemy as sa
# идентификаторы изменений, используемые Alembic.
revision = '6e059688f04e'
down_revision = None
branch_labels = None
depends_on = None
def upgrade():
# ### автоматически генерируемые команды Alembic - пожалуйста, настройте! ###
op.create_table('employees',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('name', sa.String(length=255), nullable=False),
sa.Column('designation', sa.String(length=255), nullable=False),
sa.Column('doj', sa.Date(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
# ### конец команд Alembic ###
def downgrade():
# ### автоматически генерируемые команды Alembic - пожалуйста, настройте! ###
op.drop_table('employees')
# ### конец команд Alembic ###
Ничего нового здесь нет. Функция upgrade() использует инструкцию create_table для создания таблицы, а функция downgrade() — инструкцию drop_table для ее удаления.
Запустим миграцию с помощью команды db upgrade:
(env) gvido@vm:~/flask_app$ python main2.py db upgrade
INFO [alembic.runtime.migration] Context impl MySQLImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 6e059688f04e, Adding emplo
yees table
(env) gvido@vm:~/flask_app$
Это добавит таблицу employees в базу данных.
Ограничения автоматической миграции
Автоматическая миграция не идеальна. Она не определяет все возможные изменения.
Операции, которые Alembic умеет выявлять:
- Добавление и удаление таблиц
- Добавление и удаление колонок
- Изменения во внешних ключах
- Изменения в типах колонок
- Изменения в индексах и использованных уникальных ограничениях
Изменения, которые Alembic не определяет:
- Имени таблицы
- Имени колонки
- Ограничения с отдельно указанными именами
Для создания скриптов миграции для операций, которые Alembic не умеет выявлять, нужно создать пустой скрипт миграции и заполнить функции upgrade() и downgrade() соответствующим образом.
Добавление данных
Чтобы создать новую запись с данными с помощью SQLAlchemy, нужно выполнить следующие шаги:
- Создать объект
- Добавить объект в сессию
- Загрузить (сделать коммит) сессию
В SAQLAlchemy взаимодействие с базой данных происходит с помощью сессии. К счастью, ее не нужно создавать вручную. Это делает Flask-SQLAlchemy. Доступ к объекту сессии можно получить с помощью db.session. Это объект сессии, которые отвечает за подключение к базе данных. Он же отвечает за процесс транзакции. По умолчанию транзакция запускается и остается открытой до тех пор, пока выполняются коммиты и откаты.
Запустим оболочку Python для создания некоторых объектов модели:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>>
>>> c1 = Category(name='Python', slug='python')
>>> c2 = Category(name='Java', slug='java')
>>>
Были созданы два объекта Category. Получить доступ к их атрибутам можно с помощью оператора точки (.):
>>>
>>> c1.name, c1.slug
('Python', 'python')
>>>
>>> c2.name, c2.slug
('Java', 'java')
>>>
Дальше необходимо добавить объекты в сессию.
>>>
>>> db.session.add(c1)
>>> db.session.add(c2)
>>>
Добавление объектов не записывает их в базу данных , этот процесс лишь готовит их для сохранения при следующей коммите. Удостовериться в этом можно, проверив первичный ключ объектов.
>>>
>>> print(c1.id)
None
>>>
>>> print(c2.id)
None
>>>
Значение атрибута id обоих объектов — None. Это значит, что объекты не сохранены в базе данных.
Вместо добавления по одному объекту в сессию каждый раз, можно использовать метод add_all(). Метод add_all() принимает список объектов, которые нужно добавить в сессию.
>>>
>>> db.session.add_all([c1, c1])
>>>
Если попытаться добавить объект в сессию несколько раз, ошибок не возникнет. В любой момент можно посмотреть все объекты сессии с помощью db.session.new.
>>>
>>> db.session.new
IdentitySet([<None:Python>, <None:java>])
>>>
Наконец, для сохранения объектов в базе данных нужно вызвать метод commit():
>>>
>>> db.session.commit()
>>>
Если обратиться к атрибуту id объекта Category сейчас, то он вернет первичный ключ, а не None.
>>>
>>> print(c1.id)
1
>>>
>>> print(c2.id)
2
>>>
На этом этапе таблица categories в HeidiSQL должна выглядеть примерно так:

Новые категории пока не связаны с постами. Поэтому c1.posts и c2.posts вернут пустой список.
>>>
>>> c1.posts
[]
>>>
>>> c2.posts
[]
>>>
Стоит попробовать создать несколько постов.
>>>
>>> p1 = Post(title='Post 1', slug='post-1', content='Post 1', category=c1)
>>> p2 = Post(title='Post 2', slug='post-2', content='Post 2', category=c1)
>>> p3 = Post(title='Post 3', slug='post-3', content='Post 3', category=c2)
>>>
Вместо того чтобы передавать категорию при создании объекта Post, можно выполнить следующую команду:
>>>
>>> p1.category = c1
>>>
Дальше нужно добавить объекты в сессию и сделать коммит.
>>>
>>> db.session.add_all([p1, p2, p3])
>>> db.session.commit()
>>>
Если сейчас попробовать получить доступ к атрибуту posts объекта Category, то он вернет не-пустой список:
>>>
>>> c1.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> c2.posts
[<3:Post 3>]
>>>
С другой стороны отношения, можно получить доступ к объекту Category, к которому относится пост, с помощью атрибута category у объекта Post.
>>>
>>> p1.category
<1:Python>
>>>
>>> p2.category
<1:Python>
>>>
>>> p3.category
<2:Java>
>>>
Стоит напомнить, что все это возможно благодаря инструкции relationship() в модели Category. Сейчас в базе данных есть три поста, но ни один из них не связан с тегами.
>>>
>>> p1.tags, p2.tags, p3.tags
([], [], [])
>>>
Пришло время создать теги. Это можно сделать в оболочке следующим образом:
>>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> db.session.add_all([t1, t2, t3])
>>> db.session.commit()
>>>
Этот код создает три объекта тегов и делает их коммит в базу данных. Посты все еще не привязаны к тегам. Вот как можно связать объект Post с объектом Tag.
>>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add_all([p1, p2, p3])
>>>
>>> db.session.commit()
>>>
Этот коммит добавляет следующие пять записей в таблицу post_tags.

Посты теперь связаны с одним или большим количеством тегов:
>>>
>>> p1.tags
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> p2.tags
[<2:snippet>]
>>>
>>> p3.tags
[<3:analytics>]
>>>
С другой стороны можно получить доступ к постам, которые относятся к конкретному тегу:
>>>
>>> t1.posts
[<1:Post 1>]
>>>
>>> t2.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> t3.posts
[<1:Post 1>, <3:Post 3>]
>>>
>>>
Важно отметить, что вместо изначального коммита объектов Tag и последующей их связи с объектами Post, все это можно сделать и таким способом:
>>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add(p1)
>>> db.session.add(p2)
>>> db.session.add(p3)
>>>
>>> db.session.commit()
>>>
Важно обратить внимание, что на строках 11-13 в сессию добавляются только объекты Post. Объекты Tag и Post связаны отношением многие-ко-многим. В результате, добавление объекта Post в сессию влечет за собой добавление связанных с ним объектов Tag. Но даже если сейчас вручную добавить объекты Tag в сессию, ошибки не будет.
Обновление данных
Для обновления объекта нужно всего лишь передать его атрибуту новое значение, добавить объект в сессию и сделать коммит.
>>>
>>> p1.content # начальное значение
'Post 1'
>>>
>>> p1.content = "This is content for post 1" # задаем новое значение
>>> db.session.add(p1)
>>>
>>> db.session.commit()
>>>
>>> p1.content # обновленное значение
'This is content for post 1'
>>>
Удаление данных
Для удаления объекта нужно использовать метод delete() объекта сессии. Он принимает объект и отмечает, что тот подлежит удалению при следующем коммите.
Создадим новый временный тег seo и свяжем его с постами p1 и p2:
>>>
>>> tmp = Tag(name='seo', slug='seo') # создание временного объекта Tag
>>>
>>> p1.tags.append(tmp)
>>> p2.tags.append(tmp)
>>>
>>> db.session.add_all([p1, p2])
>>> db.session.commit()
>>>
Этот коммит добавляет всего 3 строки: одну в таблицу table и еще две — в таблицу post_tags. В базе данных эти три строки выглядят следующим образом:


Теперь нужно удалить тег seo:
>>>
>>> db.session.delete(tmp)
>>> db.session.commit()
>>>
Этот коммит удаляет все три строки, добавленные в предыдущем шаге. Тем не менее он не удаляет пост, с которым тег был связан.
По умолчанию при удалении объекта в родительской таблице (например, categories) значение внешнего ключа объекта, который с ним связан в дочерней таблице (например, posts) становится NULL. Следующий код демонстрирует это поведение на примере создания нового объекта категории и объекта поста, который с ней связан, и дальнейшим удалением объекта категории:
>>>
>>> c4 = Category(name='css', slug='css')
>>> p4 = Post(title='Post 4', slug='post-4', content='Post 4', category=c4)
>>>
>>> db.session.add(c4)
>>>
>>> db.session.new
IdentitySet([<None:css>, <None:Post 4>])
>>>
>>> db.session.commit()
>>>
Этот коммит добавляет две строки. Одну в таблицу categories, и еще одну — в таблицу posts.


Теперь нужно посмотреть, что происходит при удалении объекта Category.
>>>
>>> db.session.delete(c4)
>>> db.session.commit()
>>>
Этот коммит удаляет категорию css из таблицы categories и устанавливает значение внешнего ключа (category_id) для поста, который с ней связан, на NULL.

В некоторых случаях может возникнуть необходимость удалить все дочерние записи при том, что родительские записи уже удалены. Это можно сделать, передав cascade=’all,delete-orphan’ инструкции db.relationship(). Откроем main2.py, чтобы изменить инструкцию db.relationship() в модели Catagory:
#...
class Category(db.Model):
#...
posts = db.relationship('Post', backref='category', cascade='all,delete-orphan')
#...
С этого момента удаление категории повлечет за собой удаление постов, которые с ней связаны. Чтобы это начало работать, нужно перезапустить оболочку. Далее импортируем нужные объекты и создаем категорию вместе с постом:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>> c5 = Category(name='css', slug='css')
>>> p5 = Post(title='Post 5', slug='post-5', content='Post 5', category=c5)
>>>
>>> db.session.add(c5)
>>> db.session.commit()
>>>
Вот как база данных выглядит после этого коммита.


Удалим категорию.
>>>
>>> db.session.delete(c5)
>>> db.session.commit()
>>>
После этого коммита база данных выглядит вот так:
Запрос данных
Чтобы выполнить запрос к базе данных, используется метод query() объекта session. Метод query() возвращает объект flask_sqlalchemy.BaseQuery, который является расширением оригинального объекта sqlalchemy.orm.query.Query. Объект flask_sqlalchemy.BaseQuery представляет собой оператор SELECT, который будет использоваться для осуществления запросов к базе данных. В этой таблице перечислены основные методы класса flask_sqlalchemy.BaseQuery.
| Метод | Описание |
|---|---|
| all() | Возвращает результат запроса (представленный flask_sqlalchemy.BaseQuery) в виде списка. |
| count() | Возвращает количество записей в запросе. |
| first() | Возвращает первый результат запроса или None, если в нем нет строк. |
| first_or_404() | Возвращает первый результат запроса или ошибку 404, если в нем нет строк. |
| get(pk) | Возвращает объект, который соответствует данному первичному ключу или None, если объект не найден. |
| get_or_404(pk) | Возвращает объект, который соответствует данному первичному ключу или ошибку 404, если объект не найден. |
| filter(*criterion) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором WHERE. |
| limit(limit) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором LIMIT. |
| offset(offset) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором OFFSET. |
| order_by(*criterion) | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery с оператором OFFSET. |
| join() | Возвращает новый экземпляр flask_sqlalchemy.BaseQuery после создания SQL JOIN. |
Метод all()
В своей простейшей форме метод query() принимает в качестве аргументов один или больше классов модели или колонки. Следующий код вернет все записи из таблицы posts.
>>>
>>> db.session.query(Post).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>, <4:Post 4>]
>>>
Похожим образом следующий код вернет все записи из таблиц categories и tags.
>>>
>>> db.session.query(Category).all()
[<1:Python>, <2:Java>]
>>>
>>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
Чтобы получить чистый SQL, использованный для запроса к базе данных, нужно просто вывести объект flask_sqlalchemy.BaseQuery:
>>>
>>> print(db.session.query(Post))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
>>>
В предыдущих примерах данные возвращались со всех колонок таблицы. Это можно поменять, передав методу query() названия колонок:
>>>
>>> db.session.query(Post.id, Post.title).all()
[(1, 'Post 1'), (2, 'Post 2'), (3, 'Post 3'), (4, 'Post 4')]
>>>
Метод count()
Метод count() возвращает количество результатов в запросе.
>>>
>>> db.session.query(Post).count() # получить общее количество записей в таблице Post
4
>>> db.session.query(Category).count() # получить общее количество записей в таблице Category
2
>>> db.session.query(Tag).count() # получить общее количество записей в таблице Tag
3
>>>
Метод first()
Метод first() вернет только первый запрос из запроса или None, если в запросе нет результатов.
>>>
>>> db.session.query(Post).first()
<1:Post 1>
>>>
>>> db.session.query(Category).first()
<1:Python>
>>>
>>> db.session.query(Tag).first()
<1:refactoring>
>>>
Метод get()
Метод get() вернет экземпляр объекта с соответствующим первичным ключом или None, если такой объект не был найден.
>>>
>>> db.session.query(Post).get(2)
<2:Post 2>
>>>
>>> db.session.query(Category).get(1)
<1:Python>
>>>
>>> print(db.session.query(Category).get(10)) # ничего не найдено по первичному ключу 10
None
>>>
Метод get_or_404()
То же самое, что и метод get(), но вместо None вернет ошибку 404, если объект не найден.
>>>
>>> db.session.query(Post).get_or_404(1)
<1:Post 1>
>>>
>>>
>>> db.session.query(Post).get_or_404(100)
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
>>>
Метод filter()
Метод filter() позволяет отсортировать результатов с помощью оператора WHERE, примененного к запросу. Он принимает колонку, оператор или значение. Например:
>>>
>>> db.session.query(Post).filter(Post.title == 'Post 1').all()
[<1:Post 1>]
>>>
Запрос вернет все посты с заголовком "Post 1". SQL-эквивалент запроса следующий:
>>>
>>> print(db.session.query(Post).filter(Post.title == 'Post 1'))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.title = % (title_1) s
>>>
>>>
Строка % (title_1) s в условии WHERE — это заполнитель. На ее месте будет реальное значение при выполнении запроса.
Методу filter() можно передать несколько значений и они будут объединены оператором AND в SQL. Например:
>>>
>>> db.session.query(Post).filter(Post.id >= 1, Post.id <= 2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>>
Этот запрос вернет все посты, первичный ключ которых больше 1, но меньше 2. SQL-эквивалент:
>>>
>>> print(db.session.query(Post).filter(Post.id >= 1, Post.id <= 2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
AND posts.id <= % (id_2) s
>>>
Метод first_or_404()
Делает то же самое, что и метод first(), но вместо None возвращает ошибку 404, если запрос без результата.
>>>
>>> db.session.query(Post).filter(Post.id > 1).first_or_404()
<2:Post 2>
>>>
>>> db.session.query(Post).filter(Post.id > 10).first_or_404().all()
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
>>>
Метод limit()
Метод limit() добавляет оператор LIMIT к запросу. Он принимает количество строк, которые нужно вернуть с запросом.
>>>
>>> db.session.query(Post).limit(2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>> db.session.query(Post).filter(Post.id >= 2).limit(1).all()
[<2:Post 2>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).limit(2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
LIMIT % (param_1) s
>>>
>>>
>>> print(db.session.query(Post).filter(Post.id >= 2).limit(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
LIMIT % (param_1) s
>>>
>>>
Метод offset()
Метод offset() добавляет условие OFFSET в запрос. В качестве аргумента он принимает смещение. Часто используется вместе с limit().
>>>
>>> db.session.query(Post).filter(Post.id > 1).limit(3).offset(1).all()
[<3:Post 3>, <4:Post 4>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).filter(Post.id > 1).limit(3).offset(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id > % (id_1) s
LIMIT % (param_1) s, % (param_2) s
>>>
Строки % (param_1) s и % (param_2) — заполнители для смещения и ограничения вывода, соответственно.
Метод order_by()
Метод order_by() используется, чтобы упорядочить результат, добавив к запросу оператор ORDER BY. Он принимает количество колонок, для которых нужно установить порядок. По умолчанию сортирует в порядке возрастания.
>>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> db.session.query(Tag).order_by(Tag.name).all()
[<3:analytics>, <1:refactoring>, <2:snippet>]
>>>
Для сортировки по убыванию нужно использовать функцию db.desc():
>>>
>>> db.session.query(Tag).order_by(db.desc(Tag.name)).all()
[<2:snippet>, <1:refactoring>, <3:analytics>]
>>>
Метод join()
Метод join() используется для создания JOIN в SQL. Он принимает имя таблицы, для которой нужно создать JOIN.
>>>
>>> db.session.query(Post).join(Category).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>]
>>>
SQL-эквивалент:
>>>
>>> print(db.session.query(Post).join(Category))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slug,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
Метод join() широко используется, чтобы получить данные из одной или большего количества таблиц одним запросом. Например:
>>>
>>> db.session.query(Post.title, Category.name).join(Category).all()
[('Post 1', 'Python'), ('Post 2', 'Python'), ('Post 3', 'Java')]
>>>
Можно создать JOIN для большее чем двух таблиц с помощью цепочки методов join():
db.session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Закончить урок можно завершением контактной формы.
Стоит напомнить, что в уроке «Работа с формами во Flask» была создана контактная форма для получения обратной связи от пользователей. Пока что функция представления contact() не сохраняет отправленные данные. Она только выводит их в консоли. Для сохранения полученной информации сначала нужно создать новую таблицу. Откроем main2.py, чтобы добавить модель Feedback следом за моделью Tag:
#...
class Feedback(db.Model):
__tablename__ = 'feedbacks'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(1000), nullable=False)
email = db.Column(db.String(100), nullable=False)
message = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
#...
Дальше нужно перезапустить оболочку Python и вызвать метод create_all() объекта db для создания таблицы feedbacks:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db
>>>
>>> db.create_all()
>>>
Также нужно изменить функция представления contact():
#...
@app.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
print(name)
print(Post)
print(email)
print(message)
# здесь логика базы данных
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
print("\nData received. Now redirecting ...")
flash("Message Received", "success")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
#...
Запустим сервер и зайдем на https://127.0.0.1:5000/contact/, чтобы заполнить и отправить форму.

Отправленная запись в HeidiSQL будет выглядеть следующим образом:

В этом уроке речь пойдет о взаимодействии с базой данных. Сегодня существуют две конкурирующих системы баз данных:
- Реляционные базы данных.
- Нереляционные или NoSQL базы данных.
Реляционные базы по традиции используются в веб-приложения. Многие крупные игроки на рынке веб-программирования все еще используют их. Например, Facebook. Реляционные базы данных хранят данные в таблицах и колонках и используют внешний ключ для создания связи между несколькими таблицами. Реляционные базы данных также поддерживают транзакции. Это значит, что можно исполнить набор SQL-операторов, которые должны быть атомарными (atomic). Под atomic подразумеваются все операторы, которые исполняются по принципу «все или ничего».
В последние годы выросла популярность баз данных NoSQL. Такие базы данных не хранят данные в таблицах и колонках, а вместо них используют такие структуры, как документные хранилища, хранилища ключей и значений, графы и так далее. Большинство NoSQL баз данных не поддерживают транзакции, но предлагают более высокую скорость работы.
Реляционные базы данных намного старше NoSQL. Они доказали свою надежность и безопасность во многих отраслях. Следовательно, оставшаяся часть урока будет посвящена описанию принципов использования реляционных баз данных во Flask. Это не значит, что NoSQL не используются. Есть случаи, когда в NoSQL-базах даже больше смысла, но сейчас речь пойдет только о реляционных базах данных.
SQLAlchemy и Flask-SQLAchemy
SQLAlchemy – это фреймворк для работы, который на практике используется для работы с реляционными базами данных в Python. Он был создан Майком Байером в 2005 году. SQLAlchemy поддерживает следующие базы данных: MySQL, PostgreSQL, Oracle, MS-SQL, SQLite и другие.
SQLAchemy поставляется с мощным ORM (технология объектно-реляционного отображения), который позволяет работать с разными базами данных с помощью объектно-ориентированного кода, а не сырого SQL (языка структурированных запросов). Конечно, это не обязывает использовать только ORM. В любой момент можно задействовать возможности SQL.
Flask-SQLAlchemy – это расширение, которое интегрирует SQLAlchemy во фреймворк Flask. Он также предлагает дополнительные методы, благодаря которым работать с SQLAlchemy становится немного проще. Установить Flask-SQLAlchemy вместе с дополнительными модулями можно с помощью следующей команды:
(env) gvido@vm:~/flask_app$ pip install flask-sqlalchemy
Для использования Flask-SQLAlchemy нужно импортировать класс SQLAlchemy из пакета flask_sqlalchemy и создать экземпляр объекта SQLAlchemy, передав ему экземпляр приложения. Откроем файл main2.py, чтобы изменить код следующим образом:
#...
from forms import ContactForm
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
manager = Manager(app)
db = SQLAlchemy(app)
class Faker(Command):
#...
Экземпляр db объекта SQLAlchemy предоставляет доступ к функциям SQLAlchemy.
Дальше нужно сообщить SQLAlchemy местоположение базы данных в виде URI. Формат URI базы данных следующий:
dialect+driver://username:password@host:port/database
dialect ссылается на имя базы данных, такое как mysql, mssql, postgresql и так далее.
driver ссылается на DBAPI, который он использует, чтобы соединяться с базой данных. По умолчанию SQLAlchemy работает только с SQLite без дополнительных драйверов. Чтобы работать с другими базами данных, нужно установить конкретный драйвер для базы данных, совместимый с DBAPI.
Что такое DBAPI?
DBAPI – это всего лишь стандарт, определяющий API Python для доступа к базам данных от разных производителей.
Следующая таблица содержит некоторые базы данных и драйвера для них, совместимые с DBAPI:
| База данных | Драйвер DBAPI |
|---|---|
| MySQL | PyMysql |
| PostgreSQL | Psycopg 2 |
| MS-SQL | pyodbc |
| Oracle | cx_Oracle |
Username и password указываются только при необходимости. Если указаны, они будут использоваться для авторизации в базе данных.
host — местоположение сервера базы данных.
port — порт сервера базы данных.
database — имя базы данных.
Вот некоторые примеры URL баз данных для самых популярных типов:
# URL базы данных для MySQL с использованием драйвера PyMysql
'mysql+pymysql://root:pass@localhost/my_db'
# URL базы данных для PostgreSQL с использованием psycopg2
'postgresql+psycopg2://root:pass@localhost/my_db'
# URL базы данных для MS-SQL с использованием драйвера pyodbc
'mssql+pyodbc://root:pass@localhost/my_db'
# URL базы данных для Oracle с использованием драйвера cx_Oracle
'oracle+cx_oracle://root:pass@localhost/my_db'
Формат URL базы данных для SQLite слегка отличается. Поскольку SQLite – это база данных, основанная на файле, и она не требует имени пользователя и пароля, в URL базы данных указывается только путь к файлу базы.
# Для Unix / Mac мы используем 4 слеша
sqlite:////absolute/path/to/my_db.db
# Для Windows мы используем 3 слеша
sqlite:///c:/absolute/path/to/mysql.db
Flask-SQLAlchemy использует конфигурационный ключ SQLALCHEMY_DATABASE_URI для определения URI базы данных. Откроем main2.py, чтобы добавить SQLALCHEMY_DATABASE_URI :
#...
app = Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:pass@localhost/flask_app_db'
manager = Manager(app)
db = SQLAlchemy(app)
#...
В этом курсе будет использоваться база данных MySQL. Поэтому прежде чем переходить к следующему разделу, нужно убедиться, что MySQL работает на компьютере.
Создание моделей
Модель — это класс в Python, который представляет собой таблицу базы данных. Ее атрибуты сопоставляются со столбцами таблицы. Класс модели наследуется из db.Mobel и определяет колонки как экземпляры класса db.Column. Откроем main2.py, чтобы добавить следующий класс перед функцией представления updating_session():
#...
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
#...
class Post(db.Model):
__tablename__ = 'posts'
id = db.Column(db.Integer(), primary_key=True)
title = db.Column(db.String(255), nullable=False)
slug = db.Column(db.String(255), nullable=False)
content = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onupdate=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.title[:10])
Здесь создается модель Post с 5 переменными класса. Каждая переменная класса, кроме __tablename__, — это экземпляр класса db.Column. __tablename__ — это специальная переменная класса, используемая для определения имени таблицы базы данных. По умолчанию SQLAlchemy не следует соглашению о создании имен во множественном числе, поэтому название таблицы здесь — это название модели. Если на хочется опираться на такое поведение, следует использовать переменную __tablename__, чтобы явно указать название таблицы.
Первый аргумент конструктора db.Column() — это тип колонки, которая создается. SQLAlchemy предлагает большое количество типов колонок, а если их недостаточно, то можно создать свои. Следующая таблица описывает основные типы колонок в SQLAlchemy и их соответствующие типы в Python и SQL.
| SQLAlchemy | Python | SQL |
|---|---|---|
| BigInteger | int | BIGINT |
| Boolean | bool | BOOLEAN или SMALLINT |
| Date | datetime.date | DATE |
| DateTime | datetime.date | DATETIME |
| Integer | int | INTEGER |
| Float | float | FLOAT или REAL |
| Numeric | decimal.Decimal | NUMERIC |
| Text | str | TEXT |
Также можно задать дополнительные ограничения для колонки, передав их в виде аргументов-ключевых слов конструктору db.Column. Следующая таблица включает некоторые широко используемые ограничения:
| Ограничение | Описание |
|---|---|
| nullable | Когда значение равно False, делает колонку обязательной. Значение по умолчанию — True. |
| default | Создает значение по умолчанию для колонки. |
| index | Логический атрибут. Если True, создает индексированную колонку. |
| onupdate | Создает значение по умолчанию для колонки при обновлении записи. |
| primary_key | Логический атрибут. Если True, отмечает колонку основным ключом таблицы. |
| unique | Логический атрибут. Если True, каждая колонка должна быть уникальной. |
В строках 16-17 был определен метод __repr__(). Он не необходим, но если есть, то создает строчное представление объекта.
Можно было заметить, что значениями по умолчанию для created_on и updated_on выбрано название метода (datetime.utcnow), а не его вызов (datetime.utcnow()). Так сделано, потому что при исполнении кода вызывать метод datetime.utcnow() нет необходимости. Вместо этого его стоит вызывать, когда запись добавляется или обновляется.
Актуально: Работа программистом Python: требования, вакансии и зарплаты
Определение отношений (связей)
В прошлом разделе была создана модель Post с парой полей. На практике классы моделей существуют сами по себе. Большую часть времени они связаны с другими моделями различными типами отношений: один-к-одному, один-ко-многим, многие-ко-многим.
Стоит дальше поработать над аналогией блога. Обычно, пост в блоге относится к одной категории и имеет один или несколько тегов. Другими словами, есть отношение один-к-одному между категорией и постом и отношение многие-ко-многим между постом и тегом.
Откроем main2.py, чтобы добавить модели Category и Tag:
#...
def updating_session():
#...
return res
class Category(db.Model):
__tablename__ = 'categories'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
slug = db.Column(db.String(255), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(id, self.name)
class Posts(db.Model):
# ...
class Tag(db.Model):
__tablename__ = 'tags'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
slug = db.Column(db.String(255), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(id, self.name)
#...
Отношение один-ко-многим
Для создания отношения один-ко-многим нужно разместить внешний ключ в дочерней таблице. Это самый распространенный тип отношений. Для создания отношения один-ко-многим в SQLAlchemy нужно выполнить следующие шаги:
- Создать новый экземпляр
db.Columnс помощью ограниченияdb.ForeignKeyв дочернем классе. - Определить новое свойство с помощью инструкции
db.relationshipв родительском классе. Это свойство будет использоваться для получения доступа к связанным объектам.
Откроем main2.py, чтобы изменить модели Post и Catеgory:
#...
class Category(db.Model):
# ...
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
posts = db.relationship('Post', backref='category')
class Post(db.Model):
# ...
updated_on = db.Column(db.DateTime(), default=datetime.utcnow, onupdate=datetime.utcnow)
category_id = db.Column(db.Integer(), db.ForeignKey('categories.id'))
#...
Здесь для модели Post в Category были добавлены два новых атрибута: posts и category_id.
db.ForeignKey() принимает имя столбца, внешний ключ которого используется. Здесь значение categories.id передается исключению db.ForeignKey(). Это значит, что атрибут category_id у Post может принимать значение только у колонки id таблицы categories.
Далее в модели Catagory имеется атрибут posts, определенный инструкцией db.relationship(). db.relationship() используется для добавления двунаправленной связи. Другими словами, она добавляет атрибут классу модели для доступа к связанным объектам. Простыми словами, она принимает как минимум один позиционный аргумент, который является именем класса на другой стороне отношений.
class Category(db.Model):
# ...
posts = db.relationship('Post')
Например, если есть объект Category (скажем, c), тогда доступ ко всем постам можно получить с помощью c.posts. А что, если нужно получить данные с другой стороны, то есть, получить категорию у объекта поста? Для этого используется backref. Так, код:
posts = db.relationship('Post', backref='category')
добавляет атрибут category объекту Post. Это значит, что если есть объект Post (например, p), тогда доступ к категории можно получать с помощью p.category.
Атрибуты category и posts у объектов Post и Category существуют только для удобства. Они не являются реальными колонками в таблице.
Стоит отметить, что в отличие от атрибута, представленного внешним ключом (который должен быть определен на стороне «много» в отношениях), db.relationship() можно определять с любой стороны.
Отношение один-к-одному
Создание отношения один-к-одному в SQLAlchemy – это почти то же самое, что и отношение один-ко-многим. Единственное отличие — то, что инструкции db.relationship() передается дополнительный аргумент uselist=False. Например:
class Employee(db.Model):
__tablename__ = 'employees'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(255), nullable=False)
designation = db.Column(db.String(255), nullable=False)
doj = db.Column(db.Date(), nullable=False)
dl = db.relationship('DriverLicense', backref='employee', uselist=False)
class DriverLicense(db.Model):
__tablename__ = 'driverlicense'
id = db.Column(db.Integer(), primary_key=True)
license_number = db.Column(db.String(255), nullable=False)
renewed_on = db.Column(db.Date(), nullable=False)
expiry_date = db.Column(db.Date(), nullable=False)
employee_id = db.Column(db.Integer(), db.ForeignKey('employees.id')) # Foreign key
Примечание: в этих класса предполагается, что у сотрудника (employee) не может быть большого одного водительского удостоверения (driver license). Поэтому отношения между сотрудником и правами — один-к-одному.
С объектом Employee можно использовать e.dl, чтоб вернуть объект DriverLicense. Если не передать инструкции db.relationship() значение uselist=False, тогда между Employee и DriverLicense будет установлено отношение один-ко-многим, и e.dl вернет список объектов DriverLicense, вместо одного объекта. При этом аргумент uselist=False не повлияет на атрибут employee объекта DriverLicense. Как и обычно, он вернет один объект.
Отношение многие-ко-многим
Отношение многие-ко-многим требует дополнительной ассоциативной таблицы. В качестве примера можно взять блог.
Пост в блоге обычно имеет один или несколько тегов. Аналогичным образом один тег может ассоциироваться с одним или несколькими постами. Так образовывается отношение между posts и tags. Недостаточно добавить внешний ключ, ссылающийся на id постов, потому что у тега может быть один или несколько постов.
В качестве решения нужно создать новую таблицу ассоциаций, определив 2 внешних ключа, ссылающихся на колонки post.id и tag.id.

Как видно на изображении, отношение многие-ко-многим между постом и тегом создается с помощью двух отношений один-к-одному. Первое такое отношение установлено между таблицами posts и post_tags, второе — между tags и post_tags. Следующий код демонстрирует, как создать отношение многие-ко-многим в SQLAlchemy. Откроем файл main2.py, чтобы добавить следующий код.
# ...
class Category(db.Model):
# ...
def __repr__(self):
return "<{}:{}>".format(id, self.name)
post_tags = db.Table('post_tags',
db.Column('post_id', db.Integer, db.ForeignKey('posts.id')),
db.Column('tag_id', db.Integer, db.ForeignKey('tags.id'))
)
class Post(db.Model):
# ...
class Tag(db.Model):
# ...
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
posts = db.relationship('Post', secondary=post_tags, backref='tags')
#...
На строках 7-10 таблица ассоциаций определяется в виде объекта db.Table(). Первый аргумент таблицы db.Table() — имя таблицы, а дополнительные аргументы — это колонки, представленные экземплярами db.Column(). Синтаксис для создания таблицы ассоциаций может показаться странным, если сравнивать с процессом создания класса модели. Это потому что таблица ассоциаций создается с помощью SQLAlchemy Core – еще одного элемента SQLAlchemy.
Дальше нужно сообщить классу модели о таблице ассоциаций, которая будет использоваться. За это отвечает аргумент-ключевое слово secondary. На 18 строке db.relationship() вызывается с аргументом secondary, значение которого — post_tags. Хотя отношение было определено в модели Tag, его можно так же просто определить в модели Post.
Если есть, например, объект p класса Post, тогда доступ ко всем его тегам можно получить с помощью p.tags. С помощью объекта класса Tag (t), доступ к постам можно получить командой t.posts.
Пришло время создать базу данных и таблицы.
Создание таблиц
Чтобы выполнить все шаги урока, нужно убедиться, что MySQL установлен на компьютере.
Стоит напомнить, что по умолчанию SQLAlchemy работает только с базой данных SQLite. Для работы с другими базами данных нужно установить драйвер, совместимый с DBAPI. Для использования MySQL подойдет драйвер PyMySql.
(env) gvido@vm:~/flask_app$ pip install pymysql
После этого необходимо авторизоваться на сервере MySQL и создать базу данных flask_app_db с помощью следующей команды:
(env) gvido@vm:~/flask_app$ mysql -u root -p
mysql>
mysql> CREATE DATABASE flask_app_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Query OK, 1 row affected (0.26 sec)
mysql> \q
Bye
(env) gvido@vm:~/flask_app$
Эта команда создает базу данных flask_app_db с полной поддержкой Unicode.
Для создания необходимых таблицы нужно запустить метод create_all() объекта SQLAlchemy — db. Далее нужно запустить оболочку Python и выполнить следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db
>>>
>>> db.create_all()
>>>
Метод create_all() создает таблицы только в том случае, если их нет в базе данных. Поэтому запускать его можно несколько раз. Также этот метод не берет во внимание изменения моделей при создании таблиц. Это значит, что если запустить метод create_all() после изменения его метода, когда таблица уже создана, то он не поменяет схему таблицы. Чтобы сделать это, нужно воспользоваться инструментом переноса Alembic. О том, как переносить базы данных с помощью Alembic, будет рассказано в отдельном уроке «Перенос базы данных с помощью Alembic».
Чтобы посмотреть созданные таблицы, нужно авторизоваться на сервере MySQL и выполнить следующую команду:
mysql>
mysql> use flask_app_db
Database changed
mysql>
mysql> show tables;
+------------------------+
| Tables_in_flask_app_db |
+------------------------+
| categories |
| post_tags |
| posts |
| tags |
+------------------------+
4 rows in set (0.02 sec)
mysql>
Еще один способ посмотреть таблицы — использовать инструмент администрирования базы данных, такой как HeidiSQL. HeidiSQL – это кроссплатформенное ПО с открытым исходным кодом для управления базами данных MySQL, MS-SQL и PostgreSQL. Оно позволяет просматривать и редактировать данные, смотреть схему, менять таблицу и делать многое другое без единой строчки SQL. Скачать HeidiSQL можно отсюда.
Установив HeidiSQL поверх базы данных flask_app_db, можно получить приблизительно следующий список таблиц:

База данных flask_app_db имеет 4 таблицы. Таблицы с названиями categories, posts и tags созданы прямо из моделей, а post_tags — это таблица ассоциаций, которая представляет собой отношение многие-ко-многим между моделями Post и Tag.
Класс SQLAlchemy также определяет метод drop_all(), который используется для удаления всех таблиц в базе данных. Стоит помнить, что метод drop_all() не учитывает, есть ли данные в таблице или нет. Он удаляет все данные, поэтому использовать его нужно с умом.
Все таблицы на месте. Пора добавить в них какие-то данные.
]]>Сессии — еще один способ хранить данные конкретных пользователей между запросами. Они работают по похожему на куки принципу. Для использования сессии нужно сперва настроить секретный ключ. Объект session из пакета flask используется для настройки и получения данных сессии. Объект session работает как словарь, но он также может отслеживать изменения.
При использовании сессий данные хранятся в браузере как куки. Куки, используемые для хранения данных сессии — это куки сессии. Тем не менее в отличие от обычных куки Flask криптографически отмечает куки сессии. Это значит, что каждый может видеть содержимое куки, но не может их менять, не имея секретного ключа для подписи. Как только куки сессии настроены, каждый последующий запрос к серверу подтверждает подлинность куки с помощью такого же секретного ключа. Если Flask не удается это сделать, тогда его контент отклоняется, а браузер получает новые куки сессии.
Знакомые с сессиями из языка PHP заметят, что сессии во Flask немного отличаются. В PHP куки сессии не хранят данные о сессии, а только id сессии. Это уникальная строка, которую PHP создает для ассоциации данных сессии с куки. Данные сессии хранятся на сервере в виде файла. При получении запроса от пользователя PHP использует id сессии, чтобы найти данные сессии и отобразить их в коде. Такой тип сессий известен как серверный, а те, которые используются во Flask, называется клиентскими.
По умолчанию различий между куки и клиентскими сессиями во Flask не так много. В итоге клиентские сессии страдают от тех же недостатков, что и обычные куки:
- Не могут хранить конфиденциальную информацию, такую как пароли.
- Дают лишнюю нагрузку при каждом запросе.
- Не способны хранить больше 4 КБ.
- Ограничены в общем количестве куки для одного сайта
и так далее.
Единственное реальное различие между куки и клиентскими сессиями — Flask гарантирует, что содержимое куки сессии не может быть изменено пользователям (только если у него нет секретного ключа).
Для использования клиентских сессий во Flask можно или написать собственный интерфейс сессии или использовать расширения, такие как Flask-Session или Flask-KVSession.
Как читать, записывать и удалять данные сессии
Следующий код демонстрирует, как можно читать, записывать и удалять данные сессии. Откроем файл main2.py, чтобы добавить следующий код после функции представления article():
from flask import Flask, render_template, request, redirect, url_for, flash, make_response, session
#...
@app.route('/visits-counter/')
def visits():
if 'visits' in session:
session['visits'] = session.get('visits') + 1 # чтение и обновление данных сессии
else:
session['visits'] = 1 # настройка данных сессии
return "Total visits: {}".format(session.get('visits'))
@app.route('/delete-visits/')
def delete_visits():
session.pop('visits', None) # удаление данных о посещениях
return 'Visits deleted'
#...
Стоит обратить внимание, что объект session используется как обычный словарь. Если сервер не запущен, нужно его запустить и зайти на https://localhost:5000/visits-counter/. На странице будет счетчик посещений:

Чтобы увеличить его, нужно несколько раз обновить страницу.

Flask отправляет куки сессии клиенту только при создании новой сессии или изменении существующей. При первом посещении https://localhost:5000/visits-counter/ будет исполнено тело else в функции представления visits(), в результате чего будет создана новая сессия. При создании новой сессии Flask отправит куки сессии клиенту. Последующие запросы к https://localhost:5000/visits-counter приведут к исполнению кода в блоке if, в котором обновляется значение счетчика visits сессии. При изменении сессии будет создан новый файл куки, поэтому Flask отправит новые куки сессии клиенту.
Чтобы удалить данные сессии нужно зайти на https://localhost:5000/delete-visits/.

Если сейчас открыть https://localhost:5000/visits-counter, счетчик посещений снова будет показывать 1.
По умолчанию куки сессии существуют до тех пор, пока не закроется браузер. Чтобы продлить жизнь куки сессии, нужно установить значение True для атрибута permanent объекта session. Когда значение permanent равно True, срок куки сессии будет равен permanent_session_lifetime. permanent_session_lifetime — это атрибут datetime.timedelta объекта Flask. Его значение по умолчанию равно 31 дню. Изменить его можно, выбрав новое значение для атрибута permanent_session_lifetime, используя ключ настройки PERMANENT_SESSION_LIFETIME.
import datetime
app = Flask(__name__)
app.permanent_session_lifetime = datetime.timedelta(days=365)
# app.config['PERMANENT_SESSION_LIFETIME'] = datetime.timedelta(days=365)
Как и request, объект sessions доступен в шаблонах.
Изменение данных сессии
Примечание: перед тем как следовать инструкции, нужно удалить куки, установленные локальным хостом.
Большую часть времени объект session автоматически подхватывает изменения. Но бывают случаи, например изменение структуры изменяемых данных, которые не подхватываются автоматически. Для таких ситуаций нужно установить значение True для атрибута modified объекта session. Если этого не сделать, Flask не будет отправлять обновленные куки клиенту. Следующий код показывает, как использовать атрибут modified объекта session. Откроем файл main2.py, чтобы добавить следующий код перед функцией представления delete_visitis().
#...
@app.route('/session/')
def updating_session():
res = str(session.items())
cart_item = {'pineapples': '10', 'apples': '20', 'mangoes': '30'}
if 'cart_item' in session:
session['cart_item']['pineapples'] = '100'
session.modified = True
else:
session['cart_item'] = cart_item
return res
#...
При первом посещении https://localhost:5000/session/ код в блоке else будет исполнен. Он создаст новую сессию, где данные сессии будут в виде словаря. Последующий запрос к https://localhost:5000/session/ обновляет данные сессии, установив количество «ананасов» на значении 100. В следующей строке атрибут modified получает значение True, потому что без него Flask не будет отправлять обновленные куки сессии клиенту.
Если сервер не запущен, его следует запустить и зайти на https://localhost:5000/session/. Отобразится пустой словарь session, потому что у браузера еще нет куки сессии, которые он мог бы отправить серверу:

Если страницу перезагрузить, в словаре session будет уже «10 ананасов»:

Перезагрузив страницу в третий раз, можно увидеть, что словарь session имеет значение «ананасов» равное 100, а не 10:
Объект сессии подхватил изменение благодаря атрибуту modified. Удостовериться в этом можно, удалив куки сессии и закомментировав строку, где для атрибута modified устанавливается значение True. Теперь после первого запроса значение словаря сессии будет равно «10 ананасам».
Это все, что нужно знать о сессиях во Flask. И важно не забывать, что по умолчанию сессии во Flask являются клиентскими.
]]>До этого момента все созданные в уроках страницы были очень простыми. Браузер отправляет запрос на сервер, сервер отвечает HTML-страницей, и это все. HTTP — это протокол, который не сохраняет свое состояние. Это значит, что в HTTP нет встроенных способов сообщить серверу, что оба запроса поступили от одного и того же пользователя. В результате сервер не знает, пытается ли пользователь получить доступ к странице впервые или в тысячный раз. Он обслуживает каждого так, будто бы это первое обращение к странице.
Если попробовать зайти в любой интернет-магазин и поискать определенные товары, то при следующем посещении сайт будет предлагать рекомендации, основанные на примерах прошлых поисков. Как же получается, что сайт узнает конкретного пользователя?
Ответ — куки и сессии.
Этот урок посвящен куки, а о сессиях речь пойдет в следующем.
Что такое куки?
Куки — это всего лишь фрагмент данных, которые сервер устанавливает в браузере. Вот как это работает:
- Браузер отправляет запрос на получение веб-страницы от сервера.
- Сервер отвечает на запрос, отправляя запрошенную страницу вместе с одним или несколькими куки.
- При получении ответа браузер рендерит страницу и сохраняет куки на компьютере пользователя.
- Последующий запрос на сервер будет включать информацию из куки в заголовке
Cookie. Так будет продолжаться, пока не истечет сроки куки. Как только это происходит, куки удаляется из браузера.
Настройка куки
Во Flask для настройки куки используется метод объекта ответа set_cookie(). Синтаксис set_cookie() следующий:
set_cookie(key, value="", max_age=None)
key — обязательный аргумент, это название куки. value — данные, которые нужно сохранить в куки. По умолчанию это пустая строка. max_age — это срок действия куки в секундах. Если не указать срок, срок истечет при закрытии браузера пользователем.
Откроем main2.py, чтобы добавить следующий код после функции представления contact():
from flask import Flask, render_template, request, redirect, url_for, flash, make_response
#...
@app.route('/cookie/')
def cookie():
res = make_response("Setting a cookie")
res.set_cookie('foo', 'bar', max_age=60*60*24*365*2)
return res
#...
Это пример создание куки под названием foo со значением bar, срок которых — 2 года.
Нужно запустить сервер и зайти на https://localhost:5000/cookie/. В качестве ответа откроется страница “Setting a cookie”. Чтобы посмотреть куки, настроенные сервером, нужно открыть инспектор хранилища в Firefox, нажав Shift+F9. Новое окно откроется в нижней части браузера. С левой стороны необходимо выбрать тип хранилища “Cookies” и нажать https://localhost:5000/, чтобы посмотреть все куки, настроенные сервером для https://localhost:5000/.

С этого момента куки foo будут отправляться вместе с запросом на сервер https://localhost:5000/. Убедиться в этом можно с помощью сетевого монитора в Firefox. Он открывается сочетанием Ctrl+Shift+E. В мониторе нужно открыть https://localhost:5000/. В списке запросов с левой стороны — выбрать первый запрос, чтобы в правой панели отобразились его подробности:

Стоит отметить, что когда куки настроены, последующие запросы к https://localhost:5000/cookie/ будут обновлять срок куки.
Доступ к куки
Для доступа к куки используется атрибут cookie объекта request. cookie — это атрибут типа словарь, содержащий все куки, отправленные браузером. Снова откроем main2.py, чтобы изменить функцию представления cookie():
#...
@app.route('/cookie/')
def cookie():
if not request.cookies.get('foo'):
res = make_response("Setting a cookie")
res.set_cookie('foo', 'bar', max_age=60*60*24*365*2)
else:
res = make_response("Value of cookie foo is {}".format(request.cookies.get('foo')))
return res
#...
Функция представления изменена таким образом, чтобы страница показывала значение куки, если они есть. Если нет — они будут настроены автоматически.
Если открыть https://localhost:5000/cookie/ сейчас, отобразится страница со следующим содержимым.

Объект request также доступен внутри шаблона. Это значит, что доступ к куки можно получить и с помощью кода Python. Подробнее об в этом в одном из следующих разделов.
Удаление куки
Чтобы удалить куки, нужно вызвать метод set_cookie() с названием куки, любым значением и указать срок max_age=0. В файле main2.py это можно сделать, добавив следующий код после функции представления cookie().
#...
@app.route('/delete-cookie/')
def delete_cookie():
res = make_response("Cookie Removed")
res.set_cookie('foo', 'bar', max_age=0)
return res
#...
Если сейчас зайти на https://localhost:5000/delete-cookie/, отобразится следующий ответ:

Теперь, понимая как работают куки, можно изучить следующие примеры кода и получить реальные практические примеры того, как настраивать куки для сохранения пользовательских предпочтений.
Добавим следующий код после функции представления delete_cookie() в файле main2.py.
#...
@app.route('/article/', methods=['POST', 'GET'])
def article():
if request.method == 'POST':
print(request.form)
res = make_response("")
res.set_cookie("font", request.form.get('font'), 60*60*24*15)
res.headers['location'] = url_for('article')
return res, 302
return render_template('article.html')
#...
Далее нужно создать новый шаблон article.html со следующим кодом:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Article</title>
</head>
<body style="{% if request.cookies.get('font') %}font-family:{{ request.cookies.get('font') }}{% endif %}">
Select Font Preference: <br>
<form action="" method="post">
<select name="font" onchange="submit()">
<option value="">----</option>
<option value="consolas" {% if request.cookies.get('font') == 'consolas' %}selected{% endif %}>consolas</option>
<option value="arial" {% if request.cookies.get('font') == 'arial' %}selected{% endif %}>arial</option>
<option value="verdana" {% if request.cookies.get('font')== 'verdana' %}selected{% endif %}>verdana</option>
</select>
</form>
<h1>Festus, superbus toruss diligenter tractare de brevis, dexter olla.</h1>
<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit. Aperiam blanditiis debitis doloribus eos magni minus odit, provident tempora. Expedita fugiat harum in incidunt minus nam nesciunt voluptate. Facilis nesciunt, similique!
</p>
<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit. Alias amet animi aperiam inventore molestiae quos, reiciendis voluptatem. Ab, cum cupiditate fugit illo incidunt ipsa neque quam, qui quidem vel voluptatum.</p>
</body>
</html>
При первом посещении https://localhost:5000/article страница отобразится со шрифтом по умолчанию. Если пользователь поменяет шрифт с помощью выпадающего меню, будет отправлена форма. Значение условия if request.method == 'POST' станет истинным, и будут настроены куки font со значением выбранного шрифта, срок которых истечет через 15 дней, а пользователь будет перенаправлен на страницу https://localhost:5000/article, которая отобразится с новым выбранным шрифтом.
При посещении https://localhost:5000/article станица отобразится со шрифтом по умолчанию.

Но если выбрать новый шрифт из выпадающего меню, шрифт страницы поменяется на выбранный ранее.

Недостатки куки
Перед использованием куки в реальном проекте нужно знать об их недостатках.
- Куки небезопасны. Данные, которые в них хранятся, видны всем, поэтому в куки нельзя хранить пароли, данные банковских карт и так далее.
- Куки можно отключить. Большинство браузеров дают пользователям возможность отключить куки. Если это происходит, никакого предупреждения нет. Чтобы бороться с этой проблемой, можно использовать, например, такой простейший JS-код, чтобы уведомить пользователя о том, что куки должны быть включены для корректной работы.
<script>
document.cookie = "foo=bar;";
if (!document.cookie)
{
alert("This website requires cookies to function properly");
}
</script>
- Каждая порция куки хранит не более 4 КБ данных. Помимо этого браузеры накладывают ограничения на то, сколько куки может установить сайт. Лимиты варьируются от 30 до 50.
- Куки отправляются с каждым запросом к серверу. Если предположить, что у сайта 20 куки размером 4 КБ, то каждый запрос будет давать дополнительную нагрузку в размере 80 КБ.
Некоторые из этих проблем можно решить с помощью сессий, речь о которых пойдет в следующем уроке.
]]>Формы — важный элемент любого веб-приложения, но, к сожалению, работать с ними достаточно сложно. Сначала нужно подтвердить данные на стороне клиента, затем — на сервере. И даже этого недостаточно, если разработчик приложения озабочен такими проблемами безопасности как CSRF, XSS, SQL Injection и так далее. Все вместе — это масса работы. К счастью, есть отличная библиотека WTForms, выполняет большую часть задач за разработчика. Перед тем как узнать больше о WTForms, следует все-таки разобраться, как работать с формами без библиотек и пакетов.
Работа с формами — сложный вариант
Для начала создадим шаблон login.html со следующим кодом:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Login</title>
</head>
<body>
{% if message %}
<p>{{ message }}</p>
{% endif %}
<form action="" method="post">
<p>
<label for="username">Username</label>
<input type="text" name="username">
</p>
<p>
<label for="password">Password</label>
<input type="password" name="password">
</p>
<p>
<input type="submit">
</p>
</form>
</body>
</html>
Этот код нужно добавить после функции представления books() в файле main2.py:
from flask import Flask, render_template, request
#...
@app.route('/login/', methods=['post', 'get'])
def login():
message = ''
if request.method == 'POST':
username = request.form.get('username') # запрос к данным формы
password = request.form.get('password')
if username == 'root' and password == 'pass':
message = "Correct username and password"
else:
message = "Wrong username or password"
return render_template('login.html', message=message)
#...
Стоит обратить внимание, что аргумент methods передан декоратору route(). По умолчанию обработчик запросов вызывается только в тех случаях, когда метод request.method — GET или HEAD. Это можно изменить, передав список разрешенных HTTP-методов аргументу-ключевому слову methods. С этого момента функция представления login будет вызываться только тогда, когда запрос к /login/ будет сделан с помощью методов GET, POST или HEAD. Если попробовать получить доступ к URL /login/ другим методом, появится ошибка HTTP 405 Method Not Allowed.
В прошлых уроках обсуждалось то, что объект request предоставляет информацию о текущем веб-запросе. Информация, полученная с помощью формы, хранится в атрибуте form объекта request. request.form — это неизменяемый объект типа словарь, известный как ImmutableMultiDict.
Дальше нужно запустить сервер и зайти на https://localhost:5000/login/. Откроется такая форма.

Запрос к странице был сделан с помощью метода GET, поэтому код внутри блока if функции login() пропущен.
Если попробовать отправить форму без ввода данных, страница будет выглядеть следующим образом:

В этот раз страница была отправлена методом POST, поэтому код внутри if оказался исполнен. Внутри этого блока приложение принимает имя пользователя и пароль и устанавливает сообщение для message. Поскольку форма оказалась пустой, отобразилось сообщение об ошибке.
Если заполнить форму с корректными именем пользователям и паролем и нажать Enter, появится приветственное сообщение “Correct username and password”:

Таким образом можно работать с формами во Flask. Теперь же стоит обратить внимание на пакет WTForms.
WTForms
WTForms – это мощная библиотека, написанная на Python и независимая от фреймворков. Она умеет генерировать формы, проверять их и предварительно заполнять информацией (удобно для редактирования) и многое другое. Также она предлагает защиту от CSRF. Для установки WTForms используется Flask-WTF.
Flask- WTF – это расширение для Flask, которое интегрирует WTForms во Flask. Оно также предлагает дополнительные функции, такие как загрузка файлов, reCAPTCHA, интернационализация (i18n) и другие. Для установки Flask-WTF нужно ввести следующую команду.
(env) gvido@vm:~/flask_app$ pip install flask-wtf
Создание класса Form
Начать стоит с определения форм в виде классов Python. Каждая форма должна расширять класс FlaskForm из пакета flask_wtf. FlaskForm — это обертка, содержащая полезные методы для оригинального класса wtform.Form, который является основной для создания форм. Внутри класса формы, поля формы определяются в виде переменных класса. Поля формы определяются путем создания объекта, ассоциируемого с типом поля. Пакет wtform предлагает несколько классов, представляющих собой следующие поля: StringField, PasswordField, SelectField, TextAreaField, SubmitField и другие.
Для начала нужно создать файл forms.py внутри словаря flask_app и добавить в него следующий код.
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField, TextAreaField
from wtforms.validators import DataRequired, Email
class ContactForm(FlaskForm):
name = StringField("Name: ", validators=[DataRequired()])
email = StringField("Email: ", validators=[Email()])
message = TextAreaField("Message", validators=[DataRequired()])
submit = SubmitField("Submit")
Здесь определен класс формы ContactForm с четырьмя полями: name, email, message и sumbit. Эти переменные будут использоваться, чтобы отрендерить поля формы, а также назначать и получать информацию из них. Эта форма создана с помощью двух StringField, TextAreaField и SumbitField. Каждый раз когда создается объект поля, определенные аргументы передаются его функции-конструктору. Первый аргумент — строка, содержащая метку, которая будет отображаться внутри тега <label> в тот момент, когда поле отрендерится. Второй опциональный аргумент — список валидаторов (элементов системы проверки), которые передаются конструктору в виде аргументов-ключевых слов. Валидаторы — это функции или классы, которые определяют, корректна ли введенная в поле информация. Для каждого поля можно использовать несколько валидаторов, разделив их запятыми (,). Модуль wtforms.validators предлагает базовые валидаторы, но их можно создавать самостоятельно. В этой форме используются два встроенных валидатора: DataRequired и Email.
DataRequired: он проверяет, ввел ли пользователь хоть какую-информацию в поле.
Email: проверяет, является ли введенный электронный адрес действующим.
Введенные данные не будут приняты до тех пор, пока валидатор не подтвердит соответствие данных.
Примечание: это лишь основа полей форм и валидаторов. Полный список доступен по ссылке https://wtforms.readthedocs.io.
Установка SECRET_KEY
По умолчанию Flask-WTF предотвращает любые варианты CSFR-атак. Это делается с помощью встраивания специального токена в скрытый элемент <input> внутри формы. Затем этот токен используется для проверки подлинности запроса. До того как Flask-WTF сможет сгенерировать csrf-токен, необходимо добавить секретный ключ. Установить его в файле main2.py необходимо следующим образом:
#...
app.debug = True
app.config['SECRET_KEY'] = 'a really really really really long secret key'
manager = Manager(app)
#...
Здесь используется атрибут config объекта Flask. Атрибут config работает как словарь и используется для размещения параметров настройки Flask и расширений Flask, но их можно добавлять и самостоятельно.
Секретный ключ должен быть строкой — такой, которую сложно разгадать и, желательно, длинной. SECRET_KEY используется не только для создания CSFR-токенов. Он применяется и в других расширениях Flask. Секретный ключ должен быть безопасно сохранен. Вместо того чтобы хранить его в приложении, лучше разместить в переменной окружения. О том как это сделать — будет рассказано в следующих разделах.
Формы в консоли
Откроем оболочку Python с помощью следующей команды:
(env) gvido@vm:~/flask_app$ python main2.py shell
Это запустит оболочку Python внутри контекста приложения.
Теперь нужно импортировать класс ContactForm и создать экземпляр объекта новой формы, передав данные формы.
>>>
>>> from forms import ContactForm
>>> from werkzeug.datastructures import MultiDict
>>>
>>>
>>> form1 = ContactForm(MultiDict([('name', 'jerry'),('email', 'jerry@mail.com')]))
>>>
Стоит обратить внимание, что данные передаются в виде объекта MultiDict, потому что функция-конструктор класса wtforms.Form принимает аргумент типа MutiDict. Если данные формы не определены при создании экземпляра объекта формы, а форма отправлена с помощью запроса POST, wtforms.Form использует данные из атрибута request.form. Стоит вспомнить, что request.form возвращает объект типа ImmutableMultiDict. Это то же самое, что и MultiDict, но он неизменяемый.
Метод validate() проверяет форму. Если проверка прошла успешно, он возвращает True, если нет — False.
>>>
>>> form1.validate()
False
>>>
Форма не прошла проверку, потому что обязательному полю message при создании объекта формы не было передано никаких данных. Получить доступ к ошибкам форм можно с помощью атрибута errors объекта формы:
>>>
>>> form1.errors
{'message': ['This field is required.'], 'csrf_token': ['The CSRF token is missing.']}
>>>
Нужно обратить внимание, что в дополнение к сообщению об ошибке для поля message, вывод также содержит сообщение об ошибке о недостающем csfr-токене. Это из-за того что в данных формы нет запроса POST с csfr-токеном.
Отключить CSFR-защиту можно, передав csfr_enabled=False при создании экземпляра класса формы. Пример:
>>> form3 = ContactForm(MultiDict([('name', 'spike'),('email', 'spike@mail.com')]), csrf_enabled=False)
>>>
>>> form3.validate()
False
>>>
>>> form3.errors
{'message': ['This field is required.']}
>>>
>>>
Как и предполагалось, теперь ошибка появляется только для поля message. Теперь можно создать другой объект формы, но в этот раз передать ему информацию для всех полей.
>>>
>>> form4 = ContactForm(MultiDict([('name', 'jerry'), ('email', 'jerry@mail.com'), ('message', "hello tom")]), csrf_enabled=False)
>>>
>>> form4.validate()
True
>>>
>>> form4.errors
{}
>>>
Проверка формы в этот раз прошла успешно.
Следующий шаг — рендеринг формы.
Рендеринг формы
Существует два варианта рендеринга:
- Один за одним.
- С помощью цикла
Рендеринг полей один за одним
Поскольку в шаблонах есть доступ к экземпляру формы, можно использовать имена полей, чтобы отрендерить имена, метки и ошибки:
{# выводим название поля #}
{{ form.field_name.label() }}
{# выводим само поле #}
{{ form.field_name() }}
{# выводим ошибки валидации, связанные с полем #}
{% for error in form.field_name.errors %}
{{ error }}
{% endfor %}
Стоит протестировать этот способ в консоли:
>>>
>>> from forms import ContactForm
>>> from jinja2 import Template
>>>
>>> form = ContactForm()
>>>
Здесь экземпляр объекта формы был создан без данных запроса. Так и происходит, когда форма отображается первый раз с помощью запроса GET.
>>>
>>>
>>> Template("{{ form.name.label() }}").render(form=form)
'<label for="name">Name: </label>'
>>>
>>> Template("{{ form.name() }}").render(form=form)
'<input id="name" name="name" type="text" value="">'
>>>
>>>
>>> Template("{{ form.email.label() }}").render(form=form)
'<label for="email">Email: </label>'
>>>
>>> Template("{{ form.email() }}").render(form=form)
'<input id="email" name="email" type="text" value="">'
>>>
>>>
>>> Template("{{ form.message.label() }}").render(form=form)
'<label for="message">Message</label>'
>>>
>>> Template("{{ form.message() }}").render(form=form)
'<textarea id="message" name="message"></textarea>'
>>>
>>>
>>> Template("{{ form.submit() }}").render(form=form)
'<input id="submit" name="submit" type="submit" value="Submit">'
>>>
>>>
Поскольку форма выводится первый раз, у полей не будет ошибок проверки. Следующий код наглядно демонстрирует это:
>>>
>>>
>>> Template("{% for error in form.name.errors %}{{ error }}{% endfor %}").render(form=form)
''
>>>
>>>
>>> Template("{% for error in form.email.errors %}{{ error }}{% endfor %}").render(form=form)
''
>>>
>>>
>>> Template("{% for error in form.message.errors %}{{ error }}{% endfor %}").render(form=form)
''
>>>
>>>
Вместо отображения ошибок проверки для каждого поля можно использовать form.errors, чтобы получить доступ к ошибкам валидации, относящимся к форме. forms.errors используется чтобы отображать ошибки проверки в верхней части формы.
>>>
>>> Template("{% for error in form.errors %}{{ error }}{% endfor %}").render(form=form)
''
>>>
При рендеринге полей и меток можно добавить дополнительные аргументы-ключевые слова, которые окажутся в HTML-коде в виде пар ключей-значений. Например:
>>>
>>> Template('{{ form.name(class="input", id="simple-input") }}').render(form=form)
'<input class="input" id="simple-input" name="name" type="text" value="">'
>>>
>>>
>>> Template('{{ form.name.label(class="lbl") }}').render(form=form)
'<label class="lbl" for="name">Name: </label>'
>>>
>>>
Предположим, форма была отправлена. Теперь можно попробовать отрендерить поля и посмотреть, что получится.
>>>
>>> from werkzeug.datastructures import MultiDict
>>>
>>> form = ContactForm(MultiDict([('name', 'spike'),('email', 'spike@mail.com')]))
>>>
>>> form.validate()
False
>>>
>>>
>>> Template("{{ form.name() }}").render(form=form)
'<input id="name" name="name" type="text" value="spike">'
>>>
>>>
>>> Template("{{ form.email() }}").render(form=form)
'<input id="email" name="email" type="text" value="spike@mail.com">'
>>>
>>>
>>> Template("{{ form.message() }}").render(form=form)
'<textarea id="message" name="message"></textarea>'
>>>
>>>
Стоит обратить внимание, что у атрибута value в полях name и email есть данные. Но элемент <textarea> для поля message пуст, потому что ему данные переданы не были. Получить доступ к ошибке валидации для поля message можно следующим образом:
>>>
>>> Template("{% for error in form.message.errors %}{{ error }}{% endfor %}").render(form=form)
'This field is required.'
>>>
Как вариант, form.errors можно использовать, чтобы перебрать все ошибки валидации за раз.
>>>
>>> s ="""\
... {% for field_name in form.errors %}\
... {% for error in form.errors[field_name] %}\
... <li>{{ field_name }}: {{ error }}</li>
... {% endfor %}\
... {% endfor %}\
... """
>>>
>>> Template(s).render(form=form)
'<li>csrf_token: The CSRF token is missing.</li>\n
<li>message: This field is required.</li>\n'
>>>
>>>
Стоит обратить внимание, что ошибки csfr-токена нет, потому что запрос был отправлен без токена. Отрендерить поле csfr можно как и любое другое поле:
>>>
>>> Template("{{ form.csrf_token() }}").render(form=form)
'<input id="csrf_token" name="csrf_token" type="hidden" value="IjZjOTBkOWM4ZmQ0MGMzZTY3NDc3ZTNiZDIxZTFjNDAzMGU1YzEwOTYi.DQlFlA.GQ-PrxsCJkQfoJ5k6i5YfZMzC7k">'
>>>
Рендеринг полей один из одним может занять много времени, особенно если их несколько. Для таких случаев используется цикл.
Рендеринг полей с помощью цикла
Следующий код демонстрирует, как можно отрендерить поля с помощью цикла for.
>>>
>>> s = """\
... <div>
... {{ form.csrf_token }}
... </div>
... {% for field in form if field.name != 'csrf_token' %}
... <div>
... {{ field.label() }}
... {{ field() }}
... {% for error in field.errors %}
... <div class="error">{{ error }}</div>
... {% endfor %}
... </div>
... {% endfor %}
... """
>>>
>>>
>>> print(Template(s).render(form=form))
<div>
<input id="csrf_token" name="csrf_token" type="hidden" value="IjZjOTBkOWM4ZmQ0MGMzZTY3NDc3ZTNiZDIxZTFjNDAzMGU1YzEwOTYi.DQlFlA.GQ-PrxsCJkQfoJ5k6i5YfZMzC7k">
</div>
<div>
<label for="name">Name: </label>
<input id="name" name="name" type="text" value="spike">
</div>
<div>
<label for="email">Email: </label>
<input id="email" name="email" type="text" value="spike@mail.com">
</div>
<div>
<label for="message">Message</label>
<textarea id="message" name="message"></textarea>
<div class="error">This field is required.</div>
</div>
<div>
<label for="submit">Submit</label>
<input id="submit" name="submit" type="submit" value="Submit">
</div>
>>>
>>>
Важно заметить, что вне зависимости от используемого метода нужно вручную добавлять тег <form>, чтобы обернуть поля формы.
Теперь, зная как создавать, поверять и рендерить формы, можно использовать полученные знания для создания реальных форм.
Вначале нужно создать шаблон contact.html со следующим кодом:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="" method="post">
{{ form.csrf_token() }}
{% for field in form if field.name != "csrf_token" %}
<p>{{ field.label() }}</p>
<p>{{ field }}
{% for error in field.errors %}
{{ error }}
{% endfor %}
</p>
{% endfor %}
</form>
</body>
</html>
Единственный недостающий кусочек пазла — функция представления, которая будет создана далее.
Работа с подтверждением формы
Откроем main2.py, чтобы добавить следующий код после функции представления login().
from flask import Flask, render_template, request, redirect, url_for
from flask_script import Manager, Command, Shell
from forms import ContactForm
#...
@app.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
print(name)
print(email)
print(message)
# здесь логика базы данных
print("\nData received. Now redirecting ...")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
#...
В 7 строке создается объект формы. На 8 строке проверяется значение, которое вернул метод validate_on_submit() для исполнения кода внутри инструкции if.
Почему используется validate_on_sumbit(), а не validate(), как это было в консоли?
validate() всего лишь проверяет, корректны ли данные формы. Он не проверяет, был ли запрос отправлен с помощью метода POST. Это значит, что если использовать метод validate(), тогда запрос GET к /contact/ запустит форму проверки, а пользователь увидит ошибки валидации. Вообще процедура проверки запускается только в том случае, если данные были отправлены с помощью метода POST. В противном случае вернется False. Метод validate_on_submit() вызывает метод validate() внутри себя. Также нужно обратить внимание, что при создании экземпляра объекта формы данные не передаются, потому что когда форма отправляется с помощью запроса POST, WTForm считывает данные формы из атрибута request.form.
Поля формы, определенные в классе формы становятся атрибутами объекта формы. Чтобы получить доступ к данным поля используется атрибут data поля формы:
form.name.data # доступ к данным в поле name.
form.email.data # доступ к данным в поле email.
Чтобы получить доступ ко всем данные формы сразу нужно использовать атрибут data к объекту формы:
form.data # доступ ко всем данным
Если использовать запрос GET при посещении /contact/, метод validate_on_sumbit() вернет False. Код внутри if будет пропущен, а пользователь получит пустую HTML-форму.
Когда форма отправляется с помощью запроса POST, validate_on_sumbit() возвращает True, предполагая, что данные верны. Вызовы print() внутри блока if выведут данные, введенные пользователем, а функция redirect() перенаправит пользователя на страницу /contact/. С другой стороны, если validate_on_sumbit() вернет False, исполнение инструкций внутри тела if будет пропущено, и появится сообщение об ошибке валидации.
Если сервер не запущен, его нужно запустить и открыть https://localhost:5000/contact/. Появится следующая контактная форма:

Если попробовать нажать Submit, не вводя данных, появятся следующие сообщения об ошибках валидации:

Теперь можно ввести определенные данные в поля Name и Message и некорректные данные в поле Email, и попробовать отправить форму снова.

Нужно обратить внимание, что все поля содержат данные из прошлого запроса.
Теперь можно ввести корректный email в поле Email и нажать Submit. Теперь проверка пройдет успешно, а в оболочке появится следующий вывод:
Spike
spike@gmail.com
A Message
Data received. Now redirecting ...
После отображения принятых данных в оболочке функция представления перенаправит пользователя по адресу /contact/. В этот момент должна отображаться пустая форма без ошибок валидации так, будто пользователь впервые открыл /contact/ с помощью запроса GET.
Рекомендуется отображать обратную связь пользователю после успешной отправки. Во Flask это делается с помощью всплывающих сообщений.
Всплывающие сообщения
Всплывающие сообщения — еще одна из тех функций, которые зависят от секретного ключа. Он необходим, потому что сообщения хранятся в сессиях. Сессиям во Flask будет посвящен отдельный урок. Поскольку в этом уроке секретный ключ уже был настроен, можно двигаться дальше.
Для отображения сообщения используется функция flash() из пакета flask. Функция flash() принимает два аргумента: сообщение и категория (опционально). Категория указывает на тип сообщения: _success_, _error_, _warning_ и так далее. Категория может быть использована в шаблоне, чтобы определить тип сообщения.
Снова откроем main2.py, чтобы добавить flash(“Message Received”, “success”) прямо перед вызовом redirect() в функции представления contact():
from flask import Flask, render_template, request, redirect, url_for, flash
#...
# здесь логика базы данных
print("\nData received. Now redirecting ...")
flash("Message Received", "success")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
Сообщение, заданное с помощью функции flash(), будет доступно только последующему запросу, а потом удалится.
Это только настройка сообщения. Для его отображения нужно поменять также шаблон.
Для этого нужно открыть файл contact.html и изменить его следующим образом:
Jinja предлагает функцию get_flashed_messages(), которая возвращает список активных сообщений без категории. Чтобы получить их вместе с категорией нужно передать with_category=True при вызове get_flashed_messages(). Когда значение with_categories – True, get_flashed_messages() вернет список кортежей формы (category, message).
После этих изменений следует открыть https://localhost:5000/contact снова. Заполнить форму и нажать Submit. Сообщение об успешной отправке отобразится в верхней части формы.

Расширения Flask
Расширения Flask — это пакеты, которые можно установить, чтобы расширить возможности Flask. Их суть в том, чтобы обеспечить удобный и понятный способ интеграции пакетов во Flask. Посмотреть все доступные расширения можно на странице https://flask.pocoo.org/extenstions/. На странице есть пакеты, возможности которых варьируются от отправки email до создания полноценных интерфейсов администратора. Важно помнить, что расширять возможности Flask можно не только с помощью его расширений. На самом деле, подойдет любой пакет из стандартной библиотеки Python или PyPi. Оставшаяся часть урока посвящена тому, как установить и интегрировать удобное расширение для Flask под названием Flask-Script.
Расширение Flask-Script
Flask-Script — это удобное миниатюрное расширение, которое позволяет создавать интерфейсы командной строки, запускать сервер и консоль Python в контексте приложений, делать определенные переменные видимыми в консоли автоматически и так далее.
Стоит напомнить то, что обсуждалось в уроке «Основы Flask». Для запуска сервера разработки на конкретном хосте и порте, их нужно передать в качестве аргументов-ключевых слов методу run():
if __name__ == "__main__":
app.run(debug=True, host="127.0.0.10", port=9000)
Проблема в том, что такой подход не гибкий. Намного удобнее передать хост и порт в виде параметров командной строки при запуске сервера. Flask-Script позволяет сделать это. Установить Flask-Script можно с помощью pip:
(env) gvido@vm:~/flask_app$ pip install flask-script
Чтобы использовать Flask-Script сперва нужно импортировать класс Manager из пакета flask_script и создать экземпляр объекта Manager, передав ему экземпляр приложения. Таким образом расширения Flask интегрируются. Сначала импортируется нужный класс из пакета, а затем создается экземпляр с помощью передачи ему экземпляра приложения. Нужно открыть файл main2.py и изменить его следующим образом:
from flask import Flask, render_template
from flask_script import Manager
app = Flask(__name__)
manager = Manager(app)
#...
Созданный объект Manager также имеет метод run(), который помимо запуска сервера разработки может считывать аргументы командной строки. Следует заменить строку app.run(debug=True) на manager.run(). К этому моменту main2.py должен выглядеть вот так:
from flask import Flask, render_template
from flask_script import Manager
app = Flask(__name__)
manager = Manager(app)
@app.route('/')
def index():
return render_template('index.html', name='Jerry')
@app.route('/user/<int:user_id>/')
def user_profile(user_id):
return "Profile page of user #{}".format(user_id)
@app.route('/books/<genre>/')
def books(genre):
return "All Books in {} category".format(genre)
if __name__ == "__main__":
manager.run()
Теперь у приложения есть доступ к базовым командам. Чтобы посмотреть, какие из них доступны, необходимо запустить файл main2.py:
(env) gvido@vm:~/flask_app$ python main2.py
usage: main2.py [-?] {shell,runserver} ...
positional arguments:
{shell,runserver}
shell Runs a Python shell inside Flask application context.
runserver Runs the Flask development server i.e. app.run()
optional arguments:
-?, --help show this help message and exit
Как показывает вывод, сейчас есть всего две команды: shell и runserver. Начнем с команды runserver.
runserver запускает веб-сервер. По умолчанию, он запускается на 127.0.0.1 на порте 5000. Чтобы увидеть варианты для любой команды нужно ввести --help и саму команду. Например:
(env) gvido@vm:~/flask_app$ python main2.py runserver --help
usage: main2.py runserver [-?] [-h HOST] [-p PORT] [--threaded]
[--processes PROCESSES] [--passthrough-errors] [-d]
[-D] [-r] [-R] [--ssl-crt SSL_CRT]
[--ssl-key SSL_KEY]
Runs the Flask development server i.e. app.run()
optional arguments:
-?, --help show this help message and exit
-h HOST, --host HOST
-p PORT, --port PORT
--threaded
--processes PROCESSES
--passthrough-errors
-d, --debug enable the Werkzeug debugger (DO NOT use in production
code)
-D, --no-debug disable the Werkzeug debugger
-r, --reload monitor Python files for changes (not 100% safe for
production use)
-R, --no-reload do not monitor Python files for changes
--ssl-crt SSL_CRT Path to ssl certificate
--ssl-key SSL_KEY Path to ssl key
Самые широко используемые варианты для runserver — это --host и --post. С их помощью можно запустить сервер разработки на конкретном интерфейсе и порте. Например:
(env) gvido@vm:~/flask_app$ python main2.py runserver --host=127.0.0.2 --port 8000
* Running on http://127.0.0.2:8000/ (Press CTRL+C to quit)
По умолчанию команда runserver запускает сервер без отладчика. Включить его вручную можно следующим образом:
(env) gvido@vm:~/flask_app$ python main2.py runserver -d -r
* Restarting with stat
* Debugger is active!
* Debugger PIN: 250-045-653
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Более простой способ запустить отладчик — выбрать значение True для атрибута debug у экземпляра объекта (app). Для этого нужно открыть main2.py и изменить файл следующим образом:
#...
app = Flask(__name__)
app.debug = True
manager = Manager(app)
#...
Далее о команде shell.
shell запускает консоль Python в контексте приложения Flask. Это значит, что все объекты внутри контекстов приложения и запроса будут доступны в консоли без создания дополнительных контекстов. Для запуска консоли нужно ввести следующую команду.
(env) gvido@vm:~/flask_app$ python main2.py shell
Получим доступ к определенным объектам.
>>>
>>> from flask import current_app, url_for, request
>>>
>>> current_app.name
'main2'
>>>
>>>
>>> url_for("user_profile", user_id=10)
'/user/10/'
>>>
>>> request.path
'/'
>>>
Как и ожидалось, это можно сделать, не создавая контексты приложения и запроса.
Создание команд
Когда экземпляр Manager создан, можно приступать к созданию собственных команд. Есть два способа:
- С помощью класса
Command - С помощью декоратора
@command
Создание команд с помощью класса Command
В файле main2.py добавим класс Faker:
#...
from flask_script import Manager, Command
#...
manager = Manager(app)
class Faker(Command):
'Команда для добавления поддельных данных в таблицы'
def run(self):
# логика функции
print("Fake data entered")
@app.route('/')
#...
Команда Faker была создана с помощью наследования класса Command. Метод run() вызывается при исполнении команды. Чтобы выполнить команду через командную строку, ее нужно добавить в экземпляр Manager с помощью метода add_command():
#...
class Faker(Command):
'Команда для добавления поддельных данных в таблицы'
def run(self):
# логика функции
print("Fake data entered")
manager.add_command("faker", Faker())
#...
Теперь нужно снова вернуться в терминал и запустить файл main2.py:
(env) gvido@vm:~/flask_app$ python main2.py
usage: main2.py [-?] {faker,shell,runserver} ...
positional arguments:
{faker,shell,runserver}
faker Команда для добавления поддельных данных в таблицы
shell Runs a Python shell inside Flask application context.
runserver Runs the Flask development server i.e. app.run()
optional arguments:
-?, --help show this help message and exit
Стоит обратить внимание, что теперь, в дополнение к shell и runserver, есть команда faker. Описание перед самой командой взято из строки документации класса Faker. Для запуска нужно ввести следующую команду:
(env) gvido@vm:~/flask_app$ python main2.py faker
Fake data entered
Создание команд с помощью декоратора @command
Создание команд с помощью класса Command достаточно объемно. Как вариант, можно использовать декоратор @command экземпляра класса Manager. Для этого нужно открыть файл main2.py и изменить его следующим образом:
#...
manager.add_command("faker", Faker())
@manager.command
def foo():
"Это созданная команда"
print("foo command executed")
@app.route('/')
#...
Была создана простая команда foo, которая выводит foo command executed при вызове. Декоратор @command автоматически добавляет команду к существующему экземпляру Manager, так что не нужно вызывать метод add_command(). Чтобы увидеть, как используются команды, нужно вернуться обратно в терминал и запустить main2.py.
(env) gvido@vm:~/flask_app$ python main2.py
usage: main2.py [-?] {faker,foo,shell,runserver} ...
positional arguments:
{faker,foo,shell,runserver}
faker Команда для добавления поддельных данных в таблицы
foo Это созданная команда
shell Runs a Python shell inside Flask application context.
runserver Runs the Flask development server i.e. app.run()
optional arguments:
-?, --help show this help message and exit
Поскольку команда foo теперь доступна, ее можно исполнить, введя следующую команду.
(env) gvido@vm:~/flask_app$ python main2.py foo
foo command executed
Автоматический импорт объектов
Импорт большого количества объектов в командной строке может быть утомительным. С помощью Flask-Script объекты можно сделать видимыми в терминале без явного импорта.
Команда Shell запускает оболочку. Функция конструктора оболочки Shell принимает аргумент-ключевое слово make_context. Аргумент, передаваемый make_context должен быть вызываемым и возвращать словарь. По умолчанию вызываемый объект возвращает словарь, содержащий только экземпляр приложения, то есть app. Это значит, что по умолчанию в оболочке можно получить доступ только к экземпляру приложения (app), специально не импортируя его. Чтобы изменить это поведение, нужно назначить новому объекту (функции), поддерживающему вызов, make_context. Это вернет словарь с объектами, к которым требуется получить доступ внутри оболочки.
Откроем файл main2.py, чтобы добавить следующий код после функции foo().
#...
from flask_script import Manager, Command, Shell
#...
def shell_context():
import os, sys
return dict(app=app, os=os, sys=sys)
manager.add_command("shell", Shell(make_context=shell_context))
#...
Здесь вызываемой функции shell_context() передается аргумент-ключевое слово make_context. Функция shell_context возвращает словарь с тремя объектами: app, os и sys. В результате, внутри оболочки теперь есть доступ к этим объектам, хотя их импорт не производился.
(env) gvido@vm:~/flask_app$ python main2.py shell
>>>
>>> app
<Flask 'main2'>
>>>
>>> os.name
'posix'
>>>
>>> sys.platform
'linux'
>>>
>>>
Статические файлы — это файлы, которые не изменяются часто. Это, например, файлы CSS, JavaScript, шрифты и так далее. По умолчанию Flask ищет статические файлы в папке static, которая хранится в папке приложения. Это поведение можно поменять, передав аргументу-ключевому слову static_folder название новой папки при создании экземпляра приложения:
app = Flask(__name__, static_folder="static_dir")
Это изменит расположение статических файлов по умолчанию на папку static_dir внутри папки приложения.
Пока что можно остановиться на папке по умолчанию, statiс. Сперва нужно создать папку static в папке flask_app. В static создаем CSS-файл style.css со следующим содержимым.
body {
color: red
}
Стоит вспомнить, что в уроке «Основы Flask» речь шла о том, что Flask автоматически добавляет путь в формате /static/<filename> для обработки статических файлов. Поэтому все, что остается — создать URL с помощью функции url_for():
<script src="{{ url_for('static', filename='jquery.js') }}"></script>
Вывод:
<script src="/static/jquery.js"></script>
Дальше необходимо открыть шаблон index.html и добавить тег <link>:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
</head>
...
Если сервер не запущен, его нужно запустить и открыть https://localhost:5000/. Там будет страница с красным текстом:

]]>Этот метод работы со статическими файлов подходит только для разработки. При создании реальных приложений используются реальные веб-сервера, такие как Nginx или Apache.
Flask может генерировать URL с помощью функции url_for() из пакета flask. URL можно задавать вручную в шаблонах и функциях представления, но это не очень хорошая практика. Предположим, возникла необходимость поменять структуру ссылок для блога с /<id>/<post-title>/ на /<id>/post/<post-title>/ . Если URL были заданы вручную в шаблонах и функциях, тогда придется вручную редактировать их во всех местах. Функция url_for() позволяет произвести то же изменение одним щелчком.
Функция url_for() принимает конечную точку и возвращает URL в виде строки. Стоит напомнить, что конечная точка ссылается на уникальное имя URL и в большинстве случае — это имя функции представления. Например, сейчас main2.py имеет определенный корневой путь(/):
#...
@app.route('/')
def index():
return render_template('index.html', name='Jerry')
#...
Чтобы сгенерировать корневой URL, нужно вызвать url_for() следующим образом: url_for(‘index’). Выводом будет '/'. Следующий код демонстрирует, как использовать url_for() в консоли.
>>> from main2 import app
>>> from flask import url_for
>>>
>>> with app.test_request_context('/api'): # путь /api выбран произвольно
... url_for('index')
...
'/'
>>>
Стоит обратить внимание, что сперва создается контекст запроса (и таким образом — контекст приложения). Если попробовать использовать url_for() внутри консоли без вызова контекста, выйдет ошибка. Больше о контекстах запросов и приложения можно прочитать здесь.
Если url_for() не может создать URL, она вызовет исключение BuildError.
>>>
>>> with app.test_request_context('/api'):
... url_for('/api')
...
Traceback (most recent call last):
...
werkzeug.routing.BuildError: Could not build url for endpoint '/api
Did you mean 'static' instead?
>>>
Чтобы сгенерировать абсолютной URL, нужно передать функции url_for() аргумент external=True:
>>>
>>> with app.test_request_context('/api'):
... url_for('index', _external=True)
...
'https://localhost:5000/'
>>>
Вместо того чтобы прописывать URL в функции redirect(), стоит всегда использовать url_for() для этого. Например:
@app.route('/admin/')
def admin():
if not loggedin:
return redirect(url_for('login')) # если не залогинен, выполнять редирект на страницу входа
return render_template('admin.html')
Чтобы сгенерировать URL для динамических адресов, нужно передать динамические части в виде аргументов-ключевых слов. Например:
>>>
>>> with app.test_request_context('/api'):
... url_for('user_profile', user_id = 100)
...
'/user/100/'
>>>
>>>
>>> with app.test_request_context('/api'):
... url_for('books', genre='biography')
...
'/books/biography/'
>>>
Дополнительные аргументы-ключевые слова, переданные функции url_for(), будут добавлены к URL в виде строки запроса.
>>>
>>> with app.test_request_context('/api'):
... url_for('books', genre='biography', page=2, sort_by='date-published')
...
'/books/biography/?page=2&sort_by=date-published'
>>>
url_for() — одна из тех функций, которую можно использовать внутри шаблона. Чтобы сгенерировать URL внутри шаблонов, нужно просто вызвать url_for() внутри фигурных скобок {{ … }}:
<a href="{{ url_for('books', genre='biography') }}">Books</a>
Вывод:
<a href="/books/biography/">Books</a>
Язык шаблонов (или шаблонизатор) Jinja — это маленький набор инструкций, который помогает автоматизировать создание HTML шаблонов.
Переменные, выражения и вызовы функций
В Jinja двойные фигурные скобки {{ }} позволяют получить результат выражение, переменную или вызвать функцию и вывести значение в шаблоне. Например:
Определение выражения
>>> from jinja2 import Template
>>>
>>> Template("{{ 10 + 3 }}").render()
'13'
>>> Template("{{ 10 - 3 }}").render()
'7'
>>>
>>> Template("{{ 10 // 3 }}").render()
'3'
>>> Template("{{ 10 / 3 }}").render()
'3.3333333333333335'
>>>
>>> Template("{{ 10 % 3 }}").render()
'1'
>>> Template("{{ 10 ** 3 }}").render()
'1000'
>>>
Другие операторы сравнения и присваивания и логические операторы Python также могут использоваться внутри выражений.
Вывод переменных
>>> Template("{{ var }}").render(var=12)
'12'
>>> Template("{{ var }}").render(var="hello")
'hello'
>>>
Это могут быть не только числа и строки Python. Шаблоны Jinja работают со сложными данными, такими как списки, словари, кортежи и даже пользовательские классы.
>>> Template("{{ var[1] }}").render(var=[1,2,3])
'2'
>>> Template("{{ var['profession'] }}").render(var={'name':'tom', 'age': 25, 'profession': 'Manager' })
'Manager'
>>> Template("{{ var[2] }}").render(var=("c", "c++", "python"))
'python'
>>> class Foo:
... def __str__(self):
... return "This is an instance of Foo class"
...
>>> Template("{{ var }}").render(var=Foo())
'This is an instance of Foo class'
>>>
Если обратится к индексу, который не существует, Jinja просто выведет пустую строку.
>>> Template("{{ var[100] }}").render(var=("c", "c++", "python"))
''
>>>
Вызов функции
В Jinja для определения функции ее нужно просто вызвать.
>>> def foo():
... return "foo() called"
...
>>>
>>> Template("{{ foo() }}").render(foo=foo)
'foo() called'
>>>
Атрибуты и методы
Для доступа к атрибутам и методам объекта нужно использовать оператор доступ точка (.).
>>> class Foo:
... def __init__(self, i):
... self.i = i
... def do_something(self):
... return "do_something() called"
...
>>>
>>> Template("{{ obj.i }}").render(obj=Foo(5))
'5'
>>>
>>> Template("{{ obj.do_something() }}").render(obj=Foo(5))
'do_something() called'
>>>
Комментарии
В Jinja используется следующий синтаксис для добавления комментариев в одну или несколько строк:
{# комментарий #}
{#
это
многострочный
комментарий
#}
Объявление переменных
Внутри шаблона можно задать переменную с помощью инструкции set.
{% set fruit = 'apple' %}
{% set name, age = 'Tom', 20 %}
Переменные определяются для хранения результатов сложных операций, так чтобы их можно было использовать дальше в шаблоне. Переменные, определенные вне управляющих конструкций (о них дальше), ведут себя как глобальные переменные и доступны внутри любой структуры. Тем не менее переменные, созданные внутри конструкций, ведут себя как локальные переменные и видимы только внутри этих конкретных конструкций. Единственное исключение — инструкция if.
Цикл и условные выражения
Управляющие конструкции позволяют добавлять в шаблоны элементы управления потоком и циклы. По умолчанию, управляющие конструкции используют разделитель {% … %} вместо двойных фигурных скобок {{ ... }}.
Инструкция if
Инструкция if в Jinja имитирует выражение if в Python, а значение условия определяет набор инструкции. Например:
{% if bookmarks %}
<p>User has some bookmarks</p>
{% endif %}
Если значение переменной bookmarks – True, тогда будет выведена строка <p>User has some bookmarks</p>. Стоит запомнить, что в Jinja, если у переменной нет значения, она возвращает False.
Также можно использовать условия elif и else, как в обычном коде Python. Например:
{% if user.newbie %}
<p>Display newbie stages</p>
{% elif user.pro %}
<p>Display pro stages</p>
{% elif user.ninja %}
<p>Display ninja stages</p>
{% else %}
<p>You have completed all stages</p>
{% endif %}
Управляющие инструкции также могут быть вложенными. Например:
{% if user %}
{% if user.newbie %}
<p>Display newbie stages</p>
{% elif user.pro %}
<p>Display pro stages</p>
{% elif user.ninja %}
<p>Display ninja stages</p>
{% else %}
<p>You have completed all states</p>
{% endif %}
{% else %}
<p>User is not defined</p>
{% endif %}
В определенных случаях достаточно удобно записывать инструкцию if в одну строку. Jinja поддерживает такой тип записи, но называет это выражением if, потому что оно записывается с помощью двойных фигурных скобок {{ … }}, а не {% … %}. Например:
{{ "User is logged in" if loggedin else "User is not logged in" }}
Здесь если переменная loggedin вернет True, тогда будет выведена строка “User is logged in”. В противном случае — “User is not logged in”.
Условие else использовать необязательно. Если его нет, тогда блок else вернет объект undefined.
{{ "User is logged in" if loggedin }}
Здесь, если переменная loggedin вернет True, будет выведена строка “User is logged in”. В противном случае — ничего.
Как и в Python можно использовать операторы сравнения, присваивания и логические операторы для управляющих конструкций, чтобы создавать более сложные условия. Вот несколько примеров:
{# Если user.count ревен 1000, код '<p>User count is 1000</p>' отобразится #}
{% if users.count == 1000 %}
<p>User count is 1000</p>
{% endif %}
{# Если выражение 10 >= 2 верно, код '<p>10 >= 2</p>' отобразится #}
{% if 10 >= 2 %}
<p>10 >= 2</p>
{% endif %}
{# Если выражение "car" <= "train" верно, код '<p>car <= train</p>' отобразится #}
{% if "car" <= "train" %}
<p>car <= train</p>
{% endif %}
{#
Если user залогинен и superuser, код
'<p>User is logged in and is a superuser</p>' отобразится
#}
{% if user.loggedin and user.is_superuser %}
<p>User is logged in and is a superuser</p>
{% endif %}
{#
Если user является superuser, moderator или author, код
'<a href="#">Edit</a>' отобразится
#}
{% if user.is_superuser or user.is_moderator or user.is_author %}
<a href="#">Edit</a>
{% endif %}
{#
Если user и current_user один и тот же объект, код
<p>user and current_user are same</p> отобразится
#}
{% if user is current_user %}
<p>user and current_user are same</p>
{% endif %}
{#
Если "Flask" есть в списке, код
'<p>Flask is in the dictionary</p>' отобразится
#}
{% if ["Flask"] in ["Django", "web2py", "Flask"] %}
<p>Flask is in the dictionary</p>
{% endif %}
Если условия становятся слишком сложными, или просто есть желание поменять приоритет оператора, можно обернуть выражения скобками ():
{% if (user.marks > 80) and (user.marks < 90) %}
<p>You grade is B</p>
{% endif %}
Цикл for
Цикл for позволяет перебирать последовательность. Например:
{% set user_list = ['tom', 'jerry', 'spike'] %}
<ul>
{% for user in user_list %}
<li>{{ user }}</li>
{% endfor %}
</ul>
Вывод:
<ul>
<li>tom</li>
<li>jerry</li>
<li>spike</li>
</ul>
Вот как можно перебирать значения словаря:
{% set employee = { 'name': 'tom', 'age': 25, 'designation': 'Manager' } %}
<ul>
{% for key in employee.items() %}
<li>{{ key }} : {{ employee[key] }}</li>
{% endfor %}
</ul>
Вывод:
<ul>
<li>designation : Manager</li>
<li>name : tom</li>
<li>age : 25</li>
</ul>
Примечание: в Python элементы словаря не хранятся в конкретном порядке, поэтому вывод может отличаться.
Если нужно получить ключ и значение словаря вместе, используйте метод items().
{% set employee = { 'name': 'tom', 'age': 25, 'designation': 'Manager' } %}
<ul>
{% for key, value in employee.items() %}
<li>{{ key }} : {{ value }}</li>
{% endfor %}
</ul>
Вывод:
<ul>
<li>designation : Manager</li>
<li>name : tom</li>
<li>age : 25</li>
</ul>
Цикл for также может использовать дополнительное условие else, как в Python, но зачастую способ его применения отличается. Стоит вспомнить, что в Python, если else идет следом за циклом for, условие else выполняется только в том случае, если цикл завершается после перебора всей последовательности, или если она пуста. Оно не выполняется, если цикл остановить оператором break.
Когда условие else используется в цикле for в Jinja, оно исполняется только в том случае, если последовательность пустая или не определена. Например:
{% set user_list = [] %}
<ul>
{% for user in user_list %}
<li>{{ user }}</li>
{% else %}
<li>user_list is empty</li>
{% endfor %}
</ul>
Вывод:
<ul>
<li>user_list is empty</li>
</ul>
По аналогии с вложенными инструкциями if, можно использовать вложенные циклы for. На самом деле, любые управляющие конструкции можно вкладывать одна в другую.
{% for user in user_list %}
<p>{{ user.full_name }}</p>
<p>
<ul class="follower-list">
{% for follower in user.followers %}
<li>{{ follower }}</li>
{% endfor %}
</ul>
</p>
{% endfor %}
Цикл for предоставляет специальную переменную loop для отслеживания прогресса цикла. Например:
<ul>
{% for user in user_list %}
<li>{{ loop.index }} - {{ user }}</li>
{% endfor %}
</ul>
loop.index внутри цикла for начинает отсчет с 1. В таблице упомянуты остальные широко используемые атрибуты переменной loop.
| Метод | Значение |
|---|---|
| loop.index0 | то же самое что и loop.index, но с индексом 0, то есть, начинает считать с 0, а не с 1. |
| loop.revindex | возвращает номер итерации с конца цикла (считает с 1). |
| loop.revindex0 | возвращает номер итерации с конца цикла (считает с 0). |
| loop.first | возвращает True, если итерация первая. В противном случае — False. |
| loop.last | возвращает True, если итерация последняя. В противном случае — False. |
| loop.length | возвращает длину цикла(количество итераций). |
Примечание: полный список есть в документации Flask.
Фильтры
Фильтры изменяют переменные до процесса рендеринга. Синтаксис использования фильтров следующий:
variable_or_value|filter_name
Вот пример:
{{ comment|title }}
Фильтр title делает заглавной первую букву в каждом слове. Если значение переменной comment — "dust in the wind", то вывод будет "Dust In The Wind".
Можно использовать несколько фильтров, чтобы точнее настраивать вывод. Например:
{{ full_name|striptags|title }}
Фильтр striptags удалит из переменной все HTML-теги. В приведенном выше коде сначала будет применен фильтр striptags, а затем — title.
У некоторых фильтров есть аргументы. Чтобы передать их фильтру, нужно вызвать фильтр как функцию. Например:
{{ number|round(2) }}
Фильтр round округляет число до конкретного количества символов.
В следующей таблице указаны широко используемые фильтры.
| Название | Описание |
|---|---|
| upper | делает все символы заглавными |
| lower | приводит все символы к нижнему регистру |
| capitalize | делает заглавной первую букву и приводит остальные к нижнему регистру |
| escape | экранирует значение |
| safe | предотвращает экранирование |
| length | возвращает количество элементов в последовательности |
| trim | удаляет пустые символы в начале и в конце |
| random | возвращает случайный элемент последовательности |
Примечание: полный список фильтров доступен здесь.
Макросы
Макросы в Jinja напоминают функции в Python. Суть в том, чтобы сделать код, который можно использовать повторно, просто присвоив ему название. Например:
{% macro render_posts(post_list, sep=False) %}
<div>
{% for post in post_list %}
<h2>{{ post.title }}</h2>
<article>
{{ post.html|safe }}
</article>
{% endfor %}
{% if sep %}<hr>{% endif %}
</div>
{% endmacro %}
В этом примере создан макрос render_posts, который принимает обязательный аргумент post_list и необязательный аргумент sep. Использовать его нужно следующим образом:
{{ render_posts(posts) }}
Определение макроса должно идти до первого вызова, иначе выйдет ошибка.
Вместо того чтобы использовать макросы прямо в шаблоне, лучше хранить их в отдельном файле и импортировать по надобности.
Предположим, все макросы хранятся в файле macros.html в папке templates. Чтобы импортировать их из файла, нужно использовать инструкцию import:
{% import "macros.html" as macros %}
Теперь можно ссылаться на макросы в файле macros.html с помощью переменной macros. Например:
{{ macros.render_posts(posts) }}
Инструкция {% import “macros.html” as macros %} импортирует все макросы и переменные (определенные на высшем уровне) из файла macros.html в шаблон. Также можно импортировать определенные макросы с помощью from:
{% from "macros.html" import render_posts %}
При использовании макросов будут ситуации, когда потребуется передать им произвольное число аргументов.
По аналогии с *args и **kwargs в Python внутри макросов можно получить доступ к varargs и kwargs.
varags: сохраняет дополнительные позиционные аргументы, переданные макросу, в виде кортежа.
lwargs: сохраняет дополнительные позиционные аргументы, переданные макросу, в виде словаря.
Хотя к ним можно получить доступ внутри макроса, объявлять их отдельно в заголовке макроса не нужно. Вот пример:
{% macro custom_renderer(para) %}
<p>{{ para }}</p>
<p>varargs: {{ varargs }}</p>
<p>kwargs: {{ kwargs }}</p>
{% endmacro %}
{{ custom_renderer("some content", "apple", name='spike', age=15) }}
В этом случае дополнительный позиционный аргумент, "apple", присваивается varargs, а дополнительные аргументы-ключевые слова (name=’spike’, age=15) — kwargs.
Экранирование
Jinja по умолчанию автоматически экранирует вывод переменной в целях безопасности. Поэтому если переменная содержит, например, такой HTML-код: "<p>Escaping in Jinja</p>", он отрендерится в виде "<p>Escaping in Jinja</p>". Благодаря этому HTML-коды будут отображаться в браузере, а не интерпретироваться. Если есть уверенность, что данные безопасны и их точно можно рендерить, стоит воспользоваться фильтром safe. Например:
{% set html = "<p>Escaping in Jinja</p>" %}
{{ html|safe }}
Вывод:
<p>Escaping in Jinja</p>
Использовать фильтр safe в большом блоке кода будет неудобно, поэтому в Jinja есть оператор autoescape, который используется, чтобы отключить экранирование для большого объема данных. Он может принимать аргументы true или false для включения и отключения экранирования, соответственно. Например:
{% autoescape true %}
Escaping enabled
{% endautoescape %}
{% autoescape false %}
Escaping disabled
{% endautoescape %}
Все между {% autoescape false %} и {% endautoescape %} отрендерится без экранирования символов. Если нужно экранировать отдельные символы при выключенном экранировании, стоит использовать фильтр escape. Например:
{% autoescape false %}
<div class="post">
{% for post in post_list %}
<h2>{{ post.title }}</h2>
<article>
{{ post.html }}
</article>
{% endfor %}
</div>
<div>
{% for comment in comment_list %}
<p>{{ comment|escape }}</p> # escaping is on for comments
{% endfor %}
</div>
{% endautoescape %}
Вложенные шаблоны
Инструкция include рендерит шаблон внутри другого шаблона. Она широко используется, чтобы рендерить статический раздел, который повторяется в разных местах сайта. Вот синтаксис include:
Предположим, что навигационное меню хранится в файле nav.html, сохраненном в папке templates:
<nav>
<a href="/home">Home</a>
<a href="/blog">Blog</a>
<a href="/contact">Contact</a>
</nav>
Чтобы добавить это меню в home.html, нужно использовать следующий код:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{# добавляем панель навигации из nav.html #}
{% include 'nav.html' %}
</body>
</html>
Вывод:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<nav>
<a href="/home">Home</a>
<a href="/blog">Blog</a>
<a href="/contact">Contact</a>
</nav>
</body>
</html>
Наследование шаблонов
Наследование шаблонов — один из самых мощных элементов шаблонизатора Jinja. Его принцип похож на ООП (объектно-ориентированное программирование). Все начинается с создания базового шаблона, который содержит в себе скелет HTML и отдельные маркеры, которые дочерние шаблоны смогут переопределять. Маркеры создаются с помощью инструкции block. Дочерние шаблоны используют инструкцию extends для наследования или расширения основного шаблона. Вот пример:
{# Это шаблон templates/base.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}Default Title{% endblock %}</title>
</head>
<body>
{% block nav %}
<ul>
<li><a href="/home">Home</a></li>
<li><a href="/api">API</a></li>
</ul>
{% endblock %}
{% block content %}
{% endblock %}
</body>
</html>
Это базовый шаблон base.html. Он создает три блока с помощью block, которые впоследствии будут заполнены дочерними шаблонами. Инструкция block принимает один аргумент — название блока. Внутри шаблона это название должно быть уникальным, иначе возникнет ошибка.
Дочерний шаблон — это шаблон, который растягивает базовый шаблон. Он может добавлять, перезаписывать или оставлять элементы родительского блока. Вот как можно создать дочерний шаблон.
{# Это шаблон templates/child.html #}
{% extends 'base.html' %}
{% block content %}
{% for bookmark in bookmarks %}
<p>{{ bookmark.title }}</p>
{% endfor %}
{% endblock %}
Инструкция extends сообщает Jinja, что child.html — это дочерний элемент, наследник base.html. Когда Jinja обнаруживает инструкцию extends, он загружает базовый шаблон, то есть base.html, а затем заменяет блоки контента внутри родительского шаблона блоками с теми же именами из дочерних шаблонов. Если блок с соответствующим названием не найден, используется блок родительского шаблона.
Стоит отметить, что в дочернем шаблоне перезаписывается только блок content, так что содержимое по умолчанию из title и nav будет использоваться при рендеринге дочернего шаблона. Вывод должен выглядеть следующим образом:
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<title>Default Title</title>
</head>
<body>
<ul>
<li><a href="/home">Home</a></li>
<li><a href="/api">API</a></li>
</ul>
<p>Bookmark title 1</p>
<p>Bookmark title 2</p>
<p>Bookmark title 3</p>
<p>Bookmark title 4</p>
</body>
</html>
Если нужно, можно поменять заголовок по умолчанию, переписав блок title в child.html:
{# Это шаблон templates/child.html #}
{% extends 'base.html' %}
{% block title %}
Child Title
{% endblock %}
{% block content %}
{% for bookmark in bookmarks %}
<p>{{ bookmark.title }}</p>
{% endfor %}
{% endblock %}
После перезаписи блока на контент из родительского шаблона все еще можно ссылаться с помощью функции super(). Обычно она используется, когда в дополнение к контенту дочернего шаблона нужно добавить содержимое из родительского. Например:
{# Это шаблон templates/child.html #}
{% extends 'base.html' %}
{% block title %}
Child Title
{% endblock %}
{% block nav %}
{{ super() }} {# referring to the content in the parent templates #}
<li><a href="/contact">Contact</a></li>
<li><a href="/career">Career</a></li>
{% endblock %}
{% block content %}
{% for bookmark in bookmarks %}
<p>{{ bookmark.title }}</p>
{% endfor %}
{% endblock %}
Вывод:
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<title>Child Title</title>
</head>
<body>
<ul>
<li><a href="/home">Home</a></li>
<li><a href="/api">API</a></li>
<li><a href="/contact">Contact</a></li>
<li><a href="/career">Career</a></li>
</ul>
<p>Bookmark title 1</p>
<p>Bookmark title 2</p>
<p>Bookmark title 3</p>
<p>Bookmark title 4</p>
</body>
</html>
Это все, что нужно знать о шаблонах Jinja. В следующих уроках эти знания будут использованы для созданы крутых шаблонов.
]]>До этого момента HTML-строки записывались прямо в функцию представления. Это нормально в демонстрационных целях, но неприемлемо при создании реальных приложений. Большинство современных веб-страниц достаточно длинные и состоят из множества динамических элементов. Вместо того чтобы использовать огромные блоки HTML-кода прямо в функциях (с чем еще и неудобно будет работать), применяются шаблоны.
Шаблоны
Шаблон — это всего лишь текстовый файл с HTML-кодом и дополнительными элементами разметки, которые обозначают динамический контент. Последний станет известен в момент запроса. Процесс, во время которого динамическая разметка заменяется, и генерируется статическая HTML-страница, называется отрисовкой (или рендерингом) шаблона. Во Flask есть встроенный движок шаблонов Jinja, который и занимается тем, что конвертирует шаблон в статический HTML-файл.
Jinja — один из самых мощных и популярных движков для обработки шаблонов для языка Python. Он должен быть известен пользователям Django. Но стоит понимать, что Flask и Jinja – два разных пакета, и они могут использоваться отдельно.
Отрисовка шаблонов с помощью render_template()
По умолчанию, Flask ищет шаблоны в подкаталоге templates внутри папки приложения. Это поведение можно изменить, передав аргумент template_folder конструктору Flask во время создания экземпляра приложения.
Этот код меняет расположение шаблонов по умолчанию на папку jinja_templates внутри папки приложения.
app = Flask(__name__, template_folder="jinja_templates")
Сейчас в этом нет смысла, поэтому пока стоит продолжать использовать папку templates для хранения шаблонов.
Создаем новую папку templates внутри папки приложения flask_app. В templates — файл index.html со следующим кодом:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>Name: {{ name }}</p>
</body>
</html>
Стоит обратить внимание, что в «базовом» HTML-шаблоне есть динамический компонент {{ name }}. Переменная name внутри фигурных скобок представляет собой переменную, значение которой будет определено во время отрисовки шаблона. В качестве примера можно написать, что значением name будет Jerry. Тогда после рендеринга шаблона выйдет следующий код.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>Name: Jerry</p>
</body>
</html>
Flask предоставляет функцию rended_template для отрисовки шаблонов. Она интегрирует Jinja во Flask. Чтобы отрисовать шаблон, нужно вызвать rended_template() с именем шаблона и данными, которые должны быть в шаблоне в виде аргументов-ключевых слов. Аргументы-ключевые слова, которые передаются шаблонам, известны как контекст шаблона. Следующий код показывает, как отрисовать шаблон index.html с помощью render_template().
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html', name='Jerry')
#...
Важно обратить внимание, что name в name='Jerry' ссылается на переменную, упомянутую в шаблоне index.html.
Если сейчас зайти на https://localhost:5000/, выйдет следующий ответ:
")
Если render_template() нужно передать много аргументов, можно не разделять их запятыми (,), а создать словарь и использовать оператор **, чтобы передать аргументы-ключевые слова функции. Например:
@app.route('/')
def index():
name, age, profession = "Jerry", 24, 'Programmer'
template_context = dict(name=name, age=age, profession=profession)
return render_template('index.html', **template_context)
Шаблон index.html теперь имеет доступ к трем переменным шаблона: name, age и profession.
Что случится, если не определить контекст шаблона?
Ничего не случится, не будет ни предупреждений, ни исключений. Jinja отрисует шаблон как обычно, а на местах пропусков использует пустые строки. Чтобы увидеть это поведение, необходимо изменить функцию представления index() следующим образом:
#...
@app.route('/')
def index():
return render_template('index.html')
#...
Теперь при открытии https://localhost:5000/ выйдет следующий ответ:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>Name: </p>
</body>
</html>
Сейчас должна сложиться картина того, как используются шаблоны во Flask, а в следующем разделе речь пойдет о том, как рендерить их в консоли.
Отрисовка шаблонов в консоли
Для тестирования рендерить шаблоны можно и в консоли. Это просто и не требует создания нескольких файлов. Для начала нужно запустить Python и импортировать класс Template из пакета jinja2 следующим образом.
>>> from jinja2 import Template
Для создания объекта Templates нужно передать содержимое шаблона в виде строки.
>>> t = Template("Name: {{ name }}")
Чтобы отрендерить шаблон, нужно вызвать метод render() объекта Template вместе с данными аргументами-ключевыми словами
>>> t.render(name='Jerry')
'Name: Jerry'
В следующем уроке речь пойдет о шаблонизаторе Jinja.
]]>Ответ сервера
Flask предлагает три варианта для создания ответа:
- В виде строки или с помощью шаблонизатора
- Объекта ответа
- Кортежа в формате (
response, status, headers) или (response, headers)
Далее о каждом поподробнее.
Создание ответа в виде строки
@app.route('/books/<genre>')
def books(genre):
return "All Books in {} category".format(genre)
До сих пор этот способ использовался, чтобы отправлять ответ клиенту. Когда Flask видит, что из функции представления возвращается строка, он автоматически конвертирует ее в объект ответа (с помощью метода make_response()) со строкой, содержащей тело ответа, статус-код HTTP 200 и значение text/html в заголовке content-type. В большинстве случаев это — все, что нужно. Но иногда необходимы дополнительные заголовки перед отправлением ответа клиенту. Для этого создавать ответ нужно с помощью функции make_response().
Создание ответа с помощью make_response()
Синтаксис make_response() следующий:
res_obj = make_response(res_body, status_code=200)
res_body — обязательный аргумент, представляющий собой тело ответа, а status_code — опциональный, по умолчанию его значение равно 200.
Следующий код показывает, как добавить дополнительные заголовки с помощью функции make_response().
from flask import Flask, make_response,
@app.route('/books/<genre>')
def books(genre):
res = make_response("All Books in {} category".format(genre))
res.headers['Content-Type'] = 'text/plain'
res.headers['Server'] = 'Foobar'
return res
Следующий — демонстрирует, как вернуть ошибку 404 с помощью make_response().
@app.route('/')
def http_404_handler():
return make_response("<h2>404 Error</h2>", 400)
Настройка куки — еще одна базовая задача для любого веб-приложения. Функция make_response() максимально ее упрощает. Следующий код устанавливает два куки в клиентском браузере.
@app.route('/set-cookie')
def set_cookie():
res = make_response("Cookie setter")
res.set_cookie("favorite-color", "skyblue")
res.set_cookie("favorite-font", "sans-serif")
return res
Примечание: куки обсуждаются подробно в уроке «Куки во Flask».
Куки, заданные в вышеуказанном коде, будут активны до конца сессии в браузере. Можно указать собственную дату истечения их срока, передав в качестве третьего аргумента в методе set_cookie() количество секунд. Например:
@app.route('/set-cookie')
def set_cookie():
res = make_response("Cookie setter")
res.set_cookie("favorite-color", "skyblue", 60*60*24*15)
res.set_cookie("favorite-font", "sans-serif", 60*60*24*15)
return res
Здесь, у куки будут храниться 15 дней.
Создание ответов с помощью кортежей
Последний способ создать ответ — использовать кортежи в одном из следующих форматов:
(response, status, headers)
(response, headers)
(response, status)
response — строка, представляющая собой тело ответа, status — код состояния HTTP, который может быть указан в виде целого числа или строки, а headers — словарь со значениями заголовков.
@app.route('/')
def http_500_handler():
return ("<h2>500 Error</h2>", 500)
Функция представления вернет ошибку HTTP 500 Internal Server Error. Поскольку при создании кортежей можно не писать скобки, вышеуказанный код можно переписать следующим образом:
@app.route('/')
def http_500_handler():
return "<h2>500 Error</h2>", 500
Следующий код демонстрирует, как указать заголовки с помощью кортежей:
@app.route('/')
def render_markdown():
return "## Heading", 200, {'Content-Type': 'text/markdown'}
Сможете догадаться, что делает следующая функция?
@app.route('/transfer')
def transfer():
return "", 302, {'location': 'https://localhost:5000/login'}
Функция представления перенаправляет пользователя на https://localhost:5000/login с помощью ответа 302 (временное перенаправление). Перенаправление пользователей — настолько распространенная практика, что во Flask для этого есть даже отдельная функция redirect().
from flask import Flask, redirect
@app.route('/transfer')
def transfer():
return redirect("https://localhost:5000/login")
По умолчанию, redirect() осуществляет 302 редиректы. Чтобы использовать 301, нужно указать это в функции redirect():
from flask import Flask, redirect
@app.route('/transfer')
def transfer():
return redirect("https://localhost:5000/login", code=301)
Перехват запросов
В веб-приложениях часто нужно исполнить определенный код до или после запроса. Например, нужно вывести весь список IP-адресов пользователей, которые используют приложение или авторизовать пользователя до того как показывать ему скрытые страницы. Вместе того чтобы копировать один и тот же код внутри каждой функции представления, Flask предлагает следующие декораторы:
before_first_request: этот декоратор выполняет функцию еще до обработки первого запросаbefore_request: выполняет функцию до обработки запросаafter_request: выполняет функцию после обработки запроса. Такая функция не будет вызвана при возникновении исключений в обработчике запросов. Она должна принять объект ответа и вернуть тот же или новый ответ.teardown_request: этот декоратор похож наafter_request. Но вызванная функция всегда будет выполняться вне зависимости от того, возвращает ли обработчик исключение или нет.
Стоит отметить, что если функция в before_request возвращает ответ, тогда обработчик запросов не вызывается.
Следующий код демонстрирует, как использовать эти точки перехвата во Flask. Нужно создать новый файл hooks.py с таким кодом:
from flask import Flask, request, g
app = Flask(__name__)
@app.before_first_request
def before_first_request():
print("before_first_request() called")
@app.before_request
def before_request():
print("before_request() called")
@app.after_request
def after_request(response):
print("after_request() called")
return response
@app.route("/")
def index():
print("index() called")
return '<p>Testings Request Hooks</p>'
if __name__ == "__main__":
app.run(debug=True)
После этого необходимо запустить сервер и сделать первый запрос, перейдя на страницу https://localhost:5000/. В консоли, где был запущен сервер, должен появиться следующий вывод:
before_first_request() called
before_request() called
index() called
after_request() called
Примечание: записи о запросах к серверу опущены для краткости.
После перезагрузки страницы отобразится следующий вывод.
before_request() called
index() called
after_request() called
Поскольку это второй запрос, функция before_first_request() не будет вызываться.
Отмена запроса с помощью abort()
Flask предлагает функцию abort() для отмены запроса с конкретным типом ошибки: 404, 500 и так далее. Например:
from flask import Flask, abort
@app.route('/')
def index():
abort(404)
# код после выполнения abort() не выполняется
Эта функция представления вернет стандартную страницу ошибки 404, которая выглядит вот так:

abort() покажет похожие страницы для других типов ошибок. Если нужно изменить внешний вид страниц с ошибками, необходимо использовать декоратор errorhandler.
Изменение страниц ошибок
Декоратор errorhandler используется для создания пользовательских страниц с ошибками. Он принимает один аргумент — ошибку HTTP, — для которой создается страница. Откроем файл hooks.py для создания кастомных страниц ошибок 404 и 500 с помощью декоратора:
from flask import Flask, request, g, abort
#...
#...
@app.after_request
def after_request(response):
print("after_request() called")
return response
@app.errorhandler(404)
def http_404_handler(error):
return "<p>HTTP 404 Error Encountered</p>", 404
@app.errorhandler(500)
def http_500_handler(error):
return "<p>HTTP 500 Error Encountered</p>", 500
@app.route("/")
def index():
# print("index() called")
# return '<p>Testings Request Hooks</p>'
abort(404)
if __name__ == "__main__":
#...
Стоит отметить, что оба обработчика ошибок принимают один аргумент error, который содержит дополнительную информацию о типе ошибки.
Если сейчас посетить корневой URL, отобразится следующий ответ:

Flask использует контексты, чтобы временно делать определенные глобальные доступными в глобальной области видимости.
Знакомые с Django могут обратить внимание на то, что функция представления во Flask не принимает request первым аргументом. Во Flask доступ к данным осуществляется с помощью входящего запроса, используя объект request:
from flask import Flask, request
@app.route('/')
def requestdata():
return "Hello! Your IP is {} and you are using {}: ".format(request.remote_addr,
request.user_agent)
Код выше может создать впечатление, что request — это глобальный объект, но на самом деле это не так. Если бы request был глобальным объектом, тогда в многопоточной программе приложение не смогло бы различать два одновременных процесса, поскольку программа такого типа распределяет все переменные по потокам. Во Flask используется то, что называется “Контекстами”. Они заставляют отдельные переменные вести себя как глобальные. Обращаясь к этим переменным, пользователь получает доступ к объекту в конкретном потоке. Технически такие переменные называются локальными или внутрипоточными.
Согласно документации Flask существует два вида контекстов:
- Контекст приложения
- Контекст запроса
Контекст приложения используется для хранения общих переменных приложения, таких как подключение к базе данных, настройки и т. д. А контекст запроса используется для хранения переменных конкретного запроса.
Контекст приложения предлагает такие объекты как current_app или g. current_app ссылается на экземпляр, который обрабатывает запрос, а g используется, чтобы временно хранить данные во время обработки запроса. Когда значение установлено, к нему можно получить доступ из любой функции представления. Данные в g сбрасываются после каждого запроса.
Как и контекст приложения, контекст запроса также предоставляет объекты: request и session. request содержит информацию о текущем запросе, а session — это словарь (dict). В нем хранятся значения, которые сохраняются между запросами.
Flask активирует контексты приложения и запроса, когда запрос получен и удаляет их, когда он обработан. Когда используется контекст приложения, все его переменные становятся доступным для потока. То же самое происходит и с контекстом запроса. Когда он активируется, его переменные могут быть использованы в потоке. Внутри функций представления можно получить доступ ко всем объектам контекстов приложения и запроса, так что не стоит волноваться о том, активны ли контексты или нет. Но если попробовать получить к ним доступ вне функции представления или в консоли Python, выйдет ошибка. Следующий пример демонстрирует ее:
>>> from flask import Flask, request, current_app
>>>
>>> request.method # получаем метод запроса
Traceback (most recent call last):
#...
RuntimeError: Working outside of request context.
This typically means that you attempted to use functionality that needed an active HTTP request. Consult the documentation on testing for information about how to avoid this problem.
>>>
request_method возвращает HTTP-метод, используемый в запросе, но поскольку самого HTTP-запроса нет, то и контекст запроса не активируется.
Похожая ошибка возникнет, если попытаться получить доступ к объекту, который предоставляется контекстом приложения.
>>> current_app.name # получим название приложения
Traceback (most recent call last):
#...
RuntimeError: Working outside of application context.
This typically means that you attempted to use functionality that needed to interface with the current application object in a way. To solve
this set up an application context with app.app_context(). See the documentation for more information.
>>>
Чтобы получить доступ к объектам, предоставляемым контекстами приложения и запроса вне функции представления, нужно сперва создать соответствующий контекст.
Создать контекст приложения можно с помощью метода app_context() для экземпляра Flask.
>>> from main2 import app
>>> from flask import Flask, request, current_app
>>>
>>> app_context = app.app_context()
>>> app_context.push()
>>>
>>> current_app.name
'main2'
Предыдущий код можно упростить используя выражение with следующим образом:
>>> from main2 import app
>>> from flask import request, current_app
>>>
>>>
>>> with app.app_context():
... current_app.name
...
'main2'
>>>
При создании контекстов лучше всего использовать выражение with.
Похожим образом можно создавать контекст запроса с помощью метода test_request_context() в экземпляре Flask. Важно запомнить, что когда активируется контекст запроса, контекст приложения создается, если его не было до этого. Следующий код демонстрирует процесс создания контекста запроса:
>>> from main2 import app
>>> from flask import request, current_app
>>>
>>>
>>> with app.test_request_context('/products'):
... request.path # получим полный путь к запрашиваемой странице(без домена).
... request.method
... current_app.name
...
'/products'
'GET'
'main2'
>>>
Адрес /products выбран произвольно.
Это все, что нужно знать о контекстах во Flask.
Hello World во фреймворке Flask
Начать знакомство с Flask можно с создания простого приложения, которое выводит “Hello World”. Создаем новый файл main.py и вводим следующий код.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello World'
if __name__ == "__main__":
app.run()
Это приложение “Hello World”, созданное с помощью фреймворка Flask. Если код в main.py не понятен, это нормально. В следующих разделах все будет разбираться подробно. Чтобы запустить main.py, нужно ввести следующую команду в виртуальную среду Python.
(env) gvido@vm:~/flask_app$ python main.py
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Запуск файла main.py запускает локальный сервер для разработки на порте 5000. Осталось открыть любимый браузер и зайти на https://127.0.0.1:5000/, чтобы увидеть приложение Hello World в действии.

Остановить сервер можно с помощью комбинации CTRL+C.
Создание приложения Flask
У каждого Flask-приложения должен быть экземпляр класса. Экземпляр — это WSGI-приложение (WSGI – это интерфейс для взаимодействия сервера с фреймворком), которое показывает, что сервер передает все полученные запросы экземпляру для дальнейшей обработки. Объект класса Flask создается следующим образом:
from flask import Flask
app = Flask(__name__)
В первой строке класс Flask импортируется из пакета flask.
Во второй строке создается объект Flask. Для этого конструктору Flask назначается аргумент __name__. Конструктор Flask должен иметь один обязательный аргумент. Им служит название пакета. В большинстве случаев значение __name__ подходит. Название пакета приложения используется фреймворком Flask, чтобы находить статические файлы, шаблоны и т. д.
Создание route (путей)
Маршрут (или путь) используется во фреймворке Flask для привязки URL к функции представления. Эта функция отвечает на запрос. Во Flask декоратор route используется, чтобы связать URL адрес с функций. Вот как маршрут создается.
@app.route('/')
def index():
return 'Hello World'
Этот код назначает функцию index() обработчиком корневого URL в приложении. Другими словами, каждый раз, когда приложение будет получать запрос, где путь — /, вызывается функция index(), и на этом запрос завершается.
Как вариант можно использовать метод add_url_rule() вместо декоратора route для маршрутизации. add_url_rule() — это простой метод, а не декоратор. Помимо URL он принимает конечную точку и название функции представления. Конечная точка относится к уникальному имени маршрута. Обычно, название функции представления — это и есть конечная точка. Flask может генерировать URL из конечной точки, но об этом позже. Предыдущий код аналогичен следующему:
def index():
return 'Hello World'
app.add_url_rule('/', 'index', index)
Декоратор route используется в большинстве случаев, но у add_url_rule() есть свои преимущества.
Функция представления должна вернуть строку. Если пытаться вернуть что-то другое, сервер ответит ошибкой 500 Internal Sever Error.
Можно создать столько столько, сколько нужно приложению. Например, в следующем списке 3 пути.
@app.route('/')
def index():
return 'Home Page'
@app.route('/career/')
def career():
return 'Career Page'
@app.route('/feedback/')
def feedback():
return 'Feedback Page'
Когда URL в маршруте заканчивается завершающим слешем (/), Flask перенаправляет запрос без слеша на URL со слешем. Так, запрос к /career будет перенаправлен на /career/.
Для одной функции представления может быть использовано несколько URL. Например:
@app.route('/contact/')
@app.route('/feedback/')
def feedback():
return 'Feedback Page'
В этом случае в ответ на запросы /contact/ или /feedback/, будет вызвана функция feedback().
Если перейти по адресу, для которого нет соответствующей функции представления, появится ошибка 404 Not Found.
Эти маршруты статичны. Большая часть современных приложений имеют динамичные URL. Динамичный URL – это адрес, который состоит из одной или нескольких изменяемых частей, влияющих на вывод страницы. Например, при создании веб-приложения со страницами профилей, у каждого пользователя будет уникальный id. Профиль первого пользователя будет на странице /user/1, второго — на /user/2 и так далее. Очень неудобный способ добиться такого результата — создавать маршруты для каждого пользователя отдельно.
Вместе этого можно отметить динамические части URL как <variable_name> (переменные). Эти части потом будут передавать ключевые слова функции отображения. Следующий код демонстрирует путь с динамическим элементом.
@app.route('/user/<id>/')
def user_profile(id):
return "Profile page of user #{}".format(id)
В этом примере на месте <id> будет указываться часть URI, которая идет после /user/. Например, если зайти на /user/100/, ответ будет следующим.
Profile page of user #100
Этот элемент не ограничен числовыми id. Адрес может быть /user/cowboy/, /user/foobar10/, /user/@@##/ и так далее. Но он не будет работать со следующими URI: /user/, /user/12/post/. Можно ограничить маршрут, чтобы он работал только с числовыми id после /user/. Это делается с помощью конвертера.
По умолчанию динамические части URL передаются в функцию в виде строк. Это можно изменить с помощью конвертера, который указывается перед динамическими элементами URL с помощью <converter:variable_name>. Например, /user/<int:id>/ будет работать с адресами /user/1/, /user/200/ и другими. Но /user/cowboy/, /user/foobar10/ и /user/@@##/ не подойдут.
В этом списке все конвертеры, доступные во Flask:
| Конвертер | Описание |
|---|---|
| string | принимает любые строки (значение по умолчанию). |
| int | принимает целые числа. |
| float | принимает числа с плавающей точкой. |
| path | принимает полный путь включая слеши и завершающий слеш. |
| uuid | принимает строки uuid (символьные id). |
Запуск сервера
Для запуска сервера разработки нужно использовать метод run() объекта Flask.
if __name__ == "__main__":
app.run()
Условие __name__ == "__main__" гарантирует, что метод run() будет вызван только в том случае, если main.py будет запущен, как основная программа. Если попытаться использовать метод run() при импорте main.py в другой модуль Python, он не вызовется.
Важно: сервер разработки Flask используется исключительно для тестирования, поэтому его производительность невысокая.
Теперь должно быть понятнее, как работает main.py.
Режим отладки (Debug)
Баги неизбежны в программировании. Поэтому так важно знать, как находить ошибки в программе и исправлять их. Во Flask есть мощный интерактивный отладчик, который по умолчанию отключен. Когда он выключен, а в программе обнаруживается ошибка, функция показывает 500 Internal Sever Error. Чтобы увидеть это поведение наглядно, можно специально добавить баг в файл main.py.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
print(i)
return 'Hello World'
if __name__ == "__main__":
app.run()
В этом случае программа пытается вывести значение неопределенной переменной i, что приводит к ошибке. Если открыть https://127.0.0.1:5000/, то появится ошибка 500 Internal Sever Error:

Тем не менее сам браузер не сообщает о типе ошибки. Если посмотреть в консоль, то можно увидеть отчет об ошибке. В данном случае он выглядит вот так:
File "/home/gvido/flask_app/env/lib/python3.5/site-packages/flask/app.py", line 1612, in full_dispatch_request
rv = self.dispatch_request()
File "/home/gvido/flask_app/env/lib/python3.5/site-packages/flask/app.py", line 1598, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "main.py", line 13, in index
print(i)
NameError: name 'i' is not defined
Когда режим отладки выключен, после изменения кода нужно каждый раз вручную запускать сервер, чтобы увидеть изменения. Но режим отладки будет перезапускать его после любых изменений в коде.
Чтобы включить режим, нужно передать аргумент debug=True методу run():
if __name__ == "__main__":
app.run(debug=True)
Еще один способ — указать значение True для атрибута debug.
from flask import Flask
app = Flask(__name__)
app.debug = True
После обновления файл main.py следующим образом его можно запускать.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
print(i)
return 'Hello World'
if __name__ == "__main__":
app.run(debug=True) # add debug mode
Теперь при открытии https://127.0.0.1:5000/ на странице будет отладчик.
Теперь, когда отладчик включен, вместо ошибки 500 Internal Server на странице будет отображаться отчет об ошибке. Он в полной мере описывает, какая ошибка случилась. Внизу страницы видно, что оператор print пытался вывести значение неопределенной переменной i. Там же указан тип ошибки, NameError, что подтверждает то, что ошибка заключается в том, что имя i не определено.
Кликнув на строчку кода на странице вывода ошибки, можно получить исходный код, где эта ошибка обнаружена, а также предыдущие и следующие строчки. Это помогает сразу понять контекст ошибки.

При наведении на строчку кода отображается иконка терминала. Нажав на нее, откроется консоль, где можно ввести любой код Python.

В ней можно проверить локальные переменные.

Если консоль открывается первый раз, то нужно ввести PIN-код.

Это мера безопасности, призванная ограничить доступ к консоли неавторизованным пользователям. Посмотреть код можно в консоли при запуске сервера. Он будет указан в начале вывода.

Завершить урок стоит созданием еще одного приложения Flask с применением всех имеющихся знаний.
Создаем еще один файл main2.py со следующим кодом:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello Flask'
@app.route('/user/<int:user_id>/')
def user_profile(user_id):
return "Profile page of user #{}".format(user_id)
@app.route('/books/<genre>/')
def books(genre):
return "All Books in {} category".format(genre)
if __name__ == "__main__":
app.run(debug=True)
Если запустить файл и зайти на https://127.0.0.1:5000/, браузер поприветствует выражением «Hello Flask»:

В этой новой версии приложения есть два динамических пути. Если в браузере ввести https://127.0.0.1:5000/user/123/, откроется страница со следующим содержанием:

Стоит заметить, что путь /user/<int:user_id>/ будет работать только с теми URL, где динамическая часть (user_id) представлена числом.
Чтобы проверить второй динамический путь, нужно открыть https://127.0.0.1:5000/books/sci-fi/. В этот раз получится следующее:

Если сейчас попробовать открыть URL, который не определен в путях, выйдет ошибка 404 Not Found. Например, такой ответ получите при попытке перейти на https://127.0.0.1:5000/products.
Как Flask обрабатывает запрос?
Откуда Flask знает, какую функцию выводить, когда он получает запрос от клиента?
Flask сопоставляет URL и функции отображения, которые будут выводиться. Определение соответствий (маршрутизация) создается с помощью декоратора route или метода add_url_rule() в экземпляре Flask. Получить доступ к этим соответствиям можно с помощью атрибута url_map у экземпляра Flask.
>>>
>>> from main2 import app
>>> app.url_map
Map([<Rule '/' (OPTIONS, GET, HEAD) -> index>,
<Rule '/static/<filename>' (OPTIONS, GET, HEAD) -> static>,
<Rule '/books/<genre>' (OPTIONS, GET, HEAD) -> books>,
<Rule '/user/<user_id>' (OPTIONS, GET, HEAD) -> user_profile>])
>>>
Как видно, есть 4 правила. Flask определяет соответствия URL в следующем формате:
url pattern, (comma separated list of HTTP methods handled by the route) -> view function to execute
Путь /static/<filename> автоматически добавляется для статических файлов Flask. О работе со статическими файлами речь пойдет в отдельном уроке «Обслуживание статических файлов во Flask».
Примечание: перед тем как двигаться дальше, нужно удостовериться, что в системе установлены Python и пакет virtualenv.
Создание виртуальной среды (Virtual Environment)
Виртуальная среда — это изолированная копия Python, куда устанавливаются пакеты, не затрагивающие глобальную версию Python. Начать нужно с создания папки flask_app. В ней будет храниться приложение Flask.
gvido@vm:~$ mkdir flask_app
gvido@vm:~$
Важно не забыть сменить рабочий каталог на flask_app с помощью команды cd.
gvido@vm:~$ cd flask_app/
gvido@vm:~/flask_app$
Следующий шаг — создание виртуальной среды внутри папки flask_app с помощью команды virtualenv.
gvido@vm:~/flask_app$ virtualenv env
Using base prefix '/usr'
New python executable in /home/gvido/flask_app/env/bin/python3
Also creating executable in /home/gvido/flask_app/env/bin/python
Installing setuptools, pip, wheel...done.
gvido@vm:~/flask_app$
После выполнения вышеуказанной команды в папке flask_app должна появиться еще одна под названием env. В ней будет храниться отдельная версия Python, включающая все исполняемые скрипты, как и в глобальной версии. Для использования среды ее нужно активировать.
В Linux и Mac OS это делается с помощью следующей команды.
gvido@-vm:~/flask_app$ source env/bin/activate
(env) gvido@vm:~/flask_app$
Пользователям Windows нужно использовать следующую команду.
C:\Users\gvido\flask_app>env\Scripts\activate
(env) C:\Users\gvido\flask_app>
Стоит обратить внимание, что название виртуальной среды теперь написано в скобках перед активной строкой ввода, например, (env). Это значит, что среда есть и активна. Теперь все установленные пакеты будут доступны только внутри этой среды.
Включение виртуальной среды временно меняет переменную окружения PATH. Так, если сейчас ввести в терминале python, будет вызван интерпретатор внутри среды, то есть, env, вместо глобального.
После окончания работы со средой, ее нужно выключить с помощью команды deactivate.
(env) gvido@vm:~/flask_app$ deactivate
gvido@vm:~/flask_app$
Эта же команда снова делает доступным глобальный интерпретатор Python.
Установка Flask
Для установки Flask внутри виртуальной среды нужно ввести следующую команду.
(env) gvido@vm:~/flask_app$ pip install flask
Проверить, прошла ли установка успешно, можно, вызвав интерпретатор Python и импортировав Flask.
(env) gvido@vm:~/flask_app$ python
Python 3.5.2 (default, Nov 17 2016, 17:05:23)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import flask
>>> flask.__version__
'0.12.2'
>>>
Если ошибок нет, значит Flask успешно установился.
]]>Flask — это микрофреймворк для Python, созданный в 2010 году разработчиком по имени Армин Ронахер. Но что значит это «микро»?
Это говорит о том, что Flask действительно маленький. У него в комплекте нет ни набора инструментов, ни библиотек, которыми славятся другим популярные фреймворки Python: Django или Pyramid. Но он создан с потенциалом для расширения. Во фреймворке есть набор базовых возможностей, а расширения отвечают за все остальное. «Чистый» Flask не умеет подключаться к базе данных, проверять данные формы, загружать файлы и так далее. Для добавления этих функций нужно использовать расширения. Это помогает использовать только те, которые на самом деле нужны.
Flask также не такой жесткий в отношении того, как разработчик должен структурировать свою программу, в отличие от, например, Django где есть строгие правила. Во Flask можно следовать собственной схеме.
В следующем уроке речь пойдет о том, как установить Flask.
]]>В этом уроке мы узнаем, как разрабатывать графические пользовательские интерфейсы, с помощью разбора некоторых примеров графического интерфейса Python с использованием библиотеки Tkinter.
Библиотека Tkinter установлена в Python в качестве стандартного модуля, поэтому нам не нужно устанавливать что-либо для его использования. Tkinter — очень мощная библиотека. Если вы уже установили Python, можете использовать IDLE, который является интегрированной IDE, поставляемой в Python, эта IDE написана с использованием Tkinter. Звучит круто!
Мы будем использовать Python 3.7 поэтому, если вы все еще используете Python 2.x, настоятельно рекомендуем перейти на Python 3.x, если вы не в курсе нюансов изменения языка, с целью, чтобы вы могли настроить код для запуска без ошибок.
Давайте предположим, что у вас уже есть базовые знания по Python, которые помогут понять что мы будем делать.
Мы начнем с создания окна, в котором мы узнаем, как добавлять виджеты, такие, как кнопки, комбинированные поля и т. д. После этого поэкспериментируем со своими свойствами, поэтому предлагаю начать.
Создание своего первого графического интерфейса
Для начала, следует импортировать Tkinter и создать окно, в котором мы зададим его название:
from tkinter import *
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.mainloop()
Результат будет выглядеть следующим образом:
 Прекрасно! Наше приложение работает.
Прекрасно! Наше приложение работает.
Последняя строка вызывает функцию mainloop. Эта функция вызывает бесконечный цикл окна, поэтому окно будет ждать любого взаимодействия с пользователем, пока не будет закрыто.
В случае, если вы забудете вызвать функцию mainloop , для пользователя ничего не отобразится.
Создание виджета Label
Чтобы добавить текст в наш предыдущий пример, мы создадим lbl , с помощью класса Label, например:
lbl = Label(window, text="Привет")
Затем мы установим позицию в окне с помощью функции grid и укажем ее следующим образом:
lbl.grid(column=0, row=0)
Полный код, будет выглядеть следующим образом:
from tkinter import *
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
lbl = Label(window, text="Привет")
lbl.grid(column=0, row=0)
window.mainloop()
И вот как будет выглядеть результат:
 Если функция
Если функция grid не будет вызвана, текст не будет отображаться.
Настройка размера и шрифта текста
Вы можете задать шрифт текста и размер. Также можно изменить стиль шрифта. Для этого передайте параметр font таким образом:
lbl = Label(window, text="Привет", font=("Arial Bold", 50))
 Обратите внимание, что параметр
Обратите внимание, что параметр font может быть передан любому виджету, для того, чтобы поменять его шрифт, он применяется не только к Label.
Отлично, но стандартное окно слишком мало. Как насчет настройки размера окна?
Настройка размеров окна приложения
Мы можем установить размер окна по умолчанию, используя функцию geometry следующим образом:
window.geometry('400x250')
В приведенной выше строке устанавливается окно шириной до 400 пикселей и высотой до 250 пикселей.
Попробуем добавить больше виджетов GUI, например, кнопки и посмотреть, как обрабатывается нажатие кнопок.
Добавление виджета Button
Начнем с добавления кнопки в окно. Кнопка создается и добавляется в окно так же, как и метка:
btn = Button(window, text="Не нажимать!")
btn.grid(column=1, row=0)
Наш код будет выглядеть вот так:
from tkinter import *
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
lbl = Label(window, text="Привет", font=("Arial Bold", 50))
lbl.grid(column=0, row=0)
btn = Button(window, text="Не нажимать!")
btn.grid(column=1, row=0)
window.mainloop()
Результат будет следующим:
 Обратите внимание, что мы помещаем кнопку во второй столбец окна, что равно 1. Если вы забудете и поместите кнопку в том же столбце, который равен 0, он покажет только кнопку.
Обратите внимание, что мы помещаем кнопку во второй столбец окна, что равно 1. Если вы забудете и поместите кнопку в том же столбце, который равен 0, он покажет только кнопку.
Изменение цвета текста и фона у Button
Вы можете поменять цвет текста кнопки или любого другого виджета, используя свойство fg.
Кроме того, вы можете поменять цвет фона любого виджета, используя свойство bg.
btn = Button(window, text="Не нажимать!", bg="black", fg="red")
 Теперь, если вы попытаетесь щелкнуть по кнопке, ничего не произойдет, потому что событие нажатия кнопки еще не написано.
Теперь, если вы попытаетесь щелкнуть по кнопке, ничего не произойдет, потому что событие нажатия кнопки еще не написано.
Кнопка Click
Для начала, мы запишем функцию, которую нужно выполнить при нажатии кнопки:
def clicked():
lbl.configure(text="Я же просил...")
Затем мы подключим ее с помощью кнопки, указав следующую функцию:
btn = Button(window, text="Не нажимать!", command=clicked)
Обратите внимание: мы пишем clicked, а не clicked()с круглыми скобками. Теперь полный код будет выглядеть так:
from tkinter import *
def clicked():
lbl.configure(text="Я же просил...")
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
lbl = Label(window, text="Привет", font=("Arial Bold", 50))
lbl.grid(column=0, row=0)
btn = Button(window, text="Не нажимать!", command=clicked)
btn.grid(column=1, row=0)
window.mainloop()
При нажатии на кнопку, результат, как и ожидалось, будет выглядеть следующим образом:
 Круто!
Круто!
Получение ввода с использованием класса Entry (текстовое поле Tkinter)
В предыдущих примерах GUI Python мы ознакомились со способами добавления простых виджетов, а теперь попробуем получить пользовательский ввод, используя класс Tkinter Entry (текстовое поле Tkinter).
Вы можете создать текстовое поле с помощью класса Tkinter Entry следующим образом:
txt = Entry(window, width=10)
Затем вы можете добавить его в окно, используя функцию grid.
Наше окно будет выглядеть так:
from tkinter import *
def clicked():
lbl.configure(text="Я же просил...")
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
lbl = Label(window, text="Привет")
lbl.grid(column=0, row=0)
txt = Entry(window,width=10)
txt.grid(column=1, row=0)
btn = Button(window, text="Не нажимать!", command=clicked)
btn.grid(column=2, row=0)
window.mainloop()
Полученный результат будет выглядеть так:
 Теперь, если вы нажмете кнопку, она покажет то же самое старое сообщение, но что же будет с отображением введенного текста в виджет
Теперь, если вы нажмете кнопку, она покажет то же самое старое сообщение, но что же будет с отображением введенного текста в виджет Entry?
Во-первых, вы можете получить текст ввода, используя функцию get. Мы можем записать код для выбранной функции таким образом:
def clicked():
res = "Привет {}".format(txt.get())
lbl.configure(text=res)
Если вы нажмете на кнопку — появится текст «Привет » вместе с введенным текстом в виджете записи. Вот полный код:
from tkinter import *
def clicked():
res = "Привет {}".format(txt.get())
lbl.configure(text=res)
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
lbl = Label(window, text="Привет")
lbl.grid(column=0, row=0)
txt = Entry(window,width=10)
txt.grid(column=1, row=0)
btn = Button(window, text="Клик!", command=clicked)
btn.grid(column=2, row=0)
window.mainloop()
Запустите вышеуказанный код и проверьте результат:
 Прекрасно!
Прекрасно!
Каждый раз, когда мы запускаем код, нам нужно нажать на виджет ввода, чтобы настроить фокус на ввод текста, но как насчет автоматической настройки фокуса?
Установка фокуса виджета ввода
Здесь все очень просто, ведь все, что нам нужно сделать, — это вызвать функцию focus:
txt.focus()
Когда вы запустите свой код, вы заметите, что виджет ввода в фокусе, который дает возможность сразу написать текст.
Отключить виджет ввода
Чтобы отключить виджет ввода, отключите свойство состояния:
txt = Entry(window,width=10, state='disabled')
 Теперь вы не сможете ввести какой-либо текст.
Теперь вы не сможете ввести какой-либо текст.
Добавление виджета Combobox
Чтобы добавить виджет поля с выпадающем списком, используйте класс Combobox из ttk следующим образом:
from tkinter.ttk import Combobox
combo = Combobox(window)
Затем добавьте свои значения в поле со списком.
from tkinter import *
from tkinter.ttk import Combobox
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
combo = Combobox(window)
combo['values'] = (1, 2, 3, 4, 5, "Текст")
combo.current(1) # установите вариант по умолчанию
combo.grid(column=0, row=0)
window.mainloop()
 Как видите с примера, мы добавляем элементы
Как видите с примера, мы добавляем элементы combobox, используя значения tuple.
Чтобы установить выбранный элемент, вы можете передать индекс нужного элемента текущей функции.
Чтобы получить элемент select, вы можете использовать функцию get вот таким образом:
combo.get()
Добавление виджета Checkbutton (чекбокса)
С целью создания виджета checkbutton, используйте класс Checkbutton:
from tkinter.ttk import Checkbutton
chk = Checkbutton(window, text='Выбрать')
Кроме того, вы можете задать значение по умолчанию, передав его в параметр var в Checkbutton:
from tkinter import *
from tkinter.ttk import Checkbutton
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
chk_state = BooleanVar()
chk_state.set(True) # задайте проверку состояния чекбокса
chk = Checkbutton(window, text='Выбрать', var=chk_state)
chk.grid(column=0, row=0)
window.mainloop()
Посмотрите на результат:
Установка состояния Checkbutton
Здесь мы создаем переменную типа BooleanVar, которая не является стандартной переменной Python, это переменная Tkinter, затем передаем ее классу Checkbutton, чтобы установить состояние чекбокса как True в приведенном выше примере.
Вы можете установить для BooleanVar значение false, что бы чекбокс не был отмечен.
Так же, используйте IntVar вместо BooleanVar и установите значения 0 и 1.
chk_state = IntVar()
chk_state.set(0) # False
chk_state.set(1) # True
Эти примеры дают тот же результат, что и BooleanVar.
Добавление виджетов Radio Button
Чтобы добавить radio кнопки, используйте класс RadioButton:
rad1 = Radiobutton(window,text='Первый', value=1)
Обратите внимание, что вы должны установить value для каждой radio кнопки с уникальным значением, иначе они не будут работать.
from tkinter import *
from tkinter.ttk import Radiobutton
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
rad1 = Radiobutton(window, text='Первый', value=1)
rad2 = Radiobutton(window, text='Второй', value=2)
rad3 = Radiobutton(window, text='Третий', value=3)
rad1.grid(column=0, row=0)
rad2.grid(column=1, row=0)
rad3.grid(column=2, row=0)
window.mainloop()
Результатом вышеприведенного кода будет следующий:
 Кроме того, вы можете задать
Кроме того, вы можете задать command любой из этих кнопок для определенной функции. Если пользователь нажимает на такую кнопку, она запустит код функции.
Вот пример:
rad1 = Radiobutton(window,text='Первая', value=1, command=clicked)
def clicked():
# Делайте, что нужно
Достаточно легко!
Получение значения Radio Button (Избранная Radio Button)
Чтобы получить текущую выбранную radio кнопку или ее значение, вы можете передать параметр переменной и получить его значение.
from tkinter import *
from tkinter.ttk import Radiobutton
def clicked():
lbl.configure(text=selected.get())
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
selected = IntVar()
rad1 = Radiobutton(window,text='Первый', value=1, variable=selected)
rad2 = Radiobutton(window,text='Второй', value=2, variable=selected)
rad3 = Radiobutton(window,text='Третий', value=3, variable=selected)
btn = Button(window, text="Клик", command=clicked)
lbl = Label(window)
rad1.grid(column=0, row=0)
rad2.grid(column=1, row=0)
rad3.grid(column=2, row=0)
btn.grid(column=3, row=0)
lbl.grid(column=0, row=1)
window.mainloop()
 Каждый раз, когда вы выбираете radio button, значение переменной будет изменено на значение кнопки.
Каждый раз, когда вы выбираете radio button, значение переменной будет изменено на значение кнопки.
Добавление виджета ScrolledText (текстовая область Tkinter)
Чтобы добавить виджет ScrolledText, используйте класс ScrolledText:
from tkinter import scrolledtext
txt = scrolledtext.ScrolledText(window,width=40,height=10)
Здесь нужно указать ширину и высоту ScrolledText, иначе он заполнит все окно.
from tkinter import *
from tkinter import scrolledtext
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
txt = scrolledtext.ScrolledText(window, width=40, height=10)
txt.grid(column=0, row=0)
window.mainloop()
Результат:
Настройка содержимого Scrolledtext
Используйте метод insert, чтобы настроить содержимое Scrolledtext:
txt.insert(INSERT, 'Текстовое поле')
Удаление/Очистка содержимого Scrolledtext
Чтобы очистить содержимое данного виджета, используйте метод delete:
txt.delete(1.0, END) # мы передали координаты очистки
Отлично!
Создание всплывающего окна с сообщением
Чтобы показать всплывающее окно с помощью Tkinter, используйте messagebox следующим образом:
from tkinter import messagebox
messagebox.showinfo('Заголовок', 'Текст')
Довольно легко! Давайте покажем окно сообщений при нажатии на кнопку пользователем.
from tkinter import *
from tkinter import messagebox
def clicked():
messagebox.showinfo('Заголовок', 'Текст')
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
btn = Button(window, text='Клик', command=clicked)
btn.grid(column=0, row=0)
window.mainloop()
 Когда вы нажмете на кнопку, появится информационное окно.
Когда вы нажмете на кнопку, появится информационное окно.
Показ сообщений о предупреждениях и ошибках
Вы можете показать предупреждающее сообщение или сообщение об ошибке таким же образом. Единственное, что нужно изменить—это функция сообщения.
messagebox.showwarning('Заголовок', 'Текст') # показывает предупреждающее сообщение
messagebox.showerror('Заголовок', 'Текст') # показывает сообщение об ошибке
Показ диалоговых окон с выбором варианта
Чтобы показать пользователю сообщение “да/нет”, вы можете использовать одну из следующих функций messagebox:
from tkinter import messagebox
res = messagebox.askquestion('Заголовок', 'Текст')
res = messagebox.askyesno('Заголовок', 'Текст')
res = messagebox.askyesnocancel('Заголовок', 'Текст')
res = messagebox.askokcancel('Заголовок', 'Текст')
res = messagebox.askretrycancel('Заголовок', 'Текст')
Вы можете выбрать соответствующий стиль сообщения согласно вашим потребностям. Просто замените строку функции showinfo на одну из предыдущих и запустите скрипт. Кроме того, можно проверить, какая кнопка нажата, используя переменную результата.
Если вы кликнете OK, yes или retry, значение станет True, а если выберете no или cancel, значение будет False.
Единственной функцией, которая возвращает одно из трех значений, является функция askyesnocancel; она возвращает True/False/None.
Добавление SpinBox (Виджет спинбокс)
Для создания виджета спинбокса, используйте класс Spinbox:
spin = Spinbox(window, from_=0, to=100)
Таким образом, мы создаем виджет Spinbox, и передаем параметры from и to, чтобы указать диапазон номеров.
Кроме того, вы можете указать ширину виджета с помощью параметра width:
spin = Spinbox(window, from_=0, to=100, width=5)
Проверим пример полностью:
from tkinter import *
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
spin = Spinbox(window, from_=0, to=100, width=5)
spin.grid(column=0, row=0)
window.mainloop()
 Вы можете указать числа для
Вы можете указать числа для Spinbox, вместо использования всего диапазона следующим образом:
spin = Spinbox(window, values=(3, 8, 11), width=5)
Виджет покажет только эти 3 числа: 3, 8 и 11.
Задать значение по умолчанию для Spinbox
В случае, если вам нужно задать значение по умолчанию для Spinbox, вы можете передать значение параметру textvariable следующим образом:
var = IntVar()
var.set(36)
spin = Spinbox(window, from_=0, to=100, width=5, textvariable=var)
Теперь, если вы запустите программу, она покажет 36 как значение по умолчанию для Spinbox.
Добавление виджета Progressbar
Чтобы создать данный виджет, используйте класс progressbar :
from tkinter.ttk import Progressbar
bar = Progressbar(window, length=200)
Установите значение progressbar таким образом:
bar['value'] = 70
Вы можете установить это значение на основе любого процесса или при выполнении задачи.
Изменение цвета Progressbar
Изменение цвета Progressbar немного сложно. Сначала нужно создать стиль и задать цвет фона, а затем настроить созданный стиль на Progressbar. Посмотрите следующий пример:
from tkinter import *
from tkinter.ttk import Progressbar
from tkinter import ttk
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
style = ttk.Style()
style.theme_use('default')
style.configure("black.Horizontal.TProgressbar", background='black')
bar = Progressbar(window, length=200, style='black.Horizontal.TProgressbar')
bar['value'] = 70
bar.grid(column=0, row=0)
window.mainloop()
И в результате вы получите следующее:
Добавление поля загрузки файла
Для добавления поля с файлом, используйте класс filedialog:
from tkinter import filedialog
file = filedialog.askopenfilename()
После того, как вы выберете файл, нажмите “Открыть”; переменная файла будет содержать этот путь к файлу. Кроме того, вы можете запросить несколько файлов:
files = filedialog.askopenfilenames()
Указание типа файлов (расширение фильтра файлов)
Возможность указания типа файлов доступна при использовании параметра filetypes, однако при этом важно указать расширение в tuples.
file = filedialog.askopenfilename(filetypes = (("Text files","*.txt"),("all files","*.*")))
Вы можете запросить каталог, используя метод askdirectory :
dir = filedialog.askdirectory()
Вы можете указать начальную директорию для диалогового окна файла, указав initialdir следующим образом:
from os import path
file = filedialog.askopenfilename(initialdir= path.dirname(__file__))
Легко!
Добавление панели меню
Для добавления панели меню, используйте класс menu:
from tkinter import Menu
menu = Menu(window)
menu.add_command(label='Файл')
window.config(menu=menu)
Сначала мы создаем меню, затем добавляем наш первый пункт подменю. Вы можете добавлять пункты меню в любое меню с помощью функции add_cascade() таким образом:
menu.add_cascade(label='Автор', menu=new_item)
Наш код будет выглядеть так:
from tkinter import *
from tkinter import Menu
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
menu = Menu(window)
new_item = Menu(menu)
new_item.add_command(label='Новый')
menu.add_cascade(label='Файл', menu=new_item)
window.config(menu=menu)
window.mainloop()
 Таким образом, вы можете добавить столько пунктов меню, сколько захотите.
Таким образом, вы можете добавить столько пунктов меню, сколько захотите.
from tkinter import *
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
menu = Menu(window)
new_item = Menu(menu)
new_item.add_command(label='Новый')
new_item.add_separator()
new_item.add_command(label='Изменить')
menu.add_cascade(label='Файл', menu=new_item)
window.config(menu=menu)
window.mainloop()
 Теперь мы добавляем еще один пункт меню “Изменить” с разделителем меню. Вы можете заметить пунктирную линию в начале, если вы нажмете на эту строку, она отобразит пункты меню в небольшом отдельном окне.
Теперь мы добавляем еще один пункт меню “Изменить” с разделителем меню. Вы можете заметить пунктирную линию в начале, если вы нажмете на эту строку, она отобразит пункты меню в небольшом отдельном окне.
Можно отключить эту функцию, с помощью tearoff подобным образом:
new_item = Menu(menu, tearoff=0)
Просто отредактируйте new_item, как в приведенном выше примере и он больше не будет отображать пунктирную линию.
Вы так же можете ввести любой код, который работает, при нажатии пользователем на любой элемент меню, задавая свойство команды.
new_item.add_command(label='Новый', command=clicked)
Добавление виджета Notebook (Управление вкладкой)
Для удобного управления вкладками реализуйте следующее:
- Для начала, создается элемент управления вкладкой, с помощью класса
Notebook. - Создайте вкладку, используя класс
Frame. - Добавьте эту вкладку в элемент управления вкладками.
- Запакуйте элемент управления вкладкой, чтобы он стал видимым в окне.
from tkinter import *
from tkinter import ttk
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
tab_control = ttk.Notebook(window)
tab1 = ttk.Frame(tab_control)
tab_control.add(tab1, text='Первая')
tab_control.pack(expand=1, fill='both')
window.mainloop()
 Таким образом, вы можете добавлять столько вкладок, сколько нужно.
Таким образом, вы можете добавлять столько вкладок, сколько нужно.
Добавление виджетов на вкладку
После создания вкладок вы можете поместить виджеты внутри этих вкладок, назначив родительское свойство нужной вкладке.
from tkinter import *
from tkinter import ttk
window = Tk()
window.title("Добро пожаловать в приложение PythonRu")
window.geometry('400x250')
tab_control = ttk.Notebook(window)
tab1 = ttk.Frame(tab_control)
tab2 = ttk.Frame(tab_control)
tab_control.add(tab1, text='Первая')
tab_control.add(tab2, text='Вторая')
lbl1 = Label(tab1, text='Вкладка 1')
lbl1.grid(column=0, row=0)
lbl2 = Label(tab2, text='Вкладка 2')
lbl2.grid(column=0, row=0)
tab_control.pack(expand=1, fill='both')
window.mainloop()
Добавление интервала для виджетов (Заполнение)
Вы можете добавить отступы для элементов управления, чтобы они выглядели хорошо организованными с использованием свойств padx иpady.
Передайте padx и pady любому виджету и задайте значение.
lbl1 = Label(tab1, text= 'label1', padx=5, pady=5)
Это очень просто!
]]>В этом уроке мы увидели много примеров GUI Python с использованием библиотеки Tkinter. Так же рассмотрели основные аспекты разработки графического интерфейса Python. Не стоит на этом останавливаться. Нет учебника или книги, которая может охватывать все детали. Надеюсь, эти примеры были полезными для вас.
Предыдущий урок: Python PIP
Блок try позволяет проверить блок кода на ошибки.
Блок except обрабатывает ошибку.
Блок finally позволяет выполнять код, независимо от результата блоков try и except.
Обработка исключений
Когда возникает ошибка или исключение, как его еще называют, Python обычно останавливает работу и генерирует сообщение об ошибке.
Эти исключения можно обрабатывать с помощью оператора try:
Блок try генерирует исключение, потому что x не объявлен:
try:
print(x)
except:
print("Ошибка")
Вывод:
Ошибка
Поскольку блок try вызывает ошибку, будет выполнен блок except. Без блока try программа остановится и вызовет ошибку:
print(x)
Вывод:
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
x
NameError: name 'x' is not defined
Несколько исключений
Вы можете определить столько исключений, сколько хотите.
try:
print(x)
except NameError:
print("Переменная x не существует")
except:
print("Что-то пошло не так")
Вывод:
Переменная x не существует
Else
Вы можете использовать ключевое слово else, для определения блока кода, который должен быть выполнен, если ошибок не было.
try:
print("Привет")
except:
print("Что-то пошло не так")
else:
print("Ошибок не обнаружено")
Вывод:
Привет
Ошибок не обнаружено
Finally
Блок finally, если указан, будет выполняться независимо от того, возникает ошибка в блоке try или нет.
try:
print(x)
except:
print("Что-то пошло не так")
finally:
print("Блок 'try except' завершен")
Вывод:
Что-то пошло не так
Блок 'try except' завершен
Это может быть полезно для закрытия файлов и очистки ресурсов.
Попробуем открыть и записать в файл, который не доступен для записи:
try:
f = open("demofile.txt") # фал должен быть создан, иначе исключение FileNotFound
f.write("Lorum Ipsum")
except:
print("Что-то пошло не так при записи в файл")
finally:
f.close()
Вывод:
Что-то пошло не так при записи в файл
Программа будет работать и закроет файл.
]]>Далее: Инструкции и выражения
Предыдущий урок: Регулярные выражения в Python
Что такое PIP?
PIP — это менеджер для библиотек Python или модулей.
Примечание: Если вы используете версию Python 3.4 и более позднюю, PIP уже установлен по умолчанию.
Что такое библиотека?
Библиотека содержит все файлы, необходимые для модуля.
Модули — это библиотеки кода Python, которые вы можете включить в свой проект.
Как проверить установлен ли PIP
Перейдите в командную строку в папку каталога сценариев Python и введите следующее:
pip --version
Установка PIP
Рекомендуем: Подробная инструкция по установки и настройки PIP.
Если PIP у вас не установлен, вы можете сделать это на своем устройстве, скачав с этой страницы: https://pypi.org/project/pip/
Скачивание библиотеки
Откройте командную строку и напишите pip НАЗВАНИЕ БИБЛИОТЕКИ, чтобы загрузить нужную.
Скачаем пакет “camelcase”:
pip install camelcase
Использование библиотек
Как только библиотека будет установлена, она готова к использованию. Импортируйте camelcase в свой проект.
import camelcase
c = camelcase.CamelCase()
txt = "hello world"
print(c.hump(txt))
Вывод:
Hello World
Поиск необходимых библиотек
Найдите больше библиотек здесь: https://pypi.org/.
]]>Далее: Try…Except
Предыдущий урок: Модуль JSON
RegEx, или регулярное выражение, представляет собой последовательность символов, которая формирует шаблон поиска.
Регулярные выражения используют, чтобы проверить, содержит ли строка указанный шаблон поиска.
Модуль Re
В Python есть встроенный модуль re, который можно использовать для работы с регулярными выражениями.
import re
RegEx в Python
Найдем строку, чтобы увидеть, начинается ли она с «The» и заканчивается «Spain»:
import re
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
Функции модуля Re
Модуль re предлагает набор функций, которые позволяют нам искать строку на предмет соответствия:
| Функции | Значение |
|---|---|
| findall | Возвращает список со всеми совпадениями |
| search | Возвращает объект Match, если в строке есть совпадение |
| split | Возвращает список, из строки, которую разделили по шаблону |
| sub | Заменяет совпадение по шаблону, на заданную строку |
Метасимволы
Метасимволы — это символы с особым значением:
| Символ | Значение | Пример |
|---|---|---|
| [] | Содержит символы для поиска вхождений | [a-m] |
| \ | Сигнализирует о специальном символе (также может использоваться для экранирования специальных символов) | \d |
| . | Любой символ, кроме новой строки (\n) | “he…o” |
| ^ | Строка начинается с | “^hello” |
| $ | Строка заканчивается | “world$” |
| * | 0 и более вхождений | “aix*” |
| + | 1 и более вхождений | “aix+” |
| {} | Указанное количество вхождений | “al{2}” |
| | | Или | “falls|stays” |
| () | Группирует шаблон |
Специальные пары символов
Специальная пара символов представляет собой \, за которым следует один из символов в списке ниже, и имеет специальное значение:
| Символ | Значение | Пример |
|---|---|---|
| \A | Ищет символы в начале строки | “\AThe” |
| \b | Ищет символы в начале или конец слова, в зависимости от расположения | r»\bain» r»ain\b» |
| \B | Ищет символы которые находятся НЕ в начале или конце строки | r»\Bain» r»ain\B» |
| \d | Ищет совпадения с числами 0-9 | “\d” |
| \D | Ищет совпадение, где строка не содержит числа | “\D” |
| \s | Ищет совпадение с символом пробела | “\s” |
| \S | Ищет совпадение, где строка НЕ содержит пробел | “\S” |
| \w | Ищет совпадение, где строка содержит буквы, цифры или символ по подчеркивания (_) | “\w” |
| \W | Ищет совпадение, где строка НЕ содержит буквы, цифры или символ по подчеркивания (_) | “\W” |
| \Z | Ищет символы в конце строки | “Spain\Z” |
Комбинации
Комбинации — это набор символов внутри пары квадратных скобок [] со специальным значением:
| Комбинации | Значение |
|---|---|
| [arn] | Возвращает совпадение, в котором присутствует один из указанных символов (a, r или n) |
| [a-n] | Возвращает совпадение для с символом нижнего регистра в алфавитном порядке между a и n, включая их |
| [^arn] | Возвращает совпадение для любого символа, КРОМЕ а, r и n |
| [0123] | Возвращает совпадение, в котором присутствует любая из указанных цифр (0, 1, 2 или 3) |
| [0-9] | Возвращает совпадение с любой цифрой от 0 до 9 |
| [0-5][0-9] | Возвращает совпадение с любыми двузначными числами от 0 до 59 |
| [a-zA-Z] | Возвращает совпадение с любым символом английского алфавита между a и z, включая строчные буквы и прописные |
| [а-яА-ЯёЁ] | Возвращает совпадение с любым символом русского алфавита между а и я, включая строчные буквы и прописные |
| [+] | В комбинациях символы +, *, ., |, (), $,{} не имеют особенного значения, поэтому [+]: будет искать любой + в строке |
Функция findall()
Функция findall() возвращает список, содержащий все совпадения.
import re
string = "The rain in Spain"
x = re.findall("ai", string)
print(x)
Вывод:
['ai', 'ai']
Список содержит совпадения в порядке их поиска. Если совпадений не найдено, возвращается пустой список.
import re
string = "The rain in Spain"
x = re.findall("Portugal", string)
print(x)
Вывод:
[]
Функция search()
Функция search() ищет в строке совпадение и возвращает обьект Match, если оно найдено. Если найдено более одного совпадения, будет возвращено только первое совпадение.
Найдем первый символ пробела в строке:
import re
string = "The rain in Spain"
x = re.search("\s", string)
print("Индекс первого пробела:", x.start())
Вывод:
Индекс первого пробела: 3
Если совпадений не найдено, возвращается None .
import re
string = "The rain in Spain"
x = re.search("Portugal", string)
print(x)
Вывод:
None
Функция split()
Функция split() возвращает список, в котором строка разбита по шаблону.
import re
string = "The rain in Spain"
x = re.split("\s", string)
print(x)
Вывод:
['The', 'rain', 'in', 'Spain']
Вы можете контролировать количество разбитий, указав параметр maxsplit.
import re
string = "The rain in Spain"
x = re.split("\s", string, 1)
print(x)
Вывод:
['The', 'rain in Spain']
Функция sub()
Функция sub() заменяет совпадение указанным текстом.
Заменим каждый символ пробела цифрой 9.
import re
string = "The rain in Spain"
x = re.sub("\s", "9", string)
print(x)
Вывод:
The9rain9in9Spain
Вы можете контролировать количество замен, указав параметр count.
import re
string = "The rain in Spain"
x = re.sub("\s", "9", string, 2)
print(x)
Вывод:
The9rain9in Spain
Объект Match
Объект Match — это объект, содержащий информацию о поиске и результат.
Примечание: Если совпадений нет, будет возвращено None вместо объекта Match.
Выполним поиск, который вернет объект Match.
import re
string = "The rain in Spain"
x = re.search("ai", string)
print(x) # будет выведен объект
Вывод:
<re.Match object; span=(5, 7), match='ai'>
У объекта Match есть свойства и методы, используемые для получения информации о поиске и результате:
.span() возвращает кортеж, содержащий начальную и конечную позиции совпадения.
.string возвращает строку, переданную в функцию.
.group() возвращает часть строки, где было совпадение
Выведем позицию (начальную и конечную) первого совпадения.
import re
string = "The rain in Spain"
x = re.search(r"\bS\w+", string)
print(x.span())
Вывод:
(12, 17)
Выведем строку, переданную в функцию.
import re
string = "The rain in Spain"
x = re.search(r"\bS\w+", string)
print(x.string)
Вывод:
The rain in Spain
Выведем часть строки, где было совпадение.
import re
string = "The rain in Spain"
x = re.search(r"\bS\w+", string) # Слово, которое начинается с S и продолжается буквенными символом
print(x.group())
Вывод:
Spain
Примечание: Если совпадений нет, будет возвращено None вместо объекта Match.
Углубиться в тему регулярных выражений можно помощью наше подборки документаций и примеров: Регулярные выражения
]]>Далее: Python PIP
Предыдущий урок: Даты в Python
JSON является синтаксисом для хранения и обмена данными. JSON — это текст, написанный в стиле объекта JavaScript.
JSON в Python
Python имеет встроенный модуль json, который может использоваться для работы с данными JSON.
import json
Полная документация по модулю JSON для Python 3 на русском: Модуль JSON Python для работы с форматом .json
Конвертация из JSON в Python
Если у вас есть строка JSON, вы можете провести над ней парсинг с помощью метода json.loads ().
Как результат, будет словарь python.
Конвертируем из JSON в Python:
import json
# немного JSON:
x = '{"name":"Viktor", "age":30, "city":"Minsk"}'
# парсинг x:
y = json.loads(x)
# результатом будет словарь Python:
print(y["age"])
Вывод:
30
Конвертировать из Python в JSON
Если у вас есть объект Python, вы можете преобразовать его в строку JSON с помощью метода json.dumps().
import json
# создаем словарь x:
x = {
"name": "Viktor",
"age": 30,
"city": "Minsk"
}
# конвертируем в JSON:
y = json.dumps(x)
# в результате получаем строк JSON:
print(y)
Вывод:
{"name": "Viktor", "age": 30, "city": "Minsk"}
Вы можете преобразовать следующие типов объекты Python в строки JSON:
- dict
- list
- tuple
- string
- int
- float
- True
- False
- None
Конвертируем объекты Python в строки JSON и выведите значения:
import json
print(json.dumps({"name": "Viktor", "age": 30}))
print(json.dumps(["Porsche", "BMW"]))
print(json.dumps(("Porsche", "BMW")))
print(json.dumps("hello"))
print(json.dumps(42))
print(json.dumps(31.76))
print(json.dumps(True))
print(json.dumps(False))
print(json.dumps(None))
Вывод:
{"name": "Viktor", "age": 30}
["Porsche", "BMW"]
["Porsche", "BMW"]
"hello"
42
31.76
true
false
null
Когда вы конвертируете из Python в JSON, объекты Python преобразуются в эквивалент JSON:
| Python | JSON |
|---|---|
| dict | Object |
| list | Array |
| tuple | Array |
| str | String |
| int | Number |
| float | Number |
| True | true |
| False | false |
| None | null |
Конвертируйте объект Python, содержащий все типы конвертируемых данных:
import json
x = {
"name": "Viktor",
"age": 30,
"married": True,
"divorced": False,
"children": ("Anna","Bogdan"),
"pets": None,
"cars": [
{"model": "BMW 230", "mpg": 27.5},
{"model": "Ford Edge", "mpg": 24.1}
]
}
print(json.dumps(x))
Вывод:
{"name": "Viktor", "age": 30, "married": true, "divorced": false, "children": ["Anna", "Bogdan"], "pets": null, "cars": [{"model": "BMW 230", "mpg": 27.5}, {"model": "Ford Edge", "mpg": 24.1}]}
Как конвертировать кириллицу
Если в данных Python есть символы кириллицы, метод json.dumps() преобразует их с кодировкой по умолчанию. Что бы сохранить кириллицу используйте параметр ensure_ascii=False
import json
x = {
"name": "Виктор"
}
y = {
"name": "Виктор"
}
print(json.dumps(x))
print(json.dumps(y, ensure_ascii=False))
Вывод:
{"name": "\u0412\u0438\u043a\u0442\u043e\u0440"}
{"name": "Виктор"}
Форматирование результата
В приведенном выше примере выводится строка JSON, но читать ее не так просто, без отступов и переносов строк.
У метода json.dumps() есть параметры, облегчающие чтение результата.
Используем параметр indent для определения количества отступов:
json.dumps(x, indent=4)
Вы также можете определить разделители, значение которых по умолчанию — ,, :, где запятая и пробел используются для разделения каждого объекта, а двоеточие и пробел — для разделения ключей и значений.
Используем параметр separators чтобы изменить разделитель по умолчанию:
json.dumps(x, indent=4, separators=(". ", " = "))
Упорядочивание результата
Метод json.dumps() имеет параметры для упорядочивания ключей в результате.
Используем параметр sort_keys чтобы указать, должен ли сортироваться результат.
json.dumps(x, indent=4, sort_keys=True)
]]>
Предыдущий урок: Модули Python
Дата в Python не является типом данных, но мы можем импортировать модуль с именем datetime для работы с датами в качестве объектов даты.
Импортируем модуль даты и времени и покажем текущую дату:
import datetime
x = datetime.datetime.now()
print(x)
Вывод:
2018-12-23 16:04:39.093712
Вывод даты
Дата содержит год, месяц, день, час, минуту, секунду и микросекунду.
У модуля datetime есть много методов для возврата информации об объекте даты.
Вот несколько примеров, о которых вы узнаете позже в этом уроке
Выведем год и день недели:
import datetime
x = datetime.datetime.now()
print(x.year)
print(x.strftime("%A"))
Вывод:
2018
Sunday
Создание объектов даты
Чтобы создать дату, мы можем использовать класс datetime() — (конструктор) модуля datetime.
Для класса datetime() требуется три параметра: год, месяц, день.
import datetime
x = datetime.datetime(2020, 5, 17)
print(x)
Вывод:
2020-05-17 00:00:00
Класс datetime () также принимает параметры для часовой и временной зоны (час, минута, секунда, микросекунда, часовой пояс), но они являются необязательными и имеют стандартное значение 0 (None для часового пояса).
Метод strftime()
Объект datetime имеет метод форматирования объектов даты в читаемые строки.
Подробнее о работе со строками в python: Строки в python 3: методы, функции, форматирование
Метод называется strftime() и принимает один параметр format, чтобы указать формат возвращаемой строки.
Отобразим название месяца:
import datetime
x = datetime.datetime(2018, 6, 1)
print(x.strftime("%B"))
Вывод:
June
Таблица способов форматирования даты:
| Символ | Описание | Пример |
|---|---|---|
| %a | День недели, короткий вариант | Wed |
| %A | Будний день, полный вариант | Wednesday |
| %w | День недели числом 0-6, 0 — воскресенье | 3 |
| %d | День месяца 01-31 | 31 |
| %b | Название месяца, короткий вариант | Dec |
| %B | Название месяца, полное название | December |
| %m | Месяц числом 01-12 | 12 |
| %y | Год, короткий вариант, без века | 18 |
| %Y | Год, полный вариант | 2018 |
| %H | Час 00-23 | 17 |
| %I | Час 00-12 | 05 |
| %p | AM/PM | PM |
| %M | Минута 00-59 | 41 |
| %S | Секунда 00-59 | 08 |
| %f | Микросекунда 000000-999999 | 548513 |
| %z | Разница UTC | +0100 |
| %Z | Часовой пояс | CST |
| %j | День в году 001-366 | 365 |
| %U | Неделя числом в году, Воскресенье первый день недели, 00-53 | 52 |
| %W | Неделя числом в году, Понедельник первый день недели, 00-53 | 52 |
| %c | Локальная версия даты и времени | Mon Dec 31 17:41:00 2018 |
| %x | Локальная версия даты | 12/31/18 |
| %X | Локальная версия времени | 17:41:00 |
| %% | Символ “%” | % |
]]>Далее: Модуль JSON
Предыдущий урок: Итераторы Python
Что такое модуль?
Модуль — это файл, содержащий код python, который вы хотите включить в проект.
Документацию по модулям python на русском мы собрали в разделе Модули.
Создание модуля
Для того, чтобы создать модуль достаточно просто сохранить код в файл с расширением .py:
Сохраним этот код в файл под названием mymodule.py
def greeting(name):
print("Привет, " + name)
Использование модуля
Теперь мы можем использовать только что созданный модуль, с помощью оператора import:
Импортируем модуль под названием mymodule, и вызовем функцию приветствия:
import mymodule
mymodule.greeting("Андрей")
Вывод:
Привет, Андрей
Примечание: Во время использования функции из модуля, синтаксис: module_name.function_name.
Переменные в модуле
Модуль может содержать функции, как уже описано, но также и переменные всех типов (массивы, словари, объекты и т. д.).
Сохраним этот код в файл mymodule.py
person1 = {
"name": "Виктор",
"age": 36,
"country": "Россия"
}
Импортируем модуль с названием mymodule, и получим доступ к словарю person1:
import mymodule
a = mymodule.person1["age"]
print(a)
Вывод:
36
Имя модуля
Вы можете назвать файл модуля, как вам нравится, но важно, указать расширение файла .py
Переименование модуля
Вы можете создать псевдоним при импорте модуля, используя ключевое слово as.
import mymodule as mx
a = mx.person1["age"]
print(a)
Вывод:
36
Встроенные модули
В Python есть несколько встроенных модулей, которые вы можете импортировать, когда захотите.
import platform
x = platform.system()
print(x)
Вывод:
Windows
Использование функции dir()
Существует встроенная функция для перечисления всех имен функций (или имен переменных) в модуле. Функция dir().
import platform
x = dir(platform)
print(x)
Вывод:
['DEV_NULL', '_UNIXCONFDIR', '_WIN32_CLIENT_RELEASES', '_WIN32_SERVER_RELEASES',
'__builtins__', '__cached__', '__copyright__', '__doc__', '__file__',
'__loader__', '__name__', '__package__', '__spec__', '__version__',
'_default_architecture', '_dist_try_harder', '_follow_symlinks',
'_ironpython26_sys_version_parser', '_ironpython_sys_version_parser',
'_java_getprop', '_libc_search', '_linux_distribution', '_lsb_release_version',
'_mac_ver_xml', '_node', '_norm_version', '_parse_release_file', '_platform',
'_platform_cache', '_pypy_sys_version_parser', '_release_filename',
'_release_version', '_supported_dists', '_sys_version', '_sys_version_cache',
'_sys_version_parser', '_syscmd_file', '_syscmd_uname', '_syscmd_ver',
'_uname_cache', '_ver_output', 'architecture', 'collections', 'dist',
'java_ver', 'libc_ver', 'linux_distribution', 'mac_ver', 'machine', 'node',
'os', 'platform', 'popen', 'processor', 'python_branch', 'python_build',
'python_compiler', 'python_implementation', 'python_revision', 'python_version',
'python_version_tuple', 're', 'release', 'subprocess', 'sys', 'system',
'system_alias', 'uname', 'uname_result', 'version', 'warnings', 'win32_ver']
Примечание: Функцию dir() можно использовать на всех модулях, включая те, которые вы создаете сами.
Импорт из модуля
Вы можете импортировать модуль только частично, используя ключевое слово from
def greeting(name):
print("Привет, " + name)
person1 = {
"name": "Виктор",
"age": 36,
"country": "Россия"
}
Импортируем из модуля словарь person1:
from mymodule import person1
print (person1["age"])
Вывод:
36
Примечание: При импорте с использованием ключевого слова from не используйте имя модуля при обращении к элементам. Пример: person1["age"], а не mymodule.person1["age"]
]]>Далее: Даты в Python
Предыдущий урок: Классы и объекты Python
List, tuple, dict и sets — это все итерируемые объекты. Они являются итерируемыми контейнерами, из которых вы можете получить итератор. Все эти объекты имеют метод iter(), который используется для получения итератора.
Получим итератор из кортежа и выведем каждое значение:
mytuple = ("яблоко", "банан", "вишня")
myit = iter(mytuple)
print(next(myit))
print(next(myit))
print(next(myit))
Вывод:
яблоко
банан
вишня
Даже строки являются итерируемыми объектами и могут возвращать итератор.
mystr = "банан"
myit = iter(mystr)
print(next(myit))
print(next(myit))
print(next(myit))
print(next(myit))
print(next(myit))
Вывод:
б
а
н
а
н
Цикл через итератор
Мы также можем использовать цикл for для итерации по итерируему объект.
mytuple = ("яблоко", "банан", "вишня")
for x in mytuple:
print(x)
Вывод:
яблоко
банан
вишня
Итерируйем символы строки:
mystr = "банан"
for x in mystr:
print(x)
Вывод:
б
а
н
а
н
Цикл for фактически создает объект итератора и выполняет метод next() для каждого цикла.
Создание итератора
Чтобы создать объект/класс в качестве итератора, вам необходимо реализовать методы __iter__() и __next__() для объекта.
Как вы узнали из урока «Классы и объекты Python», у всех классов есть функция под названием __init__(), которая позволяет вам делать инициализацию при создании объекта.
Метод __iter__() действует аналогично, вы можете выполнять операции (инициализацию и т. Д.), Но всегда должны возвращать сам объект итератора. Метод __next __ () также позволяет вам выполнять операции и должен возвращать следующий элемент в последовательности.
Создайте итератор, который возвращает числа, начиная с 1, и увеличивает на единицу (возвращая 1,2,3,4,5 и т. д.):
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
Вывод:
1
2
3
4
5
StopIteration
Приведенный выше пример будет продолжаться вечно, пока вы вызываете оператор next() или если используете в цикле for. Чтобы итерация не продолжалась вечно, мы можем использовать оператор StopIteration.
В метод __next __() мы можем добавить условие завершения, чтобы вызвать ошибку, если итерация выполняется указанное количество раз:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
Вывод:
1
2
3
...
18
19
20
]]>Далее: Модули Python
Предыдущий урок: Массивы
Python — объектно-ориентированный язык программирования. Почти все в Python — это объект с его свойствами и методами. Класс похож на конструктор объекта или ‘‘проект’’ для создания объектов.
Создание класса
Для того, чтобы создать класс, используйте ключевое слово class.
Создадим класс с именем MyClass и свойством x:
class MyClass:
x = 5
Создание объекта
Теперь мы можем использовать класс под названием myClass для создания объектов.
Создадим объект под названием p1, и выведем значение x:
p1 = MyClass()
print(p1.x)
Вывод:
5
Функция init
Приведенные выше примеры — это классы и объекты в их простейшей форме и не очень полезны в приложениях.
Чтобы понять значение классов, нам нужно понять встроенную функцию __init__.
У всех классов есть функция под названием __init__(), которая всегда выполняется при создании объекта. Используйте функцию __init__() для добавления значений свойствам объекта или других операций, которые необходимо выполнить, при создании объекта.
Для создания класса под названием Person, воспользуемся функцией __init__(), что бы добавить значения для имени и возраста:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p1 = Person("Василий", 36)
print(p1.name)
print(p1.age)
Вывод:
Василий
36
Обратите внимание: Функция __init__() автоматически вызывается каждый раз при использовании класса для создания нового объекта.
Методы объектов
Объекты также содержат методы. Методы в объектах — это функции, принадлежащие объекту.
Давайте создадим метод в классе Person.
Добавим функцию, которая выводит приветствие, и выполним ее:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("Привет, меня зовут " + self.name)
p1 = Person("Василий", 36)
p1.myfunc()
Вывод:
Привет, меня зовут Василий
Параметр self
Параметр self является ссылкой на сам класс и используется для доступа к переменным, принадлежащим классу.
Его не обязательно называть self, вы можете называть его как хотите, но он должен быть первым параметром любой функции в классе.
Используем слова mysillyobject и abc вместо self:
class Person:
def __init__(mysillyobject, name, age):
mysillyobject.name = name
mysillyobject.age = age
def myfunc(abc):
print("Привет, меня зовут " + abc.name)
p1 = Person("Василий", 36)
p1.myfunc()
Вывод:
Привет, меня зовут Василий
Изменение свойств объекта
Вы можете изменять свойства объектов следующим образом.
Изменим возраст от p1 на 40:
p1.age = 40
Больше примеров применения class в Python 3: Примеры работы с классами в Python
Удалить свойства объекта
Свойства объектов можно удалять с помощью ключевого слова del
del p1.age
Удаление объектов
Вы можете удалить объекты, используя ключевое слово del.
del p1
]]>Далее: Итераторы Python
Предыдущий урок: Lambda-фунция
Примечание: Python не имеет встроенной поддержки массивов, но вместо этого можно использовать списки (list) Python.
Массивы используются для хранения нескольких значений в одной переменной:
cars = ["Ford", "Volvo", "BMW"]
Что такое массив?
Массив — это специальная переменная, которая может содержать более чем одно значение.
Если у вас есть список предметов (например, список марок авто), то хранение автомобилей в отдельных переменных может выглядеть так:
car1 = "Ford";
car2 = "Volvo";
car3 = "BMW";
Однако, что, если вы хотите проскочить через все машины и найти конкретную? А что, если у вас было бы не 3 автомобиля а 300?
Решение представляет собой массив!
Массив может содержать много значений под одним именем, и вы так же можете получить доступ к значениям по индексу.
Доступ к элементам массива
Вы ссылаетесь на элемент массива, ссылаясь на индекс.
Получим значение первого элемента массива:
x = cars[0]
Изменим значение первого элемента массива:
cars[0] = "Toyota"
Длина массива
Используйте метод len() чтобы вернуть длину массива (число элементов массива).
Выведем число элементов в массиве cars:
x = len(cars)
Примечание: Длина массива всегда больше, чем индекс последнего элемента.
Циклы элементов массива
Вы можете использовать цикл for для прохода по всем элементам массива.
Выведем каждый элемент из цикла cars:
for x in cars:
print(x)
Вывод:
Ford
Volvo
BMW
Добавление элементов массива
Вы можете использовать метод append() для добавления элементов в массив.
Добавим еще один элемент в массив cars:
cars.append("Honda")
Удаление элементов массива
Используйте метод pop() для того, чтобы удалить элементы из массива.
Удалим второй элемент из массива cars:
cars.pop(1)
Так же вы можете использовать метод remove() для того, чтобы убрать элемент массива.
Удалим элемент со значением “Volvo”:
cars.remove("Volvo")
Примечание: Метод remove() удаляет только первое вхождение указанного значения.
Методы массива
В Python есть набор встроенных методов, которые вы можете использовать при работе с lists/arrays.
| Метод | Значение |
|---|---|
| append() | Добавляет элементы в конец списка |
| clear() | Удаляет все элементы в списке |
| copy() | Возвращает копию списка |
| count() | Возвращает число элементов с определенным значением |
| extend() | Добавляет элементы списка в конец текущего списка |
| index() | Возвращает индекс первого элемента с определенным значением |
| insert() | Добавляет элемент в определенную позицию |
| pop() | Удаляет элемент по индексу |
| remove() | Убирает элементы по значению |
| reverse() | Разворачивает порядок в списке |
| sort() | Сортирует список |
Примечание: В Python нет встроенной поддержки для массивов, вместо этого можно использовать Python List.
]]>Далее: Классы и объекты Python
Предыдущий урок: Функции в Python
Лямбда-функция — это небольшая анонимная функция. Она может принимать любое количество аргументов, но в то же время иметь только одно выражение.
Синтаксис
lambda аргументы : выражение
После выполнения выражения — возвращается результат. Лямбда-функции могут принимать любое количество аргументов.
lambda умножает аргумент a на аргумент b и выводит результат:
x = lambda a, b: a * b
print(x(5, 6))
Вывод:
30
А эта функция суммирует аргументы a, b и c и выводит результат:
x = lambda a, b, c: a + b + c
print(x(5, 6, 2))
Вывод:
13
Зачем использовать лямбда-функции?
Силу лямбда лучше видно, когда вы используете ее как анонимную функцию внутри другой функции. Скажем, у вас есть определение функции, которое принимает один аргумент, и этот аргумент будет умножен на неизвестное число:
def myfunc(n):
return lambda a: a * n
Используйте это определение функции для создания функции, которая всегда удваивает число, которое вы отправляете:
def myfunc(n):
return lambda a: a * n
mydoubler = myfunc(2)
print(mydoubler(11))
Вывод:
22
Или используйте то же самое определение функции, чтобы сделать функцию, которая всегда утраивает число:
def myfunc(n):
return lambda a: a * n
mytripler = myfunc(3)
print(mytripler(11))
Вывод:
33
Или, используйте то же самое определение, чтобы сделать обе функции в одной программе:
def myfunc(n):
return lambda a: a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11))
print(mytripler(11))
Вывод:
22
33
Используйте lambda-функцию, когда анонимная функция нужна в определенной части кода, но не по всем скрипте.
]]>Далее: Массивы
Предыдущий урок: Цикл for
Функция — блок кода, который запускается только при его вызове. Вы можете передавать данные, известные как параметры, в функцию. В результате у функции появляется возможность возвращать данные.
Создание функции
Функция в Python определяется с помощью ключевого слова def:
def my_function():
print("Привет из функции")
Вызов функции
Что бы вызвать функцию, используйте имя функции, за которым следуют скобки.
def my_function():
print("Привет из функции")
my_function()
Вывод:
Привет из функции
Параметры
Информация может передаваться в функции в качестве параметра. Параметры указаны после имени функции, внутри скобок. Вы можете добавить столько параметров, сколько хотите, разделив их запятой.
В следующем примере функция с одним параметром (fname). Когда функция вызывается, мы передаем имя, которое используется внутри функции для печати полного имени:
def my_function(fname):
print(fname + "Попов")
my_function("Андрей")
my_function("Влад")
my_function("Никита")
Вывод:
Андрей Попов
Влад Попов
Никита Попов
Значение параметра по умолчанию
В следующем примере можно увидеть как пользоваться значением стандартного параметра. Если мы вызываем функцию без параметра, она использует стандартное значение:
def my_function(country="Англии"):
print("Я из " + country)
my_function("Польши")
my_function("Китая")
my_function()
my_function("США")
Вывод:
Я из Польши
Я из Китая
Я из Англии
Я из США
Возвращение значения
Для возврата значения функции, воспользуйтесь оператором return:
def my_function(x):
return 5 * x
print(my_function(3))
print(my_function(5))
print(my_function(9))
Вывод:
15
25
45
]]>Далее: Lambda-фунция
Предыдущий урок: Цикл while
Цикл for используется для итерации по последовательности (list, tuple, dict, set или str).
Так же это похоже на применение ключевого слова for в других языках программирования, на метод итератора, как в других объектно-ориентированных языках программирования.
С помощью цикла for мы можем выполнить набор действий для каждого элемента в list, tuple, set и т.д.
Выведите каждый фрукт из списка фруктов:
fruits = ["яблоко", "банан", "вишня"]
for x in fruits:
print(x)
Вывод:
яблоко
банан
вишня
Цикл for не требует создания дополнительных переменных для итерации.
Итерация по строке
Даже строки являются итерируемыми объектами и содержат последовательность символов.
Получим буквы слова “Банан”:
for x in "Банан":
print(x)
Вывод:
Б
а
н
а
н
Оператор break
Благодаря оператору break мы можем остановить цикл прежде чем он закончится по всем элементам:
Завершим из цикл когда x — “банан”:
fruits = ["яблоко", "банан", "вишня"]
for x in fruits:
print(x)
if x == "банан":
break
Вывод:
яблоко
банан
Выйдем из цикла когда x — “банан”, но в этот раз if будет перед выводом:
fruits = ["яблоко", "банан", "вишня"]
for x in fruits:
if x == "банан":
break
print(x)
Вывод:
яблоко
Оператор continue
С помощью оператора continue мы можем остановить текущую итерацию цикла и перейти к следующей
Пропустим вывод “банан”:
fruits = ["яблоко", "банан", "вишня"]
for x in fruits:
if x == "банан":
continue
print(x)
Вывод:
яблоко
вишня
Функция range()
Функция range() применяется что бы выполнить действия заданное количество раз. Она возвращает последовательность чисел, начиная с 0 (по умолчанию) увеличивает число на 1 (по умолчанию) и заканчивая указанным числом.
for x in range(6):
print(x)
Вывод:
0
1
2
3
4
5
Обратите внимание range(6) означает повтор цикла 6 раз, но не числа с 0 до 6.
Функция range() по умолчанию начинается с 0, однако можно изменить начальное значение, добавив параметр: range (2, 6), что означает значения от 2 до 6 (но не включая 6):
for x in range(2, 6):
print(x)
Вывод:
2
3
4
5
Функция range () по умолчанию увеличивает последовательность на 1, однако можно указать значение приращения, добавив третий параметр: range (2, 30, 3):
for x in range(2, 30, 3):
print(x)
Вывод:
2
5
8
11
14
17
20
23
26
29
Else в цикле For
Ключевое слово else в цикле for включает блок кода, который должен быть выполнен после завершения цикла:
for x in range(6):
print(x)
else:
print("Цикл завершен!")
Вывод:
0
1
2
3
4
5
Цикл завершен!
Вложенный цикл
Вложенный цикл — это цикл в цикле. Он будет запускаться при каждой итерации основного цикла.
Выведем все фрукты с каждым прилагательным:
adj = ["желтый", "большой", "вкусный"]
fruits = ["апельсин", "банан", "ананас"]
for x in adj:
for y in fruits:
print(x, y)
Вывод:
желтый апельсин
желтый банан
желтый ананас
большой апельсин
большой банан
большой ананас
вкусный апельсин
вкусный банан
вкусный ананас
Рекурсия
Python также принимает рекурсию функций, это означает, что определенная функция может вызывать сама себя.
Рекурсия — это общая математическая и программная концепция. Означает, что функция вызывает себя. Ее преимущество, в том, что вы можете циклически проходить через данные, чтобы достичь результата.
Разработчик должен быть очень осторожен с рекурсией, довольно легко включить функцию, которая никогда не завершается, или функцию, которая использует избыточные объемы памяти, мощности процессора. Однако при правильном написании рекурсия может стать очень эффективным и математически элегантным подходом к программированию.
В этом примере tri_recursion() — это функция, которую мы определили для рекурсии. В качестве данных мы используем переменную k, которая уменьшается (-1) каждый раз, когда мы рекурсируем. Рекурсия заканчивается, когда условие не больше 0 (т. е. когда оно равно 0).
Начинающему разработчику может потребоваться некоторое время, чтобы понять, как именно это работает. Лучший способ выяснить это — протестировать и модифицировать ее.
def tri_recursion(k):
if(k>0):
result = k+tri_recursion(k-1)
print(result)
else:
result = 0
return result
print("\n\nРезультат примера рекурсии")
tri_recursion(6)
Вывод:
Результат примера рекурсии
1
3
6
10
15
21
]]>Далее: Функции в Python
Предыдущий урок: Условные выражения и конструкция if
В Python есть две простых команды циклов:
- цикл
while - цикл
for
Цикл while
С помощью цикла while мы можем выполнять действия, пока условие верно.
Выводим i, до тех пор, пока i будет меньше 6:
i = 1
while i < 6:
print(i)
i += 1
Вывод:
1
2
3
4
5
Примечание: не забудьте увеличить i, иначе цикл длиться вечно.
Для цикла while необходимо, чтобы соответствующие переменные были объявлены, в этом примере нам нужно объявить переменную индексации i, которую мы установили в 1.
Прерывание цикла
С помощью оператора break мы можем остановить цикл, даже если условие while истинно:
Выходите из цикла когда он равен 3:
i = 1
while i < 6:
print(i)
if i == 3:
break
i += 1
Вывод:
1
2
3
Оператор continue
С помощью оператора continue мы можем остановить текущую итерацию и перейти к выполнению следующей:
Продолжайте до следующей итерации пока i равна 3:
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
Вывод:
1
2
4
5
6
]]>Далее: Цикл for
Предыдущий урок: Словарь (dict)
Python поддерживает обычные логические выражения:
- Равно: a == b
- Не равно: a != b
- Меньше чем: a < b
- Меньше чем или равно: a <= b
- Больше чем: a > b
- Больше чем или равно: a >= b
Эти условные могут быть использованы несколькими способами, чаще всего в выражениях if и циклах. if записывается с использованием ключевого слова if.
a = 33
b = 200
if b > a:
print("b больше, чем a")
Вывод:
b больше, чем a
В этом примере мы используем две переменных, a и b, которые используются как часть оператора if чтобы убедиться, что b больше чем a. Учитывая, что a — 33, а b — 200, мы знаем что 200 больше чем 33, поэтому мы выводим на экран “b больше, чем a”.
Отступы
Python полагается на отступы пробелом, для определения частей кода. В других языках программирования часто используются фигурные скобки для этой цели.
Оператор if, без отступа (вызовет ошибку):
a = 33
b = 200
if b > a:
print("b больше, чем a")
Результат:
File "demo_indentation_test.py", line 2
print("b больше, чем a")
^
IndentationError: expected an indented block
elif
Ключевое слово elif — это способ Python сказать, что “если предыдущие условные были неверными, тогда попробуйте это условное”.
a = 33
b = 33
if b > a:
print("b больше, чем a")
elif a == b:
print("a равно b")
Вывод:
a равно b
В этом примере a равняется b, в связи с этим первое условие не будет верно, но условие elif — True, поэтому на экран мы выводим “a равно b”.
else
Ключевое слово else захватывает все, что не было захвачено предыдущими условиями.
a = 200
b = 33
if b > a:
print("b больше, чем a")
elif a == b:
print("a и b равны")
else:
print("a больше, чем b")
Вывод:
a больше, чем b
В этом примере a больше чем b, и поэтому первое условие не будет true, так же как и условие elif не будет true, поэтому нам нужно перейти else и вывести на экран “a больше, чем b”.
Вы можете так же использовать else без elif:
a = 200
b = 33
if b > a:
print("b больше, чем a")
else:
print("b меньше, чем a")
Вывод:
b меньше, чем a
Короткая запись If
Если у вас есть только один оператор для выполнения, поместите его в ту же строку, что и оператор if.
Однострочная запись if:
if a > b: print("a больше, чем b")
Короткая запись If … Else
Если у вас есть только один оператор для выполнения, один для if и один для else, вы можете поместить их в одну строку:
Пример
Однострочный оператор if else:
print("A") if a > b else print("B")
Так же вы можете записать сразу несколько операторов else на одной строке:
print("A") if a > b else print("=") if a == b else print("B")
And
Ключевое слово and — логический оператор, который используется для объединения условных операторов:
Проверьте больше ли a нежели b, и больше ли c чем a:
if a > b and c > a:
print("Оба условия True")
Or
Ключевое слово or — логический оператор, который используется для объединения условных операторов:
Проверьте больше a чем b, или больше ли a в сравнении с c:
if a > b or a > c:
print("Одно из усовий True")
]]>Далее: Цикл while
Предыдущий урок: Множества (set)
Словарь — неупорядоченная последовательность, гибким к изменениям и индексированным. В Python словари пишутся в фигурных скобках, и состоят из ключей и значений.
Создадим и выведем словарь:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(thisdict)
Вывод:
{'brand': 'Ford', 'model': 'Mustang', 'year': 1964}
Доступ к элементам
Вы можете получить доступ к элементам словаря ссылаясь на его ключевое название.
Получим значение по ключу “model” :
x = thisdict["model"]
Существует так же метод под названием get() который даст вам тот же результат.
x = thisdict.get("model")
Изменить значение
Вы можете поменять значение указанного элемента ссылаясь на ключевое название.
Поменяем “year” на “2018”:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict["year"] = 2018
print(thisdict)
Вывод:
{'brand': 'Ford', 'model': 'Mustang', 'year': 2018}
Цикл for по словарю
При проходе по словарю вы получите его ключи, но так же есть методы для возврата значений.
Выведем один за другим все ключи словаря:
for x in thisdict:
print(x)
Вывод:
brand
model
year
Выведем значения словаря, один за одним:
for x in thisdict:
print(thisdict[x])
Вывод:
Ford
Mustang
1964
Вы так же можете использовать функцию values() для возврата значений словаря:
for x in thisdict.values():
print(x)
Вывод:
Ford
Mustang
1964
Пройдем по ключам и значениям, используя функцию items():
for x, y in thisdict.items():
print(x, y)
Вывод:
brand Ford
model Mustang
year 1964
Длина словаря
Для того, чтобы определить сколько элементов есть в словаре, используйте метод len().
print(len(thisdict))
Вывод:
3
Добавление элементов
Добавление элементов в словарь выполняется с помощью нового ключа:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict["color"] = "red"
print(thisdict)
Вывод:
{'brand': 'Ford', 'model': 'Mustang', 'year': 1964, 'color': 'red'}
Удаление элементов
Существует несколько методов удаления элементов из словаря.
Метод pop() удаляет элемент по ключу и возвращает его:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict.pop("model")
Метод popitem() удаляет последний элемент:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict.popitem()
Ключевое слово del удаляет элемент по ключу:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
del thisdict["model"]
print(thisdict)
Вывод:
{'brand': 'Ford', 'year': 1964}
Ключевое слово del может так же удалить полностью весь словарь:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
del thisdict
print(thisdict) #это вызывает ошибку, так как "thisdict" больше не существует.
Ключевое слово clear() очищает словарь:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict.clear()
print(thisdict)
Вывод:
{}
Конструктор dict()
Вы так же можете использовать конструктор dict() для создания нового словаря.
thisdict = dict(brand="Ford", model="Mustang", year=1964)
# обратите внимание, ключевые слова не являются строками
# обратите внимание на использование "рвно", вместо двоеточия для задания
print(thisdict)
Вывод:
{'brand': 'Ford', 'model': 'Mustang', 'year': 1964}
Методы словаря
В Python существует набор встроенных методов, с помощью которых вы можете работать со словарями.
| Метод | Значение |
|---|---|
| clear() | Удаляет все элементы из словаря |
| copy() | Делает копию словаря |
| fromkeys() | Возвращает словарь с указанными ключами и значениями |
| get() | Возвращает значение по ключу |
| items() | Возвращает список, содержащий tuple для каждой пары ключ-значение |
| keys() | Возвращает список, содержащий ключи словаря |
| pop() | Удаляет элементы по ключу |
| popitem() | Удаляет последнюю пару ключа со значением |
| setdefault() | Задает значение по ключу. Если ключа нет в словаре, добавляет его с указанным значением или None |
| update() | Обновляет словарь, добавляя пары ключ-значение |
| values() | Возвращает список всех значений в словаре |
]]>
Предыдущий урок: Кортежи (tuple)
Множества — неупорядоченная и не индексируемая последовательность. В Python множества пишутся в фигурных скобках.
Создание множества:
thisset = {"set", "list", "tuple"}
print(thisset)
Вывод:
{'set', 'tuple', 'list'}
Примечание. Они не упорядочены, поэтому элементы будут отображаться в произвольном порядке.
Множество хранит только уникальные элементы:
thisset = {"set", "list", "tuple", "list"}
print(thisset)
Вывод:
{'set', 'tuple', 'list'}
Доступ к элементам
Вы не можете получить доступ к элементам множествах по индексу, так как они не упорядочены, а элементы без индекса. Но вы можете проходить по множеству с помощью цикла for или уточнять есть ли значение в множестве, используя оператор in.
Выведем каждый элемент множества:
thisset = {"set", "list", "tuple"}
for x in thisset:
print(x)
Вывод:
set
list
tuple
Проверим присутствует ли "dict" этой последовательности:
thisset = {"set", "list", "tuple"}
print("dict" in thisset)
Вывод:
False
Изменение элементов
Вы не можете менять элементы set, но можете добавлять новые.
Добавить элементы
Чтобы добавить один элемент в set используйте метод add().
Чтобы добавить больше одного — метод update().
thisset = {"set", "list", "tuple"}
thisset.add("dict")
print(thisset)
Вывод:
{'tuple', 'set', 'list', 'dict'}
Добавьте несколько элементов в thisset, используя метод update():
thisset = {"set", "list", "tuple"}
thisset.update(["dict", "class", "int"])
print(thisset)
Вывод:
{'dict', 'tuple', 'set', 'list', 'class', 'int'}
Получите длину set
Чтобы определить сколько элементов есть в наборе, воспользуйтесь методом len().
thisset = {"set", "list", "tuple"}
print(len(thisset))
Вывод:
3
Удаление элементов
Чтобы удалить элемент в множестве, воспользуйтесь методом remove(), или discard().
Уберем «list» используя метод remove():
thisset = {"set", "list", "tuple"}
thisset.remove("list")
print(thisset)
Вывод:
{'tuple', 'set'}
Примечание: Если элемент, который нужно удалить не существует, remove() вызовет ошибку.
Убрать “list” используя метод discard():
thisset = {"set", "list", "tuple"}
thisset.discard("list")
print(thisset)
Вывод:
{'tuple', 'set'}
Примечание. Если элемент для удаления не существует, discard() не будет вызывать ошибку.
Вы также можете использовать метод pop() — для удаления элемента, но он удалит только последний элемент. Помните, что set не упорядочены, поэтому вы не будите знать, какой элемент удаляете.
Возвращаемое значение метода pop () — это удаленный элемент.
thisset = {"set", "list", "tuple"}
x = thisset.pop()
print(x)
print(thisset)
Вывод:
list
{'tuple', 'set'}
Метод clear() очистит множество:
thisset = {"set", "list", "tuple"}
thisset.clear()
print(thisset)
Вывод:
set()
Ключевое слово del полностью удалит множество:
thisset = {"set", "list", "tuple"}
del thisset
print(thisset) # эта команда вызовет ошибку, так как thisset больше не существует
Конструктор set()
Есть так же возможность использовать конструктор set() для создания множества.
thisset = set(("set", "list", "tuple")) # Используем двойные скобки
print(thisset)
Вывод:
{'set', 'tuple', 'list'}
Методы Set
В Python есть встроенные методы, с помощью которых вы можете работать с sets.
| Метод | Значение |
|---|---|
| add(x) | Добавляет элементы x в set |
| clear() | Удаляет элементы из set |
| copy() | Возвращает копию set |
| x.difference(y) | Возвращает множество элементов, которые есть в х, но нет в y |
| x.difference_update(y) | Удаляет элементы, которые есть в x и y |
| discard(x) | Удаляет указанный элемент |
| x.intersection(y) | Возвращает множество, являющийся пересечением x и y |
| intersection_update(y) | Удаляет элементы в множестве, которых нет в других заданных y |
| x.isdisjoint(y) | True, если x и y не имеют общих элементов |
| x.issubset(y) | True, если все элементы из x есть в y |
| issuperset() | True, если все элементы из y есть в x |
| pop() | Удаляет и возвращает последний элемент |
| remove() | Удаляет указанный элемент |
| x.symmetric_difference(y) | Возвращает множество элементов, которые не пересекаются в х и y |
| symmetric_difference_update() | Добавляет элементы, которых нет в другом множестве |
| union() | Объединяет несколько множеств |
| x.update(y, z) | Объединяет несколько множеств, перезаписывая x |
]]>Далее: Словарь (dict)
Предыдущий урок: Списки (list)
Кортеж — это упорядоченная последовательность, неизменяемая. В Python кортежи пишутся в круглых скобках.
Создание кортежа:
thistuple = ("помидор", "огурец", "лук")
print(thistuple)
Вывод:
('помидор', 'огурец', 'лук')
Доступ к элементам кортежа
Вы можете получить доступ к элементам кортежа с помощью индекса.
Вывести элемент с индексом 1:
thistuple = ("помидор", "огурец", "лук")
print(thistuple[1])
Вывод:
огурец
Изменить элемент корежа
После создания кортежа вы не можете вносить изменения в него. Кортеж — неизменяемый.
thistuple = ("помидор", "огурец", "лук")
thistuple[1] = "морковка"
Вывод:
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
thistuple[1] = "морковка"
TypeError: 'tuple' object does not support item assignment
Итерация по кортежу
Вы можете перебирать элементы кортежа с помощью цикла for.
thistuple = ("помидор", "огурец", "лук")
for x in thistuple:
print(x)
Вывод:
помидор
огурец
лук
Узнать больше о цикле for вы можете в разделе Python цикл For.
Длина кортежа
Для определения количества элементов списка, используйте метод len().
Выведите количество элементов в кортеже:
thistuple = ("помидор", "огурец", "лук")
print(len(thistuple))
Вывод:
3
Добавление элементов
После создания кортежа, вы не можете добавлять в него элементы. Кортеж — неизменяемый.
thistuple = ("помидор", "огурец", "лук")
thistuple[3] = "морковка"
Вывод:
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
thistuple[3] = "морковка"
TypeError: 'tuple' object does not support item assignment
Удаление элементов
Вы не можете удалять элементы по отдельности, но вы можете полностью удалить кортеж:
Ключевое слово del может полностью удалить кортеж:
thistuple = ("помидор", "огурец", "лук")
del thistuple
print(thistuple) # эта команда вызовет ошибку, так как thistuple больше не существует
Конструктор tuple()
Так же конструктор tuple() можно использовать для создания кортежа.
thistuple = tuple(("помидор", "огурец", "лук")) # Обратите внимание на двойные круглые скобки
print(thistuple)
Методы кортежа
В Python так же существуют два встроенных метода, которые вы можете использовать при работе.
| Метод | Значение |
|---|---|
| count() | Возвращает количество раз, которое указанный элемент встречается в кортеже |
| index() | Ищет кортеж по указанному значению и возвращает его индекс |
]]>Далее: Множества (set)
Предыдущий урок: Операторы в Python
В языке программирования Python существует четыре типа данных для хранения последовательностей:
- List (список) — упорядоченная последовательность, которую можно изменять. Допускаются одинаковые элементы.
- Tuple (кортеж) — последовательность, которая упорядочена, но не изменяемая. Допускаются одинаковые элементы.
- Set (множество) — неупорядоченная изменяемая последовательность. Одинаковые элементы удаляются.
- Dict (словарь) — неупорядоченная изменяемая последовательность, состоящая из пар ключ, значение. Ключи не дублируются.
При выборе типа последовательности полезно знать и понимать свойства каждого из типов. Выбор правильного типа для определенного набора данных помогает сохранить смысл, и это дает повышение эффективности или безопасности.
Списки
Списки это упорядоченная и изменяемая последовательность. В Python списки записываются в квадратных скобках.
Создание списка:
thislist = ["яблоко", "банан", "вишня"]
print(thislist)
Вывод:
["яблоко", "банан", "вишня"]
Доступ к элементам списка
Вы получаете доступ к элементам списка, ссылаясь на номер индекса.
Выведем второй элемент списка:
thislist = ["яблоко", "банан", "вишня"]
print(thislist[1])
Вывод:
"банан"
Как изменить значение по индексу
Для того, чтобы изменить значение определенного элемента, ссылайтесь на номер индекса.
Поменяйте второй элемент:
thislist = ["яблоко", "банан", "вишня"]
thislist[1] = "смородина"
print(thislist)
Вывод:
["яблоко", "смородина", "вишня"]
Итерация по списку
Вы можете проходить по элементам списка с помощью цикла for
Выведем все элементы в списке, один за другим:
thislist = ["яблоко", "банан", "вишня"]
for x in thislist:
print(x)
Вывод:
яблоко
банан
вишня
Узнать больше о цикле for вы можете изучив раздел Python цикл for.
Длина списка
Чтобы определить сколько элементов списка у вас есть, пользуйтесь методом len()
Выведем число элементов в списке:
thislist = ["яблоко", "банан", "вишня"]
print(len(thislist))
Вывод:
3
Добавить элементы
Чтобы добавить элементы в конец списка, используйте метод append()
thislist = ["яблоко", "банан", "вишня"]
thislist.append("апельсин")
print(thislist)
Вывод:
["яблоко", "банан", "вишня", "апельсин"]
Для того, чтобы добавить элемент по указанному индексу, используйте метод insert():
Вставьте элемент в качестве второй позиции:
thislist = ["яблоко", "банан", "вишня"]
thislist.insert(1, "апельсин")
print(thislist)
Вывод:
["яблоко", "апельсин", "банан", "вишня"]
Удаление элементов
Существует несколько методов удаления элементов списка
Метод remove() удаляет определенные элементы:
thislist = ["яблоко", "банан", "вишня"]
thislist.remove("банан")
print(thislist)
Вывод:
["яблоко", "вишня"]
Метод pop() удаляет элемент по индексу (или последний элемент, если индекс не указан) и возвращает его:
thislist = ["яблоко", "банан", "вишня"]
last_element = thislist.pop()
print(thislist)
print(last_element)
Вывод:
["яблоко", "банан"]
"вишня"
Ключевое слово del удаляет определенный индекс:
thislist = ["яблоко", "банан", "вишня"]
del thislist[0]
print(thislist)
Вывод:
["банан", "вишня"]
Ключевое слово del может полностью удалить список:
thislist = ["яблоко", "банан", "вишня"]
del thislist
print(thislist) # это вызывает ошибку так, как "thislist" больше не существует.
Метод clear() очищает список:
thislist = ["яблоко", "банан", "вишня"]
thislist.clear()
print(thislist)
Вывод:
[]
Конструктор list()
Вы так же можете использовать конструктор list() для создания списка.
thislist = list(("яблоко", "банан", "вишня")) # обратите внимание на двойные круглые скобки
print(thislist)
Вывод:
["яблоко", "банан", "вишня"]
Методы списков
Более подробно о применении методов списков:
У Python есть набор встроенных методов, которые вы можете использовать при работе со списками:
| Метод | Значение |
|---|---|
| append() | Добавляет элемент(ы) в конец списка |
| clear() | Удаляет все элементы в списке |
| copy() | Возвращает копию списка |
| count() | Возвращает число элементов с определенным значением |
| extend() | Добавляет элементы в конец текущего списка |
| index() | Возвращает индекс первого элемента с определенным значением |
| insert() | Добавляет элемент по индексу |
| pop() | Удаляет элемент по индексу или последний |
| remove() | Удаляет элементы по значению |
| reverse() | Разворачивает список |
| sort() | Сортирует список |
]]>Далее: Кортежи (tuple)
Предыдущий урок: Строки в Python
Операторами пользуются для выполнения операций с переменными и значениями.
Python делит операторы на следующие группы:
- Арифметические операторы
- Операторы присваивания
- Операторы сравнения
- Логические операторы
- Операторы тождественности
- Операторы принадлежности
- Побитовые операторы
Арифметические операторы в Python
Арифметические операторы используются с числовыми значениями для выполнения общих математических операций:
| Оператор | Значение | Пример |
|---|---|---|
| + | добавление | 4 + 5 |
| — | вычитание | 8 — 3 |
| * | умножение | 5 * 5 |
| / | деление | 4 / 2 |
| % | остаток от деления | 7 % 2 |
| ** | возведение в степень | 2 ** 3 |
| // | целочисленное деление | 15 // 4 |
Операторы присваивания в Python
Операторы присваивания используются для присваивания значений переменным:
| Оператор | Пример | Так же как |
|---|---|---|
| = | x = 5 | x = 5 |
| += | x += 3 | x = x + 3 |
| -= | x -= 3 | x = x — 3 |
| *= | x *= 3 | x = x * 3 |
| /= | x /= 3 | x = x / 3 |
| %= | x %= 3 | x = x % 3 |
| //= | x //= 3 | x = x // 3 |
| **= | x **= 3 | x = x ** 3 |
| &= | x &= 3 | x = x & 3 |
| |= | x |= 3 | x = x | 3 |
| ^= | x ^= 3 | x = x ^ 3 |
| >>= | x >>= 3 | x = x >> 3 |
| <<= | x <<= 3 | x = x << 3 |
Операторы сравнения в Python
Операторы сравнения используются для сравнения двух значений:
| Оператор | Значение | Пример |
|---|---|---|
| == | равно | x == y |
| != | не равно | x != y |
| > | больше чем | x > y |
| < | меньше чем | x < y |
| >= | больше чем или равно | x >= y |
| <= | меньше чем или равно | x <= y |
Логические операторы в Python
Логические операторы используются для объединения условных операторов:
| Оператор | Значение | Пример |
|---|---|---|
| and | Возвращает значение True если оба утверждения верны | x < 5 and x < 10 |
| or | Возвращает True если одно из утверждений верно | x < 5 or x < 4 |
| not | Меняет результат, возвращает False если результат True | not(x < 5 and x < 10) |
Операторы тождественности в Python
Операторы тождественности используются для сравнения объектов. Являются ли они одним и тем же объектом с одинаковым местоположением в памяти:
| Оператор | Значение | Пример |
|---|---|---|
| is | Возвращает true если переменные являются одним объектом | x is y |
| is not | Возвращает true если переменные разные | x is not y |
Операторы принадлежности в Python
Операторы принадлежности используются для проверки того, представлена ли последовательность в объекте:
| Оператор | Значение | Пример |
|---|---|---|
| in | Возвращает True если последовательность присутствует в объекте | x in y |
| not in | Возвращает True если последовательность не присутствует в объекте | x not in y |
Побитовые операторы в Python
Побитовые операторы используются для работы в битовом (двоичном) формате:
| Оператор | Название | Значение |
|---|---|---|
| & | И | Устанавливает каждый бит в 1, если оба бита 1 |
| | | Или | Устанавливает каждый бит в 1 если один из двух битов 1 |
| ^ | только или | Устанавливает каждый бит в 1 если только один из битов 1 |
| ~ | Не | Переставляет все биты |
| << | Сдвиг влево | Сдвигает влево на количество бит указанных справа |
| >> | Сдвиг вправо | Сдвигает вправо на количество бит указанных справа |
]]>Далее: Списки (list)
Предыдущий урок: Присвоение типа переменной
Строковые значения
В строковых значениях в Python с двух сторон ставятся либо одинарные кавычки, либо двойные кавычки. 'привет' — это то же самое, что и "привет".
Строки могут выводиться на экран с использованием функции вывода. Например: print("привет").
Как и во многих других популярных языках программирования, строки в Python это массивы байтов, которые представляют символы unicode. Однако у Python нет символьного типа данных, один символ — это просто строка с длиной 1. Квадратные скобки могут использоваться для доступа к элементам строки.
Получим символ с индексом 1 (помните, что первый символ имеет индекс 0):
a = "Привет, Мир!"
print(a[1])
Вывод:
р
Подстрока. Получим часть строки с индекса 2 по 5 (запомните, подстрока не включает крайний индекс, в примере это b[5]):
b = "Привет, Мир!"
print(b[2:5])
Вывод:
иве
Метод strip() удаляет любые пробелы с начала или конца строки:
a = " Привет, Мир! "
print(a.strip())
Вывод:
Привет, Мир!
Метод len() возвращает длину строки:
a = "Привет, Мир!"
print(len(a))
Вывод:
12
Метод lower() возвращает строку в нижнем регистре:
a = "Привет, Мир!"
print(a.lower())
Вывод:
привет, мир!
Метод upper() возвращает строку в верхнем регистре:
a = "Привет, Мир!"
print(a.upper())
Вывод:
ПРИВЕТ, МИР!
Метод replace(x, y) заменяет часть строки x на строку y:
a = "Привет, Мир!"
print(a.replace("Ми", "Мэ"))
Вывод:
Привет, Мэр!
Если менять “и” на “э”, получим “Прэвет, Мэр!”
Метод split(x) разбивает строку на список из подстроки, по разделителю x:
a = "Привет, Мир!"
print(a.split(",")) # вернет ['Привет', ' Мир!']
]]>Далее: Операторы в Python
Предыдущий урок: Числа в Python
Порой, в работе с Python вам может понадобиться явно указать тип переменной. Это можно сделать с помощью преобразования. Python — объектно-ориентированный язык программирования, в нем используются классы для определения типов данных, включая простые типы.
Преобразование в Python выполняется с использованием функций-конструкторов:
int()— создает целочисленное число из числового значения, либо значения с плавающей точкой (округляя его до предыдущего целого числа) или строкового значение (при условии, что данная строка является целым числом)float()— так же создает число, но с плавающей точкой из целочисленного значения, значения с плавающей точкой или строкового (при условии, что строка представляет собой число с плавающей точкой или целое число)str()— создает строку из многих типов данных, включая строки, целые числа и числа с плавающей точкой.
int(): пример преобразования
x = int(1) # x станет 1
y = int(2.8) # y станет 2
z = int("3") # z станет 3
float(): пример преобразования
x = float(1) # x станет 1.0
y = float(2.8) # y станет 2.8
z = float("3") # z станет 3.0
w = float("4.2") # w станет 4.2
str(): пример преобразования
x = str("s1") # x станет 's1'
y = str(2) # y станет '2'
z = str(3.0) # z станет '3.0'
]]>Далее: Строки в Python
Предыдущий урок: Переменные в Python
Есть три типа чисел в Python:
intfloatcomplex
Переменные с числовым типом создаются при присваивании им соответствующего значения значения:
x = 1 # int
y = 2.8 # float
z = 1j # complex
Чтобы проверить тип любого объекта в Python, используйте функцию type():
print(type(x))
print(type(y))
print(type(z))
Вывод:
<class 'int'>
<class 'float'>
<class 'complex'>
Int
Int или целое число (integer) — целое число, положительное или отрицательное, без десятичных знаков и неограниченной длины.
x = 1
y = 35656222554887711
z = -3255522
print(type(x))
print(type(y))
print(type(z))
Вывод:
<class 'int'>
<class 'int'>
<class 'int'>
Float
Float, или «число с плавающей точкой», как его еще называют — это число, положительное или отрицательное, содержащее один или несколько десятичных знаков.
x = 1.10
y = 1.0
z = -35.59
print(type(x))
print(type(y))
print(type(z))
Вывод:
<class 'float'>
<class 'float'>
<class 'float'>
Float также может быть числом с «е», для указания степени десятичности.
x = 35e3
y = 12E4
z = -87.7e100
print(type(x))
print(type(y))
print(type(z))
Вывод:
<class 'float'>
<class 'float'>
<class 'float'>
Комплексные числа
Комплексные числа записываются с «j» как мнимой частью:
x = 3+5j
y = 5j
z = -5j
print(type(x))
print(type(y))
print(type(z))
Вывод:
<class 'complex'>
<class 'complex'>
<class 'complex'>
]]>Далее: Присвоение типа переменной
Предыдущий урок: Синтаксис Python
Создание переменных
В отличие от других языков программирования, Python не имеет команды для объявления переменной. Переменная создается тогда, когда вы назначили ей значение.
x = 5
y = "Саша"
print(x)
print(y)
Вывод:
5
Саша
Не нужно указывать конкретный тип переменной при объявлении. Можно даже изменять их тип после создания.
x = 4 # сейчас x с типом int
x = "Алёна" # теперь x с типом str
print(x)
Вывод:
Алёна
Имя переменной
Переменная может иметь краткое имя (например, x и y) или более содержательное имя (age, carname, total_volume).
Правила для переменных в Python:
- Имя переменной должно начинаться с буквы или символа подчеркивания.
- Оно не может начинаться с числа.
- Имя переменной может содержать только буквенно-цифровые символы и символы подчеркивания (Az, 0-9 и
_) - Имена переменных чувствительны к регистру (
age,AgeиAGE— три разных переменные)
Помните, что переменные чувствительны к регистру
Вывод переменных
Функция Python print часто используется для вывода переменных:
Чтобы комбинировать как текст, так и переменную, Python использует символ +
x = "невероятен"
print("Python " + x)
Вывод:
Python невероятен
Вы также можете использовать символ + для добавления переменной в другую переменную:
x = "Python "
y = "невероятен"
z = x + y
print(z)
Вывод:
Python невероятен
Для чисел символ + работает как математический оператор:
x = 5
y = 10
print(x + y)
Вывод:
15
Если вы попытаетесь объединить строку и число, Python покажет вам сообщение об ошибке:
x = 5
y = "Саша"
print(x + y)
Вывод:
TypeError: unsupported operand type(s) for +: 'int' and 'str'
]]>Далее: Числа в Python