PyTorch is a Python-based deep learning library that runs on CPU by default and supports GPU acceleration using CUDA. It follows a define by run approach, creating dynamic computation graphs during execution, which makes debugging and customization easier.
- Uses dynamic graphs for flexibility
- Provides automatic differentiation for gradient computation
- Supports GPU acceleration with CUDA

PyTorch can be installed on Windows, macOS and Linux using pip for CPU (without GPU):
!pip install torch torchvision torchaudio
PyTorch Tensors
Tensors are the fundamental data structures in PyTorch, similar to NumPy arrays but with GPU acceleration capabilities. PyTorch tensors support automatic differentiation, making them suitable for deep learning tasks.
import torch
x = torch.tensor([1.0, 2.0, 3.0])
print('1D Tensor: \n', x)
y = torch.zeros((3, 3))
print('2D Tensor: \n', y)
Output:

Operations on Tensors
a = torch.tensor([1.0, 2.0])
b = torch.tensor([3.0, 4.0])
print('Element Wise Addition of a & b: \n', a + b)
print('Matrix Multiplication of a & b: \n',
torch.matmul(a.view(2, 1), b.view(1, 2)))
Output:

Reshaping and Transposing Tensors
import torch
t = torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
print("Reshaping")
print(t.reshape(6, 2))
print("\nResizing")
print(t.view(2, 6))
print("\nTransposing")
print(t.transpose(0, 1))
Output:

Autograd & Computational Graphs
The autograd module automates gradient calculation for backpropagation. This is important in training deep neural networks.
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2
y.backward()
print(x.grad)
Output:
tensor(4.)
PyTorch dynamically creates a computational graph that tracks operations and gradients for backpropagation.
Building Neural Networks in PyTorch
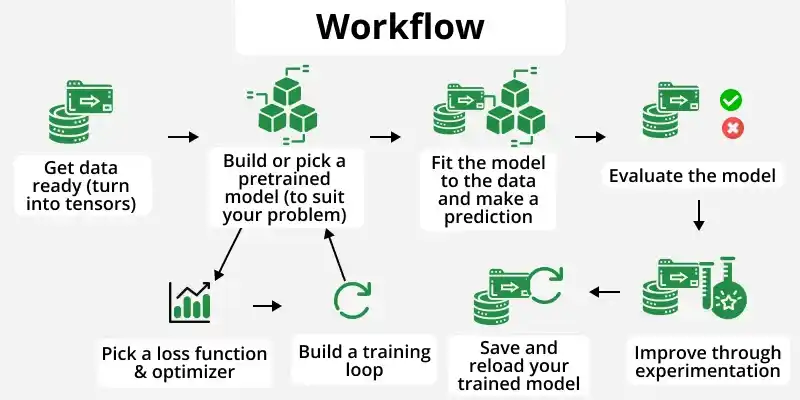
In PyTorch, neural networks are built using the torch.nn module where:
- nn.Linear(in_features, out_features) defines a fully connected (dense) layer.
- Activation functions like torch.relu, torch.sigmoid or torch.softmax are applied between layers.
- forward() method defines how data moves through the network.
To build a neural network in PyTorch, we create a class that inherits from torch.nn.Module and defines its layers and forward pass.
import torch
import torch.nn as nn
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.fc1 = nn.Linear(10, 16)
self.fc2 = nn.Linear(16, 8)
self.fc3 = nn.Linear(8, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
return x
model = NeuralNetwork()
print(model)
Output:

Define Loss Function and Optimizer
Once we define our model, we need to specify:
- A loss function to measure the error.
- An optimizer to update the weights based on computed gradients.
We use nn.BCELoss() for binary cross-entropy loss and used optim.Adam() for Adam optimizer to combine the benefits of momentum and adaptive learning rates.
model = NeuralNetwork()
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
Train the Model
The training involves generating dummy data (100 samples, each with 10 features). After this we run a training loop where we:
- optimizer.zero_grad() clears the accumulated gradients from the previous step.
- Forward Pass (model(inputs)) passes inputs through the model to generate predictions.
- Loss Computation (criterion(outputs, targets)) computes the difference between predictions and actual labels.
- Backpropagation (loss.backward()) computes gradients for all weights.
- Optimizer Step (optimizer.step()) updates the weights based on the computed gradients.
inputs = torch.randn((100, 10))
targets = torch.randint(0, 2, (100, 1)).float()
epochs = 20
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if (epoch + 1) % 5 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
Output:

PyTorch vs. TensorFlow
Lets see a quick difference between pytorch and tensorflow:
| Feature | PyTorch | TensorFlow |
|---|---|---|
| Computational Graph | Dynamic | Static (TF 1.x), Dynamic (TF 2.0) |
| Ease of Use | Pythonic, easy to debug | Steeper learning curve |
| Performance | Fast with eager execution | Optimized for large-scale deployment |
| Deployment | TorchScript & ONNX | TensorFlow Serving & TensorFlow Lite |
| Popularity in Research | Widely used | Also widely used but more in production |
Applications
- Computer Vision: PyTorch is widely used in image classification, object detection and segmentation using CNNs and Transformers (e.g., ViT).
- Natural Language Processing (NLP): PyTorch supports transformers, recurrent neural networks (RNNs) and LSTMs for applications like text generation and sentiment analysis.
- Reinforcement Learning: PyTorch is used in Deep Q-Networks (DQN), Policy Gradient Methods and Actor-Critic Algorithms.