Now, that we have the clickbaity title out of the way, let’s talk about data integrity. Specifically, disk data integrity on Linux.
RAID, or as it is less well known, Redundant Array of Independent Disks is a way to make the stored data more resilient against disk failure. Unfortunately it does not work against silent data corruption, which in studies from CERN were present in the 10-7 range, other studies have also shown non-negligible rates of data corruption.
You may say, OK, I understand fixing it doesn’t work for RAID 1 with just two copies, or with RAID 5, as you don’t know which data is correct – as any one of them can be – surely the system is more clever if it has RAID 6 or 3 drives in RAID! Again, unfortunately it isn’t so. Careful reading of the md(4) man page will reveal this fragment:
If check was used, then no action is taken to handle the mismatch, it is simply recorded. If repair was used, then a mismatch will be repaired in the same way that resync repairs arrays. For RAID5/RAID6 new parity blocks are written. For RAID1/RAID10, all but one block are overwritten with the content of that one block.
In other words, the RAID depends on the disks telling the truth: if it can’t read data, it needs to return I/O error, not return garbage. But as we’ve established, this isn’t the way disks behave.
Now you may say, but I use disk encryption! Surely encryption will detect this data modification and prevent use of damaged/changed data! Again, this is not the property of either AES in XTS mode or in CBC mode – the standard modes of encryption for disk drives – those are so-called malleable encryption modes. There is no way to detect ciphertext modification for them in general case.
This was one of the main reasons behind Btrfs and ZFS; checksumming all data and metadata so that detection of such incorrect blocks could be possible (so that at the very least this corruption is detected and doesn’t reach the application) and with addition of the in-build RAID levels, also corrected.
What if you don’t want to (or likely can’t, in case of ZFS) use either of them? Until recently, there was not much you could do. Introduction of the dm-integrity target has changed that though.
Using dm-integrity in LUKS
dm-integrity target is best integrated with LUKS disk encryption.
To enable it, the device needs to be formatted as a LUKS2 device, and integrity mechanism needs to be specified:
cryptsetup luksFormat --type luks2 --integrity hmac-sha256 \
--sector-size 4096 /dev/example/ciphertext
(Other options include --integrity hmac-sha512 and --cipher chacha20-random --integrity poly1305. Smaller tags will be discussed below)
which then can be opened as a regular LUKS device:
cryptsetup open --type luks /dev/example/ciphertext plaintext
This will create a /dev/mapper/plaintext device that is encrypted and integrity protected.
And the /dev/mapper/plaintext_dif that provides storage for authentication tags.
Note that the integrity device will report (none) as the integrity mechanism:
integritysetup status plaintext_dif
/dev/mapper/plaintext_dif is active and is in use.
type: INTEGRITY
tag size: 32
integrity: (none)
device: /dev/mapper/example-ciphertext
sector size: 4096 bytes
interleave sectors: 32768
size: 2056456 sectors
mode: read/write
journal size: 8380416 bytes
journal watermark: 50%
journal commit time: 10000 ms
This is expected, as LUKS passes the encryption tags from a higher level and dm-integrity is only used to store them. This can be verified with cryptsetup:
cryptsetup status /dev/mapper/plaintext
/dev/mapper/plaintext is active.
type: LUKS2
cipher: aes-xts-plain64
keysize: 512 bits
key location: keyring
integrity: hmac(sha256)
integrity keysize: 256 bits
device: /dev/mapper/example-ciphertext
sector size: 4096
offset: 0 sectors
size: 2056456 sectors
mode: read/write
The device can be removed (while preserving data, but making it inaccessible without providing password again) using cryptsetup:
cryptsetup close /dev/mapper/plaintext
Testing
To test if the verification works correctly, first let’s verify that the whole device is readable:
dd if=/dev/mapper/plaintext of=/dev/null bs=$((4096*256)) \
status=progress
988807168 bytes (989 MB, 943 MiB) copied, 6 s, 165 MB/s
1004+1 records in
1004+1 records out
1052905472 bytes (1.1 GB, 1004 MiB) copied, 6.28939 s, 167 MB/s
Now, let’s close the device and check if the block looks random, and overwrite it:
cryptsetup close /dev/mapper/plaintext
dd if=/dev/example/ciphertext bs=4096 skip=$((512*1024*1024/4096)) \
count=1 status=none | hexdump -C | head
00000000 70 a1 1d f7 da ae 04 d2 d5 f1 ed 6e ba 96 81 7a |p..........n...z|
00000010 90 c9 7c e7 01 95 2b 12 ed fc 46 fb 0c d7 24 dd |..|...+...F...$.|
00000020 48 a2 17 7a 17 9f 26 d8 ef ca 97 74 6e 56 2b 55 |H..z..&....tnV+U|
00000030 59 60 6c 72 e1 5d 14 b3 00 f9 70 e8 f3 31 5e 6f |Y`lr.]....p..1^o|
00000040 c7 98 c8 e0 e0 f6 52 d3 36 07 34 93 59 42 98 12 |......R.6.4.YB..|
00000050 a8 44 f4 fa 13 94 d6 30 5d 88 ee 79 4c 99 7a a8 |.D.....0]..yL.z.|
00000060 cd 35 87 52 07 66 74 68 9e 61 2e 26 c3 74 67 91 |.5.R.fth.a.&.tg.|
00000070 33 57 21 61 44 b4 2e 31 a6 61 90 3f 04 d9 5e f3 |3W!aD..1.a.?..^.|
00000080 46 dc 2c c5 cb 50 1a b4 3a b5 4d 4d ee d3 0f fd |F.,..P..:.MM....|
00000090 be 6c 5f 3a b6 f9 b3 f3 21 ac 6b cf dd f0 2e 3b |.l_:....!.k....;|
Yep, looks random (and will look different for every newly formatted LUKS volume).
dd if=/dev/zero of=/dev/example/ciphertext bs=4096 \
seek=$((512*1024*1024/4096)) count=1
dd if=/dev/example/ciphertext bs=4096 skip=$((512*1024*1024/4096)) \
count=1 status=none | hexdump -C | head
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
Not any more.
What happens when we try to read it now?
cryptsetup open --type luks /dev/example/ciphertext plaintext
dd if=/dev/mapper/plaintext of=/dev/null bs=$((4096*256)) \
status=progress
464519168 bytes (465 MB, 443 MiB) copied, 2 s, 232 MB/s
dd: error reading '/dev/mapper/example': Input/output error
496+1 records in
496+1 records out
520097792 bytes (520 MB, 496 MiB) copied, 2.43931 s, 213 MB/s
Exactly as expected, after reading about 0.5GiB of data, we get an I/O error.
(Re-writing the sector will cause checksum recalculation and will clear the error.)
Repeating the experiment without --integrity is left as an exercise for the reader
Standalone dm-integrity setup
By default, integritysetup will use crc32 which is quite fast and small (requiring just 4 bytes per block). This gives probability of random corruption not being detected of about 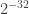 (as the value of the CRC and the data will be independently selected). Please remember that this is on top of the silent corruption of the hard drive; i.e. if the HDD has a probability of returning malformed data of
(as the value of the CRC and the data will be independently selected). Please remember that this is on top of the silent corruption of the hard drive; i.e. if the HDD has a probability of returning malformed data of 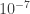 then probability of malformed data reaching upper layer is
then probability of malformed data reaching upper layer is  . There is a hidden assumption in this though – that the malformed data returned by the disk has uniform distribution, I don’t know if that is typical and was unable to find more information on this topic. If it is not uniformly distributed, the failure rate for crc32 may be higher. More research is necessary in this area.
. There is a hidden assumption in this though – that the malformed data returned by the disk has uniform distribution, I don’t know if that is typical and was unable to find more information on this topic. If it is not uniformly distributed, the failure rate for crc32 may be higher. More research is necessary in this area.
In case that probability is unsatisfactory, it’s possible to use any of the hashes supported by the kernel and listed in the /proc/crypto system file, sha1, sha256, hmac-sha1 and hmac-sha256 being the more interesting ones.
Example configuration would look like this:
integritysetup format --progress-frequency 5 --integrity sha1 \
--tag-size 20 --sector-size 4096 /dev/example/raw-1
Formatted with tag size 20, internal integrity sha1.
Wiping device to initialize integrity checksum.
You can interrupt this by pressing CTRL+c (rest of not wiped device will contain invalid checksum).
Progress: 7.5%, ETA 01:04, 76 MiB written, speed 14.5 MiB/s
Progress: 17.2%, ETA 00:49, 173 MiB written, speed 16.8 MiB/s
Progress: 25.5%, ETA 00:45, 257 MiB written, speed 16.6 MiB/s
Progress: 32.5%, ETA 00:42, 328 MiB written, speed 16.0 MiB/s
Progress: 42.1%, ETA 00:35, 424 MiB written, speed 16.5 MiB/s
Progress: 51.2%, ETA 00:29, 516 MiB written, speed 16.8 MiB/s
Progress: 58.5%, ETA 00:25, 590 MiB written, speed 16.4 MiB/s
Progress: 68.6%, ETA 00:18, 692 MiB written, speed 16.9 MiB/s
Progress: 77.3%, ETA 00:13, 779 MiB written, speed 17.0 MiB/s
Progress: 84.3%, ETA 00:09, 850 MiB written, speed 16.6 MiB/s
Progress: 93.9%, ETA 00:03, 947 MiB written, speed 16.9 MiB/s
Finished, time 00:59.485, 1008 MiB written, speed 16.9 MiB/s
A new device is created with the open subcommand:
integritysetup open --integrity-no-journal --integrity sha1 \
/dev/example/raw-1 integr-1
integritysetup status integr-1
/dev/mapper/integr-1 is active.
type: INTEGRITY
tag size: 20
integrity: sha1
device: /dev/mapper/example-raw--1
sector size: 4096 bytes
interleave sectors: 32768
size: 2064688 sectors
mode: read/write
journal: not active
(note that in line 4 we now have sha1 instead of (none))
If we want to cryptographically verify the integrity of the data, we will need to use an HMAC though.
Setting it up is fairly similar, but will require a key file (note: this key needs to remain secret for the algorithm to be cryptographically secure).
dd if=/dev/urandom of=hmac-key bs=1 count=20 status=none
integritysetup format --progress-frequency 5 --integrity hmac-sha1 \
--tag-size 20 --integrity-key-size 20 --integrity-key-file hmac-key \
--no-wipe --sector-size 4096 /dev/example/raw-1
integritysetup open --integrity-no-journal --integrity hmac-sha1 \
--integrity-key-size 20 --integrity-key-file hmac-key \
/dev/example/raw-1 integr-1
dd if=/dev/zero of=/dev/mapper/integr-1 bs=$((4096*32768))
integritysetup status integr-1
Formatted with tag size 20, internal integrity hmac-sha1.
dd: error writing '/dev/mapper/integr-1': No space left on device
8+0 records in
7+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 9.45404 s, 112 MB/s
/dev/mapper/integr-1 is active.
type: INTEGRITY
tag size: 20
integrity: hmac(sha1)
device: /dev/mapper/example-raw--1
sector size: 4096 bytes
interleave sectors: 32768
size: 2064688 sectors
mode: read/write
journal: not active
(this time I’ve used --no-wipe as dd from /dev/zero is much faster)
Combined mdadm and dm-integrity
Now that we know how to set up dm-integrity devices and that they work as advertised, let’s see if that indeed will prevent silent data corruption and provide automatic recovery with Linux RAID infrastructure.
For this setup I’ll be using files to make it easier to reproduce the results (integritysetup configures loop devices automatically).
RAID 5
Setup
First let’s initialise the dm-integrity targets:
SIZE=$((1024*1024*1024))
COUNT=6
for i in $(seq $COUNT); do
truncate -s $SIZE "raw-$i"
integritysetup format --integrity sha1 --tag-size 16 \
--sector-size 4096 --no-wipe "./raw-$i"
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-$i" "integr-$i"
dd if=/dev/zero "of=/dev/mapper/integr-$i" bs=$((4096*512)) || :
done
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-1': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 5.119 s, 207 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-2': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 6.37586 s, 166 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-3': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 6.18465 s, 171 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-4': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 6.32175 s, 167 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-5': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 5.94098 s, 178 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-6': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 6.73871 s, 157 MB/s
Then set up the RAID-5 device and wait for initialisation.
mdadm --create /dev/md/robust -n$COUNT --level=5 \
$(seq --format "/dev/mapper/integr-%.0f" $COUNT)
mdadm --wait /dev/md/robust && echo ready
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md/robust started.
ready
Single failure
To make sure that we do not work from cache, stop the array, clear cache, and then overwrite half of one of the drives:
mdadm --stop /dev/md/robust
integritysetup close integr-1
tr '\000' '\377' < /dev/zero | dd of=raw-1 bs=4096 \
seek=$((SIZE/4096/2)) count=$((SIZE/4096/2-256)) \
conv=notrunc status=progress
mdadm: stopped /dev/md/robust
415428608 bytes (415 MB, 396 MiB) copied, 1 s, 413 MB/s
131008+0 records in
131008+0 records out
536608768 bytes (537 MB, 512 MiB) copied, 1.49256 s, 360 MB/s
(As we’re not encrypting data, the 00’s actually are on the disk, so we need to write something else, 0xff in this case. Also, we’re skipping last 1MiB of data as that’s where RAID superblock lives and recovery of it is a completely different kettle of fish.)
Restart the array:
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-1" "integr-1"
mdadm --assemble /dev/md/robust $(seq --format \
"/dev/mapper/integr-%.0f" $COUNT)
mdadm: /dev/md/robust has been started with 6 drives.
Verify that all data is readable and that it has expected values (all zero):
hexdump -C /dev/md/robust
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
13ab00000
Additionally you can verify that the errors were reported to the MD layer.
First, run ls -l /dev/md/robust to get to know the number of the md, then use it in the following command instead of 127:
grep . /sys/block/md127/md/dev-*/errors
/sys/block/md127/md/dev-dm-14/errors:867024
/sys/block/md127/md/dev-dm-15/errors:0
/sys/block/md127/md/dev-dm-16/errors:0
/sys/block/md127/md/dev-dm-17/errors:0
/sys/block/md127/md/dev-dm-18/errors:0
/sys/block/md127/md/dev-dm-19/errors:0
Scrub the volume to fix all bad blocks:
mdadm --action=repair /dev/md/robust
mdadm --wait /dev/md/robust && echo ready
ready
And verify that all the incorrect blocks were rewritten/corrected:
dd if=/dev/mapper/integr-1 bs=4096 of=/dev/null status=progress
864800768 bytes (865 MB, 825 MiB) copied, 4 s, 216 MB/s
258086+0 records in
258086+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 4.68922 s, 225 MB/s
Double failure
Let’s see what happens if two drives return I/O error for the same area. Let’s introduce the errors:
mdadm --stop /dev/md/robust
integritysetup close integr-1
integritysetup close integr-2
tr '\000' '\377' < /dev/zero | dd of=raw-1 bs=4096 \
seek=$((SIZE/4096/2)) count=$((100*1025*1024/4096)) \
conv=notrunc status=none
tr '\000' '\377' < /dev/zero | dd of=raw-2 bs=4096 \
seek=$((SIZE/4096/2)) count=$((100*1025*1024/4096)) \
conv=notrunc status=none
mdadm: stopped /dev/md/robust
Then restart the array
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-1" "integr-1"
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-2" "integr-2"
mdadm --assemble /dev/md/robust $(seq --format \
"/dev/mapper/integr-%.0f" $COUNT)
mdadm: /dev/md/robust has been started with 6 drives.
Let’s verify:
hexdump -C /dev/md/robust
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
hexdump: /dev/md/robust: Input/output error
9c026000
As expected, we’ve received an I/O error. Additionally if we look at the status of the array, we’ll see that it has become degraded:
Personalities : [raid10] [raid6] [raid5] [raid4]
md127 : active raid5 dm-14[0](F) dm-19[6] dm-18[4] dm-17[3] dm-16[2] dm-15[1]
5155840 blocks super 1.2 level 5, 512k chunk, algorithm 2 [6/5] [_UUUUU]
This is most likely because the kernel will re-try to read the sectors, but if it receives a set number of read errors it cannot correct (see max_read_errors in md directory), it will kick the disk out of the array. Probably suboptimal given this setup – knowing the error came from software not hardware would mean that kicking the disk from the RAID won’t change anything.
Clean-up
mdadm --stop /dev/md/robust
for i in $(seq $COUNT); do
integritysetup close "integr-$i"
done
RAID 6
Let’s now try with RAID 6, that is, with double redundancy.
set-up:
for i in $(seq $COUNT); do
truncate -s $SIZE "raw-$i"
integritysetup format --integrity sha1 --tag-size 16 \
--sector-size 4096 --no-wipe "./raw-$i"
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-$i" "integr-$i"
dd if=/dev/zero "of=/dev/mapper/integr-$i" bs=$((4096*512)) || :
done
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-1': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 4.8998 s, 216 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-2': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 7.21848 s, 146 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-3': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 7.85458 s, 135 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-4': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 7.48937 s, 141 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-5': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 7.30369 s, 145 MB/s
Formatted with tag size 16, internal integrity sha1.
dd: error writing '/dev/mapper/integr-6': No space left on device
505+0 records in
504+0 records out
1057120256 bytes (1.1 GB, 1008 MiB) copied, 7.05441 s, 150 MB/s
RAID initialization:
mdadm --create /dev/md/robust -n$COUNT --level=6 \
$(seq --format "/dev/mapper/integr-%.0f" $COUNT)
mdadm --wait /dev/md/robust && echo ready
ready
Single failure
mdadm --stop /dev/md/robust
integritysetup close integr-1
tr '\000' '\377' < /dev/zero | dd of=raw-1 bs=4096 \
seek=$((SIZE/4096/2)) count=$((SIZE/4096/2-256)) \
conv=notrunc status=progress
mdadm: stopped /dev/md/robust
415428608 bytes (415 MB, 396 MiB) copied, 1 s, 413 MB/s
131008+0 records in
131008+0 records out
536608768 bytes (537 MB, 512 MiB) copied, 1.49256 s, 360 MB/s
Restart the array:
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-1" "integr-1"
mdadm --assemble /dev/md/robust $(seq --format \
"/dev/mapper/integr-%.0f" $COUNT)
mdadm: /dev/md/robust has been started with 6 drives.
Verify that all data is readable and that it has expected values (all zero):
hexdump -C /dev/md/robust
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
fbc00000
Good. And let’s check the status of the array:
Personalities : [raid10] [raid6] [raid5] [raid4]
md127 : active raid6 dm-19[5] dm-18[4] dm-17[3] dm-16[2] dm-15[1] dm-14[0](F)
4124672 blocks super 1.2 level 6, 512k chunk, algorithm 2 [6/5] [_UUUUU]
Not good, looks like the raid6 target has a different way of handling I/O errors than the raid5 one and even if the failures are correctible, the array is degraded.
Double failure
Faults introduction:
mdadm --stop /dev/md/robust
integritysetup close integr-1
integritysetup close integr-2
tr '\000' '\377' < /dev/zero | dd of=raw-1 bs=4096 \
seek=$((SIZE/4096/2)) count=$((100*1025*1024/4096)) \
conv=notrunc status=none
tr '\000' '\377' < /dev/zero | dd of=raw-2 bs=4096 \
seek=$((SIZE/4096/2)) count=$((100*1025*1024/4096)) \
conv=notrunc status=none
mdadm: stopped /dev/md/robust
Restart:
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-1" "integr-1"
integritysetup open --integrity-no-journal --integrity \
sha1 "./raw-2" "integr-2"
mdadm --assemble /dev/md/robust $(seq --format \
"/dev/mapper/integr-%.0f" $COUNT)
mdadm: /dev/md/robust has been started with 6 drives.
Verify:
hexdump -C /dev/md/robust
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
fbc00000
so far so good
Personalities : [raid10] [raid6] [raid5] [raid4]
md127 : active raid6 dm-14[0](F) dm-19[5] dm-18[4] dm-17[3] dm-16[2] dm-15[1](F)
4124672 blocks super 1.2 level 6, 512k chunk, algorithm 2 [6/4] [__UUUU]
not so good, both disks were marked as faulty in the array…
Clean-up
mdadm --stop /dev/md/robust
for i in $(seq $COUNT); do
integritysetup close "integr-$i"
rm "raw-$i"
done
Summary
While the functionality necessary to provide detection and correction of silent data corruption is available in the Linux kernel, the implementation likely will need few tweaks to not excerbate situations where the hardware is physically failing, not just returning garbage. Passing additional metadata about the I/O errors from the dm-integrity layer to the md layer could be a potential solution.
Update: This bug has been fixed in the upstream code in September 2019.
Also, this mechanism comes into play only when the hard drive technically already is failing, so at least you will know about the failure, and really, the failing disk is getting kicked out 🙂
Learn more
Data integrity protection with cryptsetup tools presentation by Milan Brož at FOSDEM.
Note: Above tests were performed using 4.16.6-1-ARCH Linux kernel, mdadm 4.0-1 and cryptsetup 2.0.2-1 from ArchLinux.
